
Abstract
Chinese ancient inscriptions have a long history, while natural erosion and human destruction have led to many incomplete inscriptions with low-quality textual data and blurry images. With deep learning technologies, it is expected to use relevant image and language processing tasks to restore inscriptions. To improve the efficiency of restoration tasks and promote the digital protection of cultural heritage, this study used deep learning technology to restore ancient Chinese inscriptions. We combined natural language processing and computer vision technologies to train models for restoring inscriptions. The results indicated that the joint solution had advantages over every single model for incomplete character restoration.
Similar content being viewed by others
Introduction
As a valuable collection of ancient cultural heritage, inscriptions carry rich historical information and cultural value1. With the long history of Chinese stone inscriptions, unearthed stone inscriptions are traced back to the Shang Dynasty in the Chinese Bronze Age. For thousands of years, information about the Chinese economy, politics, culture, and living have been recorded on them, and have also been continuously improved and perfected with the development of stone carving and rubbing techniques and changes in calligraphy styles. However, as time goes by, environmental and human factors have affected the preservation of a considerable number of inscriptions. Many ancient inscriptions are facing serious wear and tear problems. Many characters have been blurred, incomplete, or even disappeared, as shown in Fig. 12,3. For example, according to existing research such as Lyu’s4, the percentage of incomplete inscriptions in datasets about Luoyang inscriptions during the Republic of China reached about 34%, indicating that much valuable information was lost.

Examples of damaged Chinese ancient inscriptions.
As is well known, traditional methods to repair stone inscriptions rely on manual efforts leading to satisfactory results but are heavily limited by individual experiences, skills, and physical agility. Since deep learning and computer vision (CV) technologies have made significant progress in image and text recognition, perception, and generation5, and pre-trained natural language processing (NLP) models have significantly lowered the training cost6, AI models are introduced to inscription restoration.
Inscription restoration is an important work in cultural heritage preservation. Typical methods mainly refer to cleaning impurities on the surface of the relics, adhering cracked areas, completing and repairing incomplete texts, carrying out reinforcement, waterproofing, and other manual protective efforts7. For example, Kong J. and Yan J. used these kinds of methods to restore the inscriptions in the Confucius Temple. They provided useful references and inspirations for traditional preventive protection and restoration techniques8. However, the entire process requires manual repair skills and individual professional knowledge of relics. As a typical kind of teamwork, when facing inscriptions with different crafts, font styles, and varieties of damage, the restoration work will be confronted with unpredictable challenges in which the missing word prediction is the undisputed core part of the restoration work. In recent years, with computer science and digital technologies, inscription restoration methods have been greatly upgraded. In the paper, we reviewed relevant research on missing and incomplete character prediction and proposed a restoration method with NLP and CV models. Firstly, we collected inscription text data and Chinese calligraphy images as many as possible. Then the NLP model was trained on the inscription text data, and the CV model was trained on the calligraphy images. Finally, we used these models to restore inscription texts.
These two models have different functions. The NLP model can capture the semantic information of the inscription text to find the missing characters with the fed context, while the CV model can recognize the writing shape of the incomplete character to refine the results from the NLP model.
Methods
Related technologies and practices
Machine learning is a branch of artificial intelligence, whose goal is to make computers have human intelligence9. Deep learning is an important branch of machine learning, with complex structures that construct powerful multi-layer neural network models10.
When faced with a situation where the inscriptions have missing characters, filling in the missing characters becomes a crucial and challenging task in inscription restoration. Currently, the mainstream deep learning models for this task are based on a Transformer, which is a complicated but powerful architecture to process sequential data through self-attention mechanisms and capture long-distance dependencies of the text11. BERT12 and RoBERTa13 are two famous models based on Transformers. In practice, BERT and RoBERTa have shown excellent performance in natural language understanding tasks. Assael et al. proposed a model called Pythia, which combines LSTM14 and an attention mechanism to predict missing ancient Greek inscriptions. On the PHI-ML dataset, Pythia’s prediction error rate reached 30.1%, lower than that of epigraphers15. Afterwards, Assael et al. further proposed Ithaca, which was inspired by BigBird16. Its architecture consists of multiple Transformer decoders that can effectively capture contextual information. It achieved an accuracy of 62% when restoring damaged text. After collaborating with epigraphers, the accuracy was improved to 72%17. Fetaya et al. achieved an accuracy of 88.5% in the testing task of recovering Babylonian script based on recurrent neural networks18. Kang et al. proposed a multi-task learning method based on a Transformer network to effectively restore and transform the historical records of Joseon Dynasty19.
