
Abstract
Ancient murals, as valuable cultural heritage, preserve records of historical life and beliefs. To document and preserve these legacies, image segmentation algorithms are essential. This paper proposes a novel framework for fine-grained semantic segmentation of mythological figures and ornaments in murals, featuring an M-ViT Encoder and a Pyramid SCconv Decoder. The M-ViT Encoder incorporates a selective state-space model in the transformer units, mitigating correlations in sequential representations by building long-range dependencies, thus capturing local and global semantic information. The Pyramid SCconv Decoder reduces spatial and channel redundancy by applying separative transformations to encoder outputs, enhancing semantic feedback for fine-grained information separation. Experiments on fine-grained semantic segmentation of colored mural figures demonstrate that the proposed method outperforms other segmentation baselines, achieving 68.42% mIoU and 74.59% mAcc, and delivering state-of-the-art performance.
Similar content being viewed by others


Introduction
Murals, as important vessels of ancient cultural heritage, not only document the social life, religious beliefs, and artistic styles of their time but also reflect the humanistic values and ideological tendencies of historical dynasties. However, as immovable and inseparable tangible heritage, murals are highly susceptible to physical damage caused by natural and human factors. These irreversible damages1,2,3 include, but are not limited to, oxidation fading, substrate deterioration, surface cracking, and weathering erosion.
Traditional physical preservation methods require substantial labor costs and specialized expertise, and most mural restoration processes lack sufficient historical and artistic cultural research, often leading to secondary damage and an inability to accurately restore the original state. Therefore, digitizing mural data has become the most important technological approach today. As a key area in computer vision, image segmentation plays a crucial role in the understanding and preservation of mural images. Through semantic segmentation algorithms, researchers can better extract key features such as textures, colors, figures, and scenes, enabling pixel-level classification and semantic interpretation of the murals. This visual information enhances restorers’ comprehension of the murals’ intrinsic meanings and historical value.
In recent years, with the continuous advancement of artificial intelligence and computer vision4,5, segmentation algorithms based on deep learning frameworks6,7,8,9, have been rapidly evolving and gaining wider application across various downstream tasks. These architectures construct deep networks by stacking convolutional or attention units to capture both low-dimensional and high-dimensional image features. By leveraging GPU hardware acceleration and large-scale training data, these models are optimized to achieve high-efficiency and high-accuracy image segmentation. Based on the properties of the stacked units, these architectures can be broadly categorized into convolutional neural networks (CNNs) and transformer10 networks based on multi-head attention mechanisms.
CNNs typically combine convolutional layers, pooling layers, and activation layers to form encoder-decoder structures. This process enables end-to-end image input and mask output at any resolution through fully convolutional methods. However, excessive pooling layers reduce the resolution of mural feature maps, and the decoder stage cannot fully recover the detailed information lost during downsampling, resulting in blurred edges and unclear textures in mural segmentation tasks. Additionally, the theoretical receptive field obtained in this manner often significantly differs from the actual perceptive field, impairing the semantic interpretation of deep convolutional features, which is detrimental to fine-grained segmentation of mural content.
Transformer networks, originally proposed to address long-range semantic dependencies in NLP, utilize multi-head self-attention mechanisms to capture dependencies between distant elements in sequences. In computer vision, Transformers were introduced to develop the Vision Transformer (ViT)11,12, which effectively captures relationships between different regions of an image through its global modeling capability. Unlike traditional CNNs, Transformers do not rely on fixed local receptive fields, allowing them to better capture global dependencies for modeling panoramic segmentation tasks. However, most ViT architectures contain a vast number of trainable parameters, requiring large datasets for optimization and pre-training, making them unsuitable for mural segmentation tasks with smaller datasets and finer-grained categories.
In the fine-grained segmentation of mythological figures in ancient murals13,14, the annotated categories include both regular facial features and irregular headpieces and other ornamentation. These elements exhibit rich texture entropy variations and share similar color schemes and stylistic factors with garments, making dense pixel prediction between similar categories particularly challenging. This complexity poses significant difficulties for existing general semantic segmentation models, often resulting in blurred boundaries, loss of details, and omission of small objects. To address these challenges, this paper proposes a Mamba-based Vision Transformer (M-ViT) model for fine-grained semantic segmentation of murals. The framework utilizes the transformer as the foundational architecture, with the encoder integrating a Mamba module to create a novel hybrid encoding unit. Additionally, during the decoder’s upsampling and reconstruction stage, SCconv and standard MLP layers are employed to progressively restore the original resolution.
