
Abstract
Point cloud registration plays a crucial role in preservation and digitization of cultural heritage by accurately aligning multiple point cloud datasets to create a complete 3D model. However, the complexity and diversity of objects lead to low-overlap and significant variations, posing challenges in achieving high accuracy, robustness and generalizability. This study proposes a Cross-Domain Multi-Channel Transformer (CDMCT) to address these challenges. The multi-channel dynamic encoding to enhance model’s sensitivity to local structures and angular relationships. The cross-domain convergence network preserves the global relationships within point cloud and the overall structural information. The integration of graph networks allows for flexible handling of local feature variations. We trained on 3DMatch and KITTI, and validated on cultural heritage datasets Terracotta Warriors and WHU-TLS ancient buildings. Experimental results show that CDMCT achieves significant improvements in registration accuracy and robustness, demonstrating its broad application potential in the digital preservation of cultural heritage.
Similar content being viewed by others
Introduction
Cultural heritage encompasses historically and culturally significant assets such as ancient buildings and Terracotta Warriors. Their preservation, restoration, and digitization represent crucial tasks in modern technology. Traditional digitalization efforts of cultural heritage require precise 3D reconstruction and detailed structural analysis. Point cloud registration1,2,3 technology addresses the task of aligning point cloud data obtained from different viewpoints or times to achieve a consistent coordinate system and geometric structure. This process enables the construction of unified 3D models and facilitates the integration and analysis of multi-source point cloud data. It contributes to achieving high-precision digitalization of cultural heritage, thereby supporting the long-term preservation, restoration, and exhibition of ancient buildings and Terracotta Warriors. Point cloud registration plays a pivotal role in various fields including 3D modeling4,5, classification6, artifact restoration, autonomous driving7, robot navigation8, virtual reality, medical imaging, and cultural heritage preservation9. However, challenges such as low-overlap, large-scale scenes and across datasets generalization make point cloud registration a highly demanding research direction.
Over the past few decades, various point cloud registration methods have been proposed, including feature-based learning methods10,11,12 and End-to-End Learning Methods13,14. In feature-based learning point cloud registration methods, key features are extracted from point cloud data and matched and aligned using machine learning or deep learning algorithms to obtain high-precision 3D data. This process not only aids in the protection and restoration of ancient buildings and the Terracotta Warriors but also provides robust support for the preservation, restoration, and display of cultural heritage. In unsupervised point cloud registration, due to the absence of accurate label information, traditional inlier evaluation methods struggle to effectively differentiate inliers from outliers, leading to unstable and inaccurate registration results. To address this, Huang et al.15 proposed an innovative unsupervised learning probabilistic point cloud registration method. This method takes advantage of statistical models to overcome noise and density variation and uses alignment scores in a unified Gaussian mixture model to supervise network training while reducing reliance on supervisory information, achieving better registration accuracy and efficiency. To enhance the effectiveness of multi-view point cloud registration, Wang et al.16 proposed a multi-view point cloud registration algorithm. By utilizing reliable pose graph initialization and history re-weighting, this method resolves issues of misalignment and instability in multi-view point cloud registration, enhancing robustness and accuracy. Firstly, an initial pose graph is constructed through preprocessing and feature extraction. The pose graph represents relative pose relationships between point cloud from different viewpoints. Subsequently, global optimization is applied to the pose graph using optimization algorithms to further enhance its accuracy and consistency. Lastly, a historical re-weighting mechanism is introduced to re-weight pose graphs from previous registration steps. To address accidents and fatalities in scaffolding operations, Kim et al.17 proposed a novel method for scaffold point cloud registration considering safety nets. The method comprises three steps: firstly, LiDAR-camera calibration and SLAM-based point cloud data acquisition; secondly, object detection and coordinate transformation; and finally, identification of scaffold installation stages and point cloud registration. Experimental validation demonstrated that this method effectively achieves scaffold point cloud registration in scenarios without safety nets. Traditional Iterative Closest Point (ICP) methods perform poorly in low-overlap scenarios and have high algorithmic complexity. Feature-based methods are often sensitive to feature selection and extraction, leading to poor generalization. Additionally, some existing neural network methods often require a large amount of data labeling and model adjustment when dealing with different datasets, limiting their flexibility in practical applications.
End-to-end Learning methods directly learn and optimize the registration process through deep learning networks or optimization algorithms, thereby enhancing the overall performance and accuracy of the system. This approach typically handles the complexity within data more effectively and is suitable for various cultural heritage scenarios requiring point cloud registration. FCGF18 employs a fully convolutional network to learn geometry feature representations end-to-end, enhancing the representation capacity and automation of geometric features. Specifically, the network takes three-dimensional point cloud data as input and extracts features through a series of convolutional and pooling layers. Unlike traditional convolutional neural networks, this network performs convolution operations across the entire input point cloud rather than only on local regions. Through this approach, the network captures global geometric information and generates fully convolutional geometry feature maps. Existing point cloud descriptors rely on structural information and ignore texture information, yet texture information is crucial for distinguishing scene components. To solve this problem, Huang et al.19 proposed a method based on multi-modal fusion to generate point cloud registration descriptors that consider structural and texture information. This method achieves state-of-the-art accuracy and improves descriptor dissimilarity. To address the limitation of point cloud registration methods in terms of generalization ability, which often leads to performance degradation when applied to unseen datasets with distributions different from the training set, Yuan et al.20 proposed a novel end-to-end registration method based on random networks. The method utilizes multiple randomly initialized networks for feature extraction and correspondence establishment. Additionally, a collaborative integration strategy is introduced to prune outliers from the correspondences established by random networks, making full use of spatial consistency. Through collaborative integration pruning, the majority of outliers can be removed, enabling robust registration within an economical RANSAC iteration.
