
Abstract
Efficient and accurate identification of genetic alterations of non-small cell lung cancer is a critical diagnostic process for targeted therapies. Utilizing advanced modern deep learning is a potential solution that can accurately predict genetic alterations from H&E-stained pathological images without additional testing procedures and costs. However, clinically applicable predictive power for Anaplastic Lymphoma Kinase (ALK) rearrangement has yet to succeed. To tackle these issues, we have developed a pathologically interpretable, evidence-based deep learning algorithm to screen ALK alterations to reduce unnecessary medical costs and understand the association between genetic alterations and pathological phenotypes. The proposed model resulted in +95% accuracy with both resection and biopsy datasets, which can be applicable in the clinic. The deep learning approach can maximize the benefits for screening genetic alterations as well as provide the most clinical utility. A stand-alone Python-based open-source software package is publicly available.
Similar content being viewed by others

Introduction
Lung cancer is responsible for the deaths of over 127,000 people in 2023, accounting for 20% of all cancer deaths, which is nearly triple the death rate of colorectal cancer1. Identifying genetic alterations of non-small cell lung cancer (NSCLC) is a critical diagnostic process for targeted therapies, having efficient anticancer effects with fewer side effects than conventional chemotherapy2,3. Anaplastic Lymphoma Kinase (ALK) rearrangement is one of the therapeutic targets that leads to marked increases in survival in advanced NSCLC4. ALK rearrangement in NSCLC results in overexpression of the ALK kinase domain and inappropriate signaling downstream, leading to cancer. ALK rearrangement or ALK overexpression is referred to as ALK-positive. Fortunately, ALK overexpression can be effectively controlled by FDA-approved ALK Tyrosine Kinase Inhibitors (TKI), such as crizotinib and alectinib. Crizotinib has demonstrated significant clinical efficacy in ALK-positive NSCLC, leading to its widespread adoption in clinical guidelines5,6. Thus, the NSCLC guidelines of the National Comprehensive Cancer Network (NCCN Version 3, 2020) strongly recommend broad molecular profiling in treatment for advanced or metastatic NSCLC, including ALK, to identify rare driver mutations with available effective drugs4.
Screening ALK positives is clinically beneficial for reducing medical expenses and planning efficient target therapies (Fig. 1a). However, the current practice of ALK screening is inefficient and challenging. First, the extremely low incidence rate (only up to 5%) of ALK rearrangement in NSCLCs makes most screening tests (e.g., FISH, CDx IHC4) negative. These negative results of the additional tests incur unnecessary medical expenses for the other 95% of NSCLC patients and public/private insurance organizations. Second, the limited specimens with patients in advanced stages do not allow further screening tests. Several additional tests (e.g., PD-L1 IHC, EGFR RT-PCR) are required for immune checkpoint inhibitor therapy as well as targeted therapy with multiple genetic alterations when advanced or metastatic NSCLC is diagnosed4. About 70% of lung cancer patients are in the advanced stages when diagnosed, and surgery is not suitable for them7. Therefore, in most cases, only limited tissues are available from biopsy or cytology specimens for pathological examinations. Thus, prioritizing treatment-related tests is critical for patients in advanced stages. Lastly, the inaccessibility of lesions also makes the number of specimens limited. Lung biopsy is mainly performed by bronchoscopic biopsy (central lesion) or percutaneous (through skin) needle biopsy (peripheral lesion) for accessibility. However, these methods often fail to obtain sufficient amounts of tissue for both histopathological diagnosis and downstream molecular tests, due to the difficulty in accessing the lesion and the associated risks such as hemorrhage and pneumothorax.

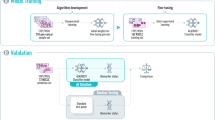
a AI-based ALK-positive screening reduces unnecessary medical expenses for most negative cases and prioritizes the ALK test. b DeepPATHO examines global and local morphological patterns simultaneously and computes the posterior probability as a patch encoder. The patch embeddings and scores are aggregated to predict ALK-positivity through multiple instance learning approaches. DeepPATHO also provides morphological evidence for reliable ALK-positive predictions. c DeepPATHO was trained with resection WSI, evaluated by multiple cross-validation, and reported patch- and slide-based AUC for comparison with benchmark models. d DeepPATHO was further validated using independent and external biopsy and resection WSIs and TCGA-LUAD datasets. The performance in the tables is with DeepPATHO coupled with MAX, showing the best recalls in most experiments.
It is extremely challenging for pathologists to determine ALK positivity in lung adenocarcinoma relying on morphologic visual features alone directly from H&E-stained slides, despite previous efforts to characterize ALK-associated patterns. Known ALK-specific morphological features of lung adenocarcinoma include solid/micropapillary/cribriform growth patterns, extra/intra-cellular mucin, and signet ring-like cells8. A scoring system for ALK positives using the ALK-specific morphological features in H&E-stained slides has been proposed, but it is not widely used due to low predictive performance (sensitivity of 88%; specificity of 45%)9. Nevertheless, these studies show a promising possibility of ALK-positive screening directly from H&E-stained slides.
Deep learning could be a promising solution to identify genetic alterations from pathological images, where histological features are often subtle and not reliably recognized by pathologists. Deep learning can learn complex and high-dimensional morphological patterns from large-scale data, detecting discriminative signals that may be beyond human perception. Despite the potential, ALK-positive screening directly from H&E-stained slides using deep learning has not been successful yet. Several deep learning models (e.g., InceptionV310, ResNet11,12, Imagene-AI13, and AutoML14) have shown the potential to predict protein expressions and genetic alterations (e.g., HER2, ROS1, PD-L1, ER, and PR)10,11,12,13,14. Several mutated genes (e.g., STK11, EGFR, FAT1, SETBP1, KRAS, and TP53) were classified by InceptionV3 directly from H&E-stained pathological images using The Cancer Genome Atlas (TCGA) datasets. However, in that study, the model was not able to detect ALK rearrangement, where accuracy was not reported10. Recent studies have explored deep learning models (e.g., ResNetV215, MobileNetV216, and DenseNet-12117) to identify ALK rearrangement. However, these studies demonstrated poor performance (e.g., accuracy~60%) for clinical application15,16,17 or reported high performance only given an extremely limited test cohort (e.g., less than ten ALK-positive cases)13, making it difficult to assess generalizability. Moreover, the black-box nature of deep learning makes the predictive mechanism untrustworthy for practical application in the clinic.
