
Abstract
Global reporting of obesity is commonly based on comparisons over multiple decades1 and lacks a granular and systematic analysis of its dynamics. We used 4,050 population-based studies with measured height and weight data on 232 million participants to assess the worldwide dynamics of obesity from 1980 to 2024. The rise in obesity decelerated in school-aged children and adolescents throughout the 1990s in many high-income countries, and subsequently plateaued in most at age-standardized prevalences spanning 20 percentage points, from 3–4% for girls in Japan, Denmark and France to 23% for boys in the USA. There were indications of a small decline in obesity in children and adolescents in some high-income western countries (for example, Italy, Portugal and France) since the 2000s. Similar trends were seen in some countries in Central and Eastern Europe. In adults, the rise in obesity slowed down in high-income western countries about a decade after children, followed by a plateau or possibly a small reversal of the rise in some countries (for example, Spain). In most low-income and middle-income countries, the annual absolute change in prevalence has remained stable or increased over time, even though prevalence has surpassed that of high-income countries. These highly varied dynamics suggest that the social, economic and technological trends that influence the availability, affordability and use of different foods may have helped control the rise in obesity in high-income countries, but require policy interventions in low-income and middle-income countries.
Similar content being viewed by others
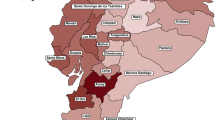
Main
Obesity increases the risk of cardiovascular, renal, liver and respiratory diseases, musculoskeletal and neuropsychiatric disorders, diabetes, some cancers, adverse reproductive and obstetric outcomes, and severe COVID-19. Obesity is currently more prevalent than in the late twentieth century1, and since the 1990s, the term ‘epidemic’ has been used to describe its rise2,3.
Change in the prevalence of obesity in a population is driven by changes in height and weight, which themselves result from the quantity and quality of nutrition, the living environment and physical activity. These determinants of obesity vary across countries and change over time owing to changes in food production, processing, storage and transportation technologies that affect the availability and cost of various foods; economic resources of countries and households; social norms and knowledge; corporate and commercial practices; and fiscal and regulatory policies that affect food price and availability1,4,5,6,7,8,9,10,11,12,13. Despite these dynamics, global reporting of obesity has typically compared prevalence over decades and has not systematically evaluated the trajectory of obesity in a population at more granular timescales1. Rather, descriptions of how obesity trends evolve over time in different countries have been largely qualitative14.
The multi-decadal timeline limits our ability to benchmark the long-term and recent performance of countries in controlling obesity, to set priorities for nutrition and public health programmes and policies, to provide access to health care such as weight loss medications or bariatric surgery, and to assess the impacts of these policies and programmes. To systematically and consistently investigate the dynamics of obesity in different countries, we analysed its velocity, calculated as the annual absolute change in prevalence and reported in percentage points per year. Positive velocity indicates an increase in prevalence, and negative velocity a decrease. We report velocity from 1980 to 2024 for school-aged children and adolescents (5–19 years of age) and adults (20 years of age and older). We analysed children and adolescents separately from adults because cut-offs for underweight and obesity differ between them and because obesity trends and dynamics may differ between school ages and adulthood1.
To estimate velocity and characterize the dynamics of the obesity epidemic, we used 4,050 population-based studies that measured height and weight in 232 million participants 5 years of age and older (Supplementary Tables 1 and 2 and Supplementary Figs. 1 and 2). We used these data to calculate body-mass index (BMI), which was then used in a Bayesian hierarchical meta-regression model to estimate the prevalence of obesity from 1980 to 2024 in 200 countries and territories (referred to as countries hereafter). Obesity was defined as BMI ≥ 30 kg m−2 for adults and BMI > 2 s.d. above the median of the WHO growth reference for children and adolescents. We calculated velocity as the annual absolute change in the estimated prevalence. We also used dimensionality reduction and clustering techniques to identify phenotypes of national obesity trajectories, defined as clusters of countries with similar estimated obesity prevalence time trends over the 45 years of analysis. Details of data and methodology are provided in Methods.
Children and adolescents
From 1980 to 2024, age-standardized prevalence of obesity increased with a posterior probability (PP) > 0.80 in all but 5 of 200 countries for girls, and all but 2 of 200 countries for boys. The countries that did not experience an increase were in Central Asia plus France for boys. The increase in obesity over these 45 years ranged from 0.6 to 27 percentage points among girls, and from 0.4 to 35 percentage points among boys. National obesity trajectories had highly heterogeneous dynamics during this period.
In most high-income western countries (that is, high-income countries in Western Europe, North America and Australasia), as well as in Japan and Taiwan, the rise in obesity prevalence among school-aged children and adolescents predominantly occurred before the beginning of the millennium; this rising trend has slowed down, plateaued or may have even reversed slightly since then (Figs. 1 and 2 and Extended Data Figs. 1 and 2). The earliest slowdown occurred around 1990 in Denmark for both sexes, followed by some other Northwestern European countries including Iceland, Switzerland, Belgium and Germany through the 1990s (Fig. 2). By the mid-2000s, obesity prevalence among school-aged children and adolescents started to stabilize in most high-income countries, and may have even started to decline in some. In 2024, the velocity of obesity was below 0.25 percentage points per year in most of these countries and may have become negative in some (for example, Italy, Portugal and France). The negative velocities had magnitudes smaller than 0.15 percentage points per year. These small velocities, including all the negative velocities, were indistinguishable from zero at a PP of 0.80 (Figs. 2 and 3 and Extended Data Figs. 3 and 4). Beyond this plateauing, in some high-income countries, such as France, the Netherlands, Switzerland and Japan, velocity remained low (less than 0.2 percentage points per year) over the entire 45-year period. The exceptions to this plateauing and reversal in high-income western countries were among girls and boys in Australia, Finland and Sweden, where the prevalence of obesity increased steadily or even accelerated.

a,b, Time-series plots of age-standardized obesity prevalence (left) and cluster allocation of these trends by country (right) for girls (a) and boys (b) from 1980 to 2024. Each panel represents a cluster of countries with similar shapes of obesity prevalence time series, and is labelled with its typology of trend. Each line on the plots represents obesity prevalence over time in one country. The maps display countries coloured according to their cluster allocation. See Extended Data Figs. 1 and 2 for allocation of countries in each super-region to clusters. See Supplementary Fig. 3 for trends in age-standardized obesity prevalence by country.

a,b, Velocity and prevalence of obesity in girls (a) and boys (b). The circular wheel plots show the year-on-year velocity of obesity from 1980 to 2024 by country. Each cell represents the velocity in one year. A positive velocity (red) indicates a year-on-year increase in obesity prevalence, whereas a negative (green) velocity indicates a year-on-year decrease. Years when no change in obesity was observed are coloured in white. Countries are labelled by their International Organization for Standardization (ISO) 3166-1 alpha-3 codes (Supplementary Note 1) and coloured by super-region. Countries are ordered by increasing 2024 velocity within each region. The top maps show the velocity of obesity in 2024 in each country, following the same colour scheme as the velocity wheel plots, and the bottom maps show the age-standardized prevalence of obesity in 2024. See Extended Data Fig. 3 for velocity of obesity in 2024 and its uncertainty by country, Extended Data Fig. 4 for a map of PP that velocity of obesity was positive in 2024, Supplementary Fig. 3 for trends in the prevalence of obesity by country and Supplementary Fig. 5 for trends in the velocity of obesity by country.

a,b, Velocity of obesity in relation to age-standardized prevalence of obesity in 2024 for girls (a) and boys (b). Each point shows one country, coloured by its super-region. The solid grey lines show the sex-specific median national prevalence and velocity of obesity in 2024.
Slowdowns or plateaus in the rise of obesity among school-aged children and adolescents also occurred in some countries in Central and Eastern Europe (for example, Croatia and Slovenia for both sexes and Czechia and Montenegro for boys) and in some middle-income countries where obesity prevalence in school ages was relatively high (for example, Mexico and Kuwait). In most of these countries, the slowdown of the rise in prevalence started in the 2000s, about a decade after the slowdown began in high-income western countries (Fig. 2). Furthermore, in some countries in Central Asia, such as Kyrgyzstan and Kazakhstan, school-aged children and adolescents, especially girls, did not experience the rise in obesity seen elsewhere throughout these four decades, or for parts of it experienced a decline (Fig. 1).
The plateauing and any possible reversal of the rise in obesity in children and adolescents happened at vastly different prevalences across countries. In many high-income countries in Western Europe and Japan, age-standardized prevalence plateaued below 10% in school ages. For example, obesity prevalence has had near-zero or negative velocity for at least the past decade at an age-standardized prevalence of 3–6% in Japan, France, Denmark and the Netherlands for one or both sexes. Elsewhere, obesity plateaued at higher endemic prevalences. For example, the velocity of obesity was indistinguishable from zero for at least the past 10 years at a PP of 0.80 among girls and boys in Kuwait and the USA, and among boys in New Zealand, where the prevalence of obesity was 19–25%, much higher than in the aforementioned countries in Western Europe (Figs. 2 and 3).
Contrasting with these plateaus and reversals, the prevalence of obesity in children and adolescents increased steadily or accelerated in most low-income and middle-income countries in Asia, Africa, Latin America, and Caribbean and Pacific Island nations (Figs. 1 and 2 and Extended Data Figs. 1 and 2). The velocity of obesity was higher in 2024 than in any other year since 1980 for girls in 110 of 200 countries and boys in 91 of 200 countries, the majority of which were in low-income and middle-income regions (Fig. 2). This steady or accelerating increase occurred both where prevalence is still low, such as in countries in East Africa (for example, Tanzania, Rwanda and Ethiopia) and South Asia (for example, Nepal and Bangladesh), and where prevalence has already increased to higher levels, in some Caribbean and Pacific Island nations (for example, Niue and the Bahamas) and some countries in the Middle East and North Africa (for example, Saudi Arabia, Qatar and Oman), Southeast Asia (for example, Brunei and Malaysia) and Latin America (for example, Chile).
There was a positive correlation between prevalence and velocity in 2024 (correlation coefficient = 0.70 for girls and 0.62 for boys), indicating that prevalence continues to grow in low-income and middle-income countries where it is already high. In 2024, obesity prevalence had a velocity of more than 0.5 percentage points per year with a PP > 0.80 in 36 countries for girls and in 35 countries for boys, with the highest velocities observed among girls in Tonga and Samoa and among boys in Peru (0.9 percentage points per year; Figs. 2 and 3 and Extended Data Figs. 3 and 4). Countries with velocity greater than 0.5 percentage points per year were in Latin America and the Caribbean, Pacific Island nations, some countries in South and Southeast Asia and sub-Saharan Africa for both sexes, and in East Asia and the Middle East and North Africa for boys. The only high-income western country with a velocity above this threshold was Finland for boys. The rise in obesity in all 36 countries in this group for girls and in 24 of the 35 countries for boys was classified as accelerating.
Adults
From 1980 to 2024, age-standardized prevalence of obesity in women increased with a PP > 0.80 in 183 countries. The remaining 17 countries, where prevalence either did not change at a PP of at least 0.80 or decreased slightly with a PP > 0.80, were all in Europe. Among men, obesity increased in all countries with a PP > 0.80. In countries where prevalence increased with a PP > 0.80, the magnitude of the increase ranged from 2 to 43 percentage points for women, and from 1 to 36 percentage points for men. National obesity trajectories among adults had highly heterogeneous dynamics during this 45-year period, as was also the case for children and adolescents.
In most high-income western countries, the prevalence of obesity among adults was increasing with a PP > 0.80 in 1980 but the rise decelerated or plateaued around or after 2000, and may have even reversed slightly in some (Figs. 4 and 5 and Extended Data Figs. 5 and 6). The deceleration and plateauing among adults began later than in children and adolescents in most countries and typically occurred among women before men. By 2024, most of these countries exhibited small velocities indistinguishable from zero at a PP of 0.80 (Figs. 5 and 6 and Extended Data Figs. 7 and 8). In some countries (Spain and Italy for both sexes and France for women), velocity had become negative, that is, obesity was declining, with PP > 0.80; the negative velocities had magnitudes smaller than 0.5 percentage points per year. However, in some high-income countries, plateaus and reversals did not occur and the increase in obesity prevalence was either steady or accelerated, such as among both sexes in Finland, and among women in Norway and Belgium. Despite the acceleration, the velocity of obesity remained below 0.5 percentage points per year in these countries.

