
Abstract
The advent of single-cell sequencing has revolutionized the study of cellular dynamics, providing unprecedented resolution into the molecular states and heterogeneity of individual cells. However, the rich potential of exon-level information and junction reads within single cells remains underutilized. Conventional gene-count methods overlook critical exon and junction data, limiting the quality of cell representation and downstream analyses such as subpopulation identification and alternative splicing detection. We introduce DOLPHIN, a deep learning method that integrates exon-level and junction read data, representing genes as graph structures. These graphs are processed by a variational graph autoencoder to improve cell embeddings. DOLPHIN not only demonstrates superior performance in cell clustering, biomarker discovery, and alternative splicing detection but also provides a distinct capability to detect subtle transcriptomic differences at the exon level that are often masked in gene-level analyses. By examining cellular dynamics with enhanced resolution, DOLPHIN provides new insights into disease mechanisms and potential therapeutic targets.
Similar content being viewed by others

Introduction
Single-cell RNA sequencing (scRNA-seq) has transformed transcriptomics by enabling the profiling of gene expression at the level of individual cells, a major advance in studying cellular diversity within complex tissues1. This technology has driven significant progress across fields such as developmental biology2,3, immunology4,5, and cancer research6,7, revealing intricate cellular landscapes, elucidating developmental pathways, and identifying previously uncharacterized cell types linked to disease states8,9. By enabling high-resolution dissection of cellular states and dynamics, scRNA-seq provides insights that bridge basic biological understanding with therapeutic applications, reshaping both basic and translational research.
Despite these advancements, conventional scRNA-seq analyses are predominantly gene-level, relying on gene count tables for cell representation learning and downstream tasks such as cell clustering, differential gene expression, and pseudotime trajectory inference10. Numerous computational tools, including SCANPY11, seurat12, scVI13, scGPT14, geneFormer15, scBERT16, scSemiProfiler17, and Cellar18 are designed to analyze this gene-level data. However, aggregating data at the gene level oversimplifies the transcriptomic landscape, as critical biological information encoded in exon-level reads and junction reads—reads spanning exon boundaries and capturing exon connectivity—is often lost19,20. This simplification masks essential details, including exon-specific expression and splicing patterns, which are crucial for accurately representing cellular states. Consequently, gene-level aggregation may lead to an oversimplified view of cellular characteristics, limiting insights into cellular function and regulation and underscoring the need for approaches that preserve this fine-grained information21.
In addition to cell representation learning, another critical task in scRNA-seq analysis is the detection and quantification of alternative splicing (AS) events. AS analysis at the gene level poses substantial challenges, as gene-level quantification obscures isoform-specific and exon-specific variations that are critical for capturing splicing dynamics. To address this, various computational tools have been developed for AS analysis in scRNA-seq data. Among junction read-based approaches, Outrigger22 constructs a de novo splicing event index by pooling junction-spanning reads across all cells and building a splice graph to identify and quantify AS events. scQuint23 adopts a different strategy by quantifying intron usage based on junction reads. To improve splicing quantification under sparse conditions, imputation-based methods such as BRIE224 and SCASL25 have been developed. BRIE2 employs a Bayesian hierarchical model to borrow information across similar cells and infer more robust Percent Spliced-In (PSI) estimates, whereas SCASL uses an iterative weighted k-nearest neighbors (KNN) strategy to impute missing PSI values. Despite these methodological advances, major gaps remain. Most existing tools were developed and benchmarked primarily on full-length scRNA-seq datasets, and their performance degrades substantially when applied to droplet-based platforms such as 10X Genomics, where coverage is sparse and biased toward transcript ends. Furthermore, nearly all methods predominantly rely on junction-spanning reads for splicing quantification. This reliance can limit sensitivity and robustness, especially in the context of scRNA-seq, where sparse coverage and frequent dropout render junction reads insufficient for capturing the full extent of splicing variability. Additionally, the exclusion of exon body reads, which represent a more abundant yet underutilized source of information, can reduce the sensitivity of existing methods in detecting subtle or complex splicing events that may be missed due to the sparsity of junction reads in scRNA-seq data.
To address these foundational limitations, we introduce DOLPHIN (\(\underline{{{{\bf{D}}}}}{{{\rm{eep}}}}\) \({{{\rm{Ex}}}}\underline{{{{\bf{o}}}}}{{{\rm{n}}}}\)-\(\underline{{{{\bf{l}}}}}{{{\rm{evel}}}}\) \({{{\rm{Gra}}}}\underline{{{{\bf{ph}}}}}\) Neural Network for \({{{\rm{S}}}}\underline{{{{\bf{i}}}}}{{{\rm{ngle}}}}\)-cell \({{{\rm{Representatio}}}}\underline{{{{\bf{n}}}}}\) Learning and Alternative Splicing), a deep learning framework that advances scRNA-seq analysis beyond conventional gene-level quantification. DOLPHIN constructs a graph for each gene, representing exons as nodes and splice junctions as edges, to model gene architecture at single-cell resolution. By integrating exon-level reads and junction reads, DOLPHIN captures a richer and more detailed transcriptional landscape compared to traditional approaches that rely solely on gene-level counts. Built on a variational graph autoencoder (VGAE) framework26,27, DOLPHIN learns cell embeddings that preserve fine-grained exon usage patterns and splicing information, enabling more accurate and informative representations of cellular states. These enhanced embeddings not only improve downstream analyses such as cell clustering and differential gene analysis but also support more sensitive AS detection. Specifically, DOLPHIN uses the learned embeddings to identify neighboring cells with similar exon and splicing profiles, aggregates junction reads across neighbors to amplify splicing signals, and substantially enhances AS detection under the sparse sequencing conditions typical of scRNA-seq. Following aggregation, PSI values are calculated using the Outrigger function from Expedition28, providing accurate and robust quantification of splicing events across diverse cell populations.
We demonstrate DOLPHIN’s general applicability by validating its performance on a diverse set of scRNA-seq datasets29,30,31 that encompass distinct sequencing technologies, including full-length and droplet-based approaches, as well as a broad spectrum of tissue types and biological conditions. These datasets span healthy tissues, normal tissues from patients with cancer, and malignant tissues, thereby representing a wide range of physiological and pathological contexts. This systematic validation highlights DOLPHIN’s robustness and adaptability, demonstrating its effectiveness in accurately capturing cell heterogeneity and refining complex downstream analyses across diverse experimental contexts. Across diverse scRNA-seq datasets and simulated data, our model consistently outperforms traditional gene count-based methods. By integrating exon-level and junction read information with advanced deep learning techniques, DOLPHIN enhances the resolution of single-cell transcriptomic analysis, improving cell embedding quality and enabling more detailed analyses of AS and differential gene expression. Ultimately, DOLPHIN provides an analytical framework that addresses the limitations of gene-count-based methods, enabling more precise insights into complex cellular processes and facilitating the study of disease mechanisms and therapeutic targets.
Results
Overview of DOLPHIN
DOLPHIN is a deep learning framework for exon-level analysis of scRNA-seq data, offering higher transcriptomic resolution than traditional gene-count methods (Fig. 1). Each gene is modeled as an exon graph, where nodes represent exons and edges represent their connections via junction reads. By integrating exon and junction data, DOLPHIN generates integrative cell representations that support applications like cell clustering, differential exon analysis, and AS detection19,32,33.

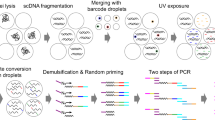
a Preprocessing of single-cell RNA-seq data, including quantification of exon-mapped reads and exon-exon junction reads. b Construction of gene-specific exon graphs, where nodes represent exons and edges represent junctions, aggregated to form an exon graph for each cell. c Learning cell embeddings from exon-level quantification and junction reads through a Variational Graph Autoencoder (VGAE). Each exon graph is converted into feature matrices (Xi) and normalized adjacency matrices (ANi), which are processed by a Graph Attention Network (GAT) layer to capture exon dependencies. The output (Hi) from the GAT layer is then passed to a Variational Autoencoder (VAE) that projects graph representations into a latent space (Z), defined by mean (μ) and standard deviation (σ) parameters, with a KL divergence term weighted by a hyperparameter (β) to regularize the latent space. The decoders reconstruct both the feature matrix (\({{\bf{X}}}_{i}^{{\prime} }\)) and raw adjacency matrix (\({{\bf{A}}}_{i}^{{\prime} }\)), with losses weighted by a hyperparameter (λ) to minimize feature and adjacency reconstruction errors, thereby learning cell-specific embeddings. d Construction of a K-nearest neighbor (KNN) graph in the latent space for refining and aggregating junction reads from neighboring cells based on consensus (majority voting), which enhances junction coverage for downstream splicing analysis. e Calculation of percent-splice-in (PSI) values from aggregated junction reads, enabling accurate alternative splicing inference at the single-cell level. f High-resolution cell embeddings generated by DOLPHIN improve the characterization of cellular heterogeneity compared to conventional gene count-based methods. g Detection of exon-specific markers and identification of biological pathways that are often missed in gene-level analyses. Exon-level biomarkers were identified through differential expression analysis using MAST. h Extensive alternative splicing analysis enabled by DOLPHIN across diverse cellular populations. By default, PSI values and splicing modalities were quantified using Expedition. However, DOLPHIN can be adapted to work with other alternative splicing quantification tools.
The method operates in three main steps. First, DOLPHIN constructs an exon graph for each gene by capturing gene-specific exon connectivity from junction reads (Fig. 1a, b)19,33. Raw scRNA-seq reads are aligned to a reference genome to identify exon reads and junction reads, which are then used to build exon graphs. Each exon graph has nodes representing exons annotated with their read counts and directional edges weighted by normalized junction read counts. This setup forms a cell-level structure comprising exon graphs for each gene. Second, these cell-level exon graphs are processed through a VGAE26 to produce informative cell embeddings (Fig. 1c). Each cell-level exon graph is converted into adjacency and feature matrices, which are processed by a graph attention (GAT) layer34. The GAT layer dynamically assigns weights to neighboring exons, emphasizing biologically relevant exon connections informed by junction reads. The variational autoencoder (VAE) encoder then learns a latent representation Z that captures critical exon-junction relationships, optimized through a composite loss function that balances reconstruction of both exon-level features and adjacency matrices35,36. Third, DOLPHIN addresses the limited detection of junction reads in scRNA-seq by aggregating junction reads from similar cells in the junction-aware latent space (Fig. 1d)37. Using a KNN approach, cells with similar exon and junction patterns are identified, and junction reads from those neighboring cells are aggregated based on majority voting. This aggregation step, schematically illustrated in Fig. 1e, enriches each cell’s profile with junction reads from consistent neighboring cells, enhancing detection sensitivity without introducing noise.
With these enhanced cell embeddings, DOLPHIN supports exon-level analyses such as refined cell clustering (Fig. 1f), differential gene analysis at the exon level (Fig. 1g), and AS detection (Fig. 1h). By integrating these embeddings with splicing detection tools like Outrigger from the Expedition suite, DOLPHIN can compute PSI values, providing detailed insights into exon usage and cell-specific splicing patterns22,28.
DOLPHIN enhances cell embeddings across diverse single-cell scenarios through graph-based exon and junction read integration
DOLPHIN enhances cell embeddings through the graph-based integration of exon-level and junction read quantification, leveraging both read types to improve the quality of cell embeddings and the accuracy of scRNA-seq clustering compared to traditional gene count methods. To demonstrate the general applicability of DOLPHIN, we validated its performance across diverse scRNA-seq datasets spanning different platforms, tissue types, and biological conditions. These included a full-length dataset from human peripheral blood mononuclear cells (PBMCs)29 and two 10X Genomics Chromium Single Cell 3′ v2 datasets from normal epithelial colon and rectum tissues from gastrointestinal cancer patients30.
For each dataset, we processed four inputs through the VAE framework–an exon feature matrix, a junction-based adjacency matrix, a gene count table, and the integrated feature and adjacency matrices from DOLPHIN. These components were assessed individually to evaluate their contributions and the enhancement achieved through integration. Clustering outcomes were compared to ground truth labels using Uniform Manifold Approximation and Projection (UMAP) visualizations38, with the ground truth annotations taken from the original publications, as shown in Fig. 2a–d and Supplementary Fig. S1. Additionally, Adjusted Rand Index (ARI)39 and Normalized Mutual Information (NMI)40 scores were used for quantitative evaluation, as presented in Fig. 2e–g. DOLPHIN’s integrated embeddings consistently outperformed individual matrices and gene count tables, capturing cell type-specific information at finer resolution and achieving higher ARI and NMI scores, as demonstrated in Fig. 2.

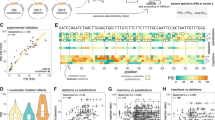
a–d UMAP plots comparing the quality of cell embeddings generated by DOLPHIN, which integrates both exon and junction read counts, against conventional gene count-based methods across multiple single-cell RNA-seq datasets. Improved clustering and separation of distinct cell populations define higher-quality embeddings. Top panels: Human peripheral blood mononuclear cells (PBMCs) analyzed using full-length single-cell RNA-seq. Middle panels: Human colon cells analyzed using 10X Genomics. Bottom panels: Human rectum cells analyzed using 10X Genomics. For each dataset, the following inputs are compared: a DOLPHIN integrating both exon and junction read counts, producing the most integrative and biologically informative embeddings. b DOLPHIN framework using gene count tables, reflecting a conventional gene-level analysis. c DOLPHIN using only exon read counts (feature matrix). d DOLPHIN using only junction read counts (adjacency matrix). e–g Box plots of Adjusted Rand Index (ARI) and Normalized Mutual Information (NMI) scores comparing embedding quality across three different datasets. DOLPHIN, through the integration of exon and junction read counts, achieves significantly higher scores than approaches using exon or junction data alone or conventional gene-count methods. These metrics confirm DOLPHIN's superior clustering accuracy and alignment with known biological cell types, highlighting its performance advantage. Each score is based on N = 50 bootstrapping replicates using different random seeds (technical replicates). Boxes indicate the interquartile range (IQR, 25th to 75th percentile), with the line inside each box representing the median. Whiskers extend to the most extreme data points within 1.5 times the IQR from the quartiles. P values from one-sided Student’s t-tests: *P < 0.05, **P < 0.01, ***P < 0.001, ****P < 0.0001; n.s. not significant. Exact P values are provided in the source data. Source data are provided as a Source Data file.
In the PBMC dataset, UMAP visualizations illustrate that DOLPHIN distinctly delineates cell clusters closely matching ground truth cell types (Fig. 2a, top panel). In contrast, gene count tables yield denser clusters, obscuring subpopulations, particularly within T cell subsets (Fig. 2b, top panel). The feature matrix and adjacency matrix are each able to resolve specific cell types, including monocytes (Mono), B cells, and natural killer cells, into distinct and well-defined clusters (Fig. 2c, d, top panels). This suggests that both matrices effectively capture biologically relevant variations, facilitating the accurate identification of cell populations. Furthermore, their integration in DOLPHIN provides the most refined results. Supplementary Fig. S2a highlights the abundance of exon and junction reads in full-length data, sufficient for constructing robust exon-level graphs for cell representation learning. Quantitative analysis with ARI and NMI metrics (Fig. 2e) shows that DOLPHIN achieves median ARI scores 0.11 higher than gene count methods, with statistical significance (P = 1.98 × 10−4).
For UMI-based platforms with limited gene coverage, DOLPHIN was applied to two 10X Genomics datasets. In the human colon dataset, UMAP plots show that DOLPHIN mitigates batch effects and produces well-defined clusters for Paneth-like, Goblet, and transient amplifying (TA) cells (Fig. 2a, middle panel). By contrast, the gene count table exhibits batch effects, blurring cell type boundaries (Fig. 2b, middle panel). The batch effect was evaluated in Supplementary Fig. S3a, b, where we show that the DOLPHIN method exhibits significantly less batch effect compared to the gene count table approach. Notably, the integration LISI (iLISI) score showed the most substantial improvement, increasing from 0.01 with the gene count table to 0.82 with DOLPHIN, with P = 1.38 × 10−23. Across multiple evaluation metrics, DOLPHIN demonstrated superior performance in reducing batch effects relative to the gene count table method. The feature matrix delineates Goblet and Paneth-like cells, while the adjacency matrix captures broader cell-type patterns with slightly diffuse boundaries (Fig. 2c, d, middle panel). DOLPHIN’s integrated embeddings achieve the best clustering accuracy, with ARI and NMI improvements of 0.10 and 0.08, respectively, over gene count tables (Fig. 2f). These results were statistically significant (P = 4.56 × 10−25 and P = 4.85 × 10−42, respectively), highlighting DOLPHIN’s robustness for low-coverage datasets.
Similarly, in the 10X rectum dataset, DOLPHIN improved clustering performance, effectively resolving Enterocyte and Goblet cell populations, as seen in UMAP plots (Fig. 2a–d, bottom panel). ARI and NMI metrics further confirmed its advantage, with improvements of 0.11 (P = 1.98 × 10−44) and 0.09 (P = 1.05 × 10−33), respectively, compared to gene count tables (Fig. 2g). We also compared the batch effect between the gene count table and DOLPHIN, as shown in Supplementary Fig. S3c, d, where the iLISI score increased from 0.06 with the gene count table to 0.40 with DOLPHIN with P = 4.91 × 10−13. These findings demonstrate DOLPHIN’s adaptability to diverse datasets and its ability to detect biologically meaningful patterns even under the 10X tag-based platforms, where exon and junction reads are much less abundant, as shown by their distribution in Supplementary Fig. S2b, c.
