
Abstract
To develop a machine learning model for early prediction of gestational diabetes mellitus (GDM) using routinely available first-trimester clinical and ultrasound data in Northern Chinese women. This multicenter prospective cohort study enrolled pregnant women from three hospitals in Northern China. We integrated first-trimester maternal characteristics and standardized ultrasound measurements of subcutaneous (SAT) and visceral (VAT) adipose tissue thickness. After addressing potential selection bias via inverse probability weighting, we employed a genetic algorithm (GA) for robust feature selection and evaluated five machine learning classifiers (XGBoost, ANN, SVM, MLR, RF). Model performance was assessed on an internal test set and an independent external validation set, with AUC as the primary metric. The GA consistently selected BMI, SAT, and VAT as core predictive features. The model combining GA-selected features with XGBoost demonstrated the highest performance, achieving an AUC of 0.962 on the internal test set and 0.878 on the external validation set, with corresponding sensitivities of 0.90 and 0.70, and specificities of 0.942 and 0.935, respectively. It significantly outperformed models using other feature selection methods or classifiers (all P < 0.001). The model exhibited robust stability across various sensitivity analyses. A machine learning model based on readily accessible first-trimester indicators provides an effective tool for early, opportunistic GDM risk stratification in Northern Chinese women.
Similar content being viewed by others


Introduction
Gestational diabetes mellitus (GDM), defined as hyperglycemia first detected in pregnancy that does not meet the diagnostic criteria for overt diabetes, is a common complication with significant implications for maternal and offspring health1,2,3,4,5,6. Current international guidelines recommend diagnosis via a 75-g oral glucose tolerance test (OGTT) at 24–28 weeks of gestation. However, this late diagnosis limits the window for early interventions aimed at mitigating associated complications, such as fetal overgrowth and hypertensive disorders. Identifying high-risk women in the first trimester is therefore critical for enabling timely, preventive strategies.
Existing research on early GDM prediction has primarily focused on clinical risk factors or second-trimester biomarkers7,8. Recently, abdominal fat distribution, measured via ultrasound, has emerged as a promising early indicator of metabolic dysfunction. Maternal visceral adipose tissue (VAT) and subcutaneous adipose tissue (SAT) thickness are linked to insulin resistance and GDM pathogenesis9,10,11,12. However, the integration of these routinely acquired, first-trimester ultrasound measures with standard clinical data into a predictive model—particularly within a resource-conscious, opportunistic screening framework—remains underexplored. Such an approach leverages existing prenatal care infrastructure without imposing additional testing burden, making it highly applicable to diverse clinical settings, including those with limited resources.
This study developed an early-pregnancy GDM prediction model by integrating routinely collected first-trimester clinical and ultrasound data. Our approach utilized opportunistic screening—leveraging existing prenatal care infrastructure—which was considered particularly relevant for resource-limited settings where specialized testing might be unavailable. The model aimed to identify high-risk pregnancies during the first trimester, enabling a shift of the intervention window from post-diagnosis management to early prevention. This earlier timeframe allowed for the implementation of feasible preventive strategies, such as basic dietary guidance and physical activity counseling, which could help mitigate subsequent pregnancy complications.
Methods
Subjects
This study was a multi-center prospective cohort investigation.This multicenter prospective cohort study was conducted in Northern China, enrolling pregnant women from three hospitals in Shandong Province, China, representing distinct regional healthcare settings: Zichuan District Hospital of Zibo City (a district-level hospital), Yidu Central Hospital of Weifang in Qingzhou City (a county-level hospital), and Shandong Provincial Qianfoshan Hospital in Jinan (a provincial tertiary hospital). Pregnant women who underwent prenatal examinations and had delivery records in medical institutions across various regions and levels from June 2023 to June 2024 were selected as research subjects. The inclusion criteria were as follows: singleton pregnancy, gestational age between 8 and 14 weeks, absence of severe internal or surgical complications, and the ability to comply with the entire prenatal care process. The exclusion criteria included women under 18 years of age, multiple pregnancies, pregnancies complicated by gestational hypertension, fetal or chromosomal abnormalities, hyperthyroidism or hypothyroidism, and pre-existing diabetes.
