
Abstract
Archaeological illustration is a graphic recording technique that delineates the shape, structure, and ornamentation of cultural artifacts using lines, serving as vital material in archaeological work and scholarly research. Aiming at the problems of low line accuracy in the results of current mainstream image generation algorithms and interference caused by severe mural damage, this paper proposes a mural archaeological illustration generation algorithm based on multi-branch feature cross fusion (U2FGAN). The algorithm optimizes skip connections in U2Net through a channel attention mechanism, constructing a multi-branch generator consisting of a line extractor and an edge detector, which separately identify line features and edge information in artifact images before fusing them to generate accurate, high-resolution illustrations. Additionally, a multi-scale conditional discriminator is incorporated to guide the generator in outputting high-quality illustrations with clear details and intact structures. Experiments conducted on the Dunhuang mural illustration datasets demonstrate that compared to mainstream counterparts, U2FGAN reduced the Mean Absolute Error (MAE) by 10.8% to 26.2%, while also showing substantial improvements in Precision (by 9.8% to 32.3%), Fβ-Score (by 5.1% to 32%), and PSNR (by 0.4 to 2.2 dB). The experimental results show that the proposed method outperforms other mainstream algorithms in archaeological illustration generation.
Similar content being viewed by others

Introduction
Murals date back to prehistoric times and are one of the oldest forms of human art. It not only shows the way of life of human beings but also reflects their religious beliefs and aesthetic concepts. The number of mural paintings preserved in ancient China is very large [1]. With time, these mural paintings are suffering from various diseases and damage. Protecting cultural artifacts is urgent, and one of the important tasks is mural archaeological illustration.
Mural archaeological illustrations, based on the orthophoto of cultural artifacts, depict the contour features of artifacts through line tracing, serving as a crucial recording method [2]. They are indispensable components for writing archaeological reports, organizing archaeological papers, and publishing archaeological books. Moreover, archaeological illustrations serve as primary data for artifact documentation, not only facilitating research, presentation, and dissemination of archaeological findings but also serving as essential references for artifact restoration work. The creation of archaeological illustrations requires strict standards and a high level of professionalism. Presently, archaeological illustrations rely on manual drawing by experts, a process often complex and time-consuming, accompanied by the risk of secondary damage to artifacts during field surveying [3]. In recent years, the development of computer technology has introduced new approaches to archaeological illustrations, with many computer-aided algorithms emerging.
Li [4], Wang et al. [5] have proposed archaeological illustration generation algorithms based on ridge feature detection techniques for the contour lines of artifact 3D models. Liu [6] employs edge tangent line flow fields and Gaussian difference filters for line feature extraction and generation. Song [7] proposed a cellular ant colony algorithm for edge extraction of artifact orthophoto to generate archaeological illustrations. Liu et al. [8] extract feature contour lines of artifact 3D models based on visual curvature estimation. The generation of illustrations from 3D models is a part of the field of archaeological illustrations, but this paper mainly studies the generation of illustrations from 2D murals. In this paper, as shown in Fig.1, we use an algorithm to convert the orthophoto of the mural directly into an archaeological illustration. These studies employ algorithmic approaches to generate illustrations and produce initial archaeology sketches, thus improving drawing efficiency. However, traditional feature extraction algorithms still encounter challenges such as cluttered lines, excessive noise, and contour artifacts.
In recent years, the rapid development of deep learning technology has brought new opportunities for archaeological illustration generation algorithms. In 2016, Badrinarayanan et al. [9] proposed SegNet, a deep network for semantic image segmentation, which used an encoder-decoder architecture to segment images into different semantic regions. The Bilateral Decomposition Convolutional Network (BDCN) [10] was introduced in 2019, which incorporates bilateral decomposition convolution to consider both spatial distances and pixel intensity differences, thus preserving more valid edge information in images. pix2pix [11], proposed by Phillip et al., is an image translation model based on Conditional Generative Adversarial Networks (CGANs) [12], capable of mapping real images to label maps. Wang [13] et al. enhanced the capabilities of pix2pix by introducing a high-resolution image generation network. This network can produce images of higher quality and more details, particularly effective in processing high-resolution images and complex scenes. Qin et al. [14] proposed a saliency object detection model named U2Net in 2020, which effectively separates the foreground and background of images and demonstrates excellent capability in capturing details.
The aforementioned deep learning methods can be used for preliminary illustration generation, which can partially alleviate issues such as noise and cluttered lines in traditional algorithms. However, there are some limitations that need to be addressed for practical applications: Firstly, these deep learning models are not specifically designed for the task of archaeological illustration generation. Complex artifact backgrounds and damage disturbances may affect the effectiveness of archaeological illustration generation. Therefore, it is necessary to optimize algorithms specifically for the characteristics of archaeological illustrations to achieve the goal of transfer learning. Secondly, current mainstream image algorithms can only handle low-resolution images, while the expected generated illustrations typically require higher resolutions. This necessitates either cropping or downsampling to reduce image resolution, which may result in loss of image information. Therefore, it is essential to design deep networks effectively to enhance their performance in handling high-resolution images. In summary, there is a need for the rational design of deep networks to strengthen their capabilities in handling high-resolution images, considering the unique requirements of archaeological illustration generation tasks.