Robustness of cell embeddings against batch effects is critical for accurately capturing biological variation in scRNA-seq data. We evaluated the robustness of DOLPHIN embeddings by conducting two complementary analyses. First, we assessed DOLPHIN’s default embeddings without applying any external batch correction to the input features. As shown in Supplementary Fig. S3, DOLPHIN’s exon-level modeling inherently mitigates batch-driven separation, resulting in robust cell embeddings even under uncorrected conditions. To further strengthen this evaluation, we compared DOLPHIN embeddings against standard batch correction methods. Specifically, we applied Harmony41 and scVI to perform batch correction on the gene count matrix, and separately applied scVI to correct batch effects in the exon-level feature matrix prior to DOLPHIN embedding. In contrast, Harmony operates only on low-dimensional embeddings and is not compatible with exon-level feature correction before DOLPHIN. As shown in Supplementary Fig. S4a–c, while all approaches reduced batch-driven separation, DOLPHIN embeddings derived from scVI-corrected exon inputs achieved the best batch mixing. This observation is further supported by quantitative metrics in Supplementary Fig. S4d, which assess both biological conservation (ARI, NMI) and batch correction performance (batch average silhouette width (ASW), graph connectivity)42,43. Notably, applying Harmony to gene-level embeddings improved the median ARI from 0.26 to 0.41 (P = 1.71 × 10−7), whereas DOLPHIN with batch-corrected exon inputs achieved a higher ARI of 0.49 compared to the Harmony-corrected gene count matrix (P = 2.09 × 10−4), indicating superior preservation of biological structure. DOLPHIN embeddings also exhibited the highest median Batch ASW and comparable graph connectivity to Harmony, reflecting strong batch mixing while maintaining biological relevance. Together, these results demonstrate that DOLPHIN’s exon-level embeddings are inherently robust against batch effects and can achieve even greater performance when built upon batch-corrected exon-level inputs.
Beyond clustering, DOLPHIN’s exon-level embeddings enable de novo cell type annotation by capturing transcriptomic differences often missed at the gene level. To systematically assess this, we compared gene-, isoform-, and exon-level expression across annotated cell types in three datasets. For each dataset, one well-established marker gene per cell type was selected30,44,45,46, and UMAP expression patterns were visualized for their corresponding isoforms (Supplementary Figs. S5–S7). While isoform expression generally resembled gene-level patterns, several isoforms revealed finer subcluster structures. For example, in the 10X colon dataset (Supplementary Fig. S6a), among five isoforms of the enterocyte marker SLC26A347, ENST00000453332 exhibited strong, localized expression, distinguishing subpopulations within enterocytes. Building on these observations, we emphasized exon-level features underlying DOLPHIN’s embeddings (Supplementary Figs. S8–S10). Exon-level expression further refined cell type-specific patterns beyond both gene- and isoform-level analyses. In the PBMC dataset, while CUX1 gene and isoform expressions broadly marked monocytes (Supplementary Fig. S11), specific exons (e.g., exons 19 and 20) localized to the CD16 monocyte subcluster48 (Supplementary Fig. S8b). These results demonstrate that DOLPHIN’s exon-level embeddings facilitate precise de novo annotation of cell types and subtypes, capturing biologically meaningful heterogeneity overlooked by conventional approaches.
To explore the broader applicability of DOLPHIN for cell representation learning beyond short-read scRNA-seq data, we further applied it to single-cell long-read RNA-seq datasets49. In this analysis, we generated isoform-level counts and subsequently analyzed them with SCANPY and scVI to establish isoform-based baselines. In parallel, DOLPHIN was applied directly to exon-informed features to learn cell embeddings. As shown in Supplementary Fig. S12, DOLPHIN consistently outperformed isoform-based approaches, achieving ARI improvements of 0.27 over SCANPY (P = 4.04 × 10−18) and 0.31 over scVI (P = 4.17 × 10−7). These results demonstrate that DOLPHIN can deliver enhanced clustering resolution even when applied to long-read datasets.
DOLPHIN outperforms conventional gene count tables in detecting cancer-related marker genes
The DOLPHIN framework leverages exon-level quantification in scRNA-seq to capture finer-grained transcriptomic details that conventional gene-level count methods often overlook. This approach enhances cell clustering accuracy and enables more insightful downstream analyses. We applied DOLPHIN to identify exon-level differentially expressed genes (EDEGs) in a pancreatic ductal adenocarcinoma (PDAC) dataset generated using the 10X Genomics Chromium Single Cell 3′ v2 chemistry31 and compared these findings to those obtained with conventional gene count tables, where differential genes are identified as differentially expressed genes (DEGs). Our analysis reveals significant improvements in sensitivity and biological relevance with DOLPHIN.
Using a 10X PDAC dataset with cells from cancer and control conditions31, we first leveraged the latent cell embeddings from DOLPHIN, which integrate exon-level quantification and junction reads, for cell clustering. As shown in Fig. 3a, the clustering results closely aligned with cell-type annotations from the original study, reflecting DOLPHIN’s ability to capture distinct cellular identities. Focusing on cells within Leiden cluster 2, we performed differential gene expression analysis between cancer and control groups. For comparability, we applied the same cluster selection to the conventional gene count table approach to identify DEGs, ensuring that observed differences could be attributed to the method rather than clustering inconsistencies.

a Clustering of the PDAC dataset using DOLPHIN, with clusters labeled by subject condition, Leiden clusters, and cell type. Leiden cluster 2, highlighted, is used as an example for subsequent analyses comparing cancer and control groups. b Enrichment analysis reveals that exon-level differentially expressed genes (EDEGs) identified by DOLPHIN are significantly enriched in pancreatic cancer-related terms with lower adjusted P-values compared to differentially expressed genes (DEGs) identified by conventional gene count-based methods. This indicates deeper biological insights. Term marked as “n.s.” indicate no significant enrichment. The P values comparing DOLPHIN and conventional methods were calculated using a one-sided Wilcoxon test. c A Venn diagram shows that DOLPHIN identifies significantly more EDEGs than DEGs detected by conventional gene-level methods, highlighting its enhanced sensitivity in detecting biologically meaningful changes. d Heatmap of differentially expressed exons uniquely identified by DOLPHIN across cancer and control groups, alongside corresponding gene expression levels. The heatmaps illustrate that DOLPHIN captures subtle transcriptomic changes that remain undetectable at the gene level. P-values for cancer versus control comparisons were calculated using a two-sided Wilcoxon test. e Enrichment analysis of the 896 DOLPHIN-only EDEGs shows significant associations with pancreatic cancer-related terms. In contrast, 483 DEGs identified by conventional gene count-only methods, but not at the exon level, showed no significant enrichment in these terms. Adjusted P values for each enrichment term were calculated using one-sided hypergeometric tests, followed by multiple testing correction using the Benjamini–Hochberg method. f Volcano plot highlighting pancreatic cancer-related EDEGs identified by DOLPHIN, specifically from the disease term highlighted in part e. These EDEGs are not detected as DEGs by conventional gene count methods, demonstrating DOLPHIN's ability to uncover biologically important exon-level differential genes missed by traditional approaches. Non-significant differences are shaded in gray. P values were derived using MAST, which fits a hurdle model accounting for both detection rate and expression level, and were adjusted for multiple testing using the Benjamini–Hochberg method. See the “Methods” section for details. Source data are provided as a Source Data file.
In Fig. 3b, we present the results of disease and pathway enrichment analysis50 on EDEGs identified by DOLPHIN compared to DEGs identified using the gene count table. Here, pancreatic cancer-related terms show strong enrichment and lower adjusted P values when using EDEGs detected by DOLPHIN, underscoring the method’s sensitivity to relevant pathways and diseases; terms labeled “n.s.” (not significant) in the DEG analysis highlight the limited detection capacity of the conventional approach51,52.
A Venn diagram in Fig. 3c illustrates the overlap between EDEGs identified by DOLPHIN and DEGs detected using the conventional gene count table, revealing 896 unique EDEGs exclusively identified by DOLPHIN. These EDEGs correspond to genes that exhibit significant exon-level differential expression, which remain undetected when analyzed solely at the gene level using conventional methods. This highlights DOLPHIN’s enhanced sensitivity in capturing subtle, exon-specific variations that are otherwise masked in gene-level analyses. To further explore the biological significance of these uniquely identified EDEGs, we specifically examined the exons that contributed to their detection. From the 896 EDEGs, we selected exons that displayed differential expression, while their corresponding genes showed no significant differential expression at the gene level. The heatmap in Fig. 3d visualizes this subset, demonstrating that these exons exhibit robust differential expression when analyzed with DOLPHIN, yet are overlooked by the conventional gene count table approach. This underscores DOLPHIN’s ability to uncover exon-level regulatory changes that are critical but often missed by traditional gene-centric analyses.
Further exploration of EDEGs unique to DOLPHIN is shown in Fig. 3e, where disease and pathway enrichment analysis reveals significant enrichment of pancreatic cancer-related terms. To illustrate the specific gene-level differences, a volcano plot in Fig. 3f shows log2 fold changes and adjusted P values for key PDAC-associated genes identified as EDEGs by DOLPHIN but missed as DEGs by the gene count table. The selection of these genes was guided by the top highlighted pancreatic cancer term in Fig. 3e. Several of these genes have well-established roles in PDAC progression and therapy response, including SMAD4, a canonical tumor suppressor gene frequently mutated or lost in PDAC and associated with poor prognosis and treatment resistance53,54,55; ERCC1, a marker implicated in chemotherapy response and DNA repair deficiency in PDAC56,57; TGFBR2, a key component of TGF-beta signaling, which plays a dual role in tumor suppression and progression in pancreatic cancer58,59; and ATM, a DNA damage response kinase frequently mutated in PDAC, where its loss impairs double-strand break repair and confers increased sensitivity to DNA-damaging agents and PARP inhibitors60,61. The identification of these genes through exon- and junction-level resolution suggests that DOLPHIN can recover biologically and clinically meaningful signals that remain undetected by conventional pipelines, with potential implications for both diagnostic biomarker discovery and therapeutic targeting. The distribution of these genes underscores DOLPHIN’s enhanced sensitivity, with many exhibiting exon-level differential expression that does not translate to gene-level differences, making them undetectable by conventional methods.
To assess the clinical relevance of the 896 DOLPHIN-unique EDEGs identified in this PDAC dataset, we conducted a Kaplan-Meier survival analysis using real patient survival data from The Cancer Genome Atlas (TCGA) PDAC cohort62, stratifying patients based on the expression of DOLPHIN-unique EDEGs. Given that pseudo-bulk expression profiles derived from single-cell data may introduce biases into downstream analyses, particularly due to dropout events and limited coverage of lowly expressed genes63, we instead validated the clinical relevance of our findings using matched bulk RNA-seq data to ensure more reliable interpretation of survival associations. This strategy moves beyond pseudo-bulk approximations and leverages orthogonal, external bulk datasets to provide a more robust assessment of the prognostic value of the identified genes. As shown in Supplementary Fig. S13a, we stratified patients into high-risk and low-risk groups based on the expression of the top 100 and all 896 EDEGs, where the genes were ranked by increasing adjusted P from our DOLPHIN-based differential analysis. Across all subsets, the separation between risk groups was statistically significant, with the strongest prognostic signal observed when using the full set of 896 EDEGs (P = 2.22 × 10−39, log-rank-sum test64). To characterize how the prognostic signal accumulates with increasing numbers of EDEGs, we plotted the association P values across ranked gene sets (Supplementary Fig. S13b). The resulting curve demonstrates a consistent and monotonic strengthening of survival association as more top-ranked EDEGs are included. These analyses collectively demonstrate that the EDEGs uniquely identified by DOLPHIN not only capture biologically relevant information missed by gene-level approaches but also exhibit strong clinical relevance when validated against independent datasets. Additionally, we conducted a similar analysis using the junction count table to identify junction-level differentially expressed genes (JDEGs), as shown in Supplementary Fig. S14b–d. This analysis further reinforces DOLPHIN’s capability in capturing transcriptomic variations beyond gene-level limitations, particularly in exon and junction reads usage.
In addition to the results observed in Cluster 2, which contains a balanced number of cells between disease and control groups, we further examined other disease-relevant clusters to assess the robustness and generalizability of DOLPHIN under realistic group size imbalances. Given the biological relevance of ductal cells to PDAC, which originates from the epithelial lining of the pancreatic ducts, we additionally included Ductal Type 1 and Type 2 cell clusters in the EDEG and DEG comparison. Unlike Cluster 2, the ductal clusters exhibit pronounced imbalance in group sizes, reflecting a common feature of real-world single-cell datasets where cell-type abundance may vary across conditions. Specifically, this ductal cluster contains 1067 cells, including 891 from cancer samples and 176 from healthy controls, providing a challenging and biologically meaningful setting to evaluate the robustness of differential analysis. Although downsampling has been proposed as a strategy to address group imbalance65, we did not employ it in this study, as doing so would further reduce the already limited number of cells in biologically relevant populations and diminish statistical power. Results are shown in Supplementary Fig. S15. DOLPHIN identified 445 more significant genes than the conventional gene count-based method, as shown in Supplementary Fig. S15b. Enrichment analysis Supplementary Fig. S15c further demonstrates the biological relevance of these additional genes: the EDEGs identified by DOLPHIN yielded stronger enrichment for pancreatic-related terms compared to DEGs. Notably, the 1491 EDEGs uniquely identified by DOLPHIN were significantly enriched in the pancreatic cancer-related term, whereas the 1046 DEGs identified only by gene count-based analysis did not yield any enrichment for such term (Supplementary Fig. S15d). These results highlight the added biological signal gained through exon-level analysis. We also analyzed JDEGs based on DOLPHIN’s junction reads. As shown in Supplementary Fig. S15f, the 2867 JDEGs were significantly enriched for pancreatic disease-related terms. Furthermore, even when considering only the 1583 JDEGs that did not overlap with DEGs, enrichment analysis still revealed pancreatic cancer-related terms Supplementary Fig. S15g. These findings emphasize the additional biological resolution provided by junction-level modeling and demonstrate that DOLPHIN’s splicing-aware framework captures disease-relevant signals that are often missed by conventional gene expression analyses.
DOLPHIN effectively detects alternative splicing events through junction read aggregation
DOLPHIN integrates exon reads and junction reads to aggregate cells based on exon-junction read patterns, making it well-suited for AS analysis at the single-cell level. To evaluate its performance, we selected Outrigger as a baseline, as it is one of the most widely used tools for AS event detection in transcriptomics65,66,67. This comparison underscores the advantages of DOLPHIN’s junction-read-aware aggregation, a key feature that enhances sensitivity and accuracy in detecting AS events at the single-cell level. Notably, DOLPHIN’s aggregation approach can be adapted to work with other AS tools (see benchmarking sections), showcasing its versatility.
In the full-length PBMC dataset, DOLPHIN shows marked improvements over Outrigger in detecting AS events. The top panel of Fig. 4a illustrates the number of Exon Skipping (ES) and Mutually Exclusive Exon (MXE) events detected per cell using Outrigger with single-cell input versus aggregated cell input generated by DOLPHIN. In this context, “single-cell input” refers to the original, unaggregated scRNA-seq reads, which were supplied directly to Outrigger without any aggregation. This configuration reflects the baseline setting used to evaluate the impact of DOLPHIN’s read aggregation strategy. The results demonstrate a substantial increase in the number of detected events using DOLPHIN, with the median count for ES rising from 183 to 1215, and for MXE increasing from 4 to 22, indicating a marked enhancement in sensitivity. We next assessed whether DOLPHIN effectively enhances single-cell splicing detection by examining AS events jointly detected by both approaches (Fig. 4a). While Fig. 4a summarizes the total number of events per cell, it does not capture how consistently each shared event is detected across cells by the two methods. To address this, we analyzed the cell-level detection patterns of overlapping AS events (Supplementary Fig. S16). On one hand, DOLPHIN robustly preserves the detection of AS events originally identified by the single-cell input. In Supplementary Fig. S16a, we present paired heatmaps for the full-length PBMC dataset, showing the detection patterns for each event across cells. We found that 97.8% of AS events detected by the single-cell input were also detected by DOLPHIN, demonstrating strong consistency. On the other hand, DOLPHIN identifies substantially more AS events beyond those captured by the single-cell input. In Supplementary Fig. S16b, we quantify this relationship by plotting the distribution of Pearson correlation coefficients between the detection patterns of the two methods for each AS event. Across cells, DOLPHIN detected ~4.8 times more events than the single-cell method alone. Together, these results demonstrate that DOLPHIN not only preserves the fidelity of single-cell AS detection but also enhances sensitivity by recovering a more complete landscape of splicing events across cells.

a–c Detection of alternative splicing (AS) events across three datasets: Top: full-length PBMC, Middle: 10X colon, and Bottom: 10X rectum. a DOLPHIN identifies significantly more AS events, including exon skipping (ES) and mutually exclusive exons (MXE), compared to the baseline Outrigger tool, demonstrating superior sensitivity in detecting splicing variations. b Scatter plots of Percent Spliced-In (PSI) values show that DOLPHIN achieves higher correlation with pseudo-bulk data (used as a proxy ground truth), indicating more accurate AS quantification than conventional approaches. c UMAP plots based on PSI values reveal that DOLPHIN captures distinct cell-type-specific splicing patterns with greater clarity and biological relevance, improving resolution of splicing events missed by baseline methods. d Sashimi plots for the AS event HsaEX0051104 in the full-length PBMC dataset show stronger junction read signals after DOLPHIN aggregation, enabling detection of splicing events overlooked by conventional methods. e Similarly, for the AS event HsaEX0013878 in the 10X colon dataset, DOLPHIN enhances junction read signals, uncovering AS events missed by the baseline approaches. P values from one-sided Student’s t-tests: *P < 0.05, **P < 0.01, ***P < 0.001, ****P < 0.0001. Exact P values are provided in the source data. Source data are provided as a Source Data file.
