
Abstract
Ancient murals, invaluable cultural artifacts, frequently suffer damage from environmental and human factors, necessitating effective restoration techniques. Traditional methods, which rely on manual skills, are time-consuming and often inconsistent. This study introduces an innovative mural restoration approach using a generative adversarial network (GAN) within a UNet architecture. The generator integrates Transformer and convolutional neural network (CNN) components, effectively capturing and reconstructing complex mural features. This work's novelty lies in integrating the Group-wise Multi-scale Self-Attention (GMSA), an Encoder-Decoder Feature Interaction (EDFI) module, and a Local Feature Enhancement Block (LFEB). These components allow the model to better capture, reconstruct, and enhance mural features, leading to a significant improvement over traditional restoration methods. Tested on a dataset of Tang Dynasty murals, the method demonstrated superior performance in PSNR, SSIM, and LPIPS metrics compared to seven other techniques. Ablation studies confirmed the effectiveness of the heterogeneous network design and the critical contributions of the GMSA, EDFI, and LFEB modules. Practical restoration experiments showed the method's ability to handle various types of mural damage, providing seamless and visually authentic restorations. This novel approach offers a promising solution for the digital preservation and restoration of cultural heritage murals, with potential applications in practical restoration projects.
Similar content being viewed by others


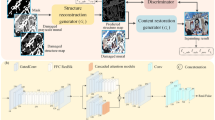
Introduction
Ancient murals are indispensable cultural treasures. However, due to the fragile painting techniques and materials used in their creation, coupled with natural and human-induced damage, murals often suffer from issues such as cracking, peeling, blistering, and fissures [1]. Therefore, the restoration of murals is an important and complex task. The Mogao Caves in Dunhuang, a treasure trove of Buddhist art, contain murals that reflect the rich Buddhist knowledge described in the documents discovered in the Library Cave. Traditional mural restoration methods are often time-consuming and labor-intensive, relying heavily on the manual skills and extensive experience of restorers, and ultimately producing varying results [2]. These methods also struggle to address large-scale damage [3] and the need for complex repairs [4]. With the development of artificial intelligence technology, research on mural restoration based on deep learning has gradually emerged, providing new solutions for the digital preservation and restoration of murals [5]. Scientific restoration methods can restore murals to their original appearance as much as possible, allowing future generations to better appreciate and study these precious cultural heritages.
Traditional mural restoration methods mainly rely on the manual operations of professional restorers, thus consuming significant time and labor. Additionally, the influence of restoration techniques and other human factors can lead to varying restoration effects, which may not meet the requirements of complex restoration tasks. With the development of computer science and artificial intelligence, research on mural restoration using deep learning has attracted widespread attention. As a branch of artificial intelligence, deep learning has achieved remarkable results in image processing, computer vision, and natural language processing. In the field of mural restoration, deep learning aids in understanding the complex features of murals, such as color, texture, and structure, enabling more precise restoration. Yu et al. proposed collecting data on murals to support data-driven image restoration methods [6]. Other researchers have designed and improved restoration algorithms to carry out mural restoration work, such as Wang et al., who used partial convolutional neural networks and multi-scale adaptive methods [7], Cao et al., who utilized local search algorithms for adaptive sample blocks [8], and Liu et al., who employed generative adversarial networks (GANs) to automatically restore damaged mural images [9]. However, existing deep learning-based mural restoration algorithms have shortcomings in detail recovery, leading to the loss of detailed information or the presence of boundary artifacts in the restored images.
In this context, this paper introduces a novel mural restoration method based on generative adversarial networks, consisting of a generator and a discriminator. The generator performs the mural image restoration, and the discriminator evaluates the quality of the restoration. The ultimate goal is to restore the murals to their original state as closely as possible, even in complex restoration scenarios. The network adopts a UNet architecture, using an encoder-decoder information exchange module instead of the original UNet pixel-wise addition operation, better utilizing the features of the encoder and decoder. The module employs cross-attention to better integrate global and local information. Additionally, the heterogeneous design of the encoder and decoder better focuses on global information while restoring local details. The contributions of this paper are summarized as follows:
1. This paper proposes a novel mural restoration network based on generative adversarial networks (GANs), with a generator using an encoder-decoder structure that combines Transformer and convolutional neural networks. By designing multi-scale sliding window attention, it excels in handling global information and long-range dependencies, while CNNs have advantages in local feature extraction and spatial information processing. Combining these two allows the generator to more effectively capture and reconstruct the complex structures and texture features in murals.
2. The network employs a UNet framework, improving restoration effects through multi-level encoder and decoder structures and skip connections. The introduction of an encoder-decoder feature interaction module and a local feature enhancement block further enhances the ability to restore details and colors in mural images, making the restoration more precise and realistic.
3. The discriminator adopts a PatchD discriminator and uses wavelet transforms to extract richer high-frequency components from the image. Since murals often suffer from the loss or damage of high-frequency information (such as textures and fine details), using wavelet transforms to enhance the discriminator's perception ability helps more accurately evaluate the restoration effect and the degree of detail reconstruction.
