
Abstract
Globally, shrimp aquaculture is a vital source of food, but disease outbreaks present serious economic challenges. Traditional diagnostic techniques, such as visual inspection and polymerase chain reaction (PCR), are limited in their ability to detect diseases in real-time because they are either resource-intensive or prone to human error. In order to overcome these obstacles, we propose FeatherNetX, a lightweight deep learning framework, designed for automated shrimp diseases classification and deployment in resource-constrained settings. Black Gill (BG), White Spot Syndrome Virus (WSSV), Yellow Head Virus, and Healthy classes were among the publicly accessible shrimp disease image datasets used to train the model using 5-fold cross-validation approach. FeatherNetX outperforms other models with an average accuracy of 93% ± 0.059, a small model size (0.739 M parameters, 2.82 MB) and low computational cost (0.48 GFLOPs) while outperforming traditional architectures in terms of efficiency. In order to improve interpretability, disease-relevant regions were visualized using Grad-CAM++, which demonstrated a high degree of correspondence between activated regions and ground-truth disease areas. Additionally, the model was incorporated into a desktop application that could classify images in real-time and offline into specific classes with confidence reporting. It achieved 94% accuracy on test images that were unseen and took an average of less than 0.2 seconds per image to classify. This study bridges the gap between deep learning research and practical aquaculture practice by offering a strong framework for automated classification of shrimp disease through the combination of lightweight architecture, model interpretability, and practical deployment.
Similar content being viewed by others

Introduction
Shrimp are widely grown in pond-based aquaculture systems and are an essential source of high-quality protein1,2. Shrimp are very vulnerable to infectious diseases, which are compounded by low dissolved oxygen levels, poor water quality, and environmental pollution, despite their economic significance. These stressors accelerate the growth of viral and microbial pathogens, frequently leading to significant mortality3. Shrimp’s lack of an adaptive immune system makes it easier for pathogens to spread through tainted water, contaminated feed, handling, or close contact with diseased or deceased individuals4. Significant economic losses have resulted from major disease outbreaks, such as Black Gill (BG) Disease in Bangladesh, Yellow Head Disease caused by Yellow Head Virus (YHV) in Thailand, and White Spot Disease caused by White Spot Syndrome Virus (WSSV) in Japan5,6,8. To safeguard shrimp production and lessen economic impacts, these difficulties underscore the pressing need for quick, accurate, and automated methods for pathogen detection7.
For the detection of disease, traditional diagnostic techniques like visual inspections and polymerase chain reaction (PCR) are still frequently employed. High specificity and sensitivity are provided by PCR, but its applicability for routine monitoring in large-scale aquaculture is limited by the need for specialized labs, skilled workers, and a significant amount of processing time. On the other hand, visual inspections are subjective and prone to human error, and they frequently detect disease only after outbreaks have escalated9,10. Interest in automated detection techniques has increased as a result of these restrictions11,12. Particularly, deep learning methods have become useful for precise shrimp disease detection, allowing for real-time monitoring, decreasing the need for labor-intensive procedures, and enabling prompt interventions to minimize economic losses9.
Deep learning and computer vision have been used in recent research to automatically classify shrimp diseases. In Vietnam, Duong-Trung et al. (2020) used the Inception architecture, with an accuracy rate of 90.02%. DenseNet was implemented by Kanakamedala et al. (2025), who reported 98.89% accuracy. Halder et al. (2023) used ResNet50 to detect BG, WSP, and YHV with 92% accuracy. Büyükarıkan (2025) achieved 97% accuracy by combining MobileNet, DenseNet121, DenseNet169, and DenseNet201 in an ensemble multi-model convolutional neural network. Random Forest, Multinomial Naive Bayes, and Bagging with Decision Trees were among the machine learning techniques examined by Ayon et al. (2023); Random Forest achieved 97.87% accuracy. Despite these achievements, several critical limitations remain. The computational complexity of many existing models limits their use in environments with limited resources1,13,14,15,16. Additionally, robust systems for the quick, real-time classification of shrimp diseases are still lacking, despite the emergence of useful tools for monitoring shrimp habitat parameters8. Lastly, these models’ interpretability is frequently inadequate, which restricts their applicability for making well-informed decisions in aquaculture management.
Despite the success of existing lightweight convolutional neural networks, most architectures such as MobileNetV2 and GhostNet are designed as general-purpose backbones and do not explicitly address the texture-sensitive and data-limited nature of shrimp disease imagery17,18. In contrast, FeatherNetX is not a direct reuse or simple combination of existing modules, but a task-specific lightweight architecture co-designed for shrimp disease classification under constrained computational and data conditions. Its novelty lies in the coordinated adaptation and integration of multiple architectural components rather than the introduction of a single isolated module. Specifically, FeatherNetX introduces learnable residual scaling within its lightweight FeatherBlocks to stabilize training and mitigate underfitting when learning from limited shrimp pathology datasets19. The architecture employs an optimized channel expansion strategy, consistently using a reduced expansion ratio across all blocks to balance representational capacity and parameter efficiency, differing from the high expansion ratio commonly used in MobileNetV220. Furthermore, FeatherNetX incorporates Ghost-based feature expansion and projection within FeatherBlocks to reduce computational redundancy while preserving fine-grained pathological textures through depthwise spatial filtering18.
In addition, FeatherNetX adopts a redesigned Cross-Stage Partial (CSP) topology in which stochastic depth regularization is applied exclusively within the feature-learning branch, while the identity branch remains deterministic to preserve stable low-level representations21. Lightweight channel attention (ECALite) is embedded at the block level following Ghost-based projection, enabling efficient channel recalibration without introducing significant overhead20. Collectively, these domain-aware design choices result in a lightweight yet expressive architecture that is explicitly optimized for shrimp disease classification, distinguishing FeatherNetX from generic lightweight models and enabling accurate, interpretable, and deployable disease detection in real-world aquaculture environments.
This study creates a lightweight deep learning model for effective shrimp disease classification that can be implemented in low-resource settings in order to overcome these difficulties. To allow for real-time monitoring on local computers, the model is incorporated into a desktop application. To guarantee offline functionality, which is essential for aquaculture farms in remote locations with unreliable or limited internet connectivity, a desktop-based solution was selected. Additionally, it offers stable local execution without depending on cloud resources or internet bandwidth, and it protects data privacy by keeping images and outbreak information on the user’s local device. Grad-CAM++ was employed to produce visual explanations, highlighting areas the model used for its predictions. To provide a quantitative measure of localization, the distance between the centroid of the ground-truth bounding box and the maximum intensity of the Grad-CAM++ activations was computed. This study bridges the gap between deep learning research and actual aquaculture practice by offering a deployable and efficient framework for real-time shrimp disease detection through the combination of a lightweight architecture, practical deployment, and interpretable predictions.
Methods
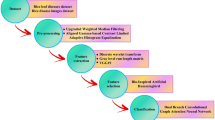
We sourced publicly available shrimp image datasets and partitioned them into training, validation, and testing sets, following a 3:1:1 ratio. Employing 5-fold cross-validation, each subset iteratively employed as the training, validation, and testing data, ensuring comprehensive model evaluation. The images were processed using the lightweight FeatherNetx architecture, with on-the-fly augmentation approaches during training to improve model robustness in classifying shrimp diseases. Ultimately, the trained model was integrated into a desktop application, enabling automated categorization of images into their respective class folders (Figure. 1).

