
Abstract
This work aims to provide an innovative solution to enhance the accessibility of images by an innovative image to text to speech system. It is applied to Hindu and Christian divine images. The method is applicable, among others, to enhance cultural understanding of these images by the visually impaired. The proposed system utilizes advanced object detection techniques like YOLO V5 and caption generation techniques like ensemble models. The system accurately identifies significant objects in images of Deities. These objects are then translated into descriptive and culturally relevant text through a Google text-to-speech synthesis module. The incorporation of text generation techniques from images introduces a new perspective to the proposed work. The aim is to provide a more comprehensive understanding of the visual content and allow visually impaired individuals to connect with the spiritual elements of deities through the immersive experience of auditory perception through a multimodal approach to make them feel inclusive in the community. This work is also applicable to preserve Cultural Heritage, Tourism and integrating with Virtual Reality (VR) and Augmented Reality (AR). Images of the artistic cultural legacy are hardly available in annotated databases, particularly those featuring idols. So we gathered, transcribed, and created a new database of Religious Idols in order to satisfy this requirement. In this paper, we experimented how to handle an issue of religious idol recognition using deep neural networks. In order to achieve this outcome, the network is first pre-trained on various deep learning models, and the best one which outperforms others is chosen. The proposed model achieves an accuracy of 96.75% for idol detection, and an approximate 97.06% accuracy for text generation according to the BLEU score.
Similar content being viewed by others
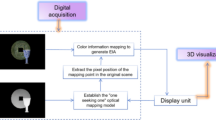
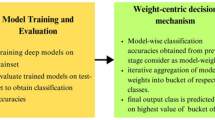
Introduction
India, known for its rich cultural diversity and spirituality, is dedicated to a vast array of deities who are deeply meaningful to its citizens. These supernatural beings stand for a deeply held belief system that spans thousands of years; they are more than just symbols. This paper explores the realm of Indian deities, including their identification, objects connected to them, and text-to-speech (TTS) synthesis. Captioning might help visually impaired people experience the essence of these deities. There are hundreds of Gods and Goddesses in India's huge and diverse pantheon, each with their own special qualities, myths, and meanings [1]. These supernatural entities are found in many different religions, including Christianity and Hinduism, to mention a few of them. The Gods are vital to daily life and cultural festivals because they are respected not only for their mythical stories but also for the ideals and ideas they represent. It requires competence to recognize and identify these deities. Each deity bears distinct visual signals that help in their identification; these cues are often seen in elaborate sculptures, paintings, and religious writings. These clues could be things like how many limbs they have, what they are holding, animals or other symbols they are connected to, or the minute details of their clothing [2].
India's cultural landscape is embellished with an abundance of Gods and Goddesses, each with their own persona, symbolism, and significance. From the friendly Ganesha to the fearsome Durga, the deities reflect the country's diverse customs and beliefs as shown in Fig. 1. However, for those who are blind or visually challenged, it is still difficult to imagine these divine beings. To bridge the gap for visually impaired individuals and to delve into the art of captioning [3] which helps visual persons to connect with the depth of Indian deities. Descriptive and detailed labels provide information on the history of each god, the significance of his or her qualities, and the cultural context in which they are found. This can also use text-to-speech (TTS) [4] technology to turn these captions into an immersive listening experience. This allows people with disabilities to understand symbols and legends, but also to experience the spiritual richness and worship these deities inspire.

Samples of Annotated Idol Categories of Images
In terms of accessibility and diversity, the use of deep learning models has resulted in significant advances, notably in comprehending and recognizing religious iconography [5]. One significant use is employing deep learning algorithms to detect objects within religious idols, allowing vision handicapped people to better understand the divine. These models can detect complex details in depictions of Gods and Goddesses using sophisticated computer vision techniques, such as face expressions, dress, accessories, and symbols. This ability allows for the creation of extensive captions that explain the meaning and symbolism connected with each selected object. Furthermore, using cutting-edge natural language processing techniques, these captions are enhanced to give complete explanations that capture the spirit of religious iconography. The synthesized textual descriptions act as a bridge, providing visually challenged people with a thorough grasp of the reality of the gods and goddesses depicted in idols. However, the innovation does not end there; using text-to-speech technology efficiently turns these written descriptions into audible form, allowing visually impaired people to immerse themselves in the rich tapestry of religious traditions and symbols. This comprehensive approach not only improves accessibility, but it also develops a stronger sense of connection and understanding among people with different abilities. As technology advances, the combination of deep learning, natural language processing, and assistive technologies has tremendous potential for increasing inclusivity and enriching the spiritual experiences of all people, regardless of visual disability.
In the following sections, we will embark on a journey through the diverse pantheon of deities, decipher their attributes, and employ the power of TTS synthesis to create an inclusive and enriching experience for everyone, regardless of their visual abilities. Join us as we unlock the world of Indian deities, where spirituality meets accessibility, and the richness of tradition knows no bounds.
Related work
Digital Hampi [6], a laudable project by the Indian government, not only preserves Hampi's tangible history but also embraces technical innovation through digital restoration procedures for artifacts such as statues, carvings, and mural artwork. The addition of mobile-based visual search improves user accessibility by allowing for the easy study of artifacts via smartphones [7]. This effort goes beyond preservation and provides an interactive learning experience through knowledge-based archiving and exploration. It not only allows for virtual exploration, which can reach a global audience interested in Hampi's legacy, but it may also entail community collaboration for long-term heritage preservation. Digital Hampi's commitment to tourism promotion, educational outreach, and research support emphasizes the need of conserving and promoting Hampi's historical and cultural legacy [8].
The California-based Cultural Objects Name Authority (CONA) is a well-managed authoritative records for a broad variety of cultural works, including artwork, carvings, designs, sketches, writings, photos, clothing, pottery, furniture, and other visual media like architectural artwork, performance art, and objects from archaeology, are available in this attribute repository. To enhance CONA, SAHARA [9] is a digital image archive of more than 100,000 photographs of buildings and landscapes that was created by Chicago's Artstor and the Association of Economic Historiographers as collaborators. WikiArt [10] is a visual art encyclopedia that expands the internet realm by offering over 250,000 artworks by 3,000 artists in eight different languages. Content for this global library comes from more than 100 countries' museums, colleges, town halls, and government buildings. With its diverse collection of 60,000 artwork, photos, carvings, blueprints, and sketches by 600 artists from various countries and times, the Art Gallery ErgsArt doubles as a visual art museum. When taken as a whole, these programmes provide a substantial contribution to the global recording, accessibility, and appreciation of cultural and artistic legacy.
The scarcity of annotated databases for artistic cultural heritage, focusing specifically on Hindu Religious Idols. The curated dataset, consisting of 14,592 images and utilizing 150 keywords related to 31 idol categories, serves as a valuable resource for recognizing religious idols. Through the application of deep neural networks, this work modified Densenet architecture showcases promising results, demonstrating the potential for efficient recognition of diverse forms of religious idols, crucial for the preservation and understanding of cultural heritage.
There isn't a database specifically for idols other than "Hindu Deities' Facial Identification with Computer Vision" which hasn't been released yet but uses gods' faces to identify Hindu deities [11]. With the exception of a few gods with unusual faces, facial recognition technology is ineffective. For instance, Lord Vinayaka's visage resembles an elephant, and Lord Krishna's forehead bears the word "Nama.". It illustrates, the features of other gods and goddesses are similar and can only be distinguished by their posture, deeds, and possessions. The only way to distinguish between the faces of Goddess Lakshmi and Goddess Saraswathi is to look at the artifacts that each one of them has to symbolize their unique qualities (Lakshmi: Crown, Pot with Gold Coins and Red Lotus; Saraswathi: Veena, Book, Mala, White Lotus, Swan, and Crown). As a result, it's important to identify idols not just by their faces but also by the things and positions that go with them.
Proposed methodology
This work offers important new insights into three main areas
First of all, it presents an entirely novel set of Deities idols in a variety of media, including sculptures, works of art, images, and sketches. Second, a modified Deep Learning architecture designed especially for religious idol recognition has been proposed by the paper. Thirdly, the introduced dataset's robustness is comprehensively evaluated by testing it with different deep networks, showcasing its adaptability and usefulness for idol recognition. When taken as a whole, these contributions enhance our knowledge of and ability to use deep learning techniques in relation to religious imagery and cultural heritage. Fourthly, this work adds meaningful labels to each Deity in the dataset, going beyond image recognition. Textual annotations enhance the dataset for thorough analysis by offering a deeper comprehension of the cultural context and meaning linked to the wide range of images as shown in Fig. 2. Finally, the paper uses the captioned data to create audio descriptions for the religious idols, a novel use of text-to-speech technology. This innovative method improves accessibility, allowing people with visual impairments to use the dataset. Text-to-speech integration complies with universal design standards, allowing a wider audience to experience cultural material. By making cultural heritage accessible to people with different sensory abilities, the study encourages inclusivity and democratizes access to religious iconography.