Related work
Traditional image restoration methods focus on finding useful small image patches from the surrounding areas to repair the damaged regions. However, these methods do not consider the semantic information contained in the image, leading to suboptimal performance in complex scenarios.
Traditional restoration methods
In traditional restoration methods, for minor damage, common techniques include local inpainting and local coloring. The Criminisi algorithm, a sample-based restoration method, selects the best repair patches by comparing the priority values of each sample [10]. Additionally, adaptive sample block restoration methods based on local search algorithms have achieved some success in restoring ancient temple murals [11]. However, these methods often perform poorly when dealing with large-scale damage, resulting in blurry or mosaic effects. Traditional methods face greater challenges when restoring extensive damage due to the lack of sufficient residual information and large missing parts. Traditional partial differential equation-based inpainting algorithms, such as the Total Variation model, although convenient and quick to use, can result in blurriness when dealing with large missing areas [12]. Furthermore, traditional techniques often struggle with complex textures and details. Despite their limitations, traditional restoration techniques still play a crucial role in mural restoration. They rely on the restorer's artistic perception and manual skills, maintaining the original style and texture of the murals to a certain extent. Additionally, traditional methods do not rely on complex technical equipment, making them suitable for restoration environments with limited resources. However, with the advancement of technology, traditional mural restoration techniques are gradually being combined with modern digital technologies. The development of digital image restoration techniques brings new possibilities for traditional mural restoration. For example, digital image processing techniques can perform virtual restoration without touching the original murals, allowing for a preview of the restoration effects and providing guidance for actual restoration [13, 14]. Due to the limitations in feature extraction, traditional methods have poor generalization capabilities and can only be used for simple and single-type mural restoration tasks.
Deep learning-based restoration methods
In 2016, Pathak et al. first proposed an unsupervised visual feature learning algorithm based on neural network context pixel prediction [15]. Meanwhile, Liu et al. introduced local convolutions to restore arbitrary, non-central, irregular regions [16]. Mu et al. proposed a deep generalized unfolding network for image restoration, combining deep learning with optimization algorithms [17]. Yu et al. introduced a unified feedforward generative network that uses a new contextual attention layer to process generated patches, using the features of known patches as convolution filters [18]. Similarly focused on generative networks, Zhang et al. proposed an end-to-end progressive generative network method that divides the entire restoration process into four stages, gradually restoring from the edges of the missing area to the center [19]. In another study, Iizuka et al. enhanced local and global consistency in the restoration area [20], while Lv et al. proposed a mural image restoration method based on generative adversarial networks, establishing skip connections between the generator and discriminator to extract and preserve multi-scale image features [3]. Cao et al. proposed a consistency-enhanced GAN algorithm to repair occluded parts of mural images, using a fully convolutional network (FCN) as the basic framework of the generative network, combined with local and global discriminator networks to optimize the model and enhance the consistency of the global and local expressions of the restored mural images [21]. Li et al. introduced a generative discriminator network model based on AI algorithms for the digital image restoration of ancient damaged murals, using real mural images and damaged images stitched together as inputs to the discriminator network [2]. Besides semantic information, some studies also utilize geometric information such as edges and contours of image regions for effective image restoration. For example, Nazeri et al. proposed an edge generator to approximate structural information by predicting the edges of missing areas and divided the image restoration task into structure prediction and image restoration using adversarial models [22]. Ren et al. proposed a two-stage model: the first stage uses edge-preserving smoothed images to train a structure reconstructor to complete the missing structures in the input, and the second stage uses an appearance flow-based texture generator to generate image details based on the reconstructed structure [23]. Yan et al. studied implicit and explicit features of Beijing masks, using a cross-domain joint communication image translation framework under weak supervision to convert face sketches and color reference images into intermediate feature domains, then synthesizing new face masks through generative networks [24]. In recent years, Transformer-based image restoration has achieved success. For example, Zamir et al. proposed an efficient Transformer model for high-resolution image restoration, using Transformers to capture long-range pixel correlations in images and optimize designs for high-resolution image restoration [25]. Alimanov and Islam utilized Transformers and cyclic consistency generative adversarial networks for retinal image restoration, ensuring content consistency in restored images through cyclic consistency [26].
Additionally, other studies have made significant progress in improving image processing and restoration techniques. For example, the application of deep transfer learning [27, 28] and multi-kernel deep neural networks [29] has shown high accuracy in complex medical image processing, directly impacting the quality of image restoration. Advances in CT scanner calibration [30] and sophisticated segmentation techniques using region-growing methods [31] have further enhanced imaging precision, while secure image retrieval systems [32] have ensured the integrity and security of restored images in medical databases. In cardiovascular imaging, enhanced 3D coronary artery reconstruction [33] and automated determination of optimal views for coronary lesions [34] have improved the accuracy and reliability of restoration processes. Furthermore, the application of machine learning in early detection of coronary microvascular dysfunction [35] and coronary artery segmentation [36] demonstrates the critical role of image restoration in advancing diagnostic capabilities. As image processing technologies continue to evolve, new methods are increasingly being applied to the field of image restoration. For instance, spectral CT material decomposition techniques aimed at mitigating photon noise [37], and the qualitative and quantitative assessment of coronary MRA features [38], highlight the need for sophisticated algorithms to achieve high-quality image restoration. Additionally, studies exploring collateral flow in severe coronary disease [39] and graph matching algorithms for coronary artery sequences [40] emphasize the importance of precise image restoration in medical diagnostics. The integration of these latest techniques and algorithms continuously pushes the boundaries of image restoration, ensuring clearer and more precise medical imaging outcomes [41, 42].
