
Abstract
A cell type’s identity can be revealed by its transcriptome and epigenome profiles, both of which can be in flux temporally and spatially, leading to distinct cell states or subtypes. The popular and standard workflow for single cell RNA-seq (scRNA-seq) data analysis applies feature selection, dimensional reduction, and clustering on the gene expression values quantified by read counts, but alternative approaches using a simple classification of a gene to “on” and “off” (i.e., binarization of the gene expression) have been proposed for clustering cells and other downstream analyses. Here, we demonstrate that a direct concatenation of the binarized scRNA-seq data and the standard single cell ATAC-seq data is sufficient and effective for vertical integrated clustering analysis, after applying term-frequency-inverse document frequency (TF-IDF) and single value decomposition (also called latent semantic indexing, LSI) algorithms to the combined data, when the two data modalities are collected using a paired multiomic technology. This proposed approach avoids the need for converting scATAC-seq data to gene activity scores for combined analysis. Furthermore it enables a direct investigation into the contribution of each data type for resolving cell type or subtype identity.
Similar content being viewed by others
Introduction
Single-cell omic analysis has been adopted widely for resolving cellular heterogeneity within biological samples, leading to novel insights into cell differentiation, tissue/organ development, and cancer formation1,2,3. A key step in the data analysis is cell clustering, based on between-cell similarity of the underlying quantitative data, for example, gene expression profiles. Not only is clustering important for distinguishing cell types (or states), but also critical for almost all the downstream bioinformatics analysis. Moreover, investigators have become increasingly interested in collecting and analyzing multiple types of omics data, either from the same cells (paired) or different cells in biologically matching samples (unpaired). Among the technologies, single-cell RNA-seq (scRNA-seq) is more advanced, followed by single-cell ATAC-seq (scATAC-seq). Commercial platforms (e.g., 10X Genomics) are also available for capturing single cells or nuclei for simultaneously interrogating the gene expression profile and chromatin accessibility of the same cells, yielding paired multiomic data.
Many software packages have been developed for analyzing these two modalities of data and their integration2. A common analytic workflow will analyze and cluster scRNA-seq data and scATAC-seq data separately and then either project the scRNA-seq clustering information to the scATAC-seq data (e.g., by label transfer), if the two data types are collected independently, or convert the scATAC-seq data to “gene activity scores” for combined analysis4,5, if data from the two modalities are collected using a multiomics platform6,7. Other advanced approaches have also been developed8. However, the method for projection of scATAC-seq data to the gene space is rather subjective, which basically sums scATAC-seq reads within a distance to a gene based on chromosomal coordinates and thus can be improved. Consequently, such a strategy only uses part of the scATAC-seq data, potentially leaving out critical information related to long-distance gene regulation. Whether the two types of data can be combined directly for vertical integrated analysis, without first projecting one to another, to our knowledge, has not been extensively studied. One concern may be that scRNA-seq quantifies gene expression by RNA abundance, which can vary in several orders of magnitude between highly expressed genes (up to hundreds of reads) and lowly expressed ones, while scATAC-seq quantifies chromatin accessible or not, with values in low single digits (95% of measurements < 2; Supplementary Fig. S1). Another concern may be related to the fact that scATAC-seq data is sparser than scRNA-seq data, even though both are very sparse with “0” entries for most cells.
The former concern can be addressed by transforming the scRNA-seq data to a binary format, by defining the expression of individual genes as on (thus “1”) or off (thus “0”) in individual cells. Previously, such a strategy has been applied successfully to cell clustering9,10, differential expression analysis11, and other downstream analysis, such as inferring cell developmental trajectory9, gene regulatory network12, and cell age13. Notably, Qiu10 found that embracing “dropouts” in scRNA-seq through binarization can effectively capture biological variation for cell clustering. Since these early works primarily focused on scRNA-seq data alone, we wondered how the binarization concept can be applied for direct and vertical integration of multiomic data, and furthermore, to leverage the algorithms that have been developed and routinely used for efficient scATAC-seq analysis.
In this work, considering the high similarity between binarized scRNA-seq data and scATAC-seq data, in terms of quantitative scales and presentation of the data (mostly 0 and 1), we first address how one popular algorithm used successfully in scATAC-seq analysis, specifically TF-IDF/LSI14, could be applied to binarized scRNA-seq data for improving cell clustering. After that, we demonstrate that the combined matrix from concatenating scATAC-seq data and binarized scRNA-seq data (from paired multiomic assays) could be analyzed and clustered using the scATAC-seq workflow employing TF-IDF/LSI, yielding clustering results comparable to or better in some cases than what could be obtained by standard integration methods. The existing standard methods, however, apply more complex algorithms and generally need more computing resources. Additionally, we show that the binarization, concatenation, and TF-IDF/LSI strategy provides a means to study how the two data modalities affect the distinction of highly similar cell types in some datasets by changing the ratio of the high variable RNA to ATAC features selected for clustering. In short, our study suggests that the binarized and concatenated approach holds promising values in integrated analysis of multiomic data, even simply by adapting existing algorithms successfully applied to scATAC-seq analysis.
Results
Clustering single cells using binarized gene expression data
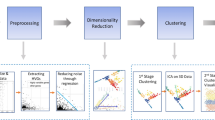
Before going directly to integrated analysis of scRNA-seq and scATAC-seq data, we wanted to evaluate the usage of binarized scRNA-seq data for cell clustering. This problem has been studied before9,10,11, but we still needed to assess our implementation and modification. We began by addressing how the clusters from binarized data match those from a standard Scanpy workflow15 without applying TF-IDF (Fig. 1). We started with a 3 K PBMC (peripheral blood mononuclear cells) scRNA-seq dataset16 that has been frequently used for benchmarking scRNA-seq software performance15,17. After standard quality control of the raw count data (i.e., removing cells of poor quality and genes expressing in few cells), we binarized the input scRNA-seq data with read counts (referred as “pre-binarized RNA” data) by converting the expression values to 1 if the raw read count was > 0, and otherwise 0 (see Methods). Using 2,000 top highly variable genes (HVG; based on pre-binarized data), 30 principal components (PCs) and otherwise default parameters in Scanpy, we obtained 7 clusters from the binarized data by Leiden clustering (resolution = 1.0) (Supplementary Fig. S2A, B). As the cell type annotations were available for the data, we compared our clusters to the previously annotated cell types and found that > 77% of cells in our clusters (ranging from 44% to 100%) were from a single PBMC cell type, except for CD4 + T cells and CD14 monocytes, which were each split into two large clusters (Supplementary Fig. S2C, D). For two of the clusters (#1 and #4), both contained two cell types (CD14 + Monocytes and FCGR3A Monocytes; CD8+ and NK cells), but the mixed cell types were relatively harder to distinguish than other cell types, as indicated by the expression of the canonical gene markers (Supplementary Fig. S2C). Using the same method and parameters, we binarized and clustered a human pancreatic cell dataset obtained by the Smart-Seq2 platform18, yielding 14 clusters (Supplementary Fig. S2E, F). In this case, over 74% of cells (ranging from 44% to 100%) were clustered in a manner highly consistent with the authors’ original cell annotation, except for alpha and beta cells, which were split into 4 and 2 clusters, respectively (Supplementary Fig. S2G, H). Multiple very small clusters, however, mistakenly combined cells from distinct cell types. Overall, these results confirm previous reports that binarized scRNA-seq data could be used for cell clustering, but some methodology improvement is needed9,10.