The GDM group was determined based on the World Health Organization (WHO)-recommended 75 g OGTT standards during 24 to 28 weeks of gestation, specifically, fasting blood glucose ≥ 5.1 mmol/L, 1-hour post-glucose-load blood glucose ≥ 10.0 mmol/L, and 2-hour post-glucose-load blood glucose ≥ 8.5 mmol/L. A diagnosis of GDM was made if any of these blood glucose values exceeded the established thresholds. The control group consisted of pregnant women with normal OGTT results during the same timeframe. It should be noted that in our clinical setting, universal first-trimester glucose screening for the detection of overt diabetes is not routinely performed. Therefore, women with undiagnosed pre-existing diabetes may not be identified until the standard 24–28 week OGTT. In such cases, if their glucose levels meet the WHO criteria for GDM but not for overt diabetes, they are managed as GDM.This study was submitted to the ethics committee and received an approval number. All methods were carried out in accordance with relevant guidelines and regulations, including the Declaration of Helsinki. Written informed consent was obtained prior to participation.
Data collection
During the sampling and inclusion process, including fasting blood glucose levels, were routinely documented in outpatient prenatal records. Clinical risk factors potentially associated with GDM, such as age, body mass index (BMI), family history of diabetes, smoking history, parity, and previous pregnancy complications (e.g., miscarriage, stillbirth, macrosomia, premature birth, eclampsia, pre-eclampsia), were also recorded. These data were meticulously detailed when pregnant women established their prenatal care records. The accuracy of the information was ensured by inquiring about medical history and reviewing prior physical examination reports. Family history of diabetes was obtained through careful questioning of the pregnant women and their relatives (parents, siblings, etc.) regarding their diabetes status. In cases where the pregnant woman was uncertain about her family history, efforts were made to contact relatives for verification or to consult family medical records.
Standardized ultrasound measurement protocol
Certified sonographers performed all abdominal fat measurements using a rigorously standardized protocol. A high-resolution linear array probe was employed to obtain precise measurements at the umbilical level during the end-expiratory phase to ensure consistency. The probe was positioned perpendicular to the skin surface with minimal applied pressure to avoid tissue compression, while maintaining optimal contact for accurate imaging.
For subcutaneous adipose tissue thickness measurement, we recorded the distance from the dermal layer of the skin to the outer edge of the rectus abdominis muscle. Visceral adipose tissue thickness was determined by measuring from the inner edge of the rectus abdominis muscle to the anterior wall of the abdominal aorta (Fig. 1). At each measurement site (umbilical level or maximal abdominal fat location), three consecutive measurements were obtained by the same operator. These measurements were then averaged to derive the final values for both SAT and VAT, with strict quality control requiring < 5% intra-observer variability to ensure measurement reliability. This standardized approach minimized potential errors and enhanced the reproducibility of our fat thickness assessments.

Ultrasound measurement of maternal abdominal SAT(white arrow) and VAT (yellow arrow) indicators. RA, rectus abdominis muscle; AO, abdominal aorta; SAT, subcutaneous adipose tissue; VAT, visceral adipose tissue.
Data partitioning and preprocessing
The modeling data were derived from the integrated dataset of Zichuan District Hospital and Yidu Central Hospital. They were divided into a training set (60%) and an internal test set (40%) using stratified random sampling. Data from Qianfoshan Hospital was separated from the cohort as an external validation set. Continuous variables (age, gestational weeks, BMI, SAT, VAT) were standardized by Z-score method, and categorical variables were factorized.
Bias correction based on inverse probability weighting (IPW)
Given that the incidence of GDM in our cohort was significantly higher than the theoretical incidence in the general population, potential selection bias existed. Therefore, we performed correction using Inverse Probability Weighting. First, propensity scores were calculated using Lasso logistic regression, and the common support between cases and controls was examined via density plots. To prevent model instability caused by extreme weights, the weights were winsorized (truncated at the 5th and 95th percentiles) and normalized. These weights were applied to all subsequent feature selection and model training.
Feature selection strategy
Genetic Algorithm (GA) was used for feature selection, with the area under the receiver operating characteristic curve (AUC) of the IPW-weighted XGBoost model serving as the fitness function. To ensure robustness and avoid local optima, five independent GA runs were conducted with different mutation and crossover rate combinations. The final features included in the model were the intersection of the results from the five runs. For comparison, Recursive Feature Elimination (RFE) and stepwise regression were also employed. RFE used the same IPW-weighted XGBoost setup, while stepwise selection used IPW-weighted logistic regression with AIC as the criterion.All feature selection procedures were accomplished on training set to avoid potential overfitting risks.
