
Abstract
The cell cycle governs a precise series of molecular events, regulated by coordinated changes in protein and phosphorylation abundance, that culminates in the generation of two daughter cells. Here, we present a proteomic and phosphoproteomic analysis of the human cell cycle in hTERT-RPE-1 cells using deep quantitative mass spectrometry by isobaric labelling. By analysing non-transformed cells and improving the temporal resolution and coverage of key cell cycle regulators, we present a dataset of cell cycle-dependent protein and phosphorylation site oscillation that offers a foundational reference for investigating cell cycle regulation. These data reveal regulatory intricacies including proteins and phosphorylation sites exhibiting cell cycle-dependent oscillation, and proteins targeted for degradation during mitotic exit. Integrated with complementary resources, our data link cycle-dependent abundance dynamics to functional changes and are accessible through the Cell Cycle database (CCdb), an interactive web-based resource for the cell cycle community.
Similar content being viewed by others
Introduction
The eukaryotic cell cycle is a highly regulated sequence of events that culminate in cell division1. It involves a complex network of regulatory proteins that ensure accurate progression through each phase of the cell cycle. Many of these proteins act in checkpoints, monitoring DNA replication and ensuring that the two daughter cells inherit an equal and identical set of chromosomes. Disruption of this intricate regulatory system can have catastrophic consequences, including uncontrolled cell proliferation and aneuploidy that are characteristics of diseases such as cancer. The cell cycle is regulated at multiple levels to ensure proper progression and control. One of the key mechanisms is the balance between transcription, translation and protein degradation2, crucial for the temporal and spatial regulation of protein expression during specific stages of the cell cycle. In parallel, kinases and phosphatases work antagonistically with each other to dynamically control the phosphorylation state of individual proteins3.
Since the discovery of cyclins over 40 years ago4, significant progress has been made in understanding the role of protein and phosphorylation oscillation in cell cycle progression. Decades of low-throughput experiments have uncovered waves of protein and phosphorylation abundance changes that robustly order the events required for cell division. However, a significant challenge lies in accessing scattered data and integrating the diverse findings from various studies across multiple experimental setups. Therefore, over the last years, several groups have investigated cell cycle regulation using Mass Spectrometry (MS) and provided valuable insights into the dynamic changes in protein and phosphorylation that occur throughout the cell cycle5,6,7,8,9. While these datasets provide a robust foundation to investigate cell cycle dynamics, they have inherent limitations: the use of cancer cell lines, which may not accurately reflect the normal processes of the cell cycle and the limited set of cell cycle phases collected through each study. Moreover, despite our growing understanding of protein dynamics in the cell cycle, there is still a significant gap in our knowledge when it comes to phosphorylation events, which are more technically challenging to detect and study in detail8. Consequently, data from multiple datasets must be combined for a broad understanding of cell cycle processes.
Several studies have used chemical synchronisation to collect cells in different cell cycle stages10,11,12. However, these methods are often associated with a negative impact on the cell cycle and increased DNA damage10. One way to address these challenges is through the use of fluorescent cell cycle reporters, such as the FUCCI system5,7. Although these reporters overcome the need for synchronisation, data collection is often limited by the low number of cells processed at different stages of the cell cycle. Therefore, induction synchrony remains the most widely used approach due to its accessibility, efficiency and ability to preserve cell viability. The CDK4/6-targeting inhibitor palbociclib has emerged as an effective and reversible tool to induce highly synchronised cell populations with minimal impact on the cell cycle by arresting cells at the natural restriction point12,13. The high degree of synchrony achieved through palbociclib offers a robust framework for exploring the mechanisms of cell cycle regulation.
In this study, we present a high resolution quantitative proteomic and phosphoproteomic analysis of cell cycle progression that integrates data from other studies to provide a comprehensive resource. We use the hTERT-immortalised retinal pigment epithelial (RPE-1) cell line, which has a complete set of cell cycle regulators and is widely recognised as a model for studying cell cycle processes14. We provide a map of the protein and phosphorylation dynamics through the cell cycle by performing deep MS analysis across seven distinct stages of the cell cycle after synchronisation with a palbociclib-induced reversible arrest. Additionally, we employed a prometaphase arrest and release into G1 phase to investigate events occurring during mitotic exit. These datasets include abundance profiles for thousands of proteins and phosphorylation sites, providing a valuable resource for studying the intricate regulatory mechanisms governing cell cycle progression. Through the analysis of the resulting temporal profiles, we identified a high-confidence set of proteins exhibiting Cell Cycle-Dependent (CCD) abundance changes, establishing a gold standard reference for investigating cell cycle regulation. We validate degradation mechanisms for under characterised cell cycle proteins and show that a significant proportion of proteins with CCD oscillation patterns have no clear mechanism for targeted degradation. Finally, we characterise the context of CCD phosphorylation sites to predict protein interactions modulated in a CCD manner. The analysis is accompanied by the Cell Cycle database (CCdb), an online platform that enables easy access and exploration of the proteins or phosphorylation abundance profiles. The CCdb provides an in-depth resource for the cell cycle community to unravel the complexity of cell cycle regulation.
Results
High resolution time course proteomic and phosphoproteomic analysis of cell cycle progression in RPE-1 cells
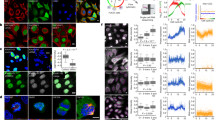
To capture the protein and phosphorylation dynamics during cell division in non-transformed hTERT-immortalised human retinal pigment epithelial (RPE-1) cells, we coupled reversible cell cycle inhibition arrest with isobaric peptide labelling (TMT) quantitative MS. Cells were synchronised with palbociclib, a CDK4/6 inhibitor that arrests cells at the restriction point in late G1 and has recently been shown to generate a synchronous cell cycle upon inhibitor withdrawal12. To generate a high temporal resolution cell cycle profile, we collected eight time points corresponding to different cell cycle phases: palbociclib arrest, late G1, G1/S, S, S/G2, G2, G2/M and M/G1 (Fig. 1A, Supplementary Fig. 1A). The cell cycle phase for each timepoint was defined by a combination of flow cytometry profiles and protein abundance data from the MS analysis. Two biological replicates were collected for each cell cycle phase. Cell synchronisation efficiency was assessed by monitoring DNA content changes over time using flow cytometry before performing MS analysis (Fig. 1B). We found that synchrony persisted after release from palbociclib arrest, with G1 cells constituting only a small percentage (8–16%) in the time points corresponding to S and G2/M phases (Supplementary Data 1). Synchronised cells were lysed, proteins digested with trypsin and peptides labelled with the TMTpro 16-plex reagents. For phosphoproteomics profiling, phosphopeptides were enriched using an Fe-NTA metal affinity resin and the flow-through fraction was used for proteomic analysis.

A General experiments workflow of cell synchronisation coupled to MS analysis. Cells were arrested in late G1 with palbociclib (Palbo) and time points corresponding to different cell cycle phases were collected upon release from the inhibitor. Sample aliquots were fixed and DNA was stained with propidium iodide for flow cytometry. For MS analysis, cells were lysed and protein digested with trypsin, followed by TMT labelling and phosphopeptide enrichment. B Flow cytometry analysis assessing DNA content at each time point. C Principal component analysis of the log2 mean normalised abundances (Supplementary Data 2) for each replicate from each time point from the proteomic data. Colour represents time point. Replicates are labelled in each circle. The loading (i.e. how much each original sample contributes to each principal component) are available in Supplementary Data 1. D Principal component analysis of the phosphoproteome, as described for (C). The loading (i.e. how much each original sample contributes to each principal component) are available in Supplementary Data 1. E Comparative analysis of our proteomics data with previously published cell cycle studies5,6,7,8,9,15. For each dataset, the coverage of the human proteome (based on the 20,377 UniProt reviewed human proteins) and the number of proteins associated with the Gene Ontology (GO) term ‘mitotic cell cycle process’ detected are listed. Cyclins identified in each study are shown with circles.
We quantified 8352 proteins across the different cell cycle phases with high reproducibility within replicates (Fig. 1C, Supplementary Fig. 1B) covering a substantial proportion of the human proteome (nearly 41%), including 385 proteins associated with the Gene Ontology (GO) term ‘mitotic cell cycle process’ (Fig. 1E, Supplementary Data 1). Additionally, we detected 15,424 phosphorylation events, with 13,299 confidently assigned to a specific residue, also exhibiting high reproducibility within the replicates of each time point (Fig. 1D). When comparing our dataset with other large-scale cell cycle studies using different cell lines (Olsen et al.8 (HeLa S3), Ly et al.5 (NB4), Ginno et al.6 (798G), Becher et al.9 (HeLa), Herr et al.7 (HeLa FUCCI), Mahdessian et al.15 (U2OS FUCCI) Supplementary Fig. 1C), we not only identified a wider range of cell cycle regulators but also provided higher temporal resolution than cell synchronisation-based large-scale datasets, thus enabling an accurate representation of protein oscillation dynamics (Supplementary Fig. 1D). This dataset, defined as the ‘Time Course dataset’, represents a detailed characterisation of the protein and phosphorylation dynamics during the cell cycle.
Defining protein and phosphorylation oscillations during the cell cycle
Since changes in protein and phosphorylation abundance determine the temporal progression of the cell cycle, we focused our analysis on the oscillatory behaviour of these changes during the first cell cycle after release. To define these oscillatory patterns, we used a curve-fitting model combined with ANOVA statistical analysis. The curve fitting model finds the curve that best fits a series of data points and provides a curve fold change score that describes to what extent protein and phosphorylation abundance changes over time. The curve fitting models take advantage of the continuous nature of the temporal data increasing robustness against outliers resulting from non-sequential changes thereby reducing noise and providing more reliable trend assessments.
As shown in Fig. 2A, we applied the two-step approach to define CCD oscillators in our proteomics and phosphoproteomics dataset. Then, based on the abundance pattern observed during the different stages of the cell cycle, proteins and phosphorylation events were categorised as oscillating and stable (Fig. 2B, C). We first performed ANOVA analysis and found 459 proteins and 5,207 phosphorylation events showing clear changes between different cell cycle phases and positive correlation between replicates (q ≤ 0.01). Next, using the curve fitting model we calculated the curve fold change for each protein and phosphorylation site (Supplementary Data 2). We found that 306 of 8352 (3.7%) proteins and 2268 of 13,299 (17%) phosphorylation events exhibited changes greater than 20% over the cell cycle (curve fold change ≥ 1.2, Supplementary Data 2). In contrast, 5466 (65%) proteins and 593 (4.5%) phosphorylation events showed no significant difference within the different time points (ANOVA q ≥ 0.01, standard deviation ≤ 0.05). The cut-offs applied to define each category were calculated based on GO term enrichment analysis to determine biologically significant changes (Supplementary Data 3). Among the oscillating proteins, we identified several cyclins (i.e. CCND1, CCND3, CCNE2, CCNA2, CCNB1) (Fig. 2D, E) and other well-known cell cycle regulators including CDK inhibitors (CDKN1A and CDKN1B), kinases (PLK1, AURKA and AURKB) and proteins regulating cell cycle checkpoints including WEE1, PKMYT1, CDC25A, CDC20 and PTTG1 (Supplementary Fig. 2A, B)1. Within the oscillating phosphorylation events, we observed numerous well characterised cell cycle-regulated phosphorylation events including the activating Thr161 and inhibitory Tyr15 phosphorylation sites of CDK1 increasing in G2/M16 (Fig. 2H, I). As expected, oscillating proteins and phosphorylation events were enriched for cell cycle-related GO terms (Fig. 2F, L, Supplementary Data 4).

A Simplified data analysis workflow used to define oscillating proteins and phosphorylation sites. B Scatter plot summarising proteomics results shows the log2 curve fold change (oscillation score) and the −log10 q-values from the ANOVA test. Significantly oscillating proteins are shown in blue and non-significant proteins are in grey. Dotted lines represent cut-offs used to define oscillating proteins (ANOVA q ≤ 0.01, curve fold change ≥ 1.2). Well-known cell cycle-regulated proteins are highlighted. C Scatter plot summarising phosphoproteomics results shows the fitted log2 curve fold change and the −log10 q-values from the ANOVA test. Significantly oscillating phosphorylation sites are shown in red and non-significant phosphorylation sites are in grey. Dotted lines represent cut-offs used to define oscillating phosphorylation events (ANOVA q ≤ 0.01, curve fold change ≥ 1.2). Well-known cell cycle-regulated phosphorylation sites are highlighted. D Heatmap showing well-known cell cycle-regulated protein changes during the cell cycle detected by MS. Protein changes are coloured according to their abundance (log2 mean normalised values). E Western blot validation of the protein changes is shown in (D). F Fisher’s exact test Gene Ontology (GO) analysis of the set of oscillating proteins. The top three significantly enriched terms for each category (Reactome, Biological Processes, Molecular Function and Cellular Components) are shown. G Overlap of the set of oscillating proteins with those detected in other studies. H Heatmap showing well-known cell cycle-regulated CDK1 phosphorylation changes during the cell cycle identified by MS. Phosphorylation changes are coloured according to their abundance (log2 mean normalised values). I Western blot validation of the phosphorylation changes shown in (H). J Fisher’s exact test Gene Ontology (GO) analysis of oscillating phosphorylation sites. The top three significantly enriched terms for each category (Reactome, Biological Processes, Molecular Function and Cellular Components) are shown. K Overlap of the set of oscillating phosphorylation sites with those detected in other studies. Western blots shown in (E, I) are representative of at least three independent experiments with similar results. Source data are provided as a Source Data file.