In this study, we have developed an evidential deep learning model, named DeepPATHO, that classifies ALK positives directly from H&E-stained whole-slide images with high performance and trustworthiness. The proposed DeepPATHO leverages attention modules to examine interactions between global and local pathological patterns at multiple magnification levels simultaneously and presents ALK-associated regions on patch images, which can support trustworthy prediction (Fig. 1b, Methods). We assessed the proposed method, DeepPATHO, by (1) conducting internal, independent, and external validations to compare the predictive performance with the current state-of-the-art benchmark models using lung resection and biopsy specimens (Fig. 1c, d), (2) applying DeepPATHO to the publicly available Cancer Genome Atlas lung adenocarcinoma (TCGA-LUAD) data for further validation (Fig. 1d), and (3) exploring potential ALK-associated regions for trustworthy predictions and model interpretation. To the best of our knowledge, this study is the first work that successfully classifies ALK-positives from H&E-stained WSI. Moreover, this study comprehensively validates DeepPATHO’s performance for ALK-positive screening with multiple datasets. DeepPATHO can be a promising, efficient screening solution that efficiently classifies genetic alterations for targeted therapy, prioritizes treatment-related tests, and reduces the cost of ALK CDx tests.
Results
The overview of the DeepPATHO framework
We propose an end-to-end framework for ALK-positive screening, including (1) building an instance-level backbone classifier for the patch encoder, (2) applying multiple instance learning (MIL) for slide-based prediction, and (3) identifying ALK-associated regions as domain-specific evidence for trustworthy prediction. First, a number of patch images (i.e., 256 × 256 pixels) are extracted from an H&E-stained gigapixel whole slide image, and DeepPATHO computes the posterior probabilities of ALK-positive with the patches as an instance-level backbone model. DeepPATHO simultaneously examines both the patches’ cell- and tissue-level morphologies at low (e.g., ×5 or ×10) and high (e.g., ×20 or ×40) magnifications by synchronizing upscale and downscale attention blocks. Then, MIL aggregates the instance-level scores and embeddings to compute the final slide-based ALK-positive score. Finally, DeepPATHO identifies ALK-associated regions on the patch images, which may correspond to known domain-specific knowledge. The morphological signatures, which are matched to known characteristics of ALK-positives, are provided as domain-specific evidence for trustworthy prediction. DeepPATHO is a novel instance-level backbone classification model that can be utilized in any MIL strategies for slide-based prediction. While most MILs adopt conventional CNN-based backbone models (e.g., ImageNet, ResNet, etc.) or foundation models as patch encoders18,19,20,21,22,23, the overall performance intrinsically relies on the performance of the backbone models24,25,26,27,28. Along with the advanced instance-level backbone classifier of DeepPATHO, the proposed framework improves predictive performance and interpretability, where instance-level (i.e., patch-level) prediction allows pathologists to assess ALK-associated regions for trustworthy predictions. The details of the framework are elucidated in Methods.
DeepPATHO classifies ALK-positives directly from H&E-stained histopathological slide images of resection specimens
We assessed DeepPATHO’s predictive performance in comparison with current state-of-the-art benchmark models using datasets obtained from Samsung Medical Center (SMC) (IRB: 2021-03-194-003) and Gyeongsang National University Hospital (GNUH) (IRB: 2021-03-005) (Table 1). The SMC dataset includes H&E-stained whole slide images of 158 ALK-positive adenocarcinoma cases, confirmed by IHC (clone 5A4) in lung resection specimens between 2010 and 2020 at SMC, and the GNUH dataset contains 130 ALK-negative adenocarcinoma cases in lung resection specimens between 2012 and 2019 at GNUH, confirmed by FISH (Vysis LSI ALK dual-color, Break-Apart Rearrangement Probe; standard protocol) and/or IHC (clone 5A4 or D5F3). Moderate or strong cytoplasmic stains of ALK IHC were referred to as ALK-positive results29. All digital WSIs were acquired from the pathology slides with the Aperio AT2 slide scanner (Leica Biosystems Division of Leica Microsystems Inc., IL, USA) at 40x magnification levels. It is worth noting that the 158 number of ALK-positive slides had been collected over a decade’s time frame since the incidence rate of NSCLC patients with ALK-positives is less than 5%.
We split the resection sample slides into 80% and 20% for training and test data by stratified sampling to preserve the ALK-positive and negative ratio. The training data was again split into 80% and 20% for training and validation. Each experiment included 102, 25, and 31 ALK-positive slides for training, validation, and testing, respectively, and 84, 20, and 26 ALK-negative slides. We then extracted patches of 256 × 256 pixels from the slides, and approximately 10,000 patches were extracted from each. At the end, training, validation, and test datasets included roughly 10 M, 2.5 M, and 3.1 M patches for ALK positives and 8.4 M, 2 M, and 2.6 M patch images for ALK-negatives. Preprocessing was performed to normalize colors and remove noise and background (Methods). The experiments were repeated twenty times for reproducibility.
We assessed both instance- and slide-level predictive performance. First, we evaluated DeepPATHO’s predictive capability as an instance-level backbone model. We computed the Area Under the Receiver Operating Characteristic Curve (AUC) on the patches to compare the instance-level performance with benchmark models without thresholding. For this instance-level assessment, we assumed that all patches in the ALK-positive slides are positive. Benchmark models included MobileNetV216, ResNetV215, DenseNet12117, InceptionV310, CATNET30, and DeepHipo31. MobileNetV2, ResNetV2, DenseNet121, and InceptionV3 were used for protein mutation prediction (i.e., ALK, STK11, EGFR, FAT1, SETBP1, KRAS, and TP53), and have still been commonly used as instance-level backbone models in many recent studies32,33,34,35,36. CATNET and Deep-Hipo produced significantly improved performance than other benchmark models for H&E slide analysis. We optimized the hyper-parameters of learning rate and weight decay using grid search with the optimizer of stochastic gradient descent or Adam37 on the validation data for all benchmark models (Methods, Supplementary Note 1). All benchmark models were trained on the same data. Any pretrained or transfer learning approaches were not considered. In the experiments, DeepPATHO achieved the best predictive performance, showing an AUC of 0.922 ± 0.0032, which is a statistically significant improvement (14% improvement; p-value by Wilcoxon ranked sum: 4e−5) to the second-best model, Deep-Hipo, with 0.807 ± 0.0038 (Fig. 2a, Supplementary Table S1).