Generated Caption Sample for Deities
Dataset description Idol images is a meticulously curated collection of high-quality images of idols and sculptures depicting various deities and venerated personalities from various religious traditions. This dataset is intended to be a comprehensive resource of visual portrayals of Gods, Goddesses and Saints from various cultures found in mythology and religious traditions. This Deities Dataset contains images of idol sculptures with 20 different categories of Gods and Goddesses from Hinduism and Christianity Religion. Each image is stored in JPEG format and is accompanied by pertinent metadata, including the name of the deity. Images in this dataset were gathered from publicly accessible search engines such as Google Image and Pinterest. To ensure the dataset's validity and accuracy, images were carefully chosen from respectable websites, cultural organizations, and other reliable sources. The suggested multimodal dataset offers diversity in the ways listed below. Images of both male and female Gods can be found in the database. For instance, the database has images of Goddess Mother Mary, Saraswathi, Lakshmi, Andal, Lord Ganesh, Krishna, and the Infant Jesus. The proposed dataset organizes idols from the most important and famous to the least category. Post image collection, data cleaning was performed to remove comical images and images with excessive noise. The objects depicted in a specific image are provided in the metadata of the Idol dataset. Classes about Gods and Goddesses were consolidated into one class file that is concerned with the various attributes and manifestations of the different deities.
The deity Ganesh, for instance, possesses items including a crown, a bowl of sweets, an axe, a noose, an offering gesture, and a mooshikan as illustrated in Fig. 3. Likewise, 88 objects representing various deities and goddesses have been utilized. Finally, as indicated in Fig. 4, a total of 2426 different images were stored in the database. Deities’ dataset’s metadata includes an identifier and an object list. The dataset images have an average resolution of 416 × 416 pixels. For example, the database contains a plethora of images of various Gods and Goddesses in various incarnations. The images were collected from several temples, illustrating the varying interpretations of many artists from various time periods and regions. To effectively identify these intricate representations within the demanding dataset, a deep learning approach becomes essential.