What our model can do
In response to the aforementioned challenges, this paper proposes an archaeological illustration generation algorithm based on multi-branch feature fusion (U2NetSE-Fusion-GAN, U2FGAN), with the following key contributions:
-
a) Introducing a Channel Attention Module, SEConvBlock, to capture correlations between feature channels, enhancing feature extraction efficiency and selectivity.
-
b) Proposing a deep feature extraction network, U2NetSE, which optimizes the skip connections in U2Net using SEConvBlock, thus improving the network ‘s ability to learn shallow feature representations.
-
c) Presenting a generator with a multi-branch feature fusion structure, comprising a Line Extraction Module (LEM) and an Edge Detection Module (EDM). The Cross Fusion Module (CFM) integrates the edge information extracted by EDM into the coarse illustration results from LEM, further enhancing the quality of illustration generation.
-
d) The proposed method achieves high-resolution archaeological illustration generation on the Dunhuang mural illustration dataset, outperforming current mainstream image generation methods.
These contributions collectively address the challenges posed by generating high-quality archaeological illustrations, providing advancements in feature extraction, feature fusion, and overall illustration generation performance.
Related works
Conditional generative adversarial network
Generative Adversarial Networks (GANs) [15] were initially proposed by Ian J. Goodfellow et al. aiming to generate realistic images through adversarial training between a generator and a discriminator, continuously optimizing their parameters to achieve the goal of generating lifelike images. However, GANs typically take random noise as input, which may lead to training difficulties due to information loss. Mehdi et al. [12] addressed this issue by adding supervised information as conditional constraints, proposing Conditional Generative Adversarial Networks (CGANs). As shown in Fig. 2, CGANs take not only random noise but also real label information as input. This improvement enables the generator to generate desired images more effectively, while the discriminator can provide more directional feedback to the generator, thereby optimizing the overall performance of the model. The method proposed in this paper is also designed based on the core idea of CGANs, allowing the model to continuously improve through the training process of generation, discrimination, and feedback optimization.

Structure of conditional generative adversarial networks
Attention mechanism
The task of image generation involves the generation and processing of a large number of intermediate feature maps, as well as complex information transformation processes. The introduction of attention mechanisms [16,17,18] allows the model to dynamically allocate weights to features, effectively enhancing the model’s ability to identify and select key information, enabling the model to focus on essential features. SENet (Squeeze-and-Excitation Network) [19] is a kind of channel attention mechanism, with its core design revolving around a branch structure comprising two key steps: feature squeezing and channel excitation, as depicted in Fig. 3.

Structure of SENet
In SENet, each channel’s feature map is first compressed through global average pooling (Avgpool) to obtain a global statistical vector on the channel dimension. Subsequently, this global information is mapped back to the original channel space using two serially connected fully connected layers (FC) and an activation function to compute adaptive weights for each channel’s features. This process can be represented by Eq. (1).
Method
The task of archaeological illustration generation imposes several requirements on the target model:
-
1. Handling High-Resolution Images: The model could process high-resolution images effectively.
-
2. Comprehensive Hierarchical Feature Extraction: It should possess complete hierarchical feature extraction capabilities, capturing not only low-level features such as edges and textures but also learning complex spatial structures and semantic information.
-
3. Stability in GAN Framework: For GAN-based generation models, the training process should be as stable as possible, avoiding issues like mode collapse and vanishing gradients. Additionally, it should maintain good robustness to artifacts accompanying the images, such as damages.
-
4. Optimized Parameterization: The model should optimize parameter quantities as much as possible to accelerate network training and inference processes, thereby improving computational efficiency.
Based on these requirements, this paper proposed an archaeological illustration generation model based on multi-branch feature cross fusion (U2NetSE-Fusion-GAN, U2FGAN), aimed at generating high-resolution and finely detailed illustrations.
The structure of U2FGAN is depicted in Fig. 4, which is designed within the framework of Conditional Generative Adversarial Networks (CGANs). It consists of a Multi-branch Feature Fusion Generator (MFFG) and a Multi-Scale Conditional Discriminator (MSCD).

Archaeological illustration generation model based on multi-branch feature cross fusion
The generator consists of two parallel branches: the Line Extraction Module (LEM) and the Edge Detection Module (EDM), followed by a Cross Fusion Module (CFM) to merge the feature maps outputted by both branches. The discriminator is built on a fully convolutional Markovian discriminator [11] and incorporates a multi-scale approach. It employs multiple sub-discriminators to resize the input image to different resolutions for discrimination, thereby capturing the authenticity of the image at multiple hierarchical levels of detail. To further enhance the feature extraction capabilities of the two branches, specific illustration labels and grayscale labels are applied separately to LEM and EDM for supervision, enabling them to focus on feature extraction in different image domains.
The workflow of U2FGAN for generating illustrations is as follows: After the input of the archaeological orthophoto Iin into the network, Branch One extracts the coarse illustration Icoarse through the Line Extraction Module (LEM), as described in Eq. (2); meanwhile, Branch Two preprocesses Iin into a gradient image Iin_gray through the Grayscale Preprocessing Module (GPM), then extracts edge information Igray using the Edge Detection Module (EDM), as described in Eq. (3). The Cross Fusion Module (CFM) integrates Igray into Icoarse, further generating a higher-quality archaeological illustration Iout, as described in Eq. (4). Multi-scale Adversarial Loss (Lmadv) and Feature Consistency Loss (Lfc) are used to quantitatively evaluate the differences between the generated illustration Iout and the ground truth label Igt. Feature Consistency Loss is also applied to LEM and EDM to compute distances, ensuring the correctness of training directions for each branch while avoiding issues such as model collapse.
where Iin ∈ ℝH×W×3, Icoarse ∈ ℝH×W×3, Iin_gray ∈ ℝH×W×1, Igray ∈ ℝH×W×1, Iout ∈ ℝH×W×3, Igt ∈ ℝH×W×3, and Concat denotes the channel concatenation operation.
U2NetSE core network
To extract effective information from archaeological images, this paper proposed a deep feature extraction network named U2NetSE. Based on this network as the core, we constructed the Line Extraction Module (LEM) and the Edge Detection Module (EDM), each designed to extract distinct features of the illustrations.
The network architecture of U2NetSE is illustrated in Fig. 5, which is nested on the basis of U-Net, forming the fundamental unit called Residual U-block (RSU). RSU-n (where n represents the depth of the internal network within the basic unit, i.e., the number of downsampling layers) at different scales are sequentially connected to form an encoder-decoder architecture. Feature skip connections are employed both within RSU and between different RSUs. The final output image integrates side output features from multiple RSUs in the decoding stage, and the final output result is obtained through concatenation and convolution operations, as shown in Fig. 5. U2NetSE inherits the advantages of lightweight U-Net, adopting the classic encoder-decoder architecture and feature skip connections. However, U2NetSE features a deeper network structure and denser feature concatenation. It also involves specific supervision of side outputs at different stages and multi-scale feature fusion, enabling the network to capture richer image information. Therefore, it exhibits a more significant capability in handling edge details and other aspects. The overall computational process is described by Eqs. (5, 6, 7, 8).
where i represents the index of encoding and decoding stages, fei denotes the feature map outputted by the i-th RSU during the encoding stage, fdi represents the feature map outputted by the i-th RSU during the decoding stage, Encoder_i and Decoder_i respectively signify the processing of feature maps by the i-th RSU in the encoding and decoding stages, Conv denotes the convolution operation, and Concat indicates the channel concatenation operation.

