
Abstract
Forensic pathology plays a vital role in determining the cause and manner of death through macroscopic and microscopic post-mortem examinations. However, the field faces challenges such as variability in outcomes, labor-intensive processes, and a shortage of skilled professionals. This paper introduces SongCi, a visual-language model tailored for forensic pathology. Leveraging advanced prototypical cross-modal self-supervised contrastive learning, SongCi improves the accuracy, efficiency, and generalizability of forensic analyses. Pre-trained and validated on a large multi-center dataset comprising over 16 million high-resolution image patches, 2, 228 vision-language pairs from post-mortem whole slide images, gross key findings, and 471 unique diagnostic outcomes, SongCi demonstrates superior performance over existing multi-modal models and computational pathology foundation models in forensic tasks. It matches experienced forensic pathologists’ capabilities, significantly outperforms less experienced practitioners, and offers robust multi-modal explainability.
Similar content being viewed by others

Introduction
The medicolegal autopsy, commonly known as a post-mortem examination, is conducted by a forensic pathologist to examine the body of a deceased individual meticulously1,2. The purpose of this examination is to determine the cause and manner of death and identify any diseases or injuries present3. As a cornerstone of forensic science, autopsies are crucial for both legal and medical analysis4. Within the criminal justice system, they provide essential evidence that may implicate or exonerate individuals5. Additionally, autopsies significantly advance medical knowledge regarding various health conditions6.
Forensic pathologists conduct autopsies using a comprehensive methodology that spans from macroscopic to microscopic analysis. This process encompasses external inspection of the body’s surface, internal examination via dissection to assess organ systems, toxicological analysis of bodily fluids, and histopathological analysis of tissue samples1,7. The insights gleaned from these assessments, including macroscopic observations at the organ level and microscopic details at the cellular level, are integral to generating precise and dependable autopsy reports. These reports are essential not only for determining the cause and manner of death but also for estimating the time since death8.
However, conducting precise post-mortem examinations, especially in forensic pathology, poses substantial challenges. The accuracy of these examinations relies heavily on the expertise and subjective assessments of forensic pathologists, leading to considerable variability in outcomes9,10. Such variability can result in inconsistent findings, even among forensic pathologists with similar training, and is especially marked in complex cases11,12. Forensic pathology is also a labor-intensive and time-consuming discipline, requiring experienced pathologists to invest significant time in analyzing a single whole slide image (WSI)13. The complexity increases when multiple organ analyses are necessary. Furthermore, the stringent standards of forensic pathology, combined with a shortage of skilled professionals, exacerbate these issues, impacting the overall efficiency and precision of the field14,15.
In recent years, computational pathology (CPath), augmented by artificial intelligence (AI), has demonstrated significant potential in a range of clinical pathology tasks, including cancer diagnosis and subtyping16,17, metastasis detection18, and patient survival prediction19. The typical approach involves training deep neural networks driven by specific tasks on carefully labeled samples. However, the arduous and expensive process of sample collection and labeling, particularly for WSIs, restricts the availability of training data, thereby limiting the scalability and generalizability of these AI models. Medical self-supervised learning (SSL) has become a transformative approach to address such challenges, enabling models to learn from vast amounts of unlabeled data and reducing reliance on costly, labor-intensive annotations. SSL techniques like contrastive learning,20,21 generative models22,23, and masked autoencoders24,25 allow for pre-training on large datasets (e.g., WSIs)26 without human supervision. These pre-trained models can then be fine-tuned with smaller labeled datasets for specific tasks27, enhancing the scalability, robustness, and performance of AI models in diverse clinical applications28,29,30. Inspired by the remarkable advancements in SSL and foundation models within the broader machine learning community, recent CPath studies have begun to pre-train models using a variety of unlabeled data, subsequently fine-tuning them for specific downstream tasks, exemplifying the SSL-based transfer learning paradigm31,32. To enhance generalization and robustness, some innovative studies have integrated pathological images with linguistic information (e.g., pathologists’ reports, scholarly articles, or medical textbooks) to pre-train visual-language models (VLMs)33,34,35. These models capitalize on the critical semantic information and in-depth domain knowledge contained in textual descriptions to improve the contextual interpretation of histopathological images, resulting in more prosperous and nuanced feature representations. Such advancements in CPath research have significantly refined the workflow and contributed to the advancement of clinical pathology, offering valuable insights for forensic pathological analysis.
Nevertheless, the direct application of clinical-focused models to forensic pathology presents challenges due to the unique characteristics of forensic samples and tasks. Autopsy is a pivotal tool in forensic pathology36, enabling comprehensive data collection, where diagnostic results are derived by integrating gross anatomical findings with histopathological observations—an approach distinct from clinical pathology6,37. Such autopsy data often exhibit intricate post-mortem changes absent in clinical biopsies. Furthermore, most forensic cases involve accidental deaths, with tumor- or cancer-related fatalities being exceedingly rare38,39. In contrast, existing CPath foundation models26,28,40,41, such as those based on The Cancer Genome Atlas (TCGA)42 and CAMELYON43, are predominantly trained on cancer-related datasets, creating a substantial domain gap. Moreover, forensic autopsies typically encompass a more comprehensive range of conditions (e.g., trauma, disease, and postmortem changes) and organs (e.g., brain, heart, and lung), whereas clinical biopsies usually concentrate on a single organ and task44,45. Consequently, forensic CPath displays more extensive large-vocabulary attributes. These distinctions necessitate the development of specialized models for forensic CPath, which requires forensic-specific pretraining data and more sophisticated SSL approaches to acquire fine-grained, multi-modal representations from such demanding data.
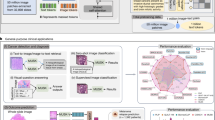
To address these deficiencies, this paper introduces a VLM tailored for extensive forensic pathology lexicons. It is pre-trained using cross-modal self-supervised contrastive learning methods on a heterogeneous collection of multi-organ post-mortem WSIs paired with descriptive texts. The model was christened SongCi in tribute to Song Ci, the trailblazer of forensic science during the Southern Song dynasty. (Note: Song Ci was a distinguished forensic medical scientist from the Southern Song dynasty, renowned as the inaugural forensic entomologist. His judicial case examinations and experiences are documented in the seminal work “Collected Cases of Injustice Rectifie”, available on Wikipedia.), aiming to augment forensic examinations' precision and efficiency. SongCi strives to deliver more comprehensive and dependable diagnostic results by integrating multi-modal data. Specifically, we collect a multi-center dataset consisting of a total of 2228 vision-language pairs of post-mortem WSIs (images), gross key findings at the organ level (texts), and final forensic diagnostic outcomes (texts) from nine different organs (Fig. 1a). These data contribute to more than 16 million high-resolution image patches and 471 different diagnostic outcomes, with only 34 of these diagnoses consistently existing across all forensic centers (Fig. 1b). Two pivotal SSL strategies have been developed for nuanced post-mortem representation learning. First, we propose a prototypical contrastive learning strategy (Fig. 1c) to construct a prototypical patch-level encoder. This encoder transforms all patches of an ultra-high resolution WSI (e.g., 10,000 × 10,000 pixels) into a lower-dimensional prototype space, effectively distilling redundant information to extract generalizable patch representations of post-mortem tissues from various organs. Second, leveraging the pre-trained prototypical patch-level encoder and a pathology-specific language model46, we introduce a cross-modal contrastive learning strategy (Fig. 1d). This strategy creates a gated-attention-boosted multi-modal block that integrates representations from paired WSI and gross key findings to align with forensic examination outcomes. Subsequently, the pre-trained prototype encoder, language model, and multi-modal block are integrated for zero-shot inference (Fig. 1e). Given gross key findings and corresponding WSIs, a forensic pathologist can propose a set of potential outcomes as textual queries for any unseen subject. SongCi then predicts the final diagnostic results, providing detailed explanatory factors that underscore the critical elements associated with these predictions. SongCi’s effectiveness is validated across a spectrum of forensic pathology tasks, including patch-level post-mortem image generation, self-supervised WSI-level segmentation, extensive forensic diagnosis, and cross-modal explainability analysis. Our results show that SongCi surpasses state-of-the-art multi-modal AI models in internal and external cohorts. Moreover, comparative analysis with forensic pathologists at varying expertise levels reveals that SongCi’s insights are on par with those of seasoned experts and significantly surpass those of less experienced pathologists.

a Overview of WSI data. The dataset spans a broad spectrum of samples from nine different human organs, each meticulously annotated. b Data structure and provenance. The dataset was compiled from three premier forensic cohorts. Diagnostic outcomes in forensic pathology were represented using a word cloud and a Venn diagram to illustrate the distribution and overlap of diagnoses. c Training process of patch-level prototype encoder. SongCi utilizes a self-supervised contrastive learning framework, augmented with prototype-based clustering strategies to enhance efficiency, forming the basis of the prototypical patch-level encoder. d Training process of cross-multimodality fusion and alignment layer. Within the SongCi framework, diverse data modalities, including gross key findings and WSIs, are integrated using an innovative gated-attention-boosted multimodal fusion block. Subsequently, the framework aligns the unified representation space with forensic pathological diagnoses through self-supervised contrastive learning, effectively establishing inter-modal correlations. e Inference process of SongCi. SongCi processes the gross anatomical key findings and WSIs to generate a potential diagnosis. Additionally, SongCi provides a diagnostic rationale by highlighting significant terms related to the gross key findings and identifying suspicious regions within the WSIs. For more detailed information, please refer to the “Methods” section.
Results
Visualization of post-mortem WSI prototypes across different organs
In a task-agnostic fashion, SongCi employs a prototypical contrastive learning strategy to derive generalizable image representations from post-mortem WSIs of various organs, as depicted in Fig. 1c. Each WSI is segmented into a collection of patches, and an image encoder extracts patch-level representations. These are then projected into a low-dimensional space defined by shared prototypes across WSIs. In our study, we learned a total of 933 prototypes using this SSL method. The organization of these prototypes was visualized using the two-dimensional UMAP technique47 and bar plot, as illustrated in Fig. 2a and Supplementary Fig. 1, where each dot signifies a prototype, color-coded according to the organ type of the nearest patches. The post-mortem WSIs encompass nine distinct organ types, each represented by a unique color: brain, adrenal gland, heart, gastrointestinal tract, kidney, liver, lung, pancreas, and spleen. Patches from the WSIs are associated with their closest prototype, imparting the corresponding color to the prototype. Figure 2a reveals distinct clustering patterns among the prototypes, with some exhibiting uniform colors, denoting intra-tissue prototypes that encode tissue-specific features, such as myocardial hypertrophy and pneumorrhagia (see Fig. 2c). Conversely, prototypes with mixed colors represent inter-tissue prototypes that encapsulate standard histopathological features across different organs, including autolysis, inflammation, fibrosis, and hemorrhage (refer to Fig. 2b). These findings suggest that the prototype representations encapsulate both tissue-specific and cross-tissue-shared characteristics from high-resolution WSIs, establishing a versatile foundation for downstream tasks.

