
Abstract
The world’s coastal regions are home to billions, yet they are also hotspots for climate change-induced adversities, such as sea level rise (SLR), which exacerbate coastal risks, increasing the likelihood and severity of floods. To assess these risks and inform adaptation measures, coastal engineers require predictive models capable of producing accurate, high-resolution flood maps under the given projected climate change impacts and potential mitigation strategies (e.g., construction of seawalls). While traditional physics-based hydrodynamic simulators can deliver accurate results, their application incurs massive computational burdens. On the other hand, supervised Deep Learning (DL) techniques offer immense potential for creating data-driven surrogates that are orders of magnitude faster than their physics-based counterparts. Nevertheless, training of such models typically demands large amounts of annotated samples, and hence numerous time-consuming hydrodynamic simulations. To remove this barrier, we devise a vision-based framework that enables the training of performant DL-based surrogates in low-data settings. Leveraging the proposed framework, we develop several such models, among which two adapted from well-known medical image segmentation models (SWIN-Unet and Attention U-Net), to predict flood depths along the entire coast of Abu Dhabi under varying shoreline protection scenarios and an SLR of 0.5 meters. Additionally, we design a lightweight Convolutional Neural Network (CNN) model, termed CASPIAN, tailored specifically for the coastal flood prediction problem at hand. The flood maps produced by CASPIAN closely and consistently matched those from a physics-based simulator (on average, with around 97% of predicted floodwater levels having an absolute error of at most 10 cm.), while offering \(10^8\) times faster inference speed. Lastly, we provide a dataset of synthetic high-resolution (up to 30 m. horizontal resolution within urban areas) flood depth maps for the coast of Abu Dhabi, which can serve as a benchmark for evaluating future coastal flood prediction models. The complete source code of the proposed framework is open-sourced at https://github.com/Arnukk/CASPIAN.
Similar content being viewed by others
Introduction
More than \(60\%\) of the world’s population resides in coastal areas that are within 60 km from the shore1. The looming global warming and its byproducts, such as rising sea levels and more frequent and severe storm surges2,3, render these regions increasingly susceptible to floods, which can inflict massive humanitarian, ecological, and economic devastation. To put this into perspective, according to the analysis by Tiggeloven et al.4, in 2010 the estimated expected annual damage from coastal flooding surpassed $ 20 billion globally, and by 2080 this figure is projected to increase 150-fold (> $ 3 trillion) if no adaptation measures are taken. To safeguard the lives and livelihoods of their residents, coastal cities have been actively taking countermeasures, the most common of which is shoreline armoring with engineered structures such as seawalls, levees, and storm barriers5,6. Notable examples of existing fortifications include communities in San Francisco (SF) Bay area7 and the Greater New Orleans region, where coastlines have been extensively reinforced with levees and seawalls covering most of their perimeters8. A more recent example is New York City, where efforts are underway to protect a two-and-a-half-mile stretch of Lower Manhattan’s shoreline with seawalls – an intervention guided by probabilistic hydrodynamic modeling and analysis9.
Despite the conferred local flood protection benefits, however, construction of these coastal defense structures significantly alters the shoreline geometry, which in turn impacts the hydrodynamics along the coast. The resulting hydrodynamic interactions can create “spillover” effects which amplify water levels outside the protected areas and spread floodwaters to adjacent regions6,10,11. For example, Hummel et al6. illustrated that protecting specific coastal stretches in SF Bay can increase flooding in other zones by up to 36 million cubic meters, owing to altered shoreline geometry. To this end, physics-based high-fidelity simulators, such as Delft3D12 and SWAN13, can be employed to resolve the detailed hydrodynamics and wave conditions around seawalls under SLR. Although these tools accurately simulate nearshore hydrodynamics and provide fine-grade time-series data on estimated depth, duration, and velocity of floods, they are notoriously expensive in terms of computational time and resources. To exemplify, with the high-fidelity simulator adopted in this work, simulation and post-processing of a single protection scenario for the coast of Abu Dhabi demand several days of runtime, as detailed in the next section. Consequently, direct incorporation of these simulators into applications requiring extensive number of model realizations (e.g., optimal shoreline protection planning, sensitivity analysis) and/or rapid model responses remains impractical.
This computational burden has spurred significant research interest towards data-driven alternatives, which are capable of learning complex relationships between systems’ inputs and outputs without explicit knowledge of the underlying sophisticated physical processes. Such models, commonly referred to as surrogate models or metamodels in the flood prediction literature, have been developed to predict various categories of floods, including pluvial (rainfall-induced)14,15, fluvial (riverine)16, and coastal (often linked to storm surges). From a design perspective, the existing models can be organized under three themes: (i) ensemble surrogates, which stack the predictions of several independently trained sub-models (e.g., one for each coastal location) to form the final output; (ii) end-to-end models, which learn a direct input-to-output mapping with no intermediate steps; and (iii) multi-stage surrogates, in which the mapping from input variables to prediction targets is performed successively through chain of methods with two or more intermediate representations. Another layer of differentiation unfolds in the scope of targeted predictive outcomes: the risk, extent, intensity, or dynamics of flooding. In the paragraphs below, we provide a concise overview of related works concerned with coastal flooding and associated hazards, while for a broader review, readers are referred to the surveys by Mosavi et al.17, Bentivoglio et al.18, Jones et al.19, and Bomers & Hulscher20.
For coastal domains, flood prediction has often been studied under one specific flood driver (e.g., wind) or within the context of short-term extreme events (e.g., storms). Al Kajbaf et al.21 reviewed the literature on storm surge prediction and compared the three most commonly adopted surrogate modeling techniques: Artificial Neural Networks, Gaussian Process Regression (also known as Kriging), and Support Vector Regression (SVR). To allow for high-resolution predictions, these techniques have been paired with dimensionality reduction methods, which convert high-dimensional data into a lower dimensional space. For instance, Kyprioti et al.22 first group the landfall locations of storms along the coasts of New Jersey and New York with the K-means algorithm, then interpolate the hazard curves produced for the centroids of these clusters over the original grid via a Kriging-based surrogate model. Different approaches to combining Kriging metamodeling with Principal Component Analysis (PCA) and/or distance-based learning methods, such as k-means clustering or k-nearest neighbors (kNN), were also explored23,24,25,26. El Garroussi et al.27 proposed a two-step surrogate hydraulic model in which the low-dimensional latent representation of the output variables is inferred through an Autoencoder (AE) as opposed to PCA. The results based on AE reduction were found to yield more accurate predictions. Unlike their end-to-end counterparts, however, two-step approaches are prone to error propagation due to their sequential structure, potentially limiting the surrogate model’s predictive performance.
More recently, several DL-based or hybrid (combining conventional Machine Learning and DL methods) approaches for spatial and spatiotemporal prediction of coastal floods have been explored. Focusing on compound flooding in coastal cities driven by heavy rainfall and high tides, Xu et al.28 designed a hybrid surrogate model, relying on Light Gradient Boosting Machine (LightGBM) and a one-dimensional CNN, to predict the spatial distribution of maximum water depths across Haidian Island, China. The model was trained on a simulated dataset generated by the stormwater modeling software PCSWMM and evaluated on a test set of five scenarios representing different return periods of rainfall and tide levels. The study by Shahabi and Tahvildari29 integrated CNN with a Long Short-Term Memory (LSTM) network to predict the spatiotemporal dynamics of coastal water levels at 10 locations across the Chesapeake Bay in the US. The model was trained on 21 years of historical data extracted from the NOAA database and evaluated against the high-fidelity hydrodynamic model ADCIRC. The results revealed comparable performance to ADCIRC in predicting water level time-series while offering reduced inference time. Taking a step further, Bian et al.30 studied spatiotemporal prediction of coastal floods while additionally accounting for SLR scenarios and accommodating high spatial resolution. Four DL models, namely U-Net, CNN-LSTM, ConvLSTM, and CNN-Transformer, were trained and evaluated on a dataset generated via the LISFLOOD-FP hydrodynamic model. The reported results indicate that U-Net emerged as the best performing model, with average mean absolute and root mean squared errors of 0.0125 and 0.0486 meters, respectively.
A parallel strand of research has focused on developing data-driven substitutes for computationally demanding physics-based wave field simulators such as SWASH or SWAN. For example, Wei and Davison31 proposed to model nearshore waves and hydrodynamics as a next-frame prediction problem. A CNN model was developed and trained on synthetic data generated with SWASH. Three hydrodynamic parameters were considered as prediction targets: water surface elevation, cross-shore velocity, and long-shore velocity. According to the reported results, the model accurately predicted all three variables and captured several important nearshore processes, including wave propagation, breaking, and crest bending. On the other hand, Jörges et al.32 based the prediction of wave properties on simulated bathymetry maps and tabular data on meteorological and oceanographic conditions. Two different hybrid architectures, combining CNN with a feed-forward neural network, were presented and applied to predict wave height maps along the coast of Norderney, Germany. The models were trained on a synthetic dataset constructed with SWAN, however, in view of extensive number of parameters, the original high-resolution input and output maps were downscaled by a factor of 10. While these studies do not directly model coastal floods, their findings illustrate that CNNs can capture complex wave dynamics, and such wave field surrogates can be embedded in coupled hydrodynamic workflows as faster substitutes for SWASH/SWAN, thereby accelerating coastal flood simulations.