Since Chinese characters are not composed of alphabets but of graphic radicals, NLP models trained for missing or incomplete ancient Chinese texts require context. Yu et al. achieved good results in automatic sentence-breaking and punctuation models for ancient Chinese by training BERT in ancient Chinese20. Dongbo et al. constructed SikuBERT and SikuRoBERTa for the intelligent processing of ancient Chinese texts using a high-quality Chinese text corpus. The result showed that their proposed models outperformed the basic BERT model and other models in ancient Chinese text-processing tasks21. Sheng et al. constructed a high-quality text corpus of ancient books of Chinese traditional medicine, trained and compared several deep learning models, and found that the Roberta model had the best performance, which could help the restoration of ancient books of traditional Chinese medicine22. Zheng J. and Sun J. used ensemble learning methods to integrate Chinese BERT, Chinese RoBERTa, SikuBERT, and SikuRoBERTa for prediction tasks related to ancient Chinese. The grid search method composed of SikuBERT and SikuRoBERTa achieved the best performance in the ensemble model23. Han et al. proposed RAC-BERT, an improved BERT model based on Chinese radical parts. By replacing random Chinese characters with the same radical, the model reduced the computational complexity while maintaining higher performance24.
CV models are also useful in inscription restoration. This kind of task involves the partially damaged characters in inscriptions. At present, the main model architectures used for ancient inscriptions are convolutional neural networks (CNN), generative adversarial networks (GAN), Transformers, and their extended architectures.
Convolutional neural network is a common model composed of convolutional layers, activation functions, pooling layers, and fully connected layers. CNN effectively extracts local features from images25. Zhang used CNN to extract features from residual inscriptions. His model adopted the cross-layer idea of ResNet26. By adding residual modules based on VGGNet27, the accuracy of residual inscription text recognition was improved28. Xing and Ren addressed the issue of insufficient character information extraction in existing models by improving the context encoder29 and adding dilated convolutions to learn the structural features of characters, thereby repairing missing stroke inscriptions30. Feng et al. used DenseNet31 from the backbone network to alleviate gradient vanishing and model degradation, while enhancing feature reuse and transfer to improve the recognition performance of ancient handwritten texts32. Zhao et al. proposed the Ga-RFR network, which reduces feature redundancy in the generated feature maps by using gated convolutions instead of regular convolutions, thereby improving the restoration performance of Chinese inscriptions33. Lou Y. also used gated convolution to improve deep networks, reducing the generation of a large amount of redundant feature information, and combining multiple loss functions to enhance the model’s ability to repair inscription images34.
GAN consists of generators and discriminators, which constantly competes during the training process, ultimately enabling the generator to generate samples increasingly difficult to distinguish from real data35. Its approach and functionality make it more suitable for image-based text restoration tasks. GAN provides a new solution to the restoration of inscriptions, especially for large-scale missing inscriptions. This network can fill in the gaps in the image through generative techniques. For example, Li N. and Yang W. used a GAN with global and local consistency preservation (GLC-GAN) to complete handwritten text images, and proposed a two-level completion system consisting of rough and fine completion36. Wenjun et al. imitated human writing behavior and proposed a dual-branch structure character recovery network EA-GAN that integrated GAN and attention. This network has good performance in extracting character features, and even if the damaged area of the text is large, EA-GAN can also accurately recover damaged characters37. Liu et al. used an edge detection module to collect edge information on character strokes and guided GAN to learn the structure and semantics of characters. Their method achieved better repair quality38.