However, the above methods often treat image restoration as a generative task, resulting in images that look natural and realistic but have low similarity to real images.
Methodology
Network structure
As illustrated in Fig. 1, our proposed image restoration network comprises two main components: the generator and the discriminator. The generator employs an encoder-decoder architecture, with the encoder using a Transformer structure and the decoder using a CNN structure. Overall, the generator network is a multi-scale feature UNet network, with skip connections between each encoder and decoder layer facilitating Encoder-Decoder Feature Interaction (EDFI). The encoder consists of two layers of Group-wise SwinTransformer Block (GSwinTB) and down-sampling operations, while the decoder comprises up-sampling, EDFI, and CNN-based Local Feature Enhancement Blocks (LFEB). The discriminator adopts a PatchD discriminator. Given the challenge of restoring high-frequency information in the repaired images, wavelet transform is used to extract richer high-frequency components, which are then stacked as inputs to the discriminator.

The architecture of the proposed Network for image restoration
Given a low-quality image \({I}{\prime}\in {\mathbb{R}}^{H\times W\times 3}\), with missing content, a 3 × 3 convolution is used to extract shallow features \({X}_{0}\in {\mathbb{R}}^{H\times W\times C}\).
where \(Con{v}_{3\times 3}(\cdot )\) denotes a 3 × 3 convolution operation and \(C\) denotes the number of channels for shallow features.
The shallow features \({X}_{0}\) are processed through a three-stage encoder-decoder, with the encoder comprising GSwinTB and down-sampling modules. For up-sampling and down-sampling operations, pixel-shuffle and pixel-unshuffle operations are employed, respectively. The features from the encoder can be represented as:
where \({E}_{i}\) denotes the \(i\) th encoding stage, and the feature \({X}_{i}\in {\mathbb{R}}^{\frac{H}{{2}^{i}}\times \frac{W}{{2}^{i}}\times {2}^{i}C},i=\text{1,2},3\)。\({X}_{i}\) is input to the corresponding decoder stage via a hopping connection and interacts with the decoder's features in a feature interaction. By establishing feature interactions between the encoder and the decoder, it allows the decoder at the next level to better utilize the high-level semantic information extracted by the encoder, as well as more fine-grained image details, to generate a more accurate and clearer output. Specifically, feature \({X}_{0}\) is used to extract global feature \({Y}_{3}\) using a GSwinTB after 3 encoder stages.
The decoder stage recovers image information layer by layer. Specifically, the decoder stage contains three stages, each of which includes an upsampling operation, codec feature interaction, and a CNN-based local feature enhancement block. In order to avoid the artifactual effect produced by the back-convolution, the input features \({Y}_{i}\in {\mathbb{R}}^{\frac{H}{{2}^{i}}\times \frac{W}{{2}^{i}}\times {2}^{i}C},i=\text{3,2},1\) are up-sampled using pixel-shufflfle in the \(i\) th stage, denoted as \({Y}_{i}^{up}\in {\mathbb{R}}^{\frac{H}{{2}^{i}}\times \frac{W}{{2}^{i}}\times {2}^{i}C},i=\text{3,2},1\). Output features and up-sampled features of the same level encoder are inputted into the EDFI at the same time, and the EDFI portion can be expressed as:
where \(H(\cdot ,\cdot )\) denotes the codec feature interaction operation and \({\widetilde{Y}}_{i-1}\) is the output feature of EDFI。
The \(i\) th decoder stage \({D}_{i}\) can be expressed as:
Finally, \({Y}_{0}\in {\mathbb{R}}^{H\times W\times C}\) extracts the features by 3 × 3 convolution and performs channel dimensionality reduction to obtain the features \({I}^{\prime}\in {\mathbb{R}}^{H\times W\times 3}\), and the final recovered result \(\widetilde{I}={I}^{\prime}+R\).
Loss function
Our network is structured as a Generative Adversarial Network (GAN), with the loss function comprising reconstruction loss and adversarial loss. Specifically, the reconstruction loss is computed using L1-Norm:
where \(I\) is the ground-truth image, \(\varpi\) is the discrimination matrix output by the PatchD discriminator, and the smaller the elements in the discrimination matrix the better the recovered results.
GAN loss with generator (Net) loss defined as follows:
The GAN loss used to train the discriminator has a symmetric form:
Finally, the total loss was:
where \(\alpha\) and \(\beta\) are hyperparameters that regulate the loss function, 1 and 0.1, respectively.