To further demonstrate DOLPHIN’s capability, we compared PSI values between pseudo-bulk and single-cell samples (top panel of Fig. 4b), using pseudo-bulk PSI values as a proxy ground truth, a strategy commonly employed for AS validation65,67,68. Each point represents the PSI value for a specific AS event, with a higher density of points along the diagonal in DOLPHIN indicating stronger concordance with pseudo-bulk data. The Pearson correlation increases by 0.06 (P = 6.37 × 10−242), indicating that the additional AS events detected by DOLPHIN exhibit comparable, if not stronger, correlation with pseudo-bulk results. This improvement reflects DOLPHIN’s enhanced detection capabilities and greater precision in capturing splicing patterns. In the scatter plot, we observed a higher density of AS events along the diagonal, reflecting a broader improvement across the entire PSI spectrum. AS in most cell populations predominantly yields near-complete exon inclusion or exclusion, with intermediate splicing states being relatively rare and technically challenging to detect22,65. Building on this observation, we analyzed the distribution of detected AS events across different PSI ranges and assessed the corresponding junction read support to characterize DOLPHIN’s aggregation-enhanced detectability. As shown in Supplementary Fig. S17a (upper panel), DOLPHIN-enhanced input increased the total number of detected exon-skipping events across all three PSI categories (PSI = 0, 0 < PSI < 1, and PSI = 1) in the full-length PBMC dataset. The most pronounced gain was observed for PSI = 1, with 431,406 additional events detected, although noticeable improvements were also seen in the other PSI ranges. We further examined the junction read support across the full PSI spectrum (Supplementary Fig. S17b, upper panel). In the single-cell input, events with intermediate PSI values (e.g., between 0.4 and 0.6) exhibited substantially lower read counts, with a mean of 66 reads. After DOLPHIN enhancement, the mean read count increased to 168, a statistically significant difference (one-sided Mann–Whitney U test, P < 10−300). These results demonstrate that DOLPHIN improves the detection of AS events across the PSI spectrum, including low-coverage events with intermediate splicing levels.
To evaluate whether the PSI values reflected biologically meaningful splicing regulation, we assessed their ability to capture cell-type-specific splicing patterns. Specifically, we used PSI values as input features for cell representation and clustering analyses. The UMAP plots in the top panel of Fig. 4c show that DOLPHIN-inferred PSIs yield sharper boundaries between cell types compared to single-cell PSI values alone. This improvement is quantitatively supported by a 0.38 increase in ARI (P = 2.70 × 10−121). These results indicate that DOLPHIN more effectively captures splicing signals that distinguish cell types, suggesting higher biological relevance and improved splicing quantification accuracy.
Beyond full-length single-cell data, we extended our evaluation to the common tag-based 10X Genomics scRNA-seq data from human colon samples to demonstrate its general applicability, where DOLPHIN showed robust performance even with limited transcriptome coverage. The middle panel of Fig. 4a shows that the distribution of detected events by DOLPHIN is shifted towards higher counts compared to single-cell data alone (without aggregation), with the median number of detected ES increasing from 58 to 224, and the maximum number of MXE detected per cell rising from 2 to 8. This underscores DOLPHIN’s sensitivity to data with partial coverage. The concordance heatmap shown in the middle part of Supplementary Fig. S16a further illustrates that DOLPHIN consistently preserves the original single-cell detection signals while detecting additional AS events across cells. The scatter plot between pseudo-bulk and single-cell PSI values (middle panel of Fig. 4b) demonstrates an improvement in Pearson correlation by 0.02 (P = 1.19 × 10−208) with DOLPHIN, further validating its accuracy. In addition to the correlation improvement, we observed a higher density of AS events along the diagonal in the scatter plot, reflecting DOLPHIN’s broader enhancement across the entire PSI spectrum. Specifically, in the lower panel of Supplementary Fig. S17b, AS events with PSI = 1 showed the greatest increase, with an additional 480,987 events detected compared to the original single-cell input. The mean junction read count supporting AS events with intermediate PSI values (i.e., between 0.4 and 0.6) increased from 65 to 116 (P = 9.16 × 10−3). These results confirm that DOLPHIN enhances the detection of low-coverage AS events with intermediate PSI values even in the sparse 10X dataset. The UMAP plots (middle panel of Fig. 4c) demonstrate that DOLPHIN achieves clear separation of specific cell types, such as TA and enterocyte cells, with an increase in the ARI score by 0.06 (P = 3.70 × 10−31) compared to single-cell data, highlighting its broad applicability across various datasets. We observed similar improvements with the tag-based 10X rectum data (the bottom panels of Fig. 4a–c and Supplementary Fig. S16a, b). Specifically, the bottom panel of Fig. 4a reveals an increase in the number of detected ES, with median values rising from 62 to 200, and for MXE events, from 1 to 2. Additionally, the bottom panel of Fig. 4b shows an improved correlation with pseudo-bulk PSI values, increasing by 0.01 (P = 1.22 × 10−187). Notably, the bottom panel of Fig. 4c shows that the UMAP plot achieves clearer separation of Enterocyte cells using DOLPHIN, further validating its robustness.
To illustrate the detailed insights DOLPHIN provides, we present examples of exon and junction read coverage for specific AS events. Fig. 4d showcases the full-length PBMC splicing event HsaEX0051104 in the naïve T cell sample “SRR18385965,” comparing single-cell data with DOLPHIN-aggregated data. HsaEX0051104, an exon-skipping event in the PTPRC gene that generates the CD45RA isoform, critical for T cell function69,70. HsaEX0051104 encompasses three exons (exon 4, exon 5, and exon 6), with junction read counts of 13 between exons 4 and 5, 31 between exons 5 and 6, and 16 between exons 4 and 6. However, in single-cell data, this splicing event is not detectable due to the absence of junction reads spanning exons 4 and 6, which are critical for validating the exon-skipping event. We applied an in silico pseudo-bulk validation strategy using CD4 T cells to independently confirm the biological existence of the AS event identified by DOLPHIN. Specifically, we generated 20 pseudo-bulk BAM files by randomly sampling 80% of CD4 T cells per replicate, simulating replicate-level coverage. VALERIE71 was then applied to profile AS events based on junction read and coverage signals across these samples. As shown in Supplementary Fig. S18a, VALERIE consistently detected the same exon-skipping event in PTPRC (HsaEX0051104) identified by DOLPHIN, with stable PSI distributions across replicates. We further confirmed this event by applying VALERIE to DOLPHIN’s single-cell BAM files for CD4 T cells (Supplementary Fig. S18b), providing orthogonal evidence of its reproducibility and biological relevance. To further support this AS event, we visualized the pseudo-bulk read coverage using ggsashimi72. As shown in Supplementary Fig. S18c, the sashimi plot based on full-length PBMC pseudo-bulk alignments clearly demonstrates the exon-skipping pattern corresponding to HsaEX0051104. In addition, DOLPHIN uncovers another splicing event (HsaEX0051102) involving exons 1, 3, and 4. This event is supported by 25 junction reads between exons 1 and 3, 11 reads between exons 3 and 4, and 22 reads connecting exons 1 and 4. Conversely, in this specific single cell, this event is not detected due to the lack of junction reads bridging exons 1 and 4, which are crucial for identifying this splicing pattern. In Fig. 4e, we investigated the splicing event HsaEX0013878 within the CD47 gene in progenitor cell “AAGCCGCCACTACAGT-1” from the 10X colon dataset. CD47 has been implicated in colorectal cancer progression73,74. This event involves exons 1, 2, and 3, with 52 junction reads supporting the connection between exons 1 and 2, 30 reads between exons 2 and 3, and 70 reads between exons 1 and 3. However, this specific cell lacks the crucial junction reads linking exons 1 and 3, thereby precluding the detection of this event in this cell. The presence of this splicing event was further supported by pseudo-bulk alignments of progenitor cells (Supplementary Fig. S18d). These examples underscore DOLPHIN’s capacity to uncover complex AS patterns and demonstrate its effectiveness in enhancing single-cell AS analyses through junction-read-informed cell aggregation, revealing biologically significant insights otherwise missed by standard methods.
DOLPHIN reveals biologically relevant alternative splicing events unique to specific cell types
We assessed DOLPHIN’s capability to detect cell-type-specific AS events by calculating PSI values for each event per cell type, enabling differential AS analysis. Genes associated with significantly differentially spliced events were identified as differentially spliced genes. Fig. 5a, b and Supplementary Fig. S19 highlight the biological relevance of these cell-type-specific events identified by DOLPHIN, underscoring its ability to detect distinct splicing patterns not captured by the raw single-cell data without DOLPHIN aggregation enhancement. Specifically, Fig. 5a displays dot plots of the top differentially spliced events across cell types in the full-length PBMC and tag-based 10X colon datasets, respectively. The labels in the plot correspond to differentially spliced genes and event identifiers, which provide detailed information for each splicing event provided in Supplementary Table S1 and Supplementary Table S2. In contrast, Supplementary Fig. S19 and Supplementary Table S3 display the top differentially spliced events identified using raw single-cell data without aggregation. Without DOLPHIN’s aggregation, the analysis based on raw data alone fails to capture the distinct splicing patterns, as evidenced by the reduced separation of PSI values across cell types. Dot colors in the plots represent the average PSI values of an event for cells from each specific cell type, further highlighting DOLPHIN’s capability to detect differential splicing events that were previously missed. For example, in the full-length PBMC dataset, unique splicing events specific to B cells were challenging to distinguish from dendritic cells (DCs) and Other cells using the raw single-cell data, but are now clearly identifiable after DOLPHIN aggregation. Similarly, in the 10X colon dataset, top differentially spliced events appear more prominently in paneth-like cells compared to the single-cell method, illustrating DOLPHIN’s enhanced sensitivity to cell-type-specific splicing.

a Dot plots showing the PSI values of the top differentially spliced events identified by DOLPHIN. b GO biological process (GOBP) enrichment analysis of biologically significant differentially spliced genes identified by DOLPHIN, with alternative splicing-related terms highlighted in red. Adjusted P-values for each enrichment term were calculated using one-sided hypergeometric tests, followed by multiple testing correction using the Benjamini–Hochberg method. c Schematic illustration explaining PSI distribution splicing modality categorization. d PSI distribution for a single alternative splicing event, categorized by splicing modality across cell types, demonstrating that DOLPHIN provides clearer distinctions of splicing differences that align with cell type identities. e Splicing modality composition across single cells shows that DOLPHIN captures more distinct and biologically relevant splicing patterns by reducing the proportion of multimodal (null) categories, which represent PSI distributions without clear features. This demonstrates that DOLPHIN reduces ambiguity in alternative splicing event detection, enabling more precise analysis. f UMAP plots of cell clusters using PSI modality one-hot encoding demonstrate that the PSI splicing modalities identified by DOLPHIN retain strong cell-type-specific signals. DOLPHIN enhances the resolution of these cell-type-specific splicing patterns, providing clearer separation and biologically meaningful clustering compared to single-cell data alone. These biologically relevant alternative splicing events can contribute to more accurate cell type classification and offer insights into cellular diversity and potential disease mechanisms. P values from one-sided Student’s t-tests: *P < 0.05, **P < 0.01, ***P < 0.001, ****P < 0.0001; n.s. not significant. Exact P values are provided in the source data. Source data are provided as a Source Data file.
Supplementary Fig. S20a highlights the top differentially spliced genes that could not be identified using traditional gene count-based differential expression methods, alongside their expression values in the PBMC and colon datasets. Unlike conventional approaches that primarily focus on gene expression differences, DOLPHIN leverages PSI-based differences to uncover differentially spliced genes that remain undetectable with single-cell gene count data alone. This capability is particularly evident in the 10X colon dataset, where unique splicing patterns are revealed across cell types, even in the absence of significant gene expression changes, underscoring DOLPHIN’s distinct advantage in detecting splicing-driven heterogeneity. To confirm the biological significance of these findings, we performed gene ontology biological process (GOBP) enrichment analysis using differentially spliced genes. In the upper panel of Fig. 5b, GOBP terms enriched in B cells from the PBMC dataset include B cell activation and B cell receptor signaling, reinforcing the biological relevance of these identified splicing events75. Additionally, GOBP terms associated with AS confirm DOLPHIN’s accuracy in detecting spliced genes involved in splicing regulation. In the 10X colon dataset, GOBP enrichment analysis (lower panel of Fig. 5b) revealed terms critical to enterocyte function, such as metabolic processes, aerobic respiration, and mitochondrial electron transport—biological processes that are essential for maintaining gut health76,77. The identification of AS-related GOBP terms reflects the adaptive role of enterocytes in modulating gene expression in response to environmental and cellular stressors78,79. GOBP enrichment analysis for other cell types is presented in Supplementary Fig. S21, further underscoring the functional relevance of splicing events detected by DOLPHIN. Supplementary Fig. S20b illustrates the distinction between differentially spliced genes identified by DOLPHIN and DEGs detected using conventional gene count methods. Supplementary Fig. S20c presents the GOBP enrichment analysis for differentially spliced genes uniquely detected by DOLPHIN, after excluding those already identified as DEGs by conventional gene count-based approaches. The GOBP enrichment analysis of these remaining genes reveals critical biological processes encoded within PSI values that cannot be detected using gene count data alone, highlighting DOLPHIN’s unique ability to uncover splicing-specific regulatory mechanisms. To provide a more granular view of splicing distributions, we applied the Anchor tool from Expedition22, categorizing PSI distributions into five splicing modalities: excluded, bimodal, included, middle, and multimodal (null) (Fig. 5c). This categorization reveals variations in PSI distributions across cell types, facilitating detection of cell type-specific splicing patterns. In scRNA-seq data, splicing events often exhibit varying degrees of PSI consistency within the same cell type22,65. Some events show concentrated PSI distributions corresponding to clear splicing modes, such as inclusion or exclusion, whereas others display dispersed or heterogeneous PSI patterns, classified as multimodal or null modalities. Multimodal splicing patterns can arise from genuine biological heterogeneity, including the co-expression of multiple isoforms and dynamic splicing regulation across cell types22,80. However, in sparse single-cell datasets, multimodal and null modalities can also result from technical factors such as incomplete read coverage, dropout, and measurement noise, making the interpretation of such events more challenging. Null modalities, in particular, indicate splicing signals lacking sufficient consistency across cells, thereby complicating the identification of robust, biologically meaningful splicing patterns. DOLPHIN improves signal clarity by enhancing read coverage and exon-level resolution, which increases the proportion of splicing events that can be classified into more interpretable modalities.
In the upper panel of Fig. 5d, we examine the splicing event HsaEX0051104 in the PBMC dataset, comparing PSI distributions from single-cell data with DOLPHIN results. DOLPHIN identifies four distinct splicing modes across eight cell types, whereas single-cell data alone captures only three modes. Notably, DOLPHIN enhances the detection of splicing variations in CD8 T cells, shifting the distribution from a null mode to a middle mode, thereby providing a clearer and more accurate representation of these events. We performed in silico validation of this splicing event using a bootstrapped pseudo-bulk strategy. Specifically, we randomly sampled 80% of CD8 T cells multiple times to construct pseudo-bulk profiles and applied VALERIE to visualize splicing signals at the event locus. As shown in Supplementary Fig. S22a, the consistent detection of junction usage and read coverage patterns across replicates confirms the presence of this ES event. In addition, we assigned splicing modality based on the PSI values derived from these pseudo-bulk replicates. The resulting modality, shown in Supplementary Fig. S22b, consistently falls within the middle modality, validating the splicing distribution identified by DOLPHIN in CD8 T cells.
In the lower panel of Fig. 5d, the 10X colon dataset displays the PSI distribution for the splicing event HsaEX0013878 within the CD47 gene across different cell types. The CD47 gene, known for its involvement in tumor progression and immune evasion, is typically upregulated in colorectal cancer tissues81. Due to its relevance in colorectal cancer, it is anticipated that multiple transcripts of CD47 would be detected in the colon dataset. Of the six annotated transcripts, three contain the splicing event HsaEX0013878: transcripts ENST00000398258 and ENST00000361309 include all three exons, while ENST00000517766 exhibits ES. To better contextualize the PSI distributions of this event, we incorporated pseudo-bulk transcript quantification using kallisto82 to estimate the exon inclusion probability across cell types for exon chr3:108049619-108049651 (HsaEX0013878). These estimates, shown as red dashed lines in the Supplementary Fig. S23a, serve as in silico reference values for comparing single-cell and DOLPHIN-aggregated results. Notably, we applied bootstrapping to quantify the absolute differences between method-specific median PSI values and pseudo-bulk estimates across cell types shown in Supplementary Fig. S23b. The DOLPHIN-aggregated PSI values showed smaller deviations from the pseudo-bulk references (P < 10−300) compared to single-cell PSI values, suggesting that DOLPHIN provides a more accurate quantification of this exon inclusion event. This improved accuracy is particularly important because traditional single-cell approaches often produce a bimodal PSI distribution due to limited junction read coverage, complicating the assessment of splicing patterns. In contrast, DOLPHIN achieves a more stable PSI distribution with reduced variability, thereby enhancing the resolution of splicing dynamics linked to CD47’s functional role in cancer.
Figure 5e presents pie charts showing the splicing modality distributions for all detected splicing events across cell types. By substantially reducing the proportion of events classified as “null” mode, DOLPHIN enhances the clarity and robustness of splicing signals, allowing for more accurate detection of AS events per cell type. This reduction in the null mode reflects the tool’s superior sensitivity and capacity to capture richer splicing distribution information.