In standard workflow, scRNA-seq raw count matrix is used for PCA, clustering and Uniform Manifold Approximation and Projection (UMAP) visualization, while scATAC-seq raw count matrix is used for TF-IDF/SVD processing, clustering, and UMAP visualization. In our proposed approach, scRNA-seq is binarized and contatenated with the raw scATAC-seq data and the contatenated data matrix is then used for TF-IDF/LSI processing and UMAP visualization, following the standard scATAC-seq procedure.
Considering the high similarity between binary scRNA-seq data and scATAC-seq data matrix in terms of sparsity and quantitatively small values (mostly 0 and 1; Supplementary Fig. S1), we decided to test whether the standard scATAC-seq analysis algorithm can be applied, i.e., subject the binarized scRNA-seq matrix to normalization by term-frequency inverse-document-frequency (TF-IDF), dimensionality reduction by singular value decomposition (SVD), and clustering by Leiden algorithm using highly variable genes selected by analytical Pearson residuals (Fig. 1). The TF-IDF-SVD is often called Latent Semantic Indexing (LSI)19, but sometimes “LSI” is used to refer to the dimensionality reduction step only, thus we use “TF-IDF/LSI” here to avoid confusion. Interestingly, this indeed led to improved clustering of the binarized 3 K PBMC data, with the mean accuracy increased to 86% (Supplementary Fig. S3A–C). Moreover, the CD8 + T and NK cells were separated correctly. So were CD14 + Monocytes and FCGR3A Monocytes. For the human pancreas dataset, the binarization protocol was followed by an integration step using Batch Based KNN (K nearest neighbor)20 to reduce the batch effects among donors. After that, we obtained 14 clusters (Supplementary Fig. S3D–F), the same as reported by the original authors18. For the pancreatic dataset, over 94% of total cells were clustered with their own cell type. We further evaluated our TF-IDF/LSI approach on a much larger dataset, containing 486k cell/nuclei barcodes from adult human hearts21. Binarization and clustering yielded 25 clusters, while the original study reported 13 (11 cell types + “doublets” and “unassigned”) (Supplementary Fig. S4A, B). Comparing the expression of the marker genes indicated that the split of multiple cardiac cell types in the binarization clusters reflected the difference in the percentages of cells expressing those markers, e.g., clusters 3, 4, and 5 were all ventricular cardiomyocytes but cluster 3 displayed a smaller % of cells expressing MYH7 (Supplementary Fig. S4C). The myeloid and lymphoid cells were also each split into 2-3 clusters (Supplementary Fig. S4D). We further compared our clusters to the cell subtypes for ventricular cardiomyocytes (vCM) and endothelial cells (EC)21, but did not find a good concordance (Supplementary Fig. S4E, F).
To demonstrate that the clustering improvement from TF-IDF/LSI is robust and not dependent on specific software implementation, we performed the binarization and clustering of a mouse bone cell atlas data using Seurat22 and Signac23 (both implemented in R). When compared to the authors’ original cell types, on average, 88% of the cells in each of our TF-IDF/LSI clusters were from a single cell type (Supplementary Fig. S5). We should point out that Scanpy/Muon and Seurat/Signac compute and use highly variable features (HVFs) quite differently.
Taken together, these results indicate that eliminating quantitative information related to gene expression magnitude does not remove signals pertinent to the distinct function of individual cell types, and that processing binarized scRNA-seq data with the TF-IDF/LSI method used in the scATAC workflow provides a marked improvement in clustering accuracy.
Integrated analysis of binarized scRNA-seq data with scATAC-seq data
A key rationale for our choice of TF-IDF/LSI for binarized scRNA-seq data (vs algorithms proposed by other investigators9) lies in its capability for direct integrated analysis of paired scRNA-seq and scATAC-seq data that are acquired from the same cells using a multiomic platform. For this, the binarized scRNA-seq data matrix is directly concatenated with the scATAC-seq peaks x cells matrix. This is feasible because both types of data are from the same cells, and the columns of the two matrices (i.e., cell barcodes) are thus the same. This enables vertical data integration24 without the need for either converting ATAC data to gene activity scores or binning the data by large genomic regions. The concatenated matrix (referred to as “BC” matrix for binarization and concatenation) is then processed as described above for binarized scRNA-seq data, following the TF-IDF/LSI workflow (Fig. 1).
To evaluate the performance of our proposed strategy, we first tested it on simulated multiomic data. We applied scMultiSim25 to generate paired scRNA-seq/scATAC-seq datasets containing 10,000 cells of five groups, using parameters matching the typical sparsity and complexity present in experimental data. Some cell groups (G4 and G5) are much harder to distinguish than others, as shown by our clustering of the pre-binarized scRNA-seq data and the un-binarized scATAC-seq data using the standard workflow (Fig. 2a, b). Significant noise (noise parameter of 0.5) was added in the simulation, such that the cell group relationship recovered from the data was slightly different from what was specified in the input model (Fig. 2c, d). We applied TF-IDF/LSI to the BC data matrix and set the cluster resolution for 5 clusters, as shown by UMAP visualization in Fig. 2e, f. For comparison, we applied scMoMaT and Multigrate to integrate and cluster the pre-binarized data (Fig. 2g, h), as well as Muon, scBFA9, and Seurat/Signac, which uses Weighted Nearest Neighbors (WNN) for integration. Next, we used a set of metrics, including adjusted rand index (ARI), adjusted mutual information (AMI), mutual information (MI), and Fowlkes-Mallows Index (FMI) (see Methods), to evaluate how well the clustering results matched the input cell groups. As shown in Table 1, the performance of our method is largely similar to those achieved by scMoMaT26 and Multigrate17. For example, compared to scMoMaT, which jointly models modalities through latent factors, our approach showed higher ARI (0.52 vs. 0.45), MI (0.83 vs 0.80), and FMI (0.64 vs 0.61) scores. Our approach consistently matched or slightly outperformed scBFA by most metrics but yielded comparable results to Multigrate. Muon and Signac (WNN method) tended to score slightly better in multiple metrics, thus become the focus of our comparison and discussion for results from real data below. It is important to note that most of these metrics can be sensitive to the number of clusters generated in the clustering step. To address this, we varied several clustering parameters, including the number of top HVFs, PC numbers, and the cluster resolution, and then computed these metrics in each iteration and reported our observed ranges in Table 1.

a UMAP of pre-binarized scRNA-seq data (Leiden resolution = 1.0). b UMAP of raw scATAC-seq data processed through Muon TF-IDF/LSI pipeline. c Ground-truth cell group relationship as a hierarchy tree used for data simulation. d Recovered cell group tree from the BC matrix. e UMAP of BC clusters colored by Leiden clusters (resolution = 0.9). f UMAP of BC clusters colored by cell groups. g UMAP of scMoMaT latent space embedding colored by cell groups. h UMAP of Multigrate integration results colored by cell groups. Source data are provided as a source Data file.
