
Abstract
Rock art is recognized globally as significant cultural heritage. Symbols in rock art capture scenes of daily life from ancient societies, revealing the cultural context of past civilizations and holding significant research value. In the research of rock art symbols, it is necessary to accurately and efficiently segment the symbols in the images to ensure subsequent research on rock art symbols and the construction of symbol system databases. Although existing methods for rock art symbol segmentation can effectively extract symbols from 2D images, they are often time-consuming, labor-intensive, and have low segmentation accuracy of the model. To address these challenges, this study proposes a rock art symbol segmentation method based on an improved YOLOv7-Seg model, which incorporates SE (Squeeze-and-Excitation Networks) and ODConv (Omni-Dimensional Dynamic Convolution) to enhance the model’s focus on rock art symbol features, enabling efficient and accurate segmentation in complex backgrounds. This model facilitates the recognition and segmentation of human and animal symbols in images. The study employs Cangyuan rock art as a case study, validating the model’s accuracy through ablation experiments and comparative analysis. The model achieves an overall AP score of 0.961, with specific AP score of 0.973 for animal segmentation and 0.948 for human segmentation. The results demonstrate that the improved model effectively segments rock art symbols in complex environments, achieving high-precision automated segmentation of rock art symbols. This research lays the foundation for the subsequent unified management of rock art symbols as well as the study of rock art protection and heritage preservation.
Similar content being viewed by others


Introduction
As a cultural heritage that has persisted over an extended period and exists in large quantities, rock art carries rich historical and cultural significance1,2,3. Additionally, the patterns in rock art exhibit similarities across various countries and regions, reflecting global or regional cultural development and dissemination4,5,6. The image symbols in rock art include depictions of real historical objects (such as humans, cattle, horses, houses, and the sun) and also reflect scenes from everyday life7,8. As cultural symbols, rock art reveal deeper cultural meanings through their symbolic information. The combination of rock art symbols can narrate stories, recreating the authentic life conditions of ancient peoples9,10. For example, Whitley11 summarized detailed ethnographic records from three cultural regions in the far western areas of North America (California, the Great Basin, and the Columbia-Fraser Plateau), demonstrating that different social groups created distinct styles of rock art within the same cultural and temporal context. Riyad Z. et al.12 studied various animals and geometric symbols in rock art, such as circles, spirals, and black dots, explaining their association with rain rituals. By comparing them with modern rain rituals of traditional tribes in East and Southern Africa, he reinterpreted the symbols and scenes in prehistoric rock art. Therefore, the study of rock art symbols is of great significance, and it is imperative to document and preserve this important cultural heritage that is currently at risk of being damaged.
Although a large amount of image data has been digitized to preserve these symbols, there is still a desire to extract these symbolic patterns from the images. However, symbol segmentation requires expert knowledge, and processing these images is time-consuming and labor-intensive. Therefore, the automated segmentation of rock art symbols from images is of great research significance. It not only greatly enhances the efficiency of data processing for the preservation of rock art symbols but also lays the foundation for the subsequent construction of rock art symbol databases.
In recent years, the rise of artificial intelligence and machine learning has introduced new possibilities in the field of cultural heritage13,14. With the help of artificial intelligence and machine learning, many advancements have been made in the field of cultural heritage preservation15,16,17. For example, Zeppelzauer et al.18 transformed complex 3D segmentation tasks into the image space, achieving more efficient rock art segmentation. Fu et al.19 developed an automated surface defect detection model based on the Swin Transformer and YOLOv5, designed for the classification, segmentation, and detection of surface defects in cultural heritage architecture images. However, research on the segmentation of rock art using neural networks remains limited, and existing studies fail to meet the need for precise segmentation of rock art symbols in complex backgrounds and blurred edges. Therefore, exploring the potential and applicability of artificial intelligence and machine learning in the segmentation of rock art symbols has become one of the urgent tasks.
Although current deep learning segmentation algorithms can be used for rock art symbol segmentation, but the differences in background color, material, and the blurred edges of symbols in rock art images make it difficult for models to extract the features of rock art symbols. To overcome these challenges, we proposed an improved YOLOv7-Seg model for rock art symbol segmentation, categorizing the symbols into two types: human and animal. Comparative experiments with the Mask R-CNN model and ablation studies of the YOLOv7-Seg variants were conducted to validate the reliability and accuracy of the proposed method. The results demonstrate that this method can achieve high-precision segmentation of rock art image symbols.