Based on the Transformer architecture, Chen et al. proposed a lightweight Qin Bamboo Slips text recognition model QBSC Transformer, which used a fusion of separable convolution and window self-attention mechanism to extract global features of Qin Bamboo Slips text. It significantly reduced computational complexity while maintaining high accuracy39. Hao and Chen combined Swin Transformer and Mask R-CNN40 to perform text segmentation on Chinese inscriptions41. Swin Transformer effectively processed image data by designing hierarchical feature maps and windowed self-attention mechanisms. It also showed excellent performance in image classification tasks42.
In addition, other models and repair strategies achieved satisfactory results. Lin et al. judged whether Chinese characters were damaged based on Chinese character splitting and embedding, and then used a bipartite graph neural network to predict the possible results of Chinese characters43. Sun C. and Hou M. focused on using edge detection methods to smooth and fill the extracted text contour to restore the fuzzy text44.
For repairing inscriptions, NLP models and CV models have achieved exciting results along with limitations. For NLP models, the performance is greatly limited by the volume of prepared ancient texts since the grammar, syntax, genre, and usage heavily vary in different dynastic periods. For the writing of Chinese characters, it is challenging to recognize a Chinese character in thousands of regular and variant character repositories with over 30 kinds of fonts45. It forces us to try two kinds of models to restore Chinese ancient inscriptions in text and vision dimensions. It is a naturally thoughtful solution. The NLP model is undoubtedly essential to missing or damaged characters prediction. It will output many possible characters in descending order of probabilities. However, expert can still hardly decide the right one due to the hallucination. If there remain partial radicals of the character, we can get characters with the same partial radicals through ancient character CV models. Experts will choose the more likely characters in smaller range from the two groups of predicted characters. However, CV models are not available if the character completely disappears.
Technical roadmap
The architecture proposed in this paper is to predict missing or incomplete characters in Chinese inscriptions through NLP model and CV model. We introduce the pre-trained models to help the model training, as well as provide the joint tactic of two models. The technical roadmap is illustrated by the flowchart in Fig. 2.
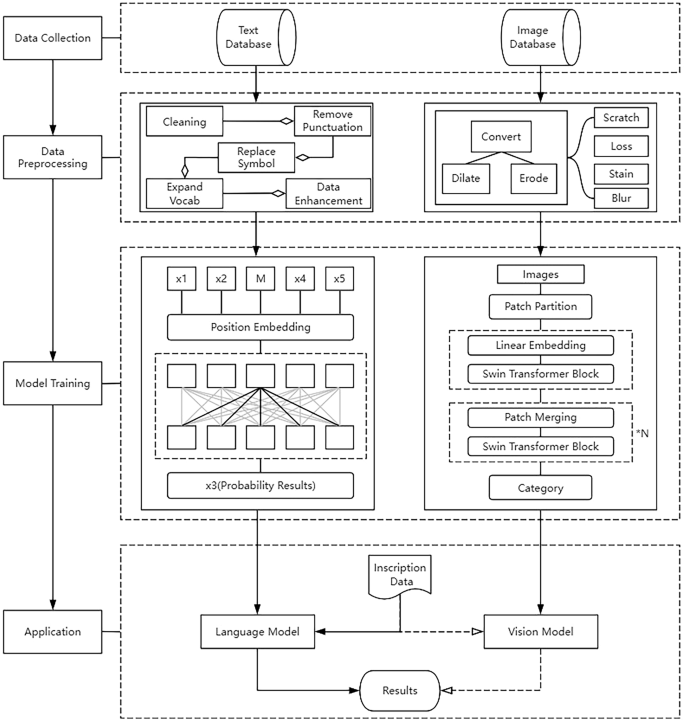
Technology Roadmap of inscription restoration.
In the model training step, texts and images of inscriptions are pre-processed for higher quality. Then, the NLP model and CV model are trained based on selected pre-trained models. When models are validated and deployed, missing or incomplete characters are fed into the models for restoration. Top n predicted characters with higher possibilities are introduced to experts for the final decision. If characters are incomplete, that means characters are partially damaged, and the CV model outputs complete characters based on incomplete images. In these most common cases, characters with the biggest f1_score are preferred recommendations. f1_score is introduced here to leverage two possibility values of NLP model and CV model, whose original definition involves precision and recall. In this research, f1_score is redefined with two possibility values in Eq. 1.