a,b, Time-series plots of age-standardized obesity prevalence (left) and cluster allocation of these trends by country (right) for women (a) and men (b) from 1980 to 2024. Each panel represents a cluster of countries with similar shapes of obesity prevalence time series, and is labelled with its typology of trend. Each line on the plots represents obesity prevalence over time in one country. The maps display countries coloured according to their cluster allocation. See Extended Data Figs. 5 and 6 for allocation of countries in each super-region to clusters and Supplementary Fig. 4 for trends in age-standardized obesity prevalence by country.

a,b, Velocity and prevalence of obesity in women (a) and men (b). The circular wheel plots show the year-on-year velocity of obesity from 1980 to 2024 by country. Each cell represents the velocity in one year. A positive velocity (red) indicates a year-on-year increase in obesity prevalence, whereas a negative (green) velocity indicates a year-on-year decrease. Years when no change in obesity was observed are coloured in white. Countries are labelled by their ISO 3166-1 alpha-3 codes (Supplementary Note 1) and coloured by super-region. Countries are ordered by increasing 2024 velocity within each region. The top maps show the velocity of obesity in 2024 in each country, following the same colour scheme as the velocity wheel plots, and the bottom maps show the age-standardized prevalence of obesity in 2024. See Extended Data Fig. 7 for velocity of obesity in 2024 and its uncertainty by country, Extended Data Fig. 8 for a map of PP that velocity of obesity was positive in 2024, Supplementary Fig. 4 for trends in the prevalence of obesity by country and Supplementary Fig. 6 for trends in the velocity of obesity by country.

a,b, Velocity of obesity in relation to age-standardized prevalence of obesity in 2024 for women (a) and men (b). Each point shows one country, coloured by super-region. The solid grey lines show the sex-specific median national prevalence and velocity of obesity in 2024.
Slowdowns or plateaus of the rise in adult obesity for one or both sexes also happened in two other groups of countries. In the first group, obesity prevalence reached high levels, exceeding 40% in some cases, before a slowdown in the rise or plateau occurred. This group included some Caribbean (for example, the Bahamas) and Pacific (for example, American Samoa and Kiribati) Island nations and some countries in the Middle East and North Africa (for example, Kuwait, Jordan and United Arab Emirates). In the second group, obesity prevalence plateaued at lower levels than in the first group. This group included some countries in Central and Eastern Europe (for example, Poland and Estonia) and for men in sub-Saharan Africa (Cameroon, Ghana, Sierra Leone and South Africa). In addition, women in some Central and Eastern European countries (for example, Czechia and Russia) did not experience a rise in obesity throughout these 45 years at a PP of 0.80, and velocity remained below 0.25 percentage points per year. Unlike high-income countries, where the slowdown or plateau in adult obesity followed that of children and adolescents, most of these countries saw a slowdown or plateau of the rise in adult obesity before or in the absence of slowdown of the rise in obesity among children and adolescents (Figs. 2 and 5).
The deceleration, plateauing and reversal of the rise in adult obesity, where it occurred, also happened at a wide range of prevalences. In high-income countries in Western Europe, the age-standardized prevalence of obesity in 2024 was typically below 25%, and as low as 11% in some countries (for example, France). By contrast, in high-income English-speaking countries such as the UK, Canada and the USA, prevalence in 2024 ranged from 25% to 43% (Fig. 6). Elsewhere, a deceleration or plateau occurred at even higher endemic levels. For example, age-standardized prevalence in 2024 ranged from 40% to 50% in some countries in the Middle East and North Africa, and from 50% to 80% in some Pacific Island nations where obesity decelerated or plateaued.
Contrasting with these decelerations, plateaus and reversals, the rise in adult obesity was steady or accelerated throughout these 45 years in the majority of low-income and middle-income countries in sub-Saharan Africa, Asia and Latin America, and in some Caribbean and Pacific Island nations. Many countries in Central Europe also experienced a steady or accelerating increase in adult obesity prevalence. The velocity of obesity was greater in 2024 than in any other year over the 45-year period for women in 84 of 200 countries and for men in 109 of 200 countries; these were predominantly low-income and middle-income countries (Fig. 5). This steady or accelerating rise occurred at a wide range of prevalences (Fig. 6). At the low end, obesity prevalence was still less than 10% but accelerating in parts of South and Southeast Asia and sub-Saharan Africa, where the burden of underweight was relatively high1. At the high end, prevalence surpassed 65% in women and men in some Pacific Island nations (for example, Tonga and Cook Islands) and was more than 35% in many other countries in the Middle East and North Africa and Latin America and the Caribbean, with a steady or accelerating increase in prevalence.
In 2024, obesity prevalence was rising in women in 100 countries and men in 66 countries with a velocity of more than 0.5 percentage points per year and a PP > 0.80 (Figs. 5 and 6 and Extended Data Figs. 7 and 8), a larger number of countries than that crossing the same threshold for children and adolescents. The only high-income western country in this group was Finland for women. The other countries were in various low-income and middle-income regions, with sub-Saharan Africa represented more for women than men, and the opposite for Central and Eastern Europe. In 41 of these countries for women and in 29 for men, the trend in prevalence was classified as accelerating. Nonetheless, the correlation coefficient between prevalence and velocity was only 0.24 for women and 0.27 for men across all countries, smaller than for children and adolescents (Fig. 6). These weaker correlations are a result of the aforementioned dynamics, including that in some countries with high prevalence, the rise in prevalence has slowed down (for example, men in some Pacific Island nations), whereas in some with low prevalence, it is rapidly increasing (for example, in some countries in South and Southeast Asia for both sexes and in some countries in sub-Saharan Africa for women). The velocity of obesity in 2024 was more than 1.0 percentage point per year in 11 countries for one or both sexes; these were predominantly low-income and middle-income countries. Velocity in 2024 was higher among men than among women in Central and Eastern Europe, Central Asia and East Asia, whereas the opposite was true in South and Southeast Asia, the Caribbean and most of sub-Saharan Africa. It was similar between women and men in high-income western countries, Latin America, the Middle East and Pacific Island nations (Extended Data Fig. 9).
Strengths and limitations
Our study has strengths related to its scope, data and methods. We conducted an analysis and presentation of trends in obesity that went beyond the traditional narrative of long-term increase and systematically quantified highly heterogeneous temporal dynamics. We used a large amount of population-based data, from countries covering more than 99% of the population of the world. We maintained a high standard of data quality through repeated checks of the study sample and characteristics, and did not use self-reported data to avoid bias. Data were analysed according to a consistent protocol. We used a statistical model that accounted for the age patterns of BMI during childhood, adolescence and adulthood. We used all available data while giving more weight to national data than to subnational and community data.
As with all global analyses, our study has limitations. Some countries had fewer data and 3 of the 200 countries (Bermuda, Djibouti and North Korea) had none; their estimates were informed to a greater extent by data from other countries, especially those in their respective regions, through a data-driven hierarchy, which was based on geography and epidemiology. Although the cross-validation analysis shows that the estimates for countries without data had relatively small errors, alternative hierarchical arrangement of countries is possible. There were also differences in data availability by time period, with less data available in the first decade of the analysis in some regions. There are other approaches for clustering besides k-means, including some that provide probabilistic allocation to clusters. Given our purpose of general classification of national obesity trajectories (not allocation of resources or policies), we used k-means, which produces non-overlapping clusters.
Implications for obesity prevention
Our results demonstrate that generalizing the trends in obesity as a global epidemic masks highly heterogeneous temporal dynamics across countries and in different age groups. In some high-income western countries, the velocity of obesity in children and adolescents began to slow down as early as around 1990 with the rise coming to a halt by the mid-2000s, and with some indications of a subsequent decline. A similar slowdown and possible reversals followed in adults in these countries and could also be observed in Central and Eastern Europe. The plateauing of the trends in these countries has created a state of endemicity at wide range of prevalences. By contrast, the rise in obesity accelerated in many developing regions among children and adolescents and among adults. In many countries in these regions, the rise continues to accelerate at prevalences that are higher than those in most high-income countries.
The results of our comparative global analysis show that the direction and pace of change in obesity vary over time in the same country, and cover the spectrum from steady or accelerating rise, to a slowdown or plateau in rise, or even decline. This feature was qualitatively presented in the obesity transition framework14. Here we quantified these dynamics and their similarities and variations across the globe using a vast amount of data. Of note, we found indications that a small decline in obesity in national populations may have begun, especially for women, which was rare when the original transition framework was formulated14. In Italy and Portugal, obesity had a negative velocity in children, adolescents and adults of both sexes in 2024, although some of these were not statistically distinguishable from zero. If these declines persist with additional years of data, they will confirm the feasibility of the fourth stage of the obesity transition, which envisioned a decline in prevalence. Our analysis revealed and quantified three further features of worldwide obesity dynamics that were not formally included in the obesity transition framework. First, countries, both across and within regions, vary in whether and when the increase in obesity accelerated, decelerated, plateaued or reversed. This diversity in shape and timing of change led to the emergence of distinct phenotypes of national obesity trends, for example, accelerating, steady or decelerating increase or recent acceleration, beyond the general concept of increase in stages 1 and 2 of transition, as presented in the obesity transition framework14. For example, countries in Eastern Europe and Latin America with similar economic development had distinct trajectories, with many countries in Eastern Europe having started to plateau, whereas most countries in Latin America are still experiencing a steady or accelerating rise in obesity. As an example of within-region diversity, in the Middle East and North Africa, obesity plateaued in Kuwait but continues to rise in Iran, Oman and Saudi Arabia. Second, for any trajectory phenotype, there is substantial variation in the prevalence of obesity both across and within regions. For example, obesity plateaued at a much higher prevalence in high-income English-speaking countries than in those in continental Western Europe for both children and adolescents and adults. Within continental Western Europe, obesity prevalence has stabilized at 11–23% for adults and 4–15% for children and adolescents; in high-income English-speaking countries, it reached 25–43% for adults and 7–23% for children and adolescents. For countries with an accelerating increase in obesity, prevalence among adults in 2024 was less than 5% in East African countries (for example, Ethiopia and Rwanda), but reached 30–40% in some countries in Central Europe (for example, Romania and Czechia) and Latin America (for example, Brazil). Within a region, for example, East and Southeast Asia, countries with an accelerating increase in obesity had a prevalence in 2024 ranging from 2–3% in Timor-Leste and Vietnam to 20–40% in Thailand and Brunei. Third, the above characteristics can vary between children and adolescents and adults, and between sexes, further distinguishing regions and countries. For example, women in both Central Asia and Latin America had a steady or accelerating increase in obesity, whereas trends among girls were largely flat in Central Asia but had an accelerating increase in Latin America. Of note, we demonstrated earlier plateauing of the rise in obesity prevalence in children and adolescents than in adults in high-income countries, whereas in most other regions, deceleration and plateauing of the rise in prevalence occurred in adults before they did in children and adolescents or while obesity continued to increase in children and adolescents. In terms of sexes, the velocity of obesity was typically higher in men than in women in Central and Eastern Europe, whereas in South and Southeast Asia and most of sub-Saharan Africa obesity had higher velocity in women than in men (Extended Data Fig. 9). Similarly, the rise in obesity plateaued or decelerated for both sexes in most high-income western countries, but this phenomenon was limited to women in Central Europe.