Structure of U2NetSE
U2NetSE is an improved version of U2Net [14], primarily featuring two enhancements. Firstly, the feature skip connections of U2Net are optimized by embedding an attention mechanism. The original feature connection method of U2Net simply concatenates shallow features with deep semantic features, treating all shallow features as equally important in both channel and spatial dimensions. However, noise and other irrelevant information within these shallow features may potentially hinder the performance of the decoder. Therefore, this paper proposes the Channel Attention Module (SEConvBlock) to enhance the feature selection capability and fusion effect of the skip connections in U2Net. As illustrated in Fig. 6, SEConvBlock replaces the fully connected layer in SENet with convolutional layers, optimizing parameter calculation through weight sharing while preserving the spatial structure of feature maps and effectively utilizing local feature correlations. Additionally, SEConvBlock introduces residual connections [20] in feature calculation, incrementally incorporating attention-weighted features into the original feature maps. This change facilitates more effective gradient propagation in the network, enhancing the feature extraction capability of deep networks and mitigating the problem of gradient vanishing to some extent. By integrating SEConvBlock into the feature skip connections, U2NetSE dynamically learns the shallow features while suppressing some noise information, as described in Eq. (9).

Structure of SEConvBlock
Another optimization in U2NetSE involves the use of instance normalization [21] to normalize data in network computations, replacing the original batch normalization [22] method. Due to the large memory requirement for processing high-resolution images, the network training adopts a strategy of small-batch training. Batch normalization may encounter significant data fluctuations in tasks involving small batches of image generation, potentially leading to decreased generation quality and mode collapse issues. In contrast, instance normalization operates on the channel dimension of individual samples, avoiding the statistical instability caused by small batch sizes and better preserving the characteristics of each independent sample.
Multi-branch archaeological illustration generation framework based on CGAN
This paper employs the Conditional Generative Adversarial Network framework to construct the illustration generation model. Compared to conventional neural networks, generative models based on GANs demonstrate superior performance in high-resolution image generation tasks [15]. By introducing an adversarial training mechanism, the generator continually learns deeper and more complex feature structures from the dataset during the adversarial process, which allows the generator to simulate subtle textures and color variations of real images at the pixel level, thereby achieving more refined and high-quality image generation.
Therefore, this paper adopted an end-to-end supervised learning approach and designs a Multi-branch Feature Fusion Generator (MFFG) and a Multi-Scale Conditional Discriminator (MSCD) based on the GAN framework, thus constructing the archaeological illustration generation model, U2FGAN. Additionally, for the task of archaeological illustration generation, Multi-scale Conditional GAN Loss (Lmadv) and Feature Consistency Loss (Lfc) are designed to guide the model training process.
Multi-branch feature fusion generator
The Multi-branch Feature Fusion Generator (MFFG) consists of the Line Extraction Module (LEM), the Edge Detection Module (EDM), the Grayscale Preprocessing Module (GPM), and the Cross Fusion Module (CFM), as illustrated in Fig. 7.

Structure of multi-branch generator
1) Line Extraction Branch Branch One is built upon the Line Extraction Module (LEM), with its core network being the U2NetSE. Its primary objective is to extract fundamental line features from archaeological images, ultimately producing a coarse illustration, as illustrated in Fig. 4. The LEM effectively filters out irrelevant details, focusing solely on capturing the shape and essential line information of archaeological artifacts. Additionally, the LEM is capable of learning high-level semantic features to express both the global context and local details of the artifacts, such as shape, texture, color, etc., enabling precise pixel-level predictions. Overall, Branch One provides the overall morphology and structural layout of archaeological lines, serving as a foundational guide for subsequent fine line generation. This ensures that the final illustration accurately represents the basic shape and proportion relationships.
2) Edge Detection Branch Branch Two consists of the Grayscale Preprocessing Module (GPM) and the Edge Detection Module (EDM). GPM initially transforms the RGB-format archaeological image into a grayscale image, denoted as ILaplacian, using the Laplacian operator. This conversion aims to reduce interference from color information and enhance the contrast between object boundaries and lines, as shown in Eq. (10). Subsequently, the image undergoes denoising using the Non-Local Means algorithm (NL-means, an image denoising technique that reduces noise by averaging similar pixel patches across the entire image, effectively preserving details like edges and textures.) [23] to eliminate noise points and other non-structured elements, resulting in Igray, as demonstrated in Eq. (11). This process improves the accuracy of edge detection. EDM, on the other hand, employs the U2NetSE core network to precisely extract fine-grained edge information from Iin_gray, yielding a detailed gradient map, Igray. Overall, Branch Two captures the boundaries and transitional areas of minor details in archaeological artifacts through precise edge detection, such as decorations, cracks, and abrasion marks. These edge details contribute to further refining the contours of archaeological artifacts and improving the accuracy of line extraction.
where ILaplacian ∈ ℝH×W×1, Ω is the set of similar blocks in the image corresponding to position (x, y), p is a pixel point in Ω with coordinates (x, y), h is a parameter controlling the similarity, Z(x, y) is the normalization factor, and N and Np are neighboring pixel blocks of point p[23].
3) Cross Fusion Module The main function of the Cross Fusion Module (CFM) is to integrate the line features extracted by LEM and the fine-edge features extracted by EDM. CFM comprises normalization layers, a cross-attention module, and convolutional output layers, as depicted in Fig. 8. This paper proposed a cross-attention module, whose structure is illustrated in Fig. 8. Different from conventional attention mechanisms, cross-attention enables interaction and fusion between two feature maps from different sources.