a The prototype representation space is visualized using a 2D UMAP, where 933 dots represent the prototypes, with each dot colored according to the proportion of tissue types it represents. Source data are provided as a Source Data file. b, c Prototype-conditioned patch-level generation results. Sub-figure b shows the results for inter-tissue-specific prototypes, including autolysis, inflammation, fibrosis, and hemorrhage. Sub-figure (c) displays intra-tissue-specific prototypes, such as myocardial hypertrophy, cerebral edema, muscular tissue, pneumorrhagia, and hepatic steatosis. d, e The conditional diffusion models are exhibited. Sub-figure (d) illustrates the prototype-based conditional diffusion model, and sub-figure (e) shows the instance-based model. f The results of instance-based patch-level generation are presented, featuring representative instances like renal tubules with hemorrhage, normal renal tubules, liver fat particles (undissolved), and splenic trabeculae.
Quality of SSL representations of post-mortem WSIs
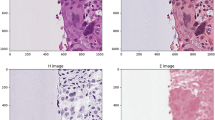
To comprehensively analyze the quality of patch-wise and prototypical image representations produced by the dedicated patch-level encoder of SongCi, we conducted a series of targeted evaluations, including (1) using these representations as the condition to generate synthetic post-mortem images, (2) quantifying the attention values between image tokens (i.e., patch-wise representations) and class tokens, and (3) low-dimensional visualization of image representations based on Principal Component Analysis (PCA). We employed conditional diffusion models48 to generate WSI patches from random noise in a controllable fashion, where pretrained prototypical and patch-wise representations were used as the conditions, respectively (as shown in Fig. 2d, e). As has been reported48, such conditional generation could be a straightforward way to quantify the generalizability of SSL representations, considering that these conditions/representations directly determine the fidelity and controllability of generated images. Figure 2b displays synthesized images conditioned on four distinct inter-tissue prototypes, respectively. It can be observed that these generated images exhibit representations of post-mortem patterns with high fidelity. That is, they correspond to various representative post-mortem states: extensive autolysis with cellular structure loss, inflammation with abundant lymphocytes, fibrosis, and hemorrhage with dense erythrocytes. Besides, Fig. 2c shows representative synthetic images conditioned on five intra-tissue prototypes, respectively, from which we can see relatively specific historiographical patterns of different organs, such as myocardial hypertrophy and cerebral edema. Figure 2b, c suggest that SongCi’s prototypical WSI representations are highly generalizable to encode both inter-tissue shared and intra-tissue specific post-mortem features across varying organs (refer to Supplementary Fig. 2 for more examples). On the other hand, Fig. 2f showcases an image generated using specific instance representations as the conditions. As can be seen, these images retain intricate details of the original instances, highlighted by yellow boxes in Fig. 2f, including renal tubules with hemorrhage, normal renal tubules, liver fat particles (undissolved), and splenic trabeculae. This indicates that SongCi’s instance embeddings are highly detailed, laying a robust groundwork for distilling generalizable prototypes across various organs.
We further calculated the visual attention maps in terms of WSIs’ instance representations and respective class tokens to verify the discriminative capacity of SongCi’s pretrained vision encoder, with typical examples summarized in Supplementary Fig. 3. These quantitative attention maps exhibit a strong focus on key pathological regions, such as tuberculous nodules in pulmonary tuberculosis, congested areas in myocardial hyperemia, and specific glandular regions in the gastrointestinal tract. It implies that, capitalized on the dedicated prototypical contrastive pretraining of the patch-level encoder, SongCi can effectively identify discriminatingly significant patterns from ultra-high-resolution WSI inputs. Furthermore, we performed a PCA-based dimensionality reduction of the learned representations and visualized the saliency (“RGB”) maps for each WSI patch encoded by the top-three PCA components. Representative cases shown in Supplementary Fig. 4 demonstrate that such saliency maps feature a strong capability to delineate the foreground boundaries within an input image. For example, they accurately segmented key structures such as glomeruli, alveoli, splenic trabeculae, and myocardial tissue. All these results provide compelling evidence of SongCi’s discriminative capacity and generalizability in representing diverse post-mortem tissue types.
Self-supervised segmentation of post-mortem WSIs
Tissue and cell segmentation are fundamental steps in CPath. Beyond image generation and feature visualizations, we applied the pre-trained prototypical patch-level encoder of SongCi for self-supervised WSI segmentation without fine-tuning. Specifically, we treated each prototype learned by SongCi as a semantic mask, enabling efficient labeling of all patches in a WSI by matching them with their closest prototypes based on the cosine similarity of their representations. Figure 3 showcases representative self-supervised segmentations by SongCi from four different organs: the spleen, brain, heart, and liver. They were compared with that obtained by two approaches typically employed in CPath analysis, including an iterative clustering algorithm, i.e., H2T49,50,51, and a clustering algorithm based on Gaussian mixture model (GMM), i.e., PANTHER52. We can observe that SongCi (Fig. 3d) led to much better WSI segmentations in all cases (refer to Supplementary Fig. 5 for more examples). Overall, the segmentations by SongCi exhibit marked superiority, e.g., as evidenced by the precisely fine-grained differentiation between parenchyma and mesenchyme within splenic and hepatic tissues, which are delineated by the red and various other colored sections, respectively. Furthermore, SongCi achieved a level of granularity in brain and myocardial segmentation that aligns closely with cellular structures. In contrast, conventional clustering algorithms (i.e., H2T and PANTHER) tend to result in noisy annotations that incorrectly separate identical tissues, as indicated by the black boxes in Fig. 3b, c. As a supplementary to such qualitative comparisons, we also conducted a rigorous quantitative comparison between SongCi, H2T, and PANTHER in the downstream diagnostic inference tasks. That is, the clustering centroids (or prototypes) obtained by H2T and PANTHER were used in the same way as SongCi’s prototypes to build the VLMs for forensic diagnosis. The corresponding results across both the Internal and two external cohorts are summarized in Supplementary Table 1. As can be seen, consistent with the qualitative segmentation comparisons, these quantitative results demonstrate that SongCi outperformed others in terms of Precision, Recall, and IOU in the diagnosis task, further verifying that SongCi learned more discriminative and generalizable prototypical representations than H2T and PANTHER.

a The original WSIs of four different tissues, including spleen, brain, myocardium, and liver tissues. b, c, d illustrate the segmentation outcomes utilizing a traditional clustering method (i.e., H2T), a GMM-based clustering method (i.e., PANTHER), and our prototype-based methods (i.e., SongCi), respectively. Specifically, the input image is partitioned into seven distinct masks, with each of them represented by a unique color based on the number of patches within: orange, yellow, pink, blue, white, green, and crimson. The top four prevalent mask types for each image are indicated at the bottom of the figure. Also, the key distinctions between the three segmentation approaches are highlighted with black borders.
Notably, in addition to better segmentation accuracy, SongCi features two technical advantages compared with existing clustering algorithms in the analysis of ultra-high-resolution WSIs. First, SongCi is much more computationally efficient, due to the fact that it avoids the iterative optimization steps commonly required by clustering algorithms like K-means and GMM. That is, SongCi derives the segmentation outputs in an one-shot fashion, in contrast to iterative optimization necessarily with multiple steps for convergence. Second, SongCi is more robust and generalizable in segmentation heterogeneous WSI across organs and centers, considering that it determines the number of clusters in a purely data-driven fashion without the need to manually select a specific number, a crucial step that largely influences the performance of conventional clustering algorithms.
Large-vocabulary forensic diagnosis, with comparisons to existing VLMs
Leveraging the pre-trained patch-level encoder and a pathology-dedicated language model (i.e., PLIP46), SongCi designs a cross-modal contrastive learning strategy to learn from multi-modal inputs (i.e., gross key findings and WSIs) a gated-attention-empowered VLM for zero-shot forensic diagnosis, with the schematic diagram shown in Fig. 1d. First of all, we applied this model to the internal cohort and two external cohorts with significantly different data distributions (Fig. 1e), and compared the performance with six state-of-the-art VLMs from both the medical and general machine-learning communities, including IRENE53, BottleNeckFusion54, DLNMS55, GIT56, Perceiver57, and MCAT19. The quantitative results in terms of three metrics (i.e., Recall, Precision, and IOU) obtained by these methods across different organs are summarized in Fig. 4 and Supplementary Table 2. We can see that, on average, SongCi consistently outperformed all other competing VLMs by large margins in terms of all three metrics. Specifically, on the internal cohort, external cohort I, and external cohort II, SongCi got a mean Recall of 0.823 ± 0.119, 0.778 ± 0.091, and 0.770 ± 0.132, a mean Precision of 0.814 ± 0.164, 0.773 ± 0.131, and 0.742 ± 0.117, and a mean IOU of 0.682 ± 0.145, 0.617 ± 0.086, and 0.594 ± 0.070, respectively. Compared with other VLMs, the average improvements range between 10 and 20% in most cases. To go into more detail, we can observe that SongCi performed significantly better than other VLMs on the two external cohorts in handling post-mortem WSIs from most organs, e.g., brain, heart, lung, and liver, which are closely related to issues such as cause of death determination and manner of death identification.

The evaluation benchmarks SongCi against six established models utilizing three key performance metrics: recall, precision, and intersection over union (IoU). Radar charts illustrate the algorithm’s efficacy across nine different organs, and the associated table below consolidates the average scores for these organs, with the highest values emphasized in bold. Source data are provided as a Source Data file.
Furthermore, to comprehensively assess the performance in large-vocabulary forensic pathological analysis, we applied SongCi to the challenging tasks of off-set and low-frequency diagnosis (Table 1). Specifically, the off-set samples are a subset of each external cohort whose ground-truth diagnostic labels do not exist in the internal cohort for pre-training. The low-frequency samples have labels occurring less than ten times in the corresponding cohorts. Table 1 shows that SongCi consistently led to the best Recall in the off-set and low-frequency diagnosis tasks compared to other VLMs. Notably, these results were obtained by the zero-shot inference via the pre-trained multi-modality models, demonstrating the promising generalizability of SongCi.
Comparisons between SongCi and forensic pathologists
We compared SongCi with five forensic pathologists with varying expertise levels, i.e., two senior forensic pathologists (SP) with more than 15 years of experience, two junior pathologists (JP) with more than 5 years of experience, and a pathologist assistant (PA). Specifically, considering the time-consuming and demanding process of forensic pathology analysis, we selected 100 samples with an unambiguous diagnosis from the two external cohorts and assigned them to these forensic pathologists. We also distributed the internal cohort and ground-truth labels to these experts. Each forensic pathologist analyzed these external samples and made their predictions independently using the internal cohort as the reference. The results quantified on such an external subset are summarized in Table 2 and Supplementary Fig. 9. From the precision-recall (PR) curve shown in Supplementary Fig. 9 and the metric values in Table 2, we can see that SongCi’s performance aligns closely with an SP and significantly surpasses the other SP, two JPs, and the PA. Notably, besides the accuracy matching up with the seasoned pathologists, SongCi outperforms in efficiency (i.e., 0.37 versus 7 h in Table 2), suggesting that it could significantly reduce the workload of forensic pathology in practice.