Where pn is the possibility of character output by NLP model and pv is the possibility of character output by CV model.
Predictions resulting from two different models contribute more to selecting the right character than any individual model. Figure 3 shows a prediction example.

The restoration example.
Data preparation
For the inscription textual data, the types of collected data include but are not limited to:
-
a.
Metal and stone vessels: bronzes, coins, etc.
-
b.
Rocks: cliff, stone carving, tablet, etc.
-
c.
Stele: tombstone, merit stele, chronicle stele, inscription stele, religious stele, etc.
-
d.
Others: seals, oracle bones, epitaphs, statue tablets, stone scriptures, tower inscriptions, architectural inscriptions, etc.
We firstly removed punctuation marks, because there are no punctuation marks in ancient Chinese inscriptions. Then, we marked the missing or incomplete characters with unweighted special symbols to keep them from the computation during model training.
Since the writing fonts of inscriptions are firmly sparse, we were confronted with the challenges of recognition of characters in inscriptions from different historical periods or stylistic variations. We conducted dataset augment with the help of multiple localized experts few-shot font generation network (MX-Font). As a few-shot font generation (FFG) model, MX-Font can extract multiple style features not explicitly conditioned on component labels, but automatically by multiple experts to represent different local concepts. With the multiple experts, MX-Font can capture diverse local concepts and show the generalization ability to unseen languages46.
We collected 22,000 calligraphy images of traditional Chinese characters from public calligraphy repositories and inscription databases. Only the stele text data from Zhejiang University stele inscription database (Fig. 4)47 and other inscription databases were up to 11,588 pieces of inscriptions.

Zhejiang University stele inscription database.
We classified calligraphy images into different stylistic groups such as Kaishu, Xingshu, Caoshu, Weibei, Xiaozhuan, Lishu and etc. Then OpenCV was used to convert calligraphy images into SVG images, and FontForge48 was used to convert the Chinese character SVG images into TTF files. These TTF files were merged with the same font style files of MX-Font. Finally, we used MX-Font to get images of over 19000 traditional Chinese characters in different calligraphy styles. Examples are shown in Fig. 5.

Traditional Chinese character font styles.
In addition, due to the long history, surfaces of many inscriptions have become illegible, so we oversampled the image data to simulate the defacement of inscriptions. We used the following operations to simulate the damage state of inscription text: scratch, loss, stain and blur. We first performed the following operations several times respectively, then merged the processed images with the original data, and expanded the dataset.
The scratch operation: randomly drawing line segments on the image.
The loss operation: randomly cropping the image in random size.
The stain operation: randomly covering areas with irregular shapes.
The blur operation: adding 8 different levels of noise to the image. Gaussian noise and salt-pepper noise were respectively used. In addition, we also used all these operations in a image.
Take the Chinese character “锕” as an example, the augmented images are shown in Fig. 6.

augmented images of Chinese character.
NLP model preparation
The Mask Language Model (MLM) is suitable for the pre-processed task of inscriptions. Meanwhile, since Chinese ancient inscriptions are all traditional characters, the writing formats and word styles are much more diverse like those in ancient books, and there have been no pre-trained models of inscriptions as yet. We chose SikuRoBERTa as the pre-trained model according to Zheng and Sun’s research. Siku series models pay more attention to the current and contextual tokens than present Bert-based models49. We have also expanded the vocabulary of SikuRoBERTa by adding 757 new Chinese characters found in collected inscriptions.
As an improved version of Bert, Roberta removes the next sentence prediction task and deepens the mask language task suitable for predicting missing or incomplete characters in inscriptions. It is praised for dynamic masks, larger batches, and more training data to obtain better performance13, in which the dynamic mask can increase the diversity of datasets and enable the model to learn different modes of data better. Taking 唐秘書監知章之後也 as an example, the role of dynamic mask results are shown in Table 1:
The pre-processed dataset was fed into the model. In order that the model can learn features of small inscriptions dataset compared with the pre-trained NLP model, we oversampled the dataset to 10 times the original volume to increase the weight of fine-tuning data and reduce the learning rate. As a result, the model well learned the context information contained in inscriptions. By the way, the mask scale was set to 0.15 proposed by MLM.