Objects Identified from Lord Ganapathy Idol

Graphical representation of sample Images in each Category
Object detection Studies on deep learning have been growing rapidly in the past decade, despite its use becoming more common in computer vision [12].The last ten years have seen a sharp increase in the use and expansion of deep learning, especially in computer vision applications. The study of complex deep-learning algorithms is still growing despite their increasing appeal. The discussion of the use of these sophisticated algorithms, which are widely used in the field of object identification, is covered in this section [13]. The field of object detection in statues, which is the identification and accurate positioning of specific objects like the Crown, Maze, Axe, Noose, etc., inside idol images, has greatly profited from deep learning developments. In this particular context, the models have significantly improved the precision and effectiveness of object detection tasks. The suggested Idol dataset is analyzed using a variety of customized deep learning techniques in order to demonstrate this advancement. DenseNet 121, ResNet 50, EfficientDet, Cascade R-CNN, FAST R-CNN, YOLO V3, and YOLO V5 are some of the models that offer various abilities and capacities for object detection and localization in statuary images.
Initially, DenseNet 121[14] are deep neural network architectures known for their distinctive features. DenseNet 121 [15], with its densely connected topology, has performed well in image classification evaluations. However, its complex structure may present difficulties in real-time deities object identification. The computational costs of tightly connected layers may limit the model's performance, particularly when rapid and accurate recognition of idols within images is required. DenseNet 121[16] focuses on the architecture's building blocks, including densely connected layers, transition layers, and the exact parameters used. The following is a simplified depiction of DenseNet 121, where 'x' represents the input to the model in below Eq. (1), (2) and (3).
where xi is the input to the i-th dense block, Hi is the output of the i-th dense block and fi is the transformation applied in the i-th dense block. The last layer is a fully connected layer with a softmax function that is used to determine the probability that a specific weather image is part of a particular category. DenseNet 121 achieves an impressive accuracy of 74.90% in idol detection tasks, showcasing its effectiveness in capturing intricate patterns and features within images.
ResNet-50 [17] is a Residual Network architecture variation that uses deep convolutional neural networks (CNNs) to detect objects with an accuracy of 63.52%, including idols. Through the use of residual connections, this 50-layer network architecture overcomes the vanishing gradient issue during training, enabling the effective training of deeper networks. Its capacity to extract information from objects in a hierarchical fashion and capture complex features is what makes it so effective.ResNet-50 is a multi-stage process [18]. First, an input image of the scene with the Indian idols and other objects is sent to the network. After that, the image is sent through a number of convolutional layers as shown in Eq. 4, which use convolution to extract information at various spatial resolutions from the input image. Subsequent layers improve and abstract these traits more and more, allowing the network to capture both high-level and low-level representations of the objects. Where \(Y\) i,j,k represents the output feature map at position (i,j) in the (k)-th layer. \(X\) i+m, j+n,l represents the input feature map at position (i + m, j + n) in the (l)-th layer. \(W\) m,n,l,k represents the weights associated with the convolutional filter at position (m,n) in the (l)-th layer, contributing to the (k)-th layer. And finally \(b\) k represents the bias term for the (k)-th layer.
Following convolution, the network introduces non-linearity by using activation functions like ReLU (Rectified Linear Unit), which enables the network to understand intricate correlations between features. In addition, the feature maps are down sampled using pooling layers, which lowers computational complexity while maintaining crucial information. Classification and localization are involved in the last phase of object detection. The probability distribution over specified classes, which represents the likelihood of each class being present in the image, is output by the network. If the retrieved features of an idol closely match those of idols in the network's training data, the network assigns the idol a high likelihood. Its effectiveness originates from its capacity to understand complicated patterns and generalize well to previously unknown data, with an accuracy of 63.52% in object detection tests involving idols.
EfficientDet [19], a cutting-edge object identification method, achieves an astonishing 63.52% accuracy in recognising idols using a combination of novel techniques and structures. EfficientDet's success stems from its ability to efficiently process and analyze images, revealing intricate details even in complex backgrounds. At its core, EfficientDet [20] uses a multi-scale feature fusion technique, combining input from several layers of a neural network to capture both fine-grained and coarse data required for accurate object detection. This fusion process improves the model's knowledge of item shapes and contextual information, which is critical for identifying idols with precision. Furthermore, EfficientDet makes use of modern convolutional neural network (CNN) architectures [21], such as the EfficientNet backbone [22], which effectively scales the network's depth and width to balance computational complexity and performance. This design allows EfficientDet to handle images at a variety of resolutions while retaining excellent detection accuracy. EfficientDet's effective combination of feature fusion, scalable architectures, and sophisticated detection mechanisms allows it to detect idols with a remarkable accuracy of 64.23%, making it an invaluable tool for a variety of applications such as cultural heritage preservation and image analysis.
The idols are identified with remarkable accuracies of 76.82% and 80.73%, respectively, using two sophisticated object detection algorithms: Cascade R-CNN [23] and FAST R-CNN [24]. To identify things in images, these algorithms make use of complex systems. Using a series of classifiers that improve on one another to further the detection process, the cascade R-CNN works [25]. In order to quickly eliminate areas that are unlikely to contain items, a coarse classifier is first used. After this stage, the regions that pass go through additional examination from later classifiers that focus on smaller details and gradually improve the detection. Cascade R-CNN is able to operate with great accuracy and computational efficiency because of this cascading mechanism. Conversely, the FAST R-CNN [26] employs a convolutional neural network (CNN) architecture that is built on regions. It makes suggestions for regions of interest (RoIs) inside the image using a selective search method. After being fed these suggested regions, a CNN is used to classify the objects within these regions and extract features. FAST R-CNN improves efficiency and accuracy by streamlining the detection process by using a single network for both region suggestion and classification.
YOLOv3, [27] which is well-known for its effectiveness and precision in object detection, uses a novel technique to identify the idols with an accuracy of 83.50%. YOLOv3 [28] predicts bounding boxes and class probabilities for numerous items in an image concurrently using a single neural network. It accurately distinguishes the idols through a complex set of procedures that include input processing, feature extraction, prediction, and non-maximum suppression. Its capacity to extract complex features from a wide range of datasets and refine them through methods like data augmentation and transfer learning is the foundation of its effectiveness. Its prediction powers are supported by statistical formulations, such as fully connected layers for classification and bounding box regression and convolutional layers for feature extraction, which guarantee precise and effective object detection [29].
The YOLO (You Only Look Once) V5 [30] model has developed as a powerful and efficient object recognition application, particularly well-suited for real-time applications as shown in Fig. 5 which represent the architecture of the deity identification model. In the context of detecting things associated with deities, the YOLO V5 model demonstrates variety and accuracy. The model's design is built on a deep neural network, which divides the input image into a grid while also predicting bounding boxes and class probabilities for each grid cell. This novel approach allows YOLO V5 [31] to process images at high speeds without neglecting accuracy. When it comes to detecting objects linked with deities, YOLO V5 delivers excellent outcomes. The model's capacity to detect many objects in a single run, combined with its high precision, make it a perfect fit for applications requiring efficiency and accuracy. The rich cultural and religious symbolism of deities necessitates a complex object detection algorithm, and YOLO V5 meets the challenge by effortlessly recognizing and classifying diverse aspects within the images, such as sacred symbols, objects, and deity representations.

Proposed System Architecture
The proposed system as shown in Fig. 5 includes image pre-processing where the input image is downsized to a fixed size that corresponds to the neural network's input size. Normalization is typically used to achieve uniform scaling of pixel values. Convolutional neural network (CNN) [32] architecture is used by YOLOv5 [33]. And convolutional layers, activation functions, batch normalization layers, and additional specialized layers constitute the network. The network layers process the input image and extract features at different spatial resolutions. High-level features are captured by the deeper layers of the network, while more specific information is retained by the more superficial levels. Primarily, it uses a detection head made up of additional convolutional layers to forecast class probabilities, bounding boxes, and objectness scores. Using feature maps created by the feature extraction layers, the detecting head functions. To forecast bounding boxes, it makes use of anchor boxes. These anchor boxes are prefabricated forms with various aspect ratios and dimensions. In relation to these anchor boxes, the network predicts bounding boxes. Over the input image, the detection head generates a grid of predictions. It predicts several bounding boxes for every grid cell, each of which is connected to a class probability and an objectness confidence score. Non-maximum suppression (NMS) is one strategy used to refine these predictions, which helps to eliminate low-confidence or duplicate detections. A loss function is computed during training in order to maximize the network's parameters. Terms for confidence loss, localization loss and classification loss are included in the loss function. To reduce this loss, the network parameters are changed by methods like gradient descent and backpropagation. The model can identify idols by comparing the predicted class probabilities with a predetermined list of idol classes once the detection results have been acquired. Identified idols are those discovered items that meet established idol classifications and have the greatest confidence scores. The following Algorithm 1 illustrates the use of Yolo v5 to detect the object of God and Goddess.