Structure of Cross Fusion Module
After inputting two feature maps, they are projected into three tensors: query vector Q, key vector K, and value vector V. Then, the attention weight map between the Q of the first feature map and the K of the second feature map is calculated through dot-product operations. Based on this weight matrix, the V of the second feature map is weighted and summed, extracting the correlation between the two feature maps. The feature map projection operations in this paper are all achieved through convolutional calculations. Additionally, the final output of the cross-attention feature map incorporates a residual accumulation operation on the original V to preserve the information of the input feature maps.
The cross-attention mechanism aids the model in extracting key parts from multiple cross-domain features, facilitating efficient information integration, and ultimately outputting high-quality archaeological illustrations.
4) Specific label monitoring To facilitate the learning of different illustration features by LEM and EDM respectively, this paper designed specific supervisions for both branches. For Branch One, illustration labels denoted as Igt, are employed for supervision, while Branch Two employs gradient labels, denoted as Igt_gray, for supervision. Igt_gray is obtained from Igt through preprocessing by GPM.
The specific supervision method enables LEM to focus on learning how to accurately extract the line structures and overall semantic information from the images. Additionally, the line intensity variation information provided by Igt_gray enhances the perception ability of EDM regarding edge continuity. This encourages EDM to pay more attention to minor changes and texture characteristics of archeological artifact edges, thus extracting more delicate edge features.
These two specific supervisions enable LEM and EDM to complement each other’s roles effectively and enhance the overall quality and robustness of illustration generation.
Multi-scale conditional discriminator
The task of the Multi-Scale Conditional Discriminator (MSCD) is to assess the authenticity of the archaeological illustrations generated by the Multi-branch Feature Fusion Generator (MFFG). Its network structure is illustrated in Fig. 8. Through adversarial training mechanisms, MSCD aims to enhance its ability to distinguish between generated illustrations and ground truth (Archaeological illustrations drawn by experts), while also driving the MFFG to optimize its output images.
MSCD is constructed based on a Markovian discriminator, with its core idea being to represent the dependency and similarity between local regions of an image. Therefore, the discriminator can focus on the local consistency and global contextual connections of the image, enabling more accurate identification of potential local distortions or overall inconsistencies in forged images. In addition, MSCD incorporates the concept of conditional discrimination by simultaneously inputting archaeological images and ground truth to guide the discrimination process. This ensures semantic correlation and visual consistency between the generated illustrations and the original artifacts, thereby better guiding the generator to generate matching line depictions based on the real content of the artifacts. Furthermore, MSCD adopts a multi-scale architecture by employing multiple sub-discriminators. It constructs an image pyramid by downsampling the input image and feeds the corresponding scale of the image to each sub-discriminator to extract features, as illustrated in Fig. 9. This multi-scale approach enhances the discriminative capability of MSCD and improves its ability to capture features at different levels of detail.

Structure of Multi-Scale Conditional Discriminator
Through conditional input and multi-scale analysis, MSCD not only enables the evaluation of the overall structure but also considers detailed information in images, enhancing the ability to distinguish complex textures and fine structures. It effectively guides the output of MFFG to produce high-quality illustrations that are rich in detail and conform to the characteristics of the original objects.
Loss function
The loss function of the model in this paper includes the multi-scale conditional adversarial loss Lmadv and the feature consistency loss Lfc. It guides the training process of U2FGAN by quantifying the differences between the outputs of each module and their corresponding labels.
1) Multi-scale conditional counteraction loss: The formula representation of the multiscale conditional adversarial loss Lmadv is expressed as Eqs. (12)(13)(14), which consist of two terms, Ladv_CFM and Ladv_LEM, respectively discerning the authenticity of the illustrations output by the Cross-Fusion Module (CFM) and the Line Extraction Module (LEM).
where Iin represents the input cultural artifact image, Igt represents the illustration labels, Iout represents the illustration output by the cross-fusion module, Icoarse represents the coarse illustration output by the line extractor, ωm1 and ωm2 represent the weights of adversarial loss for different modules.
2) Feature Consistency Loss The formula representation of the Feature Consistency Loss Lfc in U2FGAN is expressed as Eq. (15), composed of three sub-terms: Lfc_CFM, Lfc_LEM, and Lfc_EDM. Lfc uses MSCD and VGG19 [24] to extract intermediate features of images and calculates their Manhattan distance, as shown in Eqs. (16, 17, 18). Lfc ensures that the model can better capture the transition from shallow to deep features when generating high-resolution images, enabling the generated images to not only closely resemble real images at the pixel level but also possess higher coherence and consistency at the semantic level.
where Igray represents the edge feature map output by the edge detector, ωf1, ωf2, and ωf3 respectively represent the weights of feature consistency loss for different modules.
Experiment setup
Dataset
The data used in this study is sourced from the murals of the Mogao Grottoes in Dunhuang, which include depictions of Buddhas, palaces, and more. In the model training phase, these manual illustrations drawn by archeologists are essential, and the model can learn the mapping relationship from the original mural image to the illustrations based on these data. When actually using this model to generate an illustration, only the original mural image is needed as input.
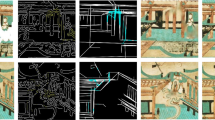
To train the model, the original data needs to be prepared into one-to-one paired images of cultural artifacts and archaeological illustrations. The process of creating the dataset is as follows: (1) Adjust the contrast of the illustrations to make the lines more prominent and remove noise from the images. (2) Align the content of the cultural artifact images with the archaeological illustrations, crop them into pairs of different scales, and then resize them to a uniform resolution of 1024 × 512. (3) Augment the dataset using data augmentation strategies and divide it into training and testing sets. In the end, this paper constructed a Dunhuang mural illustration dataset consisting of 444 pairs of training samples and 88 pairs of independent testing samples, which were used for training and testing deep neural networks. A portion of the dataset is illustrated in Fig. 10.

