
Abstract
Hidden messages in DNA molecules by employing chemical modifications has been suggested for private data storage and transmission at high information density. However, rapidly decoding these “molecular keys” with corresponding basecallers remains challenging. We present DeepSME, a nanopore sequencing and deep-learning based framework towards single-molecule encryption, demonstrated by using 5-hydroxymethylcytosine (5hmC) substitution for individual nucleotide recognition rather than sequential interactions. This non-natural, motif-insensitive methylation disrupts ion current, resulting in a readout failure of 67.2%–100%, concealing the privacy within the DNAs. We further develop an alignment-free DeepSME basecaller as a key to reconstitute the digital information. Our three-stage training pipeline, expands k-mer size from 46 to 49, achieving over 92% precision and recall from scratch. DeepSME deciphers fully 5hmC concealed text and image within 16× coverage depth with an F1-score of 86.4%, surpassing all the state-of-the-art basecallers. Demonstrated on edge computing devices, DeepSME holds supreme potential for DNA-based private communications and broader bioengineering and medical applications.
Similar content being viewed by others


Introduction
DNA storage has emerged as a promising solution for the requirement of digital memories in the “zettabyte era” due to its density and durability1. Design and realization of molecular protection2 places ever-increasing demands on the accurate storage, transmission, and assessment of DNA data rapidly and privately. Many efforts have been devoted to exploring an accessible approach for information privacy, such as cryptoristors3, metahologram4,5, quantum photonic system6,7, DNA based technology8,9,10,11, synthetic macromolecules12,13, where concealed information would not be evident to unsuspecting persons’ examination10. Among them, biomolecular steganography, which utilizes chemical modifications or interactions instead of computational schemes, has been demonstrated using nucleic acids, proteins14, aptamers15, and bacteria16 for information concealment. For instance, DNA-based steganography developed by Clelland et al.17 was further leveraged by DNA origami cryptography, which creates a key with a size of over 700 bits with oligonucleotides11. However, these strategies exploiting molecular interactions with low information densities and time-consuming processing have not fully explored the potential of chemical modifications to densely packed nucleobases, thus preventing them from being used in sequencing-based approaches.
Sequencing non-canonical DNA holds promise for private communication because current sequencing technologies and basecallers are designed for canonical DNA. When encountering modified nucleobases, these state-of-the-art sequencing technologies introduce various errors, making it challenging to retrieve the correct sequence18. Such methylated19 or oxidized20 modifications necessitate specialized methods across different sequencing platforms, such as NGS21 or long-read ones. For NGS techniques, WGBS22,23, RRBS24, MeDIP-seq25, MRE-seq26, etc. have been developed for single specific types, where the non-canonical bases may not react completely or break the DNA strands into pieces27. These methods can also be applied to the long-read fluorescent sequencing (PacBio), where the drawbacks are the same. Meanwhile, for long-read nanopore sequencing (NPS), non-canonical bases can be identified without any changes. The detection algorithms can be categorized into two classes: (1) Identification from alphabet errors. This includes Epinano for m6A28, differ for m6A29, DRUMMER for m6A30, nanoRMS for ΨU/Nm31, ELIGOS for m6A32, NanoCEM for unspecific modifications33 and Dinopore for Inosine34; (2) Identification from current features, containing DeepSignal for 5mC35, DeepMod for 5mC36, MINES for m6A37, nanoDoc for unspecific modifications38, nanom6A for m6A39, nanocompore for m6A40, Yanocomp for m6A41, xPore for m6A42, Penguin for Ψ43 m6Anet for m6A44 and exos for 8-oxo-dG20; Rerio for 5mC/5hmC and IL-AD for 5mC/5hmC/6mA45. Aiming for biological science, these developments of basecallers limit themselves within the identification of light-weighted modification46 or motifs47. None of them, to the best of our knowledge—has been reported to deal with heavily or nearly complete modifications, which remains challenging because of the lack of basecallers and references.
To address this limitation, a de novo approach to basecalling heavily modified DNA is required for pristine raw data. Nanopore data readouts, maintaining sequential information of any nucleobase or analogs into ion flow blockades, nowadays utilize neural networks (NN)48 vastly for accurate basecalling. Well-trained NNs can act as the cipher to pair with a specific molecular key; the inherent non-reversibility of NN prevents direct determination of the key from the network’s weights. However, training NNs is often a joy with tears, since rounds of sophisticated alignments and time-consuming corrections of datasets may take place49. Besides, existing prior knowledge (k-mer dictionary) and references are critical to reduce the high error rates50. The bottlenecks for nanopore private communication have two aspects: (1) to arrange private messages wisely into non-canonical DNAs and (2) to rapidly and correctly build up correlated nanopore NN with limited correct alignments. To date, constructing a framework for heavily or completely modified DNAs is therefore highly appreciated.
In this work, we propose a private framework utilizing motif-insensitive 5hmC modification combined with a NPS-based de novo basecaller for privacy. We conceal text and image into fully 5hmC modified DNA sequences and validate our approach by NPS and basecaller training, aiming to address the challenges to build the basecaller posed to heavily modified bases. We develop a three-stage alignment-free training framework for Deep-learning framework towards Single-Molecule Encryption (DeepSME), which tackles the basecalling bottleneck of the heavily modified dataset by expanding k-mer dictionary. Independent k-mer tables are generated from scratch, allowing us to process the modified sequences and their corresponded signal disruptions without prior references at single-molecule level. This framework, together with the training method of private DeepSME basecaller underpins the potential for concealed DNA-based data storage and communication with high information density, addressing the increasing demand for robust information privacy in an era of evolving biotechnological threats.
Results
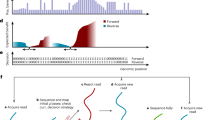
Figure 1a illustrates the scenario for digital information stored in DNA for private communications. Texts and images can be transcoded into DNA sequences, followed by the DNA synthesis as templates. Conventional polymerase chain reactions (PCR) amplify the templates into double strands and can be sequenced by either next generation sequencing (NGS)51 or NPS52 for public communications. Here, Alice acts as the sender who initiates the communication either publicly or privately. For the former case, canonical bases and conventional basecallers are publicly available. Here we proposed a DeepSME for the latter case between Alice and Bob. This allows Alice to hide information within non-canonical DNAs and creates a basecaller that serves as the key for Bob. Moreover, an unsuspecting person, Eve is not capable of accessing the information using conventional basecallers.

a Schematics of private communication for files and texts stored in DNA. Steganography is achieved by obfuscating data stored inside DNA via modifications by the sender Alice. Canonical DNAs can be transmitted publicly and readout using conventional basecaller by everyone. Non-canonical DNAs in principle cannot be easily revealed by an unsuspecting observer, Eve, while the private observer Bob should be able to use DeepSME as the key to decipher the messages from Alice. b An example of Alice’s choice with the chemical structure of deoxycytidine triphosphates (dCTP), which is labeled as cytosine (C) and 5-hydroxymethylcytosine (5hmC), respectively. c Nanopore sequencing of canonical and fully methylated 5hmC DNA strands using a state-of-the-art basecaller (Bonito/Dorado). The ionic current signals of C (cyan) and 5hmC (orange) are interpreted into DNA sequences and aligned with reference sequences/messages from Alice. The error bases are labeled in red, corresponding to the information received by Eve using the conventional basecaller. a, c contains icons from Bootstrap Icons (https://icons.getbootstrap.com/), licensed under CC BY 3.0 (https://creativecommons.org/licenses/by/3.0/).
