
Abstract
The amount of precipitation directly affects the ecological balance and the economic benefits of the region. However, the highly nonlinear and stochastic nature of precipitation time series data limits the accuracy of predictions. Therefore, improving the prediction accuracy of regional precipitation is crucial for formulating disaster prevention and mitigation measures, as well as for responding to climate change. To achieve a scientific and effective prediction of regional precipitation, this study proposed a precipitation prediction model based on the CEEMDAN-TVMD-IPO-BiLSTM framework. The model first decomposed the original precipitation data using the CEEMDAN decomposition algorithm, output the modal components and residual components, and then used the topology optimization algorithm (TTAO) to optimize the VMD, and decomposed the high-dimensional sequence in the first decomposition result for the second time. An improved parrot optimizer (IPO) algorithm based on chaotic Cat and Cauchy-Gaussian variation was introduced to optimize the bidirectional long short-term memory neural network (BiLSTM). This precisely constructed prediction model was utilized to predict regional precipitation, with historical monthly precipitation data from three representative cities in China—Guangzhou in the east region, Changsha in the central region, and Emeishan in the west region—used to validate the model’s accuracy and robustness. Experimental results indicated that the proposed CEEMDAN-TVMD-IPO-BiLSTM model achieved RMSE values of 32.373, 14.445, and 22.447 for the three cities, respectively, with corresponding R² values of 0.960, 0.972, and 0.977, outperforming other models. This demonstrated its advantages in monthly precipitation prediction, allowing for a better characterization of precipitation fluctuation patterns and providing scientific references for formulating policies to combat droughts and floods.
Similar content being viewed by others