In recent years, the Transformer architecture has achieved remarkable success in natural language processing and computer vision fields21,22,23. Its powerful sequence modeling capabilities and self-attention mechanism demonstrate great potential in point cloud registration tasks. Yew et al.24 using Transformers for point cloud correspondence. The core idea is to treat point cloud datasets as sets of points and use the Transformer model to learn point-to-point correspondences. Each point is represented as a feature vector, and attention mechanisms are employed to establish relationships between points. Through the use of a Transformer model, point cloud correspondences can be learned in an end-to-end manner without relying on traditional manual feature design or the two-step process of correspondence point extraction and matching. To address the impact of geometric structure descriptors in point cloud registration, Yuan et al.25 proposed an Enhanced Geometric Structure Transformer method to improve the modeling of geometric structures within point clouds. By employing this enhanced transformer, they aimed to learn three explicit geometric structure features and utilize them to extract reliable correspondences for point cloud registration. In contrast to conventional approaches, this method eliminates the need for explicit positional embeddings or additional feature exchange modules, thus simplifying the network architecture. Yu et al.26 introduced RIGA to address the limitations of existing neural descriptors in point cloud registration. Existing descriptors either suffer from performance degradation under large rotations or lack sufficiently unique local geometric information. To tackle this, they designed descriptors with rotation invariance and global awareness. By extracting point pair features from sparse local regions, RIGA encodes rotation-invariant local geometry into geometric descriptors and globally incorporates the 3D structure and geometric context of the entire framework in a rotation-invariant manner. Compared with traditional methods that require manual feature design, Transformer can capture global dependencies between point cloud data through self-attention, enhancing the automation and accuracy of registration. However, directly applying Transformer to point cloud registration still faces several challenges, including low-overlap between point cloud data, limited generalization ability across datasets, and insufficient robustness. These issues restrict its effectiveness in practical applications.
To address these issues, this paper proposes an end-to-end point cloud registration method based on Cross-domain Multi-channel Transformer to tackle challenges such as low-overlap, large-scenes, and across datasets generalization. We focus primarily on four representative point cloud datasets: 3DMatch27, KITTI28, Terracotta Warriors and WHU-TLS29. In terms of method innovation, this paper introduces multi-channel dynamic encoding and cross-domain convergence networks, which effectively handle registration problems between low-overlap, large-scenes, and different datasets.
The contributions of this paper are mainly reflected in the following aspects: Multi-channel Dynamic Encoding: By introducing multi-channel angular relationship modeling into the task of cultural heritage point cloud registration. By repeatedly applying ternary angular positional encoding, it generates direction-sensitive multi-channel angle matrices, and incorporates dynamic positional weighting to adapt to the complex surfaces and local structural heterogeneity of heritage point clouds. By integrating angular encodings from different channels, the model’s ability to discriminate local geometric features is significantly enhanced.
Cross-domain Convergence Network: By combining the global modeling capability of Transformer with the local topological representation power of graph neural networks, the proposed method ensures both global structure preservation and robust expression of local feature variations in cultural heritage point clouds. When facing common challenges in heritage scenarios such as occlusion and incomplete scanning, it demonstrates superior robustness and enables high-precision registration.
Algorithm Generalization Performance: CDMCT is trained on general-purpose datasets and validated on representative cultural heritage datasets, including the Terracotta Warriors and WHU-TLS ancient buildings. Experimental results show that the proposed method exhibits strong cross-domain generalization capability and can adapt to registration tasks across different heritage types and under low-overlap conditions, aligning well with the complexity and diversity of real-world digital preservation scenarios.
Methods
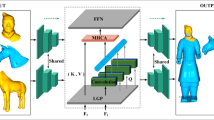
Similar to the structures of D3Feat30 and Predator31, our approach also employs a hierarchical framework, as illustrated in Fig. 1.

The figure illustrates the pipeline of the Cross-Domain Multi-Channel Transformer (CDMCT) model. Key modules include Encoder, Transformer and Decoder.
Problem setting
For two point cloud, the source point cloud \(P=\{{p}_{i}\in {{\mathbb{R}}}^{3}| i=1,2,\ldots ,N\}\) and the target point cloud \(Q=\{{q}_{i}\in {{\mathbb{R}}}^{3}| i=1,2,\ldots ,M\}\), where N and M represent the number of points in point cloud P and Q, respectively, the objective of point cloud registration is to align the two point cloud using an unknown 3D rigid transformation RT = {R, T}, comprising of a rotation matrix R ∈ SO(3) and a translation vector \(T\in {{\mathbb{R}}}^{3}\). The transformation matrix can be defined as:
Where, ϑ represents the ground truth correspondences between the points in P and Q. The notation \(\left\Vert \bullet \right\Vert\) denotes the Euclidean norm.
In our method, the correspondences between points are output. Subsequently, the optimal rigid transformation is estimated from these correspondences using RANSAC32 to achieve the final point cloud registration.
Encoder-Decoder
Encoder: For the denser source point cloud \(P\in {{\mathbb{R}}}^{N\times 3}\), \(P=\{{p}_{i}\in {{\mathbb{R}}}^{3}| i=1,2,\ldots ,N\}\). and target \(Q\in {{\mathbb{R}}}^{M\times 3}\), \(Q=\{{q}_{i}\in {{\mathbb{R}}}^{3}| i=1,2,\ldots ,M\}\). we utilize the KPConv33 module as the backbone, which consists of a series of residual modules and strided convolutions, to perform downsampling and reduce the number of keypoints to \({P}^{{\prime} }\in {{\mathbb{R}}}^{N^{\prime} \times 3}\) and \({Q}^{{\prime} }\in {{\mathbb{R}}}^{M^{\prime} \times 3}\), respectively (where \(N > N^{\prime}\) and \(M > M^{\prime}\)).