The remainder of the paper is structured as follows: Section 2, we introduce related work on rock art research; Section 3, we present the YOLOv7 model and the improvements made; Section 4 covers the studies and results; Section 5, we discuss and summarize the contributions and limitations of this work; Finally, in Section 6 we summarize the content of the research and the potential future work.
Related Work
In recent years, artificial intelligence (AI) technology has advanced rapidly, and due to its efficiency and high accuracy in prediction and recognition, deep learning has been widely applied in cultural heritage object detection20,21,22,23. Currently, researchers have employed deep learning algorithms to detect damage in cultural heritage24,25. Wang et al.26 proposed a two-stage target detection, segmentation, and measurement strategy for historical glazed tiles based on deep learning technology. In the first stage of the model, Faster R-CNN is used to automatically detect roof images and segment them into single-layer glazed tile images; in the second stage, Mask R-CNN is used to train the cropped images, enabling the segmentation and measurement of damage to historical glazed tiles. Zou et al.27 used the Faster R-CNN algorithm to detect and analyze the damage status of historical architectural components (e.g., gables, water spouts, finials) and then inferred the regularity of their positional arrangement by marking the locations of the damaged components. Angheluta et al.28 used the VGG-16 convolutional network, developed by the Visual Geometry Group at the University of Oxford, to detect cracks, blisters, and peeling in wooden paintings, ultimately enabling the detection and assessment of highly visually complex damage. Hou et al.29 applied the Mask-RCNN algorithm to detect three types of gold foil shedding, dust accumulation, and warping with very high recognition accuracy, demonstrating that object recognition algorithms can successfully detect various types of damage in cultural heritage.
Deep learning has also emerged as a prominent focus in the field of rock art recognition. Zhu et al.30 employed shape-based descriptors combined with simple image processing techniques (e.g., generalized Hough transform), focusing mainly on shape and its variations rather than the detection or classification of rock art. Seidl and Breiteneder31 studied rock art segmentation by exploring and integrating various features such as SIFT and DSIFT. In the study by Seidl et al.32, several simple shape descriptors and graph-based rock art descriptors were proposed for the automatic classification of rock art. The study mainly focused on the combination of various descriptors and used the nearest neighbor model for classification. In the study by Poier et al.33, a high-resolution 3D dataset of natural rock surfaces containing rock art was proposed. Various rock art on the rocks were manually scanned with sub-millimeter accuracy, resulting in orthophotos and corresponding depth maps. Tsigkas et al.34 attempted two methods to automatically detect three rock art sites, finding that with a large number of training instances, YOLOv2 and TinyYOLO-v2 deep learning outperformed SIFT and Random Sample Consensus (RANSAC); however, with a smaller number of annotated images, the results were the opposite. In the study by Horn4, the authors created a model to locate and classify image objects from Swedish rock art sites. The model was trained using Faster R-CNN, data augmentation, and transfer learning from images generated by 3D scans. The model performed well on some objects (e.g., boats and circles) but poorly on others (e.g., animals), which was attributed to the limited number of training samples. Jalandoni et al.35 proposed a machine learning approach based on the latest advancements in deep learning to train models for identifying images containing colored rock art (pictographs). Bai et al.36 proposed a novel Bayesian loss function (BEGL) to enhance and refine the boundaries of petroglyph images, applying it to a UNet-based image segmentation network to improve segmentation precision and accuracy. Fabrice et al.37 developed software named ERA, which utilizes machine learning techniques to automatically identify graffiti patterns in petroglyph images and generate high-quality documentation. Kowlessar et al.38 employed transfer learning techniques to perform style recognition on petroglyph images from the Arnhem Land region of Australia, analyzing the relationships between different styles and constructing a chronological sequence of petroglyph styles. Turner-Jones et al.39 developed an interdisciplinary project that integrates Indigenous cultural heritage, Indigenous education, machine learning (ML), and artificial intelligence (AI). This project is significant in enhancing Indigenous STEM education and utilizes ML for rock art classification, with results showing a Top-1 accuracy of 79.76% and a Top-5 accuracy of 94.56% for motif classification.
