
Abstract
Shui Script character recognition significantly contribute to the exploration of the abundant historical information embedded within it. However, the existing methods can only recognize a limited range of Shui Script characters. In this paper, we propose a framework that integrates a Bi-Correlational Attention module, combining Cross-Correlational and Self-Correlational Attention to align stroke position relationships between the support and query sets. Furthermore, we introduce a Dual Similarity Relation Module, designed to enhance discriminative feature representation through its Spatial Awareness Relation Module, thereby improving sensitivity to character stroke positions. To further refine feature extraction, we utilize a cosine similarity measurement based on local representation, effectively capturing fine-grained stroke features in Shui Script characters. Additionally, we construct Shui Script datasets S129 and SHD, further perform extensive experiments to validate the proposed method. Experimental results demonstrate that our approach outperforms existing few-shot learning methods in Shui Script recognition, achieving state-of-the-art performance.
Similar content being viewed by others


Introduction
The Shui ethnic group is one of the 56 ethnic minorities in China. Shui Script serves as a comprehensive record of their history, culture, and daily life, further revered as the encyclopedia of this ethnic group. Shui Script characters are ancient hieroglyphs, these unique characters constitute an invaluable intangible cultural heritage. However, not all Shui individuals are proficient in the use of Shui Script, and those who have mastered this rare knowledge are respectfully referred to as “Shui Script Masters”. Nowadays, many of the “Shui Script Masters” are advanced in years, and the number of experts capable of deciphering and translating this ancient script is decreasing rapidly. Additionally, the scattered ancient Shui Script are in poor preservation conditions, with numerous precious volumes suffering from corrosion and damage. The Shui Script culture is under imminent threat of extinction. Therefore, it is urgent to employ more scientific and efficient methods for the recognition of Shui Script, to rescue and translate this precious cultural heritage. Figure 1 illustrates a sample from the existing collection of Shui Script ancient books.

Shui Script is a type of hieroglyphic script that contains some similar characters as shown in the red rectangle. These characters with highly similar shapes but have completely different meanings increase the difficulty of recognition.
The Shui Script recognition currently faces the following challenges: Firstly, acquiring Shui Script characters is particularly challenging. The scarcity of existing handwritten Shui Script scripts and published books makes it difficult to establish Shui Script characters dataset. Secondly, new Shui Script characters are continually being unearthed, most of them have been incorporated into the official Shui Script lexicon. The recognition of these new Shui Script characters leads to an increased workload for retraining deep learning networks. Moreover, there exists a significant imbalance across the categories of Shui Script characters, with the sample data available for some categories being extremely limited. To address these issues, innovative strategies are required to enhance the recognition capabilities for Shui Script characters.
Deep learning have achieved significant performance in computer vision, especially in image recognition and segmentation1,2,3,4,5,6. Recently, numerous studies have demonstrated the efficacy of deep learning methods in the recognition of ancient characters7,8,9,10,11,12,13. Luo et al. (2023) designed a Multi-Attention Aggregation Network for the recognition of highly similar Dongba characters14. A hybrid attentional mapping unit is adopted to obtain more discriminative features while a spatial attentional aggregation unit is designed for preserving multi-scale features, achieving a recognition accuracy of 99.3%. Lin et al. (2022) integrated radical detection as an auxiliary classification basis in oracle bone characters recognition tasks15, effectively addressing the issues of numerous variant characters and complex font structure of oracles. Yin et al. (2022) constructed an online Yi characters handwriting recognition database, further designing a series of recognition models for different scenarios16. Zhuo et al. (2024) proposed a network that integrates deformable convolution and fusion attention mechanism for Chinese character recognition17. They constructed a dataset containing multiple dynastic Chinese characters named CCDD. Experiments on the CCDD dataset achieved the best performance with an accuracy of 91.50%. Despite the promising outcomes of the above ancient character recognition models, they all necessitate substantial data support. When confronted with insufficient training data and imbalanced samples, these methods are susceptible to overfitting, which can significantly degrade recognition performance18,19.
Recently, researchers began to explore few-shot learning as an adaptive approach for small-scale datasets. Few-shot learning is an approach that extracts classification rules from a limited number of labeled instances, further enabling the recognition of novel samples that have not appeared in the training set 20. This methodology effectively addresses the challenges associated with insufficient data and class imbalance21. The existing research of few-shot learning can be divided into two categories: meta-learning based methods and metric-learning based methods22. Meta-learning methods utilize meta-learning strategies to quickly adapt to new tasks in the condition of limited data. Finn et al. (2017) introduced Model-Agnostic Meta-Learning (MAML), which is adaptable to any model optimized using gradient descent with a small number of gradient steps23. Ravi et al. (2017) proposed an LSTM-based meta-learning method that emulates the precise optimization strategy employed for training a learning neural network, while the whole work is under few-shot conditions24. Oh J al. (2020) proposed a meta-learning method called Body Only update in Inner Loop25. Metric learning projects samples into a feature space, then learns distance distributions to cluster similar classes closer and separate different classes. Vinyals et al. (2016) proposed an episodic training strategy to few-shot learning for the first time and designed a memory enhancement network with external storage26. The classification experiments on Omniglot and Imagenet achieved the accuracy of 93.8% and 93.2% respectively. Snell et al. (2017) introduced the concept of class prototypes, which means that each category in the feature space is represented by a prototype, with samples of the same class clustering around their respective prototypes27. Classification is performed by computing the Euclidean distance between query set samples and the class prototypes in the learned embedding space. Sung et al. (2018) proposed a Relation Network that introduce the full connection layer to calculate the similarity in few-shot learning28. It consists of embedded modules and relational modules. The above metric-based methods have been extensively applied as a standard benchmark in the domain of few-shot learning. Li W et al. (2019) proposed a Deep Nearest Neighbor Neural Network(DN4) which introduced an image-to-class measure29. By employing local representation, the method achieved promising results across numerous fine-grained classification tasks. Several novel metric-based algorithms have recently been proposed, focusing on enhancements in feature extraction, class representation, and refinements in distance or similarity metrics. Considering the natural asymmetric relationship between the support set and query set, Li et al. (2020) introduced a novel Asymmetric Distribution Measure (ADM) network for few-shot learning30. Dong et al. (2021) employed Local Regression (LR) from the support set and the query set for similarity measurement31, while introduced an Adaptive Task-Aware Local Representation Network (ATL-Net) to fully exploit the capabilities of LR.