CV model preparation
Character recognition is also regarded as a kind of image classification task. We chose the Swin Transformer as the pre-trained model for incomplete character restoration. Compared with vision Transformers directly applying the standard Transformer structure to images50, the Swin Transformer introduces the hierarchical construction method commonly used in CNN to build a hierarchical Transformer42, which effectively extracts strokes, structures, and other textual features in images of texts at different levels.
For example, at a lower level, the model may focus on strokes. At a higher level, the model may focus on the overall layout of the text. In addition, the shifted window of Swin Transformer allows the model to capture the relative position and layout information between strokes.
Evaluation metrics
Perplexity defined in Eq. 2 is used to evaluate the NLP model after training.
Where N is the total number of tokens, x is the character in the text, and p is the probability of x predicted by the model. Perplexity indicates the performance of the model to predict the text. The lower the value is, the better the performance is.
We used accuracy to evaluate the trained CV model. It is defined in Eq. 3.
Where TP (True Positive) is the number of positive predictions whose actual values are positive.
TN (True Negative) is the number of negative predictions whose actual values are negative.
FP (False Positive) is the number of positive predictions of whose actual values are negative.
FN (False Negative) is the number of negative predictions whose actual values are positive.
Results
The models were trained on a personal computer with NVIDIA GeForce RTX 4090. The deep learning framework is Pytorch 2.7 and PaddlePaddle 2.6 in Ubuntu 22 and Anaconda 3.2.
The perplexity of NLP model (CIRoBERTa) trained in this paper was 1.35, which was a considerably satisfactory result. The accuracy of CV model (CISwin) trained in the paper reached about 86%, which was also satisfactory.
Chinese-RoBERTa51, GuwenBERT52 and SikuRoBERTa21 were used as benchmark models to compared with CIRoBERTa. ResNet101, ViT50 were used as benchmark models to compared with CISwin.
The test dataset had 50 inscriptions. We randomly prepared 10-turn test data in which 50 inscriptions were randomly masked. 10-turn test data were fed into NLP models. The average accuracy is shown in Table 2.
For CV models, we prepared 10-turn damaged images of 50 characters. The average accuracy is shown in Table 3.
Figs. 7 and 8 show an actual inscription restoration example using CIRoBERTa and CISwin. We predicted missing words from both context and shape levels. To validate the rationality of the model’s prediction results, we selected paired data with real samples and missing samples, namely the predicted “鶴“.

An actual inscription in the National Digital Library of China3.

The application of CIRoBERTa and CISwin models.
Firstly, the NLP model was used to insert missing symbols in the position of missing words, and the model predicted multiple semantic results according to its context. Then, the visual model was used to judge the complete font based on the existing font shape, and multiple possible results were output. Finally, the results of the two models were merged and handed over to experts for judgment and use.
Discussion
From the experimental results and comparison, we can see that CIRoBERTa are better than benchmark models in the task of missing or incomplete character restoration inscriptions. SikuRoBERTa also has a high score. The reason may be that inscriptions are similar to texts in ancient books like SiKuQuanShu and they were all trained in traditional Chinese characters, while Chinese-RoBERTa and GuwenBERT were trained with simplified characters as the main data, which made their performance lower than that of SikuRoBERTa and CIRoBERTa.
CISwin shows higher performance in most cases. Furthermore, when applying CISwin for recognition tasks, the probability corresponding to the correct answer is usually the highest. However, for the results output by the other two benchmark models, the correct answer may not always be the highest probability output. It can be concluded that CISwin can help CIRoBERTa to improve the accuracy of inscription restoration. It is feasible to use the CV model to assist the NLP model to predict incomplete character inscriptions.
In summary, we provided a combined restoration solution supported by the NLP model and CV model. The results showed that the solution achieved good results in Chinese inscription restoration. This study not only provided researchers with a new approach to inscription restoration but also promoted cutting-edge technical support for the digital protection of cultural heritage. From a practical point of view, we have also reduced the cost of manual repair. Professionals can use our models to complete the task of inscription restoration more effectively and economically. In addition, the methods and ideas of this study are not only applicable to the restoration of Steles but can also be extended to other similar fields, such as manuscript restoration, ancient books restoration, damaged art restoration, etc.
