
Abstract
Benzylisoquinoline alkaloids (BIAs) are important metabolites synthesized in early-diverging eudicots and magnoliids, yet the genetic basis of BIA biosynthesis in magnoliids remains unclear. Here, we decode the genomes of two magnoliid species, Saruma henryi and Aristolochia manshuriensis, and reconstruct the ancestral magnoliid karyotype and infer the chromosomal rearrangement history following magnoliid diversification. Metabolomic, transcriptomic, and phylogenetic analyses reveal the intermediate chemical components and genetic basis of BIA biosynthesis in A. manshuriensis. Although the core enzymes involved in BIA synthesis appear to be largely conserved between early-diverging eudicots and magnoliids, the biosynthetic pathways in magnoliids seem to exhibit greater flexibility. Significantly, our investigation of the evolutionary history of BIA biosynthetic genes revealed that almost all were duplicated before the emergence of extant angiosperms, with only early-diverging eudicots and magnoliids preferentially retaining these duplicated genes, thereby enabling the biosynthesis of BIAs in these groups.
Similar content being viewed by others

Introduction
Magnoliids, comprising over 10,000 species, represent a major lineage of flowering plants, contributing approximately 3% to the total species diversity of angiosperms1,2. Magnoliids are divided into four rapidly diverging monophyletic clades: Piperales, Canellales, Magnoliales, and Laurales3. Magnoliids are well-recognized for their rich production of secondary metabolites, which encompass a wide variety of bioactive compounds, including alkaloids, terpenoids, and flavonoids, all of which play important ecological and pharmacological roles4,5,6. Notably, benzylisoquinoline alkaloids (BIAs) are naturally synthesized in both magnoliids and early-diverging eudicots3,5,6,7,8,9. BIAs hold significant pharmacological value, with approximately 2500 structures elucidated to date. Among the most notable compounds are the narcotic analgesic morphine, the cough suppressant codeine, the muscle relaxant papaverine, and the antimicrobial agents sanguinarine and berberine7.
The biosynthesis of BIAs has been well studied in early-diverging eudicots, particularly in Thalictrum flavum (meadow rue), Coptis japonica, and Papaver somniferum (opium poppy)7,10,11,12, and a BIA biosynthetic pathway, referred to here as the classic BIA biosynthetic pathway, has been proposed (Supplementary Fig. 1). This pathway is initiated by (S)-norcoclaurine synthase (NCS), which catalyzes the Pictet-Spengler condensation of dopamine and 4-hydroxydihydrocinnamaldehyde (4-HDCA)13. This reaction is followed by a series of enzymatic steps, involving O-methyltransferase (OMT), N-methyltransferase (NMT), and N-methylcoclaurine 3′-hydroxylase (NMCH), ultimately yielding the core intermediate (S)-reticuline14. The shared-upstream biosynthetic pathway of BIAs includes the conversion of tyrosine to (S)-reticuline, which acts as a central intermediate for various downstream alkaloid branches. Finally, the cytochrome P450 (CYP) enzymes, including CYP719, CYP80, and others, facilitate the formation of methylenedioxy bridges and the coupling of carbon-oxygen phenols, which leads to the production of various types of BIAs15.
In magnoliids, two genomic studies on Aristolochia species have reconstructed potential BIA pathways and identified several candidate genes encoding NCS, OMT, and CNMT enzymes8,16. The BIA pathway identified in P. somniferum (opium poppy) was proposed in the study of Aristolochia contorta16, where several intermediate chemical components and genes were functionally characterized. However, an alternative route was suggested in the study of A. fimbriata, which reconstructed the pathway primarily based on data from previously published isotope feeding experiments8,17,18,19,20. Additionally, the 6OMT, 7OMT, and CNMT genes from Liriodendron chinense have been cloned and experimentally validated for their catalytic functions6. The CNMT and 6OMT genes in A. debilis, as well as the CYP80G7 and CYP80Q8 genes in A. contorta, have also been identified and functionally characterized21,22. However, it remains largely uncertain whether magnoliids possess a similar or expanded BIA biosynthesis pathway compared to early-diverging eudicots. Therefore, further investigation into the BIA pathway in magnoliids is necessary to better understand its origin and evolution in both magnoliids and early-diverging eudicots.
In this study, we present two high-quality genome sequences from the Aristolochiaceae family: A. manshuriensis and Saruma henryi, representing the subfamilies Aristolochioideae and Asaroideae, respectively (Fig. 1a). Both species are traditional medicinal plants. S. henryi, which belongs to Asaroideae, a lineage that is sister to the rest of a broadly defined Aristolochiaceae, is an endangered species in the monotypic genus Saruma. A. manshuriensis represents a highly diverse subgenus within Aristolochia, namely the subgenus Siphisia23. Together with previously published magnoliid genomes, we explored magnoliid genome evolution, encompassing whole-genome duplication events, ancestral karyotype evolution, and gene family diversification. We then characterized and functionally validated the genomic basis of BIA biosynthesis. Finally, we examined the origin and evolutionary history of the BIA pathway, providing insights into why BIA biosynthesis is restricted to early-diverging eudicots and magnoliids.

a Morphology of the flower, fruit, stem, and leaf of S. henryi and A. manshuriensis. Scale bars represent 1 cm. b, c Distribution of genomic features in the assembled S. henryi and A. manshuriensis genomes. Track h was density of intact and solo Ty3/Gypsy elements, while track I was density of intact and solo Ty1/Copia elements. d Insertion times of the bursts of intact LTR retrotransposons for Ty3/Gypsy and Ty1/Copia. e Total number of Ty3/Gypsy- and Ty1/Copia-type LTRs, along with their two main forms (intact LTRs and solo LTRs), in four Aristolochiaceae species. f Phylogenetic trees of Ty3/Gypsy and Ty1/Copia from four Aristolochiaceae species.
Results
The chromosome-level genomes of S. henryi and A. manshuriensis
To produce high-quality genomes for S. henryi and A. manshuriensis, we generated PacBio HiFi reads (S. henryi: 64 Gb; A. manshuriensis: 20 Gb), Nanopore ultra-long reads (S. henryi: 10.8 Gb; A. manshuriensis: 10.5 Gb), and Hi-C data (S. henryi: 362 Gb; A. manshuriensis: 233 Gb) (Supplementary Data 1). Genome size estimates, based on k-mer analysis using short reads, were approximately 2.81 Gb for S. henryi and 525 Mb for A. manshuriensis, with heterozygosity levels of 0.24% and 0.46%, respectively (Supplementary Data 2 and 3). We assembled 2.77 Gb (98.41% of the estimated 2.81 Gb) of S. henryi sequences, achieving contig N50 of 6.40 Mb and scaffold N50 of 238 Mb, with 2.72 Gb (98.40%) anchored onto 12 pseudochromosomes (Supplementary Fig. 2 and Supplementary Data 3–6). For A. manshuriensis, we assembled 563.0 Mb of sequences, with a contig N50 of 9.19 Mb and scaffold N50 of 30.78 Mb. A total of 514.4 Mb (92.89%) of the sequences were anchored onto 16 pseudochromosomes (Supplementary Fig. 3 and Supplementary Data 3–6).
To assess the completeness of the genome assemblies, we used Benchmarking Universal Single-Copy Orthologs (BUSCO)24 and estimated completeness at 90.9% for S. henryi and 97.5% for A. manshuriensis (Supplementary Data 7). Mapping the original reads back to the assembled sequences yielded high mapping rates: approximately 99.6% for PacBio, 100.0% for Nanopore, 95.4% for Illumina genomic reads, and 94% for transcriptomes (Supplementary Data 8 and 9). Additionally, we assembled 19 telomere regions in S. henryi and 31 in A. manshuriensis (Supplementary Data 10). Both genome assemblies demonstrated high accuracy, with CRAQ25 evaluation values of ~94 (R-AQI) and ~92 (S-AQI) for S. henryi, and ~98 for both metrics in A. manshuriensis. The final phred-like Merqury26 QV scores were 45.3 and 40.2, indicating accuracy greater than 99.99%. Collectively, these metrics indicate that the genome assemblies are of high quality (Supplementary Data 11).
We found that transposable elements (TEs) make up a significant portion of the assembled genomes in both S. henryi (87.49%) and A. manshuriensis (67.67%) (Fig. 1b, c and Supplementary Data 12). In total, approximately 54% of TEs in S. henryi and 32% in A. manshuriensis were identified as Gypsy and Copia-type long terminal repeat retrotransposons (LTR-RTs). These percentages are higher than those observed in A. fimbriata and A. contorta, which are approximately 29% and 16%, respectively (Supplementary Data 13). A. manshuriensis experienced two recent bursts of LTR-RTs, occurring approximately 0.51–1 million years ago (Ma) and 6–7 Ma, whereas S. henryi showed continuous LTR-RT proliferation over the past 10 Ma, peaking around 2–4 Ma (Fig. 1d). In S. henryi, Ty3/Gypsy elements were the most abundant LTRs, consistent with the majority of angiosperms. In contrast, Ty1/Copia elements predominated in A. manshuriensis, where most were either solo or truncated LTRs (Fig. 1e, f). Moreover, to further investigate the preferential removal of LTR-RT DNA, we compared the ratios of the numbers of solo-LTRs to paired-LTRs for Copia and Gypsy elements, adopting a similar approach to that proposed by Zhang et al. 27. Our findings revealed that A. manshuriensis and S. henryi exhibited significantly higher proportions of solo-LTRs of Copia, with ratios of 15.69 and 10.75, respectively, compared to those in A. fimbriata and A. contorta, which had ratios of 4.52 and 6.35. Notably, S. henryi had the highest ratio of solo-LTRs to paired-LTRs in Gypsy elements, at 10.51 (Supplementary Data 13), indicating its relatively high efficiency in LTR-RT removal.
We annotated 39,461 and 29,762 high-confidence gene models in the genomes of S. henryi and A. manshuriensis, respectively (Supplementary Data 9, 14–16). Of these, 31,851 genes in S. henryi and 28,681 genes in A. manshuriensis had transcriptome support, with 85.42% and 92.63% of genes functionally annotated (Supplementary Data 17). The annotated genes in S. henryi were significantly longer on average compared to those in A. manshuriensis, likely due to TE insertions within intronic regions (Supplementary Fig. 4). In addition, we found more recently duplicated genes flanked with same types of TEs in S. henryi and A. manshuriensis than those in A. fimbriata and A. contorta. 7215 and 8337 gene pairs exhibited best reciprocal hits in S. henryi and A. manshuriensis, while only 4377 and 4535 gene pairs in A. fimbriata and A. contorta. Among these best reciprocal hits, 4153 (58%) and 4484 (54%) pairs flanked with same type of TEs in S. henryi and A. manshuriensis, whereas only 1619 (37%) and 1290 (28%) flanked with same type of TEs in A. fimbriata and A. contorta. These results indicated that high proportion of TEs in S. henryi and A. manshuriensis might have facilitated recent gene duplications in their genomes.
Phylogeny of Aristolochiaceae
The previously reconstructed phylogenies of Aristolochiaceae are inconsistent, particularly concerning the phylogenetic positions of the subfamilies Lactoridoideae and Hydnoroideae28,29,30,31. Here, we used the two newly sequenced genomes along with new transcriptome data from 13 additional Aristolochiaceae species (Supplementary Data 18, 19). We first identified 1222 mostly single-copy orthogroups (OGs) from 14 representative magnoliid genomes and 2 outgroups, and then incorporated corresponding orthologs identified from the transcriptome data of the 13 Aristolochiaceae species. Based on these 1222 OGs, we found that Hydnoroideae and Aristolochioideae are sister clades (Supplementary Fig. 5). We also collected genomic skimming and Angiosperms353 probe set data for Lactoris fernandeziana (Lactoridoideae)31,32, from which we extracted 992 nuclear genes. We found that these 992 nuclear genes clustered into 752 OGs. Using the ASTRAL-Pro method, we investigated the phylogenetic position of Lactoridoideae and found that it diverged before the clade containing Hydnoroideae and Aristolochioideae (Supplementary Fig. 6). This topology is further supported by our phylogenetic analysis of 38 mitochondrial genes (Supplementary Fig. 7). Therefore, our results support the inclusion of both Lactoridoideae and Hydnoroideae within the Aristolochiaceae family and provide new evidence for their phylogenetic relationships based on nuclear and mitochondrial genes (Fig. 2d and Supplementary Figs. 5–8).

