
Abstract
Visual Question Answering (VQA) effectively integrates image and text information to provide accurate answers to user queries. Despite the advances in multi-modal learning, traditional multi-head attention models struggle with limited interaction between attention heads and the inability to capture positional information, which are critical for modeling both intra-modal and cross-modal connections. In this work, we propose a novel position-aware collaborative attention framework to address these challenges. Our framework introduces an Inter-Head Communication Matrix (IHCM) before and after normalization in multi-head attention, enabling effective information sharing across attention heads. We design two collaborative attention components, i.e., the Intra-modal Self-Attention with Collaboration (IMSAC) for refining single-modality features and the Cross-modal Guided Attention with Collaboration (CMGAC) for leveraging textual information to guide image attention. To further enhance positional awareness, absolute positional encoding is incorporated into the self-attention mechanism, significantly improving semantic understanding in text features. We evaluate our framework on the TDIUC, VQA-CP v2, and GQA datasets to demonstrate its effectiveness and robustness. Our collaborative attention block consistently improves accuracy across various question categories, with the IMSAC and CMGAC combination achieving the best results. Comprehensive ablation studies confirm the importance of inter-head collaboration and positional encoding, highlighting their contributions to addressing the “semantic gap” and enhancing cross-modal reasoning. The proposed framework achieves competitive and superior performance compared to several recent attention-based methods, showcasing superior resilience to language bias and strong compositional reasoning capabilities.
Similar content being viewed by others

Introduction
With continuous advancements in computer technology, information such as videos, images, audio, and subtitles has become ubiquitous, with each type of information format referred to as a modality. To process multi-source modality information, multi-modal learning has emerged and become a prominent research direction. Multi-modal learning encompasses common tasks such as image-text matching, image captioning, and Visual Question Answering (VQA). Compared to other multi-modal learning tasks, VQA is more challenging as it integrates computer vision and natural language processing, requiring detailed semantic understanding of both images and text1.
Previously, computer vision and Natural Language Processing (NLP) had minimal intersection. In recent decades, the explosive growth of accessible and processable visual and textual data has rapidly advanced these two fields. Computer vision tasks focus on enabling machines to process and understand image content, with primary research areas including image classification, image segmentation, image generation, and object detection. NLP involves the process of machines analyzing and understanding human language, including articles, sentences, and sentiments. Its main research tasks include sentiment recognition, intent recognition, and machine translation. Researchers are no longer satisfied with machines performing basic perception of images; they aspire for comprehensive understanding and further reasoning capabilities, ultimately presenting results through user-friendly human-computer interactions.
In typical VQA tasks, computers process image and text inputs to perceive, understand, and provide correct answers. The answers are usually a single word, a number, or a short phrase composed of several words. Examples of VQA tasks are shown in Fig. 1.

VQA Examples illustrating the two primary task types: a Multiple-choice, where the model selects from a predefined list, and b Open-ended, where the model generates a natural language answer based on the visual and textual inputs.
VQA tasks can be categorized into open-ended and multiple-choice types. For open-ended VQA tasks, the answers are indefinite; the computer has no references and generates natural language answers based solely on the image and the question. In contrast, multiple-choice VQA tasks are simpler; the machine is provided with several candidate answers for the question and selects the most correct one after reasoning over the image and the question. VQA tasks are more challenging than other computer vision tasks. Specifically, conventional computer vision tasks have a single format, and answering a single question is predetermined, with only the input image varying. However, VQA tasks must process information across different modalities, addressing the “semantic gap” between modalities, and establishing a unified semantic representation through interactions between cross-modal data.
In general, the development of research in VQA is inseparable from advancements in image segmentation, recognition, localization, and natural language understanding. The success of attention models in both the image and text processing domains has brought a certain level of interpretability to VQA2. Many research methods attempt to use attention to identify the importance interrelations within and between image and text features. With the use of pre-trained models like BERT (Pre-training of Deep Bidirectional Transformers for Language Understanding) and related concepts, models achieve increasingly higher accuracy on specific datasets. However, data integration across different modalities remains a significant challenge. In information processing, image and text information simultaneously exhibit differences and associations; textual information is characterized by high information density and low noise, while image information is abundant but noisier. Moreover, since textual and image information exist within the same semantic space, there is inherent interrelation between them.
Recent research has underscored persistent challenges in developing truly robust VQA systems, particularly in overcoming language priors, enhancing compositional reasoning, and enriching visual features to handle complex queries3,4. A key objective is to ensure models ground their answers firmly in visual evidence rather than exploiting statistical biases in the data5,6. The need for more effective multimodal feature calibration and fusion mechanisms is therefore paramount. Some studies have even explored optimized frameworks to better handle the diversity of question types and improve scalability7. These collective insights inform our work, highlighting the necessity of attention mechanisms that go beyond simple alignment to foster deeper semantic integration and mitigate systemic biases.
This paper addresses the limitations of traditional multi-head attention models in VQA tasks, specifically the lack of inter-head interaction and the inability to capture positional information. To this end, we propose a novel collaborative attention framework that incorporates inter-head communication and positional encoding to enhance both intra-modal and cross-modal feature modeling. Our experiments demonstrate the effectiveness of the proposed approach, showcasing significant improvements in accuracy across various question types. Our main contributions are as follows:
-
1)
We introduce a collaborative attention block to address the lack of inter-head interaction in the multi-head attention framework. By adding an Inter-Head Communication Matrix (IHCM) both before and after normalization, we ensure more effective information sharing among different attention heads. This approach aims to reduce information fragmentation and mitigate global context loss, potentially strengthening each head’s capacity for multi-modal feature modeling.
-
2)
We design two collaborative attention units, namely the Intra-modal Self-Attention with Collaboration (IMSAC) unit and the Cross-modal Guided Attention with Collaboration (CMGAC) unit. IMSAC focuses on refining single-modality self-attention by enabling interaction among attention heads, while CMGAC leverages textual information to guide image feature attention. Our experiments show that text-guided image attention typically yields stronger performance than image-guided text attention, results which we interpret as evidence of the rich semantic cues inherent in textual representations.
-
3)
We incorporate positional encoding in the self-attention model to compensate for the absence of positional information in standard self-attention. By adopting absolute position encoding for the question text, we capture word-order semantics more effectively. This enhancement proves crucial in complex reasoning tasks such as VQA, where the order and context of words can substantially impact the model’s interpretative capabilities.
-
4)
We conduct comprehensive ablation and comparative experiments on the TDIUC dataset to validate our framework. Our collaborative attention block, particularly the combination of IMSAC and CMGAC, consistently outperforms baseline methods in question categories such as “Yes/No,” “Number,” and “Other.” This confirms the effectiveness of our design choices and highlights the importance of inter-head collaboration and cross-modal guided attention in improving performance on diverse VQA tasks.
Related works
Researchers have proposed various VQA models with promising performance. Most of these models can be summarized into a unified framework, which consists of four main components: the image feature extraction block, the question feature extraction block, the feature integration block, and the answer generation block. The image feature extraction block typically uses VGG-Net8, ResNet9, and GoogleNet10 for extracting image features. With the continuous development of object detection, the use of Faster R-CNN11 for image feature extraction has become the mainstream approach. The question feature extraction block primarily utilizes language encoding models such as LSTM(Long Short Term Memory)12, GRU(Gated Recurrent Unit)13, Transformer14, and BERT15 to extract question features. The feature integration block aims to map image and text features into the same feature space and perform interactive integration. This block is the core of VQA models. The answer generation block can use either a classification or a generation method. For multiple-choice tasks, the integrated features are fed into a classifier to obtain the probability scores for each candidate answer, with the highest-scoring candidate chosen as the correct answer. For open-ended tasks, the integrated features are input into models such as Recurrent Neural Network(RNN) or LSTM to generate the answer. The general framework of visual question answering models is shown in Fig. 2.

General framework for VQA tasks, illustrating the standard pipeline: image and question feature extraction, multi-modal feature integration, and final answer generation.
In this section, the models are categorized into six types based on their characteristics: joint embedding-based methods, attention model-based methods, scene reasoning-based methods, external knowledge-based methods, contrastive learning-based methods, and three-dimensional point cloud-based methods. For each of these six categories, this section provides a detailed description of the rationale behind the model, its methodology, the connections between different models, and the challenges that remain.