As mentioned above, research on deep learning in the field of rock art segmentation is limited, and it has not accounted for background variations and symbol edge blurring during the recognition process. To address these limitations, this study proposes a method based on the YOLOv7 model, where the original network is replaced with a full-dimensional dynamic convolution network and the SE attention module is added, enabling the network to better focus on the edge features of rock art symbols, achieving high-precision segmentation across different backgrounds and levels of blurriness.
Rock Art Segmentation Method
YOLOv7-Seg algorithm
The YOLOv740 algorithm is the seventh generation of the YOLO series. Compared to YOLOv5 and earlier YOLO series algorithms, YOLOv7 uses an innovative multi-branch stacking structure for feature extraction in the backbone network, with denser skip connections and a novel downsampling structure for extraction and compression. YOLOv7 also accelerates model training by increasing the number of positive samples. The algorithm also calculates IoU and class based on the adjusted prediction boxes relative to the anchor boxes, to identify the best-fitting anchor box for the ground truth box.
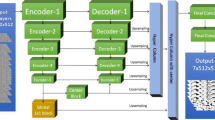
YOLOv7 is a versatile object detection algorithm, and its developers have also released a version for instance segmentation. The YOLOv7 network structure of the algorithm mainly consists of a backbone network responsible for feature extraction and a detection network (Head) for multi-scale detection. YOLOv7 first preprocesses the input color images of varying sizes to 640 × 640 pixels and then feeds them into the backbone network for feature extraction. To successfully train the framework, appropriate rock art symbol annotations must be provided. The framework is divided into three parts: the backbone network (Backbone) for extracting features from the input image; the FPN network for scaling the extracted features and enhancing the representation of target features; and the network prediction layer for predicting targets at three scales. The Yolohead layer uses post-processing techniques such as Non-Maximum Suppression (NMS) to generate the segmentation output results. In Fig. 1, to enhance the model’s adaptability to the local details, texture features, and shape characteristics of rock art symbols, the backbone network’s feature extraction component was improved by incorporating ODConv and the SE model.

Structure of the Improved YOLOv7-Seg Model.
Squeeze-and-excitation networks
To make the YOLOv7 model better adapt to the edge and contour details, texture features, and geometric shape characteristics of rock art, we incorporated the Squeeze-and-Excitation (SE) network into the model.
SE is a lightweight gating attention mechanism primarily used for effectively modeling relationships between channels in neural networks. By utilizing global pooling and fully connected layers, it combines global and local information, allowing the model to better leverage contextual information during rock art segmentation, thereby enhancing network performance and representational capacity. The SE mechanism operates through four steps:
-
(1)
Squeeze Operation: In this operation, the local feature sequence is aggregated through the spatial dimension to obtain a channel descriptor. In simple terms, spatial information from the local feature map is aggregated to generate a channel descriptor that represents the importance of each channel.
-
(2)
Excitation Operation: This is a gating mechanism that uses the channel descriptors obtained from the previous step to generate a set of weights, with each weight corresponding to the modulation value for each channel. These weights are used to scale the original feature sequence, emphasizing or suppressing feature responses from different channels.
-
(3)
Global Context Information: Through the Squeeze and Excitation operations, the SE mechanism encodes global contextual information into the feature sequence. This means that the network can consider information from the entire network, not just local features, when processing each channel.
Output
The output of the SE is a weighted feature sequence where the importance of each channel’s features has been adjusted, allowing the network to focus more on important features and reduce reliance on irrelevant ones.
The SE module structure is shown in Fig. 2. Overall, the SE attention mechanism leverages global contextual information through Squeeze and Excitation operations in an efficient manner, thereby enhancing the network’s performance and representational capacity, making it more effective and accurate in handling channel relationships, and enabling more precise extraction of rock art information.

The structure of SE Module.
