
Abstract
Assessments of the status of tidal flats, one of the most extensive coastal ecosystems, have been hampered by a lack of data on their global distribution and change. Here we present globally consistent, spatially-explicit data of the occurrence of tidal flats, defined as sand, rock or mud flats that undergo regular tidal inundation. More than 1.3 million Landsat images were processed to 54 composite metrics for twelve 3-year periods, spanning four decades (1984–1986 to 2017–2019). The composite metrics were used as predictor variables in a machine-learning classification trained with more than 10,000 globally distributed training samples. We assessed accuracy of the classification with 1,348 stratified random samples across the mapped area, which indicated overall map accuracies of 82.2% (80.0–84.3%, 95% confidence interval) and 86.1% (84.2–86.8%, 95% CI) for version 1.1 and 1.2 of the data, respectively. We expect these maps will provide a means to measure and monitor a range of processes that are affecting coastal ecosystems, including the impacts of human population growth and sea level rise.
Measurement(s) | ecosystem occurrence |
Technology Type(s) | earth observation |
Sample Characteristic - Environment | tidal flats • coastal wetlands |
Sample Characteristic - Location | global |
Similar content being viewed by others
Background & Summary
Tidal flats are a globally widespread coastal ecosystem that occur at the interface between land and sea1,2. They occur at all latitudes in physical habitats that are low-sloping and influenced by tides, and include ecotypes ranging from tidal rock platforms to fine-grained silts and clays1,2,3,4. Increasing human populations along the global coastline have caused extensive loss, degradation and fragmentation of tidal flat ecosystems worldwide1,5,6,7,8. Yet, owing to difficulties in remote-sensing a widely distributed habitat type that is regularly obscured by water in each tidal cycle1,4, until recently there has been no resource sufficient for assessing the distribution and change of tidal flats at the global scale.
Satellite remote sensing has supported global analyses of the distribution and change of an increasing variety of land cover types9. Recent technological break-throughs in the use of distributed computing for analyses of earth observation data and improved accessibility to satellite data archives have permitted end-to-end global-scale analyses that were previously impossible to achieve10,11,12. High resolution spatial datasets are now freely available for features including croplands13, bare land14, shorelines15, ecological settings16, forest cover14,17,18,19, surface water20,21,22,23, mangroves8,24,25,26,27,28, tidal wetlands8, rivers and streams29, coral reefs30,31 and river ice32, transforming our ability to estimate planetary boundaries33, monitor human impacts to the environment34, develop global accounts of biodiversity3, and estimate risks to ecosystems12,35. With many of Earth’s ecosystems undergoing continued loss and degradation3, including coastal ecosystems1,36,37,38,39, there is a strong need to continue to expand the catalogue of high quality globally consistent datasets regarding the spatial distribution and temporal trends of earth’s ecosystems3,12,35.
Here we describe the global tidal flat dataset, developed as part of the Global Intertidal Change program (http://globalintertidalchange.org), which is a consistent, 30-m representation of the global distribution of tidal flats over a 35-year period (1984–2019). These data have already been used to report the global distribution and change of tidal flat ecosystems1, pressures they are subject to1,40, extent of protection40 and have supported local-scale analyses of loss and gain41,42. Additionally, they have supported syntheses of global wetland areas3,43, assessments of impacts to species44, efforts to compile the global distributions of habitat types45 and ecosystems2,46, model the habitat preferences of migratory shorebirds47, protected area planning40 and have been identified as a potential indicator for the post-2020 Convention on Biological Diversity global biodiversity framework48.
The dataset described here is available in two versions that address a trade-off between spatial coverage and length of time-series: (i) a long, 11-step, time-series of the global extent of tidal flats (1984–2016; version 1.1), and (ii) a new shorter, 7-step time-series with improved spatial coverage and an additional time-step (1999–2019; version 1.2)49.
Methods
Overview of methods
These methods are expanded versions of descriptions in our related work1, following a generalised classification workflow summarised in Fig. 1. In particular, we focus here on describing our classification methods and detailing the methodological advances implemented to yield improved overall accuracy in the first major dataset update (version 1.2; 1999–2019).
The global tidal flat dataset was developed for the global shoreline between 60°N to 60°S from 1984 to 2019 (version 1.1, 1984–2016; version 1.2; 1999–2019)49. In this domain, the analysis was restricted to avoid elevated areas or deep water where tidal flats were not expected to occur to reduce the computing resources required to perform the full global analysis. Version 1.149 was limited to the area where Landsat Archive scenes (1984–2019) intersected a 1-km buffer of the coastline, and further restricted to areas where tidal flat habitats were expected to occur, which we defined as terrestrial areas below 100-m elevation and within 5-km of the coast, and marine areas above the 100-m depth contour and within 50-km of the coast (using the Shuttle Radar Topography Mission and ETOPO1 Global Relief Model data)1,50,51.