Comparisons between the prototypical patch-level encoder and state-of-the-art CPath models
The prototypical patch-level encoder pretrained via dedicated SSL strategies is a key component of SongCi for forensic diagnosis. To comprehensively evaluate the significance of this technical design, we first compared such a prototypical encoder with six representative pretrained CPath encoders, including LUNIT-DINO40, CTransPath41, PLIP46, CONCH29, UNI28, and Prov-GigaPath26. Specifically, for a fair and consistent comparison, we replaced our pretrained prototypical encoder with each of the competing CPath models to derive corresponding variants of SongCi. The prototype space was subsequently generated using an iterative clustering method50,58, and these variants were applied to perform forensic diagnosis under identical experimental conditions. The overall diagnostic results obtained by different patch-level encoders on the Internal and two external cohorts are shown in Table 3, with the detailed comparisons across each organ summarized in Supplementary Fig. 6 and Supplementary Table 3. From Table 3, we can see that state-of-the-art CPath foundation models, e.g., PLIP46 and Prov-GigaPath26, led to more promising results in forensic diagnosis compared with other variants, demonstrating the importance of large-scale pretraining in improving the model’s generalizability in downstream tasks. In addition, we can see that SongCi consistently outperformed these leading foundation models in terms of all metrics (i.e., recall, precision, and IOU) across both the internal and external cohorts. For example, compared with PLIP, SongCi improved the mean IOU by 12–17% across the internal and external cohorts. In terms of Precision and Recall, SongCi yielded around 5–9% improvements over Prov-GigaPath across different cohorts. Similarly, the detailed results in Supplementary Fig. 6 show that SongCi exhibits robust generalizability in handling multi-organ diagnostic tasks. For example, it outperformed these competitors in 5 out of 9 organ-specific diagnostic tasks on the internal cohort, excelling particularly in the detection of complex cross-organ pathological changes, such as those affecting the brain and the heart. Consistent observations can also be drawn on the two external cohorts. These results implies that large domain gaps exist between clinical and forensic pathology from both the data and downstream task perspectives. The prototypical patch-level encoder drove SongCi to more seamlessly match up with the specific challenges in large-vocabulary forensic diagnosis.
To further evaluate the efficacy of the dedicated SSL desgin, i.e., the prototypical contrastive learning step, we compared it with five cutting-edge SSL approaches, including Beit25, DinoV259, MAE24, SWAV60, and SimCLR21, by applying them to forensic diagnosis under the same experimental settings. Overall results on the three different datasets (Supplementary Table 4) and detailed comparisons across nine different organs (Supplementary Fig. 7) demonstrate that such a dedicated contrastive learning strategy outperformed other competitors by relatively large margins, demonstrating the effectiveness of our technical designs in handling challenging post-mortem CPath tasks.
Multi-modal explainability in forensic pathological analysis
SongCi aggregates WSI prototypes and gross key findings to align them with the diagnostic outcomes by learning word/prototype-level attention scores via cross-modal contrastive learning. By nature, these scores also provide critical multi-modal explanation factors for fine-grained analysis of the model’s final predictions. In Fig. 5 and Supplementary Fig. 8, we show some representative examples across different organs, where, for each case, the top-five prototypes (projected back to the WSIs) and top-five words (located in the text of gross key findings) are highlighted by distinct colors. From Fig. 5, we can have some exciting observations. For instance, as shown in Fig. 5a, the multi-modal attention visualizations regarding liver cirrhosis highlighted meaningful WSI regions and respective words from the gross key findings at the organ level strongly associated with such a specific disease. The WSI’s emphasized segment illustrates the typical alterations related to cirrhosis, i.e., pseudolobules. From the gross key findings aspect, the highlighted term “coarse” implies that cirrhosis-affected livers exhibit unevenly sized nodules on their surface, resulting from pseudolobule development, which seems coarse to the unaided eye. The term “1intersection” refers to the overlapping of various colors present on the cirrhosis liver’s surface. The terms “surface”, “section”, and “changed” provide important cues regarding the disease’s appearance and position. We can also find that such explanations by SongCi are relatively stable and reproducible, e.g., according to similar results presented in Fig. 5b for the same disease, although the two WSIs look different. Such fine-grained explanations, encompassing textual and visual information, can also be consistently applied to other samples. For instance, regarding the gastrointestinal tissue depicted in Figure 5c, WSI emphasizes areas with autolysis, predominantly in the glandular regions, which exhibit varying degrees of brightness corresponding to the extent of autolysis. In gross anatomical descriptions, the term “complete” denotes the intactness of the gastrointestinal mucosa and serosa. Conversely, the absence of typical lesions during gross examination is indicated by terms such as “no”, “bleeding”, “ulceration”, and “observed”. These terminologies reflect the standard normal condition of the gastrointestinal tract in gross anatomy, characterized by the presence of autolytic pathological features alone. These results suggest the generalizability of SongCi from the multi-modal explainability perspective. It demonstrates that the attention-mapping operator of SongCi could be a reliable tool to assist pathologists in post-mortem analysis, helping enhance their confidence and assessment outcomes in forensic investigation.

The multi-modality attention visualization of SongCi offers interpretable analyses for forensic pathology diagnosis across a range of tissues and organs. a, b display liver tissues; c, f gastrointestinal tissues; d brain tissues; e pancreatic tissues; and g, h spleen tissues, with i highlighting adrenal tissues. The WSI regions corresponding to the prototypes of the top five findings, along with the top five vital descriptors in the gross key findings, are delineated in distinct colors.
Ablation studies of each key component in SongCi’s VLM design
Overall, SongCi consists of three pivotal components that work synergistically to enhance forensic pathological analysis with multi-modal data. These key technical points include (1) a pretrained language model to encode gross key findings, (2) a prototypical patch-level encoder pretrained via the combination of dedicated contrastive learning components to extract post-mortem image representations, and (3) a carefully designed fusion block with gated-attention mechanisms to align multi-modal information for robust diagnostic inference. We conducted thorough ablation studies regarding the selection of a pretrained language model, the architecture, and SSL-based pretraining of the patch-level encoder, and the design of the fusion block to evaluate the efficacy of our specific implementation of SongCi.
First, the choice of pretrained language models largely determines the quality of textual embeddings of gross key findings. In SongCi, the text encoder from PLIP46 was deployed for this purpose, considering that it was pre-trained on a large-scale collection of pathological image-text pairs, thus could be a solid foundation for CPath-related tasks. To check the efficacy of this selection, we replaced such an LLM from SongCi with four other alternatives: PubmedBERT61, i.e., an encoder pre-trained on medical texts only; CLIP62, i.e., an encoder pre-trained on natural image-text pairs; BiomedCLIP63, i.e., an encoder pre-trained on medical image-text pairs cropped from research papers; and QUILT-1M64, an encoder pre-trained on pathological image-text pairs grasped from YouTube. The comparisons between these variants in the task of large-vocabulary forensic diagnosis are summarized in Table 4, from which we can have two main observations. That is, we can see that the foundation models pre-trained by image-text pairs (e.g., CLIP, BiomedCLIP, QUILT-1M, and PLIP) performed better than those use only texts (e.g., PubmedBERT), implying the merit of multi-modal learning. In addition, we can see that the two pathology-dedicated LLMs (i.e., QUILT-1M and PLIP) outperformed others by large margins, among which PLIP used in SongCi led to the best performance in most cases, demonstrating the power of domain knowledge in cross-modal information alignment and fusion.
Second, to pre-train a generalizable vision encoder, SongCi designed dedicated regularization terms to constrain the prototypical space shared across the post-mortem WSIs from varying organs. To check the efficacy of these regularization terms, we further conducted an ablation study to remove them from the loss function and quantify the influence on the diagnosis performance, with the results summarized in Table 5. As observed, the baseline model, which was pre-trained using either the instance contrastive loss (Lins) or the prototypical contrastive loss (Lpro) solely, exhibits the lowest performance. In contrast, the combination of these two terms improved the performance significantly due to their complementarity that jointly enhanced both instance-level and prototype-level feature learning. Furthermore, as additional regularization terms, i.e., Lme-max, Lipc, and Lipd that enforce sparsity and diversity, were involved to refine the prototypical space, the diagnostic performance got further gains. It implies that these added constraints contribute to a more robust and well-structured representation space, leading to improved alignment with the target diagnostic tasks, thereby enhancing the model’s capacity. On the other hand, we also evaluated the efficacy of using DeiT65 in SongCi as the WSI backbone, by replacing it with a CNN-based alternative (i.e., ResNet66) and a Transformer-based variant (i.e., XCiT67), respectively. The corresponding comparison results are summarized in Supplementary Table 5, from which we can see that DeiT led to overall best performance. It illustrates the importance of backbone selection in the forensic CPath tasks. The superior performance by DeiT could be contributed by its lightweight architecture and the capacity to efficiently capture fine-grained visual representations in post-mortem WSIs.
Third, a carefully designed multi-modal fusion module was implemented in SongCi to seamlessly align and fuse textual and imaging representations extracted from the gross key findings and post-mortem WSIs, respectively. We first conducted ablation experiments to evaluate the efficacy of the prototypical num embedding and noise embedding involved in the design of such a gated-attention-boosted multi-modal fusion block, with the results summarized in Supplementary Tables 6 and 7, respectively. The results in Supplementary Table 6 demonstrate that the integration of num embeddings into the fusion block significantly boosted the diagnostic accuracy, indicating their essential role in enriching the quality of multi-modal feature representations. The results in Supplementary Table 7 reveal that adding noise embeddings significantly improved the forensic diagnostic performance across varying datasets, especially when the noise level was tuned at a moderate level. It suggests the role of the noise embedding in enhancing the generalization of multi-modal representations. Furthermore, we assessed the impact of the gated-attention mechanisms by removing them from varying Transformer layers within the multi-modal fusion block. The corresponding comparison results (see Supplementary Table 8) confirm that such gated attentions led to a substantial improvement in accuracy and robustness, highlighting their critical function in regulating the flow of multi-modal information for high-quality fusion outcomes.
In conclusion, these ablation studies on the textual encoder, patch-level encoder, and fusion block demonstrate that the target designs of each key component of SongCi contributed to a powerful VLM for large-vocabulary forensic diagnosis with gross key findings and post-mortem WSIs.
Discussion
This study presents a generalizable and explainable VLM, i.e., SongCi, dedicated to forensic pathology. To build SongCi, we curated one of the largest post-mortem, multi-modal datasets, gathering 2228 paired WSI-text samples from three forensic centers, nine organs, and 471 diagnostic outcomes. By leveraging cutting-edge SSL techniques, the pre-trained SongCi was evaluated on a broad spectrum of downstream tasks in forensic pathological analyses, demonstrating exciting accuracy, generalizability, and explainability compared with state-of-the-art VLMs, CPath foundation models, and forensic pathologists. Our research addresses a significant gap in the availability of multi-modal AI tools for forensic pathology. This discipline has traditionally depended on expert judgment and is marked by subjectivity, inconsistency, and inefficiency.