To validate the cell type-specific relevance of splicing modality assignments and thus the quality of AS event detection, we transformed the splicing modality data into a one-hot encoded vector for each cell, reduced the dimensionality using principal component analysis (PCA), and subsequently visualized the results using UMAP, as shown in Fig. 5f. In the PBMC dataset, DOLPHIN achieves clearer separation of cell type clusters, with the ARI increasing from 0.31 to 0.57 (P = 6.62 × 10−121), indicating enhanced retention of cell-specific splicing information. For the 10X colon dataset, DOLPHIN produces improved segregation of different cell types, leading to a 0.08 (P = 2.21 × 10−111) increase in ARI, further validating its consistency in identifying cell-type-specific splicing modalities.
Benchmarking analysis demonstrates enhanced cell representation learning with DOLPHIN
In this study, we demonstrate that DOLPHIN, which integrates both exon-level and junction reads, significantly outperforms methods that rely solely on gene count tables. To evaluate DOLPHIN’s performance in cell representation learning, we benchmarked it against several state-of-the-art gene-level methods, including SCANPY, the deep generative model scVI, scGMAAE83, and scDeepCluster84. To broaden the methodological scope of our benchmarking and ensure a more rigorous comparison, we additionally incorporated scQuint and SCASL, two recently developed splicing-aware clustering tools for scRNA-seq data. scQuint employs a VAE to derive cell embeddings from intron usage profiles constructed using junction reads. Although it shares the same VAE-based architecture as DOLPHIN, scQuint relies exclusively on intron-level input and does not leverage exon read counts. As such, it serves as a conceptually aligned baseline for evaluating how AS feature representations influence the quality of learned cell embeddings. SCASL, on the other hand, performs clustering based on junction-derived AS probabilities, which are iteratively imputed using a KNN-based strategy and clustered using spectral clustering. Given its objective of cell-type inference from splicing features, SCASL also provides a relevant point of comparison for DOLPHIN’s exon graph-based framework. Since scQuint is not recommended for use with 10X Genomics Chromium data due to its strong \(3{\prime}\) bias and limited junction detection, and SCASL performs suboptimally on droplet-based \(3{\prime}\) RNA-seq with low sequencing depth, we employed the full-length RNA-seq dataset for benchmarking to ensure a fair and meaningful comparison for these two splicing-aware clustering methods. We assessed cell representation quality via cell clustering performance using five metrics: ARI, NMI, Completeness Score (CS)85, Adjusted Mutual Information (AMI)86, and Fowlkes–Mallows Index (FMI)85, which together provide a holistic view of clustering effectiveness based on learned cell embeddings.
To showcase the general applicability, benchmarking was conducted on three distinct datasets across different platforms, tissues, and biological conditions: full-length PBMC (Fig. 6a), tag-based 10X colon tissues (Fig. 6b), and tag-based 10X rectum tissues (Fig. 6c). DOLPHIN consistently achieved top performance on all datasets and across multiple evaluation metrics. In the full-length PBMC dataset, it achieved the highest median scores for ARI, NMI, CS, AMI, and FMI, with statistically significant improvements over other methods based on one-sided Student’s t-tests. Specifically, DOLPHIN’s ARI median score of 0.64 represented a 27.86% improvement over SCANPY (P = 3.45 × 10−75) and a 26.34% improvement over scVI (P = 2.86 × 10−49). Its NMI score further exceeded those of SCANPY and scVI by 0.03 (P = 1.73 × 10−29) and 0.04 (P = 9.58 × 10−21), respectively. Consistent patterns were observed in the tag-based 10X colon and rectum datasets, where DOLPHIN achieved the highest median scores across all clustering metrics, surpassing all other gene count-based clustering approaches. In the 10X colon dataset, DOLPHIN achieved an ARI of 0.38. Among all comparisons, the smallest relative improvement was observed over scDeepCluster (6.46%, P = 1.08 × 10−4), while the largest was over SCANPY, with a 39.34% gain (P = 2.30 × 10−56). In the 10X rectum dataset, DOLPHIN similarly outperformed all methods, with ARI improvements of 15.76% over SCANPY (P = 1.46 × 10−25) and 53.75% over scDeepCluster (P = 4.23 × 10−88). In addition to outperforming gene count-based methods, DOLPHIN also demonstrated superior performance compared to splicing feature-based clustering approaches. DOLPHIN consistently outperformed both SCASL and scQuint across all metrics. scQuint showed limited clustering performance in the full-length PBMC dataset, with a median ARI of only 0.15, which is substantially lower than DOLPHIN (P = 9.16 × 10−186) and all other methods. SCASL achieved moderate clustering performance, with a median ARI of 0.44, which is significantly lower than that of the DOLPHIN method (P = 4.61 × 10−117). These findings confirm DOLPHIN’s capability to generate higher-quality cell embeddings and capture distinct cell populations with superior sensitivity and precision, even across diverse datasets. This robust performance across metrics underscores the advantage of integrating exon- and junction-level data in enhancing cell representation learning in scRNA-seq analysis.

This benchmarking analysis highlights the superior cell embeddings generated by DOLPHIN, achieved through the integration of exon-level quantification and junction reads. Better cell clustering accuracy demonstrates the improved quality of these embeddings, evaluated using Adjusted Rand Index (ARI), Normalized Mutual Information (NMI), Completeness Score (CS), Adjusted Mutual Information (AMI), and Fowlkes–Mallows Index (FMI) across full-length PBMC (a), 10X colon (b), and 10X rectum datasets (c). Each score is based on N = 100 bootstrapping replicates using different random seeds (technical replicates). Boxes indicate the interquartile range (IQR, 25th to 75th percentile), with the line inside each box representing the median. Whiskers extend to the most extreme data points within 1.5 times the IQR from the quartiles. P values from one-sided Student’s t-tests: *P < 0.05, **P < 0.01, ***P < 0.001, ****P < 0.0001; n.s. not significant. Exact P values are provided in the source data. Source data are provided as a Source Data file.
DOLPHIN improves sensitivity and precision in alternative splicing detection
To evaluate the effectiveness of the DOLPHIN aggregation enhancement in detecting AS events, we conducted an extensive benchmarking analysis. We used conventional single-cell analysis tools, including SCANPY and scVI, to identify cell neighborhoods via low-dimensional embeddings at the gene level, and then applied an aggregation enhancement approach similar to DOLPHIN by randomly combining reads from neighboring cells. Single-cell data without any aggregation served as an additional baseline comparison to assess the impact of aggregation enhancement of different methods for detecting AS events. Aggregated cells were analyzed for AS events using six specialized tools, Expedition, MARVEL65, BRIE2, scASfind87, scQuint, and SCASL, focusing specifically on ES and MXE. ES is the most prevalent form of AS in mammalian cells, while together, ES and MXE account for over 50% of all AS events88,89,90. Among these, tools such as scASfind, scQuint, and SCASL are, according to their original publications, not recommended for use with 10X Genomics datasets characterized by low sequencing depth. These methods were primarily designed or validated for full-length scRNA-seq datasets, which offer more extensive transcript coverage and greater sensitivity for splice junction detection. Given the strong \(3^{\prime}\) coverage bias and limited junction representation characteristic of 10X Genomics data, applying these tools outside their intended context may introduce confounding factors and compromise the interpretability of the results. To ensure a fair and context-appropriate comparison, we conducted benchmarking across all tools primarily on full-length RNA-seq datasets. However, to showcase the general applicability of our method, we applied DOLPHIN to 10X Genomics data and conducted a comparative analysis with AS tools compatible with the 10X dataset, including Outrigger, MARVEL, and BRIE2. This benchmarking evaluated several key metrics: the number of detected AS events, correlation with pseudo-bulk profiles, cell embedding and clustering quality based on PSI values, the number of differentially spliced genes, and clustering accuracy based on splicing modality. Since real datasets lack definitive ground truth for AS events, we also generated simulated datasets specifically for ES events, providing a controlled evaluation dataset with ground truth.
One critical metric for evaluating the effectiveness and sensitivity of AS event detection is the total number of events identified by different methods. In the full-length PBMC dataset, as illustrated in Fig. 7a, DOLPHIN achieved a marked improvement in detecting ES events. When using Outrigger as the AS detection tool, DOLPHIN aggregation identified a total of 975,215 ES events across 795 cells, averaging 1227 ES events per cell. In contrast, the single-cell method without aggregation detected only 204,344 events in total, representing ~20% of the AS events identified by DOLPHIN. Aggregation via SCANPY and scVI produced similar results to the single-cell method without aggregation, identifying 293,926 and 294,658 ES events, respectively. When utilizing MARVEL as the AS detection tool, DOLPHIN further amplified its detection capabilities, identifying 1,709,186 ES events, significantly surpassing SCANPY’s 828,984 and scVI’s 827,115 events. These results highlight DOLPHIN’s enhanced sensitivity in detecting ES events. Even for MXE events, which are less frequent, DOLPHIN showed a marked improvement. Under the Outrigger tool, DOLPHIN identified 17,906 MXE events, while SCANPY and scVI detected only 4537 and 4612 events, respectively, with the single-cell method detecting the fewest at 3626 events. Using MARVEL as the AS detection method, DOLPHIN aggregation detected 18,104 MXE events, greatly surpassing SCANPY (8880) and scVI (8960). While the magnitude of improvement varied across tools, DOLPHIN-based aggregation consistently led to an increased number of detected AS events compared to using single-cell input alone for each respective tool. Notably, SCASL exhibited the smallest gain, yet still detected 1834 additional events when using DOLPHIN-enhanced inputs. It is important to note that each method quantifies distinct types of splicing events: BRIE2, MARVEL, and Outrigger focus on exon inclusion/exclusion; SCASL estimates junction-level PSI values; scQuint quantifies intron usage; and scASfind derives node-level information from splicing graphs. Therefore, comparisons were made within each tool to assess the impact of DOLPHIN inputs, rather than across tools. In the tag-based 10X colon dataset, DOLPHIN continued to demonstrate its advantage in ES event detection as shown in Supplementary Fig. S24a. Using Outrigger as the AS detection tool, DOLPHIN aggregation detected 950,816 ES events, which is ~3.8 times more than the 248,027 events detected by the single-cell method alone. Utilizing MARVEL as the AS detection tool, DOLPHIN extended its lead, detecting 1,596,731 ES events compared to SCANPY’s 1,205,204 and scVI’s 1,204,753. This represents more than a 2.3-fold increase over the single-cell method, which identified 690,410 events. Similar improvements were observed with BRIE2, where the number of detected events rose from 103,013 (single cell) to 299,625 with DOLPHIN input, again achieving the highest detection rate among all aggregation strategies.

The performance of DOLPHIN in detecting alternative splicing (AS) events was evaluated using real and simulated datasets. a–e Results from single-cell RNA-seq datasets, comparing DOLPHIN to SCANPY, scVI, Outrigger, MARVEL, BRIE2, SCASL, scASfind, and scQuint. DOLPHIN consistently outperformed these methods by leveraging exon-level information. a DOLPHIN identifies more AS events, including exon skipping (ES) and mutually exclusive exons (MXE), than all other methods. b Higher Pearson correlations between single-cell and pseudo-bulk datasets indicate DOLPHIN's improved splicing quantification, based on N = 80 bootstrapping replicates (10 per cell type across 8 cell types, using different random seeds; technical replicates). c Higher Adjusted Rand Index (ARI) scores for cell clustering based on Percent Spliced-In (PSI) values reflect DOLPHIN's ability to capture biologically meaningful splicing patterns, based on N = 100 bootstrapping replicates using different random seeds (technical replicates). d DOLPHIN detects more differentially spliced events per cell type based on Outrigger analysis, demonstrating its sensitivity to cell-type-specific splicing variations. e Higher ARI and NMI scores for splicing modality profiles, derived from Anchor analysis, further confirm DOLPHIN's ability to resolve splicing-driven cellular heterogeneity, based on N = 100 bootstrapping replicates using different random seeds (technical replicates). Boxes indicate the interquartile range (IQR, 25th to 75th percentile), with the line inside each box representing the median. Whiskers extend to the most extreme data points within 1.5 times the IQR from the quartiles. P values from one-sided Student’s t-tests: *P < 0.05, **P < 0.01, ***P < 0.001, ****P < 0.0001; n.s. not significant. Exact P values are provided in the source data. f, g DOLPHIN using simulated datasets with known ground truth. f Receiver Operating Characteristic (ROC) curves show higher area under the curve (AUC) values for DOLPHIN, confirming its superior accuracy. g Precision-Recall (PR) curves demonstrate DOLPHIN's higher area under the precision-recall curve (AUPRC), indicating better precision and recall for splicing event detection. Source data are provided as a Source Data file.
We next assessed the Pearson correlation91 between the cell and its corresponding cell-type-level pseudo-bulk profile. In the full-length PBMC dataset, as shown in Fig. 7b, the pseudo-bulk profiles were generated using the same splicing-aware tool as the corresponding single-cell analysis, serving as a within-method proxy ground truth for evaluating PSI consistency. For all splicing-aware tools, DOLPHIN-based aggregation consistently yielded the highest median PSI correlation within each tool, with statistically significant improvements over both single-cell inputs and alternative aggregation strategies, including SCANPY and scVI. Among the AS detection tools, Outrigger demonstrated the largest gain in correlation between single-cell and pseudo-bulk PSI estimates. The median Pearson correlation increased significantly from 0.22 with single-cell input to 0.96 when using DOLPHIN-based aggregation, P = 4.04 × 10−179. DOLPHIN-aggregated input also outperformed aggregation using SCANPY and scVI, with improvements in median Pearson correlation of 0.65 and 0.66, respectively, both statistically significant (P = 6.20 × 10−164 for SCANPY; P = 3.05 × 10−163 for scVI). In contrast, SCASL showed the smallest improvement among all tested methods, with the median correlation increasing only marginally from 0.90 to 0.91 under the DOLPHIN setting, and the improvement remained statistically significant, P = 1.65 × 10−9. Notably, for SCASL, both SCANPY- and scVI-based aggregations resulted in lower correlation than the original single-cell input, highlighting the robustness of DOLPHIN’s aggregation approach in preserving splicing signal fidelity. In essence, DOLPHIN detects, on average, over 2.36 times more AS events than all other methods, while maintaining superior correlation with proxy ground-truth AS events derived from pseudo-bulk data. This underscores the quality of the additional AS events uniquely identified by DOLPHIN, which are missed by other methods. In the 10X colon dataset shown in Supplementary Fig. S24b, DOLPHIN achieved the highest correlation between single-cell and pseudo-bulk PSI estimates compared to other methods. Among them, the largest improvement was observed for Outrigger, where the median correlation increased by 0.67 when using DOLPHIN-aggregated input compared to single-cell input (P = 5.53 × 10−166). Compared to DOLPHIN, the median correlation values obtained using SCANPY and scVI were substantially lower, with differences of 0.52 (P = 6.04 × 10−117) and 0.51 (P = 1.24 × 10−111), respectively.
To assess the consistency of AS patterns within the same cell type, we used PSI values for clustering and calculated the ARI against known cell type labels. A higher ARI indicates that PSI-based clustering better aligns with true cell type distinctions, suggesting that consistent PSI values within a cell type result in clearer clustering. As shown in Fig. 7c, DOLPHIN-based aggregation consistently yielded the highest ARI scores across all evaluated tools in the full-length PBMC dataset. Notably, BRIE2 exhibited the most substantial improvement, with the median ARI increasing from 0.03 (single-cell input) to 0.40 under DOLPHIN aggregation (P = 2.16 × 10−119). These findings illustrate that, in the absence of effective aggregation, PSI-based clustering may fail to reveal biologically meaningful structure. In the 10X colon dataset shown in Supplementary Fig. S24c, BRIE2 showed a relatively smaller improvement with DOLPHIN input, but its performance remained significantly higher than that of SCANPY (P = 9.32 × 10−7) and scVI-based aggregation methods (P = 2.24 × 10−2). The improved performance achieved with DOLPHIN highlights the ability of our aggregation strategy to enhance the resolution of cell-type-specific splicing patterns.
We further benchmarked cell-type-level differential AS analysis using PSI quantification results from Outrigger. As shown in Fig. 7d, the number of differentially spliced events detected per cell type is reported. The number of differential AS events varied from hundreds92 to thousands65, depending on the dataset, with DOLPHIN exhibiting superior detection across cell types. In the full-length PBMC dataset, DOLPHIN detected up to 23.3 times more differential events in monocytes compared to the single-cell non-aggregation method. Notably, in DC cells, the aggregation approach of SCANPY detected even fewer differential AS events than the single-cell non-aggregation method, indicating that random or inappropriate aggregation not only fails to highlight cell-type-specific AS events but can even diminish existing signals. In the 10X colon dataset, DOLPHIN maintained strong performance across most cell types, highlighting its ability to capture cell-type-specific splicing differences more effectively than other approaches.
We then compared the splicing modality patterns at the cell type level using the Anchor function of Expedition to categorize each AS event. The results, shown in Supplementary Fig. S25, demonstrate that DOLPHIN achieved a lower percentage of multimodal events, indicating stronger PSI signals for alternative events. Multimodal events are characterized by PSI distributions lacking clear, cell-type-specific patterns and instead displaying a broad, undifferentiated range across PSI values, which points to an absence of structured inclusion or exclusion indicative of specific cell states. In the Full-length PBMC dataset, DOLPHIN reduced the overall percentage of multimodal events across all cell types, with the most pronounced decrease observed in monocytes, where the multimodal percentage dropped by 18%. A similar pattern was observed in the 10X colon dataset. This reduction in multimodal events implies that DOLPHIN enhances the detection of cell-type-specific AS patterns, providing a more robust modality signal. These modality patterns were further validated by converting the modality composition to one-hot encoding for cell clustering (Fig. 7e). Higher ARI and NMI values for DOLPHIN indicate that the identified modalities align more closely with cell-type-level patterns, supporting the effectiveness of DOLPHIN in distinguishing biologically relevant AS events.