Joint embedding-based methods
To address VQA, researchers initially explored the concept of joint embedding of images and text. Joint embedding methods typically integrate these two features through simple operations such as concatenation, element-wise multiplication, or element-wise addition.
Malinowski et al.16 conducted early research on joint embedding in VQA. By combining the latest advancements in image representation and natural language processing, they proposed Neural-Image-QA17, a novel approach based on RNNs to tackle the challenging tasks in visual question answering. This model combines CNNs(Convolutional Neural Networks) and LSTMs into an end-to-end architecture for predicting answers based on both the question and the image. The Neural-Image-QA model generates answers in a generative manner. However, Gao et al.18 proposed the mQA model, which treats the visual question answering task as a classification problem. They fed the feature vectors into a linear classifier to generate answers from a predefined vocabulary.
Inspired by deep residual networks, Kim et al.19 introduced the Multimodal Residual Networks (MRN) for multimodal residual learning in visual question answering, extending the ideas of deep residual learning. Unlike deep residual learning, MRN effectively learns joint representations from both visual and linguistic information by using element-wise multiplication for joint residual mapping. In contrast to most models that use both an image encoder and a question encoder simultaneously, Ma et al.20 proposed a model comprising three CNNs: one for encoding the image, one for encoding the question, and a multimodal convolutional layer that learns their joint representation for classification in the candidate answer space.
Joint embedding-based methods simply concatenate image and text features, without directly aligning image regions with question keywords. These methods rely on using all available visual and textual information to generate answers. However, a significant portion of the information in both the visual and textual features is often irrelevant and can interfere with the final answer classification or generation. This integration approach is relatively coarse and does not involve reasoning based on the question, leaving considerable room for improvement.
Attention model-based methods
Attention models in deep learning are inspired by human attention, where humans quickly scan images or texts, focusing on key areas and keywords to understand the main information. The attention model has been widely adopted in various artificial intelligence fields, achieving impressive performance. In VQA tasks, attention models enhance the model’s ability to understand both images and semantics. In recent years, attention methods can generally be categorized into three types: question-guided attention, cooperative attention, and multi-granularity attention methods. The following sections provide an overview of these three approaches.
Question-guided attention methods
Early attention models used questions to identify important image regions, identifying the areas most closely related to the question. For example, Shih et al.21 proposed selecting image regions relevant to text-based queries to learn how to answer visual questions. They simply multiplied visual features with textual features to obtain attention weights, which, when applied to the visual features, updated them. Kazemi et al.22 used a ResNet-based convolutional neural network to extract image features, with the input question passed through multiple layers of LSTM. Then, the final state of the LSTM, along with the concatenated image features, was used to compute multiple attention distributions over the image features. Some methods calculated only a single visual attention distribution. To further improve the effectiveness of cross-modal feature integration, Yang et al.23 proposed a stacked attention network (SAN). This model involves a multi-step reasoning process, establishing multiple layers of attention models. The model queries an image multiple times based on the semantics of the question to gradually infer the answer.
Cooperative attention methods
Cooperative attention methods further refine early attention approaches. These methods not only consider question-guided attention for extracting image features but also leverage image features to generate question-guided attention.
To enhance the performance of VQA models, fine-grained understanding of both visual and textual content is required. Specifically, linking the key words in the question with the key objects in the image has proven to be a challenge. Yu et al.24 introduced a deep modular cooperative attention network, which is inspired by the Transformer model. The encoder part consists of six self-attention units stacked together to handle internal interactions within the text, while the decoder part combines self-attention and guiding attention units to facilitate the interaction between textual and image features. Later, many researchers made improvements based on the Transformer structure. An example of such a model is the modified attention-based network by Rahman et al.25, which introduces an AoA block in the encoder-decoder framework. This block determines the relationship between attention results and queries, generating weighted averages for each query. They also proposed a multimodal integration block to combine visual and textual information. The goal of this block is to dynamically decide how much visual and textual information to consider. In the VQA task, multimodal prediction often requires visual information from both macro and micro perspectives. Hence, how to dynamically adjust both global and local dependencies in the Transformer model becomes a new challenge. Zhou et al.26 introduced the TRAR to solve this issue. In TRAR, each visual Transformer layer is equipped with routing blocks with different attention scopes. This model can dynamically select the appropriate attention range based on the output of the previous reasoning step, thus determining the optimal routing path for each instance.
Transformer-based methods have achieved significant success in visual question answering. However, these models often have deeper networks and larger embedding dimensions, making them difficult to deploy on resource-limited platforms. Designing VQA models that support runtime adaptive pruning to meet efficiency constraints on different platforms is a valuable task. Yu et al.27 proposed a Dual Lightweight Transformer (DST), a universal framework that can be seamlessly integrated into any Transformer-based VQA model. DST simplifies the model in both width and depth, training a single model to obtain efficient sub-models adaptable to different platforms. Furthermore, Wang et al.28 proposed a cross-modal attention distillation framework for training dual-encoder models to complete visual-linguistic understanding tasks. This framework utilizes the image-text and text-image attention distributions in the integration encoder model for distillation, thereby guiding the training of the dual-encoder model.
Multi-granularity attention methods
Existing visual-linguistic models either use fine-grained, object-centered image features for aligning text or employ coarse-grained, holistic image features for aligning text. While both methods are effective, they still have some shortcomings. Fine-grained detection can identify all possible objects in an image, but some of these objects may not be relevant to the text. Object-centered features may not easily capture the relationships between multiple objects. On the other hand, coarse-grained methods cannot effectively learn fine-grained alignment between visual and textual features.
Zeng et al.29 proposed a new method called X-VLM for multi-granularity visual-linguistic pretraining. They reconstructed existing datasets into visual concepts and their corresponding text. A visual concept could be an object, region, or the entire image. The model aligns text with the corresponding visual concept, and the alignment process is multi-granular. Since image features exhibit high diversity and lack the structure and grammatical rules found in language, linguistic features are likely to lose detailed information. To better learn the attention between visual and textual features, Xiong et al.30 introduced a new multi-granularity alignment architecture. This architecture jointly learns inter- and intra-modal correlations at three levels: concept-entity, region-noun phrase, and spatial-sentence. A decision integration block is then constructed to merge outputs from Transformer blocks at different granularities.
To simultaneously pretrain an encoder for multimodal representation extraction and a language decoder for sentence generation, Li et al.31 introduced a general pre-trained encoder-decoder network (Uni-EDEN) to enhance visual-linguistic perception and generation. This model is pretrained using multi-granularity visual-linguistic proxy tasks, such as object classification, region phrase generation, image-sentence matching, and sentence generation. These multi-granularity visual-linguistic proxy tasks aim to better align visual content with various granularities of linguistic representations, ranging from single labels and phrases to natural sentences.
Attention-based methods are the mainstream approach in visual question answering tasks, attracting significant attention from researchers. Models based on attention mechanisms have been continually improved and achieved excellent performance. However, attention methods primarily focus on image regions and textual keywords, without capturing the relationships between objects in an image. This limits their ability to assist in reasoning tasks. How to incorporate reasoning chains and accurately locate image regions related to the answer in visual question answering tasks remains an area for further exploration.
Despite these advancements, recent studies emphasize that many attention-based models still struggle with fundamental issues of semantic robustness. A primary concern is the “language prior” problem, where models learn to favor frequent answers associated with certain question types, effectively ignoring the visual content4,5. To counteract this, a growing body of work focuses on enriching visual features by combining different attention strategies (e.g., spatial and channel-wise) to create more comprehensive and bias-resistant image representations6. Another critical challenge is improving compositional reasoning—the ability to decipher complex relationships between multiple objects described in a question3,4. These challenges collectively point toward the need for more sophisticated attention mechanisms that not only align modalities but also facilitate robust, calibrated feature fusion. Some researchers also propose system-level optimizations, such as question-type segregation, to improve both performance and efficiency7. Our work is situated within this context, aiming to enhance multimodal integration at a foundational level through inter-head communication, which directly addresses the need for a more holistic and less fragmented understanding of the visual and textual data.
Scene reasoning-based methods
Scene graphs provide a structured representation of a scene, clearly expressing the objects, attributes, and relationships between objects within the scene. Currently, researchers are no longer satisfied with simply detecting and recognizing objects in images; instead, higher-level visual understanding and reasoning tasks are required to capture the relationships between objects in a scene. Scene graphs serve as a powerful tool for understanding scenes. As a result, scene graphs have attracted significant attention from researchers, leading to a growing body of cross-modal, complex, and rapidly evolving research.