Overall methodology for automatic shrimp diseases classification.
Datasets and preprocessing
We utilized two publicly available shrimp disease datasets collected from aquaculture farms across Bangladesh: ShrimpDiseaseImageBD and TigerShrimpBD. ShrimpDiseaseImageBD includes images collected from Bagerhat (\(22.6552^\circ\) N, \(89.7780^\circ\) E), Satkhira (\(22.7217^\circ\) N, \(89.0682^\circ\) E), Kawran Bazar, Dhaka (\(23.7518^\circ\) N, \(90.3940^\circ\) E), and Banasree, Dhaka (\(23.7619^\circ\) N, \(90.4331^\circ\) E). TigerShrimpBD was collected from tiger shrimp farms located in Godanra village, Assasuni Upazila, Satkhira District (\(22.539656^\circ\) N, \(89.130847^\circ\) E); Bharashimla village, Kaliganj Upazila, Satkhira District (\(22.477402^\circ\) N, \(89.014488^\circ\) E); Bali Krishnapur village, Debhata Upazila, Satkhira District (\(22.560001^\circ\) N, \(88.995291^\circ\) E); and Fultola village, Bagerhat District (\(22.640984^\circ\) N, \(89.777134^\circ\) E). Although both datasets were collected within the same country, the geographically distinct sampling locations, as indicated by their differing latitude and longitude coordinates, reflect spatial and environmental heterogeneity across regions7,22. The images are RGB and were captured indoors using smartphones, resulting in relatively consistent backgrounds and limiting conditions. These datasets have been widely used in previous studies on shrimp disease recognition1,23. The ShrimpDiseaseImageBD dataset included three classes of shrimp diseases: Black Gill (BG), White Spot Syndrome Virus (WSSV), and healthy shrimp. In contrast, the TigerShrimpBD included four classes, namely BG, Yellow Head Virus (Yellowhead), WSSV, and healthy shrimp. Bounding box annotations were available for the BG and WSSV classes in ShrimpDiseaseImageBD and were used exclusively for interpretability evaluation.
In terms of experimental setup, we employed stratified 5-fold cross-validation to preserve class distribution across folds. For each disease class, images were randomly partitioned into five folds, and corresponding folds across classes were combined to form complete dataset splits. In each iteration, folds were assigned in a 3:1:1 ratio for training, validation and testing, with systematic rotation ensuring each fold served once as validation and once as testing24. During the training process, on-the-fly augmentation was performed on training datasets which was carried out for the model robustness. The original images were resized to 226 \(\times\) 226 pixels. Random horizontal flips (50% probability) and vertical flips (20% probability) were applied to simulate the different orientations. Color jittering was used to mimic variations in lighting and camera conditions, with brightness, contrast, and saturation all set to 0.2 and hue to 0.1. Furthermore, random rotations of \(\pm 15^\circ\) and affine transformations (10% horizontal/vertical shifts; scaling between 0.9 and 1.1) were used to accommodate slight misalignments and positional variations. Gaussian blur with a kernel size of 3 and sigma values between 0.1 and 2.0 was applied with a probability of 0.4 to simulate minor out-of-focus effects, and random sharpness adjustment with a factor of 2 and probability of 0.3 was used to handle differences in image clarity. Images were normalized using RGB channel means of 0.485, 0.456, and 0.406 and standard deviations of 0.229, 0.224, and 0.225, respectively. All preprocessing steps, including normalization were applied after fold splitting and independently within each training phase to prevent statistical leakage. Validation and testing datasets only underwent resizing and normalization to ensure evaluation on consistent and standardized images (Table 1).
Architectural overview
We designed the FeatherNetX main architecture (Algorithm 1) to serve as a highly efficient yet powerful hierarchical feature extractor, a necessity for deployment on resource-constrained hardware for Shrimp diseases classification. We began with an aggressive stem block to rapidly minimize the dominant computational cost associated with large initial spatial resolutions early in the network. The core consists of four CSPStages to construct a multi-scale feature pyramid, which is essential for capturing both low-level details and high-level semantic information25,26. We implemented a linear stochastic depth (drop path) schedule across all blocks specifically to combat the increased risk of overfitting in a lightweight architecture and to improve gradient flow through the network by effectively creating ensemble-like behavior during training27. We concluded with an extremely lightweight head to avoid the massive parameter count and computational overhead of traditional fully-connected layers, which is a critical requirement for maintaining a small model size and low latency.
Stem design
The stem module of FeatherNetX was the first feature extractor (Algorithm 1). We transformed the input image through a series of convolutional operations that were intended to decrease the spatial dimensions efficiently while increasing the channel dimension28. The stem had three consecutive operations. Initially, a regular \(3 \times 3\) convolution with stride 2 was applied for the first downsampling and channel expansion to the stem channels value \(C_s\), which was initially scaled by the width multiplier (\(w=0.9\)) and then made divisible by 8 for computational efficiency by the MakeDivisible operation29. After that, a depthwise \(3 \times 3\) convolution with stride 1 and groups equal to \(C_s\) was executed for spatial filtering. At last, a \(1 \times 1\) pointwise convolution was employed for channel mixing and projection. Each convolutional operation used SiLU activation functions for the non-linear change27,30. This architecture offered a computationally efficient bottleneck framework that was able to keep the spatial information while at the same time increasing the representational capacity, thus it laid an optimized ground for the next hierarchical feature extraction from the main stages of the network17,29.

FeatherNetX main architecture.
CSPStage design
FeatherNetX’s CSPStage module follows the Wang et al. (2020) design, which improves gradient flow and computational efficiency while keeping the representational capacity intact (Algorithm 2). First, we performed an initial \(3 \times 3\) convolutional operation on the stage for downsampling as well as channel expansion to the desired output dimension \(C_{\text {out}}\). Next, we divided the feature map equally into two groups of channels along the channel dimension, thus obtaining two parallel pathways: an identity path that retained the original information flow through a simple \(1 \times 1\) convolution, and a feature learning path in which we changed the feature map through a series of N FeatherBlock operations with the expansion ratio r. One of the main points of this design is the use of a linear stochastic depth schedule, in which the drop path rate increases progressively from 0 to \(d_{\text {max}}\) across network depth. This choice is motivated by the hierarchical nature of feature learning in convolutional neural networks31. Shallow blocks capture fundamental low-level patterns that are critical for shrimp disease recognition and are therefore preserved with minimal stochastic regularization. In contrast, deeper blocks learn more abstract and task-specific representations that are more susceptible to overfitting under limited data conditions and thus benefit from stronger regularization32. The linear schedule introduces stochasticity gradually, stabilizing training and avoiding optimization instability that may arise from applying a uniformly high drop rate throughout the network, ultimately leading to improved generalization in our compact architecture21. Following that, we concatenated the two paths along the channel dimension and merged them by a \(1 \times 1\) convolution, thus, combining the preserved identity features with the newly learned representations while keeping the output channel dimension33. This design lowers the computational redundancy without losing the rich feature representations throughout the network hierarchy28,34.