To further validate and benchmark DOLPHIN’s performance in detecting AS events, we developed a series of simulated datasets with known ground truth specifically designed to assess ES, the most prevalent AS event in single-cell data93,94. We generated 200 scRNA-seq datasets, each containing a total of 4, 103 simulated ES events, which served as ground truth for evaluating AS detection accuracy. Using these simulated datasets, we compared twenty method combinations by pairing five single-cell AS analysis tools (Outrigger, MARVEL, BRIE2, SCASL, and scASfind) with four aggregation strategies (no aggregation, DOLPHIN, SCANPY, and scVI). Performance was evaluated by constructing receiver operating characteristic (ROC) curves95 and precision-recall (PR) curves96 for each method, as shown in Fig. 7f, g, and Supplementary Fig. S26. In these figures, methods labeled solely by the names of AS tools indicate that the original single-cell datasets were directly analyzed without any aggregation strategy. Fig. 7f, g demonstrates that DOLPHIN-based aggregation consistently enhanced the performance of all AS detection tools, as measured by improvements in the area under the receiver operating characteristic curve (AUC) and the area under the precision-recall curve (AUPRC). Among the evaluated combinations, SCASL with DOLPHIN and MARVEL with DOLPHIN achieved the highest AUC values of 0.79, while MARVEL with DOLPHIN attained the highest AUPRC of 0.82. In addition, Supplementary Fig. S26 presents results from SCANPY- and scVI-based aggregations. Across all tested conditions, DOLPHIN consistently outperformed not only direct single-cell analyses without aggregation but also alternative aggregation strategies, achieving superior sensitivity and precision in splicing event detection under controlled conditions.
Discussion
In this study, we present DOLPHIN, a deep learning framework designed to enhance scRNA-seq analysis at exon-level resolution. DOLPHIN combines exon reads and junction reads into graph-structured representations of genes, which are processed with a VGAE and graph attention (GAT) layers to generate informative cell embeddings. These embeddings enable DOLPHIN to support a range of downstream analyses, including cell clustering, differential exon analysis, and AS detection, surpassing conventional gene count methods in both depth and accuracy. Compared to existing graph-based approaches for splicing detection, such as DiffSplice97 and Outrigger, DOLPHIN introduces several important differences that enhance its performance in single-cell contexts. DiffSplice constructs an expression-weighted splice graph from bulk RNA-seq data and identifies alternative splicing modules, but it does not model cell-level splicing variability and is not designed for single-cell resolution analyses. Outrigger, as part of the Expedition framework, builds a genome-wide splice graph based on pseudo-bulk junction reads aggregated across cells and subsequently quantifies PSI values at the single-cell level. However, it neither constructs per-cell graphs to retain cell-specific resolution nor makes use of exon-level reads in its graph construction. In contrast, DOLPHIN generates a gene-specific exon graph independently for each cell using both exon- and junction-reads. These per-cell graphs are integrated through VGAEs and attention-based learning to produce cell embeddings that encode cell-specific splicing patterns. By aggregating information based on these embeddings, which reflect both exon and junction read signals, DOLPHIN groups together cells with similar splicing profiles, thereby enhancing sensitivity for detecting AS events while fully preserving single-cell resolution.
DOLPHIN introduces several key advancements in scRNA-seq analysis: First, DOLPHIN creates a high-resolution exon-level cellular representation by integrating exon-level quantification and junction reads, addressing the limitations of conventional gene-level analysis. Traditional approaches, which simplify each gene to a single scalar value, often lose crucial transcriptomic information. DOLPHIN’s graph-based representation of exon and junction data provides a more refined and integrative view of transcriptomic architecture, significantly enhancing cell clustering accuracy. By optimizing clustering performance with the GAT layer, which emphasizes biologically relevant exon interactions, DOLPHIN enables high-resolution insights into cell type and state that extend beyond conventional methods. Second, DOLPHIN ensures broad applicability across diverse scRNA-seq platforms and biological systems, including full-length and tag-based technologies, by leveraging universally available exon and junction reads. Its modular framework is compatible with existing splicing detection tools and adaptable to datasets of varying coverage and complexity. This generalizability allows researchers to apply DOLPHIN across a range of biological systems and experimental designs, demonstrating its versatility. Furthermore, its computationally efficient architecture, which scales linearly with the number of detected genes per cell, makes DOLPHIN particularly suitable for large-scale single-cell analyses, addressing a key challenge in the field. These features position DOLPHIN as a flexible, broadly applicable framework for scRNA-seq analysis. Third, DOLPHIN enables the identification of EDEGs and cell type-specific markers, capturing subtle transcriptomic differences that remain undetectable with gene-level aggregation. This exon-level sensitivity allows DOLPHIN to uncover cell-type-specific markers and condition-specific signatures otherwise masked by gene-level data. By identifying EDEGs, DOLPHIN reveals nuanced transcriptomic profiles that distinguish subtle functional and condition-specific variations, expanding scRNA-seq analysis to capture cell-specific transcriptomic features with a precision that can benefit complex cellular analyses. DOLPHIN also enhances AS detection, a challenging area in single-cell data due to typically low junction read coverage. By leveraging VGAE-derived embeddings to aggregate junction reads from similar cells through a KNN approach and majority voting, DOLPHIN effectively increases the coverage for AS analysis. This aggregation allows for the detection of cell-type-specific splicing variations that are often missed in single-cell datasets, broadening the scope of AS analysis and advancing the identification of biologically relevant splicing patterns. Finally, DOLPHIN introduces the ability to identify differentially spliced marker genes, providing critical insights into how condition-specific splicing variations contribute to cellular diversity and functional differentiation in contexts such as diseased versus healthy cells. This analysis facilitates the discovery of novel biological mechanisms by revealing condition-specific AS patterns, enhancing the understanding of disease-associated transcriptomic changes, and supporting the identification of therapeutic targets and biomarkers. Together, these contributions position DOLPHIN as an integrative framework that extends scRNA-seq analysis beyond gene-level resolution. By incorporating exon- and junction-level data within a deep learning framework, DOLPHIN enables researchers to access previously undetectable biological insights in complex cellular systems, making it a valuable tool for studying cellular heterogeneity and gene regulation.
One current limitation of DOLPHIN lies in its lack of compatibility with many existing single-cell analysis frameworks, which predominantly operate at the gene level. In this work, we have developed and demonstrated DOLPHIN’s capability to perform exon-level analyses for several foundational single-cell tasks, including cell type marker discovery, cell representation learning, clustering, and de novo cell type annotation. These applications highlight the utility of exon-level quantification and representation in uncovering insights beyond the resolution of conventional gene-level approaches. However, certain downstream tasks, such as trajectory inference and cell-cell interaction analysis, remain incompatible with exon-level data due to the reliance of these frameworks on gene-level inputs. While indirect conversion to gene-level data is possible through well-annotated exon-gene relationships, such conversions degrade the resolution and nuanced insights that exon-level analysis provides. Despite this, the adoption of tools that natively accommodate exon-level data in these tasks could enable transformative analyses, leveraging DOLPHIN’s granularity to reveal finer-scale transcriptomic and cellular dynamics. Extending DOLPHIN to support these downstream tasks is beyond the scope of this work but represents a key direction for future development. In addition to expanding compatibility with downstream frameworks, another future direction involves broadening the range of AS events analyzed by DOLPHIN. This study focused on ES and MXE, which together account for over 50% of all AS events88,89,90. Although DOLPHIN can model other AS types, including intron retention, alternative \(5^{\prime}\) and \(3^{\prime}\) splice sites, and alternative first and last exons, these were not included in the current benchmarking. Expanding DOLPHIN’s scope to cover these events represents an important avenue for future development. Building on these directions, ongoing efforts are focused on integrating exon-level data into broader single-cell workflows, aiming to provide a robust and high-resolution framework for a wider range of applications.
DOLPHIN provides a high-resolution approach to scRNA-seq analysis by moving beyond gene-level quantification to integrate exon-level and junction read data, offering a more informative representation of cellular states. This framework enhances the detection of exon-level markers and AS events, which are essential for understanding cellular identity and functional diversity. With applications across fields such as immunology, developmental biology, and oncology, DOLPHIN supports researchers in gaining deeper insights into gene regulation and cellular dynamics in complex tissues. By introducing a flexible, high-resolution framework, DOLPHIN broadens the tools available for studying cellular heterogeneity and disease mechanisms, advancing the precision of single-cell transcriptomic analysis to support studies of disease processes and therapeutic discovery.
Methods
Data preprocessing
To create an exon-level reference genome, we modified the GRCh38 annotated GTF file from Ensembl release 10798. This modification involved merging overlapping exons from multiple transcripts of a single gene, retaining the largest range of the overlapped exons as a single representative exon, as illustrated in Supplementary Fig. S27. This approach prevents repetitive counting of overlapping exon regions across different transcripts, helping to ensure that the sum of all exon reads closely aligns with the gene-level read count. This alignment is critical for maintaining accurate quantification and avoiding distortions in downstream analyses.
The preprocessing steps differ for full-length RNA-seq and tag-based 10X Genomics data. For full-length RNA-seq data, reads were trimmed to remove adapters using Trimmomatic (v0.39)99, following the method in ref. 29. Trimmed sequences were then aligned to the modified exon-level reference genome using the splice-aware aligner STAR (v2.7.3a)100 with parameters from the original publication. BAM files generated from this alignment were processed with featureCounts (v2.0.3)101 to obtain exon and junction read counts. Gene-level counts were also extracted to support cell quality control and identify highly variable genes (HVGs). For the tag-based 10X Genomics dataset, we aligned raw RNA-seq reads to the default GRCh38 (GRCh38-2020-A) reference genome using Cell Ranger (v7.0.1)102 to generate single-cell barcodes and BAM files. BAM files were filtered to retain reads with valid barcodes using the subset-bam tool from 10X Genomics, and bamtools (v2.5.2)103 was then used to split the filtered BAM file into single-cell BAM files. Each single-cell BAM file was subsequently re-aligned to the modified exon-level reference genome using STAR under default settings. Exon and junction read counts were then obtained from these files using featureCounts with the same parameters as the full-length RNA-seq data. These exon and junction counts serve as the input for DOLPHIN. A visual overview of the preprocessing workflow for both full-length RNA-seq and 10X Genomics data is provided in Supplementary Fig. S28.
Data preprocessing for conventional scRNA-seq analysis: For analyses using conventional methods such as SCANPY, all input matrices were normalized in accordance with standard requirements. For gene-level analysis, raw scRNA-seq reads were aligned to the reference genome to generate BAM files, which were processed using featureCounts to obtain raw gene count tables. Genes detected in fewer than three cells were filtered out, followed by library size normalization and log1p transformation. HVGs (top 5000 HVGs) were then selected and used as input for SCANPY analysis. Differential expression analyses were performed using the MAST framework within Seurat, employing the same normalization procedure as above. For EDEG analysis, exons detected in fewer than three cells were removed before applying library size normalization and log1p transformation. The same normalization procedures were applied to the raw adjacency matrices prior to JDEG analysis.
Data preprocessing for deep neural networks: deep neural networks commonly used in scRNA-seq analysis, such as scVI, typically assume that the input data follow a zero-inflated negative binomial (ZINB) distribution13 and therefore require raw count data as input. In this study, DOLPHIN follows a similar strategy: we use raw exon and junction counts as input and model them under a ZINB framework. However, compared to gene-level raw counts, exon-level counts are substantially sparser and more variable across cells, presenting additional challenges for representation learning. To address these issues, we applied library size normalization to the raw exon counts to account for differences in sequencing depth across cells, followed by rounding to the nearest integer. This preprocessing strategy preserved the ZINB distribution assumption for exon-level counts after library size normalization and rounding, while also substantially improving model performance compared to using unnormalized raw counts (Supplementary Fig. S29). For feature and adjacency matrix construction, only the exons and junctions corresponding to the HVGs identified by SCANPY, as described above, were retained to ensure consistency across methods. To construct the adjacency matrix, raw junction read counts within each gene were normalized such that the total edge weight summed to one, facilitating comparability across genes. These normalized adjacency matrices were used as edge weights for message passing in the graph attention layers. Meanwhile, the original (unnormalized) raw junction matrices were retained as reconstruction targets in the decoder, enabling the model to jointly learn from both the exon graph structure (via message passing) and the raw junction counts (via reconstruction).
Graph data construction
To construct the graph data, we begin by converting exon and junction read counts into feature and adjacency matrices for each gene, processed one gene at a time. These matrices are built using a reference genome GTF file to ensure that all cells have a consistent number and ordering of exons.
In this graph representation, each exon is treated as a node with a single feature: the exon read count. Exon read counts are derived from the raw exon count table produced by featureCounts using a gene annotation GTF file, ensuring an identical set of exons across all cells. For each gene Gj, containing nj exons, the feature vector \({{{{\bf{X}}}}}_{i}^{j}\) for gene j in cell i is a one-dimensional vector of size nj, representing exon counts ordered from the 5′ to 3′ end according to the reference genome. The feature matrix for cell i is then formed by concatenating these feature vectors across all genes, resulting in a vector of size \({\sum }_{j=1}^{N}{n}_{j}\), where N is the number of genes. The feature vector for gene j in cell i is denoted as \({{{{\bf{X}}}}}_{i}^{j}=[{E}_{i}^{j,1},{E}_{i}^{j,2},\ldots,{E}_{i}^{j,{n}_{j}}]\), where \({X}_{i}^{j,k}={E}_{i}^{j,k}\) represents the read count for exon k in gene j from cell i. Consequently, the feature matrix for each cell i is a concatenation of all its gene feature vectors: \({{{{\bf{X}}}}}_{i}={{\mathrm{diag}}}\,\{{{{{\bf{X}}}}}_{i}^{1},{{{{\bf{X}}}}}_{i}^{2},\ldots,{{{{\bf{X}}}}}_{i}^{N}\}\).
After constructing the feature matrices, we generate adjacency matrices using junction count files produced by featureCounts. These files contain junction reads associated with valid primary genes, including splice site locations, which are compared with exon locations from the featureCounts exon count table to build the adjacency matrix. Specifically, each junction’s splice sites are matched to exon locations to determine the connected exons, with exons serving as nodes and junctions as directed edges from the 5′ to the 3′ end. Edges are defined as follows: for each junction, the left (5′) splice site identifies the starting exon, and the right (3′) splice site identifies the ending exon. If a splice site is within an exon region, the edge originates or terminates at that exon; if located between two exons, the edge begins or ends at the exon nearest the 5′ or 3′ end. Edges are created only when both connected exons have non-zero counts. The raw adjacency matrix \({{{{\bf{A}}}}}_{i}^{j}\) for all exons of gene j in cell i is represented as follows:
where \({A}_{i}^{j,(m,n)}\) is the matrix element at row m and column n, em,n denotes the raw junction read count between mth and nth exons, and the matrix size is nj × nj. The cell-level raw adjacency matrix Ai is constructed by arranging the gene-level raw adjacency matrices \({{{{\bf{A}}}}}_{i}^{j}\) into a block diagonal matrix, such that \({{{{\bf{A}}}}}_{i}={{\mathrm{diag}}}\,\{{{{{\bf{A}}}}}_{i}^{1},{{{{\bf{A}}}}}_{i}^{2},\ldots,{{{{\bf{A}}}}}_{i}^{N}\}\). The raw adjacency matrix is used to define the edge weights in the exon graph, and normalization yields the final adjacency matrix. The normalized adjacency matrix \({{{{\bf{AN}}}}}_{i}^{j}\) for all exons of gene j in cell i is represented as follows:
Edge weights are normalized per gene to ensure that the sum of weights equals one, enabling comparability across genes. Cell-level adjacency matrices ANi are then constructed by stacking gene-level adjacency matrices in a block diagonal format, resulting in \({{{{\bf{AN}}}}}_{i}={{\mathrm{diag}}}\,\{{{{{\bf{AN}}}}}_{i}^{1},{{{{\bf{AN}}}}}_{i}^{2},\ldots,{{{{\bf{AN}}}}}_{i}^{N}\}\). This approach ensures uniform adjacency matrix dimensions across cells, with rows and columns corresponding to the same exons across all cells.
DOLPHIN model architecture
DOLPHIN employs a VGAE to integrate exon and junction counts, deriving biologically informative cell embeddings. To effectively aggregate neighborhood information and capture complex relationships within the data, a Graph Attention Layer (GAT) is incorporated into the encoder of the VAE model.
