
Abstract
Data-driven approaches have advanced colorectal lesion diagnosis in digestive endoscopy, yet their application in endocytoscopy (EC)—a high-magnification imaging technique—remains limited, with most studies relying on conventional machine learning methods like support vector machines. Inspired by the success of large-scale language models that leverage progressive pre-training, we develop a computer-aided diagnosis (CAD) model using narrow-band imaging endocytoscopy (EC-NBI) to classify colorectal lesions (non-neoplastic lesions, adenomas, and invasive cancers). Here, we show that our model, trained through a multi-stage pre-training strategy combined with supervised deep clustering, outperforms state-of-the-art supervised methods in a multi-center retrospective cohort. Notably, it surpasses endoscopists’ diagnostic accuracy in human-machine competitions and enhances their performance when used as an assistive tool. This EC-NBI CAD model significantly improves the accuracy and consistency of diagnosing colorectal lesions, laying a foundation for future early cancer screening, particularly for distinguishing superficial and deep submucosal invasive cancers, pending further expansive multi-center data.
Similar content being viewed by others
Introduction
Early disease screening is crucial for improving patient prognosis and reducing healthcare costs1,2, which can significantly decrease morbidity and mortality rates by detecting diseases at an early, more treatable stage3,4. This is particularly crucial in the realm of colorectal lesions, including precancerous lesions and colorectal cancer (CRC). In this context, early detection via screening methods makes timely intervention and more favorable prognoses4,5,6,7. Endoscopy, as a non-invasive and highly accurate diagnostic tool, allows for direct visualization of the gastrointestinal tract8. It is instrumental in identifying precancerous lesions and early-stage cancers, facilitating timely treatment. Endocytoscopy (EC) represents an advanced endoscopic system that enables the observation of cellular atypia and glandular structures with ultra-high magnification (e.g., ×520) images following appropriate staining9,10. Additionally, EC combined with narrow-band imaging (EC-NBI) enables visualization of microvessels on the surface of colorectal lesions without the need for staining, thereby avoiding potential health risks associated with the staining process. Studies have demonstrated that EC-NBI provides diagnostic efficacy in predicting the histopathological diagnosis of colorectal lesions comparable to EC with staining11. Compared to non-magnified NBI or magnifying NBI (ME-NBI, with magnification levels of approximately ×80–100), the ultra-high magnification capability of EC-NBI enables more precise observation of surface vascular patterns, facilitating more accurate prediction of colorectal lesions. However, accurate EC diagnosis of surface microvessels heavily depends on the experience of endoscopists, making it challenging for novices to achieve sufficient diagnostic accuracy12.
To address this issue, computer-aided diagnosis (CAD) based on EC-NBI has been developed to assist endoscopists in attaining results comparable to those of experienced professionals13,14,15. Currently, for clinical application, the designed CAD model serves as a binary classifier. It has the ability to tell non-neoplastic colorectal lesions apart from neoplastic ones, but it is unable to make a more detailed distinction between adenomas and invasive cancers12. Based on clinical practice with EC-NBI, it is difficult for endoscopists to distinguish adenomas, particularly high-grade adenomas, from invasive cancers15. Therefore, there is an urgent need to develop a three-class CAD model capable of providing three predicted outcomes: non-neoplastic lesions, adenomas, and invasive cancers.
Deep learning has emerged as an extremely powerful approach in the realm of extracting valuable information from medical images. It has demonstrated tremendous promise when it comes to diagnostic prediction, particularly in the area of digestive diseases16,17,18. In contrast to traditional machine learning methods that have been utilized for EC diagnosis12, deep learning-based methods bring a significant advantage by doing away with the necessity for manual feature extraction19. Through adaptively learning feature extraction capabilities from extensive training datasets in an end-to-end manner, deep learning models can achieve far superior disease prediction capabilities in comparison to traditional machine learning approaches.
In this work, we develop a data-driven three-class CAD model for colorectal lesion diagnosis from EC-NBI images, leveraging deep learning techniques. Our model demonstrates high accuracy in classifying non-neoplastic lesions, adenomas, and invasive cancers among colorectal lesions. The distinguishing feature of our method lies in the integration of masked autoencoders20, introducing significant improvements. Encouraged by the success of the multi-stage continuing pre-training (CPT) strategy for large language models, in our work, we mimic the process of multi-stage CPT of large language models and use different data sets to pre-train the model, which finally helps to improve the model’s recognition of colorectal lesion. Specifically, during the model training stage, in the first stage of generalized network pretraining, we conduct unsupervised pre-training using a vast number of endoscopic images. Then, in the second stage of in-domain CPT, we continuously pre-train the model using an appropriate amount of unlabeled EC-NBI data in an unsupervised manner to continuously enhance the model’s feature extraction ability. In the final supervised fine-tuning (SFT) stage, we introduce the concept of supervised deep clustering (SDC) which employs the method of expectation maximization (EM) to enhance downstream classification accuracy through feature clustering, thus improving the model’s classification capabilities. After model training, we conducted validation of the performance of our model in a multi-center cohort. From diverse quantitative indicators of the model to human-machine competitions, the performance of our model comprehensively outperforms that of other advanced models and even exceeds the diagnostic performance of endoscopists. The successful implementation of our model not only enhances the diagnostic efficiency of endoscopists but also, to a certain degree, propels endoscopic diagnosis to the level of real-time biopsy diagnosis.
Results
Patient characteristics
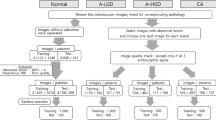
For the training and internal validation of the proposed model, a total of 32142 EC-NBI images from 723 patients with colorectal lesions were collected for this retrospective study at the First Hospital of Jilin University (Changchun, China) (seen in Fig. 1). These data were divided into a training cohort (8615 EC-NBI images from 406 lesions of 315 patients) and an internal validation cohort (23527 EC-NBI images from 498 lesions of 408 patients), with a specific time node serving as the demarcation. For the generalization verification of the model, a total of 2749 EC-NBI images from 152 lesions of 90 patients with colorectal lesions were collected as an external validation cohort for this retrospective study at the MEIHEKOU Center Hospital (Meihekou, China). The statistical characteristics of patients and lesions in each cohort are presented in Table 1 and Table 2, respectively. Detailed data can be found in Supplementary Data S1 and S2.