a A. fimbriata shows a 1:2 syntenic ratio with A. manshuriensis and a 1:4 ratio with S. henryi. The horizontal and vertical axes indicate chromosome numbers in the dot plots. b Macrosynteny between the genomes of A. fimbriata, A. manshuriensis, and S. henryi, illustrating intergenomic synteny. syntenic relationships are highlighted, showing two regions in A. manshuriensis and four regions in S. henryi corresponding to a single region in A. fimbriata, marked in red and orange. c KS distributions for paralogues within syntenic blocks (anchor pairs) of A. manshuriensis and S. henryi, as well as for orthologues (reciprocal best hit pairs) among selected Aristolochiaceae species. d The phylogeny of selected magnoliids showing WGDs. Yellow solid circles on the branches indicate WGD events.
WGD history in Aristolochiaceae
WGD is considered a major driving force behind the origin and diversification of angiosperms33,34,35,36. However, the genome of A. fimbriata does not exhibit further WGD events since the origin of extant angiosperms8. To investigate the WGD history in S. henryi and A. manshuriensis, we used the A. fimbriata genome as a reference. We observed 1:2 and 1:4 syntenic ratios when comparing A. fimbriata to A. manshuriensis and S. henryi, respectively (Fig. 2a, b and Supplementary Fig. 9a,c). This indicates that one round of WGD occurred in the lineage of A. manshuriensis and two rounds of WGD occurred in the lineage of S. henryi following their divergence from the A. subg. Aristolochia lineage here represented by A. fimbriata (Supplementary Figs. 9–12).
Further intragenomic synteny analysis revealed large, well-preserved homologous blocks with a 1:1 syntenic ratio across all chromosomes of A. manshuriensis (e.g., chromosomes 1 and 10) (Supplementary Fig. 10a and Supplementary Data 20). The distribution of synonymous substitutions per synonymous site (KS) for A. manshuriensis paralogs exhibited a pronounced peak at approximately 0.21 (Fig. 2c). Additionally, we generated new transcriptome data for other representative species within A. subg. Siphisia as well as for Thottea hainanensis. KS and phylogenomic analyses based on these data were conducted to determine the timing of the WGD event. All A. subg. Siphisia species displayed a similar peak around 0.23 (Supplementary Fig. 13a–d and Supplementary Data 21). The distribution of KS values for orthologs between A. manshuriensis and T. hainanensis showed a peak at ~0.88, indicating that the divergence of A. subg. Siphisia and T. hainanensis occurred prior to the WGD event (Supplementary Fig. 14a). For the 6162 anchor pairs identified across 234 syntenic blocks of A. manshuriensis, 3530 gene pairs duplicated before the divergence of the A. subg. Siphisia, 854 duplicated before the split between the A. subg. Siphisia and Aristolochia, and 1121 gene pairs lacked clear resolution (Fig. 2d, Supplementary Figs. 15–17 and Supplementary Data 22). These results suggest that the WGD event detected in A. manshuriensis occurred after the divergence from T. hainanensis but before the diversification within A. subg. Siphisia (Fig. 2d). Furthermore, for these 6162 anchor gene pairs, Gene Ontology (GO) enrichment analysis identified terms of DNA-binding transcription factor activity and protein phosphatase activity were significantly enriched (Supplementary Fig. 18a and Supplementary Data 23).
We also identified relatively sparse 1:3 self-syntenic blocks in S. henryi and a 1:4 syntenic ratio between A. fimbriata and S. henryi, indicating two rounds of lineage-specific WGDs in S. henryi (Fig. 2a, b, and Supplementary Figs. 9c and 10b). The KS peak for orthologs between Asarum and Saruma was approximately 0.09, while the peak for orthologs between T. hainanensis and the S. henryi (Thottea vs. Asaroideae) was around 1.06 (Fig. 2c, Supplementary Fig. 14b and Supplementary Data 21). For syntenic anchor genes located in the self-syntenic blocks of S. henryi, the KS peak was approximately 0.78, which falls between the peaks of 0.09 and 1.06 (Fig. 2c and Supplementary Fig. 14b). Among the 1263 anchor pairs identified across 127 syntenic blocks in S. henryi, we found that 455 gene pairs duplicated before the divergence of Asaroideae, 118 duplicated before the split of Aristolochiaceae, and 414 had unresolved duplication timing (Fig. 2d, Supplementary Figs. 15-17 and Supplementary Data 24). These findings suggest that the two newly identified WGDs occurred after the divergence from the T. hainanensis lineage but prior to the split between Asarum and Saruma (Fig. 2d). For these 1263 anchor gene pairs, GO terms of DNA-binding transcription factor activity and protein phosphatase activity were also significantly enriched (Supplementary Fig. 18b and Supplementary Data 25).
Ancestral karyotype and paleochromosome evolution of magnoliids
Although the ancestral karyotype and paleochromosome evolution in eudicots and monocots have been extensively studied, the ancestral magnoliid karyotype (AMK) remains largely unexplored. In this study, we sought to reconstruct the high-quality AMK using available genomes from the major orders of magnoliids, including A. manshuriensis, S. henryi, A. contorta, A. fimbriata, and Piper nigrum from Piperales; L. chinense and Magnolia biondii from Magnoliales; Litsea cubeba, Cinnamomum camphora, C. kanehirae, and Chimonanthus salicifolius from Laurales; as well as the genome of Amborella trichopoda (Supplementary Data 11).
We inferred ancestral karyotypes using the principle of maximum parsimony, aiming for the fewest structural changes, proceeding through seven main steps (Fig. 3a, Supplementary Fig. 19 and Supplementary Note 1). Orthologous regions and WGD-derived syntenic regions were identified through inter- and intra-genomic comparisons, followed by identification of contiguous syntenic regions (CSRs). Relationships among CSRs were used to infer conserved ancestral regions (CARs). Finally, using these CARs, we reconstructed the ancestral karyotype, and the evolutionary trajectories of chromosomes in extant species were inferred based on this reconstructed ancestor. The detailed reconstruction process is outlined in the Methods section.

a Overview of the seven main steps for inferring ancestral karyotypes from genomic synteny. b Ancestral karyotypes and evolutionary trajectories of chromosomes in magnoliids. Ancestral magnoliid karyotypes (AMK) are depicted using 14 distinct color-coded boxes. Chromosomes in subsequent evolutionary nodes and magnoliid species are aligned according to AMK chromosomes. Light green tetragons indicate polyploidy events in magnoliids, while gray triangles represent approximate locations of chromosome fusions. The number of chromosome fusions is denoted by hexagons, and chromosome translocations are indicated by octagons.
Using the A. manshuriensis (Aman) genome as a reference, we initially inferred the ancestral karyotype (MRCA-I) for A. fimbriata (Afim) and A. contorta (Acon). By comparing the genomes of A. fimbriata and A. contorta, we identified eight CSRs, five of which were located on complete chromosomes and thus could be confidently inferred as five CARs (Supplementary Fig. 20a). The remaining three CSRs were found between Acon1 and Afim1, Acon1 and Afim5, and Acon3 and Afim1 in the A. contorta and A. fimbriata genomes. Given the consistent connection patterns of these three CSRs in A. manshuriensis and A. contorta, we inferred that Acon1 and Acon3 evolved from two ancestral chromosomes in MRCA-I (Supplementary Fig. 20b).
Next, we inferred the karyotype of the most recent common ancestor of Aristolochia (MRCA-II) possessed eight chromosomes using the genomes of A. contorta, A. fimbriata, and A. manshuriensis, based on the ancestral karyotype MRCA-I. We observed that chromosome Acon4 in A. contorta corresponds to a single chromosome in A. fimbriata and a complete pair of paralogous chromosomes in A. manshuriensis, suggesting that this region likely represented a single chromosome in MRCA-II (defined as A2; Supplementary Fig. 20a, b). Additionally, we observed MRCA-II subsequently evolved into MRCA-I through a chromosome fusion and reciprocal translocation. We identified reciprocal translocations between chromosomes Acon1 and Acon2 in A. contorta, and between two pairs of paralogous chromosomes, Aman11-13 and Aman14-15, in A. manshuriensis. In contrast, Acon1 and Acon2 in A. contorta showed no translocations when compared to A. fimbriata (Supplementary Fig. 20a–c). When comparing the genomes of A. manshuriensis and S. henryi, we found no evidence of reciprocal translocations between chromosomes Aman11-13 and Aman14-15, suggesting that the translocations likely occurred after the divergence of MRCA-II and before the divergence of MRCA-I (Supplementary Fig. 20d). A chromosome fusion event was observed in Acon2 and Afim2, where both Acon2 and Afim2 correspond to two paralogous chromosomes of Aman (Aman3-5 and Aman11-13) (Supplementary Fig. 20b, c). However, when comparing Acon2 and Afim2, we found that their whole chromosome matched well (Supplementary Fig. 20a), suggesting that the chromosome fusion likely occurred after the divergence of MRCA-II. These results imply that MRCA-II possessed eight chromosomes, with A. manshuriensis retaining the ancestral karyotype of MRCA-II. MRCA-II subsequently evolved into MRCA-I through a chromosome fusion and reciprocal translocation. Similarly, leveraging the genomes of A. manshuriensis and S. henryi, with P. nigrum as an outgroup, we inferred that the ancestral Aristolochiaceae karyotype (AAK) comprised eight chromosomes (Supplementary Fig. 21). Our results suggest that MRCA-II originated from AAK through a single reciprocal translocation. Following a hierarchical reconstruction, we determined that the ancestral Piperales karyotype (APK) comprised nine chromosomes (Fig. 3a, b and Supplementary Figs. 20–24).
Additionally, we inferred the ancestral karyotypes of two other major lineages within magnoliids. The occurrence and precise phylogenetic timing of WGDs were carefully determined, contributing to a more accurate reconstruction of the ancestral karyotype. By thoroughly investigating the syntenic relationships among magnoliid genomes (Fig. 2d), we confirmed the majority of previously identified WGDs within this clade8,37,38. It is still uncertain whether the WGDs observed in Lauraceae and Calycanthaceae were a result of a shared event or occurred independently in each family37,39,40,41. By employing an integrated phylogenomic and synteny approach, we determined that 42.26% (1485/3514) of anchor gene pairs in syntenic blocks of C. kanehirae support a WGD event that occurred prior to the divergence of Lauraceae. Similarly, 41.92% (1630/3888) of anchor gene pairs in C. salicifolius support a distinct WGD event that took place before the divergence of Calycanthaceae. Additionally, other Lauraceae genomes corroborate the occurrence of a WGD in the most recent common ancestor of Lauraceae (Fig. 2d and Supplementary Data 26 and 27). These findings strongly suggest that two independent WGDs occurred in the Lauraceae and Calycanthaceae lineages, respectively (Fig. 2d).
By comparing the genomes of A. manshuriensis and L. chinense (Lchi), we inferred that the pre-WGD ancestor of Magnoliales and Laurales (MRAC-III) had 11 chromosomes (Supplementary Fig. 25). Subsequently, we reconstructed the ancestral karyotypes for Magnoliales and Laurales by comparing MRAC-III with species from each order. This analysis led to the identification of the most recent common ancestor of Magnoliales (AMK-I), which had 22 chromosomes, and the most recent common ancestor of Laurales (ALK-I), which had 20 chromosomes (Supplementary Figs. 26 and 27). Further comparisons of the genomes of L. cubeba, C. camphora, C. kanehirae, and C. salicifolius revealed that the most recent common ancestor of Lauraceae (ALK-II, post-WGD) had 13 chromosomes and exhibited extensive chromosomal rearrangements following the recent WGD in Lauraceae (Supplementary Fig. 28).
