
Abstract
Eddy-resolving turbulence simulations are essential for understanding and controlling complex unsteady fluid dynamics, with significant implications for engineering and scientific applications. Traditional numerical methods, such as direct numerical simulations (DNS) and large eddy simulations (LES), provide high accuracy but face severe computational limitations, restricting their use in high-Reynolds number or real-time scenarios. Recent advances in deep learning-based surrogate models offer a promising alternative by providing efficient, data-driven approximations. However, these models often rely on deterministic frameworks, which struggle to capture the chaotic and stochastic nature of turbulence, especially under varying physical conditions and complex, irregular geometries. Here, we introduce the Conditional Neural Field Latent Diffusion (CoNFiLD) model, a generative learning framework for efficient high-fidelity stochastic generation of spatiotemporal turbulent flows in complex, three-dimensional domains. CoNFiLD synergistically integrates conditional neural field encoding with latent diffusion processes, enabling memory-efficient and robust generation of turbulence under diverse conditions. Leveraging Bayesian conditional sampling, CoNFiLD flexibly adapts to various turbulence generation scenarios without retraining. This capability supports applications such as zero-shot full-field flow reconstruction from sparse sensor data, super-resolution generation, and spatiotemporal data restoration. Extensive numerical experiments demonstrate CoNFiLD’s capability to accurately generate inhomogeneous, anisotropic turbulent flows within complex domains. These findings underscore CoNFiLD’s potential as a versatile, computationally efficient tool for real-time unsteady turbulence simulation, paving the way for advancements in digital twin technology for fluid dynamics. By enabling rapid, adaptive high-fidelity simulations, CoNFiLD can bridge the gap between physical and virtual systems, allowing real-time monitoring, predictive analysis, and optimization of complex fluid processes.
Similar content being viewed by others
Introduction
Turbulent flows, characterized by their inherent chaotic and multiscale nature, are a central subject in the study of fluid dynamics, essential for understanding phenomena in diverse areas such as aerospace, oceanography, and combustion. Traditionally, simulating these complex spatiotemporal behaviors has relied on first-principle eddy-resolving methods like Direct Numerical Simulation (DNS) and Large Eddy Simulation (LES), which require numerically solving the governing partial differential equations (PDEs) for fluid flows. While these methods offer detailed insights, their application is largely limited by significant computational demands. The fine-scale spatiotemporal resolution required by DNS and LES to accurately capture the wide range of space and time scales in turbulence structure results in substantial computational loads, making them impractical for most engineering applications.
The rapid advancements in machine/deep learning (ML/DL) have profoundly influenced computational fluid dynamics (CFD)1,2, bringing a fresh and innovative dimension to the field, marked by recent developments such as advanced DL-based discretization3,4, data-driven closure modeling5,6,7, accelerated CFD solving processes8, and the differentiable hybrid neural modeling, a framework that unifies conventional CFD and DL through differentiable programming9,10. Moreover, DL has become instrumental in developing rapid surrogate or reduced-order models, offering efficient alternatives to computationally-intensive numerical solvers for emulating complex spatiotemporal dynamics. These models, often built on autoregressive learning architectures, are adept at predicting future flow states based on previous conditions, relying on temporal correlations learned from training data. An important aspect of these models is the integration of dimensionality reduction techniques, such as Proper Orthogonal Decomposition (POD) and Convolutional Neural Network (CNN) autoencoders, with sequence neural networks, e.g., Long-short Term Memory (LSTM) and transformers. Notable examples include the convolutional autoencoder-based autoregressive learning models by Fukami and co-workers for inflow turbulence synthesis and super-resolution11,12,13, and the work of Yousif et al.14, who combined CNN autoencoders with LSTM networks, further advancing these models with adversarial training and attention mechanisms15. To effectively handle unstructured flow data within irregular domains, Graph Neural Networks (GNN)-based autoencoder coupled with temporal attention models has been proposed and shown the effectiveness16. Despite the promise, challenges remain, particularly in the turbulence regime. The deterministic nature of these ML-based surrogate models often inadequately captures the stochastic behavior inherent in turbulent flows. These models, largely relying on autoregressive architectures, are able to learn the complex distribution of turbulence, limiting their capacity to produce stochastic flow realizations. This can result in substantial deviations in long-term predictions, as the chaotic nature of turbulence magnifies the impact of even minor inaccuracies or perturbations. Furthermore, there is a risk of cumulative error propagation in these models, potentially undermining the robustness and reliability of their long-term forecasting capabilities.
Generative AI, rooted in probabilistic learning and statistical inference, offers a promising direction to overcome these limitations. These models are capable of learning the complex probabilistic distributions within datasets, allowing for the generation of new data samples that statistically resemble the training sets. In the context of turbulence simulation, generative models are particularly valuable as they can capture the multi-scale and stochastic characteristics of turbulence, thereby enabling the synthesis of instantaneous flow field realizations that align with the statistical characteristics observed in real-world turbulent data. The recent surge in deep generative models for turbulence, primarily driven by Generative Adversarial Networks (GANs), underscores their potential and promise. GANs operate through a dynamic interplay between a generator, which creates synthetic turbulent data, and a discriminator, which distinguishes between synthetic and real data. This iterative adversarial process refines the generator’s output, aiming for convergence to the actual data distribution. Variants like Wasserstein GAN (WGAN), conditional GAN (cGAN), deep convolutional GAN (DCGAN), super-resolution GAN (SRGAN), and cycle-consistent GAN (CycGAN) have been adapted for specific tasks, such as turbulence generation17,18, super-resolution19,20,21,22, and data inpainting23. However, the primary limitation of these models is their focus on single-snapshot generation, as they are trained on isolated flow snapshots without temporal coherence, which restricts their ability to synthesize spatiotemporal turbulence. Attempts to integrate GANs with sequential networks have been made, but these often result in GANs acting as deterministic encoders, not fully exploiting their stochastic generation capabilities15. Only a few studies, such as TempoGAN by Xie et al.24 and WGAN-RNN model by Kim and Lee25, have leveraged GANs for stochastic turbulence generation. While GANs have shown potential for turbulence synthesis, they often face significant challenges: their training is notoriously challenging due to the oscillatory behavior between the generator and discriminator components26. Additionally, they are susceptible to “mode collapse”, a limitation that results in a reduced diversity of output in the generated simulations27. These factors critically impede their efficacy in accurately modeling complex turbulent dynamics. In addition to GANs, normalizing flows (NFlows) have also been explored for turbulence generation. These models stand out for their ability to directly model complex data distributions through a series of invertible, differentiable transformations, which is particularly useful in emulating intricate dynamics like turbulence. Geneva and Zabaras28 have utilized NFlows for super-resolving Very Large Eddy Simulation data, and Sun et al.29 developed a sequential NFlows model integrating GNN-autoencoding and attention mechanism to synthesize instantaneous backward-facing-step flows. However, NFlows have the known scalability issue due the complexity of computing Jacobians in transformations, making them infeasible to handle real-world turbulence data.
Diffusion models have recently advanced the field of generative modeling, outperforming GANs and NFlows in a variety of computer vision tasks30,31,32. These models are uniquely characterized by their progressive approach of transforming data from a simple distribution into a complex one. This is achieved by initially introducing noise into the dataset and then systematically denoising it through deep neural networks (DNNs). There are two primary categories of diffusion models: denoising diffusion probabilistic models (DDPMs)33 and score-based diffusion models34, both of which can be unified within the stochastic differential Equation (SDE)-based framework35. The advantages of diffusion models are manifold, including the ease of training, the capability of capturing multi-scale features, and their proficiency in conditional generation, particularly within a Bayesian framework. While diffusion models have recently shown significant success in fields like image generation and super-resolution30,36, their application in turbulence simulation represents an emerging and largely uncharted domain. Recent studies have explored the use of DDPMs in super-resolution or inpainting of turbulence data37,38,39. However, these initial works mainly focused on single-snapshot generations, typically in 2D Komogrov flows, homogenous and isotropic in nature. Most recently, Gao et al.40 have taken a leap forward with the development of a Bayesian conditional diffusion model for spatiotemporal turbulence generation. This model has showcased its capability to stochastically generate the temporal evolution of complex, wall-bounded turbulence in a variety of conditions, including URANS super-fidelity, auto-regressive generation, and super-resolution generation. However, the foundational architecture of this model, VideoDiffusion41, utilizes 3D convolution in physical spatiotemporal space, encountering scalability and efficiency challenges. This limitation confines its application to small-scale 2D spatial fields with a limited temporal extent of the generated segments. Furthermore, the model’s backbone architecture, a CNN-based 3D U-Net, inherently requires regular domains with uniform grids, posing a limitation in handling complex, irregular geometries with unstructured grids, which are prevalent in CFD, thereby restricting its adaptability to a broader range of real-world turbulence simulation scenarios.
In this work, we proposed a conditional neural field latent diffusion (CoNFiLD) model, designed for efficiently generating complex spatiotemporal dynamics of chaotic and turbulent systems across diverse conditions, addressing both regular and irregular geometrical configurations. Distinct from the majority of existing literature that focuses on single-snapshot (image) generation, CoNFiLD emphasizes capturing the probabilistic distribution of time-evolving turbulent flow sequences, operating as a sophisticated stochastic spatiotemporal process, allowing for an effective generation of new instantaneous flow realizations through random sampling under a variety of conditions. The proposed model synergistically integrates conditional neural field (CNF) techniques with a latent probabilistic diffusion model, enabling forward and reverse diffusion process being operated in the CNF-encoded latent space. This innovative architecture leverages the advantage and effectiveness of CNF for meshless nonlinear dimension reduction, which have been demonstrated in recent literature42,43, ensuring robust performance in diverse geometrical configurations and scalable applications. By significantly improving the scalability and efficiency of both offline training and online generation, this work overcomes the limitations of the previous model: scalability constraints and uniform grid requirements40. Moreover, the proposed CoNFiLD is also featured for its zero-shot conditional generation by leveraging the Bayesian formulation and differentiable programming, thereby eliminating the need for retraining when adapting to new flow conditions. The generative learning capability of our CoNFiLD model has been showcased through its application to a wide range of real-world 3D turbulent flow cases, including scenarios with wall-bounded turbulence, flow separations, and intricate 3D geometries. Remarkably versatile, the unconditionally trained CoNFiLD model can be directly applied for conditional generation tasks without the need of re-training. These applications span from reconstructing full-field spatiotemporal flows from sparse sensor data to generating super-resolution spatiotemporal flows and restoring corrupted flow data. This work represents a significant contribution to the field of spatiotemporal generative modeling and turbulence simulation, offering a comprehensive and efficient solution for generating realistic, complex instantaneous turbulent flows in various scenarios. To the best of the authors’ knowledge, this study represents the first development of a neural field encoded latent diffusion model for the 4D (i.e., 3D spatial and 1D temporal) generation of spatiotemporal dynamics in chaotic and turbulent systems with complex, irregular domains.
The remainder of this paper is structured as follows: Section 2 provides an overview of the proposed CoNFiLD framework and a comprehensive set of numerical experiments to evaluate and demonstrate CoNFiLD’s generative capabilities across various wall-bounded turbulence scenarios. The computational efficiency, memory usage, and scalability comparisons of CoNFiLD with other methodologies are discussed in Section 3. Section 4 elaborates on the proposed CoNFiLD method and its implementation details.
Results
Overview of CoNFiLD generative learning framework
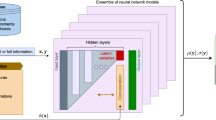
Turbulent flows, inherently chaotic and stochastic across various spatial and temporal scales, fundamentally represent stochastic spatiotemporal processes. The work aims to construct a data-driven model capable of generating unsteady instantaneous turbulent flows. This is achieved through generative AI techniques designed to learn the underlying probability distribution \(p\left({{\mathbf{\Phi }}}({{\bf{x}}},t)\right)\) of the spatiotemporal turbulent flow fields Φ(x, t) from instantaneous flow datasets \({{\mathbf{\Phi }}}({{\bf{x}}},t)\in {{{\mathcal{A}}}}_{train}\). To this end, we present the Conditional Neural Field Latent Diffusion (CoNFiLD) model, a generative learning framework that leverages neural implicit representations to facilitate efficient and scalable diffusion-based generation within a compact latent space. As depicted in Fig. 1, our CoNFiLD features a unique combination of Conditional Neural Field (CNF) and Latent Diffusion Models (LDM), distinguishing it from prior work that applied diffusion processes directly in the high-dimensional physical domain, which encounters significant computational hurdles and memory constraints40. Schematics for CNF and LDM modules are provided in the Figs. S1 and S2 respectively. Specifically, the CoNFiLD model is constructed in three stages.

a Architectures: a FiLM-based CNF for encoding dynamic flow sequences into latent space, where the underlying distribution of the latent vectors is implicitly captured by learning reverse diffusion (denoising) processes. b Zero-shot generation: synthesizing new spatiotemporal flow fields with arbitrary length, either unconditionally or based on specific conditions (e.g., sparse sensor data), without the need for retraining.