Although prior works have advanced coastal flood prediction significantly, limited attention has been paid to the joint incorporation of SLR and shoreline protection scenarios. Developing accurate and reliable surrogates for predicting peak water levels across extended coastal domains in this climate adaptation-aware setting remains markedly challenging, especially when DL models are employed. In particular, successful training of deep networks typically requires many thousands of annotated samples33, yet in the current context such volumes are rarely attainable, since generating these samples via high-fidelity hydrodynamic simulators is time- and resource-intensive, as noted above. Another obstacle lies in the sought-after high resolution for detailed inundation mapping, which leads to a dense prediction task with tens of thousands of output variables. The most recent surrogate model for this problem, proposed by Jia et al.24, was developed following the aforementioned common two-stage approach employing Kriging with PCA. The model was designed considering county-level protection of SF Bay area under 1.5 m. of SLR and evaluated (under leave-one-out cross-validation) on a dataset of 40 scenarios generated with the physics-based hydrodynamic simulator Delft3D. Departing from this methodology, here we tackle the problem in a different fashion by recasting the underlying high-dimensional regression problem as a computer vision task of translating a two-dimensional (2D) segmented grid into a matching grid with real-valued entries corresponding to peak floodwater depths. This reformulation facilitates the deployment of effective data augmentation techniques, thereby enabling the training of performant and inherently scalable (w.r.t. the number of coastal locations) DL-based surrogate models. More concretely, the key contributions of the present work are three-fold:
-
First, we present a systematic pipeline for training, possibly in data-scarce regimes (e.g., with around 100 training samples), efficient vision-based DL models for high-resolution coastal flood prediction in climate adaptation-aware settings. Leveraging this framework, we produce several such models to predict flood depths along the entire coast of Abu Dhabi under varying shoreline protection scenarios and an SLR of 0.5 meters. Among these, two are based on established vision models originally designed for medical imaging tasks: SWIN-Unet34 (a fully Transformer-based architecture) and Attention U-net35 (a CNN with additive attention gates). The developed DL models are contrasted with the aforementioned commonly used surrogates (Kriging with PCA and SVR) and conventional ML techniques (Linear Regression and Lasso with polynomial features). The comparison results reveal significant gains in predictive performance, with improvements from the devised DL models ranging from 100% to 400% across key metrics. The complete source code of the framework, along with the trained models, is publicly released at https://github.com/Arnukk/CASPIAN to facilitate further research in this area.
-
Next, we introduce a deep CNN architecture, dubbed Cascaded Pooling and Aggregation Network (CASPIAN), stylized explicitly for climate adaptation-aware coastal flood prediction. The model was designed with a particular focus on its compactness and practicality to cater to resource-constrained scenarios and accessibility aspects. Specifically, featuring as little as 0.36 million parameters and only a few main hyperparameters, CASPIAN can be easily trained and fine-tuned on a single GPU. On the current dataset, the performance of CASPIAN closely tracked the results obtained from the physics-based hydrodynamic simulator (on average, with \(\approx 97\)% of predicted floodwater levels having an absolute error of at most 10 cm.), effectively reducing the computational cost of producing a flood depth map from days to milliseconds.
-
Lastly, we provide a database of high-resolution (up to 30 m. horizontal resolution within urban areas) synthetic flood depth maps of Abu Dhabi’s coast for 174 different shoreline protection scenarios under an SLR of 0.5 meters. The maps were generated via the high-fidelity physics-based hydrodynamic simulator presented in the following section. The compiled dataset, available at https://doi.org/10.7910/DVN/M9625R, to the best of our knowledge, is the first of its kind, and thus can serve as a benchmark for evaluating future coastal flooding metamodels.
Taken together, these contributions can assist policymakers in designing reliable and effective coastal protection programs, thereby enhancing the flood resilience of coastal cities in the face of accelerating sea level rise. The introduced model CASPIAN, in particular, equips coastal engineers with a practical and accessible flood prediction method that can be readily integrated into large-scale optimization/planning workflows.
The rest of this paper is structured as follows. Sec. ”Study Area and Hydrodynamic Model” describes the studied coastal area and presents the details of the adopted hydrodynamic model. In Sec. ”Methods”, we first formalize the prediction problem and highlight the associated challenges; then lay out the proposed Deep Vision-based surrogate modeling framework and the lightweight CNN model, CASPIAN; and finally detail the numerical experiments, the generated dataset, and the benchmark models considered in this study. In Sec. ”Results”, we evaluate and compare the models’ performance. Sec. ”Ablation Experiments” provides ablation studies to validate the architectural choices proposed in CASPIAN. Lastly, Sec. ”Discussion” concludes the paper with a discussion on the proposed framework’s distinctive features and current limitations, and suggests several immediate extensions for future work.
Study area and hydrodynamic model
For the purposes of the current investigation, the proposed framework was applied to the coastal city of Abu Dhabi, which is the capital of the United Arab Emirates (UAE) situated inside the Persian Gulf. UAE’s coastline features a low-lying and shallow-sloping (about 35 cm per km) topography36. Over 85% of the population and more than 90% of the local infrastructure of the UAE is within a few meters of the present-day sea level37. Notably, Abu Dhabi is comprised of a system of coastal mangrove islands, coral reefs and artificial islands, with 50% of its area lying only within 1 m above sea level38,39. Considering that possible SLR estimates are on the order of 0.5 meters by 2050 and 1 to 1.5 meters by the end of 21 st century40, most of the built and natural mangrove ecosystem of Abu Dhabi, along with its coastal communities, will potentially be subjected to permanent flooding.

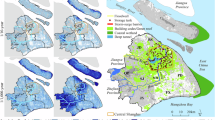
(A) Nearshore locations of interest susceptible to flooding under a 0.5 m SLR scenario without any shoreline protection. (B) Candidate coastal segments considered for installation of seawalls. (C) Flood depth map of Abu Dhabi’s coast produced with a physics-based high-fidelity hydrodynamic simulator under a sample shoreline fortification scenario and an SLR projection of 0.5 meters. The figure was created with Python (v3.10.13, https://www.python.org/) using Matplotlib (v3.10.1, https://matplotlib.org/), Contextily (v1.6.2, https://contextily.readthedocs.io/) and Pandas (v2.0.2, https://pandas.pydata.org/).
Given the complex structure of Abu Dhabi’s coastline, it is necessary to consider the protection of different sections. The partitioning scheme chosen for the purposes of this study was informed by the precincts defined in the 2030 Urban Structure Framework Plan of Abu Dhabi41. For further refinement of partitions, we divided the main island of Abu Dhabi, grouped other islands, and delineated the boundaries between some precincts, which yielded 17 individual coastal segments that constitute the candidate sites for installation of engineered fortifications, as depicted in Fig. 1b. The aforementioned urban structure plan of Abu Dhabi envisions mid-century development goals, and hence our choice of a 0.5-meter SLR scenario, which reflects plausible global mean projections by 2050 under intermediate emission pathways40.
To allow for detailed and accurate modeling of coastal hydrodynamics of the selected area under SLR, storm events and shoreline fortifications, we adopt a coupled model proposed by Chow and Sun42, which combines a Gulf-wide tidal model, a spectral wave model, and a wave run-up model (see Supplementary Fig. S1 for illustration). The tidal model relies on Delft3D simulator, which is a hydrodynamic model that solves the time-dependent Reynolds Averaged Navier Stokes differential equations. That is, Delft3D is a physics-based numerical model that considers the time-varying forces exerted on a water body (such as the entire Persian Gulf) due to hydrostatic pressures (such as SLR), tidal forcing, wind and storm stresses, bottom (seabed) friction, and river inflows over a finite-element computational grid (up to 30 m in horizontal resolution) spread over variable bathymetry. For any point in this grid, it can provide time series outputs, with 30-minute intervals, of water levels and local water circulation velocities throughout the specified simulation period. Importantly, Delft3D can handle computational grid cells that alternate between dry and wet states43. The tidal model was validated by running the Delft3D simulator over a 3-month period between 1 January and 31 March 2017 (without wind forcing) and computing the root mean squared error between the model outputs of hourly water levels at 194 locations throughout the Gulf and hourly tidal gauge water level data obtained from the TPXO8 Ocean Atlas for the same period (https://www.tpxo.net/global/tpxo8-atlas. Also see the study by Egbert and Erofeeva44). The model was calibrated by adjusting the bottom Manning’s roughness coefficient for the entire Gulf domain from 0.015 to 0.030. The lowest overall error was attained under the coefficient of 0.02, which was taken as the calibrated roughness value for the Gulf model going forward. Supplementary Fig. S2 demonstrates the fit between water level values (relative to the mean sea level) outputted by the model and the tidal gauge data at two locations near the UAE shore: the upper panel illustrates a representative fit exhibited by 31 of the 33 gauges, whereas the lower panel shows one of the worst-fit cases observed at 2 of the 33 gauges. Further details concerning the employed hydrodynamic model and its validation can be consulted in the paper by Chow and Sun42.