Following the roles for Alice, Bob, and Eve, Fig. 1b displays an example of chemical structures of Alice’s choice—deoxycytidine triphosphate (dCTP), where the two analogies are labeled as cytosine (C) and 5-hydroxymethylcytosine (5hmC). Due to an additional hydroxymethyl group at 5′, a distinct steric hinderance on the blockage of nanopore signals could be expected with close-to-neutral hydrophilicity. Following synthetic methods36, all the cytosines are substituted in vitro by the chemically stable 5hmCs regardless of any motifs or contexts. This complete replacement of 5hmC surpasses the medication ratio in any biological systems, in particular human genome23,53,54, where only 1.28% of C (2.62% of a given whole microbial genome) is currently modified to 5mC or 5hmC.
We next examined the privacy of full 5hmC modification using NPS in Fig. 1c. As DNA molecules pass through the nanopore, they generate characteristic ionic current signals that are recorded as squiggle patterns (shown as black lines in the figure). For canonical DNA (top panel), the current signal (shown in cyan) is correctly interpreted by conventional basecallers to reveal Alice’s reference sequence (GCTGACCCGCCGCATCGGTG). However, current signals in the bottom panel drastically deviated (shown in orange) when containing full 5hmC modifications. These heavily modified signals confuse conventional basecallers, for example Bonito/Dorado, resulting in severe misinterpretation of the message (TGCTTGCCGTTCGCGTTATA, with 16 out of 20 bases incorrectly called), demonstrating the successful privacy protection away from Eve in this scenario.
For the corresponding key produced by either Alice or Bob, we propose a three-stage alignment-free pipeline for DeepSME basecaller, shown in Fig. 2a. Eleven samples of DNA sequences ranging from 1145 nt to 1341 nt are firstly sequenced to construct the 6-mer quality check dataset without any sequence-to-current alignments50. Tolerating these errors caused by the alignment-free segmentation, an initial 6-mer QC DeepSME is trained to provide a k-mer model as a new dictionary. Benefiting from investigated k-mer dictionary and nanopore simulators such as scrappie squiggle55, squigulator56, and deepsimulator57, in silico dataset can be generated for length variation and expanded the dictionary from 46 to 49. Not only mitigating the overall errors, simulated current signals can also expand the physical redundancy (also named as coverage depth, denoting the depth or completeness of DNA sequencing on the reference sequence). Depicted in Fig. 2b, the upper heatmap of full 6-mers shows a sparse occupation (2.60%) in the 9-mer space, while in silico dataset can cover almost all the 9-mers, comparable to the experimental microbial whole-genome sequences (gDNA) dataset with slightly different frequency (see Supplementary Table 1). Lastly, three types of microbial gDNA are sequenced by nanopore and processed by enhanced DeepSME, which leads to the final training of the reinforced DeepSME.

a Training DeepSME with a three-stage alignment-free pipeline. b 9-mer coverages of three used training datasets. c Training error rate as a function of standard deviation of segmented lengths. Inset depicts the uncertainty (standard deviation of a certain segmented length). d Mean absolute current difference (MACD) of both canonical cytosine (top) and 5hmC (bottom) at different nucleotide positions of a k-mer oligonucleotide. e Methylated 5hmC vs. canonical cytosine of normalized current levels. f Recall vs. precision of DeepSME for both canonical and methylated 5hmC. a contains icons from Bootstrap Icons (https://icons.getbootstrap.com/), licensed under CC BY 3.0 (https://creativecommons.org/licenses/by/3.0/).
In the first stage, the 6-mer QC DNA is sensitive to initiate the DeepSME. It is hardly practical to mark 500 annotations and segmentations for every 10,000 heavily modified nucleobases manually with no prior knowledge. Taking conventional segmentation tool Tombo58 (Nanopolish59 also works) on canonical dataset as a control, 3.9% errors will always exist. Considering billions of sequences and bases that are being used, Fig. 2c shows the overall error rate as a function of length variation. Given ~450 nt/s as the sequencing speed of a nanopore60, individual current signals segmented as 2.22 s (corresponding to roughly 1000 nt), 4.44 s (~2000 nt), 6.66 s (~3000 nt), 8.88 s (~ 4000 nt) and 11.10 s (~5000 nt) contribute to the length variations of 40–85 nt. The longer the segmentation goes, the more errors the preliminary DeepSME holds.
The inset of Fig. 2c illustrates the segmentation-induced length variation. A fixed number of bases can be assigned to segmented current blocks each time as a chunk, creating a dataset containing tens of thousands of chunks for the training of the basecaller. The length variation itself is proportional to the segmented time. Our preliminary DeepSME segmented chunks at 2.22 s is estimated to have a total error of 11.6%, which seems tolerable for further investigations.
We further analyzed the reduced ionic currents with the modification of 5hmC. Figure 2d shows the normalized current difference for the canonical C and 5hmC in the extracted k-mer model from DeepSME in the second training stage. By substituting either C or 5hmC at each position (x-axis), the mean averaged current difference (MACD) is calculated over all k-mers in the model. In this 6-mer model, the base at index 2 has the highest impact on the current change. This is in a reasonable agreement with reported k-mer model from ONT61. Additionally, the weight of the bases at index #0, #1, #2, and #3 on the current significantly decreases when 5hmC modification takes place. This indicates that 5hmC modification leads to a reduction in the normalized currents at these corresponding base positions compared to the canonical state.
On the other hand, Fig. 2e presents a comparative analysis of normalized ionic current levels between canonical and 5hmC-modified DNA sequences. Each point in the figure represents a specific k-mer (6-mer), where those not containing any C’s shown in black, and those containing 1–6 C’s shown in orange. The saturation of the orange color correlates with the number of cytosines in the k-mer–darker orange indicates more cytosines. The black dashed line with a slope of 0.83 with the offset of 0.58 represents a linear fitting for 6-mers without C’s. Notably, this line deviates from the gray diagonal one, aligning with the k-mer for 5hmC modified DNA reported by Kovaka et al.61. This significant deviation in slope indicates substantial changes in the normalized current signals, making the non-natural heavily modification more effective for private communications. Furthermore, k-mers containing 5hmC modifications consistently show lower normalized current levels compared to their canonical counterparts, which matches well with our previous observations in Fig. 2d.
The basecalling accuracy and recall are evaluated at the third stage. Figure 2f illustrates the relationship between recall and precision of DeepSME at three stages for both canonical C and 5hmC. First, the preliminary basecallers are located at the bottom left, meaning low precision and low recall capabilities since only 6-mer features of DNA are learnt so far. Second, the enhanced basecallers perform much better on precision but remain low on the recall, which is reasonable since the simulated dataset lacks the ability of generalization for variant conditions. Last, the reinforced basecallers show significant improvements in both precision (0%–82.9%–93.0%) and recall (0%–2.5%–92.9%). The reinforced 5hmC basecaller has a slightly lower accuracy but a higher recall than that of canonical one. Compared with the commercial basecallers (Bonito FAST, HAC—high accuracy and SUP—super accuracy config), the reinforced 5hmC basecaller is beyond the F1-score of 0.85 (gray dashed line), surpassing Bonito SUP, HAC as well as FAST.