First, a CNF, \({{{\mathscr{E}}}}_{\zeta,\gamma }({{\bf{X}}},{{\bf{L}}})\), is designed to encode a time sequence of instantaneous flow fields, discretized as \(\Phi ({{\bf{x}}},t)\in {{\mathbb{R}}}^{{N}_{m}\times {N}_{t}}\), into a time sequence of latents \({{{\bf{z}}}}_{0}\in {{\mathbb{R}}}^{{N}_{l}\times {N}_{t}}\), where ζ, γ are trainable parameters of the CNF encoder, and Nm, Nl, Nt represent the dimensions of spatial space, latent space, and time length, respectively. Once trained, the CNF forms a neural implicit representation of the spatiotemporal flow field conditioned on the latent vector L = z0, i.e., \({{\mathbf{\Phi }}}({{\bf{x}}},t)\approx {{{\mathscr{E}}}}_{{\zeta }^{*},{\gamma }^{*}}({{\bf{X}}},{{\bf{L}}})\). Unlike conventional encoders, the CNF encoder here is formulated in an auto-decoding fashion44, where the latents L are optimized by minimizing the mismatch between the field of interest values and corresponding CNF outputs,
In practice, all the snapshots {Φ(: , ti)}, i ∈ [1, …, Nt] are encoded into latent vectors \({\{{{{\bf{z}}}}_{0}(:,{t}_{i})\}}_{1}^{{N}_{t}}\) simultaneously, forming a latent-time snapshot z0 as a 2D “image".
Following the encoding phase, a probabilistic diffusion module is introduced to implicitly learn the underlying probability distribution p(z0) of the latent dynamics z0 through bi-direction diffusion processes. Initially, the latent samples undergo a forward Markovian diffusion process, characterized by a series of carefully designed white noise additions that incrementally nudge the latent representations towards the fully perturbed state with an isotropic Gaussian distribution. Subsequently, by learning the reverse diffusion process (i.e., denoising process) through neural networks, the model is capable of generating new latent samples z0 from randomly sampled white noises using the learned denoising scheme.
Finally, the newly generated latents \({{{\bf{z}}}}_{0}\in {{{\mathcal{L}}}}_{test}\) is fed into the trained CNF to decode them back to the physical space for obtaining the synthesized spatiotemporal flow fields \({{\mathbf{\Phi }}}({{\bf{x}}},t)\in {{{\mathcal{A}}}}_{test}\) (see Fig. 1),
The much higher data compression ratios of the CNF-based encoder, compared to other encoding methods, allow the generative model to operate in a significantly reduced-dimensional latent space, which addresses the computational challenges in synthesizing large-scale, high-dimensional spatiotemporal turbulence data. Moreover, the CNF’s ability to process arbitrary point queries significantly enhances the model’s versatility in managing irregular domains and adaptive meshes. The training of the CoNFiLD model unfolds in a decoupled two-step strategy: firstly, the CNF encoder is trained to transform spatiotemporal flow fields into latent representations; this is followed by the diffusion model being trained on these representations. This dual-phase training strategy facilitates efficient utilization of the latent space and enables robust model optimization and inference.
Upon completing its training, the CoNFiLD model can rapidly generate new 4D spatiotemporal flow samples, \({{\mathbf{\Phi }}}\in {{\mathbb{R}}}^{{N}_{m}\times {N}_{T}}\). Notably, the length NT of the generated time sequences can significantly exceed the length Nt of those used during training (NT > Nt). This capability is achieved through the shift-invariance property of the convolution kernels learned in the latent space, where the latent diffusion model can synthesize arbitrarily extended sequences of latent vectors, which are then decoded into spatiotemporal flow fields with extended time horizon. Additionally, this “one-shot” approach can be combined with an autoregressive conditional generation method, allowing us to generate very long spatiotemporal sequences without being constrained by GPU memory limitations. Another distinctive feature of CoNFiLD is its zero-shot conditioned generation capability, which enables the creation of 4D flow realizations under specific conditions (e.g., sparse sensor measurements, low-resolution data) without the need for retraining the model. Unlike traditional conditional generative methods, which require conditionally paired training data and necessitate retraining for new conditions, CoNFiLD’s diffusion process is trained unconditionally only once and can then generate samples under a variety of conditions during inference. As shown in Fig. 1, this novel feature holds significant practical value, finding applications in a range of inverse problems, such as spatiotemporal super-resolution of flow data (super-resolution), full-field reconstruction of instantaneous flow fields from sparse sensor measurements (flow reconstruction), and restoring missing information in damaged flow data (data restoration). The major highlights of our method include: (1) CNF-based encoding with a high compression ratio, facilitating efficient diffusion processes within the latent space; (2) the ability of CNF to process arbitrary pointwise queries, enhancing adaptability to irregular domains and enabling support for unstructured data and adaptive meshes; (3) a Bayesian conditioning sampling mechanism that allows for versatile conditional generation without the necessity for retraining; (4) significant reduction of memory usage in subsampling-based conditional generation scenarios. Note that other generative techniques, such as VAE, GAN, and NFlows, can also be used as the latent generation module in the proposed CoNFiLD framework. These CoNFiLD variants are compared in Supplementary Note 3.
To validate our model, we conduct extensive numerical experiments to assess the performance of our proposed CoNFiLD method on a variety of stochastic spatiotemporal flow generation scenarios, including irregular pipe flow with stochastic forcing, turbulent channel flow, flow over periodic hills, and wall-bounded turbulence with roughness, highlighting the model’s proficiency in navigating both regular and irregular geometries and managing scenarios with varying flow separation. For each flow case, a separate CoNFiLD model with the same setting is trained from scratch. The dynamics of these fluid flows are governed by the unsteady incompressible Navier-Stokes (NS) equations.
where u(x, t) denotes the velocity vector, p(x, t) the pressure, ν the viscosity, and f(x, t) the forcing term. We will first present the model’s capability to synthesize new 4D instantaneous flow fields across these scenarios, with a comparison against DNS references. Additionally, the trained CoNFiLD will be used for zero-shot conditional generation for various data assimilation and inverse problem applications without the need for retraining. These applications range from the full-field reconstruction of flow sequences from sparse sensor measurements to super-resolved spatiotemporal generation and turbulence data restoration. The hyperparameters chosen for each numerical experiment is provided in the Table. S1.
Unconditional generation for two dimensional irregular pipe flow with stochastic forcing
We begin with a 2D flow within an irregular pipe subject to stochastic forcing to demonstrate CoNFiLD’s capability of handling unstructured flow data with irregular geometries. This system can be described by Eq. (3) with a stochastic forcing term \({{\boldsymbol{f}}}={[{f}_{x}({{\bf{x}}},t),{f}_{y}({{\bf{x}}},t)]}^{T}\), which is governed by a stochastic diffusion equation,
where \({{\boldsymbol{\delta }}}={[{\delta }_{x},{\delta }_{y}]}^{T}\) represents a stochastic source term, with each component sampled from a standard normal distribution \({\delta }_{x},{\delta }_{y} \sim {{\mathcal{N}}}(0,1)\), and νf = 2 is the diffusion coefficient for spreading the stochastic forcing. To generate training data, DNS is conducted by solving these stochastic incompressible NS equations on a 2D irregular domain with unstructured grids (see Fig. 2(d)). The details for performing the DNS on the unstructured mesh are provided in the Table. S2. A long-span spatiotemporal flow sequence Φdns consisting of 16, 000 instantaneous flow fields of u, v, p is obtained from the DNS, subsequently partitioned into 15, 873 shorter sub-sequences \({\tilde{{{\mathbf{\Phi }}}}}_{i}\), each consisting of Nt = 128 snapshots, to assemble a dataset, of which 80% is used for training (\({{{\mathcal{A}}}}_{train}={\{{\tilde{{{\mathbf{\Phi }}}}}_{i}\}}_{i=1}^{12,698}\)) and remaining is reserved for testing purpose. The CoNFiLD is trained on \({{{\mathcal{A}}}}_{train}\) unconditionally.

a A trajectory of velocity magnitude (∥u∥) fields of the DNS data Φdns. b Three randomly generated flow sequence samples by CoNFiLD (velocity magnitude fields at selected time steps). c Comparison of the PDF of the velocity magnitude (left panel) and pressure p (right panel) between the CoNFiLD generated samples (red solid line) and the DNS labels (blue dashed line). d The irregular computational domain with unstructured grids. e, f The comparison of the time-averaged mean (e) and standard deviation over time (f) between the generated samples (left) and label data (middle), with the absolute discrepancy (right).
The results generated by the CoNFiLD model are compared with DNS references in Fig. 2. Panel (a) depicts a sequence of velocity magnitude snapshots from DNS at the 0th, 320th, 640th, 960th, and 1280th numerical time steps, showcasing the stochastic spatiotemporal dynamics through irregular vortex movement patterns over time. For comparison, three randomly generated flow sequence samples by CoNFiLD are presented in panel (b), which exhibit similar stochastic behaviors, maintaining visual and physical consistency with coherent temporal evolution and clearly defined boundary layers. Despite their similar stochastic spatiotemporal behavior, the instantaneous flow patterns differ across different generated trajectory samples and the DNS reference, highlighting CoNFiLD’s ability to capture the underlying distribution of the training dataset instead of merely replicating label data. This is further substantiated in Fig. 2(c), through a comparison of the probability density function (PDF) of velocity magnitude and pressure between the 25 CoNFiLD generated flow sequences and the DNS datasets. The PDFs of velocity magnitude (left panel) and pressure (right panel) for both CoNFiLD-generated samples (red solid lines) and DNS data (blue dashed lines) show close alignment, with only minor discrepancies observed at certain peaks of the velocity magnitude PDF. For brevity, we showcase only the contours of the instantaneous velocity magnitude along with the first and second order statistics in 2. We refer the reader to Fig. S11 for visualizing the contours of pressure. In Fig. 2e, the time-averaged velocity magnitude, \(M(x,y)=\frac{1}{{N}_{t}}{\sum }_{t=1}^{{N}_{t}}| | {{{\bf{u}}}}_{t}(x,y)| | \), derived from the CoNFiLD-generated samples is almost identical to that of the reference DNS data, with an average discrepancy value of merely 0.041, representing approximately 4% difference from the reference mean. Figure 2f presents the standard deviation of velocity magnitude over time, \(S(x,y)=\sqrt{\frac{1}{{N}_{t}}\mathop{\sum }_{i=1}^{{N}_{t}}{\left(| | {{{\bf{u}}}}_{t}(x,y)| | -M(x,y)\right)}^{2}}\), for generated samples against reference DNS data. The minimal discrepancy in standard deviation, with an absolute mean spatial discrepancy of 0.0294-approximately 8.4% of the reference, demonstrates CoNFiLD’s capability to not only generate accurate spatiotemporal samples but also effectively capture the underlying distributions.
Unconditional generation for equilibrium inflow turbulence of 3D channel flows
In this subsection, we demonstrate the CoNFiLD model on synthesizing sequences of instantaneous inlet velocity and pressure fields for 3D turbulent channel flows, highlighting its utility in generating accurate inflow turbulence boundary conditions, critical for eddy-resolving simulations. Focused on a fully-developed turbulent channel flow, governed by the incompressible NS equations with a forcing term f that simulates constant pressure gradients driving the flow, this setup ensures homogeneity in the streamwise and spanwise directions, while turbulence statistics exhibit variations only in the wall-normal direction45. Our objective here is to generate time-coherent, three-dimensional instantaneous velocity fields at the channel’s z − y cross-section (\(({{\bf{u}}}(y,z,t),p(y,z,t))=({[u(y,z,t),v(y,z,t),w(y,z,t)]}^{T},p(y,z,t)):\,\partial \Omega \times {{\mathbb{R}}}^{+}\to {{\mathbb{R}}}^{4}\)). The training data, obtained from fully-resolved DNS of a 3D turbulent channel flow at a friction Reynolds number of Reτ = 180, is sampled over a duration of four flow-through-time (Tflow) with a learning step size of \(\Delta {t}_{{{\rm{train}}}}^{+}=0.4\) that is 100 × numerical time step size δt = 0.004, exhibiting temporal correlation. The details about the numerical setup used for performing 3D channel flow DNS are provided in Table. S3. Only instantaneous velocity and pressure flow fields on one cross section Φdns of 1200 learning time steps are collected to create our dataset. The same DNS resolution is maintained, i.e., Nz × Ny = 100 × 400. The DNS flow sequence is divided into 945 shorter sub-sequences \({\tilde{{{\mathbf{\Phi }}}}}_{i}\), with each comprising Nt = 256 snapshots roughly corresponding to one Tflow. This forms a database, of which 80% is used as the training set \({{{\mathcal{A}}}}_{{{\rm{train}}}}={\{{\tilde{{{\mathbf{\Phi }}}}}_{i}\}}_{i=1}^{756}\) and the remaining 20% is reserved as the test set \({{{\mathcal{A}}}}_{{{\rm{test}}}}={\{{\tilde{{{\mathbf{\Phi }}}}}_{i}\}}_{i=1}^{189}\) in the conditional generation.