Building upon this, we further design a shared encoder to simultaneously process the key points of the source and target point clouds. The architecture of this shared encoder consists of the following steps:
First, the input passes through the KPConv layer, which uses a kernel point convolution to convolve the local neighborhood of each key point, thereby extracting local geometric information. Next, residual connections are applied to alleviate the vanishing gradient problem in deep networks and enhance feature representation capability. This is followed by Batch Normalization and ReLU activation, which accelerate convergence and improve nonlinear modeling capacity. Finally, a shared parameter mechanism is employed: the source point cloud \({P}^{{\prime} }\) and the target point cloud \({Q}^{{\prime} }\) are simultaneously fed into the encoder, sharing all convolutional layers and weights to extract consistent local structural features across both domains.
Through the shared encoder, we obtain the feature representations of the source and target point clouds as \({F}_{{P}^{{\prime} }}^{{\prime} }\in {{\mathbb{R}}}^{N^{\prime} \times D}\) and \({F}_{{Q}^{{\prime} }}^{{\prime} }\in {{\mathbb{R}}}^{M^{\prime} \times D}\), where D represents the feature dimension. This structure ensures that the source and target domains have a consistent feature space during the encoding phase, which is helpful for the subsequent registration task.
Decoder: In this module, set up in the usual manner, there is a 3-layer network structure that primarily consists of upsampling, linear transformation, and skip connections.
Transformer
Multi-channel Dynamic Encoding (MCDE): In traditional Transformer models, positional encoding is typically applied in a fixed manner. However, the geometric structure and distribution characteristics of point cloud data may make it challenging for traditional positional encoding methods to capture changes in local features. MCDE addresses this issue by iteratively applying ternary angle positional encoding and incorporating dynamic positional encoding, allowing each point to more fully express different angular relationships and effectively capture the geometric information of the point cloud. This enhances the model’s ability to perceive the local structure and angular relationships of the point cloud. In this process, each channel corresponds to different angular relationships, forming multiple channels of angle encoding through weight-adjusted angle encoding to ensure that the model can fully understand and utilize the various angle information present in the point cloud. The network architecture of Transformer is illustrated in Fig. 2.

MCDE: Multi-channel Dynamic Encoding. GCN: Graph Convolutional Networks. MC: Multi-head Cross-attention.
For each point Pi in the point cloud, the three angular relationships between it and the points in the neighbor set Ni are first computed and denoted as θij, as follows:
Where, pi, pj, and pk represent three different points, arccos represents the inverse cosine function, and ∥ ⋅ ∥ represents the modulus of the vector.
To adapt to the local structure of the point cloud, dynamic positional encoding is utilized to adjust the weights for optimizing the local perception of the point cloud. For each point Pi, the weights of its neighboring points are computed as αi,j:
Where, Φ represents a multi-layer perceptron, Cat denotes the concatenation operation, and PE represents the relative position encoding.
By iteratively applying ternary angle positional encoding, multiple-channel angle encoding is generated. Each channel corresponds to different angular relationships, ensuring that the model can fully understand and utilize various angle information present in the point cloud. Multi-channel dynamic encoding is achieved through weight-adjusted angle encoding to capture richer geometric features. The specific formula for multi-channel dynamic encoding is:
Where, MCDEc represents the multi-channel dynamic encoding for the Cth channel, K is the number of neighboring points, and PE represents the relative position encoding.
Finally, the multi-channel dynamic encoding is fused with the original features of the point cloud to form the final feature representation, integrating the original features and angle information of the point cloud.
Where, \({F}_{{P}^{{\prime} }}^{{\prime} }\) represents the original features of point \({P}^{{\prime} }\) in the point cloud.
Overall, ternary angle positional encoding computes the angle relationships between each point and its neighbors, encoding this angle information into each point’s feature representation. This angle information provides important insights into the local geometric structure of point clouds. Meanwhile, dynamic positional encoding adjusts the influence of each neighboring point on the current point through weighting, allowing the model to better adapt to different local features within point clouds. Their combination enables a more comprehensive utilization of geometric information and angle relationships in point cloud data, collectively enhancing the model’s ability to capture the geometric structure and angle relationships of point clouds.
Cross-domain Convergence Network (CC-Net): The CC-Net aims to address the issue of insufficient capture of local features in point cloud registration tasks by traditional Transformer models. Traditional Transformer models typically capture global features through cross-attention mechanisms. However, in point cloud registration tasks, local features are equally crucial. Therefore, CC-Net adopts the design concept of cross-domain convergence networks, integrating multi-head cross-attention mechanisms with graph convolutional networks at different levels.
CC-Net utilizes multi-head cross-attention mechanisms to preserve the global relationships of point cloud data, which helps the model capture overall structural information. Simultaneously, the introduction of graph convolutional networks better handles the variations in local features because graph convolutional networks excel at capturing local connectivity relationships between nodes in graph-structured data. Thus, by integrating multi-head cross-attention mechanisms and graph convolutional networks at different levels, CC-Net can more comprehensively utilize both global and local information of point cloud data, thereby improving the generalization and robustness of the registration model.
Firstly, we define the position relation MCDE embedding for the cross-attention module. We define a 4-layer multi-head cross-attention module, which inherits the feature information from the previous module while focusing on the mutual information between two point clouds.
Where, Q, K, and V represent Query, Key, and Value matrices, respectively. The operation He1 to HeH involves multiple attention heads (Head1 to HeadH) which capture different aspects of the input.