Moreover, several studies have adopted few-shot learning in ancient character recognition. Li et al. (2020) introduced a matching network that establishes correlations between templates and handwritten characters, enhancing its capacity to recognize new Chinese characters previously unseen in the training set with robust generalization32. Zhao et al. (2022) proposed a few-shot learning method based on an augmentation algorithm for oracle character recognition33. This method can preserve the orthographic units and semantic information of oracle characters, and achieve great performance without pre-training. Liu et al. (2022) introduced a similarity network, proposing a multi-scale fusion backbone and embedded structure to enhance the feature extraction capabilities21. They also introduced a soft similarity contrastive loss function for training, achieving an accuracy of 97.9% and 98.3% on the public datasets HWOBC and Omniglot respectively.
However, researchers studying the recognition of Shui Script characters have faced challenges that are distinct from ancient character recognition34,35,36,37,38. Although existing methods have yielded exceptional results in few-shot classification tasks, directly transposing these methods to our task of Shui Script character recognition is problematic. This limitation is primarily attributed to several key challenges and limitations within the current research domain. The distinctive strokes and structural nuances inherent in Shui Script, which is a form of the ideographic writing system. It poses significant difficulties for existing models that are primarily designed for general image or character recognition tasks. These models may not fully capture the unique features and patterns of Shui Script characters, leading to suboptimal performance. Moreover, the complexity and diversity of Shui Script characters also present additional challenges. Shui Script characters often exhibit complex structures and variations, making it difficult for models to accurately distinguish between similar characters. This complexity requires models to own a high level of discriminative power and robustness, which may not be fully achieved by existing few-shot learning methods. Therefore, investigating a model based on the stroke features of Shui Script would be more suitable for few-shot recognition tasks. Such a model could potentially capture the unique characteristics of Shui Script characters more effectively, leading to improved recognition performance. Additionally, developing new methods that can effectively leverage limited labeled data and generalize well to unseen characters is crucial for advancing the field of Shui Script character recognition.
The Relation Network (RN) is a classical method within the realm of few-shot learning28. RN first proposed a learnable nonlinear classifier for calculating the similarity between samples. Compared with the method of adopting distance measure classification, it can adapt to complex data distributions. Moreover, RN exhibits robustness and has achieved favorable outcomes in a diverse range of applications. Therefore, we utilize the RN as a baseline model. To overcome its constraints in effectively capturing the spatial relationships among the fundamental strokes of Shui Script characters, we introduce a Bi-Correlational Attention module. This module enables the metric network to align stroke information between the support set and query set, improving overall metric performance. Considering the sensitivity of stroke position awareness in Shui Script character recognition, we introduce a Dual Similarity Relation Module to enhance the preservation of fine-grained information of Shui Script, further resulting in more precise relational scoring and improved recognition performance. The primary contributions of this paper can be summarized as follows:
1. We construct a few-shot learning Shui Script characters recognition dataset. The samples within this dataset are derived from ancient Shui Script, such as the Zhengqi Volume, Jiuxing Volume, and Yinyangwuxing Volume. By implementing a series of procedures including scanning, character segmentation, and clustering, we have constructed a dataset consisting of 129 prevalent categories of Shui Script characters, with 20 samples for each category.
2. A novel few-shot learning method based on improved RN is proposed, where both Bi-Correlational Attention module((BCAM)) and Dual Similarity Relation Module(DSRM) are designed. BCAM can effectively match semantically related local regions. DSRM is developed to minimize the parameter count while enhancing the preservation of spatial structural information of Shui Script strokes.
3. Extensive experiments on the collected dataset are conducted to demonstrate the effectiveness of our proposed method. Experimental results demonstrate that our proposed method outperforms state-of-the-art methods on 5-way 1-shot task.
Methods
This section will provide a comprehensive introduction to our model. We first define the concept of few-shot learning tasks and then present an overview of the framework. At last, the details of the Bi-Correlational Attention module and the Dual Similarity Relation Module proposed in this paper are introduced.
Problem definition
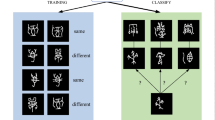
In the context of few-shot learning, the concepts of Support Set, Query Set, and Auxiliary Set are commonly introduced. The Support Set is comprised of C categories, each containing K samples; the Query Set consists of unlabeled samples sharing the same label space as the Support Set and includes q samples. The Auxiliary Set encompasses a large number of labeled samples, its quantity substantially surpassing that of C. It is crucial to highlight that the label space of the Auxiliary Set is entirely distinct from that of the Support Set. This form of few-shot learning is defined as a C-Way K-Shot task.
By the aforementioned definitions, the few-shot learning task can be described as training a classifier using the Support Set to accurately categorize the unlabeled samples within the Query Set. This process is illustrated in Fig. 2. Nevertheless, training an accurate classifier from such a limited number of labeled samples proves challenging. Therefore, we employ the episodic training mechanism proposed by Vinyals et al. (2016) to extract transferrable knowledge26. Specifically, during each training iteration, an episode is constituted by a C-Way K-Shot task, which involves the random selection of C-category samples from the Auxiliary Set. The selected samples compose the Support Set samples \(S={({x}_{i},{y}_{i})}_{i = 1}^{KC}\) and the Query Set samples \(Q={({x}_{j},{y}_{j})}_{j = 1}^{qC}\). Finally, through episode-based training, the unlabeled samples in Query Set can be classified into their corresponding categories.

During the training process, randomly selecting C categories from the training dataset, with each category comprising K samples, referred to as the support set. Additionally, a separate set of samples is identified as the prediction target, known as the query set. The task of learning to distinguish the query set from the support set data is termed the C-way K-shot task.