The primary idea behind scene graph-based VQA models is to leverage semantic cues from the question to guide visual content reasoning. Yang et al.32 proposed a novel approach using prior visual relationship learning to solve relational reasoning tasks, i.e., SceneGCN. This model vectorizes the objects and relationships in a scene graph using a pretrained object detector and visual relationship encoder, and then employs scene graph convolution to update the hidden state of each node by utilizing information about objects and relationships. In contrast to SceneGCN, Liang et al.33 introduced a language-guided graph neural network framework called GraphVQA. This framework first converts the question into M instruction vectors, then uses a graph neural network to propagate messages through each instruction vector, and finally aggregates the final state after message passing to predict the answer.
Since scene graphs represent entities along with their semantic and spatial relationships, it is feasible to model VQA tasks as pathfinding problems on a scene graph. Konečný et al.34 introduced a novel method called Graphhopper, which is the first VQA approach to apply reinforcement learning for multi-hop reasoning on scene graphs. Specifically, the core idea of Graphhopper is to train a reinforcement learning agent to autonomously navigate through the scene graph based on the content of the question, generating reasoning paths that form the foundation for obtaining answers. Compared to purely embedding-based approaches, Graphhopper provides explicit reasoning chains that guide the model toward the correct answer.
In previous studies, images were properly represented by scene graphs, but the questions were often simply embedded and did not fully capture the entire semantic meaning. To address this, Cao et al.35 proposed a Graph Matching Attention (GMA) network. This algorithm constructs scene graphs from both the visual aspects, geometric features, and spatial relationships of objects, as well as from a syntax tree and language features extracted from the question. First, a two-stage graph encoder captures the intra-modal relationships, then bi-directional cross-modal graph matching attention is applied to infer the relationships between the image and the question, propagating cross-modal information.
Existing visual question answering models embed various types of information, but they do not always conduct fine-grained search for answers, potentially introducing noise that can interfere with the model’s ability to give the correct answer. How to accurately obtain supporting evidence for the question is a key challenge. Zhu et al.36 used multi-modal heterogeneous graphs to describe images. These graphs contain richer information than traditional scene graphs, including multi-layer information related to visual features, semantic features, and factual features of the image. They then built a modality-aware heterogeneous graph convolution network that iteratively selects and collects intra-modal and cross-modal evidence. This method provides strong interpretability in the process of deriving answers.
Compared to traditional VQA methods, scene graphs capture the fundamental information of an image in the form of a graph structure, which makes scene graph-based VQA approaches superior to traditional algorithms. However, scene graph-based visual question answering methods are still not perfect. While models can search for answers within scene graphs based on the question, they perform well on relational reasoning tasks, but their effectiveness on tasks such as counting, causality, and time-related questions remains suboptimal. Additionally, the process of reasoning answers using scene graphs lacks transparency, and its interpretability needs further investigation.
Knowledge-based methods
VQA tasks typically involve complex and diverse questions, and relying solely on limited visual information may not provide sufficient answers. In such cases, VQA models need to obtain information from external knowledge bases to support the answering process. For instance, for a question such as “Which object in this image can be used to protect the head?“, the model needs to understand that head protection is a function, and then search for an object that serves this purpose. Knowledge-based methods in VQA are a promising direction for future research, particularly in specialized fields where they hold significant application potential.
Knowledge reasoning methods
Wang et al.37 proposed Ahab, a VQA method that performs reasoning on image content using large-scale knowledge bases. Specifically, Ahab first detects relevant content in the image and associates it with available information from the knowledge base. It processes natural language questions into appropriate queries and combines image content with knowledge base information for querying. These queries may require multiple reasoning steps to complete, and the final answer is formed based on the feedback from the query. Previous methods could only pose a set of specific questions to the system, and the query generation methods used were highly specific. To make it applicable to general knowledge bases and address a broader range of questions, Wu et al.38 proposed a VQA method that constructs a textual representation of the image’s semantic content and integrates it with textual information from the knowledge base to deepen the understanding of the observed scene. This enables the model to answer a wider variety of questions, including more complex ones. Existing methods depend on retrieving basic facts for answering questions, but real-world applications may pose questions about facts that are not found in the knowledge graph. Ramnath et al.39 developed a new QA framework that can handle FVQA tasks even in the absence of required edges in the knowledge graph. This method combines complementary lexical features and semantic features from the knowledge graph to improve the accuracy of answer retrieval.
These methods typically construct models in a pipeline manner, querying knowledge graphs, which often leads to error cascading. Additionally, VQA reasoning abilities remain weak, as these methods cannot predict answers that are not present in the training data. To address this, Chen et al.40 introduced the Zero-shot VQA algorithm. In this approach, VQA is reformulated as a mapping-based alignment task to better integrate external knowledge and predict answers to previously unseen questions. The alignment between the image/question and the knowledge graph is implicitly completed through multiple feature spaces. The answer prediction block adjusts the prediction score using a mask-based approach. This soft/hard masking method effectively enhances the alignment process and reduces error cascading.
Scene text recognition is gradually transitioning from experimental settings to industrial applications. However, incorporating text recognition into knowledge reasoning-based VQA models has not been fully explored. Singh et al.41 proposed a VQA model that reads scene text and performs reasoning on the knowledge graph to obtain accurate answers. This model seamlessly integrates visual content, recognized words, questions, and factual knowledge, using Gated Graph Neural Networks (GGNNs) to reason over multi-relational graphs.
Knowledge reasoning methods have shown good results in complex problems requiring external knowledge. However, these knowledge-based reasoning methods do not autonomously select domain-specific knowledge from large knowledge graphs, and the reasoning process remains relatively simple. Future work should focus on developing models that can select more specific knowledge from the knowledge graph, enabling multi-hop and more complex reasoning.
Knowledge search methods
Recent research has started to explore how knowledge search methods can be integrated into VQA. These methods investigate how knowledge bases and retrieval methods can be combined with VQA datasets to provide a set of relevant facts for each question. Marino et al.42 proposed a knowledge-based baseline called ArticleNet. The method first identifies words in the question and associates them with words recognized by trained image and scene classifiers to gather all possible queries for each question. Then, it uses the Wikipedia search API to obtain the most popular articles for each query. Next, it selects the most relevant sentence from the articles based on the frequency of the query terms within the sentence. Finally, to find the answer, the method selects the highest-scoring words from the retrieved sentences.
Knowledge search-based VQA methods utilize large-scale knowledge bases, which may retrieve irrelevant or noisy knowledge, complicating the task of understanding facts and finding answers. To address this issue, Wu et al.43 introduced MAVEx, a new method that considers three sources of knowledge: Wikipedia, ConceptNet, and Google Images, which provide factual, common-sense, and visual knowledge, respectively. By using multimodal knowledge retrieval and guiding knowledge search with candidate answers in open-domain VQA, the model learns to verify the effectiveness of the candidate answers and determine the reliability of each source. Unlike previous knowledge search-based VQA methods, Qu et al.44 explored article retrieval suitable for the OK-VQA dataset, which can be applied to a wider range of unstructured knowledge resources. Their article retrieval method includes sparse retrieval using BM25 and dense retrieval using a dual-encoder, where the query encoder is LXMERt, a multimodal pre-trained transformer used to learn interactions between images and questions.
Existing works rely on different knowledge bases to acquire external knowledge. Since the knowledge bases vary, it is difficult to make fair comparisons of model performance. To address this issue, Luo et al.45 collected a natural language knowledge base that can be used by any VQA system and proposed a visualized retrieval-reader pipeline structure. The visual retriever is responsible for retrieving relevant knowledge, while the visual reader predicts the answer based on the known knowledge. Both the retriever and reader are trained under weak supervision.
Knowledge search-based VQA has attracted increasing attention from researchers. However, most of the questions require only a small amount of knowledge from the knowledge base. Overcoming the challenge of filtering noisy information and accurately extracting relevant knowledge remains a key challenge in the field.
Contrastive learning-based methods
Self-supervised learning is a type of unsupervised learning that does not require manually labeled category information. Instead, it utilizes the supervisory signals inherently provided by the data itself to learn feature representations of sample data for downstream tasks. Contrastive learning is a key method within self-supervised learning. In visual-language representation learning, contrastive learning is employed to achieve image-text alignment. This alignment strategy is successful because it maximizes the mutual information (MI) between the image and the corresponding text. Mutual information is a metric that measures the interdependence between variables, and it is used to evaluate the relationship between images and their associated textual descriptions by distinguishing between positive and negative sample pairs.