Each attention head uses learnable transformation matrices \({W}_{h}^{Q}\), \({W}_{h}^{K}\), and \({W}_{h}^{V}\) to linearly transform the input Q, K, and V matrices. The transformed values are then used to compute attention scores.
The dimensions of Q, K, V, and each attention head (dQ, dK, dV, dHead) are related, where dQ = dK = dV = dHead = D/H. Here, D is the model’s dimensionality and H is the number of attention heads.
Given a graph G = (V, E), where V is the set of nodes and E is the set of edges, Graph Convolutional Network (GCN) can perform convolution operations on each node v, and its output representation hv is given by:
Where, N(v) is the set of neighboring nodes of node v, cv is a normalization factor, WG is a learnable weight matrix, and σ is the sigmoid activation function.
Moving forward, let’s denote input matrices as \({F}_{{P}^{{\prime} }}^{{\prime} }=({x}_{1}^{{P}^{{\prime} }},{x}_{2}^{{P}^{{\prime} }}\cdots {x}_{N^{\prime} }^{{P}^{{\prime} }})\) and \({F}_{{Q}^{{\prime} }}^{{\prime} }=({x}_{1}^{{Q}^{{\prime} }},{x}_{2}^{{Q}^{{\prime} }}\cdots {x}_{N^{\prime} }^{{Q}^{{\prime} }})\), and the output matrix as \(Z^{\prime} =({z}_{1}^{{P}^{{\prime} },{Q}^{{\prime} }},{z}_{2}^{{P}^{{\prime} },{Q}^{{\prime} }}\cdots {z}_{N^{\prime} }^{{P}^{{\prime} },{Q}^{{\prime} }})\). The computation involves summing weighted contributions of \(MHA({F}_{{P}^{{\prime} }}^{{\prime} },{F}_{{Q}^{{\prime} }}^{{\prime} },{F}_{{Q}^{{\prime} }}^{{\prime} })\) based on attention scores:
Where, the weight coefficient \({\alpha }_{i,j}^{Cross-}\) is defined as:
Finally, the output encapsulates the correspondence between point cloud as follows:
Loss function
The network we propose is based on end-to-end training and supervised training using ground truth. The specific loss function is as follows:
Feature Loss: We utilize a circular loss function to evaluate feature loss and constrain the per-point feature descriptors training for 3D point cloud. Its definition is as follows:
Where, \({d}_{i}^{j}\) represents the Euclidean distance between features, \({d}_{i}^{j}={\Vert {f}_{{p}_{i}}-{f}_{{q}_{j}}\Vert }_{2}\). εp and εn respectively represent the matching and unmatching points of the point set PRS (random sampling points of the source point cloud), which correspond to the positive and negative areas, respectively. Δp and Δn represent positive and negative regions, and λ is a predefined parameter. Similarly, the feature loss \({{\mathcal{L}}}_{FL}^{P}\) of the target point cloud is calculated in the same way. The total feature loss is given by \({{\mathcal{L}}}_{FL}=\frac{1}{2}({{{\mathcal{L}}}_{FL}}^{P}+{{\mathcal{L}}}_{FL}^{Q})\).
Overlap Loss: We use a binary cross-entropy loss function for supervised training, defined as follows:
Where, \({O}_{{p}_{i}}^{label}\) represents the overlapping mark of ground truth at point pi, which is defined as follows:
Where \({T}_{P,Q}^{GT}\) represents the ground truth rigid transformation between the overlapping point cloud, and NN represents the nearest neighbor. τ1 is the overlap threshold. Similarly, the overlap loss \({{\mathcal{L}}}_{OL}^{Q}\) of the target point cloud is calculated in the same way. The total overlap loss is defined as \({{\mathcal{L}}}_{OL}=\frac{1}{2}({{\mathcal{L}}}_{OL}^{P}+{{\mathcal{L}}}_{OL}^{Q})\).
Matching loss: For any point pi in the source point cloud, a corresponding feature can be found at point qi in the target point cloud, indicating that pi and qi form a pair of matching points. To handle the sparsity of ground truth points after downsampling, we use a matching loss function to address this issue.
Where, \({M}_{{p}_{i}}^{label}\) represents the ground truth label of the registration point pi, defined as follows:
Where, τ2 represents the overlap threshold. Similarly, the matching loss \({{\mathcal{L}}}_{ML}^{Q}\) of the target point cloud is calculated in the same way. The total matching loss is given by \({{\mathcal{L}}}_{ML}=\frac{1}{2}({{\mathcal{L}}}_{ML}^{P}+{{\mathcal{L}}}_{ML}^{Q})\).
In summary, the overall loss function is \({\mathcal{L}}={{\mathcal{L}}}_{FL}+{{\mathcal{L}}}_{OL}+{{\mathcal{L}}}_{ML}\).
Ethics approval and consent to participate
Written informed consent has been obtained from the School of Information Science and Technology of Northwest University and all authors for this article, and consent has been obtained for the data used.
Results
Dataset, Implementation Details and Evaluation Metrics
To evaluate the effectiveness of the proposed algorithm in handling issues such as low-overlap, generalization, and large-scale scenes, we conducted extensive experiments on various datasets, including 3DMatch27 and 3DLoMatch31 for indoor real scenes, and Odometry KITTI28 for outdoor large-scale scenes, and validated it on various cultural heritage datasets, including the Terracotta Warriors and WHU-TLS29.
3DMatch: The 3DMatch dataset comprises depth images from 62 different scenes collected from datasets like 7-Scenes and SUN3D. These scenes encompass various types such as houses, buildings, etc. Among these, 46 scenes are used for training, 8 for validation, and another 8 for testing. 3DLoMatch is a dataset derived from the 3DMatch dataset. Notably, the overlap ratio for 3DMatch and 3DLoMatch datasets is greater than 30 % and between 10 % to 30 %, respectively.