The map area was modified for version 1.2 to reflect an improved knowledge of the distribution of coastal ecosystems1,24,52, allowing us to further reduce the total mapped area and associated computing resource use (see Usage Notes). The analysis was performed in the area above the 40-m depth contour, below 40-m elevation and within 5-km of the coast. To account for coastal ecosystems that may occur outside of this area28, we included the area within a 5-km buffer to all known spatial datasets depicting coastal wetlands1,24,52,53.
The binary raster file “datamask”, delivered with each version of the dataset, indicates all areas where the classification was implemented.
Training data
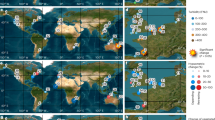
To support the remote sensing classification model developed for mapping tidal flats, we established a globally distributed training set of confirmed locations of three target map classes (‘tidal flat’, ‘permanent water’, ‘other’; Fig. 2). To collect training samples for the training set, we used our extensive global field experience in tidal flat ecosystems, data and maps from peer-reviewed publications, and developed an online interactive application to enable simultaneous reference to six image sets to assist with confirming the location of tidal flats, including multiple visualisations of the Landsat satellite imagery in the validation period (2014–2016). The image sets were (1) high resolution Google Earth imagery, (2) the median of the Landsat Operational Land Imager (OLI) Near Infrared (NIR) band, (3) a Landsat OLI true colour composite (median values of bands 4, 3 and 2), (4) a Landsat OLI false colour image composite (median values of bands 5, 4 and 3), (5) the standard deviation of the Normalised Difference Water Index (NDWI), and (6) the standard deviation of the Automatic Water Extraction Index (AWEI). To further enable confirmed occurrences to be recorded in the training set, analysts could also refer to time-series of Google Earth imagery to explore tidal inundation dynamics at a sample location if required. A total of 10,701 geo-referenced points annotated with three target classes for classification were developed for version 1.1 (run in 2018), which was enlarged to 14,100 points for version 1.2 (run in 2021) using the same methods Figs. 1–3.

Simplified remote sensing classification approach for mapping the global distribution of tidal flats. Training data is used to develop a random forest model with 56 predictor data layers that assigns each pixel in the mapping area to one of three classes. The maps are then post-processed and delivered as map products representing the distribution of tidal flat ecosystems from 1984 to 2019.

Global map showing the distribution of the training set used to map the global distribution of tidal flats between 60°N to 60°S. (a) Training set annotated with class ‘Other’. (b) Training set annotated with class ‘Permanent water’. (c) Training set annotated with class ‘Tidal flat’. The figure shows that training data was collected along the entire global coastline, though training samples for tidal flat are naturally concentrated in areas where tidal flats occur. The bounding box of the analysis is shown with a bold dashed line. Note maps show training data used for Version 1.2 of the tidal flat maps (n = 14,100 points).

Distribution of the validation set used for the independent accuracy assessment of the global tidal flat dataset. The samples (n = 1,358) were assigned to the classes (‘tidal flat’ and ‘other’) by three independent analysts. The validation set was randomly sampled from the mapped area, stratified by class and continent. In addition to showing the global distribution of the validation samples, the figure highlights concentrations of validation samples in areas with greater extent of tidal flats, including the Australian coast, the northern coast of South America, and the Chinese coast. The bounding box of the analysis is shown with a bold dashed line. Figure sourced from1 and used to validate version 1.1 of the dataset.
Predictor variables
We developed a set of 56 predictor variables to be used in the remote sensing classification1. Our predictor set consisted of 54 spectral variables derived from all Landsat Archive imagery collected during the study period (1984–2019), and a further two static variables that represent the occurrence of surface water20 and topographic and bathymetric information from ETOPO1 Global Relief model50, which was resampled to 30-m. A total of 707,528 images were used for version 1.1 (1984–2016) and 1,166,385 for version 1.2 (1999–2019).
To enable time-series remote sensing classifications, we produced each spectral predictor data layer from stacks of pre-processed54,55 Landsat images that comprised all images acquired within each three-year time period across the time series (12 time-steps, 1984–2019, Table 1). Prior to assembling the image stacks for each time step, we masked pixels identified as cloud, cloud shadow and snow in each image by applying the FMask algorithm56. In addition to pixel masking, we added bands to each image that represented several Landsat indices, including Normalised Difference Water Index and the Automatic Water Extraction Index (see1). The image stacks were then reduced by band to per-pixel summary statistics, yielding 54 spectral predictor layers per time period for the classification model1.