Finally, we reconstructed the most recent common ancestral karyotype of the magnoliids by integrating the karyotypes of the Piperales, Magnoliales, and Laurales. Our pairwise comparisons revealed that A. manshuriensis and L. chinense have among the most conserved genomes in the magnoliids. Consequently, we inferred the most recent common ancestral karyotype of the magnoliids primarily from the genomes of A. manshuriensis and L. chinense, using A. trichopoda (Atri) as an outgroup (Supplementary Fig. 29). We defined homologous chromosomes between A. manshuriensis and L. chinense that remain intact as independent ancestral chromosomes in the MRAC of magnoliids. For example, a pair of paralogous chromosomes, Lchi8 and Lchi11 in L. chinense, perfectly correspond to a pair of paralogous chromosomes, Aman3 and Aman5 in A. manshuriensis, indicating that these four chromosomes represent an independent ancestral chromosome (Supplementary Fig. 29a). Alternatively, we used the corresponding orthologous chromosomes in A. trichopoda to determine the ancestral state for magnoliids. For example, chromosomes Lchi19 and Lchi1 in L. chinense are syntenic with two sets of chromosomes in A. manshuriensis (Aman8-Aman12 and Aman11-Aman13). However, when compared to A. trichopoda, the orthologous region of Lchi19 is found solely on chromosome Atri2, suggesting that Lchi19 may represent the ancestral state for magnoliids, with subsequent specific changes occurring in Piperales (Supplementary Fig. 29b). Based on this analysis, we inferred that the most recent common ancestor of the magnoliids had 14 chromosomes. In addition, we inferred the ancestral gene content of the karyotypes of 12 evolutionary nodes in magnoliids, and reconstructed the AMK comprising 17,705 protogenes (Fig. 3b and Supplementary Data 28). These results could help to delineate the chromosomal evolutionary trajectories from the ancestral genomes to the extant magnoliid genomes (Fig. 3b and Supplementary Data 28).
Genomic and metabolic investigation of enriched metabolites biosynthesis in magnoliids
It is well recognized that magnoliids naturally synthesize a diverse array of secondary metabolites, particularly alkaloids, terpenes, and flavonoids6,8,42,43,44. Several metabolites, including magnoflorine, aristolochic acid, piperine, camphor, and kavalactones, are recognized for their significant economic value. Leveraging our newly sequenced genomes alongside other available magnoliid genomes, we explored the genomic foundations underlying the biosynthesis of these valuable metabolites in magnoliids.
We first analyzed gene family gains and losses along the branches leading to magnoliids and Aristolochaceae using 30 selected genomes within the reconstructed angiosperm phylogeny (Supplementary Data 29–31). Our findings indicate that 55 OGs were gained and 96 OGs were expanded in the most recent common ancestor (MRCA) of extant magnoliids (Supplementary Fig. 30). The expanded OGs are predominantly associated with the KEGG pathway of isoquinoline alkaloid synthesis. Notably, three key enzymes in the benzylisoquinoline alkaloid (BIA) biosynthesis pathway—OG0000515 (CYP719), OG0000097 (BBE), and OG0000380 (TYDC)—show significant expansion in the common ancestor of magnoliids (Supplementary Data 32). In the common ancestor of Aristolochiaceae, 53 OGs were identified as expanded, with enriched KEGG pathways related to alkaloids, terpenes, polyketides, and phenylpropanoids (Supplementary Data 33). Additionally, we detected numerous gene clusters associated with secondary metabolism in the A. manshuriensis genome (Supplementary Data 34), which may be linked to the enriched metabolites observed in Aristolochaceae.
The metabolome composition of A. manshuriensis flowers and stems was analyzed using a widely targeted liquid chromatography-tandem mass spectrometry (LC-MS/MS) approach. We observed that the three replicates of each tissue exhibited a high degree of overlap in detected metabolites (Supplementary Fig. 31a, b), while the metabolomic profiling of flowers and stems revealed differences (Supplementary Fig. 31c). A total of 1226 distinct analytes were identified, comprising 16.64% flavonoids (204/1226), 14.11% phenolic acids (173/1226), 12.81% alkaloids (157/1226), 5.14% terpenoids (63/1226), and 3.43% lignans and coumarins (42/1226) (Supplementary Fig. 31d, e and Supplementary Data 35). Among these, 824 compounds were found to be differentially expressed between flowers and stems (Supplementary Fig. 32 and Supplementary Data 36). Specifically, 150 compounds were uniquely detected in flowers, primarily enriched in KEGG pathways related to flavonoid biosynthesis, flavone, and flavonol biosynthesis. Conversely, 145 compounds were uniquely detected in stems, with notable enrichment in KEGG pathways related to isoquinoline alkaloid biosynthesis and tyrosine metabolism (Supplementary Data 37 and 38).
Using the new widely targeted metabolic profiling data from A. manshuriensis, we reconstructed the potential biosynthetic pathways for BIAs and their derivatives, extending beyond previous models (Fig. 4a). We identified key intermediates in the classic BIA biosynthetic pathway7,10,11,12, including (S)-norcoclaurine, (S)-coclaurine, (S)-N-methylcoclaurine, (S)-3’-hydroxy-N-methylcoclaurine and (S)-reticuline. We also experimentally verified these intermediate metabolites utilizing commercially available standards in the root, stem, leaf, and flower tissues of A. manshuriensis (Supplementary Fig. 34 and Supplementary Data 39 and 40). Additionally, we identified components in previously proposed alternative BIA routes8,18,20,21, such as (S)-6-O-methylnorlaudanosoline, (S)-nororientaline, and orientaline (Supplementary Fig. 33). Notably, we uncovered intermediate metabolites involved in the conversion of (S)-reticuline and orientaline into aporphine alkaloids, including orientalinone, orientalinol, and prestephanine (Fig. 4a and Supplementary Fig. 33). Of the 15 components in the reconstructed aristolochic acid I (AA-I) pathway, 13 were detected in the widely targeted metabolic profiling, with the exceptions being (S)-norlaudanosoline and stephanine (Fig. 4a). These findings suggest that the early steps in the AA-I biosynthesis pathway might have alternative reaction routes (Fig. 4a).

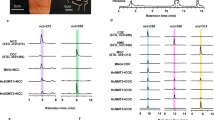
a Proposed biosynthesis pathway for aristolochic acid I/A. The partial pathway was predicted based on widely targeted LC-MS/MS metabolome analysis and previous radioisotopic feeding experiments. The pathways highlighted with orange shading represent the shared-upstream biosynthetic pathway of BIAs. b Phylogenetic tree of the CNMT subfamily. c Structural comparison of TfCNMT and AmCNMT proteins. Cyan represents TfCNMT, green represents AmCNMT. Enlarged views on the right side of panels c and d highlight catalytic determinants, key residues, and S-adenosylmethionine. d Sequence logo of multiple sequence alignments for CNMT-I and CNMT-II clades. Boxed residues marked by asterisks indicate significant differences between the two clades. e Transient expression of Am6OMT1 and Am6OMT2 in N. benthamiana leaves, followed by injection of the substrate (S)-norcoclaurine. The extracted ion chromatograms (EICs) show the methylated product (S)-coclaurine (m/z 286). f Transient expression of AmCNMT in N. benthamiana leaves, followed by injection of the substrate (S)-coclaurine. The EICs show the methylated product (S)-N-methylcoclaurine (m/z 300). g Transient expression of AmNMCH in N. benthamiana leaves, followed by injection of the substrate (S)-N-methylcoclaurine. The EICs show the methylated product (S)−3’-hydroxy-N-methylcoclaurine (m/z 316). The experiments were repeated three times with consistent results. The MS signal intensities were normalized to the maximum value within the dataset for comparative analysis.
Identification and experimental verification of BIA biosynthesis genes in A. manshuriensis
To identify putative genes involved in the BIA pathway, we examined gene family phylogeny, key residues, catalytic determinants, and expression patterns (Supplementary Figs. 35–40 and Supplementary Data 41 and 42). For instance, phylogenetic analysis of the CNMT gene family indicated that an ancient duplication event in vascular plants led to the formation of two distinct CNMT clades. All previously validated CNMT genes clustered in the CNMT-I clade, which includes genes from magnoliids and early-diverging eudicots (Fig. 4b and Supplementary Fig. 37b). We compared the CNMT protein structure of A. manshuriensis with T. flavum CNMT (TfCNMT), a previously well-studied CNMT gene45,46. We found that TfCNMT and AmCNMT share highly similar protein functional structures (root mean square deviation (RMSD) = 0.531 Å), and their residues in the types of catalytic determinants, key residues, and S-adenosylmethionine are highly conserved (Fig. 4c and Supplementary Fig. 37d). Comparative analysis revealed that functional CNMT genes in the CNMT-I clade have 57 divergent amino acid sites compared to those in the CNMT-II clade (Supplementary Data 43). Notably, we found 42 of these divergent sites located within the CMAS domain (PF02353), in which the 840-870 amino acid region exhibited high density of variations (Fig. 4d).
Phylogenetic analysis of the O-methyltransferases (OMT) gene family revealed five OMT genes within the II-D group of the Class II clade, which are closely related to previously identified OMT genes in meadow rue, Nelumbo nucifera (sacred lotus), and L. chinense (Supplementary Fig. 37a–c). These genes were classified based on the position of the methyl group on BIA and specific amino acids in conserved catalytic residues into 6OMT (Am04G071300, Am04G071000), 4’OMT (Am02G209000), and 7OMT (Am13G028000) (Supplementary Fig. 36d and Supplementary Data 42). Based on their expression patterns, we identified the candidate genes for 6OMT (Am04G071300 and Am04G071000), 4’OMT (Am02G209000), and 7OMT (Am13G028000) in A. manshuriensis.
Using the same approach, we identified 14 norcoclaurine synthase (NCS) genes, five O-methyltransferases (OMT) genes, two N-methyltransferases (CNMT) genes, and one N-methylcoclaurine 3’-hydroxylase (CYP80B/NMCH) gene. Additionally, two candidate genes were identified for intramolecular C-C (CYP80G2) and intermolecular C-O (CYP80Q) couplings, which are involved in the biosynthesis of aporphine and bisbenzylisoquinoline/proaporphine alkaloids. Five candidate genes were also found to be responsible for introducing the methylenedioxy bridge on aporphine alkaloid substrates (CYP719) (Supplementary Data 42). We further investigated whether TEs have contributed to the expansion of these functional genes. We found a pair of NCS-I genes (Am05G154100 and Am05G155000) flanked with Copia elements which have identity >84%, suggesting they might be duplicated due to TE’s activity (Supplementary Fig. 42).
We conducted transient expression experiments in Nicotiana benthamiana to functionally characterize these candidate genes involved in the core BIA biosynthetic pathway. Two 6OMT candidate genes, Am04G071300 and Am04G071000, were found to exhibit strong and weak catalytic activity, respectively, in converting (S)-norcoclaurine to (S)-coclaurine (Fig. 4e and Supplementary Data 44 and 45). Among the predicted CNMT candidate genes, Am05G021710 was shown to catalyze the conversion of (S)-coclaurine to (S)-N-methylcoclaurine (Fig. 4f and Supplementary Data 44 and 45). The CYP80B/NMCH candidate gene, Am04G071200, successfully catalyzed the conversion of (S)-N-methylcoclaurine to (S)-3’-hydroxy-N-methylcoclaurine (Fig. 4g and Supplementary Data 44 and 45). However, despite testing 14 NCS and two 4’OMT genes using the N. benthamiana transient expression system, none of these genes demonstrated catalytic activity.