Introduction
Intense precipitation during the summer season is a common meteorological phenomenon in the southeastern region of China1. The impact of climate change has led to an increased frequency of extreme precipitation events2while precipitation variations directly affect the ecological environment and socio-economic conditions of the region3. Excessive rainfall can trigger natural disasters such as flooding and landslides4while insufficient precipitation can result in water resource scarcity and land degradation. The prediction of precipitation remains a challenging task due to the complex nature of meteorological systems5. Precipitation time series exhibit high non-linearity and randomness, which are influenced by multiple uncertain factors such as geographical location, topographical features, and anthropogenic activities6. These characteristics introduce significant variability into precipitation patterns. As a result, the accuracy of precipitation prediction models is severely constrained by these inherent uncertainties. Therefore, improving the accuracy of regional precipitation forecasts is of paramount importance. Monthly precipitation forecasting plays a crucial role in contemporary water resource management and sustainable agricultural development7. Accurate monthly precipitation predictions can optimize agricultural water resource allocation, significantly enhance irrigation efficiency, and improve crop yield8. Furthermore, monthly precipitation forecasting provides essential decision-making support for addressing climate change challenges6. Long-term precipitation monitoring serves a vital function in water resource management and disaster prevention, enabling the assessment of spatial and temporal trends9. Additionally, monthly precipitation forecasting provides important support for estimating cultivated areas in irrigated agriculture, offering extended precipitation records for irrigation zone planning, thereby facilitating better estimation of irrigated areas that available water resources can sustain10.
In recent years, many experts and scholars have conducted extensive research on precipitation prediction, employing various methods. Currently, these methods can be mainly divided into two categories: traditional and modern precipitation prediction methods. The former primarily focuses on the influencing factors of precipitation, exploring the potential relationships between these factors and precipitation, and constructing predictive models using physical process analysis and mathematical statistics. In contrast, the latter uses a single precipitation time series as input and employs computer technology and artificial intelligence techniques to build data-driven models for precipitation prediction.
In traditional precipitation prediction research based on physical causation methods, Ma et al.11 established a comprehensive framework by extracting characteristic vectors including the intensity of the Pacific warm pool, the intensity of the polar front zone, changes in the geopotential height field at 100 hPa over the Tibetan Plateau, and the intensity of the westerly circulation as factor fields. They developed a physical statistical model to predict precipitation during the main flood season in the Sichuan-Chongqing region, demonstrating the importance of incorporating multiple atmospheric parameters. Building upon statistical methodologies, Sun et al.12 employed ordered clustering methods to establish grading indices for precipitation patterns and implemented weighted Markov chain models to predict future precipitation variations. Their approach, applied to nearly 50 years of precipitation data from a hydrological station in Shanxi Province, achieved satisfactory outcomes and highlighted the potential of statistical learning techniques in long-term precipitation analysis. Modern short-term precipitation forecasting has extensively utilized grey system theory approaches. Wang et al.13 proposed an innovative grey forecasting model specifically designed for precipitation processes in the Bohai Rim region. Their methodology incorporated function variation techniques to enhance the smoothness of precipitation time series, thereby significantly improving prediction accuracy and establishing a foundation for subsequent advanced modeling approaches.
With the rapid development of computer technology, neural network models have been widely employed in precipitation forecasting. Liu et al.14 employed long short-term memory network to predict precipitation in the Tibetan Plateau. Xu et al.15 applied temporal convolutional networks to predict precipitation in the Shanzhou District of Sanmenxia City, achieving favorable results. Through these approaches, researchers continue to enhance the accuracy and reliability of precipitation forecasts. Based on a thorough review of previous research, this paper notes the significant advantages of long short-term memory (LSTM) network in precipitation prediction, particularly in handling nonlinear time series. LSTM optimizes the traditional recurrent neural network by addressing the issues of gradient vanishing and gradient explosion that often occur during long sequence training. Kumar et al.16 had validated that the prediction accuracy of LSTM for monthly precipitation in climate-similar regions of India surpassed that of RNN. However, the application of LSTM in precipitation forecasting has certain limitations. Directly predicting a single time series may not fully account for the influence of the physical mechanisms underlying precipitation formation, making the model’s performance susceptible to the initial data sequence and the model’s inherent parameters17 To overcome this limitation, numerous scholars have proposed various coupling models.
Researchers commonly utilize wavelet decomposition and variational mode decomposition (VMD) methods to extract subsequences from complex time series data to capture the periodicity and patterns within the subsequence data. Nourani et al.18 proposed a hybrid approach combining discrete wavelet transform with the Mann-Kendall test, enhancing the confidence of hydrological process trend analysis through multi-temporal scale decomposition. Sattari et al.19 developed a probabilistic machine learning framework based on wavelet transform-LSTM Monte Carlo (PLSTM-WT) for daily extreme hydrological event prediction, decomposing observed streamflow data into constituent components through wavelet transformation to identify trend characteristics, which significantly outperformed conventional LSTM models in Hurricane Harvey event validation across southeastern Texas basins, demonstrating the effectiveness of wavelet decomposition techniques in enhancing probabilistic prediction accuracy for extreme events. Mohammadi et al.20 developed a hybrid framework integrating the GR6J-CemaNeige hydrological model with gradient boosting machine learning techniques, systematically incorporating hydrological process knowledge through signal processing techniques including Maximal Overlap Discrete Wavelet Transform (MODWT) and Multiresolution Analysis (MRA), achieving significant performance improvements in daily runoff prediction for northern Swedish catchments, particularly excelling in capturing complex snow-water processes. Jiang Xinyun21 proposed a joint prediction model based on complementary ensemble empirical mode decomposition (CEEMD) and long short-term memory neural network and conducted training and testing on the monthly precipitation in Changde City. The results indicated that the LSTM model optimized by CEEMD demonstrated high accuracy in monthly precipitation forecasting. Ren et al.22 utilized extreme-point symmetric mode decomposition (ESMD) and variational mode decomposition (VMD) to decompose the original precipitation time series. Subsequently, they applied LSTM predictions to each sub-series separately. The results indicated that the prediction model combining signal decomposition algorithms exhibited greater superiority in monthly precipitation forecasting. Wang et al.23 proposed a novel hybrid precipitation forecasting framework (WPD-ELM) that integrates Extreme Learning Machine (ELM) with Wavelet Packet Decomposition (WPD), wherein the Wavelet Packet Decomposition (WPD) technique is employed to preprocess the original precipitation data, and the Extreme Learning Machine is utilized to forecast the decomposed series. However, most of the aforementioned studies focus on either optimizing a single model structure or decomposing data sequences, with relatively few studies combining these approaches in the field of precipitation forecasting. Xu et al.24 applied the combination of CEEMDAN and VMD to monthly runoff prediction, and the results showed that after performing VMD secondary decomposition on the high-frequency subsequences of CEEMDAN, the prediction accuracy of the model was improved.
Monthly precipitation prediction represents a fundamental challenge in meteorological research with critical implications for water resource management, agricultural planning, and climate adaptation strategies. Current research approaches predominantly employ Long Short-Term Memory (LSTM) networks, which have demonstrated considerable success in extracting temporal features of precipitation patterns and modeling the complex relationships between various meteorological factors. However, these conventional models exhibit several inherent limitations that constrain their predictive performance. Traditional LSTM networks process temporal information unidirectionally, effectively capturing historical precipitation patterns but failing to account for how future precipitation trends may influence current precipitation levels. This unidirectional processing approach creates an incomplete understanding of precipitation dynamics, as meteorological systems often exhibit bidirectional temporal dependencies where future atmospheric conditions can provide valuable context for understanding present conditions. Furthermore, precipitation data are characterized by non-stationarity, significant volatility, and complex temporal correlations that traditional decomposition methods struggle to address adequately. Without effective signal decomposition, important temporal features remain embedded within noise components, limiting the model’s ability to identify and leverage meaningful precipitation patterns. Existing models also frequently encounter optimization challenges, where conventional parameter tuning approaches converge to local optima rather than achieving optimal network performance.
To address these limitations, this study introduces a comprehensive prediction framework combining Bidirectional LSTM networks with advanced signal processing and optimization techniques. The proposed approach employs Bidirectional LSTM (BiLSTM) networks to capture temporal dependencies by processing historical sequences in both forward and backward directions, enabling a more complete understanding of precipitation patterns within the available historical data. To effectively handle the complex, non-stationary nature of precipitation data, the framework implements a two-stage decomposition strategy. Initially, the Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN) algorithm decomposes the original precipitation time series into multiple components, separating different frequency patterns while preserving essential temporal characteristics. Subsequently, high-dimensional components undergo secondary decomposition using Variational Mode Decomposition (VMD) optimized through a Triangulation Topology Aggregation Optimizer (TTAO), ensuring comprehensive extraction of multi-scale temporal patterns. To overcome optimization limitations, an Improved Parrot Optimization (IPO) algorithm incorporating chaotic Cat mapping and Cauchy-Gaussian mutation strategies optimizes the BiLSTM network parameters. This enhanced optimization approach facilitates more robust convergence and improved predictive accuracy. The resulting CEEMDAN-TVMD-IPO-BiLSTM model integrates these components to provide enhanced monthly precipitation predicting capabilities that account for bidirectional temporal influences, multi-scale signal decomposition, and optimized network architecture. The effectiveness of this integrated framework is validated using historical monthly precipitation data from three geographically diverse Chinese cities: Guangzhou representing eastern coastal conditions, Changsha representing central continental patterns, and Emeishan representing western mountainous regions. This geographic diversity ensures comprehensive evaluation of the model’s robustness across varying climatic conditions and precipitation regimes, providing strong evidence for the framework’s broad applicability in regional precipitation prediction.
Experimental method and principle
CEEMDAN algorithm
The CEEMDAN algorithm24 evolved from the Empirical Mode Decomposition (EMD), Ensemble EMD (EEMD), and Complementary Ensemble EMD (CEEMD) algorithms. It effectively suppressed the mode-mixing phenomenon in EMD, generated reconstructed signals with lower residual noise than EEMD, and resolved the misalignment or errors caused by inconsistent decomposition results across subsequence groups in CEEMD. The theoretical steps of the CEEMDAN algorithm are as follows:
(1) Add Gaussian white noise of the same length to the original signal sequence \(f(t)\) to be decomposed n times, thereby constructing n sequences to be decomposed, where \(i=1,2,3, \cdots ,n\), This process can be represented as:
Where, \({\varepsilon _0}\) is the weight coefficient of Gaussian white noise, and \({\delta _i}(t)\) is the Gaussian white noise for the ith time.
(2) Decompose the above sequence \({f_i}(t)\) using the EMD algorithm to obtain the modal component \(IM{F_i}(t)\). Repeat the decomposition n times and take the average to obtain the first modal component \(IM{F_1}(t)\) and residual component \(Re{s_1}(t)\) of CEEMDAN. This process can be represented as:
(3) Add Gaussian white noise to the residual component obtained in the k-th stage after decomposition, and continue to apply EMD for further decomposition. This process can be represented as:
(4) Repeat step (3) until the residual component becomes a monotonic signal and can no longer be decomposed, at which point the iteration ends. Ultimately, the original signal sequence is decomposed into N modal components and a residual component.
VMD algorithm
VMD is an adaptive, completely non-recursive modal variation signal processing method25. Its fundamental principle is to decompose a signal into multiple components with fixed bandwidths, where each component corresponds to a specific frequency and amplitude within the signal. By optimizing a variational regularization function, VMD can adaptively match the optimal center frequency and limited bandwidth for each mode, thereby achieving effective separation of intrinsic mode functions (IMF), frequency domain partitioning of the signal, and obtaining effective decomposition components of the given signal26.
In addition to decomposing one-dimensional signals, VMD can also be extended to the decomposition of multi-dimensional signals. The research on multi-dimensional VMD aims to extract spatial and temporal features from multi-dimensional signals and apply them to fields such as image processing27,28 and video processing13providing new methods and insights for multi-dimensional data analysis.
The implementation formula is as follows:
Where, \({u_k}\) is the mode variable of the kth decomposition, \({\omega _k}\) is the center frequency of \({u_k}\), \(\delta (t)\) is the Dirac distribution, \(\partial (t)\) is the mathematical operator for gradient calculation, and \(f(t)\) is the input signal sequence to be decomposed.
To solve the optimal solution of the above variational model, a penalty factor \(\alpha\) and Lagrange operator \(\lambda\) are introduced to transform it into an unconstrained variational solution. The specific formula is as follows:
Where, the penalty factor and Lagrange operator are intended to maintain the strictness of the constraints and ensure the accuracy of signal reconstruction. By continuously iterating using the alternate direction method of multipliers, the optimal solution of formula (9) is obtained. Therefore, the variables \({u_k}\) and \({\omega _k}\) can be updated according to formulas (10) and (11):
Where, n represents the iteration number.
TTAO algorithm
The TTAO algorithm29 is based on the principle of similar triangles. During the iterative process, it searches using the three vertices and one interior point of the triangular topology unit. Optimization is achieved through aggregation within the triangular topology unit and between different triangular topology units. The optimization process consists of three main stages: the construction of triangular topology units, global aggregation, and local aggregation.
(1) Construction of triangular topology units: The number of individuals N can be divided into \([{N \mathord{\left/ {\vphantom {N 3}} \right. \kern-0pt} 3}]\) triangular topology units, where \([\cdot ]\) represents the floor value. The process is as follows:
Where, \(\overrightarrow {{X_{i,1}}}\), \(\overrightarrow {{X_{i,2}}}\) and \(\overrightarrow {{X_{i,3}}}\) represent the three vertices of the ith triangular topology unit, and \(\overrightarrow {{X_{i,4}}}\) indicates a randomly chosen interior vertex within the ith triangular topology unit. \(\overrightarrow {UB}\) and \(\overrightarrow {LB}\) are the upper and lower bounds of the search space. l represents the size of the triangular topology unit. Additionally, \(\overrightarrow {f\left( {\overrightarrow \theta } \right)}\) and \(\overrightarrow {f\left( {\overrightarrow {\theta +\frac{\pi }{3}} } \right)}\) denote the direction vectors of the other two edges guided by the first vertex.
(2) Global aggregation: This process represents the exploration phase of the algorithm. By collecting information from excellent individuals within different triangular topology units, new feasible solutions are generated. Specifically, at kth iteration, the optimal vertex \(\overrightarrow {X_{{i,best}}^{k}}\) of each triangular topology unit interacts with the optimal vertex \(\overrightarrow {X_{{rand,best}}^{k}}\) of a randomly selected topology unit to aggregate and form a new feasible solution \(\overrightarrow {X_{{i,new1}}^{{k+1}}}\), as shown in the following formula:
Next, the fitness of the new solution is compared with the fitness of the optimal or suboptimal solution at kth iteration, in order to update the optimal solution, that is:
(3) Local aggregation: This process is the development phase of the algorithm. Within each triangular topology unit, perturbations are applied to the optimal solution based on the differences between the optimal and suboptimal solutions, in order to prevent the optimal individuals from getting trapped in local optima, as shown in Eq. (18).
Where, the \(\alpha\) is continuously reduced to allow the algorithm to gradually approach the optimal solution. To improve convergence, the fitness values of the two vertices before and after the local development are compared to determine the update position. If the new individual is better than the original individual, the position is updated; otherwise, no update is performed, that is:
TVMD algorithm
The VMD algorithm improves the predictive accuracy of data by decomposing it to reduce non-stationarity and non-linearity. However, if the number of modes for decomposition is too few, it may leave behind a residual with high complexity, which cannot guarantee prediction accuracy. Conversely, if the number of modes is too high, it can lead to over-decomposition of the data. Therefore, in the VMD algorithm, the number of decomposed modes k and the penalty factor \(\alpha\) are interdependent and jointly affect the decomposition results. Thus, obtaining the optimal parameter combination \([k,\alpha ]\) based on the characteristics of the input signal is key to achieving adaptive decomposition through VMD.
Therefore, this paper employed the TTAO optimization algorithm to optimize the optimal parameter combination of the VMD decomposition algorithm, referred to as the TVMD decomposition algorithm. This algorithm uses the minimum envelope entropy \(\hbox{min} {E_e}\) as the fitness function. After the signal undergoes VMD decomposition, the more noise contained in the subsequences, the greater the envelope entropy value will be. The calculation formula for envelope entropy is as follows:
Where, \(a(j)\) represents the result obtained by applying Hilbert transform to the IMF component of the original data after VMD decomposition. \({b_j}\) is the normalized form of \(a(j)\).
The steps of the proposed TVMD decomposition algorithm are as follows:
(1) Initialize the TTAO parameters, set the population size, number of iterations, and the value ranges for K and \(\alpha\).
(2) Obtain the fitness value using Eq. (20), and update the positions of the triangular topology units according to Eqs. (17) and (19) until the maximum number of iterations is reached, resulting in the corresponding optimal parameter combination \([k,\alpha ]\).
(3) Perform VMD decomposition on the original precipitation data based on the optimal parameter combination, outputting K intrinsic mode function components and the residual component.
PO algorithm
The Parrot Optimization Algorithm30 is a meta heuristic optimization algorithm proposed in 2024, which solves the optimal parameters by simulating the four key behavioral characteristics of parrots. The solution process is as follows:
(1) Population Initialization: The algorithm initializes a set of candidate solutions as the parrot population, with each parrot representing a potential solution. Assume the population size is N, the maximum number of iterations is \(Ma{x_{iter}}\) and the lower and upper bounds of the search space are lb and ub. The initial positions of the parrots are:
Where, \(rand(0,1)\) represents a random number in the range \([0,1]\), and \(X_{w}^{0}\) denotes the initial position of the wth parrot.
(2) Foraging behavior: Parrots estimate the approximate location of food by observing its position or the position of its owner, and then fly towards their respective positions, where the position movement follows the following equation:
Where, \(X_{w}^{d}\) represents the current position, \(X_{w}^{{d+1}}\) denotes the updated position, \({X_{best}}\) indicates the best position found so far and the master’s current position, \(Levy(dim)\) denotes the Levy distribution, which describes the parrot’s flight, d indicates the current iteration number, and \(X_{{mean}}^{d}\) represents the average position of the current population, i.e.:
(3) Staying Behavior: The parrot suddenly flies to any part of the owner’s body and remains still for a period of time. This process can be represented as:
Where, \(ones(1,dim)\) represents an all-ones vector of dimension dim.
(4) Communication Behavior: This behavior involves close interaction within the flock, including both flying towards and not flying towards the group. It is simulated by calculating the average position of the population and adjusting candidate solutions accordingly to promote information sharing and collaboration. This process can be represented as:
Where, when \(P \leqslant 0.5\) represents an individual joining a parrot group for communication, when \(P>0.5\) represents the process of the individual immediately flying out after communication.
(5) Fear behavior: Individuals usually keep a distance from unfamiliar individuals and seek a safe environment together with their owner. This behavior avoids excessive concentration of candidate solutions through a repulsion mechanism, maintaining population diversity. This process can be represented as:
IPO algorithm
(1) Population initialization with chaotic reverse learning strategy.
Traditional population initialization methods rely heavily on random number generation, which can lead to uneven distribution of individuals in the search population. To maintain population diversity and ensure that the initial population is as evenly distributed as possible, this paper introduced an initialization strategy based on chaotic reverse learning31. This approach helps accelerate the convergence speed of the algorithm. The steps of this strategy are: first, use the Cat chaotic sequence to generate N initial solutions \({X_i}\). For each initial solution, generate the corresponding reverse solution using the following method:
Where, \(X_{{\hbox{min} }}^{d}\) and \(X_{{\hbox{max} }}^{d}\) represent the minimum and maximum values of the dth dimension vector among all initial solutions.
Finally, the initial solutions with the reverse solutions was combine to sort in ascending order based on their fitness values. The top N solutions with the best fitness values was selected to form the initial population.
(2) Improving Nonlinear Convergence Factor Strategy.
When \(P \leqslant 0.5\) represents an individual joining a parrot group for communication, when \(P>0.5\) represents the process of the individual immediately flying out after communication. Therefore, the value of P is closely related to the communication behavior in the parrot optimization algorithm. However, in the traditional parrot algorithm, the value of P is random, which does not reflect the changes in the optimization algorithm during the iterative process. Therefore, this paper proposed an improved nonlinear formula:
(3) Cauchy-Gaussian variation.
The variation strategy can prevent the algorithm from getting trapped in local optima and also maintain the diversity of the population. To reduce the probability of the parrot algorithm falling into local optima, this paper introduced the Cauchy-Gaussian variation operator32. This mutation operator combines the Cauchy variation operator33 and the Gaussian variation operator34. It allows global search during the early stages of population optimization and local search during the later stages of iteration, thereby significantly enhancing its optimization capability. The expression for this operator is:
Where, \(X_{{best}}^{d}\) represents the optimal position of the parrot population in the dth iteration. \(X_{{new}}^{d}\) is the new position generated from the optimal position in the dth iteration using the Cauchy-Gaussian variation strategy. \(Cauchy(0,1)\) and \(Causs(0,1)\)are the random number following a Cauchy distribution and a Gaussian distribution. \({\beta _1}=1 - {\raise0.7ex\hbox{$d$} \!\mathord{\left/ {\vphantom {d {Ma{x_{iter}}}}}\right.\kern-0pt}\!\lower0.7ex\hbox{${Ma{x_{iter}}}$}}\) and \({\beta _2}={\raise0.7ex\hbox{$d$} \!\mathord{\left/ {\vphantom {d {Ma{x_{iter}}}}}\right.\kern-0pt}\!\lower0.7ex\hbox{${Ma{x_{iter}}}$}}\).
BiLSTM network
The LSTM network model35 is proposed based on recurrent neural network36 and is renowned for its excellent ability to process sequential data. The LSTM model introduces gate control units (forget gate, input gate, and output gate) and memory cell states, which address the issues of gradient vanishing and gradient explosion that often occur during long sequence training37.
LSTM network can only encode time series data in a forward direction and cannot learn patterns from both forward and backward information in the sequence. In contrast, BiLSTM neural networks consist of a combination of forward and backward LSTM, allowing them to consider the impact of forward and backward time series data on the current state. Therefore, BiLSTM typically provides better prediction accuracy than LSTM38.
Materials and methods
Monthly precipitation prediction model
To further explore the temporal features of monthly precipitation data, this paper established a precipitation prediction model based on CEEMDAN-TVMD-IPO-BiLSTM. The flowchart of the model is shown in Fig. 1, with the specific steps as follows:

Flowchart of the Prediction Model.
(1) Using the CEEMDAN decomposition algorithm to decompose the original precipitation data, outputting intrinsic mode function components and residual components;
(2) Initialize the TTAO parameters, set the population size, number of iterations, and the value ranges for K and \(\alpha\).
(3) Obtain the fitness value using Eq. (20), and update the positions of the triangular topology units according to Eqs. (17) and (19) until the maximum number of iterations is reached, resulting in the corresponding optimal parameter combination \([k,\alpha ]\).
(4) Perform VMD decomposition on the high-dimensional components in the first decomposition result based on the optimal parameter combination, outputting K intrinsic mode function components and the residual component.
(5) Use the IPO algorithm to optimize the parameters of the BiLSTM, finding the optimal parameters for each component (learning rate, number of hidden layers in BiLSTM, and number of iterations).
(6) Divide the original data into a training set and a test set, with the first 70% of the data used as the training set and the latter 30% used as the test set to evaluate the model’s prediction accuracy. To ensure robust model validation and prevent overfitting, a five-fold cross-validation strategy is implemented within the training set during the hyperparameter optimization process.
(7) Input the training set samples into the IPO-BiLSTM model to train the model, and then input the test set into the model to assess the prediction performance of the model.
(8) Finally, the prediction results of each subsequence and residual of the first and second decompositions are superimposed to obtain the final monthly precipitation prediction value. It should be noted that the entire optimization process, including TTAO parameter optimization for TVMD and IPO hyperparameter tuning for BiLSTM, is performed separately for each of the three cities (Guangzhou, Changsha, and Emeishan) to account for their distinct precipitation characteristics and local climatic conditions, ensuring location-specific model performance optimization.
Data processing
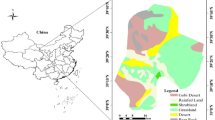
Using the “Global Surface Recompiled Dataset - Daily Products,” independently developed by the National Meteorological Information Center, as the source for monthly statistical values, the statistical monthly values are further integrated with the United States’ GHCNM to form a consolidated dataset. GHCNM, managed by the U.S. NCEI, collects massive amounts of foundational global data through long-term international exchange and data rescue efforts. Based on this, data comparison, integration, and quality control processes are gradually carried out to form an authoritative set of foundational global data products, which have been applied in the operations and research work of various international organizations and research institutes. This paper selected the monthly precipitation data from 1990 to 2022 for three cities: Guangzhou in Guangdong Province in the eastern region, Changsha in Hunan Province in the central region, and Emeishan in Sichuan Province in the western region. The training set and test set account for 70% and 30% of the entire dataset, respectively. This article uses minimum, maximum, median, mean, standard deviation (std.), coefficient of variation (cv), and skewness to statistically analyze precipitation data. The data statistics of precipitation in three cities are shown in Table 1; Fig. 2.