Multimodal encoder learning for image-text interaction is a challenging task. To address this issue, Li et al.46 proposed the ALBEF model, which introduces image-text contrastive learning. The model leverages an image encoder, a text encoder, and a multimodal encoder for pretraining. The goal of the pretraining is to maximize the mutual information between the image and text, facilitate fine-grained interactions between them, and establish image-text pair alignments. Wang et al.47 proposed a unified vision-language pretraining model called VLMo, which jointly learns a dual encoder and a shared MoME Transformer network. MoME introduces a modality-specific expert pool to encode modality-specific information and utilizes a shared self-attention module to align different modalities. Through MoME, the unified pretraining shares model parameters across tasks such as image-text contrastive learning, masked language modeling, and image-text matching. Most models extract information primarily from irrelevant or noisy image patches or text tokens. To overcome this limitation, Yang et al.48 proposed a new visual-language pretraining framework called TCL. Unlike previous research, which aligns image and text representations through simple cross-modal contrastive losses, TCL further incorporates within-modality supervision, which in turn benefits cross-modal alignment and joint multimodal embedding learning. To integrate local and structural information into representation learning, TCL introduces local mutual information, maximizing the mutual information between global representations and local information from image patches or text tokens.
Contrastive learning ensures that matching image-text pairs are as close as possible while keeping non-matching pairs as distant as possible. The objective of contrastive learning is to facilitate the multimodal encoder in learning easier interactions between modalities. However, in VQA, contrastive learning still faces certain limitations. While it enhances the global mutual information between images and texts, it overlooks local and structural information in the input. Additionally, some noise may dominate the mutual information, causing the model to learn irrelevant features.
Methods based on 3D point clouds
VQA has made significant progress in recent years. However, current research mainly focuses on 2D image-based VQA tasks. Researchers have attempted to extend VQA to the 3D domain, which can advance artificial intelligence in understanding 3D real-world scenes, thereby simulating real-world environments and facilitating a wide range of applications. Unlike image-based 2D VQA, 3D VQA uses point clouds as input, requiring both language processing and 3D scene understanding when answering questions related to 3D scenes.
Existing 2D image-based models face challenges in accurately understanding the 3D world. For example, 2D images lack precise perception of relative orientations and distances in a 3D scene, and some objects may be occluded by others during overlap. To address these challenges, Azuma et al.49 proposed a baseline model for 3D VQA called ScanQA. The ScanQA model consists of 3D and language encoders, a 3D-language integration module, and an object localization and QA layer. The 3D and language encoder layers convert the question into a feature vector representation and transform the point cloud into object bounding boxes. The 3D-language fusion layer uses a Transformer-based encoder-decoder to merge the language-guided 3D object features and text information. The object localization and QA layer evaluates the target object bounding boxes and labels and predicts answers related to the question and scene content. Compared to other 3D scene understanding tasks, 3D VQA requires a deeper understanding of 3D geometry, not only the appearance and geometry of objects but also the spatial relationships between different objects. Ye et al.50 proposed a novel Transformer-based 3D VQA framework, i.e., 3DQA-TR, which uses a language tokenizer for question embedding and two encoders to extract appearance and geometric information, respectively. Then, 3D-BERT is used to correlate the appearance, geometry, and language question modalities to predict the target answer. Traditional 3D scene understanding tasks focus more on individual objects, often neglecting the relationships between objects. Yan et al.51 introduced the visual question answering task in 3D real-world scenes, aiming to answer all possible questions related to a given 3D scene. They designed TranVQA3D, which first uses a cross-modal Transformer to fuse question and object features. Then, it applies scene graph initialization and leverages additional scene graph edges to perform scene graph-aware attention, capturing relationships between objects and inferring answers.
3D scene understanding is an emerging research field. Compared to reasoning based on 2D images, reasoning in real 3D scenes can avoid the spatial ambiguities present in 2D data, providing more accurate geometric information and relationships between objects. Additionally, 3D scenes often contain more objects and involve more complex relationships between them. Despite significant efforts by researchers in enhancing spatial representations for improved scene understanding, current research still faces shortcomings in 3D perception tasks (such as counting, verification, and existence) and obtaining object attributes (such as size, material, and structure), leaving room for further improvement.
Materials and methods

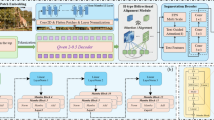
The proposed position-aware collaborative attention framework. The architecture consists of four key components: Feature Extraction (Faster R-CNN & Bi-LSTM), Conversational Attention (incorporating IHCM and positional encoding), Feature Integration, and Classification Prediction.
Overview
To address the lack of interaction between heads in VQA multi-head attention models, we propose an improved framework that captures the latent connections and enhances the attention interrelations between different multi-head attention heads. By designing various attention blocks, a conversational self-attention block is used to extract text features, and a conversational guided attention block is used to extract image features, which are then integrated. To address the inability of self-attention to capture positional information, position encoding is added to the self-attention layer. Through an adaptive multi-modal integration block, more efficient integration of visual and textual features is achieved.
In VQA, effective integration of image and text information is crucial for obtaining answers that align with human expectations. We treat VQA as a classification problem, where the input consists of an image and a related question, and the output is a predicted answer. Given an input image I and a corresponding question text Q, the model needs to select the correct answer from K possible candidates with high accuracy.
Overall framework
As shown in Fig. 3, the proposed algorithm consists of four main blocks:
-
1)
Feature Extraction Block: This block uses a fast region-based convolutional neural network for visual image feature extraction and a long short-term memory network for text feature extraction, converting the input image and question text into corresponding feature vectors.
-
2)
Conversational Attention Block: This block uses an attention model based on multi-head attention and self-attention with position encoding. It processes the question and image using conversational self-attention units and conversational guided attention units, and then combines the two units using an encoder-decoder structure.
-
3)
Feature Integration Block: This block performs integration of visual and textual features based on fully connected layers and single-input penalties to generate a unified feature vector.
-
4)
Classification Prediction Block: This block uses a feedforward neural network (FNN) for classification prediction.
Feature extraction block
Textual feature extraction block
Since the question is expressed in natural language, where words exhibit inherent sequential connections, a bidirectional-LSTM (Bi-LSTM) is used for encoding. The input question text is limited to no more than 20 words. Specifically, we first convert a question containing K words into a FastText vector\(\{ v_{1}^{T},v_{2}^{T},...,v_{K}^{T}\}\), where the vector is an K*300 sequence. This vector is then fed into a single-layer Bi-LSTM with residual connections. The process can be expressed as follows:
Equations (1) and (2) represent the forward and backward LSTM links, respectively. A matrix \(Q=[{q_1},{q_2},...,{q_K}] \in {R^{d*K}}\)is created, where\({q_K}=[\mathop {q_{k}^{T}}\limits^{ \to } ,\mathop {q_{k}^{T}}\limits^{ \leftarrow } ](k=1,2,...,K)\). To obtain the final hidden state representation of the input text, the text features are saved as\(Featur{e_K}=[\mathop {q_{K}^{T}}\limits^{ \to } ,\mathop {q_{1}^{T}}\limits^{ \leftarrow } ]\), with the Bi-LSTM network initialized randomly. We add positional encoding to text features to resolve the positional information issue in multi-head attention. Considering the relatively short length of the text, absolute positional encoding is used, as shown in the following equations, with sine and cosine functions encoding the even and odd positions of the vectors:
In which, pos is the position of a word in the sequence (starting from 0). i is the index of the dimension in the embedding vector. d is the dimension of the word embedding.
In text processing, since Transformer models do not have inherent sequential awareness, adding positional encoding helps the model understand the position of words in the sequence, thereby capturing semantic differences caused by word order. Absolute positional encoding assigns a unique encoding to each word’s position, allowing the model to retain word order information while processing in parallel. This not only enhances the model’s understanding of text structure and context but also proves particularly important in tasks involving long texts or long-range dependencies. In VQA tasks, positional encoding enables the model to better understand the order of words in the question, improving contextual awareness and enhancing the attention model to focus on relevant parts of both the image and the question, thus increasing answer accuracy and improving the model’s ability to handle complex queries.