Evolution of the BIAs biosynthesis pathway
To understand why BIAs are found only in magnoliids and early-diverging eudicots (such as Ranunculales and sacred lotus) among angiosperms, we traced the evolutionary history of key genes involved in the BIA biosynthesis pathway (e.g., NCS, 6OMT, CNMT, 4’OMT, NMCH, CYP80G2, and CYP80Q). Most BIA biosynthesis genes generally located in conserved regions of the reconstructed AMK chromosomes. For instance, we found that the CNMT (Am05G021710) and NCS (Am05G154200) genes are located on chromosome 5 (Aman5) in A. manshuriensis. As shown in Fig. 3b, Aman5 (pink color) exhibits well-retention of the ancestral AMK10, which is also well-retained in A. fimbriata, L. chinense, and other species. A similar scenario is observed for the 4OMT (Am02G209000), CYP80B/NMCH (Am04G071200), and 6OMT (Am04G071300, Am04G071000) genes, which are located on Aman2 and Aman4 (marked in green), well-preserved from the AMK7 without any chromosomal rearrangements. Other genes, including CYP80G2 (Am01G103600) and CYP80Q (Am01G106500) derived from AMK12, and the 7OMT (Am13G028000) gene retained from AMK1 (Fig. 3b), are also found in large, well-conserved chromosomal blocks in magnoliids.
We conducted phylogenetic analyses using gene families from a broad range of angiosperms, gymnosperms, and ferns to examine the patterns of gene duplication and retention. For the NCS genes, we found they belong to the Bet v1 subfamily and are grouped into two main clades (NCS-I and NCS-II), which diverged before the emergence of extant angiosperms (Supplementary Fig. 35a, b and Supplementary Data 46). Most experimentally validated NCS genes are located in the NCS-I clade, which is predominantly found in magnoliids and early-diverging eudicots. In contrast, the NCS-II clade includes genes from monocots, eudicots, and some magnoliids (Fig. 5a, b and Supplementary Fig. 35). The OMT genes form a large gene family. Phylogenetic analysis revealed a clade containing functional 6OMT, 4’OMT, and 7OMT genes from magnoliids, early-diverging eudicots, and Acorus tatarinowii. This clade originated from a duplication event that occurred before the divergence of angiosperms (Fig. 5a, b and Supplementary Fig. 36). Subsequent duplications led to the formation of the 6OMT, 4’OMT, and 7OMT subclades (Supplementary Fig. 36). The CYP80 subfamily exhibited a similar pattern of duplication and retention, resulting in the diversification into CYP80B/NMCH, CYP80G2, and CYP80Q groups (Fig. 5a, b and Supplementary Fig. 38). Our analyses indicate that most experimentally verified functional BIA genes are clustered within specific clades that include only magnoliid and early-diverging eudicot genes. This functional clade underwent duplication events before the origin of angiosperms. Notably, nearly all monocot and core-eudicot genes in these functional clades appear to have been lost, which explains the absence of BIAs in monocots and core-eudicots (Fig. 5a, b).

a Schematic of the evolutionary history of plant BIA biosynthetic genes. Here specifically showed the duplication and retention pattern of the functional clade. The lowest branch represents the other clade of these ancient duplications, and the lineage names were determined by the species in these corresponding clades. Solid lines in different colors represent these lineages retained homologous genes, while gray dashed lines indicate those lineages that lost the duplicated genes. b Prediction of putative functional BIA biosynthetic genes. Evidence from phylogenetic clustering, key residues conservation, and experimental validation were used to predict BIA biosynthetic genes. Note, the previously identified CNMT gene in N. nucifera9 is not in the same clade of functional orthologs in other species. Enzymes involved in the shared-upstream biosynthetic pathway of BIAs were shown with red bold font. Microsynteny comparisons of syntenic blocks where CYP80B/NMCH (c), CNMT (d), 6OMT (e) located on. BIA biosynthetic genes in magnoliids and early-diverging eudicots exhibited an obvious syntenic relationship. Rectangles represent annotated genes, while directions differentiated with blue and green. Solid red lines linked the syntenic BIA biosynthesis genes. Dashed black lines linked the orthologous regions where the lost BIA genes located on. Species are abbreviated as: S. polyrhiza, Spol; A. tatarinowii, Atat; A. manshuriensis, Aman; S. henryi, Sahe; Piper nigrum, Pnig; C. kanehirae, Ckan; L. chinense, Lchi; Arabidopsis thaliana, Atha; Vitis vinifera, Vvin; Papaver somniferum, Psom; Coptis chinensis, Cchi; Nymphaea colorata, Ncol; A. trichopoda, Atri.
In addition, we investigated the evolution of BIA genes following the common ancestor of magnoliids and the recent WGD event in the A. manshuriensis lineage. We found that the ancestral OMT gene was located on AMK7, and the recent WGD event gave rise to a pair of homologous genes, Am02G209000 (a candidate gene for 4’OMT) and Am04G071000 (a candidate gene for 6OMT). This likely suggests that a sub-functionalization event occurred after the duplication. Another case involves the CNMT gene, where we found that the Am03G024800 and Am05G021710 genes arose from the WGD event. In this case, Am05G021710 retained the CNMT function, while the Am03G024800 gene lost the CMAS domain (PF02353) and thus no longer has CNMT function. Moreover, we also found that NCS, CYP80G2, CYP80Q, and other genes have experienced independent gene loss after the WGD, given that their homologous blocks were retained but their corresponding paralogs underwent gene loss (rediploidization process).
We further investigated why the clade of functional BIA genes is retained only in magnoliids and early-diverging eudicots, and how monocots and core eudicots lost the corresponding duplicated copies. By integrating phylogenetic and synteny analyses, we found that the syntenic block containing BIA genes was present in the common ancestor of angiosperms. For instance, in the CYP80 gene family, syntenic blocks containing the CYP80B/NMCH branch genes are well-conserved in early-diverging eudicots such as P. somniferum and C. chinensis, as well as in magnoliids including S. henryi, C. kanehirae and L. chinensis. However, while these syntenic blocks are also present in monocots (e.g., A. tatarinowii and Spirodela polyrhiza), core eudicots (e.g., Vitis vinifera and Arabidopsis thaliana), and basal angiosperms (e.g., A. trichopoda and Nymphaea colorata), the CYP80B/NMCH gene is absent from these blocks (Fig. 5c). Similar patterns of synteny and gene losses were observed for other BIA biosynthetic genes, including CNMT, 6OMT, 4’OMT, 7OMT, CYP80G2, CYP80B/NMCH, and CYP80Q (Fig. 5c-e and Supplementary Fig. 41). These observations suggest that BIA biosynthetic genes likely originated in the common ancestor of angiosperms and were selectively retained in early-diverging eudicots and magnoliids. Conversely, these genes were lost independently in monocots, core eudicots, and basal angiosperms through single gene loss events. This highlights the complex evolutionary dynamics of the BIA biosynthetic pathway and the differential retention of ancient gene duplicates across angiosperm lineages.
Discussion
Gene duplication is a key mechanism for evolution47,48,49,50. WGDs can lead to the creation of multiple sets of genomes, resulting in a significant number of duplicated genes. These duplications are considered a major driving force in evolutionary processes. WGDs are widely recognized as a prevalent phenomenon in plant evolution33,34,50,51. Previously, we observed that A. fimbriata lacked additional WGDs since the divergence of extant angiosperms8. However, it remains unclear whether this absence of WGDs is characteristic of all members of the Aristolochiaceae family. In this study, we reconstructed the phylogenetic relationships within Aristolochiaceae and identified WGD events in the subfamilies Aristolochioideae and Asaroideae. It appears that only the A. subg. Aristolochia and the subfamily Hydnoroideae (comprising Hydnora and Prosopanche) have not experienced lineage-specific WGDs (Fig. 2c, d and Supplementary Fig. 13). These newly available genomes from closely related species with varying WGD histories could enable us to further investigate why certain species have lacked WGDs over nearly 200 million years, while others have undergone multiple WGDs.
Evolutionary innovations often arise from the acquisition of new genes or the neofunctionalization of gene duplicates. In this study, we observed that key enzyme-encoding genes for BIA biosynthesis from magnoliids and early-diverging eudicots are clustered in clades that lack homologs in other angiosperm branches, such as monocots and core eudicots, despite these ancestral genes being traceable to early land plants or even green plants (Fig. 5). Further investigation into the evolutionary history of these genes (e.g., NCS and CNMT) revealed that this functional clade underwent duplication at least before the divergence of extant mesangiosperms. Notably, nearly all monocots and core eudicots have lost these duplicated gene copies (Fig. 5c–e and Supplementary Figs. 36–39). The specific mechanisms behind these ancient duplications and subsequent gene losses warrant further investigation. Additionally, magnoliids and early-diverging eudicots have often experienced species-specific duplications, retaining only one or a few functional genes based on experimental evidence. Functional copies within these species frequently exhibit shared residues in their protein sequences (Supplementary Figs. 36–39 and Supplementary Data 42 and 43), suggesting convergent evolution within these clades. Thus, the patterns of gene presence and absence, along with the convergently evolved key residues, help explain why BIAs are predominantly found in magnoliids and early-diverging eudicots.
Magnoliids appear to have retained a more complex BIA biosynthesis pathway compared to early-diverging eudicots (Fig. 4a). Previous studies in early-diverging eudicots have identified the classic BIA biosynthetic pathway7,9,10,11,12,52, and while isotope feeding experiments in Aristolochia have revealed a potential BIA biosynthetic pathway8,16,18,20,21. In this study, we identified intermediate products from both classic and potential BIA pathways in the metabolome of A. manshuriensis. These intermediates include products from various reaction stages such as O-methylation, N-methylation, and 3’-hydroxylation. It also has been confirmed that the sequence of O-methylation and N-methylation in the BIA biosynthetic pathway can be switched in A. contorta and L. chinense6,21. Additionally, we found that magnoliids exhibit a high retention of gene duplicates in the CYP80G2 and CYP80Q clades, which are involved in the biosynthesis of aporphine alkaloids9,22,53,54. Our phylogenetic analysis revealed that magnoliids possess both CYP80Q and CYP80G2 orthologs, while Ranunculales retain only CYP80G2, and N. nucifera has only CYP80Q (Fig. 5a and Supplementary Fig. 38). These results suggest that magnoliids potentially exhibit greater diversity in the reactions of the BIA biosynthesis process.
The genomes of Aristolochiaceae provide a valuable opportunity to study the biosynthesis and origins of AA-I, a compound recognized as a carcinogen and naturally synthesized within the Aristolochiaceae family55. In this study, we performed metabolic profiling of the stem and flower of A. manshuriensis using widely targeted liquid chromatography-tandem mass spectrometry (LC-MS/MS). We successfully identified 13 out of 15 intermediates in the reconstructed biosynthetic pathway of AA-I. However, several final steps in the pathway remain unresolved, particularly those involving the complex processes of ring opening in nitrogen-containing heterocycles and the formation of carboxyl and nitro groups during the conversion from prestephanine to AA-I (Fig. 4a). The metabolites detected in our study may serve as a valuable resource for identifying these intermediate components. Given that aristolochic acid and aristolactam are unique to the Aristolochiaceae family56, we hypothesize that the genes encoding the enzymes responsible for the final steps of the AA-I biosynthesis pathway may be specific to this family.
In conclusion, the genomic analysis of S. henryi and A. manshuriensis, along with transcriptomic data from other species in the Aristolochiaceae family, has facilitated the construction of a comprehensive phylogenetic framework for the family. This work also uncovered several lineage-specific WGDs within the Aristolochiaceae. We have reconstructed the ancestral karyotypes of magnoliids, providing a clearer understanding of their genomic evolutionary history. Our study highlights the preferential retention of ancient gene duplicates and the convergent evolution of key sequences, which have enabled magnoliids and early-diverging eudicots to synthesize BIAs. In contrast, monocots and core-eudicots have lost these gene duplicates, resulting in the absence of BIAs in these clades. Overall, our findings offer better understanding about the genomic evolution of magnoliids and the development and evolution of specialized BIA metabolites.