The unconditional inflow turbulence generation results of CoNFiLD are compared with DNS reference in Fig. 3, illustrating both the fidelity and diversity of the CoNFiLD-generated spatiotemporal velocity field samples. For this assessment, an ensemble of 50 flow sequences, each with 256 snapshots (equivalent to 25,600 numerical steps), was synthesized to ensure statistical convergence. Out of these, three exemplary flow sequences generated by CoNFiLD are showcased in Fig. 3b, where the stochastic behavior and vortex patterns all visually resemble those of the DNS reference in Fig. 3a, affirming the model’s fidelity in capturing the essence of turbulent flows. Notably, the individual instantiations of the generated flow fields exhibit substantial variability, showcasing a departure from the deterministic nature of neural solvers like ConvLSTM or Transformer architectures16, which are conventionally engineered to output a single deterministic realization. This comparison underscores CoNFiLD’s ability to not only capture the complex dynamics of turbulent flows but also to introduce a rich diversity in the synthesized spatiotemporal velocity field samples, a critical aspect for the realistic representation of turbulence phenomena. Due to space constraints, we omit the contours of the instantaneous pressure fields from Fig. 3, and provide these figures in Fig. S12. To further quantitatively evaluate the performance of the CoNFiLD model, we conducted a detailed analysis of the turbulence statistics across all generated flow sequence samples. As shown in Fig. 3c, the turbulence statistics obtained from our model are in good agreement with those obtained by DNS. In particular, the mean streamwise velocity profile generated by CoNFiLD (red line) accurately matches with the DNS (blue dots), reflecting the expected behavior across the linear viscous sublayer, buffer layer, and logarithmic law region. Similarly, the root-mean-square (RMS) of velocity fluctuations generated by CoNFiLD (blue dots for u, orange squares for v and green triangles for w) is in good agreement with the DNS results (blue line for u, orange line for v and green line for w). Additionally, the two-point correlation exhibits an initial decline to negative values before asymptotically approaching zero, aligning with DNS observations. In Supplementary Note 6, turbulence energy spectrum for the DNS and the synthesized flow at different wall normal locations are presented, which are in good agreement. Note that these statistics are calculated using half-channel averaging, as turbulent channel flow is symmetric with respect to the channel center. In addition, further spatial error analysis results are presented in Supplementary Note 5. While the generated flow shows slightly large discrepancies compared to DNS near the wall, most of the coherent structures captured by the model exhibit reasonably accurate statistics. This analysis demonstrates that CoNFiLD-generated flow captures the entire range of turbulence scales and structures, resembling those identified in DNS with remarkable accuracy. Notably, we didn’t find any discernible bumps and wiggling in the two point correlations of generated flow as reported in Gao et al.40, showing CoNFiLD’s superior performance compared to state-of-the-art generative methods such as the video diffusion model.

a Instantaneous streamwise velocity u obtained by DNS. b Three distinct realizations of u generated by CoNFiLD. c Analysis of turbulence statistics: Left panel displays mean streamwise velocity from CoNFiLD (blue dots) and DNS (red line). Middle panel shows root-mean-square (RMS) of velocity fluctuations from CoNFiLD (blue dots for u, orange squares for v and green triangles for w) and DNS (blue line for u, orange line for v and green line for w). Right panel presents two-point correlations of each velocity component at y+ = 150 from CoNFiLD and DNS (same legends as the middle panel). \(\overline{\square }\) indicates time-averaged quantities, while 〈□〉 denotes ensemble average across all samples. Spatial coordinates are normalized by the wall unit \({y}^{+}=\frac{y{u}_{\tau }}{\nu }\), where y is the wall normal distance, uτ is the friction velocity, and ν is the kinematic viscosity. Velocity statistics are scaled by uτ for normalization. See Supplementary Video 1 for animation.
Unconditional generation for non-equilibrium turbulence of periodic hill
In addition to the previous scenario, we further demonstrate CoNFiLD’s capability in generating spatiotemporal non-equilibrium turbulence flows through a classical periodic hill benchmark case, featuring a broad spectrum of complex flow behaviors including separation, recirculation, and reattachment. These complex turbulence phenomena are prevalent in a wide range of engineering applications, from aerospace propulsion to chemical processing, and pose significant challenges for both traditional numerical models and data-driven surrogates46. For the periodic hill case, the turbulence is statistically two-dimensional – in streamwise (x-) and wall-normal (y-) directions. Therefore, the CoNFiLD here is trained to generate time-coherent, three-dimensional instantaneous velocity fields at the x − y plane, u(x, y, t) = [u(x, y, t), v(x, y, t), w(x, y, t)]T: \({{\mathbb{R}}}^{2}\times {{\mathbb{R}}}^{+}\to {{\mathbb{R}}}^{3}\). Details about the simulation setup for this study is summarized in the Table. S4, and the computational domain is illustrated in Fig. S3. Similar to the previous example, the training data is a subset of fully-resolved 3D DNS simulation results with Reh = 2800, defined by the height h of the hill. Specifically, to manage computational costs, we first downsample the 3D DNS data over a duration of 10Tflow using a learning time step size of \(\Delta {t}_{{{\rm{train}}}}^{+}=1.9\), which consists of 300 numerical timesteps, retaining the temporal coherence. We then select three spanwise cross sections along the z axis from the downsampled data, spaced apart by a distance of \(\Delta {z}_{{{\rm{slice}}}}^{+}=112\), thereby reducing spatial correlation. Fourier Fast Transform (FFT) filter is applied to eliminate high frequencies beyond a certain threshold and reduce the spatial resolution to Nx × Ny = 88 × 133, with the threshold set by the highest frequency the downsampled mesh can represent, according to the Nyquist-Shannon sampling theorem.
This extensive flow sequence Φdns is partitioned into 2, 115 shorter sub-sequences \({\tilde{{{\mathbf{\Phi }}}}}_{i}\), each containing Nt = 256 snapshots. This forms a dataset \({\{{\tilde{{{\mathbf{\Phi }}}}}_{i}\}}_{i=1}^{2115}\), where 80% is used for training \({{{\mathcal{A}}}}_{{{\rm{train}}}}={\{{\tilde{{{\mathbf{\Phi }}}}}_{i}\}}_{i=1}^{1692}\) and 20% is reserved for testing \({{{\mathcal{A}}}}_{{{\rm{test}}}}={\{{\tilde{{{\mathbf{\Phi }}}}}_{i}\}}_{i=1}^{423}\).
The comparison of instantaneous flows unconditionally generated by CoNFiLD against the ground truth, derived from DNS data, is shown in Fig. 4, where velocity contours and turbulence statistics are analyzed. Three of the 150 CoNFiLD-generated spatiotemporal trajectories are randomly selected and presented in panel (b), each comprising a total of NT = 1024 snapshots (equivalent to 307, 200 numerical steps), against the DNS ground truth in panel (a). Note that only the first 75k steps are shown in Fig. 4 for compactness, and more generated samples with a longer temporal range are shown in Fig. S13. The comparison shows that all the CoNFiLD-generated flow samples vividly recreate similar vortex structures and flow characteristics of this non-equilibrium turbulent flow as the reference, showcasing CoNFiLD’s exceptional ability to synthesize realistic and physically accurate non-equilibrium turbulent behaviors. Similar to the prior example, each generated sample retains uniqueness while closely mimicking the physical behavior of ground truth. The physical validity of generated flows is further quantitatively evidenced by the statistical analysis presented in Fig. 4c, where the time-averaged mean flow profiles of the generated flow sequences (red lines) align closely with the labeled data (blue dots) in both streamwise and wall-normal directions. Detailed examination of the velocity profiles identifies a consistent pattern of flow separation immediately downstream of the hill (at x/h ≤ 5) across all generated samples, mirroring the DNS results. Additionally, both the generated and DNS data exhibit a clear recirculation zone between x/h = 2 and x/h = 4 with reattachment occurring around x/h = 5 ~ 5.5, where no negative mean velocity is observed. More remarkably, the Reynolds shear stress \(\langle \overline{u^{\prime} v^{\prime} }\rangle \) and turbulence kinetic energy (TKE) \(\bar{k}\) (=\(\frac{1}{2}\left(\langle \overline{u^{\prime} u^{\prime} }\rangle+\langle \overline{v^{\prime} v^{\prime} }\rangle \right)\) of the generated samples closely match those of the ground truth, with peaks observed in the free shear layer (shown in Fig. 4c). Additionally, Reynolds shear stress \(\overline{u^{\prime} u^{\prime} }\) and \(\overline{{v}^{\prime} {v}^{\prime} }\) (see Fig. S17) are in very good agreement with the ground truth. These results affirm that the turbulence synthesized by CoNFiLD faithfully replicates the statistical characteristics of the label data. Notably, conventional RANS and LES methods tend to underpredict some of these statistical metrics, especially in complex flow regimes with separations and recirculations. In contrast, CoNFiLD can accurately capture the flow statistics yet with substantially less computational cost, as further discussed in Sec. 3.

a Instantaneous velocity magnitude of the DNS flow data. b Instantaneous velocity magnitudes of three randomly generated realizations by CoNFiLD. c Turbulence statistics at selected locations from CoNFiLD (red lines) and DNS (blue dots), including the mean streamwise velocity \(\bar{u}\) (upper left), mean vertical velocity \(\bar{v}\) (upper right), Reynolds shear stress \(\overline{u^{\prime} v^{\prime} }\) (lower left), and the total turbulence kinetic energy (\(\bar{k}\)) (lower right). The spatial coordinates are normalized by the hill height h, and the statistical quantities are normalized by the bulk velocity Ub. See Supplementary Video 2 for animation.
Unconditional generation for 3D wall-bounded turbulence with wall roughness
After showcasing CoNFiLD’s effectiveness in synthesizing cross-sectional spatiotemporal turbulence, we extend its application to a more challenging scenario: the spatiotemporal generation of sophisticated instantaneous wall-bounded turbulent flows within 3D domains featuring regular wall-roughness elements. Turbulent flows over a rough surface are ubiquitous in various naval systems due to manufacturing processes or service-induced erosion and biofouling47. Different roughness conditions significantly affect near-wall turbulence structures and the transfer of scalar, momentum, and energy, impacting the safety, performance, and efficiency of marine systems. However, accurately modeling and predicting rough-wall turbulence with eddy-resolving simulations demand prohibitive computational resources, positioning CoNFiLD as a valuable alternative for fast surrogate modeling. In response, CoNFiLD is applied in this case to learn from high-fidelity DNS data, enabling the efficient generation of realistic turbulent flows over rough surfaces with significant speedup.
Specifically, our goal here is to generate time-coherent, four-dimensional realistic instantaneous velocity fields (u(x, y, z, t) = [u(x, y, z, t), v(x, y, z, t), w(x, y, z, t)]T: \(\Omega \times {{\mathbb{R}}}^{+}\to {{\mathbb{R}}}^{3}\)). The training data originates from a fully resolved 3D transient DNS of wall-bounded turbulence over cubic roughness elements, at a Reynolds number of Reh = 3200, which is based on the cube height h. Detail about the simulation setup for the 3D wall-bounded turbulence are highlighted in the Table. S5. We subsample exclusively during the fully developed phase of flow using a time step of \(\Delta {t}_{{{\rm{train}}}}^{+}=0.8\), which is 100 × the numerical timestep, to preserve temporal correlation. Due to the GPU memory limitations in our lab, the training and turbulence generation for this 3D domain focus to a sub-region. We apply the same filtering and downsampling methods as detailed in “Unconditional generation for 3D wall-bounded turbulence with wall roughness” for the 3D sub-region, resulting in a spatiotemporal flow sequences Φdns consisting of 1200 snapshots with a resolution of Nx × Ny × Nz = 32 × 34 × 62. The computational domain and the cropped sub-region are shown in the Fig. S4. This long-span sequence is partitioned into 817 shorter sub-sequences \({\tilde{{{\mathbf{\Phi }}}}}_{i}\), each consisting of Nt = 384 snapshots, to assemble the dataset \({\{{\tilde{{{\mathbf{\Phi }}}}}_{i}\}}_{i=1}^{817}\). During training, 80% of the database is used as the training set \({{{\mathcal{A}}}}_{{{\rm{train}}}}={\{{\tilde{{{\mathbf{\Phi }}}}}_{i}\}}_{i=1}^{653}\) and the remaining 20% is reserved as the test set \({{{\mathcal{A}}}}_{{{\rm{test}}}}={\{{\tilde{{{\mathbf{\Phi }}}}}_{i}\}}_{i=1}^{164}\) for conditional generation validation.
Figure 5b showcases two instances of flow generated unconditionally by CoNFiLD, encompassing 1536 learning steps, equivalent to 153,600 numerical timesteps, alongside the labeled flow trajectory depicted in Fig. 5a. Here we only show the first 25k numerical timesteps for the generated samples, the rest timesteps are illustrated in Figs. S14 and S15, respectively. These flow trajectory samples are visualized through the velocity magnitude contours and the isosurfaces of the Q criterion, providing a detailed view of the three-dimensional turbulence characteristics within the domain. Notably, our CoNFiLD accurately reproduces the large-scale vortices associated with the roughness, closely mirroring the dynamics observed in DNS. Meanwhile, noticeable differences in the small-scale vortices among the generated samples and DNS highlight CoNFiLD’s capability to capture the inherent probabilistic nature of wall-bounded turbulence. Additionally, the first- and second-order turbulence statistics of flows generated by CoNFiLD (red lines) and those obtained from DNS (blue dots) are compared in Fig. 5c, featuring both time-averaged velocity and turbulence intensity at three representative locations. The agreement of flow statistics between CoNFiLD and DNS demonstrates the model’s efficacy in vividly reproducing the instantaneous unsteady flow patterns, which preserve the accurate mean flow characteristics, indicating a successful replication of the primary flow mechanism. The results underscore the model’s proficiency in generating varied instances of wall-bounded turbulence over extended duration beyond the training scope, providing statistical and physical fidelity superior to traditional RANS or unsteady RANS, which often fails to accurately predict flow separations and reattachments around roughness elements48.

The instantaneous velocity magnitude (top) and iso-surfaces of Q-criterion (bottom) of (a) DNS and (b) two randomly generated realizations by CoNFiLD. c The turbulence statistics from CoNFiLD (red lines) and DNS (blue dots), including the time-averaged streamwise velocity \(\bar{u}\) (left), and turbulence intensity Iu (right), both above and between the roughness elements. Spatial coordinates are normalized by the height of the roughness elements, and the statistics are normalized by bulk velocity Ub. See Supplementary Video 3 for animation.