Algorithm of YOLO V5 to detect God and Goddess Objects.
-
For a single bounding box, the localization loss (\({L}_{loc}\)) can be calculated as
$$ L_{loc} \, = \,\lambda_{coord} \,\mathop \sum \limits_{i = 0}^{{S^{2} }} \mathop \sum \limits_{j = 0}^{{\text{B}}} 1_{ij}^{obj} \,[( x_{i} - \widehat{{x_{i} }})^{{{2} }} + \, (y_{i} - \widehat{{y_{i} }} )^{{2}} ] $$where \({\lambda }_{coord}\) is a coefficient that balances the impact of localization loss, S2 is the number of grid cells, B is the number of bounding boxes per grid cell, \({1}_{ij}^{obj}\) is an indicator function that equals 1 if object appears in cell \(i\) and box \(j , ({x}_{i }, {y}_{j})\) are predicted box coordinates, and (\(\widehat{{x}_{i}}\),\(\widehat{{y}_{j}}\)) are ground truth box coordinates.
-
For a single bounding box, the confidence loss (\({L}_{conf}\)) can be calculated as
$$ L_{conf} \, = \,\mathop \sum \limits_{i = 0}^{{S^{2} }} \mathop \sum \limits_{j = 0}^{{\text{B}}} \,[1_{ij}^{obj} \,. \, ({\text{ CE }}(\widehat{{p_{o} }},p_{o } )) \, + \,\lambda_{noobj} . \,1_{i} j^{n} oobj\,.{\text{ CE }}(\widehat{{p_{o} }},p_{o } ))] $$where CE (\(\widehat{{p}_{o}}\),\({p}_{o}\)) is the binary cross-entropy loss between predicted objectness score \(\widehat{{p}_{o}}\) and ground truth \({p}_{o}\), \({\lambda }_{noobj}\) is a coefficient to balance the contribution of no-objectness scores, and \({1}_{ij}^{noobj}\) is an indicator function that equals 1 if no object appears in cell \(i\) and box\(j\).
-
For a single bounding box, the classification loss (\({L}_{cls}\))can be calculated as
$$ L_{cls} \, = \,\lambda_{cls} \mathop \sum \limits_{i = 0}^{{S^{2} }} \mathop \sum \limits_{j = 0}^{{\text{B}}} \,1_{ij}^{obj} \,. \, ({\text{ CE }}(\widehat{{p_{c} }},p_{c } )) $$where \({\lambda }_{cls}\) is a coefficient to balance the impact of classification loss, \(\widehat{{p}_{c}}\) are predicted class probabilities, and \({p}_{c}\) are one-hot encoded ground truth class labels.
-
Overall Loss Function
The overall loss function (\(L\)) is the sum of localization loss, confidence loss, and classification loss:
where \(S\) is the number of grid cells.
\(B\) is the number of bounding boxes per grid cell.
\({1}_{ij}^{obj}\) is an indicator function that equals 1 if object appears in cell \(i\) and box \(j\).
\({1}_{ij}^{noobj}\) is an indicator function that equals 1 if no object appears in cell \(i\) and box \(j\).
\(\widehat{{x}_{i}}\), \(\widehat{{y}_{i}}\), \(\widehat{{p}_{o}}\), \(\widehat{{p}_{c}}\) represent predicted values.
\({x}_{i}\), \({y}_{i}\), \({p}_{o}\), \({p}_{c}\) represent ground truth values.
This loss function incorporates the key components necessary for training an object detection model like YOLOv5, balancing the errors in localization, confidence scores, and class predictions. Figure 6 displayed the sample output of deity image from YOLO V5 algorithm.

YOLO V5 Sample output
Table 1 highlights the comparison of deep learning techniques for the object detections of the newly proposed Deity Dataset (in bold). YOLOv5 leads all other models in terms of accuracy, precision, recall, and F1-score. It has the highest accuracy of 96.75% and the highest F1-score of 0.91. This shows that YOLOv5 has the best overall performance over the models listed.
Table 2 displays the top rank F1 score for learning on the validation dataset. Idols like Saraswati Having Veena as the major object, and Krishna The flute, as the principal object, has a unique visual aspect and produces excellent results. But Goddess Andal has nothing remarkable. The things and appearance are comparable to other goddesses like Lakshmi and Saraswathi, resulting in a poor F1 score.
Similarly, Idol Balarama resembles God Krishna and has a lower F1 score. The network recognises idols based on their overall appearance, including objects, poses, and facial expressions.
Table 3 Describes various dataset which has been trained by YOLO V5 model and their accuracy has been displayed.
Image captioning
"Indian Idol contestants captivate the visually impaired with their soulful performances”. Using cutting-edge technology, their images are analyzed by YOLO v5 to detect the presence of objects. After being detected by the YOLO v5 model, the Idol images are subjected to a thorough analysis and interpretation. Next, three advanced image captioning models are used to describe the essence of the situation as shown in Fig. 7. The VGG-19 and LSTM models [40], with their deep convolutional features and sequential understanding, provide a rich picture of the statue's emotions and surroundings. Meanwhile, the attention mechanism [41] model meticulously dissects the visuals, emphasizing the minute details that form the spirit of the Idol stage. Finally, with an astonishing 96% accuracy, the ensembler model effortlessly blends the characteristics of both prior models, offering a comprehensive and authentic picture of the Idol experience that captivates fans around the visually disabled people.

An example of caption generation for Deities
In the context of Idol image captioning, the combination of VGG-19 and LSTM (Long Short-Term Memory) networks emerges as a powerful selection. Initially, the VGG-19 convolutional neural network is used to extract rich visual information from input photographs of participants participating in the show. These attributes are then sent into an LSTM network, a sort of recurrent neural network designed to understand sequential data like language, to produce captions that accurately describe the core of the performance. The method starts with the encoding of image features using VGG-19 as shown in below Eq. (5).
Here \(IF\) is Image Feature and \(I\) is Input image, the weight \({W}_{1} and {W}_{2}\) matrices of the convolutional layers are the bias \({b}_{1} and {b}_{2}\) terms, and \(ReLU\) signifies the rectified linear unit activation function used element-wise to the output of each convolutional layer. These attributes are then input into the LSTM network, along with a specific start token, which initiates the captioning process. The LSTM network then iteratively creates words for the caption, taking into account the context of the previous words. This iterative procedure continues until an end token is anticipated, signalling that the caption is complete. Mathematically, the LSTM's output at each time step t is calculated as given in Eq. (6) and (7).
where \({h}_{t}\) represents the hidden state at time step \(t, W\) and \(b\) are the weight matrix and bias term, respectively, and \({y}_{t}\) is the probability distribution over the vocabulary at time step \(t.\) By combining VGG-19 for image feature extraction and LSTM for sequential caption generation, the model learns to produce descriptive captions that capture the essence of Idol performances with an accuracy of 65%.
In the realm of image captioning for Idol, attention mechanisms play a crucial role in enhancing the accuracy and contextual relevance of generated captions. Using this method, the model selectively focuses on different sections of the image when creating captions, emulating the capacity for people to notice key features. Attention mechanisms [42] entail assigning attention weights to each spatial area within the image, indicating the importance of each region in respect to the captioning task. The equations typically entail calculating attention scores with a compatibility function, as indicated in Eq. (8), followed by a softmax operation to generate normalized attention weights, as given in Eq. (9).These weights are then added to the feature maps, resulting in the context vector presented in Eq. (10), which is then used in the captioning process. By incorporating attention mechanisms in the captioning process, the model can capture the vitality of each idol's performance with accuracy of 82%.
where \({e}_{ij}\) is the attention score between the previous hidden state \({s}_{i-1}\) and the j-th feature map \({h}_{j}.\) \(f\) is a compatibility function, such as dot product or concatenation followed by a neural network layer. \({\alpha }_{ij}\) is the attention weight associated with the j-th feature map at time step i. T is the total number of feature maps. \({c}_{i}\) is the context vector at time step i, representing the weighted sum of all feature maps.\({h}_{j}\) is the j-th feature map.The below Fig. 8 represents the output from the attention mechanism.