Flowcharts of the dataset.
Development of the proposed deep learning-based model
The overall study design is presented in Fig. 2. A deep learning model was trained with the aid of a multi-stage CPT strategy and validated by using a multi-center cohort of EC-NBI images to provide three predicted outcomes: non-neoplastic lesions, adenomas, and invasive cancer. In our work, we conduct large-scale generalized unsupervised pre-training with the aid of almost 480,000 endoscopic images, which are compiled from several public datasets21,22,23,24,25,26,27,28,29,30,31. These datasets comprise colonoscopy, gastroscopy, limited esophagus images and videos, etc. They are primarily in white light modality with some fluorescence and narrow-band imaging. From these, we extracted a frame image per second to enrich the dataset for video. Then, we performed unsupervised CPT with unlabeled EC-NBI images. Finally, combined with the ground truth, we fine-tuned the EC-NBI image classification model in a supervised manner.

a Study design and the flowchart of the multi-stage continuing pre-training (CPT) strategy. b The model evaluation via different metrics.
The proposed model accurately makes diagnosis at the image level
Given that each lesion is associated with several EC-NBI images, a comprehensive evaluation of the model’s performance is conducted at both the EC-NBI image level and the lesion level. As depicted in Fig. 3, the proposed deep learning model exhibits remarkable accuracy in classifying specific classes in both the training and validation cohorts at the image level. Specifically, in the internal validation cohort, for non-neoplastic lesions, the area under the curve (AUC) is 0.939, with a 95% confidence interval (95% CI) of (0.936, 0.942). Adenomas have an AUC of 0.917 (0.914, 0.921), and invasive cancers have an AUC of 0.969 (0.967, 0.972). In the external validation cohort, for non-neoplastic lesions, the area under the curve (AUC) is 0.837, with a 95% confidence interval (95% CI) of (0.823, 0.851). Adenomas have an AUC of 0.827 (0.813, 0.841), and invasive cancers have an AUC of 0.908 (0.897, 0.919) (Fig. 3a). Furthermore, the confusion matrices for the training cohort and both internal and external validation cohorts are presented, which can provide a more detailed view of the model’s performance (Fig. 3b).

At the image level, we quantitatively perceive the model performance by calculating the receiver operating characteristic (ROC) (a) and confusion matrix (b) of the training and validation cohorts of the model. Further, through the T-SNE method, we perform dimensionality reduction and visualization of the features of the samples. The clustering situation between different classes can be observed (c), and their silhouette scores are quantitatively calculated. The same indicators calculation and visualization are also displayed at the lesion level (d–f).
Typically, the performance of a disease model depends on the separability of images within the feature space. We first output the sample features that have passed through the model. Subsequently, we employ the dimensionality reduction method of T-SNE to visualize the aggregation of features and calculate the corresponding silhouette score, which can quantitatively reflect the quality of feature aggregation. The larger the value, the better the separability of features. To be specific, in Fig. 3c, we can obtain a silhouette score of 0.4724 in the training cohort, 0.4284 in the internal validation cohort, and 0.4622 in the external validation cohort.
The proposed model accurately makes the diagnosis at the lesion level
We further conduct an evaluation of the performance of our model at the lesion level. Due to the voting mechanism, whereby the final prediction result of a lesion is determined through voting within the same lesion and the final feature can be computed by averaging all the related features. As a result, the final result can disregard a small number of inaccurately predicted samples, leading to a marginally higher performance at the lesion level compared to that at the image level (Fig. 3d, e). This slightly higher performance can also be intuitively verified from the visualization of feature visualization using T-SNE (Fig. 3f). Specifically, we can obtain a silhouette score of 0.6914 in the training cohort, 0.8116 in the internal validation cohort, and 0.6673 in the external validation cohort. These silhouette scores are significantly higher than those obtained at the image level (Fig. 3c), indicating that features are more separable at the lesion level through the voting mechanism. Noting that our method underperformed on the external validation set compared to the internal validation set, both at the image level and lesion level. The potential explanation for this discrepancy is the inconsistency in imaging devices used for data acquisition between the external and internal validation sets. Variations in image quality (e.g., resolution, lighting, and noise profiles) caused by different devices led to a mismatch in data distributions between the external validation set and the training data, thereby diminishing the model’s generalization performance.
The proposed model outperforms the traditional deep-learning approach
We systematically evaluated the performance of various state-of-the-art (SOTA) deep learning models, including ResNeSt32, ViT-B/1633, Convnext34, MambaOut35, and MaxViT36. As shown in Fig. 4, whether at the image level or the lesion level, in comparison with other SOTA methods, although for certain disease categories, some metrics of specific methods may be on a par with ours or slightly superior to ours (for example, at the image level, in the invasive cancers category, MaxViT surpasses our model in PPV. At the lesion level, in the identification of invasive cancers, the sensitivity is marginally better than the result of our model), we take the area enclosed by the five indicators as the comprehensive performance of the model on the five indicators, which can be seen under each Radar chart in Fig. 4, and the area of our method is optimal in most cases. This can be observed from the fact that the blue lines in Fig. 4 are essentially on the outermost periphery. Detailed quantitative metrics are provided in Tables S1 and S2 in the Supplementary Information File.

a At the image level, the performance of different comparison methods on different disease types in the training cohort. b At the image level, the performance of different comparison methods on different disease types in the internal validation cohort. c At the image level, the performance of different comparison methods on different disease types in the external validation cohort. d At the lesion level, the performance of different comparison methods on different disease types in the training cohort. e At the image level, the performance of different comparison methods on different disease types in the internal validation cohort. f At the image level, the performance of different comparison methods on different disease types in the external validation cohort. Note: The closer to the periphery, the better the performance. The numerical comparison below each radar chart represents the area enclosed by the five indicators under the different methods; the larger the area, the higher the comprehensive performance of the method.