a Patch- and slide-based predictive performance with resection WSIs for cross-validation evaluation using HipoMap’s slide aggregation strategy. b Independent evaluation with biopsy data coupled with various multiple instance learning strategies, including HipoMap and MAX. c External validation using CGNUH dataset. d Evaluation with publicly available TCGA LUAD data.
We then assessed the slide-level predictive performance of DeepPATHO, coupled with multiple MIL strategies, including random forest-based (RF)38, posterior mean (MEAN), maximum posterior (MAX), HipoMap39, and CAMIL20. As instance-level MIL pooling approaches, RF, MEAN, and MAX aggregate the instance-level scores for the slide-level scores40. Whereas, the embedding-based MIL models, HipoMap and CAMIL, manipulate the patch embeddings obtained from the instance-level backbone model, to compute slide-based scores. The detailed implementation of the patch aggregation methods is in the Supplementary (Supplementary Note 2). The MIL strategies computed AUCs on the test slides with the instance-level backbone classifiers. The highest performance was with DeepPATHO coupled with CAMIL, showing an AUC of 0.962 ± 0.0047 (Supplementary Table S1). The second-best instance-level classifier was with Deep-Hipo with CAMIL (AUC: 0.849 ± 0.0025), which indicates a 11.2% improvement by DeepPATHO. DeepPATHO with HipoMap showed an AUC of 0.958 ± 0.0037, which improved 12.8% from Deep-Hipo with HipoMap. In a similar way, DeepPATHO with MAX achieved an AUC of 0.826 ± 0.027, whereas DeepHipo with MAX produced the next best performance with an AUC of 0.788 ± 0.031, which indicates a 3.8% improvement. Overall, DeepPATHO coupled with CAMIL had 0.84 slides as false negatives and 1.74 false positives per trial across 20 cross-validation experiments, while DeepPATHO with HipoMap had 0.78 false negatives and 1.86 false positives. The second-best instance-level classifier, Deep-Hipo with CAMIL, showed 3.0 false negatives and 2.88 false positives on average.
Furthermore, we examined the performance of a foundation model-based patch-encoder approach, and we compared it with DeepPATHO. For the experiment, we considered UNI2-h as a patch-encoder, which is a recently developed general-purpose foundation model for pathology image analysis18. We considered the two following configurations: (1) fine-tuning of UNI2-h patch-encoder and (2) considering the pre-trained UNI2-h model as a patch-encoder. First, we fine-tuned UNI2-h by using transfer learning. For the fine-tune, a fully connected layer was added to the output of UNI2-h’s Vision Transformer backbone for our binary classification problem. We initialized the parameters using the pretrained UNI2-h model’s optimal parameters and re-trained the entire architecture using training and validation patches, as we have done for DeepPATHO. Then, patch features were extracted from UNI2-h decoder on the test dataset and input to CAMIL for slide-level classification. Second, we utilized UNI2-h as a pretrained feature extractor, maintaining its pretrained weights without further optimization. The extracted instance-level features were subsequently processed using CAMIL. We trained CAMIL as a MIL strategy with the features from fine-tuned and pretrained UNI2-h patch encoders for the fair comparison. We used the same cross-validation dataset of the twenty experiments. The fine-tuned UNI2-h and the pretrained UNI2-h showed the slide-level AUC of 0.827 ± 0.0041 and 0.864 ± 0.0164, respectively, over twenty experiments (Supplementary Fig. S1). DeepPATHO with CAMIL still showed an 11.3% performance improvement, compared to the foundation model-based approaches (p < 0.01 by Wilcoxon ranked sum).
Although DeepPATHO coupled with CAMIL showed the best performance in the cross-validation experiments, MIL strategies can be optimally chosen with consideration of their strengths and weaknesses. CAMIL captures rich morphological features as well as relationships of inter-patches and inter-channels, whereas HipoMap quantifies discriminative class-specific morphological patterns of top-ranked patches. The embedding-based MIL models of CAMIL and HipoMap often result in robust slide-based predictions with enough numbers of patches in general. The MAX pooling strategy can be potentially sensitive to misclassified predictions of a few patches. Furthermore, we examined the distributions of the slide-level prediction scores by the five MIL strategies with DeepPATHO on the test data (Supplementary Fig. S2). We observed that the embedding-based MIL strategies of HipoMap and CAMIL showed well-distributed posterior probability scores without skew, compared to the MIL pooling models of RF, MEAN, and MAX.
DeepPATHO accurately classified ALK-positives on independent biopsy slides
We validated DeepPATHO using a fully independent biopsy cohort that was not included in any part of the training or cross-validation dataset. The hypotheses in the experiment include (1) a deep learning model trained by resection whole slide images can reliably predict biopsy slides and (2) DeepPATHO reproduces the most robust predictive performance with additional data. This independent dataset consisted of 92 adenocarcinoma WSI (26 ALK-positive and 66 ALK-negative), collected at Samsung Medical Center (SMC) between 2018 and 2020 (IRB: 2021-03-194-003) (Table 1). All samples were obtained via bronchoscopic biopsy, percutaneous needle biopsy, or excisional biopsy. The ALK status of the samples was confirmed by FISH (Vysis LSI ALK dual-color, Break-Apart Rearrangement Probe, standard protocol) and/or IHC (clon 5A4 or D5F3). The ALK-negative samples included two ROS1-rearranged adenocarcinoma slides, whose common morphological patterns are similar to ALK-positives41. These biopsy slides are distinct from the resection samples used for model training, presenting a greater challenge due to their smaller tissue area, lower patch counts, and less distinct morphological patterns. The challenges are often caused by artifacts such as crushing, tearing, or tissue fragmentation, which are common in small biopsy specimens. As most NSCLC diagnoses in clinical practice rely on biopsy specimens, this cohort provides a practical test case for evaluating model performance.