Compared to two large-scale time course studies defining cell cycle oscillating proteins7,15, our dataset revealed 211 proteins exhibiting previously uncharacterised changes in abundance during cell cycle progression (Fig. 2G, Supplementary Data 2). The biological role of this subset of oscillators was assessed using GO term analysis to investigate their functional relevance. This analysis revealed a significant enrichment for protein associated with the ‘cell cycle’ GO term (90 proteins, sig = 1.5 × 10−46), confirming that many of these oscillators play a role in cell cycle regulation. Our data also included 95 proteins overlapping with one other cell cycle dataset7, and 37 proteins were observed across all three studies7,15 (Fig. 2G, Supplementary Data 2). The largest overlap was observed with the Mahdessian et al. oscillating set (71.1%, 59/83). The 24 proteins defined as oscillating only in the Mahdessian et al. set included proteins that were not observed in our proteomic data (e.g. DBF4 and MYBL2), proteins that were oscillating without statistical significance (e.g. SGO1), or proteins where we observed a distinct paralogue as an oscillating protein (e.g. D- and E-type cyclins). There was a smaller overlap with the Herr et al. oscillating set (42.7%, 73/171), however, we noted that the majority of proteins from this study were not observed in other datasets (55.6%) and these unique proteins were not enriched for ‘cell cycle’ GO terms (16 proteins, sig = 0.0023). The phosphoproteomic dataset revealed a greater amount of heterogeneity across various studies compared to proteomic data (Supplementary Fig. 1C). Comparison with two large-scale studies defining cell cycle oscillating phosphorylation events8,17 revealed only 212 oscillating phosphorylation events were also detected in these two datasets (Fig. 2K, Supplementary Data 2).
Protein and phosphorylation changes during mitotic exit
Our proteomics and phosphoproteomics analysis of cell cycle progression revealed that CDK4/6 inhibitor withdrawal provides a high degree of synchrony from late G1 to G2. However, because cells tend to differ in the rate at which they go through the cell cycle, synchrony was less robust at the entry to mitosis. As a result, investigating the changes occurring in mitosis with this synchronisation approach is challenging. Therefore, to improve our resolution from M to G1, we arrested cells in prometaphase using the Eg5 inhibitor Dimethylenastron (DMA) and subsequently released them to complete mitosis and progress into early G1. To prevent potential mitotic defects resulting from prolonged DMA treatment, cells were first synchronised in late G1 with palbociclib before DMA treatment in G2. In this analysis, we also included cells synchronised with serum deprivation to investigate the protein signatures of cells in G1 without the use of chemical agents. As shown in Fig. 3A and Supplementary Fig. 3A, this additional cell cycle dataset includes the following cell cycle phases: palbociclib arrest (late G1)—DMA arrest (prometaphase)—DMA release (early G1)—serum starvation arrest (G0)—serum starvation release (G1), defined as the ‘Arrest/Release dataset’. As in the Time Course dataset, synchronised cells were lysed, proteins digested with trypsin and peptides labelled with the TMTpro 16-plex reagents in three biological replicates. For phosphoproteomics profiling, phosphopeptides were enriched with an Fe-NTA metal affinity resin and the flow-through fraction was used for proteomics analysis. Before MS analysis, the efficiency of cell synchronisation was evaluated by monitoring changes in DNA content over time using flow cytometry (Supplementary Fig. 3B).

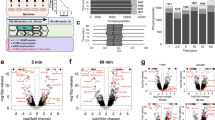
A Experimental workflow of cell synchronisation coupled to MS analysis. G2 phase cells pre-synchronised in G1 with palbociclib (Palbo) were incubated with DMA for 4 h. Prometaphase-arrested cells were harvested by mitotic shake-off and released in fresh medium. 5 h after release, early G1 cells were collected. For MS analysis, cells were lysed and protein digested with trypsin, followed by TMT labelling and phosphopeptides enrichment. B Simplified data analysis workflow used to define proteins and phosphorylation events significantly changing in prometaphase arrest and early G1. C Volcano plot showing limma adjusted p-values versus absolute limma log2 fold change of protein abundance in prometaphase arrest and early G1. Statistically significant proteins are shown in blue, non-statistically significant proteins are shown in grey. Dotted lines represent cut-offs used to define oscillating proteins (limma adjusted p ≤ 0.01, log2 fold change ≥ |0.5|). CCNB1 is significantly enriched in prometaphase arrest. D Volcano plot showing limma adjusted p-values versus absolute limma log2 fold change of phosphorylation sites abundance in prometaphase arrest and early G1. Statistically significant phosphorylation sites are shown in red, non-statistically significant phosphorylation sites are shown in grey. Dotted lines represent cut-offs used to define oscillating phosphorylation events (limma adjusted p ≤ 0.01, log2 fold change ≥ 1). Phosphorylation at Ser670 of BUBR1 is significantly enriched in prometaphase arrest. E Fisher’s exact test Gene Ontology (GO) analysis of proteins significantly changing in the Mitotic Exit dataset. The top three significantly enriched terms for each category (Reactome, Biological Processes, Molecular Function and Cellular Components) are shown. F Heatmap showing oscillating proteins detected in the Time Course dataset clustered based on the abundance profile of known cell cycle markers using T-distributed stochastic neighbour embedding. Protein changes are coloured according to their abundance (min-max normalised values). Bar plot on the right shows curve fold change (oscillation score) in grey and proteins significantly differentially expressed in prometaphase or early G1 in the Mitotic Exit dataset in blue. Clusters are grouped by colour and their respective reference protein is reported on the right. G Scatterplot comparing protein changes in the Mitotic Exit (fold change) and Time Course datasets (curve fold change). Statistically significant proteins are shown in blue, non-statistically significant proteins are shown in grey. Point size denotes −log10 q-values from the Time Course dataset. Representative cell cycle markers are labelled and proteins from the Cell Cycle-Dependent (CCD) set are coloured blue. H Overview of the datasets presented in this study. The Time Course dataset covers seven cell cycle stages from late G1 to M/G1. The Mitotic Exit dataset involves prometaphase arrest and early G1. The Cell Cycle-Dependent (CCD) set is defined as the union of proteins and phosphorylation sites that exhibit changes in the Time Course and Mitotic Exit datasets. The total number of proteins and phosphorylation sites in each dataset is shown.
TMT-based analysis revealed 8555 proteins and 17,785 phosphorylation sites, quantified with strong correlation between the three replicates (Supplementary Fig. 3C, Supplementary Data 5). Comparison between the G0 and G1 phases from Serum Starvation arrest and release, in the ‘Serum Starvation dataset’, revealed minimal changes. However, in line with previous studies18, we observed a significant depletion in CCND1 levels and an enrichment in CDKN1B expression in the serum starvation arrest compared to the release samples (Supplementary Fig. 3D). The G1 phase in the serum starvation dataset, while comparable to that of the palbociclib-arrested cells, represents a distinct stage within G1. For instance, CCND1 and CDKN1B levels remained unchanged, whereas CCNA2 was higher in the palbociclib-arrested cells, indicating a later phase of G1 (Supplementary Fig. 3E). As expected, pronounced changes were observed when comparing the prometaphase arrest to the early G1 phase in the DMA Arrest/Release experiments, defined as the ‘Mitotic Exit dataset’. Consistent with the dynamic nature of regulatory processes mediated by phosphorylation during mitosis, we found a significant difference in the overall levels of phosphorylation sites recognised by a phospho-CDK antibody between prometaphase and early G1 (Supplementary Fig. 3F). To address this discrepancy, we corrected the total intensity of phosphopeptides in the DMA arrest samples based on the stable phosphorylation sites detected in the Time Course set (Supplementary Fig. 3G, see ‘Methods’). Next, to identify proteins and phosphorylation events strongly modulated at the M to G1 transition we employed a limma statistical analysis and defined cut-offs based on the enrichment of ‘cell cycle’ GO term (Fig. 3B, Supplementary Data 3). Using this approach, we identified 169 proteins and 5,046 phosphorylation sites differentially expressed between prometaphase or early G1 phase (limma adjusted p ≤ 0.01, absolute limma fold change ≥ |0.5|, Fig. 3B, Supplementary Data 5). Among the significantly changing proteins, we detected numerous known Anaphase-promoting Complex/Cyclosome (APC/C) substrates. For example, CCNB1 was significantly enriched in prometaphase arrest compared to early G1, consistent with its metaphase degradation required to exit from mitosis19 (Fig. 3C). We also detected significant changes for several well-characterised CCD phosphorylation sites, including the enrichment of BUB1 phosphorylation at Ser670 during prometaphase (Fig. 3D). BUB1 is known to be phosphorylated at kinetochores at the beginning of mitosis and subsequently dephosphorylated before anaphase to facilitate proper chromosome alignment and error correction20. Proteins significantly changing in the Mitotic Exit set showed significant enrichment of GO terms related to cell cycle processes, chromosome segregation and spindle organisation (Fig. 3E, Supplementary Data 6).
Comparing time course and mitotic exit datasets
Given that the Mitotic Exit set introduced additional complementary data to the Time Course dataset, we anticipated a substantial overlap, especially among proteins peaking in mitosis. Therefore, we first clustered oscillating proteins identified in the Time Course dataset based on their abundance profile similarity with known cell cycle markers (Fig. 3F, Supplementary Data 7). Reference proteins used in this analysis were CCND1, CCNE2, MYB, GMNN, CCNA2 and CCNB1. Next, we annotated each of the clustered proteins with their corresponding abundance changes from the Mitotic Exit dataset. Overall, the largest clusters (i.e. CCNA2 and CCNB1) comprised proteins peaking in mitosis in both proteomics datasets. In contrast, clusters corresponding to proteins peaking in late G1, G1/S and S were under-represented in our analysis, suggesting that protein oscillation changes are modest in the early stages of the cell cycle. Furthermore, protein abundance profiles clustered into different temporal ‘waves’ of oscillation. Although the majority of the proteins peaked at the end of the cell cycle, specific protein clusters started accumulating at different cell cycle phases. For instance, proteins found to cluster with GMNN increased from G1/S phase, while protein clustering with CCNA2 started to rise from S, despite both clusters reaching their peak in G2/M. GO term enrichment analysis for each cluster revealed an overall enrichment in the expected cell cycle phase-specific terms (Supplementary Data 7). For example, the CCNE2 cluster was enriched for ‘cell cycle G1/S phase transition’, the MYB and GMNN cluster for ‘DNA replication’, the CCNA2 cluster for ‘chromosome organisation’ and the CCNB1 cluster for ‘chromosome segregation’. Moreover, the CCNA2 and CCNB1 clusters showed enrichment in mitotic localisation GO terms (kinetochore, spindle and centriole). This cluster analysis also revealed a strong correlation between proteins with high curve fold change scores (oscillation) in the Time Course dataset and fold change in the Mitotic Exit dataset (Fig. 3G), particularly for proteins with increased abundance in mitosis (e.g. CCNA2, CCNB1 and GMNN). However, we also observed overlap between proteins peaking in late G1 in the Time Course and early G1 from the Mitotic Exit dataset (e.g. CDKN1A, CDKN1B, JUNB and CCND1). Similarly to the protein abundance, when comparing the Time Course with the Mitotic Exit dataset a significant overlap was observed at both the protein and phosphorylation level (Supplementary Fig. 3H). Therefore, we combined the Time Course with the Mitotic Exit dataset to define a single Cell Cycle-Dependent (CCD) dataset, defined as the union of differentially regulated proteins and phosphorylation sites identified in each dataset (Fig. 3H). This CCD dataset will be functionally investigated in the next sections. Moreover, the CCD proteins, clustered based on their temporal oscillation profile, discussed in this section can serve as a valuable reference set for investigating and comparing oscillation patterns, providing invaluable insights into cell cycle signatures (Supplementary Data 8).