Human-machine collaboration can improve the accuracy of endoscopists
To further validate the clinical performance of our model, we also evaluated the capacity of the deep learning model to enhance the performance of endoscopists in disease prediction with and without the assistance of artificial intelligence (AI). To illustrate the influence of the deep learning model on the individualized assessment of endoscopists, four endoscopists independently conducted the histopathological diagnosis assessment of each lesion in both the internal and external validation cohorts. Subsequently, on the same day, they re-evaluated the histopathological diagnosis after taking into account the predictions of our proficiently trained AI model. The evaluation metrics encompass accuracy, recall, F1-score, specificity, sensitivity, as well as positive and negative predictive values (PPV and NPV). The results are presented in Fig. 5.

Performance comparison between our model and endoscopists, as well as the improvement in endoscopists’ prediction results with the assistance of AI. (AI) means this doctor has AI assistance. The solid dark-red curves represent AI-assisted endoscopist diagnoses. The dashed light-red curves represent endoscopist-only diagnoses. The solid blue curves represent AI-only diagnoses (Our method).
As depicted in Fig. 5, the diagnostic performance of four endoscopists exhibited measurable improvement when augmented by AI assistance within the internal validation dataset. This is substantiated by the observation that the solid dark-red curves (representing AI-assisted endoscopist diagnoses) consistently encompass the dashed light-red curves (baseline endoscopist performance) across all diagnostic dimensions. Furthermore, the proposed AI-only methodology demonstrated statistically superior predictive accuracy compared to AI-assisted endoscopists in the vast majority of evaluated metrics spanning three disease categories, with the exception of the third endoscopist, whose sensitivity for invasive carcinoma marginally exceeded our AI-only approach.
Further, external validation revealed analogous trends: AI assistance enhanced diagnostic discrimination across all endoscopists. However, both the AI-only system and endoscopist performance exhibited modest declines across all metrics, attributable to distributional shifts in the external dataset. Notably, while the AI-only approach outperformed diagnoses by the first and second endoscopists (junior clinicians with 3 and 1 years of endoscopic experience, respectively), the third and fourth endoscopists (senior clinicians with 9 and 7 years of experience) achieved comparable or marginally superior diagnostic accuracy in specific metrics. This discrepancy likely stems from the differential integration of clinical expertise, where senior endoscopists’ experiential knowledge compensated for dataset heterogeneity more effectively than junior counterparts. (Detailed experimental results are presented in the Supplementary Data S3 and S4)
Interpretation of the proposed deep learning-based model
The deep learning-based classification model typically consists of the feature extractor and the classifier. Such models are often difficult to understand. On the one hand, the extracted features are not interpretable in clinical practice. On the other hand, due to the errors of the classifier, there is a certain perturbation between the features and the final classification prediction, which means good features do not necessarily represent correct prediction results. Regarding the uninterpretability of extracted features in clinical practice, we employed the Gradient-weighted Class Activation Mapping (Grad-CAM) method to generate class activation mapping, which regions of image features play a key role in determining a particular category output of the features from different layers of our model (Fig. 6a). From this, we can see that the model mainly focuses on the blood vessels, which is consistent with our clinical knowledge. Further, we also output all the class activation mappings of each transformer block in our model, and we can see that with the deepening of the blocks, the model’s region of interest gradually converges to the vascular area in the EC images (see Fig. S1 in the Supplementary Information File). By perturb the labels, we can see that the model’s class activation mappings are also changed, thus: λfor the non-neoplastic category, the model mainly focuses on the fuzzy and unclear margin microvessels of the image; for the adenomas category, the model primarily focuses on the dense, regular and clear margin micronetworks in the EC images; and for the invasive cancer category, the model mainly focuses on the irregular, thick and sparse microvessels in the EC images. (see Fig. S2 in the Supplementary Information File).

a The class activation mapping of the model when predicting samples of different categories was obtained through Gradient-weighted Class Activation Mapping (Grad-CAM). b Bee swarm summary plot of feature importance based on Shapley Additive exPlanations (SHAP) analysis. The bee swarm plot is designed to display an information-dense summary illustrating how the top features in a dataset affect the output of a model. Each observation in the data is represented by a single dot on each feature row. The vertical axis represents the features, sorted from top to bottom according to their importance as predictors. The position of a dot on a feature row is determined by the SHAP value of the corresponding feature, and the accumulation of dots on each feature row illustrates its density. The feature value determines the color of the dots, with red indicating large SHAP values and blue indicating small SHAP values. c Feature importance plot. Passing the SHAP value matrix to the bar plot function creates a global feature importance plot for each class, where the global importance of each feature for each class is considered as the average absolute value of that feature overall given samples.
For the relationship between features and classification output, we employed an explanatory model named Shapley Additive exPlanations (SHAP)37,38, which functions as an additive method in feature attribution interpretation. It explains the model’s predicted values as the cumulative sum of attribution values assigned to each input feature. A significant SHAP value highlights the important influence of each feature in terms of the effectiveness of classification prediction, enabling researchers and practitioners to better understand the model’s behavior and make more informed decisions. In this work, we computed the feature importance and impact using SHAP for each class. We ranked the feature importance in descending order. The results are presented through a beeswarm summary plot (Fig. 6b) and a feature importance plot (Fig. 6c). For example, we can see that “Feature 520” has a significant impact on the prediction of non-neoplastic lesions, “Feature 385” for adenomas, and “Feature 340” for invasive cancers, which can be used to determine the reliability of prediction results. To this end, in clinical practice, following the capture of EC images containing potential abnormalities by endoscopists, heatmaps can be applied to enhance the interpretability of the model, providing visual explanations that support clinicians in achieving more accurate and reliable diagnostic assessments.