Methods
Plant materials and sequencing
Fresh leaves of Saruma henryi and Aristolochia manshuriensis were collected from the Institute of Botany, Chinese Academy of Sciences (IBCAS) in Beijing, China. Genomic DNA was extracted using the DNeasy Plant Mini Kit (Qiagen). Paired-end libraries with 500 bp insert sizes were prepared and sequenced on the Illumina HiSeq 2500 platform. For PacBio HiFi sequencing, a 15-kb library was constructed using the SMRTbell Express Template Prep Kit 2.0 and sequenced on the PacBio Sequel II platform. Ultra-long Nanopore libraries were created using the nuclei isolation method and sequenced on the Nanopore PromethION platform. Hi-C libraries were prepared by extracting DNA, crosslinking it, digesting with Hind III, and sequencing 150 bp paired-end reads on the Illumina NovoSeq 6000 platform. Various plant tissues, including leaves, seeds, stems, and flowers, were sampled for total RNA extraction and transcriptome sequencing. RNA was extracted using Trizol reagent, and Paired-end cDNA libraries with 150 bp insert sizes were sequenced on the Illumina HiSeq 2500 platform. Additionally, full-length transcriptome sequencing was performed using cDNA libraries generated with the SMARTer PCR cDNA Synthesis Kit, screened with a BluePippin system, and sequenced on a PacBio RS II instrument.
Genome assembly and assessment
Genome size, heterozygosity, and repeat content were estimated using Jellyfish v2.2.057 to generate k-mer frequency distributions, which were then analyzed with GenomeScope258. For SNP calling and further estimation of heterozygosity, DeepVariant59 was employed. Contig assembly from HiFi read data was performed using Hifiasm60 with the parameters set to “--hom-cov 28 --hg-size 525 m -D 10”. To address the impact of high organelle genome copy numbers on nuclear genome assembly, organelle-related reads were filtered out before assembly. chloroplast and mitochondrial genomes of A. manshuriensis and S. henryi, previously published, served as references; HiFi reads were mapped to these genomes using minimap261. Filtering and assembly showed optimal contiguity when reads mapping to organelle genomes exceeded 80% of their length. Purge_dups62 was used to refine assembly results based on sequence similarity and read depth, with parameters set to “-f 0.5 -l 5 -m 16 -u 63 -d 1”. SAMBA63 connected and verified contigs using Nanopore ultra-long reads, with the parameters set to “-d ont -m 20000 -o 1000.” Scaffolds larger than 100 kb were anchored and oriented based on Hi-C contact maps using 3D-DNA64 with parameters set to “-m haploid -r 0”. Manual correction of scaffold order and orientation was performed with Juicebox assembly tools (JBAT)65 based on Hi-C contact frequencies. As a result, the genomes of S. henryi and A. manshuriensis were resolved into 12 and 16 chromosomes, respectively.
To assess the quality and completeness of the assembled genomes, Illumina DNA and RNA reads were mapped to the final genome assembly using BWA66 and HISAT267, respectively. Genome-wide sequence accuracy was evaluated with Merqury26 using Illumina genomic DNA data. Assembly completeness was determined using BUSCO24 to check for conserved genes. Pacbio HiFi and Nanopore ultra-long reads were aligned to the genome with minimap261, and the CRAQ pipeline was used to evaluate assembly accuracy based on clipping information from these read mappings25.
Transcriptome analyses
For Pacbio Iso-seq analysis, we utilized the ccs module in SMRT Link software (https://www.pacb.com/support/software-downloads) to generate consistent sequences, including primer sequences in each read. The parameters were set to “--noPolish --minPasses 1”. Primer and barcode sequences were removed using lima (https://github.com/PacificBiosciences/barcoding), with the parameters set to “--isoseq --no-pbi”. Further analysis was conducted using IsoSeq3 (https://github.com/PacificBiosciences/IsoSeq), which involved refining CCS sequences to eliminate chimeric reads, clustering to remove poly(A) tails and linked structures, and polishing and merging clustered transcripts into complete consensus sequences. We performed de novo assembly of the high-quality reads using Trinity software68 with default parameters. The assembled transcripts were annotated using hmmscan69 and diamond70 against Pfam database71 and UniPort database (https://www.uniprot.org/), as well as against eight magnoliid genomes. Protein-coding sequences were predicted using TransDecoder (https://github.com/TransDecoder/TransDecoder), and redundant transcripts were removed with a 98% similarity threshold using CD-HIT (https://github.com/weizhongli/cdhit).
Repeat annotation and analysis
TEs were identified using a combination of evidence-based search and ab initio prediction approaches. For the evidence-based search, the genome was queried against the Repbase database72 using RepeatMasker73 with default parameters. For ab initio prediction, a consensus sequence library was constructed using RepeatModeler (http://repeatmasker.org/RepeatModeler), with RMBlast74 as the search engine. All unannotated (‘unknown’) repeat families from the RepeatModeler library were classified using TEclass75. Subsequently, LTRharvest76, LTR_FINDER77, and LTR_retriever78 were employed to construct an LTR library with default parameters. Both libraries were then used to annotate the genomes of S. henryi and A. manshuriensis using RepeatMasker. The detected TEs were combined to generate the final TE annotation and results from these two runs of RepeatMasker were merged.
Phylogenetic analyses focused on the reverse transcriptase (RT) domains of both Ty3-Gypsy (PF000078) and Ty1-Copia (PF07727) LTR retrotransposons in the four Aristolochiaceae species. Amino acid sequences of RT domains from Gypsy and Copia elements were aligned using MUSCLE79 and poorly aligned regions were automatically removed with trimAl80. Neighbor-Joining phylogenetic trees were constructed using FastTree81, with 1000 bootstrap replications for statistical support.
Gene prediction and functional annotation
We employed a comprehensive approach for gene prediction, integrating transcriptome analysis, homology-based annotation, and ab initio gene prediction. For ab initio prediction, we utilized AUGUSTUS82, SNAP83, GlimmerHMM84, and GeneMark-ET85 on the repeat-masked scaffolds. Homology-based prediction involved using inferred amino acid sequences from the genomes of A. thaliana, Oryza sativa, A. fimbriata, A. contorta, P. nigrum, L. chinense, and C. kanehirae. Gene models were annotated with GeMoMa86 based on these amino acid sequence alignments. For transcriptome-based prediction, we used Cufflinks87, PASA88, and TransDecoder (https://github.com/TransDecoder/TransDecoder) for gene model projections. The integrated results from these approaches were used to generate gene models with EVidenceModeler (EVM)89 for the main annotated protein-coding gene set.
To refine gene structures, we developed a pipeline to identify and replace problematic genes. Initially, gene predictions from Pacbio Iso-seq were considered more reliable and substituted for the original EVM-integrated genes. We then carefully examined the remaining genes with transcriptome evidence, manually curating those with abnormal exon expression abundance using GSAman (https://gitee.com/CJchen/IGV-sRNA) and transcriptome data. Finally, newly identified genes supported by Iso-seq or transcriptome evidence were incorporated into the EVM-annotated gene sets.
Gene functional annotation was performed by mapping protein sequences against several databases using BLAST90 with parameter “-num_alignments 1”: The databases included non-redundant (Nr) (https://ftp.ncbi.nlm.nih.gov/blast/db/FASTA), KEGG (https://www.genome.jp/kegg), GO (https://www.uniprot.org/), Pfam (http://ftp.ebi.ac.uk/pub/databases/Pfam/releases), and SwissPro (https://www.uniprot.org/downloads).
Gene family classification and phylogenetic analysis
We performed an all-against-all BLASTP90 alignment of genome-annotated protein sequences with an E-value threshold of <10−5. Gene families were constructed using OrthoFinder91 with an inflation factor of 1.5. For each orthologous group (OG), amino acid sequences were aligned using MAFFT92 with the parameters “--maxiterate 1000 --localpair -auto”. Amino acid-based alignments were used to convert nucleotide sequences to codon-based alignments via PAL2NAL93. The nucleotide alignments were then trimmed with trimAl80 using the parameter “-automated1”. For the concatenation method, a Python script was employed to concatenate the multiple sequence alignment results into a supermatrix in orthologous group (OG) order for the selected gene families. We applied IQ-TREE294 to construct a maximum-likelihood phylogenetic tree. The optimal partitioning of concatenated alignments was calculated using the parameters “-m MF + MERGE -rclusterf 5 -rcluster-max 5000 -mset GTR”. ModelFinder95 selected the best model based on the Bayesian Information Criterion (BIC), followed by 1000 bootstrap iterations with the parameters “-B 1000 --runs 10 -safe”. For the coalescence method, single-gene trees were built from the amino acid and nucleotide matrices of each OG using IQ-TREE294. ModelFinder95 selected the best model based on BIC, followed by 1000 bootstrap replicates with the parameters “-seed 12345 -bb 1000 -m MFP -safe”.
The nw_ed program96 from the newick utilities was used to filter bootstrap values in the single-gene trees. Phylogenetic analysis based on the coalescence method was conducted using ASTRAL-II97, focusing on gene trees with node bootstrap values greater than 50%.
Whole-genome duplication analysis
For synteny analyses, we conducted all-against-all BLASTP90 with an E-value threshold of <10−5 and a score >100, both within and between genomes. The top ten BLAST matches were selected to infer syntenic blocks. MCScanX98 was used to identify syntenic blocks, with the maximum gap between anchor genes set to 25. Multiple sequence alignments of amino acid sequences for anchor genes were performed using MUSCLE79, and nucleotides were converted to codon-based alignments using PAL2NAL93. The KS values between gene pairs were calculated using the F3 × 4 method of Yang & Nielsen (2000)99 with the yn00 module in PAML100. The median KS value of anchor genes within syntenic blocks was used to estimate the timing of WGD and species divergence.
We applied two criteria to identify reliable gene duplication events: (1) the presence of genes from at least one species in both subclades, and (2) a bootstrap value of ≥50%33,34,101 for both the parent node and one of the subclades. Gene duplications were scored using Notung102 in a large-scale gene family analysis. Duplications at each node were counted using the duplication-loss model, with parameters set to “--reconcile --rearrange --threshold 50% --edgeweights name”. This parameter rearranges and reconciles nodes with support values lower than 50% to mitigate the impact of topological changes. Additionally, syntenic anchor genes provide direct evidence of WGD. If gene duplication results from WGD events, retention of syntenic anchor genes is expected; thus, we further assessed syntenic results at WGD nodes.
Ancestral magnoliids karyotype (AMK)
The reconstruction of ancestral karyotypes provides crucial insights into the evolutionary history of karyotypes and chromosomal rearrangements in extant species103,104. Magnoliids, the third largest group of angiosperms after monocots and eudicots, have been understudied in terms of karyotype evolution. This study leverages data from eleven genomes representing three orders within magnoliids, including A. manshuriensis, S. henryi, A. contorta, A. fimbriata, and P. nigrum in Piperales; L. chinense and M. biondii in Magnoliales; and L. cubeba, C. camphora, C. kanehiraea, and C. salicifolius in Laurales. The genome of A. trichopoda was included as an outgroup. We reconstructed the karyotypes of the most recent common ancestor of magnoliids, along with those at key phylogenetic nodes.
To infer ancestral chromosome structure, we employed maximum likelihood theory and a bottom-up hierarchical approach (Fig. 3a). The main steps are as follows: (1) Genome selection: We selected genomes with high-quality assemblies, minimal polyploidization events, and conserved genome structures. (2) Inference of syntenic regions: Syntenic regions between genomes were identified using BLASTP90 with an E-value threshold of <10−5 and a score >100, followed by analysis with MCScanX98, with a maximum gap of 25 between anchor genes. (3) Synteny dotplots and Ks analysis: Synteny dotplots were used to visualize conserved genomic regions and detect chromosomal rearrangements. Ks distributions were calculated for syntenic blocks to identify evolutionary events such as species divergence and polyploidy. (4) Distinguishing event-related synteny regions: Orthologous regions associated with species divergence and paralogous regions resulting from genomic polyploidy were identified. (5) Identification of contiguous syntenic regions (CSRs): Syntenic blocks on the same chromosome that are adjacent to each other were considered maximal CSRs. (6) Determining ancestral chromosome composition: CSRs were identified as conserved ancestral regions (CARs) if they preserved consistent connections or matched those of outgroups or reference genomes, leading to the reconstruction of a maximally parsimonious ancestral chromosome structure. (7) The reconstructed ancestral chromosomes and pivotal clade ancestors were compared with extant genomes to elucidate the history of chromosome rearrangements throughout genome evolution. 8) Bottom-up inferences were made regarding the chromosome composition of older ancestors and the karyotypes of the most recent common ancestor of magnoliids (Supplementary Fig. 19a). The process of modern genome formation is characterized by changes in chromosome number, either increasing or decreasing. Chromosome fusion, a primary mechanism for reducing chromosome numbers after polyploidy, includes three patterns: end-to-end joining (EEJ), nested chromosome fusion (NCF), and non-reciprocal or reciprocal chromosome translocation105 (Supplementary Fig. 19b). The methods described for reconstructing the evolutionary history of ancestral and current chromosomes have been successfully applied to infer the ancestors of several angiosperm families, including Fabaceae106, Asteraceae107, and Cucurbitaceae108.