While the Persian Gulf does not typically experience tropical cyclones, it is known for its northwesterly winds generally occurring with winds at about 20 m/s with sudden onset and sustained over a period of up to 3–5 days. These are called the Shamal winds and occur at least 10 times annually, mainly during the winter months45,46. To account for wind-induced wave activity in the vicinity of Abu Dhabi’s coast, the validated Delft3D model was rerun with hourly wind and atmospheric pressure forcing from the ERA5 database, and the results were fed to an additional spectral wave model, SWAN, which simulates wind-wave generation, wave diffraction, amplification and refraction of water surface waves as they approach the shoreline. The SWAN model was applied at a scale of about 100 km along the shoreline to about 50 km offshore under the same forcing from the ERA5 database. As some of the unstructured grid cells in the Gulf computational domain were pentagons and hexagons, an offline coupling with SWAN was used rather than a dynamic coupling, thus it was assumed that the wave effects could be added linearly to the tidal and storm surge effects to obtain the final water level. Finally, along the interface of the waves with the coastline, the SWAN-computed significant wave heights and the local shoreline slope were used to calculate the run-up elevations along the coastline where the waves hit the shore. An empirical run-up model from Holman47 was used to calculate the top 2% of run-up events along a natural sloping beach, using the local slope and the significant wave length and wave heights calculated using SWAN (for further details, readers are referred to the paper by Chow and Sun42).
With this coupled hydrodynamic model in place, one can run a reference case with no shoreline armoring (except those already existing in Abu Dhabi) to evaluate the maximum extent of flooding due to SLR and storms. To implement the protection of the identified 17 coastal segments, “fixed weirs” were inserted into the model along the segments’ boundaries. These weirs enforce flow barriers at the corresponding locations in the domain, effectively acting as impermeable seawalls with no overtopping. For every such placement combination of containments (that is, a protection scenario), the raw output of the model includes 3 months worth of hourly water levels for more than 400, 000 grid point locations throughout the Persian Gulf. To filter the nearshore inland locations of interest, which will potentially be exposed to flooding at 0.5 m. of SLR, the following two steps were taken: (i) the points lying outside the urban region of Abu Dhabi were excluded; (ii) the inland cells that never experienced flooding even in the case of no coastal protection (i.e., are not hydraulically connected to the Gulf or bear no correlation with the input) were removed. This resulted in the final set of 12066 locations along the coastline, which appear in Fig. 1a. For each location, the peak water levels (i.e., the maximum value of water depth over the simulated timeframe of 3 months) under different protection scenarios were then extracted to construct the dataset for training coastal flood prediction models, as elaborated in the following sections.
Computational Cost of the Hydrodynamic Model: Depending on protection scenario, generating a peak flood depth map for the coast of Abu Dhabi (e.g., the one appearing in Fig. 1c) via the above described coupled hydrodynamic model takes \(\approx\) 71–73 hours of elapsed runtime or \(\approx\) 1500-1660 CPU-hours, as follows: Delft3D runs take around 6–7 hours on 28 CPU cores (Intel Xeon E5-2680 @ 2.40 GHz; \(\approx\) 168–196 CPU-hours); SWAN simulations require about 10–11 hours on 128 CPU cores (AMD EPYC 7742 @ 2.25GHz; \(\approx\) 1280–1408 CPU-hours); Post-processing of Delft3D outputs (based on a Matlab script) costs \(\approx\)7 hours on a single core (Intel Core i7-1065G7 @ 1.30GHz); Run-up calculations and combination of results (based on a Matlab script) take nearly 48 hours on a single core (Intel Xeon Bronze 3104 @ 1.70GHz).
Methods
In this section, we first define the studied coastal flood prediction problem formally and discuss the associated challenges, then present the details of the proposed framework, which is graphically summarized in Fig. 2, and the devised compact CNN model CASPIAN, which is illustrated in Fig. 3.
Notational Convention: In what follows, unless stated otherwise, constants or variables are denoted in normal font (e.g., H, n), vectors and matrices are distinguished by boldface lowercase and uppercase letters, respectively (e.g., \(\varvec{x}\), \(\varvec{X}\)), and sets are written in calligraphic or blackboard fonts (e.g., \(\mathcal {X}\), \(\mathbb {R}\)). We let \(\varvec{0}\) and \(\varvec{1}\) symbolize the vectors of all zeros and ones, respectively. Lastly, for a given positive integer n, the notation [n] shall serve as a shorthand for \(\{1, 2, \ldots , n\}\).
Problem formulation
As previously mentioned, shoreline alterations caused by the installation of protective engineering structures (e.g., seawalls) can affect coastal water levels and flood patterns. Specifically, depending on which segments of the coastline these seawalls are raised (i.e., protection scenario), the ensuing hydrodynamic interactions and feedbacks can elevate water levels along other parts of the coast. Accordingly, we focus on the following problem: given an input protection scenario, predict the maximum floodwater levels along the coast. To formalize, denote by \(d_{\varvec{x}}\) the number of candidate shoreline segments considered for fortification and let \(x_i \in \{0,1\}\) be the corresponding decision made for the segment \(i \in [d_{\varvec{x}}]\) with 1 indicating the placement of containments and 0 otherwise. Then, a protection scenario would be represented by a \(d_{\varvec{x}}\)-dimensional binary vector \(\varvec{x}\) and the set of all possible protection scenarios (\(2^{d_{\varvec{x}}}\) in total) can be defined as \(\mathcal {X} \triangleq \{\varvec{x} \mid \varvec{x} \in \{0,1\}^{d_{\varvec{x}}} \}\). Let \(\varvec{y}\) be a (non-negative) real-valued vector quantifying the peak water levels at \(d_{\varvec{y}}\) nearshore locations of interest. With this notation, the problem can be formulated as a regression task of learning a mapping function \(f: \varvec{x} \in \mathcal {X} \rightarrow \varvec{y} \in \mathbb {R}^{d_{\varvec{y}}}\) provided with a set \(\{(\varvec{x}^k, \varvec{y}^k) \mid k \in [n], \varvec{x}^k \in \mathcal {X}, \varvec{y}^k \in \mathbb {R}^{d_{\varvec{y}}}\}\) of n available training examples. Since the generation of these input-output pairs involves running high-fidelity hydrodynamic simulations, extensive data collection can prove prohibitively expensive in terms of both time and resources. Consequently, for double-digit values of \(d_{\varvec{x}}\) (as in the current setting, where \(d_{\varvec{x}} = 17\)), the cardinality of the training set can turn disproportionately small compared to that of the input space (i.e., \(n \ll 2^{d_{\varvec{x}}}\)), enforcing an extremely low-resource learning setting. The inference of f is further complicated by its output size \(d_{\varvec{y}}\), which is typically in the order of tens of thousands (here, \(d_{\varvec{y}} = 12066\)).
Proposed deep visual learning framework
The workflow of the proposed vision-based surrogate modeling framework, graphically summarized in Fig. 2, can be dissected into four parts, of which first is the generation of training tuples \((\varvec{x}^k, \varvec{y}^k)\). It is crucial to ensure a sufficiently representative selection of points \((\varvec{x}^k)_{k \in [n]}\) for which f will be evaluated, especially under the imposed low-data regime. The scheme adopted herein relies on a combination of judicious manual selection and random sampling. In the former category, the following base scenarios were included: full protection (i.e., \(\varvec{x} = \varvec{1}\)), protection of the first and second halves, no protection (i.e., \(\varvec{x} = \varvec{0}\)), protection of single precincts (i.e., all binary unit vectors in \(\mathcal {X}\)) and the inverses thereof, resulting in a total of \(4 + 2d_{\varvec{x}}\) input instances. The remaining (out of n) random cases were constructed by drawing uniformly distributed random points from a \(d_{\varvec{x}}\)-dimensional unit cube via Latin Hypercube Sampling48, then rounding their entries to the nearest integer value. For each selected input \(\varvec{x}^k\), the respective output \(\varvec{y}^k\) was computed by carrying out a numerical simulation with the previously descibed coupled hydrodynamic model.
Recall that every element of \(\varvec{y}\) corresponds to a specific geographical location parameterized by a latitude and longitude. In vectorial representation, however, this information is abstracted away, leaving the potential of exploiting the spatial correlations and interdependencies between these locations untapped. To enrich the data representation, the proposed pipeline remodels the input and output vectors into matrices as follows. From each \(\varvec{y}^k, k \in [n]\), we construct a corresponding flood depth map \(\varvec{Y}^k \in \mathbb {R}^{H \times W}\) through a mapping \(\Phi : \mathbb {R}^2 \rightarrow (i,j), i \in [H], j \in [W]\) that converts the geographic coordinates associated with the components of \(\varvec{y}\) into grid indices (i, j). This transformation \(\Phi\) and the grid size \(H \times W\) should be selected such that the existing spatial relationships among the output locations are minimally distorted. For the current application site, the coordinate conversion was performed by discretizing the axes of the geographical domain. The dimensions of the formed regular mesh grid, which underlies \(\varvec{Y}^k\)-s, were equated for ease of processing, and the grid size was set to \(H \times W = 1024 \times 1024\) to sustain the desired fine geographic granularity of predictions at a reasonable computational cost while maintaining the overall spatial structure of output locations. The mapping conflicts due to discretization were resolved according to the nearest neighbor principle. Subsequently, the established indexing is leveraged to translate the binary protection scenarios \((\varvec{x}^k)_{k \in [n]}\) into hypothetical flood susceptibility maps \((\varvec{X}^k)_{k \in [n]}\), where each \(\varvec{X}^k \in \mathcal {C}^{H \times W}\) and \(\mathcal {C}\) stands for some discrete set of three predefined values that represent categories. Here, the latter was defined as \(\mathcal {C} \triangleq \{-1,0,1\}\) and for \(\forall ~ k \in [n]\), \(X_{i,j}^k\) was assigned \(-1\) if the shoreline segment in \(\varvec{x}^k\) closest to the location tied to the (i, j)-th index was marked as unprotected, 1 if protected and the rest of the cells were filled with zeros. In a sense, \(\varvec{X}^k\)-s are segmented matrices in which the \(d_{\varvec{y}}\) nearshore locations are classified by their distance to unprotected parts of the coast, and the proximity is perceived as a proxy indication of flood risk. It should, nevertheless, be noted that these input matrices may not necessarily reflect the actual risk or susceptibility of flooding but are, instead, conceptual constructs devised for modeling input protection scenarios, hence the terming “hypothetical”.