Machine learning model development
Based on the selected features, five machine learning models were developed: Extreme Gradient Boosting (XGBoost), Multivariate Logistic Regression (MLR), Weighted Support Vector Machine (WSVM), Random Forest (RF), and Artificial Neural Network (ANN). All models incorporated the sample weights derived from IPW during training to mitigate the impact of selection bias on prediction probabilities.
Model evaluation and statistical analysis
Model performance was evaluated on the internal test set and the external validation set, with the evaluation metrics including AUC, Accuracy, Balanced Accuracy, Sensitivity, Specificity, F1 score, and Macro F1 score. The optimal thresholds were determined by maximizing Youden’s index (Youden’s index = sensitivity + specificity – 1). Pairwise comparisons of model performance were conducted using the one-sided Bonferroni corrected DeLong test, with the GA-feature-based XGBoost model as the benchmark. Descriptive statistical analyses and hypothesis tests were performed with SPSS 26.0. Machine-learning workflows were implemented in R using scikit-learn, XGBoos.
Results
Basic characteristics of the study subjects
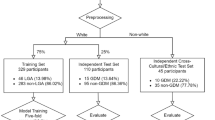
The flowchart of the study design presented the detailed process of model development (Fig. 2). A total of 222 participants were excluded due to predefined criteria: age < 18 years (n = 12), multiple pregnancies (n = 58), pre-pregnancy diabetes (n = 43), thyroid diseases (n = 37), gestational hypertension (n = 45), and missing data (n = 27). Finally, 534 pregnant women were included in this study. Among them, 177 cases were in the case group (pregnant women with GDM), and 357 cases were in the control group (pregnant women without GDM). The distribution of the basic characteristics of the pregnant women in the two groups was shown in Table 1.

Flowchart of the study design. The diagram illustrates the number of women assessed for eligibility, excluded (with reasons: pre-pregnancy diabetes, multiple gestation, age < 18 years, thyroid disease, gestational hypertension, other exclusions, loss to follow-up, or incomplete data), and finally included from each of the three participating centers.
Statistically, there were no significant differences in age, gestational weeks, and history of pregnancy disorders (P > 0.05). In the GDM group, the BMI (26.59 ± 4.69 vs. 21.77 ± 3.31 kg/m², P < 0.001), the incidence of family history of diabetes (25.99% vs. 16.29%, P < 0.001), and the parity (1.44 ± 0.05 vs. 1.20 ± 0.40, P < 0.001) were significantly higher.
When comparing the differences in ultrasonic parameters between the two groups, both the fetal SAT and VAT in the GDM group were higher than those in the control group. According to the independent samples t test, the differences were statistically significant (P < 0.001).
Inverse probability weighting for bias correction
Propensity score and common support
To address the sampling bias from the higher-than-population GDM incidence in the cohort, Lasso logistic regression was used to calculate propensity scores. The optimal regularization parameter (λ_min = 0.022) was selected via 10-fold cross-validation. The propensity score distributions of the case (GDM) and control groups exhibited substantial overlap in the common support region (Supplementary Figure S1.1), satisfying the positivity assumption required for IPW.
Weight calculation and adjustment
Based on the propensity scores and assuming a target population GDM incidence of 10% (P(GDM = 1) = 0.1), initial sample weights were derived. The raw weights showed a long-tailed distribution with extreme values. After Winsorization (clipped at the 5th and 95th percentiles) and normalization, the weight distribution became more concentrated and reasonable (Supplementary Figure S1.2), ensuring stability in subsequent model training.
Feature selection
Three feature selection methods were applied:
Genetic Algorithm: After five independent runs, the intersection of selected features consistently identified three core variables: BMI, SAT, and VAT (Supplementary Table S2.1 and Figure S2.1).
Recursive Feature Elimination : Cross-validation indicated that four features—SAT, VAT, age, and gestational weeks—yielded the highest AUC (Supplementary Figure S2.2).
Stepwise Regression: The minimal feature set selected by the AIC criterion comprised SAT and history of pregnancy disorders (Supplementary Table S2.2).