Gene family evolution
To estimate divergence times in angiosperms, a species tree was constructed using 164 OGs from 30 species, with A. capillus-veneris as the outgroup. Divergence times were calibrated using the following fossil records: 405 Ma for the root node based on the average of multiple studies from Timetree (http://timetree.org/); 308-366 Ma for seed plant crown groups; 125-247 Ma for angiosperm crown groups; 120-129 Ma for eudicots; 113-247 Ma for monocots; and 111-247 Ma for magnoliids109,110. We used BASEML from the PAML package100 to estimate branch lengths and substitution rates under the GTR + G model (model = 7). The substitution rate per 100 million years was estimated as 0.171948 ± 0.001565, with the total substitution rate (rgene gamma) and rate drift (sigma2 gamma) parameters set to G (1, 5.8) and G (1, 4.0), respectively. The approximate maximum likelihood method (usedata = 3) in MCMCTree100 was employed to calculate the gradient (g), hessian (H) parameters, and branch lengths. All analyses were conducted independently in duplicate to verify consistency and ensure an effective sample size (ESS) > 200, as assessed using Tracer (http://tree.bio.ed.ac.uk/software/tracer/). Phylogenetic trees were visualized using the R package ggtree111.
In order to study the evolutionary history of gene families in magnoliids, we used the CAFÉ112 software for analyzing gene family expansion and contraction. The stochastic birth-and-death model in CAFÉ was applied to assess the expansion and contraction of gene families. Gene families with more than 100 species-specific members in each OG were excluded from the analysis. The remaining gene families were then analyzed for gene family evolution, with parameters λ and μ estimated automatically. KEGG and GO enrichment analyses for expanded and contracted gene families were conducted using ClusterProfiler113.
Metabolome profiling
Metabolome profiling was performed using a widely targeted metabolome method by Wuhan MetWare Biotechnology Co., Ltd. (Wuhan, China). We selected flower and stem tissues, with three biological replicates for each tissue. Stem and flower samples were freeze-dried using a vacuum freeze-dryer (Scientz-100F). The lyophilized samples were ground for 1.5 minutes at 30 Hz using a mixer mill (MM 400, Retsch) with zirconia beads. For each sample, 50 mg of the lyophilized powder was dissolved in 1.2 mL of 70% methanol, vortexing for 30 seconds every 30 minutes for a total of six cycles to ensure thorough mixing. Following centrifugation at 13,523 g for 3 minutes, the extracts were filtered through a 0.22 μm pore size filter (SCAA-104, ANPEL, Shanghai, China) before UPLC-MS/MS analysis.
The sample extracts were analyzed using a UPLC-ESI-MS/MS system (UPLC, SHIMADZU NexeraX2; MS, Applied Biosystems 4500 Q TRAP). The UPLC-ESI-MS/MS analysis employed an Agilent SB-C18 column (1.8 μm, 2.1 mm × 100 mm). The mobile phase comprised solvent A (pure water with 0.1% formic acid) and solvent B (acetonitrile with 0.1% formic acid), with a gradient elution starting at 95% A and 5% B for 9 minutes, transitioning to 5% A and 95% B for 1 minute, then readjusting to 95% A and 5% B within 1.1 minutes, and maintaining this composition for 2.9 minutes. The flow rate was 0.35 mL/min, the column oven was set to 40 °C, and the injection volume was 4 μL. The analysis was conducted using an ESI-triple quadrupole-linear ion trap (QTRAP)-MS.
Mass spectrometry-based qualitative and quantitative analysis of metabolites was performed using the MetWare in-house database (MWDB, MetWare Biotechnology Co., Ltd., Wuhan, China), the KEGG compound database, and multiple reaction monitoring (MRM) methodology. Metabolite identification was based on the accurate mass, MS2 fragment patterns, and retention times (RT). A proprietary intelligent secondary spectrum matching algorithm developed by MetWare was employed to compare and match the secondary spectra and RT of metabolites with those in the company’s database, and the mass tolerance for MS and MS2 data was set at 2 ppm and 5 ppm, respectively.
We used the R package ggvenn (https://github.com/yanlinlin82/ggvenn) to compare the metabolites detected in the widely targeted metabolomics analysis of stem and flower tissues, examining both the variation between different biological replicates within the same tissue and the differences between metabolites detected across different tissues. Supervised orthogonal partial least-squares discriminant analysis (OPLS-DA) was conducted using R package MetaboAnalystR114 to explore metabolic variations across samples. Differentially accumulated metabolites were identified based on variable importance in projection (VIP) scores >1 and a fold-change (FC) > 2 or <0.5. A heatmap was generated using the R package ComplexHeatmap115.
Identification and evolutionary analysis of BIA biosynthetic genes
To identify candidate genes involved in BIA biosynthesis, we performed BLASTP90 searches for homologs of known BIA biosynthesis genes (listed in Supplementary Data 41) across 30 plant genomes, including two representative BIA-producing plants, Papaver somniferum and Coptis chinensis, using an E-value threshold of <10−5. We further employed HMMER to search these protein sequences against a curated hidden Markov model from the Pfam domain family. For phylogenetic analysis, amino acid sequences were aligned using MAFFT92 and refined by removing poorly aligned regions with trimAL80 using a gap threshold parameter of “-g 0.3”. The phylogenetic tree was inferred using the maximum likelihood method in IQ-TREE294, with the best-fit substitution model determined by ModelFinder95 and 1000 bootstrap replicates. Homology models for TfCNMT and AmCNMT were constructed using a modified version of AlphaFold116 via ColabFold117, with TfCNMT (Q5C9L6) as the template. The models were visualized using PyMOL (Schrödinger).
We conducted synteny analysis within and between species using MCScanX98. To estimate divergence times between species, we employed the NG86 method in PAML100 to calculate the mean of the median KS values (Ki) for the 30 longest syntenic blocks. Given that magnoliids and early-diverging eudicots have retained BIA biosynthetic genes, we defined orthologous blocks as those containing syntenic BIA genes between species. In other lineages, where BIA biosynthetic genes are infrequently retained and the evolutionary histories of WGDs differ, we identified orthologous syntenic blocks based on the length of syntenic blocks, the number of BLASTP best-hitting genes, the size of gaps, and the median KS values of these blocks. The detailed method is as follows:
-
1.
Using BIA biosynthetic genes from magnoliids or early-diverging eudicots as anchor points, we extended the search range by including 50 genes upstream and downstream. We then screened for syntenic blocks within this range in the genomes of other lineages.
-
2.
If the median KS value (Kb) of a screened block is near the divergence time peak (Ki) between species, specifically within the range 0 <Kb ≤ Ki + 0.2, the block is considered for further analysis; otherwise, it is discarded.
-
3.
We assigned a comprehensive score (S) to the remaining blocks, identifying the highest-scoring block as the best-matching orthologous block. The formula for the score is:
Where \({W}_{l}\) and \({W}_{n}\) are the weights for block length and gap size, set to 0.6 and 0.4, respectively. \(L\), \({L}_{\min }\) and \({L}_{\max }\) denote the length of the selected block, the minimum length, and the maximum length of the blocks, respectively. Similarly, \(N\), \({N}_{\min }\) and \({N}_{\max }\) represent the gap size of the selected block, the minimum gap size, and the maximum gap size of the blocks, respectively.
The formula for \(N\) is:
Where \({O}_{s1}\) and \({O}_{e1}\) are the start and end gene orders of the selected block in species 1, and \({O}_{s2}\) and \({O}_{e2}\) are the start and end gene orders in species 2.
Ultimately, we used these orthologous syntenic blocks between different species to investigate the origin and evolution of BIA biosynthetic genes.
Identification of TE-mediated recent gene duplications
Genome-wide, all-by-all BLASTP90 searching was performed with parameters “-outfmt 6 -evalue 1e-5”. The best reciprocal matches were then extracted as recent gene duplicates. For each gene pairs, their upstream and downstream 3000 base pairs flanking sequences were compared to check whether any similar types of TEs (e.g., Gypsy, Copia, LINE) located in. Then, the identify of similar types of TEs were calculated and investigated. Gene duplicates were referred as TE-mediated duplicates if the gene pairs flanked by same types of TEs with high sequence similarity118.
Transient expression of candidate genes in N. benthamiana
We cloned candidate gene from the cDNA of A. manshuriensis and transiently expressed it in N. benthamiana leaves, subsequently conducting in planta activity assays using LC-MS analysis. N. benthamiana plants were grown in a 1:1:1 mixture of nutrient soil, vermiculite, and turfy soil, under a 16-hour light/8-hour dark cycle at room temperature. After 4-5 weeks, the plants were infiltrated with Agrobacterium tumefaciens carrying the candidate genes. Following infiltration, the tissues were snap-frozen in liquid nitrogen and stored at −80 °C for subsequent analysis.
We amplified the full-length sequence of the candidate gene from A. manshuriensis cDNA using SuperNova PCR Mix (Genstar). The gene was inserted into the pCAMBIA1300 vector, which had been previously digested with KpnI and HindIII (Thermo), through EZ-HiFi Seamless Cloning Kit (Genstar). The recombination vector was then chemically transformed into DH5α Escherichia coli (Qingke Biotechnology) and screened on solid lysogeny broth (LB) medium supplemented with kanamycin (100 mg/L). Positive clones were identified by bacterial PCR and confirmed by Sanger sequencing. The plasmid was subsequently transformed into A. tumefaciens EHA105, which was screened on solid LB medium with rifampicin (25 mg/L) and kanamycin (100 mg/L) for 48 hours. Selected clones were cultured in liquid LB medium with antibiotics for 48 hours, mixed with 50% glycerol, and stored at −80 °C.
A. tumefaciens was cultured in liquid LB medium with 100 mg/L kanamycin for 12 hours, then centrifuged at 4000 × g for 10 minutes. The pellet was resuspended in activation buffer (10 mM MES, 10 mM MgCl2, 150 µM acetosyringone) to an OD600 of 0.8 and incubated at 26 °C for 2–3 hours. Using a needle-free syringe, A. tumefaciens was infiltrated into N. benthamiana leaves grown in a greenhouse under a 16-hour light/8-hour dark cycle at 26 °C. A 1% methanol solution containing 1 mM substrate was injected into the infiltrated leaves. After 2 days, the leaves were ground with steel balls at 45 Hz for 60 seconds, extracted with 80% methanol, vortexed, centrifuged at 13,523 g for 5 minutes, and the supernatant was collected for LC-MS analysis.
Standards were analyzed using a UPLC system (Waters, ACQUITY) equipped with an ACQUITY UPLC HSS T3 column (Waters) and detected by MS/MS on a Triple Quad Xevo TQ-S mass spectrometer (Waters), operated in positive ion mode with multiple reaction monitoring (MRM). The mobile phase consisted of buffer A (5 mM ammonium acetate) and buffer B (100% acetonitrile). Quantification of the standards was achieved by measuring mass transitions from precursor ions to product ions. Standard curves were generated by analyzing standards at various concentrations, with the peak area used to fit the curve and calculate the compound’s content in the samples. Three independent biological replicates were performed to ensure reproducibility and reliability.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The raw genome and transcriptome sequencing data generated in this study are deposited in the National Genomics Data Center (https://ngdc.cncb.ac.cn/) database under accession code PRJCA028952. The genome assemblies reported in this paper are deposited in the Genome Warehouse of the National Genomics Data Center (https://ngdc.cncb.ac.cn/gwh), A. manshuriensis is under accession number: GWHFCTA00000000 [https://ngdc.cncb.ac.cn/gwh/Assembly/85984/show] and S. henryi is under accession number: GWHFCTG00000000 [https://ngdc.cncb.ac.cn/gwh/Assembly/85985/show]. The metabolome data (LC-MS datasets) are available in the Open Archive for Miscellaneous Data (https://ngdc.cncb.ac.cn/omix) under accession number OMIX008425. The assembly and annotation of A. manshuriensis and S. henryi are also deposited in figshare at https://doi.org/10.6084/m9.figshare.26788381 (ref. 119).