Biological role of cell cycle-dependent proteins
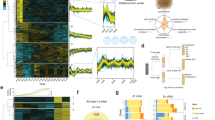
We further characterised the CCD protein set by integrating data on biological function, localisation, protein complexes and gene essentiality to investigate the functional role of protein oscillation during the cell cycle. As expected, given the observed enrichments of the Time Course and Mitotic Exit protein datasets, CCD proteins were highly enriched in cell cycle annotations, cell cycle-specific cellular structures (e.g. the kinetochore) and cell cycle-related pathways (Fig. 4A, full GO terms list Supplementary Data 9). Next, we investigated the oscillation pattern of proteins within the same complex or subcellular localisation during cell cycle progression. We identified proteins belonging to the same complex using the Complex Portal and the CORUM databases21,22, or localising to the same subcellular localisation using GO Cellular Component annotations (Supplementary Data 10). We assessed the variability of protein oscillation within the complexes and subcellular localisation (Fig. 4B), revealing three main classes based on their oscillation patterns23. The first group consisted of stable complexes/localisations with low variability, characterised by consistent protein levels throughout the cell cycle. One example is the general transcription factor complex TFIID, which functions as a general transcription factor for transcription initiation by RNA polymerase II. The second group comprised complexes/localisations that exhibited high oscillation with low variability. In these sets each protein is co-oscillating, for example, the chromosomal passenger complex where each subunit displayed oscillation behaviour through the cell cycle, reflecting its essential role in regulating chromosome segregation and cytokinesis. The third group included complexes/localisations with high variability where only a subset of proteins are cell cycle regulated while the remaining proteins are stable. For example, the median oscillation of proteins localised at the replication fork was relatively small, however, specific components, including ORC6 and GMNN, exhibited strong oscillatory behaviour (Fig. 4B, C). Conversely, other ORC subunits were stable throughout the cell cycle (Supplementary Fig. 4A). Similarly, the scaffolding proteins within the APC/C complex remained constant, while several regulatory subunits oscillated (Fig. 4C and Supplementary Fig. 4A). The APC/C activator CDC20, which plays a crucial role in promoting the degradation of various mitotic regulators, exhibited a strong oscillatory behaviour within the complex together with the ubiquitin-conjugating enzymes UBE2C and UBE2S. Within the kinetochore, a multitude of components were strongly oscillating and peaking in mitosis, including CDC20, MPS1, PLK1, BUB3, BUB1, BUBR1, CENPE, ZWINT, CENPF and KNL1 (Fig. 4C and Supplementary Fig. 4A). These components play critical roles in regulating diverse aspects of kinetochore function, including spindle checkpoint control, microtubule interactions and chromosome attachment. In contrast, the inner kinetochore components, which provide structural integrity and support proper kinetochore function, largely remained stable throughout the cell cycle. Notably, our dataset revealed a distinct oscillation profile for CENPQ, peaking in G2, while its phosphorylation on the Ser50, a site that is required for the recruitment of CENPE to the kinetochore24, was found to peak specifically during mitosis (Supplementary Fig. 4B).

A Fisher’s exact test Gene Ontology (GO) analysis of CCD proteins. The top three significantly enriched terms for each category (Reactome, Biological Processes, Molecular Function and Cellular Components) are shown. B The oscillation of CCD proteins within the same cellular localisation or complex. Scatter plot showing the curve fold change median (global oscillation of proteins within each complex) and standard deviation (global variance in oscillation within each protein group) for protein sets grouped based on Gene Ontology-defined protein localisation (left panel) or proteins within the same complex obtained from CORUM and Complex Portal complexes21,22 (right panel). C Schematic of CCD proteins localised at the replication fork, Anaphase Promoting Complex/Cyclosome and kinetochore. Protein colour indicates protein abundance detected in the Time Course dataset (Dark blue: curve fold change > 2.5; Blue: curve fold change > 1.2; White: curve fold change < 1.2 and standard deviation ≤ 0.05; Dotted grey: not detected). Dotted borders indicate non statistically significant oscillating proteins. Yellow borders with the tag indicate proteins also enriched in prometaphase in the Mitotic Exit dataset. D Heatmaps of the top 14 (according to their curve fold change) kinases and components of the ubiquitin-proteasome system (UPS) detected in the Time Course dataset (top panel). Protein changes are coloured according to their abundance (log2 mean normalised values). In the middle panel, profile plots showing the most significantly oscillating proteins. Number of oscillating (blue) and stable (grey) proteins are shown and proteins validated by Western blot (bottom panel) are in bold. Proteins significantly differentially expressed in the Mitotic Exit dataset are marked with an asterisk. E Venn diagram showing the overlap between oscillating proteins detected in the Time Course proteomics dataset (blue) and oscillating transcripts obtained from Mahdessian et al.15 (purple). The heatmap further classifies the overlapping proteins according to the cell cycle phase they are peaking in our set and in the transcript level. The colour intensity reflects the percentage of proteins peaking at each time point in our dataset, with darker colours representing higher percentages. F Boxen plot comparing oscillating and stable proteins detected in the Time Course proteomics dataset with protein half-life values obtained from a cycloheximide chase proteomics dataset27. Boxen plots show the median (50th percentile) as a central line. The first box shows the interquartile range, covering 50% of the data (25th to 75th percentiles). Each additional box represents a quantile of half the size of the previous quantile (e.g. box 2 covers 25% of the data (12.5th to 87.5th percentiles), box 3 covers 12.5% of the data (6.25th to 93.75th percentiles) and so on). G Essentiality of oscillating proteins detected in the Time Course proteomics dataset. Scatter plot comparing the curve fold change (oscillation score) and mean gene effect obtained from the Cancer Dependency Map resource28. A lower score indicates a higher probability of gene essentiality, with a score of zero indicating that the gene is not required for cell survival, and a score of −0.5 suggesting essentiality in most cell lines. CCD proteins are shown in blue, and non-CCD proteins are shown in grey. Well-known cell cycle markers are highlighted. Boxen plot shows a significant association between protein oscillation and lower mean gene effect scores (two-sided Mann-Whitney p-value: 2.76 × 10−17). Western blots shown in (D) are representative of at least three independent experiments with similar results. Source data are provided as a Source Data file.
To explore the CCD oscillation of regulatory proteins, we focused on specific classes of proteins known to play key roles in cell cycle progression and investigated their oscillation dynamics using the Time Course proteomics data. We classified the CCD proteins into three distinct regulatory classes: protein kinases, components of the ubiquitin-proteasome system (UPS) and transcription factors (TFs). We found that only a subset of these regulatory proteins exhibited oscillatory patterns during the cell cycle. Out of 201 kinases detected, only 16 showed significant oscillation, including CDK1, CDK2 and PLK1 (Fig. 4D, Supplementary Data 2—column Kinase domain containing). Notably, eight of these protein kinases had not been previously reported to oscillate in other studies (CDK1, CDK2, CDK4, WEE1, CHEK1, VRK1, PKMYT1, MASTL)7,15. Interestingly, we observed a continuous increase in the levels of CDKs during S phase, persisting through G2/M phase and confirmed these changes for CDK1 and CDK2 by immunoblot analysis of synchronised cells (Fig. 4D). This observation contrasts with the conventional understanding that CDKs remain stable during the cell cycle and their activity is primarily regulated by cyclins and regulatory phosphorylation. This effect was particularly pronounced for CDK1, in agreement with previous studies which showed that the transcription of CDK1 is cell cycle regulated15,25,26. Among the 482 observed components of the UPS, 24 revealed significant oscillation (Fig. 4D, Supplementary File 2—column UPS components). These included several APC/C components, such as the previously mentioned CDC20 and UBE2S. Immunoblot analysis of synchronised cells confirmed the temporal changes detected by MS and validated the oscillation of the ubiquitin ligase UBR7, not previously described to be cell cycle regulated (Fig. 4D). In contrast to the kinases and UPS components, the oscillation of TFs was generally less pronounced (Supplementary Fig. 4C, Supplementary File 2—column Transcription Factor). Only 14 TFs, including FOXM1, MYB, and JUNB, exhibited high levels of oscillation, consistent with their established role in cell cycle regulation and transcriptional control. Notably, among the 14 CCD TFs detected in our study, only four (FOXM1, MYB, AHR, E2F3) of these were annotated with the ‘cell cycle’ GO term, and none of them had been previously reported to oscillate in other studies7,15.
To further investigate the link between transcription and protein oscillation during the cell cycle, we integrated our Time Course proteomics data with mRNA profiles from the Human Protein Atlas15 (Supplementary Data 11). We found that approximately half of the oscillating proteins (159 out of 306, Supplementary Fig. 5) also displayed oscillations on the transcript level, suggesting there is a strong link with transcriptional regulation (Fig. 4E). Conversely, the remaining oscillating proteins (147 out of 306, Supplementary Fig. 5) were found to have stable transcripts, suggesting that their regulation occurs primarily at the post-transcriptional level and protein stability plays a significant role in determining their CCD expression dynamics. We further integrated protein half-life data obtained from cycloheximide chase experiments27 to gain insights into the contribution of protein degradation to the oscillatory behaviour during the cell cycle (Supplementary Data 8). We anticipated that oscillating proteins would exhibit higher turnover rates compared to non-oscillating proteins. Consistent with our expectations, this analysis revealed a significant difference (Mann-Whitney p-value: 1.6 × 10−14) in protein half-lives between oscillating (mean of 12.1 h, 25.1% less than 5 h) and non-oscillating proteins (mean of 16.8 h, 10.8% less than 5 hours) (Fig. 4F). This observation underscores the impact of protein degradation in shaping the oscillatory behaviour of proteins during the cell cycle.
To explore the essentiality of cell cycle-regulated proteins for cell viability, we investigated the connection between CCD proteins and gene essentiality using the Mean Gene Effect scores obtained from CRISPR gene knockout and cell viability assays available in the Cancer Dependency Map resource28 (Supplementary Data 8). The Mean Gene Effect score represents the likelihood that a particular gene is essential across a diverse set of cell lines, with lower values corresponding to higher essentiality. In agreement with previous findings7, we observed a significant association between protein oscillation and lower Mean Gene Effect scores (Fig. 4G). Among the CCD proteins detected in this study, we found several essential proteins, including CCND1, CCNB1, CCNA2, PLK1, WEE1 and CDC20. Our dataset also revealed some essential proteins not previously reported to oscillate in other studies7,15. These include several components of the replication fork (e.g. GINS1, GINS2, MCM7, MCM6, ORC6, POLD1, POLD3, POLE, POLA2, RFC2 and RFC5). Interestingly, there were also CCD proteins that were not classified as essential for cell viability, such as CCNE2, PCLAF, FOXM1 and MKI67 (Fig. 4G). These findings raise intriguing questions regarding redundancy in protein function and why proteins that have no effect on cell proliferation when knocked out are highly regulated through the cell cycle.
Phosphorylation dynamics driving cell cycle progression
Protein phosphorylation is widely recognised as one of the major mechanisms regulating cell cycle progression29. In this study, we identified a total of 22,305 phosphorylation events in the Time Course and Mitotic Exit datasets. Of these, 6528 phosphorylation sites mapping to 4693 proteins exhibited CCD behaviour (Fig. 5A). This set of phosphorylation events was predominantly on serines (78.6%) and threonines (21.2%) with only a minor fraction occurring on tyrosines (0.1%) (Supplementary Fig. 6A). The vast majority of phosphorylation sites were found within disordered (92.8%) and accessible (92.5%) regions of the proteins (Fig. 5B). We observed no difference in accessibility (Mann-Whitney p = 0.53) or disorder (Mann-Whitney p = 0.41) between the CCD and non-CCD sites. Since functionally important phosphorylation sites have been shown to be more likely to be conserved across different species30, CCD phosphorylation sites were annotated with conservation scores quantifying the degree to which each site is conserved relative to its surrounding regions using the PepTools peptide annotation tool31. Interestingly, we found that non-CCD phosphorylation sites were on average more conserved than CCD phosphorylation sites (Fig. 5C). However, many CCD phosphorylations were highly conserved including phosphorylation events implicated in important cell cycle regulation mechanisms such as the phosphorylation of the Thr395 of CCNE1, which is known to regulate CCNE1 ubiquitination by the Fbw7 regulatory subunit-containing Skp, Cullin, F-box (SCF) E3 Ubiquitin ligase complex and subsequent targeting for degradation32 and the phosphorylation of the kinesin-like protein KIF11 at Thr927, required for spindle association33. We further investigated the taxonomic range of the CCD phosphorylation set and found that 72.4% of the phosphorylation sites were also phosphorylatable residues (S, T or Y) in the aligned position in mouse (M. musculus), 44.5% in fish (D. rerio), 15.6% in fly (D. melanogaster), 3.3% in budding yeast (S. cerevisiae) and 5.5% in plant (A. thaliana melanogaster) (Fig. 5D). Finally, to further investigate the temporal dynamics of phosphorylation regulation during cell cycle progression, we predicted the specific protein kinases responsible for CCD phosphorylation events. Using consensus motifs encoding the specificity of CDK, AURK, PLK and PIKK kinases, we predicted the targeting kinase of each phosphorylation site identified in the study and observed that the mean cell cycle oscillation pattern of phosphosites for a predicted kinase correlated with the activity of that kinase (Fig. 5E). Substrates predicted for CDK exhibited the strongest oscillation, with enrichment beginning in G1/S and peaking late in the cell cycle, reflecting the known dynamics of CDK activity. PLK peaks late in the cell cycle, however, PLK sites accumulate after CDK sites in agreement with kinase activity organisation in sequential waves during the cell cycle. Furthermore, we observed an increase of PIKK substrates during the S phase in line with their known role in the DNA damage response34 despite observing stable protein levels through the cell cycle for ATM and ATR.