To test the performance on experimental data, we obtained and analyzed a paired multiomic 10 K PBMC data provided by 10X Genomics. The cell type annotation for individual cells is unfortunately unavailable for us, so we clustered the pre-binarized scRNA-seq data (and separately the scATAC-seq data) to recapitulate the known cell types in PBMC, using the canonical markers provided in the Muon tutorial as reference (see Methods). At the level of individual cells, our cell type reannotation is neither expected to be identical to the one in Muon nor to the biological truth in the sample, but it serves as the reference for us to compare the performance of our BC/LSI clustering and other methods. Our clustering of the pre-binarized scRNA-seq data (Fig. 3a) and the scATAC-seq data (Fig. 3b) yielded 13 and 12 clusters, respectively. Analyses of the gene expression (or chromatin accessibility) patterns of the marker genes identified previously for the same data27 allowed us to successfully assign the cell type for each cluster (Supplementary Fig. S6A, B). We also clustered the binarized scRNA-seq data (Supplementary Fig. S7A). Clustering of the scRNA-seq and scATAC-seq BC data yielded 21 clusters (Fig. 3), with several cell types being split into multiple clusters as indicated by the expression of the cell type markers (Fig. 3d and Supplementary Fig. S6C). Comparison of the clusters from the scRNA-seq or scATAC-seq data with the integrated clusters (referred to as “BC” clusters hereafter as they were from the BC data matrix) further showed that five of the 13 cell types were split to more than one clusters in the integration result (Fig. 3e), as expected from increased clustering resolution. Interestingly, 4 BC clusters (0, 6, 7, 13) all contained a mixture of two cell types, CD14 monocytes and intermediate monocytes, when compared to the clusters based on scRNA, but this mix-up did not occur when compared to the clusters generated with scATAC data only. Thus, we compared the clusters from the two modalities before integration and found a large disagreement in their clustering of these two cell types (Supplementary Fig. S7B, C). Nevertheless, > 80% of the cells in the majority of the 21 BC clusters were from a single cell type defined by either scRNA or scATAC data modal (Fig. 3f, Supplementary Fig. S7D, E). We should mention that we tried lower resolution to reduce cluster numbers, but the clustering accuracy did not change significantly.

a UMAP visualization of the pre-binarized scRNA-seq data, colored by Leiden clusters with our re-annotated cell types. b UMAP of the scATAC-seq data, colored by re-annotated cell types. c Integrated clustering of the binary scRNA-seq data and the scATAC-seq data, colored by clusters. The number of BC clusters were chosen to match that from MOFA integration (Fig. 4). d Bubble plot showing the expression of the cell type markers previously used to annotate cell types. Note that the expression in all bubble plots was from pre-binarized data. e Alluvia plot showing the cell relationship among RNA cell types in (a) (left), the BC clusters in (c) (middle), and the ATAC clusters in (b) (right). f Cluster accuracy, as determined by the %s of cells belong to the dominant cell type determined in (a) or (b) for each of the integrated BC clusters (x-axis). Cell type annotations were derived using canonical markers and served as a standard for benchmarking method comparison rather than definitive biological truth. Source data are provided as a Source Data file.
We performed a cluster marker identification from the BC matrix using the ‘rank_genes_groups’ function in Scanpy (adjusted p < 0.05 and log2(fold change) > 0.5; t-test) and found that the ratios of marker genes to marker ATAC peaks varied significantly across the 21 clusters, from 0.03 to 0.31 (excluding the “CD8_Naive_2” as the outlier) while the ratio for the total features was 0.25 (Supplementary Data 1), indicating that some clusters are defined by one data modality bettere than the other. Moreover, a significant number of marker peaks were not linked to the marker genes in the same clusters (Supplementary Data 1), suggesting that those peaks might be long-distance enhancers for regulating cell type specific genes and thus supporting the value of our integration approach that makes use of all ATAC features, in contrast to other methods using only ATAC-seq features pre-associated with genes.
Compare our BC/LSI approach to other integration methods for real data
After showing that binarized scRNA-seq data and scATAC-seq data could be directly combined for LSI clustering analysis, we set out to compare the clustering results from our integrated approach to those using the non-binarized multi-omic data and other methods. We applied the MOFA algorithm (Muon implementation)28 to integrate the 10 K PMBC multiomic data, followed by nearest-neighbor graph construction, UMAP calculation and Leiden clustering. The result showed that clustering results from the two methods are mostly comparable when the cells were separated into the same number of clusters (Fig. 4a–c). A key difference is that some intermediate monocytes in the BC cluster 0 were split into 5 clusters by MOFA (Fig. 4d, e and Supplementary Fig. S7F), but both approaches split intermediate monocytes to multiple clusters (Figs. 3, 4), suggesting these monocytes have high transcriptomic and epigenomic diversity (see below). Such a difference in cluster splitting was observed for clusters 6, 7 and 13 too. When the qualities of the Leiden-based clusters were assessed by the Silhouette scores29, clusters from both methods had comparable scores (0.13 vs 0.18), indicating similar compactness (Table 1). Using the cell types defined by clustering the pre-binarized scRNA-seq data as reference (Fig. 3a), we also computed ARI30 for the clusters and obtained comparable values (0.54 for BC vs 0.62 for MOFA). Since the ARI is a quantification for how often cells of the same type are correctly clustered, and both integration methods yielded very similar results, we concluded that integration using BC data is a valid approach. We should note that cluster numbers would affect ARI, and we had significantly more clusters than the 13 cell types, because for the purpose of comparison, we have set the parameters in clustering our BC data (Leiden resolution = 1.0) to match the cluster number from MOFA integration using their default parameters (Leiden resolution = 0.9). To overcome this limitation, we applied additional metrics to quantitatively compare the BC clusters and MOFA clusters, which also support comparable performances of these two approaches (Table 1).

a UMAP of BC clustering results as in Fig. 3C but here colored with cell types. b, c UMAPs of the clustering result of the MOFA integration, colored by Leiden clusters (b) or cell types (c). d, e Alluvial plots showing the relationship of known cell types with the MOFA integration clusters (d) and the relationship between MOFA and BC clusters (e). f, g UMAPs of Multigrate integration colored by clusters (f) or cell types (g). h, i First two-factor projection of scBFA integration colored by clusters (h) or cell types (i). j, k Alluvial plots showing the relationship of known cell types with the Multigrate integration clusters (j) or the scBFA clusters (k). Source data are provided as a Source Data file.
In addition to MOFA, we applied Multigrate and scBFA to integrate the PBMC data (Fig. 4f–k), along with scMoMaT and Seurat/Signac (WNN) (Table 1). Interestingly, the cluster results from applying Seurat/Signac to either the pre-binary data using WNN or the BC data using TF-IDF/LSI received very similar scores. We observed that the GPU-enabled Multigrate performed comparably to our BC method, across the various metrics, but scBFA and scMoMAT underperformed (Table 1). Because scBFA requires greater GPU computing resources and more parameter optimizations, it was not evaluated further. Other tools, however, were continuously applied with BC methods (both Scanpy and Seurat/Signac workflows) to two more data described below, with their performance metrics in Table 1.
Altering the ratio of RNA and ATAC features for integration analysis
An important reason for collecting multiomic data is that the two data modalities provide complementary information and are thus better for resolving cell types, especially subtypes. We examined the top 25,000 HVFs from the combined BC data matrix, which contained features from both RNA and ATAC modalities (Fig. 5). Interestingly, the ratio of the RNA to ATAC features changed as more HVFs were selected, with RNA more prevalent among the most top features (Fig. 5a), suggesting that RNA may be more informative, despite the total number of ATAC features (i.e., high quality peaks after QC, n = 106,806) being much bigger than that of RNA features (i.e., genes after QC, n = 26,349) in this PBMC data. We checked the sparsity of the two data types but found not much difference (both have > 95% “0”). Additionally, the top 500 RNA HVFs were only slightly less sparse than the top 500 ATAC HVFs (RNA at 92.96% zero vs ATAC at 92.35%); so were the top 1000 (RNA at 93.82% vs ATAC at 92.82%) and 2,000 features (RNA at 94.27% vs ATAC at 94.48%).