A primary challenge in building forensic VLMs is extracting and aligning multi-modal representations from challenging post-mortem data for large-vocabulary analyses. For this purpose, one major technical strength of SongCi lies in customizing a prototypical contrastive learning algorithm to pre-train a powerful image encoder for fine-grained feature extraction from post-mortem WSI with atypical and varying appearances. In a task-agnostic fashion, it maps millions of patches from WSIs into a low-dimensional space spanned by limited prototypes, where similar instances or patches are grouped tightly from intrinsic semantic views across different organs. The joint visualization of the learned prototypical and instance representations via the UMAP technique provides an intuitive way to understand their organization and relationships among various tissue types. Such visualization revealed that SongCi learns to partition the complex post-mortem WSI space into interpretable clusters corresponding to distinct histopathological entities or disease states, either inter-tissue shared or intra-tissue specific. Two downstream tasks, post-mortem image generation at the patch level and self-supervised semantic segmentation at the WSI level, evaluated the utility of the pre-trained image encoder. The image generation results demonstrate that SongCi’s pre-trained image encoder effectively guided advanced diffusion models, producing highly realistic image patches with precise pathological details. Quantitative evaluation shows exceptional fidelity, with a low Fréchet Inception Distance (FID) value of 17.521, accurately capturing fine-grained post-mortem changes and organ-specific lesions. Based on the learned prototypes, the self-supervised semantic segmentation results show that a gigapixel WSI can be efficiently segmented as meaningful and essential areas of interest under remarkable precision. These evaluations suggest the generalizability and reliability of SongCi’s image encoder as a CPath tool in forensic pathology, even without fine-tuning. Comparisons between our prototypical patch-level encoder and other state-of-the-art CPath foundation models (e.g., PLIP46, CONCH29, UNI28, and Prov-GigaPath26) confirmed its superior accuracy and generalizability in the specific task of large-vocabulary forensic diagnosis. In summary, the prototypical contrastive learning algorithm plays a pivotal role in enhancing patch representation quality, ensuring consistency across modalities, and reducing variability in downstream aggregation, thereby significantly improving the robustness and reliability of SongCi in large-vocabulary forensic diagnosis tasks.
To seamlessly align multi-modal, post-mortem data, another key innovation of SongCi is the design of a cross-modal contrastive learning algorithm to establish a dedicated fusion block empowered by gated-attention mechanisms. It plays a pivotal role in integrating macroscopic observations at the organ level (i.e., gross key findings) with microscopic cues at the tissue level (i.e., WSIs) to produce higher-level representations encoding multi-modal knowledge for accurate and coherent forensic pathological analyses. The downstream applications demonstrate that this design led to much better large-vocabulary diagnostic performance than other open-sourced VLMs in forensic pathology. More importantly, its accuracy has matched that of experienced forensic pathologists while significantly improving efficiency, further implying the meaning of SongCi in the autopsy practice. The gated-attention mechanisms in this fusion block assign relative importance or scores to each input element, i.e., each patch in a WSI and each word in the textual description of the gross key findings, by which SongCi straightforwardly focuses on the most salient aspects of both modalities. This mimics the workflow of a forensic pathologist, who typically makes his/her judgments by analyzing organ-level autopsy findings in conjunction with microscopic assessments. Including num and noise embedding significantly enhances SongCi’s performance in processing complex, multi-modal datasets. The noise embedding technique acts as a regularization mechanism, mitigating the model’s sensitivity to irrelevant or noisy data, which is especially important in the context of medical imaging, where artifacts can obscure meaningful information. Meanwhile, the num embedding, similar to techniques like RoPE(Rotary Position Embedding)68, proves crucial for efficiently handling large-vocabulary datasets, particularly when numerical attributes such as lesion size, tissue density, or organ measurements play a vital role in diagnosis. These embeddings work in tandem with the gated-attention mechanisms, which assign varying importance to different elements within both visual and textual data, allowing SongCi to adapt to the specific needs of each task. The results of explainability analysis demonstrate that such attention mechanisms can capture fine-grained cross-modal factors to uncover how SongCi makes a particular prediction given specific multi-modal inputs, which is very critical considering that AI tools for forensic pathology by nature have exceptionally high requirements in reliability and trustiness. Building upon the foundational approach of cross-modal contrastive learning outlined above, there is also an opportunity to further enhance the system’s capabilities by integrating generative methods. While multimodal contrastive learning excels at comparing and aligning diverse modalities to extract robust features, generative techniques could introduce greater flexibility and innovation in tasks that require complex reasoning across modalities, such as visual question answering in forensic pathology29,33,69. This approach could enable dynamic cross-modal reasoning, where the AI can generate plausible scenarios or hypotheses based on the multimodal data. However, the effectiveness of generative models is contingent on large-scale, diverse datasets, which are often challenging to obtain in specialized fields like forensic pathology70. Nevertheless, combining multimodal contrastive learning with generative methods could lead to synergistic benefits, especially in data-scarce situations. By dynamically applying these complementary methods based on the available data and task requirements, we can drive further advancements in multimodal representation learning for forensic pathology, enhancing both accuracy and robustness in diagnostic processes.
Strong zero-shot learning capability is a standout advantage of SongCi, indicating its adaptability and generalizability to novel scenarios, a featured challenge in forensic pathology, considering that autopsies typically involve a broad array of investigations across multiple organs and varying conditions. The success of this zero-shot transfer learning capability lies in SongCi’s robust cross-modal fusion and alignment layer, which effectively combines information across modalities to create an aligned representation space for both textual and visual data. Specifically, in the inference stage, given the post-mortem WSI and gross key findings of a particular subject, an operator can list a set of suspicious diagnoses (in texts) as candidates, which could be new cases that have not yet been seen in the pre-training stage. Then, SongCi calculates the cosine similarity between the multi-modal fusion representations and the embeddings of the provided candidate diagnoses, based on which the most likely outcome can be ranked out, together with detailed explanation factors pinpointing specific aspects of the multi-modal data that significantly influence the model’s decision. This empowers a forensic pathologist to assess in detail the relationships between a given sample and various potential diagnoses by providing a quantitative measure of confidence, thus assisting pathologists in making accurate assessments and potentially reducing diagnostic errors or inconsistencies. The large-vocabulary forensic diagnostic results across the two external cohorts, especially the offset and low-frequency quantifications presented in Table 1, demonstrate the superior zero-shot learning performance of SongCi. Furthermore, the comprehensive comparisons with existing VLMs and forensic pathologists show that SongCi is a generalizable, explainable, and, more importantly, forensic pathology-dedicated AI tool, adept at efficiently amalgamating various data sources, thereby enhancing the efficiency, accuracy, and consistency of forensic diagnoses across varying cases and organs. Delightfully, the transfer of our pretrained VLM to clinical CPath implied that SongCi also led to competitive accuracy in cancer diagnosis/prognosis, as evaluated on three public WSI-level datasets (TCGA-lung cancer, TCGA-BRCA, and CAMELYON16) and five public patch-level datasets(CRC-100K, UniToPatho, TCGA-TIL, TCGA Uniform Tumor and PCAM), compared with twelve state-of-the-art approaches, which include both SOTA MIL methods and SOTA CPath models (refer to Supplementary Tables 9 and 10). The generalizability of SongCi across various CPath tasks is promising, demonstrating its potential for broader applications. However, despite these strengths, it remains inadequate in addressing the complexities inherent in tumor pathology. This limitation underscores the necessity for continued refinement and adaptation of SongCi, particularly to accommodate the unique challenges presented within oncology pathology. By improving its capacity to handle these specific intricacies, SongCi could enhance its applicability and effectiveness in clinical settings, thereby advancing its role in clinical tumor-related tasks.
This work has several limitations that deserve continual research in the future. First, although an unprecedentedly large dataset of paired post-mortem WSIs and gross key findings were collected for the SSL of SongCi, the current data collection inevitably brings biases regarding organ types and diagnostic outcomes. The assumption that WSI representations learned by SongCi across multiple organs can be generalized to all forensic pathology cases may not hold in all contexts. To further improve the robustness and generalizability of SongCi to work on other forensic pathology contexts (e.g., new organ types in addition to the nine specific ones studied in this work), consistently collecting more data with significant diversity to refine the pretrained model is needed and technically feasible. Considering that data collection in forensic pathology is practically more complicated than in clinical applications, national or even international collaborations on this topic are urgently necessary. On the other hand, to mitigate the diagnostic outcome bias mainly caused by the significantly large-vocabulary property of forensic pathology, integrating additional sources of information in addition to more data collection could also be important. In practice, an autopsy includes multiple steps, which produce a wide spectrum of data formats, like textual, multi-omics, and imaging data. Intuitively, the fusion of this multi-modal information could further improve the outcomes in AI-empowered forensic pathology. That is, integrating SongCi’s multi-modal representations with LLM-based generative frameworks could significantly advance AI-powered forensic pathology. This fusion would enhance SongCi’s diagnostic accuracy and scalability, enabling robust performance across complex and diverse cases. Besides, although we have justified the efficacy of SongCi by a bunch of downstream tasks, there are still some other applications that need further investigations, such as the prediction of post-mortem time and the simulation of longitudinal post-mortem changes conditioned on varying organs, environments, and death causes. A more comprehensive design of downstream evaluations is important in enhancing the practical usage of SongCi. Moreover, the use of English-based LLMs may limit the applicability of SongCi in non-English communities, necessitating adaptations for broader adoption, e.g., developing multilingual language models based on forensic knowledge to enhance SongCi’s multimodal representation capabilities further.
In summary, both the presented applications and SongCi’s existing limitations pronounce the significance of continuous research and evaluation to advance and better understand the strengths and practical usage of cross-modal self-supervised pre-training (or even so-called multi-modal foundation models) for forensic pathology.
Methods
Ethics statement
All procedures involving human biological materials adhered to the 2013 revision of the Declaration of Helsinki, relevant Chinese regulations governing post-mortem investigations, and institutional guidelines. The internal cohort from the Forensic Judicial Expertise Center of Xi’an Jiaotong University was approved by the Medical Ethics Committee of Xi’an Jiaotong University; the external cohort I from the Shaanxi Zhongjin Judicial Expertise Center was approved by the Medical Ethics Committee of the Shaanxi Zhongjin Forensic Science Centre; and the external cohort II from the Shanghai Academy of Forensic Science was approved by the Medical Ethics Committee of the Institute of Forensic Science, Ministry of Justice, China. All whole-slide images, gross key findings, and associated diagnostic labels were fully de-identified before transfer, stored on encrypted servers with restricted access, and shared strictly in line with the original data-use agreements and Chinese regulations on human genetic resources. Because the study used post-mortem material collected during routine forensic examinations, no living participants were recruited, and informed consent or subject compensation was therefore not applicable. Sex or gender information was not collected or analysed, as the objective was to assess overall model performance rather than subgroup differences. All investigators completed institutional training in responsible research conduct and data protection, and no ethical issues were identified during the study.
SongCi
SongCi is a multi-modal deep learning model tailored for forensic pathological analyses. The architecture consists of three main parts: an imaging encoder for WSI(patch-level) feature extraction, a text encoder for embedding gross key findings and diagnostic queries, and a multi-modal fusion block that integrates the embeddings of WSI and gross key findings to align with those of the diagnostic queries. Specifically, we used an open-sourced, pathology-dedicated language model, i.e., PLIP46, in SongCi as the textual encoder directly. To deal with post-mortem data with varying conditions, we designed two SSL algorithms to build the imaging encoder and multi-modal fusion block in a task-agnostic fashion. In inference, SongCi can flexibly conduct large-vocabulary (or even open-vocabulary) diagnosis, as an operator only needs to provide a set of candidate outcomes, based on which the model ranks out the possible diagnosis associated with detailed explanation factors identified from the multi-modal inputs.
Prototypical patch-level encoder
We propose a hybrid contrastive learning algorithm to learn from gigapixel, post-mortem WSIs fine-grained representations generalizable across different organs (Fig. 1c). The algorithm is built upon a straightforward assumption that image patches (i.e., instances) from different spatial locations, organs, and conditions, are grouped as meaningful clusters in the desired representation space that captures both intra-tissue-specific and inter-tissue-specific information; besides, in each cluster, instance representations present a certain degree of variance to preserve detailed patch-wise specificity. Accordingly, such a hybrid SSL algorithm consists of an instance contrastive learning part and a prototypical contrastive learning part.