A Workflow used to investigate phosphorylation dynamics during the cell cycle. CCD phosphorylation events detected in the Time Course and Mitotic Exit datasets were classified as protein-dependent and protein-independent based on their correlation with protein abundance. Furthermore, CCD phosphorylation events were annotated with structural features to define phosphorylation sites located at protein interfaces and phosphorylated residues that overlapped with known motifs. B Boxen plot comparing accessibility and disorder scores for CCD phosphorylation events. C Boxen plot showing the differences in conservation scores between CCD and non-CCD phosphorylation events, where higher −log10 conservation score values indicate more conserved residues. D CCD phosphorylation sites conservation across different species. The numbers on the right represent the phosphorylation events identified in each species, and the percentage of enrichment is reported. E Heatmap showing the oscillation of phosphorylation sites predicted to be CDK, Aurora, PLK, PIKK and other kinases substrates. Phosphorylation changes are coloured according to their average abundance (log2 mean normalised values). Phosphorylation consensus motifs were obtained from Alexander et al.71. F Heatmaps showing the log2 mean normalised protein (blue) and phosphorylation (red) abundance changes during the cell cycle detected by MS. CDKN1B and NCL are shown as representative examples of protein-dependent and protein-independent phosphorylation events. G Western blot validation of protein abundance changes shown in (F). H Structure of MKI67 bound to NIFK (PDB ID: 2AFF). MKI67 is shown in yellow and NIFK in pink. This interaction is mediated by the phosphorylation of NIFK on Thr234, shown in red sticks. NIFK protein (blue) and pThr234 (red) abundance changes during cell cycle progression detected by MS are shown in the heatmap (bottom). Protein and phosphorylation changes are coloured according to their abundance (log2 mean normalised values). I Structure of KPNA2 bound to TP53BP1 (PDB ID: 6IU7). KPNA2 is shown in light blue and TP53BP1 in purple. This interaction is mediated by the phosphorylation of TP53BP1 on Ser1678, shown in red sticks. TP53BP1 protein (blue) and pSer1678 (red) changes during cell cycle progression detected by MS are shown in the heatmap (bottom). Protein (blue) and phosphorylation changes (red) are coloured according to their abundance (log2 mean normalised values). J Examples of proteins containing motif consensus of phosphorylation sites adjacent to an NLS found in our dataset. Western blots shown in (G) are representative of at least three independent experiments with similar results. Source data are provided as a Source Data file.
Phosphorylation dynamics during the cell cycle can be classified as protein-dependent and protein-independent, based on whether the phosphorylation patterns correlate with changes in protein abundance. To investigate these dynamics, we compared the oscillation profiles of the proteome and phosphoproteome using the CCD dataset (Fig. 5A). We found that 669 phosphorylation sites exhibited protein-dependent oscillation, meaning that their phosphorylation dynamics mirrored protein changes throughout the cell cycle. For instance, we observed a rise in the phosphorylation of Ser10 on CDKN1B from late G1 to S phase closely correlating with the protein level changes (Fig. 5F, G). This phosphorylation has been shown to regulate CDKN1B export from the nucleus to the cytoplasm for proteasomal degradation35,36. In contrast, we identified 5464 phosphorylation sites that exhibited protein-independent oscillation, not directly associated with changes in protein abundance. This suggests that proteins in this category may be more tightly regulated at the phosphorylation level. For example, the protein abundance of the Origin Recognition Complex subunit 2 (ORC2) was largely stable throughout the cell cycle, but the levels of phospho-Thr266 increased from S to M phase (Supplementary Fig. 6C). This phosphorylation event is known to be mediated by cyclin-dependent kinases to control the binding of ORC to chromatin and replication origins37. Similarly, we identified nucleolin (NCL) to be stable throughout the cell cycle, however, several phosphorylation sites were significantly increasing in mitosis. We confirmed these findings by western blot showing the phosphorylation of Thr76 to increase rapidly in G2/M while the protein remained stable (Fig. 5F, G).
To identify phosphorylation events involved in cell cycle regulation, we annotated the CCD phosphorylation sites located at protein interfaces and overlapping with known motifs (Supplementary Data 12). Among the 6528 CCD phosphorylation events observed, we found 162 phosphorylation sites overlapping protein domain-domain interfaces and 214 phosphorylation sites overlapping with motifs (Fig. 5A). One example of CCD phosphorylation sites specifically localised at protein interaction interfaces is Thr234 of NIFK, known to interact with the FHA domain of Ki67 during mitosis38. NIFK is initially phosphorylated by the nuclear kinase CDK1 on Thr238 and subsequently by the cytosolic kinase GSK3 on Thr23439. Importantly, we observed these phosphorylation sites to rise between the S and M phases of the cell cycle (Fig. 5H), suggesting that the interaction between MKI67 and NIFK is temporally-regulated through changes in phosphorylation. An example of CCD phosphorylation sites not previously shown to oscillate during the cell cycle is the interaction between Importin subunit alpha-1 (KPNA2) and TP53-binding protein 1 (TP53BP1). This interaction is essential for the nuclear import of TP53BP1. Previous studies have shown that the phosphorylation of Ser1678 in TP53BP1, which is adjacent to a Nuclear Localisation Signal (NLS), is mediated by CDK1/cyclin B40. Furthermore, the substitution of Ser1678 with aspartate has been shown to reduce the binding affinity between TP53BP1 and KPNA2, leading to impaired nuclear import of TP53BP141. We observed this phosphorylation site to peak from G1/S to G2/M phase, in agreement with the known role of TP53BP1 in DNA double-strand break repair during cell cycle progression (Fig. 5I). Interestingly, CCD phosphorylation sites were observed flanking validated NLSes in several additional proteins involved in various cell cycle mechanisms (Fig. 5J). For instance, we found that the X-ray repair cross-complementing protein 6 (XRCC6) exhibited phosphorylation on the Ser550, a mitosis specific site matching a PLK consensus. This suggests that the oscillation of these phosphorylation sites may play a regulatory role in protein translocation during the cell cycle.
Degradation mechanisms of CCD proteins
Ubiquitin-dependent protein degradation plays a key role in cell cycle progression42. To investigate protein degradation mechanisms of CCD proteins, we cross-referenced the CCD proteomics dataset with a curated set of characterised degrons, a class of motif that recruits an E3 Ubiquitin ligase resulting in substrate ubiquitination and subsequent degradation. We found that 55 out of the 401 CCD proteins contained a previously described degron (Supplementary Data 13). Of these, 42 proteins contained experimentally validated APC/C recognition motifs, mainly D box and KEN box degrons. In most cases, these proteins displayed the canonical abundance profiles observed in APC/C substrates defined by a peak in abundance during mitosis, followed by a pronounced decrease by G143 (Fig. 6A). Within this protein subset, we identified mitotic cyclins (CCNB1, CCNA2) together with several key mitotic regulators (PTTG1/Securin) that are degraded to promote mitotic exit. We also detected a subset of proteins containing experimentally validated degradation motifs, yet exhibiting non-canonical abundance pattern changes for APC/C substrates. These included proteins degraded before mitosis, such as CDC6 and proteins with no abundance changes between DMA arrest and release, such as FOXM1 and CDC25C. These proteins have previously been shown to have a dual mechanism of degradation requiring the activity of both the APC/C and SCF to finely modulate their expression during the cell cycle44,45,46. Furthermore, several validated APC/C degron-containing proteins were not found to oscillate in our dataset (GLS, ID1). We observed distinct behaviours within several closely related proteins. For instance, while PLK1 exhibited high oscillation, PLK2 remained stable throughout the cell cycle. We speculate this difference can be attributed to the absence of a degradation motif in PLK2 (Supplementary Fig. 7A). Among the 55 proteins identified in the CCD dataset with known degradation mechanisms, 13 contained degradation motifs that were not recognised by the APC/C and displayed a distinct oscillation pattern compared to APC/C substrates. These include proteins with PIP degron (CDKN1A, KMT5), β-TrCP degron (WEE1, UHRF1, BORA) and Fbw7 degron (CCNE2, UNG) motifs. Interestingly, for the phosphorylation-dependent Fbw7 degron in Uracil-DNA Glycosylase (UNG), we detected the phosphorylation on Thr60 and Ser64 (Supplementary Fig. 7B) previously shown to promote its degradation suggesting a delay between phosphorylation and degradation47.

A Heatmap showing canonical protein abundance profile for experimentally validated APC/C recognition motifs in both Time Course and Mitotic Exit datasets. Protein changes are coloured according to their abundance (log2 palbociclib arrest normalised values). Degradation motif classes are indicated with different colours. Proteins not detected are shown with a dashed box. B The proportion of CCD proteins with experimentally validated APC/C recognition motifs and established degradation mechanisms (dark grey) versus those without a known mechanism (white). Proteins found to contain unstable peptides in a global peptide stability dataset48 are shown in light grey. C Heatmap showing protein abundance changes for CCD proteins predicted to contain a degradation motif with high confidence and selected for validations. Protein changes are coloured according to their abundance (log2 palbociclib arrest normalised values). D Representative western blot analysis (n = 3) of predicted mitotic APC/C substrates degradation in HeLa cells in the presence (+ANAPC4) and absence (−ANAPC4) of APC/C activity. To allow mitotic exit without APC/C activity the CDK1 inhibitor RO-3306 was added. Known APC/C substrate CCNB1 and SGO2 as well as candidates GTSE1, MELK, FAM38D are stabilised by ANAPC4 depletion and proteasome inhibition with MG132. Source data are provided as a Source Data file.
Out of the 401 CCD proteins identified in this study, only a small subset of 55 were found to contain experimentally validated degradation motifs (Fig. 6B). As a result, the mechanism of degradation for the remaining 346 proteins is still unknown. By integrating proteome-wide peptide stability data into our dataset48, we found that 101 of the proteins without a validated degron also contain peptides that are unstable in global peptide stability assays48, suggesting they are likely to include degradation signals (Supplementary Data 13). The 346 proteins that do not possess known degradation motifs were screened using the PSSMSearch tool49 to predict putative degradation motifs. This bioinformatic approach uncovered 60 regions with high similarity to the consensus of degron motifs known to modulate protein abundance in a CCD manner (Fbw7, β-TrCP, D box, KEN box, ABBA, PIP degrons) (Supplementary Data 13). To validate our predictions, we selected four CCD protein candidates (Fig. 6C) based on statistically robust predictions and other high-confidence attributes such as degron accessibility and match to the canonical motif consensus. Since we previously showed that the depletion of ANAPC4, a crucial subunit of the APC/C results in the stabilisation of known APC/C substrates50,51, we used this approach to validate candidates assessing protein stability upon mitotic release in ANAPC4-depleted or control-treated HeLa cells by western blot analysis (Fig. 6D, Supplementary Fig. 7D). Among the candidates showing strong motif predictions and protein abundance profiles consistent with the canonical APC/C substrate pattern, we confirmed that SGO2 was stabilised by ANAPC4 depletion (half-life: 59.2 versus 248.0 min) and follows a degradation pattern similar to the well-known substrate CCNB1 (half-life: 38.5 versus 538.0 min) in agreement with our previous findings50. However, further experiments are required to validate the SGO2 degradation motif, which we predicted to be a KEN box. Next, we found that GTSE1 accumulated upon APC4 depletion or proteasome inhibition, confirming that it is a mitotic APC/C substrate. Mouse GTSE1 has been previously identified as a KEN box-dependent APC/C substrate52, indicating that this degradation motif is evolutionarily conserved. Within this group we also found proteins, such as MELK, that exhibited partial stabilisation upon ANAPC4 depletion, suggesting that their degradation may be regulated by multiple degradation pathways. Additionally, we identified protein candidates with strong motif predictions that did not follow the canonical APC/C substrate abundance pattern. For example, CHAF1B increased in abundance through the cell cycle but did not exhibit a significant decrease upon prometaphase release in the Mitotic Exit dataset. We found that the degree of depletion we achieved for ANAPC4 was not sufficient to observe stabilisation of CHAF1B, suggesting that it is not regulated through the APC/C but rather through alternative degradation mechanisms that are yet to be defined (Supplementary Fig. 7C). Finally, the majority of our predicted candidates showed protein CCD abundance profiles consistent with APC/C substrates, yet, they did not contain an obvious APC/C degron. For instance, the half-life of the spindle-associated protein FAM83D53 increased from 82.67 min to 228.9 min in ANAPC4-depleted cells (Supplementary Fig. 7E, F) consistent with typical APC/C substrate patterns (Fig. 6D). This observation aligns with other examples of APC/C substrates that lack canonical degradation motifs, such as AURKA and SGO1 which contain a non-canonical D box54,55. This set of proteins with non-canonical degradation motifs raises intriguing questions about the intricacies underlying their degradation mechanisms.