The GA-derived feature set (BMI, SAT, VAT) was chosen for final modeling because these features were consistently selected across all GA runs, are directly related to GDM pathophysiology, and provided a balance between predictive performance and model stability.
Model performance on the internal test set
The default 0.5 threshold is often suboptimal for imbalanced data; therefore, the Youden index was used to determine the optimal cut-off for each model. Table 2 summarizes the performance of the 20 model combinations (five classifiers × four feature sets).
Best-performing model: XGBoost with GA-selected features (XGBoost_GA) achieved the highest AUC (0.962), accuracy (0.924), balanced accuracy (0.921), sensitivity (0.90), and specificity (0.942).
Impact of feature selection: GA-based features consistently improved model performance; XGBoost_GA significantly outperformed both full-feature (XGBoost_FULL, AUC 0.885) and RFE-based models (XGBoost_RFE, AUC 0.870). Stepwise-selected features led to notably lower performance (e.g., XGBoost_Step AUC 0.781).
Classifier comparison: With the same GA features, XGBoost outperformed all other classifiers (ANN_GA AUC 0.861, SVM_GA AUC 0.831, MLR_GA AUC 0.817, RF_GA AUC 0.802).
Statistical significance: Delong tests with Bonferroni correction confirmed that XGBoost_GA’s AUC was significantly higher than that of every other model (all P < 0.05).
ROC curves for the four feature sets (Fig. 3) showed that models using GA-selected features (Panel A) clustered near the upper-left corner, with XGBoost_GA (AUC 0.962) being the top performer. In contrast, models built on stepwise-selected features (Panel D) displayed jagged curves and substantially lower AUCs, indicating instability due to excessive feature reduction.

Comparison of ROC curves for different feature selection methods and machine‑learning models on the training set. The figure displays the receiver operating characteristic (ROC) curves for five machine‑learning models (XGBoost, MLR, SVM, Random Forest, ANN) across four feature selection strategies: (A) genetic algorithm (GA) selection; (B) all features (Full); (C) recursive feature elimination (RFE); and (D) stepwise regression (Stepwise). The area under the curve (AUC) for each model‑feature combination is annotated.
The corresponding heatmap (Fig. 4) visually reinforced these results: the GA column exhibited the deepest red hues (high AUCs), while the stepwise column was predominantly light-colored, especially for SVM_Step (AUC 0.415), highlighting the detrimental effect of over-reduction on support-vector machines.

Heatmap of AUC performance for different feature selection methods and machine‑learning models on the internal test set. Color intensity corresponds to the AUC value, with darker red indicating higher performance. The XGBoost_GA combination shows the darkest shade (highest AUC), whereas SVM_Step shows the lightest shade (lowest AUC).
External validation
Overall performance
Models were further evaluated on an independent external cohort (Table 3). XGBoost_GA maintained robust predictive ability with an AUC of 0.878, accuracy of 0.885, sensitivity of 0.70, and specificity of 0.935. Although its AUC dropped slightly from the internal test set (0.962), the model showed no signs of severe overfitting and demonstrated good cross-dataset adaptability.
Robustness of feature selection methods
GA-based models (XGBoost_GA, ANN_GA, RF_GA) again showed smooth ROC curves near the upper-left corner (Fig. 5) with AUCs mostly above 0.8, confirming the stable predictive value of the core features (BMI, SAT, VAT) across populations. Conversely, models built on stepwise-selected features suffered a severe performance drop (e.g., XGBoost_Stepwise AUC 0.393, SVM_Stepwise AUC 0.523), indicating that oversimplified feature sets lack the generalizability needed for external data.

Comparison of ROC curves for different feature selection methods and machine‑learning models on the external validation set. ROC curves are shown for the same five machine‑learning models using the four feature selection approaches: (A) GA; (B) Full; (C) RFE; and (D) Stepwise. AUC values are indicated for each curve.
The external-validation heatmap (Fig. 6) further illustrated that the GA column contained the highest AUCs, while the stepwise column was predominantly pale, underscoring the superior generalizability of GA-selected features.