We turn our focus onto the decoding results of 5hmC modified DNA that conceals text file (sustech_introduction.txt, 978 bytes, 55 strands) and image file (sustech_logo.jpg, 7775 bytes, 432 strands). Without knowing exact types of DNA modifications, Fig. 3a shows the decoding performance of the identical text file using state-of-the-art basecallers on modified DNA from the unsuspecting observer Eve’s view with 16× coverage. For the basecallers that could not reach the coverage amount, all basecalled sequences were obliged to use. Guppy 6.0 achieved a decode rate of 5.45% (3/55), Bonito/Dorado reached 3.64% (2/55), Rerio 5mC 5hmC managed 3.64% (2/55), while IL-AD was unable to decode any sequences (0/55) at all.

a Decoding performance of the text file by the unsuspecting observer Eve using Guppy 6.0 (dna_r9.4.1_450bps_hac config), Bonito/Dorado (dna_r9.4.1_e8_sup@v3.3 config), Rerio 5mC 5hmC (res_dna_r941_min_modbases_5mC_5hmC_v001 config), incremental learning and anomaly detection (IL-AD, 5hmC config) with coverage depths of 16×. b Decoding performance of the text file by the private observer Bob using DeepSME with coverage depths of 2×, 4×, 8×, and 16×. c The percentage of data recovered as a function of coverage for the text file stored in canonical (cyan) or 5hmC (orange) using corresponding canonical or 5hmC DeepSME, respectively (n = 10). d Base bias of substitutions for canonical DeepSME. e Base bias of substitutions for 5hmC DeepSME. f F1-scores for variant basecallers on obfuscated (5hmC) DNA.
Encouraged by the high precision and recall of DeepSME, we perform decoding experiments displayed in Fig. 3b from the private observer Bob’s view. The recovered texts are shown with the increasing physical redundancy (the coverage depth from 2× to 16×). It is evident that DeepSME produced up to 52.73% (29/55) of the text after decoding with 4×, reached up to 94.5% (52/55) data retrieval with 8× coverage and correctly decoded all of the text with 16× coverage. Figure 3c compares the text data retrieval performance of the two DeepSMEs as a function of coverage depth. They exhibit almost identical data recover rate, with small variations across experiments. At each coverage level, the data recover rate was measured 10 times with different random seeds.
To gain more insights from the two basecallers, the substitution probabilities of canonical and 5hmC DeepSME are illustrated in Fig. 3d, e. The substitutions from T to C and C to T are 11.67% and 13.39%, while these values go to 15.14% and 13.78% for T-5hmC and 5hmC-T. A-G and G-A are also high for both. The two matrices are quite comparable, which are also in agreement with the matrix from Lopez et al.52.
To analyze the comparison with alternative basecaller configs, Fig. 3f presents the F1-scores on our modified DNA storage dataset. DeepSME achieved a leading F1-score of 0.864 to date, while other basecallers such as Guppy 6.0, Bonito/Dorado Super, Rerio, and IL-AD had F1-scores ranging only from 0.025 to 0.040.
Discussion
Our work demonstrates that the challenge of pairing key generation with nanopore basecallers can be coped with the DeepSME framework. This could enable private communication between Alice and Bob with a superior F1-score of 86.42%, shown in Fig. 3f. Our DeepSME framework offers several advantages:
-
1.
Knowledge growing. First, the initial 6-mer QC DeepSME basecaller does extract 5hmC-modified features. This is supported by the shift of k-mer current in Fig. 2e, where 89.63% of C-containing k-mers deviate from the diagonal and only 12.35% of k-mers that don’t contain C deviate from the diagonal. Second, the Enhanced DeepSME basecaller could learn more abundant features from 6-mers to 9-mers, which can be ascribed to the substantial precision increase on the modified test dataset from 0% to 82.87% (see Fig. 2f and Supplementary Table 2). Third, the reinforced DeepSME basecaller could get polished smoothly along with experimental 9-mer gDNA dataset. This can be accredited by the fact of achieving 92.99% precision and 92.93% recall.
-
2.
Alignment free. We used the strategy of fixing chunk size of 1000 bp instead, shown in Fig. 2c. Based on the assumption of constant sequencing velocity at 450 bp, this strategy holds an error rate as high as 11.6%. Compared with 5.63% error as the minimal, this high error rate is no more a trouble as the overall basecalling errors went down to 7.01% in Fig. 2f.
-
3.
Prior-knowledge free. Our training of fully modified dataset can be performed without pre-existing k-mer tables nor basecaller weights. This is underpinned by a smart use of the output from the Connectionist Temporal Classification (CTC) layer of our 6-mer QC DeepSME basecaller. Once this basecaller gets trained, one can directly derive a new k-mer table from the CTC layer, which is particularly beneficial to link with the trained weights. To this end, prior k-mer tables and basecaller weights can be detoured.
-
4.
Affordable. We show in the Methods that 266.4 min of thee-stage basecaller training in 19.9 GB VRAM are sufficient for our open-sourced deep-learning NN. While lightweight models can reduce computational demands, they led to much lower F1-scores (75.77–84.36%). Different programming language-based software (Python-based Bonito and C-based Dorado) and hardware platform (NVIDIA RTX 3090 and Jetson Xavier AGX) were thoroughly evaluated (see Supplementary Tables 7 and 8) confirming the operational feasibility of the current model size in edge-computing environments.
For the generalizability, DeepSME basecallers could be custom-tailored and delivered for variant combinations on promise, including diverse modification types, modification ratios as well as nanopore sensors. For instance, our preliminary tests demonstrate successful alignment of the sequence primer current extracted from the 6-mer QC sequence (using an R9.4.1 pore) to its corresponding current in an R10.4.1 pore via dynamic time warping62 (Supplementary Fig. 5). Although high error rates have been mitigated by Composite Hedges Nanopore (CHN) code, the advances on R10.4.1 flowcells could further manage the error rate below 1%63. This cross-pore compatibility suggests the adaptability of the DeepSME framework across different types of nanopores or other hardware such as CycloneSEQ64 or PolyseqOne65.
Our three-stage training pipeline is essential, as removing any stage would compromise the overall performance and reliability of the framework. First, the initial 6-mer QC DeepSME basecaller lays the foundation of generating a unique 6-mer table for subsequent steps. Without this initial step, fewer than 0.2% of the chunks can be identified for the rest steps, making basecaller training nearly impossible. Second, the in silico training of the Enhanced DeepSME basecaller boosts the accuracy to over 80% while expanding the k-mer coverage from 6-mers to 9-mers. Without 81,490 simulated strands, the 6-mer QC DeepSME basecaller would recognize less than 0.5% of chunks of gDNA dataset, hindering basecalling. However, the Enhanced DeepSME basecaller has the recall rate remaining at 2.5%, showing its overfitting of in silico data. Last, the reinforced DeepSME basecaller incorporating real-world gDNA data, reached 93.0% precision on DNA storage dataset (Fig. 3). This demonstrates the successful mitigation of overfitting risks.