For the validation with the independent biopsy data, we retrained the DeepPATHO model (i.e., final model) using all the cross-validation data of resection specimens. We optimized the thresholds of the discriminant functions for the benchmark models separately with False Discovery Rates (FDR) of 0.05 and 0.01 using only the ALK-negative resection slides with the final model (Methods). The optimal thresholds for the slide-based posterior probability scores were 0.635, 0.52, and 0.73 for DeepPATHO with CAMIL, HipoMap, and MAX for FDR of 0.05, respectively. We computed weighted accuracy, F1 score, precision, recall, and AUC to evaluate the predictive performance with the highly imbalanced data. In the experiment, interestingly, DeepPATHO with MAX remarkably achieved the highest weighted accuracy of 0.977 and the best F1-score of 0.983, which is at least 20% improved compared to other benchmark methods (Fig. 2b, Supplementary Table S2). DeepPATHO with HipoMap produced a weighted accuracy of 0.971 and an F1-score of 0.975. As H&E screening tools, higher recall is more critical than precision since reducing false negatives is the primary concern in clinics. DeepPATHO achieved the weighted recall of 1 with MAX and 0.988 with HipoMap (FDR < 0.05). DeepPATHO predicted all actual ALK-positive samples as positives (i.e., no false negative) with MAX and one false negative with HipoMap (Supplementary Fig. S3a). The one false negative WSI with HipoMap was due to the extremely small size of the biopsy, which had only 42 patches, compared to at least 1000 patches in other biopsies. DeepPATHO produced two false positives on the ROS1 rearrangement with MAX. The scores of the false positive ROS1 were 0.78 and 0.79. DeepPATHO with HipoMap also produced two false positives, including one harboring ROS1 rearrangement (score: 0.99). Another false positive was scored 0.76 with HipoMap. The slide was also predicted to be ALK-positive with MAX (score: 0.72). It is worth noting that the weighted recall of DeepPATHO with CAMIL significantly dropped to 0.923, compared to the recall with MAX and HipoMap (1 and 0.988, respectively), although it showed competitive accuracy with MAX and HipoMap.
External validation using an independent institutional dataset
To further assess the generalizability of DeepPATHO, we evaluated the performance on an external dataset collected between 2016 and 2022 from Changwon Gyeongsang National University Hospital (CGNUH) (IRB: CGNUH 2023-02-009) (Table 1). CGNUH is an independent institute, located in a different city from GNUH. The dataset consisted of ten adenocarcinoma WSIs, including five ALK-positive and five ALK-negative cases, comprising both resection and biopsy specimens. The ALK status was confirmed by IHC (clone 5A4 or D5F3). In this external validation experiment, DeepPATHO significantly outperformed the benchmark models, achieving perfect classification with CAMIL (i.e., AUC of 1) (Supplementary Table S3). DeepPATHO coupled with MAX and HipoMap both showed an accuracy of 0.90 and weighted F1-score of 0.91. Among the five ALK-positive cases, DeepPATHO with MAX and HipoMap correctly predicted all ALK-positive cases without false negatives, but one false positive in each method.
Validation of DeepPATHO using the TCGA dataset
We also validated DeepPATHO using the publicly available Cancer Genome Atlas Lung Adenocarcinoma (TCGA-LUAD) dataset. The TCGA-LUAD dataset contains 566 resection slide images of lung adenocarcinoma. We considered the ALK annotation on cBioPortal, where we identified five ALK-positives and 561 ALK-negatives. We reviewed all TCGA-LUAD images and excluded frozen section images and slides of poor quality (e.g., tissue folding and tearing, extensive necrosis and hemorrhage, air bubble insertion). Finally, we examined four ALK-positives and 324 ALK-negatives using the final models that were trained with the resection slides during the evaluation.
DeepPATHO significantly outperformed the benchmark models, achieving the highest weighted accuracy of 0.99 and weighted F1-score of 0.99 coupled with HipoMap, compared to the second best Deep-Hipo with a weighted accuracy of 0.734 and an F1-score of 0.848 (Fig. 2c and Supplementary Table S4). DeepPATHO with MAX showed the highest weighted recall of 0.99, where the F1-scores were 0.998 and precision was 1. In a similar way, DeepPATHO with CAMIL showed a weighted accuracy of 0.929, but a relatively lower weighted recall of 0.92 than HipoMap and MAX. Among the four ALK-positives, DeepPATHO with both HipoMap and MAX predicted three ALK-positives (e.g., TCGA-86-A4P8, TCGA-67-6216, TCGA-67-6215) as positive and all ALK-negatives as negative (i.e., no false positives) (Supplementary Fig. S3b). TCGA-78-7163 was the only false negative, which shows rare patterns in lung adenocarcinoma, showing a papillary growth pattern, abundant extracellular mucin, and little stromal invasion (Fig. 3a). On a high-power view, the tumor cells had apical intracellular mucin (Fig. 3b, yellow arrowheads) and a filigree growth pattern. (Fig. 3b, green boxes). Floating tumor cell clusters were found in the mucin pool (Fig. 3b, red arrowheads). Interestingly, the tumor cells had round ovoid nuclei with prominent nucleoli (Fig. 3b, red box in the right-bottom corner), whose patterns were similar to the previously reported ALK-rearranged adenocarcinoma with extensive mucin production42. Recurrence was not reported to the patient of the false negative (TCGA-78-7163; disease-free survival, 238.3 months), so the response to the ALK inhibitor is unknown. Although we excluded the frozen section slides in the experiments, we additionally analyzed the ALK-positive frozen slide (TCGA-50-8460) using DeepPATHO. DeepPATHO with both HipoMap and MAX predicted it as ALK-positive. The scores were 0.67 with HipoMap and 0.84 with Max.

a The tumor showed a papillary growth pattern, abundant extracellular mucin, and little stromal invasion. b The tumor had apical intracellular mucin (yellow arrowheads), a filigree growth pattern (green boxes), and floating tumor cell clusters (red arrowheads) in the mucin pool. The tumor cells were found to avoid nuclei with prominent nucleoli (red box in the bottom right corner).
DeepPATHO identifies ALK-associated regions and morphological features
DeepPATHO identifies ALK-associated regions as evidence for a trustworthy prediction. We assessed the ALK-associated regions that DeepPATHO identified, assuming that IHC images are referenced as ground truth. We generated heatmaps of patch-wise ALK-positive probabilities and compared the heatmaps with the IHC-images (Fig. 4). The patches of high probability on the heatmaps are well aligned with the ALK-positive areas on the IHC-stained images. The most patch images of the tumor areas from the H&E slides show a high probability of being ALK-positive. The IHC-stained images also visualized the areas of the tumor cells as brownish dye, which indicates ALK expression.

Heatmap of patch-wise ALK-positive probabilities is compared in the IHC-images.
We further investigated ALK-specific morphological patterns, primarily observed in the top-ranked patches of the ALK-positive adenocarcinoma. Our proposed PATHO-CAM identified ALK-associated morphologies in the top 5 patches of All ALK-positive adenocarcinoma (Fig. 5), and we describe the morphological patterns in a pathological manner. PATHO-CAM’s visualization of the top 5 patch images supports that the basis of DeepPATHO’s prediction is consistent with domain knowledge in pathology.