Caption for Lord Shiva generated from attention mechanism
In this section, we describe our methods for image captioning [43] using ensemble learning techniques, which we apply to the Caption for Deities dataset. This dataset was generated because it is lower in size than other existing datasets, allowing for faster computations while maintaining realism and sample quality. The dataset contains 2426 captions, including 1941 for training, 1000 for development, and 498 for testing, providing a robust set of samples suitable for pattern learning. Furthermore, each image in the dataset is accompanied by two independent captions, which serve as training data for the model. The workflow of an image captioning system is made up of several important components. First, there's the essential process of feature extraction. This entails preparing the images and their descriptions to prepare them for model training. Images are transformed into vector representations, which capture key features and encode them as floating-point numbers. The size of these vectors vary with the model's output layer settings. The next step is to Clean Description Text, which requires building a vocabulary and preparing the dataset's descriptions before putting them in a separate file for easy handling. Finally, we have to define the model. Here, the model's essential architecture is explained, built to generate captions that connect together a sequence of words, eventually building a meaningful sentence that represents an input image. During the caption generating phase, a recurrent neural network sequentially generates words. To train the model, provide a list of previously created words as input and predict the next word. Word representations are transformed into dense vectors, which improves the model's capacity to analyze word relationships.
After creating word embeddings for all vocabulary terms, the result is sent into the recurrent neural network layer. This layer can be a simple RNN, an LSTM, or a Gated Recurrent Unit (GRU). Our research investigates all three networks, using them to create unique ensembles. Following model training, evaluation is carried out using a test dataset and metrics to assess model performance. The Bleu score, which is extensively used for picture captioning evaluation, is applied. On a scale of 0.0 to 1.0, 1.0 represents a perfect match while 0.0 denotes a complete mismatch. The Bleu score works by comparing the n-grams in the predicted sentence to those in the reference sentences. A more substantial match count leads to a higher BLEU score, where N-grams denote the number of words matched at each instance. Ensemble learning entails training numerous varied models rather than a single one, and then combining their predictions to address the problem at hand efficiently. This strategy frequently produces more accurate forecasts than individual models. Table 4 shows that all three image captioning approaches significantly enhance prediction accuracy compared to the best individual model. Boosting is the ensemble with the largest increase. Ensemble models produced higher-quality captions for images in the proposed dataset [44].
Text generation
Text generation can be incredibly beneficial for visually impaired individuals in gaining knowledge about idols. Natural language processing (NLP) models [45], such as RoBERT, can be used to convert information about idols into accessible text format, allowing visually impaired people to learn about their cultural and religious heritage. These generated descriptions can include information about the significance, mythology, rituals, and historical contexts of various idols, including Infant Jesus, Ganapathy, St. Antony, Hanuman, Mother Mary, St. Joseph, Krishna, Andal, Durga, Kala Bhairava, Kali Amman, Lakshmi, Saraswathi, Machle God, Murugan, Ram, Shiva, Vishnu, and Varagi Amman. Furthermore, text generation technology can provide personalized and engaging experiences, allowing visually impaired people to ask questions, get answers, and gain deeper insights about their idols via conversational interfaces or audio-based platforms. Text generation enables visually impaired people to engage with their cultural and religious past, building a sense of belonging and understanding in an inclusive manner.
The proposed text generative model is RoBERTa [46], a Transformer architecture version, works by training a deep neural network on massive volumes of text input with a masked language modeling target. Initially prompts are taken from the captions which are generated from an ensemble model which provide context about each idol.These prompts should be informative enough for the model to generate appropriate text. During training, RoBERTa learns to anticipate masked tokens within input sequences, which requires it to grasp context and word relationships. Tokenize the prompts with the same tokenizer as used during RoBERTa's pretraining. This stage translates the text into numerical representations that the model can comprehend. This enables RoBERTa to recognise complex verbal patterns and semantic meaning. Feed the tokenized prompts into the RoBERTa model to generate text continuations. When generating text, RoBERTa uses learned representations to estimate the most likely future tokens based on a starting prompt or context. RoBERTa produces coherent and contextually relevant language by producing tokens recursively using probabilities. Additionally, fine-tuning for certain activities or domains improves its performance and adaptability. Overall, RoBERTa's ability to understand and generate text is due to its rigorous training process and sophisticated modeling of language semantics, making it a versatile tool for a wide range of natural language processing tasks, including text generation about idols such as Infant Jesus, Ganapathy, St. Antony, Hanuman, and others. The below Fig. 9 represents the evaluation metrics for idol text generation.

Evaluation metrics for Text Generation
A Context Enhanced Large Language Model (CE-LLM) is a formidable model for understanding and establishing complex ontologies, especially in domains such as religious idols. It leverages advanced natural language processing capabilities to analyse vast amounts of textual and structured data to identify by linking multiple identities, attributes, and relationships between various deities or idols. The model utilizes contextual knowledge to create ontologies, which are structured representations of the deities' attributes, their various forms or versions, and their relationships with other deities. By analyzing texts and descriptions, the model can discern different aspects of each deity, such as their characteristics, mythological roles, and familial connections, providing a comprehensive view of the complex interrelations within a religious framework. Figure 10 displays the ontologies of Lord Shiva and Goddess Parvati. Shiva is recognized as the "destroyer and transformer" in Hinduism, with several manifestations like Natarajan, Ardhanarishvara, and Bhairava. The model captures these identities and links them to a single core entity, Shiva. Additionally, the model maps his familial relationships, such as his wife, Parvati, and their children, Ganesha and Kartikeya. Similarly, Parvati's ontology encompasses her diverse manifestations, such as Durga and Kali. The model links these forms to Parvati while associating her with Shiva as his consort and connecting her to their children. This interconnected ontology allows the CE-LLM to navigate complex narratives and relationships, providing a holistic understanding of the deities' roles and interconnections. By constructing this detailed network of connections, the CE-LLM enables a deeper understanding of how Shiva and Parvati’s various forms and relationships contribute to their overarching ontology, thereby assisting in the accurate recognition and contextualization of idols in diverse religious contexts. This approach not only enhances digital recognition and interpretation but also supports a richer appreciation of cultural and religious narratives.