Remote sensing classification
We used the random forest algorithm57 to assign every 30-m pixel in the mapped area to the classes ‘tidal flat’, ‘permanent water’ or ‘other’. We trained the model using the training set annotated with pixel values for each of the 56 predictor variables, with the spectral data sampled from the 2014–2016 Landsat image stacks to align with the period for which training data was developed. We performed the global classifications in Google Earth Engine, with paramaterisations between version 1.1 and version 1.2 only differing only by the number of trees evaluated (ntree = 10, version 1.1; ntree = 100, version 1.2). We ran the analysis for each time-step in the spectral data, yielding maps of tidal flats for 11 time-steps (version 1.1) and 7 time-steps (version 1.2).
Post processing
After performing the classification, we masked the permanent water and land classes, ran a majority filter to remove isolated pixels identified as tidal flat and manually removed obvious misclassifications. As part of the data package, we provide a set of quality assurance layers that represent per-pixel the depth of the image stacks used in the classification (“qa_pixel_count_20172019_V1_2”). The data ingestion, predictor compilation and classification model was implemented end-to-end in Google Earth Engine10.
Data Records
The global tidal flat time-series maps version 1.1 (1984–2016) and version 1.2 (1999–2019)49 are made available directly via Google Earth Engine (https://earthengine.google.com/; Version 1.1 Asset ID: UQ/murray/Intertidal/v1_1/global_intertidal; Version 1.2 Asset ID: UQ/murray/Intertidal/v1_2/global_intertidal). Model training data and code are archived on Zenodo58. In addition, the data are made interactively available at the global intertidal change website (https://www.intertidal.app/download) and at the UNEP-WCMC Ocean Data Viewer (https://data.unep-wcmc.org/datasets/47). Additional data layers to interpret the global tidal flat data include a data mask depicting the mapped area (“datamask”) and a quality assurance layer representing the number of Landsat pixels used in the analysis (“qa_pixel_count”). To support data archiving required for this manuscript, version 1.1 and version 1.2 have been archived in a Figshare data repository49.
Technical Validation
Validation of the version 1.1 global tidal flat data was performed in three ways, (1) a standard remote sensing error matrix approach59, (2) a bootstrapping approach to enable the estimation of overall map accuracy and confidence intervals60, and (3) an independent map agreement approach1. To support the first two approaches, we randomly sampled the mapped area, stratified by map class and continent, to form a validation set. The size of the validation set was determined using power analysis (n = 1,358 random samples) and later confirmed to be sufficient with post-hoc sensitivity analyses1. Validating a highly dynamic target map class at the global scale is a challenge. We therefore provided the set of validation points to three independent, experienced remote sensing analysts, who used the online image viewer application (see methods) to assign each point independently to each map class, without reference to the classification results or with each other.
The standard remote sensing error matrix approach was performed using standard methods59, with the mode of the three independently annotated validation sets representing the validated class. To align with reference imagery in the online application, map classes in the validation set were sampled from the version 1.1 2014–16 map. The initial error matrix analysis suggested overall map accuracy was 82.3% (Table 2) and the bootstrapped estimate of map accuracy, performed with 1,000 iterations1 suggested an overall map accuracy of 82.2% (80.0–84.3%, 95% confidence interval). To perform the third validation, an assessment of agreement with an independently produced map of intertidal extent for Australia from Landsat Archive data61, we randomly sampled the Australian map at 4,000 location across the Australian coastline with stratification over the two map classes (‘intertidal’ and ‘other’). The results indicated an 84.6% agreement between the two map products, with disagreement primarily attributed to the different periods mapped by each project (Australia, 1987–2016, global tidal flats, 2014–16) and potentially different definitions of target map classes1.
To validate the version 1.2 global tidal flat data, we used the multi-analyst validation set (n = 1,358 random samples) to sample the 2014–16 map and perform the using standard accuracy assessment methods54 described above. The initial error matrix using the mode of the three analyst annotations suggested an overall map accuracy of 86.1% (Table 3). The bootstrapped estimate of overall map accuracy was 86.1% (84.2–86.8%, 95% confidence interval).
Reference to imagery suggests that most classification errors in the tidal flat map class were due to the presence of highly turbid water, polluted waterways, seasonal sea ice and aquaculture1. Due to a lack of historical high-resolution imagery sufficient for use in validating the historical time-series maps, map validation was conducted only for the 2014–16 global map (version 1.1 and version 1.2). Refer to Usage Notes for further information.