The tumors show a cribriform pattern (a, e), papillary pattern (b), or solid pattern (c, d, f). Some tumors have intracellular mucin (b, f). Tumors with hepatoid (exhibiting abundant cytoplasm, round nuclei, and conspicuous nucleoli) features are found (d). Generally, the regions of tumor cells show higher association (lime color) with ALK-positive on Grad-CAM (a–c, e, and f) except the tumor with hepatoid feature (d). The intratumoral stroma and mucin showed different degrees of association with ALK positivity. Circles indicate areas of tumor cells, and the others point to tumor stromal areas.
Generally, the regions of tumor cells show relatively higher association with ALK positivity on PATHO-CAM (circles in Fig. 5a–c, e, f, Supplementary Fig. S4a–c, S1f) in each patch, except the tumor with hepatoid features (circle in Fig. 5d, Supplementary Fig. S4d). The tumors showed cribriform (Fig. 5a, e), papillary (Fig. 5b, Supplementary Fig. S4a, b), or solid growth patterns (Fig. 5c, d, f, Supplementary Fig. S4e). Some tumors had intracellular mucin (Figs. 5b, f, Supplementary Fig. S4e). Tumors with hepatoid features, abundant cytoplasm, round nuclei, and conspicuous nucleoli were found (Fig. 5d, Supplementary Fig. S4d)9. Additionally, the intratumoral stroma in the top 5 patches showed various degrees of association with being ALK-positive. Non-inflamed fibrotic stroma (rhombus in Fig. 5a, square in 5b, Supplementary Fig. S4b, c) showed a relatively higher association with ALK-positivity in each patch. Less-fibrotic loose stroma (square in Fig. 5a) and inflammatory stroma (square in Fig. 5c, d, rhombus in Supplementary Fig. S4b, c) showed a lower association. Intra- (squares in Fig. 5e, f) or extracellular (triangle in Fig. 5a) mucin showed a lower association, but intracellular mucin (circles in Fig. 5b) of the tumor with papillary patterns showed a higher association.
Efficient model training without pixel-based annotation
DeepPATHO provides an efficient strategy of model training that avoids the heavy workload of pixel-based annotation by pathologists in giga-pixel pathological images. To reduce the annotation burden while maintaining ALK prediction performance, we have explored two approaches: (1) model training using manual annotation of tumor areas instead of precisely labeling ALK-expressing tumor cells and (2) computational annotation using pre-trained LUAD prediction models instead of manual tumor annotation. We assume that ALK-relevant features mainly belong to LUAD-relevant regions. For the manual tumor annotation, pathologists roughly annotated LUAD, including tumor cells and intratumoral stroma, except hemorrhage, necrosis, large vessels or bronchi. We then extracted patches only from the annotated regions for training models, and we also utilized pre-trained LUAD prediction models (i.e., CATNET) to automate the tumor annotation. The experimental results show that training models with annotated patches by pre-trained models produced competitive predictive performance compared to model learning using manually annotated tumor patches (Supplementary Table S5). The automated tumor annotation showed only 1.1% lower performance compared to manual tumor annotation. DeepPATHO using automated tumor annotation produced the patch-based AUC of 0.874\(\pm\)0.032 and slide-based AUC of 0.937\(\pm\)0.022 with Hipomap. However, we mainly used the manual tumor annotation strategy for better performance in this study.
Discussion
In this study, we present a novel evidential deep learning model for screening ALK-positives directly from H&E WSIs in non-small cell lung cancer. Our proposed DeepPATHO accurately classified ALK-positives in resection and biopsy slides with a high predictive performance power (i.e., +95% weighted accuracy and F1-score). To the best of our knowledge, this study is the first to successfully screen ALK-positives from H&E slides without additional procedures or tests, showing clinically applicable predictive power. DeepPATHO also provides trustworthy predictions with ALK-specific evidence, which is consistently aligned with domain knowledge, so that pathologists can confirm the predictions reliably. Consequently, the efficiency of ALK-positive screening is expected to improve by performing CDx IHC tests on only ALK-positive candidates, and the cost of the CDx test will be saved.
It is worth noting that the DeepPATHO model was trained with resection specimens but independently validated with both biopsy and resection specimens. We hypothesized that resection specimens are more suitable for training the deep learning model than biopsy specimens, since resection specimens are typically larger in size, include fewer artifacts, and preserve higher quality morphological features than biopsy specimens. On the other hand, biopsy specimens often have artifacts during the acquisition process, such as tearing or crushing. This issue is particularly evident in aspiration specimens, where the tumor tissue is fragmented into small pieces by the fine needle, making it challenging to evaluate architectural growth patterns43. Such structural limitations may hinder accurate pathological assessment and molecular testing, including ALK interpretation. However, the majority of lung cancer patients cannot undergo surgery at the time of diagnosis. Thus, the high predictive performance of DeepPATHO in the independent biopsy datasets shows its potential in clinical practice.
To further assess the potential impact of institutional or specimen-type bias, we validated the proposed model on three additional independent/external datasets collected from different sources: a biopsy dataset from SMC, a mixed biopsy and resection cohort from CGNUH, and a resection dataset from TCGA. These evaluations consistently demonstrated the model’s robust predictive performance across different institutions and specimen types. However, the number of test cases remains limited, and broader validation will be necessary in future studies.
The novel multi-magnification attention architecture of DeepPATHO provides an alternative powerful choice as a cutting-edge patch encoder or an instance-level pretrained model for multiple instance learning and generic foundation models in various clinical applications using pathological images18. DeepPATHO synchronizes attention between low- and high-magnifications in a unified architecture, whereas most MIL strategies combine multiple scales in a post-hoc manner. DeepPATHO allows joint learning of cell- and tissue-level morphologies, which mimics the diagnostic workflow of pathologists and contributes directly to performance and interpretability. In this study, DeepPATHO’s outperformance was assessed by comparing predictive performance with various CNN models that have been commonly used as instance-level backbone models with MIL and foundation models.