Image feature extraction block
In VQA, the model needs to minimize irrelevant noise in the image, which requires the model to focus on the key areas of the image that are related to the question when extracting features. Consequently, we replace traditional CNN-based methods with Faster R-CNN to extract regional features from the image. Faster R-CNN uses its Region Proposal Network (RPN) to automatically generate potential regions of interest (ROIs), helping the model focus on the parts of the image that are relevant to the question and reducing the influence of irrelevant areas. This approach effectively improves the model’s attention to the key regions of the image, thereby enhancing the accuracy of the answer to the question. Given an image I, the model generates m candidate bounding boxes with the highest probability after non-maximum suppression. We use a target detection-based model to extract N region features from the image, where N represents the number of recognizable objects. Each region feature is represented as a 2048-dimensional vector, and the total feature matrix has a dimension of N*2048:
After obtaining the image feature matrix, the image features are combined with the text feature matrix and passed into the subsequent conversational attention block.
Collaborative attention block
Inspired by the Transformer model and the encoder-decoder framework, deep modularized mutual attention network (MCAN) introduced by Yu et al.52, consisting of modularized co-attention (MCA) layers. Each MCA layer is a modular combination of two basic attention components: the self-attention (SA) component and the guided-attention (GA) component, which jointly model the self-attention of the question and image, as well as the guided attention for the image.
As an improvement to the MCAN, the proposed collaborative attention block is also composed of several sub-units combined in an encoder-decoder manner. These sub-units are referred to as the Collaborative Modular Co-Attention Layer (C-MCAN). A C-MCAN layer is formed by the modular combination of two basic attention components: the Intra-Modal Self-Attention component with Collaboration (IMSAC) and the Cross-Modal Guided-Attention component with Collaboration (CMGAC) component.
Specifically, we address two issues in the MCA’s SA and GA components. First, both components use multi-head attention, but there is no interaction between the attention heads within a single computation. This lack of interaction may limit the capture of global information. We hypothesize that this restriction contributes to information fragmentation, reduced feature integration capability, and increased redundancy. To solve this, we introduce an Inter-Head Communication Matrix (IHCM) before and after the softmax normalization operation in multi-head attention. Our experiments show that this modification improves the effectiveness of the two attention components. On the other hand, one problem with SA is that it does not encode the positional information of the input vectors, and the position of vectors is an important feature in VQA. Therefore, absolute positional encoding is added to the input vectors in this model.
The multi-head attention block consists of H attention heads or self-attention layers, which operate in parallel. The self-attention model is based on scaled dot-product attention, with the following computation formula:
Where Q is the query vector, K is the key vector, and V is the value vector, with d representing the dimension of the vectors. Thus, the computation formula for each attention head is:
Where\(W_{i}^{Q},W_{i}^{K},W_{i}^{V}\)are learnable weight matrices. In multi-head attention, each attention head performs its calculation in the self-attention layer, then the results are concatenated and a normalization operation is applied. Linear mappings are introduced before and after the normalization operation to model the collaborative connections between attention heads. Although this adds a small number of parameters, it improves the modeling of inter-head connections. The computation formula is expressed as:
As shown in Fig. 4, IHCMbf and IHCMaf are two parameter matrices used to merge the information from different attention heads before and after the normalization operation. IHCMbf is initialized using low-rank initialization, while IHCMaf using normal distribution initialization.

Structure of the Inter-Head Communication Matrix (IHCM). IHCMbf facilitates information sharing before normalization to refine initial weights, while IHCMaf operates after normalization to integrate global context across attention heads.
Based on the collaborative attention mechanism, we propose two basic attention components, i.e., IMSAC and CMGAC.Specifically, IMSAC encodes the input vector into query, key, and value vectors, which are then fed into a collaborative multi-head attention layer. The output feature vector Z is obtained through fully connected layers and normalization. CMGAC uses a guiding vector X as the query vector, while the vector Y only inputs key and value vectors, thereby guiding the attention distribution of Y with X.
Considering the high information density of text features and the noise in image features, we use the Talking Guided-Attention to process image features, where text is used to guide the attention generation of image features, and the Talking Self-Attention is used for processing the text features. These two inputs are then combined using an encoder-decoder structure. Additionally, a random mask function is added to each attention head to control the range of attention and accelerate convergence. Figures 5 and 6 illustrate the principles of the improved IMSAC and CMGAC.

Structure of the Intra-modal Self-Attention with Collaboration (IMSAC) unit. This unit refines single-modality features (Query, Key, Value) by incorporating inter-head collaboration to capture internal dependencies.

Structure of the Cross-modal Guided Attention with Collaboration (CMGAC) unit. Textual features (X) serve as the Query to guide the attention distribution over Image features (Y), leveraging semantic context to focus on relevant visual regions.
As shown in Fig. 7, the encoder-decoder attention model can be understood as follows: the encoder uses l stacked Talking Self-Attention units to learn the text features Xl related to the question. The decoder uses the text features to guide the stacked IMSAC and CMGAC to learn the image features Yl. Finally, the learned image and text features are passed to the feature integration block.

The Encoder–Decoder attention model. Stacked Talking Self-Attention units (Encoder) process text features, which then guide the stacked IMSAC and CMGAC units (Decoder) to extract and refine image features.
Introducing the inter-head collaboration matrix between attention heads appears to enhance the performance of the multi-head attention mechanism, bringing several advantages.
Firstly, it facilitates the sharing and integration of global information. In traditional multi-head attention, the calculations of each attention head are independent, which prevents direct interaction between the heads, potentially leading to the loss of global information. This issue becomes especially apparent in tasks that require a deep understanding of multi-level features. By adding an inter-head collaboration matrix between the heads, information can be effectively exchanged, allowing each attention head to share global information. This prevents the fragmentation of information and strengthens the model’s global understanding capability.
Secondly, the introduction of the inter-head collaboration matrix enhances the model’s ability to model complex connections in multi-modal tasks. In cross-modal tasks like visual question answering, the connections between image and text are often highly intricate, involving detailed interactions between different modalities. The inter-head collaboration matrix helps the model capture and integrate the dependencies between image regions and textual words, improving cross-modal understanding and reasoning abilities.
Moreover, the inter-head collaboration matrix improves the focusing effect of the attention model. In traditional multi-head attention, the lack of effective interaction between the heads can result in the failure to fully capture important information. By introducing the inter-head collaboration matrix, the outputs of different heads can interact and be integrated, enabling the model to focus more accurately on the most relevant parts. This improves the attention allocation and feature selection effectiveness of the model.
Finally, the inter-head collaboration matrix is designed to reduce redundant information and alleviate information bottlenecks. In multi-head attention, although different heads focus on distinct feature dimensions, these subspaces may overlap, leading to redundant calculations and a decrease in information flow efficiency. The inter-head collaboration matrix optimizes the flow of information between the heads, suggesting a reduction in redundancy and enhancing information transmission efficiency, thereby improving the overall performance of the model.
Feature integration block
The decoder outputs encapsulate both image and question information. Thus, the model requires an effective mechanism to integrate these two feature representations. In this paper, we adopt two multimodal integration networks to aggregate these features, i.e., integration between multimodal features and integration within unimodal features.
First, the features Xn and Yn are passed through a two-layer Feedforward Neural Network (FNN) to generate aggregated features x′ and y′, as defined by the following equations:
This results in distributional features for the two modalities. Each modality should then attend to the other to improve prediction accuracy. Therefore, the integration block determines the extent to which information from one modality should influence the other. The final integrated feature out can either be computed as the direct sum of image and text features or as a weighted sum. In this work, we adopt the weighted sum approach, as defined by Eq. (12). The weighted sum approach offers two benefits: it avoids over-reliance on a single modality, thus reducing linguistic bias, and it adaptively adjusts the weights of the two modalities to balance their contributions.
Classification block
Since VQA tasks are inherently multi-class classification problems, where the correct answer must be chosen from a predefined answer space, we use a FNN for classification. The integrated feature is first passed through a layer normalization (LN) block, followed by a fully connected layer and a sigmoid activation to generate the predicted answer z. The answer with the highest probability is selected as the final output.
To train the network, we utilize binary cross-entropy loss (BCE). The training process is terminated when either the BCE loss falls below a specific threshold or the maximum number of training epochs is reached.