Encoder stage
The encoding stage includes GSwinTB and downsampling operation, as shown in Fig. 2(a), GSwinTB contains two layers of Group-wise Multi-scale Self-Attention (GMSA) operation internally, and the input feature \({X}_{i-1}\) goes through two layers of GMSA to get the output feature \({\widetilde{X}}_{i}\). \({\widetilde{X}}_{i}\) then goes through down sampling operation to obtain feature \({X}_{i}\), which is used as the input feature for the next encoding stage. This is represented as follows:
where \({X}_{i-1}^{1}\) is the output feature of the first layer and the input feature of the second layer, \({\widetilde{X}}_{i}\) is the output feature of the second layer, GMSA denotes Group-wise Multi-scale Self-Attention operation, \(LN\) and \(MLP\) denote layer normalization and multilayer perceptron, respectively。

The architecture of the proposed Sub-module
Group-wise Multi-scale Self-Attention. Given a feature map of size \(H\times W\times C\), the window-based self-attention method uses a non-overlapping window of size \(M\times M\) with a computational complexity of \(2{M}^{2}HWC\). The window size \(M\) determines the scope of the self − attention computation, and a larger \(M\) helps to utilize more self-similar information. However, directly increasing \(M\) increases the computational cost and resource consumption by a square order of magnitude. In order to compute long-range self-attention more efficiently, we propose the GMSA module, as shown in Fig. 3. We first divide the input features \(X\) into \(K\) groups, denoted as \({\left\{{X}_{k}\right\}}_{k=1}^{K}\), and then compute the self-attention on the \(k\) thgroup of features using the window size \({M}_{k}\). In this way, we can flexibly control the computational cost by setting the ratio of different window sizes. For example, assuming that the \(K\) th group of features is equally divided into \(C/K\) channels, the computational cost of self-attention on the \(K\) th group is \(2\sum_{k} {M}_{k}HWC\). The self-attention computed on the different groups is subsequently feature spliced by 1 × 1 convolution to obtain \(\widetilde{X}\), which is finally summed element by element with the original features to get \(\overline{X}\).

The architecture of the Group-wise Multi-scale Self-Attention
Decoder stage
The decoding stage consists of three parts: pixel-shufflfle upsampling operation, codec feature interaction (EDFI) and local feature enhancement block (LFEB). In the decoder stage, the input feature \({Y}_{i}\) first undergoes the up-sampling operation to obtain the feature \({Y}_{i}^{up}\), and the feature \({Y}_{i}^{up}\) and the decoder jump − connected feature \({\widetilde{X}}_{i}\) are simultaneously input into the coder-decoder feature interaction as shown in Fig. 2(c), and both \({\widetilde{X}}_{i}\) and \({Y}_{i}^{up}\) pass through the 1 × 1 convolution before global average pooling operation to obtain the feature vectors \({v}_{x}\in {\mathbb{R}}^{1\times 1\times {2}^{i}C}, i=\text{0,1},2\) and \({v}_{y}\in {\mathbb{R}}^{1\times 1\times {2}^{i}C},i=\text{0,1},2\). Their generation process is as follows:
where GAP denotes global average pooling and \(Con{v}_{1\times 1}(\cdot )\) denotes 1 × 1 convolution operation.
The vectors \({v}_{x}\) and \({v}_{y}\) go through a fully connected layer to map the feature vectors into a new space, which is activated by a Sigmoid activation function after a nonlinear transformation of the features to obtain \({\widetilde{v}}_{x}\in {\mathbb{R}}^{1\times 1\times {2}^{i}C},i=\text{0,1},2\) and \({\widetilde{v}}_{y}\in {\mathbb{R}}^{1\times 1\times {2}^{i}C},i=\text{0,1},2\). The process of generating the vectors is represented as follows:
where FC denotes the fully connected layer and \(\sigma\) denotes the Sigmoid activation function.
The resulting vectors \({\widetilde{v}}_{x}\) and \({\widetilde{v}}_{y}\) are multiplied element by element with \({Y}_{i}^{up}\) and \({\widetilde{X}}_{i}\), respectively. Subsequently, the Concatenation operation is performed and the spliced features are downscaled using a 1 × 1 convolution channel to obtain the output features \({\widetilde{Y}}_{i-1}\) of EDFI. The output feature \({\widetilde{Y}}_{i-1}\) is represented as follows:
where \(Con{v}_{1\times 1}(\cdot )\) denotes a 1 × 1 convolution operation, \([\cdot ,\cdot ]\) denotes a splicing operation, and \(\odot\) denotes element-by-element multiplication.