Conditional generation: flow reconstruction from sparse sensor measurements
In addition to generating diverse flow realizations that adhere to the underlying distribution learned during its training phase, the trained CoNFiLD model is also capable of producing specific flow realizations conditioned on given inputs, without the need for retraining. This feature significantly highlights our model’s versatility, enabling efficient and tailored flow predictions for various application scenarios. The following three sections will introduce three different conditional generation applications, including sensor-based flow reconstruction, flow data restoration, and super-resolved generation.
In this section, we explore the first application of significant practical importance: full-field spatiotemporal reconstruction of flow from sparse sensor data through zero-shot conditional generation, underpinned by Bayesian posterior sampling. This capability is essential across various engineering domains, where obtaining comprehensive full-field flow information is challenging due to complex setups, prohibitive computational costs, or the inherent sparsity and noise in direct measurements. Traditional approaches have primarily adopted deterministic models, incorporating dimensionality reduction techniques like POD or DNN-based autoencoders49,50,51. Although these methods have demonstrated some success in flow reconstruction, they often struggle with accuracy, robustness, and scalability, particularly in large-scale, complex turbulent flow scenarios52.
We demonstrate CoNFiLD’s sensor-based conditional generation capability on the two non-equilibrium wall-bounded turbulence cases: flow over periodic hills and wall roughness elements, as presented in “Unconditional generation for non-equilibrium turbulence of periodic hill” and “Unconditional generation for 3D wall-bounded turbulence with wall roughness”. The problem is formulated as following: placing limited number of flow sensors sparsely within the flow field simulated by DNS to collect velocity signals at different times (Ψ). These measurements serve as conditional inputs for CoNFiLD to generate full-scale spatiotemporal fields of this specific flow realization that is observed. For the periodic hill case, we randomly selected a flow sequence Φ from the test dataset (\({{\mathbf{\Phi }}}\in {{{\mathcal{A}}}}_{{{\rm{test}}}}\)) as the ground truth, containing NT = 256 snapshots, equivalent to 76, 800 numerical steps. Similarly, for the 3D wall-roughness case, the ground truth is a randomly selected test flow sequence of NT = 384, corresponding to 38,400 numerical steps. For the periodic hill and wall roughness cases, we randomly placed 10 and 100 sensors, corresponding to 0.1% and 0.17% of the grid points in each case, respectively. These sparse sensor measurements are then utilized to reconstruct the full-field spatiotemporal flows. Performance is assessed by comparing the reconstructed flows to the ground truth, as shown in Fig. 6a, which displays contour comparisons and single-point time-series signal analysis at the sensor location. Unlike unconditional generation, the reconstructed flows, despite being one of many realizations generated by CoNFiLD, show notable similarities to the ground truth in both contour maps and sensor signal patterns, owing to the inclusion of conditional information (i.e., sensor measurements). Note that the conditionally generated samples, though very similar, are still slightly different from each other. The scattering of the generated ensemble can be viewed as the uncertainty of the flow reconstruction, bypassing the necessity for model retraining. This adaptability and stochasticity of CoNFiLD enable it to not only reconstruct the specific flow realization observed by the sensors but also provide uncertainty estimates accordingly. This capability distinctively differentiates our approach from deterministic regression-based reconstruction methods, which are restricted to producing a single deterministic flow sequence. A closer examination of the contours indicates minor discrepancies in capturing small-scale flow structures, consistent with unconditional generation. The disparity is slightly more noticeable in the 3D rough-wall turbulence case, reflecting its higher complexity. Future improvements in model capacity and computational resources may address these limitations.

a Comparison of label trajectory and the reconstructed on for non-equilibrium turbulence over periodic hill (1st and 2nd rows) and 3D wall-bounded turbulence (3rd and 4th rows), where right panel shows the contours and left panel shows sensor locations and single-point time-series signals at one sensor location. b Sensitivity study for number of sensors (1st column v.s. 2nd column) and w/o noise (2nd column v.s. 3rd column) at probed points (first row) and unprobed location (2nd row) for periodic hill case. Ground truth (DNS) and its measurements are denoted by blue dashed line and black circles, respectively. Reconstructed data and its uncertainty are denoted by red solid lines and shaded regions. See Supplementary Video 5 and 6 for the animation.
We further explored how sensor configuration influences flow reconstruction performance in the periodic hill case. This involved adjusting the number of sensors and incorporating noise to better simulate real-world conditions, with the results presented in Fig. 6b. The first and second columns compare the reconstruction performance using 1 and 100 sensors, respectively, by plotting mean (red lines) and standard deviation (std) (shaded regions) together with the ground truth (blue dashed lines for the DNS data and black dots for its measurements) for both probed and unprobed locations. To ensure statistical reliability, we generated and analyzed 50 samples, determining the mean and std. The uncertainty is visualized by shading an area that spans three stds from the mean, providing clear insight into the variability of generated realizations. With a single sensor, the reconstructed uncertainty is considerable; however, the mean, despite deviating from the ground truth, roughly follows its trend at both probed and unprobed locations. Increasing the sensor count to 100 significantly enhances the alignment of the mean curve with the actual data and markedly narrows the uncertainty bounds. This improvement aligns with the expectations from Bayesian perspective, as more conditional information sharpens the high-density regions of the likelihood function, resulting in a more concentrated posterior distribution. Intuitively, our certainty about the reconstructed flow increases with more observations. Additionally, we introduced Gaussian noise (10% of the original data range) to the signal of the 100 sensors and plotted the results in the third column. Compared to the second column, there is no notable performance drop at both probed and unprobed points even with noisy measurements, indicating the robustness of our model. These findings underscore the significant potential of our CoNFiLD model in scaling up to various real-world applications, demonstrating its flexibility with respect to sensor arrangements and its robustness against variations in signal quality.
In addition to the sensor settings presented, we have also evaluated CoNFiLD’s performance in more practical scenarios. One such scenario involves placing the sensors exclusively near the wall, a common configuration in real-world applications. This near-wall setup introduces slightly higher uncertainty in the reconstructed flow due to higher prediction errors in that region and the typically smaller velocity magnitudes. More details can be found in Appendix Supplementary Note 8.1. Another scenario we examined involves cases where the data quality (e.g., gappy regions or sparsity) differs across different variables such as u, v, w, p. Despite these variations in data completeness, CoNFiLD can still robustly perform accurate flow reconstructions using a customized state-to-observable function within the Bayesian framework. Further details on this are provided in Appendix Supplementary Note 8.2. Notably, the proposed reconstruction method is not restricted to measuring and reconstructing the same variables, and it can be extended to all different inverse reconstruction problems beyond fluid domains, as long as there exists an explicit differentiable functional relation \({{\mathcal{F}}}\) that maps the state variables to the observed variables. In summary, CoNFiLD can adapt to a range of practical scenarios with different sensor configurations and data qualities without requiring retraining, demonstrating significant advantages over existing flow reconstruction methods.
Conditional generation: flow restoration from damaged data
The storage of turbulence data presents a substantial challenge within the CFD community, with data corruption noted as a major concern53. Although physics-based54,55 and deep learning strategies56 have shown success in recovering fluid dynamics data for canonical flows, such as lid-driven cavity and flow around a cylinder, their applications in restoring turbulent flow data is less explored. To tackle this problem, we demonstrate another novel application of CoNFiLD: high-fidelity restoration of corrupted turbulence data. We use the damaged data as conditional input (Ψ) to facilitate the recovery of lost flow information by conditional generation. In this study, the data damage is defined as the absence of flow information at a central subregion of the fluid domain, mathematically described as a spatiotemporal masking operation. This objective is to precisely restore the missing flow details by leveraging the information available from the surrounding regions.
Using the turbulence inlet case previously presented in Section “Unconditional generation for non-equilibrium turbulence of periodic hill”, we illustrate the data restoration capability of the CoNFiLD model. A subset of the trajectory (Φ) with NT = 32 frames (equivalent to 3200 numerical time steps) from the test dataset, previously unseen by the CoNFiLD model, is selected as the ground truth. The corrupted data are created by masking the central subregion of the ground truth across all time steps, as shown in the second row of Fig. 7(a). These corrupted data then serve as conditional information for CoNFiLD to infer the flow dynamics within the masked area. Notably, the square damaged region defined here is illustrative; in practice, the shape of the damaged region can vary significantly, extending to the domain’s boundaries without restrictions.

a Instantaneous velocity magnitude contours of DNS, damaged and recovered data. b Comparison of the PDF of the velocity magnitude between DNS (blue line), damaged (green line) and recovered data (red line). c, d Comparison of the velocity magnitude profile between DNS (blue dashed line), damaged (green line), and recovered data (red line for the mean and shaded regions for its uncertainty) at three spanwise locations (d–f).
To accurately quantify uncertainty in the restoration process, we generate 18 conditioned samples, two of which are presented in Fig. 7a alongside the original and damaged data. The CoNFiLD model consistently restores the flow within the masked areas, seamlessly integrating with the surrounding data without noticeable discrepancies/inconsistencies at the interface. However, each generated sample varies slightly from the others, subtle in the contour plots but apparently reflected in the depiction of uncertainty regions shown in Fig. 7d. The results further show the velocity magnitude ∣∣u∣∣ profiles at three cross-sections (Fig. 7d) for CoNFiLD recovered flow (red line for the mean and shaded region for the uncertainty), damaged flow (green line), and the DNS flow (blue dashed line). It reveals an increasing trend of uncertainty from the periphery towards the center of the damaged area. This trend is due to higher spatial covariance with adjacent known flow information near the edges, leading to reduced uncertainty compared to the central portion of the masked area. Nonetheless, the overall uncertainty remains minimal, suggesting that CoNFiLD effectively utilizes surrounding flow information to draw from the posterior distribution closely aligned with the ground truth. Further evidence of CoNFiLD’s proficiency is presented in Fig. 7c, where it significantly refines the probability density function (PDF) of the velocity magnitude ∣∣u∣∣ of the damaged data, aligning it closely with the PDF of the original data.
Conditional generation: spatiotemporal super-resolution of low-fidelity data
Super-resolution techniques are rapidly being adopted across various computational and experimental communities to derive significant details from low-resolution (LR) images and data. Analytical, physics-based, and deep learning super-resolution techniques have shown promising results, from improving low-fidelity simulation results to enhancing under-resolved 4D flow MR imaging data28,37,57,58,59,60,61. Motivated by these advancements, we present another capability of our proposed CoNFiLD model—creating highly detailed instantaneous flows from LR counterparts, showcasing significant potential for large-scale super-resolution challenges. Through the turbulence channel flow case, we demonstrate the zero-shot super-resolution capability of the trained CoNFiLD model, regardless of the quality of LR data. We select a sub-trajectory (Φ) comprising NT = 256 frames (equivalent to 25600 numerical time steps) from the test dataset to serve as the ground truth. Three different levels of LR data are generated by downsampling the high-resolution (HR) DNS (400 × 100) to three different resolutions, 64 × 16, 16 × 4, and 4 × 1, to cover a spectrum of LR scenarios typically encountered in practice. 25 samples are generated for each LR scenario to ensure accurate estimation of the statistical metrics.
The performance of the CoNFiLD is illustrated in Fig. 8, with panel (a) showing the ground truth trajectory (400 × 100) and (b) displaying pairs of LR input and its super-resolved (SR) flow contours, across three different LR settings. Impressively, regardless of the initial quality of the LR data, all CoNFiLD-reconstructed flows are up-scaled to the original high resolution of 400 × 100, achieving a visual fidelity closely akin to the DNS reference. This can be further substantiated through the TKE spectrum analysis in Fig. 8c, comparing the SR flows (red lines) against both the ground truth (blue dots) and the baseline SR result (red dashed lines) using bicubic interpolation. The bicubic SR method significantly fails to recover high-frequency details starting from such low resolution input, and its performance deteriorates with decreasing input quality. In stark contrast, CoNFiLD’s reconstructions accurately replicate the true spectrum across all scales, even for the input with the lowest resolution (4 × 1). Upon closer examination of the instantaneous flow contour comparisons, the SR reconstructions for the lowest resolution (at the bottom of Panel (b)) deviate from ground truth data, primarily because the exceedingly low input resolution provides negligible informative conditions, rendering the model’s behavior similar to unconditional generation. As input resolution increases (from bottom to top in panel (b)), the conditionally generated SR samples increasingly align with the instantaneous flow patterns of the ground truth, with samples generated from the 64 × 16 LR input nearly indistinguishable from the DNS data. CoNFiLD’s Bayesian formulation enables robust SR across varying input qualities, contrasting with many existing SR methods highly dependent on input resolution. Notably, CoNFiLD’s ability to handle super-resolution tasks across different discretized flow representations-structured or unstructured-without retraining highlights its versatility. This adaptability clearly surpasses the capabilities of CNNs, which require retraining for different input resolutions and qualities. Similarly, although GNNs can manage unstructured data, they struggle with scale generalization. These attributes emphasize CoNFiLD’s efficacy and adaptability in super-resolution applications, underlining its potential to tackle complex engineering challenges beyond flow data enhancement.