CSPStage (cross-stage partial stage).
FeatherBlock design
The FeatherBlock was the main lightweight building block of the FeatherNetX architecture, which aimed to increase the computational efficiency of the model while maintaining its representational power17 (Algorithm 3). To generate the redundant features in an efficient way, we first multiplied the input feature channels by the factor of the expansion ratio r through a GhostModule, then we applied a depthwise separable convolution with kernel size 3 and stride s for spatial filtering18. The expanded features were then projected to the original output channel dimension by a second GhostModule, after that an efficient channel attention (ECALite) mechanism was employed to raise the inter-channel dependencies without major computational cost20. A residual connection was introduced when the stride was 1 and the input and output channels matched. This connection was enhanced with a learnable scaling parameter (\(\alpha\)), initialized to 1.0, which multiplies the residual branch before being added to the identity skip connection (Algorithm 3). The parameter \(\alpha\) is optimized via backpropagation alongside the other network weights. This design stabilizes training by starting from an identity mapping (\(\alpha = 1.0\)) and allowing the network to dynamically modulate the residual contribution, thereby mitigating underfitting while maintaining gradient flow through the skip connection19. Besides that, stochastic depth regularization with drop path rate d was applied during training to improve generalization21. The integration of ghost convolutions, attention, and carefully designed residual connections resulted in a very efficient yet highly expressive block, which is ideal for mobile and embedded vision applications17.

FeatherBlock.
GhostModule design
The GhostModule was a concept to produce feature maps more efficiently than typical convolution layers by separating the process to one main convolution and a series of cheap, linear operations (Algorithm 4). Firstly, we created a set of intrinsic feature maps by a primary \(1 \times 1\) pointwise convolution, which resulted in \(\lceil C_\text {out}/r_g \rceil\) channels. To produce the rest feature maps, we decided not to use additional costly convolutions. Instead, each of these primary features was subjected to a depthwise convolution with a kernel size of 3. This inexpensive, linear operation was able to compose the necessary number of ghost feature maps \((C_\text {out} - C_\text {primary})\), thus, simulating the redundancies that are usually present in the learned features. After that, we combined the intrinsically generated feature maps with the artificially generated ghost maps along the channel dimension to get the final output18. This method essentially lowered the computational cost and the number of parameters, which would have been needed for a full set of \(C_\text {out}\) feature maps. At the same time, the richness and expressiveness of the feature representation, which was of great importance for the downstream tasks, were kept intact.

GhostModule.
ECALite design
The ECALite component realized an effective channel attention method that was created to model inter-channel dependencies with minimal additional computations20,33. The first step involved global average pooling being applied in order to squeeze the spatial dimensions and yield a channel-wise descriptor. After that, 1D convolution with a kernel size of k (usually \(k=3\)) was used to change this 1D signal which efficiently captured local cross-channel interactions without the need for dimensionality reduction33. The convolution was carefully planned to cover a certain percentage of the closest channels so that all channels could take part in the attention calculation while the structure remained lightweight. The obtained activations were converted into a sigmoid function to get attention weights ranging from 0 to 1, which were then used to recalibrate the original input features through element-wise multiplication. This method eliminated the heavy computation of fully-connected layers used in older attention mechanisms20, thus it was a very effective and extremely efficient method for feature refinement that contributed to model representational power extending with almost negligible parameter (Algorithm 5).

ECALite (efficient channel attention).
Baseline models and experimental setup
To benchmark FeatherNetX comprehensively, we selected comparison baseline models across multiple dimensions. We included recent CNN architectures suitable for resource-constrained deployment, such as MobileNetV2 (an efficiency competitor) and DenseNet121 (a parameter-efficient modern architecture)17,34. We also incorporated general-purpose CNNs for performance context, including VGG16 (a classic architecture) and ResNet34 (a modern image classification standard)28,35. For aquaculture relevance, we included baselines from prior shrimp disease studies, notably ShrimpNet-3 (model size: 9.7MB)36. This selection enables evaluation of FeatherNetX in terms of accuracy, efficiency, and practical applicability for shrimp disease classification under real-world constraints, including limited computation and low-data scenarios. To ensure fair and methodologically reliable comparative evaluation, all baseline models and FeatherNetX were trained and evaluated under an identical experimental protocol. A fixed batch size of 16, learning rate of \(1 \times 10^{-4}\), and training duration of 100 epochs were used across all architectures, with data loading performed using four worker threads. The same stratified five-fold cross-validation strategy was applied to all models to preserve class distributions across training, validation, and testing splits. Identical on-the-fly augmentation pipeline were employed during training, while validation and testing datasets were processed using resizing and normalization only, ensuring unbiased evaluation. For architectural consistency, all comparison baseline models employed global average pooling to aggregate spatial features, followed by a dropout layer of 0.1 and a fully connected classification layer with four output neurons corresponding to the four shrimp disease classes.
Performance metrics
In this study, we evaluate the performance of all models using multiple metrics, including accuracy, precision, recall, and F1-score. The evaluation is based on the average scores obtained from 5-fold cross-validation, defined in equations (1)–(4). Specifically, accuracy measures the overall proportion of correctly predicted instances across all classes, precision quantifies the correctness of positive predictions, recall assesses the proportion of true positive instances that are correctly identified, and the F1-score represents the harmonic mean of precision and recall. Additionally, we employ Grad-CAM++ to visualize the regions of input images that most strongly influence the model’s predictions. For model evaluation, we also use the ground truth bounding boxes of the BG and WSSV classes. Specifically, we select the largest bounding box in each image and measure the average intensity within this bounding box. Furthermore, we compute the distance between the peak intensity location in the Grad-CAM++ map and the center of the corresponding large bounding box to assess how well the model focuses on the correct regions.
Statistical analysis
To quantitatively evaluate performance differences between models, paired-sample t-tests were applied to the accuracy scores obtained across the five cross-validation folds. For each baseline model, fold-wise paired differences were computed relative to the proposed model (FeatherNetX) as \(\text {Difference} = \text {Accuracy}_{\text {FeatherNetX}} - \text {Accuracy}_{\text {Baseline}}\). A one-sample t-test was then performed on these five difference values to assess whether the mean difference was significantly different from zero, with statistical significance defined as \(p < 0.05\). Beyond accuracy, model efficiency was assessed using an efficiency score defined as \(\text {Efficiency}_{\text {score}} = (\text {Accuracy} \times 100) / \text {Parameters}\)29. We used kernel density estimation (KDE) to visualize the joint distribution of distance and maximum intensity, with a fixed bandwidth selected according to Scott’s rule and adjusted by a factor of 0.937. We additionally compute a \(95\%\) confidence region for the estimated mean by modeling the joint variability using the sample covariance matrix; this region is derived from the corresponding multivariate chi-square distribution and displayed as a confidence ellipse.
Desktop application
A desktop application was developed through the use of Tkinter, where a proposed lightweight shrimp diseases classification model was incorporated. The decision to develop a desktop solution was based on the necessity of having a reliable tool with offline capability that could work in the remote coastal areas typical of shrimp farms, where the internet is either very poor or completely absent36,38. This way, the farm information remains private since it’s only kept on the local machine and the users experience consistent operation without being affected by network delays. The application is targeted at solving the problem of economic losses in the global shrimp farming industry due to disease outbreaks which need instant and easily available diagnosis; thus, the application goes beyond traditional laboratory methods39,40. The application had six different buttons besides an image viewer for displaying images. The Import Image button served to import a single image while the Import Folder button was there to import a complete folder of images. The Next button was used to display the next image. Similarly, a Delete button was created to remove the currently displayed image, and a Retrieve button was implemented to recover a deleted image. Finally, a Save button was designed to save images into their respective class names. The images were saved according to the class predicted by the model, and the predicted class along with the confidence level was displayed below the image viewer.
Results
Model performance
During training our proposed model, both training and validation accuracy increased from 0.6 to nearly 0.94, while the loss decreased from 1.3 to 0.10. Through rigorous 5-fold cross-validation, the model achieved an average test accuracy of \(0.93 \pm 0.059\) (Fig. 2).
Our proposed model demonstrates a good balance among accuracy, computation cost, and size. With only 0.739 million parameters and a memory footprint of 2.82 MB, it is much smaller than traditional architectures like VGG16 (14.717 million, 56.15 MB) and ResNet34 (21.287 million, 81.16 MB). It requires just 0.48 G FLOPs. Despite its small size, it achieves an accuracy of 0.93 ± 0.06, surpassing VGG16 and matching other models such as MobileNetV2 and ResNet34. Although DenseNet121 achieved a statistically higher accuracy than our proposed model (mean \(\Delta = -2.0\%\), 95% CI [\(-3.5\%\), \(-0.5\%\)], \(p = 0.014\)), our proposed model significantly outperformed VGG16 (mean \(\Delta = +6.0\%\), 95% CI [\(+0.5\%\), \(+11.5\%\)], \(p = 0.03\)). No statistically significant differences were observed relative to MobileNetV2 or ResNet34 (\(p = 0.210\) and \(p = 0.187\), respectively). In contrast, the efficiency analysis revealed a markedly different ranking (Table 2). FeatherNetX attained the highest efficiency score of 125.8, substantially exceeding those of MobileNetV2 (41.3), DenseNet121 (13.7), VGG16 (5.9), and ResNet34 (4.3). These results demonstrate that, despite a modest accuracy trade-off compared with the most parameter-heavy baseline, the proposed model delivers markedly superior accuracy per parameter. It also maintains a clear advantage in compactness over the shrimp-specific ShrimpNet-3 model, which while achieving 96.8% accuracy on physical shrimp defect classification for instances crushed or malformed shrimp, has a model size of 9.7 MB, approximately 3.4 times larger than our proposed model. This highlights how efficient our model is in situations with limited resources (Table 2).