For the unsuspecting observer Eve, it is hardly possible to circumvent DeepSME with public basecallers and their weights. Alternative basecallers have fewer than 5% of the correct sequences for modified sequences in Fig. 3f (see the Supplementary Table 5 for recall and precision of these basecallers). We believe this could be attributed to the shifted current deviations (Figs. 1c and 2e): some of the points are still located close to the black dashed line, which could be recognized by basecaller and aligned to the reference sequence. Meanwhile, other points are far away from the black dashed line, being ill-interpreted.
Beyond enumerating basecalling attempts, the interception of DeepSME could be executed by Eve as the weights lack inherent encryption. Thus, employing traditional66 or post-quantum cryptographic algorithms67 becomes essential and be a critical direction to avoid cybersecurity threats between Alice and Bob. Furthermore, reverse engineering of modification patterns represents another potential vulnerability. However, the diversity of existing modifications19,68,69 and the availability datasets for heavily modified DNA, may hinder the timely training of such reverse-engineering models, providing DeepSME with a valuable, albeit potentially temporary, window for privacy, though not absolute security.
Lastly, privacy may be inferred, assuming an ultimate modification caller that can accurately decode any level of modified data. While theoretically plausible, achieving this in practice presents considerable hurdles. On one hand, the complexity of the “molecular key space” increases with 429 existing types19,68,69 and upcoming new ones. On the other hand, the parameters and memory consumption will inflate drastically for training an 100-letter basecaller (may need \(5.6+14.3\times \frac{{100}^{6}}{{4}^{6}}=3.49\times {10}^{9}\) GB of VRAM). These practical issues offers DeepSME a substantial layer of privacy against current threats and resource-constrained adversaries.
We speculate that DeepSME could evolve into a functional encryption system. The original DNA sequence could stand for the plaintext, the nanopore current readouts from modified DNA for the ciphertext, the specific modification types and their ratios for the key space, while in vitro modification process and DeepSME weights governed basecalling for encryption and decryption, respectively. While sharing similarities as a quintuple scheme for the definition of encryption70, we are at a very infant stage towards encryption. Given the key length is defined as \({\log }_{2}\big({C}_{N}^{M}\big)\), where M is the known nucleobase analogs and N is the chosen nucleobase types, our implementation with a single modification type achieves a key length of approximately \({\log }_{2}\big({{{\rm{C}}}}_{4}^{429}\big)=30.37\) bits, supposing the existence of at least 429 known nucleobase modifications19,68,69. This is far behind National Institute of Standards and Technology’s (NIST) recommended minimum of 128 bits for secure encryption66. In this theory, 24 types of nucleobase analogs used in one in vitro process could fulfill the key length requirement of \({\log }_{2}\big({C}_{24}^{429}\big)=129.89\) bits. Alternatively, block encryption offers a promising approach to increase key length. By splitting the data into blocks and employing different combinations of nucleobase analogs for each block, we can linearly increase the overall key length. For instance, using four blocks and focusing on a subset of 140 common base analogs mentioned by Juan et al.19, we can select four distinct sets of six analogs to encrypt each data block. This approach could theoretically achieve a key length of \(4\times {\log }_{2}\big({C}_{6}^{140}\big)=132.51\) bits, thereby meeting NIST’s requirements. These methods, while beyond the scope of this work, highlight the potential of DeepSME for future development as a robust encryption system.
We also verified the integration of DeepSME with post-quantum cryptography (PQC) such as frameworks like FrodoKEM71. This could also be applied onto the raw texts and images. For tamper-evident DNA storage protocols; we foresee that techniques such as molecular tags, sequence watermarks, and enzymatic protection mechanisms could be explored72. Some simplified methods, like monitoring 5hmC/canonical cytosine ratios and basecaller discrepancies which reuse the developed basecallers, may also provide effective tamper-evidence. We further note that 5hmC DeepSME basecaller also performs well on canonical DNA sequences (see Supplementary Table 6), which shows its promise to be utilized as a framework to detect methylations from epigenomics.
For ethical considerations, we have implemented multi-layered biosecurity screening measures and advocate for adherence to guidelines like the International Gene Synthesis Consortium standards and ISO regulations73. Concerns regarding illicit data smuggling via microbes are taken into our thoughts. Although they could be mitigated by the likely toxicity of extensive 5hmC modifications74, proactive biosecurity, ethical guidelines, and dual-use risk assessments remain essential for responsible DeepSME development, as we have solely focused on in vitro investigations75.
In conclusion, we have proposed and experimentally validated a communication framework (DeepSME) with non-naturally existing hydromethylation DNAs for information privacy, paired with a de novo trained nanopore basecaller. Avoiding tremendous alignments and corrections, we demonstrate that our three-stage training method is essential for DeepSME to achieve both 92% recall and precision incrementally, exceeding state-of-the-art basecallers on the digital information stored in 5hmC DNA dataset. Within just 16× coverage depth and negligible prior knowledge requirements, our independent DeepSME framework fulfills the readout of heavily-modified single-molecule DNA, showcasing its great promise towards biomolecular-based private communications, unclonable functions, and anticounterfeiting systems.
Methods
Information concealment via 5‑hydroxymethylcytosine (5hmC) based polymerase chain reaction
Synthetic DNA sequences with designed digital information were purchased from Twist Bioscience, while plasmids and primers were obtained from Tsingke Biotech. PCR were performed using 10 mM dATP, dTTP, dGTP, and dCTP supplied by Sangon Biotech. The PCR process utilized Phanta Max Super-Fidelity DNA Polymerase (P505-d1) from Vazyme.
For each 50 µl reaction system, 15 µl of ddH2O was added along with 25 µl of 2× Phanta Max Buffer. Additionally, 1 µl of each 10 mM dATP, dTTP, dCTP, and dGTP was included. To this mixture, 2 µl of Forward Primer and 2 µl of reverse primer were added. Finally, 1 µl of Phanta Max Super-Fidelity DNA Polymerase (1 U/µl) and 1 µl of DNA were incorporated to complete the reaction mixture. Specifically, 5-hydroxymethyl-dCTP (Cat. No. NU-932s) was purchased from Jena Bioscience as the alternative PCR substrate for dCTP. The PCR conditions were as follows: (1) Pre-denaturation at 95 °C for 3 min, (2) Denaturation at 95 °C for 15 s, (3) Annealing at 60 °C for 15 s, (4) Extension at 72 °C for 1.2 min or 1 min per 1 kb sequence, (5) Final Extension at 72 °C for 5 min. After performing 30 cycles, the resulting products can be considered as a complete conversion from cytosine (C) to methylated 5hmC. To confirm the fidelity of amplification with DNA modification, the 5hmC PCR products were sent to Sanger sequencing showing identical sequences (Supplementary Fig. 6).