Usage Notes
In addition to a wide range of already published examples1,2,3,40,41,42,43,44,45,46,47, we expect the global tidal flat map data will support a range of efforts to investigate coastal environments at the global scale. Rapid migration of humans to coastal environments over the last few decades necessitate a detailed understanding of growing pressures on coastal ecosystems62,63, and time-series spatial data can support investigations of how natural ecosystems are responding to these pressures. In addition, integrating our fine-scale data of intertidal coastal zones into topographic or bathymetric models can improve our understanding of the observed and expected effects of sea level rise on factors such as tidal dynamics and coastal sediment dynamics8,64. The dataset is also likely to support growing efforts to assess risks of ecosystem collapse of a variety of coastal ecosystem types under the IUCN Red List of Ecosystems categories and criteria12,65,66.
By providing an empirical understanding of the distribution of tidal flat ecosystems, we also expect the global tidal flat data to improve simulation models that aim to estimate the future distribution of coastal environments at the global scale67. Such models must account for dynamic transitions in intertidal ecosystem types in response to changing sea level across the full land-sea interface. If combined with map data of other coastal ecosystems8,27,68, our data allows an incremental step towards synoptic analyses of dynamic intertidal ecosystem transitions at the global scale.
However, there are several important considerations regarding use of the global tidal flat map data:
-
(1)
Map coverage. Owing to the seasonal presence of sea ice and limitations in the use of Landsat sensor data to image high arctic regions1,69, the tidal flat maps do not include tidal flats that occur north of 60°N or south of 60°S.
-
(2)
Time-series coverage. Consistent time-series data is only available for a subset of the mapped area because Landsat archive data has not been consistently available for all areas of the world’s coastline1. Furthermore, when version 1.1 of the data was run, the entire Landsat Archive had not been fully ingested into Earth Engine. Thus, some areas, such as North America, East Asia and the Middle East, had more data available in each time period to compute predictor layers1. As noted in Murray et al.1, time-series of the map data should be developed using the quality assurance layers, which depict the number of pixels used to develop the 54 Landsat composite metric layers, to ensure sufficient imagery to reliably compute the predictors representing pixel-scale variance. Note version 1.2 improves the coverage of the world where globally consistent time-series can be developed but, owing to resource limitations, has been run only for the period 1999–2019. Users should expect the next update in 2023 (version 1.3).
-
(3)
Accuracy. Although the accuracy assessment indicated 82.3% (version 1.1) and 86.1% (version 1.2) overall accuracy when compared to validation data, there are unavoidable commission and omission mapping errors in the dataset. In many coastal areas, other land cover types such as aquaculture and rice agriculture undergo a similar wetting and drying regime as tidal flat pixels, resulting in mapping commission error. In addition, areas where there are few satellite images available or where waterbodies are highly turbid can result in commission error. Lastly, some areas where significant coastal change has occurred within each 3-year time period, such as rapid coastal development, have been incorrectly mapped as tidal flat. We therefore recommend statistical analysis approaches that account for variable measurement error1,35, and encourage users to provide feedback for incorporation in future releases (https://www.intertidal.app/contribute).
-
(4)
Comparisons with publicly available data. Our dataset was the first to map tidal flat ecosystems at the global scale. Since the open-access publication of the data1, several regional scale analyses have been conducted to advance the field of tidal flat remote sensing, which offers the opportunity to compare our methods, designed to meet design criteria including worldwide spatial consistency and an ability to implement in Google Earth Engine. These studies suggest that, despite differing study aims, the global tidal flat data showed an overall average agreement of >93% with tidal flat maps for the USA70 and ‘good agreement’ with newly developed tidal wetland maps developed for China71. The global tidal flat data also supported the development of 10-m spatial resolution maps of the intertidal zone for United Kingdom and Republic of Ireland72. Two studies63,71 reported that the global tidal flat data overestimated tidal flat extent in Asia due to commission error with coastal aquaculture. However, as noted in User Note (3), we discourage directly estimating tidal flat extent from our dataset without propagating known data uncertainties and reporting uncertainty estimates.
-
(5)
Observed tidal flat extent. It is unlikely that the full extent of tidal flats is acquired during satellite image acquisition. Therefore, the dataset should be considered ‘observed tidal flat extent’ 1,35.
-
(6)
Differences between Version 1.1 and Version 1.2. Relative to the version 1.1 map product, several modifications have been made:
-
a.
A shorter study overall time-period. The shorter period (1999–2019) due primarily to resource limitations and significantly higher numbers of Landsat images requiring processing.
-
b.