Ontology representation of Lord Shiva and Goddess Parvati
Text-To-Speech synthesis
After creating textual descriptions for deities using the integrated Large Language Models, the next step is to make this information available to visually impaired people via Text-to-Speech (TTS) technology [47]. TTS turns written text into spoken words, creating an audio representation of the generated descriptions. Once the image's captioning model has generated the textual descriptions, the raw text is converted to TTS [48]. These systems may reliably convert textual descriptions into natural-sounding voices by leveraging powerful application programming interfaces like the Google Text To Speech (GTTS) [49]. The transformer model for text-to-speech synthesis uses self-attention mechanisms and encoder-decoder architecture to produce natural-sounding speech from input text, providing significant advantages in capturing long-range dependencies and maintaining sequential coherence without recurrent connections. These engines frequently allow for the adjustment of speech parameters such as pitch, tempo, and accent to improve the listening experience. This endeavor not only assures accessibility for visually impaired people, but also develops a sense of inclusion and representation within the nation's cultural fabric. Using deep learning for text-to-speech synthesis becomes a strong tool for closing accessibility gaps while honoring the rich diversity of customs and languages, ultimately enriching the lives of countless people through technology. This notion holds immense promise for visually impaired persons, giving them access to cultural representations like idol performances. By offering detailed captions, this technology not only increases accessibility but also promotes a more inclusive cultural experience, allowing everyone, regardless of visual ability, to enjoy and appreciate the rich range of musical traditions. The below Fig. 11 represents the sample wave form of converted text- to-speech process.

Sample waveform of generated text
In alignment with India's Bhashini initiative, our work has been successfully implemented across 30 languages, including major South Indian languages such as Tamil, Telugu, Kannada, and Malayalam. This extensive coverage ensures that the model can cater to a diverse audience, bridging linguistic gaps and making culturally rich content accessible to various communities. For these languages, we have created a comprehensive speech graph shown in Fig. 12 that not only visualizes the linguistic and dialectal diversity covered by the model but also highlights the intricate nuances of each language's phonetic and syntactic structures. This graph serves as a powerful tool to analyze and optimize the TTS outputs, ensuring that the model delivers high-quality, natural-sounding speech across different dialects. By mapping out the relationships between various dialects and regional variations within these languages, the graph demonstrates the model’s robust capability to adapt to subtle linguistic shifts. This adaptability is crucial for delivering culturally relevant content that resonates with native speakers. Moreover, this approach aligns with the broader goals of the Bhashini initiative, which aims to support the preservation and promotion of India’s linguistic diversity by leveraging advanced AI technologies to provide localized, contextually accurate translations and speech synthesis. Such a system not only enhances accessibility but also contributes to the digital empowerment of communities speaking lesser-known dialects, ensuring that no linguistic group is left behind in the digital age.

Sample pitch graph for Indian Languages
Results and discussion
Experiment result
Various pre-trained Deep Learning models were evaluated on the proposed Deities dataset for trials, and the highest performing network was chosen for further research. The pretrained networks were trained for 100 epochs with a batch size of 12 during this experiment. For training, the Adam optimizer and the mean absolute error loss function are used in Fig. 14a. Table 1 clearly shows that YOLO V5 outperforms the other networks with highest accuracy of 96% as shown in Fig. 14b and the same has been chosen for further examination with validation data. The Deities dataset was randomly divided into training, testing and validation with a ratio of 70% and 30%, respectively for evaluation. In the validation set, a minimum of 25 samples and a maximum of 485 are chosen at random from each category. The remaining images are being considered for training of a total number 1941 Training data. The Idol images were scaled to 416*416 pixels before training the network. All images have also undergone a preprocessing operation called min–max normalization. In the training phase, the following fundamental data augmentation techniques were utilized to supplement the data. Figure 13 shows the Deep neural network architectures that were evaluated on the proposed idol dataset. Further the captions are generated for the Idols in the dataset.

Evaluation of Deep Learning Models
Figure 14 represents the output from the YOLO V5 Object detection method where Accuracy, Precision and Recall are displayed.

Evaluation Metrics of YOLO V5
This proposed method additionally performs an extensive amount of experiments to assess the effectiveness of the object detection. In this divine image, the ethereal presence of deities is depicted in a perfect blend of vibrant colors and meticulous detailing. Each deity, was attired with celestial ornaments, exudes transcendence and spiritual power. The artwork's elaborate symbolism depicts India's vast mythology and cultural past, inspiring contemplation and devotion. In this paper, we used Deities Caption Datasets (DCD), which contain images with English captions. The DCD dataset contains 2426 images with descriptions, three descriptions per image, and 727 testing samples. The initial stage in adding comments to an image is to generate a fixed-length vector that effectively summarizes the image's information. We make use of three Deep learning models namely VGG 19- LSTM, Attention mechanism with LSTM and Ensemble models to caption the image. This network has been preliminarily trained on 2426 images from the IDC dataset. We obtain the output vector representation from the last convolution layer for any image in the training set. This vector is fed as the input to NLP model. Then the model is evaluated using prominent metrics such as BLEU. BLEU (Bilingual Evaluation Understudy) is a method that calculates the precision of an n-gram between the generated and reference captions. The length of the reference sentence, the generated phrase, the uniform weights, and the adjusted n-gram precisions can all be used to obtain BLEU-N (N = 1,2, 3,4) scores. The experimental results show that the proposed method can automatically create appropriate captions for images with a BLEU score of 97.06% as displayed in Fig. 15.