The proposed method and contributions can be summarized as follows:
-
1.
A foundational M-ViT encoding unit is constructed for mural feature extraction. This module introduces Mamba-based hybrid units in the encoder to assign semantic weights to local regions, enhancing the model’s ability to identify small objects.
-
2.
A multi-level pyramid SCconv module is proposed for the encoder. By employing separative transformations to reduce spatial and channel redundancy it provides improved semantic feedback for fine-grained information separation in the image.
-
3.
Comparative and ablation experiments were conducted on a challenging fine-grained mural segmentation dataset, demonstrating superior performance, particularly in categories with the lowest pixel ratios and the most difficult to distinguish.
Methods
In this section, we propose a Mamba-based ViT network that incorporates a hybrid architecture encoding layer and a multi-level pyramid SCconv decoding layer. Section “Experimental settings” outlines the overall architecture of the proposed network, while Sections “Comparison to state of the art methods” and “Ablation studies” provide detailed descriptions of the implementation processes and fundamental principles of the M-ViT module and the multi-level pyramid SCconv module, respectively. Section “Robustness study” describes the training loss associated with the proposed framework.
Overview
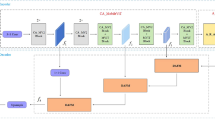
The overall structure of the proposed mural image segmentation network is illustrated in Fig. 1. It is primarily divided into a feature extraction layer constructed from M-ViT units serving as the encoder and a composite decoder composed of multi-level pyramid SCconv. During the encoding phase, the input image is first partitioned into patches and embedded into a linear sequence, followed by four downsampling stages, each containing N M-ViT units and downsampling layers. In the decoding phase, the multi-level pyramid SCconv performs convolutional reconstruction on the outputs from four different scale intermediate layers across spatial and channel dimensions, integrating the final results into a unified scale for pixel-wise classification to produce the mask output.

The overall framework diagram of the proposed network.
M-ViT encoder
The basic building unit of the encoder decisively influences the performance of the semantic segmentation network in mapping image features. By stacking multiple layers of these units, the network enables computers to comprehend complex and hard-to-interpret scene semantics. In this paper, the encoder utilizes M-ViT units as its core components. As shown in Fig. 2, M-ViT is a composite unit comprising three modules: Efficient Self-Attention, Mix-FFN in a dual-stream branch, and the Mamba module.

The basic architecture of M-ViT. The architecture includes the efficient self-attention module, the Mix-FFN module, and the Mamba module.
For each encoding stage at different scales, the feature map from the previous level first passes through the Efficient Self-Attention module, which applies feature self-attention. This module avoids the high computational complexity of dot-product transformers by using linear computation, while achieving performance equivalent to dot-product transformers in feature extraction. For the input feature x, value \(V\in {{\mathbb{R}}}^{n\times {d}_{\nu }}\) and key \(K\in {{\mathbb{R}}}^{n\times {d}_{k}}\) are generated through depthwise convolution (DWConv)15 and linear transformation, while the query \(Q\in {{\mathbb{R}}}^{n\times {d}_{k}}\) is obtained via a linear layer. Unlike traditional transformers, Efficient Self-Attention prioritizes dot-product aggregation between key and value, reducing the computational complexity from O(n2) to O(dk*dv). Afterward, dot-product is performed with the query following softmax. The overall expression is as follows:
In equation (1), τq and τk represent the softmax operations applied at different stages.