Framework overview
The overall architecture of the network is illustrated in Fig. 3. Initially, images from both the support and query sets are processed through an encoder to extract embedded features, followed by a dual-branch network that integrates two distinct measurement approaches. The first branch employs the Relation Module (RM) as its foundational model. Given the unique characteristics of Shui Script, it is essential to address the limitation of RM in aligning the stroke positional relationships between samples in the support and query sets. In this paper, we propose a Bi-Correlational Attention(BCAM) module. By computing both cross-correlational and self-correlational matrices to weight features, the BCAM module effectively captures global information within local features specific to Shui Script, enhancing measurement precision through improved positional discernment tailored to its distinct stroke patterns. Furthermore, we implement a Spatial Awareness Relation Module, which replaces fully connected layers with 1 × 1 convolutions. This modification preserves positional information crucial for understanding the spatial arrangement of strokes in Shui Script characters.

The model architecture comprises an embedding module followed by a Dual Similarity Relation Module (DSRM). Branch 1 involves a Bi-Correlational Attention module(BCAM) to aggregate global information.
To effectively utilize the stroke characteristics of Shui Script within local features, Branch 2 incorporates an Image-to-Class module based on local representational strategies. This module utilizes cosine similarity to measure the similarity between local representations of the support and query sets, specifically tailored to capture the nuanced stroke variations in Shui Script. By combining these two distinct measurement approaches—the BCAM and the Image-to-Class module within the Spatial Awareness Relation framework—we fully utilize both global and local information for comprehensive measurement. This integration significantly enhances the discriminative and generalizability abilities of our model, particularly in dealing with the unique attributes of Shui Script. Collectively, the Spatial Awareness Relation Module and the Image-to-Class module are designated as the Dual Similarity Relation Module (DSRM), detailed in Sections “Comparative Performance Evaluation” and “Ablation study”.
Bi-correlational attention module
Shui Script represents a distinctive ideographic writing system, characterized by its unique composition of elementary strokes. The simple strokes arranged into various configurations can represent distinctive meanings of characters. During the feature extraction process, it is prevalent for extracted strokes from divergent regions to represent identical attributes. Directly utilizing such features for metric learning can precipitate ambiguity. Consequently, it becomes imperative to spatially align strokes from disparate regions, calibrating their positional relationships when comparing features between the support and query sets. To address this issue, we propose a Bi-correlational Attention module (BCAM). This mechanism will capture a cross-correlation matrix and a self-correlation matrix between any two spatial positions within the support and query set features. Subsequently, it employs the captured correlation matrix to aggregate global information at each spatial position of features. By this method, the localized features of each region are enriched with the inclusion of fine-grained features from all positions, without a substantial increment in the parameter count.
As shown in Fig. 4, our proposed BCAM module contains a Cross-Correlational Attention (CCA) module and a Self-Correlational Attention (SCA) module.

BCAM module consists of Cross-Correlational Attention (CCA) module and Self-Correlational Attention (SCA) module. fc indicates cross-correlational attention map, and fs indicates self-correlational attention map. C multiplies fc and fs with \({Z}_{S}^{{\prime} }\) and \({Z}_{Q}^{{\prime} }\) respectively and concatenates them along the channel dimension.
Cross-correlational attention module is described as follows: Given a pair of extracted features \({F}_{S}\in {{\mathbb{R}}}^{C\times {H}_{1}\times {W}_{1}}\) and \({F}_{Q}\in {{\mathbb{R}}}^{C\times {H}_{2}\times {W}_{2}}\), which are extracted from a query set qj and one of support set images si. Initially, we employ parameter-shared 1 × 1 convolutional layer to transform the channel dimensions of FS and FQ, from C to \(C{\prime}\). Thereby obtaining a more compact representation, the new query and support representations are denoted as ZS and ZQ. Then we flatten the two-dimensional feature maps into one-dimension, resulting in \({Z}_{S}^{{\prime} }\in {{\mathbb{R}}}^{C\times H1W1}\) and \({Z}_{Q}^{{\prime} }\in {{\mathbb{R}}}^{C\times H2W2}\). From the one-dimensional feature vectors, we utilize cosine similarity to calculate the cross-correlation matrix between the support set and the query set formulated as equation (1):
where \({z}_{Si}^{{\prime} }\) and \({z}_{Qj}^{{\prime} }\) denote the spatial locations within \({Z}_{S}^{{\prime} }\) and \({Z}_{Q}^{{\prime} }\) respectively, with i ∈ {1, …, H1W1} and j ∈ {1, …, H2W2}. Here, fc represents a one-dimensional cross-correlation tensor, encompassing all correlations between every spatial position of \({Z}_{S}^{{\prime} }\) and \({Z}_{Q}^{{\prime} }\).
Then the cross-correlational attention map fc performs dot-product operations with \({Z}_{S}^{{\prime} }\) and \({Z}_{Q}^{{\prime} }\). After incorporating the cross-correlational attention operation, each spatial position of IQS and ISQ contains global information between the support set and the query set. The BCAM module enables the RN network to generate positional awareness of the Shui Script stroke features, aligning the relevant stroke information. This enhances the accuracy of the metric process. Finally, 1 × 1 convolutions are applied to increase the channel dimensions of IQS and ISQ back to the original number of channels.
The Self-Correlation Attention (SCA) module differs from the CCA module. Specifically, the SCA module accepts individual fundamental representations of either the support set or the query set as inputs. Similar to the CCA module, SCA module employs a 1 × 1 convolution layer to compress the channel dimensions of FS and FQ. Subsequently, ZS and ZQ are transformed into one-dimensional feature maps \({Z}_{S}^{{\prime} }\) and \({Z}_{Q}^{{\prime} }\), respectively. The module then computes the self-correlation matrix for either the support set or the query set utilizing cosine similarity formulated as equations (2) and (3):
which resulting in matrix fs1 and fs2, with \({f}^{s1}\in {{\mathbb{R}}}^{{H}_{1}{W}_{1}\times {H}_{1}{W}_{1}}\) and \({f}^{s2}\in {{\mathbb{R}}}^{{H}_{2}{W}_{2}\times {H}_{2}{W}_{2}}\). The self-correlation matrix fs1 and fs2 are then performed dot-product with the feature \({Z}_{S}^{{\prime} }\) and \({Z}_{Q}^{{\prime} }\) respectively. Subsequently, the features containing global information, ISS and IQQ, are respectively reshaped to their original dimensions of The feature maps that pass through the SCA module capture global information at each spatial location without a significant increase of parameter numbers. After obtaining the features weighted by both self-correlational attention and cross-correlational attention, these features are aggregated along the channel dimension and passed through a Spatial Awareness Relation Module to compute the final relation score.