These heterogeneities collectively demonstrate that obesity dynamics and trajectories differ across countries that are similar in their economy (for example, national income; market-driven versus managed economy; and agricultural, manufacturing or service economy), environment (for example, extent of urbanization) and technology (for example, extent of mechanization, motorization, electrification and penetration of information technology). Explanations of the rise in obesity have typically been based on generalizations about the so-called shared triggers and global drivers, such as availability and marketing of certain foods and energy expenditure of physical activity at work, transport and leisure, and framed as consequences of macro trends such as urbanization. Although these factors may be relevant, they alone do not explain the heterogeneities that we uncovered, which suggests that their roles are modified or even countered by other social, economic and policy factors. These may include cultural factors and social norms and roles that influence what and how much children, adolescents and adults eat at home and in social settings15,16,17, how much they participate in sports, play and active commuting18,19, and social norms and perceptions related to body image and the discordance between ideal, perceived and actual body weight20,21,22. They also include levels and distributions of income and education that affect food choices and participation in sports, either through access and affordability or the ability to use information about the nutritional value and potential harms of specific foods23,24,25,26. Finally, some of these heterogeneities may reflect differences across countries in technological, institutional and community characteristics that influence food, sports and other forms of physical activity, such as healthy school meals and, in some countries, sports and physical education programmes at schools and community centres27. Identifying the role of these phenomena, and their complex interactions, can inform programmes and policies that curb or reverse the rise in obesity. Doing so requires detailed data on food and physical activity, and the related technological, economic, social and cultural factors, including their distributions within each country, and methods to estimate their contributions to change. However, such data are even more scarce than data on obesity. As a result, understanding the complex drivers of change and drawing lessons on good practice has to use a combination of multi-country analyses and in-depth case studies in specific countries, especially those where obesity did not increase, plateaued at low levels or plateaued early (for example, Denmark, France and Spain for both children and adolescents and adults; and Kazakhstan, Japan and Taiwan for children and adolescents), as has been done for growth and nutrition in children28,29. There may also be an as-yet-unmeasured effect from variations in a broader group of factors such as sleep duration and patterns, stress and other psychosocial factors, and environmental exposures such as endocrine-disrupting chemicals. Furthermore, these environmental and nutritional factors interact with genetics and possibly with the phenotypic characteristics that arise from fetal and early-life nutrition30. Although recent medications are efficacious in terms of weight loss, their effects on trends presented here are likely to be small given relatively low coverage in most countries during the period of our analysis31; these medicines may nonetheless have an increasingly important influence on future trends.
The distinction in trends between high-income countries and low-income and middle-income countries, in relation to the shape of the trajectories and the timing of acceleration, plateau and deceleration at different ages, may be because in high-income countries, the rise in obesity resulted from gradual economic and technological trends that affected food availability, composition and cost5,6,7,32. This gradual change coincided with expanding opportunities for healthier diets among those with higher income and education25,26, which contributed to a subsequent deceleration in obesity in these populations. The predominant policy response to obesity has been provision of information about its harms, and encouraging prevention through nutrition and physical activity, which became more common in the 2000s33. A side effect of such a response, which relies on individuals’ use of information and advice without enhancing access to and affordability of healthy foods, has been increasing inequality in obesity in these countries23,24,25,26,34,35,36,37,38,39. There have been few policies and programmes that have attempted to systematically change nutrition and physical activity40,41, especially in those with lower education and income where obesity prevalence is higher, beyond demonstration projects42, which have not been scaled and sustained nationally. There is insufficient evidence to ascertain whether specific policies and programmes have curbed the rise in obesity, or even improved nutrition and physical activity, in real-world settings43,44,45,46,47,48, with the possible exception of sugar-sweetened beverage taxes, which have had a measurable, albeit small, effect on obesity in multiple places49,50,51,52,53. These taxes have only been recently implemented hence do not account for the earlier plateaus.
In low-income and middle-income countries, despite the heterogeneities in the shape and pace of increase, the rise in obesity continues unabated both where prevalence is still low and where prevalence has already surpassed those of high-income countries, especially for children and adolescents as seen by the correlation between velocity and prevalence. In these settings, the mechanization of work and transport54, improved purchasing power and food trade and commercialization4,55 brought many health and nutritional benefits, including gains in height56, while also leading to a rise in obesity because the public health system and household consumption practices11,57 were primarily focused on addressing undernutrition. Furthermore, until recently, there was no or limited fiscal or regulatory response to aggressive marketing of items such as sugar-sweetened beverages that have no nutritional benefit and worsen obesity. The food production, supply and distribution infrastructure, and in many cases income58, remain insufficient for regular availability and purchase of healthy foods such as fresh fruits and vegetables or unprocessed whole-grain items. This is particularly the case in many island nations where rapid changes in diet followed changes from locally sourced to imported processed foods59.
Our results, and the potential reasons for these dynamics and their heterogeneities, highlight both opportunities and challenges for curbing the rise in obesity across the world. The numerous cases of plateau and even reversal in obesity show that the rise can be contained even at low levels. At the same time, the wide variation in whether, when and at what prevalence the plateau occurred shows that stopping and reversing the rise may be harder in some places owing to the diverse factors that affect what and how much people eat. Some of these factors go beyond those commonly stated as drivers of obesity, and may include social norms, the food culture, and levels and inequalities in education, income, food infrastructure and access, the living environment and health care. In the future, weight loss medications also provide an additional route for addressing obesity, but their highly variable costs through public and private providers are currently an obstacle to increasing their coverage and may increase inequalities. The combination of the opportunities and challenges demonstrates that what is needed is nuanced nutritional and health policies and programmes that are relevant for each country, especially those that support people with lower income and education towards eating healthy foods, having an active lifestyle and using relevant health care interventions to attain and maintain health, functional capacity and quality of life across the life course.
Methods
Our analytical aim was to quantify and characterize the dynamics of how obesity has changed over time, building on studies that reported the extent of change over long multi-decade periods1. As a quantitative measure of the dynamics of obesity, we calculated the velocity of obesity as the rate of absolute change in prevalence between consecutive years. This metric allows understanding whether the rise in the prevalence of obesity has been uniform over time, or if its pace has changed, including acceleration, deceleration, plateauing and reversal. In addition, we used clustering to categorize the national trajectories of obesity prevalence based on their shape. The input to both analyses was prevalence of obesity in 200 countries from 1980 to 2024, a period during which obesity was recognized as an epidemic2,3,60. To estimate prevalence, we pooled population-based studies with measurements of height and weight. Pooled data were analysed using a Bayesian hierarchical meta-regression model. The posterior estimates were then used for calculating velocity and clustering.
Our analyses addressed the dynamics of obesity in school-aged children and adolescents 5–19 years of age and in adults 20 years of age and older. Our primary outcome was the prevalence of obesity, defined as BMI ≥ 30 kg m−2 for adults 20 years of age and older and as BMI > 2 s.d. above the median of the WHO growth reference for children and adolescents 5–19 years of age61,62. Following previous work1,10,63, we conducted separate analyses for children and adolescents and for adults, because different cut-offs are used to measure obesity in the two groups61,62,64.
Data access and data inclusion
We pooled population-based studies with measurements of height and weight in samples of the general population from a database collated by the NCD Risk Factor Collaboration (NCD-RisC). Data were obtained from publicly available multi-country and national measurement surveys (for example, Demographic and Health Surveys, WHO STEPwise approach to Surveillance (STEPS) surveys, and those identified via the Inter-University Consortium for Political and Social Research, European Health Interview & Health Examination Surveys Database and the UK Data Service). With the help of the WHO and its regional and country offices, we identified and accessed population-based survey data from national health and statistical agencies. We searched and reviewed published studies as previously detailed63,65,66,67 and invited eligible studies to join NCD-RisC, as we did with data holders from earlier pooled analyses of cardiometabolic risk factors68,69,70,71. The NCD-RisC database is continuously updated through all the above routes as well as through periodic requests to NCD-RisC members to suggest additional sources in their countries.
We carefully checked that each study met our inclusion criteria, which are listed below. All NCD-RisC members were also periodically asked to review the list of sources from their country, to verify that they met the inclusion criteria and were not duplicates. Potential duplicate data sources were first identified by comparing studies from the same country and year, followed by checking with NCD-RisC members who had provided data whether sources from the same country and year, and with similar sample sizes and age ranges, were the same or distinct. If two sources were confirmed as duplicates, one was discarded.
For each study, we recorded the study population, the sampling approach, the years of measurement and measurement methods. Only data that were from samples of the general population were included. All data were assessed and classified by whether they covered the whole country, one or more subnational regions (that is, one or more provinces or states, more than three cities, or more than five rural communities), or one or a small number of communities (limited geographical scope not meeting above national or subnational criteria). As stated in statistical methods, these study-level attributes were included in the Bayesian hierarchical meta-regression model so the modelling was informed by all available data, but accounted for the aforementioned differences in the populations from which different studies had sampled. All submitted data were checked by at least two people independently. Questions and clarifications were discussed with NCD-RisC members and resolved before data were incorporated into the database.
Data were included if the following criteria were met: measured data on height and weight were available; study participants were 5 years of age and older; data were collected using a probabilistic sampling method with a defined sampling frame; data were from population samples at the national, subnational or community level as defined above; and data were from the countries listed in Supplementary Table 1.
We excluded all studies that were solely based on self-reported height and weight, without any measurement, because these data are subject to biases that vary by geography, time, age, sex and socioeconomic characteristics72,73,74. Owing to these variations, approaches to correcting self-reported data may leave residual bias. We excluded data sources on population subgroups whose anthropometric status may differ systematically from the general population, including studies that had included or excluded people based on their health status; and female individuals 15–19 years of age in surveys that sampled only ever-married women or measured height and weight only among mothers. We excluded studies whose participants were only from specific educational, occupational, socioeconomic or ethnic subgroups of the general population, with the exceptions of school-based studies in countries and age–sex groups with school enrolment of 80% or higher. We also excluded studies that recruited participants through contact with health facilities; the exceptions to this exclusion criterion were studies whose sampling frame was health insurance schemes whose membership is not based on occupation or socioeconomic status in countries where at least 80% of the population were insured, and studies based on the primary-care system in high-income and Central European countries with universal insurance, as contact with the primary-care systems in these countries tends to be as good as or better than response rates for population-based surveys.
Data cleaning and management
We excluded participants whose age was younger than 18 years if their data were not reported by single year of age (less than 0.01% of all participants), because the age associations of height and weight may be non-linear in these ages, especially during growth spurts. We excluded BMI data for female individuals who were pregnant at the time of measurement (0.33% of participants), because weight changes during pregnancy. We excluded 0.23% of participants with recorded values outside of the following predefined ranges: recorded height below 60 cm or above 180 cm for those younger than 10 years of age; below 80 cm or above 200 cm for those 10–14 years of age; and below 100 cm or above 250 cm for those 15 years of age or older; recorded weight below 5 kg or above 90 kg for those younger than 10 years of age; below 8 kg or above 150 kg for those 10–14 years of age; and below 12 kg or above 300 kg for those 15 years of age or older; or recorded BMI below 6 kg m−2 or above 40 kg m−2 for those younger than 10 years of age; below 8 kg m−2 or above 60 kg m−2 for those 10–14 years of age; and below 10 kg m−2 or above 80 kg m−2 for those 15 years of age or older. As in previous uses of these data1,9,10,56,75, we excluded these participants because values outside these ranges were likely to reflect measurement or data recording errors.
Anonymized individual data from the studies from 1980 to 2024 in the NCD-RisC database were reanalysed according to a common protocol. We calculated prevalence in the following BMI ranges: for children and adolescents, the prevalence of BMI less than −2 s.d., −2 s.d. to less than −1 s.d., −1 s.d. to 1 s.d., more than 1 s.d. to 2 s.d., and more than 2 s.d. from the median of the WHO growth reference61; for adults, the prevalence of BMI less than 18.5 kg m−2, 18.5 kg m−2 to less than 20 kg m−2, 20 kg m−2 to less than 25 kg m−2, 25 kg m−2 to less than 30 kg m−2, 30 kg m−2 to less than 35 kg m−2, 35 kg m−2 to less than 40 kg m−2, and 40 kg m−2 or higher.
Of the studies with BMI data, 79% were included in the NCD-RisC database as individual participant data; another 14% were provided as summary statistics, that is, age–sex-specific prevalence of relevant BMI categories. When summary statistics were prepared by study investigators, detailed instructions were provided, as was computer code when requested, to ensure analysis was conducted according to the study protocol. The cut-offs for calculating prevalence in the BMI categories for school-aged children and adolescents were all age-specific and sex-specific and were applied to data in single years of age. All analyses incorporated sample weights and complex survey design, when applicable, in calculating summary statistics. Information on survey design and sample weights were provided by participating studies. For studies that used multistage (stratified) sampling, we accounted for survey design features when calculating standard errors, including clusters, strata and sample weights, using Taylor series linearization as implemented in the R package ‘survey’ (v4.4.2)76.