a Bar plot shows the top 25,000 HVF in the binary integrated PBMC dataset, separated to features from RNA or ATAC modalities. b Clustering accuracy with respect to the number of top HVFs (n = 21, total number of clusters). c Silhouette scores and ARIs for clusters using different numbers of HVFs. d,e UMAPs showing the 10X Multiome data from a normal mouse breast sample analyzed by our BC approach, with cells colored by BC clusters (d) or cell types (e). f, g Violin plots showing the clustering accuracies among clusters when different numbers of RNA features (f) or ATAC features (g) were included in clustering the mouse breast cells (n = 9, number of clusters). h, i UMAPs showing a human cortex 10X Multiome data analyzed by our BC approach, with cells colored by Louvain clusters (h) or the published cell types (i). j, k Violin plots showing the clustering accuracies among clusters when different numbers of RNA features (j) or ATAC features (k) were included in clustering the human cortex cells (n = 15, total number of clusters). In the boxplots, the middle line is the median while the whisker lines are 25% and 75% percentiles. Source data are provided as a Source Data file.
This observation prompted us to study how the ratio of the two features could impact the clustering results, and moreover, if some cell types were more affected. This was further motivated by our findings that (i) scRNA and scATAC data seemed to provide conflicting clustering for CD14 + monocytes and intermediate monocytes (Supplementary Fig. S7C), (ii) a main difference between BC clusters and MOFA clusters is that four of our BC clusters (0, 6, 7, 9) were split in the latter, such that our clustering result matched clusters based only on ATAC better while MOFA result matched clusters derived from only RNA better, and (iii) the ratios of RNA to ATAC in marker features differ significantly among clusters (Supplementary Data 1). We decided to use the top 5000 to 25,000 HVFs in a 5000 increment to cluster the PBMC data. The results indicated that the ratios of RNA to ATAC features had different impacts on the cluster accuracies, with the clusters containing monocyte cells being affected more (Fig. 5b). However, the distinctions by varying numbers of RNA and ATAC HVFs were globally not as prominent as we had expected, supported by Silhouette scores and ARIs (Fig. 5c).
To investigate this more closely and systematically, we first varied the ratio from 0.0 (only scRNA HVFs) to 1.0 (all scRNA and all scATAC HVFs) in increments of 0.1, with respect to ATAC features and considered a different metric (“congregated scores”, see “Methods”) (Supplementary Fig. S8A). Starting from only RNA HVFs (n = 7348), we observed that the cell types with conflicting RNA and ATAC supports for their clustering, especially intermediate mono and CD14 mono, exhibited significant fluctuations in clustering accuracy as ATAC features were incrementally added. For example, intermediate monocytes showed a congregated score of ~ 0.58 (i.e., 58% of cells are in the largest intermediate mono cluster) at ratio 0.0 ATAC (i.e., only RNA), improved to ~ 0.67 at ratio 0.1 (10% ATAC, n = 1765), but dropped to ~ 0.64 at ratio 0.2 (20% ATAC, n = 3530). Similarly, CD14 mono showed a congregated scores ranging from ~ 0.67 to ~ 0.86 across different ratios, with the highest score observed at ratio 0.0 (only RNA) and a notable drop at ratio 0.1 (10% ATAC). These suggest that some cell types are more sensitive to how much ATAC features is included for clustering, likely due to the distinct biological states captured by the two modalities. Interestingly and consistent with our observation, intermediate monocytes are a transitional population derived from CD14 monocytes, which later differentiate to CD16 monocytes31. As such, the regulatory regions (measured by scATAC) of some intermediate monocyte genes can be opened before the genes are fully activated for transcription, thus partially explaining our observation.
Conversely, when starting from 100% scATAC HVFs (n = 17,652) and incrementally adding in scRNA features, we observed that well-separated cell types like NK, memory B, and pDC maintained high clustering scores (> 0.95 in the dominant clusters) across all ratios, indicating they were less affected by the ratio change (Supplementary Fig. S8B), likely because they are biologically very distinct cell types. However, other cell types such as CD8 + naïve T and CD4 + memory T showed moderate fluctuations in clustering accuracy but did not exhibit a clear trend of deterioration as more ATAC features were included. For example, CD8+ naïve T showed clustering accuracy ranging from ~0.79 to ~0.93, with a peak at a ratio of 0.1 (10% RNA). This suggests that while these cell types are somewhat sensitive to the ratio, they are not as strongly affected as the inconsistent cell types. Zooming into the CD14 + and intermediate monocytes, we found that their clustering were less affected when ATAC features were fixed but adding various numbers of RNA features, suggesting ATAC features may be more stable in these cell types (Supplementary Fig. S8B).
We should point out that we tried to use the cell types learned from either the scRNA-seq or scATAC-seq alone as the “true” reference cell types (Fig. 3a, b and Supplementary Fig. S8C–F) in our evaluation of clustering. The results described above are for the data using cell types from scRNA-seq data as reference. In general, greater cell type congregated scores with smaller variation were observed for the results when scATAC-seq derived cell types were considered as reference (Supplementary Fig. S8A, B, yellow lines). The underlying reason needs further investigation, but it may be due to the possibility that chromatin accessibility changes before transcription is activated and then the changes persist as cells proliferate.
Overall, these results suggest a potential value in carefully evaluating the contribution of different data modalities in distinguishing cell clusters in multiomic data analysis and that the direct integrated analysis of the BC matrices could be useful in this regard. Although simply varying the ratio of top features from different modalities may not be the best strategy for this purpose, it nevertheless provides a useful means to map out the gradient effect for better understanding how the inclusion of more features from one modality impacts clustering accuracy of each cell type. Additionally, the result can be evaluated together with the ratios of RNA/ATAC features among the cluster markers, which may help to uncover the genes and ATAC peaks contributing to the inconsistency.
To explore further, we applied our BC/LSI clustering approach to a second multiomic data from mouse breast tissues (mammary parenchyma)32, generating 9 clusters (BC-Scanpy version) (Fig. 5d). The authors identified five major cell types in the sample but did not share publicly the annotation for individual cells. Using the information as guidance, however, we were able to assign cell types to the 9 clusters based on canonical markers (see Methods) (Fig. 5e). The performance of our BC method and others were shown in Table 1. We then fixed the number of top ATAC HVFs (n = 12,300; from Muon used in our full analysis) and added in gradually increased numbers of RNA HVFs for BC clustering. While increased usage of RNA features did not impact the clustering performance dramatically, the accuracies, however, seemed to increase and then decrease slightly (Fig. 5f and Supplementary Fig. S9). Conversely, we fixed the top RNA HVF number (n = 7700) and added in different numbers of top ATAC HVFs for clustering. As shown in Fig. 5g and Supplementary Fig. S9, we found a gradual decrease in the mean clustering accuracies, suggesting for this dataset, the ATAC data may be less informative. Interestingly, we found that some cell types were more affected than others by the RNA:ATAC ratio (e.g., endothelial cells and myeloid cells) (Supplementary Fig. S10). Moreover, we were able to assign the Endothelial-1 cluster as epithelial cells, as the cluster was Epcam and Muc1 positive, while the Myeloid-3 and Myeloid-1 clusters most likely contained dendritic cells and macrophages (CD68 + ), when more features were used.