Local feature extraction module, as shown in Fig. 2(b), the \({\widetilde{Y}}_{i-1}\) features are used as inputs to the Local Feature Enhancement Block (LFEB), which consists of a cascade of two network layers with the same structure, where the network layer is designed by designing the channel attention and the spatial attention in parallel to capture spatial correlation and channel correlation in the feature map. \({\widetilde{Y}}_{i-1}\) is obtained by layer normalization and two-layer convolution operation to get the feature \({\widehat{Y}}_{i-1}\), \({\widehat{Y}}_{i-1}\) is spliced into the feature map by spatial attention and channel attention after respectively, and then subsequently dimensionality reduction is done by using 1 × 1 convolutional channel, and after dimensionality reduction, the feature is compared with \({\widetilde{Y}}_{i-1}\) element by element to get the feature \({\widetilde{Y}}_{i-1}^{1}\) as the input of the second layer. \({\widetilde{Y}}_{i-1}^{1}\) through the layer normalization and two − layer convolution operation to get the feature \({\widehat{Y}}_{i-1}^{1}\), \({\widehat{Y}}_{i-1}^{1}\) through the spatial attention and the channel attention, respectively, after the feature map splicing, spliced features using the 1 small constant 1 convolution channel dimensionality reduction, and in with the original feature \({\widehat{Y}}_{i-1}\) are added element by element. The final output of the second layer yields \({Y}_{i-1}\), and the augmented feature \({Y}_{i-1}\) obtained after LFEB is used as the input feature for the next decoding stage. The specific representation is as follows:
where \(Con{v}_{3\times 3}(\cdot )\) denotes a 3 × 3 convolution operation, \(Con{v}_{1\times 1}(\cdot )\) is a 1 × 1 convolution operation, LN denotes layer normalization, and CA and SA are channel attention and spatial attention, respectively.
Experimental verification and analysis
Experimental setup
(1) Dataset
The heterogeneous networks for GAN-based ancient mural restoration is trained with complete mural images. Given that we are targeting datasets with unique characteristics, murals from the Tang Dynasty were chosen for building the dataset. In total, 56,338 images were obtained. Out of these, 50,704 images were used as the training set. The number of images in the test set was 5634 and the ratio of images in the test set to the training set is 11.11%. For the test set, masks were applied to simulate damaged portions of the murals.
(2) Evaluation metrics
The restoration quality was evaluated using three key metrics: (1) Peak Signal-to-Noise Ratio (PSNR), which quantifies the clarity of the restored image by comparing the signal strength to noise; (2) Structural Similarity Index (SSIM), which measures the preservation of luminance, contrast, and structural details in the restored image compared to the ground truth; and (3) Learned Perceptual Image Patch Similarity (LPIPS) [43], which uses deep neural network features to assess perceptual similarity, ensuring that the visual appearance of the restored image closely resembles the original mural. An irregular mask dataset [16] is used to create damaged images. Seven state-of-the-art methods were compared with the proposed method: EdgeConnect [22], PUT [44], JPGNet [45], RFR-Net [20], Uformer [46], MPRNet [47], MIRNetv2 [48]. These methods were chosen for comparison because they have performed well in many real-world applications and therefore permit an accurate assessment of the performance and advantages of our proposed method across a wide range of metrics and aspects.
(3) Experimental conditions
We used the Adam [49] optimizer with a learning rate of 0.0001. During training, the network underwent approximately 350,000 training iterations with a batch size of 16. These parameters were carefully fine-tuned to improve the overall learning process of the network, ensuring that the model captures intricate mural details while maintaining stability during training. Experiments were conducted on a single platform using an NVIDIA RTX 3090 GPU.
Experimental results
Using heterogeneous Networks for GAN-based ancient mural restoration method, restored images were obtained from the test set under the above experimental conditions, and example images are shown in Figures 4 and 5.

Inpainting results of example images

Inpainting results of example images
The above comparisons clearly show that our method is able to generate structures and textures that are closer to the original image while maintaining the quality of the restoration. Specific comparison results are described in Sect. "Comparison of Experimental Results".
Comparison of experimental results
(1) Quantitative comparison
Table 1 shows the results of the comparison of our method with four advanced restoration methods. Our method achieved superior PSNR and SSIM scores compared with the others. Specifically, when compared with RFRNet [20], our method achieved a 32.49% increase in PSNR on the test set. Overall, these results demonstrate the superiority of our method in ancient mural restoration.
Since restoration of murals is our goal, we use LPIPS [44] as a reference metric. It offers the following advantages.
Perceptual Similarity: In mural restoration, the goal is not solely to replicate the original mural at the pixel level but, more crucially, to restore the visual perceptual quality of the mural. LPIPS assists in quantifying the visual perceptual similarity between restoration results and original murals.
Handling Complexity: Mural restoration often involves intricate image challenges such as cracks, fading, and surface erosion. While these issues might be difficult to address at the pixel level, LPIPS offers an understanding and handling of these challenges.
Effect Evaluation: LPIPS provides a quantitative standard for assessing and comparing the effectiveness of different restoration methods. By comparing the LPIPS scores of murals before and after restoration, one can grasp their performance across various tasks, which facilitates further optimization.
Results from an LPIPS evaluation of the quality of all example images in Fig. 4 are displayed in Table 2. Our method achieved an LPIPS 56.61% lower than that of PUT. These results highlight the significant advancements made in perceptual restoration by the proposed method. Furthermore, the test parameters indicate that our method boasts impressive generalizability.