Discussion
It is well known that EC offers the highest magnification among endoscopic imaging modalities, holding significant potential for achieving ‘optical biopsy’. From non-neoplastic lesions to adenomas and invasive cancers, the microvessels become increasingly thicker and irregular with an increasing grade of lesion dysplasia (Fig. 6a). The precise real-time endoscopic diagnosis of colorectal lesions is critical for endoscopists in selecting appropriate treatment strategies. However, it is difficult for endoscopists, especially novice endoscopists, to make accurate diagnoses using EC-NBI. To address this issue, we collected approximately 480,000 publicly available endoscopic images to pre-train the foundation of the large model. Then, we collected 8615 EC-NBI images (from 315 patients) at the First Hospital of Jilin University to conduct in-domain CPT and SFT of the model. Ultimately, we have successfully developed a computer-aided diagnosis model based on EC-NBI for predicting the classification of colorectal lesions. In contrast to previous machine learning-based binary classification CAD models, our model effectively discriminated non-neoplastic lesions, adenomas, and invasive cancers, which can be integrated into the clinical workflow to provide real-time assistance for disease diagnosis (An example of real-time diagnosis in the Supplementary Movie 1). By rapidly determining lesion pathology, endoscopists optimize treatment strategies, enhancing clinical outcomes.
Approximately 90% of colorectal lesions detected during colonoscopy are diminutive (≤ 5 mm) or small (≤ 10 mm) polyps, primarily non-neoplastic with minimal malignant potential39. Aligned with the American Society for Gastrointestinal Endoscopy introduced the Preservation and Incorporation of Valuable Endoscopic Innovations (PIVI) guidelines for optimal management, “resect-and-discard” or “leave-in-situ” strategies effectively reduce unnecessary pathological examinations and associated risks40. Generally, hyperplastic polyps (Hps), which account for the majority of non-neoplastic lesions, exhibit fine and fuzzy microvessels. While NBI, ME-NBI, and EC-NBI have all been shown to effectively identify characteristic HPs, EC-NBI has demonstrated the ability to distinguish diminutive HPs with reticular capillary patterns, which account for over 10% of HPs41. The EC-NBI shows these HPs with unclear margin microvessels. It could be challenging for endoscopists to discern these microvessel patterns. Our results demonstrate that our model achieves superior performance in differentiating these HPs compared to endoscopists. Furthermore, when assisted by the CAD model, endoscopists exhibit significantly enhanced lesion classification accuracy. (Fig. 5). As we know, about 80 to 95% of colorectal cancers develop from adenomas. It is crucial to distinguish adenoma and invasive cancer because it is directly related to the choice of endoscopic or surgical treatment. To accurately predict adenomas and invasive cancers, an endoscopic diagnostic approach with high sensitivity and specificity is imperative. Our deep learning model demonstrated excellent diagnostic performance in predicting different histopathologies of colorectal lesions. Our model shows the accuracy of predicting non-neoplastic lesions, adenomas, and invasive cancers at the image level is 0.904, 0.856, and 0.944 in the internal validation set, 0.877, 0.853, and 0.975 in the external validation set, respectively.
In addition, the diagnostic accuracy of EC-NBI is significantly related to the experience of the endoscopist. Previous study has shown that the accuracy of EC-NBI in diagnosing adenomas is sharply lower for non-expert endoscopists (63.3% [59.1%–67.5%]) compared to expert endoscopists (84.2% [81.2%–86.8%])12. At the same time, our study also indicates that there is a significant difference in the diagnostic performance of EC-NBI among endoscopists at different levels. Nevertheless, with the aid of our CAD model, the diagnostic accuracy of endoscopists has been improved. For instance, in the internal validation set, for non-neoplastic lesions, the sensitivity remains unchanged while the specificity is increased by approximately 4 basis points. For adenomas, the specificity remains unchanged while the sensitivity is maximally increased by 5 basis points. For invasive cancers, all indicators improved further. Thus, the CAD model will significantly improve the accuracy and homogeneity of EC-NBI in the diagnosis of colorectal lesions and achieve the purpose of optical biopsy. The utilization of this model eliminates the potential risks associated with traditional biopsy, streamlines the time-consuming process of pathological diagnosis, and enables prompt diagnosis and removal of adenomas and colorectal cancers. The strategy of observation for certain non-neoplastic lesions, in the meantime, serves to reduce costs and avoid the risks associated with polypectomy.
When developing the deep learning model, we trained a Transformer-based neural network using a multi-stage CPT strategy. We have demonstrated that this approach is superior to traditional neural networks and models without multi-stage CPT in predicting EC-NBI diseases (Table S5 in the Supplementary Information File). Compared with traditional machine learning, our method can utilize a large amount of labeled and unlabeled clinical data and has achieved performance far exceeding that of traditional machine learning. Compared with traditional convolutional neural networks, our model is the first large model related to EC-NBI, with a parameter amount exceeding 80 M, which can greatly promote the model performance, as seen in Table S1 and S2 in the Supplementary Information File. Under the pre-training of a large amount of unlabeled data, we can provide a very robust starting point for subsequent SFT, enabling SFT to be completed in a few epochs. Additionally, during the brief period of SFT, the supervised clustering loss can greatly promote the aggregation of samples in the feature space and improve the recognition ability of the model, as seen in Table S4 in the Supplementary Information File.