Dual similarity relation module
The RN is a metric-based few-shot learning method that adopts convolutional neural networks to learn similarity. This learnable metric approach enhances the flexibility of the model, enabling more precise matching between support set images and query set images. In addition, the metric-based few-shot learning framework also include methodologies that directly learn distance measures. The most typical DN4 proposes an Image-to-Class module that directly computes the cosine distance of local representations from the support set and query set. The idea of employing local features for comparison proves efficacious in capturing the critical information inherent in Shuishu strokes. Both measurement methods above exhibit substantial advantages. Therefore, we proposed a Dual Similarity Relationship Module (DSRM), which integrates two branches of similarity measurement. This module comprises an enhanced Spatial Awareness Relation Module and an Image-to-Class module.
RN is a typical approach that initially incorporates fully connected layers to compute a similarity metric between embedded features, which is referred to Relation Module(RM). This module is constructed with two hidden layers, with the first layer owning 8 nodes and the second layer containing a single node. The Semantic Alignment Metric Learning (SAML) method enhances the functionality of RM by utilizing a Multi-Layer Perceptron (MLP) network to compute relation scores39. These methods utilize fully connected layers to integrate distributed feature representations and map them into the sample label space. This attribute reduces the influence of feature location on classification. Specifically, the target can be positioned anywhere within the image. The fully connected layers further disregard the spatial structural features of the target, effectively aggregating the target features. Consequently, the neural network will produce consistent classification results, irrespective of the spatial location of the target within the image.
However, the insensitivity to spatial orientation may result in poor performance when the task requires spatial awareness. A typical example is presented by Shui Script characters. The majority of Shui Script characters are formed from identical fundamental strokes. When these strokes are arranged distinctively, they compose unique Shui Script characters. Consequently, the positional relationships between these strokes are imperative for accurately comparing samples within the support set and the query set. While the BCAM module effectively aligns local regions that share comparable semantic attributes, the utilization of fully connected layers to derive metric scores neglects to capture the critical positional information of these strokes. This limitation in capturing essential positional information can lead to metric biases and result in suboptimal comparison results.
To address the limitation above, we propose a Spatial Awareness Relation Module (SARM) to replace the fully connected layers as depicted in Fig. 5. Within the SARM framework, the two fully connected layers of the Relation Module (RM) are replaced with 1 × 1 convolutional operations, which merge features while simultaneously reducing the channel dimension to a single unit. This operation yields feature dimensions of (B, 1, h, w). Subsequently, the resultant tensor is reshaped to (B, 1, hw), and features are aggregated along the specified axis to obtain the metric scores. In this paper, we explore a summation aggregation method. The enhanced RM module exhibits excellent performance in discerning spatial patterns, thereby preserving the spatial relationships among strokes within Shui Script characters more effectively. Hence, this modification leads to more accurate feature comparisons between the support set and the query set.

Our approach involves replacing the fully connected layers in both the RM and MLP with 1 × 1 convolutional layers. This modification not only reduces the number of parameters but also preserves spatial relationships and strengthens feature representation.
The Image-to-Class module (ITCM) accepts local descriptions from both the support sets and query sets as inputs. These local descriptions capture the fine-grained details of Shui Script characters, which can be represented as Equations (4) and (5):
Subsequently, the cosine distance is computed between the local representation of each image and the representations of the known classes formulated as Equation (6):
where xi and \({\hat{x}}_{i}\) represent the feature vector of the query image and a known class from the support set, respectively. Upon computation of the cosine distances, the k-nearest neighbors algorithm is employed to select the top three cosine distances, which are then summed to derive a similarity measure. Ultimately, the Image-to-Class module utilizes this similarity metric to align query images with the most similar images within the support set. This process can be concisely expressed as Equation (7):
where k represents the number of nearest neighbors to select for the similarity calculation, while Fs and Fq denote the set of local descriptors from the support set and query set, respectively. Cosine distance can effectively handle high-dimensional data. Despite its insensitivity to the magnitude of feature vectors, the cosine distance prioritizes the analysis of their orientation within the feature space. This characteristic makes it particularly well-suited for comparing the orientations of Shui Script stroke feature vectors, which is essential for distinguishing between different classes. The dual similarity module compares the support set and query set using two measurement methods based on global and local features respectively. This fusion measurement method enhances discriminative capabilities, leading to more accurate similarity evaluations.
Results
In this section, we initially introduce the Shui Script few-shot classification dataset S129. Subsequently, a series of ablation studies are conducted to validate the effectiveness of the method proposed in this paper. Finally, we compare our method with classical few-shot learning recognition methods and previous state-of-the-art approaches on two datasets to verify its advancement.
Datasets
S129. According to the survey, there is a notable absence of publicly available Shui Script character datasets. Consequently, we have meticulously gathered five ancient books in Shui Script, scanning the original volumes and subsequently processing them to obtain the S129 dataset, as depicted in Fig. 6. Initially, high-resolution chapter-level images of Shui Script were systematically captured through the digital scanning of vintage textual materials. An augmented projection-based algorithm was applied for the segmentation of Shui Script textual content subsequently, yielding a comprehensive compilation of discrete Shui Script character images. Then we clustered the discrete Shui Script character images using the K-means algorithm. Each cluster of Shui Script characters was manually labeled with precision.

The process of establishing the S129 dataset involves the segmentation of individual characters using a projection-based algorithm, followed by the application of the K-means algorithm for clustering. Through these methods, we categorize characters extracted from authentic ancient books.