Distribution of Precipitation.
Before inputting data into the neural network, it is necessary to perform normalization to constrain the data within a certain range, thereby accelerating the convergence process39. To reduce the differences between data points, this paper adopted the min-max normalization method to scale the precipitation data to the [0,1] interval. The formula for this calculation is:
Where, \({x_i}\) is the current precipitation value, while \({x_{\hbox{min} }}\) and \({x_{\hbox{max} }}\) are the minimum and maximum precipitation values in the dataset, respectively.
This paper used a sliding window to reconstruct the dataset. The window should be set to include as much information as possible; however, if the window length is too long, it can lead to redundant information. In this study, the window length was set to 6, and by sliding the window backward with a step size of 1, multiple time-step features were obtained, resulting in multiple sets of input-output data.
Evaluation metric
To objectively evaluate the prediction accuracy and effectiveness of the CEEMDAN-TVMD-IPO-BiLSTM model on the dataset in this paper, the root mean square error (RMSE), mean absolute error (MAE), mean squared error (MSE), and R-squared (R²) were chosen to measure the model’s prediction accuracy. The Willmott index of agreement (WIA) was selected to assess the model’s external prediction ability and generalization capability. A larger WIA indicates a higher degree of match between the estimated values and actual values. The calculation formulas were provided in Eqs. (31)-(35).
Where, \({y_i}\) represents the actual monthly precipitation values, \({\hat {y}_i}\) represents the predicted monthly precipitation values, and m is the number of predictions.
Furthermore, this study also evaluated the computational time required for the model during parameter optimization, model training, and model prediction phases, denoted as T(optimize), T(train), and T(predict), respectively, with all time units measured in seconds.
Experimental configuration
The experiments in this study were conducted on a desktop computer equipped with an Intel(R) Core(TM) i7-10700KF CPU, 64GB RAM, and RTX3070 GPU, using MATLAB R2024b. The parameter configurations for the LSTM and BiLSTM models were set as follows: 128 hidden layer units, maximum training epochs of 500, Adam optimizer, and an initial learning rate of 0.01. The optimization parameters for PO and IPO algorithms included initial learning rate, number of hidden layer units, and maximum training epochs, where the initial learning rate ranged from 0.001 to 0.01, hidden layer units ranged from 16 to 128, and maximum training epochs ranged from 300 to 500.
Experiment results and analysis
Selected model result
To validate the effectiveness of the selected model, precipitation prediction accuracy was evaluated across three cities using different models. Five baseline models were selected for comparison: Back Propagation Neural Network (BP)40Random Forest (RF)41Support Vector Machine (SVM)42Long Short-Term Memory (LSTM)43and Bidirectional Long Short-Term Memory (BiLSTM)44. These models represented different categories of machine learning and deep learning methods, providing a comprehensive benchmark for evaluating the performance of various prediction approaches. The experimental results are presented in Table 2.
The analysis of experimental results for different models in Table 2 demonstrates that although the training time of BiLSTM and LSTM models is substantially greater than that of the three computational models, the prediction time required by these five machine learning models shows no significant differences. Moreover, the prediction accuracy of BiLSTM and LSTM models is superior to that of other models, indicating that recurrent neural networks possess superior capability in capturing temporal dependencies in precipitation data. Moreover, compared to the LSTM model, the BiLSTM model was able to process both forward and backward temporal information, enabling more comprehensive feature extraction. Traditional machine learning methods, such as BP, RF, and SVM models, exhibited lower prediction performance, indicating their limitations in simulating the inherent complex nonlinear patterns in precipitation sequences. The experimental results demonstrated that the BiLSTM model provided the most robust and accurate predictions across different geographical regions.
Decomposition algorithm result
To verify the accuracy and feasibility of the decomposition algorithm proposed in this paper, this section conducted comparative experiments using the CEEMDAN-TVMD-BiLSTM model, the TVMD-BiLSTM model, the CEEMDAN-BiLSTM model, the VMD-BiLSTM model, and the BiLSTM model in three typical cities. The prediction results of these models were shown in Table 3.
From the comparison results of different models in Table 3, it could be seen that after decomposing the original precipitation sequence data using the decomposition algorithm, whether it was VMD, TVMD, CEEMDAN or CEEMDAN-TVMD decomposition algorithm, they could better capture the nonlinear fluctuation patterns in different dimensions of the sequence data, greatly improving the accuracy of the prediction model. Additionally, by comparing the VMD-BiLSTM and TVMD-BiLSTM models for the cities of Guangzhou, Changsha, and Emeishan, it could be observed that the parameters optimized through TTAO allowed for a more precise adaptive decomposition of precipitation sequence data in different locations. Comparing the CEEMDAN BiLSTM model, TVMD BiLSTM model, and CEEMDAN BiLSTM model of Changsha, Emeishan and Guangzhou, it could be found that the decomposition effect of the CEEMDAN decomposition algorithm was worse than that of the TVMD decomposition algorithm, and the decomposition effect of the secondary decomposition algorithm on the data was better than that of the primary decomposition algorithm. Consequently, the model constructed in this paper achieved a more robust and accurate prediction of precipitation across various regions.
To comprehensively and intuitively compare the prediction errors of different models and evaluate the predictive performance of the models constructed in this study, a systematic assessment of five prediction models (BiLSTM, VMD-BiLSTM, CEEMDAN-BiLSTM, TVMD-BiLSTM, and CEEMDAN-TVMD-BiLSTM) across three different regions was conducted using seven charts. These charts included: scatter plots of predicted versus observed values for the three regions of Changsha, Emeishan, and Guangzhou (Figs. 3, 4 and 5), precipitation prediction time series comparison and absolute prediction error analysis charts for each region (Figs. 6, 7 and 8), and a multi-dimensional performance radar chart synthesizing all methods’ performance across the three cities (Fig. 9).