Experiment
Dataset
To evaluate our model’s effectiveness and reliability, we utilize the widely adopted large-scale public dataset, i.e., TDIUC (Task Directed Image Understanding Challenge) dataset53. Specifically, TDIUC is a multi-task VQA benchmark designed to evaluate a model’s performance across diverse visual understanding tasks. Derived from MS COCO images, it includes 148,478 questions categorized into 12 distinct types, such as scene recognition, object presence, spatial connections, and attribute identification. Unlike datasets like VQA, which primarily focus on overall question answering performance, TDIUC emphasizes fine-grained task categorization, allowing for a more detailed analysis of a model’s strengths and weaknesses across different visual reasoning tasks. Its balanced question distribution addresses the data imbalance often seen in other datasets, ensuring comprehensive task evaluation and reducing bias towards high-frequency answer types. By focusing on testing both simple tasks like binary or counting questions and more complex reasoning tasks involving spatial and logical connections, TDIUC provides a well-rounded benchmark for assessing a model’s multi-task learning capabilities.
Evaluation metrics
We treat the VQA task as a classification problem, where the model must return the answer with the highest score from multiple candidate answers. However, due to the subjective nature of VQA, different annotators may provide varying answers to the same question. Therefore, we adopt the accuracy metric used in the official VQA Challenge to evaluate model performance. The metric is computed using the following formula:
In which, K represents the total number of annotations, a is the model-predicted answer, aj represents the annotators’ answers, \(\delta ( \cdot )\)is an indicator function that equals 1 if a = aj, and 0 otherwise.
The accuracy is determined based on how many annotators’ answers agree with the predicted answer a. The scoring is as follows:
-
1)
Acc = 0 if no annotator agrees;
-
2)
Acc = 0.3 if two annotators agree;
-
3)
Acc = 0.9 if three annotators agree;
-
4)
Acc = 1 if at least four annotators agree.
Experiment settings
We conducted experiments on a Linux Ubuntu system equipped with an RTX 2070 GPU, an i7-12700KF processor, and 32GB of memory, utilizing the PyTorch deep learning framework with Python 3.7. The batch size was fixed at 64, and the RMSprop optimizer was employed, effective for tasks with highly varying gradients. The parameters for RMSprop included a learning rate (η) set between 0.001 and 0.01, a decay rate of 0.9, and ϵ of 1e− 7. To prevent overfitting, a dropout rate of 0.1 was applied to all fully connected layers.
Ablation experiments
Ablation of IHCM location
We evaluated the collaborative attention block’s effectiveness through ablation experiments on the TDIUC validation set, where inter-head collaboration matrices were added both before and after normalized operation in the original model in Yu et al.52. As shown in Fig. 8, incorporating the matrices improves accuracy across binary, numeric, and other task categories under optimal iterations. We observed the following precision ranking: (1) adding the matrix both before and after normalization yields the highest precision; (2) adding it only after normalization achieves the second-highest precision; and (3) adding it only before normalization results in relatively lower precision. Different impacts on attention optimization offer a plausible explanation for this ranking. Adding the matrix both before and after normalization achieves the best performance by combining early-stage feature refinement with late-stage global feature integration, facilitating comprehensive local-to-global information sharing. Adding it only after normalization focuses on refining output features for better global consistency and integration, improving accuracy but lacking early-stage optimization. In contrast, adding the matrix only before normalization primarily enhances the initial weight computation, improving local interactions but missing global feature integration, leading to lower performance. This highlights the importance of combining local and global optimizations for complex tasks like VQA.

Ablation study on the impact of IHCM location. The chart compares accuracy percentages across four metrics: “All” (Overall), “Other”, “Yes/No”, and “Number”. The lines represent the baseline model (Yu et al.52 and three variations of our method: adding IHCM only after normalization (&IHCMaf), only before normalization (&IHCMbf), and at both stages (&IHCMaf+bf). The results demonstrate that the combined approach (&IHCMaf + bf) yields the highest accuracy across all categories.
Ablation of collaborative attention block combinations
This section explores different combinations of the collaborative attention block. For the input image I and text Q, we investigated applying IMSAC to both modalities, CMGAC to both, and cross-modal combinations of the two, as shown in Table 1. The experimental results indicate that the directional design of the collaborative attention blocks, along with the incorporation of positional encoding in text feature extraction, plays a significant role in improving performance on VQA tasks. The IMSACI&CMGACQ combination achieves the best performance, suggesting that leveraging textual context to guide image attention is more effective than using image information to enhance text features. This observation supports the interpretation that text features are semantically richer and more structured, enabling the model to better focus on relevant image regions while mitigating background noise interference. Conversely, the CMGACQ&IMSACQ combination yields limited improvement, indicating that relying on image information to enhance text features is less effective, as text typically provides stronger semantic cues. Furthermore, while the addition of positional encoding in text feature extraction results in a modest improvement, it demonstrates that capturing word order and sequence information is beneficial for tasks requiring semantic reasoning. These findings underscore the importance of designing attention models that align closely with the characteristics of the task and data modalities.
Ablation of feature integration
This section investigates the impact of different feature integration functions on the results. Keeping other conditions constant, we conducted experiments using various feature integration functions, such as concatenation, addition, bi-linear, and sum-pooling. As shown in Table 2, using concatenation and addition, which directly concatenate image and text features, achieved higher accuracy compared to methods like fully connected layers that rely on weighted integration. A possible reason is that the features were already integrated during the generation of image and text representations, and further weighted integration introduces a risk of overfitting. On the other hand, combining FNN with addition allows for fine-tuning the feature weights in the final stage while avoiding excessive reliance on a single modality.
Contrast experiments
To evaluate the effectiveness of the proposed method, we compared it with several recent attention-based VQA methods and their enhancements developed over the past few years. The baseline methods are introduced as follows:
-
1)
Zhang et al.54: Proposed a integration model, i.e., OMniBAN, which integrates orthogonal loss, multi-head attention, and bilinear attention networks. It achieves high computational efficiency and strong performance without requiring pretraining.
-
2)
Sood et al.55: Integrated attention predictions from two state-of-the-art text and image saliency models into the neural self-attention layers of recent transformer-based VQA models.
-
3)
Kumari et al.56: Developed an end-to-end deep neural network architecture based on CNN, consisting of two subblocks: (i) a co-attention-based block and (ii) a multimodal factorized bilinear pooling block, to represent the textual and visual features of memes more granularly.
-
4)
Guo et al.57: Proposed a Multimodal co-attention relational network, which combines co-attention with visual object relationship reasoning. They models visual representations at both the object and relationship levels, and its visual relationship reasoning block significantly improves accuracy on “Number” questions.
-
5)
Cao et al.58: Introduced the SceneGATE network, a scene graph-based TextVQA co-attention network. This network uncovers semantic relationships between objects, optical character recognition tokens, and question words by leveraging scene graphs to discover underlying semantics in images. It also incorporates a guided attention block to capture intra-modal interactions, which guide inter-modal interactions. Additionally, two attention blocks, i.e., scene-graph-based semantic relationship-aware attention and positional relationship-aware attention, were proposed and integrated to explicitly teach the relationships between these modalities.
Table 3 indicates that our model achieves superior performance across the “All,” “Yes/No,” “Other,” and “Number” question categories, with accuracies of 71.23%, 88.05%, 61.47%, and 54.11%, respectively. The accuracy rates are consistently higher or marginally better than those of the baseline methods, further validating the rationality of the proposed architecture.
Our results demonstrate that the proposed method achieves the best performance across all question categories, highlighting the benefits of the inter-head collaboration matrix and the collaborative attention block, which effectively enhance multimodal feature integration. For “Yes/No” questions, the proposed method achieves the highest accuracy (88.05%), followed by Guo et al.57 (86.93%), whose visual relationship reasoning module significantly improves understanding in this category. Cao et al.58 (86.52%) ranks third, leveraging scene graph-based attention mechanisms, while Sood et al.55 (85.98%) and Zhang et al.54 (85.65%) perform slightly worse. Kumari et al.56 (84.78%) shows the lowest accuracy, reflecting its limited capacity to capture binary question patterns.
For “Other” questions, the proposed method outperforms its competitors significantly (61.47%), with Guo et al.57 (60.45%) ranking second due to its robust multimodal relationship modeling. Cao et al.58 (60.12%) demonstrates moderate performance, followed by Sood et al.55 (59.74%) and Zhang et al.54 (59.35%). Kumari et al.56 (58.92%) lags behind, indicating room for improvement in handling diverse question types.