This method yielded over 800 character categories. However, statistical analysis revealed a pronounced long-tail distribution in the frequency of these characters. Specifically, high-frequency character categories accounted for more than 90% of the total occurrences, while the remaining categories exhibited extremely low frequencies, with the vast majority appearing only once. This distribution pattern is closely related to the actual usage scenarios of the Shui script. As a functional script primarily employed in divination, rituals, and agricultural guidance, the content of Shui script texts demonstrates marked domain specificity. Consequently, certain characters such as those representing solar terms or auspicious signs recur frequently, whereas others are relatively rare. To meet the requirements of small-sample learning tasks, we established a minimum threshold of 20 samples per character category, ultimately identifying 129 representative character categories for our research corpus. The frequency distribution of selected representative characters appearing more than 20 times in historical manuscripts is visualized in Fig. 7. This distribution pattern reflects the functional nature of Shui Script, which were primarily used for divination and ritual purposes, resulting in certain characters (e.g., those denoting auspicious/inauspicious signs or seasonal markers) appearing repeatedly while others remained rare. The 129 categories are divided into 94, 15, 20 for meta-training, meta-validation and meta-testing, respectively. As Shui Script is primarily used for divination and recording knowledge on astronomy, geography, and the like. In these special domains, the 129 characters selected are the most representative and frequently used ones, which can effectively reflect the overall characteristics and patterns of Shui Script characters.

Left panel displays frequently used divinatory terms including “Inauspicious” (669 occurrences), “Propitious” (478), and Heavenly Stems symbols (e.g., “Jia” - 148, “Bing” - 292, “Xin” - 462). Right panel shows seasonal indicators ("Spring” - 31, “Summer” - 43) and directional/spatial markers ("Straight” - 60, “Place” - 21), revealing the functional specialization of Shui script in ritual and calendrical contexts. Notably, the character for “Day” (1316 occurrences) demonstrates exceptional frequency, underscoring its central role in chronological recordings.
This dataset provides crucial support for the digitization and research of Shui Script. Through systematic analysis of core Shui Script character samples, we proposes a few-shot learning framework capable of effectively identifying structural features of Shui Script characters. This approach is particularly suitable for digital preservation of low-resource writing systems.
SHD. Building upon the S129 dataset, we further developed the Shui Handwritten Dataset (SHD) to enhance the breadth of Shui script character research. To maintain consistency with the S129 framework for few-shot learning applications, we preserved the standard of including 20 high-quality samples per character category. Addressing the limited availability of character samples in ancient manuscripts, we organized a team of trained volunteers to systematically reproduce another 1,396 representative characters which were not existed in S129, strictly following the authoritative “Complete Dictionary of Shui Script". Through expert evaluation, we ultimately establishing 1525 fundamental character categories to form the SHD. The 1525 categories are divided into 900, 300, 325 for meta-training, meta-validation and meta-testing, respectively. This expanded dataset not only retains the core high-frequency characters from S129 but also incorporates numerous low-frequency characters and their variants. The SHD dataset provides more comprehensive data support for few-shot learning research on Shui script.
Implementation details
To ensure a fair comparison with previous work, we adopt an embedding setting consistent with previous studies. The embedding module consists of four layers, each comprising a 64-filter of 3 × 3 convolutions, followed by batch normalization, and culminating in a ReLU nonlinearity layer. The first two layers employ a max pooling layer with a kernel size of 2. The architecture of the embedding module is shown in Fig. 8.

The Conv64F Embedding Network employs a layered structure beginning with a 3 × 3 convolutional layer, immediately followed by batch normalization, ReLU activation, and 2 × 2 max pooling operations.
The SARM and ICTM modules are combined as the Dual Similarity Relation Module. As shown in Fig. 3, SARM and ICTM are denoted as h and ν respectively. Given support set samples si and query set samples qj, upon transmission through the encoder fϕ, they are subsequently entered into h and ν, yielding similarity scores yij1 and yij2 as equations (8) and (9):
During the meta-training phase, the loss function employs cross-entropy loss. Let li and lj denote the labels of samples si and qj, then the loss functions of the SARM module and ICTM module can be represented as Equations (10) and (11):
The training loss is formulated as Equation (12):
The parameters a and b represent the respective weights of Lγ and Lλ. Through a series of experiments, we identified the optimal values that yield the highest classification performance, which was attained when both a and b were set to 1.
All experiments were conducted utilizing the PyTorch framework, facilitated by a GeForce GTX 2080 Ti GPU. The Adam optimization algorithm was adopted throughout our experiment, initiating with a learning rate of 0.01. The learning rate underwent adjustments utilizing the StepLR, experiencing decay by 0.01 at every 20-step interval. All input images were consistently resized to 84 × 84 pixels.
In this section, we amalgamate the BCAM and the DSRM module to constitute the proposed model, subsequently comparing its efficacy against state-of-the-art methods, including both meta-based and metric-based methods. To verify the superiority of our proposed method, experimental evaluations were conducted across our benchmark dataset S129 and extended dataset SHD. Experiments on these datasets convincingly validate the proposed method.
Comparative performance evaluation
To assess the efficacy of our proposed model, we primarily conducted a comparative analysis against existing methods using the Shui Script dataset S129 and SHD. The results are presented in Table 1. It reveals that our model achieved superior performance across both the 5-way 1-shot and 5-way 5-shot tasks on S129 and SHD. During the task on S129, our method exhibited a marked improvement in accuracy by 2.26% and 1.44% over the meta-based methods MAML and BOIL during the 5-way 1-shot task. It’s worth noting that our proposed method demonstrates a more expeditious convergence rate when compared with meta-based methods. Furthermore, the accuracy has significantly improved by 2.83% compared with the metric-based ProtoNet. It promotes the capacity of our module using BCAM to capture intricate relationships between strokes within the characters, while DSRM enhances the ability of the model to capture both global and local features, collectively optimizing the capacity of matching query set samples with support set samples. Furthermore, our method has achieved an improvement from 98.28% to 98.79%, compared to the most comparable few-shot method ADM.
Our proposed method was further evaluated on the SHD to comprehensively assess its generalization capability across a broader range of character categories. Comparative experimental results reveal that our approach maintains a consistent performance advantage, demonstrating a 0.29% accuracy improvement over the current state-of-the-art method in the challenging 1-shot task. The observed performance enhancement on SHD relative to the S129 dataset stems from fundamental differences in data characteristics. Unlike authentic historical manuscripts, SHD mainly comprises carefully transcribed samples that exhibit greater structural regularity and consistency. These modern reproductions inherently avoid several recognition challenges present in ancient texts, including ink diffusion, material degradation artifacts, and natural handwriting variations. This contribute to the superior recognition accuracy achieved by all evaluated methods on this dataset compared to their performance on genuine historical specimens. This systematic comparison not only validates the robustness of our method but also quantitatively illustrates how preservation conditions and writing conventions influence recognition system performance.