Accuracy and loss curves for training and validation datasets based on the averaged results of five-fold cross-validation.
The classification performance of our proposed model was illustrated using the confusion matrix, representing the total predictions across all five folds of cross validation. The matrix revealed that the model correctly classified the majority of samples across all four shrimp disease classes: 1110 BG samples, 938 healthy samples, 1243 WSSV samples, and 888 Yellowhead samples. Misclassifications occurred primarily between the BG and Healthy classes, with 78 BG samples incorrectly predicted as Healthy and 101 healthy samples incorrectly predicted as BG, indicating some overlap in features between these two classes. A smaller number of misclassifications were observed between WSSV and other classes for instance, 49 BG samples were predicted as WSSV, and 12 healthy samples were incorrectly predicted as WSSV. The Yellowhead class showed the fewest misclassification, with only 7 samples incorrectly classified, reflecting the distinctiveness of its features (Fig. 3).
Performance metrics across all classes were consistently high as determined by 5-fold cross validation. With respect to classification for Yellowhead shrimp disease the model performed exceptionally. Precision, recall and F1 score were \(0.988 \pm 0.007\), \(0.984 \pm 0.005\) and \(0.987 \pm 0.003\) respectively. The performance for the BG class was slightly lower, but still dependable (precision = \(0.885 \pm 0.004\); recall = \(0.882 \pm 0.006\); F1 = \(0.884 \pm 0.004\)). The Healthy class was also robust (precision = \(0.917 \pm 0.008\); recall = \(0.893 \pm 0.002\); F1 = \(0.911 \pm 0.002\)) and the WSSV class was similarly strong (precision = \(0.919 \pm 0.004\); recall = \(0.951 \pm 0.001\); F1 = \(0.932 \pm 0.001\)) which provided strong indicators for consistently accurate classification for all Shrimp disease categories (Fig. 4, Table 3). The predictions of our model as applied to the test image datasets (Fig. 5). In the visualizations the true class labels were in black, correct predictions were in green and misclassifications were in red. Misclassifications were most evident between BG and Healthy classes. The results nevertheless, demonstrate accurate performance of our model and class distinction.

Overall confusion matrix obtained from five-fold cross-validation results.

Performance metrics (mean ± 95% CI) for the classification of four shrimp disease classes using 5-fold cross-validation.

Actual and predicted evaluation on sample images.
To visualize the image regions that mostly influenced the model’s predictions, we employed Grad-CAM++ technique as a qualitative suitability and alignment check. The resulting heatmaps, normalized to a range of 0 to 1, highlight areas of high relative activation (where values closer to 1 indicate the most salient regions within an image). Visual inspection suggested that for many cases across all disease classes, these high-activation regions often corresponded to visibly affected tissue. For the BG and WSSV classes, where spatial annotations were available, we further quantified this alignment. We observed that the peak model activation frequently aligned with the annotated diseased areas (Fig. 6a, b). In a subset of cases, the peak activation was offset from the ground-truth annotation, highlighting a potential focus for future refinement in model localization or annotation consistency (Fig. 6c, d).

Activation across all shrimp diseases: (a) on healthy shrimp, (b) on shrimp with Yellowhead disease, (c) activation on WSSV shrimp disease with ground truth bounding box, (d) activation on BG shrimp disease with ground truth bounding box.
Target area activation
We performed a Grad-CAM++ analysis for the four classes of shrimp diseases and observed distinct maximum values for attention intensity corresponding to the classification performance. For the BG class, mean maximum value for the intensity of 0.623±0.157 was observed, with a range from 0.146 to 0.897, resulting in 88.8% accuracy with a significant ANOVA difference (\(F=85.99\), \(p<0.001\)). For the Healthy class, mean maximum value for the intensity of 0.71±0.12 was observed, ranging from 0.35 to 0.97, resulting in 90.0% accuracy and a significant ANOVA result (\(F=283.95\), \(p<0.001\)). For the WSSV, we found mean maximum value for the intensity to be 0.74±0.13, with the range varying from 0.20 to 0.90, corresponding to an accuracy of 95.2% and a significant ANOVA difference (\(F=278.61\), \(p<0.001\)). Finally, for the class Yellowhead disease, we obtained mean maximum value for the intensity to be 0.54±0.09 with accuracy 98.1% and a significant ANOVA result (\(F=754.74\), \(p<0.001\)) (Table 4). Tukey‘s HSD post-hoc test revealed specific pairwise differences: BG intensity differed significantly from all disease classes (\({\textrm{p}} < 0.001\)), and Yellowhead exhibited significantly lower intensity compared to Healthy and WSSV samples (\({\textrm{p}} < 0.001\)). Notably, no significant difference in mean attention intensity was found between healthy and WSSV sample (p = 0.30) (Table 5). The results indicated that the Grad-CAM++ intensity scores showed a strong relationship with the model classification accuracy for the various classes for shrimp diseases (Fig. 7).
We calculated the maximum intensity within the ground-truth bounding boxes for the BG and WSSV shrimp disease classes. A bivariate confidence ellipse at the 95% level was constructed for each class based on the chi-square distribution with two degrees of freedom (\(\chi ^2= 5.9915\)), using kernel density estimation (KDE). For the BG class, the mean distance was 51.76 and the mean intensity was 0.638. The empirical 95% quantile of the chi-square statistic was 6.19, and 94.59% of the observations lay within the 95% confidence ellipse (\(p < 0.001\) for the overall distribution test). For the WSSV class, the corresponding mean distance and intensity were 33.89 and 0.73, respectively. The empirical 95% quantile was 8.99, with 92.99% of the observations contained within the confidence ellipse (\(p < 0.001\)) (Fig. 8a). Additionally, we measured the distance from the maximum Grad-CAM++ activation to the center of each bounding box and found that an maximum intensity of around 0.8 was highly localized, occurring approximately 10 pixels from the bounding box center for both BG and WSSV (Fig. 8a). Furthermore, the maximum intensity was found to be significantly negatively correlated with the distance to the center of each bounding box for both BG (\(y = -0.001x + 0.81\), \(R^2 = 0.922\), \(p < 0.001\)) and WSSV (\(y = -0.001x + 0.84\), \(R^2 = 0.946\), \(p < 0.001\)) shrimp disease classes (Fig. 8b).