The instance contrastive learning part aims to build a vision transformer (ViT)71, which leverages the local patches of a WSI as the input and learns instance-level representations via self-distillation. In line with DINO72, contrastive learning is achieved by a teacher-student strategy. A batch of (say totally N) instances is first transformed by a series of data augmentation operations, including multi-cropping73, random resizing, flipping, color jittering, solarization, and Gaussian blurring, which produces two different views for each input instance (say \({X}_{s}^{n}\) and \({X}_{t}^{n}\) for the n-th instance). Then, \({X}_{s}^{n}\) and \({X}_{t}^{n}\) are fed into the student and teacher branches, respectively, and we want the corresponding predictions by the two branches to be cross-view consistent. Specifically, the student branch consists of a ViT fs( ⋅ ), a projector \({g}_{s}^{pro}(\cdot )\), and a predictor \({g}_{s}^{pre}(\cdot )\). Compared with the student branch, the teacher branch also contains a ViT ft( ⋅ ) and a projector \({g}_{t}^{pro}(\cdot )\), while the last component is replaced by a sharpening & centering module Jt( ⋅ ), which adjusts the distribution of the instance representations to avoid mode collapse. The model parameters of the student branch are optimized by gradient back-propagation, based on which the teacher branch is updated via the exponential moving average (EMA)74. To this end, we quantify the predictions from the two branches via soft-max normalization, such as:
where τs and τt are two hyperparameters that control the sharpness of the output probability distributions, respectively. After that, the model parameters are iteratively optimized by minimizing the cross-entropy loss that encourages cross-view consistency, such as :
The prototypical contrastive learning part further distills from the instance representations a more abstract and generalizable feature space spanned by a set of learnable prototypes shared across different WSIs, organs, and conditions. Similar to instance contrastive learning, here we have two different views for an input instance after data augmentation; the difference in this prototypical learning procedure is that the learnable parameters of the student branch are updated via back-propagation and the teacher branch shares weights with the student branch. Both branches contain a ViT followed by a projector. Let their output embeddings for N input instances be \({Z}_{s}\in {{\mathbb{R}}}^{D\times N}\) and \({Z}_{t}\in {{\mathbb{R}}}^{D\times N}\), respectively. We want to learn a set of M prototypical embeddings, say \(P\in {{\mathbb{R}}}^{D\times M}\), for which we can find a linear mapping \({C}_{t}\in {{\mathbb{R}}}_{+}^{M*N}\) that maximizes their similarities with Zt, i.e., minimizes the Sinkhorn distances of the associated optimal-transport problem75, defined as
where 1N and 1M denote the N- and M- dimensional all-ones vectors, respectively. The function Tr( ⋅ ) stands for the matrix trace operation, h(Ct) = −∑ijCt[i, j]log(Ct[i, j]) quantifies the entropy of the linear mapping, and ϵ is a tuning parameter controls its influence. Given P and Zt, a Ct qualified for the above objective realizes that all instances in Zt can be matched up to the prototype space P and each prototype is selected at least \(\frac{N}{M}\) times on average. Such a constrained optimization problem can have an approximate solution by using the iterative Sinkhorn-Knopp algorithm60,75, with each iteration defined as:
where \(u\in {{\mathbb{R}}}^{M}\) and \(v\in {{\mathbb{R}}}^{N}\) are re-normalization vectors, and diag( ⋅ ) formulate them as the diagonal matrices. Following SwAV60, the number of iterations was set as three in our study.
To establish the cross-view consistency, we use \({\hat{C}}_{t}\) from the teacher branch as the pseudo label to constrain the prediction in the student branch. That is, the student branch predicts the mapping matrix as
where \({\tau }_{s}^{prototype}\) is an element-wise scaling parameter. Then, the main loss function for the prototypical contrastive learning is defined as
Furthermore, to stabilize the learning of the prototypical representations, we design three regularization terms in addition to the main loss function. Ideally, the prototype-instance mapping matrix should be sparse rather than dense, by which the prototypes are encouraged to encode diverse information, and each instance tends to have the most similar prototype(s). To this end, we impose an instance-prototype cross-entropy loss (Lipc) and an instance-prototype distance loss (Lipd), which are defined as
where zi and pj denote the L2-normalized D-dimensional representation of the i-th instance and j-th prototype, respectively, and \({p}_{j}^{i}\) is the nearest prototype of zi. As a result, Lipc encourages inter-prototype differences, and Lipd encourages intra-cluster consistency, i.e., instances close to a particular prototype should be grouped tightly. In addition, to obtain fine-grained representations by the prototypes, we encourage the prototype-instance mapping to fully use all these prototypes, for which a mean-entropy maximization regularization76 is attached, such as
where \(\bar{{C}_{s}^{i}}=\frac{1}{N}{\sum }_{j=1}^{N}{C}_{s}[i,j]\). Therefore, the global loss for the hybrid contrastive learning is defined as
where λ1 was set as 0.6, λ3 was 0.1, and λ2 = λ4 = λ5 = 1.0 in our implementation.
After the contrastive learning, the ViT, the projector, and the prototypes are frozen to be the pre-trained prototypical patch-level encoder. All the patches’ nearest prototypes determine the WSI-level representation.
Gated-attention-boosted multi-modal fusion block
We propose a multi-modal fusion block empowered by gated attention mechanisms for the adaptive fusion of gross key findings and WSI information, which produces multi-modal representations encoding macroscopic and microscopic cues for large-vocabulary forensic pathological analyses.
This gated-attention-boosted fusion block adopts initial imaging embeddings of a WSI and textual embeddings of the paired gross key findings as the multi-modal input. The pre-trained prototypical patch-level encoder produces the initial imaging embeddings. That is, each patch of a WSI is denoted by the nearest prototype according to the cosine similarity between instance and prototypical representations, and the combination of all patches’ nearest prototypes forms the WSI-level prototypical feature embedding, say \({z}_{pro}^{i}\). Moreover, it is worth noting that the frequency of a particular prototype occurring in a WSI could encode critical information regarding the WSI’s specific patterns. For example, in a pathology section of brain autolysis, the proportion of normal brain tissue varies due to the degree of autolysis, which can be reflected by the frequency of the post-mortem autolysis-related prototype selected by the pathological image. To encode such key information, we further quantify the number of occurrences of each prototype for a WSI and use them as the WSI’s prototypical number embedding, say \({z}_{num}^{i}\). On the other hand, the initial word-wise textual embeddings of gross key findings (say zt) are produced by PLIP, a pathology-dedicated LLM. To better align PLIP with forensic pathology, we attach a simple but effective adaptation layer, i.e., a text-to-image adapter fadapter( ⋅ ) onto PLIP, which fine-tunes zt in a few-shot knowledge transfer fashion77,78. Furthermore, considering that the initial mono-modal feature embedding brings inevitable information loss that could cause a cross-modal mismatch, we follow C-MCR79 to update these initial embeddings by adding a small amount of Gaussian noise to improve their robustness for subsequent cross-modal fusion. More specifically, given the initial embeddings of the paired WSI (i.e., \({z}_{pro}^{i}\) and \({z}_{num}^{i}\)) and gross key findings (i.e., zt), they are first refined before feeding into the fusion block, such as
where ϵi and ϵt denote the random Gaussian noises, and ∥ ⋅ ∥2 stands for L2-normalization.
Given the refined multi-modal inputs (i.e., \({\hat{z}}^{i}\) and \({\hat{z}}^{t}\)), the fusion block designs gated cross-attention and feed-forward network (FFN) layers to update the representations of each modality by considering the complementary information from the other modality. The gated mechanism80 adaptively controls the inter-modal information transfer, thus balancing the contributions of different modalities during cross-modal communication, which has been proven to have typically better performance than conventional cross-attention strategies19,53. Specifically, using \({\hat{z}}^{t}\) as the guidance, the WSI embedding \({\hat{z}}^{i}\) is updated by the gated knowledge-guided cross-attention layer followed by a gated FFN, which can be formulated as
where Wq, Wk, and Wv stand for learnable matrices for linear mappings, \({\lambda }_{att}^{i}\) and \({\lambda }_{ffn}^{i}\) are learnable scalars (i.e., the gated-attention coefficients), and tanh( ⋅ ) denotes the tanh activation. Similarly, by using \({\hat{z}}^{i}\) as the guidance, \({\hat{z}}^{t}\) is updated by the gated prototype-guided cross-attention layer followed by a gated FFN:
where \({\lambda }_{att}^{i}\) and \({\lambda }_{ffn}^{i}\) are the respective gated-attention coefficients. After that, we concatenate \({\hat{z}}_{l+1}^{t}\) and \({\hat{z}}_{l+1}^{i}\), and apply a gated Transformer-based encoder (with two layers) to update these representations. They are further processed by a modality projector to obtain the multi-modal representations, say \({z}^{f}\in {{\mathbb{R}}}^{D*M}\), where M denotes the number of tokens, and D stands for feature dimensionality.
Considering the large-vocabulary property of forensic pathological analysis, the flexibility in aligning the multi-modal representation zf with the diagnostic outcomes is a key issue. Practically, an autopsy investigation could lead to multi-label outcomes from different views (or according to different downstream needs). For instance, given a post-mortem liver case, one could have the diagnoses of liver autolysis, cirrhosis, and rupture from the perspectives of post-mortem changes, diseases, and injury patterns, respectively. Thus, the multi-modal representation zf should be able to seamlessly align with each of them without bias to any particular outcome, a common limitation of many existing VLMs, like CLIP62,81,82,83. It is intuitive to assume that different diagnostic outcomes (after the embedding by a text encoder) are associated with varying parts of zf, based on which we design an adaptive alignment strategy to flexibly align between the representations of multi-modal inputs and large-vocabulary outcomes. Specifically, any particular diagnostic outcome is regarded as a caption of the corresponding case and is mapped by the frozen PLIP and a learnable linear projector to obtain its caption embedding, say \({z}^{d}\in {{\mathbb{R}}}^{D*1}\). By calculating the cosine similarities between the normalized zd and zf across different tokens, we can obtain the attention scores (say \({z}^{s}\in {{\mathbb{R}}}^{1*M}\)) indicating the contribution of each token to this diagnosis, such as:
where ∥ ⋅ ∥2 stands for L2-normalization. Finally, we leverage zs to aggregate zf, yielding \({\hat{z}}^{f}={z}^{f}{({z}^{s})}^{T}\) to align with zd. Notably, changing zd leads to changing zs, thus different \({\hat{z}}^{f}\).
Finally, given \({\hat{z}}^{f}\) and zd for training samples, we minimize the InfoNCE loss84 to update the learnable parts of this multi-modal fusion block, such as:
where N is the batch size and λ is the scaling temperature parameter.