The Graph Attention Layer is specifically designed for graph-structured data and leverages an attention mechanism to dynamically weight neighboring nodes based on their relevance, enhancing the model’s flexibility and expressiveness. Unlike standard GAT layers that primarily focus on node features, our model includes edge features in the GAT layer, improving the ability to capture nuanced relationships between nodes. The attention scores in our model are computed using both node and edge features. The GAT layer is defined as fGAT(Xi, Ai) = Hi, where Hi represents the attended feature vectors (or embeddings) for cell i. These attended feature vectors are obtained by averaging the outputs from multiple attention heads, denoted by M, as follows:
In this equation, σ represents the activation function applied to the layer output, such as ReLU, while M is the total number of attention heads, with each head processing the graph structure independently. The term \({\alpha }_{uv}^{(m)}\) denotes the attention coefficient between node u and node v for the mth attention head, indicating the weighted importance of node v in relation to node u. Θ(m) is the learnable weight matrix for the mth attention head, used to transform the node features, and Xv represents the feature vector for node v. The term \({{{\mathcal{N}}}}(u)\cup \{u\}\) denotes the set of nodes consisting of u’s neighbors \({{{\mathcal{N}}}}(u)\) and the node u itself. Including u in this set allows node u to incorporate information from its own features in addition to those of its neighbors during the aggregation process. The attention coefficient \({\alpha }_{uv}^{(m)}\) between node u and node v for each head m is calculated using both node and edge features as follows:
In this equation, LeakyReLU is the activation function applied to the transformed features, providing non-linearity to the attention calculation. The parameters \({{{{\bf{a}}}}}_{s}^{m}\), \({{{{\bf{a}}}}}_{t}^{m}\), and \({{{{\bf{a}}}}}_{e}^{m}\) are learnable weight vectors for the mth head, used in the attention mechanism to determine the importance of the source node, target node, and edge features, respectively. The matrices \({{\bf{\Theta }}}_{s}^{(m)}\), \({{\bf{\Theta }}}_{t}^{(m)}\), and \({{\bf{\Theta }}}_{e}^{(m)}\) are learnable weight matrices for the mth head that transform the source node, target node, and edge features into a latent space, facilitating more complex representations of relationships in the graph. The feature vectors Xu and Xv represent the source and target nodes, u and v, respectively, while euv denotes the edge feature between nodes u and v. The denominator in the expression normalizes the attention scores across all neighbors of u, including u itself, ensuring that the sum of the attention scores across all connected nodes equals one. This normalization produces a weighted importance value for each connection, allowing the model to aggregate node features in a way that reflects the relevance of each node’s neighbors based on both node and edge characteristics. By incorporating edge features, the model gains additional context, allowing it to weigh the importance of neighboring nodes more effectively based on edge characteristics. This results in a richer representation and more informative aggregation of node features, enhancing model performance.
The encoder of the DOLPHIN model consists of a GAT layer followed by multiple Multi-Layer Perceptrons (MLPs). The GAT layer processes the input features from the node and adjacency matrices, producing an attention-weighted node feature representation Hi. This output is then fed into two separate MLPs, which map the node features into a latent space. Specifically, for the VAE, these MLPs compute the mean vector μ = fμ(Hi) and the standard deviation vector σ = fσ(Hi) for a multivariate Gaussian distribution. The latent representation Z is then sampled from this Gaussian distribution, \({{{\mathcal{N}}}}(\mu,{\sigma }^{2})\), capturing the probabilistic nature of the encoded data. In this way, the encoder defines the approximate posterior distribution qθ(Z∣Xi, ANi), where Z denotes the learned latent representation for cell i.
To reconstruct the original data, DOLPHIN utilizes two decoders: one for the adjacency matrix \({{{{\bf{A}}}}}_{i}^{{\prime} }\) and another for the feature matrix \({{{{\bf{X}}}}}_{i}^{{\prime} }\). This dual reconstruction strategy allows the model to learn and preserve both structural and attribute information of the graph. By reconstructing both aspects of the input data, the model enhances the richness and interpretability of the latent space representation, capturing detailed properties of the graph structure. Moreover, reconstructing multiple data components increases the model’s robustness and generalization ability, improving its performance on unseen data.
In the VAE model, the distributions of both the feature matrix Xi and the adjacency matrix Ai are assumed to follow a ZINB distribution, which effectively models the overdispersed and zero-inflated nature of single-cell data. The likelihood for cell i in the decoder is defined as:
where \({p}_{{\varphi }_{X}}({{{{\bf{X}}}}}_{i}| {{{\bf{Z}}}})\) and \({p}_{{\varphi }_{A}}({{{{\bf{A}}}}}_{i}| {{{\bf{Z}}}})\) represent the likelihoods of reconstructing the feature matrix Xi and the adjacency matrix Ai given the latent variable Z. Specifically, these likelihoods are detailed as follows:
and
In these expressions, \({\mu }_{{X}_{i}^{j,k}},{\theta }_{{X}_{i}^{j,k}},{\pi }_{{X}_{i}^{j,k}}\) are the parameters of the ZINB distribution for the kth exon of the jth gene of cell i, and \({\mu }_{{A}_{i}^{j,(m,n)}},{\theta }_{{A}_{i}^{j,(m,n)}},{\pi }_{{A}_{i}^{j,(m,n)}}\) are the ZINB parameters for the junction between mth exon and nth exon of the jth gene of cell i. These parameters allow the decoder to capture the complex distributional properties of both gene features and their interactions within each cell, making it more suited to the inherent variability of single-cell data. The likelihood function, therefore, models the probability of observing the reconstructed data Xi and Ai given the latent variables Z.
The VAE model’s objective is to minimize the Kullback–Leibler (KL) divergence between the approximate posterior qθ(Z∣Xi, ANi) and the prior p(Z) distributions while simultaneously minimizing the reconstruction loss for both the feature matrix Xi and the adjacency matrix Ai. The VAE loss function is formulated as:
In this formulation, the KL divergence term, scaled by the hyperparameter β, regularizes the latent space by encouraging the learned latent distribution to approximate the prior Gaussian distribution. The hyperparameter β thereby controls the trade-off between enforcing a smooth latent space and preserving reconstruction accuracy. The reconstruction loss terms for the feature matrix and adjacency matrix measure how accurately the decoder reconstructs the original data from the latent variables. The hyperparameter λ controls the balance between the reconstruction losses for the feature matrix and adjacency matrix, allowing the model to adjust to the underlying data distribution. This multi-objective loss function, with β and λ as balancing factors, enables the model to learn a meaningful latent representation while effectively reconstructing both the structural and feature information from the input data. The training time and memory usage of the DOLPHIN model are presented in the Supplementary Fig. S30.
Cell clustering and aggregation
The latent representation Z obtained from the model is used for cell clustering. We first compute a neighborhood graph of cells and identify clusters using the Leiden algorithm104. The clustering results are visualized through UMAP38 to reveal the relationships among cells. Once cell embeddings are established, the next step is cell aggregation, which serves as the basis for analyzing AS across these aggregated cells. Aggregation is performed at the BAM file level, where each single-cell BAM file, generated during data preprocessing, is aggregated individually for each cell. Here, cell i is treated as the target cell in the aggregation process, though the procedure is repeated for all cells.
The aggregation process consists of three main steps, beginning with identifying neighboring cells for the target cell i. Using the latent representation Z, we employ a KNN approach to identify neighboring cells, with K = 10 as the selected default in this study. This choice of K was determined by benchmarking different values against clustering accuracy, as shown in Supplementary Fig. S31. The AS detection performance is comparable between K = 10 and K = 15, with an average difference of only 1.4%. However, increasing K to 15 raises the computational complexity for AS detection by ~40%. Therefore, we set K = 10 as the default.
The second step addresses library size normalization at the BAM file level to correct for variations in sequencing depth across cells, ensuring balanced read counts within the neighborhood and reducing potential bias. For each cell i, the total read count is calculated, and all neighborhood reads are adjusted to match the read count of cell i. This normalization preserves the original sequencing data for the target cell. If a neighboring cell has fewer reads than the target, its reads are duplicated to match the target’s count. Conversely, if a neighboring cell has more reads, excess reads are randomly removed. The read count for cell i remains unchanged, providing effective library size normalization. For any neighboring cell k, the library size normalization is given by:
where mk represents the original set of reads from neighboring cell k, ∣mk∣ is the total read count for k, and Sample(mk, Q) denotes the sampling function that randomly selects Q reads from mk when ∣mk∣ > ∣mi∣.
The final step in aggregation consolidates junction reads from neighboring cells into the target cell using a majority voting approach. Only junction reads are aggregated; thus, BAM files of neighboring cells, \({m}^{\prime}_{k}\), are first filtered to retain only junction read sequences. Junctions are identified as spliced alignments, and start and end positions are provided by the STAR output file SJ.out.tab. A combined set of unique junction reads is defined as \({\bigcup }_{k\in {{{\mathcal{N}}}}(i)\cup \{i\}}{\, j}_{k}\), where jk represents the junction reads in each neighboring cell k, and \({{{\mathcal{N}}}}(i)\) denotes the set of neighbors for cell i as identified by the KNN algorithm. This combined set captures all distinct junctions across the neighborhood of cell i, including cell i itself. Each junction jt is considered for inclusion in cell i’s BAM file based on its prevalence across the neighborhood. Specifically, if a junction read jt appears in over half of the neighboring cells, it is added to cell i’s BAM file; otherwise, it is excluded. This condition is represented as:
where \({\mathbb{I}}(\cdot )\) denotes the indicator function, which outputs 1 if the condition is met and 0 otherwise. The specific indicator function \({{\mathbb{I}}}_{{m}_{k}\, {{{\rm{if}}}}\, k=i,\, {m}^{\prime}_{k} \, {{{\rm{if}}}}\, k\ne i}({\,j}^{t})\) is defined as:
This condition checks whether the junction jt is present in more than half of the K cells in the neighborhood (including cell i). The aggregated junction reads for cell i are then represented as:
where \({j}_{i}^{{\prime} }\) denotes the aggregated junction reads for cell i, and ji is the original junction read set of cell i. After aggregation, exon read sequences remain unchanged, resulting in a final set of reads for cell i represented as the combination of exon read sequences and \({j}_{i}^{{\prime} }\). All retained junction locations are saved in a BED file, and neighborhood BAM files are filtered by these locations. The filtered BAM files of neighboring junctions and the BAM file of cell i are then merged. This aggregation process is repeated for each cell, with each cell sequentially serving as the target. Aggregating BAM files, rather than directly modifying exon or junction count tables, ensures compatibility with downstream analyses that rely on BAM file inputs. This approach also allows for the generation of count tables from BAM files, enhancing the flexibility of DOLPHIN for various analytical applications.
Exon-level differentially expressed genes (EDEGs) analysis
To identify EDEGs, we analyzed scRNA-seq data from four subjects in ref. 31: three patients with PDAC as the cancer group and one subject with normal pancreas tissue and duodenal intraepithelial neoplasia as the control group. Data preprocessing adhered to the 10X Genomics protocol specified in the “Data preprocessing” section, including only cells annotated in the original study and retained through our processing pipeline. The resulting feature matrix was used as input for differential exon analysis. Cell embeddings were generated using the DOLPHIN model and subsequently clustered using SCANPY with the Leiden algorithm.
To identify EDEGs, the exon count table obtained from the “Data preprocessing” section was used as input to the MAST framework105, to compute P values and log2 fold changes (log2FC) for each exon. Gene-level P values were then aggregated using the Stouffer method106,107, weighted by exon length. This weighting strategy reflects the rationale that longer exons, by receiving more consistent read coverage, provide more reliable statistical estimates and thus serve as a biologically grounded proxy for measurement stability in sparse scRNA-seq data. To evaluate the impact of this weighting scheme, we compared it to two alternative strategies: weighting by the mean exon read count across cells and applying uniform weights across all exons. As shown in Supplementary Fig. S32, weighting by exon length resulted in the most biologically relevant enrichment analysis outcomes among all strategies. Similarly, the ∣log2FC∣ values were averaged at the gene level, weighted by exon length. Bonferroni correction108 was applied to account for multiple testing across all genes, producing adjusted gene-level P-values and log2FC values derived from exon-level data. Genes with adjusted P < 0.05 and log2FC > 1 were classified as EDEGs. Additionally, we applied FDR correction using the Benjamini–Hochberg procedure to DEG and EDEG analyses across multiple thresholds. As shown in Supplementary Fig. S33, BH correction increased the number of detected genes compared to Bonferroni correction, with EDEGs consistently outnumbering DEGs, indicating that their greater sensitivity is not solely due to the choice of correction method.
To assess the distinct advantages of the EDEGs analysis in comparison to the conventional differential gene analysis, we also conducted a conventional DEGs analysis on normalized gene counts for cells in Cluster 2, using MAST to calculate adjusted P-values and log2FC for each gene. Using DOLPHIN, we identified 896 genes classified as EDEGs that were not detected as DEGs. To further refine this list, we filtered out genes that were not significantly differentially expressed in the gene count table based on the Wilcoxon rank-sum test (adjusted P > 0.05) using SCANPY. The remaining genes were selected for visualization in the heatmap shown in Fig. 3d. The P values between the two conditions were computed using a two-sided Wilcoxon test based on the average expression values of each gene (or exon) within each group. This heatmap demonstrates that, regardless of whether MAST or the Wilcoxon test is used, genes that do not show differential expression at the gene level can still exhibit significant differential expression at the exon level when analyzed with DOLPHIN. The same analysis pipeline was applied to the comparison of ductal cells. Supplementary Fig. S14a schematically illustrates the identification of differential exons and junctions, even when no differential expression is observed at the gene level. Toppgene50 was used to identify the enrichment of EDEGs, DEGs, and JDEGs in disease and pathways. For pathway enrichment, we utilized the WikiPathways109 dataset, while for disease enrichment, we used data from AllianceGenome110, Clinical Variation111, DisGeNET Curated112, and OMIM MedGen113 databases. For survival analysis, we first obtained bulk RNA-seq gene expression data and corresponding clinical survival information for 181 PDAC patients from TCGA62 via the UCSC Xena platform114. Genes used for survival evaluation were selected from the 896 EDEG-unique genes identified by DOLPHIN. These genes were ranked by adjusted P values in ascending order, and subsets containing the top 100,200,300 genes, and so forth up to all 896 EDEGs were sequentially selected for downstream analysis. We then followed the Scissor framework115 to assess the prognostic relevance of these EDEGs in stratifying patient risk. Specifically, patients were grouped into high-risk and low-risk categories based on the aggregate expression levels of the selected top-ranked EDEGs. Statistical significance of survival differences between these groups was evaluated using the log-rank-sum test.
Junction-level differentially expressed genes (JDEGs) analysis
To complement exon-level findings, we further investigated differential expression at the junction level by considering each exon-exon junction as an independent unit. Normalized junction counts derived from the “Data preprocessing” section were used as input to the MAST framework105 to estimate P values and log2FC changes for each junction. These junction-level statistics were subsequently aggregated to the gene level using an unweighted Stouffer’s method106,107, followed by Bonferroni correction. Similarly, gene-level log2FC were computed by averaging the absolute log2FC values across all junctions belonging to the same gene. Genes with adjusted P < 0.05 and absolute log2FC > 1 were designated as JDEGs.
DOLPHIN alternative splicing analysis
Aggregated BAM files from DOLPHIN were aligned to the reference genome with STAR to generate junction files for input to Outrigger in Expedition: the outrigger index function identifies all AS events by pooling junction reads across cells and traversing the resulting splice graph, the outrigger validate function filters events to retain only those with canonical splice sites (commonly conserved splice junctions in transcriptomes)116, and the outrigger psi function calculates PSI values for events supported by at least 10 valid junction reads. PSI values range from 0 (complete ES) to 1 (full exon inclusion). Outrigger detects ES and MXE events directly based on observed junction reads, without any imputation. As a result, splicing events with insufficient read support yield missing (NaN) PSI values. The number of detected events is determined by counting only those events with valid (non-NaN) PSI values. Given the central role of PSI matrices in multiple downstream analyses, we adopted distinct strategies for handling missing PSI values depending on the specific analytical context. Below, we detail the origin of missing values and the imputation approaches applied in different parts of the study to ensure accurate and biologically meaningful interpretation of AS patterns.
For PSI-based cell clustering, random-value imputation was performed to address missing PSI entries and facilitate dimensionality reduction and clustering analyses. This imputation step was necessary because the PSI matrices generated during quantification contained NaN values arising from insufficient junction read coverage, leading to each cell being characterized by PSI values for a different subset of splicing events. Standard dimensionality reduction algorithms cannot accommodate such missing entries. To overcome this limitation, we adapted an imputation strategy from the MARVEL framework, whereby missing values were randomly sampled from a uniform distribution between 0 and 1. Although this approach introduces some smoothing, it preserves the underlying cell-type-associated splicing structures that would otherwise be obscured by data sparsity.
For differential splicing analysis, a different imputation strategy was employed to account for the high sparsity of PSI values, which is particularly pronounced in droplet-based scRNA-seq datasets. Specifically, missing PSI values for each splicing event were imputed using the mean PSI across cells of the same cell type, following the strategy adopted in the BRIE2 framework. Without imputation, many events would exhibit insufficient read coverage across conditions, hindering robust statistical testing. This cell-type-specific mean imputation provides a conservative approximation that facilitates differential analysis while preserving the observed variation among cells with valid PSI values. Following imputation, differential splicing was analyzed using the Wilcoxon rank-sum test, and P values were adjusted for multiple testing using the Benjamini–Hochberg method, with significance determined at an adjusted P value cutoff of 0.05. Genes associated with significant AS events were designated as differentially spliced genes, and GOBP enrichment analysis was performed using ToppGene50.
Splicing modalities for each event were identified using the Anchor function in Expedition, which employs a Bayesian framework to fit PSI distributions to Beta distributions. Bayes Factors were used to assign splicing modalities, such as “included,” “excluded,” “bimodal,” or “null.” To preserve the natural shape of PSI distributions, PSI values obtained from Outrigger were directly used for modality classification without applying any imputation. Cells with missing PSI values were excluded from the analysis, thereby avoiding artificial centering effects that could arise from imputing missing values with cell-type means. These modalities were numerically encoded using one-hot encoding to create a cell-by-modality matrix (Figs. 5f and 7e), which was used for dimensionality reduction with PCA, followed by Leiden clustering. This approach facilitated the identification of splicing-driven subpopulations and patterns of cellular diversity.