Electrical readout via nanopore sequencing
Following PCR amplification, both the canonical (ATCG) and 5hmC-modified (AT5hmCG) DNA products were separately subjected to electrophoresis on a 1.5% agarose gel for length validation and purification. The bands corresponding to the reference sequence length were excised, followed by DNA extraction using the E.Z.N.A. Cycle Pure Kit (V-spin) from Omega Bio-Tek. A solution containing 200 ng of DNA was prepared using the ND608 kit from Vazyme for DNA damage repair, end preparation, and adapter ligation. This includes two steps: (1) Damage repair and end preparation: 2 µl damage prep enzyme, 5 µl end prep enzyme, and 10 µl end prep buffer were added, with ddH2O supplemented to a total volume of 65 µl. This mixture was incubated in a PCR thermal cycler at 30 °C for 20 min, followed by 65 °C for 15 min. (2) Adapter ligation: 25 µl rapid ligation buffer 2, 5 µl Rapid DNA Ligase, and 5 µl AMX-F from the LSK-110 kit from Oxford Nanopore Technology were added to the reaction solution, and the mixture was incubated in a PCR thermal cycler at 20 °C for 15 min.
Next, DNA purification was performed using VAHTS DNA Beads (N411-01) from Vazyme according to the bead purification protocol in the LSK-110 kit. The VAHTS DNA Beads were first resuspended by vortexing. Subsequently, 40 µl of the resuspended beads were added to the reaction in previous step and mixed by flicking the tube. The mixture was then incubated on a Hula mixer (rotator mixer) for 5 min at room temperature. After spinning down the sample and pelleting it on a magnet, the supernatant was pipetted off while keeping the tube on the magnet. The beads were then washed by adding 250 µl short fragment buffer, flicking to resuspend, spinning down, and returning the tube to the magnetic rack to allow the beads to pellet. The supernatant was removed using a pipette and discarded. This washing step was repeated. After spinning down and placing the tube back on the magnet, residual supernatant was pipetted off and the beads were allowed to dry for about 30 s, ensuring the pellet did not crack. The tube was removed from the magnetic rack, and the pellet was resuspended in 15 µl elution buffer. The mixture was spun down and incubated for 10 min at room temperature. The beads were then pelleted on a magnet until the eluate was clear and colorless, for at least 1 min. Finally, 15 µl of eluate containing the DNA library was removed and retained in a clean 1.5 ml Eppendorf DNA LoBind tube.
Furthermore, DNA quantification was performed using a Qubit Fluorometer to measure 50 fmol of DNA. For flow cell priming and loading according to the LSK-110 protocol, 30 µl of thawed and mixed Flush Tether (FLT) was added directly to the tube of thawed and mixed flush buffer and mixed by vortexing at room temperature. Then, 800 µl of the priming mix was loaded into the flow cell (FLO-MIN106) via the priming port, avoiding the introduction of air bubbles, and left to sit for 5 min. During this time, the library for loading was prepared by mixing 37.5 µl Sequencing Buffer II (SBII), 25.5 µl Loading Beads II (LBII), and 12 µl DNA library including 50 fmol of DNA. An additional 200 µl of the priming mix was loaded into the flow cell via the priming port, again avoiding air bubbles. The prepared library was then mixed gently by pipetting up and down just before loading. Finally, 75 µl of the sample was added to the flow cell via the SpotON sample port in a dropwise fashion, ensuring each drop flowed into the port before adding the next.
Finally, the MinION was connected to a computer, and the MinKNOW v24.02.6 software was launched. The LSK-110 protocol and other default settings were selected. We also adjust the “sequence length cutoff options” on MinKNOW (200 bp for DNA Storage experiment, 1000 bp for 6-mer QC DeepSME Basecaller experiment). Finally, the sequencing button was clicked to begin collecting NPS current data.
Constructing of DeepSME pipeline
Design and synthesis of 6-mer QC sequence
The Cate_NAN plasmid (see Supplementary Data 1) of total length 5262 nt was used to constructing ten sequences of our 6-mer QC dataset. Ten pairs of forward and reverse primers, ranging from 40 nt to 50 nt (see Supplementary Data 2), were designed and synthesized by Tsingke Biotech to generate corresponding ten samples of DNA sequences with length of 1330 nt, 1340 nt, 1340 nt, 1340 nt, 1340 nt, 1200 nt, 1200 nt, 1230 nt, 1226 nt and 1262 nt containing ~20–30 nt without cytosine (C) in their forward and reverse primers to serve as barcode of the sequence (see Supplementary Data 3). An additional sequence of 1144 nt was derived from a synthesized 1206 nt DNA template. These eleven key sequences contribute to 99.93% physical redundancy of 6-mers (4093/4096) with a median occurrence of three. The non-C segments on the eleven sequences were further used to facilitate subsequent data classification.
Both unmethylated and methylated PCR products were pooled and sequenced using an Oxford Nanopore Technology R9.4.1 flowcell with LSK-110 reagents. Specifically, the sequences were purified using the E.Z.N.A. Cycle Pure Kit (V-spin), followed by end repair and adapter ligation using the DNA damage repair enzyme and end prep enzyme from the ND608 kit, and Rapid DNA Ligase, respectively. The final DNA samples were purified using VHATS DNA Beads, quantified with Qubit Flow, and loaded onto the flowcell for sequencing.
Preliminary training of DeepSME with 6-mer datasets
The sequenced raw data were processed using Guppy 6.0 basecaller (dna_r9.4.1_450bps_hac.cfg) (https://nanoporetech.com/document/Guppy-protocol) as a control. The barcode region of basecalled fastq sequences were aligned back to the ionic currents using Tombo58 1.5.1 (https://github.com/nanoporetech/tombo) to provide primer cutoff point. The current data were cataloged into 11 sequences, recognized by the non-C regions of the primers. These segments were also correctly recognized with 5hmC modification, ensuring automated classification of raw data into these 11 types of 6-mer QC sequences. The primer regions were then carefully trimmed, leaving only the 6-mer QC sequence regions.
Ionic current dataset from these 11 sequences were used for a preliminary training of a NN with Encoder-Decoder architecture with CTC decoding layer (modified version of bonito_bonitorev_ctc based on basecaller_benchmark repository48, see Supplementary Table 9). The stride of the Encoder CNN layer was reconfigured to 1 to achieve high CTC layer resolution of DeepSME, resulting in the training convergence among 6-mer QC dataset in 151.8 min with an RTX 3090 GPU.
Extracting 6-mer statistics (k-mer model)
Ionic current data were segmented by the probability matrix obtained from the CTC segmentation76 of the trained 6-mer QC DeepSME, then enhanced by executing three times of k-mer extraction and alignment by Tombo to get the k-mer table (6-mer). Sequenced average currents, standard deviations as well as averaged dwell times and related standard deviations can be analyzed for either canonical or fully methylated 5-hmC sequenced by the R9.4.1 nanopore.
Expanding 6-mer to 9-mer with in silico simulations
Using the k-mer model from the previous step, simulated currents were generated for the whole genome fasta sequences of 50 microorganisms (Fasta can be download from https://github.com/marcpaga/nanopore_benchmark/blob/main/download/links_wick_data_train.txt) and simulated using Squigulator56 v0.3.0 (https://github.com/hasindu2008/squigulator) with a specified k-mer table csv file.