Database
The data produced and collected in this study is available in the CCdb resource (see Supplementary Information for a detailed description). The database holds the cell cycle abundance changes for proteins and phosphorylation sites for the Time Course, Mitotic Exit and Serum Starvation datasets, the respective statistical metrics and the cell cycle dependency status. The data is additionally enriched with external information on protein, phosphorylation site, mRNA abundance and cell cycle dependency from publicly available datasets. Protein level information on stability and degrons is also provided. For phosphorylation sites, annotations on the accessibility, domain and motif overlap, and presence in other publicly available phosphoproteomic datasets are annotated. The CCdb links CCD abundance dynamics to functional changes illuminating the biological role of oscillating proteins and phosphorylation events and is available at https://slim.icr.ac.uk/cell_cycle/.
Discussion
In this study, we present a detailed analysis of protein and phosphorylation changes during the human cell cycle in non-transformed cells. We have characterised a set of 401 cell cycle oscillating proteins with high-temporal resolution and coverage using deep quantitative MS. This cell cycle signature set includes 190 well-known proteins, along with 211 proteins newly found to oscillate during the cell cycle, thus providing a valuable resource for researchers in this field (Supplementary Data 8). Furthermore, we developed the Cell Cycle database (CCdb; https://slim.icr.ac.uk/cell_cycle), a user-friendly web-based resource that allows for interactive exploration of our dataset, thereby providing a valuable tool for the cell cycle research community.
We aimed to address the limitations of previous research by providing a detailed understanding of the protein and phosphorylation changes that occur throughout the cell cycle. Existing datasets have primarily focused on cancer cell lines (Hela7,8,9, NB45, T98G6), which may not closely reflect the normal cell cycle progression56,57. Instead, we used RPE-1 cells, which have been immortalised by the addition of hTERT and contain a normal repertoire of cell cycle regulators. We carefully optimised the conditions to induce robust synchrony while minimising the impact on the cell cycle14. Previous studies have used chemical synchronisation methods such as double thymidine block known to cause DNA damage and chromosomal rearrangements10,11,12 or serum starvation that has been shown to induce cell stress and semi-synchronous re-entry into cell cycle progression58,59. Moreover, FACS-based methods have drawbacks in terms of protein coverage and temporal resolution due to the limited number of cells obtained and the parameters used to collect different cell cycle stages. To overcome these limitations, we used palbociclib-induced synchronisation to investigate global changes throughout the cell cycle. Palbociclib is a CDK4/6 inhibitor shown to efficiently arrest cells before the natural restriction point and generate highly synchronised cell cycle progression upon release12,13. Although it is important to acknowledge palbociclib synchronisation may influence cell cycle timing and impact the protein and phosphorylation profiles observed in this study, we found that using palbociclib arrest is an effective approach to collect a large population of cells in specific phases of the cell cycle, in line with previous reports12,13. However, we observed reduced synchrony towards the end of the cell cycle due to their natural progression through different cell cycle phases. Therefore, we generated an additional dataset specifically focusing on events occurring at mitotic exit by inducing prometaphase arrest with the Eg5 inhibitor DMA and subsequent release into early G1.
Previous studies have identified several cell cycle regulators using MS-based proteomics. However, when comparing existing datasets only a small number of key cell cycle regulators, such as CCNB1, were consistently detected across different studies (Supplementary Fig. 1D). Moreover, due to technical advancements in MS over the last decades, cell cycle proteomics and phosphoproteomics datasets have improved in resolution and allowed for a more precise representation of cell cycle dynamics. As the most recent study, our dataset provides an unprecedented resolution, covering the major cyclins as well as key regulatory proteins throughout critical phases of the cell cycle. We define a set of proteins with oscillating abundance patterns throughout the cell cycle as CCD proteins (Supplementary Data 8). These include well-known and uncharacterised proteins whose cell cycle dynamics were not previously reported or clearly understood. One example is the oscillation of CCND3, showing opposite patterns to CCND1 (Fig. 2D, E). Another intriguing finding is the oscillation of CDKs, which rises from the S to G2/M phase (Fig. 4D, left panel) and contradicts the conventional knowledge that CDKs remain constant throughout the cell cycle but is consistent with previous research showing that CDK1 is regulated at the transcription level15,25. Overall, the majority of the detected proteins remained stable throughout the cell cycle, highlighting that protein abundance represents only one layer of the complex regulation.
Our dataset provides a valuable opportunity to study the regulation of protein degradation during the cell cycle. We not only identified 52 proteins with a well-established CCD degradation mechanism but also revealed several potential substrates of the anaphase-promoting complex/cyclosome (APC/C), a key regulator of protein degradation during mitosis (Supplementary Data 13). We investigate the degradation mechanisms for a set of proteins that we predicted to contain uncharacterised degradation motifs. Among these, we confirmed that GTSE1, MELK and FAM83D are targeted for degradation by the APC/C during mitotic exit (Fig. 6C, D). Interestingly, the majority of the CCD proteins do not have any clear validated or predicted degradation mechanism, suggesting they are regulated through uncharacterised modes of protein degradation. One possibility is that there may be variations of the canonical degradation motifs not yet identified, as most cell cycle-associated degradation motifs (Fbw7, β-TrCP, D box, KEN box, ABBA, PIP degrons) remain poorly characterised, or a undiscovered class of degradation motif. Alternatively, protein degradation might occur through interactions with other proteins containing a degradation motif. A final explanation is cell cycle dependent regulation on the transcriptional or translational level with a constant rate of protein turnover.
While substantial progress has been made in mapping the cell cycle proteome, there is still a considerable lack of knowledge regarding the complexity of the cell cycle phosphoproteome8(Fig. 2M, Supplementary Fig. 3H). Despite technological advancements in the identification of phosphorylations using MS, many cell cycle phosphorylation events remain to be discovered due to their transient nature and technical limitations. Our study uncovers 6528 CCD phosphorylation events, 5464 of which oscillate independently of the protein oscillation underlining the critical role played by phosphorylation in regulating protein function throughout the cell cycle. Of note, the vast majority of these phosphorylation events had not previously been reported to oscillate during cell cycle progression (Fig. 2M). The limited overlap with similar studies indicates that existing phosphoproteomic datasets capture only a fraction of CCD phosphorylation sites, advocating for further studies in this area. The phosphorylation events characterised in the current study include several well-established regulatory phosphorylations, such as the inhibitory and activating phosphorylation of CDK1 (Fig. 2H, I), and numerous CCD phosphorylation sites overlapping known protein interaction interfaces (Fig. 5A). However, the functional role of most CCD phosphorylation events is currently uncharacterised and poses an intriguing opportunity for further investigation considering the potential cell cycle stage-dependent regulation encoded by these sites.
In summary, we present a detailed proteomic and phosphoproteomic analysis of the human cell cycle in RPE-1 cells with high-temporal resolution and coverage. We provide a detailed view of the dynamic changes in the human proteome and phosphoproteome throughout the cell cycle. These data have been made accessible in the Cell Cycle database (CCdb; https://slim.icr.ac.uk/cell_cycle), a web-based resource for the cell cycle community. This cell cycle dataset, along with the associated exploration tools, holds significant potential for diverse applications and provides valuable insights for researchers exploring this fundamental cellular process.
Methods
Cell lines
Human Retinal Pigment Epithelial hTERT (RPE-1) FRT (gender: female) and hTERT RPE-1 mRuby-PCNA (gender: female) cells were a kind gift from Jonathon Pines (ICR, London, UK) and were grown in DMEM/F12 medium supplemented with 10% (v/v) foetal bovine serum (FBS), 1% (v/v) Glutamax, 0.348% sodium bicarbonate and 1% (v/v) penicillin-streptomycin. HeLa Kyoto (gender: female) and HeLa FRT/TR 3xFLAG-Venus-SBP-APC4 + NLS-TIR1/NES-TIR1 + mAID-nanobody (gender: female) cells51 were grown in DMEM supplemented with 10% (v/v) FBS, 1% (v/v) penicillin-streptomycin, 1% (v/v) Glutamax, 0.5 mg/ml Amphotericin B.
Cell synchronisation
For the Time Course dataset, cells were seeded at a confluency of 4.4 × 103/cm2 overnight. Then, palbociclib was added at a final concentration of 150 nM. Upon 24 h incubation with the inhibitor, cells were washed three times with phosphate-buffered saline (PBS) buffer, released in fresh medium and subsequently collected at different time points: 0 h (Late G1 palbociclib arrest), 2 h (late G1 phase), 4 h (G1/S phase), 6 h (S phase), 8 h (S/G2 phase), 10 h (G2 phase), 12 h (G2/M phase) and 15 h (M/early G1 phase). For the Mitotic Exit dataset, cells were first released from palbociclib synchronisation for 10 h (G2 phase) and then incubated with Dimethylenastron (DMA) at 1 μM final concentration. After 4 h, mitotic cells were harvested by shake-off and washed four times in PBS. Then, cells were released in fresh medium and harvested at two time points: 0 h (prometaphase arrest) and 5 h (early G1 phase).
For the Serum Starvation dataset, ~2.5 million cells were seeded in 150 mm plates overnight. The next day, cells were washed three times with PBS and incubated with serum free medium for 24 h. Cells were then released in complete medium and harvested at two time points: 0 h (G0 phase) and 8 h (G1 phase). Synchronised cells were harvested at the indicated time points, washed twice with PBS and stored at −80 °C before MS analysis. Aliquots from each time point were fixed for flow cytometry analysis.
For APC/C substrates validations, HeLa Kyoto cells were synchronised in early S phase by a double thymidine block and release protocol. Briefly, cells at 40% confluency were treated with 2.5 mM Thymidine for 19 h, followed by a release into fresh medium for 12 h and a second thymidine block for 16 h. After the second release cells were collected at the indicated time points.
Sample preparation for proteomics and phosphoproteomics analysis
Pellets from synchronised cells were lysed in 150 μL lysis buffer of 100 mM triethylammonium bicarbonate (TEAB), 1% sodium deoxycholate (SDC), 10% isopropanol, 50 mM NaCl and Halt protease and phosphatase inhibitor cocktail on ice, with 15 s of pulsed probe sonication followed by heating at 90 °C for 5 min and another round of sonication for 5 s. Protein concentration was measured with the Quick Start Bradford protein assay according to manufacturer’s instructions. Protein aliquots of 60 μg were reduced with 5 mM tris-2-carboxyethyl phosphine (TCEP) for 1 h at 60 °C and alkylated with 10 mM iodoacetamide (IAA) for 30 min in the dark. Proteins were digested overnight with trypsin at 75 ng/μL final concentration. Peptides were labelled with the TMTpro-16plex reagents (Thermo Fisher Scientific) according to manufacturer’s instructions. The pooled sample was acidified with 1% formic acid (FA), the precipitated SDC was removed by centrifugation and the supernatant was SpeedVac dried.
High-pH Reversed-Phase peptide fractionation
Peptides were fractionated with high-pH Reversed-Phase (RP) chromatography using the XBridge C18 column (2.1 × 150 mm, 3.5 μm, Waters) on a Dionex UltiMate 3000 HPLC system. Mobile phase A was 0.1% (v/v) ammonium hydroxide and mobile phase B was acetonitrile, 0.1% (v/v) ammonium hydroxide. The TMTpro labelled peptides were fractionated at 0.2 mL/min with the following gradient: 5 min at 5% B, up to 12% B in 3 min, linear gradient to 35% B in 32 min, gradient to 80% B in 5 min, isocratic for 5 min and re-equilibration to 5% B. Fractions were collected every 42 s, combined in 30 fractions and SpeedVac dried.
Phosphopeptide enrichment
Phosphopeptide enrichment was performed in the first 24 peptide fractions with the High-Select Fe-NTA Phosphopeptide Enrichment Kit using a modified protocol in a well plate tip-array format. A volume of 50 μL resin/buffer was transferred on top of 10 μL filter tips that were fitted on a 96-well plate using a tip rack. The resin was washed three times with 40 μL wash/binding solution and centrifugation at 500 × g for 1 min. Peptides were reconstituted in 30 μL wash/binding solution and loaded onto the tip-columns with the resin. After 30 min, the resin was washed three times with wash/binding solution and the flow-throughs were collected in a clean 96-well plate with centrifugation at 500 × g for 1 min each time. Phosphopeptides were eluted twice with 40 μL elution buffer in a clean 96-well plate with centrifugation at 500 × g for 1 min, transferred in glass vials and SpeedVac dried.