After applying self-attention, the resulting feature map is processed by a dual-branch structure to capture long-range dependencies. This structure includes Mix-FFN and Mamba linear operations. Mix-FFN incorporates convolution into the feedforward network, embedding positional information in a two-dimensional manner within the one-dimensional transformer architecture. This enhances Mix-FFN’s robustness to positional information across different resolutions. Additionally, the GELU activation function, inserted midway, increases the non-linear mapping capability of the entire module, with GELU’s stochastic regularization better aligning with the Gaussian distribution of natural data. Its mathematical form is equation (2):
Mix-FFN constructs the post-processing step for self-attention features by inserting a 2D convolution operation and the GELU activation function between two MLP linear operations. To prevent gradient explosion and vanishing during training, residual connections are applied to this process. The final Mix-FFN can be expressed by the following equation (3):
Another branch employs Mamba for linear processing. Mamba has been proven superior to transformers in serializing discrete data by constructing a hidden state space model (SSM) to capture the temporal and spatial relationships within the discretized data. The state-space model (SSM) is a fundamental model in modern linear deterministic system control theory, capable of mapping a one-dimensional function or sequence \({{\rm{x}}}({{\rm{t}}})\in {\mathbb{R}}\) to an output \({{\rm{y}}}({{\rm{t}}})\in {\mathbb{R}}\). Its dynamic behavior can be described using linear ordinary differential equations (ODEs):
In Eqs. (4), (5), the input signal is \({{\rm{x}}}({{\rm{t}}})\in {\mathbb{R}}\), the output signal is \({{\rm{y}}}({{\rm{t}}})\in {\mathbb{R}}\), and the hidden state is \(h\in {{\mathbb{R}}}^{N}\). The matrix \(A\in {{\mathbb{R}}}^{N\times N}\) is the state transition matrix, while \(B\in {{\mathbb{R}}}^{N\times 1}\) and \(C\in {{\mathbb{R}}}^{N\times 1}\) are projection matrices representing the system’s parameters. However, compared to convolutional neural networks, this approach incurs greater computational and memory overhead, limiting its application in deep learning.
The Structured State Space Sequence Model (S4) addresses the structured processing of the state transition matrix A using Higher-Order Polynomial Projection Operators (HIPPO), resulting in a deep sequence model with efficient long-range dependency modeling capabilities. S4 successfully overcomes the performance bottlenecks of SSMs when handling long-range dependency issues.
Recent research mamba introduces a framework based on an input selection mechanism that effectively filters out irrelevant information from the input, thereby enhancing computational efficiency. Furthermore, Mamba presents a hardware-aware optimization algorithm that integrates the state-space model module with linear layers, achieving superior performance and computational efficiency.
Overall, both Mamba and S4 achieve the state-space model of continuous systems through a discretization approach. During the process of equation (6) and equation (7), matrices A and B are discretized using a Zero-Order Holder (ZOH) and a time step parameter Δ is introduced. This discretization can be computed in two ways: first, through linear recursive relations, and second, via global convolution operations.
After discretization, the convolution kernel \(K\in {{\mathbb{R}}}^{L}\) takes on a structured form, where L represents the length of the input sequence. This enables the SSM to perform efficient long-range inference in deep learning tasks. The final output y is obtained from Eqs. (8), (9), (10) and (11):
During image processing, the one-dimensional linear sequence from the self-attention mechanism is directly input into Mamba, leveraging its linear scaling advantage to adaptively enhance context reconstruction. Given the linear feature input \(x\in {{\mathbb{R}}}^{B\times L\times C}\), where B represents the batch size, L denotes the length of the linear features (for two-dimensional features, L = H × W), and C the number of feature channels. This is followed by two similar linear branches: the first expands the dimensionality through a linear layer, followed by 1D convolution, SiLU activation, and the SSM model. The second branch employs a linear layer and SiLU activation as a residual path. The outputs from the SSM path and the residual path are then multiplied element-wise. A final linear layer reduces the dimensionality back to match the input. The Mamba module can be formulated as equation(12):
In the equation, γlinear represents the linear layer, SSM denotes the state-space model, σSiLU refers to the SiLU activation function, ⊗ indicates the element-wise product, and γConv1d stands for the 1D convolution.
As illustrated in Fig. 2, the M-ViT unit systematically arranges and computes the aforementioned three modules, and the resulting functional form can be expressed as equation (13):
In this equation, \({\mathbb{N}}\) represents the normalization operation applied to the current feature.
The encoder comprises four downsampling stages, each containing N M-ViT units stacked repetitively. In this study, the four stages include 3, 4, 6, and 3 M-ViT units, respectively. The first downsampling stage implements a 4× reduction, while the subsequent stages apply a 2× reduction, simultaneously enhancing channel dimensions. Ultimately, the feature dimensions are reduced to 1/32 of the input size.