Examples of archaeological illustration datasets
Experiment parameter
The experiments were conducted on a deep learning platform equipped with an NVIDIA GeForce RTX 3090Ti GPU (with a memory capacity of 24 GB) running Windows 10. The deep learning framework used was PyTorch. The Adam optimization strategy was employed to update network parameters, with an initial learning rate set to 0.0002, a momentum decay factor β1 set to 0.5, and an infinite norm decay factor β2 set to 0.999. The entire training process was divided into two stages, with a total of 200 epochs. During the first 100 epochs, the initial learning rate remained unchanged, while a linear learning rate decay strategy was adopted for the subsequent 100 epochs to train the network.
Evaluation index
To objectively evaluate the differences between generated illustrations and labels, this paper constructs an archaeological illustration evaluation system using Mean Absolute Error (MAE), Precision, Fβ-Score, and Peak Signal-to-Noise Ratio (PSNR).
MAE is defined as the absolute difference between the pixel values of the generated illustrations and the labels, directly reflecting the extent of deviation calculated by the model. The formula is as follows:
where I1(i, j) and I2(i, j) represent the pixel values of two images at position (i, j) respectively, and W and H denote the number of pixels in the width and height directions of the images.
Precision and Recall are both used to evaluate the proportion of correctly predicted line pixel points in the generated illustration, reflecting the accuracy of the model in generating lines. The difference lies in Precision’s focus on whether the prediction is correct, while Recall tends to indicate whether there are any omissions in the prediction. The formulas are as follows:
where Npred_true represents the number of pixels corresponding to correctly predicted lines in the generated illustration, Npred represents the total number of pixels of lines in the generated illustration, and Ngt represents the total number of pixels of lines in the ground truth labels.
Fβ-Score combines the evaluation indexes of Precision and Recall, enabling the simultaneous consideration of the accuracy and completeness of the model in generating lines. The formula is:
where β is the parameter for adjusting the weight, and in this paper, the value of β is set to 0.3.
PSNR is used to assess the level of picture quality loss in the generated illustrations and is defined as:
where MAXI represents the maximum pixel value of the image, i.e., 255, and MSE represents the mean squared error.
In the above indexes, a smaller MAE value indicates better quality of the generated illustrations, while larger Precision, Fβ-Score, and PSNR values represent higher accuracy in illustration generation.
Experiment result and analysis
Comparison with other networks
Qualitative analysis
To evaluate the effectiveness of the proposed method in generating illustrations in this paper, we compared the U2FGAN proposed in this paper with four other algorithms: BDCN, SegNet, pix2pixHD, and U2Net. The experiments were conducted using a self-built dataset of Dunhuang mural illustrations.
Figure 11 compares the results of illustration generation by the aforementioned five algorithms. From the figure, it can be observed that the generation results of BDCN, SegNet, and pix2pixHD are not satisfactory, as they struggle to capture the details inside the Buddhas, exhibiting only rough overall outlines. BDCN produces thick lines, and the lines in densely populated areas are blurry and indistinguishable. pix2pixHD can extract more details, such as the head decorations and facial features of the Buddhas in the third image, but it still suffers from line breaks and distortions. SegNet shows improved line extraction compared to pix2pixHD, as seen in the clothing patterns and facial features in the first image, but there is still room for enhancement in overall semantic and structural information.