Although this study has achieved preliminary results, there are still challenges and shortcomings: (1) The diversity of inscriptions used in our NLP model training is insufficient, due to the rare existing inscriptions and their digital data. In the future, we will try to collect as many inscriptions and calligraphy writings as possible for model training. (2) The generalization ability of restoration models needs to be further improved, and more font styles of Chinese traditional characters will be generated. In future research, large-scale multimodal datasets should be used to train the hybrid deep learning models, which can process text and image data in one model and output the right results. (3) Hallucination of NLP models. The main reasons may be related to grammar variation in different historical periods and data compression in model training. Retrieval-augmented generation (RAG) is an ideal technology to assist NLP models in generating more accurate and richer content by retrieving relevant information from the traditional Chinese grammar databases created by linguists and historians.
Data availability
Data are available on request to corresponding author.
Code availability
Not applicable.
References
Shaughnessy, E. L. History and inscriptions, China. The Oxford History of Historical Writing Vol. 1 (eds Feldherr, A., & Hardy, G.) 371–393 (OUP Oxford, 2011).
Zhang, H.-M. & Mao, Y.-M. An overview of ancient Chinese character inscriptions of national minorities. J. Chin. Writ. Syst. 1, 19–28 (2017).
National museum of classic books of national digital library of China of national library of China. https://www.nlc.cn.
Lyu, J. Q. The Contents and Composition of Dataset for Luoyang Inscriptions during the Republic of China. J. Glob. Chang. Data. Discov. 5, 490–500+647–657. https://doi.org/10.3974/geodp.2021.04.13 (2021).
Valente, J., António, J., Mora, C. & Jardim, S. Developments in image processing using deep learning and reinforcement learning. J. Imaging 9, 207 (2023).
Wang, H., Li, J., Wu, H., Hovy, E. & Sun, Y. Pre-trained language models and their applications. Engineering 25, 51–65 (2023).
Nan, P., Tian, J., Wang, X. & Zhang, H. Scientific analysis, conservation, and restoration of the Stupa Stele in Qiyan Bodhimanda of the Sui Dynasty. Sci. Conserv. Archaeol. 33, 83–93 (2021).
Kong, J. & Yan, J. Research on preventive protection and restoration techniques for Confucian temple inscriptions. Orient. Collect. 11, 116–118 (2024).
Liu, H., Chaudhary, M. & Wang, H. Towards trustworthy and aligned machine learning: a data-centric survey with causality perspectives. arXiv preprint arXiv:2307.16851. https://doi.org/10.48550/arXiv.2307.16851 (2023).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436–444 (2015).
Vaswani, A. et al. Attention is all you need. Advances in Neural Information Processing Systems 30. https://doi.org/10.48550/arXiv.1706.03762 (2017).
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proc. 2019 conference of the North American Chapter of the Association For Computational Linguistics: Human Language Technologies Vol. 1 (long and short papers). 4171–4186. https://doi.org/10.48550/arXiv.1810.04805 (2019).
Liu, Y. et al. Roberta: A robustly optimized Bert pretraining approach. arXiv preprint arXiv:1907.11692. https://doi.org/10.48550/arXiv.1907.11692 (2019).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9, 1735–1780 (1997).
Assael, Y., Sommerschield, T. & Prag, J. Restoring ancient text using deep learning: a case study on Greek epigraphy. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. 6369–6376, https://doi.org/10.18653/v1/D19-1668 (2019).
Zaheer, M. et al. Big bird: transformers for longer sequences. Adv. neural Inf. Process. Syst. 33, 17283–17297 (2020).
Assael, Y. et al. Restoring and attributing ancient texts using deep neural networks. Nature 603, 280–283 (2022).
Fetaya, E., Lifshitz, Y., Aaron, E. & Gordin, S. Restoration of fragmentary Babylonian texts using recurrent neural networks. Proc. Natl. Acad. Sci. 117, 22743–22751. https://doi.org/10.1073/pnas.2003794117 (2020).