Finally, we analyzed the effects of varying the top RNA to ATAC feature ratio using the Seurat/Signac workflow on a human cerebral cortex data33, in this case using the authors’ Seurat/WNN integration of the RNA and ATAC as the reference clusters since they were available (Fig. 5h, i). As above, our clustering results were evaluated by a set of metrics and with other integration tools (Table 1). The results from using different numbers of RNA and ATAC features for BC clustering support that the ratios could affect BC clustering accuracies (Fig. 5j, k). Close examination of the data found that some brain cell types were affected significantly more than others (Supplementary Fig. S11); again, some cell types (or clusters) became more separated with more RNA or ATAC features included (e.g., inhibitory neuron subtypes) (Supplementary Fig. S12).
Taken together, our results indicate that the scRNA-seq and scATAC-seq BC data provides a good means for investigators to adjust the contribution of the two data modalities in their analysis, which in our view has the advantage in making better usage of the multiomic data and addressing which of the two types of omic data plays more important roles in defining the cell types of their interest. In the future, it will be useful to narrow down the specific small sets of RNA or ATAC features that make the difference, because conceivably, they may provide important biological insights.
Discussion
Cell clustering is a fundamental step in single-cell omic data analysis. In this study, consistent with previous reports, we found that applying TF-IDF/LSI algorithms to binarized scRNA-seq data could obtain clustering results comparable to what were obtained with non-binary data. This has been observed previously and the finding may be explained by this possibility: cells are clustered by similarities in their gene expression profiles, but given the sparsity of the data the similarities may have more to do with gene co-detection (i.e., co-expression) than the degree of their quantitative expression correlation, as suggested before9,10. Our observation is consistent with Qiu’s10 finding that binary transformation of scRNA-seq data can effectively capture biological variation. While their work established the utility of binarization for single modality data analysis, our study demonstrates that this approach, when combined with LSI-based algorithms, enables direct integration with scATAC-seq data, thus providing a novel strategy for multiomic analysis. Although more studies and further improvement are needed, our results also suggest that “excess zeros” (i.e., technical 0 count for moderately to highly expressed genes in some cells), a commonly debated issue in single cell data, may not be as critical as discussed before34, at least with respect to cell clustering, potentially because their co-expressed genes could provide the missing information. We should also note that TF-IDF transformation was previously tested on scRNA-seq data, in combination with various clustering algorithms, but the binarization step was different14. From a biological perspective, our finding suggests that a cell type is likely defined by a set of critical marker genes, whose activation is sufficient for its specification. The expression levels, on the other hand, may be important to define functional (or transcriptomic) states. More studies will be needed in the future to carefully address if these hold true. Additionally, it will be valuable to evaluate if other algorithms could perform better than LSI on the TF-IDF transformed BC matrix35, or new algorithms need to be developed for BC data. We did test the options of binarizing scRNA data by the mean expression of each gene or using three discrete states on the simulated data, but did not find significant changes in clustering.
While performing analysis on a binary data matrix has advantages regarding computational efficiency, as described recently34, the key advantage in our view lies in the integration analysis of multiple types of omic data. In the current study, we only address scRNA-seq and scATAC-seq data from the multiomic platform. The standard method is to compute gene activity scores from the scATAC-seq data and use them for integration. To do that, one needs to map individual scATAC-seq peaks to genes, often based on their distances on chromosomes. A caveat to consider here is that some peaks may be associated to the wrong genes or no genes, while in fact they actually correspond to regulatory elements controlling genes far away from their locations. Furthermore, this method applied a cutoff to the physical distance, excluding many ATAC-seq data in the clustering. Our approach does not have this prediction step, as all genes and all peaks are considered together. Although we did not directly perform the analysis, it is conceivable that marker genes and ATAC peaks of the same cluster(s) are more likely to have a regulatory relationship than no markers. Interestingly, for the 10 K PMBC data, we found that the ratios of marker peaks associated with a marker gene of the same cluster to those without varied significantly among cell types and BC clusters, from 1.3 to 10.5 with a mean of 3.9 (Supplementary Data 1). Moreover, a high percentage (15% on average) of marker peaks were more than 50 kb away from the assigned genes, regardless of if the genes were markers or not.
Using concatenation, data of other modalities can all be directly merged for vertical integration analysis, after binarization when necessary, if all are acquired from the same cells. Note that we did not binarize scATAC-seq data, but the LSI was initially tested on the binarized scATAC-seq data19. Therefore, we believe binarization of scRNA-seq provides a logical and simple strategy for integrated analysis of multiomic data. Given its simplicity and interpretability, we would even suggest the BC approach to be considered as a potential baseline integration method before using more complex algorithms. This suggestion also considers the fact that a typical multiomic data integration starts with an analysis of individual data types, and the investigators should have a favor scATAC-seq analysis workflow already. More importantly, as the scRNA-seq and scATAC-seq data are subject to the same computing process (TF-IDF/LSI, clustering, and visualization), it provides a good opportunity to investigate how these two modalities of data contribute to cell type identification. Although among the three datasets we tested, we did not see a significant change in overall cluster accuracy when more RNA or ATAC features were included. One possible explanation is that our starting point, using only the top RNA or ATAC features, already reached a high accuracy, and thus there was not much room for improvement. Note that this adjusting step occurs after HVFs are computed and ranked, which may be computed for each data modality independently, with the selected ones combined for clustering. On the other hand, the feature increment may need optimization, depending on individual datasets, so that a transition point can be uncovered when the “right” group of features is added. A caveat of our “unimpressive” results may also be due to the lack of known clusters to be used as “gold standard” as all our performance metrics could be affected by the cluster numbers. Alternatively, clustering and cluster-based evaluation metrics may need to change, because the affected cells may exist at continuous states with a change in chromatin accessibility followed by a gradual increase of transcription of some genes. Nevertheless, we did observe that the two types of data modalities affected cluster accuracies in a cell type dependent manner, especially for intermediate and CD14+ monocytes in the PBMC data (Supplementary Fig. S8–S12). In the case of the mouse breast data, it seems RNA features are the dominant factor (Supplementary Fig. S9, S10). Our analysis also revealed an important trade-off: while increasing RNA or ATAC features could improve the resolution for certain cell types, it often came at the cost of reduced accuracy for other cell populations. This suggests that there is a need to develop new computational methods for optimal feature selection from the BC data. However, this may become complicated if we need to define optimal feature combinations for individual cell types. Nevertheless, we think by exploring the full spectrum of data, i.e., not just the scATAC-seq features that can be associated with genes, the binarization approach provides a unique framework for investigating how different data modalities contribute to cell type identification. It is possible to do the same with non-binarized data, but it may be more challenging due to the inherent differences in the quantitative ranges of values associated with RNA and ATAC measurements. It will be valuable to test this on more datasets in the future.
Our binarization method leads to some information loss and thus has limitations. Differential expression analysis is as important as clustering in single-cell analysis and is applied to cluster marker gene identification and gene expression comparison across samples or conditions. The binary scRNA-seq data probably would not be suitable for these analyses, but they may be used to provide helpful information, for example, the fraction of cells in which a gene is expressed. The other limitation is that small cell clusters or cell types with very few detected genes seem more likely to be split and merged into other cell clusters in the clustering of either binary scRNA-seq data or after they were concatenated with scATAC-seq data. It would be important to investigate how this can be overcome in the future, or just to flag the cluster result for those cells as unreliable. Overall, we believe that our proposed binarization strategy has promising applications but needs other investigators’ input for further improvement.