Results of comparative experiments (a) The original painted mural images; b Ground truth; c BDCN; d SegNet; e pix2pixHD; f U2Net; g Ours; The figures below (a1-g1) are the corresponding partially enlarged details
The three models only exhibit some similarity to the labels in terms of the outer contours and fail to effectively convey the overall structure and local details of the artifacts. U2Net not only generates complete outer contours but also extracts some local details. However, it suffers from severe line artifacts and generates many false lines. Moreover, the distinction between lines in densely detailed areas is not clear, resulting in inaccurate line generation in detail-rich regions such as clothing textures and eyes.
Compared to the existing four algorithms, the proposed method in this paper not only ensures the accuracy of the lines but also preserves the basic features of the artifacts. The line expression in local areas such as faces, hair decorations, and clothing patterns is more accurate and smoother. There is also improvement in structural integrity and noise suppression. In summary, the overall generation effect is optimal.
Quantitative analysis
Table 1 presents a comparison of the performance indexes of the aforementioned five algorithms in generating illustrations. From the table, it can be observed that the algorithm proposed in this paper outperforms the other algorithms in all evaluation indexes. Specifically, the MAE values are reduced by 26.18%, 11.96%, 19.43%, and 10.75% relative to the aforementioned four algorithms, indicating a higher similarity between the generated illustrations and the labels. In terms of Precision, the algorithm proposed in this paper improves by 27.37%, 18.21%, 32.33%, and 9.84% relative to the aforementioned four algorithms, indicating more accurate lines with smaller errors in the generated illustrations.
Furthermore, the Fβ-Score of the algorithm proposed in this paper improves by 5% to 32% compared to other models, indicating superior completeness and accuracy of line generation. Lastly, the PSNR improves by 3.77% to 22% compared to other algorithms, demonstrating a stronger ability to suppress noise and a higher quality of generated line graphs.
In summary, the illustrations generated by U2FGAN outperform current mainstream algorithms in terms of both image quality and evaluation indexes.
The analysis of model design
The proposed method is based on U2Net, with improvements made by introducing an attention mechanism. Subsequently, we incorporated the CGAN framework and designed a multi-branch structure, ultimately forming the complete model. To evaluate the effectiveness of each design component, we conducted four sets of comparative experiments.
Effects of core network U2NetSE
The core network U2NetSE proposed in this paper is the result of optimizing skip connections in the U2Net. We designed comparative experiments to evaluate its effectiveness in illustration generation tasks. We used BDCN, SegNet, U2Net, and U2NetSE to generate illustrations from the Dunhuang mural dataset and compared the performance of each network.
The evaluation results for different networks are presented in Table 2. U2Net exhibits an average error 17% lower than BDCN and 1% lower than SegNet, this suggests that U2Net generates lines that are closer to the ground truth. Examining the Fβ-Score index, U2Net achieves 15% higher than BDCN and 11% higher than SegNet. This indicates that U2Net achieves a better balance between precision and recall, outperforming conventional networks.
In addition, we compared the visual perception of the illustration generation effects of different networks, as shown in Fig. 12. Sketches generated by BDCN appear rough, with thick and blurry lines. The second and third images exhibit fewer noise and defects, but they lack many facial details of the Buddhas. SegNet generates clearer line directions with richer illustration details, but there is more displacement compared to the actual labels, especially evident in the third image, where facial distortion is severe, making it difficult to discern facial contours. U2Net depicts more details in the illustrations. For instance, there are more clothing patterns in the first image, and rudimentary eyes and mouths are visible in the third image, indicating U2Net’s stronger line extraction capability and generation accuracy. We also compared the generation effects of U2Net and U2NetSE. From the third image, we notice that U2NetSE produces smoother curves and clearer boundaries in different areas, with distinct outlines of eyes and mouths.

Results of U2NetSE comparative experimental
According to the indexes in Table 2, U2NetSE performs slightly worse than U2Net. This could be due to some unclear boundaries in the original images and the enhanced ability of the attention mechanism to recognize and extract small local details, mistakenly identifying textures of defects as contour lines. Although the overall results of U2NetSE may have blurry line edges, it better preserves subtle lines in the images, which is crucial for accurately identifying severely damaged areas and generating high-quality illustrations. Therefore, we chose U2NetSE as the core network and proceeded with further improvements.
Effects of the CGAN framework
To address the drawback of line blurring in the U2NetSE network proposed in this paper, we adopted the CGAN framework. We used U2NetSE as the generator in CGAN, with real images as input to the discriminator, seamlessly integrating U2NetSE with CGAN to form a new model (Different from U2FGAN, there is no multi-branch cross-fusion, and the purpose is only to verify the effects of CGAN framework, referred to as U2GAN hereafter). Traditional discriminators typically focus only on the overall features of images, resulting in weaker discrimination capabilities for detailed parts. To overcome this issue, we employed a multi-scale discriminator, enabling discrimination of images at different scales to better capture detailed information and improve line clarity.
To evaluate the effectiveness of this design, we compared the results of U2NetSE, CGAN, and U2GAN, as shown in Fig. 13.

Results of U2GAN comparative experimental
The results of CGAN exhibit lower overall line accuracy, with tendencies for line misalignment and poorer fluidity, leading to line breaks. In the first image, the folds of the clothing appear chaotic, while U2NetSE shows coherent lines that indicate the direction of the clothing folds. In the second image, facial details are missing, and the lines are completely distorted and indistinguishable. Despite CGAN’s inferior performance, its lines exhibit clearer edges compared to U2NetSE. After embedding U2NetSE into the CGAN framework, we observed that U2GAN’s results assimilate the advantages of both networks. It generates illustrations with clearer line edges, higher line accuracy, and smoother flow, thereby better preserving the genuine information of the images.
The generator of the CGAN network used in this study employs only a few fully connected layers to generate images through operations such as deconvolution. While this structure can learn the overall distribution of images, it lacks the ability to depict fine details, often resulting in generated images missing many details. U2NetSE adopts an encoder-decoder structure, which can excavate deep-level information from images at multiple scales. However, it is susceptible to interference from diseases or noise, leading to errors such as false lines. The CGAN framework can utilize a discriminator to discern and correct generated images, thereby improving the realism and accuracy of the generated images.
Experimental comparisons demonstrate that U2GAN achieves excellent practical results, effectively addressing the issue of line blurring in U2NetSE. However, careful observation of its results reveals the presence of some noise around the lines, indicating the direction for further improvement.
Effects of multi-branch design
Because U2GAN tends to generate many noise points when generating illustrations, we designed a multi-branch feature fusion generator composed of LEM and EDM branches. LEM extracts line features to generate rough illustrations, while EDM is responsible for detecting edge details and supplementing information. Finally, these branches are fused to produce the final illustration. The optimized model is compared with the U2GAN effect in Fig. 14.