Kang, K. et al. Restoring and mining the records of the Joseon dynasty via neural language modeling and machine translation. In Proceedings of 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021. 4031–4042, https://doi.org/10.18653/v1/2021.naacl-main.317 (2021).
Yu, J., Wei, Y. & Zhang, Y. Automatic ancient Chinese texts segmentation based on BERT. J. Chin. Inf. Process. 33, 57–63 (2019).
Wang, D. et al. Construction and application of pre-trained models of siku quanshu in orientation to digital humanities. Libr. Trib. 42, 31–43 (2022).
Sheng, W., Lu, Y., Liu, W., Hu, W. & Zhou, C. The restoration of missing texts in ancient books of Traditional Chinese Medicine based on deep learning. Chin. J. Med. Libr. Inf. Sci. 31, 1–7. https://doi.org/10.3969/j.issn.1671-3982.2022.08.001 (2022).
Zheng, J. & Sun, J. Ensembles of BERT models for ancient chinese processing. In 16th International Conference on Advanced Computer Theory and Engineering (ICACTE) 1–7. https://doi.org/10.1109/ICACTE59887.2023.10335238 (IEEE, 2023).
Han, L. et al. RAC-BERT: character radical enhanced BERT for ancient Chinese. In CCF International Conference on Natural Language Processing and Chinese Computing 759–771. https://doi.org/10.1007/978-3-031-44696-2_59 (Springer, 2023).
Hadji, I. & Wildes, R. P. What do we understand about convolutional networks? arXiv preprint arXiv:1803.08834. https://doi.org/10.48550/arXiv.1803.08834 (2018).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proc. IEEE Conference on Computer Vision and Pattern Recognition 770–778. https://doi.org/10.1109/CVPR.2016.90 (2016).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556. https://doi.org/10.48550/arXiv.1409.1556 (2014).
Zhang, W. Q. Research on Recognition Algorithm of Damaged Inscriptions Based on Deep Learning, North University of China. https://doi.org/10.27470/d.cnki.ghbgc.2020.000398 (2020).
Pathak, D., Krahenbuhl, P., Donahue, J., Darrell, T. & Efros, A. A. Context encoders: feature learning by inpainting. In Proc. IEEE Conference on Computer Vision and Pattern Recognition 2536–2544. https://doi.org/10.1109/CVPR.2016.278 (2016).
Xing, C. & Ren, Z. Binary inscription character inpainting based on improved context encoders. IEEE Access 11, 55834–55843 (2023).
Huang, G., Liu, Z., Van Der Maaten, L. & Weinberger, K. Q. Densely connected convolutional networks. In Proc. IEEE Conference on Computer Vision and Pattern Recognition 4700–4708. https://doi.org/10.1109/CVPR.2017.243 (2017).
Feng, R., Zhao, F., Chen, S., Zhang, S. & Zhu, S. A handwritten ancient text detector based on improved feature pyramid network. Pattern Recognit. Lett. 172, 195–202 (2023).
Zhao, L. et al. Ga-RFR: Recurrent Feature Reasoning with Gated Convolution for Chinese Inscriptions Image Inpainting. In Proc. International Conference on Artificial Neural Networks. 320–331. https://doi.org/10.1007/978-3-031-44210-0_26 (Springer, 2023).
Lou, Y. Research on Inscription Image Inpainting Technology Based on Gated Convolution and Attention Mechanism, Qilu University of Technology. https://doi.org/10.27278/d.cnki.gsdqc.2024.000626 (2024).
Goodfellow, I. et al. Generative adversarial networks. Commun. ACM 63, 139–144 (2020).
Nong-qin, L. & Wei-xin, Y. Handwritten character completion based on generative adversarial networks. J. Graph. 40, 878 (2019).
Wenjun, Z., Benpeng, S., Ruiqi, F., Xihua, P. & Shanxiong, C. EA-GAN: restoration of text in ancient Chinese books based on an example attention generative adversarial network. Herit. Sci. 11, 42 (2023).