An additional time step. A new time step (2017–2019) is available in version 1.2.
-
c.
Different mapped areas. We further reduced the area for which each 30-m pixel was subject to classification in version 1.2 to reduce computing time and enable saving of covariate data (which were produced and discarded on-the-fly for version 1.1).
-
d.
Transition to Landsat Collection data. Version 1.2 uses Landsat Collection-1 data, whereas version 1.1 used a deprecated surface reflectance product that was formerly available in Google Earth Engine. Use of Landsat Collection-1 additionally allowed the per-pixel masking of snow and ice during development of the Landsat covariates, which was not done in version 1.1, yielding improvements to overall map accuracy (Table 3).
-
e.
Expanded area where consistent time-series can be produced. Owing to increased numbers of Landsat images from the Landsat Archive available in Google Earth Engine between version 1.1 and version 1.2, the area for which consistent time-series can be produced has been greatly expanded. Refer to Usage Notes point (2) for recommendations on how to use the quality assurance layers to develop consistent time-series.
-
f.
Expansion of the training set. The version 1.2 classification model uses additional training data that was targeted in areas where there was classification error in version 1.1.
-
g.
Model parameters. The number of trees evaluated in the Random Forest classification model was changed from n = 10 (version 1.1) to n = 100 (version 1.2).
-
h.
The post-processing mask to remove obvious misclassifications was updated.
-
a.
It should be noted that the majority of these changes were implemented to promote data freshness73 of the tidal flat data (by adding the additional time-step).
Code availability
The Google Earth Engine JavaScript code to develop covariate layers and estimate the distribution of tidal flats globally is archived on Zenodo58.
References
Murray, N. J. et al. The global distribution and trajectory of tidal flats. Nature 565, 222–225, https://doi.org/10.1038/s41586-018-0805-8 (2019).
Bishop, M. J., Murray, N. J., Swearer, S. & Keith, D. A. In The IUCN Global Ecosystem Typology 2.0: Descriptive profiles for biomes and ecosystem functional groups (eds D. A. Keith, J. R. Ferrer-Paris, E. Nicholson, & R. T. Kingsford) (IUCN, 2020).
Keith, D. A. et al. Earth’s ecosystems: a function-based typology for conservation and sustainability. Nature (In review).
Murray, N. J., Phinn, S. R., Clemens, R. S., Roelfsema, C. M. & Fuller, R. A. Continental scale mapping of tidal flats across East Asia using the Landsat Archive. Remote Sensing 4, 3417–3426, https://doi.org/10.3390/Rs4113417 (2012).
Murray, N. J., Clemens, R. S., Phinn, S. R., Possingham, H. P. & Fuller, R. A. Tracking the rapid loss of tidal wetlands in the Yellow Sea. Fron. Ecol. Environ. 12, 267–272, https://doi.org/10.1890/130260 (2014).
Murray, N. J., Ma, Z. & Fuller, R. A. Tidal flats of the Yellow Sea: A review of ecosystem status and anthropogenic threats. Austral Ecol. 40, 472–481, https://doi.org/10.1111/aec.12211 (2015).
Dhanjal-Adams, K. et al. Distribution and protection of intertidal habitats in Australia. Emu 116, 208–214 (2015).
Murray, N. J. et al. High-resolution mapping of losses and gains of Earth’s tidal wetlands. Science 376, 744–749, https://doi.org/10.1126/science.abm9583 (2022).
Gong, P. et al. Finer resolution observation and monitoring of global land cover: first mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 34, 2607–2654 (2013).
Gorelick, N. et al. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 202, 18–27, https://doi.org/10.1016/j.rse.2017.06.031 (2017).
Turner, W. et al. Free and open-access satellite data are key to biodiversity conservation. Biol. Conserv. 182, 173–176 (2015).
Murray, N. J. et al. The role of satellite remote sensing in structured ecosystem risk assessments. Sci Total Environ 619–620, 249–257, https://doi.org/10.1016/j.scitotenv.2017.11.034 (2018).
Ying, Q. et al. Global bare ground gain from 2000 to 2012 using Landsat imagery. Remote Sens. Environ. 194, 161–176, https://doi.org/10.1016/j.rse.2017.03.022 (2017).
Song, X.-P. et al. Global land change from 1982 to 2016. Nature 560, 639–643, https://doi.org/10.1038/s41586-018-0411-9 (2018).
Noble, S. et al. A new 30 meter resolution global shoreline vector and associated global islands database for the development of standardized ecological coastal units AU - Sayre, Roger. Journal of Operational Oceanography, 1–10, https://doi.org/10.1080/1755876X.2018.1529714 (2018).