Odometry KITTI: The Odometry KITTI dataset is captured in real-time using the Velodyne HDL-64E S3 LiDAR scanner, covering urban, rural, and highway environments across 11 large scenes. The dataset is split into 0-5 scenes for training, 6-7 for validation, and 8-10 for testing.
Terracotta Warriors: The Terracotta Warriors dataset contains three-dimensional scans of the Terracotta Warriors excavated from the mausoleum of the First Emperor of China, Qin Shi Huang. These data encompass various quantities and types of Terracotta Warriors, including soldiers, chariots, and horses.
WHU-TLS: The WHU-TLS ancient architecture dataset was acquired using a RIEGL VZ-400 laser scanning system and a 5D Mark II camera. It consists of 9 sites and approximately 240 million points. The dataset includes unstructured features such as eaves and tiles, making it suitable for 3D model reconstruction of ancient buildings and digital preservation of cultural heritage.
Implementation Details: Our algorithm is deployed on a system with an NVIDIA RTX 4090 GPU, an Intel(R) Core(TM) i7-13700KF CPU @ 3.40GHz, and 128GB RAM, running on a Windows 10 operating system. We use PyTorch for training.
Evaluation Metrics: Following the metrics used in Predator31, REGTR24, and GMCNet34, we evaluate the datasets using Relative Rotation Error (RRE) and Relative Translation Error (RTE). Additionally, we use Registration Recall (RR) to evaluate the 3DMatch dataset, The definitions of RRE and RTE are as follows:
Where, RGT and tGT represent the ground truth rotational error and translational error, respectively.
Registration recall(RR) is defined as the root mean square error of the transformation being less than 0.2 m. The formula is shown below:
Where, \({C}_{ij}^{GT}\) represents the set of ground truth correspondences.
For Terracotta Warriors dataset, we use Chamfer Distance (CD) and Hausdorff Distance (HD) evaluate, The definitions of CD and HD are as follows:
3DMatch and 3DLoMatch
To validate the registration performance of the proposed algorithm under low-overlap scenarios, we followed the training methodology of the Predator approach and conducted validation on the 3DMatch and 3DLoMatch datasets. Additionally, we compared the proposed algorithm against other state-of-the-art methods, including FCGF18, D3Feat30, Predator31, OMNet35, REGTR24, GeoTrans36, RoReg37, UDPReg38, MAC39, and RIGA26. Figure 3 shows the registration visualization of the 3DMatch and 3DLoMatch datasets, respectively.

3DMatch example shows accurate alignment of overlapping fragments, 3DLoMatch example demonstrates performance under low-overlap.
From Table 1, it can be observed that our proposed algorithm outperforms other methods in terms of registration results. When compared to UDPReg, RoReg, and RIGA algorithms, our proposed algorithm demonstrates improvements of 11 %, 4.1 %, and 11.2 % respectively in the RR metric for scenarios with low-overlap. In terms of time complexity, our algorithm demonstrates excellent performance in handling data of different scales. Compared to RoReg, GeoTrans, Predator, and D3Feat, our algorithm reduces the Time metric by 2.52 s, 0.08 s, 0.39 s, and 0.25 s respectively in low-overlap scenarios.
Odometry KITTI
To verify the registration performance of our proposed algorithm in large-scale scenes, we adopted the training methodology of the Predator approach. We then conducted validation on the outdoor Odometry KITTI dataset, which represents significant environments. Furthermore, we compared our proposed algorithm against other advanced methods, including FCGF18, D3Feat30, Predator31, SpinNet40, HRegNet41, GeoTrans36, SHMDGR42, GeDi43, MAC39, SC2 -PCR++44, RNC20 and RIGA26. Figure 4 shows the registration visualization of the Odometry KITTI datasets.

Visualizations show registration results under straight-road frame alignment and curved-road frame alignment.
From Table 2 and Fig. 4, it is evident that our proposed algorithm achieves superior registration results on the Odometry KITTI dataset compared to other methods. Through comparison with the performance of other algorithms, our proposed method demonstrates a distinct advantage in addressing point cloud registration tasks in large-scale scenes.
Terracotta Warriors
To validate the accuracy and generalization ability of our algorithm on the Terracotta Warriors dataset, we used real-world fragments collected from the Mausoleum of the First Qin Emperor. This dataset offers a rich variety of cultural heritage point cloud samples, including fragments of different parts such as the head, upper body, arms, legs, and lower body. In addition, we compared our proposed algorithm with other advanced methods, including D3Feat30 and Predator31.
As shown in Table 3, our proposed method demonstrates superior registration performance on the Terracotta Warriors dataset compared to methods D3Feat and Predator. Specifically, in terms of evaluation metrics, our method achieves the best results in both Chamfer Distance (CD) and Hausdorff Distance (HD). The CD value of 0.0066 is significantly lower than that of D3Feat (0.0089) and Predator (0.0081), indicating a smaller average distance between point clouds and thus higher registration accuracy. Additionally, the HD value of 0.2814 is also better than those of the other methods, suggesting reduced worst-case alignment error. These results strongly validate the robustness and accuracy of our algorithm in complex cultural heritage scenarios.
In the experiment, we evaluated the performance of the algorithm by conducting registration tests on partial and complete Terracotta Warrior models and visualizing the data. Figures 5 and 6 show the registration results of different fragments, while Fig. 7 illustrates the registration visualization of the entire Terracotta Warrior model. The registration results demonstrate that our method effectively aligns fragments of the Terracotta Warriors and maintains geometric consistency even in areas of low-overlap. This indicates that our method has good applicability and robustness in handling complex heritage data such as the Terracotta Warriors.