Enhanced training of DeepSME with simulated datasets
In silico experiments were performed to generate training datasets of 118,299 chunks with a chunk size of 3600 (0.9 s) using the data preparation functionality of Bonito 0.8.1 (https://github.com/nanoporetech/bonito). These datasets were used to train the Encoder-Decoder architecture with conditional random field (CRF) decoding layer (dna_r9.4.1_e8_sup@v3.3 model in Bonito 0.8.1, see supplementary Table. 10) over 5 epochs with a learning rate of 5e-4, resulting in the enhanced DeepSME in 64.6 min with an RTX 3090 GPU.
Generating and sequencing of fully methylated 5-hmC bacteria genome DNA (gDNA)
Genome DNA from Pseudomonas_aeruginosa_PAO1 (https://www.ncbi.nlm.nih.gov/datasets/genome/GCF_000006765.1/), Aeromonas_hydrophila_BJ054 (https://www.ncbi.nlm.nih.gov/datasets/genome/GCF_046708825.1/), and Vibrio_cholera_E1 (https://www.ncbi.nlm.nih.gov/datasets/genome/GCF_026013235.1/) microorganisms were extracted using the Qiagen Miniprep kit. The DNA was fragmented using the TD502 kit (TruePrep DNA Library Prep Kit V2 for Illumina) from Vazyme and modified using 5-Hydroxymethyl-dCTP (NU-932s) from Jena Bioscience. PCR was performed with Phanta Max Super-Fidelity DNA Polymerase (P505-d1) from Vazyme over 18 cycles under the following conditions of six steps: (1) Extension at 72 °C for 3 min. (2) Pre-denaturation at 95 °C for 3 min, (3) Denaturation at 95 °C for 15 min, (4) Annealing at 60 °C for 15 s, (5) Extension at 72 °C for 60–72 s per kilobase sequence, (6) Final Extension at 72 °C for 5 min. The modified DNA samples were sequenced using the Oxford Nanopore Technology R9.4.1 flowcell and LSK-110 reagents.
Reinforced DeepSME with fully 5-hmC bacteria gDNA datasets
The Enhanced DeepSME was used to basecall gDNA and map to the corresponding genome. The gDNA datasets from the three microbial samples also lead to 118,096 chunks with a chunk size of 3600 (0.9 s). These data were then used to reinforce the Encoder-Decoder architecture with CRF decoding layer (dna_r9.4.1_e8_sup@v3.3 model in Bonito 0.8.1) over 5 epochs with a learning rate of 5e-4, yielding our final reinforced DeepSME, which takes 50.0 min with an RTX 3090 GPU. The weights of our basecallers could also be compatible with Dorado and be ready for deployed to edge devices like Jetson Xavier AGX for further use. We have also tried using FrodoKEM framework to encrypt our 5hmC-DeepSME basecaller weight with FrodoKEM-640-AES algorithm (see https://github.com/sparkcyf/FrodoKEM_demo)to demo the feasibility for integrating DeepSME with PQC.
Recovering data stored in 5-hmC DNA using DeepSME
Dataset for digital information stored in DNA were prepared using our CHN codec77 in the four-letter configuration. The binary forms of two selected files (219 bytes and 4109 bytes) were extracted and split into payloads with 36 bytes. Next, Reed-Solomon (40,36) code was used to add redundancy to these payloads to generate segments. Then, a 34 nt barcode as addresses for random access followed with three 5-mer anchors are added to each segment. Finally, an oligo pool containing 487 single-stranded 243 nt DNA sequences was sent to Twist Biosciences, including 55 sequences that encode a.txt file and 432 sequence that encode a.jpeg image (see Supplementary Data 4).
For the PCR amplification, a pair of carefully designed 23 nt 5′- and 11 nt 3′-flanking sequences was added to both ends of each DNA sequence. Canonical or modified 5hmC PCR were performed to obtain DNA sequences without or with modification, followed by above described NPS procedure to obtain the current data.
The reinforced 5hmC DeepSME was used to process the sequenced raw data. The resulting fastq and aligned bam files were performed using the aboved-mentioned CHN decoder. For performance metrics, “the rate of the number of reads that could be aligned to the reference FASTA in total reads” was used as recall, “the rate of the number of correct bases in total bases” was used as Precision, and their product was used as the F1-score.
Statistics and reproducibility
Statistics used to analyze DNA storage decoding performance are described in the methods section. Analysis can be reproduced using datasets deposited in the NCBI SRA and Zenodo (see “Data availability” statement) and the code developed for this work (see “Code availability” statement). All sequencing data from 6-mer QC sequences and bacterial gDNA were used to train DeepSME. All sequencing data from DNA storage strands were used to perform the DNA decoding experiments. The decoding rates under different coverages shown in Fig. 3c were determined by repeating the analysis 10 times using random seeds 0–9 when selecting reads from each sequence group.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The sequencing pod5 files from 5hmC-modified 6-mer QC sequences, bacterial gDNA for training the 5hmC DeepSME basecaller, and conducting the DNA storage decoding experiments have been deposited to Zenodo [https://doi.org/10.5281/zenodo.12704171]. The FASTQ file generated by the 5hmC reinforced DeepSME from Bacterial gDNA has been deposited to NCBI sequence read archive (SRA) accession numbers SRR32782578 [https://www.ncbi.nlm.nih.gov/sra/SRX28066745], SRR32782579 [https://www.ncbi.nlm.nih.gov/sra/SRX28066744], SRR32782580 [https://www.ncbi.nlm.nih.gov/sra/SRX28066743] under NCBI BioProject PRJNA1238011. The FASTQ file generated by the reinforced 5hmC DeepSME from the 5hmC DNA storage dataset has been deposited to NCBI SRA accession number SRR32782578 [https://www.ncbi.nlm.nih.gov/sra/SRX28067610] under NCBI BioProject PRJNA1238011. All other data described in this work are available in the main text, provided in the Supplementary Materials, or can be reproduced using the deposited datasets and GitHub code (see “Code availability” section). Source data are provided with this paper.
Code availability
The code package for this study is available in the GitHub repository [https://github.com/sparkcyf/DeepSME] under Apache License 2.0 and is also available on Zenodo under [https://doi.org/10.5281/zenodo.15064695].
References
Goldman, N. et al. Towards practical, high-capacity, low-maintenance information storage in synthesized DNA. Nature 494, 77–80 (2013).
Stavroulakis, P. & Stamp, M. Handbook of Information and Communication Security (Springer, 2010).
Kim, S. I. et al. Cryptographic transistor for true random number generator with low power consumption. Sci. Adv. 10, eadk6042 (2024).
Qu, G. et al. Reprogrammable meta-hologram for optical encryption. Nat. Commun. 11, 5484 (2020).
Lim, K. T. P., Liu, H., Liu, Y. & Yang, J. K. W. Holographic colour prints for enhanced optical security by combined phase and amplitude control. Nat. Commun. 10, 25 (2019).
Paraïso, T. K. et al. A photonic integrated quantum secure communication system. Nat. Photonics 15, 850–856 (2021).
Babin, C. et al. Fabrication and nanophotonic waveguide integration of silicon carbide colour centres with preserved spin-optical coherence. Nat. Mater. 21, 67–73 (2022).
Dickinson, G. D. et al. An alternative approach to nucleic acid memory. Nat. Commun. 12, 1–10 (2021).