Results of U2FGAN comparative experimental
From an overall perspective, the first and third images display the complete view of the entire Buddha. Our method presents a cleaner overall picture, with clearer details in densely packed lines. Comparing the second and fourth images, the effectiveness of our method is evident. There are no isolated noise points or gray clusters around the lines. In contrast, U2GAN’s processing of the Buddha’s lower part in the second image almost merges two adjacent lines into one, whereas our method successfully distinguishes them. The fourth image not only removes noise but also better restores details on the face, with contours of the eyes and mouth more realistically depicted. This improvement may be attributed to the complementary nature of the dual branches, which focus on the generation of authentic lines by reducing noise generation. The differences in the results from the dual branches also drive the optimization of the line’s correct position through the Cross Fusion Module. These improvements in the results demonstrate that our model U2FGAN effectively addresses the shortcomings of U2GAN and produces satisfactory results through the extraction of multi-branch.
In Fig. 15, we present the convergence curves of the loss functions for our model on the training dataset. The three modules of U2FGAN (LEM, EDM, and CFM), as well as the generator and discriminator, exhibit favorable convergence curves on the Dunhuang mural dataset, with the loss values steadily and rapidly decreasing towards convergence. Throughout the training process, we observed a good balance in the adversarial learning between the generator and discriminator. This indicates that the loss functions and network architecture we adopted effectively promote stable training and convergence of the model.

Loss of each module
Overall, our strategy has effectively enhanced the model’s generation capability and convergence speed. In future research, we aim to further explore the model’s generalization ability and its applicability to other artistic datasets, thereby further enhancing the performance and practical value of the model.
Effects of attention module selection
The model proposed in this paper originates from U2Net and uses SEconvBlock to optimize U2Net, resulting in the core network U2NetSE. Subsequently, the CGAN framework and multi-branch design are introduced. It can be said that the effectiveness of U2NetSE forms the foundation of the overall model’s generation performance. Among them, the most crucial aspect to consider is the selection and optimization of attention modules. Therefore, this paper compares and analyzes various attention mechanisms and the original SENet.
The attention mechanisms involved in the comparison are SE, ECA, CBAM, and DA. These attention modules are respectively replaced with the original SEconvBlock in the model, and their evaluation indexes are presented in Table 3. The U2FGAN model, which employs SEconvBlock, outperforms the other attention modules across all four evaluation indexes. Therefore, from an index-based evaluation standpoint, using SEconvBlock yields superior generation results compared to other attention modules.
The performance comparison is illustrated in Fig. 16. In the absence of attention mechanisms, U2GAN results may exhibit some discontinuities and gaps. When the SE module is incorporated, the generation performance does not improve, and even more details are lost, as seen in the fourth image where most of the Buddha’s clothing folds are not generated. This may be attributed to the SE module causing the model to focus more on relatively prominent edge information, thus reducing the extraction of less prominent internal details. ECA, being an improved version of SE, yields similar effects to the SE module.

Results of attention modules comparative experimental
CBAM and DA both consist of new attention modules formed by concatenating or paralleling two attention modules. Compared to not including any attention modules, the generated illustrations are richer in some aspects but also lose some details. For example, in the third image, both CBAM and DA supplement the right upper edge of the hair, but there is a deficiency in the top hair bun. In the fourth image, CBAM generates more complete clothing folds, while DA only produces a few dashed lines. This may be because the model is already complex enough, and using structurally complex attention modules increases the overall computational load, leading to slower training speeds and increased latency during inference. This is reflected in the decrease in model performance.
The results of CBAM and DA indicate that complex attention modules may not be suitable for the architecture of the U2Net model. Therefore, we opted for relatively lightweight attention modules, SE and ECA, for improvement. Ultimately, based on actual performance, we chose SEconvBlock (an improved version of SE), as shown in the last column of Fig. 16. Compared to the results of other attention modules on the left, SEconvBlock generates richer and more complete details. Overall, SEconvBlock exhibits the best performance among the various attention modules, evaluating the relatively rational choice of attention modules in our model.
Generalization verification
This model performs excellently on the Dunhuang mural dataset. Due to the diverse styles of different archaeological artifacts’ images, we must design specific illustration generation models for different data. If this model can achieve good results on other artifact datasets, it could greatly facilitate archaeological illustration work. Therefore, we also investigate the generalization of the model on other datasets.
We constructed a dataset of murals with a completely different style and used the U2Net and U2FGAN mentioned in this paper for illustration generation, as shown in Fig. 17. U2Net restores the overall contour and many details of the Buddha statues, but there are problems of line blurring and overlapping, resulting in a very blurry visual effect in Fig. 17. The effect of U2FGAN is relatively much better, with more solid lines and details that were ignored by U2Net being supplemented. The second and fourth columns of Fig. 17 are enlarged detailed images, where it can be seen that the clothing lines generated by U2FGAN are coherent, with more details restored, and the overall effect is closer to the ground truth.