We observed notable performance differences by varying MIL strategies in the validation experiments. Interestingly, DeepPATHO with MAX, which is a relatively simple instance-level MIL strategy with max pooling, showed the highest recall (1.000) as well as the competitive weighted accuracy (0.982) and F1-scores (0.983) (Supplementary Table S2), while HipoMap and CAMIL showed higher AUC (0.962 ± 0.0047) than MAX (0.826 ± 0.027) using DeepPATHO in the cross-validation experiments (Supplementary Table S1). The scheme of MAX was originally motivated by a pathological principle: in practice, a slide is diagnosed as ALK-positive even though a small number of tumor cells show positive staining on ALK in CDx IHC. We also found that MAX not only improved recall but also reduced false positives, possibly because it ignores weak or noisy signals from irrelevant patches. These findings may suggest that simple, pathology-based decisions can improve model robustness. HipoMap was the best choice when optimizing the balance between precision and recall, whereas CAMIL relatively lowered recall, which is critical in ALK+ screening.
A potential future work is to develop strategies to describe morphologies of ALK-positives in a pathological manner. These visualizations allow pathologists to assess the specific subregions within the tumor, such as tumor cells versus stromal or mucinous areas, that are contributing to the model’s ALK-positive prediction. The highlighted features generally align with established morphologies, the interpretability remains qualitative, and future work is needed to quantify such associations. In this study, we have identified ALK-specific regions by highlighting the regions and empirically validating the regions’ associations with ALK-positives. Such visualization could help pathologists understand which regions the deep learning model examines, making it possible to integrate pathology expertise. We have also discussed potential morphologies that may be related to ALK-positives as post-hoc analysis. However, it is insufficient to directly infer ALK-specific morphologies, which can be interpreted with morphometric analysis for cellular components of tumor and semantic segmentation for tumor microenvironment.
DeepPATHO is a general deep-learning model that can be applied to any pathological image analysis, although this study focuses on the ALK-positive classification problem. The capability of DeepPATHO to simultaneously examine cell- and tissue-level morphologies with the attention mechanism would enhance the capture of complex morphological patterns and their interactions between multiple magnification levels in whole slide images.
Methods
Architecture of DeepPATHO
The instance-level classifier DeepPATHO architecture consists of (1) multi-scale receptive field layers, (2) inception modules, (3) multi-magnification attention modules (MMA), (4) fully connected layers, and (5) an output layer (Supplementary Fig. S5). The multi-scale receptive field layers introduce two patches of a low magnification (global, e.g., 5x) and a high magnification (local representation, e.g., 20x) simultaneously to examine both cell- and tissue-level morphologies. Both global and local representation patches are extracted with the same center point, while having the same pixel dimensions (e.g., 256×256 pixels), which ensures spatial correspondence across magnification levels. The global patch is captured at a lower magnification (5X), while the local patches are captured at a higher magnification (20X). Specifically, a global patch covers a region at a lower magnification level that spatially corresponds to 16 local patches. The centers of the local patch and global patch are matched, allowing precise alignment between global contextual features and local detailed representations. The multi-scale receptive field layers comprise a pair of dilated convolutional blocks that capture morphological patterns in each magnification level while increasing convolutional kernel views. The following five inception modules (i.e., Inception A to E) learn high-dimensional global and local morphological features through multiple spatial combinations of convolutions. Then, the Multi-Magnification Attention (MMA) module synchronizes the morphologies of the inception modules between the local- and global-attention blocks. The local- and global-attention blocks adapt key, query, and value representations inspired by natural language processing and self-attention computer vision models44,45.
Let \({A}_{{\mathcal{G}}}\in \,{{\mathfrak{R}}}^{c\times h\times w}\) and \({A}_{{\mathcal{L}}}\in \,{{\mathfrak{R}}}^{c\times h\times w}\) be feature maps of the Inception-block output in the low (global) and high (local) magnification levels, where \(c,h,\) and \(w\) are the depth, height, and width of the feature maps, respectively. In each of the attention blocks, the key (\({A}_{{\mathcal{G}}}^{k}\), \({A}_{{\mathcal{L}}}^{k}\)), query (\({A}_{{\mathcal{G}}}^{q}\), \({A}_{{\mathcal{L}}}^{q}\)), and value (\({A}_{{\mathcal{G}}}^{v}\), \({A}_{{\mathcal{L}}}^{v}\)) of \({A}_{{\mathcal{G}}}\) and \({A}_{{\mathcal{L}}}\) are generated:
where \({W}_{{\mathcal{G}}{\mathcal{L}}}^{q\left|k\right|v}\,\in \,{{\mathfrak{R}}}^{c\times 1\times 1}\) are the kernel weights of the attention blocks. Then, the global attention \({\mathcal{G}}{\mathscr{\in }}{{\mathfrak{R}}}^{\left(h\times w\right)\times ({h}\times w)}\) and local \({\mathcal{L}}{\mathscr{\in }}{{\mathfrak{R}}}^{\left(h\times w\right)\times ({h}\times w)}\) are computed from \({A}_{{\mathcal{G}}|{\mathcal{L}}}^{{q|k}}\) as:
To synchronize the global and local morphologies, the global attention \(G\) is upsampled, and the local attention \(L\) is downsampled. For upsampling, \(G\) is cropped from the center to make the dimension \(\frac{(h\times w)}{b}\times \,\frac{(h\times w)}{b}\,\), where \({b}\) is the ratio of lower magnification to higher magnification (i.e., \(5/20\)). The cropped output of \(G\) is then bilinear interpolated to the size of \(\left(h\times w\right)\times (h\times w)\). For downsampling, the average pooling is computed on the local attention, \(L\), with kernel of \(\frac{(h\times w)}{b}\times \,\frac{(h\times w)}{b}\,\), followed by zero-padding for the identical dimensions between \(L\) and \(G\). The synchronized feature maps between global feature maps \(({R}_{{\mathcal{G}}}\,\in \,{{\mathfrak{R}}}^{c\times h\times w})\) and local feature maps \(\left({R}_{{\mathcal{L}}}\,\in \,{{\mathfrak{R}}}^{c\times h\times w}\right)\) are calculated from upsampled and downsampled outputs of \(G\) and \(L\) as
where ⊗ is element-by-element multiplication. Then, the synchronized feature maps of \({R}_{{\mathcal{L}}}\) and \({R}_{{\mathcal{G}}}\) and original feature maps of \({A}_{{\mathcal{L}}}\) and \({A}_{{\mathcal{G}}}\) are concatenated, flattened, and connected to fully connected layers. The architecture details, e.g., the number of layers and kernel sizes, are in Supplementary Table S6.