(2) Qualitative comparison
Sample images from the dataset are shown in Fig. 4. We observed that, compared to other methods, our proposed approach generates more natural and realistic images. Even in areas with substantial missing content, the restored images closely resemble the original murals. In contrast, comparative methods introduced numerous artifacts in areas with significant missing content, such as structural distortions and blurriness. While all methods produced similar results in regions with minor damage, our method provided finer granularity and better detail restoration. Additionally, the comparisons in Fig. 5 indicate that, although other methods can restore murals, they exhibit significant disadvantages in sensory authenticity, with noticeable smudging and clear distinctions between restored parts and the surrounding original regions. Our approach, on the other hand, effectively organizes the structures of lines and color blocks in various mural restoration scenarios, restoring them in a style more akin to the original murals.
The local structures around the yellow circles in Fig. 6 demonstrate that EdgeConnect, PUT, and RFRNet fail to recover detailed structures. In contrast, our method successfully handles all the intricate details.

Comparison of mural restoration results of EdgeConnect, PUT, RFRNet, and the proposed method
Enlarged comparisons with Uformer, MPRNet, and MIRNetv2 are shown in Fig. 7. It is evident that MPRNet produces poorer restoration quality, while Uformer and MIRNetv2 exhibit significant blurriness, with restored regions noticeably different from the surrounding areas. The enlarged images reveal unclear boundaries between the black and yellow portions. Our method ensures the authenticity of image restoration, without introducing smudging, unclear boundaries, or a strong sense of artificial generation in the restored regions. Furthermore, our approach not only effectively repairs damaged murals but also eliminates real cracks in the corresponding areas, which is highly beneficial for practical mural restoration applications.

Comparison of mural restoration results of Uformer, MPRNet, MIRNetv2, and the proposed method
Ablation study
To validate the effectiveness of the proposed network, we compared it with UNet frameworks based on pure Transformer and pure CNN architectures, as well as our heterogeneous network combining both. In the ablation experiments, we designed networks with identical encoder-decoder structures and networks with different encoder-decoder structures for comparison. In the Transformer-based network, we utilized dual-layer SwinTransformer blocks as both the encoder and decoder. Conversely, the CNN-based network employed our designed local information extraction modules as the encoder and decoder. Additionally, we verified that using encoder-decoder interactive attention at the skip connections between the encoder and decoder enhances the overall network performance. In the ablation experiments, we evaluated the network using a mural dataset with 1000 epochs. The specific PSNR comparisons are shown in Fig. 8. The results demonstrate that the heterogeneous network achieved the best performance in terms of PSNR, outperforming the single CNN or Transformer frameworks. This validates the effectiveness of the heterogeneous design.

PSNR Comparison of Base-Transformer, Base-CNN and FF(Proposed)
Furthermore, to verify the effectiveness of the Swin Transformer's designed Grouped Multi-head Self-Attention (GMSA), Encoder-Decoder Feature Interaction (EDFI) module, and Local Feature Extraction Block (LEFB), we conducted ablation experiments on the mural restoration test dataset. In the ablation experiments, we sequentially removed the LEFB, EDFI, and GMSA blocks from the complete model and compared the performance of the modified models with the full model. The experimental results are presented in Table 3. As shown in Table 3, the removal of LEFB, EDFI, and GMSA blocks resulted in a performance decline, indicating that our designed LEFB, EDFI, and GMSA blocks contribute significantly to enhancing the model's performance.
Experimental restoration of original damaged murals
We selected five mural photographs for an experimental restoration using our proposed method. The results of these restorations are presented in Fig. 9. The chosen murals exhibited various forms of natural and artificial damage, including scratches, mold, flaking, and cracks. Our method demonstrated effectiveness across these different types of mural damages. Although the restoration results in some extensive and continuous areas of damage were not entirely ideal, it is notable that the restored sections maintained the original style of the murals. The transitions between the restored and the surrounding areas were seamless, avoiding any conspicuous or abrupt sense of repair. This confirms that our method can be applied to restoration work in museums and galleries to support historical research by providing clearer reconstructions of damaged murals. It also has the potential to serve as an educational tool for art conservation and cultural heritage research.

Results of the restoration of the original broken mural
Conclusions
The proposed mural restoration method employs a generative adversarial network (GAN) integrated with a UNet architecture, incorporating Group-wise Multi-scale Self-Attention (GMSA), Encoder-Decoder Feature Interaction (EDFI), and Local Feature Enhancement Block (LFEB). This approach significantly enhances mural restoration quality, achieving superior PSNR, SSIM, and LPIPS metrics compared to state-of-the-art methods. The GMSA module improves long-distance attention mechanisms, EDFI facilitates better feature integration between the encoder and decoder, and LFEB enhances local detail recovery. Experimental results demonstrate the method's robustness and efficacy, confirming its value for the digital preservation and restoration of cultural heritage murals.
Availability of data and materials
No datasets were generated or analysed during the current study.
Abbreviations
- PSNR:
-
Peak signal-to-noise ratio
- SSIM:
-
Structural similarity index
- LPIPS:
-
Learned perceptual image patch similarity
- GAN:
-
Generative adversarial network
- CNN:
-
Convolutional neural network
- GSMA:
-
Group-wise Multi-scale Self-Attention
- EDFI:
-
Encoder-decoder feature interaction
- LFEB:
-
Local feature enhancement block
References
Deng X, Yu Y. Ancient mural inpainting via structure information guided two-branch model. Herit Sci. 2023;11:131.