Pyramid SCconv decoder
The M-ViT encoding layer decouples the input mural image into four distinct scales of high-level semantic feature maps. To fully leverage these features for recovering detailed segmentation results, each of the four feature maps is reconstructed using the SCconv module, resulting in the Pyramid SCconv Decoder (P-SCconv). Each SCconv module comprises two convolutional modules that process different spatial information: the spatially separable gating module (SSGM) and the channel-separable convolution module.
As shown in Fig. 3, the overall structure of the Pyramid SCconv Decoder consists of a pyramid decoding layer constructed from four identical SCconv channels. For any given channel, the encoded output features first pass through the SSGM. The SSGM splits the features using separable weights and computes masks through a gating mechanism. Subsequently, the information gating mask and non-information gating mask are reconstructed and concatenated, thereby reducing redundancy along the spatial dimension by employing different weights. The specific operational flow is as follows: given a set of two-dimensional feature maps \(X\in {{\mathbb{R}}}^{N\times C\times H\times W}\), where N represents the batch size, C denotes the number of channels, and H and W are the height and width of the feature maps, normalization as shown in equation (14) is performed first:
where μ and σ represent the mean and standard deviation of X, ε is a small constant added for division stability, and φ and β are trainable affine transformations.

The fundamental architecture of the P-SCconv decoder. Multiscale feature fusion and upsampling decoding are achieved through four distinct SCconv structures.
We calculate the γ weights Wγ and the importance weights WI using γ, and Wγ and WI are calculated using Eqs. (15) and (16).
Based on the gating mechanism, the importance weights are compared with a threshold (set at 0.5 in the experiments) to compute a binary weight mask, which consists of values in {0, 1}. This binary mask is then multiplied by the input features to suppress non-essential information along the spatial dimension, ultimately achieving the elimination and reconstruction of spatial redundancy.
Subsequently, we input the feature information, from which spatial redundancy has been eliminated, into the Channel-Separating Convolution Module (CSCM). Similar to the SSGM, the CSCM also employs separation and reconstruction to reduce channel redundancy. Initially, we perform equal separation of the features, transforming the original channel dimension C into two features of C/2. A lightweight 1 × 1 convolution is then utilized to compress the channel of the feature maps, enhancing computational efficiency. The compression ratio employed in the experiments is 2, resulting in a post-convolution channel dimension of C/4.
We define the two output features from convolution compression as sparse features and dense features. The dense features undergo bilateral vanilla convolution stages of 3 × 3 and 1 × 1 to extract representative information while restoring the channel dimension. The 1 × 1 convolution effectively compensates for the information loss incurred by the 3 × 3 convolution and facilitates the flow of information between different functional channels. Ultimately, the results of the bilateral convolutions are combined through a channel-wise summation. The dense features are mapped via a 1 × 1 convolution path that constructs a residual structure, and the mapping results are restored through concatenation. This process can be expressed as equation(17):
where fsparse represents the sparse features and fdense denotes the dense features.
Finally, we perform an adaptive fusion of the two features. Initially, we concatenate the two feature sets and employ adaptive global average pooling to compute the mean information for each channel dimension, representing the importance vector of that channel’s features. Subsequently, we apply a softmax operation to this vector and multiply it with the original features, thereby establishing a separable channel attention mechanism. The entire summarization process can be expressed as Eq. (18):
where \({\sigma }_{soft\max }\) denotes the softmax operation and γadvavg represents adaptive global average pooling.
Sequentially processing through the SSGM and CSCM modules, we apply a residual operation to the SCconv module via an additional MLP channel. This stage employs one-dimensional convolution for simple linear reconstruction of the input features, thereby mitigating gradient collapse to some extent. Ultimately, the residual inputs at four different scales are subjected to bilinear interpolation upsampling to a size 1/4 that of the original mural image input, followed by concatenation along the dimensional axis. After concatenation, the features undergo a preliminary classification layer before being further upsampled to match the original input size, ultimately passing through a multi-class classifier to output the segmentation mask.
Loss function
To balance the segmentation results across categories with the global pixel-level segmentation outcomes, we employed a composite loss to establish the optimization objectives for the proposed network architecture.