Scatter plot of predicted and observed values in Changsha.

Scatter plot of predicted and observed values in Emeishan.

Scatter plot of predicted and observed values in Guangzhou.
The scatter plot results demonstrated that compared to the single BiLSTM model, prediction models enhanced with data decomposition algorithms exhibited significant performance improvements, with the CEEMDAN-TVMD-BiLSTM and TVMD-BiLSTM models showing the most superior performance in terms of R² and consistency index, where data points were distributed more closely around the ideal diagonal line.

Line chart of predicted and observed values in Changsha.

Line chart of predicted and observed values in Emeishan.

Line chart of predicted and observed values in Guangzhou.
Several important phenomena were observed from the time series comparison charts. First, by comparing models employing decomposition algorithms (VMD-BiLSTM, TVMD-BiLSTM, CEEMDAN-BiLSTM, and CEEMDAN-TVMD-BiLSTM) with those without decomposition algorithms (BiLSTM), it was found that the BiLSTM model’s predictions exhibited pronounced lag phenomena, approximately equivalent to one prediction time interval. This lag phenomenon may be attributed to the insufficient feature extraction capability of the BiLSTM model for precipitation time series data, causing the model to tend to utilize data from the previous time step as the prediction for the current time step. In contrast, the prediction results from VMD-BiLSTM, TVMD-BiLSTM, CEEMDAN-BiLSTM, and CEEMDAN-TVMD-BiLSTM models did not exhibit such lag phenomena, indicating that decomposition algorithms can effectively decompose different dimensional feature fluctuation patterns in time series data, thereby improving feature extraction from each subsequence and enabling more accurate precipitation predictions. Second, when comparing VMD-BiLSTM and TVMD-BiLSTM models, it was clearly observed that the TVMD-BiLSTM model’s predictions were closer to actual observed values under both high and low precipitation conditions. This phenomenon indicated that TTAO could identify the most robust parameter combinations for precipitation time series data in different regions, thereby decomposing time series data into more accurate subsequences. Finally, through comparison of the prediction performance of CEEMDAN-BiLSTM, TVMD-BiLSTM, and CEEMDAN-TVMD-BiLSTM models, it was found that the secondary decomposition algorithm performed significantly better in data decomposition than the primary decomposition algorithm, further validating the effectiveness of multi-level decomposition strategies in improving prediction accuracy.

Multidimensional performance radar chart.
The multi-city dimensional performance radar chart revealed that the CEEMDAN-TVMD-BiLSTM model occupied the outer regions of the radar chart across most evaluation metrics, demonstrating its strong generalization capability and prediction accuracy under different geographical environments, thereby validating the effectiveness and superiority of the combined decomposition method proposed in this study.
IPO optimization algorithm result
To verify the accuracy and feasibility of the IPO optimization algorithm proposed in this paper, this section conducted comparative experiments using the IPO-BiLSTM model, PO-BiLSTM model, and BiLSTM model in three typical cities. The prediction results of these models were shown in Table 4.
As can be seen from the comparison results of different models in Table 4, although manual setting of empirical parameters saves parameter optimization time, the PO and IPO optimization algorithms yield results that are more consistent with the actual conditions of each region. Furthermore, although the IPO constructed in this study requires more optimization time, the IPO optimization algorithm achieves more precise parameter optimization than the PO optimization algorithm, making it more suitable for practical applications.
Similarly, this section employed seven charts to systematically evaluate three prediction models (BiLSTM, PO-BiLSTM, and IPO-BiLSTM) across three different regions. These charts also included: scatter plots of predicted versus observed values for the three regions of Changsha, Emeishan, and Guangzhou (Figs. 10, 11 and 12), precipitation prediction time series comparison and absolute prediction error analysis charts for each region (Figs. 13, 14 and 15), and a multi-dimensional performance radar chart synthesizing the performance of all methods across the three cities (Fig. 16).

Scatter plot of predicted and observed values in Changsha.