In the “Number” category, the proposed method again leads with an accuracy of 54.11%, followed by Guo et al.57 (53.21%), whose visual relationship reasoning module enhances numerical comprehension. Cao et al.58 (52.85%) ranks third, using scene graph-based reasoning to improve numerical understanding. Sood et al.55 (52.23%) and Zhang et al.54 (51.89%) show moderate results, while Kumari et al.56 (51.34%) has the lowest accuracy, likely due to its weaker feature representation for fine-grained numerical reasoning.
Across all question types, the proposed method consistently outperforms its peers, demonstrating the effectiveness of its enhanced attention models and multimodal feature integration strategies. This performance advantage underscores its robust design and applicability to diverse VQA tasks.
Generalization and robustness on additional benchmarks
To further evaluate the robustness and generalization capabilities of the proposed framework beyond the TDIUC dataset, we conducted additional experiments on two challenging benchmarks: VQA-CP v259 and GQA60. VQA-CP v2 is specifically designed to evaluate a model’s resistance to language prior bias by enforcing different answer distributions between training and testing sets. GQA focuses on evaluating compositional reasoning through complex questions that require spatial understanding and multi-step inference. We compared our method against three representative baselines: UpDn61, a foundational bottom-up and top-down attention model; MCAN52, the direct predecessor to our work; and LXMERT62, a powerful pre-trained cross-modality model. The detailed comparative results are presented in Tables 4 and 5.
As presented in Table 4, our proposed method achieves a strong overall accuracy of 61.85% on the VQA-CP v2 test set, significantly outperforming the strong baseline LXMERT (57.60%) and our predecessor MCAN (48.31%). Notably, the most substantial improvement is observed in the “Yes/No” category, where accuracy surges to 74.12%. This category is typically the most susceptible to language priors, where models often guess the most frequent answer (e.g., “Yes”) without looking at the image. Our model’s superior performance here supports the hypothesis that the Inter-Head Communication Matrix (IHCM) effectively mitigates this bias. By enforcing information sharing and collaboration across attention heads, the IHCM prevents individual heads from overfitting to superficial textual correlations, compelling the model to ground its binary decisions in robust visual evidence. Consistent gains in the “Number” (42.56%) and “Other” (59.33%) categories further validate the model’s ability to handle diverse question types under distribution shifts.
Table 5 summarizes the results on the GQA test-dev set, where our model achieves an overall accuracy of 65.12%, surpassing the LXMERT baseline of 64.21%. In the challenging “Open” category, which requires generating specific answers based on complex compositional reasoning, our method achieves 48.75%. This performance highlights the effectiveness of our position-aware mechanism. The absolute positional encoding allows the model to accurately parse the intricate word order and syntactic structures inherent in GQA questions, which is critical for understanding spatial and logical relationships. Furthermore, the collaborative attention mechanism excels at integrating disparate pieces of evidence from both the image and the question to form a coherent reasoning chain. The strong performance in the “Binary” category (82.38%) parallels our findings on VQA-CP v2, reinforcing the model’s reliability in verification tasks and demonstrating that our framework generalizes well to scenarios requiring deep semantic understanding and multi-step reasoning.
Qualitative analysis and failure cases
To provide a deeper understanding of the model’s capabilities and limitations, we visualized representative prediction results in Figs. 9 and 10.
Figure 9 demonstrates the model’s robust capability in spatial reasoning and complex attribute identification. In the second example, for the question “Is the guy on the ground?“, the model correctly answers “Yes.” This indicates that our position-aware attention mechanism successfully captured the spatial relationship between the person and the environment, accurately interpreting the “sitting” posture as being “on the ground.” In the third example, “Who doesn’t have a glass?“, the model identifies “The lady in blue.” This is a challenging query requiring multi-step reasoning: detecting multiple people, identifying their clothing attributes (blue), and verifying the absence of a specific object (glass). The success here validates the effectiveness of the Cross-modal Guided Attention (CMGAC) in leveraging text to guide fine-grained visual search.

Success Cases illustrating the model’s reasoning capabilities. (Left) The model accurately counts distinct objects in a dynamic scene. (Center) The model correctly resolves spatial queries (“on the ground”) by understanding posture and position. (Right) The model performs complex reasoning involving attribute identification (“lady in blue”) and object negation (“doesn’t have a glass”), demonstrating effective cross-modal feature alignment.
Despite these strengths, Fig. 10 highlights specific limitations, particularly in dense counting and fine-grained recognition. As seen in the first and third examples (Boats and Crowd), the model predicts “Nine” instead of “Ten” and “Fifty-eight” instead of “Sixty.” These errors occur in scenarios with high object density and occlusion, where the Intra-modal Self-Attention (IMSAC) may struggle to distinguish overlapping boundaries, leading to undercounting. Additionally, in the second example (Clock Tower), the model answers “Ten” while the ground truth is “Ten past ten.” Although the model correctly recognizes the clock and the hour, it fails to capture the precise minute detail. This suggests that while our framework excels at semantic integration, it may require higher-resolution visual features to resolve extremely fine-grained details in small regions.

Failure Cases highlighting current limitations. (Left & Right) The model exhibits counting errors in scenes with high object density and occlusion (e.g., missing one boat or two people in a crowd), indicated by the discrepancy between the prediction (A) and Ground Truth (GT). (Center) The model fails to capture fine-grained details, such as the exact minute on a clock face, suggesting a need for higher-resolution feature processing.
Conclusion
We presented a novel position-aware collaborative attention framework to address critical limitations in traditional multi-head attention mechanisms for Image-English Question Answering. By introducing the IHCM before and after normalization, our framework effectively enhances inter-head interaction, thereby aiming to mitigate global information loss and reduce redundancy. This design significantly improves the performance of the multi-head attention mechanism through a parameter-efficient approach. By introducing a lightweight linear mapping (IHCM) rather than complex architectural additions, our framework achieves substantial accuracy gains with minimal computational overhead. Similar to residual connections in ResNet, which offer a simple yet effective solution to gradient issues, the IHCM provides a streamlined method to resolve the lack of inter-head interaction, optimizing attention focus and cross-modal modeling without unnecessary complexity. Furthermore, we designed two collaborative attention units, IMSAC and CMGAC, to refine intra-modal and cross-modal feature modeling, leveraging text to guide image attention and improving the model’s ability to focus on task-relevant regions while suppressing noise. Additionally, the incorporation of absolute positional encoding compensates for the lack of positional awareness in self-attention, significantly improving semantic understanding in textual features. Comprehensive experiments on the TDIUC, VQA-CP v2, and GQA datasets demonstrate that the proposed framework consistently outperforms existing methods across diverse question types and under challenging data distributions, establishing a strong benchmark among the models evaluated. Ablation studies validate the effectiveness of inter-head collaboration and positional encoding, highlighting the importance of carefully designed attention mechanisms for cross-modal tasks. The framework also accelerates model convergence and improves generalization, showcasing its robustness and scalability.
Despite these advancements, this study has limitations that must be acknowledged. First, while we extended our evaluation to include VQA-CP v2 and GQA to test for bias and compositionality, the model’s generalization to unstructured, open-world scenarios or low-resource languages remains unverified. Second, although the framework enhances spatial and semantic understanding, it lacks an explicit neuro-symbolic reasoning module, which limits its capacity for solving questions that require extensive, multi-hop logical deduction. Finally, while the IHCM itself is parameter-efficient, the underlying multi-head attention backbone still incurs significant computational costs, potentially restricting deployment on resource-constrained edge devices.
Future work will focus on addressing these challenges by integrating higher-resolution visual backbones to improve fine-grained recognition, exploring lightweight attention variants for edge deployment, and incorporating external knowledge bases to resolve semantic ambiguities. Our findings emphasize the importance of enhancing both intra-modal and cross-modal interactions in multi-modal tasks. The proposed collaborative attention framework provides a strong foundation for future research in Visual Question Answering and other multi-modal reasoning tasks.
Data availability
The TDIUC dataset used in this study is publicly available from the Task Directed Image Understanding Challenge repository, accessible at https://kushalkafle.com/projects/tdiuc.html. The VQA-CP v2 dataset is available via its official repository at https://github.com/aishagrawal/vqa-cp, and the GQA dataset is available at https://cs.stanford.edu/people/dorarad/gqa/download.html.
References
Ishmam, M. F. et al. From image to language: A critical analysis of visual question answering (VQA) approaches, challenges, and opportunities. Inf. Fusion 102270 (2024).
Pandey, A. et al. The quest for visual understanding: A journey through the evolution of visual question answering. arXiv:2501.07109 (2025).