Although our method can significantly enhance the diagnostic performance of colorectal lesions with EC-NBI images and to a certain extent improve the discriminatory ability of diagnosticians at different levels, this study had several limitations. (1) This study’s data has several bias-related aspects. The training data from only the First Hospital of Jilin University leads to institutional-specific distribution. The model’s performance varies greatly between the internal and external validation sets, as seen in Fig. 4, due to differences in image acquisition systems and annotation standards. Also, since both hospitals are in Northeast China, the data has regional characteristics, and the model’s cross-regional generalization ability needs further study, especially when applied to diverse populations. Moreover, clinical data naturally lack balance in factors like gender, age, and lesion features, causing data bias. But this bias is in line with clinical reality, and the model’s results are somewhat recognized by endoscopists, as shown in Fig. 5, demonstrating its robustness in real-world scenarios. (2) Due to the limited lesion number, the CAD model is currently unable to distinguish between superficial submucosal invasive cancer and deep submucosal invasive cancer. This limitation will be addressed in future work by expanding the training dataset with a larger and more diverse dataset of relevant cases collected from multiple hospitals. (3) External validation experiments demonstrate that disparities in image quality across hospitals, arising from regional variations and differences in equipment characteristics, such as resolution, illumination, and noise profiles, adversely affect model performance. To address this challenge, we propose two complementary strategies: Expanding multi-center datasets to enhance the diversity of the training set or implementing an EC-NBI image quality control system at the model’s input stage to enforce rigorous standardization of input data. (4) This study is a retrospective analysis, lacking prospective clinical validation. However, we have developed a real-time EC-NBI diagnostic system that has demonstrated effective clinical diagnostic performance in laboratory settings. Pending approval from relevant regulatory bodies, this system will be poised for clinical deployment to facilitate prospective clinical validation, which is a key objective of our future research agenda.
Methods
Patients and lesions
We retrospectively collected the clinical data and endocytoscopic images of colorectal lesions that were pathologically diagnosed after endocytoscopic observation between June 2023 and October 2024. Exclusion criteria were: a history of inflammatory bowel disease, radiation therapy for colorectal cancer, special pathological types such as malignant lymphoma, submucosal lesions, sessile serrated lesions (SSLs), and those lesions with endocytoscopic images of poor quality.
Inclusion and ethics statement
The study protocol was approved by the Ethics Committee of the First Hospital of Jilin University and the Ethics Committee of the MEIHEKOU Center Hospital. Informed consent from patients was exempted because of the retrospective nature of this study.
Development of deep learning model
Inspired by the observation that proper model initialization can significantly enhance performance in downstream tasks20, we have developed a multi-stage CPT strategy for diagnostic decision-making using EC-NBI images. In Fig. 2a, in the first stage, we utilized a substantial volume of endoscopy images (480,000) from publicly available datasets, which were unlabeled, to pre-train the encoder of our well-designed model. To be specific, we compile this large-scale dataset from several public datasets21,22,23,24,25,26,27,28,29,30,31 for the first-stage network pre-training. These datasets include colonoscopy, gastroscopy, and limited esophagus images and videos, primarily in white light modality with some fluorescence and narrow-band imaging. For image, each image has been adopted. For video, we extract images per frame per second to enrich the dataset. This pre-training enables the model to acquire superior feature extraction capabilities. In our study, we employed the Masked Image Modeling framework42 to train an image restoration network. To be specific, utilizing a substantial dataset, the network was trained to reconstruct images where 75% of the content had been masked. For our model, we used MAE encoder as the backbone. In the second stage, we further utilized all the EC-NBI images without labels in the training dataset (8615 images) to continue pre-train our model in the same way.
In the third stage, following model pre-training, we fine-tuned the pre-trained encoder using labeled EC-NBI datasets in a supervised manner. This SFT process, combined with a straightforward classifier, was tailored to optimize the model for the downstream task of colorectal lesion diagnosis from EC-NBI image. To be specific, we incorporated the concept of SDC based on the method of expectation maximization43,44 into the fine-tuning process. By maintaining class centers, we ensured that samples within the same class were as close as possible in the feature space, while samples from different classes were maximally distant. This approach encourages the fine-tuned feature extractor to generate features that are distinctly separable in the feature space.
Backbone
In this study, we chose MAE encoder as the backbone of our model. MAE is an unsupervised technique that learns image representations by recovering partially masked images, thereby effectively capturing both local and global information in the data. It can make full use of unlabeled data, which is particularly advantageous in fields where labeled data is expensive. Specifically, in our work, we followed the suggestion in the original paper20 to randomly occlude 75% of the image patches and input the remaining 25% of visible patches into the model. During model training, the model uses these visible patches to predict and restore the content of the remaining 75%.
Supervised deep clustering
The primary objective of classification problems lies in extracting features that are separable within the feature space. Although traditional supervised classification methods may perform well on specific testing sets, they often encounter issues with poor generalization. A significant contributing factor to this is that the features extracted by these models are not readily distinguishable in the feature space. Consequently, new samples are prone to being misclassified in the feature space. Thus, to obtain a feature extractor that yields easily distinguishable features in the feature space, the fundamental principle is to minimize the intra-class distance and maximize the inter-class distance. In our work, we incorporate the concept of expectation-maximization to alternately optimize our ultimate objective through two steps: expectation and maximization. By reducing the distance between samples and their corresponding class centers and increasing the distance between samples and the centers of other classes, we achieve intra-class compactness and inter-class separation. This approach enables excellent classification performance even with a simple classifier. Experiments have demonstrated that supervised deep clustering can enhance the accuracy of downstream classification tasks and assist the encoder in learning sample-specific representations.
Supervised fine-tuning via downstream dataset
After dual-stage continuing pre-training, we can obtain a well initial weight for the model and a feature extractor with strong feature extraction capabilities. To achieve good performance in downstream EC-NBI diagnostic tasks, we first added a simple classifier which includes a fully-connection hidden layer after the pre-trained feature extractor. Then, we used the labeled EC-NBI training data to fine-tune our model. During the fine-tuning process, we not only optimize the classification loss but also simultaneously optimize the supervised deep clustering loss.