Maximum Grad-CAM++ intensity using the proposed model for all shrimp disease classifications, along with the corresponding accuracy.

Relationship of maximum intensity with distance from the center of the bounding box for BG and WSSV shrimp diseases (a) contour plot illustration with the solid ellipse at 95% confidence level, (b) regression line illustration.
Lightweight model implementation in desktop application
We developed a “Shrimp Disease Classifier” desktop application that provide a user-friendly interface for rapid, automated diagnosis. When evaluated on test image datasets of 453 unseen shrimp disease images, the classifier achieved an overall accuracy of 94%. The application produced a high-confidence prediction of BG (98.74%), illustrating the model‘s reliability. In addition, the system demonstrated high efficiency, with an average processing time of less than 0.2 s per image, making it well-suited for automatic Shrimp diseases classification task. The application not only reports predictions with associated confidence scores but also organize input images into class-specific folders (BG, Healthy, WSSV, Yellowhead), enabling efficient data management (Fig. 9).

Implementation of lightweight model in desktop application.
Discussion
Automatic detection of shrimp disease is vital to the prevention of economical losses and efficient management of the aquaculture industry. Some of the conventional monitoring methods, such as visual inspection and polymerase chain reaction (PCR), are cumbersome, labour-intensive, and consuming even more time9,10. Many computer vision methods has been built for the automated classification of the diseases found among shrimp, with retained performance levels higher than 95%. The computational requirements for the aforementioned technology, however, limit the usage to real-time monitoring irrespective of the technology’s exemplary accuracy levels1,13,14,41.
We present FeatherNetX, a lightweight neural network architecture that maintains accuracy while minimizing memory requirements and computational footprint, in order to overcome these constraints. FeatherNetX achieves 93% ± 0.06 accuracy, uses only 2.82 MB of memory, has 0.739 million parameters, and operates at 0.48 GFLOPs. It outperforms MobileNetV2, a well-known lightweight neural model with 2.229 million parameters, 8.50 MB of memory, 0.83 GFLOPs, and 92% ± 0.12 accuracy17. DenseNet121’s accuracy advantage is offset by its \(9.4\times\) larger parameter count, yielding an efficiency score nearly an order of magnitude lower than that of FeatherNetX (Table 2). In real-world aquaculture applications, where deployment targets often have limited computational and memory resources, such efficiency is critical42. FeatherNetX matches the accuracy of lightweight models such as MobileNetV2 (\(p = 0.210\)) while being \(3.0\times\) more parameter efficient, and it also demonstrates a clear advantage over larger architectures like VGG16. Collectively, these characteristics place FeatherNetX at an optimal point on the performance—complexity frontier. Consequently, FeatherNetX represents not merely an alternative, but a strategically superior choice for scalable and real-time shrimp disease classification in aquaculture monitoring systems. Additionally, in direct comparison, with shrimp-specific ShrimpNet-3 model our proposed FeatherNetX model demonstrates a significant advantage in model efficiency. It is approximately 3.4 times more compact (2.82 MB vs 9.7 MB) than the ShrimpNet-3 model, which was designed for classifying obvious physical defects (e.g., crushed or malformed shrimp)36. While ShrimpNet-3 achieves high accuracy on its task, FeatherNetX achieves its compactness while addressing the more subtle and critical challenge of disease classification (e.g., healthy, WSSV, BG, and Yellowhead). The superior compactness of FeatherNetX to run faster, consume less power, and be deployed on more affordable, low memory edge hardware, making it particularly suitable for real-time field diagnostics (Table 2).
Our proposed model showed robust performance for all categories of shrimp diseases, as confirmed by 5-fold cross-validation (Fig. 3). Macro-average precision, recall, and F1-score were all above 0.85, indicating high performance for the overall classification task (Fig. 4). Variation at the class-specific level was seen, with the lowest F1-score for Black Gill (0.88) and the highest for Yellowhead (0.98) (Table 3). This variation may result from differences in the pathophysiological properties of these diseases. For example, Yellowhead virus produce acute and visually distinctive manifestations, such as pale head and yellow cephalothorax, providing clear visual cues for the model. Black Gill, in contrast, arises from parasitic, fungal, or environmental causes, resulting in gill melanization and necrosis with highly variable appearance. These subtle and sometimes ambiguous features can resemble normal gill or debris43,44,45.
The use of Grad-CAM++ was employed to provide a descriptive visualization of the image regions that contributed most strongly to the model’s predictions46,47. To complement the qualitative assessment, we recorded the maximum (peak) attention intensity for each image and averaged these maxima across images in each class. Mean maximum attention intensities were highest for WSSV (0.74), healthy (0.71), and BG (0.62), compared to Yellowhead (0.54), indicating differences in the concentration of the model activations across classes47. One-way ANOVA confirmed significant differences among classes (\({\textrm{p}} < 0.001\)) (Table 4). Post-hoc Tukey‘s HSD tests on these mean peak intensities revealed specific inter-class differences: the peak activation for BG was significantly lower than for healthy and WSSV, and higher than for Yellowhead (\({\textrm{p}} < 0.001\)). Yellowhead exhibited significantly lower peak activation than both healthy and WSSV (\({\textrm{p}} < 0.001\)). Crucially, the mean peak intensity did not differ significantly between healthy and WSSV classes (p = 0.304) (Table 5). This indicates that while model achieves high classification accuracy for healthy (90%) and WSSV (95%), it does so not by allocating a consistently different peak level attention to each class, but rather by attending to distinct spatial features or patterns within the highlighted regions46,48.
We further analyzed the spatial properties of Grad-CAM++ activations relative to available annotations. For both the BG and WSSV classes, there was a significant negative correlation between maximum attention intensity and the distance from the peak activation to the center of the bounding box, with peak activations typically located within 10 pixels of the box center (Fig. 8b). This quantitative spatial correlation supports the visual observation of alignment between regions of high model activation and annotated areas of disease49. These methods are correlative and descriptive however high activation in a region doesn’t provide causal evidence of the model‘s reasoning process or guarantee that the highlighted features are clinically meaningful50,51,52. The model‘s internal decision-making may not fully correspond to expert human assessment. Therefore, the Grad-CAM++ analysis is presented as evidence of broad spatial alignment and model focus, not as rigorous validation of clinical explainability48,50,51 (Fig. 8).
The practical deployment potential of FeatherNetX was evaluated on hardware equipped with an Intel Core i7–10700F CPU, 32 GB of RAM, and an NVIDIA GeForce RTX 3060 Ti GPU. For the proposed model with 0.74 M parameters and 0.24 GFLOPs, the estimated inference latency is 15.2 ms on the CPU and 1.8 ms on the GPU, with a peak GPU memory footprint of approximately 130 MB and a storage size of 0.48 MB. This represents a significant efficiency gain over standard lightweight baselines; for example, MobileNetV2 (2.2 M parameters and 0.83 GFLOPs) typically requires higher latency (approximately \(3\times\) on the CPU and \(2\times\) on the GPU) and substantially more memory (around 200 MB) under comparable conditions. These results confirm that FeatherNetX operates well within the resource constraints of common edge devices such as the Raspberry Pi 4, which typically exhibits inference latencies of 50–100 ms for comparable workloads53. The minimal computational complexity and memory requirements of the proposed model make it well suited for real-time shrimp disease classification under the power and memory constraints inherent to in-field aquaculture deployment.
Lightweight FeatherNetX model was successfully utilized for a desktop application, presenting a viable method to the automation of real-time classification of shrimp diseases. The model presented an overall accuracy rate of 94%, along with an average 0.2-s inference time, a performance indicator that allows for fast, real-time diagnosis independent of continuous internet connectivity54. The offline functionality is invaluable for practical field deployment at remote shrimp farms. Beyond this, incorporation of an automated sorting system that directs outputs to class-specific folders greatly enhances the usefulness of the tool, offering researchers and aquaculturists an instant and organized dataset for keeping records and for further analysis, consequently easing the entire workflow of diagnosis (Fig. 9).
Challenges
1. Generalization challenge: the cross-dataset evaluation reveals a substantial generalization challenge. Specifically, a model trained and validated (8:2 split) on the ShrimpDatasetImageBD dataset showed a 13.84% performance drop when tested on the TigerShrimpBD. During this experiment, three common classes (healthy, BG, and WSSV) were included. However, Yellowhead was excluded because this class is available only in TigerShrimpBD dataset (Table 6). Notably, this degradation occurs despite both datasets originating from the same country, underscoring the sensitivity of vision-based shrimp diseases classification to domain shifts even within geographically constrained settings55. The observed performance gap can be attributed to differences between mixed urban-coastal environments in ShrimpDatasetImageBD and exclusively rural coastal farms in TigerShrimpBD, including variations in camera equipment, lighting conditions, and farm management practices7,22. Class-wise analysis indicates that WSSV classification exhibits greater robustness across datasets (F1-score: 0.81) compared to healthy shrimp classification (F1-score: 0.70) and BG classification (F1-score: 0.69). The nearly identical, lower performance on the healthy and BG classes suggests that the model’s primary confusion in the new domain is between healthy shrimp and those of BG disease. This is likely due to the visual symptoms of BG (necrotic, darkened gill tissue) and subtler and more easily confounded with healthy shrimp under varying environmental and imaging conditions. In contrast, the visual markers for WSSV are more distinctive and invariant to such domain shifts–45. The inclusion of 95% CI further quantifies performance variability and provides a statistically grounded assessment of model reliability under domain shift (Table 6).
2. Robustness challenges:we conducted a severity-based robustness evaluation to assess the sensitivity of the proposed model to lighting variation, background clutter, and image quality degradation under realistic aquaculture conditions. The proposed model achieved an accuracy of 93.16 percent on the original dataset (Severity 0). Under mild distortions at Severity 1, including moderate lighting variation, slight blur, and low-level noise, accuracy decreased to 73.51 percent, corresponding to an absolute drop of 19.65 percent. As distortion severity increased, performance declined further to 45.76 percent at Severity 2 and 31.06 percent at Severity 3, which incorporated strong illumination changes, heavy blur, sensor noise, turbidity, and background clutter. This degradation trend reflects the increasing difficulty of visual perception under challenging environmental conditions to increasingly challenging visual conditions. A comparable severity-based evaluation of MobileNetV2 revealed similar degradation patterns across all severity levels (Table 7), indicating that these robustness challenges are not unique to our proposed architecture. From a deployment perspective, these findings highlight the importance of adaptability in heterogeneous aquaculture environments. The lightweight FeatherNetX architecture enables efficient on-site fine-tuning using a limited number of farm-specific samples, providing a practical pathway to mitigate robustness challenge under real-world conditions56,57. The actual and predicted classes produced by our model across various severity levels on the test image datasets, with severity levels indicated in black, correct predictions in green, and misclassifications in red (Fig. 10).