Sayre, R. et al. A global ecological classification of coastal segment units to complement marine biodiversity observation network assessments. Oceanography 34, 120–129 (2021).
Hansen, M. C. et al. High-resolution global maps of 21st-century forest cover change. Science 342, 850–853, https://doi.org/10.1126/science.1244693 (2013).
Margono, B. A., Potapov, P. V., Turubanova, S., Stolle, F. & Hansen, M. C. Primary forest cover loss in Indonesia over 2000–2012. Nature Climate Change 4, 730–735, https://doi.org/10.1038/nclimate2277 (2014).
Curtis, P. G., Slay, C. M., Harris, N. L., Tyukavina, A. & Hansen, M. C. Classifying drivers of global forest loss. Science 361, 1108–1111, https://doi.org/10.1126/science.aau3445 (2018).
Pekel, J. F., Cottam, A., Gorelick, N. & Belward, A. S. High-resolution mapping of global surface water and its long-term changes. Nature 540, 418–422, https://doi.org/10.1038/nature20584 (2016).
Pickens, A. H. et al. Mapping and sampling to characterize global inland water dynamics from 1999 to 2018 with full Landsat time-series. Remote Sens. Environ. 243, 111792, https://doi.org/10.1016/j.rse.2020.111792 (2020).
Yamazaki, D., Trigg, M. A. & Ikeshima, D. Development of a global ~ 90 m water body map using multi-temporal Landsat images. Remote Sens. Environ. 171, 337–351, https://doi.org/10.1016/j.rse.2015.10.014 (2015).
Fluet-Chouinard, E., Lehner, B., Rebelo, L.-M., Papa, F. & Hamilton, S. K. Development of a global inundation map at high spatial resolution from topographic downscaling of coarse-scale remote sensing data. Remote Sens. Environ. 158, 348–361, https://doi.org/10.1016/j.rse.2014.10.015 (2015).
Bunting, P. et al. The Global Mangrove Watch—A new 2010 global baseline of mangrove extent. Remote Sensing 10, 1669 (2018).
Worthington, T. A. et al. Harnessing Big Data to Support the Conservation and Rehabilitation of Mangrove Forests Globally. One Earth 2, 429–443, https://doi.org/10.1016/j.oneear.2020.04.018 (2020).
Worthington, T. A. et al. A global typology of mangroves and its relevance for ecosystem services and deforestation. Scientific reports (2020).
Thomas, N. et al. Distribution and drivers of global mangrove forest change, 1996–2010. PLOS ONE 12, e0179302, https://doi.org/10.1371/journal.pone.0179302 (2017).
Simard, M. et al. Mangrove canopy height globally related to precipitation, temperature and cyclone frequency. Nature Geoscience 12, 40–45, https://doi.org/10.1038/s41561-018-0279-1 (2019).
Allen, G. H. & Pavelsky, T. M. Global extent of rivers and streams. Science 361, 585–588, https://doi.org/10.1126/science.aat0636 (2018).
Lyons, M. et al. Mapping the world’s coral reefs using a global multiscale earth observation framework. Remote Sensing in Ecology and Conservation (2020).
Li, J. et al. A global coral reef probability map generated using convolutional neural networks. Coral Reefs https://doi.org/10.1007/s00338-020-02005-6 (2020).
Yang, X., Pavelsky, T. M. & Allen, G. H. The past and future of global river ice. Nature 577, 69–73, https://doi.org/10.1038/s41586-019-1848-1 (2020).
Newbold, T. et al. Has land use pushed terrestrial biodiversity beyond the planetary boundary? A global assessment. Science 353, 288–291, https://doi.org/10.1126/science.aaf2201 (2016).
Tittensor, D. P. et al. A mid-term analysis of progress toward international biodiversity targets. Science 346, 241–244, https://doi.org/10.1126/science.1257484 (2014).
Lee, C. K. F., Nicholson, E., Duncan, C. & Murray, N. J. Estimating changes and trends in ecosystem extent with dense time-series satellite remote sensing. Conserv Biol 35, 325–335, https://doi.org/10.1111/cobi.13520 (2021).
Deegan, L. A. et al. Coastal eutrophication as a driver of salt marsh loss. Nature 490, 388–392 (2012).
Goldberg, L., Lagomasino, D., Thomas, N. & Fatoyinbo, T. Global declines in human-driven mangrove loss. Glob Chang Biol 26, 5844–5855, https://doi.org/10.1111/gcb.15275 (2020).