Loss Function
In the pre-training stage, we continuously trained our encoder on endoscopic images and EC-NBI images, respectively. We employed the combination of \({L}_{1}\) loss and perceptual loss \({{{L}}}_{{{{pl}}}}\) as the overall loss function \({L}_{{Pre\_train}}\):
Here, \({{{X}}}_{{{{i}}}}\) is the ith EC-NBI image an \({\bar{{{X}}}}_{{{{i}}}}\) is the ith predicted output. N is the number of EC-NBI images. In the third stage of model fine-tuning via labeled EC-NBI dataset, we not only employed cross entropy \({L}_{{CE}}\) as the loss function of classification, but also used a loss function of supervised deep clustering \({L}_{{SDC}}\). The final loss function in the stage of SFT can be formulated as follows:
Here, \({{{\bf{f}}}}_{{{\boldsymbol{{i}}}}}\) is the feature of the ith EC-NBI image, \({{{\bf{c}}}}_{{{\boldsymbol{{i}}}}}\) is the cluster center of the ith class. T is the transpose operation.
Experimental implementation
This experiment is divided into three stages. In the first stage, a large amount of unlabeled endoscopic data is used for network pre-training. In the second stage, continuing unsupervised pre-training is conducted on the downstream task training set without any labels. In the third stage, SFT is performed for the downstream task. In this work, all images are resized to 224\(\times\)224. Subsequently, the mean and standard deviation of Imagenet45 are used to standardize the images. We set the batch size at 128 and used AdamW as the optimizer. In the stage of network pre-training, a small learning rate of \({10}^{-6}\) is used for warm-up and we set the training epoch at 2 for warm-up. The difference between stage one and stage two is that we conduct 50 epochs of pre-training in the first stage, and 100 epochs for the second stage. We used a cosine scheduler for learning rates whose maximum learning rates involved are set to \({10}^{-4}\) for stage one and \({10}^{-5}\) for stage two, respectively. The minimum learning rate is \({10}^{-5}\) for both. During the pre-training process, all the data will also undergo random cropping, colorization, and rotation through transformation. In addition, perception loss is used via a pretrained VGG with ImageNet for perception loss. For the downstream fine-tuning, the maximum learning rate is \({10}^{-4}\), and the minimum learning rate is \({10}^{-6}\) for the cosine scheduler, and we set the training epoch at 10.
Evaluation of model accuracy for disease diagnosis
Image-level diagnosis
After comprehensive network training, we employed receiver operating characteristic (ROC) analysis to assess the performance of the proposed model in predicting the types and probabilities of colorectal diseases on the internal validation cohort consisting of 23,527 EC-NBI images from 408 patients and the external validation cohort consisting of 2749 EC-NBI images from 90 patients. In the process of calculating various metrics, the optimal cutoff value we adopted is determined by selecting the best cutoff based on the Youden index at the image level in the training cohort, which maximizes the sum of sensitivity and specificity. We computed evaluation metrics, including the area AUC, sensitivity, specificity, and positive and negative predictive values.
Lesion-level diagnosis
Clinically, multiple EC-NBI images can be obtained for a single lesion. In this paper, our inference at the lesion level is obtained through voting based on the results of multiple EC-NBI images. Specifically, for a lesion, we predict the result of each EC-NBI image separately and then take the disease with the largest number of predicted categories as the final prediction result for that lesion. Additionally, we evaluated the ability of the deep learning model to enhance endoscopists’ performance in predicting colorectal lesions with and without artificial intelligence assistance. Endoscopists (1st doctor: 3 years of experience; 2nd doctor: 1 year; 3rd doctor: 9 years; 4th doctor: 7 years) independently assessed the intestinal disease status of each lesion. Then, after considering the predictions of the artificial intelligence model, they re-evaluated the histologic classification on the same day, demonstrating the impact of the model on individual assessments.
Interpretation of the model
To address the issue of black-box predictions in deep learning models, we first apply Grad-CAM to explore the class activation mapping per transformer block of the proposed model. Grad-CAM is a model-agnostic interpretability technique that generates class-specific localization maps by computing the weighted sum of feature maps from the final convolutional layer, highlighting important regions in an input image for a particular prediction. Subsequently, SHAP, a game-theoretic approach, to analyze the data generated by the proposed model, was employed. SHAP values offer an in-depth understanding of the contribution of each feature to the model’s predictions, providing a clear and interpretable understanding of the model’s decision-making process. By calculating the SHAP value for each feature, we can determine the importance and impact of individual features on the predicted outcomes. High SHAP values signify a significant influence of a feature on the prediction, while low SHAP values imply a minimal impact. SHAP analysis is conducted using the SHAP library (V.0.42.1).
Improvement of representation learning
Typically, the performance of a disease model depends on the separability of images within the feature space. If image features are closer together within the same class and farther apart between different classes in the feature space, the model’s predictions will be more reliable and exhibit better generalization performance. To evaluate the model’s representation learning ability, we visualize the clustering effect of image features. Specifically, we convert the encoder’s output features into one-dimensional vectors through global pooling and then apply T-SNE for dimensionality reduction to create feature visualizations. Additionally, we calculate the silhouette score to assess the effectiveness of each method in separating different disease types. The silhouette score measures the similarity of an object to its cluster compared to other clusters, providing an evaluation of clustering quality. Higher silhouette scores indicate better model performance in differentiating between various disease types, reflecting more reliable and generalizable prediction results.
Ablation study
In this paper, our method is a complex approach that combines a multi-stage pre-training strategy and supervised deep clustering. To explore the impact of different components on the model’s performance, we conducted ablation experiments for different parts. The comprehensive quantitative results are shown in Table S3, S4, and S5 in the Supplementary Information File.
Ablation study on pre-training dataset: To explore the role of large-scale endoscopic images in the first-stage pre-training, we replaced them with large-scale natural vision data, ImageNet, which contains approximately one million images. We maintained various hyperparameters and methods in the experimental settings and conducted the same pre-training. Eventually, our method exceeded ImageNet by approximately 30.7% in terms of Accuracy, shown Table S3 in the Supplementary Information File. According to the experimental phenomena, for the magnifying endoscopy classification task, using more closely related ordinary endoscopic data is more helpful compared to general pre-training data sets like ImageNet.