Heatmap of AUC performance for different feature selection methods and machine‑learning models on the external validation set. The color gradient reflects AUC values, with deep red representing the highest performance. XGBoost_GA occupies the darkest cell (AUC = 0.878), while ANN_Full corresponds to the lightest cell (AUC = 0.383).
Statistical significance in external validation
Delong tests on the external set revealed that ANN_GA (P = 0.329), MLR_RFE (P = 0.234), and SVM_Full (P = 0.136) did not differ significantly from the benchmark XGBoost_GA. In contrast, all stepwise-based models and the full-feature XGBoost_Full performed significantly worse (all P < 0.001), reinforcing the necessity of GA feature selection within the XGBoost framework.
Robustness testing
A series of sensitivity analyses confirmed the robustness of the proposed model. The performance of XGBoost_GA remained optimal with minimal fluctuation when the random seed was altered and the training-to-test ratio was adjusted to 0.7/0.3. Modifying the prior probability in inverse probability weighting (P = 0.04 or 0.07) had a negligible impact on model performance. Furthermore, when a weighted ensemble approach was applied, the ensemble built on GA-selected features significantly outperformed those based on other feature sets in both internal and external validation (all P < 0.05). Together, these results demonstrate that the model maintains stable performance across varying data splits, weighting assumptions, and ensemble strategies.
Discussion
This study systematically evaluated the predictive value of early-pregnancy clinical and ultrasonographic indicators for GDM. By integrating genetic algorithm based feature selection with multiple machine learning models, we successfully developed and validated a robust GDM risk prediction model. BMI, VAT, and SAT were identified as highly stable core predictors. The model demonstrated exceptional discriminative ability in the internal test set and maintained good generalizability in an independent external validation set, providing strong technical support for opportunistic screening of GDM using routine first-trimester data in clinical practice, particularly in resource-limited settings.
Our study contributes to the development of early GDM prediction in Chinese populations. While existing models mainly use clinical and laboratory data13,14,15, our model incorporates first-trimester ultrasound measurements of visceral and subcutaneous adipose tissue thickness. This approach utilizes the concept of opportunistic screening by repurposing routinely acquired imaging data for risk assessment. Compared to traditional logistic regression models, our machine learning approach (XGBoost) could potentially capture more complex relationships among variables.
As a well-established indicator of adiposity, BMI retained significant value in predicting GDM, with mechanisms involving chronic inflammation, mitochondrial dysfunction, and adipose tissue hypoxia16,17,18. Notably, several multi-ethnic studies, particularly those conducted in Western populations, reported a relatively lower population attributable risk (PAF) of BMI for GDM among Asian women19. This apparent discrepancy was explained by the observation that Asian women developed GDM at substantially lower BMI thresholds than other ethnic groups. Rather than contradicting the value of BMI, this finding shifted the etiological emphasis from overall adiposity to fat distribution patterns—a perspective supported by growing evidence20,21. In line with this, our study demonstrated that visceral adipose tissue thickness also possessed significant predictive ability.
Visceral fat accumulation can trigger a series of metabolic disorders. Excessive visceral fat prompts adipocytes to secrete inflammatory factors, such as tumor necrosis factor-α and interleukin-6. These inflammatory factors interfere with the normal insulin signaling pathway, reducing cellular sensitivity to insulin and leading to insulin resistance. Insulin resistance is a critical factor in the development of gestational diabetes mellitus. To maintain normal blood glucose levels, the body compensatorily increases insulin secretion. When the pancreas cannot meet this demand, blood glucose levels rise, ultimately resulting in GDM. Multiple prospective cohort studies have confirmed a significant positive correlation between early-pregnancy visceral fat thickness and the subsequent risk of GDM, consistent with the findings of this study22,23,24. Compared to traditional waist circumference measurements, the quantitative assessment of visceral fat thickness more accurately reflects metabolic risk, which explains its strong predictive ability in the prediction model.
Subcutaneous fat thickness is a significant indicator for predicting gestational diabetes mellitus, which aligns with the findings of Nassr et al. 25. Their study demonstrated through ultrasound measurements that the predictive efficacy of subcutaneous fat for GDM is markedly superior to that of the traditional BMI indicator25. Mechanistically, excessive proliferation of subcutaneous adipose tissue, functioning as an active endocrine organ, leads to disordered secretion of adipokines. This includes a reduction in adiponectin levels and the development of leptin resistance, while simultaneously promoting the release of pro-inflammatory factors such as IL-6 and MCP-1, which collectively exacerbate the insulin-resistant state during pregnancy. In contrast to previous studies that primarily focused on overall obesity indicators, our results further affirm the unique value of fat distribution characteristics in predicting GDM. Subcutaneous fat indicators effectively address the limitations of BMI in distinguishing fat distribution and provide a more accurate reflection of variations in fat distribution.