a Instantaneous velocity magnitude contours of DNS. b Super-resolved (SR) generation results by CoNFiLD, comparing the conditional LR input and SR contours. c Comparison of TKE spectra cross DNS (blue dots), CoNFiLD SR results (red solid lines), and bicubic interpolation baseline (red dashed lines). Notably, due to its inadequate performance, bicubic interpolation is excluded for the most extreme downscaling scenario (4 × 1 → 400 × 100). See Supplementary Video 4 for animation.
Quantitative error comparison between unconditional and conditional generations
To quantitatively evaluate conditional generation performance, we have conducted additional analyses to compute the MSE between the reconstructed flow fields and the corresponding DNS ground truth in the unobserved regions. We also computed the PDF of the MSE to capture the variability of the reconstruction accuracy across different regions of the flow field, as suggested in62. Specifically, we define the instantaneous Mean Squared Error (MSE) Δ∣u∣(x, t) as,
where ∣u∣(x, t) represents the spatiotemporal velocity magnitude, and the normalizing factor E∣u∣ = σ(gen)σ(gt), with
where V is the unobserved volume and N is the number of generated samples for a given test flow trajectory. σ(gt) is defined similarly. The instantaneous MSE is thus a spatiotemporal field with the same dimension as the instantaneous flow state. To further visualize the MSE and understand its distribution across space and time, we also perform averaging over these dimensions. Specifically, the temporally averaged MSE is defined as,
and the spatially averaged MSE as,
Additionally, the spatiotemporal mean error is denoted as < Δ∣u∣ > (s, t). Since CoNFiLD is a probabilistic model, multiple (N) samples can be generated for each test case to quantify the variance in the conditional generation results.
Figure 9 shows the PDFs of instantaneous MSEs (Fig. 9c, g, k), spatial contours of temporally averaged MSEs (Fig. 9a, e, i), time series of spatially averaged MSEs (Fig. 9b, f, j), and spatiotemporal MSEs (Fig. 9d, h, l) for all three conditional generation cases. These MSE metrics have also been computed for the corresponding unconditional generation cases for comparison. It is evident that the unconditional (blue) generated samples exhibit much higher MSE values than the conditional ones (red) across all scenarios. Additionally, the scattering in the MSEs has been significantly reduced by incorporating conditional information (i.e., observations), as shown by the reduced error bars in Fig. 9d, h, l. More error analysis results can be found in Supplementary Note 9.

a–d Inpainting (e–h) and sensor reconstruction (i–l) tasks. Conditional and unconditional results are represented by red and blue color, respectively. The time-averaged MSEs, spatial-averaged MSEs, PDFs of instantaneous MSEs, and spatiotemporal averaged MSEs of 10 conditionally and unconditionally generated samples are compared.
Discussion
In this study, we introduce CoNFiLD, an innovative deep generative learning framework designed for probabilistic generation of complex, three-dimensional spatiotemporal turbulence. At its core, CoNFiLD uniquely combines a conditioned neural field (CNF) with a latent diffusion model to enable scalable, long-span spatiotemporal generation. Specifically, the CNF leverages its high-efficiency compression capabilities to encode high-dimensional, intricate scientific data into a compact latent space, and simultaneously, an unconditional diffusion model operates in the CNF-encoded latent space, effectively generating new spatiotemporal sequences in a scalable manner. This unique integration forms a novel class of latent diffusion models for space-time generation, marking a significant advancement in the field of generative modeling.
CoNFiLD has demonstrated its proficiency in generating a broad spectrum of turbulent flows across complex and irregular domains, successfully capturing intricate chaotic dynamics and turbulent phenomena. Moreover, CoNFiLD offers versatile zero-shot conditional generation capabilities, making it highly applicable to real-time data assimilation or scalable inverse problems in a variety of scientific and engineering applications, such as sensor-based flow reconstruction, data restoration, and super-resolution data enhancement, all without the necessity for model retraining. In this section, we further discuss key aspects of our model, including its computational and memory efficiency, uncertainty analysis, current limitations, and future prospects.
Efficiency and memory usage evaluation
To evaluate CoNFiLD’s efficiency improvements over traditional CFD methods and existing DL-based generative models, we assessed its computational cost compared to established benchmarks, such as OpenFOAM (a CPU-based CFD solver in C++)63, Diff-FlowFSI (an in-house GPU-enabled, fully-vectorized differentiable CFD solver in JAX)64, and the video diffusion model for spatiotemporal turbulence generation40. This comparison was made using the inlet turbulence generation case detailed in Section “Unconditional generation for non-equilibrium turbulence of periodic hill”, reporting the expected time cost for generating NT = 300 (60,000 numerical timesteps) of spatiotemporal turbulence flow sequences in Fig. 10a. Compared to OpenFOAM, the GPU-accelerated fully vectorized JAX solver, Diff-FlowFSI achieves a 30-fold increase in speed. The video diffusion model, operating directly on physical space, further boosts this speedup to 128 times. Remarkably, by operating a diffusion process in latent space, our CoNFiLD extends this speedup to an impressive 1737-fold. This exceptional efficiency stems from multiple factors: Firstly, CoNFiLD runs on GPUs, contrasting with CPU-based OpenFOAM, providing an initial efficiency boost at the cost of higher memory demand. Secondly, compared to GPU-accelerated solvers like Diff-FlowFSI facing timestep constraints by the CFL condition, CoNFiLD can employ significantly greater timestep size without convergence issues. It leverages pre-trained knowledge on the probability distribution of all possible flow solutions for rapid online inference, offering an additional layer of efficiency boost. Thirdly, existing DL-based video generative modeling techniques such as the video diffusion model, though a similar probabilistic view, directly operate in pixel/physical space, which can be easily bottlenecked by memory for extended sequences. Unlike the model by Gao et al.40, which requires an auto-regressive conditional generation for long-span generation, CoNFiLD generates latent images for large NT with a much smaller memory footprint, enabling direct generation without the need for auto-regressive sequential conditioning. The only overhead of the CoNFiLD model is the cost of the decoding process (shown in blue region), which is negligible compared to the latent diffusion process (red region) — approximately ten times less). This distinction adds another layer of performance boost to our model. In summary, CoNFiLD achieves unparalleled performance gains among peer methods, showing substantial potential for scaling up.

a Inference time cost comparison among OpenFOAM ran on CPU and Diff-FLowFSI ran on GPU, Video-diffusion model40, and CoNFiLD (ours). Red and blue regions denote the computational cost for dynamics generation and decoding, respectively. b GPU memory cost comparison for unconditional generation with (red line) and without (gray line) CNF encoder. c GPU memory cost comparison for implicit (ours, denoted by red bars) and explicit decoding strategy (e.g., POD, CNN, denoted by gray bars) in subsampling-based conditional generation.
We further explored the memory usage differences when CoNFiLD performs diffusion processes either in physical space (without the CNF encoder) or in latent space (with the CNF encoder), focusing on unconditional generation scenarios for a fair comparison (shown in Fig. 10b). This comparison also relates to other generative AI-based spatiotemporal flow generators that lack an encoding mechanism (e.g., video-diffusion40). Monitoring CoNFiLD’s memory demand over a range of inference lengths, from 1 to 8000 learning steps, both with (red line) and without (gray line) the CNF encoder, we found significant performance differences. As illustrated in Fig. 10b, absent the CNF encoder (gray line), memory usage quickly reaches the maximum capacity of current top-tier GPUs with increasing inference length, maxing out at 16 learning time steps for the Nvidia RTX4090 and 20 steps for the Nvidia A100. In contrast, with the CNF encoder (red line), memory consumption increases more gradually, enabling significantly longer inference stretches-up to 3900 and 8000 steps for the Nvidia RTX4090 and A100, respectively. This results in an extraordinary extension of inference lengths by factors of 243 and 400 for the two GPUs, underscoring the substantial benefits of latent space synthesis facilitated by the CNF encoder’s robust encoding capabilities. Notably, the CNF achieves compression ratios of 0.017% for periodic hill case and 0.002% for 3D rough wall turbulence case, an impressive achievement given the complexity of the flows processed. While convolutional autoencoders (CAE) may reach similar compression ratios, as suggested by related research42,65,66, the memory constraints of loading the full-field 3D/4D data become the bottleneck. Moreover, CNF’s inherent implicit nature to handle unstructured data sets it apart, which explicitly encode data via convolutions and pooling on fixed regular grids, CNF allows CoNFiLD to train on and generate turbulence on unstructured grids simply by querying the CNF with desired coordinates and latent vectors.
Surprisingly, the advantages of incorporating CNF extend beyond this, as we found a distinct benefit for memory efficiency brought by the CNF in the subsampling-based conditional generation of CoNFiLD. In particular, the conditional generation process entails a forward evaluation and backpropagation of Eq.(29). Note that this requires resolving the whole field before performing the forward function \({{\mathcal{F}}}\). The procedure remains the same if the CNF encoder is substituted by an explicit ML-based encoder like CAE. However, if the function \({{\mathcal{F}}}\) involves a subsampling process \({{\mathcal{M}}}\) in time and the spatial dimension, we can apply the subsampling \({{\mathcal{M}}}\) on the query spatiotemporal coordinates before passing them into the CNF decoder, thereby bypassing the recovery of the whole flow field and significant reducing the memory usage both in forward computation and backward gradient estimation. To demonstrate this, we define the forward function \({{\mathcal{F}}}\) simply as a masking function that preserves 10% spatial points. The memory consumption of CoNFiLD using this pre-subsampling technique (only available with CNF) versus the original process (the only option for explicit encoders) for different inference lengths N are plotted in Fig. 10(c), where one can observe that using an explicit encoder (gray bars) quickly exceeds the top tier GPUs at N = 64 and N = 128 for Nvidia RTX4090 and A100 respectively. In contrast, the presence of CNF (red bars) controls the memory cost under the limit of Nvidia RTX4090 in all three occasions. This fully verifies the memory benefit of CNF during the subsampling-based conditional generation of the CoNFiLD.
Uncertainty estimation and propagation in CoNFiLD framework
It is essential to understand the sources of uncertainty within the CoNFiLD framework, which are discussed below for both unconditional and conditional generation scenarios.
For unconditional generation, the uncertainty captured by CoNFiLD can primarily be regarded as aleatoric uncertainty, which is associated with the inherent variability in the data, i.e., the stochastic nature of turbulent flows. Aleatoric uncertainty arises from intrinsic randomness in the data and is typically irreducible. In turbulence modeling, this type of uncertainty captures the inherent randomness of flow structures and their dynamics. In CoNFiLD, this is reflected in the variability of generated flow fields when given the same input conditions, accounting for multiple possible realizations of the underlying stochastic processes. While CoNFiLD focuses on capturing aleatoric uncertainty, epistemic uncertainty related to neural networks is not explicitly addressed in the current formulation.
For conditional generation, the goal is to generate/reconstruct a specific spatiotemporal realization that is monitored, given sparse measurements. In this context, the trained unconditional diffusion model serves as a prior, which can be treated as epistemic uncertainty for reconstructing a particular flow realization. This uncertainty can be reduced by increasing the amount of sensor data or incorporating stronger conditional information. Additionally, during diffusion posterior sampling, the aleatoric uncertainty introduced by the measurement noise is considered through the state-to-observable map. Thus, the posterior reconstruction results reflect both aleatoric uncertainty from measurement noise and epistemic uncertainty from the diffusion learned prior. However, note that the epistemic uncertainty associated with neural network parameters has not been explicitly considered in this work.
Limitation and future prospects of current framework
The CoNFiLD framework demonstrates strong generalization capabilities through zero-shot conditional generation, meaning it can generate corresponding spatiotemporal flow realizations given specific conditions without requiring retraining. For example, CoNFiLD can reconstruct instantaneous full-field turbulent flows from sparse sensor data, adapting to varying observation configurations. This capability is particularly useful in scenarios where complete data coverage is unavailable, allowing the model to probabilistically fill in missing information. However, CoNFiLD, in its current form, has limitations in generalizing to scenarios involving significantly different geometries, flow regimes, or non-stationary statistics without retraining. The model is trained on specific flow setups and does not automatically adapt to new geometries or flows with evolving turbulence statistics, such as transient or laminar-to-turbulence transitions. These scenarios require the model to learn new statistical distributions, which is beyond its current capabilities without retraining.
To address this limitation, the training data needs to be expanded to include various geometries and flow regimes. Furthermore, the number of training subsequences plays a critical role in CoNFiLD’s performance. For effective generalization, it is essential to have a sufficiently large training set, typically on the order of 103 training subsequences. Smaller training sets may lead to memorization or the inability to capture the inherent stochasticity of the system. To extend CoNFiLD’s ability to handle statistically transient behaviors, an auto-regressive posterior conditional generation method can be developed, which auto-regressively samples the next-step flow distribution conditioned on the flow PDF of the current step, allowing CoNFiLD to learn the evolution of flow statistics over time. Alternatively, a latent transient model (either physics-based coarse solvers or data-driven neural networks) could be integrated to capture the transient transitional probability p(ut∣ut−1), guiding the diffusion sampling process. For example, a low-cost, hybrid neural differentiable solver could be developed to predict the dynamics of large-scale flow structures, which are more geometry-dependent, while CoNFiLD would focus on generating the smaller, more universal turbulence eddies conditioned on the large-scale flow predictions67. This hybrid approach would enable the model to handle more complex and evolving flow regimes beyond those seen during training. We believe this direction represents an exciting avenue for future research.