Chowdhury, S. & Soni, B. R-VQA: A robust VQA model. KBS 309, 112827 (2025).
Chowdhury, S. & Soni, B. Handling Language priors in VQA. Neurocomputing 635, 129906 (2025).
Chowdhury, S. & Soni, B. ESC-Net for VQA. Comput. Intell. 40 (6), e70010 (2024).
Chowdhury, S. & Soni, B. EnvQA: enriched visual features for VQA. EAAI 142, 109948 (2025).
Chowdhury, S., Soni, B. & QSFVQA Time-efficient VQA framework. AJSE 48 (8), 10479–10491 (2023).
Sengupta, A. et al. Going deeper in spiking neural networks: VGG and residual architectures. Front. NeuroSci. 13, 95 (2019).
Targ, S., Almeida, D. & Lyman, K. ResNet in resnet: generalizing residual architectures. arXiv:1603.08029 (2016).
Al-Qizwini, M. et al. Deep learning algorithm for autonomous driving using GoogLeNet. In IEEE Intelligent Vehicles Symposium, 89–96 (2017).
Ren, S. et al. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE TPAMI. 39 (6), 1137–1149 (2016).
Xiaoyun, Q. et al. Short-term prediction of wind power based on deep LSTM. In IEEE APPEEC, 1148–1152 (2016).
Dey, R. & Salem, F. M. Gate-variants of gated recurrent unit (GRU) neural networks. In IEEE MWSCAS, 1597–1600 (2017).
Han, K. et al. Transformer in transformer. NeurIPS 34, 15908–15919 (2021).
Devlin, J. & BERT Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805 (2018).
Yu, Y., Kim, J. & Kim, G. Joint sequence fusion model for video question answering and retrieval. ECCV, 471–487 (2018).
Ju, X., Wang, B. & Li, X. Contrastive visual-question-caption counterfactuals on biased samples for VQA. CCC, 7603–7609 (2024).
Wu, Q. et al. Visual question answering: A survey of methods and datasets. CVIU 163, 21–40 (2017).
Tan, C. et al. Retrieval meets reasoning: High-school textbook knowledge benefits multimodal reasoning. arXiv:2405.20834 (2024).
Lymperaiou, M. & Stamou, G. A survey on knowledge-enhanced multimodal learning. Artif. Intell. Rev. 57 (10), 284 (2024).
Vosoughi, A. et al. Cross modality bias in VQA: A causal view with possible worlds VQA. IEEE TMM. 26, 8609–8624 (2024).
Courtney, L. & Sreenivas, R. Deep convolutional LSTM networks for learning Spatiotemporal features. ACPR, 307–320 (2020).
Gunti, R. R. & Rorissa, A. Dual of stacked attention networks and VGG-16 for VQA evaluation. CLEF Working Notes, 1478–1487 (2023).
Fuertes, D. et al. Solving routing problems for UAVs using transformer networks. Eng. Appl. AI 122, 106085 (2023).
Lian, Z. et al. Cross modification attention-based deliberation model for image captioning. Appl. Intell. 53 (5), 5910–5933 (2023).
Shen, X. et al. Local self-attention in transformer for VQA. Appl. Intell. 53 (13), 16706–16723 (2023).
Zhang, R. et al. Evolutionary dual-stream transformer. IEEE TCyb. 54 (4), 2166–2178 (2022).
Wang, Z. et al. Distilled dual-encoder model for vision-language understanding. arXiv:2112.08723 (2021).
Sun, J., Zheng, Z. & Ding, G. Filtering-WoRA paradigm for efficient text-based person search. arXiv:2404.10292 (2024).
Sheng, X. INT2-VQA: Image-to-English VQA via inter-modality collaborations. PLoS ONE. 18 (8), e0290315 (2023).
Li, Y. et al. Uni-EDEN: universal encoder-decoder network by multi-granular VL pretraining. ACM TOMM. 18 (2), 1–16 (2022).
Yang, Z. et al. Scene graph reasoning with prior visual relationship for VQA. arXiv:1812.09681 (2018).
Liang, W., Jiang, Y. & Liu, Z. GraghVQA: Language-guided GNNs for graph-based VQA. arXiv:2104.10283 (2021).
Koner, R. et al. Graphhopper: Multi-hop scene graph reasoning for VQA. ISWC, 111–127 (2021).
Cao, J. et al. Bilateral cross-modality Graph Matching Attention for VQA (IEEE TNNLS, 2022).
Bai, N. et al. Heri-graphs: dataset creation for multimodal ML on heritage values. IJGI 11 (9), 469 (2022).
Zakari, R. Y. et al. VQA and visual reasoning: Overview of datasets and methods. arXiv:2212.13296 (2022).
Su, Z. & Gou, G. Knowledge enhancement and scene Understanding for knowledge-based VQA. KAIS 66 (3), 2193–2208 (2024).
Ramnath, K. Fact-based VQA using knowledge graph embeddings. PhD Thesis, UIUC. (2021).
Chen, Z. et al. Zero-shot VQA using knowledge graph. ISWC, 146–162 (2021).
Singh, A. K. et al. Knowledge-enabled VQA that can read and reason. ICCV, 4602–4612 (2019).
Gardères, F. et al. ConceptBERT: Concept-aware representation for VQA. EMNLP Find., 489–498 (2020).
Wu, J. et al. Multi-modal answer validation for KB-VQA. arXiv:2103.12248 (2021).
Yang, Z. et al. Empirical study of GPT-3 for few-shot KB-VQA. arXiv:2109.05014 (2021).
Kovacevic, A., Basaragin, B. & Milosevic, N. N. G. De-identification of clinical free text using NLP: systematic review. AI Med. 151, 102845 (2024).
Hwang, S. J. & Grauman, K. Learning relative importance of objects for cross-modal search. IJCV 100 (2), 134–153 (2012).
Wang, W. et al. VLMo: unified VL pretraining with mixture-of-experts. arXiv:2111.02358 (2021).
Ray, P. P. & Majumder, P. Comments on AI-driven medicine & ethics. J. Clin. Neurol. 20 (1), 111–112 (2024).
Mo, W. & Liu, Y. Fusion approach for 3D VQA (2024).
Ye, S. et al. 3D question answering. arXiv:2112.08359 (2021).
Azuma, D. et al. ScanQA: 3D question answering for Spatial scene Understanding. CVPR, 19129–19139 (2022).
Yu, Z. et al. Deep modular co-attention networks for VQA. CVPR, 6281–6290 (2019).
Kafle, K. & Kanan, C. Analysis of VQA algorithms. ICCV, 1965–1973 (2017).
Zhang, Z. et al. Efficient bilinear attention for medical VQA. arXiv:2410.21000 (2024).
Sood, E. et al. Human-like attention integration in VQA. CVPR, 2648–2658 (2023).
Kumari, G., Das, A. & Ekbal, A. Co-attention bilinear pooling for meme analysis. ICON, 261–270 (2021).
Guo, Z. & Han, D. Multi-modal co-attention relation networks for VQA. Vis. Comput. 39(11), 5783–5795 (2023).
Cao, F. et al. SceneGate: Scene-graph co-attention for text VQA. Robotics 12 (4), 114 (2023).
Agrawal, A. et al. Don’t just assume; look and answer. CVPR, 4971–4980 (2018).
Hudson, D. A. & Manning, C. D. GQA: dataset for real-world VQA. CVPR, 6700–6709 (2019).
Anderson, P. et al. Bottom-up and top-down attention. CVPR, 6077–6086 (2018).
Tan, H. & Bansal, M. LXMERT: Cross-modality encoder representations. arXiv:1908.07490 (2019).
Acknowledgements
This work was supported by Research on Digital Competence of English Teachers in Vocational Colleges under the Background of Digital Education Transformation- 2023 project of vocational education in Yantai City.
Author information
Authors and Affiliations
Contributions
Conceptualization, Y.L.; methodology, Y.L.; software, Y.L.; validation, Y.L. and H.T.; formal analysis, Y.L.; investigation, Y.L.; resources, H.T.; data curation, Y.L.; writing—original draft preparation, Y.L.; writing—review and editing, H.T.; visualization, Y.L.; supervision, H.T.; project administration, H.T.; funding acquisition, Y.L. and H.T. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, Y., Teng, H. Collaborative positional attention for image to English question answering. Sci Rep 16, 2017 (2026). https://doi.org/10.1038/s41598-025-31627-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-31627-5