Omni-Dimensional Dynamic Convolution
The model of Omni-Dimensional Dynamic Convolution (ODConv) is to innovate the design of convolutional layers in traditional convolutional neural networks (CNNs). In traditional CNNs, each convolutional layer typically uses fixed, static convolutional kernels to extract features. In contrast, ODConv introduces a dynamic, multidimensional attention mechanism that comprehensively improves the design of convolutional kernels. The core innovation of ODConv lies in its multidimensional dynamic attention mechanism. Traditional dynamic convolution usually achieves dynamism only in the dimension of the number of convolutional kernels, by weighting and combining multiple kernels to adapt to different input features. Figure 3 illustrates the core concept of the ODConv model, which dynamically adjusts not only the number of convolution kernels but also their three other dimensions: spatial size, input channels, and output channels. This enables ODConv to more precisely adapt to the characteristics of input data, thereby enhancing feature extraction performance. Additionally, ODConv employs a parallel strategy to simultaneously learn attention across different dimensions. This strategy allows the network to be more efficient in processing features in each dimension while ensuring complementarity and synergy between dimensions.

The structure of ODConv.
Experiments
Dataset preparation
Figure 4 shows the study area of this research, which focuses on the Cangyuan rock art located in Cangyuan Wazu autonomous county Yunnan Province. And the Cangyuan rock paintings were created over 3500 years ago by the Wa ancestors, first widely recognized in 1965. To date, 15 sites have been discovered, with 1098 identifiable figures in the Cangyuan rock paintings. Among them, there are 812 human figures, accounting for 73.95% of the total paintings, and 108 animal figures, accounting for 9.84% of the total.

Cangyuan rock art located in Cangyuan Wazu Autonomous County, Yunnan Province.
This study utilizes the YOLOv7-Seg segmentation algorithm to extract the rock art symbols from images. During the data preparation stage, a total of 168 usable images were obtained by using Python web scraping techniques to collect public rock art images online, combined with manually captured rock art data. Additionally, to ensure the generalization capability of the dataset, some publicly available rock art images from the internet were added to the dataset beyond the study area. And all images were reviewed and confirmed to have no copyright issues.
In the image dataset preparation stage, we annotated the 168 images using LabelMe software and converted the resulting JSON files into the format required by the YOLO model. However, due to the limited number of training samples, we performed data augmentation on the existing data using methods such as mirroring, rotation, and random cropping, eventually expanding the dataset to 2348 images. Of this dataset, 90% of the images were used as the training and validation dataset, while the remaining 10% were used as the test set. Additionally, the dataset categories are primarily divided into two classes: people and animals. In this model, the input image size is uniformly set to 640 × 640. Figure 5 shows the annotated data samples.

Dataset samples used for training the improved model (The yellow annotations represent people, and the blue annotations represent animals).
The training process was conducted using GPU mode on a workstation with the following configuration: CPU is a 13th Gen Intel(R) Core(TM) i9-13900K with a clock speed of 3.00 GHz, 64.0 GB of RAM, and an NVIDIA GeForce RTX3090 GPU. The code was written in Python 3.9, and the virtual environment used was torch 2.0.0 + cu118. The entire training process was completed on a Windows 10 × 64 system.
Improvement of the YOLOv7-Seg model for rock art segmentation
The dataset was divided into a training set (1644 images), a validation set (469 images), and a test set (235 images) for the rock art image segmentation task. To evaluate the effectiveness of the model improvements, a series of ablation studies were conducted. These included the original model, variants with the SimAM attention mechanism, and variants with the SE attention mechanism. Furthermore, we will compare the performance of these models with the Mask R-CNN model. The main parameters modified during the training process are shown in Table 1, while all other parameters are set to their default values.
Figure 6a illustrates the loss curves during training, where train/box_loss represents the loss related to bounding box prediction, train/seg_loss denotes the loss for the segmentation task, train/obj_loss corresponds to the loss for object detection or classification tasks, and train/cls_loss indicates the loss for class prediction or classification. Figure 6b displays the loss curves during the validation process. Both Fig. 6a, b indicate that the model starts to decline gradually after 10 epochs, and the total loss converges and stabilizes around 50 epochs. Comparison reveals that the loss values after 100 epochs of training for both training and validation processes are very low, remaining between 0 and 0.03, indicating that the model achieves high accuracy in detection and segmentation.

a Loss curve during training b Loss curve during validation.
The PR Curve and F1-Confidence Curve of the model after 100 epochs of training are shown in Fig. 7. After training, the model’s segmentation performance on rock art is evaluated using the PR curve and F1 score. Figure 7a displays the AP values for rock art, where AP is the area under the precision-recall curve. Higher AP values indicate more accurate model detection results. The AP value for people is 0.948, for animals is 0.973, and the overall AP value is 0.961. Figure 7b shows the F1-Confidence curve, with the highest F1 score of 0.95 achieved at a confidence level of 0.510. Both figures confirm the model’s high detection accuracy.