Schematic diagram of the proposed vision-based framework for training performant DL-based coastal flooding metamodels in low-data settings.
Observe that with the remodeled input-output format, the initial regression model is effectively transformed into a problem of learning a mapping of the form \(\varvec{X} \in \mathcal {C}^{H \times W} \rightarrow \varvec{Y} \in \mathbb {R}^{H \times W}\), where \(\varvec{X}\) and \(\varvec{Y}\) can be visualized graphically as grayscale (i.e., single channel) images. From a computer vision viewpoint, this problem generally falls under the umbrella of image-to-image translation tasks49, however, it can also be deemed as a variant of monocular depth estimation from a single image50,51 since the predicted output is a depth map (of floodwaters). While both of these directions have been extensively researched, to the best of our knowledge, the present problem of inferring flood depth information from a grayscale, segmented image has not been explored.
Capitalizing on the new image-like representation of inputs and outputs, as a third step of the proposed framework, we artificially increase the volume of training data through image augmentation. Let \(\mathcal {D} \triangleq \{(\varvec{X}^k, \varvec{Y}^k) \mid k \in [n]\}\) be the dataset constructed as prescribed above. From each existing pair \((\varvec{X}^k, \varvec{Y}^k)\) in \(\mathcal {D}\), m new training examples \((\varvec{X}^{k(1)}, \varvec{Y}^k), \ldots , (\varvec{X}^{k(m)}, \varvec{Y}^k)\) are generated via the Cutout technique52, which applies a fixed-size zero-mask to a random location(s) within the input. By masking out contiguous sections of input images, we essentially erase some information, introducing samples that are partially occluded, noisy copies of original data yet will appear novel to the DL model. Apart from enlarging the size of the training set, this technique exerts a regularization effect, combating the potential for overfitting, and encourages DL models to exploit the full context of the image rather than focus on a few key visual features, which may not always be present52. In general, training neural networks on a combination of clean and noisy data, where the noise is added to the inputs, outputs, or gradients, has often been proven instrumental for boosting not only the generalizability but also the predictive capacity of the network, especially in situations when only few training samples are available53,54, as is the case here. To further increase the variety of training examples, the Cutout method can be applied in conjunction with other image augmentation techniques, such as rotation, flipping, or shifting. Here, the application of the former method alone (yet in an excessive manner) was found to be sufficient. The size and number of cutout patches, which control the amount of added noise, were determined based on experimentation and are specified in Sec. ”Evaluation Setup and Settings”.
As the final part of the proposed pipeline, it remains to select the type of neural network that will power the surrogate model and the loss function it will learn to minimize. Now that the problem has been transformed into an image processing task, one has a powerful arsenal of DL techniques at disposal, including both generative models, such as GANs (e.g., pix2pix49) and Diffusion models (e.g., GeoWizard51), as well as discriminative models, such as Vision Transformers (e.g., SWIN Transformer55) and CNNs. One salient CNN architecture that has arguably passed the test of time is the U-shaped network, known as U-Net33, which was originally designed for biomedical imaging tasks, where the available training data is usually scant (as also in the current setting). Since its inception, U-Net has been widely adopted in the biomedical community and beyond, inspiring various new variants and vision models56. Drawing on the success of this architecture, in the following section we design a lightweight U-Net-like CNN model, coined CASPIAN, aligned to the priorities set forth in this work and the characteristics of the studied prediction problem. In particular, we adapt the original U-Net model to (i) further enhance the predictive performance of the network, and (ii) reduce the number of parameters, and hence the memory and computational resources required for training, so as to facilitate the reproducibility and accessibility of the developed coastal flooding metamodel. To demonstrate the generality of the proposed surrogate modeling approach, we test it additionally on two existing architectures: SWIN-Unet34 and Attention U-net35. SWIN-Unet incorporates Transformer-based context modeling into the U-Net layout by replacing convolutions with hierarchical Swin Transformer blocks that rely on shifted-window self-attention, while retaining encoder-decoder skip connections. The input image is tokenized into patches and passed through these blocks, which merge patches during encoding and expand them during decoding, enabling multi-scale feature learning that can capture both local detail and global context. Attention U-Net augments the classic U-Net architecture with additive attention gates, which weigh skip-connected features with learned coefficients to suppress irrelevant activations and emphasize salient structures. The performance comparison of these three models is reported in Sec. ”Results”.
Turning to the selection of the loss function, a number of alternatives can be considered, including mean squared error, mean absolute error, Huber loss57, and its reversed variant Berhu58. The choice can be informed by analyzing the distribution of water depth values in the dataset and through experimentation. For the current data, the best results were attained with the Huber loss function, denoted by \(L_{\text {Huber}}\), which sets the loss for each point in the output to
where \(\delta\) quantifies the error between the predicted and ground truth water depth values and \(\theta \ge 0\) is a parameter. Recall that by construction, the predicted inundation maps will contain artificially added (background) points for which depth estimation is irrelevant. Therefore, the latter were masked out, and the loss was evaluated only on the valid points that correspond to the \(d_{\varvec{y}}\) locations of interest.
CASPIAN
The architecture of the introduced lightweight CNN model CASPIAN, a detailed breakdown of which is presented in Fig. 3, can be interpreted as a two-layered structure consisting of (i) a fully convolutional encoder-decoder network with a central bottleneck comprised of a series of aggregated residual transformation blocks, and (ii) a cascade of consecutive pooling operations and corresponding supervision blocks linked by skip connections and stacked on top of the encoder and decoder, respectively. The input flood susceptibility maps are simultaneously fed into both of these pathways. While running parallel to one another, these two paths operate in tandem: at every downsampling (upsampling) stage within the network, the outputs from the top pooling path are merged into (multiplied with) the feature maps produced by the bottom convolutional path. The naming of CASPIAN stems from its two distinctive features, namely the cascaded pooling operations and the deep central bottleneck with aggregated residual transformations. The idea behind this dual-path architecture rests on the observation that, under the proposed input representation, the pooling layers, which are traditionally applied after convolutions to compress the extracted feature maps, can instead be employed for capturing the global context of the input image, which in our case amounts to the detection of protected and unprotected precincts. In what follows, we discuss the constituents of the proposed model separately, elaborating on their structure, role, and key parameters.

Detailed architecture of the proposed lightweight CNN model, CASPIAN, for high-resolution coastal flood prediction under SLR and shoreline fortifications. The input image passes through two concurrent paths: a pooling path (colored in red) and a fully convolutional path. The modulation blocks drawn as sketches in dotted outlines are optional and could be substituted by the output from the initial block. The operations followed by non-linear activation functions are marked with a blue border.
The encoder part of CASPIAN consists of K successive downsampling blocks, which progressively filter and downscale (by a factor of 2 each) the input image (of size \(H \times W\)) to generate low-resolution hierarchical feature representations. To allow for efficient utilization of model parameters, we construct these blocks in a style similar to Xception59. Specifically, each block, except the first, is built from depthwise convolutions (with stride 2) followed by concatenation (with the feature maps from the pooling path), then pointwise (i.e., \(1 \times 1\)) convolutions and a residual connection around them. The initial downsampling block, which for clarity is illustrated in a disassembled form in the topmost left corner of Fig. 3, instead employs a regular convolution with F filters. To save the number of parameters at higher resolutions, we keep the number of filters F constant across all downsampling blocks. The first block is additionally supplied with the output of a stack of operations from the pooling path, which collectively we refer to as segregated pooling. This unit filters the non-background points in the segmented input maps based on their class values into separate channels, which are then concatenated and fed into a pooling layer.
The central segment of CASPIAN, which serves as a bridge between the encoder and decoder, is formed by M repeated ResNeXt60 blocks with identical configurations and fixed output size of \(\frac{H}{2^K} \times \frac{W}{2^K} \times F\). Each block aggregates identity mapping with a set of transformations realized through grouped and pointwise convolutions, as illustrated in Fig. 3. As the low-resolution feature maps produced by the encoder undergo these transformations, the proposed network learns more complex and increasingly global (due to enlarging receptive field) feature representations. In addition to the depth M, this bottleneck path is parameterized by cardinality C and group width w, which control the size and extent of the transformations.