Brown, A. C. & McLachlan, A. Sandy shore ecosystems and the threats facing them: some predictions for the year 2025. Environ. Conserv. 29, 62–77, https://doi.org/10.1017/s037689290200005x (2002).
Krumhansl, K. A. et al. Global patterns of kelp forest change over the past half-century. Proc. Natl. Acad. Sci. USA 113, 13785–13790, https://doi.org/10.1073/pnas.1606102113 (2016).
Hill, N. K., Woodworth, B. K., Phinn, S. R., Murray, N. J. & Fuller, R. A. Global protected-area coverage and human pressure on tidal flats. Conserv Biol, https://doi.org/10.1111/cobi.13638 (2021).
Murray, N. J. et al. Myanmar’s terrestrial ecosystems: Status, threats and conservation opportunities. Biol. Conserv. 252, 108834, https://doi.org/10.1016/j.biocon.2020.108834 (2020).
Jackson, M. V. et al. Dual threat of tidal flat loss and invasive Spartina alterniflora endanger important shorebird habitat in coastal mainland China. J Environ Manage 278, 111549, https://doi.org/10.1016/j.jenvman.2020.111549 (2021).
Davidson, N. C. & Finlayson, C. M. Updating global coastal wetland areas presented in Davidson and Finlayson (2018). Marine and Freshwater Research 70, 1195–1200, https://doi.org/10.1071/MF19010 (2019).
Duan, H. et al. Identifying new sites of significance to waterbirds conservation and their habitat modification in the Yellow and Bohai Seas in China. Global Ecology and Conservation, e01031 (2020).
Jung, M. et al. A global map of terrestrial habitat types. Scientific Data 7, 256, https://doi.org/10.1038/s41597-020-00599-8 (2020).
Keith, D. et al. The IUCN Global Ecosystem Typology v2.0: Descriptive profiles for Biomes and Ecosystem Functional Groups. (The International Union for the Conservation of Nature (IUCN), Gland, 2020).
Fink, D. et al. Modeling avian full annual cycle distribution and population trends with citizen science data. Ecol. Appl. 30, e02056, https://doi.org/10.1002/eap.2056 (2020).
Convention on Biological Diversity. Indicators for the post-2020 Global Biodiversity Framework. (Convention on Biological Diversity, 2021).
Murray, NJ. et al. High-resolution global maps of tidal flat ecosystems from 1984 to 2019, Figshare, https://doi.org/10.6084/m9.figshare.c.5884598.v1 (2022).
Amante, C. & Eakins, B. W. ETOPO1 1 arc-minute global relief model: procedures, data sources and analysis. (US Department of Commerce, National Oceanic and Atmospheric Administration, National Environmental Satellite, Data, and Information Service, National Geophysical Data Center, Marine Geology and Geophysics Division, 2009).
Farr, T. G. et al. The shuttle radar topography mission. Rev. Geophys. 45, Rg200410.1029/2005rg000183 (2007).
Mcowen, C. et al. A global map of saltmarshes. Biodiversity Data Journal 5, https://doi.org/10.3897/BDJ.5.e11764 (2017).
Giri, C. et al. Status and distribution of mangrove forests of the world using earth observation satellite data. Global Ecology and Biogeography 20, 154–159, https://doi.org/10.1111/j.1466-8238.2010.00584.x (2011).
US Geological Survey. Product Guide: Landsat 4–7 Surface Reflectance (LEDAPS) Product (2018).
US Geological Survey. Product Guide: Landsat 8 Surface Reflectance Code (LASRC) Product (2018).
Foga, S. et al. Cloud detection algorithm comparison and validation for operational Landsat data products. Remote Sens. Environ. 194, 379–390 (2017).
Breiman, L. Random forests. Machine learning 45, 5–32 (2001).
Murray, N. J. et al. Code and data supplement to “High-resolution global maps of tidal flat ecosystems from 1984 to 2019”. Zenodo https://doi.org/10.5281/zenodo.6332960 (2020).
Congalton, R. G. & Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices. (CRC press, 2008).
Lyons, M. B., Keith, D. A., Phinn, S. R., Mason, T. J. & Elith, J. A comparison of resampling methods for remote sensing classification and accuracy assessment. Remote Sens. Environ. 208, 145–153, https://doi.org/10.1016/j.rse.2018.02.026 (2018).
Sagar, S., Roberts, D., Bala, B. & Lymburner, L. Extracting the intertidal extent and topography of the Australian coastline from a 28 year time series of Landsat observations. Remote Sens. Environ. 195, 153–169, https://doi.org/10.1016/j.rse.2017.04.009 (2017).