It should be noted that the novelty of this study lay not in identifying new risk factors, but in developing a prediction model for the Northern Chinese pregnant population that combined routinely available ultrasound-derived abdominal fat distribution indicators (VAT/SAT) with BMI, tailored for first-trimester opportunistic screening. In regions with relatively limited clinical resources, such a model based on the most basic and accessible data holds practical value, enabling early risk stratification without increasing the medical burden.
While this pragmatic approach defines the core utility of our model, a closer examination of its predictive performance reveals important boundaries. Analysis of model errors clarifies its clinical scope. False positives may occur in women with high adiposity but preserved metabolic health, or in cases where early lifestyle intervention prevented GDM. False negatives may reflect GDM driven by non-adiposity factors (e.g., genetics) or metabolic changes not yet evident in early fat distribution. Therefore, this model is best used for initial risk stratification rather than definitive diagnosis.
Several limitations should be noted. First, the predictive feature set was constrained by both practical considerations for resource-limited settings and data availability, particularly the limited early-pregnancy metabolic markers. Additionally, as the model was developed in a Northern Chinese cohort, its application to other populations requires external validation and potential recalibration. Future studies should incorporate more comprehensive metabolic and genetic indicators where feasible and establish standardized imaging protocols across centers.
Conclusion
This study integrated genetic algorithm-based feature selection with multiple machine-learning models and leveraged routinely available first-trimester clinical and ultrasonographic indicators to successfully develop and validate an early GDM prediction model in Northern Chinese pregnant women. The model demonstrated excellent discriminatory performance and high generalization stability, providing an effective tool for implementing low‑cost, non‑invasive opportunistic screening in clinical practice.
Data availability
The de-identified datasets generated and analyzed during this study are available from the corresponding author upon reasonable request, subject to institutional review board approval and data sharing agreements.
References
Sweeting, A., Wong, J., Murphy, H. R. & Ross, G. P. A Clinical update on gestational diabetes mellitus. Endocr. Rev. 43 (5), 763–793 (2022).
Zhu, W. W. et al. High prevalence of gestational diabetes mellitus in Beijing: Effect of maternal birth weight and other risk factors. Chin. Med. J. 130, 1019–1025 (2017).
Chan, J. C., Zhang, Y. & Ning, G. Diabetes in China: A societal solution for a personal challenge. Lancet Diabetes Endocrinol. 2, 969–979 (2014).
Pouliot, A., Elmahboubi, R. & Adam, C. Incidence and outcomes of gestational diabetes mellitus using the new international association of diabetes in pregnancy study group criteria in hôpital maisonneuve-rosemont. Can. J. Diabetes. 43 (8), 594–599 (2019).
Alesi, S., Ghelani, D., Rassie, K. & Mousa, A. Metabolomic biomarkers in gestational diabetes mellitus: A review of the evidence. Int. J. Mol. Sci. 22 (11), 5512 (2021).
Dłuski, D. F., Wolińska, E. & Skrzypczak, M. Epigenetic changes in gestational diabetes mellitus. Int. J. Mol. Sci. 22 (14), 7649 (2021).
Schoenaker, D. A. J. M., Vergouwe, Y., Soedamah-Muthu, S. S., Callaway, L. K. & Mishra, G. D. Preconception risk of gestational diabetes: Development of a prediction model in nulliparous Australian women. Diabetes Res. Clin. Pract. 146, 48–57 (2018).
Zhao, B., Han, X., Meng, Q. & Luo, Q. Early second trimester maternal serum markers in the prediction of gestational diabetes mellitus. J. Diabetes Investig. 9 (4), 967–974 (2018).
Gur, E. B. et al. Ultrasonographic visceral fat thickness in the first trimester can predict metabolic syndrome and gestational diabetes mellitus. Endocrine 47 (2), 478–484 (2014).