It presents the registration results of the front and back sides of different parts, mainly including small fragments of the head, upper body, and lower body.

It presents the registration results of the front and back sides of different parts, mainly including large fragments of the arm, upper body, and leg.

It presents the registration results of the front and back sides of entire parts, mainly including large fragments of the arm and leg.
Terracotta Warriors and similar relic fragments often exhibit wear, missing parts, and other issues due to prolonged burial, resulting in low-overlap between point cloud data and significant morphological differences between fragments. Under these conditions, traditional methods often produce noticeable errors at edges and in local details. The CDMCT method enhances the model’s perception of local geometric information through multi-channel dynamic encoding, maintains global structural consistency through a cross-domain convergence network, and adapts to local feature variations with the graph network. CDMCT provides an effective tool for 3D digital preservation in the field of archaeology, supporting the refined restoration and digital preservation of relics and offering promising potential for broader application in the preservation of cultural heritage.
WHU-TLS
To further validate the generalization capability of our proposed algorithm, we used real-world cultural heritage building data from the WHU-TLS dataset. This dataset contains high-precision point cloud data of multiple ancient buildings, covering complex geometries and large-scale scenes, with significant diversity and complexity.
Figures 8 and 9 show the application of our algorithm in independent experiments, including the registration of point cloud data for main gate and the both sides of the ancient building. Specifically, the registration of the main gate requires handling more geometric details and structural complexity, while the registration of the sides involves larger-scale geometric scenes. The results indicate that the algorithm not only accurately aligns the geometric shapes of different parts of the building but also maintains structural consistency, particularly in regions with low-overlap, successfully achieving global geometric alignment. This demonstrates that our method can address geometric differences between different data sources and maintain accurate perception of global structure.

It presents the registration results of No. 6 and No. 7, as well as No. 4 and No. 5 for main gate.

It presents the registration results of No. 8 and No. 9, as well as No. 2 and No. 1 for both sides.
Figure 10 shows the overall digital model of the WHU-TLS ancient building. It is evident that the algorithm successfully handles point cloud registration in large-scale scenes and can effectively merge point cloud data from different sources to construct a high-precision and detailed digital model. This performance is achieved thanks to the innovative modules introduced in our method, including multi-channel dynamic encoding and cross-domain convergence networks, which enable the model to process diverse geometric structures while maintaining global consistency.

It presents the overall modeling result of the nine fragmented parts.
In light of the demands of cultural heritage digitization, the results of this experiment demonstrate the versatility of our algorithm when faced with complex and fragmented cultural heritage data. For large-scale architectural digital modeling, the CDMCT method provides reliable and accurate results, offering strong support for the preservation and restoration of cultural heritage.
Ablation Study
To validate the effectiveness of the individually selected modules in our model, we conducted ablation experiments on the 3DMatch and 3DLoMatch datasets.
From Table 4, it can be observed that all the proposed modules contribute to improving the registration accuracy of point cloud to varying degrees. In particular, compared to using only the Cross-domain Convergence Network (CC-Net), combining it with Multi-Channel Dynamic Encoding (MCDE) reduces the Relative Rotation Error (RRE) from 1.633° to 1.523° and the Relative Translation Error (RTE) from 0.057 m to 0.041 m on the 3DMatch dataset. On the more challenging 3DLoMatch dataset, the Registration Recall (RR) increases by 1.4 percentage points to 75.3 %, demonstrating the enhanced robustness of this module in low-overlap scenarios. In addition, the introduction of Multi-Channel Angle Encoding (MAE) also yields stable improvements, indicating that angular information serves as a valuable supplement for structurally complex targets. This performance enhancement is mainly attributed to the integration of MCDE on top of the original cross-domain convergence attention module, which effectively improves the algorithm’s sensitivity to local structural and angular variations. Moreover, the inclusion of local information within the attention mechanism also positively contributes to the overall performance of the algorithm.
Robustness Study
To assess the model’s robustness performance, we conducted noise experiments based on the indoor 3DMatch and 3DLoMatch datasets, as well as the outdoor Odometry KITTI dataset.
As shown in Table 5 and Fig. 11, the proposed CDMCT algorithm demonstrates strong robustness when subjected to varying levels of noise interference, both in indoor datasets (3DMatch and 3DLoMatch) and in the large-scale outdoor Odometry KITTI dataset.

a Comparison of RRE under different noise levels (b). Comparison of RTE under different noise levels.
In the indoor datasets, when the noise level increases from 0.005 to 0.04, the registration recall (RR) of CDMCT decreases by only about 1.8 % (from 94.1 % to 92.3 %), which is significantly better than methods such as D3Feat and Predator. Under the same noise variation, Predator’s performance drops by 3.6 %, while D3Feat sees a larger decline of 5.0 %. On the more challenging 3DLoMatch dataset, CDMCT also outperforms both Predator and D3Feat significantly in terms of RR.
Furthermore, as illustrated in Fig. 11, the relative rotation error (RRE) experiments on the Odometry KITTI dataset show that CDMCT maintains an RRE below 0. 4° across noise levels ranging from 0.1 to 0.5, whereas the RRE of Predator exceeds 0. 5°, indicating that CDMCT is more resilient to noise in large-scale scenes. Similarly, in terms of relative translation error (RTE), CDMCT consistently stays within the 6-8 cm range, while Predator exceeds 9 cm, further highlighting its instability under noisy conditions.