a PR curve b F1-Confidence curve.
This study involves annotating and augmenting a custom dataset, then inputting the research data into the model and using the trained model to segment the rock art regions. To evaluate the performance of the trained model, we tested it using the pre-defined test set (235 images). During the prediction process, the confidence threshold parameter was set to 0.45, the IoU threshold parameter was set to 0.45, and the image size was set to the default of 640 × 640. Both the confidence threshold and IoU are metrics for the model’s segmentation accuracy; a segmentation is considered successful if the results exceed the set values. Figure 8a–h show the rock art segmentation results in different backgrounds. The model successfully segments rock art across various background environments and resolutions. Figure 8a, b also shows successful segmentation of both people and animal categories.

Among them a, c, e, g are the original images, b, d, f, h are the segmented images. (Green annotations represent people, and blue annotations represent animals).
This study utilizes the improved YOLOv7-Seg algorithm, which not only detects the presence of rock art regions in images but also accurately marks the boundaries of specific rock art areas at the pixel level, enhancing the precision of rock art symbol segmentation. Furthermore, by incorporating the SE attention mechanism and ODConv full-dimensional dynamic convolution into the YOLOv7-Seg model, the segmentation accuracy of rock art regions has been further enhanced while maintaining efficiency. In conclusion, the model performs effectively under various backgrounds and conditions. This indicates that the improved YOLOv7-Seg can achieve more accurate and high-precision detection results under diverse conditions.
Discussion
Currently, rock art segmentation primarily relies on expert knowledge, which is time-consuming and labor-intensive. Deep learning algorithms offer a solution to these challenges by assisting in the detection process. This study uses the Cangyuan rock art as a case study and employs the improved YOLOv7-Seg algorithm for segmentation. This algorithm can automatically detect rock art objects, resulting in shorter processing times and higher accuracy. After 100 epochs of training, the model achieved an AP value of 0.961 for segmentation. Additionally, we conducted ablation studies on the improved model and compared it with the Mask-RCNN model to verify the accuracy of the rock art segmentation achieved by the improved model. Table 2 shows the precision comparison of various models for rock art symbol segmentation, where AP stands for Average Precision, and MAP@0.5 refers to the Mean Average Precision when the Intersection over Union (IoU) threshold is 0.5.
The research data utilized in this study consists of high-resolution images of Cangyuan rock art. During model training, a validation dataset was employed to assess model performance. After training the model, 235 images from the test set were used to evaluate the performance of the trained model. Results show that the trained model can accurately detect rock art information in varying backgrounds and lighting conditions. This method can be applied to rock art detection in other regions by simply adding new images to the dataset to enhance the model’s applicability. The improved YOLOv7-Seg algorithm effectively detects rock art elements, including human and animal figures. It offers high accuracy and practical value, enabling segmentation of rock art regions and providing a foundation and new ideas for subsequent rock art database construction and heritage preservation.
However, this study has certain limitations. Due to the constraints of rock art data, the research is mainly focused on Cangyuan rock art, and future work needs to include a wider range of rock art from different regions for more extensive validation. Additionally, there is a need to further integrate the characteristics of rock art with the design and architecture of neural network submodules to optimize the model, with the aim of improving detection accuracy and achieving clearer boundaries. Future work should focus on expanding the dataset in terms of quantity and variety, and employing more advanced deep learning algorithms to improve the accuracy of rock art segmentation.
Conclusion
This study explores the application of an improved YOLOv7-Seg deep learning model for the segmentation of rock art symbols. By integrating the SE attention mechanism and ODConv full-dimensional dynamic convolution, the model enhances its focus on the features of rock art symbols, achieving high-precision segmentation in complex backgrounds. And the improved YOLOv7-Seg model was validated through ablation and comparative experiments. Experimental results show that the improved YOLOv7-Seg model achieved a 18.1% increase in average precision (MAP@0.5) compared to the original model and a 13.4% improvement over the Mask RCNN model, significantly enhancing the accuracy and efficiency of rock art symbol segmentation, achieving high-precision segmentation in complex backgrounds.