Furthermore, to validate the effectiveness of our method in Cross-Dataset recognition tasks, we conducted two sets of cross-dataset experiments. In the first configuration, the model was trained on the S129 dataset (comprising authentic historical manuscripts) and tested on SHD (containing standardized transcriptions). The second configuration employed the inverse training-testing scheme. As shown in Table 2, our model achieved superior performance when trained on S129 and tested on SHD, benefiting from the more consistent writing style in the latter dataset, while suboptimal results was observed in the reverse task (SHD-trained model tested on S129). This performance discrepancy stems from fundamental differences in dataset characteristics. The S129 dataset captures the natural variations inherent in genuine historical documents, while SHD consists of carefully transcribed samples with standardized glyphs. Notably, our method demonstrates remarkable robustness in this challenging cross-domain evaluation, maintaining a 0,98% performance advantage over state-of-art models. These results not only confirm the efficacy of our approach but also highlight the unique value of S129’s authentic samples for few-shot Shui script recognition research, owing to their inherent diversity that better reflects real-world application scenarios.
Despite the absolute accuracy gains appear modest, our method exhibits robust advantages in extended category recognition and cross-dataset generalization. These capabilities confirm the technical efficacy of our approach in achieving superior recognition performance under severe data scarcity constraints. This breakthrough provides a transferable technical paradigm for similar low-resource paleographic studies. More importantly, it establishes a computationally feasible pathway for digitizing and preserving endangered historical writing systems, thereby contributing to the conservation of intangible cultural heritage.
Ablation study
In this section, we conduct a series of ablation experiments on the S129 dataset to validate the effectiveness of BCAM and DSRM modules. The results of the ablation study are presented in Tables 3 and 4.
The BCAM module integrates both the SCA and CCA components. It is designed to enhance feature representation by extracting intrinsic self-correlations within an identical set of features, as well as extrinsic cross-correlations between the support and query sets. Initially, a benchmark performance was established using the RN framework devoid of the BCAM module. Then the SCA and CCA modules were independently incorporated into the RN model. Finally, the unified integration of both SCA and CCA formed the complete BCAM module, which was then embedded into RN. As shown in Table 3, the baseline RN served as a reference point for comparison, demonstrating an accuracy of 96.01% for the 5-way 1-shot task and 98.29% for the 5-way 5-shot task. The proposed CCA and SCA modules each exhibited performance enhancements, with accuracy increases of 0.44% and 1.06% in the 5-way 1-shot task, respectively.
It is evident that the implementation of the CCA module yields superior performance compared to the SCA module, demonstrating that it is significant for CCA to measure the similarity between the support and query set features. This metric is crucial for accurately aligning corresponding stroke features across disparate sets. The integration of both SCA and CCA not only exceeds the performance of their individual modules but also substantially outperforms the baseline model, resulting in an accuracy increase of 1.45% in the 5-way 1-shot task. This indicates that the joint consideration of self-correlation and cross-correlation is effective in enhancing the performance of the model on the S129 dataset.
To investigate the efficacy of the proposed Dual Similarity Relation Module, a comparative analysis was conducted between our proposed methods and baseline model RN. The incorporation of the DSRM was approached incrementally. The SARM was integrated initially, followed by the integration of the ICTM, and finally the complete DSRM was implemented. Table 4 reveals that the incorporation of the SARM results in an accuracy augmentation of 0.66% for the 5-way 1-shot task and 0.27% for the 5-way 5-shot task. This suggests that our aggregation method, which preserves the spatial positional information between Shui Script strokes, is superior to using fully connected layers for deriving global features as similarity scores for the support and query sets. The integration of the ICTM module significantly boosts accuracy by 1.61% and 0.73%, attributable to its emphasis on local representations rich with stroke information, which is critical for refining measurement precision. Employing local features for direct comparison mitigates the loss of positional information between strokes, thus enabling a more exacting evaluation of key information within Shui Script characters. The unification of both the BCAM and DSRM modules propels the accuracy to 98.79% and 99.59% respectively, representing a significant improvement of 2.78% and 1.3% over the baseline model. This demonstrates the synergistic efficacy of employing the BCAM module for the integration of global information within local features, as well as using DSRM module for the amalgamation of local and global similarity assessments. The integration of the all above modules enables the model to achieve superior performance, verifying the effectiveness of the method proposed in this paper.
Visualization analysis
We performed a visualization analysis of the experimental results using t-SNE method. To make the clustering effect more obvious, we randomly selected 19 query instances for each of the 5-way 1-shot tasks. The experimental results are shown in Fig. 9. Figure 9a is the visualization result of the baseline model RN. It can be seen that the query features of each category are relatively scattered, and there are significant deviations in the clustering results of certain sample features. Figure 9b is the t-SNE result after adding BCAM. It is evident that the introduction of BCAM has significantly reduced the number of anomalous clustering instances. This suggests that incorporating global information through SCA and aligning the query set with the support set via CCA effectively enhances metric accuracy and reduces classification errors. Figure 9c is the visualization result of our proposed model. It is apparent that the features of different categories have clear boundaries and no abnormal features appear. Meanwhile, the clustering effect of each category is tighter compared to Fig. 9a, b. This indicates that DSRM uses a dual similarity metric module, which enables the model to learn more discriminative feature representations, further proving the effectiveness of our proposed method.

a t-SNE visualization of the baseline Relation Network (RN). b Feature distribution after integrating the BCAM module. c t-SNE visualization of our proposed model, demonstrating improved feature separation.
Weight selection of loss function
The optimal configuration of the loss function was determined by fine-tuning the weighting parameters a and b as shown in Equation 3. The experimental results are shown in Table 5. Due to the marginal difference in model efficacy associated with an incremental expansion of the sample size within the 5-way 5-shot task, our experiment was conducted under the 5-way 1-shot task during the weight selection process. As shown in Table 5, the model exhibits the best performance, achieving a classification accuracy of 98.79%, when both a and b are assigned a value of 1. While other distributions resulted in slightly diminished accuracy rates, the overall variance was not statistically significant. Consequently, we have adopted the same weight of 1 for both a and b in the training loss.