Tumurbaatar, B. et al. Adipose tissue insulin resistance in gestational diabetes. Metab. Syndr. Relat. Disord. 15 (2), 86–92 (2017).
De Souza, L. R. et al. First-trimester maternal abdominal adiposity predicts dysglycemia and gestational diabetes mellitus in midpregnancy. Diabetes Care. 39 (1), 61–64 (2016).
Bourdages, M. et al. Firsttrimester abdominal adipose tissue thickness to predict gestational diabetes. J. Obstet. Gynaecol. Can. 40 (7), 883–887 (2018).
Wang, Y. et al. Plasma lipidomics in early pregnancy and risk of gestational diabetes mellitus: A prospective nested case-control study in Chinese women. Am. J. Clin. Nutr. 114 (5), 1763–1773 (2021).
Wu, Y. et al. Early prediction of gestational diabetes mellitus using maternal demographic and clinical risk factors. BMC Res. Notes. 17 (1), 105 (2024).
Lou, Y., Xiang, L., Gao, X. & Jiang, H. Clinical value of early-pregnancy glycated hemoglobin, fasting plasma glucose, and body mass index in screening gestational diabetes mellitus. Lab. Med. 53 (6), 619–622 (2022).
Lappas, M. Activation of inflammasomes in adipose tissue of women with gestational diabetes. Mol. Cell. Endocrinol. 382 (1), 74–83 (2014).
McElwain, C. & McCarthy, C. M. Investigating mitochondrial dysfunction in gestational diabetes mellitus and elucidating if BMI is a causative mediator. Eur. J. Obstet. Gyn R B. 251, 60–65 (2020).
Catalano, P. M. & Shankar, K. Obesity and pregnancy: Mechanisms of short term and long term adverse consequences for mother and child. BMJ 356, j1 (2017).
Read, S. H. et al. BMI and risk of gestational diabetes among women of South Asian and Chinese ethnicity: A population-based study. Diabetologia 64 (4), 805–813 (2021).
Zhang, Z. et al. The possible role of visceral fat in early pregnancy as a predictor of gestational diabetes mellitus by regulating adipose-derived exosomes miRNA-148 family: Protocol for a nested case-control study in a cohort study. BMC Pregnancy Childbirth. 21 (1), 262 (2021).
Crume, T. L. et al. Association of exposure to diabetes in utero with adiposity and fat distribution in a multiethnic population of youth: The Exploring Perinatal Outcomes among Children (EPOCH) Study. Diabetologia 54 (1), 87–92 (2011).
Li, G. J. et al. The association between visceral adipose thickness and gestational diabetes mellitus in the first trimester. Zhonghua Yu Fang Yi Xue Za Zhi. 58 (7), 1004–1010 (2024). Chinese.
Alves, J. G. et al. Visceral adipose tissue depth in early pregnancy and gestational diabetes mellitus—a cohort study. Sci. Rep. 10 (1), 2032 (2020).
Thaware, P. K., Patterson, C. C., Young, I. S., Casey, C. & McCance, D. R. Clinical utility of ultrasonography-measured visceral adipose tissue depth as a tool in early pregnancy screening for gestational diabetes: A proof-of-concept study. Diabet. Med. 36 (7), 898–901 (2019).
Nassr, A. A. et al. Body fat index: A novel alternative to body mass index for prediction of gestational diabetes and hypertensive disorders in pregnancy. Eur. J. Obstet. Gyn R B. 228, 243–248 (2018).
Acknowledgements
The study was supported by Weifang Science and Technology Development Plan Project(2025YX096).
Funding
Declaration No funding.
Author information
Authors and Affiliations
Contributions
Y.L., Z.M., H.T.Z. T.X., and N.L.,conceived the study and designed the methodology. L.F.C.,C.S.L, Y.L., X.R.Z, and J.X. were responsible for data collection and quality control. Y.Q.L. conducted the statistical analyses. Y.L.drafted the manuscript. All authors contributed to data interpretation, critically revised the manuscript for important intellectual content, and approved the final version.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhai, H., Che, L., Xu, T. et al. Opportunistic screening data for early prediction of GDM in Northern Chinese women: a multicenter machine learning study. Sci Rep 16, 12818 (2026). https://doi.org/10.1038/s41598-026-42700-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-42700-y