Inference process
The pre-trained SongCi model serves as an auxiliary tool for forensic pathologists, facilitating diagnosis and analysis through zero-shot learning62. When presented with a case that includes multi-modal inputs, such as WSIs and macroscopic gross findings from various organs, a forensic pathologist can propose multiple diagnostic hypotheses from different perspectives, including post-mortem alterations, disease classifications, and injury patterns. SongCi then computes organ-specific multi-modal feature embeddings and evaluates their cosine similarity with each proposed diagnosis. The model ranks the most probable diagnoses based on normalized similarity scores, applying a predefined threshold to identify the top outcomes. In our research, we established the threshold at 0.88, corresponding to the point on the PR curve where precision and recall are optimally balanced. In addition to the possible diagnostic results, fine-grained interpretable analytical factors are also available to forensic pathologists. This process enables them to scrutinize the interpretable results and refine their assessments.
Implementation details
In this study, 3.15 million WSI patches were extracted from the internal cohort to train a prototypical patch-level encoder. The backbone network was initialized using the DEiT-small model65, which includes a patch embedding layer, 12 self-attention layers, and corresponding FFNs. Both the instance and prototype projection layers (projectorins and projectorpro), as well as the instance prediction layer (predictorins), shared the same architecture, consisting of two fully connected layers, a batch normalization layer85, and a Gaussian Error Linear Unit (GELU) activation layer86. These components were trained from scratch using Xavier initialization. The projection layers aimed to map learned instance representations to the corresponding prototype embedding space, while the prediction layer decoupled the student network’s representation from that of the teacher network, preventing mode collapse. To enhance model robustness, several data augmentation techniques were applied, including multi-crop, random cropping, random horizontal flipping, color jittering, Gaussian blur, and random exposure adjustments. The AdamW optimizer87 was employed with a cosine annealing strategy for learning rate decay. The initial learning rate was set to 1e−6, eventually decreasing to 1e−7. Weight decay started at 0.04 and gradually increased to 0.4 to further improve generalization. The initial size of the prototype vector space was set to 1, 024, with each prototype having a dimensionality of 256. During the initial phase of training, the parameters of the prototype vectors were frozen to maintain stability. After 5000 iterations, the prototype vectors were unfrozen and included in the training process to ensure effective convergence. The whole training procedure consisted of 250 epochs with a mini-batch size of 768, where the first 10 epochs served as a warm-up phase. After training, each WSI patch from the training set was matched to the most similar prototype in the prototype space, generating a patch representation within this space. The analysis of all these 3.15 million patches revealed that 933 of 1024 learned prototypes can represent all of them, indicating that these prototypes were highly representative within the prototype space.
The multimodal fusion layer consists of several key components, including a text-to-image adapter, two cross-attention layers, two FFNs, a Transformer encoder with a depth of two layers, and a modality projection layer. The text-to-image adapter aligns the dimensions of the text embeddings with those of the image prototype embeddings to facilitate effective multimodal integration. The cross-attention layers are responsible for aligning data across different modalities to enable cross-modal information fusion. The Transformer encoder performs deep feature fusion between modalities, and the modality projection layer maps the fused representations to the diagnostic space for cross-modal contrastive learning. All attention and feed-forward layers are enhanced with gated mechanisms to improve model capacity and stability. For data processing, all image patches of the same tissue sample were processed by the pretrained prototype patch-level encoder to generate prototype representation vectors, which were then used as input to the fusion stage. The frequency of occurrence of each prototype was recorded as a part of the frequency encoding embedding. In the fusion stage, only the top 128 prototypes, based on frequency of occurrence, were retained, resulting in a token length limit of 128. Prototypes with lower frequency were discarded. For text processing, following the CLIP setup, the token length for word embeddings was fixed at 77, and sequences were truncated or padded accordingly to maintain this fixed length. To improve the generalization and robustness of the fusion module, random noise drawn from a normal distribution (mean = 0, standard deviation = 0.5) was injected into both the text and prototype embeddings. Overall, the model was trained for 500 epochs with a mini-batch size of 64. The AdamW optimizer and a cosine annealing learning rate scheduler were utilized to adjust the learning rate. After a 20-epoch warm-up phase, the cross-modal contrastive learning phase was conducted using an initial learning rate of 2e−5 and a final learning rate of 1e−6. All training and experiments were conducted on a server equipped with 8 NVIDIA GEFORCE RTX 3090 GPUs.
Prototype visualization and patch-level post-mortem WSI generation
We adopted the Umap method47 to visualize in 2-D the prototypes learned by SongCi, as shown in Fig. 2a. Each prototype was marked by one or multiple color(s) according to the ratio of organ types of nearest image patches. To check the generalizability of the patch and prototypical embeddings produced by SongCi, we conducted a downstream patch-level post-mortem image generation task. Specifically, a diffusion model88 was trained to generate image patches conditioned on a prototype or patch embedding. Consistent with DDPM89 and DDIM90, the training of our diffusion model contains a forward process to add noises and a reverse process that learns to predict added noises. In the noise prediction, we incorporate conditions by combining learned embedding and time embedding, such as
where ϵ~N(0, I),ϵθ is a Unet91, and f( ⋅ ) and g( ⋅ ) are two fully connected networks. The hyperparameter δt controls the generation process90, and αt controls the accumulation of noise intensity at the moment (t) of the diffusion process.
Self-supervised WSI segmentation and diagnostic explainability analysis
Based on the prototypes produced by SongCi, we conducted a downstream task of self-supervised post-mortem WSI segmentation. Specifically, we assume that each prototype encodes specific semantic information, and then each patch of a WSI was assigned a semantic label according to its nearest prototype. Notably, for a particular WSI, if the resulting prototype categories exceed a predefined threshold, we further cluster58 the number of prototypes to be equal to the threshold for comparison with other methods. In our experiments, the threshold was set as seven.
In the zero-shot diagnosis process, for a candidate outcome, the cross-modal fusion block of SongCi assigns respective attention scores to each patch of the input WSI as well as each word of the gross key findings, which provide fine-grained, cross-modal explanations regarding the network prediction. Specifically, we visualized the patches and words with the top five attention scores in our experiments.
Comparative analysis study
In our study, SongCi was compared with six state-of-the-art multi-modal fusion methods in the medical domain. For a fair comparison, all these methods were implemented under the same configurations with SongCi, such as the batch size and number of epochs etc. Consistent with SongCi, these multimodal fusion methods adopt the embeddings of a WSI and respective gross key findings as the multimodal input, from which they learn fused representations in different ways to align with the diagnostic outcomes. These competing methods include:
-
Multimodal co-attention transformer (MCAT)19: MCAT is a transformer-based model that designs a genomic-guided co-attention layer to fuse multimodal information. In this study, we replaced the input of genomic embedding with gross key findings. Other operations remained the same as in the original implementation of MCAT.
-
Generative image-to-text transformer(GIT)56: This model uses a specific text decoder to fuse multimodal embeddings via multiple self-attention layers. For a fair comparison, we trained such a model using the same loss functions of SongCi.
-
IRENE53: As an extension of GIT, IRENE designed a bidirectional multimodal attention block for cross-modal information fusion. We change the image patch tokens to WSI image prototype tokens and clinical text tokens representing key gross findings.
-
Perceiver57: The input of the Perceiver has two parts: a latent array and a byte array. The byte array stores input multi-modal embeddings and the latent array is a learnable embedding with random initialization. Based on the byte array, the model updates the latent array by alternatively calling self-attention and cross-attention layers. After that, the learned latent array is output as the fused representation.
-
Bottleneck-Fusion54: The original Bottleneck-Fusion method was proposed to combine WSI and tabular clinical data to predict lymph node metastasis of papillary thyroid carcinoma35. We replaced tabular clinical data with the textual description of gross key findings for forensic pathological analyses.
-
DLNMS55: As a classic late-fusion method, DLNMS directly concatenates multi-modal embeddings and feeds them into an attention-based, fully connected network for diagnosis or prediction. The original model was developed for occult nodal metastasis prediction. We kept the methodological design but applied it to our task of forensic pathological diagnosis.
Moreover, our prototypical patch-level encoder in SongCi was also compared with six pretrained CPath models in the task of forensic diagnosis. For a fair comparisons, we replaced our pretrained patch-level encoder with these state-of-the-art foundation models to reimplement the variants of SongCi. These competing methods include:
-
CTransPath41: CTransPath is a powerful model that combines the strengths of convolutional neural networks (CNNs) with the multi-scale capabilities of the Swin Transformer architecture. Pretrained on over 15 million patches from publicly available datasets, such as TCGA and PAIP, it encompasses a diverse range of organs and cancer types, providing the model with a broad foundation of knowledge.
-
LUNIT-DINO40: LUNIT-DINO leveraged over 32.6 million image patches extracted from TCGA and TULIP datasets to evaluate various SSL methods across five downstream datasets. The results of their study clearly demonstrate that SSL pre-training on large, domain-aligned pathology datasets consistently outperforms conventional ImageNet pre-training in both linear evaluation and fine-tuning protocols.
-
UNI28: UNI is trained on over 100 million images derived from more than 100,000 diagnostic WSIs, covering 20 major tissue types. The model employs SSL using the DINOv259 algorithm in combination with the ViT-Large architecture to generate rich, transferable representations of pathology data.
-
CONCH29:CONCH utilizes over 1.17 million curated image-caption pairs from diverse biomedical sources to enhance its capabilities. Its architecture consists of an image encoder, a text encoder, and a multimodal fusion decoder, following the CoCa92 framework. This design enables CONCH to generalize across a wide range of downstream tasks, including image classification, segmentation, captioning, and text-to-image or image-to-text retrieval.
-
PLIP46:PLIP utilizes the large-scale OpenPath dataset, which comprises 208,414 pathology images paired with natural language descriptions curated from publicly available sources, such as medical Twitter and the LAION dataset. This robust dataset enables PLIP to classify unseen images without the need for additional retraining, marking a significant leap forward in model efficiency.
-
Prov-GigaPath26:Prov-GigaPath is trained on an extensive dataset of 1.3 billion image tiles extracted from 171,189 whole pathology slides, sourced from over 30,000 patients and covering 31 tissue types within the Providence Health Network. The model leverages GigaPath, a ViT architecture that integrates the DINOv259 and LongNet methods. This unique combination allows Prov-GigaPath to efficiently capture both local tile-level features and global slide-level patterns, making it highly effective in processing gigapixel pathology images.
Forensic pathology cohorts
This work included three cohorts: an internal cohort provided by the Forensic Judicial Expertise Center of Xi’an Jiaotong University and two external cohorts provided by Shaanxi Zhongjin Judicial Expertise Center and Shanghai Academy of Forensic Science, China. The data collection procedures satisfied the requirements of local laws and were approved and supervised by the Ethics Committee of the corresponding institutions. The internal cohort contains 164 decedents from 2018 to 2023, for which a total of 1451 paired samples of gross key findings and WSIs (together with corresponding pathological diagnoses) were collected. The external cohort I (Shaanxi Zhongjin Judicial Expertise Center) contains 50 decedents with a total of 467 gross key findings—WSIs—forensic pathological diagnoses. The external cohort II (Shanghai Academy of Forensic Science) contains 14 deceased individuals with a total of 310 gross key findings—WSIs—forensic pathological diagnoses. These data were from nine different organs, including the brain, heart, lung, kidney, liver, pancreas, spleen, adrenal gland, and gastrointestinal tract (see Fig. 1a, b). The gross key findings (text) represent the forensic pathologist’s description of the organ’s condition at autopsy, encompassing organ-level information. WSIs (image) are sections derived from regions of interest (ROIs) selected by the forensic pathologist from the deceased’s organs, capturing tissue-level information. The forensic pathological diagnoses (text) detail specific outcomes for each organ, typically addressing trauma, disease, and post-mortem changes. Thus, each sample contains multiple forensic diagnoses (multi-labels).