This pipeline integrates PSI-based clustering and splicing modality analysis, enabling the discovery of biologically meaningful splicing patterns while addressing the inherent sparsity of scRNA-seq data. By linking computational insights to functional pathways, these analyses advance our understanding of cell-type-specific splicing and transcriptomic diversity.
DOLPHIN ablation analysis and benchmarking in cell representation learning
To evaluate the necessity of DOLPHIN’s core components, we conducted an ablation study to examine the performance of different versions of the method in cell representation learning, as shown in Fig. 2. We also benchmarked these variations against other single-cell clustering methods for comparison, as illustrated in Fig. 6. The cell type annotations were directly taken from the original publications, which generated them based on gene count tables, and were used as ground truth for evaluating cell embedding performance. All benchmarking results were obtained using a bootstrapping strategy. Specifically, in each iteration, 80% of the data were randomly subsampled, and the process was repeated 100 times to ensure robustness. Statistical significance was assessed using a one-sided Student’s t-test. As shown in Supplementary Fig. S34, the resulting score distributions closely approximated a Gaussian distribution, thereby justifying the use of the t-test in this context.
For the ablation analysis in Fig. 2, we used the DOLPHIN VAE model, selectively removing components to assess their impact. Specifically, we removed the GAT layer and retained only a single decoder to create baseline versions. We tested these simplified VAE models with three distinct input configurations: the gene count table, the feature matrix, and the adjacency matrix. All inputs were preprocessed following the procedure described in the “Data preprocessing” section for deep neural networks. This design isolates the effect of input data type on embedding quality, independent of model architecture. The latent space extracted from each configuration served as the cell representation for subsequent Leiden clustering using SCANPY. Clustering performance was evaluated against ground truth cell types using ARI and NMI as part of the ablation study. Using these metrics, our ablation study demonstrated the importance of each component in DOLPHIN, underscoring the effectiveness of its full architecture in optimizing cell representation learning. For the single-cell long-read RNA-seq dataset, raw reads were first processed using the scNanoGPS pipeline, generating high-confidence BAM files and isoform-level quantifications. Exon- and junction-level counts were then extracted from the BAM files using featureCounts and subsequently imported into DOLPHIN to obtain embeddings for comparative analysis.
In the batch effect analysis, we assessed batch effects using 10 distinct random seeds and quantitatively evaluated them with the batch-adjusted ASW117, the integrated local inverse Simpson’s index (iLISI)41, and the KNN batch effect test118. For the batch correction analysis, we applied Harmony and scVI. Harmony was performed on the normalized gene count table (the same input as used in SCANPY), with PCA applied first, followed by Harmony batch correction in the PCA space. The adjusted principal components were then used for clustering. For scVI correction, the raw gene count table was used as input with the batch key specified. Batch-aware embeddings were generated and used for clustering. For exon-level batch correction, scVI was applied to the raw feature matrix to obtain a batch-corrected feature matrix, which was subsequently used by DOLPHIN for embedding generation, while the adjacency matrix remained unchanged. Batch correction performance was evaluated using ARI, NMI, batch-adjusted ASW, and graph connectivity scores computed with OmicVerse43.
In the benchmarking analysis shown in Fig. 6, we compared DOLPHIN with gene-level clustering methods. The gene expression inputs for SCANPY and scVI were processed according to the normalization steps described in the “Data preprocessing” section, while inputs for scGMMAE and scDeepCluster were processed following their respective requirements. Subsequently, we applied Leiden clustering to each latent space to standardize comparisons. For scQuint, junction reads obtained with STARsolo119 were used to compute intron usage profiles, which were input to its VAE for cell embedding. The resulting low-dimensional representations were clustered using the Leiden algorithm to identify cell populations. For SCASL, junction reads extracted from STAR were used to calculate splicing probabilities, followed by KNN-based imputation and spectral clustering on the resulting splicing feature matrix.
We evaluated clustering performance using five metrics: ARI, NMI, CS, AMI, and FMI. These metrics assess various aspects of clustering quality: ARI and NMI measure alignment with ground truth cell types, CS assesses cluster homogeneity, and AMI and FMI account for overlap between predicted and ground truth cell types.
Benchmarking of alternative splicing detection methods
To benchmark DOLPHIN’s performance in detecting AS events, we compared four approaches that differed only in the input scRNA-seq reads, while keeping the splicing detection tools fixed. Specifically, all four conditions used the same AS detection tools but applied them to different versions of the raw scRNA-seq reads. The first approach, referred to as “single-cell AS analysis,” used the original unaggregated single-cell reads as input and served as the baseline. The remaining three approaches employed read aggregation strategies based on SCANPY, scVI, and DOLPHIN, respectively. This setup allowed us to isolate and evaluate the effect of DOLPHIN’s aggregation strategy on improving AS event detection.
For single-cell AS analysis, the original scRNA-seq data were aligned to the reference genome using STAR, generating both junction and BAM files. The resulting single-cell BAM files served as input for aggregation with SCANPY, scVI, and DOLPHIN. Aggregation methods employed low-dimensional embeddings of single cells (SCANPY and scVI) or DOLPHIN’s graph-based representation to identify neighborhoods via a KNN algorithm (N = 10). Aggregated BAM files from all methods were re-aligned to the reference genome using STAR, producing junction files for junction read analysis with Outrigger or any other AS detection methods.
To ensure a fair comparison, each of the four input types was analyzed using an identical pipeline across all AS detection tools. For Outrigger, we followed the procedure described in the “DOLPHIN alternative splicing analysis” section. For MARVEL, STAR generated BAM and junction files; rMATS120 identified splicing events from BAMs, and PSI values were computed from junction files at single-cell resolution, retaining only events supported by 10 reads. For BRIE2, BAM files were used to quantify read counts per splicing event per cell. PSI values were then estimated using the mode1 option, which models cell-specific variation by incorporating an individual offset term for each cell. For SCASL, junction files from STAR alignment were used as input. SCASL computed splicing probabilities from junction reads and applied iterative imputation to recover missing values, enabling robust estimation of single-cell splicing profiles. For scQuint, junction reads obtained with STARsolo119 were used to compute intron counts and calculate PSI values. For scASfind, PSI values were quantified using Whippet121 and subsequently processed to generate an index for rapid querying and downstream analysis across single cells.
The number of AS events was quantified by counting valid PSI values. For Outrigger, MARVEL, scQuint, scASfind, and SCASL, detected events were defined as those with non-NaN PSI values. For BRIE2, events were considered detected if the 95% confidence interval of the imputed PSI value was less than 0.1. To evaluate cell-type-specific pseudo-bulk correlations (Fig. 7b), pseudo-bulk BAM files were generated by merging the BAM files of cells belonging to the same cell type. For each splicing-aware tool, the corresponding pseudo-bulk BAM files were independently processed using the same pipeline as applied to its single-cell input, serving as a tool-specific ground truth for PSI correlation evaluation. PSI correlations were calculated based on the set of splicing events detected by at least one of the input methods. For the PSI-based clustering benchmark (Fig. 7c), each tool’s PSI matrix was processed using a common pipeline with PCA for dimensionality reduction and Leiden clustering. Clusters were evaluated against ground-truth cell type labels. All tools followed this procedure except SCASL, which used its own clustering method.
Assessing the accuracy and robustness of DOLPHIN in simulated alternative splicing datasets
We used Polyester122 to simulate raw RNA-seq datasets for benchmarking AS detection, specifically targeting ES events with planted ground truth. Polyester requires two inputs: a reference sequence FASTA file and a transcript count table. RNA-seq fragments are simulated based on sequence abundance, guided by the count table. Transcript counts were derived from the full-length PBMC dataset using kallisto82. These counts were modeled with a negative binomial distribution to generate count tables for each cell, using 200 different seeds to ensure variability. For the reference sequences, exon sequences from the Ensembl GRCh38 genome were extracted, and one exon was randomly removed to create isoform2 (exon-skipping). Isoform1 (exon inclusion) retained the skipped exon and adjacent exons. Together, these isoforms formed the reference sequence for simulating ES events, serving as ground truth for evaluating AS detection methods.
We evaluated the robustness of DOLPHIN across varying sequencing depths and protocols by simulating scRNA-seq datasets from three common platforms: full-length, 10X Genomics \(3{\prime}\), and 10X Genomics \(5{\prime}\) protocols. Precision, recall, and F1 score were used as evaluation metrics. Two splicing detection tools (Outrigger and MARVEL) were benchmarked across four input strategies (Supplementary Fig. S35). Simulations used 100 bp reads for 200 cells, with total read counts ranging from 50,000 to 500,000 per cell123. Full-length simulations used complete isoform sequences, while droplet-based simulations extracted 300 bp fragments from the \(3^{\prime}\) or \(5^{\prime}\) ends to mimic coverage biases. Across all conditions, DOLPHIN-enhanced inputs substantially improved recall and F1 scores while maintaining high precision, particularly under low-depth and biased-coverage scenarios. Fig. 7f, g, and Supplementary Fig. S26 show the performance under the full-length protocol with 500,000 reads per cell. For differential splicing benchmarking (Fig. 7d), Outrigger was compared using either original single-cell inputs or DOLPHIN-aggregated profiles, with PSI analysis following the “DOLPHIN alternative splicing analysis” procedure.
We next evaluated DOLPHIN’s sensitivity to ES under varying \(3{\prime}\) and \(5{\prime}\) tag biases (Supplementary Fig. S36). We simulated tag-based directional coverage by extracting 100–500 bp from the isoform \(3{\prime}\) or \(5{\prime}\) ends. When the captured region was ≤100 bp, splicing detection was poor across all methods. However, above 300 bp, performance substantially improved, with DOLPHIN consistently outperforming alternatives in both recall and F1. Importantly, the 300–400 bp capture length threshold aligns with the empirical properties of 10X Genomics 3′ scRNA-seq data, where cDNA molecules are biased toward fragments of this size124,125. Analysis of our 10X colon dataset (Supplementary Fig. S37) confirmed that 96.9% of transcripts had \(3{\prime}\) capture lengths greater than 200 bp, consistent with our simulation assumptions. These findings demonstrate that our simulations reflect realistic droplet-based sequencing conditions and highlight DOLPHIN’s effectiveness in improving splicing detection sensitivity and accuracy in 10X-based platforms.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
We evaluated DOLPHIN using four publicly available single-cell RNA-seq datasets. The full-length human PBMC dataset from Hahaut et al.29 is accessible via the Sequence Read Archive (SRA) under project number PRJNA816486. The 10X Genomics colon and rectum single-cell RNA-seq datasets from Wang et al.30 are available in the Gene Expression Omnibus (GEO) with accession number GSE125970. Additionally, the PDAC cancer single-cell RNA-seq dataset from Peng et al.31 is hosted in the Genome Sequence Archive under project number PRJCA001063. The PDAC bulk RNA-seq data and corresponding survival information were obtained from TCGA62 and downloaded via the UCSC Xena platform114. Each single-cell RNA-seq dataset includes raw RNA-seq FASTQ files and cell type annotations, supporting replication, benchmarking, and analyses such as AS detection, clustering, and cell type classification. The example datasets associated with this study are available on Zenodo at https://doi.org/10.5281/zenodo.15611935126. Source data are provided with this paper.
Code availability
The code used to develop the model, perform the analyses, and generate results in this study is publicly available and has been deposited in GitHub at https://github.com/mcgilldinglab/DOLPHIN, under the MIT license. The specific version of the code associated with this publication is archived in Zenodo and is accessible via https://doi.org/10.5281/zenodo.15602232127.
References
Wang, S. et al. The evolution of single-cell RNA sequencing technology and application: progress and perspectives. Int. J. Mol. Sci. 24, 2943 (2023).
Choe, K., Pak, U., Pang, Y., Hao, W. & Yang, X. Advances and challenges in spatial transcriptomics for developmental biology. Biomolecules 13, 156 (2023).
Cai, C., Yue, Y. & Yue, B. Single-cell RNA sequencing in skeletal muscle developmental biology. Biomed. Pharmacother. 162, 114631 (2023).
Zhang, J., Wang, X. & Xing, X. et al. Single-cell landscape of immunological responses in patients with COVID-19. Nat. Immunol. 21, 1107–1118 (2020).
Mogilenko, D. A., Shchukina, I. & Artyomov, M. N. Immune ageing at single-cell resolution. Nat. Rev. Immunol. 22, 484–498 (2022).
Zheng, Y. et al. A deep generative model for deciphering cellular dynamics and in silico drug discovery in complex diseases. Nat. Biomed. Eng https://doi.org/10.1038/s41551-025-01423-7 (2025).
Chang, X., Zheng, Y. & Xu, K. Single-cell RNA sequencing: technological progress and biomedical application in cancer research. Mol. Biotechnol. 66, 1497–1519 (2024).
Van de Sande, B., Lee, J. S. & Mutasa-Gottgens, E. et al. Applications of single-cell RNA sequencing in drug discovery and development. Nat. Rev. Drug Discov. 22, 496–520 (2023).
Miranda, A. M. A., Janbandhu, V. & Maatz, H. et al. Single-cell transcriptomics for the assessment of cardiac disease. Nat. Rev. Cardiol. 20, 289–308 (2023).
Zhang, Z. et al. Critical downstream analysis steps for single-cell RNA sequencing data. Brief. Bioinform. 22, bbab105 (2021).
Wolf, F., Angerer, P. & Theis, F. Scanpy: large-scale single-cell gene expression data analysis. Genome Biol. 19, 15 (2018).
Satija, R., Farrell, J. A., Gennert, D., Schier, A. F. & Regev, A. Spatial reconstruction of single-cell gene expression data. Nat. Biotechnol. 33, 495–502 (2015).
Lopez, R., Regier, J. & Cole, M. B. et al. Deep generative modeling for single-cell transcriptomics. Nat. Methods 15, 1053–1058 (2018).
Cui, H. et al. scGPT: toward building a foundation model for single-cell multi-omics using generative AI. Nat. Methods 21, 1470–1480 (2024).
Theodoris, C. V. et al. Transfer learning enables predictions in network biology. Nature 618, 616–624 (2023).
Yang, F., Wang, W. & Wang, F. et al. scBERT as a large-scale pretrained deep language model for cell type annotation of single-cell rna-seq data. Nat. Mach. Intell. 4, 852–866 (2022).
Wang, J., Fonseca, G. J. & Ding, J. scSemiProfiler: advancing large-scale single-cell studies through semi-profiling with deep generative models and active learning. Nat. Commun. 15, 5989 (2024).
Hasanaj, E., Wang, J. & Sarathi, A. et al. Interactive single-cell data analysis using Cellar. Nat. Commun. 13, 1998 (2022).
Pan, L., Dinh, H. Q., Pawitan, Y. & Vu, T. N. Isoform-level quantification for single-cell RNA sequencing. Bioinformatics 38, 1287–1294 (2021).
Joglekar, A., Foord, C., Jarroux, J., Pollard, S. & Tilgner, H. U. From words to complete phrases: insight into single-cell isoforms using short and long reads. Transcription 14, 92–104 (2023).
Hu, H. et al. Gene function and cell surface protein association analysis based on single-cell multiomics data. Comput. Biol. Med. 157, 106733 (2023).
Song, Y. et al. Single-cell alternative splicing analysis with expedition reveals splicing dynamics during neuron differentiation. Mol. Cell 67, 148–161 (2017).
Benegas, G., Fischer, J. & Song, Y. Robust and annotation-free analysis of alternative splicing across diverse cell types in mice. eLife 11, e73520 (2022).
Huang, Y. & Sanguinetti, G. BRIE2: computational identification of splicing phenotypes from single-cell transcriptomic experiments. Genome Biol. 22, 251 (2021).
Xiang, X., He, Y., Zhang, Z. & Yang, X. Interrogations of single-cell RNA splicing landscapes with SCASL define new cell identities with physiological relevance. Nat. Commun. 15, 2164 (2024).
Kipf, T. N. & Welling, M. Variational graph auto-encoders. NIPS Bayesian Deep Learning Workshop (2016).
Kingma, D. P. & Welling, M. Auto-encoding variational bayes. In Proc. 2nd Int. Conf. Learning Representations (ICLR, 2014).
Schafer, S. et al. Alternative splicing signatures in RNA-seq data: Percent Spliced In (PSI). Curr. Protoc. Hum. Genet. 87, 11–16 (2015).
Hahaut, V. et al. Fast and highly sensitive full-length single-cell RNA sequencing using flash-seq. Nat. Biotechnol. 40, 1447–1451 (2022).
Wang, Y. et al. Single-cell transcriptome analysis reveals differential nutrient absorption functions in human intestine. J. Exp. Med. 217, e20191130 (2019).
Peng, J. et al. Single-cell RNA-seq highlights intra-tumoral heterogeneity and malignant progression in pancreatic ductal adenocarcinoma. Cell Res. 29, 725–738 (2019).
Tang, F., Barbacioru, C. & Wang, Y. et al. mrna-seq whole-transcriptome analysis of a single cell. Nat. Methods 6, 377–382 (2009).
Arzalluz-Luque, C. A. Single-cell RNAseq for the study of isoforms-how is that possible? Genome Biol. 19, 110 (2018).
Veličković, P. et al. Graph attention networks. In Int. Conf. Learning Representations (ICLR, 2018).
Grønbech, C. H. et al. scVAE: variational auto-encoders for single-cell gene expression data. Bioinformatics 36, 4415–4422 (2020).