Liquid Chromatography (LC) Mass Spectrometry (MS) analysis
LC-MS analysis was performed on a Dionex UltiMate 3000 UHPLC system coupled with the Orbitrap Lumos Mass Spectrometer (Thermo Fisher Scientific). Peptides were loaded onto the Acclaim PepMap C18 trapping column (100 μm × 2 cm, 5 μm, 100 Å) at flow rate 10 μL/min and analysed with an Acclaim PepMap (75 μm × 50 cm, 2 μm, 100 Å) C18 capillary column connected to a stainless-steel emitter. Mobile phase A was 0.1% FA and B was 80% acetonitrile, 0.1% FA. For the phosphopeptide analysis, the separation method was: 60 min linear gradient 5–38% B at flow rate 300 nL/min. For the flow-through analysis a 90 min gradient 5%-38% B was used. MS scans were acquired in the range of 375–1500 m/z with mass resolution of 120 k, AGC 4 × 105 and max IT 50 ms. Precursors were selected with the top speed mode in 3 s cycles and isolated for HCD fragmentation with quadrupole isolation width 0.7 Th. Collision energy was 36% with AGC 1 × 105 and max IT 100 ms (or 86 ms for flow-throughs) at 50k resolution. Targeted precursors were dynamically excluded for further fragmentation for 30 s (or 45 s for flow-throughs) with 7 ppm mass tolerance.
Flow cytometry analysis
Cells were fixed by adding ice-cold 70% ethanol in PBS dropwise to the pellet while vortexing and stored at −20 °C prior to staining. Fixed cells were washed twice with PBS and incubated with propidium iodide and RNase at 37 °C for 20 min in the dark. Stained cells were analysed on a BD LSR II flow cytometer and data acquired using BD FACSDiva software. Data was analysed using Flowjo software.
ANAPC4 depletion assay
To deplete endogenous ANAPC4, we employed a previously established HeLa cell line where endogenous ANAPC4 was fused at its N-terminus with 3× FLAG—streptavidin binding protein (SBP)—monomeric Venus (mVenus). In addition, these cells express nuclear and cytoplasmic localised TIR1 (NLS-TIR1/NES-TIR1) and a GFP-nanobody60 fused to a auxin-inducible degron (mAID-nanobody) to acutely induce ANAPC4 degradation in response to addition of the synthetic auxin analogue 1-Naphthaleneacetic acid (NAA)51. Cells were synchronised at the beginning of S phase with 2.5 mM thymidine for 24 h and released into fresh medium containing 0.5 mM NAA and 245 nM taxol for a total of 13 h. Then mitotic cells were harvested by mitotic shake off, washed twice in warm PBS and released into fresh medium. To allow mitotic exit in the absence of APC/C activity, 9 μM CDK1 inhibitor RO-3306 was added to both NAA-treated (-ANAPC4) and control-treated (+ANAPC4) cells. As indicated, 10 μM proteasome inhibitor MG-132 was added to stabilise substrates to confirm proteasomal degradation. After the indicated time, cells were harvested, washed twice in PBS, snap frozen in liquid nitrogen and stored at −80 °C before further analysis. Cell pellets were extracted for 20 min on ice with PBS containing 400 mM NaCl, 1% TX-100, cOmplete protease cocktail and PhosSTOP tablets (Roche), 1 mM PMSF in 2-propanol, and 250U benzonase (E1014, Millipore), cleared by spinning for 15 min at 12,000 × g at 4 °C on a tabletop centrifuge, followed by the addition of NuPAGE LDS sample buffer with 100 mM DTT, SDS-PAGE and western blot on low-fluorescence PVDF membranes (Millipore). For quantitative western blot analyses fluorescent secondary antibodies and an Odyssey near-infrared scanning system (LICOR) was used. Band intensities were quantified using Imagestudio (LICOR), and data was visualised and analysed for statistical significance with Graphpad Prism 10.0. The half-life was determined by non-linear-phase 1-phase decay curve fitting with GraphPad Prism 10.0 using robust regression and constraining the starting point (Y0) to 1 and the plateau to 0.
Western blot analysis
For total protein and phosphorylation changes validations, cell pellets were lysed in extraction buffer (1% (v/v) Triton X-100, 10 mM Tris-HCl, pH 7.4, 5 mM EDTA, 50 mM NaCl, 50 mM sodium fluoride, 2 mM Na3VO4, supplemented with cOmplete™ EDTA-free Protease Inhibitor Cocktail and Phosstop™- phosphatase inhibitor tablets) by passage through a 26-gauge needle six times. The lysate was incubated on ice for 5 min and then clarified by centrifugation (14,000 × g for 10 min at 4 °C). For ANAPC4 depletion assay, cell pellets were lysed in extraction buffer (PBS/1% Triton-X100 supplemented with cOmplete™ EDTA-free Protease Inhibitor Cocktail, Phosstop™ phosphatase inhibitor tablets and 1 mM DL-Dithiothreitol (DTT)). The lysate was incubated on ice for 25 min, sonicated for 20 s to shear DNA, boiled for 10 min at 95 °C and then clarified by centrifugation (14,000 × g for 10 min at 4 °C). The protein concentration was quantified with a Bradford assay. Proteins were resolved by SDS-PAGE and transferred onto a nitrocellulose or PVDF membrane for immunoblot analysis. After 1 h blocking with 5% milk in TBST at room temperature (RT) for 1 h, membranes were incubated overnight at 4 °C with the following primary antibodies: CCND1 (Santa Cruz Biotechnology, sc-20044, 1:500), CCND3 (Santa Cruz Biotechnology, sc-6283, 1:500), CCNE2 (Santa Cruz Biotechnology, sc-248, 1:500), CCNA (Santa Cruz Biotechnology, sc-271682, 1:500), CCNA (Santa Cruz Biotechnology, sc-596, 1:500), CCNB1 (Santa Cruz Biotechnology, sc-245, 1:500), GAPDH (Santa Cruz Biotechnology, sc-51907, 1:500), CDK1 pT161 (Cell Signalling Technology, 9114, 1:1000), CDK1 pY15 (Cell Signalling Technology, 9111, 1:1000), Alpha Tubulin (Abcam, ab52866, 1:5000), PLK1(Millipore, 05-844, 1:1000), CDK2 (Santa Cruz Biotechnology, sc-163, 1:500), CDK1 (Abcam, ab32094, 1:1000), CDC20 (Santa Cruz Biotechnology, sc-13162, 1:500), UBR7 (Thermo Fisher Scientific, A304-130A, 1:1000), UBE2S (Cell Signalling Technology, 11878, 1:1000), CDKN1B (Dako, M7203, 1:1000), CDKN1B pS10 (Santa Cruz Biotechnology, sc-12939, 1:500), NCL (Abcam, ab22758, 1:2000), NCL pT76 (Abcam, ab168363, 1:1000), CCNB1 (Santa Cruz Biotechnology, sc-245, 1:500), SGO2 (Thermo Fisher Scientific, A301-261A, 1:1000), GTSE1 (Abnova, H00051512-B01P, 1:1000), MELK (Thermo Fisher Scientific, A303-136A, 1:1000), FAM83D (Custom antibody from Erich Nigg, 1:500), ANAPC4 (Thermo Fisher Scientific, A301-175A, 1:1000), Phospho-CDK substrate motif [(K/H)pSP] (Cell Signalling Technology, 9477, 1:1000), JUNB (Proteintech, 10486-1-AP, 1:1000), CHAF1B (Thermo Fisher Scientific, A301-085A, 1:2000), Histone H3 pS10 (Cell Signalling Technology, 3377, 1:1000), Actin (Sigma-Aldrich, A5441, 1:5000). After washed with TBST for three times, membranes were incubated for 1 h at RT with the following secondary antibodies: IRDye 680RD Donkey anti-Rabbit IgG (H + L) (LI-COR Biosciences, 926-68073, 1:10000), IRDye 800CW Donkey anti-Rabbit IgG (H + L) (LI-COR Biosciences, 926-32213, 1:10000), IRDye 800CW Donkey anti-Mouse IgG (H + L) (LI-COR Biosciences, 926-32212, 1:10000), IRDye 680RD Donkey anti-Rabbit IgG (H + L) (LI-COR Biosciences, 926-68073, 1:10000), anti-mouse HRP (Cell Signalling Technology, 7076, 1:2000), anti-rabbit HRP (Cell Signalling Technology, 7074, 1:2000). After washing three times with TBST, blots were detected with an Odyssey infrared scanner or SuperSignal™ West Pico PLUS Chemiluminescent Substrate on an ChemiDoc™ MP Imaging System. Western blot experiments were performed in duplicate and representative blots are shown.
Immunofluorescence
hTERT RPE-1 mRuby-PCNA cells were seeded on glass cover glasses. After 24 h, cells were fixed for 5 min in 4% paraformaldehyde in PBS at RT, permeabilised in 0.1% Triton X-100, 0.02% SDS in PBS for 5 min at RT, blocked in blocking buffer (2% albumin fraction V (Roth, 8076.4) in PBST) for 1 h at RT, and incubated for 1 h with the following primary antibodies: CCNB1 (Santa Cruz Biotechnology, sc-245, 1:500), FAM83D (Custom antibody from Erich Nigg). Afterwards, cover glasses were washed 3 times in PBST, incubated in blocking buffer supplemented with 1 µg/ml Hoechst 33342 for 1 h at RT with secondary antibodies: Alexa Fluor 647 goat anti-mouse (Invitrogen, A-21236, 1:1000), Alexa Fluor 488 chicken anti-rabbit (Invitrogen, A-21441, 1:1000). Then, washed 3 times in PBST, post-fixed in 4% paraformaldehyde, washed once in PBST, and mounted on glass slides using Vectashield mounting medium. Digital images were captured on a Delta Vision wide-field deconvolution fluorescence microscope equipped with a PCO Edge/sCMOS camera (Imsol) at binning = 2, and a Olympus Plan Apo N 60X/NA 1.42 lens (Olympus) objective.
MS data processing
The mass spectra were processed using Proteome Discoverer 2.4 (Thermo Scientific) with the Sequest HT search engine for peptide identification and quantification. Protein quantification was determined by summing the corresponding peptide TMT signal-to-noise values in Proteome Discoverer. The precursor and fragment ion mass tolerances were 20 ppm and 0.02 Da respectively. Spectra were searched for fully tryptic peptides with a maximum of 2 missed-cleavages. TMTpro at N-terminus/K and Carbamidomethyl at C were set as static modifications. Oxidation of M, Deamidation of N/Q and Phosphorylation of S/T/Y were set as dynamic modifications. Spectra were searched against reviewed UniProt Homo sapiens protein entries (version 20apr21), peptide confidence was estimated with the Percolator node and peptides were filtered at q < 0.01 based on target-decoy database search. The consensus search result was filtered to a protein false discovery rate adjusted (FDR) of 0.01 (High) and 0.05 (Medium). External contaminants from the common Repository of Adventitious Proteins (cRAP; https://www.thegpm.org/crap/) set were removed from protein lists before further analysis. The reporter ion quantifier node included a TMTpro quantification method with an integration window tolerance of 15 ppm. Only peptides with average reporter signal-to-noise >3 were used, and phosphorylation localisation probabilities were estimated with the IMP-ptmRS node. Abundances from Proteome Discoverer were processed in Python and R for the Time Course, Mitotic Exit and Serum Starvation datasets. The protein and phosphorylation abundances were normalised by dividing the median intensity for each sample to account for changes in the total cell content during the cell cycle. Abundances of phospho-peptides that corresponded to the same phosphorylation site in the same protein were added to produce a single abundance for each phosphorylation site. Protein and phosphorylation site abundances were subsequently normalised using further approaches to allow specific analyses (described in Supplementary Information).
Defining cell cycle-dependent (CCD) proteins and phosphorylation sites
To define significant protein and phosphorylation changes in the Time Course dataset, we performed one-way ANOVA analysis and corrected p-values using the Benjamini-Hochberg method for multiple hypothesis testing. We then used a polynomial curve to model the oscillation patterns of each protein and phosphorylation site abundance. The 0-max normalised abundance was modelled by a polynomial of degree 2 curve, where y encoded the abundance and x encoded the time points in incrementing steps size 1. The curve was calculated using numpy.poly1d method from the numpy library and curve fold change was calculated, using fitted abundances at the measured timepoints, by dividing the maximum value of the new curve fitted abundance by the minimum curve fitted abundance. Fitted abundances below zero were given a pseudo-abundance of 0.05. CCD proteins and phosphorylation sites were defined for the Time Course dataset based on GO term enrichment analysis on the term ‘cell cycle’ (GO:0007049). Protein curve fold change cut-offs were defined by quantifying the enrichment of the ‘cell cycle’ term at a range of curve fold change or fold change cut-offs in increments of 0.1. Each analysis compared the proteins above that cut-off against all remaining proteins observed in MS data (Supplementary Data 3). Cut-offs were selected so that the CCD set had a significant enrichment of the ‘cell cycle’ term with a p-value less than 0.01. For the Time Course dataset, a curve fold change cut-off of 1.2 (i.e. at least 20% difference between the minimum and maximum abundance) was determined and applied, and further filtering based on adjusted ANOVA p ≤ 0.01 and FDR confidence (FDR ≤ 0.05 for proteins and peptide FDR ≤ 0.01 for phosphorylation) were performed to define the CCD set.