While binarization may not always outperform other approaches using non-binarized data, a value lies in its potential for direct investigation of an individual modality’s contribution to cell type identification and providing a framework for optimizing feature selection in a cell-type-specific manner. This capability, combined with its computational efficiency and interpretability, suggests that it could be used as a useful baseline method for initial exploration of multi-modal data integration. Given that a typical multiomic analysis starts with analyses of each modality separately, and TF-IDF/LSI is often used to analyze the scATAC-seq data, it makes good sense to quickly apply the same TF-IDF/LSI workflow to the BC data matrix before exploring other data integration approaches.
Methods
Processing and clustering of scRNA-seq data using standard workflow
Throughout our study, we explored and applied in parallel two popular single-cell data analysis platforms, based on either Scanpy36 (Python) or Seurat software (R)22 to demonstrate robust performance. We refer to the general scRNA-seq analysis workflow outlined in the Scanpy tutorial36 and implemented in Scanpy (v1.9.3; Python v3.10) as the “standard workflow.” Likewise, the general workflow in the Seurat tutorial was considered the “standard workflow” (Fig. 1). In both cases, we used default parameters unless specified. These standard workflows included quality control (QC) to filter out poor quality cells and genes detected in a few cells, read count normalization and scaling, highly variable feature (HVF) selection, and dimensionality reduction by principal component analysis (PCA). In the Scanpy workflow, we also regressed out the effect of mitochondrial genes by the “regress_out” function, while 30 PCs (unless specified otherwise) were used for dimensionality reduction, neighborhood detection, clustered by the Leiden algorithm (v0.9.1)37, and visualized by either Uniform Manifold Approximation and Projection (UMAP) or t-distributed stochastic neighbor embedding (t-SNE). Batch correction, if required, was achieved by utilizing the Batch Balanced KNN algorithm (v1.5.1)20. In the Seurat workflow, for non-binary data analysis, Seurat (v5.0.1)22 was used with the SingleCellTransform38 workflow and default parameters. Elbow plots were used to determine the optimal number of PCs. Graph construction, UMAP visualization, and Louvain clustering were used with dataset-specific PC and resolution parameters as described in more detail in the Supplement.
Processing and clustering of scATAC-seq data using standard workflow
We followed the standard scATAC workflow of MUON39 (v0.1.5; Python v3.10; part of scverse ecosystem40) as outlined in its documentation for analyzing scATAC-seq data. For QC, ATAC peaks detected in less than 10 cells were removed with the “filter_vac” function, as were cells with less than 2000 genes, by the “filter_obs” function. The resulted peaks by cells matrix was then normalized using term-frequency inverse-document-frequency (TF-IDF), followed by singular value decomposition (SVD) for dimensionality reduction in Muon. The TF-IDF/SVD is known as Latent Semantic Indexing (LSI), but some also use LSI for the dimensionality reduction step after TF-IDF, e.g., in Muon. The resulted quantitative matrix was then processed using the standard Scanpy workflow described above for scRNA-seq data, including visualization in t-SNE or UMAP, and clustering by the Leiden algorithm.
Processing and clustering of binarized scRNA-seq data using scATAC-seq workflow
Binarization of scRNA-seq data was accomplished by thresholding the gene expression matrix (after QC filtering described above), converting any value above zero to 1, while the rest as 0. The resulted binary matrix was then processed as described above for scATAC-seq data matrix, including normalized by TF-IDF and LSI in Muon. The subsequent clustering and low-dimensional visualization also followed the standard scATAC-seq workflow, referred to as BC-Scanpy.
In parallel, we applied the Seurat/Signac workflow on binarized scRNA-seq data and concatenated scRNA-seq and scATAC-seq data, referred to as BC-Signac. The R package Signac23 (v1.11.0) was used with default settings for LSI (TF-IDF/SVD) analysis. Elbow plots and “depth correlation” plots were used to inspect LSI components. LSI component 1 was always excluded. Graph construction, UMAP visualization, and Louvain clustering were used with data-specific PC and resolution parameters described in the Supplement.
Datasets specific processing
Simulated dataset: to evaluate our method with known ground truth for cell type labels, we generated simulated multi-modal datasets using scMultiSim (v1.0.0)25 We simulated 10,000 cells with 5 distinct cell groups using the random tree structure in scMultiSim, generating paired scRNA-seq (2000 genes) and scATAC-seq (7500 peaks) data. The simulation parameters were set to reflect the typical sparsity level and complexity observed in real multi-modal data. We then binarized the scRNA-seq data and concatenated them with the scATAC-seq data for clustering, using the cell group labels to directly assess clustering performance.
Human pancreatic islet scRNA-seq data (accession numbers: E-MTAB-5061 and E-MTAB-5060) were obtained from a previous study described in Segerstolpe et al. 18. It contained 2209 cells from both healthy and type 2 diabetic donors and was generated by the Smart-seq2 technology. The expression data in either raw count or RPKM (Reads Per Kilobase of transcript per Million mapped reads) form were used, while the cell cluster and corresponding type annotation from the authors were used without modification in this study.
Two sets of data from human peripheral blood mononuclear cells (PBMC) were used. One is scRNA-seq data from 3000 PBMCs (referred to as “3 K”), downloaded from the 10X Genomics16. This dataset has been used as a standard for many software developments, including Seurat and Scanpy15,22, with predefined cell type labels. The other is a multiomic dataset provided by the 10X Genomics and contains scRNA-seq and scATAC-seq data from 11,909 PBMCs (referred to as “10 K”)41. In the ATAC-seq portion, cells contained a median of 13,486 high-quality ATAC peaks. The publicly released data did not contain metadata for predefined cell type clusters or annotations, so we used the previously identified cell types and their corresponding canonical markers to assist our own clustering and cell type annotation27, i.e., to reproduce previous cell type annotation (see below, “Cell type annotation”).
A large snRNA-seq dataset comprising of 45,870 cells, 78,023 CD45+ enriched cells and 363,213 nuclei from 14 adult human hearts was obtained from a previous study21 (Human Cell Atlas Accession no. ERP123138). It has a total of 487,106 cell/nuclei barcodes and 11 major cell types (plus two groups called “doublets” and “unassigned”). We used the filtered and normalized data provided by the authors, as well as their cell clusters and annotations for individual cells.
A dataset from the human cerebral cortex consisting of paired single-nuclei RNA- and ATAC-seq of 45,549 nuclei prepared via the 10X Multiome platform was also used33. The count matrices were downloaded from the GEO (Accession “GSE204684”) while cell annotation metadata was from the Broad Single Cell Portal under accession “SCP1859”. The data were used for clustering by our method and all other integration methods, and the cluster results were scored by a set of metrics shown in Table 1, with the results from Seurat and Signac discussed in more details (see Supplementary Results).
A dataset from non-hematopoietic bone tissue comprising the bone marrow stromal niche, consisting of single-cell RNA-seq of 20,581 cells prepared via the 10X Chromium v2 platform, was used42. The expression count matrix and cell annotation metadata were obtained from the Broad Single Cell Portal under accession “SCP361”.
