
Abstract
Memorability, the likelihood that a stimulus is remembered, is an intrinsic stimulus property that is highly consistent across people—participants tend to remember or forget the same faces, objects and more. However, these consistencies in memory have thus far only been observed for visual stimuli. Here we investigated memorability in the auditory domain, collecting recognition memory scores from over 3,000 participants listening to a sequence of speakers saying the same sentence. We found significant consistency across participants in their memory for voice clips and for speakers across different utterances. Regression models incorporating both low-level (for example, fundamental frequency) and high-level (for example, dialect) voice properties were significantly predictive of memorability and generalized out of sample, supporting an inherent memorability of speakers’ voices. These results provide strong evidence that listeners are similar in the voices they remember, which can be reliably predicted by quantifiable low-level acoustic features.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$32.99 / 30 days
cancel any time
Subscribe to this journal
Receive 12 digital issues and online access to articles
$119.00 per year
only $9.92 per issue
Buy this article
- Purchase on SpringerLink
- Instant access to the full article PDF.
USD 39.95
Prices may be subject to local taxes which are calculated during checkout




Similar content being viewed by others

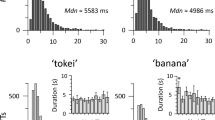
Data availability
All data analysed in this study are available via the Open Science Framework at https://osf.io/pybwd/ (ref. 63). The DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus used in this study is available for download at https://academictorrents.com/details/34e2b78745138186976cbc27939b1b34d18bd5b3.
Code availability
All experiment code is available via the Open Science Framework at https://osf.io/pybwd/ (ref. 63).
References
Bainbridge, W. A., Isola, P. & Oliva, A. The intrinsic memorability of face photographs. J. Exp. Psychol. Gen. 142, 1323–1334 (2013).
Isola, P., Xiao, J., Torralba, A. & Oliva, A. What makes an image memorable? In 24th IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 145–152 (IEEE, 2011).
Kahana, M. J., Aggarwal, E. V. & Phan, T. D. The variability puzzle in human memory. J. Exp. Psychol. Learn. Mem. Cogn. 44, 1857–1863 (2018).
Wakeland-Hart, C. D., Cao, S. A., deBettencourt, M. T., Bainbridge, W. A. & Rosenberg, M. D. Predicting visual memory across images and within individuals. Cognition 227, 105201 (2022).
Antony, J. W. et al. Semantic relatedness retroactively boosts memory and promotes memory interdependence across episodes. Elife 11, e72519 (2022).
Cortese, M. J., Watson, J. M., Wang, J. & Fugett, A. Relating distinctive orthographic and phonological processes to episodic memory performance. Mem. Cognit. 32, 632–639 (2004).
Davis, T. M. & Bainbridge, W. A. Memory for artwork is predictable. Proc. Natl Acad. Sci. USA 120, e2302389120 (2023).
Needell, C. D. & Bainbridge, W. A. Embracing new techniques in deep learning for estimating image memorability. Comput. Brain Behav. 5, 168–184 (2022).
Isola, P., Xiao, J., Parikh, D., Torralba, A. & Oliva, A. What makes a photograph memorable? IEEE Trans. Pattern Anal. Mach. Intell. 36, 1469–1482 (2014).
Kramer, M. A., Hebart, M. N., Baker, C. I. & Bainbridge, W. A. The features underlying the memorability of objects. Sci. Adv. 9, eadd2981 (2023).
Xie, W., Bainbridge, W. A., Inati, S. K., Baker, C. I. & Zaghloul, K. A. Memorability of words in arbitrary verbal associations modulates memory retrieval in the anterior temporal lobe. Nat. Hum. Behav. 4, 937–948 (2020).
Borkin, M. A. et al. What makes a visualization memorable? IEEE Trans. Visual Comput. Graphics 19, 2306–2315 (2013).
Ongchoco, J. D. K., Chun, M. M. & Bainbridge, W. A. What moves us? The intrinsic memorability of dance. J. Exp. Psychol. Learn. Mem. Cogn. 49, 889-899 (2023).
Clapp, W., Vaughn, C. & Sumner, M. The episodic encoding of talker voice attributes across diverse voices. J. Mem. Lang. 128, 104376 (2023).
Palmeri, T. J., Goldinger, S. D. & Pisoni, D. B. Episodic encoding of voice attributes and recognition memory for spoken words. J. Exp. Psychol. Learn. Mem. Cogn. 19, 309–328 (1993).
Belin, P., Fecteau, S. & Bedard, C. Thinking the voice: neural correlates of voice perception. Trends Cogn. Sci. 8, 129–135 (2004).
Young, A. W., Frühholz, S. & Schweinberger, S. R. Face and voice perception: understanding commonalities and differences. Trends Cogn. Sci. 24, 398–410 (2020).