Future work could consider the following directions:
-
(1)
This study focuses on improving the accuracy of the YOLOv7 model to enhance its performance in rock art detection, with potential future attempts on the YOLOv8 model.
-
(2)
Expand the scale and diversity of the dataset to enhance the model’s generalization ability.
-
(3)
Build a rock art symbol system library for unified management of rock art symbols.
Data availability
All data generated or analyzed during this study are included in this published article.
References
Ashrafi, B., Kloos, M. & Neugebauer, C. Heritage Impact Assessment, beyond an Assessment Tool: A comparative analysis of urban development impact on visual integrity in four UNESCO World Heritage Properties. J. Cultural Herit. 47, 199–207 (2021).
Waterton, E. & Smith, L. Heritage protection for the 21st century. Cultural Trends 173, 197–203 (2008).
Kakiuchi, E. Cultural heritage protection system in Japan: current issues and prospects for the future. GRIPS Discussion Papers, https://doi.org/10.4467/23538724GS.16.013.6170 (2014).
Horn, C. et al. Artificial intelligence, 3D documentation, and rock art—approaching and reflecting on the automation of identification and classification of rock art images. J. Archaeological Method Theory 29, 188–213 (2022).
Jalandoni, A. An overview of remote sensing deliverables for rock art research. Quat. Int 572, 131–138 (2021).
May, S. K. et al. New insights into the rock art of Anbangbang Gallery, Kakadu National Park. J. Field Archaeol. 45, 120–134 (2020).
Domingo, I. et al. Latest developments in rock art recording: towards an integral documentation of Levantine rock art sites combining 2D and 3D recording techniques. J. Archaeological Sci. 40, 1879–1889 (2013).
Ochoa, B. et al. Dating Iberian prehistoric rock art: Methods, sampling, data, limits and interpretations. Quat. Int. 572, 88–105 (2021).
Burney, D. A. et al. Rock art from andriamamelo cave in the beanka protected area of western Madagascar. J. Isl. Coast Archaeol. 17, 171–194 (2022).
May, S. K. et al. Survival, social cohesion and rock art: the painted hands of Western Arnhem Land, Australia. Camb. Archaeological J. 30, 491–510 (2020).
Whitley, D. S. Ethnography, shamanism, and Far Western North American rock art. Boletín del Museo Chileno de Arte Precolombino, 28 https://doi.org/10.56522/BMCHAP.0110010280003 (2023).
Riyad, Z. Rainmaking through the rock art in east and south africa: a comparison with current traditional tribes. J. Gen. Union Arab Archaeologists 8, 92–120 (2023).
Davis, D. S. Object‐based image analysis: a review of developments and future directions of automated feature detection in landscape archaeology. Archaeological Prospection 26, 155–163 (2019).
Caspari, G. & Crespo, P. Convolutional neural networks for archaeological site detection–Finding “princely” tombs. J. Archaeological Sci. 110, 104998 (2019).
Sharafi, S. et al. Application of pattern recognition in detection of buried archaeological sites based on analysing environmental variables, Khorramabad Plain, West Iran. J. Archaeological Sci: Rep. 8, 206–215 (2016).
Sabatelli, M. et al. Deep transfer learning for art classification problems//Proceedings Of The European conference on computer vision (ECCV) workshops. 0-0. https://doi.org/10.1007/978-3-030-11012-3_48 (2018).
Verschoof-Van der Vaart, W. B. & Lambers, K. Learning to look at LiDAR: The use of R-CNN in the automated detection of archaeological objects in LiDAR data from the Netherlands. J. Computer Appl Archaeol. 2, 31–40 (2019).
Zeppelzauer, M. et al. Interactive 3D segmentation of rock-art by enhanced depth maps and gradient preserving regularization. J. Comput Cultural Herit. (JOCCH) 9, 1–30 (2016).
Fu, X. & Angkawisittpan, N. Detecting surface defects of heritage buildings based on deep learning. J. Intell. Syst. 33, 20230048 (2024).
Kumar, P. et al. Detection of disaster-affected cultural heritage sites from social media images using deep learning techniques. J. Comput Cultural Herit. (JOCCH) 13, 1–31 (2020).