We used two additional types of studies, accounting for 7% of all studies. First, we included some data from a previous pooling analysis68. We invited these studies to join NCD-RisC, as stated above. However, data from some studies were no longer available, for example, because the authors had retired or moved, data had been permanently archived or data were stored using older storage technologies that could not be easily retrieved. Second, summary statistics for nationally representative data from sources that were identified but not accessed via the above routes were extracted from published reports. Data were also extracted for two STEPS surveys that were not publicly available77,78. The two additional types of studies made up 0.7% of our data points for children and adolescents and 8.4% for adults (a data point is an age–sex–study-specific prevalence in a BMI category, which is used in the Bayesian meta-regression model as described below to make estimates for all age groups, countries and years). These studies had information on mean BMI and/or on a subset of BMI categories that were analysed in this work. To enable us to use these data, we used previously validated conversion regressions to estimate the missing primary outcome from the available BMI metric (or metrics). Additional details on conversion regression model specifications and the model coefficients are reported on GitHub (https://github.com/NCD-RisC/ncdrisc-methods/blob/main/NCD-RisC-conversion-model-for-prev-bmi.pdf).
After the data access and cleaning procedure described above, we used 4,050 population-based studies that measured height and weight in 232 million participants 5 years of age and older from 197 countries in this study. The data included 2,582 studies for children and adolescents from 189 countries, and 2,980 studies for adults from 196 countries. We had at least one study for 197 (99%) of the 200 countries for which estimates were made (Supplementary Fig. 1), at least two studies for 188 countries (94%) and at least three studies for 177 countries (89%). 189 countries had at least one national study, of which 181 had at least two national studies and 166 had at least three national studies. Countries in the high-income western super-region (with an average of 53.3 studies per country) and the East and Southeast Asia super-region (with an average of 33.5 studies per country) had the most data, and those in Pacific Island nations (6.0 studies per country) and sub-Saharan Africa (8.6 studies per country) had the least data (Supplementary Figs. 1 and 2). Other super-regions on average had 12.1–26.7 studies per country. Details of the studies are provided in Supplementary Table 2.
Statistical model
Overview
We used a Bayesian hierarchical meta-regression model to estimate trends in the prevalence of different BMI categories by sex, age, country and year from 1980 to 2024. The statistical methods for analysis of pooled data, including its implementation and computation, are described in detail in a statistical paper79 and related substantive papers1,9,10,56,71,80,81. Model specification is summarized here and described using statistical notation in the sections below. In summary, the model had a hierarchical structure, in which countries were nested in regions, which were nested in super-regions, which were nested in the globe (Supplementary Table 1). Estimates for each country and year were informed by its own data, if available, and by data from other years in the same country and from other countries, especially those in the same region with data for similar time periods. The extent to which estimates for each country-year were influenced by data from other years and other countries depended on whether the country had data, the sample size of data, whether the sources were at national, subnational or community level, and the within-country and within-region variability of the available data. The model incorporated non-linear time trends through the combination of linear and second-order random walk terms, all modelled hierarchically.
The age association of BMI was modelled using a cubic spline to allow for non-linear age patterns, which might vary across countries. The coefficients of the splines were modelled hierarchically1,10,81. For adults, we allowed the coefficients to vary over time to reflect changing age associations1,81. For children and adolescents, model testing showed that a simpler model without age–time interaction had better performance1,10. For adults, two knots were placed at 45 and 60 years, and for children and adolescents, at 10 and 15 years, on the basis of exploratory analyses1,10,56.
The model accounted for the possibility that BMI in subnational and community samples might systematically differ from, and have larger variation than, nationally representative surveys through the inclusion of fixed-effect and random-effect terms. The fixed effects adjusted for systematic differences between subnational or community studies and national studies and allowed these differences to vary over time. The random effects allowed national data to have a larger influence on the estimates than subnational or community data with similar sample sizes. The model also accounted for urban–rural differences in the prevalence of a BMI category, through data-driven fixed effects for urban-only and rural-only studies. These urban and rural effects were weighted by the difference between study-level and country-level urbanization in the year when the study was conducted and were also permitted to vary across time.
We fitted the statistical model using Markov chain Monte Carlo (MCMC). For model fitting, data on participants 5–19 years of age were included in the analysis of trends in children and adolescents, and on participants 18 years of age and older in the analysis of trends in adults. Data on participants 18 and 19 years of age were included in both sets of models because these groups form a transitional age from adolescence to adulthood, hence these data are informative for estimates in both groups. All analyses were done separately by sex because age, geographical and temporal patterns of BMI differ between sexes1,56,82. Computational details, including on initialization of MCMC chains and model convergence, are provided in the section on model implementation.
Model specification
Each study contributed up to 15 data points for each BMI category and sex, with the exact number depending on the age groups represented in the study. In the model specification, an observation yh,i, that is, the number of people in the prevalence category from age group h of study i, carried out in country j at time t, was specified to have a binomial distribution conditional on the sample size nh,i and prevalence ph,i:
We modelled the prevalence ph,i from age group h of study i via a latent variable \({\alpha }_{h,i}\,=\,{\varPhi }^{-1}({p}_{h,i})\), representing probit-transformed prevalence, through the following Gaussian distribution:
where j, the country in which a study was carried out, and t, the study year, are uniquely determined by the study index i; we denote this determination of j and t on i by \(j[i]\) and \(t[i]\), respectively. The country-specific intercept and linear time slope from country j are denoted aj and bj, respectively, with j \(\epsilon \,\{1,\,..\,J\},\) where J = 200 is the total number of countries and territories in our analysis. We describe the hierarchical model used for the a’s and the b’s in the section ‘Linear components of country time trends’. Letting T = 45 be the total number of years from 1980 to 2024, the T-length vector uj captures smooth non-linear change over time in country j, as described in the section ‘Nonlinear change’. The contribution of the age term for age group h (with mid-age zh) in study i is denoted by \({\gamma }_{i}({z}_{h})\); these are described in detail in the section ‘Age model’. The matrix X contains terms describing whether studies were representative at the national, subnational or community level, and whether they were urban only, rural only or covered both areas, and \({\boldsymbol{\beta }}\) contains the associated fixed effects. In addition, a random effect ei was estimated for each study. These study-specific terms are described in the section ‘Study-level terms and study-specific random effects’. The variance term \({\tau }^{2}\) captures variability not accounted for by the study-specific random effects, described in the section ‘Residual age-by-study variability’. Priors assigned to model hyperparameters are summarized in Supplementary Table 3. Details on model fitting and convergence are given in the section ‘Model implementation’. Finally, details on how country-level inference was performed are given in the section ‘Inference and post-processing’.
Linear components of country time trends
The model had a hierarchical structure, in which studies were nested in countries, which were nested in regions (indexed by l), which were nested in super-regions (indexed by m), which were all nested in the globe (see Supplementary Table 1 for a list of countries in each region and regions in each super-region). This structure allowed the model to share information across units to a greater degree when data were non-existent or weakly informative (for example, had a small sample size or were not nationally representative) and, to a lesser extent, in data-rich countries and regions83.
The a and b terms are country-specific linear intercepts and time slopes with terms at each level of the hierarchy, denoted by the superscripts c, r, s and g, respectively:
where \(x\in \{c,{r},{s}\}\). The \(\kappa \) terms were each assigned a flat prior on the standard deviation scale84. We also assigned flat priors to \({a}^{g}\) and \({b}^{g}\).
Nonlinear change
The prevalence of a BMI category may change nonlinearly over time1,82. We captured smooth nonlinear change in time in country j using the vector \({u}_{j}\). Just as \({a}_{j}\) and \({b}_{j}\) are each defined as the sum of country, region, super-region and global components, we defined
To allow the model to differentiate between the degrees of nonlinearity that exist at the country, region, super-region and global levels, we assigned the four components of each \(u\) a discrete second-order Gaussian autoregressive prior85,86. In particular, the vectors \({u}_{j}^{c},{j}\in \{1,\,\ldots ,{J}\}\), \({u}_{l}^{r},{l}\in \{1,\,\ldots ,{L}\}\), \({u}_{m}^{s},{m}\in \{1,\,\ldots ,{M}\},\) and \({u}^{g}\), all of length T, are each given a Gaussian prior with mean zero and precision \({\lambda }_{c}P\), \({\lambda }_{r}P\), \({\lambda }_{s}P\) and \({\lambda }_{g}P\), respectively, where the scaled precision matrix \(P\) in the Gaussian autoregressive prior penalizes first and second differences as follows:
\(P\) is multiplied by the estimated precision parameters \({\lambda }_{c}\), \({\lambda }_{r}\), \({\lambda }_{s}\) and \({\lambda }_{g}\), thus upweighting or downweighting the strength of its penalties and ultimately determining the degree of smoothing at each level. For each of the four precision parameters, we used a truncated flat prior on the standard deviation scale (1/√λ)84. We truncated these priors such that logλ ≤ 20 for each of the four λ’s. This upper bound is enforced as a computational convenience, so that models with logλ > 20 are treated as equivalent to a model with logλ = 20, as they essentially have no extra-linear variability in time. In practice, this upper bound had little effect on the parameter estimates. Furthermore, we ordered the λ’s a priori as follows: \({\lambda }_{c} < {\lambda }_{r} < {\lambda }_{s} < {\lambda }_{g}\). This prior constraint conveys the expectation that the global trend in the prevalence of a BMI category has less extra-linear variability than the trend of any given super-region, which has less than those of constituent regions, which in turn has less variability than the trends of constituent countries.
The matrix \(P\) has rank \(T\) − 2, corresponding to a flat, improper prior on the mean and the slope of the \({u}_{j}^{c}\)’s, the \({u}_{l}^{r}\)’s, the \({u}_{m}^{s}\)’s and \({u}^{g}\), and is not invertible87. Thus, we had a proper prior in a reduced-dimension space85, with the prior expressed as follows:
If \({u}_{j}^{c}\) had a non-zero mean, this would introduce nonidentifiability with respect to \({a}_{j}^{c}\). By the same token, \({b}_{j}^{c}\) would not be identifiable if \({u}_{j}^{c}\) had a non-zero time slope, and similarly for the other means and slopes. Thus, to achieve identifiability of the \(a\)’s, \(b\)’s and \(u\)’s, we constrained the mean and slope of each of \({u}^{g}\), \({u}^{s}\), \({u}^{r}\) and \({u}^{c}\) to be zero. Enforcing orthogonality between the linear and nonlinear portions of the time trends meant that each can be interpreted independently.
For the cases in which we have observations for at least two different time points, this improper prior will not lead to an improper posterior because the data will provide information about the mean and slope. To enforce the desired orthogonality between the linear and nonlinear portions of the model, we used the Rue and Held correction85. For the countries without data (for adults, 4 for women and 8 for men; for children and adolescents, 11 for girls and 19 for boys), we took the Moore–Penrose pseudoinverse of P88, setting to infinity those eigenvalues that correspond to the non-identifiability. This effectively constrained the non-identified portions of the model to zero, as the corresponding variances are set to zero86; in this case the Rue and Held correction85 is not needed. An intermediate case occurs when data are observed for only one time point in a country. In this case, the full conditional precision has rank \(T\) − 1 because the mean but not the linear trend of \({u}_{j}^{c}\) is identified by the data. We therefore constrained the linear trend of \({u}_{j}^{c}\) to zero in this case, by taking the generalized inverse of the full conditional precision. We then constrained the mean of \({u}_{j}^{c}\) to zero using the one-dimensional version of the Rue and Held correction85. Computational details have been given in previous papers71.
Age model
We sought a smooth function that could characterize gradual changes in the prevalence of BMI categories over age, as seen in the data. To achieve this, we modelled age using cubic splines, with the number and position of the knots of the spines selected based on epidemiological and physiological knowledge about changes in body shape61,89 and statistical considerations, as previously described1,56,82. Statistically, we used age-stratified residuals to confirm the number and position of knots.
For age group h with mid-age \({z}_{h}\), in study i, the age term is given by
where for children and adolescents, the two knots were placed at ages \(({k}_{1},{k}_{2})=(\mathrm{10,\; 15})\) and for adults at \(({k}_{1},{k}_{2})=(\mathrm{45,\; 60})\) years. To reduce dependence among model parameters, we centred the age variable.
We used different age models for children and adolescents and for adults, as explained below, following previous analyses10,56,81, and visual inspection of results as well as formal model testing carried out using the Watanabe–Akaike information criterion90,91.