Cleary, A. M., Winfield, M. M. & Kostic, B. Auditory recognition without identification. Mem. Cognit. 35, 1869–1877 (2007).
Kostic, B. & Cleary, A. M. Song recognition without identification: when people cannot ‘name that tune’ but can recognize it as familiar. J. Exp. Psychol. Gen. 138, 146–159 (2009).
Bainbridge, W. A. The memorability of people: intrinsic memorability across transformations of a person’s face. J. Exp. Psychol. Learn. Mem. Cogn. 43, 706–716 (2017).
McAleer, P., Todorov, A. & Belin, P. How do you say ‘Hello’? Personality impressions from brief novel voices. PLoS ONE 9, e90779 (2014).
Mileva, M. & Lavan, N. Trait impressions from voices are formed rapidly within 400 ms of exposure. J. Exp. Psychol. Gen. 152, 1539–1550 (2023).
Todorov, A., Said, C. P., Engell, A. D. & Oosterhof, N. N. Understanding evaluation of faces on social dimensions. Trends Cogn. Sci. 12, 455–460 (2008).
Tompkinson, J., Mileva, M., Watt, D. & Mike Burton, A. Perception of threat and intent to harm from vocal and facial cues. Q. J. Exp. Psychol. 77, 326–342 (2023).
Brady, T. F., Konkle, T., Alvarez, G. A. & Oliva, A. Visual long-term memory has a massive storage capacity for object details. Proc. Natl Acad. Sci. USA 105, 14325–14329 (2008).
Standing, L. Learning 10000 pictures. Q. J. Exp. Psychol. 25, 207–222 (1973).
Bigelow, J. & Poremba, A. Achilles’ ear? Inferior human short-term and recognition memory in the auditory modality. PLoS ONE 9, e89914 (2014).
Cohen, M. A., Horowitz, T. S. & Wolfe, J. M. Auditory recognition memory is inferior to visual recognition memory. Proc. Natl Acad. Sci. USA 106, 6008–6010 (2009).
Fritz, J., Mishkin, M. & Saunders, R. C. In search of an auditory engram. Proc. Natl Acad. Sci. USA 102, 9359–9364 (2005).
Clifford, B. R. Voice identification by human listeners: on earwitness reliability. Law Hum. Behav. 4, 373–394 (1980).
Pautz, N. et al. Time to reflect on voice parades: the influence of reflection and retention interval duration on earwitness performance. Appl. Cogn. Psychol. 38, e4162 (2024).
Yarmey, A. D., Yarmey, A. L. & Yarmey, M. J. Face and voice identifications in showups and lineups. Appl. Cogn. Psychol. 8, 453–464 (1994).
Pazdera, J. K. & Kahana, M. J. Modality effects in free recall: a retrieved-context account. J. Exp. Psychol. Learn. Mem. Cogn. 49, 866–888 (2023).
Smith, R. E. & Hunt, R. R. Presentation modality affects false memory. Psychon. Bull. Rev. 5, 710–715 (1998).
Munoz-Lopez, M. M., Mohedano-Moriano, A. & Insausti, R. Anatomical pathways for auditory memory in primates. Front. Neuroanat. 4, 129 (2010).
Peters, J., Suchan, B., Köster, O. & Daum, I. Domain‐specific retrieval of source information in the medial temporal lobe. Eur. J. Neurosci. 26, 1333–1343 (2007).
Bradshaw, A. R. & McGettigan, C. Instrumental learning in social interactions: trait learning from faces and voices. Q. J. Exp. Psychol. 74, 1344–1359 (2021).
Goldinger, S. D. Echoes of echoes? An episodic theory of lexical access. Psychol. Rev. 105, 251–279 (1998).
Magnuson, J. S., Nusbaum, H. C., Akahane-Yamada, R. & Saltzman, D. Talker familiarity and the accommodation of talker variability. Atten. Percept. Psychophys. 83, 1842–1860 (2021).
Magnuson, J. S. & Nusbaum, H. C. Acoustic differences, listener expectations, and the perceptual accommodation of talker variability. J. Exp. Psychol. Hum. Percept. Perform. 33, 391–409 (2007).
Zhang, C. & Chen, S. Toward an integrative model of talker normalization. J. Exp. Psychol. Hum. Percept. Perform. 42, 1252–1268 (2016).
Garofolo, J. S., Lamel, L. F., Fisher, W. M., Fiscus, J. G. & Pallett, D. S. DARPA TIMIT Acoustic-phonetic Continuous Speech Corpus (US Department of Commerce, 1993).
Shue, Y. L., Keating, P., Vicenik, C. & Yu, K. VoiceSauce: a program for voice analysis. In Proc. ICPhS XVII, 1846–1849 (ICPhS, 2011).
Oosterhof, N. N. & Todorov, A. The functional basis of face evaluation. Proc. Natl Acad. Sci. USA 105, 11087–11092 (2008).