Lee, J. et al. The first national scale evaluation of organic carbon stocks and sequestration rates of coastal sediments along the West Sea, South Sea, and East Sea of South Korea. Sci Total Environ 793, 148568, https://doi.org/10.1016/j.scitotenv.2021.148568 (2021).
Zhang, Z., Xu, N., Li, Y. & Li, Y. Sub-continental-scale mapping of tidal wetland composition for East Asia: A novel algorithm integrating satellite tide-level and phenological features. Remote Sens. Environ. 269, 112799, https://doi.org/10.1016/j.rse.2021.112799 (2022).
Hooijer, A. & Vernimmen, R. Global LiDAR land elevation data reveal greatest sea-level rise vulnerability in the tropics. Nat. Commun. 12, 1–7 (2021).
Rodríguez, J. P. et al. A practical guide to the application of the IUCN Red List of Ecosystems criteria. Philos. Trans. R. Soc. B-Biol. Sci. 370, 20140003, https://doi.org/10.1098/rstb.2014.0003 (2015).
Keith, D. A. et al. The IUCN Red List of Ecosystems: Motivations, Challenges, and Applications. Conservation Letters 8, 214–226, https://doi.org/10.1111/conl.12167 (2015).
Spencer, T. et al. Global coastal wetland change under sea-level rise and related stresses: The DIVA Wetland Change Model. Global and Planetary Change 139, 15–30 (2016).
Bunting, P., Rosenqvist, A., Hilarides, L., Lucas, R. M. & Thomas, N. Global Mangrove Watch: Updated 2010 Mangrove Forest Extent (v2.5). Remote Sensing 14, 1034 (2022).
US Geological Survey. Landsat 4–7 Collection 1 (C1) Surface Reflectance (LEDAPS) Product Guide. Version 3.0. (USGS, 2020).
Xu, C. & Liu, W. Mapping and analyzing the annual dynamics of tidal flats in the conterminous United States from 1984 to 2020 using Google Earth Engine. Environmental Advances 7, 100147, https://doi.org/10.1016/j.envadv.2021.100147 (2022).
Wang, X. X. et al. Rebound in China’s coastal wetlands following conservation and restoration. Nature Sustainability 4, 1076-+, https://doi.org/10.1038/s41893-021-00793-5 (2021).
Fitton, J. M., Rennie, A. F., Hansom, J. D. & Muir, F. M. E. Remotely sensed mapping of the intertidal zone: a Sentinel-2 and Google Earth Engine methodology. Remote Sensing Applications: Society and Environment, 100499, https://doi.org/10.1016/j.rsase.2021.100499 (2021).
Murray, N. J., Kennedy, E., Álvarez-Romero, J. G. & Lyons, M. B. Data freshness in ecology and conservation. Trends in Ecology and Evolution 36, 485–487, https://doi.org/10.1016/j.tree.2021.03.005 (2021).
Acknowledgements
The global intertidal change research program has been funded by a Google Earth Engine Research Award (version 1.1) and an Australian Research Council Discovery Early Career Researcher Award (DE190100101) funded by the Australian Government (version 1.2). Landsat data are courtesy of NASA Goddard Space Flight Center and the US Geological Survey. We thank the Google Earth Engine team, and J. Wilshire, N. Hill, D. Keith, R. Kingsford, N. Mallot, C. Roelfsema, Z. Xie and R. Lucas for support during version 1.1. We thank R. Canto for support to develop version 1.2.
Author information
Authors and Affiliations
Contributions
N.J.M., S.R.P. and R.A.F. conceived the study. N.J.M. developed the remote sensing method with support from S.R.P. and R.A.F. N.J.M., M.D., R.J. and N.C. ran the remote sensing classification. N.J.M. and M.B.L. performed the validation. N.J.M. wrote the manuscript with contributions from all authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Murray, N.J., Phinn, S.P., Fuller, R.A. et al. High-resolution global maps of tidal flat ecosystems from 1984 to 2019. Sci Data 9, 542 (2022). https://doi.org/10.1038/s41597-022-01635-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-022-01635-5
This article is cited by
-
National coastal wetland mapping over the last four decades: An annual classification with high accuracy
Scientific Data (2026)
-
Dynamics and drivers of tidal flat morphology in China
Nature Communications (2025)
-
Analysing the spatiotemporal dynamics of coastal aquaculture along the northern coastal plains of Tamil Nadu, India, using remote sensing time series data
Aquaculture International (2025)
-
Global annual wetland dataset at 30 m with a fine classification system from 2000 to 2022
Scientific Data (2024)
-
Critical turbidity thresholds for maintenance of estuarine tidal flats worldwide
Nature Geoscience (2024)