The decoding module in CASPIAN, structurally mirroring the encoder, is assembled from K blocks, which, relying on transposed convolutions (a.k.a., deconvolutions) and pointwise operations, learn to gradually upsample the feature maps distilled by the bottleneck back to the original input resolution \(H \times W\). Similar to SegNet61, instead of channeling the entire feature maps from the encoder to the decoder through skip connections as in U-Net, the proposed network transfers only the output of corresponding pooling layers as depicted in Fig. 3. Additionally, these feature maps are reused for modeling the hydrodynamic interactions among protected and unprotected parts of the coast and guiding the decoding process accordingly. In particular, we complement the first upsampling block with a Modulation block constructed similarly to Squeeze-and-Excitation (SE) unit62. This block takes the propagated pooling maps as input and produces a set of F weights, one for each channel in the upsampled feature maps. Scaling the latter with these weights allows the network to recalibrate and rectify the decoding process, selectively emphasizing some channels and suppressing others. As illustrated in Fig. 3, in subsequent upsampling steps, the corresponding modulation blocks can be substituted by the output of the first block.
The output from the decoder is fed to a \(1 \times 1\) convolution and simultaneously summed over channels. The resulting two \(H \times W \times 1\) feature maps are summed, and a ReLU activation is applied to it to produce the predicted flood depth map. The incorporation of the summation operator (which incurs no additional trainable parameters) serves two purposes: (i) aid in preventing overfitting by keeping the learned kernel weights in the final convolutional layers small, and (ii) improve the training by forcing the network to reuse the decoder feature maps (see Sec. ”Ablation Experiments” for supporting ablation experiments).
Evaluation setup and settings
Dataset: Following the proposed workflow, a total of 142 input protection scenarios were generated, and the corresponding flood depth maps were produced with the employed physics-based coupled hydrodynamic model to construct the main dataset, which we denote by \(\mathcal {D}\). To ensure the robustness of the results and the reliability of the evaluation, splitting of \(\mathcal {D}\) into training, validation and testing sets was repeated multiple times. Specifically, \(\mathcal {D}\) was randomly split thrice according to 112-12-18 partitioning, resulting in three different training, validation, and testing sets. For each split, it was ensured there were no overlaps among the three sets. On the training and validation sets, 19-fold data augmentation was applied through the Cutout technique with two patches, each of size \(60 \times 60\). To assess the models’ generalizability to out-of-distribution inputs (i.e., scenarios with protection patterns different from those included in training, validation and test sets), a Holdout dataset consisting of 32 handcrafted protection scenarios was additionally constructed (see Supplementary Table S1). These scenarios were deliberately curated to be challenging, spanning high-contrast and structurally atypical layouts unseen during the training, such as alternating protected/unprotected precincts; protection of every other contiguous block of precincts of length 2–5; and the inverses of these patterns.
Candidate Approaches: The pool of coastal flood prediction methods selected for evaluation comprises two main groups as highlighted in Table 1. The first (benchmark) group includes two commonly employed approaches (as informed by the reviewed literature), namely Kriging with PCA and Support Vector Regression (SVR), and two standard ML techniques, namely Linear Regression and Lasso Regression with polynomial features (referred to as Lasso with Poly.). The second group is populated by the DL models developed via the proposed framework. Among these, three are based on two existing networks, Attention U-Net35 and SWIN-Unet34, originally designed for medical image segmentation. To adapt to the present settings, the segmentation heads in both networks were replaced by a \(1 \times 1\) convolution with a ReLU activation. Additionally, to experiment with the transfer learning technique, we substitute the encoder stack in Attention U-Net with the first 16 convolutional layers from the VGG19 network63 (a 19-layer CNN for image classification relying on small \(3\times 3\) convolutional filters) and consider two versions, one with the encoder weights initialized randomly while the other with those pre-trained on the popular ImageNet dataset, which contains more than a million images. The latter model is denoted as Attention U-Net\(^{\ddagger \ddagger }\) to discern between these two. To conform to the three-channel input format of VGG19, for both models, the depth of input matrices was expanded by replacing the class values with RGB codes, resulting in an input size of \(H \times W \times 3\). The final fourth model in this cohort is based on the introduced CNN architecture CASPIAN. To allow for an impartial inter-group comparison, predictions produced by the benchmark models were post-processed to replace the negative values with zeros. As an additional reference, we employ a naive regressor, termed Baseline Predictor, which outputs 0 if the corresponding coastal location in the input vector was (hypothetically) classified (based on the proximity to protected shoreline segments) as inundation-safe or otherwise the average peak water level across the flooded areas in the entire main dataset.
Model Configurations and Implementation Details: Settings of the classical and generalized regression models in the benchmark group were determined under experimentation and are listed in Table 1. Linear Regression, SVR, Lasso with Poly., and Kriging with PCA were implemented via Scikit-learn64 and SMT65 Python packages. The implementations (in Tensorflow Keras v2.1) of Attention U-Net and SWIN-Unet were borrowed and adapted from Sha66. The proposed model CASPIAN was built with Tensorflow Keras v2.1. The hyperparameters of Attention U-Net were tuned manually and then transferred identically (except the weight initialization in the encoder) to Attention U-Net\(^{\ddagger \ddagger }\). For SWIN-Unet and CASPIAN, the selection of hyperparameters was optimized through the Random Search algorithm provided as part of the Keras Tuner library67 (see Supplementary Sec. D for details). For brevity, Table 1 reports only the total number of trainable parameters of these models, whereas the hyperparameter values are relegated to Sec. C in the Supplementary materials.
Training Specifications: All four DL models were trained with Adam optimizer under the Huber Loss (as defined in Eq. 1) function with \(\theta = 0.5\) and batch size of 2. The adopted learning schedule, determined through trials with several alternatives, was set to start with a gradual warm-up that increases the learning rate from 0 to \(\text {LR}\) linearly for 20 epochs, followed by 200 epochs of the main training session wherein the learning rate was reduced (\(\times 0.85\)) whenever the validation loss plateaued (patience = 10). During the main training, early stopping was applied if no improvement in the validation loss was recorded for 40 consecutive epochs. \(\text {LR}\) was set to \(1.5 \cdot 10^{-4}\) for Attention U-Net and Attention U-Net\(^{\ddagger \ddagger }\), to \(1.8 \cdot 10^{-4}\) for SWIN-Unet, and to \(8 \cdot 10^{-4}\) for CASPIAN. All the models were trained and evaluated on a desktop machine with an Intel Core i9 3.00 GHz CPU, 64 GB of RAM and a single NVIDIA RTX 4090 GPU.
Model Interpretability: To investigate the decision-making process within the trained DL models, we employ a post-hoc explanatory visualization method, known as Grad-CAM68. Grad-CAM produces visual explanations, in the form of heatmaps, which reveal the salient regions in the input image that contributed most to the model’s output (in other terms, where the model “looked” to make the prediction). Specifically, this method back-propagates gradients from a chosen scalar target to a deep layer within the network and applies global average pooling on those gradients to derive per-channel weights. The weighted sum of the layer’s feature maps is then passed through ReLU, yielding a saliency map that can be superimposed on the input image to highlight the regions most influential for the target. For the current prediction setting, we set the scalar target to a normalized weighted sum of peak water levels over the entire output grid, with the weights of the selected 12066 coastal locations of interest assigned 1 and a small Gaussian noise elsewhere for numerical stability.
Evaluation Metrics: As emphasized by Al Kajbaf and Bensi21, the metamodels developed in prior works have often been assessed relying only on a few basic aggregate metrics, such as Root Mean Squared Error (rmse), Mean Absolute Error (mae) or Coefficient of Determination (\(R^2\)), which may not adequately reflect the actual quality of predictions. To provide a more comprehensive evaluation, we consider 6 different metrics, including both error and accuracy measures, formally defined as follows:
where N is the number of evaluated samples; \(\varvec{y}\) and \(\varvec{\hat{y}}\) correspond to the ground truth and predicted peak water levels (in meters) of the \(d_{\varvec{y}}\) locations of interest, respectively; \(\bar{\varvec{y}}^k \triangleq \textbf{1} \cdot \frac{1}{d_{\varvec{y}}} \sum _{i=1}^{d_{\varvec{y}}} y_i^k\) denotes the mean vector of actual peak water level values for the k-th sample; \(\Delta\) is an error threshold (in meters); \(\mathcal {S}_\Delta \triangleq \{ i \in [d_{\varvec{y}}] ~:~ |y_i^k - \hat{y}_i^k|> \Delta \}\); \(\mathcal {O}_{k} \triangleq \{ i \in [d_{\varvec{y}}] ~:~ y_i^k =0\}\); \(\hat{\mathcal {O}}_{k} \triangleq \{ i \in [d_{\varvec{y}}] ~:~ \hat{y}_i^k =0\}\). In Eqs. 2 and 3, artae, armse, and amae stand for average relative total absolute error, average rmse, and average mae, respectively; \(\delta> \Delta\) quantifies (in %) the average fraction of coastal locations where the absolute error in predicted floodwater levels exceeds the specified threshold \(\Delta\) (here two values for \(\Delta\) were considered: 0.1 and 0.5 meters), serving as an important metric for assessing models’ performance and gaining a more nuanced understanding of their performance; and Acc[0] measures the zero detection rate (that is, models’ accuracy of detecting non-flooded locations).