Comparison of generalization verification
Conclusion
This paper proposed a mural archaeological illustration generation algorithm called U2FGAN based on multi-branch feature cross fusion. The algorithm introduces a channel attention module, SEConvBlock, which optimizes SENet using convolutional calculations and residual connections to enhance the module’s computational efficiency and feature selection capability. By improving the skip connections in U2Net with SEConvBlock, the U2NetSE core network is proposed, which enhances the representation of line features while suppressing some noise. Based on U2NetSE, line extractors and edge detectors are constructed for extracting line features and edge information of artifact images, respectively, and then fused to obtain precise illustrations. Experimental results show that compared to current mainstream image generation methods, U2FGAN generates illustrations with clearer details and more accurate lines, achieving optimal performance in evaluation indexes such as MAE, Precision, Fβ-Score, and PSNR, with overall results closer to the ground truth. However, the proposed method exhibits less stability in small sample data, potentially resulting in issues like line breaks and detail loss, and the overall network parameter size is relatively large with lower computational efficiency. Therefore, future work will focus on improving network structure and training strategies, such as lightweight model design and transfer learning strategies, to achieve better illustration generation results.
Availability of data and materials
No datasets were generated or analysed during the current study.
Abbreviations
- U2FGAN:
-
U2NetSE-Fusion-GAN
- U2GAN:
-
U2NetSE-GAN
- LEM:
-
Line Extraction Module
- EDM:
-
Edge Detection Module
- CFM:
-
Cross Fusion Module
- CGAN:
-
Conditional Generative Adversarial Network
- MFFG:
-
Multi-branch Feature Fusion Generator
- GPM:
-
Grayscale Preprocessing Module
- MSCD:
-
Multi-Scale Conditional Discriminator
References
Yu T, Lin C, Zhang S, Wang C, Ding X, An H, Liu X, Qu T, Wan L, You S, Wu J, Zhang J. Artificial intelligence for Dunhuang cultural heritage protection: the project and the dataset. Int J Comput Vision. 2022;130(11):2646–73. https://doi.org/10.1007/s11263-022-01665-x.
Adkins L, Adkins R. Archaeological illustration. Cambridge: Cambridge University Press; 1989.
Ma H. Drawing of archaeological artifacts. Beijing: Peking University Press; 2008.
Li X. Research and implementation of line graph generation and measurement method of 3D model of cultural relics. Xi’an: Northwest University; 2013.
Wang X, Geng G, Li X, Zhou J. A cultural relic line drawings generation algorithm based on explicit ridge line. In: 2015 International Conference on Virtual Reality and Visualization. 2015. pp. 173–176. https://doi.org/10.1109/ICVRV.2015.14.
Liu F. Generation and rendering of non-photorealistic line graph based on two-dimensional images. Xi’an: Northwest University; 2013.
Song Q. Research and implementation of cultural relics line drawing method based on cellular ant colony edge extraction. Xi’an: Northwest University; 2019.
Liu J, Zhou M, Geng G, Shen Y. Drawing method of cultural relics line drawing based on visual curvature estimation. Comput Sci. 2017;44(Z11):244–50.
Badrinarayanan V, Kendall A, Cipolla R. Segnet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans Pattern Anal Mach Intell. 2017;39(12):2481–95. https://doi.org/10.1109/TPAMI.2016.2644615.
He J, Zhang S, Yang M, Shan Y, Huang T. Bi-directional cascade network for perceptual edge detection. Proc IEEE/CVF Conf Comput Vision Pattern Recognit. 2019;2019:3828–37. https://doi.org/10.1109/CVPR.2019.00395.
Isola P, Zhu J, Zhou T, Efros A A. Image-to-image translation with conditional adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. pp. 1125–1134. https://doi.org/10.48550/arXiv.1611.07004.
Mirza M, Osindero S. Conditional generative adversarial nets. arXiv. 2014. https://doi.org/10.48550/arXiv.1411.1784.
Wang T, Liu M, Zhu J, Tao A, Kautz J, Catanzaro B. High-resolution image synthesis and semantic manipulation with conditional GANs. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. pp. 8798–8807. https://doi.org/10.1109/CVPR.2018.00917.
Qin X, Zhang Z, Huang C, Dehghan M, Zaiane OR, Jagersand M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recogn. 2020;106:107404. https://doi.org/10.1016/j.patcog.2020.107404.
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y. Generative adversarial networks. Commun ACM. 2020;63(11):139–44. https://doi.org/10.1145/3422622.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, Kaiser L, Polosukhin I. Attention is all you need. Advances in Neural Information Processing Systems. 2017. https://doi.org/10.48550/arXiv.1706.03762.
Woo S, Park J, Lee J, Kweon I S. CBAM: Convolutional block attention module. In: Proceedings of the European Conference on Computer Vision. 2018. pp. 3–19. https://doi.org/10.1007/978-3-030-01234-2_1.
Hou Q, Zhou D, Feng J. Coordinate attention for efficient mobile network design. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021. pp. 13713–13722. https://doi.org/10.1109/CVPR46437.2021.01350.
Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. pp. 7132–7141. https://doi.org/10.1109/CVPR.2018.00745.
He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. pp. 770–778. https://doi.org/10.1109/CVPR.2016.90.
Ulyanov D, Vedaldi A, Lempitsky V. Instance normalization: The missing ingredient for fast stylization. arXiv. 2016. https://doi.org/10.48550/arXiv.1607.08022.
Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv. 2015. https://doi.org/10.48550/arXiv.1502.03167.
Buades A, Coll B, Morel J-M. A non-local algorithm for image denoising. In: 2005 IEEE computer society conference on computer vision and pattern recognition. 2005;2:60–65. https://doi.org/10.1109/CVPR.2005.38.
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: International Conference on Learning Representations. 2015. pp. 1–14. https://doi.org/10.48550/arXiv.1409.1556.
Acknowledgements
None.
Funding
Financial support of this work from the Shenzhen Stable Support Natural Fund (Grant No. WDZC20200821140447001).
Author information
Authors and Affiliations
Contributions
All the authors have contributed to the current work. ZXL devised the study plan and led the writing of the article; CL conducted experiments and analysis, and LSN performed data collection and processing. LXP reviewed the article and supervised the whole process. All the authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Zeng, X., Cheng, L., Li, S. et al. An algorithm based on multi-branch feature cross fusion for archaeological illustration of murals. Herit Sci 12, 368 (2024). https://doi.org/10.1186/s40494-024-01470-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1186/s40494-024-01470-4