Ablation study on supervised deep clustering (SDC): To explore the role of supervised deep clustering (SDC) in the model, we conducted a new experiment without the deep clustering loss. Through experimental comparison, it can be found that with the assistance of deep clustering loss, all quantitative indicators of our method are improved by more than approximately 10%, shown Table S4 in the Supplementary Information File. This demonstrates that supervised deep clustering can extract more effective feature representations by optimizing the feature differences of similar samples in the same category, thereby helping the model achieve better classification results.
Ablation study on multi-stage training strategy: During multi-stage training, the pre-training in the first stage is of tremendous help as it can effectively assist the model in optimizing to a better performance state. The second stage can make more comprehensive use of downstream task data, that is, magnifying endoscopy data. The multi-stage pre-training strategy can help the model improve its accuracy by approximately 31.9% compared to that without the assistance of multi-stage pre-training, and the improvement in other indicators is even more significant, shown in Table S5 in the Supplementary Information File.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
Source data are provided with this paper. Supplementary Movie 1 and the source data underlying Fig. 1 and Figs. 3–6 are provided as a Source Data. The remaining data are available within the Article, Supplementary Information, or Source Data. All data supporting the findings described in this manuscript are available in the article and in the Supplementary Information and from the corresponding author upon request. The de-identified individual patient data including EC images, are available. A data transfer agreement is required that includes a brief research plan submitted by the user, and data usage is restricted to non-commercial academic research purposes. Request for data access can be submitted to H.X. and will receive a response typically within 30 days. Data will be shared through cloud storage and available for 1 year once access has been granted. Source data are provided with this paper.
Code availability
The code associated with this work is publicly available on GitHub at the repository https://github.com/CorleoneJW/EC-DL46. This repository contains the source code related to the project, which includes implementations of key algorithms, data processing scripts, model architectures, and associated configuration files. Additionally, it includes a “README.md” file that provides guidance on environment setup, usage instructions, and other relevant details to facilitate the use and reproduction of the work. Users can access, download, and utilize the code from this repository following the terms of the license specified in the repository.
References
Shaukat, A. & Levin, T. R. Current and future colorectal cancer screening strategies. Nat. Rev. Gastroenterol. Hepatol. 19, 521–531 (2022).
Crosby, D. et al. Early detection of cancer. Science 375, eaay9040 (2022).
Xiao-Nong, Z. & Xiao-Nong, Z. Epidemic trend, screening, and early detection and treatment of cancer in Chinese population. Cancer Biol. Med. 14, 50–59 (2017).
Bretthauer, M. et al. Effect of colonoscopy screening on risks of colorectal cancer and related death. N. Engl. J. Med. 387, 1547–1556 (2022).
Burnett-Hartman, A. N., Lee, J. K., Demb, J. & Gupta, S. An update on the epidemiology, molecular characterization, diagnosis, and screening strategies for early-onset colorectal cancer. Gastroenterology 160, 1041–1049 (2021).
Fang, Y. et al. An early report of a screening program for colorectal cancer in Guangzhou, China. Ann. Transl. Med. 7, 604–604 (2019).
Kotelevets, S. M. Global strategy for prevention of gastric cancer. World J. Clin. Cases 12, 6353–6357 (2024).
Tang, Y. & Anandasabapathy, S. & Richards-Kortum, R. Advances in optical gastrointestinal endoscopy: a technical review. Mol. Oncol. 15, 2580–2599 (2021).
Takamaru, H., Wu, S. Y. S. & Saito, Y. Endocytoscopy: technology and clinical application in the lower GI tract. Transl. Gastroenterol. Hepatol. 5, 40–40 (2020).
Suzuki, K. et al. Diagnostic performance of endocytoscopy with normal pit-like structure sign for colorectal low-grade adenoma compared with conventional modalities. DEN Open 4, e238 (2024).
Kudo, S. et al. Endocytoscopic microvasculature evaluation is a reliable new diagnostic method for colorectal lesions (with video). Gastrointest. Endosc. 82, 912–923 (2015).
Misawa, M. et al. Accuracy of computer-aided diagnosis based on narrow-band imaging endocytoscopy for diagnosing colorectal lesions: comparison with experts. Int. J. Comput. Assist. Radiol. Surg. 12, 757–766 (2017).
Mori, Y. et al. Novel computer-aided diagnostic system for colorectal lesions by using endocytoscopy (with videos). Gastrointest. Endosc. 81, 621–629 (2015).
Mori, Y. et al. Impact of an automated system for endocytoscopic diagnosis of small colorectal lesions: an international web-based study. Endoscopy 48, 1110–1118 (2016).
Takeda, K. et al. Accuracy of diagnosing invasive colorectal cancer using computer-aided endocytoscopy. Endoscopy 49, 798–802 (2017).
Jiang, Y. et al. Biology-guided deep learning predicts prognosis and cancer immunotherapy response. Nat. Commun. 14, 5135 (2023).
Han, Z. et al. Development and interpretation of a pathomics-driven ensemble model for predicting the response to immunotherapy in gastric cancer. J. Immunother. Cancer 12, e008927 (2024).
Jiang, Y. et al. Predicting peritoneal recurrence and disease-free survival from CT images in gastric cancer with multitask deep learning: a retrospective study. Lancet Digit. Health 4, e340–e350 (2022).
Afshar, P., Mohammadi, A., Plataniotis, K. N., Oikonomou, A. & Benali, H. From handcrafted to deep-learning-based cancer radiomics: challenges and opportunities. IEEE Signal Process. Mag. 36, 132–160 (2019).
He, K. et al. Masked autoencoders are scalable vision learners. in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 15979–15988 (IEEE, 2022). https://doi.org/10.1109/CVPR52688.2022.01553.
Vázquez, D. et al. A benchmark for endoluminal scene segmentation of colonoscopy images. J. Healthc. Eng. 2017, 1–9 (2017).