Results
Quantitative evaluation
Table 2 summarizes the candidate models’ performance on the Test and Holdout datasets, averaged over the predictions pooled from three runs, each corresponding to one of the three train-validation-test splits mentioned above. Before turning to the comparative analysis, we first examine the performance of the Baseline (naive) regressor, which indirectly provides some insights into the distribution of flood depth values and underscores scenario differences across the Test and Holdout datasets. Specifically, the \(\delta>0.1\) m. and \(\delta>0.5\) m. errors of the Baseline predictor in Table 2 indicate that, in the test scenarios, on average around 56% (\(\pm 25\%\)) and 27% (\(\pm 11\%\)) of coastal locations, respectively, differed by more than 0.1 m. and 0.5 m. from the global mean peak floodwater level of the main dataset; in the holdout scenarios, the corresponding proportions were about 53% (\(\pm 12\%\)) and 30% (\(\pm 7\%\)). Importantly, the Acc[0] scores of the Baseline predictor, reveal that, for the test scenarios, on average \(57.9 \%\) of coastal locations in the vicinity of protected shoreline segments were not flooded, yet the variability was substantial (\(\pm 29.9\%\)), signaling the limited standalone predictive value of proximity in these scenarios. On the other hand, on the holdout scenarios, the naive regressor attained an Acc[0] score of \(70.9\% \pm 12\%\), implying that, for those scenarios, proximity to coastal defenses was a relatively more reliable indicator of non-flooding. These observations suggest that the test scenarios exhibit broader variability of flooding patterns, whereas holdout scenarios are characterized by relatively higher share of flood depth levels with large departures (\(>0.5\) m.) from the main dataset mean, suggesting more extreme conditions in the latter.
Compared to the naive regressor, the models in the benchmark group demonstrated notably improved performance in terms of error metrics. The two-stage Kriging with PCA approach, commonly employed in the field, slightly improved upon Linear Regression by achieving 22.1% artae, but \(\delta\) errors were comparable, indicating similar predictive quality. Lasso with Poly. reached the highest armse of 0.42 meters and \(R^2 = 0.95\) across all models while attaining a \(\delta> 0.5\) m. error of 5–7%, about half of that produced by Kriging with PCA. Yet, the Acc[0] scores of Lasso with Poly. were the lowest among all models (including the Baseline predictor), rendering it unreliable for accurate detection of non-flooded areas. Among the benchmark models, SVR achieved the lowest \(\delta\) errors, which indicates a higher quality of predictions, however, similar to Lasso with Poly., Acc[0] was extremely low at around 20%. It should be noted that in the case of SVR, a separate model has to be trained for every output coastal location independently, which raises potential scalability issues.
The DL models trained with the proposed framework significantly outperformed the above benchmark models in terms of amae (by a factor of 2 on average), artae (by a factor of 2–5) and \(\delta\) errors (by a factor of 2–5), and especially for Acc[0] (more than two-fold). The version of Attention U-Net with the pre-trained weights achieved only modest improvements over the version trained from scratch, specifically a marginal improvement of 0.1% of artae and 0.01% of \(\delta> 0.5\) m. error. This result could possibly be attributed to the stark difference in image modalities and sizes between the current dataset and ImageNet. The two best-performing candidate models were SWIN-Unet and CASPIAN, the former a close runner-up to the latter for the majority of the metrics. Notably, CASPIAN attained the highest scores for all metrics in the Holdout dataset while requiring only a fraction of SWIN-Unet’s model size (see Table 1). As reported in Table 2, on average, CASPIAN achieved a \(\delta> 0.5\) m. error of only \(\approx 1\)% on both datasets and the average \(\delta> 0.1\) m. error was between 3% and 4%, indicating that, on average, roughly \(99\%\) and \(97\%\) of predictions in the flood depth maps produced by CASPIAN had absolute errors of no more than 50 cm. and 10 cm., respectively. The performance with respect to the other metrics also remained consistent on both datasets, demonstrating CASPIAN’s generalization capabilities.
Qualitative evaluation
To gain further insights into the performance of the candidate models, we next analyze the quality of predicted flood depth maps. Specifically, we visualize and categorize the signed percent errors in predicted peak water levels relative to the ground truth values. Figure 4 presents the resulting error maps for three protection scenarios from the Holdout dataset with varying degrees of shoreline armoring: high, moderate, and low, appearing in the top, middle, and bottom rows, respectively (additional scenarios can be found in Supplementary Fig. S3). For clarity of illustration, the maps produced by the two best-performing DL models, CASPIAN and SWIN-Unet, and the top three benchmark methods, Kriging with PCA, Lasso with Poly., and SVR, are examined.

Comparison of flood depth prediction errors, expressed as signed percent deviation from the ground truth, across CASPIAN, SWIN-Unet, and benchmark models. Rows correspond to different protection scenarios, whereas columns to models. Green and light cyan colors indicate \(0 \%\) error or within \(\pm 5 \%\) variation from ground truth values, while darker colors represent higher discrepancies. The superscript \(^{**}\) denotes an ensemble of individual models, each trained for one specific coastal location. The figure was created with Python (v3.10.13, https://www.python.org/) using Matplotlib (v3.10.1, https://matplotlib.org/), Contextily (v1.6.2, https://contextily.readthedocs.io/) and Pandas (v2.0.2, https://pandas.pydata.org/).
As can be deduced from Fig. 4, the flood depth maps produced by the proposed DL models accurately and closely aligned with those generated by the physics-based hydrodynamic simulator. This is reflected in the predominance of green and light cyan colored regions in the error maps, indicating low relative errors (\(0\%\) or within \(\pm 5\%\)), and is consistent with the results of the quantitative evaluation, particularly the high Acc[0] scores and low \(\delta\) errors. Importantly, the errors in CASPIAN and SWIN-Unet predictions are sparse, spatially scattered, and appear to be isolated outliers rather than systematic deviations. The flood maps produced by these two DL models exhibited strong spatial consistency across all three protection scenarios with no discernible tendency to overestimate or underestimate flood depths. In contrast, the three benchmark models produced a large number of errors that are spatially clustered in concentrated regions across multiple parts of the shoreline, signifying poor generalization across protection scenarios and limited robustness in capturing spatial flood dynamics.
Another important observation transpiring from Fig. 4 concerns the ability of the candidate models to correctly identify non-flooded areas. In highly and moderately armored scenarios – corresponding to the top two rows in Fig. 4 – the performance gap between the proposed DL models and the benchmark models becomes particularly pronounced. In these cases, SVR and Lasso with Poly. produced highly inaccurate flood depth maps, substantially overestimating flood extent. This observation is also supported by their extremely low Acc[0] scores reported in Table 2. While Kriging with PCA demonstrated relatively improved performance over these two in identifying non-flooded areas, it still remains well behind the proposed DL models. Taken together, the observed qualitative and quantitative patterns suggest that CASPIAN and SWIN-Unet have learned to distinguish the protection status of coastal locations and have internalized the principle that fully protected coastal areas should not experience flooding, which provides further support to these models’ predictive capabilities.
Interpretability analysis
We finalize the evaluation by applying Grad-CAM, as described in Methods, to shed light on the decision basis of the trained DL models. Fig. 5 illustrates the resulting Grad-CAM explanations for the predictions produced by CASPIAN and SWIN-Unet for the three protection scenarios considered in Fig. 4. Values in the Grad-CAM heatmaps are jointly normalized across scenarios for each model.
The heatmaps reveal a consistent and interpretable pattern. Saliency concentrates along the coast, with a higher emphasis on vulnerable, unprotected segments where flooding is more likely to occur, whereas protected precincts receive low attribution. This pattern holds across both models and all three scenarios, with CASPIAN displaying a slightly starker unprotected-to-protected attribution gap relative to SWIN-Unet. Importantly, the heatmaps lend additional empirical evidence to the earlier interpretation that the models appear to have learned to distinguish between protected and unprotected coastal areas and down-weight fully enclosed precincts.

Grad-CAM visualizations for CASPIAN and SWIN-Unet. Column titles denote protection scenarios, while rows correspond to models. Heatmaps for each model share a common normalization across scenarios and are overlaid on the Abu Dhabi basemap with shoreline segments delineated by protection status. Darker colors indicate higher saliency. Coastal points are slightly dilated to improve legibility. The figure was created with Python (v3.10.13, https://www.python.org/) using Matplotlib (v3.10.1, https://matplotlib.org/), Contextily (v1.6.2, https://contextily.readthedocs.io/) and Pandas (v2.0.2, https://pandas.pydata.org/).
Ablation experiments
Supplementing the evaluation results reported above, this section presents ablation studies of the key design elements proposed in CASPIAN. In particular, we remove or truncate individual modules/blocks in four separate experiments and analyze the resulting changes in predictive performance. The following versions were considered: (i) CASPIAN without the final channel-wise summation, abbreviated as CASPIAN\(_{\text {B}}\), (ii) CASPIAN with the depth of the central bottleneck reduced to 2 (i.e., \(M=2\)), denoted as CASPIAN\(_\Gamma\), (iii) CASPIAN with the modulation block removed, denoted as CASPIAN\(_{\text {Z}}\), (iiii) CASPIAN with the pooling path completely eliminated, referred to as CASPIAN\(_{\Omega }\).
The results of ablation experiments are reported in Table 3. CASPIAN\(_{\text {B}}\) achieved similar results on the Test dataset compared to CASPIAN, yet \(\delta> 0.1\) m. error of the produced predictions on the Holdout dataset nearly doubled, indicating poorer generalizability. This observation corroborates the importance of the proposed final summation operator. With CASPIAN\(_\Gamma\), the quality of predictions degraded further, as reflected in higher artae and \(\delta> 0.1\) m. errors on both the Test and Holdout datasets relative to CASPIAN, thereby substantiating the inclusion of the deep central bottleneck. In the case of CASPIAN\(_{\text {Z}}\) and CASPIAN\(_{\Omega }\), a significant drop in performance was observed on both datasets, approaching the scores of Attention U-Net. This outcome can be expected, since removing the modulation block and the pooling path reduces the architecture to a plain encoder-decoder network without skip connections.