Actual and predicted classes across various severity levels applied to test image datasets.
Limitations and future directions
1. Generalization limitation: first, although cross-dataset validation is performed, both datasets are geographically limited to Bangladesh, preventing conclusions about broader generalization across different countries, and climatic conditions. Second, while the cross-dataset setup implicitly captures real-world domain shifts, the evaluation does not include controlled robustness analyses isolating specific factors such as camera type, seasonal variation or water quality parameters. As a result, the reported 13.84% performance gap may underestimate the performance degradation expected in completely unseen deployment environments with substantially different imaging systems or aquaculture practices. In computer vision tasks, performance degradation due to domain shift has been observed to reach up to 25%58. From a deployment perspective, these limitations directly impact real-world applicability across heterogeneous farms, cameras and environmental conditions. To mitigate these challenges, the proposed lightweight FeatherNetX architecture offers a practical adaptation pathway. Its low computational and memory requirements enable rapid on-site- fine-tuning a small number of farm-specific images, allowing the model to adapt efficiently to local imaging conditions, camera variations, and environmental factors without extensive computational resources. This fine tuning design choice facilitates personalized model adaptation at individual farms and partially offsets the generalization limitations observed in cross-dataset testing58,59,60. Future work should combine this lightweight adaptation capability with larger, geographically diverse datasets and explicit domain adaptation strategies to ensure reliability and scalability deployment across global aquaculture environments.
2. Performance constraints: the classification accuracy is greatly affected by the ease with which disease symptoms are readily apparent. The model succeeds greatly with diseases that are marked with strong visual cues, for example, Yellowhead; however, it is found to be less successful with Black Gill, where symptoms are lacking or inconsistent among individual shrimp, or very similar to normal gill configurations44,61. Furthermore, inherent class imbalance exists in the available datasets, particularly for Yellowhead category. While extensive data augmentation was employed to increase data diversity, no explicit class-weighting loss function or balanced sampling strategies were applied in order to isolate the architectural contribution of FeatherNetX. Incorporating class-aware learning strategies represents an important direction for future work. In addition, the current implementation is only provided for the desktop, consequently restricting the practical usefulness under field circumstances where mobile deployment would be more convenient for farmers. Therefore, it is recommended that future studies focus more on increasing the model’s ability to recognize less overt disease attributes through the incorporation of a wider set of training datasets. In addition, the development of a mobile application is encouraged to enable direct usage within aquaculture complexes, thus making the diagnostic program more convenient for routine health assessments62.
3. Individual-level metadata: in this study, individual shrimp identifiers were not available in the publicly available datasets used7,8. Consequently, multiple images of the same shrimp individual may appear in different folds during cross validation. This may lead to slightly optimistic generalization estimates and is a common limitation in public image datasets lacking individual-level metadata63. In future work, datasets with individual shrimp identifiers could be used for more rigorous evaluation.
4. Ablation analysis: while FeatherNetX was designed with modular architectural components to facilitate interpretability and extensibility, a full quantitative ablation analysis of individual components was not conducted in this study. While ablation analysis is valuable for architectural interpretability, the primary focus of this work is end-to-end performance and deployment efficiency in real-world aquaculture settings. All baseline models and FeatherNetX were trained and evaluated under identical experimental conditions, enabling a fair end-to-end performance comparison. Future work will systematically evaluate the contributions of key design elements, such as FeatherBlocks, stochastic depth within CSPStages, and learnable residual scaling, through controlled ablation experiments to further quantify their impact on performance and efficiency.
4. Longitudinal disease analysis: finally, a limitation of this study is its focus on automatic shrimp disease classification rather than early detection. The proposed model identifies shrimp disease classes (healthy, BG, WSSV, Yellowhead) from static data and does not analyze longitudinal disease progression. Future studies using temporal data are needed to investigate true early detection and disease dynamics.
Conclusions
This study demonstrates that the proposed FeatherNetX model achieves robust and reliable shrimp disease classification while maintaining a highly compact and computationally efficient design. Across five-fold cross-validation, the model consistently attained high classification accuracy (0.93 ± 0.059) with stable training behavior, despite having substantially fewer parameters and lower computational cost than conventional deep architectures. Comparative and statistical analyses confirmed that FeatherNetX delivers competitive performance relative to larger baseline models, while achieving markedly superior accuracy per parameter and efficiency scores, making it well suited for resource-constrained environments. Class-wise evaluation further showed strong and balanced precision, recall, and F1 scores across all disease categories, with minimal confusion except between visually similar BG and Healthy samples. Qualitative and quantitative Grad-CAM++ analyses indicated that the model’s predictions are driven by discriminative image regions, with attention intensity strongly associated with classification accuracy and spatial alignment to annotated disease areas where available. Finally, the successful deployment of the model in a lightweight desktop application, achieving real-time inference with high accuracy on unseen data, highlights its practical applicability for rapid and automated shrimp disease screening in real-world settings.