Li J, Wang H, Deng Z, Pan M, Chen H. Restoration of non-structural damaged murals in Shenzhen Bao’an based on a generator–discriminator network. Herit Sci. 2021;9:6.
Lv C, Li Z, Shen Y, Li J, Zheng J. SeparaFill: Two generators connected mural image restoration based on generative adversarial network with skip connect. Herit Sci. 2022;10:135.
Wang H, Li Q, Zou Q. Inpainting of dunhuang murals by sparsely modeling the texture similarity and structure continuity. J Comput Cult Herit. 2019;12:1–21.
Li L, Zou Q, Zhang F, Yu H, Chen L, Song C, et al. Line drawing guided progressive inpainting of mural damages. arXiv preprint arXiv:221106649. 2022;
Yu T, Lin C, Zhang S, You S, Ding X, Wu J, et al. End-to-end partial convolutions neural networks for dunhuang grottoes wall-painting restoration. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops. 2019.
Wang N, Wang W, Hu W, Fenster A, Li S. Thanka mural inpainting based on multi-scale adaptive partial convolution and stroke-like mask. IEEE Trans on Image Process. 2021;30:3720–33.
Cao J, Li Y, Zhang Q, Cui H. Restoration of an ancient temple mural by a local search algorithm of an adaptive sample block. Herit Sci. 2019;7:39.
Liu K, Wu H, Ji Y, Zhu C. Archaeology and restoration of costumes in tang tomb murals based on reverse engineering and human-computer interaction technology. Sustainability. 2022;14:6232.
Criminisi A, Perez P, Toyama K. Region filling and object removal by exemplar-based image inpainting. IEEE Trans on Image Process. 2004;13:1200–12.
Wang X, Xie L, Dong C, Shan Y. Real-ESRGAN: training real-world blind super-resolution with pure synthetic data. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops. 2021. p. 1905–14.
Chan TF, Shen J. Nontexture inpainting by curvature-driven diffusions. J Vis Commun Image Represent. 2001;12:436–49.
Purkait P, Chanda B. Digital restoration of damaged mural images. Proceedings of the Eighth Indian Conference on Computer Vision, Graphics and Image Processing. ACM; 2012. p. 1–8.
Chanda B, Ratra D, Mounica BLS. Virtual restoration of old mural paintings using patch matching technique. 2012 Third International Conference on Emerging Applications of Information Technology. 2012. p. 299–302.
Pathak D, Krahenbuhl P, Donahue J, Darrell T, Efros AA. Context encoders: feature learning by inpainting. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016. p. 2536–44.
Liu G, Reda FA, Shih KJ, Wang T-C, Tao A, Catanzaro B. Image inpainting for irregular holes using partial convolutions. Proceedings of the European conference on computer vision (ECCV). 2018. p. 85–100.
Mou C, Wang Q, Zhang J. Deep generalized unfolding networks for image restoration. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2022. p. 17399–410.
Yu J, Lin Z, Yang J, Shen X, Lu X, Huang TS. Generative image inpainting with contextual attention. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018. p. 5505–14.
Zhang H, Hu Z, Luo C, Zuo W, Wang M. Semantic image inpainting with progressive generative networks. Proceedings of the 26th ACM international conference on Multimedia. Seoul Republic of Korea; 2018. p. 1939–47.
Li J, Wang N, Zhang L, Du B, Tao D. recurrent feature reasoning for image inpainting. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2020. p. 7757–65.
Cao J, Zhang Z, Zhao A, Cui H, Zhang Q. Ancient mural restoration based on a modified generative adversarial network. Herit Sci. 2020;8:7.
Nazeri K, Ng E, Joseph T, Qureshi F, Ebrahimi M. EdgeConnect: structure guided image inpainting using edge prediction. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops. 2019.
Ren Y, Yu X, Zhang R, Li TH, Liu S, Li G. StructureFlow: image inpainting via structure-aware appearance flow. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 2019. p. 181–90.
Yan M, Xiong R, Shen Y, Jin C, Wang Y. Intelligent generation of Peking opera facial masks with deep learning frameworks. Herit Sci. 2023;11:20.
Zamir SW, Arora A, Khan S, Hayat M, Khan FS, Yang M-H. Restormer: efficient transformer for high-resolution image restoration. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2022. p. 5728–39.
Alimanov A, Islam MB. Retinal image restoration using transformer and cycle-consistent generative adversarial network. 2022 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS). 2022. p. 1–4.
Pathak Y, Shukla PK, Tiwari A, Stalin S, Singh S, Shukla PK. Deep transfer learning based classification model for COVID-19 disease. IRBM. 2022;43:87–92.
Narayan Das N, Kumar N, Kaur M, Kumar V, Singh D. Automated deep transfer learning-based approach for detection of COVID-19 infection in chest x-rays. IRBM. 2022;43:114–9.