Discussion
In this paper, we presented a data-driven framework for developing accurate and reliable climate adaptation-aware coastal flooding metamodels powered by vision-based DL techniques. The proposed framework was tested on three different DL architectures, including a lightweight CNN model CASPIAN introduced in this work. The developed models were shown to significantly outperform the most recently developed surrogate model for this problem, based on Kriging with PCA. The best-performing model, CASPIAN, closely and consistently emulated the results obtained with the high-fidelity hydrodynamic simulator, on average achieving an \(\textsc {amae}\) of 0.06 m. and \(\delta> 0.5\) m. error of only around 1% on both Test and Holdout datasets. Overall, the combined evidence from the evaluation studies and the interpretability analysis demonstrates that CASPIAN can deliver accurate, reliable, and interpretable predictions, reinforcing its value as a practical and accessible tool for coastal engineers.
A key distinguishing feature of the proposed framework lies in the image-like representation of inputs and outputs, which serves as the cornerstone of the approach. This design offers several distinctive advantages. First, the representation is inherently scalable with respect to the number of coastal locations: while the current study considers 12, 066 locations, the framework can readily accommodate hundreds of thousands of grid points, as they can be fit within the defined spatial resolution of 1024x1024. Second, framing the problem as an image-to-image translation task, allows one to leverage the powerful arsenal of computer vision models and techniques, as demonstrated here through the successful adaptation of two established vision models, SWIN-Unet and Attention U-Net, and the deployment of the Cutout technique. Lastly, the proposed representation is computationally conducive, since the outputs can be produced relying on convolutional layers only, avoiding dense, fully connected layers, whose cost grows with output dimensionality. While the studied flood prediction problem naturally admits a graph-based formulation, and the application of graph neural networks would be an interesting direction for future work, the focus of this study was on enabling easily implementable and scalable modeling, which motivated the vision-based design.
Once successfully trained, the proposed vision-based DL models effectively reduce the time of producing a flood depth map from approximately 72 hours (the runtime of the employed physics-based hydrodynamic simulator) to milliseconds – a speedup on the order of \(10^{8}\). Consequently, they can be employed to rapidly screen large numbers of coastal-protection scenarios, supporting planners and policy-makers in designing more effective coastal adaptation programs, informing long-term planning projects, and enhancing disaster preparedness, thereby contributing to the resilience of coastal cities. At the same time, to ensure accountability in decision support, final verification of protection scenarios and consequent engineering or regulatory decisions should continue to rely on high-fidelity hydrodynamic simulations.
Nevertheless, despite the advantages of the proposed framework and the promising performance of the developed DL models, several challenges and limitations remain and warrant further investigation. These pertain both to the employed hydrodynamic model and to the DL models.
There were a number of limitations in the employed hydrodynamic model and the performed simulations. Firstly, due to the lack of availability of storm induced water levels, the validation of the storm impacts were limited for the hydrodynamic model. Secondly, while a full physics model was adopted (Delft3D and SWAN), the components were not dynamically coupled. That is, while the SWAN model computes the significant wave heights using the Delft3D computed water levels, atmospheric pressure and wind fields at each time step, the SWAN water levels were not then fed back to Delft3D at the next time step to generate a new water surface. Given the long computational requirements for a dynamically coupled hydrodynamic model, a software package such as SFINCS69 can be adopted as a reduced-physics surrogate model for the SWAN and run-up components of the full physics model, to speed up the generation of training data.
The seawalls in the hydrodynamic model were represented as impermeable structures, whereas in reality, the engineering design of individual coastal protections can take various forms other than seawalls, such as berms or nature-based solutions such as mangroves. In light of this, the predicted flood depth maps reflect idealized protection capabilities offered by locating an impermeable seawall at candidate shoreline segments. Future work could incorporate the characteristics of the protection as inputs to the DL models. Note that, while the above improvements to the hydrodynamic model would provide a more refined training set for the DL models, they would not alter the proposed framework.
Given the generated dataset’s scope on a single coastal region (Abu Dhabi), one SLR scenario, and a fixed set of wind parameters, the developed DL models in the current form are domain-specific. However, without major changes to the proposed framework, the DL models can be extended to other coastal settings and regions by enriching the input rasters with geospatial descriptors (e.g., local slope, bathymetry, shoreline orientation, land elevation/roughness, and hydraulic connectivity) and by expanding the training corpus to span multiple regions and SLR levels. In fact, our preliminary experiments on the San Francisco Bay area (1 m. SLR) signify that the models transfer well to a new geography, even with minimal adjustment. Another possible extension would be to expand the predictive scope and, in addition to peak water levels, also estimate the maximum velocities of floodwaters, a key prediction required for coastal damage assessment.
Data availability
The introduced dataset of synthetic flood depth maps is available at https://doi.org/10.7910/DVN/M9625R.
Code availability
The complete source code for reproducing the results reported in this study, including the trained models and the evaluation scripts, is publicly accessible at https://github.com/Arnukk/CASPIAN.
References
UN Atlas of the Oceans. United Nations Atlas of the Oceans. http://www.oceansatlas.org/facts/en/ (2016).
Garner, A. J. et al. Impact of climate change on New York City’s coastal flood hazard: Increasing flood heights from the preindustrial to 2300 CE. Proc. Natl. Acad. Sci. 114, 11861–11866. https://doi.org/10.1073/pnas.1703568114 (2017).
Sweet, W. V. et al. Global and regional sea level rise scenarios for the United States: Updated mean projections and extreme water level probabilities along US coastlines (National Oceanic and Atmospheric Administration, 2022).
Tiggeloven, T. et al. Global-scale benefit-cost analysis of coastal flood adaptation to different flood risk drivers using structural measures. Nat. Hazards Earth Syst. Sci. 20, 1025–1044. https://doi.org/10.5194/nhess-20-1025-2020 (2020).
Jongman, B. Effective adaptation to rising flood risk. Nat. Commun. 9, 1986. https://doi.org/10.1038/s41467-018-04396-1 (2018).
Hummel, M. A., Griffin, R., Arkema, K. & Guerry, A. D. Economic evaluation of sea-level rise adaptation strongly influenced by hydrodynamic feedbacks. Proc. Natl. Acad. Sci. United States Am. 118, e2025961118. https://doi.org/10.1073/PNAS.2025961118/SUPPL_FILE/PNAS.2025961118.SAPP.PDF (2021).
Beagle, J. et al. San Francisco Bay shoreline adaptation atlas: Working with nature to plan for sea level rise using operational landscape units. (SFEI publication# 915, 2019).
Papacharalambous, M., Davis, M., Marshall, W., Weems, P. & Rothenberg, R. Greater new orleans urban water plan: Implementation. (Waggonner & Ball Archit. New Orleans, LA, USA, 2013).
Lewis, A. After a Decade of Planning, New York City Is Raising Its Shoreline. Yale School of the Environment (2023). https://e360.yale.edu/features/new-york-city-climate-plan-sea-level-rise.
Wang, R. Q., Stacey, M. T., Herdman, L. M. M., Barnard, P. L. & Erikson, L. The Influence of Sea Level Rise on the Regional Interdependence of Coastal Infrastructure. Earth’s Futur. 6, 677–688. https://doi.org/10.1002/2017EF000742 (2018).
Haigh, I. D. et al. The Tides They Are A-Changin’: A Comprehensive Review of Past and Future Nonastronomical Changes in Tides, Their Driving Mechanisms, and Future Implications. Rev. Geophys. 58, e2018RG000636, https://doi.org/10.1029/2018RG000636 (2020).
Deltares. Delft3d. https://oss.deltares.nl/web/delft3d.
Delft University of Technology. Simulating waves nearshore (swan). https://swanmodel.sourceforge.io (2022).
Guo, Z., Leitão, J. P., Simões, N. E. & Moosavi, V. Data-driven flood emulation: Speeding up urban flood predictions by deep convolutional neural networks. J. Flood Risk Manag. 14, e12684. https://doi.org/10.1111/JFR3.12684 (2021).
Hofmann, J. & Schüttrumpf, H. floodGAN: Using Deep Adversarial Learning to Predict Pluvial Flooding in Real Time. Water, 13, 2255, https://doi.org/10.3390/W13162255 (2021).
Chu, H., Wu, W., Wang, Q. J., Nathan, R. & Wei, J. An ANN-based emulation modelling framework for flood inundation modelling: Application, challenges and future directions. Environ. Model. & Softw. 124, 104587. https://doi.org/10.1016/J.ENVSOFT.2019.104587 (2020).
Mosavi, A., Ozturk, P. & Chau, K.-w. Flood Prediction Using Machine Learning Models: Literature Review. Water 10 (2018).
Bentivoglio, R., Isufi, E., Jonkman, S. N. & Taormina, R. Deep learning methods for flood mapping: a review of existing applications and future research directions. Hydrol. Earth Syst. Sci. 26, 4345–4378. https://doi.org/10.5194/HESS-26-4345-2022 (2022).