We first constructed the Dice loss, where the Dice coefficient serves as a metric function for assessing the similarity between two samples; a higher value indicates greater similarity. The calculation process is based on Eq. (19):
Here, \(\left\vert \right.X\cap Y\left\vert \right.\) denotes the number of intersecting elements between X and Y, while \(\left\vert \right.X\left\vert \right.\) and \(\left\vert \right.Y\left\vert \right.\) represent the number of elements in X and Y, respectively. Thus, the Dice loss, utilized to measure the optimization direction of the network, is formulated as equation (20):
In image segmentation tasks, X denotes the pixel labels of the ground truth segmentation image, while Y represents the pixel classes of the model’s predicted segmentation image. \(\left\vert \right.X\cap Y\left\vert \right.\) represents the inner product, approximates the multiplication of pixels between the predicted image and the ground truth labels, summing the results, while \(\left\vert \right.X\left\vert \right.\) and \(\left\vert \right.Y\left\vert \right.\) approximate the total number of pixels in their respective images.
Subsequently, we formulated the Cross Entropy Loss to evaluate the proximity between actual and expected outputs. During the training of deep learning models, it serves to balance the penalties for prediction errors across various class labels, expressed as Eq. (21):
Where C represents the number of classes, pi denotes the probability distribution of the actual labels, and qi signifies the predicted probability for each class by the model.
To balance the pixel distribution discrepancies among multiple classes with the overall classification accuracy of the mask, we ultimately combine the Dice loss and Cross Entropy loss to obtain Eq. (22):
Here, λ is chosen as an empirical value, with a value of 0.2 utilized in this study.
Results
We conducted comparative and ablation experiments on the mural semantic segmentation dataset to validate the efficacy of the M-ViT encoder and Pyramid SCconv decoder. First, we outline the process of constructing the mural dataset, training details, and evaluation metrics. Subsequently, we compare the performance of our method with recent semantic segmentation networks and provide visual representations of the results. Finally, we perform ablation studies on the encoder and decoder components to demonstrate the effectiveness of our approach.
Experimental settings
Dataset: This study acquired the dataset through web scraping and public mural scan catalogs, followed by manual selection to obtain images of figure murals. After cropping, we obtained 522 original images with a resolution of 512 × 512, primarily featuring figures such as flying deities and bodhisattvas from ancient Chinese mythology. The collected images were divided into training and testing datasets in an 80–20% ratio, and data augmentation techniques such as random rotation, translation, scaling, and the addition of weak noise were applied. The facial features, headdresses, bracelets, and armlets of the figures in the murals exhibit significant variations depending on cultural backgrounds and historical periods. The segmentation targets for the figures in the murals are categorized into five classes: face, headwear, bracelet, armlet, and other.
Parameter Settings: The proposed method is implemented using the open-source deep learning libraries MMSegmentation and PyTorch. Each model is trained using the Adam optimization algorithm. During the training phase, the initial learning rate is set to 0.01, with a weight decay of 5 × 10−4 applied at each epoch. A total of 100 iterations are conducted, with a momentum factor of 0.9. The experiments are carried out on an NVIDIA GTX 3090 GPU with 24GB of memory.
Evaluation Metrics: We employ the following metrics to assess the efficacy of the proposed method, focusing particularly on the balance between accuracy and error rates for each category. The selected metrics include pixel accuracy (Acc), mean pixel accuracy (mAcc), global pixel accuracy (aAcc), intersection over union (IoU) for each category, and mean intersection over union (mIoU). Pixel accuracy measures the proportion of correctly segmented pixels to the total number of pixels, while intersection over union represents the ratio of the intersection to the union of the segmentation results and the ground truth labels. To account for categories with low pixel representation and those that are challenging to segment, the mean intersection over union provides a more effective measure in the final quantitative results.
Comparison to state-of-the-art methods
To validate the efficacy of the proposed method, we conducted qualitative comparisons and quantitative evaluations. We compared the methods described in this paper with various advanced techniques, generating segmentation results through experiments and performing visual analyses. The comparison methods can be broadly categorized into two types: CNN-based semantic segmentation networks, such as PSPNet and OCRNet16, and transformer-based networks, including Segmenter17, SegFormer7, DDRNet18, and SAN19.
PSPNet: PSPNet introduces a pyramid pooling module that enhances semantic segmentation accuracy by integrating multi-scale contextual information. It effectively captures global context in scene parsing tasks, making it suitable for large objects and distant global information.
OCRNet: OCRNet emphasizes the relationship between objects and their context by explicitly modeling this relationship to enhance feature representation. Its contextual modeling improves segmentation accuracy, particularly in scenes with complex backgrounds and overlapping regions.