Kuzdraliński, A. et al. Unlocking the potential of DNA-based tagging: current market solutions and expanding horizons. Nat. Commun. 14, 1–7 (2023).
Meiser, L. C. et al. Synthetic DNA applications in information technology. Nat. Commun. 13, 352 (2022).
Zhang, Y. et al. DNA origami cryptography for secure communication. Nat. Commun. 10, 5469 (2019).
Soete, M., Mertens, C., Badi, N. & Du Prez, F. E. Reading information stored in synthetic macromolecules. J. Am. Chem. Soc. 144, 22378–22390 (2022).
Arcadia, C. E. et al. Multicomponent molecular memory. Nat. Commun. 11, 691 (2020).
Wong, N. Y., Xing, H., Tan, L. H. & Lu, Y. Nano-encrypted Morse code: a versatile approach to programmable and reversible nanoscale assembly and disassembly. J. Am. Chem. Soc. 135, 2931–2934 (2013).
Liu, Y. et al. An aptamer-based keypad lock system. Chem. Commun. 48, 802–804 (2011).
Palacios, M. A. et al. InfoBiology by printed arrays of microorganism colonies for timed and on-demand release of messages. Proc. Natl. Acad. Sci. USA 108, 16510–16514 (2011).
Clelland, C. T., Risca, V. & Bancroft, C. Hiding messages in DNA microdots. Nature 399, 533–534 (1999).
Logsdon, G. A., Vollger, M. R. & Eichler, E. E. Long-read human genome sequencing and its applications. Nat. Rev. Genet. 21, 597–614 (2020).
Alfonzo, J. D. et al. A call for direct sequencing of full-length RNAs to identify all modifications. Nat. Genet. 53, 1113–1116 (2021).
Pagès-Gallego, M. et al. Direct detection of 8-oxo-dG using nanopore sequencing. bioRxiv https://doi.org/10.1101/2024.05.17.594638 (2024).
Goodwin, S., McPherson, J. D. & McCombie, W. R. Coming of age: ten years of next-generation sequencing technologies. Nat. Rev. Genet. 17, 333–351 (2016).
Irizarry, R. A. et al. Comprehensive high-throughput arrays for relative methylation (CHARM). Genome Res. 18, 780–790 (2008).
Loyfer, N. et al. A DNA methylation atlas of normal human cell types. Nature 613, 355–364 (2023).
Meissner, A. et al. Reduced representation bisulfite sequencing for comparative high-resolution DNA methylation analysis. Nucleic Acids Res. 33, 5868–5877 (2005).
Taiwo, O. et al. Methylome analysis using MeDIP-seq with low DNA concentrations. Nat. Protoc. 7, 617–636 (2012).
Li, D., Zhang, B., Xing, X. & Wang, T. Combining MeDIP-seq and MRE-seq to investigate genome-wide CpG methylation. Methods 72, 29–40 (2015).
Meyer, C. A. & Liu, X. S. Identifying and mitigating bias in next-generation sequencing methods for chromatin biology. Nat. Rev. Genet. 15, 709–721 (2014).
Liu, H., Begik, O. & Novoa, E. M. EpiNano: detection of m6A RNA modifications using Oxford nanopore direct RNA sequencing. Methods Mol. Biol. 2298, 31–52 (2021).
Parker, M. T. et al. Nanopore direct RNA sequencing maps the complexity of arabidopsis mRNA processing and m6A modification. Elife 9, e49658 (2020).
Price, A. M. et al. Direct RNA sequencing reveals m6A modifications on adenovirus RNA are necessary for efficient splicing. Nat. Commun. 11, 6016 (2020).
Begik, O. et al. Quantitative profiling of pseudouridylation dynamics in native RNAs with nanopore sequencing. Nat. Biotechnol. 39, 1278–1291 (2021).
Jenjaroenpun, P. et al. Decoding the epitranscriptional landscape from native RNA sequences. Nucleic Acids Res. 49, e7 (2021).
Guo, Z. et al. Nanopore current events magnifier (nanoCEM): a novel tool for visualizing current events at modification sites of nanopore sequencing. NAR Genom. Bioinform. 6, lqae052 (2024).
Nguyen, T. A. et al. Direct identification of A-to-I editing sites with nanopore native RNA sequencing. Nat. Methods 19, 833–844 (2022).
Ni, P. et al. DeepSignal: detecting DNA methylation state from nanopore sequencing reads using deep-learning. Bioinformatics 35, 4586–4595 (2019).
Ahsan, M. U., Gouru, A., Chan, J., Zhou, W. & Wang, K. A signal processing and deep learning framework for methylation detection using Oxford nanopore sequencing. Nat. Commun. 15, 1–21 (2024). 2024 151.
Lorenz, D. A., Sathe, S., Einstein, J. M. & Yeo, G. W. Direct RNA sequencing enables m6A detection in endogenous transcript isoforms at base-specific resolution. RNA 26, 19–28 (2020).
Ueda, H. nanoDoc: RNA modification detection using nanopore raw reads with deep one-class classification. bioRxiv https://doi.org/10.1101/2020.09.13.295089 (2021).
Gao, Y. et al. Quantitative profiling of N6-methyladenosine at single-base resolution in stem-differentiating xylem of Populus trichocarpa using nanopore direct RNA sequencing. Genome Biol. 22, 22 (2021).
Leger, A. et al. RNA modifications detection by comparative nanopore direct RNA sequencing. Nat. Commun. 12, 7198 (2021).
Parker, M. T., Barton, G. J. & Simpson, G. G. Yanocomp: robust prediction of m6A modifications in individual nanopore direct RNA reads. bioRxiv (2021).
Pratanwanich, P. N. et al. Identification of differential RNA modifications from nanopore direct RNA sequencing with xPore. Nat. Biotechnol. 39, 1394–1402 (2021).
Hassan, D., Acevedo, D., Daulatabad, S. V., Mir, Q. & Janga, S. C. Penguin: a tool for predicting pseudouridine sites in direct RNA nanopore sequencing data. Methods 203, 478–487 (2022).
Hendra, C. et al. Detection of m6A from direct RNA sequencing using a multiple instance learning framework. Nat. Methods 19, 1590–1598 (2022).
Wang, Z. et al. Adapting nanopore sequencing basecalling models for modification detection via incremental learning and anomaly detection. Nat. Commun. 15, 7148 (2024).
Rand, A. C. et al. Mapping DNA methylation with high-throughput nanopore sequencing. Nat. Methods 14, 411–413 (2017).
Yuen, Z. W. S. et al. Systematic benchmarking of tools for CpG methylation detection from nanopore sequencing. Nat. Commun. 12, 1–12 (2021).
Pagès-Gallego, M. & de Ridder, J. Comprehensive benchmark and architectural analysis of deep learning models for nanopore sequencing basecalling. Genome Biol. 24, 1–18 (2023).
Teng, H. et al. Chiron: translating nanopore raw signal directly into nucleotide sequence using deep learning. Gigascience 7, giy037 (2018).
Stoiber, M. H. et al. De novo identification of DNA modifications enabled by genome-guided nanopore signal processing. bioRxiv 094672 https://doi.org/10.1101/094672 (2016).