Finally, the mouse breast multiomic data were described in a previous publication by Foster et al. 32. The study analyzed both human and mouse normal breast tissues and breast cancer samples using the 10X Multiomic platform, but we used only one of the samples from the normal non-tumor mammary parenchyma of mouse breast tissue (GEO: GSM6543819). After QC, we obtained 9057 cells with 25,767 genes from scRNA-seq and 93,484 fragments/peaks from scATAC-seq for our integration study. The author’s cell type annotation was not available in the publicly released data, so we performed our own annotation. The data were then used for clustering by our method and all other integration methods, and the cluster qualities were scored by a set of metrics shown in Table 1.
Methods and metrics for evaluating clustering performance
To comprehensively evaluate the accuracy of clustering results from individual methods, we employed multiple complementary metrics implemented through scikit-learn43. The Adjusted Rand Index (ARI) was used to measure the agreement between new clusters from each method and the predefined cell type labels, accounting for chance in the clustering assignments30. The Adjusted Mutual Information (AMI) and Normalized Mutual Information (NMI) scores quantify the mutual dependence between the predefined cell types and new cluster assignments while adjusting for chance and normalization, respectively44. The Fowlkes-Mallows Index (FMI) provides a measure of clustering similarity based on the geometric mean of precision and recall45. For internal validation where the ground truth of cell types is unknown, we utilized the silhouette coefficient to assess cluster cohesion and separation29. All metrics were computed using scikit-learn version 1.3.2.
These metrics (e.g., ARI/AMI) may be sensitive to cluster numbers, thus, we computed and used two other simpler metrics: “cluster accuracy” and “cell type congregated score”. The former addresses if a cluster is dominated by one cell type, which is computed for each cluster as the number of cells from the most frequent known cell type divided by the total cell number in the cluster. A value of 1 indicates that all cells in a cluster is the same type, but cells of the same type may be in more than one cluster. Conversely, the latter addresses whether cells of a type are predominantly in one cluster. We first searched for the cluster containing the most cells of a given type, counted the number of cells belong to that type, and then divided it by the total cell number of that type in the sample. Thus, a value of 1 for a predefined cell type indicates that all cells of this type are in a single cluster, but there may be cells of other type(s) in this cluster. The congregated score is robust to long-tail distributions where a small subset of cells from a known type may scatter across multiple clusters, which explicitly decouples cluster resolution effects from core integration performance evaluation.
Application of other integration software
Single cell Multi-omics integration using Matrix Tri-factorization (scMoMaT)
For scMoMaT integration26 (v0.2.2), paired scRNA-seq and scATAC-seq data were preprocessed by converting sparse matrices to dense arrays and binarizing counts (RNA: log = False; ATAC: peak retention without gene activity conversion). The model was initialized with K = 30 latent factors after systematic testing of values (K = 20–50) across datasets to balance computational efficiency and biological resolution. Training ran for T = 4000 epochs on GPU hardware, with epoch ranges (2000–6000) validated through loss convergence analysis. Post-processing included constructing a k-nearest neighbor graph (k = 30, selected via parameter sweeps of k = 10–50) from latent embeddings and performing Leiden clustering at resolution 0.6–1.0 across replicates, with resolutions optimized per dataset to match predefined cell type numbers. Scores were calculated in PCA-reduced space (15 components selected via variance-explained analysis) using Euclidean distances.
Multigrate
For Multigrate integration46 (v0.0.2), paired scRNA-seq and scATAC-seq data were preprocessed by retaining highly variable features (RNA: Scanpy’s HVG selection; ATAC: peak-based filtering) and aligning observations across modalities using Muon’s “intersect_obs” function to ensure matched cells. The MultiVAE model was initialized through Multigrate’s organize_multiome_anndatas pipeline, configured with MSE reconstruction losses for both modalities and default learning rates. Training proceeded for 400 epochs on GPU hardware with latent embeddings extracted for post-convergence, verified via loss stabilization. Post-processing involved constructing a k-nearest neighbor graph (default parameters) from latent embeddings, followed by Leiden clustering at resolution 0.3–0.5 (flavor = “igraph”, 2 iterations) and UMAP visualization using Scanpy’s default settings.
Single cell binary factor analysis (scBFA)
For scBFA integration9 (v1.16.0), paired scRNA-seq and scATAC-seq data were combined into a single matrix to interface with scBFA’s framework, with peaks and genes concatenated row-wise and cell barcodes standardized across modalities. The model was configured with 6 latent factors after systematic testing of values (K = 4–12) across datasets, with the final value selected based on plateauing silhouette scores and stable adjusted Rand index (ARI) compared to predefined cell type annotations. Training was conducted on GPU hardware and utilized conjugate gradient descent (CG) for 300 optimization steps, initialized via scBFA’s default settings with fixed random seeds for reproducibility. Post-training, latent factors underwent UMAP dimensionality reduction (default parameters) and k-means clustering (k = number of annotated cell types) to derive cell states. Integration performance was quantified using ARI, AMI, and MI between cluster labels and latent factors, computed via the mclust and aricode packages. Three independent runs were taken to confirm metric stability.
Cell type annotation for datasets lacking predefined cell type labels
For the datasets in which the authors did not release cell type annotations for individual cells, we performed cell clustering and annotation using a standard workflow and the published cell types and known marker genes as guidance. For the 10 K PBMC dataset, cell clusters and cell type assignments were based on canonical markers available in the Muon tutorial. To annotate the mouse breast tissue data, we identified five major cell types using established markers for mammary cell populations, including Epcam and Muc1 for epithelial cells, and Cd68 for macrophages32. Unfortunately, we could not evaluate the degree of consistency between our reannotation and the authors’ original one.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
No new wet-lab experimental data were collected in this study. Source data are provided with this paper. The human pancreatic data from healthy donors (E-MTAB-5061) are available at. The pancreatic data from type-2-diabete donors (E-MTAB-5060) are available at. The 10X Genomics 3k PBMC scRNA-seq (pbmc3k) are from. The 10X Genomics 10k PBMC Multiome (RNA + ATAC) are available at [https://support.10xgenomics.com/single-cell-multiome-atac-gex/datasets/1.0.0/pbmc_granulocyte_sorted_10k]. The adult human heart data (ERP123138) are available at. The Human cerebral-cortex Multiome data (GSE204684) are available at, with cell type annotation from [https://singlecell.broadinstitute.org/single_cell/study/SCP1859]. The bone atlas data (SCP361) are from. The Mouse mammary-parenchyma Multiomic data (GSM6543819) are at. Source data are provided in this paper.
Code availability
The codes used for the data analysis are publicly available at GitHub (https://github.com/bioinfoDZ/sc_binarization) and Zenodo (https://doi.org/10.5281/zenodo.15447106)47 under the MIT license.
References
Stegle, O., Teichmann, S. A. & Marioni, J. C. Computational and analytical challenges in single-cell transcriptomics. Nat. Rev. Genet. 16, 133–145 (2015).
Heumos, L. et al. Best practices for single-cell analysis across modalities. Nat. Rev. Genet. 24, 550–572 (2023).
Stuart, T. & Satija, R. Integrative single-cell analysis. Nat. Rev. Genet. 20, 257–272 (2019).
Cusanovich, D. A. et al. A single-cell atlas of in vivo mammalian chromatin accessibility. Cell 174, 1309–1324 (2018).
Granja, J. M. et al. ArchR is a scalable software package for integrative single-cell chromatin accessibility analysis. Nat. Genet. 53, 403–411 (2021).
Miao, Z., Humphreys, B. D., McMahon, A. P. & Kim, J. Multi-omics integration in the age of million single-cell data. Nat. Rev. Nephrol. 17, 710–724 (2021).