Vokey, J. R. & Read, J. D. Familiarity, memorability, and the effect of typicality on the recognition of faces. Mem. Cognit. 20, 291–302 (1992).
Bainbridge, W. A. & Rissman, J. Dissociating neural markers of stimulus memorability and subjective recognition during episodic retrieval. Sci. Rep. 8, 8679 (2018).
Johnsrude, I. S. et al. Swinging at a cocktail party: voice familiarity aids speech perception in the presence of a competing voice. Psychol. Sci. 24, 1995–2004 (2013).
Nygaard, L. C., Sommers, M. S. & Pisoni, D. B. Speech perception as a talker-contingent process. Psychol. Sci. 5, 42–46 (1994).
Bishop, J. & Keating, P. Perception of pitch location within a speaker’s range: fundamental frequency, voice quality and speaker sex. J. Acoust. Soc. Am. 132, 1100–1112 (2012).
Busso, C., Lee, S. & Narayanan, S. Analysis of emotionally salient aspects of fundamental frequency for emotion detection. IEEE Trans. Audio Speech Lang. Process. 17, 582–596 (2009).
Baumann, O. & Belin, P. Perceptual scaling of voice identity: common dimensions for different vowels and speakers. Psychol. Res. 74, 110–120 (2010).
Zhang, C., van de Weijer, J. & Cui, J. Intra-and inter-speaker variations of formant pattern for lateral syllables in standard Chinese. Forensic Sci. Int. 158, 117–124 (2006).
Zhou, X. et al. A magnetic resonance imaging-based articulatory and acoustic study of ‘retroflex’ and ‘bunched’ American English/r/. J. Acoust. Soc. Am. 123, 4466–4481 (2008).
Syrdal, A. K. & Gopal, H. S. A perceptual model of vowel recognition based on the auditory representation of American English vowels. J. Acoust. Soc. Am. 79, 1086–1100 (1986).
Jacewicz, E., Fox, R. A. & Wei, L. Between-speaker and within-speaker variation in speech tempo of American English. J. Acoust. Soc. Am. 128, 839–850 (2010).
Schweinberger, S. R., Kawahara, H., Simpson, A. P., Skuk, V. G. & Zäske, R. Speaker perception. Wiley Interdiscip. Rev. Cogn. Sci. 5, 15–25 (2014).
Van Lancker, D., Kreiman, J. & Emmorey, K. Familiar voice recognition: patterns and parameters part I: recognition of backward voices. J. Phon. 13, 19–38 (1985).
Szendro, P., Vincze, G. & Szasz, A. Pink-noise behaviour of biosystems. Eur. Biophys. J. 30, 227–231 (2001).
Kawahara, H., Cheveigne, A. D. & Patterson, R. D. An instantaneous-frequency-based pitch extraction method for high-quality speech transformation: revised tempo in the straight suite. In Fifth International Conference on Spoken Language Processing 0659 (ISCA, 1998).
Sjölander, K. The Snack Sound Toolkit. https://www.speech.kth.se/snack/ (KTH, 2004).
Boersma, P. & Weenink, D. Praat: Doing Phonetics by Computer. Version 6.3.18. http://www.praat.org/ (2023).
Sun, X. Pitch determination and voice quality analysis using subharmonic-to-harmonic ratio. In 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing Vol. 1 I-333 (IEEE, 2002).
Revsine, C., Goldberg, E. & Bainbridge, W. A. Characterizing the intrinsic memorability of voices. OSF https://osf.io/pybwd/ (2025).
Acknowledgements
This research was supported by the National Science Foundation under Grant No. 2329776 awarded to W.A.B., the NSF Graduate Research Fellowship (Grant No. 1746045) awarded to C.R., and the University of Chicago Quad Undergraduate Research Scholarship awarded to E.G. The funders had no role in study design, data collection and analysis, decision to publish or preparation of the manuscript. We thank K. Van Engen, H. Nusbaum and M. Berman for their insightful feedback on the analyses and the work as a whole.
Author information
Authors and Affiliations
Contributions
C.R. collected the data, analysed the datasets and drafted the manuscript. W.A.B. designed the research, supervised analyses and edited the manuscript. E.G. assisted in data collection and analysed the Experiment 3 data.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Human Behaviour thanks Abbie Bradshaw and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information
Supplementary Figs. 1–3 and Tables 1–3.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Revsine, C., Goldberg, E. & Bainbridge, W.A. The memorability of voices is predictable and consistent across listeners. Nat Hum Behav 9, 758–768 (2025). https://doi.org/10.1038/s41562-025-02112-w
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41562-025-02112-w
This article is cited by
-
Event segmentation applications in large language model enabled automated recall assessments
Communications Psychology (2025)
-
Memorability of visual stimuli and the role of processing efficiency
Nature Reviews Psychology (2025)
-
Universally memorable voices
Nature Human Behaviour (2025)