Liu, H., He, X., Zhu, J. & He, X. Inscription-image inpainting with edge structure reconstruction. In International Conference on Image and Graphics 16–27. https://doi.org/10.1007/978-3-031-46311-2_2 (Springer, 2023).
Chen, M., Chen, B. & Xia, R. Qin bamboo slips character recognition algorithm based on lightweight transformer model. Comput. Simul. 42, 459–467 (2025).
He, K., Gkioxari, G., Dollár, P. & Girshick, R. Mask R-CNN. In Proc. IEEE International Conference on Computer Vision 2961–2969. https://doi.org/10.1109/ICCV.2017.322 (2017).
Hao, S. & Chen, Y. A text detection algorithm for ancient Chinese writing based on Swin transformer and mask R-CNN. In Proc. of Third International Conference on Computer Science and Communication Technology (ICCSCT 2022). 1250602. https://doi.org/10.1117/12.2661859 (SPIE, 2022).
Liu, Z. et al. Swin transformer: hierarchical vision transformer using shifted windows. In Proc. IEEE/CVF International Conference on Computer Vision 10012–10022. https://doi.org/10.1109/ICCV48922.2021.00986 (2021).
Lin, G., Wu, N., He, M., Zhang, E. & Sun, Q. Damaged inscription recognition based on hierarchical decomposition embedding and bipartite graph. J. Electron. Inf. Technol. 46, 564–573 (2024).
Sun, C. & Hou, M. Virtual restoration of stone inscriptions based on image enhancement and edge detection. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 10, 217–222 (2023).
Wang, C. et al. Review of Chinese characters generation and font transfer based on deep learning. J. Image Graph. 27, 3415–3428 (2022).
Park, S., Chun, S., Cha, J., Lee, B., & Shim, H. Multiple heads are better than one: few-shot font generation with multiple localized experts. In Proc. IEEE International Conference on Computer Vision 13880–13889. https://doi.org/10.1109/ICCV48922.2021.01364 (2021).
Zhejiang stele inscription database. http://csid.zju.edu.cn/tomb/stone.
FontForge. https://github.com/fontforge/fontforge.
Zheng, J. & Sun, J. Exploring the word structure of ancient Chinese encoded in BERT models. Proc. 16th International Conference on Advanced Computer Theory and Engineering (ICACTE) 41–45. https://doi.org/10.1109/ICACTE59887.2023.10335485 (IEEE, 2023).
Dosovitskiy, A. et al. An image is worth 16x16 words: transformers for image recognition at scale. Conference paper of the International Conference on Learning Representations (ICLR) 2021. https://openreview.net/pdf?id=YicbFdNTTy (2021).
Cui, Y. et al. Revisiting pre-trained models for Chinese natural language processing. In Findings of the Association for Computational Linguistics: EMNLP 2020. Association for Computational Linguistics. 657–668, https://doi.org/10.18653/v1/2020.findings-emnlp.58 (2020).
GuwenBERT: A Pre-trained Language Model for Classical Chinese (Literary Chinese). https://github.com/ethan-yt/guwenbert.
Acknowledgements
This work was funded by the Social Science Foundation of Liaoning Province “A Blockchain-based Development Scheme of Digital Historical Material Databases” (L21BZS006). And The authors would like to thank ChinaCreative (Dalian) for the support of the high-performance deep learning platform.
Author information
Authors and Affiliations
Contributions
Zhen Wang: Writing—Original Draft, Methodology, Data Curation, Software, Investigation, Visualization, Formal analysis; Yujun Li: Validation, Supervision; Honglei Li: Methodology, Resources, Validation, Writing—Review & Editing, Project administration, Funding acquisition.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, Z., Li, Y. & Li, H. Chinese inscription restoration based on artificial intelligent models. npj Herit. Sci. 13, 326 (2025). https://doi.org/10.1038/s40494-025-01900-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s40494-025-01900-x
This article is cited by
-
AttGraph disentangling confusable ancient Chinese characters via component-correlation synergy
npj Heritage Science (2026)
-
GAN Augmented Hybrid Transformer Network (GHTNet) For Ancient Tamil Stone Inscription Recognition
npj Heritage Science (2025)