In summary, CDMCT exhibits excellent robustness and stability across diverse datasets, maintaining high registration accuracy even in low-overlap, complex, or high-noise scenarios, thereby validating its broad applicability and reliability in real-world applications.
Discussion
The proposed cross-domain multi-channel Transformer point cloud registration method (CDMCT) is designed to address common challenges in cultural heritage scenarios, such as low-overlap, partial data loss, large-scale scenes, and cross-domain generalization difficulties. It is particularly suitable for representative cultural heritage datasets such as the Terracotta Warriors and WHU-TLS ancient buildings.
In terms of multi-channel dynamic encoding, we introduce multi-channel angular relationship modeling, which leverages ternary angular positional encoding and dynamic weighting mechanisms to enhance the model’s sensitivity to complex local structures. In our experiments, the Terracotta Warriors dataset includes numerous curved surfaces, fine decorative details, and damaged cracks and features that traditional methods struggle to align accurately. CDMCT achieves high-precision registration on datasets, achieving the best performance in terms of Chamfer Distance and Hausdorff Distance, which validates the effectiveness and adaptability of the multi-channel dynamic encoding in handling complex surface structures in cultural heritage.
The cross-domain convergence network integrates the global modeling capabilities of Transformer with the local topological representation strength of graph neural networks. On one hand, it preserves the global spatial relationships between point clouds. On the other, it enhances robustness to local feature variations. In the cultural heritage domain, such a combination is uncommon, as most existing methods struggle to simultaneously maintain global consistency and handle local incompleteness. Our experiments on the WHU-TLS dataset demonstrate that CDMCT maintains high-quality registration even in the presence of occlusions and missing scans, indicating its clear advantages in complex heritage scenarios.
CDMCT is trained on public general-purpose datasets such as 3DMatch and KITTI and is validated on cultural heritage datasets. This choice is based on two considerations: first, heritage data are expensive to obtain, small in scale, and difficult to annotate, making them unsuitable for large-scale training; second, we aim to evaluate the model’s zero-shot cross-domain generalization to improve its practicality. Experimental results show that CDMCT achieves strong registration performance on previously unseen heritage datasets, demonstrating good domain transfer capability. However, this strategy has its limitations, as the model may not fully adapt to some extreme structural features. In future work, we plan to fine-tune the model with a small amount of heritage-specific data to further enhance its adaptability to cultural heritage scenarios.
In conclusion, the CDMCT method not only incorporates multi-channel geometric modeling and cross-domain structural fusion mechanisms tailored to the complexities of cultural heritage, but also demonstrates strong practicality and robustness through validation on representative datasets. It offers a promising solution for heritage point cloud registration with both strong performance and application value.
Data Availability
The data will be available upon reasonable request.
References
Wang, M., Chen, G., Yang, Y., Yuan, L. & Yue, Y. Point tree transformer for point cloud registration. IEEE Trans. Circuit. Syst. Video Technol. 35, 6756–6772 (2025).
Fu, S. et al. Modified lshade-spacma with new mutation strategy and external archive mechanism for numerical optimization and point cloud registration. Artif. Intel. Rev. 58, 72 (2025).
Markiewicz, J., Kot, P., Markiewicz, Ł. & Muradov, M. The evaluation of hand-crafted and learned-based features in terrestrial laser scanning-structure-from-motion (tls-sfm) indoor point cloud registration: the case study of cultural heritage objects and public interiors. Heritage Sci. 11, 254 (2023).
Liu, S., Mohd Jaki, B. M., Huang, Y., Dong, M. & Liu, Q. Multiscale hierarchy denoising method for heritage building point cloud model noise removal. NPJ Heritage Sci. 13, 199 (2025).
Chen, J. et al. High precision 3d reconstruction and target location based on the fusion of visual features and point cloud registration. Measurement 243, 116455 (2025).
Wu, P. et al. Spiking point transformer for point cloud classification. Artif. Intel. 39, 21563–21571 (2025).
Yan, X. et al. Adversenet: A unified lidar point cloud denoising network for autonomous driving in adverse weather. IEEE Sensors J. 25, 8950–8961 (2025).
Han, R. et al. Neupan: Direct point robot navigation with end-to-end model-based learning. IEEE Trans. Robot. 41, 2804–2824 (2025).
Wang, Y., Zhou, P., Geng, G., An, L. & Zhou, M. Enhancing point cloud registration with transformer: cultural heritage protection of the terracotta warriors. Heritage Sci. 12, 314 (2024).
Yue, Y. et al. Edgeregnet: Edge feature-based multimodal registration network between images and lidar point clouds. arXiv https://doi.org/10.48550/arXiv.2503.15284 (2025).
Leahy, J., Jabari, S., Lichti, D. & Salehitangrizi, A. Enhancing cross-modal camera image and lidar data registration using feature-based matching. Remote Sens. 17, 357 (2025).
Hu, Y., Li, B., Xu, C., Saydam, S. & Zhang, W. Featsync: 3d point cloud multiview registration with attention feature-based refinement. Neurocomputing 600, 128088 (2024).
Li, M., Liu, H., Xie, F. & Huang, H. Point cloud-based end-to-end formation control using a two stage sac algorithm. IEEE Robot. Autom. Lett. 10, 2319–2326 (2025).
Jiang, L., Liu, Y., Dong, Z., Li, Y. & Lin, Y. Lightweight deep learning method for end-to-end point cloud registration. Graphical Models 137, 101252 (2025).
Huang, X. et al. Unsupervised point cloud registration by learning unified gaussian mixture models. IEEE Robot. Autom. Lett. 7, 7028–7035 (2022).
Wang, H. et al. Robust multiview point cloud registration with reliable pose graph initialization and history reweighting. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9506–9515 (IEEE, 2023).