Segmenter: Segmenter utilizes a Transformer architecture for direct pixel-level classification, enhancing the ability to capture dependencies across pixels through attention mechanisms. Compared to traditional convolutional neural networks, it excels in complex scenes, particularly in fine-grained segmentation between objects.
SegFormer: SegFormer combines Transformer and lightweight convolutional modules, retaining the global feature capturing capability of Transformers while maintaining high computational efficiency. This method enables rapid inference in resource-constrained environments while preserving high accuracy and low computational costs.
DDRNet: DDRNet introduces a dual-resolution network that employs high-resolution and low-resolution branches for feature extraction and fusion, balancing detail with global information. It demonstrates exceptional performance in urban scene segmentation, particularly in handling road markings and boundary details.
SAN: SAN enhances open-vocabulary semantic segmentation capabilities by incorporating side adapters into pre-trained models. It utilizes adapters to adjust the model’s feature representation, accommodating new, unseen categories. This method effectively extends the model’s generalization ability for unseen classes, particularly excelling in open-vocabulary and large-scale scene segmentation tasks.
Quantitative Analysis of Results: Tables 1 and 2 present the test results of our method compared to state-of-the-art approaches based on IoU and Acc metrics. Table 1 demonstrates that our method achieves optimal IoU and mIoU scores across the majority of categories, indicating its generalizability and comprehensiveness. Notably, in the challenging case of the armlet category, our method significantly outperforms others. The IoU metric, which reflects the ratio of correctly predicted pixels to erroneous ones, highlights our method’s superior accuracy in distinguishing between the easily confusable Bracelet and Armlet categories, resulting in the highest IoU score. This suggests that our approach effectively mitigates interference from fine-grained categories. In contrast, the segmentation results are less remarkable in terms of Acc, as this metric does not account for erroneous pixels, leading to a loss of reliability in multi-class comparisons. Nevertheless, our method still excels in mAcc and aAcc. Given that the primary categories predominantly consist of small pixel proportions, with a significant portion classified as “other," the aAcc metric does not reveal significant variation. Thus, we prefer to utilize mIoU and mAcc for evaluating quantitative results.
Qualitative Results Analysis: The segmentation masks of various methods presented in Fig. 4 further validate the qualitative results. For the categories of Bracelet and Armlet, which are prone to misidentification, our method demonstrates precise local semantic judgments. In the second column, our method exhibits segmentation regions that closely align with the labels compared to other methods, which show unstable and irregular segmentation boundaries for the Bracelet category. This corresponds to the significantly low IoU scores observed for those methods in the Bracelet category. Although our method shows slight disadvantages in high pixel proportion categories like face and Headwear, particularly in the loss of detail in headwear segmentation, it excels in categories with lower pixel proportions, resulting in a more balanced overall performance. Our approach exhibits a more pronounced advantage in local pixel regions and small-scale categories, attributed to the adaptive focus on local linear features provided by the multi-scale SCconv module and mamba. Experimental results confirm that our method is particularly suited for fine-grained semantic segmentation tasks.

Visualized results of the proposed method compared to state-of-the-art approaches for mural figures on the test set.
Visualization of Feature Maps: Fig. 5 illustrates the feature heatmaps generated by our method during the Pyramid SCconv Decoder phase. The SSGM and CSCM exhibit markedly different areas of focus when addressing encoded feature inputs at various scales and stages. SSGM demonstrates a pronounced local attention to the fine texture details of large-scale features, subsequently evolving into an emphasis on clothing and headgear. The regions of interest (indicated in red) are primarily concentrated in a dispersed manner on the headdress, hands, attire, and body, with distinctly separated areas, validating the binary nature of the gated regions for feature selection. In contrast, CSCM prioritizes broad semantic areas, showing excellent semantic discrimination in the facial and body regions of the mural characters. The SCconv decoder adaptively integrates and weights the feature maps across the four stages, yielding reasonable and refined segmentation results for the face, headdress, and bracelets in both global and local contexts.

Feature heatmaps in the SSGM and CSCM modules. From left to right are feature maps at four different scales.
Ablation studies
We conducted an ablation study to analyze the proposed M-ViT encoder and Pyramid SCconv Decoder, resulting in the formation of four experimental groups: baseline, baseline + M-ViT encoder, baseline + Pyramid SCconv Decoder, and baseline + M-ViT encoder + Pyramid SCconv Decoder. Ultimately, we performed both quantitative and qualitative analyses on the results from these four models.