References
Drinnan, A. N., Crane, P. R. & Hoot, S. B. Patterns of floral evolution in the early diversification of non-magnoliid dicotyledons (eudicots). (Springer, 1994).
Moore, M. J., Bell, C. D., Soltis, P. S. & Soltis, D. E. Using plastid genome-scale data to resolve enigmatic relationships among basal angiosperms. Proc. Natl Acad. Sci. USA 104, 19363–19368 (2007).
Soltis, P. S. & Soltis, D. E. The origin and diversification of angiosperms. Am. J. Bot. 91, 1614–1626 (2004).
Heinrich, M., Chan, J., Wanke, S., Neinhuis, C. & Simmonds, M. S. Local uses of Aristolochia species and content of nephrotoxic aristolochic acid 1 and 2—A global assessment based on bibliographic sources. J. Ethnopharmacol. 125, 108–144 (2009).
Liscombe, D. K., MacLeod, B. P., Loukanina, N., Nandi, O. I. & Facchini, P. J. Evidence for the monophyletic evolution of benzylisoquinoline alkaloid biosynthesis in angiosperms. Phytochemistry 66, 1374–1393 (2005).
Cheng, W. et al. Characterization of benzylisoquinoline alkaloid methyltransferases in Liriodendron chinense provides insights into the phylogenic basis of angiosperm alkaloid diversity. Plant J. 112, 535–548 (2022).
Ziegler, J. & Facchini, P. J. Alkaloid biosynthesis: metabolism and trafficking. Annu. Rev. Plant Biol. 59, 735–769 (2008).
Qin, L. et al. Insights into angiosperm evolution, floral development and chemical biosynthesis from the Aristolochia fimbriata genome. Nat. Plants 7, 1239–1253 (2021).
Menéndez-Perdomo, I. M. & Facchini, P. J. Elucidation of the (R)-enantiospecific benzylisoquinoline alkaloid biosynthetic pathways in sacred lotus (Nelumbo nucifera). Sci. Rep. 13, 2955 (2023).
Guo, L. et al. The opium poppy genome and morphinan production. Science 362, 343–347 (2018).
Singh, A., Menéndez-Perdomo, I. M. & Facchini, P. J. Benzylisoquinoline alkaloid biosynthesis in opium poppy: an update. Phytochem. Rev. 18, 1457–1482 (2019).
Li, Y., Winzer, T., He, Z. & Graham, I. A. Over 100 million years of enzyme evolution underpinning the production of morphine in the Papaveraceae family of flowering plants. Plant Commun. 1, 100029 (2020).
Samanani, N., Liscombe, D. K. & Facchini, P. J. Molecular cloning and characterization of norcoclaurine synthase, an enzyme catalyzing the first committed step in benzylisoquinoline alkaloid biosynthesis. Plant J. 40, 302–313 (2004).
Liscombe, D. K. & Facchini, P. J. Evolutionary and cellular webs in benzylisoquinoline alkaloid biosynthesis. Curr. Opin. Biotechnol. 19, 173–180 (2008).
Beaudoin, G. A. & Facchini, P. J. Benzylisoquinoline alkaloid biosynthesis in opium poppy. Planta 240, 19–32 (2014).
Cui, X. et al. Chromosome-level genome assembly of Aristolochia contorta provides insights into the biosynthesis of benzylisoquinoline alkaloids and aristolochic acids. Hortic. Res. 9, uhac005 (2022).
Spenser, I. & Tiwari, H. Biosynthesis of aristolochic acid. Chem. Commun. 1, 55–56 (1966).
Schütte, H., Orban, U. & Mothes, K. Biosynthesis of aristolochic acid. Eur. J. Biochem. 1, 70–72 (1967).
Comer, F., Tiwari, H. & Spenser, I. Biosynthesis of aristolochic acid. Can. J. Chem. 47, 481–487 (1969).
Sharma, V., Jain, S., Bhakuni, D. S. & Kapil, R. S. Biosynthesis of aristolochic acid. J. Chem. Soc. Perkin Trans. 1, 1153–1155 (1982).
Tuo, X. et al. Characterization of two putative norlaudanosoline methyltransferases from Aristolochia debilis. J. Plant Physiol. 285, 153983 (2023).
Meng, F. et al. Characterization of two CYP80 enzymes provides insights into aporphine alkaloid skeleton formation in Aristolochia contorta. Plant J. 118, 1439–1454 (2024).
Tetsuo, O.-T. & Murata, J. Nomenclature of Isotrema, Siphisia, and Endodeca, and their related infrageneric taxa of Aristolochia (Aristolochiaceae). Taxon 65, 152–157 (2016).
Simão, F. A., Waterhouse, R. M., Ioannidis, P., Kriventseva, E. V. & Zdobnov, E. M. BUSCO: assessing genome assembly and annotation completeness with single-copy orthologs. Bioinformatics 31, 3210–3212 (2015).
Li, K., Xu, P., Wang, J., Yi, X. & Jiao, Y. Identification of errors in draft genome assemblies at single-nucleotide resolution for quality assessment and improvement. Nat. Commun. 14, 6556 (2023).
Rhie, A., Walenz, B. P., Koren, S. & Phillippy, A. M. Merqury: reference-free quality, completeness, and phasing assessment for genome assemblies. Genome Biol. 21, 1–27 (2020).
Zhang, S. J., Liu, L., Yang, R. & Wang, X. Genome size evolution mediated by Gypsy retrotransposons in Brassicaceae. Genom. Proteom. Bioinform. 18, 321–332 (2020).
Nickrent, D. L. et al. Molecular data place Hydnoraceae with Aristolochiaceae. Am. J. Bot. 89, 1809–1817 (2002).
Naumann, J. et al. Single-copy nuclear genes place haustorial Hydnoraceae within piperales and reveal a cretaceous origin of multiple parasitic angiosperm lineages. PLoS ONE 8, e79204 (2013).
Massoni, J., Forest, F. & Sauquet, H. Increased sampling of both genes and taxa improves resolution of phylogenetic relationships within Magnoliidae, a large and early-diverging clade of angiosperms. Mol. Phylogenet. Evol. 70, 84–93 (2014).
Jost, M., Samain, M. S., Marques, I., Graham, S. W. & Wanke, S. Discordant phylogenomic placement of Hydnoraceae and Lactoridaceae within piperales using data from all three genomes. Front. Plant Sci. 12, 642598 (2021).
Baker, W. J. et al. A comprehensive phylogenomic platform for exploring the angiosperm tree of life. Syst. Biol. 71, 301–319 (2022).
Jiao, Y. et al. Ancestral polyploidy in seed plants and angiosperms. Nature 473, 97–100 (2011).
Wu, S., Han, B. & Jiao, Y. Genetic contribution of paleopolyploidy to adaptive evolution in angiosperms. Mol. Plant 13, 59–71 (2020).
Landis, J. B. et al. Impact of whole‐genome duplication events on diversification rates in angiosperms. Am. J. Bot. 105, 348–363 (2018).
Tank, D. C. et al. Nested radiations and the pulse of angiosperm diversification: increased diversification rates often follow whole genome duplications. N. Phytol. 207, 454–467 (2015).
Ma, J. et al. The Chloranthus sessilifolius genome provides insight into early diversification of angiosperms. Nat. Commun. 12, 6929 (2021).
Xue, J. Y. et al. The Saururus chinensis genome provides insights into the evolution of pollination strategies and herbaceousness in magnoliids. Plant J. 113, 1021–1034 (2023).
Chen, Y. C. et al. The Litsea genome and the evolution of the laurel family. Nat. Commun. 11, 1675 (2020).
Lv, Q. et al. The Chimonanthus salicifolius genome provides insight into magnoliid evolution and flavonoid biosynthesis. Plant J. 103, 1910–1923 (2020).
Shen, Z. et al. The red flower wintersweet genome provides insights into the evolution of magnoliids and the molecular mechanism for tepal color development. Plant J. 108, 1662–1678 (2021).
Chaw, S. M. et al. Stout camphor tree genome fills gaps in understanding of flowering plant genome evolution. Nat. Plants 5, 63–73 (2019).
Hu, L. et al. The chromosome-scale reference genome of black pepper provides insight into piperine biosynthesis. Nat. Commun. 10, 4702 (2019).
Pluskal, T. et al. The biosynthetic origin of psychoactive kavalactones in kava. Nat. Plants 5, 867–878 (2019).
Liscombe, D. K., Ziegler, J., Schmidt, J., Ammer, C. & Facchini, P. J. Targeted metabolite and transcript profiling for elucidating enzyme function: isolation of novel N-methtltransferasea from three benzylisoquinoline alkaloid-producing species. Plant J. 60, 729–743 (2009).
Morris, J. S., Yu, L. & Facchini, P. J. A single residue determines substrate preference in benzylisoquinoline alkaloid N-methyltransferases. Phytochemistry 170, 112193 (2020).
Ohno, S. Evolution by Gene Duplication (Springer, 1970).
Force, A. et al. Preservation of duplicate genes by complementary, degenerative mutations. Genetics 151, 1531–1545 (1999).
Lynch, M. Gene duplication and evolution. Science 297, 945–947 (2002).
OneKP Initiative. One thousand plant transcriptomes and the phylogenomics of green plants. Nature 574, 679–685 (2019).
Van de Peer, Y., Mizrachi, E. & Marchal, K. The evolutionary significance of polyploidy. Nat. Rev. Genet. 18, 411–424 (2017).
Menéndez-Perdomo, I. M. & Facchini, P. J. Isolation and characterization of two O-methyltransferases involved in benzylisoquinoline alkaloid biosynthesis in sacred lotus (Nelumbo nucifera). J. Biol. Chem. 295, 1598–1612 (2020).
Ikezawa, N., Iwasa, K. & Sato, F. Molecular cloning and characterization of CYP80G2, a cytochrome P450 that catalyzes an intramolecular C–C phenol coupling of (S)-reticuline in magnoflorine biosynthesis, from cultured Coptis japonica cells. J. Biol. Chem. 283, 8810–8821 (2008).
Kraus, P. F. & Kutchan, T. M. Molecular cloning and heterologous expression of a cDNA encoding berbamunine synthase, a C-O phenol-coupling cytochrome P450 from the higher plant Berberis stolonifera. Proc. Natl Acad. Sci. USA 92, 2071–2075 (1995).
Das, S. et al. Aristolochic acid-associated cancers: a public health risk in need of global action. Nat. Rev. Cancer 22, 576–591 (2022).
Kumar, V., Poonam, Prasad, A. K. & Parmar, V. S. Naturally occurring aristolactams, aristolochic acids and dioxoaporphines and their biological activities. Nat. Prod. Rep. 20, 565–583 (2003).
Marçais, G. & Kingsford, C. A fast, lock-free approach for efficient parallel counting of occurrences of k-mers. Bioinformatics 27, 764–770 (2011).
Ranallo-Benavidez, T. R., Jaron, K. S. & Schatz, M. C. GenomeScope 2.0 and Smudgeplot for reference-free profiling of polyploid genomes. Nat. Commun. 11, 1432 (2020).
Poplin, R. et al. A universal SNP and small-indel variant caller using deep neural networks. Nat. Biotechnol. 36, 983–987 (2018).
Cheng, H., Concepcion, G. T., Feng, X., Zhang, H. & Li, H. Haplotype-resolved de novo assembly using phased assembly graphs with hifiasm. Nat. Methods 18, 170–175 (2021).
Li, H. Minimap2: pairwise alignment for nucleotide sequences. Bioinformatics 34, 3094–3100 (2018).