Experiments on different backbone networks
We experimentally investigate the impact of different feature extraction networks on the performance of the proposed method. Figure 10 presents the experimental results for Conv64F, Conv32F, and ResNet12.

Classification accuracy comparison of Conv64F, Conv32F, and ResNet12 across training epochs. Conv64F consistently achieves superior performance as the backbone network, outperforming both Conv32F and ResNet12 after convergence.
It is evident from the figures that employing Conv64F as the feature extraction network achieves the best classification performance. The use of Conv32F yields relatively inferior results, indicating its insufficient feature extraction capability for Shui Script characters. Under the same experimental setup, employing ResNet12 for feature extraction was not satisfactory. Due to the substantial number of parameters in the model, it suffers from slow training speeds and exhibits significant challenges in achieving convergence on the training data for this specific task. Consequently, we opted for Conv64F as the feature extraction network to address these limitations.
Analysis of parameter efficiency
In our approach, the baseline model adopts a Relation Network (RN), with the majority of its parameters originating from two core components: the embedding module and the relation module. To further enhance model performance, we introduce a BCAM to the baseline model. Notably, the design of BCAM does not introduce additional trainable parameters. Instead, it computes a cross-correlation matrix and a self-correlation matrix between any two spatial positions within the features of the support set and the query set to generate attention weights. This mechanism not only significantly improves the feature representation capability of the model but also maintains high parameter efficiency.
Furthermore, we incorporate a branch based on directly learned distance measures to capture critical discriminative information in the features. This branch is non-parametric and operates by computing the similarity between the query set and the support set. This design avoids the introduction of additional parameters while enhancing the model’s discriminative power through the integration of dual similarity measures.
In summary, our method adheres to the principle of parameter efficiency throughout the introduction of the Bi-correlational Attention mechanism and the Dual Similarity Relation Module. Compared to traditional strategies that increase parameters, our approach significantly improves model performance without introducing any additional parameters, thereby offering greater flexibility for efficient deployment and scalability of the model.
Discussion
In this study, we constructed a few-shot learning dataset by extracting individual characters from precious Shui Script ancient books. To address the challenges posed by variant characters, similar characters, and unbalanced sample sizes in Shui Script, we proposed a metric-based few-shot learning method that integrates the BCAM and DSRM modules. The BCAM module aligns stroke features between characters in the support and query sets by computing cross-correlation and self-correlation matrices, which significantly improves the accuracy of character comparisons. Meanwhile, the DSRM module introduces an improved global relation module that replaces fully connected layers with a novel fusion approach, effectively preserving stroke location information. Additionally, the ICTM module leverages local representations for measurement, enabling more comprehensive capture of stroke-level details. This combination of local and global similarity measurements allows the network to discern subtle inter-class differences while avoiding overfitting to local patterns.
Experimental results demonstrate that the integration of BCAM and DSRM modules substantially enhances the model’s performance. The proposed method demonstrates remarkable stability through extensive dataset validation and cross-dataset generalization tests. Particularly under low-resource conditions, it exhibits significant advantages—achieving comparable recognition accuracy to conventional approaches with substantially fewer training samples while dramatically reducing computational requirements. This breakthrough provides an efficient and practical technical solution for the digitization of ancient scripts. This study will next focus on building a more comprehensive and authentic Shui script ancient documents dataset by systematically collecting original character samples from different historical periods and carrier types, gradually replacing existing imitated data. Concurrently, we will enhance the model’s robustness in handling complex real-world scenarios such as document degradation and deformations, thereby establishing a more reliable digital foundation for Shui script research.
Data availability
The datasets analysed during the current study are not publicly available due to copyright issues, but are available from the corresponding author on reasonable request.
Code availability
The code used to analyze the data and generate the results during the current study is not publicly available due to licensing restrictions, but it can be made available from the corresponding author upon reasonable request.
References
Ding, X. et al. Repvgg: Making VGG-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13733–13742 (2021).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778 (2016).
Ismail Fawaz, H., Forestier, G., Weber, J., Idoumghar, L. & Muller, P.-A. Deep learning for time series classification: a review. Data Min. Knowl. Discov. 33, 917–963 (2019).
Wu, Z., Shen, C. & Van Den Hengel, A. Wider or deeper: Revisiting the ResNet model for visual recognition. Pattern Recognit. 90, 119–133 (2019).
Zhou, Z., Rahman Siddiquee, M. M., Tajbakhsh, N. & Liang, J. Unet++: A nested U-Net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, September 20, 2018, Proceedings 4, 3–11 (Springer, 2018).
Dong, S., Wang, P. & Abbas, K. A survey on deep learning and its applications. Comput. Sci. Rev. 40, 100379 (2021).
Qaroush, A., Awad, A., Modallal, M. & Ziq, M. Segmentation-based, omnifont printed Arabic character recognition without font identification. J. King Saud. Univ. Computer Inf. Sci. 34, 3025–3039 (2022).
Li, M. et al. Trocr: Transformer-based optical character recognition with pre-trained models. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, 13094–13102 (2023).
Tang, M., Xie, S., He, M. & Liu, X. Character recognition in endangered archives: Shui manuscripts dataset, detection and application realization. Appl. Sci. 12, 5361 (2022).
Narang, S. R., Kumar, M. & Jindal, M. K. Deepnetdevanagari: a deep learning model for devanagari ancient character recognition. Multimed. Tools Appl. 80, 20671–20686 (2021).
Boufenar, C., Kerboua, A. & Batouche, M. Investigation on deep learning for off-line handwritten Arabic character recognition. Cogn. Syst. Res. 50, 180–195 (2018).
Ptucha, R. et al. Intelligent character recognition using fully convolutional neural networks. Pattern Recognit. 88, 604–613 (2019).
Kavitha, B. R. & Srimathi, C. B. Benchmarking on offline handwritten Tamil character recognition using convolutional neural networks. J. King Saud. Univ. Comput. Inf. Sci. 34, 1183–1190 (2022).
Luo, Y., Sun, Y. & Bi, X. Multiple attentional aggregation network for handwritten Dongba character recognition. Expert Syst. Appl. 213, 118865 (2023).
Lin, X., Chen, S., Zhao, F. & Qiu, X. Radical-based extract and recognition networks for oracle character recognition. Int. J. Doc. Anal. Recognit. (IJDAR) 25, 219–235 (2022).