Hyperparameter tuning and the optimal threshold for the final discriminant function
We have empirically determined the optimal model architecture, including the number of Inception blocks (i.e., five blocks) and dilated rates (i.e., \(2\times 2\)). We optimized the hyper-parameters of the optimizer (i.e., SGD or ADAM), the learning rate, and the regularization (lambda) that minimizes the total loss on the validation data in each experiment. The optimal learning rate and regularization lambda were \(1{e}^{-5}\) and 0.85. For the optimal magnification levels for global and local modules, we found the optimal combination through experiments (Supplementary Note 3). To optimize the classification threshold in the final discriminant function, we calculated the false discovery rate by tolerating 5% and 1% of false positives on the negative WSIs in the developing datasets. We obtained the thresholds DeepPATHO coupled with all four patch-aggregation methods of HipoMap, MAX, MEAN, and RF. The optimal thresholds for the four slide-based methods for FDR of 5% were 0.52, 0.73, 0.36, and 0.33 for HipoMap, MAX, MEAM, and RF, respectively. We improved the performance using a naïve ensemble learning to repeat the training multiple times and average the results (Supplementary Note 4).
PATHO-CAM to discover ALK-specific morphologies
DeepPATHO identifies ALK-specific morphological patterns using our proposed PATHO-CAM. PATHO-CAM captures class-specific morphological patterns rather than edge and shape features, which are critical for general image analysis, so PATHO-CAM makes the interpretation more effective than conventional Grad-CAM46.
PATHO-CAM computes the ALK discriminative map \(({\rm{{\rm I}}}\,\in \,{{\mathfrak{R}}}^{h\times w})\) from intermediate outputs of the local attention block in DeepPATHO. To obtain the discriminative map \({\rm{{\rm I}}}\), first, we compute each feature map’s important score \((\alpha )\) as
where \({P}_{{ALK}+}\) is a ALK + score for a patch (before sigmoid), and \({A}_{{ij}}^{k}\) is the node value for \({i}^{{th}}\) row and\(\,{j}^{{th}}\) for \({k}^{{th}}\) the feature map \((\,1\,\le {i}\le w,\,1\,\le {j}\le h,\) and \(1\,\le {k}\le c\)). Then, \({\rm{{\rm I}}}\) is computed as
Finally, \({I}\) it is normalized based on each patch, each slide, and the entire data for interpretation. Additionally, we compute the mean ranked interpretation map by normalizing \(I\) with the minimum and maximum values of the top K highest probability patches.
Datasets and prepossessing
The pre-processing, such as noise removal, color normalization, and patch extraction, was performed with our open-source python package, PyHistopathology (http://dataxlab.org/pyhistopathology). Noises and artifacts, including tissue tears, folding, and over-staining, in the WSIs were removed by Gaussian blur smoothing, and the background was filtered out by thresholding. Patches containing at least 20% tissues were considered for this study.
Data availability
The extended data, which were the further results of our analyses from the current study, are available from the corresponding author upon reasonable request. However, the original pathological image datasets of GNUH, SMC, and CGNUH will not be shared to protect privacy. TCGA LUAD dataset is publicly available at https://www.cancer.gov/ccg/research/genome-sequencing/tcga.
Code availability
A stand-alone Python-based open-source software package is publicly available at: https://github.com/datax-lab/DeepPATHO.
References
Wolf, A. M. D. et al. Screening for lung cancer: 2023 guideline update from the American Cancer Society. CA Cancer. J. Clin. 74, 50–81 (2024).
Min, H. & Lee, H. Molecular targeted therapy for anticancer treatment. Exp. Mol. Med. 54, 1670–1694 (2022).
Bai, J., Qiu, S. & Zhang, G. Molecular and functional imaging in cancer-targeted therapy: current applications and future directions. Signal. Transduct Target Ther. 8, 89 (2023).
Ettinger, D. S. et al. Non-Small Cell Lung Cancer, Version 3.2022, NCCN Clinical Practice Guidelines in Oncology. J. Natl Compr. Canc Netw. 20, 497–530 (2022).
Solomon, B. J. et al. First-line crizotinib versus chemotherapy in ALK-positive lung cancer. N. Engl. J. Med. 371, 2167–2177 (2014).
Peters, S. et al. Alectinib versus crizotinib in untreated ALK-positive non-small-cell lung cancer. N. Engl. J. Med. 377, 829–838 (2017).
Nicholson, A. G. et al. The 2021 WHO classification of lung tumors: impact of advances since 2015. J. Thorac. Oncol. 17, 362–387 (2022).
Warth, A. et al. Clonality of multifocal nonsmall cell lung cancer: implications for staging and therapy. Eur. Respir. J. 39, 1437–1442 (2012).
Nishino, M. et al. Histologic and cytomorphologic features of ALK-rearranged lung adenocarcinomas. Mod. Pathol. 25, 1462–1472 (2012).
Coudray, N. et al. Classification and mutation prediction from non-small cell lung cancer histopathology images using deep learning. Nat. Med. 24, 1559–1567 (2018).
Bychkov, D. et al. Deep learning identifies morphological features in breast cancer predictive of cancer ERBB2 status and trastuzumab treatment efficacy. Sci. Rep. 11, 4037–6 (2021).
Shamai, G. et al. Deep learning-based image analysis predicts PD-L1 status from H&E-stained histopathology images in breast cancer. Nat. Commun. 13, 6753–6759 (2022).
Mayer, C. et al. Direct identification of ALK and ROS1 fusions in non-small cell lung cancer from hematoxylin and eosin-stained slides using deep learning algorithms. Mod. Pathol. 35, 1882–1887 (2022).
Tan, X. et al. Predicting EGFR mutation, ALK rearrangement, and uncommon EGFR mutation in NSCLC patients by driverless artificial intelligence: a cohort study. Respir. Res. 23, 132–132 (2022).
Ren, W. et al. Deep learning-based classification and targeted gene alteration prediction from pleural effusion cell block whole-slide images. Cancers (Basel) 15, 752 (2023).
Ishii, S. et al. Machine learning-based gene alteration prediction model for primary lung cancer using cytologic images. Cancer. Cytopathol. 130, 812–823 (2022).
Terada, Y. et al. Artificial intelligence-powered prediction of ALK gene rearrangement in patients with non-small-cell lung cancer. JCO Clin. Cancer. Inform. 6, e2200070 (2022).
Chen, R. J. et al. Towards a general-purpose foundation model for computational pathology. Nat. Med. 30, 850 (2024).
Lu, M. Y. et al. Data-efficient and weakly supervised computational pathology on whole-slide images. Nat. Biomed. Eng. 5, 555 (2021).