For adults, each of the spline coefficients was allowed to vary across countries and was modelled hierarchically, and was further allowed to vary across time, to reflect different trends in prevalence across age groups. We modelled spline coefficients as follows, consistent with previous analyses1,81, with the k-th age term coefficients for study i given as follows:
Here \({\psi }^{g}\), \({\psi }^{c},\,{\psi }^{r}\) and \({\psi }^{s}\) are global, country, region and super-region intercepts, and \({\phi }^{g}\), \({\phi }^{c}\), \({\phi }^{r}\) and \({\phi }^{s}\) are global, country, region and super-region time slope parameters. A flat improper prior was placed on each of the \({\sigma }_{\psi }\)’s and \({\sigma }_{\phi }\)’s.
For children and adolescents, use of the model comparison criteria Watanabe–Akaike information criterion showed that the age–time interaction terms, \(\phi \), did not improve model fit. Therefore, each of the spline coefficients was still allowed to vary across countries and was modelled hierarchically but was held constant over time, consistent with previous analyses1,10. The k-th age term coefficients for study i were given as follows:
with flat improper prior placed on each of the \({\sigma }_{\psi }\)’s.
Study-level term and study-specific random effects
The prevalence of a BMI category as measured in individual studies may vary from the true unobserved country–year prevalence owing to study implementation factors such as those associated with sampling, participation and response, and measurement. We included time-varying offsets (referred to above as fixed effects) to help account for potential systematic differences associated with data sources that are representative of subnational or community populations, and data sources that are representative of urban-only or rural-only populations, through the term \({{\boldsymbol{X}}}_{{\boldsymbol{i}}}{\boldsymbol{\beta }}\):
where \({{\boldsymbol{X}}}_{i}^{\mathrm{cvrg}}\) is the indicator for whether the coverage of study i, in country j and year \(t\), is subnational or community, \({{\boldsymbol{X}}}_{i}^{{\rm{s}}.\mathrm{urb}}\) is the indicator for whether the study i covered rural-only or urban-only populations, and \({{\boldsymbol{X}}}_{j[i],t[i]\,}^{{\rm{c}}.\mathrm{urb}}\) is the percentage of the national population of country \(j\) in year t living in urban areas, as obtained from the 2018 revision to the United Nation’s World Urbanization Prospects92. We note that \({\beta }_{5}\) through \({\beta }_{8}\) are all multiplied by zero for studies that are urban only in countries where all residents lived in urban areas (for example, Singapore) and for studies that are rural only in countries where all residents lived in rural areas (for example, Tokelau), that is, in such cases, the model does not consider studies classified as urban (respectively rural) to have potential systematic differences from the true underlying prevalence in the country.
Even after accounting for sampling variability, national studies may still not reflect the true prevalence of a BMI category in a country with perfect accuracy, and subnational and community studies have even larger variability. We include the study-specific random effect \({e}_{i}\) to allow all age groups from the same study to have an unusually high or an unusually low prevalence, after conditioning on the other terms in the model. Each \({e}_{i}\) is assigned a Gaussian prior with variance dependent on whether study i is representative at the national, subnational or community level. Random effects from national studies were constrained to have smaller variance (\({v}_{n}\)) than random effects of subnational studies (\({v}_{s}\)), which were in turn constrained to have smaller variance than community studies (\({v}_{c}\)).
Residual age-by-study variability
The age patterns across communities within a given country may differ from the overall age pattern of that country. This within-study variability cannot be captured by the \({e}_{i}\) terms, which are equal across age-specific observations in each study, so we included an additional variance component for each study, \({\tau }^{2}\).
Model implementation
The model was fitted through a bespoke MCMC sampler coded in R, which uses a combination of Metropolis–Hastings and Gibbs updates93. To generate starting values for the model runs, we ran an initial set of eight MCMC chains. We generated the starting values of each initial chain by first randomly generating log variance parameter values from diffuse Gaussian distributions centred on estimates from previous analyses, and then generating all other starting values conditional on these variance parameters. We ran each of the initial chains for 50,000 iterations after burn-in, thinned and combined across chains to obtain 5,000 posterior draws. To estimate a distribution from which to sample initial values for the final model runs, we fitted a multivariate Gaussian distribution to the posterior distribution of all non-study-specific parameters obtained from the initial chains, scaling the variance–covariance matrix by a factor of 1.5; this equates to an increase in the variance of the multivariate Gaussian distribution of approximately 50% relative to the target posterior distribution. This is a larger overdispersion than that of 10%, which is considered sufficient for the Rhat convergence diagnostic94, and allows a larger spread of initial values to be included. To obtain initial values for study-specific parameters, we first sampled a study-specific random effect \({e}_{i},\) for each study i, from a Gaussian distribution with mean zero and variance given by the sampled initial values of \({v}_{n}\), \({v}_{s}\) or \({v}_{c}\), dependent on whether study i was representative at the national, subnational or community level. We then sampled initial values of the latent variable \({\alpha }_{h,{i}}\) for each age group h and study i from its Gaussian distribution, conditional on all other sampled parameter values, including the study-specific random effect \({e}_{i}\).
We had a target of eight converged MCMC chains for generating our estimates, which is twice the recommended minimum number to assess convergence using the Rhat diagnostic91,95. The exact numbers of chains used for the model runs are not critical so long as at least four chains are run to enable us to estimate between chain variation, which is needed for the Rhat convergence diagnostic to be meaningful95, and so long as there are sufficient computational resources to run chains to convergence and subsequently to collect samples. We ran ten chains for each BMI category sex combination, with chains ordered by their seeds. The additional two chains were run to allow for a small number of the first eight chains to be discarded if mixing was slow. In practice, no chain was replaced. We did not run more chains because the computational and time cost outweighed the gains, if any, in results. We identified, through visual inspection of hyperparameter trace plots, a burn-in period of 20,000 iterations for adult prevalence categories, and 30,000 for child and adolescent categories. We took 50,000 post-burn-in iterations from each of the eight target chains, and combined and thinned to obtain a final sample of 5,000 posterior draws for each outcome.
Convergence was confirmed through visual inspection as well as through calculated split-Rhat diagnostic for country–year–age outcomes as implemented in the R package ‘rstan’ (v2.26.15)95,96. The 97.5th quantile of split-Rhat ranged across BMI categories and sexes from 1.003 to 1.013 for adults, and from 1.004 to 1.014 for children and adolescents. Over 99% of country–year–age outcomes across all categories and sexes for adults and for children and adolescents had split-Rhat < 1.05.
Inference and post-processing
All inference was done for country–year–age combinations, through combining the a, b, u and \(\gamma \) terms, and setting \(\beta =0\) and \({e}_{i}=0\). We set \(\beta =0\) as fixed effects associated with study design are not relevant for country-level inference. We set \({e}_{i}=0\) as random effects arising from imperfections and variations in study design and implementation, and from within-country variability of the prevalence of a BMI category, are also not relevant for country-level inference.
Posterior estimates were made in 1-year age groups for 5–19 years of age, because BMI changes rapidly in relation to age in these ages, and in 5-year age groups for 20 years of age and older. As in previous work1,82, we rescaled the estimated prevalence of different BMI ranges so that their sum was 1.0 in each sex, age, country and year. The average scaling factors across samples ranged from 1.00 to 1.02 for children and adolescents and 0.99 to 1.03 for adults, that is, the sum of the separately estimated prevalence categories was close to 1. We calculated the prevalence of obesity at the draw level as the sum of the prevalence of BMI of 30 kg m−2 to less than 35 kg m−2, 35 kg m−2 to less than 40 kg m−2, and 40 kg m−2 or higher.
For presentation, we summarized results for 5–19 years of age for children and adolescents, and for 20 years of age and older for adults, as age-standardized results. Age standardization puts the population for each country–year on the same (standard) age distribution, hence enables comparisons to be made over time and across countries. Age standardization was performed by taking the weighted means of age–sex-specific estimates, separately for children and adolescents and for adults, using age weights from the WHO standard population97. We calculated the velocity of obesity for a given year at the draw level as the absolute difference in age-standardized obesity prevalence between consecutive years. To simplify reporting notation, we refer to velocity for each set of consecutive years by the terminal year: for example, the 2023−2024 velocity is referred to as velocity in 2024.
The uncertainties of our estimates, represented by their posterior distributions, capture the following sources of uncertainty in true obesity prevalence: uncertainty due to sampling in each data source; uncertainty associated with the variability of national data beyond what is accounted for by sampling; uncertainty associated with subnational and community data, which are more variable than national data; and uncertainty due to making estimates by country, year and age when data were missing, scarce or weakly informative. The reported credible intervals represent the 2.5–97.5th percentiles of the posterior distributions, which contain the true estimates with 95% probability. We obtained the PP that an estimated change in obesity represented a true increase as the proportion of draws from the posterior distribution that indicated an increase, that is, a positive change. We obtained the PP that an estimated velocity of obesity was positive (that is, prevalence is increasing) as the proportion of posterior draws for which the velocity was positive.
Validation of statistical model
To evaluate how well our statistical model fitted the data, we calculated the difference between the posterior estimates of obesity prevalence from the model and data from national studies. Median errors were very close to zero (0.11 percentage points for children and adolescents and 0.06 percentage points for adults) and median absolute errors were 1.09 percentage points for children and adolescents and 1.11 percentage points for adults, indicating that the estimates were unbiased and had small deviations relative to national studies.
Although we had data for 189 out of 200 (95%) countries for children and adolescents, and 196 of 200 (98%) for adults, we also conducted the more challenging test of how well our statistical model predicts missing data, known as external predictive validity. We evaluated external predictive validity in two different tests. In test 1, we held out all data from 10% of countries with data (that is, created the appearance of countries with no data where we actually had data), a higher percentage than the actual missingness in the dataset that we used. The countries whose data were withheld were randomly selected from the following three groups: data-rich (12 or more data sources for girls, 10 or more for boys, 13 or more for women and 10 or more for men), data-poor (1–3 data sources for girls, 1−2 for boys, 1–4 for women and 1−2 for men) and average data (4–11 data sources for girls, 3–9 for boys, 5–12 for women and 3–9 for men) availability. All data-rich countries had at least one data source after 2010. We fitted the model to the data from the remaining 90% of countries and made estimates of the held-out observations. In test 2, we assessed other patterns of missing data by holding out 10% of our data sources, again from a mix of data-rich, data-poor and average-data countries, as defined above. For a given country, we either held out a random one-third of the data of that country or all of the 2010−2024 data of that country to determine, respectively, how well we filled in the gaps for countries with intermittent data and how well we estimated in countries without recent data. Given that test 1 held out 10% of countries with data and we had data for 95% of countries for children and adolescents and 98% for adults, test 2 is a better reflection of external predictive validity of our analysis.
We fitted the model to the remaining 90% of the dataset and made estimates of the held-out observations. We repeated each test five times, holding out a different subset of data in each repetition. In both tests, we calculated the differences between the held-out data and the estimates. We also calculated the 95% credible intervals of the estimates; in a model with good external predictive validity, 95% of held-out values would be included in the 95% credible intervals, a metric referred to as coverage.
Our statistical model also performed well in the external validation tests, that is, in estimating obesity prevalence when data were missing. The estimates of obesity prevalence had median errors that were close to zero or small globally (for test 1 and test 2, respectively, 0.61 and 0.17 percentage points for girls, 1.02 and 0.63 percentage points for boys, 1.82 and 0.21 percentage points for women, and 1.46 and 0.15 percentage points for men), and ±4 percentage points or less in every subset of withheld data except for Pacific Island nations in test 1 for adults where median error was −4.51 and 4.94 percentage points for women and men, respectively (Supplementary Table 4). The 95% credible intervals of estimated prevalence of obesity covered 92–97% of true data globally for children and adolescents and 87–91% for adults; coverage was above 85% in most subsets of withheld data. Median absolute errors globally ranged from 1.72 to 3.53 percentage points for children and adolescents and from 2.21 to 4.57 percentage points for adults. Median absolute errors were smaller in test 2, where a subset of data sources from some countries are withheld, than in test 1, where all data from some countries are withheld. For comparison, median absolute differences for prevalence of obesity between pairs of nationally representative surveys done in the same country and in the same year was 2.06 percentage points for children and adolescents and 1.76 percentage points for adults, indicating that our estimates perform almost as well as conducting two distinct surveys in the same country and year.
Clustering obesity prevalence time series
We used clustering analysis to identify national obesity prevalence time series that have similar shapes in a data-driven (unsupervised) approach. The input to the analysis was the posterior mean age-standardized obesity prevalence for each country from 1980 to 2024 estimated via the Bayesian meta-regression model as detailed above. Data preprocessing and clustering were performed separately by sex and for children and adolescents and for adults.