To define significant protein and phosphorylation changes in the Mitotic Exit and Serum Starvation datasets, the three replicates were grouped based on their time points (DMA arrest, DMA release, serum starvation arrest, serum starvation release and palbociclib arrest). First, phosphopeptide abundances in the DMA Arrest were correct to remove the bias introduced by the total intensity in this hyperphosphorylated time point as described in Supplementary Information. Next, time points were paired, and pairwise limma (Linear Models for Microarray Data) analyses were conducted to generate fold changes and adjusted p-values for each protein and phosphorylation site61. Key comparisons included the DMA arrest/release (Mitotic Exit) and Serum Starvation arrest/release. Fold changes and standard errors were estimated by fitting a linear model to the log2 sum-transformed abundance values using the lmFit function in R. The standard errors were then smoothed using the empirical Bayes method with the eBayes function in R. The resulting p-values from the limma analysis were adjusted for multiple testing using the Benjamini-Hochberg method. Protein fold change cut-offs were defined as described for the Time Course dataset. For the Mitotic Exit dataset, a log2 fold change cutoff of 0.5 was determined and applied for proteins and a cutoff of 1 was chosen for phosphorylation sites. The more conservative cut-off for phosphorylation sites reflects the large phosphorylation abundance changes observed in the Mitotic Exit set. Proteins and phosphorylation sites were further filtered with adjusted limma p ≤ 0.01 to define the CCD set.
Stable proteins and phosphorylation sites were defined based on the Time Course data as those with: (i) a standard deviation ≤0.05; (ii) an adjusted ANOVA p > 0.001; and an FDR ≤ 0.05 for proteins and peptide FDR ≤ 0.01 for phosphorylation sites. The standard deviation was calculated on the 0-max normalised abundance data. Finally, for both the Time Course and Mitotic Exit sets, protein-dependent and protein-independent phosphorylation abundance changes were defined. Protein-dependent phosphorylation dynamics refer to phosphorylation events that directly correlate with changes in protein abundance. CCD phosphorylation sites in CCD proteins were characterised as ‘CCD phosphorylation site - protein-dependent’, whereas CCD phosphorylation sites in non-CCD proteins were characterised as ‘CCD phosphorylation site - protein-independent’.
Cluster analysis for protein abundance profiles
Protein abundance profile clustering was performed with the T-distributed Stochastic Neighbour Embedding (TSNE) approach and using the sklearn.manifold.TSNE function from the Scikit-learn library. The TSNE approach converts high-dimensional data into lower dimensions, allowing relationships in complex datasets to be easily extracted. The min-max normalised abundance was calculated on the Time Course CCD protein set. The min-max abundance normalisation defines the minimum value as 0 and the maximum value as 1, and permits comparison of abundance profiles independent of the amplitude of the abundance change. The 16 min-max abundances were collapsed to one dimension. The distance of each protein in the Time Course CCD protein set was calculated to a set of 6 well-known cell cycle markers: cyclin D1, cyclin E2, MYB, Geminin, cyclin A2 and cyclin B1 and the protein was classified to the closest marker’s cluster.
Protein annotation
A range of sources of data were used to functionally annotate the proteins quantified during the analysis. General protein information was retrieved from the UniProt resource. For protein localisation, ‘Cellular Component’ GO term annotations were retrieved from the QuickGO Gene Ontology and Gene Ontology annotation database62. Protein members of complexes were retrieved from the Complex Portal21. Three key regulatory protein classes were defined as follows: (i) Proteins containing a Pfam kinase domain were defined as kinases63; (ii) Proteins matching with the GO Term ‘DNA-binding transcription factor activity’ (GO:0003700) were defined as transcription factors; and (iii) E3 ubiquitin ligases were derived from manual curation. Protein stability information on the mean protein half-life and the proportion of 0 h protein remaining 8 h after cycloheximide addition was retrieved from cycloheximide chase coupled to MS experiments by Li et al.27. A set of validated degron motifs (degrons) was collected, this included APC/C degrons from Davey et al.64, non-APC/C degrons from the ELM database65 and manually curated motifs. A set of peptides containing sequence-dependent degrons was collected from Zhang et al.48, peptides were annotated by Peptools and inaccessible peptides (AlphaFold Accessibility <0.5) were discarded. The Mean Gene Effect scores from a CRISPR gene knockout and cell viability assays were retrieved from the Cancer Dependency Map resource28. Data on a protein’s association with and role in cancer was retrieved from the Cancer Gene Census database (https://cancer.sanger.ac.uk/census) and 299 DRIVE cancer driver genes derived from a PanCancer and PanSoftware analysis were retrieved for66.
Phosphorylation site annotation
The phosphorylation sites quantified during the analysis were annotated with a range of relevant data. Phosphorylation site accessibility and disorder scores are calculated from the DSSP residue accessible surface area of AlphaFold2 models67. Accessibility is the surface accessibility score derived from AlphaFold2 models for the single phosphorylated residue normalised by the maximum possible accessibility for that residue (described in Supplementary Information). The disorder score is a windowed version of the accessibility score, disordered regions contain many contiguous highly accessible residues, and is calculated as the mean accessibility for a region overlapping a given site with flanking regions of 15 amino acids. The cutoff for considering a phosphorylation site as accessible and located in a disordered region was set at 0.4. The taxonomic range of each phosphorylation site was calculated using the PepTools peptide annotation tool31. The taxonomic range was derived from orthologue alignments created using the GOPHER algorithm against the Quest of Orthologs (QFO) protein set. The taxonomic range of each phosphorylation site was annotated based on their conservation in the following model organisms H.sapiens, P.troglodytes, M.musculus, D.rerio, X.tropicalis, D.melanogaster, C.elegans, S.cerevisiae and A.thaliana. A phosphorylation site was defined as conserved in a species when a serine, threonine or tyrosine was present in the same position as the human site in Metazoan ProViz alignments68. The conservation scores used in the analysis were Metazoan WCS_W_p scores calculated using Peptools31,69. The phosphorylation site functional region overlap was tested on two datasets: (i) domain-domain interfaces and (ii) domain-motif interfaces. The set of interaction interfaces was derived from the structurally characterised complexes from the PDB database70. Interface residues were determined as residues with heavy atoms within less than 6 Å distance from another protein chain in structures of protein complexes with 2 or more subunits. Binding partners defined as motifs using in-house software were added to the domain-motif interfaces and the remaining were added to the domain-domain interfaces set. The majority of the domain-motif interfaces set of validated short linear motifs were derived from ELM65 and in-house curated motifs. Finally, phosphorylation sites were annotated for similarity to the specificity determinants of key cell cycle-related kinases. Optimal substrate phosphorylation motifs for each kinase were defined as follows: PLK: ‘[DNE].[ST][FGAVLIMW][GAVLIPFMW]’, CDK: ‘[ST]P.[RK]’, Aurora kinase: ‘R.[ST][GAVLIFMW]’ and PIKK ‘[ST]Q’71. Each phosphorylation site was compared to the regular expressions and matches to one or more consensus was annotated.
Enrichment analysis annotation
Classical enrichment analysis using a Fisher’s exact test to identify enriched functional annotations. The analysis includes GO term (Biological Process, Molecular Function and Cellular Component) and Reactome pathway annotation. Both the protein and phosphorylation datasets analyses are performed on the protein level. All MS data was split into CCD and non-CCD proteins or phosphorylation and CCD enrichment was calculated using Fisher’s exact test with Benjamini-Hochberg False Discovery Rate for multiple test correction was performed using the PANTHER enrichment tool72 with the non-CCD set as the background.
Degrons predictions
Peptides from the ELM DEG (i.e. degron) functional classes were retrieved programmatically from the ELM database65. The degron classes were categorised as CC Degron Class based on their known functional role in the cell cycle. The peptides for each class were aligned with their ELM consensus and converted to PSSM with the PSI-BLAST IC PSSM scoring method. The PSSMs were scanned against the CCD proteins using the PSSMSearch motif discovery software49 with a PSSM p-value cutoff of 0.001. High Confidence Degron predictions were defined as all uncharacterised instances that belong to a CC Degron Class, had a PSSM p < 0.00005, accessibility > 0.5, and disorder score > 0.5.
Publicly available cell cycle datasets
Proteomics and phosphoproteomics data were parsed from the supplementary material of the following studies: Ly et al.5, Ginno et al.6, Herr et al.7, Olsen et al.8, McCloy et al.17 and Becher et al.9. Protein abundance data from immunofluorescence experiments was parsed from the Human Protein Atlas15. Transcriptomics data were parsed from Herr et al.7, Giotti et al.73, Bar-Joseph et al.74, Grant75, Whitfield et al.76, and Pena-Diaz et al.77. Cell cycle transcriptomics data linked to FUCCI fluorescent cell cycle reporter expression was retrieved from Mahdessian et al.15. The TPMs (transcripts per million) for each protein were grouped according to their FUCCI reporter pseudo times into three time points (G1, S and G2/M) and the median TPM value for each time point was taken as the representative TPM. The time point with the maximum median TPM was considered the peak. The CCD status of the proteins and transcripts were taken directly from Mahdessian et al.15.
Additional resources
To facilitate the exploration of the data presented in this study, we have created the CCdb (Supplementary Information). The CCdb is a repository of proteins and phosphorylation sites exhibiting CCD oscillation. The data is enriched with information on protein, phosphorylation site and mRNA abundance, protein localisation, protein complexes, cancer dependency and interaction interfaces. CCdb is available as an interactive web server at https://slim.icr.ac.uk/cell_cycle/.
Software and server implementation
All data processing was performed in Python and R. The CCdb web server interface is written in JavaScript using the React framework. The server side is written as a Python FastAPI Web Framework. Data is stored in a PostgreSQL database. A detailed description of CCdb usage and output is provided on the help page (https://slim.icr.ac.uk/cell_cycle/blog?blog_id=ccdb_help). CCdb has been successfully tested on all major modern browsers.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The mass spectrometry data generated in this study have been deposited in the ProteomeXchange78 database under accession code PXD047266. The processed data are available at the project GitHub page at: https://github.com/ifigenia-t/cell-cycle-analysis. Source data are provided with this paper.
Code availability
Original code for data processing is deposited at Zenodo [https://doi.org/10.5281/zenodo.14796050].
References
Morgan, D. O. The Cell Cycle: Principles of Control (OUP/New Science Press, 2007).
Edfors, F. et al. Gene-specific correlation of RNA and protein levels in human cells and tissues. Mol. Syst. Biol. 12, 883 (2016).
Novak, B., Kapuy, O., Domingo-Sananes, M. R. & Tyson, J. J. Regulated protein kinases and phosphatases in cell cycle decisions. Curr. Opin. Cell Biol. 22, 801–808 (2010).
Hunt, T., Evans, T., Rosenthal, E. T., Youngblom, J. & Distel, D. Cyclin: a protein specified by maternal mRNA in sea urchin eggs that is destroyed at each cleavage division. Cell 33, 389–396 (1983).
Ly, T. et al. Proteomic analysis of cell cycle progression in asynchronous cultures, including mitotic subphases, using PRIMMUS. eLife 6, e27574 (2017).
Ginno, P. A., Burger, L., Seebacher, J., Iesmantavicius, V. & Schübeler, D. Cell cycle-resolved chromatin proteomics reveals the extent of mitotic preservation of the genomic regulatory landscape. Nat. Commun. 9, 4048 (2018).
Herr, P. et al. Cell cycle profiling reveals protein oscillation, phosphorylation, and localization dynamics. Mol. Cell. Proteom. 19, 608–623 (2020).
Olsen, J. V. et al. Quantitative phosphoproteomics reveals widespread full phosphorylation site occupancy during mitosis. Sci. Signal. 3, ra3 (2010).
Becher, I. et al. Pervasive protein thermal stability variation during the cell cycle. Cell 173, 1495–1507.e18 (2018).
Kurose, A., Tanaka, T., Huang, X., Traganos, F. & Darzynkiewicz, Z. Synchronization in the cell cycle by inhibitors of DNA replication induces histone H2AX phosphorylation: an indication of DNA damage. Cell Prolif. 39, 231–240 (2006).
Yang, S. J., Hahn, G. M. & Bagshaw, M. A. Chromosome aberrations induced by thymidine. Exp. Cell Res. 42, 130–135 (1966).
Trotter, E. W. & Hagan, I. M. Release from cell cycle arrest with Cdk4/6 inhibitors generates highly synchronized cell cycle progression in human cell culture. Open Biol. 10, 200200 (2020).
Scott, S. J., Suvarna, K. S. & D’Avino, P. P. Synchronization of human retinal pigment epithelial-1 cells in mitosis. J. Cell Sci. 133, jcs247940 (2020).
Bodnar, A. G. et al. Extension of life-span by introduction of telomerase into normal human cells. Science 279, 349–352 (1998).
Mahdessian, D. et al. Spatiotemporal dissection of the cell cycle with single-cell proteogenomics. Nature 590, 649–654 (2021).
Coulonval, K., Kooken, H. & Roger, P. P. Coupling of T161 and T14 phosphorylations protects cyclin B-CDK1 from premature activation. Mol. Biol. Cell 22, 3971–3985 (2011).
McCloy, R. A. et al. Global phosphoproteomic mapping of early mitotic exit in human cells identifies novel substrate dephosphorylation motifs. Mol. Cell. Proteom. 14, 2194–2212 (2015).