Erfanian, N. et al. Deep learning applications in single-cell genomics and transcriptomics data analysis. Biomed. Pharmacother. 165, 115077 (2023).
Dudani, S. A. The distance-weighted k-nearest-neighbor rule. IEEE Trans. Syst. Man Cybern. 6, 325–327 (1976).
McInnes, L., Healy, J. & Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. Preprint at arXiv https://arxiv.org/abs/1802.03426 (2018).
Hubert, L. & Arabie, P. Comparing partitions. J. Classif. 2, 193–218 (1985).
Strehl, A. & Ghosh, J. Cluster ensembles—a knowledge reuse framework for combining multiple partitions. J. Mach. Learn. Res. 3, 583–617 (2002).
Korsunsky, I. et al. Fast, sensitive and accurate integration of single-cell data with harmony. Nat. Methods 16, 1289–1296 (2019).
Tran, H. et al. A benchmark of batch-effect correction methods for single-cell RNA sequencing data. Genome Biol. 21, 12 (2020).
Zeng, Z. et al. Omicverse: a framework for bridging and deepening insights across bulk and single-cell sequencing. Nat. Commun. 15, 5983 (2024).
Hao, Y. et al. Integrated analysis of multimodal single-cell data. Cell 184, 3573–3587 (2021).
Grün, D. et al. Single-cell messenger RNA sequencing reveals rare intestinal cell types. Nature 525, 251–255 (2015).
Haber, A. et al. A single-cell survey of the small intestinal epithelium. Nature 551, 333–339 (2017).
Gao, H. et al. A prognosis marker slc2a3 correlates with EMT and immune signature in colorectal cancer. Front. Oncol. 11, 638099 (2021).
Frankenberger, M. et al. Transcript profiling of CD16-positive monocytes reveals a unique molecular fingerprint. Eur. J. Immunol. 42, 957–974 (2012).
Shiau, C.-K. et al. High throughput single cell long-read sequencing analyses of same-cell genotypes and phenotypes in human tumors. Nat. Commun. 14, 4124 (2023).
Chen, J., Bardes, E. E., Aronow, B. J. & Jegga, A. G. ToppGene Suite for gene list enrichment analysis and candidate gene prioritization. Nucleic Acids Res. 37, W305–W311 (2009).
Morani, A. C. et al. Hereditary and sporadic pancreatic ductal adenocarcinoma: Current update on genetics and imaging. Radiol. Imaging Cancer 2, e190020 (2020).
McGuigan, A. et al. Pancreatic cancer: a review of clinical diagnosis, epidemiology, treatment and outcomes. World J. Gastroenterol. 24, 4846 (2018).
Ahmed, S., Bradshaw, A., Gera, S., Dewan, M. & Xu, R. The TGF-β/SMAD4 signaling pathway in pancreatic carcinogenesis and its clinical significance. J. Clin. Med. 6, 5 (2017).
Dardare, J., Wendum, D., De la Fouchardiére, C., Couvelard, A. & Poté, N. SMAD4 and the TGFβ pathway in patients with pancreatic ductal adenocarcinoma. Int. J. Mol. Sci. 21, 3534 (2020).
Racu, M.-L. et al. SMAD4 positive pancreatic ductal adenocarcinomas are associated with better outcomes in patients receiving FOLFIRINOX-based neoadjuvant therapy. Cancers 15, 3765 (2023).
Strippoli, A. et al. ERCC1 expression affects outcome in metastatic pancreatic carcinoma treated with FOLFIRINOX: a single institution analysis. Oncotarget 7, 35159 (2016).
Kirschner, K. & Melton, D. Multiple roles of the ERCC1-XPF endonuclease in DNA repair and resistance to anticancer drugs. Anticancer Res. 30, 3223–3232 (2010).
Zhu, X. et al. A super-enhancer controls TGF-β signaling in pancreatic cancer through downregulation of TGFBR2. Cell. Signal. 66, 109470 (2020).
Huang, H. et al. Targeting TGFβR2-mutant tumors exposes vulnerabilities to stromal tgfβ blockade in pancreatic cancer. EMBO Mol. Med. 11, e10515 (2019).
Armstrong, S., Pan, T., Dicker, D., Arteaga, C. & El-Deiry, W. Atm dysfunction in pancreatic adenocarcinoma and associated therapeutic implications. Mol. Cancer Ther. 18, 1899–1908 (2019).
Martino, C. et al. Atm-mutated pancreatic cancer: clinical and molecular response to gemcitabine/nab-paclitaxel after genome-based therapy resistance. Pancreas 49, 143–147 (2020).
Weinstein, J. N. et al. The Cancer Genome Atlas pan-cancer analysis project. Nat. Genet. 45, 1113–1120 (2013).
Guo, S. et al. A deconvolution framework that uses single-cell sequencing plus a small benchmark data set for accurate analysis of cell type ratios in complex tissue samples. Genome Res. 35, 147–161 (2025).
Kleinbaum, D. G. & Klein, M. Kaplan-Meier Survival Curves and the Log-Rank Test 3rd edn. 55–96 (Springer, 2012).
Wen, W. X., Mead, A. J. & Thongjuea, S. MARVEL: an integrated alternative splicing analysis platform for single-cell RNA sequencing data. Nucleic Acids Res. 51, e29 (2023).
Chi, H. et al. Analysis of alternative splicing heterogeneity during early stages of mouse embryonic development. Current Bioinformatics https://doi.org/10.2174/0115748936376211250429102627 (2025).
Liu, W. & Zhang, X. Single-cell alternative splicing analysis reveals dominance of single transcript variant. Genomics 112, 2418–2425 (2020).
Huang, Y. & Sanguinetti, G. Brie: transcriptome-wide splicing quantification in single cells. Genome Biol. 18, 1–11 (2017).
Al Barashdi, M. A., Ali, A., McMullin, M. F. & Mills, K. Protein tyrosine phosphatase receptor type c (PTPRC or CD45). J. Clin. Pathol. 74, 548–552 (2021).
Alexander, D. The CD45 tyrosine phosphatase: a positive and negative regulator of immune cell function. Semin. Immunol. 12, 349–359 (2000).
Wen, W. X., Mead, A. J. & Thongjuea, S. Valerie: visual-based inspection of alternative splicing events at single-cell resolution. PLOS Comput. Biol. 16, e1008195 (2020).
Garrido-Martín, D., Palumbo, E., Guigó, P. P. & Eyras, E. ggsashimi: Sashimi plot revised for browser- and annotation-independent splicing visualization. PLOS Comput. Biol. 14, e1006360 (2018).
Hu, T. et al. Tumor-intrinsic CD47 signal regulates glycolysis and promotes colorectal cancer cell growth and metastasis. Theranostics 10, 4056–4072 (2020).
Zhang, Y., Sime, W., Juhas, M. & Sjölander, A. Crosstalk between colon cancer cells and macrophages via inflammatory mediators and cd47 promotes tumour cell migration. Eur. J. Cancer 49, 3320–3334 (2013).
Carsetti, R. et al. Comprehensive phenotyping of human peripheral blood B lymphocytes in healthy conditions. Cytom. Part A 101, 131–139 (2022).
Pelaseyed, T. et al. The mucus and mucins of the goblet cells and enterocytes provide the first defense line of the gastrointestinal tract and interact with the immune system. Immunol. Rev. 260, 8–20 (2014).
Vereecke, L., Beyaert, R. & van Loo, G. Enterocyte death and intestinal barrier maintenance in homeostasis and disease. Trends Mol. Med. 17, 584–593 (2011).
Mojica, W. & Hawthorn, L. Normal colon epithelium: a dataset for the analysis of gene expression and alternative splicing events in colon disease. BMC Genom. 11, 1–14 (2010).
Hall, A. E. et al. RNA splicing is a key mediator of tumour cell plasticity and a therapeutic vulnerability in colorectal cancer. Nat. Commun. 13, 2791 (2022).
Buen Abad Najar, C. F., Yosef, N. & Lareau, L. F. Coverage-dependent bias creates the appearance of binary splicing in single cells. eLife 9, e54603 (2020).
Oh, H.-H. et al. CD47 mediates the progression of colorectal cancer by inducing tumor cell apoptosis and angiogenesis. Pathol. Res. Pract. 240, 154220 (2022).
Bray, N. L., Pimentel, H., Melsted, P. & Pachter, L. Near-optimal probabilistic RNA-seq quantification. Nat. Biotechnol. 34, 525–527 (2016).
Wang, H.-Y., Zhao, J.-P., Zheng, C.-H. & Su, Y.-S. scGMAAE: Gaussian mixture adversarial autoencoders for diversification analysis of scRNA-seq data. Brief. Bioinform. 24, bbac585 (2023).
Tian, T., Wan, J., Song, Q. & Wei, Z. Clustering single-cell RNA-seq data with a model-based deep learning approach. Nat. Mach. Intell. 1, 191–198 (2019).
Rosenberg, A. & Hirschberg, J. V-measure: a conditional entropy-based external cluster evaluation measure. In Proc. 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL). 410–420 (ACL SIGDAT and ACL SIGNLL, 2007).
Vinh, N. X., Epps, J. & Bailey, J. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. J. Mach. Learn. Res. 11, 2837–2854 (2010).
Song, Y. et al. Mining alternative splicing patterns in scrna-seq data using scasfind. Genome Biol. 25, 197 (2024).
Sugnet, C. W., Kent, W. J., Ares, M. & Haussler, D. Transcriptome and genome conservation of alternative splicing events in humans and mice. In Proc. Pacific Symposium on Biocomputing 2003 66–77 (World Scientific, 2003).
Jiang, W. & Chen, L. Alternative splicing: Human disease and quantitative analysis from high-throughput sequencing. Comput. Struct. Biotechnol. J. 19, 183–195 (2021).
Yeo, G., Holste, D., Kreiman, G. & Burge, C. B. Variation in alternative splicing across human tissues. Genome Biol. 5, 1–15 (2004).
Pearson, K. LIII. On lines and planes of closest fit to systems of points in space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 2, 559–572 (1901).
Halperin, R. F. et al. Improved methods for RNAseq-based alternative splicing analysis. Sci. Rep. 11, 10740 (2021).
Pan, Q., Shai, O., Lee, L. J., Frey, B. J. & Blencowe, B. J. Deep surveying of alternative splicing complexity in the human transcriptome by high-throughput sequencing. Nat. Genet. 40, 1413–1415 (2008).
Sultan, M. et al. A global view of gene activity and alternative splicing by deep sequencing of the human transcriptome. Science 321, 956–960 (2008).
Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 27, 861–874 (2006).
Boyd, K., Eng, K. H. & Page, C. D. Area under the precision-recall curve: point estimates and confidence intervals. In Proc. Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2013, Prague, Czech Republic, September 23-27, 2013 Vol. Part III, 451–466 (Springer Berlin Heidelberg, 2013).
Hu, Y. et al. Diffsplice: the genome-wide detection of differential splicing events with RNA-seq. Nucleic Acids Res. 41, e39–e39 (2013).
Cunningham, F. et al. Ensembl 2022. Nucleic Acids Res. 50, D988–D995 (2022).
Bolger, A. M., Lohse, M. & Usadel, B. Trimmomatic: a flexible trimmer for illumina sequence data. Bioinformatics 30, 2114–2120 (2014).
Dobin, A. et al. Star: ultrafast universal RNA-seq aligner. Bioinformatics 29, 15–21 (2013).
Liao, Y., Smyth, G. K. & Shi, W. featurecounts: an efficient general purpose program for assigning sequence reads to genomic features. Bioinformatics 30, 923–930 (2014).
Zheng, G., Terry, J. & Belgrader, P. et al. Massively parallel digital transcriptional profiling of single cells. Nat. Commun. 8, 14049 (2017).
Barnett, D. W., Garrison, E. K., Quinlan, A. R., Strömberg, M. P. & Marth, G. T. Bamtools: a C++ API and toolkit for analyzing and managing BAM files. Bioinformatics 27, 1691–1692 (2011).
Traag, V. A., Waltman, L. & Van Eck, N. J. From Louvain to Leiden: guaranteeing well-connected communities. Sci. Rep. 9, 1–12 (2019).
Finak, G., McDavid, A. & Yajima, M. et al. Mast: a flexible statistical framework for assessing transcriptional changes and characterizing heterogeneity in single-cell RNA sequencing data. Genome Biol. 16, 278 (2015).
Darlington, R. B. & Hayes, A. F. Combining independent p values: extensions of the Stouffer and binomial methods. Psychol. Methods 5, 496 (2000).
Li, Y. & Ghosh, D. Meta-analysis based on weighted ordered p-values for genomic data with heterogeneity. BMC Bioinform. 15, 1–12 (2014).
Olkin, S. & Pratt, J. W. Unbiased estimation of certain correlation coefficients. Ann. Math. Stat. 29, 201–211 (1958).
Martens, M. et al. Wikipathways: connecting communities. Nucleic Acids Res. 49, D613–D621 (2021).
of Genome Resources Consortium, A. The alliance of genome resources: Building a modern data ecosystem for model organism databases. Genetics 213, 1189–1196 (2019).
Landrum, M. J. et al. Clinvar: improving access to variant interpretations and supporting evidence. Nucleic Acids Res. 46, D1062–D1067 (2018).
Piñero, J. et al. DisGeNET: a comprehensive platform integrating information on human disease-associated genes and variants. Nucleic Acids Res. 45, D833–D839 (2016).
Hamosh, A., Scott, A. F., Amberger, J. S., Bocchini, C. A. & McKusick, V. A. Online Mendelian Inheritance in Man (OMIM), a knowledgebase of human genes and genetic disorders. Nucleic Acids Res. 33, D514–D517 (2005).
Goldman, M. J. et al. Visualizing and interpreting cancer genomics data via the Xena platform. Nat. Biotechnol. 38, 675–678 (2020).
Sun, D. et al. Identifying phenotype-associated subpopulations by integrating bulk and single-cell sequencing data. Nat. Biotechnol. 40, 527–538 (2022).
Burset, M., Seledtsov, I. A. & Solovyev, V. V. Analysis of canonical and non-canonical splice sites in mammalian genomes. Nucleic Acids Res. 28, 4364–4375 (2000).
Rousseeuw, P. J. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 20, 53–65 (1987).
Büttner, M., Miao, Z., Wolf, F. A., Teichmann, S. A. & Theis, F. J. A test metric for assessing single-cell RNA-seq batch correction. Nat. Methods 16, 43–49 (2019).
Kaminow, B., Yunusov, D. & Dobin, A. STARsolo: accurate, fast and versatile mapping/quantification of single-cell and single-nucleus RNA-seq data. Preprint at bioRxiv https://www.biorxiv.org/content/10.1101/2021.05.05.442755v1 (2021).
Shen, S. et al. rmats: robust and flexible detection of differential alternative splicing from replicate RNA-seq data. Proc. Natl. Acad. Sci. USA 111, E5593–E5601 (2014).
Sterne-Weiler, T., Weatheritt, R. J., Best, A. J., Ha, K. C. & Blencowe, B. J. Efficient and accurate quantitative profiling of alternative splicing patterns of any complexity on a laptop. Mol. Cell 72, 187–200.e6 (2018).
Frazee, A. C., Jaffe, A. E., Langmead, B. & Leek, J. T. Polyester: simulating Rna-seq datasets with differential transcript expression. Bioinformatics 31, 2778–2784 (2015).
Rizzetto, S. et al. Impact of sequencing depth and read length on single cell RNA sequencing data of T cells. Sci. Rep. 7, 12781 (2017).
10x Genomics. If full-length mRNA is transcribed, how is the assay biased to 3’ or 5’? Accessed 26 April 2025; https://kb.10xgenomics.com/hc/en-us/articles/360004740391-If-full-length-mRNA-is-transcribed-how-is-the-assay-biased-to-3-or-5 (2023).
10x Genomics. What is the difference between single cell 3’ and 5’ gene expression libraries? Accessed 26 April 2025; https://kb.10xgenomics.com/hc/en-us/articles/360000939852-What-is-the-difference-between-Single-Cell-3-and-5-Gene-Expression-libraries (2023).
Song, K. et al. Dolphin advances single-cell transcriptomics beyond gene level by leveraging exon and junction reads. https://doi.org/10.5281/zenodo.15611935 (2025).
Song, K. et al. Dolphin advances single-cell transcriptomics beyond gene level by leveraging exon and junction reads. https://doi.org/10.5281/zenodo.15602232 (2025).
Acknowledgements
This work is supported by grants from the Canadian Institutes of Health Research (CIHR) [PJT-180505 to J.D.]; the Funds de recherche du Québec—Santé (FRQS) [295298 to J.D., 295299 to J.D., 366764 to J.D.]; the Natural Sciences and Engineering Research Council of Canada (NSERC) [RGPIN2022-04399 to J.D.]; and the Meakins-Christie Chair in Respiratory Research [to J.D.].
Author information
Authors and Affiliations
Contributions
J.D. conceived and designed the study, developed the methodology, and planned the experiments. K.S. contributed to the design, implementation of the methodology and conducted the experiments. J.D. and K.S. participated in data collection and the analysis of computational experiments. All authors (J.D., K.S., Y.Z., B.Z., D.E., J.T.) contributed to writing the manuscript. Each author has read and approved the final manuscript for publication.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Sean Wen and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Song, K., Zheng, Y., Zhao, B. et al. DOLPHIN advances single-cell transcriptomics beyond gene level by leveraging exon and junction reads. Nat Commun 16, 6202 (2025). https://doi.org/10.1038/s41467-025-61580-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-61580-w