We first normalized the posterior mean obesity prevalence in each country by subtracting the mean and dividing by the standard deviation so that the time series for each country had zero mean and unit variance. This step allowed the subsequent clustering to be determined by the shape of trajectory as opposed to its level and magnitude of change, which are captured by prevalence and velocity metrics. We then, for each year, subtracted the annual mean normalized prevalence across all countries from the country-specific (normalized) prevalence to remove the overall temporal trend in normalized prevalence. We used principal component analysis to identify the features that explained most variance, hence removed low-variance features98. The first three principal components explained more than 97.9% of the variance and characterized the shape of the time series of each country.
We applied k-means clustering to the country scores of the first three principal components. The k-means algorithm partitions the data into k mutually exclusive clusters that are relatively homogeneous while maximizing the heterogeneity among clusters, by minimizing the sum of Euclidean distances of all data points from the centre of the cluster they belong to. It is a widely used and computationally efficient clustering algorithm that produces non-overlapping clusters.
In k-means analysis, the number of clusters k must be pre-specified. Various heuristics have been suggested for selecting a suitable number of clusters such as the elbow method and the silhouette method. These metrics compare measures of cluster cohesion and cluster separation for different choices of k. We ran the k-means algorithm across a range of k values from 3 to 20, and selected k = 6 based on these heuristics as well as epidemiological interpretability of the results and consistency between sexes and between children and adolescents and adults. The k-means algorithm uses random starting values and iteratively minimizes the sum of distances until reaching an optimum. To minimize the risk of converging to local optima, we initiated with 50 different random starting values and used the best cluster allocation, that is, the one with the minimum sum of distances across the 50 runs99. We labelled each cluster based on the typology of obesity prevalence trends of the countries in the cluster.
We evaluated the stability of the resultant clusters by calculating the mean Jaccard index100 between the clustering results over all countries and that of 1,000 subsamples of countries drawn without replacement (Supplementary Table 5). The Jaccard index is a measure of similarity between two groups and ranges from 0 to 1, with 0 indicating no overlap and 1 indicating identical results. We calculated the Jaccard index across a range of subsample proportions from 50%, which is an extreme situation in terms of the share of countries removed, to 90%. We computed a cluster-wise Jaccard index for each cluster in a comparison with the most similar cluster obtained in each subsample100. The mean Jaccard index across 1,000 subsamples reflects how consistently the same cluster appears across repeated subsampling and reclustering. As a practical guideline, a mean Jaccard index larger than 0.75 is considered as showing good recovery and overall stability, whereas values smaller than 0.60 suggest that the cluster is not consistently recovered across repeated subsampling100,101,102. The results indicate highly stable clusters with average Jaccard indices across the six clusters for the four age group and sex combinations ranging 0.90–0.96 when 90% of countries were used, 0.84–0.92 when 80% were used and 0.77–0.83 in the difficult task of clustering with only 50% of countries. For children and adolescents, the Jaccard index remained above 0.75 for all clusters when up to 20% of countries were dropped. When 30% or more of countries were dropped, the Jaccard index was above 0.75 for all but one cluster each for girls (decelerating increase) and for boys (recent decline). For adults, the Jaccard index remained above 0.75 when up to 20% of countries were dropped for all but one cluster (recent decline for men) possibly because some of its constituent countries were absorbed into the related clusters such as plateau as countries were dropped. The average Jaccard index for the cluster of decelerating increase or plateau for women also became lower than 0.75 when 30% or more of countries were dropped, as it exchanged some constituent countries with other clusters. Nonetheless, even in the extreme situation of using only 50% of countries, Jaccard index was over 0.60 for all but one cluster for boys (recent decline) where it was just below the threshold (0.59).
All analyses were performed in statistical software R (v4.3.0).
Comparison with prior studies
One study14 presented an obesity transition framework with four stages and qualitatively applied the staging in 30 example countries. The qualitative features of the four obesity transition stages are consistent with our findings. However, the framework paper did not use data after 2016 and found few countries in the proposed fourth stage where obesity prevalence declines. The study only qualitatively considered the differences in trends between sexes and age groups in its application and did not analyse the range of prevalences at which trends plateaued. Prior global studies1,82,103,104 have reported changes in obesity prevalence over multi-decadal periods but did not attempt to categorize or quantify dynamic trajectories, hence our results cannot be directly compared with theirs. Two of these studies graphically showed a continuing increase in obesity in most world regions from 1990 to 2021103,104, different from our quantitative findings of plateauing of the rise in obesity in many high-income countries. The plateauing of obesity prevalence that we reported in many high-income countries for one or both sexes is consistent with reports of prevalence time series in specific countries105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121 and reviews of published studies122,123,124,125. Only one study126 has quantitatively classified obesity prevalence trends for different US states, reporting mixed typologies of subnational trends similar to what we found globally.
Ethics and inclusion statement
This research followed the recommendations set out in the Global Code of Conduct for Research in Resource-Poor Settings.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
Age-standardized and age-specific results of this study are available on NCD-RisC (www.ncdrisc.org) in machine-readable numerical format and as visualizations. Input data from publicly available sources and contact information for data providers can be downloaded from NCD-RisC (www.ncdrisc.org) and Zenodo127 (https://doi.org/10.5281/zenodo.18368826).
Code availability
The computer codes for the Bayesian hierarchical model and clustering analysis used in this work are available on NCD-RisC (www.ncdrisc.org) and Zenodo127 (https://doi.org/10.5281/zenodo.18368826).
References
NCD Risk Factor Collaboration (NCD-RisC). Worldwide trends in underweight and obesity from 1990 to 2022: a pooled analysis of 3663 population-representative studies with 222 million children, adolescents, and adults. Lancet 403, 1027–1050 (2024).
World Health Organization. Obesity: Preventing and Managing the Global Epidemic: Report of a WHO Consultation; https://iris.who.int/handle/10665/42330 (2000).
Stamler, J. Epidemic obesity in the United States. Arch. Intern. Med. 153, 1040–1044 (1993).
Reardon, T., Timmer, C. P., Barrett, C. B. & Berdegué, J. The rise of supermarkets in Africa, Asia, and Latin America. Am. J. Agric. Econ. 85, 1140–1146 (2003).
Scheiner, J. A century of motorisation in urban and rural contexts: paths of motorisation in German cities. Erdkunde 66, 313–328 (2012).
Bleich, S. N., Cutler, D., Murray, C. & Adams, A. Why is the developed world obese? Annu. Rev. Public Health 29, 273–295 (2008).
Cutler, D. M., Glaeser, E. L. & Shapiro, J. M. Why have Americans become more obese? J. Econ. Perspect. 17, 93–118 (2003).
Tanner, J. M. Growth as a mirror of the condition of society: secular trends and class distinctions. Acta Paediatr. Jpn 29, 96–103 (1987).
NCD Risk Factor Collaboration (NCD-RisC). Rising rural body-mass index is the main driver of the global obesity epidemic in adults. Nature 569, 260–264 (2019).
NCD Risk Factor Collaboration (NCD-RisC). Diminishing benefits of urban living for children and adolescents’ growth and development. Nature 615, 874–883 (2023).
Subramanian, S. & Deaton, A. The demand for food and calories. J. Political Econ. 104, 133–162 (1996).
Smith, L. C., Ruel, M. T. & Ndiaye, A. Why is child malnutrition lower in urban than in rural areas? Evidence from 36 developing countries. World Dev. 33, 1285–1305 (2005).
Lenardson, J. D., Hansen, A. Y. & Hartley, D. Rural and remote food environments and obesity. Curr. Obes. Rep. 4, 46–53 (2015).
Jaacks, L. M. et al. The obesity transition: stages of the global epidemic. Lancet Diabetes Endocrinol. 7, 231–240 (2019).
Hawks, S. R., Madanat, H. N., Merrill, R. M., Goudy, M. B. & Miyagawa, T. A cross-cultural analysis of ‘motivation for eating’ as a potential factor in the emergence of global obesity: Japan and the United States. Health Promot. Int. 18, 153–162 (2003).
Pérez-Cueto, F. J. A. et al. Food-related lifestyles and their association to obesity in five European countries. Appetite 54, 156–162 (2010).
García-González, J. M. & Martín-Criado, E. A reversal in the obesity epidemic? A quasi-cohort and gender-oriented analysis in Spain. Demogr. Res. 46, 273–290 (2022).
Ayllón, E., Moyano, N., Lozano, A. & Cava, M.-J. Parents’ willingness and perception of children’s autonomy as predictors of greater independent mobility to school. Int. J. Environ. Res. Public Health 16, 732 (2019).
Weir, L. A., Etelson, D. & Brand, D. A. Parents’ perceptions of neighborhood safety and children’s physical activity. Prev. Med. 43, 212–217 (2006).
de Saint Pol, T. Norms and attitudes to body fatness: a European comparison. Popul. Soc. 455, 1–4 (2009).
Pallan, M. J., Hiam, L. C., Duda, J. L. & Adab, P. Body image, body dissatisfaction and weight status in South Asian children: a cross-sectional study. BMC Public Health 11, 21 (2011).
Takimoto, H., Yoshiike, N., Kaneda, F. & Yoshita, K. Thinness among young Japanese women. Am. J. Public Health 94, 1592–1595 (2004).
French, S. A., Tangney, C. C., Crane, M. M., Wang, Y. & Appelhans, B. M. Nutrition quality of food purchases varies by household income: the SHoPPER study. BMC Public Health 19, 231 (2019).
Wiggins, S. & Keats, S. The rising cost of a healthy diet: changing relative prices of foods in high-income and emerging economies. Report No. 2052-7209. ODI Global https://odi.org/en/publications/the-rising-cost-of-a-healthy-diet-changing-relative-prices-of-foods-in-high-income-and-emerging-economies/ (2015).
Darmon, N. & Drewnowski, A. Contribution of food prices and diet cost to socioeconomic disparities in diet quality and health: a systematic review and analysis. Nutr. Rev. 73, 643–660 (2015).
Carrillo-Alvarez, E. et al. Diet-related health inequalities in high-income countries: a scoping review of observational studies. Adv. Nutr. 16, 100439 (2025).
Støckel, J. T., Strandbu, Å, Solenes, O., Jørgensen, P. & Fransson, K. Sport for children and youth in the Scandinavian countries. Sport Soc. 13, 625–642 (2010).
Núñez, J. & Pérez, G. The escape from malnutrition of Chilean boys and girls: height-for-age Z scores in late XIX and XX centuries. Int. J. Environ. Res. Public Health 18, 10436 (2021).
Paes-Sousa, R. & Vaitsman, J. The zero hunger and Brazil without extreme poverty programs: a step forward in Brazilian social protection policy. Cien Saude Colet 19, 4351–4360 (2014).
Wells, J. C. et al. The double burden of malnutrition: aetiological pathways and consequences for health. Lancet 395, 75–88 (2020).
Rader, B., Hazan, R. & Brownstein, J. S. Changes in adult obesity trends in the US. JAMA Health Forum 5, e243685 (2024).
Luke, A. & Cooper, R. S. Physical activity does not influence obesity risk: time to clarify the public health message. Int. J. Epidemiol. 42, 1831–1836 (2013).
Nimegeer, A., Patterson, C. & Hilton, S. Media framing of childhood obesity: a content analysis of UK newspapers from 1996 to 2014. BMJ Open 9, e025646 (2019).
Hoebel, J. et al. Socioeconomic inequalities in the rise of adult obesity: a time-trend analysis of national examination data from Germany, 1990–2011. Obes. Facts 12, 344–356 (2019).
Magnusson, M. et al. Social inequalities in obesity persist in the Nordic region despite its relative affluence and equity. Curr. Obes. Rep. 3, 1–15 (2014).
Hoffmann, K. et al. Trends in educational inequalities in obesity in 15 European countries between 1990 and 2010. Int. J. Behav. Nutr. Phys. Act. 14, 63 (2017).
Beauchamp, A., Backholer, K., Magliano, D. & Peeters, A. The effect of obesity prevention interventions according to socioeconomic position: a systematic review. Obes. Rev. 15, 541–554 (2014).
Pickett, K. E., Kelly, S., Brunner, E., Lobstein, T. & Wilkinson, R. G. Wider income gaps, wider waistbands? An ecological study of obesity and income inequality. J. Epidemiol. Community Health 59, 670–674 (2005).