Fan, Y. & Meyer, T. Molecular control of cell density-mediated exit to quiescence. Cell Rep. 36, 109436 (2021).
Clute, P. & Pines, J. Temporal and spatial control of cyclin B1 destruction in metaphase. Nat. Cell Biol. 1, 82–87 (1999).
Huang, H. et al. Phosphorylation sites in BubR1 that regulate kinetochore attachment, tension, and mitotic exit. J. Cell Biol. 183, 667–680 (2008).
Meldal, B. H. M. et al. Complex Portal 2018: extended content and enhanced visualization tools for macromolecular complexes. Nucleic Acids Res. 47, D550–D558 (2019).
Giurgiu, M. et al. CORUM: the comprehensive resource of mammalian protein complexes-2019. Nucleic Acids Res. 47, D559–D563 (2019).
Kimata, Y., Baxter, J. E., Fry, A. M. & Yamano, H. A role for the Fizzy/Cdc20 family of proteins in activation of the APC/C distinct from substrate recruitment. Mol. Cell 32, 576–583 (2008).
Bancroft, J., Auckland, P., Samora, C. P. & McAinsh, A. D. Chromosome congression is promoted by CENP-Q- and CENP-E-dependent pathways. J. Cell Sci. 128, 171–184 (2015).
Dalton, S. Cell cycle regulation of the human cdc2 gene. EMBO J. 11, 1797–1804 (1992).
Barbiero, M. et al. Cell cycle-dependent binding between Cyclin B1 and Cdk1 revealed by time-resolved fluorescence correlation spectroscopy. Open Biol. 12, 220057 (2022).
Li, J. et al. Proteome-wide mapping of short-lived proteins in human cells. Mol. Cell 81, 4722–4735.e5 (2021).
Dempster, J. M. et al. Chronos: a cell population dynamics model of CRISPR experiments that improves inference of gene fitness effects. Genome Biol. 22, 343 (2021).
Ochoa, D. et al. The functional landscape of the human phosphoproteome. Nat. Biotechnol. 38, 365–373 (2020).
Strumillo, M. J. et al. Conserved phosphorylation hotspots in eukaryotic protein domain families. Nat. Commun. 10, 1977 (2019).
Benz, C. et al. Proteome-scale mapping of binding sites in the unstructured regions of the human proteome. Mol. Syst. Biol. 18, e10584 (2022).
Hao, B., Oehlmann, S., Sowa, M. E., Harper, J. W. & Pavletich, N. P. Structure of a Fbw7-Skp1-cyclin E complex: multisite-phosphorylated substrate recognition by SCF ubiquitin ligases. Mol. Cell 26, 131–143 (2007).
Rapley, J. et al. The NIMA-family kinase Nek6 phosphorylates the kinesin Eg5 at a novel site necessary for mitotic spindle formation. J. Cell Sci. 121, 3912–3921 (2008).
Shin, S., Walker, K. A. & Yoon, S.-O. The PIKK-AKT connection in the DNA damage response. Sci. Signal. 15, eabm6211 (2022).
Ishida, N., Kitagawa, M., Hatakeyama, S. & Nakayama, K. Phosphorylation at serine 10, a major phosphorylation site of p27(Kip1), increases its protein stability. J. Biol. Chem. 275, 25146–25154 (2000).
Besson, A. et al. A pathway in quiescent cells that controls p27Kip1 stability, subcellular localization, and tumor suppression. Genes Dev. 20, 47–64 (2006).
Lee, K. Y. et al. Phosphorylation of ORC2 protein dissociates origin recognition complex from chromatin and replication origins. J. Biol. Chem. 287, 11891–11898 (2012).
Takagi, M., Sueishi, M., Saiwaki, T., Kametaka, A. & Yoneda, Y. A novel nucleolar protein, NIFK, interacts with the forkhead associated domain of Ki-67 antigen in mitosis. J. Biol. Chem. 276, 25386–25391 (2001).
Byeon, I.-J. L., Li, H., Song, H., Gronenborn, A. M. & Tsai, M.-D. Sequential phosphorylation and multisite interactions characterize specific target recognition by the FHA domain of Ki67. Nat. Struct. Mol. Biol. 12, 987–993 (2005).
Matsuura, Y. Structural and biochemical characterization of the recognition of the 53BP1 nuclear localization signal by importin-α. Biochem. Biophys. Res. Commun. 510, 236–241 (2019).
von Morgen, P., Lidak, T., Horejsi, Z. & Macurek, L. Nuclear localisation of 53BP1 is regulated by phosphorylation of the nuclear localisation signal. Biol. Cell 110, 137–146 (2018).
Dang, F., Nie, L. & Wei, W. Ubiquitin signaling in cell cycle control and tumorigenesis. Cell Death Differ. 28, 427–438 (2021).
Singh, S. A. et al. Co-regulation proteomics reveals substrates and mechanisms of APC/C-dependent degradation. EMBO J. 33, 385–399 (2014).
Jeffery, J. M. et al. FBXO31 protects against genomic instability by capping FOXM1 levels at the G2/M transition. Oncogene 36, 1012–1022 (2017).
Walter, D. et al. SCF(Cyclin F)-dependent degradation of CDC6 suppresses DNA re-replication. Nat. Commun. 7, 10530 (2016).
Jin, J. et al. SCFbeta-TRCP links Chk1 signaling to degradation of the Cdc25A protein phosphatase. Genes Dev. 17, 3062–3074 (2003).
Hagen, L. et al. Cell cycle-specific UNG2 phosphorylations regulate protein turnover, activity and association with RPA. EMBO J. 27, 51–61 (2008).
Zhang, Z. et al. Elucidation of E3 ubiquitin ligase specificity through proteome-wide internal degron mapping. Mol. Cell 83, 3377–3392.e6 (2023).
Krystkowiak, I., Manguy, J. & Davey, N. E. PSSMSearch: a server for modeling, visualization, proteome-wide discovery and annotation of protein motif specificity determinants. Nucleic Acids Res. 46, W235–W241 (2018).
Bakos, G. et al. An E2-ubiquitin thioester-driven approach to identify substrates modified with ubiquitin and ubiquitin-like molecules. Nat. Commun. 9, 4776 (2018).
Daniel, K. et al. Conditional control of fluorescent protein degradation by an auxin-dependent nanobody. Nat. Commun. 9, 3297 (2018).
Pfleger, C. M. & Kirschner, M. W. The KEN box: an APC recognition signal distinct from the D box targeted by Cdh1. Genes Dev. 14, 655–665 (2000).
Santamaria, A., Nagel, S., Sillje, H. H. W. & Nigg, E. A. The spindle protein CHICA mediates localization of the chromokinesin Kid to the mitotic spindle. Curr. Biol. 18, 723–729 (2008).
Abdelbaki, A. et al. Revisiting degron motifs in human AURKA required for its targeting by APC/CFZR1. Life Sci. Alliance 6, e202201372 (2022).
Karamysheva, Z., Diaz-Martinez, L. A., Crow, S. E., Li, B. & Yu, H. Multiple anaphase-promoting complex/cyclosome degrons mediate the degradation of human Sgo1. J. Biol. Chem. 284, 1772–1780 (2009).
Scheffner, M., Münger, K., Byrne, J. C. & Howley, P. M. The state of the p53 and retinoblastoma genes in human cervical carcinoma cell lines. Proc. Natl Acad. Sci. USA 88, 5523–5527 (1991).
Forbes, S. A. et al. COSMIC: somatic cancer genetics at high-resolution. Nucleic Acids Res. 45, D777–D783 (2017).
Dalman, A. et al. Synchronizing cell cycle of goat fibroblasts by serum starvation causes apoptosis. Reprod. Domest. Anim. 45, e46–e53 (2010).
Fox, M. H., Arndt-Jovin, D. J., Jovin, T. M., Baumann, P. H. & Robert-Nicoud, M. Spatial and temporal distribution of DNA replication sites localized by immunofluorescence and confocal microscopy in mouse fibroblasts. J. Cell Sci. 99, 247–253 (1991).
Saerens, D. et al. Identification of a universal VHH framework to graft non-canonical antigen-binding loops of camel single-domain antibodies. J. Mol. Biol. 352, 597–607 (2005).
Ritchie, M. E. et al. limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 43, e47 (2015).
Huntley, R. P. et al. The GOA database: gene Ontology annotation updates for 2015. Nucleic Acids Res. 43, D1057–D1063 (2015).
Finn, R. D. et al. Pfam: the protein families database. Nucleic Acids Res. 42, D222–D230 (2014).
Davey, N. E. & Morgan, D. O. Building a Regulatory Network with Short Linear Sequence Motifs: Lessons from the Degrons of the Anaphase-Promoting Complex. Mol. Cell 64, 12–23 (2016).
Kumar, M. et al. The Eukaryotic Linear Motif resource: 2022 release. Nucleic Acids Res. 50, D497–D508 (2022).
Bailey, M. H. et al. Comprehensive characterization of cancer driver genes and mutations. Cell 173, 371–385.e18 (2018).
Akdel, M. et al. A structural biology community assessment of AlphaFold2 applications. Nat. Struct. Mol. Biol. 29, 1056–1067 (2022).
Jehl, P., Manguy, J., Shields, D. C., Higgins, D. G. & Davey, N. E. ProViz-a web-based visualization tool to investigate the functional and evolutionary features of protein sequences. Nucleic Acids Res. 44, W11–W15 (2016).
Davey, N. E. et al. SLiMPrints: conservation-based discovery of functional motif fingerprints in intrinsically disordered protein regions. Nucleic Acids Res. 40, 10628–10641 (2012).
Berman, H. M. et al. The protein data bank. Nucleic Acids Res. 28, 235–242 (2000).
Alexander, J. et al. Spatial exclusivity combined with positive and negative selection of phosphorylation motifs is the basis for context-dependent mitotic signaling. Sci. Signal. 4, ra42 (2011).
Mi, H. et al. Protocol Update for large-scale genome and gene function analysis with the PANTHER classification system (v.14.0). Nat. Protoc. 14, 703–721 (2019).
Giotti, B., Joshi, A. & Freeman, T. C. Meta-analysis reveals conserved cell cycle transcriptional network across multiple human cell types. BMC Genom. 18, 30 (2017).
Bar-Joseph, Z. et al. Genome-wide transcriptional analysis of the human cell cycle identifies genes differentially regulated in normal and cancer cells. Proc. Natl Acad. Sci. USA 105, 955–960 (2008).
Grant, G. D. et al. Identification of cell cycle-regulated genes periodically expressed in U2OS cells and their regulation by FOXM1 and E2F transcription factors. Mol. Biol. Cell 24, 3634–3650 (2013).
Whitfield, M. L. et al. Identification of genes periodically expressed in the human cell cycle and their expression in tumors. Mol. Biol. Cell 13, 1977–2000 (2002).
Peña-Diaz, J. et al. Transcription profiling during the cell cycle shows that a subset of Polycomb-targeted genes is upregulated during DNA replication. Nucleic Acids Res. 41, 2846–2856 (2013).
Perez-Riverol, Y. et al. The PRIDE database and related tools and resources in 2019: improving support for quantification data. Nucleic Acids Res. 47, D442–D450 (2019).
Acknowledgements
We thank Luca Cirillo for critical feedback on the manuscript, Eleanor Wendy Trotter for expert assistance on palbociclib synchronisation, Graeme Benstead-Hume for organising the ProteomeXchange data submission, and the cell cycle community for their testing and suggestions for the CCdb resource. We thank Anna Santamaria and Erich Nigg for sharing the FAM83D antibody. We thank the Proteomics, Flow Cytometry, and Light Microscopy and Confocal Microscopy facilities at the ICR. This work was funded by a Cancer Research UK Senior Cancer Research Fellowship to C.R., I.T., N.E.D (C68484/A28159); and J.V. and J.M. (RCCSCF-Nov22/100001).
Author information
Authors and Affiliations
Contributions
C.R. and N.E.D. conceived the study. C.R., I.T., J.P., J.C., J.M. and N.E.D designed the experiments. C.R. performed the sample collection and follow up western blot validation. T.I.R. and L.Y. prepared the samples and performed the mass spectrometry experiments. T.I.R. performed the mass spectrometry data processing. I.T. analysed, integrated and annotated the protein and phosphosite abundance data. C.R., M.P., J.V. and J.M. performed the substrate degradation assays. I.K., I.T. and N.E.D. designed and coded the CCdb resource website. C.R., I.T. and N.E.D. interpreted the results and wrote the manuscript with input from all authors. All authors reviewed, edited and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Anthony Cesnik, Brian Joughin, Michael Yaffe and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Rega, C., Tsitsa, I., Roumeliotis, T.I. et al. High resolution profiling of cell cycle-dependent protein and phosphorylation abundance changes in non-transformed cells. Nat Commun 16, 2579 (2025). https://doi.org/10.1038/s41467-025-57537-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-025-57537-8