BLEU score for image captioning models
In the realm of artificial intelligence, the fusion of ensemble models and advanced transformers like RoBERTa has ushered in a new era of text generation, particularly in the context of image captions. The process begins with the ensemble model, which aggregates diverse perspectives and features from multiple sources, enhancing the robustness and accuracy of predictions. These image captions, crafted by the ensemble, serve as rich prompts for the RoBERTa transformer model. With its unparalleled proficiency in understanding context and semantics, RoBERTa delves into the essence of these captions, deciphering the intricacies of visual content described within. As the transformer model unfolds its linguistic prowess, it generates coherent and contextually relevant textual narratives, complementing the images with vivid descriptions and nuanced insights. This symbiotic relationship between ensemble models and transformers not only amplifies the interpretability of visual data but also augments the depth and richness of generated text, fostering a deeper understanding of the interconnectedness between images and language in the realm of AI-driven content generation.
To transform the above caption to voice, advanced natural language processing (NLP) models can be used. A text-to-speech (TTS) model trained on a wide range of voices and linguistic variations can bring the caption to life through emotive intonation and intelligibility. The synthesized voice would express the profound essence of the Indian deities, boosting the immersive experience for individuals who interact with the artwork. The synthesis method includes intricate linguistic parsing, prosody modeling, and voice modulation to ensure that the narration accurately reflects the caption's intended sentiment. The delicate pronunciation of god names, the rhythm of spiritual references, and the regulated tempo of explanation all combine to produce aural stimulation that effortlessly coincides with the visual impact of the image. This integration of visual and audio aspects results in a multimodal experience, strengthening the link to the image's spiritual and cultural value. This versatility guarantees that the voice captures the cultural diversity and subjective preferences involved in the interpretation of Indian deities' iconography. As technology advances, the combination of NLP and image captioning not only bridges the gap between text and voice, but it also deepens the immersive and inclusive nature of the storytelling experience, opening up new avenues for appreciating the rich tapestry of cultural and spiritual narratives. The synthesized voice serves as a bridge, connecting the visually impaired community to the complex beauty and spiritual significance embodied in depictions of deities. Below Fig. 16 represents the converted speech in waveform (Fig. 17).