Guan, D. et al. Identifying and removing haplotypic duplication in primary genome assemblies. Bioinformatics 36, 2896–2898 (2020).
Zimin, A. V. & Salzberg, S. L. The SAMBA tool uses long reads to improve the contiguity of genome assemblies. PLoS Comput. Biol. 18, e1009860 (2022).
Dudchenko, O. et al. De novo assembly of the Aedes aegypti genome using Hi-C yields chromosome-length scaffolds. Science 356, 92–95 (2017).
Dudchenko, O. et al. The Juicebox Assembly Tools module facilitates de novo assembly of mammalian genomes with chromosome-length scaffolds for under $1000. Preprint at https://doi.org/10.1101/254797v1 (2018).
Li, H. Aligning sequence reads, clone sequences and assembly contigs with BWA-MEM. Preprint at https://arxiv.org/abs/1303.3997 (2013).
Kim, D., Langmead, B. & Salzberg, S. L. HISAT: a fast spliced aligner with low memory requirements. Nat. Methods 12, 357–360 (2015).
Grabherr, M. G. et al. Trinity: reconstructing a full-length transcriptome without a genome from RNA-Seq data. Nat. Biotechnol. 29, 644 (2011).
Potter, S. C. et al. HMMER web server: 2018 update. Nucleic Acids Res. 46, W200–W204 (2018).
Buchfink, B., Xie, C. & Huson, D. H. Fast and sensitive protein alignment using DIAMOND. Nat. Methods 12, 59–60 (2015).
Mistry, J. et al. Pfam: The protein families database in 2021. Nucleic Acids Res. 49, D412–D419 (2021).
Bao, W., Kojima, K. K. & Kohany, O. Repbase Update, a database of repetitive elements in eukaryotic genomes. Mob. DNA 6, 1–6 (2015).
Tarailo-Graovac, M. & Chen, N. Using RepeatMasker to identify repetitive elements in genomic sequences. Curr. Protoc. Bioinforma. 4, 10 (2009).
Altschul, S. F., Gish, W., Miller, W., Myers, E. W. & Lipman, D. J. Basic local alignment search tool. J. Mol. Biol. 215, 403–410 (1990).
Abrusán, G., Grundmann, N., DeMester, L. & Makalowski, W. TEclass—a tool for automated classification of unknown eukaryotic transposable elements. Bioinformatics 25, 1329–1330 (2009).
Ellinghaus, D., Kurtz, S. & Willhoeft, U. LTRharvest, an efficient and flexible software for de novo detection of LTR retrotransposons. BMC Bioinf 9, 1–14 (2008).
Xu, Z. & Wang, H. LTR_FINDER: an efficient tool for the prediction of full-length LTR retrotransposons. Nucleic Acids Res. 35, W265–W268 (2007).
Ou, S. & Jiang, N. LTR_retriever: a highly accurate and sensitive program for identification of long terminal repeat retrotransposons. Plant Physiol. 176, 1410–1422 (2018).
Edgar, R. C. MUSCLE: multiple sequence alignment with high accuracy and high throughput. Nucleic Acids Res. 32, 1792–1797 (2004).
Capella-Gutiérrez, S., Silla-Martínez, J. M. & Gabaldón, T. trimAl: a tool for automated alignment trimming in large-scale phylogenetic analyses. Bioinformatics 25, 1972–1973 (2009).
Price, M. N., Dehal, P. S. & Arkin, A. P. FastTree: computing large minimum evolution trees with profiles instead of a distance matrix. Mol. Biol. Evol. 26, 1641–1650 (2009).
Hoff, K. J. & Stanke, M. Predicting genes in single genomes with AUGUSTUS. Curr. Protoc. Bioinform. 65, e57 (2019).
Korf, I. Gene finding in novel genomes. BMC Bioinf 5, 1–9 (2004).
Majoros, W. H., Pertea, M. & Salzberg, S. L. TigrScan and GlimmerHMM: two open source ab initio eukaryotic gene-finders. Bioinformatics 20, 2878–2879 (2004).
Lomsadze, A., Burns, P. D. & Borodovsky, M. Integration of mapped RNA-Seq reads into automatic training of eukaryotic gene finding algorithm. Nucleic Acids Res. 42, E119–E119 (2014).
Keilwagen, J., Hartung, F. & Grau, J. GeMoMa: homology-based gene prediction utilizing intron position conservation and RNA-seq data. Methods Mol. Biol. 1962, 161–177 (2019).
Trapnell, C. et al. Differential gene and transcript expression analysis of RNA-seq experiments with TopHat and Cufflinks. Nat. Protoc. 7, 562–578 (2012).
Xu, Y., Wang, X., Yang, J., Vaynberg, J. & Qin, J. PASA–a program for automated protein NMR backbone signal assignment by pattern-filtering approach. J. Biomol. NMR 34, 41–56 (2006).
Haas, B. J. et al. Automated eukaryotic gene structure annotation using EVidenceModeler and the program to assemble spliced alignments. Genome Biol. 9, 1–22 (2008).
Camacho, C. et al. BLAST+: architecture and applications. BMC Bioinf 10, 1–9 (2009).
Emms, D. M. & Kelly, S. OrthoFinder: phylogenetic orthology inference for comparative genomics. Genome Biol. 20, 1–14 (2019).
Katoh, K. & Standley, D. M. MAFFT multiple sequence alignment software version 7: improvements in performance and usability. Mol. Biol. Evol. 30, 772–780 (2013).
Suyama, M., Torrents, D. & Bork, P. PAL2NAL: robust conversion of protein sequence alignments into the corresponding codon alignments. Nucleic Acids Res. 34, W609–W612 (2006).
Minh, B. Q. et al. IQ-TREE 2: new models and efficient methods for phylogenetic inference in the genomic era. Mol. Biol. Evol. 37, 1530–1534 (2020).
Kalyaanamoorthy, S., Minh, B. Q., Wong, T. K., Von Haeseler, A. & Jermiin, L. S. ModelFinder: fast model selection for accurate phylogenetic estimates. Nat. Methods 14, 587–589 (2017).
Junier, T. & Zdobnov, E. M. The Newick utilities: high-throughput phylogenetic tree processing in the UNIX shell. Bioinformatics 26, 1669–1670 (2010).
Mirarab, S. & Warnow, T. ASTRAL-II: coalescent-based species tree estimation with many hundreds of taxa and thousands of genes. Bioinformatics 31, i44–i52 (2015).
Wang, Y. et al. MCScanX: a toolkit for detection and evolutionary analysis of gene synteny and collinearity. Nucleic Acids Res. 40, E49–E49 (2012).
Yang, Z. & Nielsen, R. Estimating synonymous and nonsynonymous substitution rates under realistic evolutionary models. Mol. Biol. Evol. 17, 32–43 (2000).
Yang, Z. PAML 4: phylogenetic analysis by maximum likelihood. Mol. Biol. Evol. 24, 1586–1591 (2007).
Jiao, Y., Li, J., Tang, H. & Paterson, A. H. Integrated syntenic and phylogenomic analyses reveal an ancient genome duplication in monocots. Plant Cell 26, 2792–2802 (2014).
Chen, K., Durand, D. & Farach-Colton, M. NOTUNG: a program for dating gene duplications and optimizing gene family trees. J. Comput. Biol. 7, 429–447 (2000).
Murat, F., Armro, A., Pon, C., Kopp, C. & Sas, J. Reconstructing the genome of the most recent common ancestor of flowering plants. Nat. Genet. 49, 490–496 (2017).
Pont, C. et al. Paleogenomics: reconstruction of plant evolutionary trajectories from modern and ancient DNA. Genome Biol. 20, 29 (2019).
Wang, X. et al. Telomere-centric genome repatterning determines recurring chromosome number reductions during the evolution of eukaryotes. N. Phytol. 205, 378–389 (2015).
Zhuang, W. et al. The genome of cultivated peanut provides insight into legume karyotypes, polyploid evolution and crop domestication. Nat. Genet. 51, 865–876 (2019).
Kong, X. et al. Two-step model of paleohexaploidy, ancestral genome reshuffling and plasticity of heat shock response in Asteraceae. Hortic. Res. 10, uhad073 (2023).
Wang, J. et al. A common whole-genome paleotetraploidization in Cucurbitales. Plant Physiol. 190, 2430–2448 (2022).
Morris, J. L. et al. The timescale of early land plant evolution. Proc. Natl Acad. Sci. USA 115, E2274–E2283 (2018).
Yang, L. et al. Phylogenomic insights into deep phylogeny of angiosperms based on broad nuclear gene sampling. Plant Commun. 1, 100027 (2020).
Yu, G., Smith, D. K., Zhu, H., Guan, Y. & Lam, T. T. Y. Ggtree: an R package for visualization and annotation of phylogenetic trees with their covariates and other associated data. Methods Ecol. Evol. 8, 28–36 (2017).
De Bie, T., Cristianini, N., Demuth, J. P. & Hahn, M. W. CAFE: a computational tool for the study of gene family evolution. Bioinformatics 22, 1269–1271 (2006).
Yu, G., Wang, L. G., Han, Y. & He, Q. Y. clusterProfiler: an R package for comparing biological themes among gene clusters. OMICS J. Integr. Biol. 16, 284–287 (2012).
Chong, J. & Xia, J. MetaboAnalystR: an R package for flexible and reproducible analysis of metabolomics data. Bioinformatics 34, 4313–4314 (2018).
Gu, Z., Eils, R. & Schlesner, M. Complex heatmaps reveal patterns and correlations in multidimensional genomic data. Bioinformatics 32, 2847–2849 (2016).
Jumper, J. et al. Highly accurate protein structure prediction with AlphaFold. Nature 596, 583–589 (2021).
Mirdita, M. et al. ColabFold: making protein folding accessible to all. Nat. Methods 19, 679–682 (2022).
Wang, X. et al. A recent burst of gene duplications in Triticeae. Plant Commun. 3, 100268 (2022).
Hu, Y. H. & Jiao, Y. N. The Aristolochiaceae genomes. Figshare https://doi.org/10.6084/m9.figshare.26788381 (2025).
Acknowledgements
We thank Pichang Gong for providing us with the N. benthamiana seed and pEAQ-HT expression plasmid, Ze Wei, Zexin Li and Renbin Zhu for photographs, Runxian Yu, Ming Yue (Xi’an Botanical Garden of Shaanxi Province, Institute of Botany of Shaanxi Province), Jianfei Ye (Sun Yat-sen University) and Guifeng Cui (Baotianman National Nature Reserve, Henan, China) for helping collecting samples, Weijia Cheng (Wuhan University) for his assistance with standard procurement and LC-MS analysis. We also acknowledge support from the National Key R&D Program of China (2021YFA0909600), the National Natural Science Foundation of China (32221001), and CAS Youth Interdisciplinary Team (JCTD-2022-06) to Y.J.
Author information
Authors and Affiliations
Contributions
Y.J. conceived and initiated the project. Y.Hu and L.L. collected materials for genome and transcriptome sequencing. Y.Hu, X.Y., L.L., L.Q., and K.L. contributed to the genome assembly and annotation. Y.Hu, J.P.W., J.Y.W., Y.Hao, and Y.F. performed the whole-genome duplication and genome structural analyses. Y.Hu performed gene family clustering and phylogenomic analyses. Y.Hu and X.W. conducted evolutionary analyses of BIA-related gene families. X.W. and L.L. performed the N. benthamiana transient-expression experiment and LC-MS analyses. Z.Z. for performed the karyotyping of S. henryi. L.L. and H.W. cultivated the plants and performed the tissue culture. Y.Hu, J.W., L.L., X.Y., and X.W. drafted the corresponding result parts they analyzed and Y.J. and Y.Hu wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Li Guo, De-Zhu Li and Kyo Bin Kang for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Hu, Y., Wang, J., Liu, L. et al. Evolutionary history of magnoliid genomes and benzylisoquinoline alkaloid biosynthesis. Nat Commun 16, 4039 (2025). https://doi.org/10.1038/s41467-025-59343-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-025-59343-8