Jones, A. et al. AI for climate impacts: applications in flood risk. npj Clim. Atmospheric Sci. 6, 63 (2023).
Bomers, A. & Hulscher, S. J. M. H. Neural networks for fast fluvial flood predictions: Too good to be true?. River Res. Appl. 39, 1652–1658 (2023).
Al Kajbaf, A. & Bensi, M. Application of surrogate models in estimation of storm surge: A comparative assessment. Appl. Soft Comput. 91, 106184 (2020).
Kyprioti, A. P., Taflanidis, A. A., Nadal-Caraballo, N. C. & Campbell, M. Storm hazard analysis over extended geospatial grids utilizing surrogate models. Coast. Eng. 168, 103855. https://doi.org/10.1016/J.COASTALENG.2021.103855 (2021).
Jia, G. et al. Surrogate modeling for peak or time-dependent storm surge prediction over an extended coastal region using an existing database of synthetic storms. Nat. Hazards 81, 909–938. https://doi.org/10.1007/S11069-015-2111-1/TABLES/7 (2016).
Jia, G., Wang, R. Q. & Stacey, M. T. Investigation of impact of shoreline alteration on coastal hydrodynamics using Dimension REduced Surrogate based Sensitivity Analysis. Adv. Water Resour. 126, 168–175. https://doi.org/10.1016/J.ADVWATRES.2019.03.001 (2019).
Kyprioti, A. P., Taflanidis, A. A., Nadal-Caraballo, N. C., Yawn, M. C. & Aucoin, L. A. Integration of node classification in storm surge surrogate modeling. J. Mar. Sci. Eng. 10, 551 (2022).
Rohmer, J., Sire, C., Lecacheux, S., Idier, D. & Pedreros, R. Improved metamodels for predicting high-dimensional outputs by accounting for the dependence structure of the latent variables: application to marine flooding. Stoch. Environ. Res. Risk Assess. 1–23 (2023).
El Garroussi, S., Ricci, S., De Lozzo, M., Goutal, N. & Lucor, D. Tackling random fields non-linearities with unsupervised clustering of polynomial chaos expansion in latent space: application to global sensitivity analysis of river flooding. Stoch. Environ. Res. Risk Assess. 36, 693–718. https://doi.org/10.1007/S00477-021-02060-7/FIGURES/11 (2022).
Xu, K., Han, Z., Bin, L., Shen, R. & Long, Y. Rapid forecasting of compound flooding for a coastal area based on data-driven approach. Nat. Hazards 121, 1399–1421. https://doi.org/10.1007/s11069-024-06846-0 (2025).
Shahabi, A. & Tahvildari, N. A deep-learning model for rapid spatiotemporal prediction of coastal water levels. Coast. Eng. 190, 104504, https://doi.org/10.1016/j.coastaleng.2024.104504 (2024).
Bian, W. et al. Deep learning surrogate models for spatiotemporal prediction of coastal flooding inundations in tianjin, china. J. Hydrol. Reg. Stud. 60, 102593, https://doi.org/10.1016/j.ejrh.2025.102593 (2025).
Wei, Z. & Davison, A. A convolutional neural network based model to predict nearshore waves and hydrodynamics. Coast. Eng. 171, 104044. https://doi.org/10.1016/J.COASTALENG.2021.104044 (2022).
Jörges, C., Berkenbrink, C., Gottschalk, H. & Stumpe, B. Spatial ocean wave height prediction with CNN mixed-data deep neural networks using random field simulated bathymetry. Ocean. Eng. 271, 113699. https://doi.org/10.1016/J.OCEANENG.2023.113699 (2023).
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Navab, N., Hornegger, J., Wells, W. M. & Frangi, A. F. (eds.) Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, 234–241 (Springer International Publishing, Cham, 2015).
Cao, H. et al. Swin-unet: Unet-like pure transformer for medical image segmentation. In European conference on computer vision, 205–218 (Springer, 2022).
Oktay, O. et al. Attention u-net: Learning where to look for the pancreas. In Medical Imaging with Deep Learning (2018).
Melville-Rea, H. et al. A roadmap for policy-relevant sea-level rise research in the united arab emirates. Front. Mar. Sci. 8, 670089 (2021).
Al Ahbabi, F. Department of urban planning and municipalities. Plan Maritime: Abu Dhabi coastal and marine framework plan. Abu Dhabi 238 (2017).
Hereher, M. E. Assessment of climate change impacts on sea surface temperatures and sea level rise—the arabian gulf. Climate 8, 50 (2020).
Subraelu, P. et al. Global warming climate change and sea level rise: Impact on land use land cover features along uae coast through remote sensing and gis. J Ecosys Ecograph 12, 2 (2022).
Masson-Delmotte, V. et al. (eds.). Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change, 33–144 (Cambridge University Press, Cambridge, United Kingdom and New York, NY, USA, 2021).
Abu Dhabi Urban Planning Council. Plan Abu Dhabi 2030: Urban Structure Framework Plan (2007).
Chow, A. C. & Sun, J. Combining sea level rise inundation impacts, tidal flooding and extreme wind events along the Abu Dhabi coastline. Hydrology 9, 143 (2022).
Barnard, P. L. et al. Development of the coastal storm modeling system (cosmos) for predicting the impact of storms on high-energy, active-margin coasts. Nat. hazards 74, 1095–1125 (2014).
Egbert, G. D. & Erofeeva, S. Y. Efficient inverse modeling of barotropic ocean tides. J. Atmospheric Ocean. technology 19, 183–204 (2002).
Al Senafi, F. & Anis, A. Shamals and climate variability in the northern arabian/persian gulf from 1973 to 2012. Int. J. Climatol. 35, 4509–4528 (2015).
Li, D., Anis, A. & Al Senafi, F. Physical response of the northern arabian gulf to winter shamals. J. Mar. Syst. 203, 103280 (2020).
Holman, R. A. Extreme value statistics for wave run-up on a natural beach. Coast. Eng. 9, 527–544 (1986).
McKay, M. D., Beckman, R. J. & Conover, W. J. A comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics 21, 239–245 (1979).
Isola, P., Zhu, J.-Y., Zhou, T. & Efros, A. A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017).
Yang, L. et al. Depth anything: Unleashing the power of large-scale unlabeled data (2024). arxiv:2401.10891.
Fu, X. et al. Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a single image. arXiv preprint arXiv:2403.12013 (2024).
DeVries, T. & Taylor, G. W. Improved regularization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552 (2017).
Hedderich, M. A. & Klakow, D. Training a neural network in a low-resource setting on automatically annotated noisy data. In Haffari, R., Cherry, C., Foster, G., Khadivi, S. & Salehi, B. (eds.) Proceedings of the Workshop on Deep Learning Approaches for Low-Resource NLP, 12–18 (Association for Computational Linguistics, Melbourne, 2018).
Goodfellow, I., Bengio, Y. & Courville, A. Deep learning (MIT press, 2016).
Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, 10012–10022 (2021).
Azad, R. et al. Medical image segmentation review: The success of u-net. arXiv preprint arXiv:2211.14830 (2022).
Huber, P. J. Robust estimation of a location parameter. In Breakthroughs in statistics: Methodology and distribution, 492–518 (Springer, 1992).
Owen, A. B. A robust hybrid of lasso and ridge regression. Contemp. Math. 443, 59–72 (2007).
Chollet, F. Xception: Deep learning with depthwise separable convolutions. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1800–1807 (IEEE Computer Society, Los Alamitos, CA, USA, 2017).
Xie, S., Girshick, R., Dollár, P., Tu, Z. & He, K. Aggregated residual transformations for deep neural networks. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 5987–5995, https://doi.org/10.1109/CVPR.2017.634 (2017).
Badrinarayanan, V., Kendall, A. & Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Transactions on Pattern Analysis Mach. Intell. 39, 2481–2495 (2017).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7132–7141, https://doi.org/10.1109/CVPR.2018.00745 (2018).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
Pedregosa, F. et al. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Bouhlel, M. A. et al. A python surrogate modeling framework with derivatives. Adv. Eng. Softw. (2019).
Sha, Y. Keras-unet-collection. https://github.com/yingkaisha/keras-unet-collection, https://doi.org/10.5281/zenodo.5449801 (2021).
O’Malley, T. et al. Kerastuner. https://github.com/keras-team/keras-tuner (2019).
Selvaraju, R. R. et al. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) (2017).
Leijnse, T., van Ormondt, M., Nederhoff, K. & van Dongeren, A. Modeling compound flooding in coastal systems using a computationally efficient reduced-physics solver: Including fluvial, pluvial, tidal, wind-and wave-driven processes. Coast. Eng 163, 103796 (2021).
Acknowledgements
Supplementary information: Please see the attached supplementary document.
Author information
Authors and Affiliations
Contributions
S.M. and A.K. conceived the idea of this study. A.K. designed and developed the proposed framework, implemented and trained the prediction models, and conducted the evaluation studies. A.C. developed the hydrodynamic model and carried out the hydrodynamic simulations. A.K. and A.C. jointly wrote the manuscript. All authors provided critical feedback and helped shape the research, analysis and manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Karapetyan, A., Chow, A.C.H. & Madanat, S. Deep vision-based framework for coastal flood prediction under sea level rise and shoreline protection. Sci Rep 16, 3663 (2026). https://doi.org/10.1038/s41598-025-33803-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-33803-z