In addition to its current capabilities, CoNFiLD has the potential to be extended for optimizing flow control strategies, which often require numerous flow simulations. By efficiently generating flow samples under different control parameters, CoNFiLD could serve as a fast forward model for flow control tasks, such as lift and drag optimization in aerodynamic applications. The ability to generate multiple realizations for a single set of control parameters further enables probabilistic objective functions, offering a more robust optimization process under uncertainty compared to traditional deterministic surrogate models.
Methods
Conditional neural field encoding
Neural fields (NF) have emerged as state-of-the-art in learning implicit representations of coordinate-based functional fields, demonstrating exceptional performance in modeling and compressing complex signals such as images68,69, videos70,71, 3D scenes72, and 3D shapes44,73. Despite their tremendous success in computer vision, the exploration of NFs in dimension reduction of large-scale spatiotemporal data of physical systems (e.g., turbulence data) remains sparse. A recent effort in this direction by Pan et al.42 employs a neural field fully conditioned by hyper-network for spatiotemporal dimension reduction, where the parameters of the NF are fully determined by the hyper-network. This architecture, while effective, necessitates explicit conditions (e.g., sensor signals, time stamps) and considerable memory overhead for the hyper-network, often surpassing that of the NF itself. In contrast, the CNF of our CoNFiLD utilizes a more flexible and robust conditioning mechanism, the Feature-wise Linear Modulation (FiLM)74, and the encoder is formulated in an auto-decoding manner. The primary NF leverages the SIREN network architecture68, renowned for its capacity to capture domains with rich periodic features through sinusoidal activation functions. The mathematical representation is as follows,
where \({\{{{{\bf{W}}}}_{i}\}}_{0}^{p}\) and \({\{{{{\bf{B}}}}_{i}\}}_{0}^{p}\) are trainable parameters of NF (collectively denoted as ζ ), oi−1 is the i − 1th layer output, and ω0 is a hyperparameter that modulates the initial input signal frequency. SIREN requires a unique initialization, \({w}_{i} \sim {{\mathcal{U}}}(-r/\sqrt{n},r/\sqrt{n}),r\in {\mathbb{R}}\), ensure outputs across layers follow a standard normal distribution, where wi is individual entry of weight matrices and \({{\mathcal{U}}}(\cdot )\) represents a uniform distribution with lower/upper bound hyperparameters r. Typically, ω0 = 30 and \(r=\sqrt{6}\) are chosen for robust performance.
The SIREN is modulated by FiLM conditioning, where latent vectors L are passed into multiple linear transformation layers. Thus, the CNF, denoted by \({{\mathscr{E}}}\), is described as follows,
where \({\{{{\mathbf{W}}}_{i}^{cond}\}}_{1}^{p}\) and \({\{{{\bf{B}}}_{i}^{cond}\}}_{1}^{p}\) (collectively denoted as γ) are trainable parameters for the FiLM conditioning layers, which introduce a bias adjustment ci on each SIREN layer before the activation function is applied and \(\eta^{{\prime} }_{i}\) represents the ith FiLM-modified intermediate layer. This implicit model represents a continuous function across the spatial domain Ω, usually being trained on discretized datasets. Within our CoNFiLD framework, the CNF functions dually as an encoder and decoder, enabling seamless data transform between physical and latent space. The encoding strategy was meticulously designed to ensure that the SIREN exclusively models the spatial field, whereas the conditional information is encapsulated within a latent vector corresponding to each spatial field frame at discrete time steps ti. Consequently, the latent encoding of a spatiotemporal field segment is structured as a 2D “image", effectively preserving the original time dimension. This configuration enables unrestricted kernel convolution across images of any temporal length, introducing an innovative approach for time forecasting in the generation process, further detailed in the Section “Latent probabilistic diffusion modeling”.
The CNF is trained on the dataset \({{\mathbf{\Phi }}}\in {{{\mathcal{A}}}}_{train}\) by solving the following optimization,
where the optimized latent vectors L*, representing the latents z0 of the spatiotemporal flow field Φ, are obtained. This optimization employs an alternating-direction strategy, which involves updating the CNF parameters (ζ, γ) and the latent vectors (L) in turns. Specifically, the latent vectors are updated per batch with the CNF parameters frozen; subsequently, ζ and γ are updated while the latent vectors remain temporarily fixed. This alternating-direction optimization approach has been empirically shown to foster a stable and robust convergence during the training process75. After training, encoding a new spatiotemporal field necessitates an optimization, as described by Eq. (1), whereas the decoding phase simply involves feeding the latent vectors and spatial coordinates into the trained CNF to retrieve the corresponding Field of Interest (FOI) values. The efficiency of the CNF decoder becomes particularly evident during the latent diffusion-based generation phase.
Latent probabilistic diffusion modeling
Given a CNF-encoded latent state z0 whose underlying distribution is p(z0), i.e., z0 ~ p(z0), a forward diffusion process is defined by progressively perturbing z0 with Gaussian noise of variance βτ, through the transition kernel,
where τ = 1, ⋯ Nτ denotes the diffusion step index with Nτ as the total number of steps, and \({{\bf{I}}}\in {{\mathbb{R}}}^{{({N}_{l}\times {N}_{t})}^{2}}\) is the identity matrix. This forward diffusion process yields a sequence of incrementally noised latent states \({{{\bf{z}}}}_{1},\cdots \,,{{{\bf{z}}}}_{{N}_{\tau }}\) with the joint probability density \(p({{{\bf{z}}}}_{1},\cdots \,,{{{\bf{z}}}}_{{N}_{\tau }}| {{{\bf{z}}}}_{0})\),
With sufficient perturbation steps, the marginalized distribution \(p({{{\bf{z}}}}_{{N}_{\tau }}| {{{\bf{z}}}}_{0})\) asymptotically converges to an isotropic Gaussian distribution, denoted by \(p({{{\bf{z}}}}_{\tau })={{\mathcal{N}}}({{\mathbf{0}}},{\sigma }_{{N}_{\tau }| 0}^{2}{{\bf{I}}})\), facilitating straightforward sampling. Using the re-parameterization trick33, the conditional distribution of each noised latent state given z0 is also Gaussian, explicitly defined as,
where ατ = 1 − βτ and \({\bar{\alpha }}_{\tau }={\prod }_{s=1}^{\tau }{\alpha }_{s}\). The forward diffusion is characterized through a predetermined series of variance parameters βτ, known as variance schedule, which can adopt various forms, such as linear, quadratic, or cosine schedules32.
Upon establishing the forward diffusion process, its reversal (i.e., reverse diffusion process) becomes particularly compelling since it enables the synthesis of new latent samples of z0 from white noise vectors sampled from the isotropic Gaussian distribution \(p({{{\bf{z}}}}_{{N}_{\tau }})\). This process relies on the assumption that each step’s perturbation is sufficiently small, ensuring that the conditional probability p(zτ−1∣zτ), or the reverse transition kernel, remains Gaussian. However, directly computing this reverse transition kernel is infeasible, as it requires the knowledge of the distribution of the entire latent space, which is unknown a priori. To overcome this challenge, all existing diffusion-based generation methods rely on neural networks to learn either the reverse transition kernel or the score function with trainable parameters θ, both of which can be unified in the same framework33,34,35. Training the neural network parameterization can be formulated as a likelihood maximization problem,
However, as \(\log {p}_{{{\mathbf{\theta }}}}({{{\bf{z}}}}_{0})\) is not tractable, we can instead minimize the variational bound LVB on the negative log likelihood (derivation can be found in76),
where DKL( ⋅ ∥ ⋅ ) represents Kullback-Leibler (KL) divergence operator. Since the first term of LVB contains no trainable parameters θ and remains a constant during training, it can be dropped. Therefore, the diffusion model can be trained by minimizing \({\tilde{L}}_{{{\rm{VB}}}}\),
The reverse transition kernel is Gaussian, \({p}_{{{\mathbf{\theta }}}}({{{\bf{z}}}}_{\tau -1}| {{{\bf{z}}}}_{\tau },{{{\bf{z}}}}_{0})={{\mathcal{N}}}\left({{{\bf{z}}}}_{\tau -1};{{{\boldsymbol{\mu }}}}_{{{\mathbf{\theta }}}}({{{\bf{z}}}}_{\tau },t),{{{\mathbf{\Sigma }}}}_{{{\mathbf{\theta }}}}({{{\bf{z}}}}_{\tau },t)\right)\), where the mean and covariance functions are parameterized by neural networks. Specifically, the parameterization is designed based on the reverse conditional probability p(zτ−1∣zτ, z0), which is analytically tractable when conditioned on z0,
where the ϵτ is the noise added at step τ. Therefore, the mean function μθ(zτ, τ) of reverse kernel is parameterized as follows,
where the noise function ϵθ(zτ, τ; θ) is approximated by a U-Net variant with residual blocks, self-attention blocks, and group normalization30,77. The variance function Σθ remains fixed as \({{{\mathbf{\Sigma }}}}_{\theta }=(1-{\bar{\alpha }}_{\tau -1}){\beta }_{\tau }/(1-{\bar{\alpha }}_{\tau }){{\bf{I}}}\) based on Eq. (18). Since the KL divergence between two Gaussian distributions has a closed form, \({\tilde{L}}_{{{\rm{VB}}}}\) in Eq. (17) can be expressed as,
Ho et al.33 further simplified the VB loss by ignoring the weighting term,
In this work, the latent diffusion model training adopts a hybrid form suggested by Nichol and Dhariwal77, which uses both \({\tilde{L}}_{{{\rm{simple}}}}\) and \({\tilde{L}}_{{{\rm{vb}}}}\) with a weight parameter λ, leading to the following optimization,
where noise vector ϵ is randomly sampled from a standard Gaussian distribution, i.e., \({{\boldsymbol{\epsilon }}} \sim {{\mathcal{N}}}({{\boldsymbol{0}}},{{\bf{I}}})\), and τ is randomly sampled from a discrete uniform distribution \({{\mathcal{U}}}(1,{N}_{\tau })\).
Bayesian conditional generation of spatiotemporal fields
Upon completing the training phase, the CoNFiLD model can rapidly generate new 4D spatiotemporal flow fields \({{\mathbf{\Phi }}}\in {{\mathbb{R}}}^{{N}_{m}\times {N}_{T}}\) by sampling from the latent diffusion model and performing the CNF decoding. Remarkably, the model enables the generation of time sequences of flow fields that far exceed the temporal scope of the training data, i.e., NT > Nt. This extended generative capacity allows the CoNFiLD to not only synthesize new spatiotemporal flow data possessing turbulence statistics consistent with the training data, but also to extrapolate temporally well beyond the time sequence length of the training set. The selection of Nt and NT can be guided by the underlying flow physics, particularly by considering temporal correlations and integral time scales. A more detailed analysis on this is provided in Supplementary Note 4. More importantly, a particularly notable feature of the CoNFiLD model is its adeptness at zero-shot conditional generation within a Bayesian sampling framework. This capability allows for the spatiotemporal generation under various conditions, such as specific initial states, sparse observations, or low-fidelity simulations, all without necessitating retraining for each specific scenario. This aspect highlights the CoNFiLD’s versatility and adaptability, offering tailored turbulence predictions based on available data or desired outcomes.
Unconditional generation
The trained CoNFiLD model can be utilized to generate new spatiotemporal turbulent flow sequences by sampling the learned distribution via the reverse diffusion process. Starting from samples of a multivariate isotropic Gaussian distribution, \({{{\bf{z}}}}_{{N}_{\tau }} \sim {{\mathcal{N}}}({{\boldsymbol{0}}},{{\bf{I}}})\), the noises are progressively removed using the learned reverse transition kernel \({p}_{{{{\mathbf{\theta }}}}^{*}}({{{\bf{z}}}}_{\tau -1}| {{{\bf{z}}}}_{\tau },{{{\bf{z}}}}_{0})\),
allowing for the sampling of zτ−1 based on the sample zτ at step τ. Namely, the following reverse sampling is conducted,
By iteratively applying Eq. (24), a new latent z0 starting from white noise \({{{\bf{z}}}}_{{N}_{\tau }}\) can be obtained, which is then decoded back to a spatiotemporal turbulent flow field \({{\mathbf{\Phi }}}={{{\mathcal{E}}}}_{{\zeta }^{*},{\gamma }^{*}}({{\bf{x}}},{{{\bf{z}}}}_{0})\) via the CNF decoder. This process aligns with the score-based generative modeling framework34, where Eq. (24) can be expressed in terms of the score function,
where the Stein score function \({{\boldsymbol{s}}}({{{\bf{z}}}}_{\tau },\tau )={\nabla }_{{{{\bf{z}}}}_{\tau }}\log p({{{\bf{z}}}}_{\tau })\) is approximated by neural network parameterization \({{{\boldsymbol{s}}}}_{{{{\mathbf{\theta }}}}^{*}}({{{\bf{z}}}}_{\tau },\tau ;{{{\mathbf{\theta }}}}^{*})\) with optimized parameters θ*.