Data availability
In this study, we make use of publicly available datasets that can be downloaded from https://data.mendeley.com/datasets/jhrtdj9txm/3 and https://data.mendeley.com/datasets/9dj4sk5d55/1. The codedeveloped and utilized for this research is openly accessible on GitHub at https://github.com/sand198/shrimp_lightweight (accessed on 29 September 2025), where detailed instructions for executing the code are also provided.
References
Büyükarıkan, B. Robust shrimp disease detection using multi-model convolutional neural networks-based ensemble strategies. Aquac. Eng. 111, 102616. https://doi.org/10.1016/j.aquaeng.2025.102616 (2025).
Hu, W.C., Wu, H.T., Zhang, Y.F., Zhang, S.H. & Lo, C.H. Shrimp recognition using ShrimpNet based on convolutional neural network. J. Ambient Intell. Humaniz. Comput. 1–8 (2020).
Shinn, A.P., Pratoomyot, J., Griffiths, D., Trong, T., Vu, N.T., Jiravanichpaisal, P. & Briggs, M. Asian shrimp production and the economic costs of disease. Asian Fish. Sci. 31, 29–58 (2018). https://doi.org/10.33997/j.afs.2018.31.S1.003.
Paul, J. E., Nagarajan, S., Rayappan, J. B. B. & Kulandaisamy, A. J. Combating WSSV based crustacean loss through early pond site detection: A review. Aquaculture 607, 742696. https://doi.org/10.1016/j.aquaculture.2025.742696 (2025).
Omori, R., Hagino, T., Pattama, P., Ozaki, K. & Hirono, I. Estimating the basic reproduction number and final epidemic size of white spot syndrome virus outbreak in Penaeous japonicus in aquaculture ponds. Aquaculture 582, 740548. https://doi.org/10.1016/j.aquaculture.2024.740548 (2024).
Walker, P. J. & Mohan, C. V. Viral disease emergence in shrimp aquaculture: origins, impact and the effectiveness of health management strategies. Rev. Aquac. 1(2), 125–154. https://doi.org/10.1111/j.1753-5131.2009.01007.x (2009).
Islam, M.M., Sarker, A., Choudhury, A., Ahmed, N. & Ahmed, A.S.R. ShrimpDiseaseImageBD: An image dataset for computer vision-based detection of shrimp diseases in Bangladesh. Mendeley Data V3 (2025). https://doi.org/10.17632/jhrtdj9txm.3.
Ahmed, F., Bijoy, H. I., Hemal, H. B. & Noori, S. R. H. Smart aquaculture analytics: enhancing shrimp farming in Bangladesh through real-time IoT monitoring and predictive machine learning analysis. Heliyon 10(17), e37330. https://doi.org/10.1016/j.heliyon.2024.e37330 (2024).
Eder, M. S., Ampolitod, K. C., Bolao, N. H., Pajal, R. J. A. & Racho, E. M. D. SHRIMPAI: A mobile application for the early detection of white spot syndrome virus in shrimp using convolutional neural network. MJST 22(2) (2024). https://doi.org/10.61310/mjst.v22i2.2189.
Yang, X. et al. Deep learning for smart fish farming: Applications, opportunities and challenges. Rev. Aquacult. 13(1), 66–90. https://doi.org/10.1111/raq.12464 (2021).
Chouhan, S.S., Kaul, A. & Singh, U.P. Radial basis function neural network for the segmentation of plant leaf disease. In The Proceedings of 4th International Conference on Information Systems and Computer Networks, Mathura, India. 713–716 (2019). https://doi.org/10.1109/ISCON47742.2019.9036299.
Chouhan, S.S., Patel, R.K., Singh, U.P. & Tejani, G.G. Integrating drone in agriculture: Addressing technology, challenges, solutions, and applications to drive economic growth. Remote Sens. Appl. Soc. Environ. 101576 (2025).
Duong-Trung, N., Quach, L. D. & Nguyen, C. N. Towards classification of shrimp diseases using transferred convolutional neural networks. Adv. Sci. Technol. Eng. Syst. J. 5(4), 724–732 (2020). https://doi.org/10.25046/aj050486.
Kanakamedala, P., Sunkara, V. M., Kumar, J. R., Reddy, M. B. & Prasad, D. D. Shrimp disease classification and medicine recommendation using deep learning techniques. In International Conference on Innovations in Intelligent Systems: Advancements in Computing, Communication, and Cybersecurity (ISAC3), Bhubaneswar, India. 1–6 (2025). https://doi.org/10.1109/ISAC364032.2025.11156739.
Ayon, S. S., Hossain, M. E., Rabbi, A., Saef Ullah Miah, M. & Rahman, M. M. Predictive modeling and early detection of white spot disease in shrimp farming using machine learning: A case study in bangladesh. In International Conference on Trends in Electronics and Health Informatics. 263-273. https://doi.org/10.1007/978-981-97-3937-0_18 (Springer, 2023).
Halder, S., Maity, A., Manna, A. & Chattopadhyay, S. Identifying prawn disease using improved CNN. In National Conference on Control Instrumentation System Conference. 39–50 (Springer, 2023).
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A. & Chen, L. C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 4510–4520. https://doi.org/10.1109/CVPR.2018.00474 (2018).
Han, K. et al. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1580–1589 (2020).
Zhang, X., Zhou, X., Lin, M. & Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 6848–6856. https://doi.org/10.1109/CVPR.2018.00716 (2018).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7132–7141 (2018).
Huang, G., Sun, Y., Liu, Z., Sedra, D. & Weinberger, K. Q. Deep networks with stochastic depth. In European Conference on Computer Vision, Springer International Publishing. 646–661 (2016).
Ahmed, S.I. & Farid, D. TigerShrimpBD: A tiger shrimp image dataset. In Mendeley Data V1. https://doi.org/10.17632/9dj4sk5d55.1 (2025).
Jone, I.H., Masud, D.M., Sarker, P., Labib, S.F.A., Islam, N. & Billah, F. ShrimpXNet: A transfer learning framework for shrimp disease classification and augmented regularizatio, adversarial training, and explainable AI. arXiv:2601.00832 (2025).
Yuan, W. et al. CV-YOLOv10-AR-M: Forign object detection in Pu-Erh Tea based on five-fold cross-validation. Foods 14, 1680 (2025).
Lin, T. Y., Dollár, P., Girshick, R., He, K., Hariharan, B. & Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2117–2125 (2017).
Wang, C. Y. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 390–391 (2020). https://doi.org/10.1109/CVPRW50498.2020.00203.
Tan, M., & Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In The Proceedings of the 36th International Conference on Machine Learning, Long Beach, California, (PMLR). 6105–6114 (2019).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 770–778 (2016).
Howard, A. G. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 (2017).
Howard, A. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 1314–1324 (2019).