Turkoglu M. COVID-19 detection system using chest CT images and multiple kernels-extreme learning machine based on deep neural network. IRBM. 2021;42:207–14.
Chaikh A, Giraud J-Y, Balosso J. Effect of the modification of CT scanner calibration curves on dose using density correction methods for chest cancer. IRBM. 2014;35:255–61.
Orkisz M, Hernández Hoyos M, Pérez Romanello V, Pérez Romanello C, Prieto JC, Revol-Muller C. Segmentation of the pulmonary vascular trees in 3D CT images using variational region-growing. IRBM. 2014;35:11–9.
Janani T, Darak Y, Brindha M. Secure similar image search and copyright protection over encrypted medical image databases. IRBM. 2021;42:83–93.
Li S, Nunes JC, Toumoulin C, Luo L. 3D coronary artery reconstruction by 2D motion compensation based on mutual information. IRBM. 2018;39:69–82.
Feuillâtre H, Sanokho B, Nunes J-C, Bedossa M, Toumoulin C. Automatic determination of optimal view for the visualization of coronary lesions by rotational X-ray angiography. IRBM. 2013;34:291–5.
Zhao X, Gong Y, Zhang J, Liu H, Huang T, Jiang J, et al. Early detection of coronary microvascular dysfunction using machine learning algorithm based on vectorcardiography and cardiodynamicsgram features. IRBM. 2023;44: 100805.
Mabrouk S, Oueslati C, Ghorbel F. Multiscale graph cuts based method for coronary artery segmentation in angiograms. IRBM. 2017;38:167–75.
Hohweiller T, Ducros N, Peyrin F, Sixou B. Spectral CT material decomposition in the presence of poisson noise: a kullback-leibler approach. IRBM. 2017;38:214–8.
Velut J, Lentz P-A, Boulmier D, Coatrieux J-L, Toumoulin C. Assessment of qualitative and quantitative features in coronary artery MRA. IRBM. 2011;32:229–42.
Harmouche M, Maasrani M, Verhoye J-P, Corbineau H, Drochon A. Coronary three-vessel disease with occlusion of the right coronary artery: What are the most important factors that determine the right territory perfusion? IRBM. 2014;35:149–57.
Feuillâtre H, Nunes J-C, Toumoulin C. An improved graph matching algorithm for the spatio-temporal matching of a coronary artery 3D tree sequence. IRBM. 2015;36:329–34.
Karthik R, Menaka R, Hariharan M, Kathiresan GS. AI for COVID-19 detection from radiographs: incisive analysis of state of the art techniques key challenges and future directions. IRBM. 2022;43:486–510.
Huyut MT. Automatic detection of severely and mildly infected COVID-19 patients with supervised machine learning models. IRBM. 2023;44: 100725.
Zhang R, Isola P, Efros AA, Shechtman E, Wang O. The Unreasonable effectiveness of deep features as a perceptual metric. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018. p. 586–95.
Liu Q, Tan Z, Chen D, Chu Q, Dai X, Chen Y, et al. Reduce information loss in transformers for pluralistic image inpainting. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2022. p. 11347–57.
Guo Q, Li X, Juefei-Xu F, Yu H, Liu Y, Wang S. JPGNet: joint predictive filtering and generative network for image inpainting. Proceedings of the 29th ACM International Conference on Multimedia. 2021. p. 386–94.
Wang Z, Cun X, Bao J, Zhou W, Liu J, Li H. Uformer: a general U-shaped transformer for image restoration. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2022. p. 17662–72.
Zamir SW, Arora A, Khan S, Hayat M, Khan FS, Yang M-H, et al. Multi-stage progressive image restoration. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2021. p. 14816–26.
Zamir SW, Arora A, Khan S, Hayat M, Khan FS, Yang M-H, et al. Learning enriched features for fast image restoration and enhancement. arXiv; 2022.
Kingma DP, Ba J. Adam: A method for stochastic optimization. arXiv preprint arXiv:14126980. 2014;
Acknowledgements
None.
Author information
Authors and Affiliations
Contributions
All authors contributed to the current work. RH proposed the research plan and supervised the whole process to provide constructive comments, ZFH completed the method design and model construction, and SK and ZX completed the dataset production and organized the experimental data. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Zhao, F., Ren, H., Sun, K. et al. GAN-based heterogeneous network for ancient mural restoration. Herit Sci 12, 418 (2024). https://doi.org/10.1186/s40494-024-01517-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1186/s40494-024-01517-6
Keywords
This article is cited by
-
DiffuMural: a diffusion model for dunhuang murals restoration via multi-scale convergence and cooperative guidance
npj Heritage Science (2026)
-
Multimodal intelligent reconstruction-driven digital regeneration of cultural heritage in Qing Dynasty tea plantation landscapes
npj Heritage Science (2026)
-
EdgeConnect model based on Fourier convolution for Dunhuang mural costume image restoration
npj Heritage Science (2025)
-
An improved mural image restoration method based on diffusion model
npj Heritage Science (2025)
-
Application of GANs in Ancient Architectural Heritage Image Restoration
npj Heritage Science (2025)