Song, L. et al. Robust data storage in DNA by de Bruijn graph-based de novo strand assembly. Nat. Commun. 13, 5361 (2022).
Lopez, R. et al. DNA assembly for nanopore data storage readout. Nat. Commun. 10, 2933 (2019).
Hood, L. & Rowen, L. The human genome project: Big science transforms biology and medicine. Genome Med. 5, 1–8 (2013).
Perez, G. et al. The UCSC genome browser database: 2025 update. Nucleic Acids Res. 1, 13–14 (2013).
Oxford Nanopore Technologies Ltd. GitHub—nanoporetech/scrappie: scrappie is a technology demonstrator for the Oxford nanopore research algorithms group. https://github.com/nanoporetech/scrappie.
Gamaarachchi, H. et al. Simulation of nanopore sequencing signal data with tunable parameters. Genome Res. gr.278730.123 https://doi.org/10.1101/GR.278730.123 (2024).
Li, Y. et al. DeepSimulator1.5: a more powerful, quicker and lighter simulator for nanopore sequencing. Bioinformatics 36, 2578–2580 (2020).
Stoiber, M. et al. De novo identification of DNA modifications enabled by genome-guided nanopore signal processing. bioRxiv 094672 https://doi.org/10.1101/094672 (2017).
Loman, N. J., Quick, J. & Simpson, J. T. A complete bacterial genome assembled de novo using only nanopore sequencing data. Nat. Methods 12, 733–735 (2015).
Tyler, A. D. et al. Evaluation of Oxford nanopore’s MinION sequencing device for microbial whole genome sequencing applications. Sci. Rep. 8, 1–12 (2018).
Kovaka, S., Hook, P. W., Jenike, K. M. et al. Uncalled4 improves nanopore DNA and RNA modification detection via fast and accurate signal alignment. Nat Methods 22, 681–691 (2025).
Silva, D. F. & Batista, G. E. A. P. A. Speeding up all-pairwise dynamic time warping matrix calculation. In Proc. 16th SIAM International Conference on Data Mining 2016, SDM 2016 https://doi.org/10.1137/1.9781611974348.94 (SIAM, 2016).
Sereika, M. et al. Oxford nanopore R10.4 long-read sequencing enables the generation of near-finished bacterial genomes from pure cultures and metagenomes without short-read or reference polishing. Nat. Methods 19, 823–826 (2022).
Liang, H. et al. Efficiently constructing complete genomes with CycloneSEQ to fill gaps in bacterial draft assemblies. bioRxiv https://doi.org/10.1101/2024.09.05.611410 (2024).
Li, Q., Sun, C., Wang, D. & Lou, J. GCRTcall: a transformer based basecaller for nanopore RNA sequencing enhanced by gated convolution and relative position embedding via joint loss training. Front. Genet. 15, 1443532 (2024).
Barker, E. Recommendation for Key Management: Part 1—General https://doi.org/10.6028/NIST.SP.800-57PT1R5 (2020).
Alagic, G. et al. Status Report on the Third Round of the NIST Post-Quantum Cryptography Standardization Process. https://doi.org/10.6028/NIST.IR.8413 (2022).
Sood, A. J., Viner, C. & Hoffman, M. M. DNamod: the DNA modification database. J. Cheminform. 11, 30 (2019).
Boccaletto, P. et al. MODOMICS: a database of RNA modification pathways. 2021 update. Nucleic Acids Res. 50, D231–D235 (2022).
Jonsson, J. & Kaliski, B. Public-Key Cryptography Standards (PKCS) #1: RSA Cryptography Specifications Version 2.1. at https://doi.org/10.17487/RFC3447 (2003).
Longa, P., Bos, J. W., Ehlen, S. & Stebila, D. FrodoKEM: Key Encapsulation from Learning with Errors. https://datatracker.ietf.org/doc/draft-longa-cfrg-frodokem/00/ (2025).
Berezin, C. T., Peccoud, S., Kar, D. M. & Peccoud, J. Cryptographic approaches to authenticating synthetic DNA sequences. Trends Biotechnol. 42, 1002–1016 (2024).
International Organization for Standardization. Biotechnology—Nucleic acid synthesis—Part 2: Requirements for the production and quality control of synthesized gene fragments, genes, and genomes. https://www.iso.org/standard/75852.html (2024).
Xing, X. W. et al. Mutagenic and cytotoxic properties of oxidation products of 5-methylcytosine revealed by next-generation sequencing. PLoS ONE 8, e72993 (2013).
National Academies of Sciences, Engineering, and Medicine. Biodefense in the Age of Synthetic Biology https://doi.org/10.17226/24890 (National Academies Press, 2018).
Kürzinger, L., Winkelbauer, D., Li, L., Watzel, T. & Rigoll, G. CTC-Segmentation of Large Corpora for German End-to-End Speech Recognition. In Proc. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) Vol. 12335 (Springer, 2020).
Zhao, X. et al. Composite hedges nanopores: a high INDEL-correcting codec system for rapid and portable DNA data readout. Nat. Commun. 15, 9395 (2024).
Acknowledgements
This work was supported by the National Key Research and Development Program of China (no. 2022YFF1203400), National Natural Science Foundation of China (nos. 62171211, 32371526, 32100021 and 32371372) and Science and Technology Innovation Commission of Shenzhen (JCYJ20220814170440001, JCYJ20220818100218039, JCYJ20220530113013030 and JCYJ20230807092459028), NSQKJJ under grant K21799109 and K21799116, Zhejiang Provincial Collaborative Innovation Center for High-end Digital Intelligence Diagnosis and Treatment Equipment and Center for Computational Science and Engineering at Southern University of Science and Technology.
Author information
Authors and Affiliations
Contributions
Q.Y.F. and Y.L. designed the experiment and the training pipeline. Q.Y.F., R.H.L. and Y.L. conducted the sequence design of the 6-mer QC sequence, Q.Y.F., R.H.L. Y.P.L. and J.X.Z. conducted the primers for the 6-mer QC sequence. M.L., Q.S.F., and Y.F. provided the plasmid samples for sequencing experiments. Q.Y.F. wrote the code for the k-mer extraction and the architecture of the preliminary basecaller. Q.Y.F., J.Y.L, and X.Y.Z. conducted the nanopore basecalling and related quality check. Q.Y.F. conducted the construction of the datasets and training of the basecaller. Q.Y.F., X.Y.Z., and Y.L. prepared the figures and tables. Q.Y.F., Q.P., and Y.L. drafted the manuscript. Q.P. and Y.L. supervised the study. All authors read, revised, and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
Q.F., X.Z., J.L., R.L., and Y.L. have a patent filed with application number CN117238360A pertaining to the training framework of DeepSME. The remaining authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Hasindu Gamaarachchi, Hadi Ravan, and the other anonymous reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Fan, Q., Zhao, X., Li, J. et al. De novo non-canonical nanopore basecalling enables private communication using heavily-modified DNA data at single-molecule level. Nat Commun 16, 4099 (2025). https://doi.org/10.1038/s41467-025-59357-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-59357-2
This article is cited by
-
Motif caller for sequence reconstruction in motif-based DNA storage
Scientific Reports (2025)