Adams, J., Mytton, O., White, M. & Monsivais, P. Why are some population interventions for diet and obesity more equitable and effective than others? The role of individual agency. PLoS Med. 13, e1001990 (2016).
Rechel, B. et al. The Role of Public Health Organizations in Addressing Public Health Problems in Europe: the Case of Obesity, Alcohol and Antimicrobial Resistance (European Observatory on Health Systems and Policies, 2018).
German Federal Government. Action plan for a healthier lifestyle. Bundesregierung https://www.bundesregierung.de/breg-en/service/archive/in-form-campaign-1926220 (2021).
Gortmaker, S. L. et al. Reducing obesity via a school-based interdisciplinary intervention among youth: Planet Health. Arch. Pediatr. Adolesc. Med. 153, 409–418 (1999).
Olsen, N. J. et al. A literature review of evidence for primary prevention of overweight and obesity in healthy weight children and adolescents: a report produced by a working group of the Danish Council on Health and Disease Prevention. Obes. Rev. 25, e13641 (2024).
Tseng, E. et al. Effectiveness of policies and programs to combat adult obesity: a systematic review. J. Gen. Intern. Med. 33, 1990–2001 (2018).
Clarke, N. et al. Calorie (energy) labelling for changing selection and consumption of food or alcohol. Cochrane Database Syst. Rev. 1, CD014845 (2025).
Baker, P. R., Francis, D. P., Soares, J., Weightman, A. L. & Foster, C. Community wide interventions for increasing physical activity. Cochrane Database Syst. Rev. 1, CD008366 (2015).
Murtagh, E. M. et al. Interventions outside the workplace for reducing sedentary behaviour in adults under 60 years of age. Cochrane Database Syst. Rev. 7, CD012554 (2020).
Bleich, S. N. et al. Strengthening the public health impacts of the supplemental nutrition assistance program through policy. Annu. Rev. Public Health 41, 453–480 (2020).
Petimar, J. et al. Associations of the Philadelphia sweetened beverage tax with changes in adult body weight: an interrupted time series analysis. Lancet Reg. Health Am. 39, 100906 (2024).
Jones-Smith, J. C. et al. Sweetened beverage tax implementation and change in body mass index among children in Seattle. JAMA Netw. Open 7, e2413644 (2024).
Popkin, B. M. & Ng, S. W. Sugar-sweetened beverage taxes: lessons to date and the future of taxation. PLoS Med. 18, e1003412 (2021).
Chung, S. H. & Xu, L. Impact of sugar-sweetened beverages tax on obesity and obesity-related health conditions: evidence from Washington State’s soft drink syrup tax. Health Econ. Rev. 15, 92 (2025).
Pfinder, M. et al. Taxation of unprocessed sugar or sugar-added foods for reducing their consumption and preventing obesity or other adverse health outcomes. Cochrane Database Syst. Rev. 4, CD012333 (2020).
Ng, S. W. & Popkin, B. M. Time use and physical activity: a shift away from movement across the globe. Obes. Rev. 13, 659–680 (2012).
Khoury, C. K. et al. Increasing homogeneity in global food supplies and the implications for food security. Proc. Natl Acad. Sci. USA 111, 4001–4006 (2014).
NCD Risk Factor Collaboration (NCD-RisC). Height and body-mass index trajectories of school-aged children and adolescents from 1985 to 2019 in 200 countries and territories: a pooled analysis of 2181 population-based studies with 65 million participants. Lancet 396, 1511–1524 (2020).
Zeng, Q., He, Z. & Wang, Y. The direct and structure effect of income on nutrition demand of Chinese rural residents. Int. J. Environ. Res. Public Health 19, 13388 (2022).
World Bank. Food Prices for Nutrition DataHub: Global Statistics on the Cost and Affordability of Healthy Diets; www.worldbank.org/en/programs/icp/brief/foodpricesfornutrition (2024).
Sievert, K., Lawrence, M., Naika, A. & Baker, P. Processed foods and nutrition transition in the Pacific: regional trends, patterns and food system drivers. Nutrients 11, 1328 (2019).
Popkin, B. M. & Doak, C. M. The Obesity epidemic is a worldwide phenomenon. Nutr. Rev. 56, 106–114 (1998).
de Onis, M. et al. Development of a WHO growth reference for school-aged children and adolescents. Bull. World Health Organ. 85, 660–667 (2007).
de Onis, M. & Lobstein, T. Defining obesity risk status in the general childhood population: which cut-offs should we use? Int. J. Pediatr. Obes. 5, 458–460 (2010).
NCD Risk Factor Collaboration (NCD-RisC). Trends in adult body-mass index in 200 countries from 1975 to 2014: a pooled analysis of 1698 population-based measurement studies with 19.2 million participants. Lancet 387, 1377–1396 (2016).
Lelijveld, N. et al. Towards standardised and valid anthropometric indicators of nutritional status in middle childhood and adolescence. Lancet Child Adolesc. Health 6, 738–746 (2022).
NCD Risk Factor Collaboration (NCD-RisC). Worldwide trends in diabetes since 1980: a pooled analysis of 751 population-based studies with 4.4 million participants. Lancet 387, 1513–1530 (2016).
NCD Risk Factor Collaboration (NCD-RisC). Worldwide trends in blood pressure from 1975 to 2015: a pooled analysis of 1479 population-based measurement studies with 19.1 million participants. Lancet 389, 37–55 (2017).
NCD Risk Factor Collaboration (NCD-RisC). Repositioning of the global epicentre of non-optimal cholesterol. Nature 582, 73–77 (2020).
Finucane, M. M. et al. National, regional, and global trends in body-mass index since 1980: systematic analysis of health examination surveys and epidemiological studies with 960 country-years and 9.1 million participants. Lancet 377, 557–567 (2011).
Farzadfar, F. et al. National, regional, and global trends in serum total cholesterol since 1980: systematic analysis of health examination surveys and epidemiological studies with 321 country-years and 3.0 million participants. Lancet 377, 578–586 (2011).
Danaei, G. et al. National, regional, and global trends in fasting plasma glucose and diabetes prevalence since 1980: systematic analysis of health examination surveys and epidemiological studies with 370 country-years and 2.7 million participants. Lancet 378, 31–40 (2011).
Danaei, G. et al. National, regional, and global trends in systolic blood pressure since 1980: systematic analysis of health examination surveys and epidemiological studies with 786 country-years and 5.4 million participants. Lancet 377, 568–577 (2011).
Hayes, A. J., Clarke, P. M. & Lung, T. W. Change in bias in self-reported body mass index in Australia between 1995 and 2008 and the evaluation of correction equations. Popul. Health Metr. 9, 53 (2011).
Ezzati, M., Martin, H., Skjold, S., Vander Hoorn, S. & Murray, C. J. Trends in national and state-level obesity in the USA after correction for self-report bias: analysis of health surveys. J. R. Soc. Med. 99, 250–257 (2006).
Gorber, S. C., Tremblay, M., Moher, D. & Gorber, B. A comparison of direct vs. self-report measures for assessing height, weight and body mass index: a systematic review. Obes. Rev. 8, 307–326 (2007).
NCD Risk Factor Collaboration (NCD-RisC). General and abdominal adiposity and hypertension in eight world regions: a pooled analysis of 837 population-based studies with 7.5 million participants. Lancet 404, 851–863 (2024).
Lumley, T. Analysis of complex survey samples. J. Stat. Softw. 9, 1–19 (2004).
World Health Organization. Chronic Non-Communicable Diseases Risk Factors Survey in Iraq; https://www.who.int/publications/m/item/2006-steps-country-report-iraq (2006).
World Health Organization. Research Report on NCD Risk Factors Surveillance in Nepal; https://www.who.int/publications/m/item/2003-steps-country-report-nepal (2003).
Finucane, M. M., Paciorek, C. J., Danaei, G. & Ezzati, M. Bayesian estimation of population-level trends in measures of health status. Stat. Sci. 29, 18−25 (2014).
Stevens, G. A. et al. Trends and mortality effects of vitamin A deficiency in children in 138 low-income and middle-income countries between 1991 and 2013: a pooled analysis of population-based surveys. Lancet Glob. Health 3, e528–e536 (2015).
NCD Risk Factor Collaboration (NCD-RisC). Worldwide trends in hypertension prevalence and progress in treatment and control from 1990 to 2019: a pooled analysis of 1201 population-representative studies with 104 million participants. Lancet 398, 957–980 (2021).
NCD Risk Factor Collaboration (NCD-RisC). Worldwide trends in body-mass index, underweight, overweight, and obesity from 1975 to 2016: a pooled analysis of 2416 population-based measurement studies in 128.9 million children, adolescents, and adults. Lancet 390, 2627–2642 (2017).
Gelman, A. & Hill, J. Data Analysis using Regression and Multilevel/Hierarchical Models (Cambridge Univ. Press, 2006).
Gelman, A. Prior distributions for variance parameters in hierarchical models (comment on article by Browne and Draper). Bayesian Anal. 1, 515–534 (2006).
Rue, H. & Held, L. Gaussian Markov Random Fields: Theory and Applications (Chapman and Hall/CRC, 2005).
Breslow, N. E. & Clayton, D. G. Approximate inference in generalized linear mixed models. J. Am. Stat. Assoc. 88, 9–25 (1993).
Wood, S. N. Generalized Additive Models: an Introduction with R (Chapman and Hall/CRC, 2017).
Harville, D. A. Matrix Algebra from a Statistician’s Perspective (Springer-Verlag, 2008).
Cameron, N. & Bogin, B. Human Growth and Development (Elsevier Science, 2012).
Watanabe, S. Asymptotic equivalence of Bayes cross validation and widely applicable information criterion in singular learning theory. J. Mach. Learn. Res. 11, 3571–3594 (2010).
Gelman, A., Hwang, J. & Vehtari, A. Understanding predictive information criteria for Bayesian models. Stat. Comput. 24, 997–1016 (2014).
United Nations Department of Economic and Social Affairs, Population Division. World Urbanization Prospects: the 2018 Revision (United Nations, 2019).
Smith, A. F. & Roberts, G. O. Bayesian computation via the Gibbs sampler and related Markov chain Monte Carlo methods. J. R. Stat. Soc. Series B Stat. Methodol. 55, 3–23 (1993).
The Stan Forums. Overdispersed initial values – general questions. The Stan Forums https://discourse.mc-stan.org/t/overdispersed-initial-values-general-questions/3966 (2018).
Vehtari, A., Gelman, A., Simpson, D., Carpenter, B. & Bürkner, P.-C. Rank-normalization, folding, and localization: an improved R for assessing convergence of MCMC (with discussion). Bayesian Anal. 16, 667–718 (2021).
Stan Development Team. RStan: the R interface to Stan. Stan https://mc-stan.org (2022).
Ahmad, O. B. et al. Age standardization of rates: a new WHO standard. GPE Discussion Paper Series 31. (World Health Organization, 2001).
Liao, T. W. Clustering of time series data — a survey. Pattern Recognit. 38, 1857–1874 (2005).
Jain, A. K., Murty, M. N. & Flynn, P. J. Data clustering: a review. ACM Comput. Surv. 31, 264–323 (1999).
Hennig, C. Cluster-wise assessment of cluster stability. Comput. Stat. Data Anal. 52, 258–271 (2007).
Tang, M. et al. Evaluating single-cell cluster stability using the Jaccard similarity index. Bioinformatics 37, 2212–2214 (2021).
Cebola, I. et al. Epigenetics override pro-inflammatory PTGS transcriptomic signature towards selective hyperactivation of PGE2 in colorectal cancer. Clin. Epigenetics 7, 74 (2015).
GBD 2021 Adult BMI Collaborators. Global, regional, and national prevalence of adult overweight and obesity, 1990–2021, with forecasts to 2050: a forecasting study for the Global Burden of Disease Study 2021. Lancet 405, 813–838 (2025).
GBD 2021 Adolescent BMI Collaborators. Global, regional, and national prevalence of child and adolescent overweight and obesity, 1990–2021, with forecasts to 2050: a forecasting study for the Global Burden of Disease Study 2021. Lancet 405, 785–812 (2025).
Olds, T. et al. Evidence that the prevalence of childhood overweight is plateauing: data from nine countries. Int. J. Pediatr. Obes. 6, 342–360 (2011).