Scatter plot of predicted and observed values in Emeishan.

Scatter plot of predicted and observed values in Guangzhou.
The scatter plot analysis results demonstrated that compared to the baseline BiLSTM model, prediction models incorporating optimization algorithms exhibited moderate performance improvements. Across the Changsha, Emeishan, and Guangzhou regions, the IPO-BiLSTM model showed slight superiority over the PO-BiLSTM and BiLSTM models in terms of R² and consistency index, with data points distributed more closely around the ideal diagonal line.

Line chart of predicted and observed values in Changsha.

Line chart of predicted and observed values in Emeishan.

Line chart of predicted and observed values in Guangzhou.
The time series comparison charts revealed that regardless of whether optimization algorithms were employed, all models’ predictions exhibited pronounced lag phenomena, with lag times approximately equivalent to one prediction time interval. This further indicated that precipitation time series data contained multidimensional subsequences with different fluctuation patterns, rendering single models incapable of effectively extracting feature information from undecomposed data. Furthermore, comparison of the prediction performance between IPO-BiLSTM and PO-BiLSTM models clearly demonstrated that the IPO-BiLSTM model performed better in predicting sharp peaks. This suggested that the hyperparameters optimized by the IPO algorithm enhanced the robustness of the BiLSTM model, enabling it to better capture abrupt changes in precipitation data. Finally, while all optimization models displayed similar capabilities in tracking precipitation variation trends, IPO-BiLSTM exhibited higher stability in handling extreme value predictions.

Multidimensional performance radar chart.
The multi-city dimensional performance radar chart indicated that the IPO-BiLSTM model occupied relatively outer regional positions across most evaluation metrics, demonstrating that the IPO-BiLSTM model possessed relatively strong adaptability and prediction accuracy under different geographical environments. However, compared to models employing decomposition algorithms, the overall performance of all three models still required further improvement, thereby validating the crucial role of data decomposition techniques in precipitation prediction.
Model prediction result
In order to fully verify the accuracy and feasibility of the prediction results of each module in the model constructed in this article, this section used CEEMDAN-TVMD-IPO-BiLSTM model, IPO-BiLSTM model, CEEMDAN-TVMD-BiLSTM model, and BiLSTM model to conduct comparative experiments in three typical cities. The model prediction results were shown in Table 5.
From the comparison results of different model predictions in Table 5, it was evident that the CEEMDAN-TVMD-IPO-BiLSTM model proposed in this paper achieved the smallest prediction error across the three cities, with RMSE values of 32.373, 14.445, and 22.447, respectively. In contrast, the BiLSTM model had the largest prediction error, with RMSE values of 131.815, 74.470, and 83.829. Additionally, the CEEMDAN-TVMD-IPO-BiLSTM model achieves the highest R² values in the three cities, at 0.960, 0.972, and 0.977, respectively, whereas the BiLSTM model has the lowest R² values, at 0.335, 0.247, and 0.675. Comparing the CEEMDAN-TVMD-BiLSTM model and the CEEMDAN-TVMD-IPO-BiLSTM model constructed in this paper, it could be observed that the BiLSTM model optimized through the IPO algorithm effectively enhanced prediction accuracy, though the improvement was less pronounced than that achieved by the TVMD method. Furthermore, by comparing the IPO-BiLSTM model with the CEEMDAN-TVMD-IPO-BiLSTM model, it was apparent that the CEEMDAN-TVMD method could further improve model accuracy when applied to the BiLSTM model optimized by the IPO algorithm.
To comprehensively and intuitively compare the prediction errors of different models and evaluate the predictive performance of the models constructed in this study, this section similarly employed seven charts to systematically assess the ablation experimental results across three different regions, thereby demonstrating the collaborative optimization of multiple methods to improve precipitation prediction accuracy. These charts included: scatter plots of predicted versus observed values for the three regions of Changsha, Emeishan, and Guangzhou (Figs. 17, 18 and 19), precipitation prediction time series comparison and absolute prediction error analysis charts for each region (Figs. 20, 21 and 22), and a multi-dimensional performance radar chart synthesizing the performance of all methods across the three cities (Fig. 23).

Scatter plot of predicted and observed values in Changsha.

Scatter plot of predicted and observed values in Emeishan.

Scatter plot of predicted and observed values in Guangzhou.
From the comparison of predicted and observed values in the scatter plots, it can be seen that the CEEMDAN-TVMD-IPO-BiLSTM model performed most excellently, with its data points most closely distributed around the ideal diagonal line, demonstrating excellent prediction accuracy. This model achieved the highest correlation coefficients and consistency indices across all cities while maintaining the lowest error levels. In contrast, the basic BiLSTM model showed more scattered data point distribution with obviously insufficient prediction performance, while the other two improved models’ performance fell between the basic model and the optimal model.

Line chart of predicted and observed values in Changsha.

Line chart of predicted and observed values in Emeishan.

Line chart of predicted and observed values in Guangzhou.
The time series prediction comparison charts further revealed the differences in capabilities among various models in capturing dynamic precipitation changes. The CEEMDAN-TVMD-IPO-BiLSTM model demonstrated excellent peak-capturing capability when handling extreme precipitation events, accurately tracking the timing and intensity changes of sudden heavy precipitation. In contrast, the basic model often exhibited obvious lag phenomena and amplitude estimation deviations when facing complex precipitation patterns. During calm precipitation periods, the improved models showed higher stability, effectively suppressing noise interference and significantly reducing prediction deviations. Absolute error analysis results indicated that the basic BiLSTM model had the most severe error fluctuations, particularly during extreme weather events, while the combined optimization model consistently maintained stable and smaller error ranges.