Cipriani, C., Fornasier, M. & Scagliotti, A. From NeurODEs to AutoencODEs: A mean-field control framework for width-varying neural networks. Eur. J. Appl. Math. 36, 188–230 (2025).
Paren, A., Berrade, L., Poudel, R. P. & Kumar, M. P. A stochastic bundle method for interpolation. J. Mach. Learn. Res. 23, 1–57 (2022).
Wang, Q. et al. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11534–11542 (2020). https://doi.org/10.1109/CVPR42600.2020.01155.
Huang, G., Liu, Z., Van Der Maaten, L. & Weinberger, K. Q. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition. 4700–4708 (2017).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556 (2014).
Liu, Z., Jia, X. & Xu, X. 2019. Study of shrimp recognition methods using smart networks. Comput. Electron. Agric. 165, 104926 (2019).
Scott, D.W. Multivariate density estimation. In Very Deep Convolutional Networks for Large-Scale Image Recognition. ( Simonyan, K. & Zisserman, A. eds. ) https://doi.org/10.1002/9780470316849. arXiv:1409.1556 (Wiley, 2014).
Rastegari, H. et al. Internet of things in aquaculture: A review of the challenges and potential solutions based on current and future trends. Smart Agric. Technol. 4, 100187. https://doi.org/10.1016/j.atech.2023.100187 (2023).
Stentiford, G. D. et al. Disease will limit future food supply from the global crustacean fishery and aquaculture sectors. J. Invertebr. Pathol. 110, 141–157. https://doi.org/10.1016/j.jip.2012.03.013 (2012).
Lightner, D. V. Virus diseases of farmed shrimp in the western hemisphere (the Americas): A review. J. Invertebr. Pathol. 106(1), 110–130. https://doi.org/10.1016/j.jip.2010.09.012 (2011).
Chouhan, S.S., Saxena, E., Shukla, A., Patel, R.K. & Singh, U.P. Optimizing YOLO-based models for real-time guava detection with probabilistic fused wiener filter-enhanced feature fusion. Appl. Fruit Sci. 67 (Springer, 2025).
Fernandes, S. & DMello, A. Artificial intelligence in the aquaculture industry: Current state, challenges and future directions. Aquaculture 598, 742048 (2025).
Lightner, D. V. A handbook of shrimp pathology and diagnostic procedures for diseases of cultured penaeid shrimp (1996).
Pazir, M. K. et al. Black gill disease in Litopenaeus vannamei made by various agents. Aquacult. Fish. 9(4), 626–634. https://doi.org/10.1016/j.aaf.2022.10.002 (2024).
Soto-Rodriguez, S., Gomez-Gil, B. & Roque, A. Shrimp diseases and molecular diagnostic methods. In Aquaculture Microbiology and Biotechnology. 101–131 (Taylor & Francis Group, 2009).
Chattopadhay, A., Sarkar, A., Howlader, P. & Balasubramanian, V. N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). 839–847. https://doi.org/10.1109/WACV.2018.00097 (2018).
Fayyaz, A. M. et al. Grad-CAM (Gradient-weighted class activation mapping): A systematic literature review. Comput. Biol. Med. 198, 111200 (2025).
Samek, W., Wiegand, T. & Müller, K. R. Explainable artificial intelligence: Understanding, visualizing and interpreting deep learning models. arXiv preprint arXiv:1708.08296 (2017).
Tang, J. et al. The interpretable multimodal dimension reduction framework SpaHDmap enhances resolution in spatial transcriptomics. Nat. Cell Biol. 1–15 (2026).
Chaddad, A., Hu, Y., Wu, Y., Wen, B. & Kateb, R. Generalizable and explainable deep learning for medical image computing: An overview. Curr. Opin. Biomed. Eng. 33, 100567 (2025).
Kumar, A.K., Mai, N.N., Kumar, A., Chand, N.V. & Assaf, M.H. Quantum classifier for recognition and identification of leaf profile features. Eur. Phys. J. D. 76. https://doi.org/10.1140/epjd/s10053-022-00429-z (Springer, 2022).
Livieris, I. E., Pintelas, E., Kiriakidou, N. & Pintelas, P. Explainable image similarity: Integrating siamese networks and Grad-CAM. J. Imaging 9, 224 (2023).
Jain, M. & Shah, A. Convolutional neural networks for real-time object detection with raspberry Pi. World J. Adv. Eng. Technol. Sci. 4, 87–105 (2021).
Mirza, H. T., Chen, L., Hussain, I., Majid, A. & Chen, G. A study on automatic classification of users’ desktop interactions. Cybernet. Syst. 46(5), 320–341. https://doi.org/10.1080/01969722.2015.1012372 (2015).
Rostami, M. & Galstyan, A. Overcoming concept shift in domain-aware settings through consolidated internal distributions. In Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 37. 9623–9631.
Li, K., Ferrand, J.N., Sheatsley, R., Hoak, B., Beugin, Y., Pauley, E. & McDaniel, P. On the robustness tradeoff in fine-tuning. arXiv:2503.1436v2. https://doi.org/10.48550/arXiv.2503.14836.
Liu, Y. et al. A scalable benchmark to evaluate the robustness of image stitching under simulated distortions. Sci. Rep. 15, 32816 (2025).
Bayram, F. & Ahmed, B. S. A domain-region based evaluation of ML performance robustness to covariate shift. Neural Comput. Appl. (Springer Nature) 35, 17555–17577 (2023).
Goodarzi, P. & Schütze, A. Practical test-time domain adaptation for industrial condition monitoring by leveraging normal-class data. Sensors 25, 7614 (2025).
Guo, B., Lu, D., Szumel, G., Gui, R., Wang, T., Konz, N. & Mazurowski, M. A. The impact of scanner domain shift on deep learning performance in medical imaging: An experimental study. arXiv:2409.04368 (2024).
Flegel, T.W., Lightner, D.V., Lo, C.F. & Owens, L. Shrimp disease control: Past, present and future, pp. 355-378. In Diseases in Asian Aquaculture VI, Fish Health Section, Asian Fisheries Society, Manila, Philippines (Bondad-Reantaso, M.G., Mohan, C.V. et al. eds.) . Vol. 505. 355–378 (2018).
Mirza, M. & Osindero, S. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784 (2014).
Mesman, J.P. et al. Challenges of open data in aquatic sciences: Issues faced by data users and data providers. Front. Environ. Sci. 12. https://doi.org/10.3389/fenvs.2024.1497105 (2024).
Acknowledgements
We are grateful to the Project-Based Learning-AI (PBL-AI) program and the Muroran Institute of Technology for awarding a scholarship to Sandhya Sharma.
Author information
Authors and Affiliations
Contributions
Conceptualization- S.S., B.P.G. and K.S.; Methodology- S.S. and K.S.; Supervision- K.S. and B.P.G.; Writing—Original Draft Preparation- S.S.; Writing—Review and Editing S.S., P.S.R., B.P.G., K.S., Y.O., S.W. and S.K. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Sharma, S., Rumahorbo, P.S., Kondo, S. et al. A lightweight deep learning architecture for automatic shrimp disease classification. Sci Rep 16, 13837 (2026). https://doi.org/10.1038/s41598-026-44195-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-026-44195-z