Nazarian, E. et al. Machine-learning-based approach for post event assessment of damage in a turn-of-the-century building structure. J. Civ. Struct. Health Monit. 8, 237–251 (2018).
Fiorucci, M. et al. Machine learning for cultural heritage: A survey. Pattern Recognit. Lett. 133, 102–108 (2020).
Hatır, E. et al. The deep learning method applied to the detection and mapping of stone deterioration in open-air sanctuaries of the Hittite period in Anatolia. J. Cultural Herit. 51, 37–49 (2021).
Meng, T. et al. Highly sensitive terahertz non‐destructive testing technology for stone relics deterioration prediction using SVM-based machine learning models. Herit. Sci. 9, 1–9 (2021).
Valero, E. et al. Automated defect detection and classification in ashlar masonry walls using machine learning. Autom. Constr. 106, 102846 (2019).
Wang, N. et al. Autonomous damage segmentation and measurement of glazed tiles in historic buildings via deep learning. Computer‐Aided Civ. Infrastruct. Eng. 35, 277–291 (2020).
Zou, Z. et al. CNN-based statistics and location estimation of missing components in routine inspection of historic buildings. J. Cultural Herit. 38, 221–230 (2019).
Angheluţă, L. M. & Chiroşca, A. Physical degradation detection on artwork surface polychromies using deep learning models. Rom. Rep. Phys. 72, 805 (2020).
Hou, M. et al. Using mask R-CNN to rapidly detect the gold foil shedding of stone cultural heritage in images. Herit. Sci. 12, 46 (2024).
Zhu, Q. et al. An efficient and effective similarity measure to enable data mining of petroglyphs. Data Min. Knowl. Discov. 23, 91–127 (2011).
Seidl, M., & Breiteneder, C. Automated petroglyph image segmentation with interactive classifier fusion[C]//Proceedings of the Eighth Indian Conference on Computer Vision, Graphics and Image Processing. 1–8. https://doi.org/10.1145/2425333.2425399 (2012).
Seidl M, Wieser E, Alexander C. Automated classification of petroglyphs. Digit. Appl. Archaeol. Cult. Herit. 2, 196–212 (2015).
Poier G, Seidl M, Zeppelzauer M, et al. The 3d-pitoti dataset: a dataset for high-resolution 3D surface segmentation//Proceedings of the 15th International Workshop on Content-Based Multimedia Indexing. 1-7. https://dl.acm.org/doi/abs/10.1145/3095713.3095719 (2017)
Tsigkas, G. et al. Markerless detection of ancient rock carvings in the wild: rock art in Vathy, Astypalaia. Pattern Recognit. Lett. 135, 337–345 (2020).
Jalandoni, A., Zhang, Y. & Zaidi, N. A. On the use of Machine Learning methods in rock art research with application to automatic painted rock art identification. J. Archaeological Sci. 144, 105629 (2022).
Bai, C. et al. BEGL: boundary enhancement with Gaussian Loss for rock-art image segmentation. Herit. Sci. 11, 17 (2023).
Monna, F. et al. ERA: A new, fast, machine learning-based software to document rock paintings. J. Cultural Herit. 58, 91–101 (2022).
Kowlessar, J. et al. Reconstructing rock art chronology with transfer learning: A case study from Arnhem Land, Australia. Aust. Archaeol. 87, 115–126 (2021).
Turner-Jones, R. et al. Digitising the Deep Past: Machine Learning for Rock Art Motif Classification in an Educational Citizen Science Application. ACM Journal on Computing and Cultural Heritage. https://doi.org/10.1145/3665796.
Wang, C. Y., Bochkovskiy, A., Liao, H. Y. M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 7464–7475. https://doi.org/10.1109/CVPR52729.2023.00721 (2023).
Acknowledgements
This research was funded by National Natural Science Foundation of China grant number 42171444.
Author information
Authors and Affiliations
Contributions
D.H., M.H., S.Y. conceived the presented idea. D.H. conducted the analysis process and wrote the manuscript. M.H. and S.Y. revised and supervised the manuscript. All authors approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Huo, D., Yang, S. & Hou, M. Using the improved YOLOv7-Seg model to segment symbols from rock art images. npj Herit. Sci. 13, 16 (2025). https://doi.org/10.1038/s40494-025-01620-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s40494-025-01620-2