Data preprocessing
Forensic pathology slides (WSIs)
In the analysis of pathology slides, the initial step involves the extraction of regions containing tissue. Utilizing the finding contours method in OpenCV, we delineate the edges of pathological tissue within a WSI. The process begins by converting the WSI’s RGB image at ×10 magnification to a binary image using a threshold of 200. Subsequently, we employ the findContours method to generate a hierarchical tree-structured contour. We iterate through all contours, retaining those with an area exceeding 100,000, which we classify as foreground information. This preliminary contour allows us to differentiate between WSI foreground and background, resulting in a mask image. The mask image guides the segmentation patch process, wherein we preserve patches with more than 40% foreground information. Each patch is archived as a PNG file with dimensions of 256 × 256 pixels, facilitating subsequent analytical tasks. Due to the nature of forensic pathology, which typically features a high tissue density per slide, the number of patches extracted can range from tens to hundreds of thousands per slide.
Gross key findings
During an autopsy, the forensic pathologist systematically examines each organ and documents the autopsy’s gross key findings in detail. Our study aimed to address two main issues in response to the gross anatomical findings. Firstly, the challenge of language diversity: the existing open-source medical foundational language models, such as PLIP, QUILT, and BioMedClip, only accept English input, necessitating the translation of texts into English. Secondly, the anatomical records often contain text of varying lengths with extra information; hence, we sought to standardize the key findings’ text to a uniform size, facilitating the foundational model’s learning process. Leveraging ChatGPT’s93 capabilities, this preprocessing was achieved using a prompt-based learning approach. The prompt instructed: As a professor in the field of AI in forensic medical imaging, translate the following paragraph into English, summarize it into no more than four sentences, and ensure it adheres to academic writing standards. Provide only the summarized content, omitting any extraneous information. Subsequently, two forensic pathologists reviewed and validated the processed text, with their amendments constituting the final version.
Forensic pathology diagnosis
Forensic pathological diagnosis is conducted by meticulously examining an organ’s gross anatomy and histopathology. This discipline primarily focuses on three aspects: trauma, disease, and postmortem changes. Consequently, a single organ may have multiple forensic pathological diagnoses, in contrast to oncologic pathology, which primarily determines the presence or absence of a tumor. From a deep learning perspective, forensic pathology diagnosis represents a complex detection task characterized by a broad spectrum of labels and a substantial quantity of labels rather than a mere classification task. In our study, we engaged three forensic pathologists to consolidate the pathological diagnoses according to the aforementioned tripartite framework. These diagnoses were then compiled into phrases and depicted using a word cloud (see Fig. 1b). For instance, a forensic pathological diagnosis of brain tissue might include cerebral congestion (indicative of postmortem changes), cerebral contusion (suggestive of trauma), and brain degeneration (signifying disease).
Statistics and reproducibility
We analysed three mutually exclusive datasets-a 1451-sample internal cohort from the Forensic Judicial Expertise Center of Xi’an Jiaotong University and two external cohorts comprising 467 and 310 samples from the Shaanxi Zhongjin Judicial Expertise Center and the Shanghai Academy of Forensic Science, respectively-and retained only those cases that contained the full complement of modalities (whole-slide image, gross-finding text and diagnostic label); any sample lacking one or more of these components was discarded during preprocessing and not considered in subsequent experiments. Model performance was quantified with average precision (AP), intersection-over-union (IoU), recall, and precision; for recall and precision, we reported the operating point on each PR curve where the absolute difference between the two metrics was minimal, and all metrics are presented as mean ± standard deviation across cross-validated runs. Diagnostic generalization was further probed with two challenging subsets: (i) offset diagnoses, present in an external cohort but absent from the internal training cohort, and (ii) low-frequency diagnoses, occurring fewer than ten times in the cohort concerned; a diagnosis was deemed correct when the model’s candidate list contained the ground-truth label, otherwise incorrect, and accuracy was computed accordingly. Multimodal explainability was assessed by highlighting, for every test case, the five image prototypes receiving the highest cross-modal attention scores and the five most-attended words in the paired gross-finding description. For human benchmarking, 100 external samples were drawn uniformly at random (without replacement) and independently evaluated by two senior pathologists (>15 years’ experience), two JP (>5 years), and one assistant, with every submitted answer included in the analysis. All experiments were conducted with Python 3.9.0, PyTorch 1.13.1, and CUDA 11.7.1 on eight NVIDIA RTX 3090 GPUs, with global random seeds fixed (NumPy, PyTorch CPU/CUDA, and cuDNN in deterministic mode) to guarantee exact reproducibility. All scripts that reproduce the preprocessing, training, and evaluation pipelines-together with configuration files specifying every hyperparameter, are available at Zenodo94 under an MIT licence.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
All third-party datasets analysed in this study are openly available from community repositories: TCGA-LUAD and TCGA-BRCA at the NCI Genomic Data Commons (https://portal.gdc.cancer.gov/), CAMELYON-16 (https://camelyon16.grand-challenge.org/), CRC-100K (https://zenodo.org/records/1214456), UniToPatho (https://ieee-dataport.org/open-access/unitopathohttps://ieee-dataport.org/open-access/unitopatho), TCGA-TIL (https://zenodo.org/records/6604094), TCGA Uniform Tumor (https://zenodo.org/records/5889558https://zenodo.org/records/5889558) and PCam (https://github.com/basveeling/pcam). Custom datasets for model training, inference and evaluation is archived on GitHub (https://github.com/shenxiaochenn/SongCi) and Zenodo(https://zenodo.org/records/15570430). The proprietary SongCi training dataset contains personally identifiable forensic information and was collected under consent agreements that preclude public deposition; it is therefore available under restricted access for privacy reasons. A de-identified minimum reproducible dataset sufficient to verify all results is held in a secure Google Drive folder. Researchers wishing to access the full training data for non-commercial academic purposes should submit a signed data-use agreement and ethical-approval documentation to the corresponding author (email provided in the paper and Github Repository); qualified requests will be evaluated individually and, if approved, a data-transfer agreement will be issued within 14 days, after which the dataset will remain accessible for 12 months. Source data are provided with this paper.
Code availability
The training and inference scripts and trained models have been publicly released. Please refer to https://github.com/shenxiaochenn/SongCiand https://huggingface.co/shenxiaochen/SongCi for more details, including the explanations of forensic pathology diagnoses and gross key findings. A permanent version is released on Zenodo94.
References
Fox, S. E., Akmatbekov, A., Harbert, J. L., Li, G. & Brown, J. Q. Vander Heide RS. Pulmonary and cardiac pathology in African American patients with COVID-19: an autopsy series from New Orleans. Lancet Resp. Med. 8, 681–686 (2020).
Wichmann, D. et al. Autopsy findings and venous thromboembolism in patients with COVID-19. Ann. Intern. Med. 173, 268 (2020).
Roberts, I. S. et al. Post-mortem imaging as an alternative to autopsy in the diagnosis of adult deaths: a validation study. Lancet 379, 136–142 (2012).
Bryce, C. et al. Pathophysiology of SARS-CoV-2: the Mount Sinai COVID-19 autopsy experience. Mod. Pathol. 34, 1456–1467 (2021).
Cole, S. A. Forensic science and wrongful convictions: from exposer to contributor to corrector. N. Eng. Law Rev. 46, 711 (2011).
Burton, J. L. & Underwood, J. Clinical, educational, and epidemiological value of autopsy. The Lancet 369, 1471–1480 (2007).
Menter, T. et al. Postmortem examination of COVID-19 patients reveals diffuse alveolar damage with severe capillary congestion and variegated findings in lungs and other organs suggesting vascular dysfunction. Histopathology 77, 198–209 (2020).
Hanley, B., Lucas, S. B., Youd, E., Swift, B. & Osborn, M. Autopsy in suspected COVID-19 cases. J. Clin. Pathol. 73, 239–242 (2020).
Kujan, O. et al. Why oral histopathology suffers inter-observer variability on grading oral epithelial dysplasia: an attempt to understand the sources of variation. Oral Oncol 43, 224–231 (2007).
Chi, A. C., Katabi, N., Chen, H. S. & Cheng, Y. L. Interobserver variation among pathologists in evaluating perineural invasion for oral squamous cell carcinoma. Head Neck Pathol 10, 451–464 (2016).
Elmore, J. G. et al. Diagnostic concordance among pathologists interpreting breast biopsy specimens. JAMA 313, 1122–1132 (2015).
Bera, K., Schalper, K. A., Rimm, D. L., Velcheti, V. & Madabhushi, A. Artificial intelligence in digital pathology - new tools for diagnosis and precision oncology. Nat. Rev. Clin. Oncol. 16, 703–715 (2019).
Wang, X. et al. Weakly supervised deep learning for whole slide lung cancer image analysis. IEEE Trans. Cybern. 50, 3950–3962 (2020).
Davis, G. G. et al. Report and recommendations of the Association of Pathology Chairs’ autopsy working group. Acad. Pathol. 5, 2374289518793988 (2018).
Nelson, A. M. et al. Training the next generation of African pathologists. Clin. Lab. Med. 38, 37–51 (2018).
Coudray, N. et al. Classification and mutation prediction from non-small cell lung cancer histopathology images using deep learning. Nat. Med. 24, 1559–1567 (2018).
Cheng, S. et al. Robust whole slide image analysis for cervical cancer screening using deep learning. Nat. Commun. 12, 5639 (2021).
Huang, S.-C. et al. Deep neural network trained on gigapixel images improves lymph node metastasis detection in clinical settings. Nat. Commun. 13, 3347 (2022).
Chen, R.J. et al. Multimodal co-attention transformer for survival prediction in gigapixel whole slide images. In Proc. IEEE/CVF International Conference on Computer Vision (IEEE, 2021).
Chen, X. & He, K. Exploring simple siamese representation learning. In Proc. IEEE/CVF Conference On Computer Vision and Pattern Recognition (IEEE, 2021).
Chen, T., Kornblith, S., Norouzi, M. & Hinton, G. A simple framework for contrastive learning of visual representations. In Proc. International Conference on Machine Learning 1597–1607 (PmLR, 2020).
Vaswani, A. Attention is all you need. In Proc. 31st Conference on Neural Information Processing Systems (NIPS, 2017).
Brown, T. et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 33, 1877–1901 (2020).
He, K. et al. Masked autoencoders are scalable vision learners. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (IEEE, 2022).
Bao H, Dong L, Piao S, Wei F. BEiT: BERT Pre-Training of Image Transformers. In International Conference on Learning Representations (2022).
Xu, H. W. et al. A whole-slide foundation model for digital pathology from real-world data. Nature 630, 181–188 (2024).
Zhang, C., Zheng, H. & Gu, Y. Dive into the details of self-supervised learning for medical image analysis. Med. Image Anal. 89, 102879 (2023).
Chen, R. J. et al. Towards a general-purpose foundation model for computational pathology. Nat. Med. 30, 850–862 (2024).
Lu, M. Y. et al. A visual-language foundation model for computational pathology. Nat. Med. 30, 863–874 (2024).