Yin, Z., Chen, S., Wang, D., Peng, X. & Zhou, J. Yi characters online handwriting recognition models based on recurrent neural network: Rnnnet-yi and parallelrnnnet-yi. In International Conference on Frontiers in Handwriting Recognition, 375–388 (Springer, 2022).
Zhuo, S. & Zhang, J. Attention-based deformable convolutional network for Chinese various dynasties character recognition. Expert Syst. Appl. 238, 121881 (2024).
Shafiq, M. & Gu, Z. Deep residual learning for image recognition: A survey. Appl. Sci. 12, 8972 (2022).
Wang, Y., Yao, Q., Kwok, J. T. & Ni, L. M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. (csur) 53, 1–34 (2020).
Li, X., Yang, X., Ma, Z. & Xue, J.-H. Deep metric learning for few-shot image classification: A review of recent developments. Pattern Recognit. 138, 109381 (2023).
Liu, X. et al. One shot ancient character recognition with Siamese similarity network. Sci. Rep. 12, 14820 (2022).
Cai, Q., Pan, Y., Yao, T., Yan, C. & Mei, T. Memory matching networks for one-shot image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4080–4088 (2018).
Finn, C., Abbeel, P. & Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In International Conference on Machine Learning, 1126–1135 (PMLR, 2017).
Ravi, S. & Larochelle, H. Optimization as a model for few-shot learning. In International Conference on Learning Representations (2016).
Oh, J., Yoo, H., Kim, C. & Yun, S.-Y. Boil: Towards representation change for few-shot learning. arXiv preprint arXiv:2008.08882 (2020).
Vinyals, O., Blundell, C., Lillicrap, T., Wierstra, D. et al. Matching networks for one shot learning. Advances in Neural Information Processing Systems 29 (2016).
Snell, J., Swersky, K. & Zemel, R. Prototypical networks for few-shot learning. Advances in Neural Information Processing Systems 30 (2017).
Sung, F. et al. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1199–1208 (2018).
Li, W. et al. Revisiting local descriptor based image-to-class measure for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7260–7268 (2019).
Li, W. et al. Asymmetric distribution measure for few-shot learning. arXiv preprint arXiv:2002.00153 (2020).
Dong, C., Li, W., Huo, J., Gu, Z. & Gao, Y. Learning task-aware local representations for few-shot learning. In Proceedings of the Twenty-ninth International Conference on International Joint Conferences on Artificial Intelligence, 716–722 (2021).
Li, Z., Wu, Q., Xiao, Y., Jin, M. & Lu, H. Deep matching network for handwritten Chinese character recognition. Pattern Recogn. 107, 107471 (2020).
Zhao, X., Liu, S., Wang, Y. & Fu, Y. Ffd augmentor: Towards few-shot oracle character recognition from scratch. In Proceedings of the Asian Conference on Computer Vision, 1622–1639 (2022).
Zhang, X.-Y., Yin, F., Zhang, Y.-M., Liu, C.-L. & Bengio, Y. Drawing and recognizing Chinese characters with recurrent neural network. IEEE Trans. pattern Anal. Mach. Intell. 40, 849–862 (2017).
Liu, X., Hu, B., Chen, Q., Wu, X. & You, J. Stroke sequence-dependent deep convolutional neural network for online handwritten chinese character recognition. IEEE Trans. Neural Netw. Learn. Syst. 31, 4637–4648 (2020).
Zhang, X.-Y., Bengio, Y. & Liu, C.-L. Online and offline handwritten Chinese character recognition: A comprehensive study and new benchmark. Pattern Recogn. 61, 348–360 (2017).
Memon, J., Sami, M., Khan, R. A. & Uddin, M. Handwritten optical character recognition (OCR): A comprehensive systematic literature review (SLR). IEEE Access 8, 142642–142668 (2020).
Liu, B., Xu, X. & Zhang, Y. Offline handwritten Chinese text recognition with convolutional neural networks. arXiv preprint arXiv:2006.15619 (2020).
Hao, F. et al. Collect and select: Semantic alignment metric learning for few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 8460–8469 (2019).
Acknowledgements
This study was financially supported by the National Natural Science Foundation of China (Grant No. 51779050) and the National Social Science Foundation of China (Grant No. 20ZD279), with Professor Xiaojun Bi as the funder. The authors would like to express their sincere gratitude to the Laboratory of Ethnic Language Intelligent Analysis and Security Governance of MOE for providing essential facilities and research resources that were instrumental in conducting this study.
Author information
Authors and Affiliations
Contributions
W.Q., L.H. and X.B. conceptualized the study. W.Q., L.H. and X.B. contributed to the methodology development, while W.Q. and L.H. leading the effort. L.H. was responsible for the validation of the results. W.Q. and L.H. performed the formal analysis. The investigation was conducted by L.H., while X.B. provided the necessary resources for the study. W.Q. and L.H. jointly wrote the original draft of the manuscript. X.B was responsible for reviewing and editing the manuscript. They also created the visualizations for the study. X.B. supervised the project. L.H. managed the project administration, while W.Q. and X.B. acquired the funding. All authors have reviewed and agreed to the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Participate declaration
All participants in this study were voluntarily recruited and provided informed consent prior to their participation. They were fully informed about the purpose, procedures, potential risks, and benefits of the study. Their privacy and confidentiality were strictly protected throughout the research process.
Publish declaration
The manuscript titled “Few-shot Shui Script Character Recognition: Dual-branch Similarity Network using Bi-Correlational Attention Mechanism” submitted for publication in Heritage Science is an original work and has not been published previously, nor is it under consideration for publication elsewhere. We have made substantial contributions to the conception, design, execution, and interpretation of the reported study.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Qiao, W., Han, L. & Bi, X. DuaL-branch similarity network with Bi-correlative attention for few-shot Shui script recognition. npj Herit. Sci. 13, 361 (2025). https://doi.org/10.1038/s40494-025-01929-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s40494-025-01929-y
This article is cited by
-
AttGraph disentangling confusable ancient Chinese characters via component-correlation synergy
npj Heritage Science (2026)
-
Lightweight visual feature recognition of Tibetan Opera costumes: framework design and implementation
npj Heritage Science (2025)