Multidimensional performance radar chart.
From the performance radar chart, it can be seen that the CEEMDAN-TVMD-IPO-BiLSTM model formed the largest coverage area across all evaluation dimensions, fully demonstrating its superior performance under different geographical and climatic environments. The experimental results showed that the three cities exhibited regional characteristic differences in prediction difficulty, which mainly stemmed from their unique climate patterns and geographical conditions.
In summary, although the BiLSTM model had advantages in handling the nonlinear relationships of time series data, it showed significant biases in precipitation prediction, particularly in capturing complex precipitation patterns and noise processing. To overcome these limitations, the CEEMDAN-TVMD-BiLSTM model introduced the improved CEEMDAN-TVMD decomposition algorithm, which effectively removed noise and irregular fluctuations by decomposing the original precipitation time series into several intrinsic mode functions and residual components, thereby improving prediction accuracy. The CEEMDAN-TVMD-IPO-BiLSTM model combined the denoising and feature extraction advantages of CEEMDAN-TVMD with the parameter optimization of the BiLSTM model using the improved IPO, significantly enhancing parameter selection efficiency and model performance. As a result, the CEEMDAN-TVMD-IPO-BiLSTM model achieved the lowest errors on the test set and obtained the highest R² values and WIA indices, demonstrating its significant advantages in precipitation prediction.
Parameter sensitivity analysis
In this parameter sensitivity analysis experiment, two core parameters of the IPO optimization algorithm were analyzed: population size and maximum number of iterations. These two parameters directly affect the search capability and convergence performance of the optimization algorithm, serving as key factors determining the optimization effectiveness. Among them, the population size determines the coverage extent of the search space during algorithm iterations, while the maximum number of iterations controls the search depth and convergence time of the optimization algorithm. Tables 6 and 7 present the parameter sensitivity experimental results for population size and maximum number of iterations across three cities, respectively.
As shown in Table 6, the IPO-SVMD-BiLSTM model exhibits significant differences across the three cities under varying population sizes. Changsha and Emeishan achieve optimal performance with a population size of 2, while Guangzhou obtains the best results with a population size of 3. Furthermore, it can be observed that as the population size increases, the optimization time required by the algorithm grows exponentially, and the model’s prediction accuracy declines after reaching the optimal point as the population size continues to increase, indicating a clear performance saturation phenomenon in the model.
The differences in optimal population sizes mainly stem from the inherent complexity characteristics of precipitation data from different cities. As an eastern coastal city, Guangzhou exhibits more complex volatility and nonlinear features in its precipitation data, requiring a larger population size to adequately explore the solution space. In contrast, Changsha and Mount Emei, as central and western cities, have relatively simple precipitation data, allowing smaller populations to achieve effective search. When the population size is further increased, the predictive model performance of all three cities shows varying degrees of deterioration. This is primarily because excessive population size leads to reduced search efficiency, increases the risk of the algorithm becoming trapped in local optima, and significantly increases computational overhead.
As shown in Table 7, the predictive models for Changsha and Mount Emei achieve optimal prediction results when the maximum number of iterations is 2, while Guangzhou requires the 3rd iteration to obtain optimal performance. This is also due to the fact that Guangzhou, as an eastern coastal city, has diversified meteorological driving mechanisms that make its precipitation patterns exhibit higher nonlinear characteristics and randomness, requiring a more thorough exploration process. The additional search time in the 3rd iteration helps the prediction algorithm better capture the intrinsic patterns of complex precipitation models. Similarly, all cities show performance degradation trends after exceeding the optimal number of iterations, which may be because the models overfitted the precipitation patterns in the training set while ignoring the inherent randomness and uncertainty of the climate system. Overly refined parameter adjustments may weaken the model’s generalization ability.
Therefore, from a practical application perspective, the above parameter sensitivity analysis can provide important theoretical guidance for the deployment of precipitation prediction models in different regions. For coastal cities with more complex climates, higher population sizes and maximum iteration numbers need to be set, with more computational resources invested for adequate hyperparameter optimization, while for inland regions with relatively simple climates, more economical parameter setting strategies can be adopted. This differentiated modeling approach not only improves prediction accuracy but also effectively controls computational costs, providing scientific basis for practical applications in meteorological forecasting services.
Conclusion
Due to the randomness and uncertainty of monthly precipitation data, which can lead to insufficient extraction of time series features by models, this study aimed to effectively improve the accuracy of monthly precipitation prediction. Historical monthly precipitation data from three typical cities in China-an eastern city (Guangzhou), a central city (Changsha), and a western city (Emeishan)-were selected as research subjects. A CEEMDAN-TVMD-IPO-BiLSTM precipitation prediction model was constructed. The model first decomposed the original precipitation data using the CEEMDAN decomposition algorithm, output the modal components and residual components, and then used the topology optimization algorithm (TTAO) to optimize the VMD, and decomposed the high-dimensional sequence in the first decomposition result for the second time. Additionally, an IPO algorithm based on Cat and Cauchy-Gaussian variation was proposed to optimize the BiLSTM network. The optimized algorithm was then used to predict regional precipitation with a precisely constructed model. Experimental results indicatd the following: First, the proposed CEEMDAN-TVMD algorithm effectively captured nonlinear fluctuation patterns across different dimensions of the time series data, significantly improving the accuracy of the prediction model. Second, the IPO algorithm achieved more accurate hyperparameter tuning for the prediction model, thereby enhancing both prediction accuracy and model robustness. Compared to other models, the proposed CEEMDAN-TVMD-IPO-BiLSTM model achieved the lowest errors, the highest R² values, and the highest WIA, demonstrating its superiority in monthly precipitation prediction. Moreover, it better characterized the fluctuation patterns of precipitation, providing a scientific reference for formulating policies to mitigate drought and flood disasters.
Although the CEEMDAN-TVMD-IPO-BiLSTM model constructed in this study has achieved significant efficacy in monthly precipitation prediction, it also faces several challenges and limitations. First, the model integrates multiple complex algorithmic modules involving numerous hyperparameters that require selection and optimization. The optimal configuration of these parameters typically demands extensive empirical knowledge and experimental adjustments, thereby increasing the complexity and time costs of model implementation. Second, due to the adoption of a dual decomposition strategy, errors may propagate and accumulate across multiple decomposition and prediction stages. When prediction deviations occur at any stage, they may affect the stability and accuracy of the final reconstruction results. Finally, the model’s generalization capability is primarily based on validation from three Chinese cities, and its applicability under different climatic regions and meteorological conditions requires further verification. Future research can focus on the model’s adaptive parameter selection, computational efficiency optimization, cross-regional generalization capability enhancement, and improvement of prediction mechanism interpretability.
Data availability
The data are available from the first author on reasonable request.
References
Yang, S., Chen, D. & Deng, K. Global effects of climate change in the South China sea and its surrounding areas. Ocean-Land-Atmos Res. 3, 0038 (2024).
Chen, Y., Zhang, S., Wang, H., Chen, D. & Liu, J. Human-Induced climate change intensifies extreme precipitation events in central china’s urban areas. Geophys. Res. Lett. 52, e2024GL111818 (2025).
Ma, T. et al. Pollution exacerbates china’s water scarcity and its regional inequality. Nat. Commun. 11, 650 (2020).
Miao, L. et al. Unveiling the dynamics of sequential extreme precipitation-heatwave compounds in China. Npj Clim. Atmos. Sci. 7, 67 (2024).
Rojas-Campos, A., Langguth, M., Wittenbrink, M. & Pipa, G. Deep learning models for generation of precipitation maps based on numerical weather prediction. Geosci. Model. Dev. 16, 1467–1480 (2023).
El Hafyani, M., El Himdi, K. & El Adlouni, S. E. Improving monthly precipitation prediction accuracy using machine learning models: a multi-view stacking learning technique. Front. Water. 6, 1378598 (2024).
Si, L. & Li, Z. Atmospheric precipitation chemistry and environmental significance in major anthropogenic regions globally. Sci. Total Environ. 926, 171830 (2024).
Ye, Z., Yin, S., Cao, Y. & Wang, Y. AI-driven optimization of agricultural water management for enhanced sustainability. Sci. Rep. 14, 25721 (2024).
Hussain, A. et al. Observed trends and variability of seasonal and annual precipitation in Pakistan during 1960–2016. Intl J. Climatology. 42, 8313–8332 (2022).
Kaune, A. et al. Can global precipitation datasets benefit the Estimation of the area to be cropped in irrigated agriculture? Hydrol. Earth Syst. Sci. 23, 2351–2368 (2019).
Ma, Z. & Tan, Y. A physical statistic model for predicting the rainfall during flood season in Sichuan-Chongqing region. Chin. J. Atmospheric Sci. 28, 138–145 (2004).
Sun, C. Z., Zhang, G. & Lin, X. Y. Model of Markov chain with weights and its application in predicting the precipitation state[J]. Syst. Eng. Theory Pract. 4(4), 100–105 (2003).
Wang, Z. et al. Application of grey model for precipitation forecast around Bohai sea. J. Arid Meteorol. 30, 272–275 (2012).
Liu, X., Zhao, N., Guo, J. & Guo, B. Prediction of monthly precipitation over the Tibetan plateau based on LSTM neural network. J. Geo-information Sci. 22, 1617–1629 (2020).
Xu, D., Wang, Y. & Wang, W. Monthly precipitation prediction model based on VMD-TCN. J. China Hydrology. 42, 13–18 (2022).
Kumar, D., Singh, A., Samui, P. & Jha, R. K. Forecasting monthly precipitation using sequential modelling. Hydrol. Sci. J. 64, 690–700 (2019).
Sun, G., Li, B., Xu, D. & Li, Y. Monthly runoff prediction model based on VMD-SSA-LSTM. Water Resour. Power. 40, 18–21 (2022).
Nourani, V., Nezamdoost, N., Samadi, M. & Daneshvar Vousoughi, F. Wavelet-based trend analysis of hydrological processes at different timescales. J. Water Clim. Change. 6, 414–435 (2015).
Sattari, A. A probabilistic machine learning framework for daily extreme events forecasting. (2025).
Mohammadi, B. et al. Enhancing daily runoff prediction: A hybrid model combining GR6J-CemaNeige with wavelet-based gradient boosting technique. J. Hydrol. 657, 133114 (2025).
Jiang, X. A combined monthly precipitation prediction method based on CEEMD and improved LSTM. PLoS ONE. 18, e0288211 (2023).
Torres, M. E., Colominas, M. A., Schlotthauer, G. & Flandrin, P. A complete ensemble empirical mode decomposition with adaptive noise. in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 4144–4147 (IEEE, Prague, Czech Republic, 2011). 4144–4147 (IEEE, Prague, Czech Republic, 2011). (2011). https://doi.org/10.1109/ICASSP.2011.5947265
Wang, H., Wang, W., Du, Y. & Xu, D. Examining the Applicability of Wavelet Packet Decomposition on Different Forecasting Models in Annual Rainfall Prediction. Water 13, (2021). (1997).
Xu, D., Liao, A., Wang, W., Tian, W. & Zang, H. Improved monthly runoff time series prediction using the CABES-LSTM mixture model based on CEEMDAN-VMD decomposition. J. Hydroinformatics. 26, 255–283 (2024).
Ren, S., Yan, J., Luo, J. & Han, Y. An improved LSTM prediction method for monthly precipitation based on boundary correction and double decomposition. China Rural Water Hydropower. 26, 26–34 (2023).
Peng, S., Ding, Y., Liu, W. & Li, Z. 1 Km monthly temperature and precipitation dataset for China from 1901 to 2017. Earth Syst. Sci. Data. 11, 1931–1946 (2019).
Lu, J., Chai, Y., Hu, Z. & Sun, Y. A novel image denoising algorithm and its application in UAV inspection of oil and gas pipelines. Multimed Tools Appl. 83, 34393–34415 (2023).
Sikha, O. K., Soman, K. P. & Kumar, S. S. VMD-DMD coupled data-driven approach for visual saliency in noisy images. Multimed Tools Appl. 79, 1951–1970 (2020).
Zhao, S., Zhang, T., Cai, L. & Yang, R. Triangulation topology aggregation optimizer: A novel mathematics-based meta-heuristic algorithm for continuous optimization and engineering applications. Expert Syst. Appl. 238, 121744 (2024).
Lian, J. et al. Parrot optimizer: algorithm and applications to medical problems. Comput. Biol. Med. 172, 108064 (2024).
Xu, C., Li, C., Yu, X. & Huang, Q. Improved grey Wolf optimization algorithm based on chaotic Cat mapping and Gaussian mutation. Comput. Eng. Appl. 53, 1–9 (2017).
Yang, Z., Zou, D., Li, C., Shao, Y. & Ma, L. Dung beetle optimizer algorithm with restricted reverse learning and Cauchy-Gauss variation. Journal Comput. Applications 1–17 (2024).
Wei, X., Peng, M. & Huang, H. Node coverage optimization of wireless sensor network based on multi-strategy improved butterfly optimization algorithm. J. Comput. Appl. 44, 1009–1017 (2024).
Wei, C., Wei, X. & Huang, H. Pigeon cluster algorithm based on chaotic initialization and Gaussian mutation. Comput. Eng. Des. 44, 1112–1121 (2023).
Liang, F., Chen, X., He, S., Song, Z. & Lu, H. An aerial target recognition algorithm based on Self-Attention and LSTM. CMC 81, 1101–1121 (2024).
Muthunambu, N. K. et al. A novel eccentric intrusion detection model based on recurrent neural networks with leveraging LSTM. CMC 78, 3089–3127 (2024).
Han, Y., Tan, Wang, L. & Luo, J. Application of improved LSTM model in monthly precipitation forecast. Comput. Simul. 40, 535–540 (2023).
Wang, T., Wang, T., Wang, P., Qiao, H. & Xu, M. An intelligent fault diagnosis method based on attention-based bidirectional LSTM network. J. Tianjin Univ. (Scienceand Technology). 53, 601–608 (2020).
Jia, R. et al. Combined wind power prediction method based on CNN-LSTM & GRU with adaptive weights. Electr. Power. 55, 47–56 (2022).
Cao, Y. et al. Predicting peak particle velocity in pre-splitting of gas-producing devices using improved particle swarm optimization algorithm. Sci. Rep. 15, 13663 (2025).
Lv, X., Gu, D., Liu, X., Dong, J. & Li, Y. Momentum prediction models of tennis match based on catboost regression and random forest algorithms. Sci. Rep. 14, 18834 (2024).
Sun, F. & Lian, S. ν-Improved nonparallel support vector machine. Sci. Rep. 12, 17855 (2022).
Li, H., Zhang, B., Shen, Y., Zhang, L. & Liu, K. Research on prediction of nanocrystalline alloy hysteresis properties based on long short-term memory network. Sci. Rep. 15, 6536 (2025).
Abduljabbar, R. L., Dia, H. & Tsai, P. W. Development and evaluation of bidirectional LSTM freeway traffic forecasting models using simulation data. Sci. Rep. 11, 23899 (2021).
Acknowledgements
Thanks to the National Meteorological Information Center for providing monthly precipitation data.
Funding
This study had no financial support.
Author information
Authors and Affiliations
Contributions
The authors confirm contribution to the paper as follows: Conceptualization, Weiie Zhang and Yuming Zeng; methodology, Weiie Zhang and Yuming Zeng; software de-velopment, Weiie Zhang and Shubo Zhou; validation, Weiie Zhang, Yuming Zeng, and Shubo Zhou; formal analysis, Weiie Zhang; investigation, Weiie Zhang, Libin Zhang, and Haiquan Li; resources, Weiie Zhang and Haiquan Li; data curation, Weiie Zhang and Libin Zhang; writing—original draft preparation, Weiie Zhang and Yuming Zeng; writing—review and editing, Weiie Zhang, Shubo Zhou, and Libin Zhang; visualization, Weiie Zhang and Libin Zhang; supervision, Yao Zhongsheng and Rusheng Zhou; project administration, Yao Zhongsheng and Rusheng Zhou; funding acquisition, Rusheng Zhou. All authors reviewed the results and approved the final version of the manu-script.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, W., Zeng, Y., Zhou, S. et al. Monthly precipitation prediction based on quadratic decomposition and improved parrot algorithm. Sci Rep 15, 26503 (2025). https://doi.org/10.1038/s41598-025-12493-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-12493-7