Quantitative Analysis of Results: Table 3 illustrates the varying impacts of the M-ViT encoder and the Pyramid SCconv Decoder on pixel and structural information extraction from mural data across different categories. The M-ViT module uniformly enhances the representational capacity of the transformer, leading to slight improvements in all category metrics. This suggests that M-ViT, compared to ViT, encompasses more nuanced texture, boundary, and semantic information, which is further corroborated by Table 4. The Pyramid SCconv Decoder consolidates multi-scale information to improve confidence in fine-grained categories, reinforcing minor and easily misclassified categories like Bracelet. By leveraging gating mechanisms and channel separation, it effectively eliminates channel and spatial redundancies, yielding metric improvements in most categories over the baseline. In the combined encoder-decoder network, the Pyramid SCconv Decoder receives and filters out spatial redundancy from the Mamba hybrid architecture, while the integration of local linear extraction and spatial gating significantly enhances small-scale semantic recognition. Consequently, both IoU and Acc metrics for the Armlet category show substantial improvement.
Qualitative Results Analysis: Fig. 6 presents comparative ablation results for the modules proposed in this paper. In the first column, it is apparent that M-ViT yields segmentation results in the armlet class that closely align with the label, although it performs suboptimally on ribbon-like elements in the Headwear category compared to the base model. The SCconv module attempts to restore this feature through multi-scale information fusion. In the third column, the base model shows a loss of boundary detail in Headwear, lacking comprehensive spatial features, while M-ViT reconstructs prominent elements at the top of the Headwear. Additionally, in easily misclassified classes like bracelet and armlet, the final fused model produces segmentation with minimal class pixels, where all results in this column are errors that the fused model strives to mitigate.

M-ViT and SCconv modules’ ablation study visualization results on the test set.
Robustness study
Meanwhile, considering that most of the data collected in actual mural studies involve various types of damage, including but not limited to defects, blurring, corrosion, occlusion, and fading, we additionally reconstructed and manually annotated a more natural damage dataset. The supplementary dataset encompasses a greater variety of styles and types of human murals, providing a more intuitive validation of the model’s generalization and robustness. It consists of 641 natural human mural images, divided into training and testing datasets in an 80–20% ratio. To standardize and balance the complex categories within the dataset, the human pixels are classified into face, headwear, body, and others.
Figure 7 illustrates the visual performance of the proposed method compared to various baseline methods on the supplementary dataset. The results demonstrate that damages such as defects and blurring in murals significantly impact the segmentation process. These issues are mainly reflected in misidentifications caused by similar colors and structures, as well as the inability of semantic segmentation networks to restore incomplete information. However, it is worth noting that obvious damages and defects are similarly less perceptible to human visual cognition. Despite these challenges, Tables 5 and 6 confirm that the proposed method outperforms other algorithms in terms of overall detail and evaluation metrics. Notably, for fine-grained and low-pixel-ratio categories like headwear, the Pyramid SCconv architecture achieves more precise edge extraction in the visual results and demonstrates state-of-the-art performance in the mIoU metric.

Visualized results of the proposed method compared to state-of-the-art approaches for mural figures on the test set.
Discussion
In this paper, we developed a hybrid architecture based on transformers and Mamba for fine-grained semantic segmentation of figures and ornaments in ancient mythological murals. Our architecture incorporates the M-ViT encoding unit, addressing the issue of local semantic deficiencies within fine-grained categories. Additionally, during the scale enhancement phase, we employed the Pyramid SCconv module to mitigate spatial and channel redundancy, reconstructing the decoded semantics through compressed sensing while isolating fine-grained information. Experimental results on our custom ancient mural dataset demonstrate that our method achieves superior performance across most category metrics and average indicators, excelling particularly in the most challenging categories. Visualizations further corroborate this claim. However, we acknowledge that precise segmentation of small targets remains a significant challenge. In future work, we will focus on harmonizing local region understanding with global semantic analysis and applying this approach to expand capabilities in new mural segmentation tasks.
Data availability
No datasets were generated or analysed during the current study.
References
Li, J. et al. Investigation of the renewed diseases on murals at Mogao Grottoes. Herit. Sci. 1, 1–9 (2013).