Wabitsch, M., Moss, A. & Kromeyer-Hauschild, K. Unexpected plateauing of childhood obesity rates in developed countries. BMC Med. 12, 17 (2014).
Emmerich, S. D. et al. Trends in obesity-related measures among US children, adolescents, and adults. JAMA 333, 1082–1084 (2025).
Mitchell, R. T., McDougall, C. M. & Crum, J. E. Decreasing prevalence of obesity in primary schoolchildren. Arch. Dis. Child. 92, 153–154 (2007).
Lauria, L., Spinelli, A., Buoncristiano, M. & Nardone, P. Decline of childhood overweight and obesity in Italy from 2008 to 2016: results from 5 rounds of the population-based surveillance system. BMC Public Health 19, 618 (2019).
Moss, A. et al. Declining prevalence rates for overweight and obesity in German children starting school. Eur. J. Pediatr. 171, 289–299 (2012).
Lissner, L., Sohlström, A., Sundblom, E. & Sjöberg, A. Trends in overweight and obesity in Swedish schoolchildren 1999–2005: has the epidemic reached a plateau? Obes. Rev. 11, 553–559 (2010).
Schmidt Morgen, C. et al. Trends in prevalence of overweight and obesity in Danish infants, children and adolescents — are we still on a plateau? PLoS ONE 8, e69860 (2013).
Miqueleiz, E., Lostao, L. & Regidor, E. Stabilisation of the trend in prevalence of childhood overweight and obesity in Spain: 2001–11. Eur. J. Public Health 26, 960–963 (2016).
Howel, D. Trends in the prevalence of obesity and overweight in English adults by age and birth cohort, 1991–2006. Public Health Nutr. 14, 27–33 (2011).
Flegal, K. M., Carroll, M. D., Kit, B. K. & Ogden, C. L. Prevalence of obesity and trends in the distribution of body mass index among US adults, 1999–2010. JAMA 307, 491–497 (2012).
Balthasar, M. R. et al. Trends in overweight and obesity in Bergen, Norway, using data from routine child healthcare 2010–2022. Acta Paediatr. 113, 2098–2106 (2024).
de Bont, J., Bennett, M., León-Muñoz, L. M. & Duarte-Salles, T. The prevalence and incidence rate of overweight and obesity among 2.5 million children and adolescents in Spain. Rev. Esp. Cardiol. 75, 300–307 (2022).
Marques, A., Gaspar de Matos, M., Machado, M. D. C., Naia, A. & Mota, J. The prevalence of overweight and obesity in adolescents from 1988 to 2014: results from the HBSC Portuguese Survey. Port. J. Public Health 36, 134–140 (2018).
Keane, E., Kearney, P. M., Perry, I. J., Kelleher, C. C. & Harrington, J. M. Trends and prevalence of overweight and obesity in primary school aged children in the Republic of Ireland from 2002–2012: a systematic review. BMC Public Health 14, 974 (2014).
Tambalis, K. D. et al. Eleven-year prevalence trends of obesity in Greek children: first evidence that prevalence of obesity is leveling off. Obesity (Silver Spring) 18, 161–166 (2010).
World Health Organization & European Childhood Obesity Surveillance Initiative. Brief Review of Results from Round 6 of COSI (WHO European Childhood Obesity Surveillance Initiative) 2022–2024 (2024).
Rokholm, B., Baker, J. L. & Sørensen, T. I. The levelling off of the obesity epidemic since the year 1999 — a review of evidence and perspectives. Obes. Rev. 11, 835–846 (2010).
Garrido-Miguel, M. et al. Prevalence and trends of overweight and obesity in European children from 1999 to 2016: a systematic review and meta-analysis. JAMA Pediatr. 173, e192430 (2019).
Lien, N., Henriksen, H. B., Nymoen, L. L., Wind, M. & Klepp, K. I. Availability of data assessing the prevalence and trends of overweight and obesity among European adolescents. Public Health Nutr. 13, 1680–1687 (2010).
Koliaki, C., Dalamaga, M. & Liatis, S. Update on the obesity epidemic: after the sudden rise, is the upward trajectory beginning to flatten? Curr. Obes. Rep. 12, 514–527 (2023).
Vorpe, K., Hessinger, S., Poth, R. & Miljkovic, T. Clustering regions with dynamic time warping to model obesity prevalence disparities in the United States. J. Appl. Stat. 51, 793–807 (2024).
NCD Risk Factor Collaboration (NCD-RisC). Obesity rise plateaus in developed nations and accelerates in developing nations. Zenodo https://doi.org/10.5281/zenodo.18368826 (2026).
Acknowledgements
This study was funded by the UK Medical Research Council (grant number MR/V034057/1) and UK Research and Innovation (Innovate UK grant number 10103595, for participation in the OBCT consortium funded by the European Union grant agreement 101080250). The authors alone are responsible for the views expressed in this Article and they do not necessarily represent the views, decisions or policies of the institutions with which they are affiliated.
Author information
Authors and Affiliations
Consortia
Contributions
B.Z., A.G., L.J., Y.D.D.B., A.B.P., N.H.P., F.D., O.N.O., G.A.S., R.M.C.L., A.W.R., A.Z. and N.R.E. collated data from different studies and checked data sources. B.Z., A.G., N.H.P. and V.N. managed the database. B.Z., N.H.P., A.M., J.E.B., O.N.O., V.K., A.R.M. and Y.F. developed and coded the statistical method with inputs from C.J.P. and M.E. B.Z., A.G., O.N.O. and N.H.P. analysed the data and prepared the results. Other authors collected and reanalysed the data and checked the pooled data. M.E., B.Z., A.G., N.H.P., O.N.O. and J.E.B. wrote the first draft of the report with input from other authors. The corresponding author (M.E.) had the final responsibility for the decision to submit for publication.
Corresponding author
Ethics declarations
Competing interests
G.D. reports research consulting fees from Resolve to Save Lives, outside of the submitted work. K.K. reports grants in support of investigator and investigator-initiated trials from AstraZeneca, Novartis, Novo Nordisk, Sanofi, Eli Lilly, Merck Sharp & Dohme and Boehringer Ingelheim; consultancy fees from AstraZeneca, Bayer, Novartis, Novo Nordisk, Sanofi-Aventis, Eli Lilly, Merck Sharp & Dohme, Boehringer Ingelheim, Oramed Pharmaceuticals, Pfizer, Roche and Applied Therapeutics; and payments for speaking from AstraZeneca, Bayer, Novartis, Novo Nordisk, Sanofi, Eli Lilly, Merck Sharp & Dohme, Boehringer Ingelheim, Oramed Pharmaceuticals, Pfizer, Roche and Applied Therapeutics, all outside of the submitted work. L.-L.L. reports research grants via her institution from Abbott Diabetes Care, AstraZeneca and Novartis; speaker honoraria from Abbott, AstraZeneca, Boehringer Ingelheim, Novo Nordisk, Roche Diabetes Care and Zuellig Pharma, all outside of the submitted work. C.J.P. reports holding stocks in Pfizer, outside of the submitted work. F.Z. reports consulting fees from Daiichi Sankyo, Servier and Menarini, all outside of the submitted work. M.E. reports payment for advisory board from Lean, outside the submitted work.
Peer review
Peer review information
Nature thanks Barry Popkin, Johanna Ralston, Boyd Swinburn and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Phenotypes of national obesity trajectories by super-region in girls.
Each coloured line shows age-standardized obesity prevalence trends over time for one country belonging to a cluster and super-region combination. They are coloured by super-region. Grey lines show all countries belonging to a cluster across all super-regions. The number at the top of each panel shows the number of countries belonging to each cluster-super-region combination. The trend line for the most populous country in each super-region is identified by their ISO 3166-1 alpha-3 codes (Supplementary Note 1).
Extended Data Fig. 2 Phenotypes of national obesity trajectories by super-region in boys.
Each coloured line shows age-standardized obesity prevalence trends over time for one country belonging to a cluster and super-region combination. They are coloured by super-region. Grey lines show all countries belonging to a cluster across all super-regions. The number at the top of each panel shows the number of countries belonging to each cluster-super-region combination. The trend line for the most populous country in each super-region is identified by their ISO 3166-1 alpha-3 codes (Supplementary Note 1).
Extended Data Fig. 3 Posterior distribution of velocity of obesity in children and adolescents in 2024 by country.
For each country, the shaded area shows the posterior distribution of the velocity of obesity in 2024. Darker shading denotes higher posterior probability and lighter shading denotes lower posterior probability. The point for each country shows the posterior mean of velocity in 2024. Countries are ordered by region and the posterior mean velocity in 2024. Country names are coloured by super-region.
Extended Data Fig. 4 Posterior probability that velocity of obesity in children and adolescents was positive in 2024 by country.
If a positive velocity (i.e. an increase in obesity) is statistically indistinguishable from a negative velocity (i.e. a decrease in obesity), the PP is 0.5. PPs closer to 1 indicate more certainty of a positive velocity, those towards 0 indicate more certainty of a negative velocity, and those closer to 0.5 indicate less certainty of a positive or negative velocity.
Extended Data Fig. 5 Phenotypes of national obesity trajectories by super-region in women.
Each coloured line shows age-standardized obesity prevalence trends over time for one country belonging to a cluster and super-region combination. They are coloured by super-region. Grey lines show all countries belonging to a cluster across all super-regions. The number at the top of each panel shows the number of countries belonging to each cluster-super-region combination. The trend line for the most populous country in each super-region is identified by their ISO 3166-1 alpha-3 codes (Supplementary Note 1).
Extended Data Fig. 6 Phenotypes of national obesity trajectories by super-region in men.
Each coloured line shows age-standardized obesity prevalence trends over time for one country belonging to a cluster and super-region combination. They are coloured by super-region. Grey lines show all countries belonging to a cluster across all super-regions. The number at the top of each panel shows the number of countries belonging to each cluster-super-region combination. The trend line for the most populous country in each super-region is identified by their ISO 3166-1 alpha-3 codes (Supplementary Note 1).
Extended Data Fig. 7 Posterior distribution of velocity of obesity in adults in 2024 by country.
For each country, the shaded area shows the posterior distribution of the velocity of obesity in 2024. Darker shading denotes higher posterior probability and lighter shading denotes lower posterior probability. The point for each country shows the posterior mean of velocity in 2024. Countries are ordered by region and the posterior mean velocity in 2024. Country names are coloured by super-region.
Extended Data Fig. 8 Posterior probability that velocity of obesity in adults was positive in 2024 by country.
If a positive velocity (i.e. an increase in obesity) is statistically indistinguishable from a negative velocity (i.e. a decrease in obesity), the PP is 0.5. PPs closer to 1 indicate more certainty of a positive velocity, those towards 0 indicate more certainty of a negative velocity, and those closer to 0.5 indicate less certainty of a positive or negative velocity.
Extended Data Fig. 9 Female and male velocity of obesity in 2024.
Relationship between velocity of obesity for girls and boys (a) and for women and men (b). Each point shows one country, coloured by super-region. The solid grey line denotes equality of female and male velocity.
Supplementary information
Supplementary Information (download PDF )
This PDF file contains Supplementary Notes, Supplementary Tables, Supplementary Figs. and Supplementary References. Supplementary Note 1. List of countries’ ISO 3166-1 alpha-3 codes. Supplementary Table 1. List of analysis regions and super-regions, and countries in each region. Supplementary Table 2. Data sources used in the analysis. Supplementary Table 3. Specification of the Bayesian hierarchical model. Supplementary Table 4. Results of model validation. Supplementary Table 5. Average Jaccard index of the clusters. Supplementary Fig. 1. Number of data sources used in the analysis, by country. Supplementary Fig. 2. Number of data sources used in the analysis, by region and year. Supplementary Fig. 3. Age-standardized prevalence of obesity in children and adolescents from 1980 to 2024 by country. Supplementary Fig. 4. Age-standardized prevalence of obesity in adults from 1980 to 2024 by country. Supplementary Fig. 5. Velocity of obesity in children and adolescents from 1980 to 2024 by country. Supplementary Fig. 6. Velocity of obesity in adults from 1980 to 2024 by country.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
NCD Risk Factor Collaboration (NCD-RisC). Obesity rise plateaus in developed nations and accelerates in developing nations. Nature 653, 510–518 (2026). https://doi.org/10.1038/s41586-026-10383-0
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41586-026-10383-0