Conditional generation
Mathematically, conditions can be systematically represented by a vector \({{\mathbf{\Psi }}}\in {{\mathbb{R}}}^{{N}_{{{\mathbf{\Psi }}}}}\), hereafter referred to as the condition vector. This vector Ψ may represent low-fidelity solutions, instantaneous flow measurements from sparse sensor array, low-resolution observation data, or other related information regarding to the spatiotemporal flow field of interest Φ. From Bayesian perspective, conditional generation involves the sampling of the conditional probability p(Φ∣Ψ), which can be bridged to the unconditioned density p(Φ) via Bayes’ rule,
where p(Φ) is learned by the CoNFiLD after the unconditional training,
The relationship between the condition Ψ and corresponding flow sequences Φ is defined as follows,
where \({{\mathcal{F}}}:{{\mathbb{R}}}^{{N}_{m}\times {N}_{T}}\to {{\mathbb{R}}}^{{N}_{{{\mathbf{\Psi }}}}}\) is a nonlinear mapping from the spatiotemporal turbulent field Φ to its associated condition vector Ψ (e.g., partial observation); ϵc represents the uncertainty inherent in the state-to-condition mapping, typically modeled as a zero-mean Gaussian random variable. Conditional generation can be conceptualized as a Bayesian inverse problem, which has attracted significant interest within the computer vision community, notably in the area of image restoration78. In these contexts, the state-to-condition mapping often exhibits a linear nature. The Diffusion Posterior Sampling (DPS) technique, which accommodates both linear and nonlinear mappings within the pixel space, represents a recent advancement in this area, albeit operating within the pixel space79. Expanding upon the DPS concept, we adapt it to the CNF-encoded latent diffusion process, facilitating zero-shot conditional generation. In CoNFiLD, Eq. (28) is reformulated as,
The conditional relationship between the perturbed latent states and the conditions Ψ is expressed via Bayes’s theorem as p(zτ∣Ψ) = p(Ψ∣zτ)p(zτ)/p(Ψ), with the normalizing constant p(Ψ) being generally intractable. This complexity is circumvented by shifting the formulation to score functions,
where second term \({\nabla }_{{{{\bf{z}}}}_{\tau }}\log p({{{\bf{z}}}}_{\tau })\) is the score function for unconditional generation, approximated by \({{{\boldsymbol{s}}}}_{{{{\mathbf{\theta }}}}^{*}}({{{\bf{z}}}}_{\tau },\tau )\) post-training. However, the gradient of log-likelihood term, \({\nabla }_{{{{\bf{z}}}}_{\tau }}\log p({{\mathbf{\Psi }}}| {{{\bf{z}}}}_{\tau })\), remains to be estimated. To this end, the likelihood density is factorized,
which can be approximated by,
The approximation error is theoretically bounded with the Jensen gap80. Accordingly, the gradient of the log likelihood can be approximated as,
where the posterior mean \({\hat{{{\bf{z}}}}}_{0}={\mathbb{E}}[{{{\bf{z}}}}_{0}| {{{\bf{z}}}}_{\tau }]\) can be computed as,
where the Stein score \({\nabla }_{{{{\bf{z}}}}_{\tau }}\log p({{{\bf{z}}}}_{\tau })\) has been learned during the unconditional diffusion modeling training, i.e., \({\nabla }_{{{{\bf{z}}}}_{\tau }}\log p({{{\bf{z}}}}_{\tau })\approx {{{\boldsymbol{s}}}}_{{{{\mathbf{\theta }}}}^{*}}({{{\bf{z}}}}_{\tau },\tau ;{{{\mathbf{\theta }}}}^{*})\). Then we have approximated \({\hat{{{\bf{z}}}}}_{0}\),
Based on the nested probabilistic nonlinear relationship between the condition Ψ and CNF-encoded flow field latents z0, the approximated likelihood is,
if the uncertainty term ϵc in Eq. (28) has a zero-mean Gaussian distribution, i.e., \({\epsilon }_{c} \sim {{\mathcal{N}}}({{\mathbf{0}}},{\sigma }_{c}^{2}{{\bf{I}}})\). By differentiating the approximated log likelihood with respect to zτ, we have
which can be computed using the chain rule,
by leveraging the automatic differentiation (AD) capability using differentiable programming for the implementation. Finally, the gradient of log posterior (i.e., guided score function \({{{\boldsymbol{s}}}}_{{{{\mathbf{\theta }}}}^{*},{\zeta }^{*},{\gamma }^{*}}^{{{\rm{guided}}}}\)) as shown by Eq. (30), can be computed as,
Therefore, conditional sampling can be achieved by modifying the unconditional score function as above. Without the need of retraining the CoNFiLD, new spatiotemporal turbulent flow fields Φ∣Ψ given conditions Ψ can be rapidly generated using the guided score function \({{{\boldsymbol{s}}}}_{{{{\mathbf{\theta }}}}^{*},{\zeta }^{*},{\gamma }^{*}}^{{{\rm{guided}}}}\) derived in Eq. (39).
To elucidate the use of conditional generation in diffusion models, consider the following example of reconstructing transient instantaneous turbulent flow fields from sparse sensor measuremnts. Suppose we want to reconstruct transient 3D flow field in a wind tunnel using velocity and pressure measurements from a limited number of sensors distributed across the domain. The full-field flow state Φ is defined on a discrete spatiotemporal domain, i.e.,\({{\mathbf{\Phi }}}\in {{\mathbb{R}}}^{4{N}_{m}\times {N}_{T}}={[{{{\bf{u}}}}^{T},{{{\bf{v}}}}^{T},{{{\bf{w}}}}^{T},{{{\bf{p}}}}^{T}]}^{T}\) where u, v, w, and \({{\bf{p}}}\in {{\mathbb{R}}}^{{N}_{m}\times {N}_{T}}\) are velocity and pressure spatiotemporal fields flattened into one-dimensional vectors of length Nm × NT. Nm represents the total number of mesh nodes, and NT denotes the total number of time steps.
The sensor signals for each variable are subsets of the full signal \({{\mathbf{\Psi }}}\in {{\mathbb{R}}}^{{N}_{s}^{u}+{N}_{s}^{v}+{N}_{s}^{w}+{N}_{s}^{p}}={\{{u}_{{s}_{i}^{u}}\}}_{i=1}^{{N}_{s}^{u}}\cup {\{{v}_{{s}_{i}^{v}}\}}_{i=1}^{{N}_{s}^{v}}\cup {\{{w}_{{s}_{i}^{w}}\}}_{i=1}^{{N}_{s}^{w}}\cup {\{{p}_{{s}_{i}^{p}}\}}_{i=1}^{{N}_{s}^{p}}\), where \({s}_{i}^{u},i\in [1,{N}_{s}^{u}]\), \({s}_{i}^{v},i\in [1,{N}_{s}^{v}]\), \({s}_{i}^{w},i\in [1,{N}_{s}^{w}]\), \({s}_{i}^{p},i\in [1,{N}_{s}^{p}]\), are the indices corresponding to sensor placements for each variable (\({N}_{s}^{u},{N}_{s}^{v},{N}_{s}^{w},{N}_{s}^{p}\ll ({N}_{m}\times {N}_{T})\)).
The forward function \({{\boldsymbol{{{\mathcal{F}}}}}}\), which maps from Φ to Ψ with added Gaussian noise (denoted by ϵc in equation 22), acts as a masking operator that extracts the values from Φ at those specified indices. Formally it is represented as:
where q ∈ {u, v, w, p} represents the query variable, while \({a}_{i,j}^{q}\) is the element of the masking matrix Aq, collectively forming a block diagonal masking matrix A.
This forward function \({{\boldsymbol{{{\mathcal{F}}}}}}\) is implemented using differentiable programming (DP), leveraging DP frameworks such as PyTorch81, which supports automatic differentiation. During the conditional generation process, the first term on the right-hand side of Eq. (39) is computed based on Eq. (38), which is then added to the original score (i.e., the second term on the RHS of Eq. (39)) at each diffusion time step, ultimately driving the conditional generation to produce the full spatiotemporal flow realizations consistent with the sensor data.
Generating extended spatiotemporal flow sequences
The proposed CoNFiLD model has the capability generate extended spatiotemporal flow sequences, where generated sequence length NT significantly exceeds the training length Nt (i.e., NT ≫ Nt). This is achieved by leveraging the shift-invariance property of convolutional kernels in the latent space, allowing for “one-shot” generation of the entire sequence. Unlike previous flow surrogate models that rely primarily on autoregressive formulations, which are known for their stability issues in long-term predictions, our one-shot generation approach avoids these challenges. Additionally, this method can be seamlessly combined with autoregressive conditional overlapping sampling, which stabilizes the process through probabilistic autoregressive formulation. This combination enables the generation of very long trajectories without being constrained by GPU memory limitations, as explained below.
Specifically, each training sample, once compressed into the latent space, is transformed into a “latent spatiotemporal image” with dimensions Nt × Nl, where Nt represents the temporal length and Nl is the latent dimension size. Once the latent diffusion model is trained, we can generate spatiotemporal samples with much longer temporal lengths NT (NT ≫ Nt) by creating a “noisy latent spatiotemporal image” zτ with dimensions NT × Nl, where the values are randomly drawn from a standard normal distribution. This noisy image is then iteratively denoised by the trained diffusion model to z0, which is then decoded into the physical spatiotemporal trajectory with a time length of NT. This process works because the trained diffusion model can be directly applied to noisy images with arbitrary shape (NT × Nl), different from the training latent image shape (Nt × Nl), thanks to the shift-invariance property of the convolutional kernels in the diffusion model. This novel use of the shift-invariance of convolutional kernels on latent spatiotemporal images allows for “one-shot” generation of continuous spatiotemporal flow trajectories with arbitrary lengths.
However, the length of the one-shot generated trajectory is constrained by the available GPU memory. To generate even longer trajectories beyond hardware memory constraints, we employ autoregressive conditional overlapping generation, whereby one-shot generation is applied autoregressively with overlapping segments. Specifically, the one-shot generated latent representation of the flow field \({{{\bf{z}}}}_{0}^{current}\in {{\mathbb{R}}}^{{N}_{T}\times {N}_{l}}\) is split into two non-overlapping subsequences, e.g.,
The second half the current latent trajectory \({{{\bf{z}}}}_{0}^{current}({N}_{split}+1:{N}_{T},:)\) serves as the conditional information to guide the next one-shot generation, i.e., \({{{\bf{z}}}}_{0}^{next}| {{{\bf{z}}}}_{0}^{current}({N}_{split}+1:{N}_{T},:)\). In this context, the differentiable forward function \({{\mathcal{F}}}\) used in conditional generation acts as a masking function, extracting the first Nsplit columns of the input sequence for further generation.
Data availability
The datasets for all the cases in this study have been deposited in the Zenodo database under accession code 1403778282. Videos of all numerical experiments can be found in supplementary files (Supplementary videos 1–6) as well as at Animations.
Code availability
All the source codes to reproduce the results in this study openly available on GitHub at https://github.com/jx-wang-s-group/CoNFiLD83 upon publication.
References
Brunton, S. L., Noack, B. R. & Koumoutsakos, P. Machine learning for Fluid Mechanics. Annu. Rev. Fluid Mech. 52, 477–508 (2020).
Vinuesa, R. & Brunton, S. L. Enhancing Computational Fluid Dynamics with machine learning. Nat. Comput. Sci. 2, 358–366 (2022).
Bar-Sinai, Y., Hoyer, S., Hickey, J. & Brenner, M. P. Learning data-driven discretizations for partial differential equations. Proc. Natl Acad. Sci. 116, 15344–15349 (2019).
Kochkov, D. et al. Machine learning–accelerated Computational Fluid Dynamics. Proc. Natl Acad. Sci. 118, e2101784118 (2021).
Wang, J.-X., Wu, J.-L. & Xiao, H. Physics-informed machine learning approach for reconstructing reynolds stress modeling discrepancies based on DNS data. Phys. Rev. Fluids 2, 034603 (2017).
Maulik, R., San, O., Rasheed, A. & Vedula, P. Subgrid modelling for two-dimensional turbulence using neural networks. J. Fluid Mech. 858, 122–144 (2019).
Shankar, V., Maulik, R. & Viswanathan, V. Differentiable turbulence ii, arXiv preprint arXiv:2307.13533 (2023).
Tompson, J., Schlachter, K., Sprechmann, P. & Perlin, K. Accelerating eulerian fluid simulation with convolutional networks. In International Conference on Machine Learning, PMLR, 2017, pp. 3424–3433.
Liu, X.-Y., Zhu, M., Lu, L., Sun, H. & Wang, J.-X. Multi-resolution partial differential equations preserved learning framework for spatiotemporal dynamics. Commun. Phys. 7, 31 (2024).
Fan, X. & Wang, J.-X. Differentiable hybrid neural modeling for fluid-structure interaction. J. Comput. Phys. 496, 112584 (2024).
Fukami, K., Nabae, Y., Kawai, K. & Fukagata, K. Synthetic turbulent inflow generator using machine learning. Phys. Rev. Fluids 4, 064603 (2019).
Fukami, K., Fukagata, K. & Taira, K. Super-resolution reconstruction of turbulent flows with machine learning. J. Fluid Mech. 870, 106–120 (2019).
Fukami, K., Fukagata, K. & Taira, K. Machine-learning-based spatio-temporal super resolution reconstruction of turbulent flows. J. Fluid Mech. 909, A9 (2021).
Yousif, M. Z., Yu, L. & Lim, H. Physics-guided deep learning for generating turbulent inflow conditions. J. Fluid Mech. 936, A21 (2022).
Yousif, M. Z., Zhang, M., Yu, L., Vinuesa, R. & Lim, H. A transformer-based synthetic-inflow generator for spatially developing turbulent boundary layers. J. Fluid Mech. 957, A6 (2023).
Han, X., Gao, H., Pfaff, T., Wang, J.-X. & Liu, L. Predicting physics in mesh-reduced space with temporal attention. In International Conference on Learning Representations, (2022).
Stengel, K., Glaws, A., Hettinger, D. & King, R. N. Adversarial super-resolution of climatological wind and solar data. Proc. Natl Acad. Sci. 117, 16805–16815 (2020).