Wang, X. Y. et al. A pathology foundation model for cancer diagnosis and prognosis prediction. Nature 634, 970–978 (2024).
Deng, R. et al. Cross-scale multi-instance learning for pathological image diagnosis. Med. Image Anal. 94, 103124 (2024).
Abbet, C., Zlobec, I., Bozorgtabar, B. & Thiran, J.-P. Divide-and-rule: self-supervised learning for survival analysis in colorectal cancer. In International Conference on Medical Image Computing and Computer-Assisted Intervention (Springer, 2020).
Seyfioglu, M. S., Ikezogwo, W. O., Ghezloo, F., Krishna, R. & Shapiro, L. Quilt-llava: Visual instruction tuning by extracting localized narratives from open-source histopathology videos. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024).
Li, H. et al. Generalizable whole slide image classification with fine-grained visual-semantic interaction. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024).
Wang, Z., Yu, L., Ding, X., Liao, X. & Wang, L. Shared-specific feature learning with bottleneck fusion transformer for multi-modal whole slide image analysis. IEEE Trans. Med. Imaging 42, 3374–3383 (2023).
Friberg, N. et al. Cause of death and significant disease found at autopsy. Virchows Arch 475, 781–788 (2019).
Pastores, S. M., Dulu, A., Voigt, L., Raoof, N., Alicea, M. & Halpern, N. A. Premortem clinical diagnoses and postmortem autopsy findings: discrepancies in critically ill cancer patients. Crit. Care 11, R48 (2007).
Zaorsky, N. G. et al. Causes of death among cancer patients. Ann. Oncol. 28, 400–407 (2017).
Murphy, G. K. Cancer and the coroner. JAMA 237, 786–788 (1977).
Kang, M., Song, H., Park, S., Yoo, D. & Pereira, S. Benchmarking self-supervised learning on diverse pathology datasets. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (IEEE, 2023).
Wang, X. et al. Transformer-based unsupervised contrastive learning for histopathological image classification. Med. Image Anal. 81, 102559 (2022).
Cancer Genome Atlas Research N. The Cancer Genome Atlas Pan-Cancer analysis project. Nat. Genet. 45, 1113–1120 (2013).
Bejnordi, B. E. et al. Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer. JAMA 318, 2199–2210 (2017).
Dolinak, D., Matshes, E. & Lew, E. O. Forensic Pathology: Principles and Practice (Elsevier, 2005).
DiMaio, D. & DiMaio, V. J. Forensic Pathology (CRC Press, 2001).
Huang, Z. et al. A visual-language foundation model for pathology image analysis using medical Twitter. Nat. Med. 29, 2307–2316 (2023).
McInnes, L. & Healy, J. UMAP: uniform manifold approximation and projection for dimension reduction. Preprint at https://arxiv.org/abs/1802.03426 (2018).
Bordes F, Balestriero R, Vincent P. High Fidelity Visualization of What Your Self-Supervised Representation Knows About. Transact. Mach. Learn. Res. (2022).
Wang, W. et al. Neuropathologist-level integrated classification of adult-type diffuse gliomas using deep learning from whole-slide pathological images. Nat. Commun. 14, 6359 (2023).
Vu, Q. D., Rajpoot, K. & Raza, S. E. A. & Rajpoot, N. Handcrafted histological transformer (H2T): unsupervised representation of whole slide images. Med. Image Anal. 85, 102743 (2023).
Yu, J. G. et al. Prototypical multiple instance learning for predicting lymph node metastasis of breast cancer from whole-slide pathological images. Med. Image Anal. 85, 102748 (2023).
Song, A. H. et al. Morphological prototyping for unsupervised slide representation learning in computational pathology. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (IEEE, 2024).
Zhou, H. Y. et al. A transformer-based representation-learning model with unified processing of multimodal input for clinical diagnostics. Nat. Biomed. Eng. 7, 743–755 (2023).
Nagrani, A. et al. Attention bottlenecks for multimodal fusion. Adv. Neural Inf. Process. Syst. 34, 14200–14213 (2021).
Zhong, Y. F. et al. PET/CT based cross-modal deep learning signature to predict occult nodal metastasis in lung cancer. Nat. Commun. 14, 7513 (2023).
Wang J, et al. GIT: A Generative Image-to-text Transformer for Vision and Language. Transact. Mach. Learn. Res. (2022).
Jaegle, A. et al. Perceiver: general perception with iterative attention. In Proc. 38th International Conference on Machine Learning (eds Meila, M. & Zhang, T.) 4651–4663 (PMLR, 2021).
Arthur, D. & Vassilvitskii, S. k-means++: the advantages of careful seeding. In Proc. Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms (Society for Industrial and Applied Mathematics, 2007).
Oquab M, et al. DINOv2: Learning Robust Visual Features without Supervision. Transact. Mach. Learn. Res. (2024).
Caron, M., Misra, I., Mairal, J., Goyal, P., Bojanowski, P. & Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural Inf. Process. Syst. 33, 9912–9924 (2020).
Gu, Y. et al. Domain-specific language model pretraining for biomedical natural language processing. ACM Trans. Comput. Healthc. (HEALTH) 3, 1–23 (2021).
Radford, A. et al. Learning transferable visual models from natural language supervision. In Proc. International Conference on Machine Learning Vol. 139 (PMLR, 2021).
Zhang, S. et al. BiomedCLIP: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs. Preprint at https://ui.adsabs.harvard.edu/abs/2023arXiv230300915Z (2023).
Ikezogwo, W. et al. Quilt-1m: One million image-text pairs for histopathology. Adv. Neural Inf. Process. Syst. 36, 37995–38017 (2023).
Touvron, H et al. Training data-efficient image transformers & distillation through attention. In Proc. 38th International Conference on Machine Learning (eds Marina M. & Tong, Z.) (PMLR, 2021).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proc. IEEE Conference on Computer Vision and Pattern Recognition (IEEE, 2016).
Ali, A. et al. Xcit: cross-covariance image transformers. Adv. Neural Inf. Process. Syst. 34, 20014–20027 (2021).
Touvron, H et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:230213971, (2023).
Li, C. et al. Llava-med: training a large language-and-vision assistant for biomedicine in one day. Adv. Neural Inf. Process. Syst. 36, 28541–28564 (2024).
Laurençon, H., Tronchon, L., Cord, M. & Sanh, V. What matters when building vision-language models? Adv. Neural Inf. Process. Syst. 37, 87874–87907 (2024).
Dosovitskiy A, et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In International Conference on Learning Representations (2021).
Caron, M et al. Emerging properties in self-supervised vision transformers. In Proc. 2021 IEEE/CVF International Conference on Computer Vision (ICCV 2021) 9630–9640 (IEEE, 2021).
Zhou J, et al. Image BERT Pre-training with Online Tokenizer. In: International Conference on Learning Representations (2022).
He, K. Fan, H. Wu, Y. Xie, S. & Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proc. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (IEEE, 2020).
Cuturi, M. Sinkhorn distances: lightspeed computation of optimal transport. In Proc. 26th International Conference on Neural Information Processing Systems Vol. 2 (Curran Associates Inc., 2013).
Assran, M. et al. Masked Siamese networks for label-efficient learning. In European Conference on Computer Vision 456–473 (Springer Nature, 2022).
Gao, P. et al. Clip-adapter: Better vision-language models with feature adapters. Int. J. Comput. Vis. 132, 581–595 (2024).
Zhang R, et al. Tip-adapter: Training-free adaption of clip for few-shot classification. In European Conference on Computer Vision. (Springer, 2022).
Wang, Z. et al. Connecting multi-modal contrastive representations. Adv. Neural Inf. Process. Syst. 36, 22099–22114 (2023).
Alayrac, J.B. et al. Flamingo: a visual language model for few-shot learning. In Proc. 2022 Advances in Neural Information Processing Systems (NIPS) 23716–23736 (IEEE, 2022).
Ranasinghe, K. et al. Perceptual grouping in contrastive vision-language models. In Proc. 2023 Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 5571–5584 (IEEE, 2023).
Abdelfattah, R et al. CDUL: CLIP-driven unsupervised learning for multi-label image classification. In Proc. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) 1348-1357 (IEEE, 2023).
Mukhoti, J. et al. Open vocabulary semantic segmentation with patch aligned contrastive learning. In Proc. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 19413–19423 (IEEE, 2023).
Oord, A., Li, Y. & Vinyals, O. Representation learning with contrastive predictive coding. Preprint at https://doi.org/10.48550/arxiv.1807.03748 (2018)
Ioffe, S, Szegedy, C., Batch normalization: accelerating deep network training by reducing internal covariate shift. In Proc. 32nd International Conference on International Conference on Machine Learning Vol. 37 (JMLR.org, 2015).
Hendrycks, D. & Gimpel, K. Gaussian Error Linear Units (GELUs). Preprint at https://ui.adsabs.harvard.edu/abs/2016arXiv160608415H (2016).
Loshchilov I, Hutter F. Decoupled Weight Decay Regularization. In International Conference on Learning Representations (2019).
Dhariwal, P. & Nichol, A. Diffusion models beat GANs on image synthesis. In 2021 Advances in Neural Information Processing Systems (NIPS), 8780–8794 (ACM, 2021).
Ho, J, Jain, A. & Abbeel, P., Denoising diffusion probabilistic models. In Proc. 34th International Conference on Neural Information Processing Systems (Curran Associates Inc., 2020).
Song J, Meng C, Ermon S. Denoising Diffusion Implicit Models. In International Conference on Learning Representations (2021).
Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention. (Springer, 2015).
Yu J, Wang Z, Vasudevan V, Yeung L, Seyedhosseini M, Wu Y. CoCa: Contrastive Captioners are Image-Text Foundation Models. Transact. Mach. Learn. Res. (2022).
OpenAI. Introducing ChatGPT. https://openai.com/blog/chatgpt/ (2023).
Shen, C. Large-vocabulary forensic pathological analyses via prototypical cross-modal contrastive learning. Zenodo https://zenodo.org/records/15570430 (2025).
Acknowledgements
The authors acknowledge the funding of the Council of the National Natural Science Foundation of China (No. NSFC81730056), NSFC Grants (Nos. 12326616, 62101431, and 62101430) and Natural Science Basic Research Program of Shaanxi (No. 2024JC-TBZC-09). And, we are grateful to Wen Li (Biomedical Experimental Center of Xi’an Jiaotong University) for her technical support.
Author information
Authors and Affiliations
Contributions
C.S. and C.L. conceived the study and wrote the manuscripts. C.S. and W.Z. developed the SongCi model and wrote the code. C.S., F.W., and K.L. performed the experiment analysis. X.W., G.W., H.W., and X.L. preprocessed the datasets. S.F., J.Z., and H.M. provided the datasets. C.L., J.M., and Z.W. supervised the project.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Yixiao Ge, Hong-Yu Zhou, and the other anonymous reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Shen, C., Lian, C., Zhang, W. et al. Large-vocabulary forensic pathological analyses via prototypical cross-modal contrastive learning. Nat Commun 16, 6773 (2025). https://doi.org/10.1038/s41467-025-62060-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-025-62060-x
This article is cited by
-
Large-vocabulary forensic pathological analyses via prototypical cross-modal contrastive learning
Nature Communications (2025)
-
Leveraging chatgpt’ s advanced data analysis for forensic science research and applications
Forensic Science, Medicine and Pathology (2025)