Mao, J. et al. CAMIL: channel attention-based multiple instance learning for whole slide image classification. Bioinformatics 41, btaf024 (2025).
Moon, S. W. et al. Leveraging explainable AI and large-scale datasets for comprehensive classification of renal histologic types. Sci. Rep. 15, 1745–1748 (2025).
Juyal, D., Shingi, S., Ashar Javed, S., Taylor-Weiner, A. & Inc, P. SC-MIL: supervised contrastive multiple instance learning for imbalanced classification in pathology. In 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) pp. 7931–7940 (Waikoloa, HI, USA, 2024). https://doi.org/10.1109/WACV57701.2024.00776.
Vorontsov, E. et al. A foundation model for clinical-grade computational pathology and rare cancers detection. Nat. Med. 30, 2924–2935 (2024).
Li, J. et al. Can we simplify slide-level fine-tuning of pathology foundation models? Preprint at https://arxiv.org/abs/2502.20823 (2025).
Zhang, S. & Metaxas, D. On the challenges and perspectives of foundation models for medical image analysis. Med. Image Anal. 91 (2023).
He, Y. et al. Foundation model for advancing healthcare: challenges, opportunities and future directions. IEEE Rev. Biomed. Eng. 18, 172–191 (2025).
Oakden-Rayner, L. Exploring large-scale public medical image datasets. Acad. Radiol. 27, 106–112 (2020).
Raghu, M., Zhang, C., Kleinberg, J., Bengio, S. & Brain, G. Transfusion: understanding transfer learning for medical imaging. In Proc. 33rd International Conference on Neural Information Processing Systems. Curran AssociatesInc. Article 301, 3347–3357 (Red Hook, NY, USA, 2019).
Choi, I. H. et al. Analysis of histologic features suspecting anaplastic lymphoma kinase (ALK)-expressing pulmonary adenocarcinoma. J. Pathol. Transl. Med. 49, 310–317 (2015).
Tsaku N. Z. et al. Texture-based deep learning for effective histopathological cancer image classification. In 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) pp. 973–977 (San Diego, CA, USA, 2019). https://doi.org/10.1109/BIBM47256.2019.8983226.
Kosaraju, S. C., Hao, J., Koh, H. M. & Kang, M. Deep-Hipo: Multi-scale receptive field deep learning for histopathological image analysis. Methods 179, 3–13 (2020).
Linde, G. et al. A comparative evaluation of deep learning approaches for ophthalmology. Sci. Rep. 14, 21829 (2024).
Ochoa-Ornelas, R., Gudiño-Ochoa, A., García-Rodríguez, J. A. & Uribe-Toscano, S. Enhancing early lung cancer detection with MobileNet: a comprehensive transfer learning approach. Franklin Open 10, 100222 (2025).
Kumar, Y. et al. Automating cancer diagnosis using advanced deep learning techniques for multi-cancer image classification. Sci. Rep. 14 (2024).
Balasubramanian, A. A. et al. Ensemble deep learning-based image classification for breast cancer subtype and invasiveness diagnosis from whole slide image histopathology. Cancers (Basel) 16, 2222 (2024).
Ramamoorthy, P., Ramakantha Reddy, B. R., Askar, S. S. & Abouhawwash, M. Histopathology-based breast cancer prediction using deep learning methods for healthcare applications. Front. Oncol. 14, 1300997 (2024).
Kingma, D. P. & Lei Ba, J. Published as a conference paper at ICLR 2015 ADAM: a method for stochastic optimization (2015).
Vu, Q. D. et al. Methods for segmentation and classification of digital microscopy tissue images. Front. Bioeng. Biotechnol. 7, 53 (2019).
Kosaraju, S., Park, J., Lee, H., Yang, J. W. & Kang, M. Deep learning-based framework for slide-based histopathological image analysis. Sci. Rep. 12, 19075 (2022).
Ilse, M., Tomczak, J. M. & Welling, M. Attention-based deep multiple instance learning. In Proc. 35th International Conference on Machine Learning, 80:2127–2136, https://proceedings.mlr.press/v80/ilse18a.html (2018).
Chen, Y. et al. Clinical and the prognostic characteristics of lung adenocarcinoma patients with ROS1 fusion in comparison with other driver mutations in East Asian populations. J. Thorac. Oncol. 9, 1171–1179 (2014).
Cha, Y. J. et al. ALK-rearranged adenocarcinoma with extensive mucin production can mimic mucinous adenocarcinoma: clinicopathological analysis and comprehensive histological comparison with KRAS-mutated mucinous adenocarcinoma. Pathology 48, 325–329 (2016).
Qu, L. et al. Rethinking multiple instance learning for whole slide image classification: a good instance classifier is all you need. IEEE Trans. Circuits Syst. Video Technol. 34, 9732–9744 (2024).
Zhao, H., Jiaya, C. & Cuhk, J. Exploring self-attention for image recognition. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10073–10082 (Seattle, WA, USA, 2020). https://doi.org/10.1109/CVPR42600.2020.01009.
Vaswani, A. et al. Attention is all you need. In Proc. 31st International Conference on Neural Information Processing Systems (NIPS'17) pp. 6000–6010 (Curran Associates Inc., Red Hook, NY, USA, 2017).
Selvaraju R. R. et al. Grad-CAM: visual explanations from deep networks via gradient-based localization. In 2017 IEEE International Conference on Computer Vision (ICCV) pp. 618–626. (Venice, Italy, 2017). https://doi.org/10.1109/ICCV.2017.74.
Acknowledgements
This work was supported by the National Science Foundation Major Research Instrumentation (NSF MRI) (Grant# 2117941) and the Biomedical Research Institute fund (GNUHBRIF-2021-0003) from the Gyeongsang National University Hospital.
Author information
Authors and Affiliations
Contributions
M.K. and J.Y. designed the study. S.K. and S.P. wrote the computer code and conducted the analysis. S.K., M.K., and J.Y. led the writing. D.H., H.A., Y.C., and J.Y. collected data with annotation. D.H., H.A., Y.C., J.Y., J.H., and J.Y. conducted analysis in pathology and interpreted the computational results. All authors contributed to the manuscript and to the interpretation of the results. All authors approved the final version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Kosaraju, S.C., Parsa, S.P., Song, D.H. et al. Evidential deep learning-based ALK-expression screening using H&E-stained histopathological images. npj Digit. Med. 8, 610 (2025). https://doi.org/10.1038/s41746-025-01981-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41746-025-01981-9