Drygala, C., Winhart, B., di Mare, F. & Gottschalk, H. Generative modeling of turbulence. Phys. Fluids 34, 035114 (2022).
Deng, Z., He, C., Liu, Y. & Kim, K. C. Super-resolution reconstruction of turbulent velocity fields using a Generative Adversarial Network-based artificial intelligence framework, Phys. Fluids 31, 125111 (2019).
Kim, H., Kim, J., Won, S. & Lee, C. Unsupervised deep learning for super-resolution reconstruction of turbulence. J. Fluid Mech. 910, A29 (2021).
Güemes, A. et al. From coarse wall measurements to turbulent velocity fields through deep learning. Phys. fluids 33, 075121 (2021).
Yu, L. et al. Three-dimensional ESRGAN for super-resolution reconstruction of turbulent flows with tricubic interpolation-based transfer learning, Physics of Fluids 34, (2022).
Buzzicotti, M., Bonaccorso, F., Di Leoni, P. C. & Biferale, L. Reconstruction of turbulent data with deep generative models for semantic inpainting from TURB-Rot database. Phys. Rev. Fluids 6, 050503 (2021).
Xie, Y., Franz, E., Chu, M. & Thuerey, N. tempoGAN: A temporally coherent. volumetric GAN super.-Resolut. fluid flow., ACM Trans. Graph. (TOG) 37, 1–15 (2018).
Kim, J. & Lee, C. Deep unsupervised learning of turbulence for inflow generation at various Reynolds numbers. J. Computational Phys. 406, 109216 (2020).
Gui, J., Sun, Z., Wen, Y., Tao, D. & Ye, J. A review on Generative Adversarial Networks: Algorithms, theory, and applications. IEEE Trans. Knowl. data Eng. 35, 3313–3332 (2021).
Bau, D. et al. Seeing what a GAN cannot generate. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 4502–4511.
Geneva, N. & Zabaras, N. Multi-fidelity generative deep learning turbulent flows. Found. Data Sci. 2, 391–428 (2020).
Sun, L., Han, X., Gao, H., Wang, J.-X. & Liu, L. Unifying predictions of deterministic and stochastic physics in mesh-reduced space with sequential flow generative model. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
Dhariwal, P. & Nichol, A. Diffusion models beat GANs on image synthesis. Adv. neural Inf. Process. Syst. 34, 8780–8794 (2021).
Croitoru, F.-A., Hondru, V., Ionescu, R. T. & Shah, M. Diffusion models in vision: A survey, IEEE Transactions on Pattern Analysis and Machine Intelligence (2023).
Yang, L. et al. Diffusion models: A comprehensive survey of methods and applications. ACM Comput. Surv. 56, 1–39 (2023).
Ho, J., Jain, A. & Abbeel, P. Denoising diffusion probabilistic models. Adv. neural Inf. Process. Syst. 33, 6840–6851 (2020).
Song, Y. & Ermon, S. Generative modeling by estimating gradients of the data distribution. Proceedings of the 33rd International Conference on Neural Information Processing Systems. 11918–11930 (2019).
Song, Y. et al. Score-based generative modeling through stochastic differential equations, arXiv preprint arXiv:2011.13456 (2020).
Gao, S. et al. Implicit diffusion models for continuous super-resolution, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10021–10030 (2023).
Shu, D., Li, Z. & Farimani, A. B. A physics-informed diffusion model for high-fidelity flow field reconstruction. J. Comput. Phys. 478, 111972 (2023).
Wan, Z. Y. et al. Debias coarsely, sample conditionally: Statistical downscaling through optimal transport and probabilistic diffusion models. In Proceedings of the 37th International Conference on Neural Information Processing Systems (NIPS '23). 47749–47763 (2024).
Li, T., Lanotte, A. S., Buzzicotti, M., Bonaccorso, F. & Biferale, L. Multi-scale reconstruction of turbulent rotating flows with generative diffusion models. Atmosphere 15, 60 (2023).
Gao, H. et al. Bayesian conditional diffusion models for versatile spatiotemporal turbulence generation. Computer Methods Appl. Mech. Eng. 427, 117023 (2024).
Ho, J. et al. Video diffusion models, arXiv:2204.03458 (2022).
Pan, S., Brunton, S. L. & Kutz, J. N. Neural implicit flow: a mesh-agnostic dimensionality reduction paradigm of spatio-temporal data. J. Mach. Learn. Res. 24, 1–60 (2023).
Yin, Y., Kirchmeyer, M., Franceschi, J.-Y. & Rakotomamonjy, A., P. Gallinari, Continuous PDE dynamics forecasting with implicit neural representations. In International Conference on Learning Representations (LCLR), (2023).
Park, J. J., Florence, P., Straub, J., Newcombe, R. & Lovegrove, S. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, (2019), pp. 165–174.
Pope, S. B. & Pope, S. B. Turbulent flows, Cambridge University Press, (2000).
Breuer, M., Peller, N., Rapp, C. & Manhart, M. Flow over periodic hills–numerical and experimental study in a wide range of Reynolds numbers. Computers Fluids 38, 433–457 (2009).
Kadivar, M., Tormey, D. & McGranaghan, G. A review on turbulent flow over rough surfaces: Fundamentals and theories. Int. J. Thermofluids 10, 100077 (2021).
Santiago, J. L., Martilli, A. & Martín, F. CFD simulation of airflow over a regular array of cubes. part i: Three-dimensional simulation of the flow and validation with wind-tunnel measurements. Bound.-layer. Meteorol. 122, 609–634 (2007).
Dubois, P., Gomez, T., Planckaert, L. & Perret, L. Machine learning for fluid flow reconstruction from limited measurements. J. Computational Phys. 448, 110733 (2022).
Callaham, J. L., Maeda, K. & Brunton, S. L. Robust flow reconstruction from limited measurements via sparse representation. Phys. Rev. Fluids 4, 103907 (2019).
Erichson, N. B. et al. Shallow neural networks for fluid flow reconstruction with limited sensors. Proc. R. Soc. A 476, 20200097 (2020).
Sofos, F. et al. Current trends in fluid research in the era of artificial intelligence. Rev. fluids 7, 116 (2022).
Khaleel, M. A. Scientific grand challenges: Crosscutting technologies for computing at the exascale-february 2-4, 2010, washington, dc, Tech. rep., Pacific Northwest National Lab.(PNNL), Richland, WA (United States) (2011).
Lee, S., Kevrekidis, I. G. & Karniadakis, G. E. Resilient algorithms for reconstructing and simulating gappy flow fields in cfd. Fluid Dyn. Res. 47, 051402 (2015).
Han, J., Khieu, L. H. & Johnsen, E., Reconstruct corrupted data in DG-based CFD simulations, in: AIAA AVIATION 2022 Forum, 2022, p. 4155.
de Frahan, M. T. H. & Grout, R. W. Data recovery in computational fluid dynamics through deep image priors, arXiv preprint arXiv:1901.11113 (2019).
Gao, H., Sun, L. & Wang, J.-X. Super-resolution and denoising of fluid flow using physics-informed convolutional neural networks without high-resolution labels. Phys. Fluids 33, 073603 (2021).
de Hoon, N. H., Jalba, A. C., Eisemann, E., A., Vilanova, Temporal interpolation of 4D PC-MRI blood-flow measurements using bidirectional physics-based fluid simulation., in: VCBM/MedViz, 2016, pp. 59–68.
Töger, J. et al. Blood flow imaging by optimal matching of Computational Fluid Dynamics to 4D-flow data. Magn. Reson. Med. 84, 2231–2245 (2020).
Ferdian, E. et al. 4DFlowNet: super-resolution 4D flow MRI using deep learning and computational fluid dynamics. Front. Phys. 8, 138 (2020).
Rutkowski, D. R., Roldán-Alzate, A. & Johnson, K. M. Enhancement of cerebrovascular 4D flow MRI velocity fields using machine learning and Computational Fluid Dynamics simulation data. Sci. Rep. 11, 10240 (2021).
Li, T. et al. Multi-scale reconstruction of turbulent rotating flows with proper orthogonal decomposition and generative adversarial networks. J. Fluid Mech. 971, A3 (2023).
Jasak, H. et al. OpenFOAM: A C++ library for complex physics simulations, in: International workshop on coupled methods in numerical dynamics, Vol. 1000, pp. 1–20 (2007).
Fan, X., Liu, X.-Y.Wang, M. & Wang, J.-X., Diff-FlowFSI: A JAX-based differentiable solver for turbulent flow and fluid-structure interactions (2024 in. prep).
Nakamura, T., Fukami, K., Hasegawa, K., Nabae, Y. & Fukagata, K., Convolutional neural network and long short-term memory based reduced order surrogate for minimal turbulent channel flow, Phys. Fluids 33, 025116 (2021).
Hasegawa, K., Fukami, K., Murata, T. & Fukagata, K. CNN-LSTM based reduced order modeling of two-dimensional unsteady flows around a circular cylinder at different Reynolds numbers. Fluid Dyn. Res. 52, 065501 (2020).
Fan, X., Akhare, D. & Wang, J.-X. Neural differentiable modeling with diffusion-based super-resolution for two-dimensional spatiotemporal turbulence. Comput. Methods Appl. Mech. Eng. 433, 117478 (2025).
Sitzmann, V., Martel, J., Bergman, A., Lindell, D. & Wetzstein, G. Implicit neural representations with periodic activation functions. Adv. neural Inf. Process. Syst. 33, 7462–7473 (2020).
Tancik, M. et al. Fourier features let networks learn high frequency functions in low dimensional domains. Adv. Neural Inf. Process. Syst. 33, 7537–7547 (2020).
Li, T. et al. Neural 3D video synthesis from multi-view video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5521–5531 (2022).
Chen, H. et al. Nerv: Neural representations for videos. Adv. Neural Inf. Process. Syst. 34, 21557–21568 (2021).
Mildenhall, B. et al. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 65, 99–106 (2021).
Chen, Z. & Zhang, H. Learning implicit fields for generative shape modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5939–5948 (2019).
Perez, E., Strub, F., De Vries, H., Dumoulin, V. & Courville, A. FiLM: visual reasoning with a general conditioning layer. In: Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence. 3942–3951 (AAAI Press, 2018).
Serrano, L. et al. Operator learning with neural fields: Tackling PDEs on general geometries. In: Proceedings of the 37th International Conference on Neural Information Processing Systems (NIPS '23) 70581–70611 (2024).
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N. & Ganguli, S., Deep unsupervised learning using nonequilibrium thermodynamics, in: International Conference on Machine Learning, PMLR, pp. 2256–2265 (2015).
Nichol, A. Q. & Dhariwal, P. Improved denoising diffusion probabilistic models. In International Conference on Machine Learning, PMLR, pp. 8162–8171 (2021).
Li, X. et al. Diffusion models for image restoration and enhancement–a comprehensive survey, arXiv preprint arXiv:2308.09388 (2023).
Chung, H., Kim, J., Mccann, M. T., Klasky, M. L. & Ye, J. C., Diffusion posterior sampling for general noisy inverse problems, arXiv preprint arXiv:2209.14687 (2022).
Gao, X., Sitharam, M. & Roitberg, A. E. Bounds on the jensen gap, and implications for mean-concentrated distributions, arXiv preprint arXiv:1712.05267 (2017).
Paszke, A. et al. PyTorch: An imperative style, high-performance deep learning library, in: Wallach, H. et al. (Eds.), Advances in Neural Information Processing Systems 32, Curran Associates, Inc., 2019, pp. 8024–8035.
Du, P., Parikh, M. H., Fan, X., Liu, X.-Y. & Wang, J.-X., Conditional Neural Field Latent Diffusion Model for Generating Spatiotemporal Turbulence https://doi.org/10.5281/zenodo.14037782 (2024).
Du, P., Parikh, M. H., Fan, X., Liu, X.-Y. & Wang, J.-X. jx-wang-s-group/CoNFiLD: Initial release of CoNFiLD https://doi.org/10.5281/zenodo.14058397 (2024).
Acknowledgements
This work has been supported by the Office of Naval Research under award numbers N00014-23-1-2071 (MA, XF, JXW) and National Science Foundation under award numbers OAC-2047127 (PD, XL, JXW).
Author information
Authors and Affiliations
Contributions
P.D., M.H.P., and J.X.W. contributed to the ideation and design of the research; P.D., M.H.P. and X.Y.L. implemented the model and conducted numerical experiments; X.F. and X.Y.L. conducted DNS simulation and generated high-fidelity data; P.D., M.H.P., X.F., X.Y.L., J.X.W. contributed to data and results analysis; P.D., M.H.P., X.F., X.Y.L. and J.X.W. wrote the manuscript; J.X.W. supervised the entire project.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Kai Fukami, Suraj Pawar and the other, anonymous, reviewer for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Du, P., Parikh, M.H., Fan, X. et al. Conditional neural field latent diffusion model for generating spatiotemporal turbulence. Nat Commun 15, 10416 (2024). https://doi.org/10.1038/s41467-024-54712-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-024-54712-1
This article is cited by
-
Stochastic reconstruction of gappy Lagrangian turbulent signals by conditional diffusion models
Communications Physics (2025)
-
A new perspective on the simulation of stochastic problems in fluid mechanics with diffusion models
Nature Machine Intelligence (2025)
-
Breakthroughs and Perspectives of Artificial Intelligence in Turbulence Research: From Data Parsing to Physical Insights
Archives of Computational Methods in Engineering (2025)