Nam, A. S., Chaligne, R. & Landau, D. A. Integrating genetic and non-genetic determinants of cancer evolution by single-cell multi-omics. Nat. Rev. Genet. 22, 3–18 (2021).
Stanojevic, S., Li, Y., Ristivojevic, A. & Garmire, L. X. Computational Methods for Single-cell Multi-omics Integration and Alignment. Genom. Proteom. Bioinform. 20, 836–849 (2022).
Li, R. & Quon, G. scBFA: modeling detection patterns to mitigate technical noise in large-scale single-cell genomics data. Genome Biol. 20, 193 (2019).
Qiu, P. Embracing the dropouts in single-cell RNA-seq analysis. Nat. Commun. 11, 1169 (2020).
Bouland, G. A., Mahfouz, A. & Reinders, M. J. T. Differential analysis of binarized single-cell RNA sequencing data captures biological variation. NAR Genom. Bioinform. 3, lqab118 (2021).
Moignard, V. et al. Decoding the regulatory network of early blood development from single-cell gene expression measurements. Nat. Biotechnol. 33, 269–276 (2015).
Yu, D. et al. CellBiAge: Improved single-cell age classification using data binarization. Cell Rep. 42, 113500 (2023).
Moussa, M. & Măndoiu, I. I. Single cell RNA-seq data clustering using TF-IDF based methods. BMC Genom. 19, 569 (2018).
Wolf, F. A., Angerer, P. & Theis, F. J. SCANPY: large-scale single-cell gene expression data analysis. Genome Biol. 19, 15 (2018).
pbmc3k -Datasets -Single Cell Gene Expression -Official 10x Genomics Support. https://support.10xgenomics.com/single-cell-gene-expression/datasets/1.1.0/pbmc3k.
Hao, Y. et al. Integrated analysis of multimodal single-cell data. Cell 184, 3573–3587 (2021).
Segerstolpe, Å et al. Single-cell transcriptome profiling of human pancreatic islets in health and type 2 diabetes. Cell Metab. 24, 593–607 (2016).
Cusanovich, D. A. et al. Multiplex single-cell profiling of chromatin accessibility by combinatorial cellular indexing. Science 348, 910–914 (2015).
Polański, K. et al. BBKNN: fast batch alignment of single cell transcriptomes. Bioinformatics 36, 964–965 (2020).
Litviňuková, M. et al. Cells of the adult human heart. Nature 588, 466–472 (2020).
Hao, Y. et al. Dictionary learning for integrative, multimodal and scalable single-cell analysis. Nat. Biotechnol. 42, 293–304 (2023).
Stuart, T., Srivastava, A., Madad, S., Lareau, C. A. & Satija, R. Single-cell chromatin state analysis with Signac. Nat. Methods 18, 1333–1341 (2021).
Argelaguet, R., Cuomo, A. S. E., Stegle, O. & Marioni, J. C. Computational principles and challenges in single-cell data integration. Nat. Biotechnol. 39, 1202–1215 (2021).
Li, H., Zhang, Z., Squires, M., Chen, X. & Zhang, X. scMultiSim: simulation of single-cell multi-omics and spatial data guided by gene regulatory networks and cell–cell interactions. Nat. Methods 22, 982–993 (2025).
Zhang, Z. et al. scMoMaT jointly performs single cell mosaic integration and multi-modal bio-marker detection. Nat. Commun. 14, 384 (2023).
Processing chromatin accessibility of 10k PBMCs — muon-tutorials documentation. https://muon-tutorials.readthedocs.io/en/latest/single-cell-rna-atac/pbmc10k/2-Chromatin-Accessibility-Processing.html (2022).
Argelaguet, R. et al. Multi-Omics factor analysis-a framework for unsupervised integration of multi-omics data sets. Mol. Syst. Biol. 14, e8124 (2018).
Rousseeuw, P. J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 20, 53–65 (1987).
Hubert, L. & Arabie, P. Comparing partitions. J. Classif. 2, 193–218 (1985).
Patel, A. A. et al. The fate and lifespan of human monocyte subsets in steady state and systemic inflammation. J. Exp. Med. 214, 1913–1923 (2017).
Foster, D. S. et al. Multiomic analysis reveals conservation of cancer-associated fibroblast phenotypes across species and tissue of origin. Cancer Cell 40, 1392–1406.e7 (2022).
Zhu, K. et al. Multi-omic profiling of the developing human cerebral cortex at the single-cell level. Sci. Adv. 9, eadg3754 (2023).
Bouland, G. A., Mahfouz, A. & Reinders, M. J. T. Consequences and opportunities arising due to sparser single-cell RNA-seq datasets. Genome Biol. 24, 86 (2023).
Zandigohar, M. & Dai, Y. Information retrieval in single cell chromatin analysis using TF-IDF transformation methods. In 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) 877–882 (2022).
Tutorials — Scanpy 0.1.0.dev documentation. https://scanpy.readthedocs.io/en/stable/tutorials.html (2025).
Traag, V. A., Waltman, L. & van Eck, N. J. From Louvain to Leiden: guaranteeing well-connected communities. Sci. Rep. 9, 5233 (2019).
Hafemeister, C. & Satija, R. Normalization and variance stabilization of single-cell RNA-seq data using regularized negative binomial regression. Genome Biol. 20, 296 (2019).
Bredikhin, D., Kats, I. & Stegle, O. MUON: multimodal omics analysis framework. Genome Biol. 23, 42 (2022).
Virshup, I. et al. The scverse project provides a computational ecosystem for single-cell omics data analysis. Nat. Biotechnol. 41, 604–606 (2023).
pbmc_granulocyte_sorted_10k -Datasets -Single Cell Multiome ATAC + Gene Exp. -Official 10x Genomics Support https://support.10xgenomics.com/single-cell-multiome-atac-gex/datasets/1.0.0/pbmc_granulocyte_sorted_10k.
Baryawno, N. et al. A cellular taxonomy of the bone marrow stroma in homeostasis and Leukemia. Cell 177, 1915–1932.e16 (2019).
Pedregosa, F. et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Vinh, N. X., Epps, J. & Bailey, J. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. J. Mach. Learn. Res. 11, 2837–2854 (2010).
Fowlkes, E. B. & Mallows, C. L. A method for comparing two hierarchical clusterings. J. Am. Stat. Assoc. 78, 553–569 (1983).
Lotfollahi, M., Litinetskaya, A. & Theis, F. J. Multigrate: single-cell multi-omic data integration. 2022.03.16.484643 Preprint at https://doi.org/10.1101/2022.03.16.484643 (2022).
Misra R., Ferrena, A. & Zheng D. Facilitate integrated analysis of single cell multiomic data by binarizing gene expression values. Zenodo. https://doi.org/10.5281/zenodo.15447106 (2025).
Acknowledgements
We would like to thank the support of the Einstein High Performance Computing. This work was partially supported by grants from the US National Institutes of Health, R01HL153920, R01HL163667, and P50HD105352 (D.Z.).
Author information
Authors and Affiliations
Contributions
D.Z. conceived of the BC integration method. R.M. performed all the data analysis involving Python. A.F. performed most of the data analysis involving R, with help from R.M. R.M., A.F., and D.Z. wrote the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks the anonymous reviewers for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Misra, R., Ferrena, A. & Zheng, D. Facilitate integrated analysis of single cell multiomic data by binarizing gene expression values. Nat Commun 16, 5763 (2025). https://doi.org/10.1038/s41467-025-60899-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-025-60899-8