Kim, J., Kim, J., Paik, S. & Kim, H. Point cloud registration considering safety nets during scaffold installation using sensor fusion and deep learning. Autom. Construct. 159, 105277 (2024).
Choy, C., Park, J. & Koltun, V. Fully convolutional geometric features. In Proc. IEEE/CVF international conference on computer vision, 8958–8966 (IEEE, 2019).
Yuan, M., Huang, X., Fu, K., Li, Z. & Wang, M. Boosting 3d point cloud registration by transferring multi-modality knowledge. In 2023 IEEE International Conference on Robotics and Automation (ICRA), 11734–11741 (IEEE, 2023).
Yuan, M. et al. Robust point cloud registration via random network co-ensemble. IEEE Trans. Circuits Syst. Video Technol. 34, 5742–5752 (2024).
Wu, X. et al. Point transformer v3: Simpler faster stronger. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4840–4851 (IEEE, 2024).
Chen, Z. et al. Vision transformer adapter for dense predictions. arXiv https://doi.org/10.48550/arXiv.2205.08534 (2023).
Lu, Y. et al. Transflow: Transformer as flow learner. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 18063–18073 (IEEE/CVF, 2023).
Yew, Z. J. & Lee, G. H. Regtr: End-to-end point cloud correspondences with transformers. arXiv https://doi.org/10.48550/arXiv.2205.08534 (2022).
Yuan, Y. et al. Egst: Enhanced geometric structure transformer for point cloud registration. IEEE Transactions on Visualization and Computer Graphics, 6222−6234 (2023).
Yu, H. et al. Riga: Rotation-invariant and globally-aware descriptors for point cloud registration. IEEE Transactions on Pattern Analysis and Machine Intelligence, 3796−3812 (IEEE, 2024).
Zeng, A. et al. 3dmatch: Learning local geometric descriptors from rgb-d reconstructions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 199−208 (IEEE, 2017).
Geiger, A., Lenz, P. & Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, 3354−3361 (IEEE, 2012).
Yang, B., Han, X. & Dong, Z. Point cloud benchmark dataset whu-tls and whu-mls for deep learning. J. Remote Sens 25, 231–240 (2021).
Bai, X. et al. D3feat: Joint learning of dense detection and description of 3d local features. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 6359–6367 (2020).
Huang, S., Gojcic, Z., Usvyatsov, M., Wieser, A. & Schindler, K. Predator: Registration of 3d point clouds with low overlap. In Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, 4267–4276 (2021).
Fischler, M. A. & Bolles, R. C. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 24, 381–395 (1981).
Thomas, H. et al. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 6411–6420 (IEEE, 2019).
Pan, L., Cai, Z. & Liu, Z. Robust partial-to-partial point cloud registration in a full range. IEEE Robot. Autom. Lett. 9, 2861–2868 (2024).
Xu, H., Liu, S., Wang, G., Liu, G. & Zeng, B. Omnet: Learning overlapping mask for partial-to-partial point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 3132–3141 (IEEE, 2021).
Qin, Z. et al. Geometric transformer for fast and robust point cloud registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11143–11152 (IEEE/CVF, 2022).
Wang, H. et al. Roreg: Pairwise point cloud registration with oriented descriptors and local rotations. IEEE Trans. Pattern Anal. Mach. Intell. 45, 10376–10393 (2023).
Mei, G. et al. Unsupervised deep probabilistic approach for partial point cloud registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13611–13620 (IEEE, 2023).
Zhang, X., Yang, J., Zhang, S. & Zhang, Y. 3d registration with maximal cliques. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 17745–17754 (IEEE, 2023).
Ao, S., Hu, Q., Yang, B., Markham, A. & Guo, Y. Spinnet: Learning a general surface descriptor for 3d point cloud registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11753–11762 (IEEE, 2021).
Lu, F. et al. Hregnet: A hierarchical network for large-scale outdoor lidar point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 16014–16023 (IEEE, 2021).
Zhang, Z. et al. End-to-end learning the partial permutation matrix for robust 3d point cloud registration. In Proceedings of the AAAI Conference on Artificial Intelligence, 3399–3407 (AAAI, 2022).
Poiesi, F. & Boscaini, D. Learning general and distinctive 3d local deep descriptors for point cloud registration. IEEE Trans. Pattern Anal. Mach. Intell. 45, 3979–3985 (2022).
Chen, Z., Sun, K., Yang, F., Guo, L. & Tao, W. Sc2-pcr++: Rethinking the generation and selection for efficient and robust point cloud registration. IEEE Trans. Pattern Anal. Mach. Intell. 45, 12358–12376 (2023).
Acknowledgements
This research was funded by the National Natural Science Foundation of China: 62571051, 62271393. National Social Science Fund Art Major Project: 24ZD10. Technology Innovation Leading Project of Shaanxi(2024QY-SZX-11). National Science and Technology Support Program: 2023YFF0906504. Xi'an Science and Technology Plan Project: 24SFSF0002.
Author information
Authors and Affiliations
Contributions
Pengbo Zhou: Conceptualization, Methodology, Resources, Writing, original draft preparation, Writing, review and editing.Li An: Writing, review and editing, Writing, review and editing, Visualization.Yong Wang:Methodology, Writing, review and editing, Visualization.Guohua Geng: Conceptualization, Methodology, original draft preparation.Yang Xu: Resources, Writing-review and editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhou, P., An, L., Wang, Y. et al. Cross-Domain multi-channel transformer for point cloud registration in cultural heritage digital preservation. npj Herit. Sci. 13, 503 (2025). https://doi.org/10.1038/s40494-025-02064-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s40494-025-02064-4