Sawicki, T. The conservation of murals–a new trend in protecting works of art. Acta Universitatis Lodziensis. Folia Philosophica. Ethica-Aesthetica-Practica 81–95 (2022).
Alonso-Villar, E. M., Rivas, T., Pozo-Antonio, J. S., Pellis, G. & Scalarone, D. Efficacy of colour protectors in urban art paintings under different conditions: from a real mural to the laboratory. Heritage 6, 3475–3498 (2023).
Yan, L. et al. Digan: distillation model for generating 3d-aware terracotta warrior faces. Herit. Sci. 12, 317 (2024).
Gao, J., Zhang, Y., Liu, Z. & Li, S. Hdrnet: High-dimensional regression network for point cloud registration. In Computer Graphics Forum, vol. 42, 33–46 (Wiley Online Library, 2023).
Zhang, Q. et al. P-msdiff: Parallel multi-scale diffusion for remote sensing image segmentation. arXiv preprint arXiv:2405.20443 (2024).
Xie, E. et al. Segformer: Simple and efficient design for semantic segmentation with transformers. Adv. neural Inf. Process. Syst. 34, 12077–12090 (2021).
Badrinarayanan, V., Kendall, A. & Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. pattern Anal. Mach. Intell. 39, 2481–2495 (2017).
Zhao, H., Shi, J., Qi, X., Wang, X. & Jia, J. Pyramid scene parsing network. In Proc. of the IEEE conference on computer vision and pattern recognition, 2881–2890 (2017).
Han, K. et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 45, 87–110 (2022).
Yuan, L. et al. Tokens-to-token vit: Training vision transformers from scratch on ImageNet. In Proc. of the IEEE/CVF international conference on computer vision, 558–567 (2021).
Han, K. et al. Transformer in transformer. Adv. neural Inf. Process. Syst. 34, 15908–15919 (2021).
Cao, J., Tian, X., Chen, Z., Rajamanickam, L. & Jia, Y. Ancient mural segmentation based on a deep separable convolution network. Herit. Sci. 10, 11 (2022).
Yu, K. et al. Automatic labeling framework for paint loss disease of ancient murals based on hyperspectral image classification and segmentation. Herit. Sci. 12, 192 (2024).
Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proc. of the IEEE conference on computer vision and pattern recognition, 1251–1258 (2017).
Yuan, Y., Chen, X. & Wang, J. Object-contextual representations for semantic segmentation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VI 16, 173–190 (Springer, 2020).
Strudel, R., Garcia, R., Laptev, I. & Schmid, C. Segmenter: Transformer for semantic segmentation. In Proc. of the IEEE/CVF international conference on computer vision, 7262–7272 (2021).
Pan, H., Hong, Y., Sun, W. & Jia, Y. Deep dual-resolution networks for real-time and accurate semantic segmentation of traffic scenes. IEEE Trans. Intell. Transport. Syst. 24, 3448–3460 (2022).
Xu, M., Zhang, Z., Wei, F., Hu, H. & Bai, X. Side adapter network for open-vocabulary semantic segmentation. In Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2945–2954 (2023).
Acknowledgements
This research was funded by the Shaanxi Province Technology Innovation Guidance Special Project (Fund) (2024QY-SZX-11), Xi’an Science and Technology Plan Project (24SFSF0002), National Social Science Fund of China Major Projects in Art Studies (24ZD10).
Author information
Authors and Affiliations
Contributions
Qi Zhang, Guohua Geng, Longquan Yan and Yangyang Liu designed and implemented the entire model architecture and manuscript writing. Pengbo Zhou and Zhaodi Li provided guidance on algorithm optimization and manuscript revision. Mingquan Zhou and Zhaodi Li were responsible for manuscript writing, editing and polishing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, Q., Geng, G., Zhou, P. et al. A Mamba based vision transformer for fine grained image segmentation of mural figures. npj Herit. Sci. 13, 204 (2025). https://doi.org/10.1038/s40494-025-01682-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s40494-025-01682-2
This article is cited by
-
Multimodal intelligent reconstruction-driven digital regeneration of cultural heritage in Qing Dynasty tea plantation landscapes
npj Heritage Science (2026)
-
A detection-screening framework for karez (ancient underground irrigation system) using deep learning and geospatial analysis
npj Heritage Science (2025)