Mesejo, P. et al. Computer-aided classification of gastrointestinal lesions in regular colonoscopy. IEEE Trans. Med. Imaging 35, 2051–2063 (2016).
Ma, Y., Chen, X., Cheng, K., Li, Y. & Sun, B. LDPolypVideo benchmark: a large-scale colonoscopy video dataset of diverse polyps. In Medical Image Computing and Computer Assisted Intervention – MICCAI, 387–396 (Springer, Cham, 2021).
Coelho, P., Pereira, A., Leite, A., Salgado, M. & Cunha, A. A Deep Learning Approach for Red Lesions Detection in Video Capsule Endoscopies. in Image Analysis and Recognition (eds. Campilho, A., Karray, F. & Ter Haar Romeny, B.). 10882 553–561 (Springer International Publishing, 2018).
Esmaeili, N. et al. Contact endoscopy—narrow band imaging (CE-NBI) data set for laryngeal lesion assessment. Sci. Data 10, 733 (2023).
Borgli, H. et al. HyperKvasir, a comprehensive multi-class image and video dataset for gastrointestinal endoscopy. Sci. Data 7, 283 (2020).
Pogorelov, K. et al. KVASIR: A multi-class image dataset for computer aided gastrointestinal disease detection. in Proceedings of the 8th ACM on Multimedia Systems Conference 164–169 (ACM, 2017). https://doi.org/10.1145/3083187.3083212.
Smedsrud, P. H. et al. Kvasir-Capsule, a video capsule endoscopy dataset. Sci. Data 8, 142 (2021).
Ali, S. et al. Endoscopy artifact detection (EAD 2019) challenge dataset. https://doi.org/10.17632/C7FJBXCGJ9.1 (2019).
Ozyoruk, K. B. et al. EndoSLAM dataset and an unsupervised monocular visual odometry and depth estimation approach for endoscopic videos. Med. Image Anal. 71, 102058 (2021).
Bernal, J. et al. WM-DOVA maps for accurate polyp highlighting in colonoscopy: Validation vs. saliency maps from physicians. Comput. Med. Imaging Graph. 43, 99–111 (2015).
Zhang, H. et al. ResNeSt: split-attention networks. in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) 2735–2745 (IEEE, 2022). https://doi.org/10.1109/CVPRW56347.2022.00309.
Dosovitskiy, A. et al. An image is worth 16x16 words: transformers for image recognition at scale. (2021).
Woo, S. et al. ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders. in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 16133–16142 (IEEE, 2023). https://doi.org/10.1109/CVPR52729.2023.01548.
Yu, W. & Wang, X. MambaOut: Do We Really Need Mamba for Vision? in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR, 2025).
Tu, Z. et al. MaxViT: Multi-Axis Vision Transformer. in European Conference on Computer Vision (ECCV) 459–479 (Springer, 2022). https://doi.org/10.48550/arXiv.2204.01697.
Lundberg, S. M. & Lee, S.-I. A unified approach to interpreting model predictions.
Lundberg, S. M. et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat. Biomed. Eng. 2, 749–760 (2018).
Barua, I. et al. Real-time artificial intelligence–based optical diagnosis of neoplastic polyps during colonoscopy. NEJM Evid. 1, (2022).
Rex, D. K. et al. The American Society for Gastrointestinal Endoscopy PIVI (Preservation and Incorporation of Valuable Endoscopic Innovations) on real-time endoscopic assessment of the histology of diminutive colorectal polyps. Gastrointest. Endosc. 73, 419–422 (2011).
Kataoka, S. et al. Endocytoscopy with NBI has the potential to correctly diagnose diminutive colorectal polyps that are difficult to diagnose using conventional NBI. Endosc. Int. Open 08, E360–E367 (2020).
Xie, Z. et al. SimMIM: a Simple Framework for Masked Image Modeling. in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 9643–9653 (IEEE, 2022). https://doi.org/10.1109/CVPR52688.2022.00943.
Moon, T. K. The expectation-maximization algorithm. IEEE Signal Process. Mag. 13, 47–60 (1996).
Do, C. B. & Batzoglou, S. What is the expectation maximization algorithm?. Nat. Biotechnol. 26, 897–899 (2008).
Deng, J. et al. ImageNet: A Large-Scale Hierarchical Image Database.
Wang, J. et al. Deep learning-based narrow-band imaging endocytoscopic classification for predicting colorectal lesions: a retrospective study. https://doi.org/10.6084/m9.figshare.29851883. (2025).
Acknowledgements
This work was partially supported by the National Key Research and Develop Program of China (2022YFE0118100(H.X.), 2023YFC2706400(Z.Z.)), the Beijing Natural Science Foundation (L245015(Z.Z.)), and the Chongqing Natural Science Foundation (CSTB2024NSCQ-MSX0451(Z.Z.)).
Author information
Authors and Affiliations
Contributions
Z.Z., H.X., and N.Z. conceived and designed the study; M.L., J.F., H.Z., T.M., D.Y., F.N., F.Z., and G.J. acquired the data; J.W., M.L., H.L., J.Y., J.H., X.L., and Z.Z. did the statistical analyses; J.W., J.H., X.L., and Z.Z. developed, trained, and applied the artificial neural network. J.W., M.L., N.Z., and Z.Z. implemented quality control of data and the algorithms; M.L., J.F., H.Z., T.M., D.Y., F.N., F.Z., G.J., and H.X. verified the underlying raw data; All authors had access to the data presented in the manuscript. All authors analyzed and interpreted the data: J.W., M.L., H.L., N.Z., H.X., and Z.Z. prepared the first draft of the manuscript; H.X., and Z.Z. revised the manuscript; All authors contributed to manuscript preparation.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Esmaeil S. Nadimi and the other anonymous reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, J., Liu, M., Liao, H. et al. Development of deep learning-based narrow-band imaging endocytoscopic classification for predicting colorectal lesions from a retrospective study. Nat Commun 16, 8351 (2025). https://doi.org/10.1038/s41467-025-63812-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-025-63812-5