Accuracy graph and confusion matrix for text generation

Waveform, spectrogram and MFCC representation of the audio
Conclusion
In conclusion, there is much potential for improving the spiritual experience of visually impaired people through the initiative that focuses on identifying objects associated with Indian deities and producing descriptive texts for comparable images. A further advantage is that the text can be auditory. Recognizing religious idols is a difficult issue because there are hundreds of idol types that are associated with religion and all the statues are collected from the church and temple. In this research, we have created a database for Religious Idols acquired from the web by querying multiple search engines using various names of similar deities. After analyzing seven deep neural network baselines for idol recognition, Yolo v5 was chosen for thorough examination. By providing detailed audio descriptions of cultural and religious artifacts, the system can enhance visitors' understanding and appreciation in cultural heritage sites and during cultural festivals. For tourism, it offers multilingual audio descriptions of sites, making experiences more inclusive and informative for international tourists. When integrated with VR and AR, it can deliver immersive audio descriptions, enriching virtual tours and educational programs. This paper also demonstrates the transformative potential of combining technology and empathy to make a meaningful impact on the lives of visually impaired individuals. It offers a tactile link to spirituality and serves as an example of how cutting-edge innovations can drive significant positive change. To our knowledge, this work is the first of its kind to meet the needs of visually challenged people. As a future work, this system can be developed as a mobile application with an intuitive user interface with enhanced accessibility features.
Availability of data and material
No datasets were generated or analysed during the current study.
References
Bama B, Sathya S, Mohamed Mansoor Roomi, D, Sabarinathan M, Senthilarasi M, Manimala G. "Idol dataset: a database on religious idols and its recognition with deep networks. In Proceedings of the Twelfth Indian Conference on Computer Vision, Graphics and Image Processing 1–7. 2021.
Huang ML, Liao YC, Shiau KL, Tseng YL. Traditional chinese god image dataset: a glimpse of chinese culture. Data Brief. 2023;46: 108861.
Sharma H, Agrahari M, Singh SK, Firoj M, Mishra RK. "Image captioning: a comprehensive survey." In 2020 International Conference on Power Electronics & IoT Applications in Renewable Energy and its Control (PARC). 325–328. IEEE, 2020.
Hossain MZ, Sohel F, Shiratuddin MF, Laga H, Bennamoun M. Text to image synthesis for improved image captioning. IEEE Access. 2021;9:64918–28.
Bhaumik G, Govil MC. Buddhist hasta mudra recognition using morphological features. In: Bhattacharjee A, Borgohain S, Soni B, Verma G, Xiao-Zhi G, editors. Machine Learning Image Processing Network Security and Data Sciences: Second International Conference, MIND 2020, Silchar, India, July 30-31, 2020, Proceedings, Part I 2. Singapore: Springer Singapore; 2020. p. 356–64.
Chandru V, Kumar NA, Vijayashree CS, Chandru UV. Digitally archiving the heritage of Hampi. Digital Hampi Pres Indian Cult Herit. 2017;373:389.
Girdhar R, Panda J, Jawahar CV. Mobile visual search for digital heritage applications. In: Mallik A, Chaudhury S, Chandru V, Srinivasan S, editors. Digital Hampi: Preserving Indian Cultural Heritage. Singapore: Springer Singapore; 2018. p. 317–36.
Mallik A, Chaudhury S, Chandru V, Srinivasan S. Digital Hampi: preserving Indian cultural heritage. Springer Singapore: Singapore; 2017.
Gershman B, Rivera D. Subnational diversity in Sub-Saharan Africa: insights from a new dataset. J Dev Econ. 2018;133:231–63.
Zhao W, Zhou D, Qiu X, Jiang W. Compare the performance of the models in art classification. PLoS ONE. 2021;16(3): e0248414.
Nathan S, Beham MP. "LightNet: deep learning based illumination estimation from virtual images Computer Vision–ECCV 2020 Workshops Workshops: Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16. Cham: Springer International Publishing; 2020.
Bhagya C, Shyna A. "An overview of deep learning based object detection techniques." In 2019 1st International Conference on Innovations in Information and Communication Technology (ICIICT). 1–6. IEEE, 2019.
Chhabra M, Kumar R. A smart healthcare system based on classifier DenseNet 121 model to detect multiple diseases. In: Marriwala N, Tripathi CC, Jain S, Dinesh K, editors. Mobile Radio Communications and 5G Networks: Proceedings of Second MRCN 2021. Singapore: Springer Nature Singapore; 2022. p. 297–312.
Li B. "Facial expression recognition by DenseNet-121 Multi-Chaos, Fractal and Multi-Fractional Artificial Intelligence of Different Complex Systems. Academic Press: Elsevier; 2022.
Hiremath G, Mathew JA, Boraiah NK. Hybrid statistical and texture features with densenet 121 for breast cancer classification. Int J Intell Eng Syst. 2023. https://doi.org/10.22266/ijies2023.0430.03.
Zahisham Z, Lee CP, Lim KM. "Food recognition with resnet-50." In 2020 IEEE 2nd international conference on artificial intelligence in engineering and technology (IICAIET). 1–5. IEEE, 2020.
Reddy ASB, Juliet DS. "Transfer learning with ResNet-50 for malaria cell-image classification." In 2019 International conference on communication and signal processing (ICCSP). 0945–0949. IEEE, 2019.
Kamath V, Renuka A. "Performance analysis of the pretrained efficientdet for real-time object detection on raspberry pi." In 2021 International Conference on Circuits, Controls and Communications (CCUBE) 1–6. IEEE, 2021.
Jia J, Fu M, Liu X, Zheng B. Underwater object detection based on improved efficientdet. Remote Sensing. 2022;14(18):4487.
Velvizhy P, Kannan A, Abayambigai S, Sindhuja AP. Food recognition and calorie estimation using multi-class SVM classifier. Asian J Inform Technol. 2016;15(5):866–75.
Afif M, Ayachi R, Said Y, Atri M. An evaluation of EfficientDet for object detection used for indoor robots assistance navigation. J Real-Time Image Proc. 2022;19(3):651–61.
Lin Q, Ding Y, Xu H, Lin W, Li J, Xie X. "Ecascade-rcnn: Enhanced cascade rcnn for multi-scale object detection in uav images." In 2021 7th International Conference on Automation, Robotics and Applications (ICARA). 268–272. IEEE, 2021.
Cai Z, Vasconcelos N. Cascade R-CNN: high quality object detection and instance segmentation. IEEE Trans Pattern Anal Mach Intell. 2019;43(5):1483–98.
Ren S, He K, Girshick R, Sun J. "Faster r-cnn: Towards real-time object detection with region proposal networks." Advances in neural information processing systems 28 (2015).
Rani S, Ghai D, Kumar S. Object detection and recognition using contour based edge detection and fast R-CNN. Multimedia Tools and Appl. 2022;81(29):42183–207.
Zhao L, Li S. Object detection algorithm based on improved YOLOv3. Electronics. 2020;9(3):537.
Cheng X, Guihua Q, Yu J, Zhaomin Z. An improved small object detection method based on Yolo V3. Pattern Anal Appl. 2021;24:1347–55.
Tu R, Zhu Z, Bai Y, Jiang G, Zhang Q. Improved YOLO v3 network-based object detection for blind zones of heavy trucks. J Electron Imaging. 2020;29(5):053002–053002.
Li S, Li Y, Li Y, Li M, Xu X. Yolo-firi: improved yolov5 for infrared image object detection. IEEE access. 2021;9:141861–75.
Wan D, Lu R, Wang S, Shen S, Xu T, Lang X. Yolo-hr: Improved yolov5 for object detection in high-resolution optical remote sensing images. Remote Sensing. 2023;15(3):614.
Karthi M, Muthulakshmi V, Priscilla R, Praveen P, Vanisri K. "Evolution of yolo-v5 algorithm for object detection: automated detection of library books and performance validation of dataset." In 2021 International Conference on Innovative Computing, Intelligent Communication and Smart Electrical Systems (ICSES) 1–6. IEEE, 2021.
Jung HK, Choi GS. Improved yolov5: efficient object detection using drone images under various conditions. Appl Sci. 2022;12(14):7255.
Cao F, Xing B, Luo J, Li D, Qian Y, Zhang C, Bai H, Zhang H. An efficient object detection algorithm based on improved YOLOV5 for high-spatial-resolution remote sensing images. Remote Sensing. 2023;15(15):3755.
Chen Z, Cao L, Wang Q. YOLOv5-based vehicle detection method for high-resolution UAV images. Mob Inf Syst. 2022;2022(1):1828848.
Mahendrakar T, Ekblad A, Fischer N, White R, Wilde M, Kish B, Silver I. "Performance study of yolov5 and faster R-CNN for autonomous navigation around non-cooperative targets." In 2022 IEEE aerospace conference (AERO). 1–12. IEEE, 2022.
Chen H, Chen Z, Yu H. Enhanced YOLOv5: an efficient road object detection method. Sensors. 2023;23(20):8355.
Horvat M, Gledec G. "A comparative study of YOLOv5 models performance for image localization and classification." In 33rd Central European Conference on Information and Intelligent Systems. 349. 2022.
Zhang J, Zhang J, Zhou K, Zhang Y, Chen H, Yan X. An improved YOLOv5-based underwater object-detection framework. Sensors. 2023;23(7):3693.
Alzubi JA, Jain R, Nagrath P, Satapathy S, Taneja S, Gupta P. Deep image captioning using an ensemble of CNN and LSTM based deep neural networks. J Intell Fuzzy Syst. 2021;40(4):5761–9.
Yan S, Xie Y, Wu F, Smith JS, Lu W, Zhang B. Image captioning via hierarchical attention mechanism and policy gradient optimization. Signal Process. 2020;167: 107329.
Yuan J, Zhang L, Guo S, Xiao Y, Li Z. Image captioning with a joint attention mechanism by visual concept samples. ACM Trans Multimedia Comput Commun Appl. 2020;16(3):1–22.
Castro R, Pineda I, Lim W, Morocho-Cayamcela ME. Deep learning approaches based on transformer architectures for image captioning tasks. IEEE Access. 2022;10:33679–94.
Zohourianshahzadi Z, Kalita JK. Neural attention for image captioning: review of outstanding methods. Artif Intell Rev. 2022;55(5):3833–62.
Yu W, Zhu C, Li Z, Hu Z, Wang Q, Ji H, Jiang M. A survey of knowledge-enhanced text generation. ACM Comput Surv. 2022;54(11s):1–38.
Zhang H, Song H, Li S, Zhou M, Song D. A survey of controllable text generation using transformer-based pre-trained language models. ACM Comput Surv. 2023;56(3):1–37.
Sain Y, Cobar J. Improving students’ pronunciation in word stress through TTS (Text To Speech) feature: on a google translate application. J English Language Teach Learn Linguistics Lit. 2023. https://doi.org/10.24256/ideas.v11i1.3321.
Kumar Y, Koul A, Singh C. A deep learning approaches in text-to-speech system: a systematic review and recent research perspective. Multimedia Tools Appl. 2023;82(10):15171–97.
Kim J, Kim S, Kong J, Yoon S. Glow-tts: a generative flow for text-to-speech via monotonic alignment search. Adv Neural Inf Process Syst. 2020;33:8067–77.
Cambre J, Colnago J, Maddock J, Tsai J, Kaye J. Choice of voices: a large-scale evaluation of text-to-speech voice quality for long-form content. Proc 2020 CHI Conf Human Fact Comput Syst. 2020;1:13.
Acknowledgements
We extend our gratitude to the Department of Computer Science and Engineering at the College of Engineering Guindy, Anna University, Chennai, for their support in conducting this research.
Funding
No funding was received for this work.
Author information
Authors and Affiliations
Contributions
P. Steffy Sherly: Conceptualization of the research study Methodology development Software development for the AI-driven system Manuscript writing P. Velvizhy: Supervision of the research project Guidance throughout the research process Manuscript review and editing Principal investigator of the project All authors: Review and approval of the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Sherly, P.S., Velvizhy, P. “Idol talks!” AI-driven image to text to speech: illustrated by an application to images of deities. Herit Sci 12, 371 (2024). https://doi.org/10.1186/s40494-024-01490-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40494-024-01490-0
