
Abstract
Several studies have assessed crop water requirements based on soil properties, but these have been on a small scale or on soils with similar textures. Here, a data base of soil measurements in the field and laboratory from sites across Irrigation District 023, San Juan del Rio, Queretaro, Mexico was sampled, collected, analyzed, and integrated. The data base, named, NaneSoil, contains information on 900 samples obtained from irrigated plots. NaneSoil cover 10 of the 12 textural classes with the following information: sand, silt, clay contents, bulk density, saturated volumetric water content, field capacity, permanent wilting point and saturated hydraulic conductivity. The aim of this work is to provide the scientific community with sufficient information to perform a large number of analyses, for example, development of pedotransfer functions, calculation of water requirements of plants in soils with similar characteristics, modeling of infiltration, optimal irrigation discharge calculation, among others. The dataset also promotes the scientific community to contribute their own measurements to further strengthen the knowledge of flow in the porous medium.
Similar content being viewed by others

Background & Summary
The crop water requirement calculation is of critical importance to meet the demands at different stages, and is sometimes performed using parameters and constants that are obtained from the literature due to lack of on-site measurements1,2,3. According to the U.S. Department of Agriculture (USDA) textural triangle the soil can be classified into 12 different textures according to the percentages of sand (Sa), silt (Si) and clay (Cl) in each soil sample4. The water infiltration rate in each type of soil is completely different and knowing its value is of fundamental importance for the correct design of pressurized irrigation systems5,6,7,8 or the optimal irrigation discharge calculation to be supplied in each border or furrow9,10,11,12,13,14.
For the knowledge of some soil parameters such as saturated moisture content (θs) and saturated hydraulic conductivity (Ks) can be obtained by field and laboratory tests, but they are costly and time consuming, also, they can be estimated by pedotransfer functions15,16 or neural networks17,18,19 that relate more properties of the soil being analyzed. However, to achieve the above, sufficient data is required to have a representative equation of the soil being analyzed. In addition, studies differ in their results, as an example: they make use of parameters that are not normally easy to obtain: pH, cation exchange capacity (CEC), organic matter content (OM), among others, and the results obtained are different with each of the equations being analyzed20,21,22.
Soil samples were collected from plots adequately prepared prior to seeding, located in the Irrigation District 023, San Juan del Rio, Queretaro during the period 2016–2018, where 20% maize (Zea mays L.), 15% sorghum (Sorghum vulgare Pers.), 10% wheat (Triticum aestivum L.), 15% oats (Avena sativa L.), 5% beans (Phaseolus vulgaris L.), 15% barley (Hordeum vulgare L.), 5% carrots (Daucus carota L.) and 15% alfalfa (Medicago sativa L.) have been traditionally sown. The integration of all soil information was performed in a dataset named NaneSoil23. The information contained in the dataset can be used to perform statistical analysis, to develop pedotransfer functions19,24, use of neural networks19,25, calculation of crop water requirement as a function of soil texture26,27,28, surface irrigation system design29 and pressurized30, or any other agronomic parameter of interest. NaneSoil contains most of the agronomic parameters necessary for the study of crop water requirements in different soils, and therefore, it is an excellent tool that can be used by farmers, academics, students, and people involved in crop production and research.
In addition, there are different databases worldwide such as Harmonized World Soil Database (HWSD)31 or SoilGrids32. However, they have a spatial variability ranging from 250 m to 1000 m per pixel side, which means that even plots of different textures are taken as one. Whereas this work has a resolution of 100 m per pixel side. In addition, they also do not work with field capacity moisture, permanent wilting point or Ks, which is relevant for the calculation of crop requirements.
Methods
Data collection
NaneSoil contains information from 900 soil samples (Fig. 1) that have been classified into 10 of the 12 existing soil textural classes (Table 1). The parameters measured were Ks, θs, field capacity (θFC), permanent wilting point (θPWP), bulk density (BD), Sa, Si, and Cl.

Spatial distribution of the textures contained in the dataset.
Soil samples were collected over a 3-year period and analyzed in the laboratory following conventional methodologies. Ks was obtained in the laboratory using the variable head permeability, BD using the cylinder of known volume or core method33,34, θs, θFC, and θPWP by the pressure membrane pot35, Sa, Si, Cl were obtained by the granulometric curve using mesh analysis and the Bouyoucos hydrometer36 and were classified according to the United States Department of Agriculture (USDA) system. Sa has a particle size ranging from 0.050 to 2.000 mm, Si from 0.002 to 0.050 mm, and Cl less than 0.002 mm. For the laboratory measurements, six subsamples were randomly collected from each plot at a depth of 0–30 cm. The depth is determined by crop type (root development) to manage fertilization, based on soil nutritional supply, crop water demand and that most if the root mass is located in the first 30 cm for the main crops present in the Irrigation District 02337. Also, it should be noted that the specified depths are calculated after removal of undecomposed organic residues. There is no standard number of subsamples to be taken in each sampling unit, however, in this dataset the descriptive statistics of the areas of the plots analyzed were considered, which are mean = 2.65 ha, standard deviation (SD) = 1.6099 ha and coefficient of variation (CV) = 0.5357 with which it was decided to set at six subsamples per plot. With this method each sample or soil property has the same probability of being collected and included. In addition, the six subsamples were grouped until a seventh homogeneous sample was obtained from which 1 kg was taken according to the Mexican Official Standard-021-SEMARNAT-200035.
Data processing
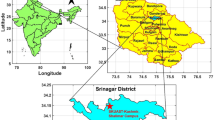
The data processed in each of the laboratory tests were classified by textural class using a worksheet. The total samples were randomly collected from an area of 5,000 ha (Fig. 2). A total of 2,704.5 ha were sampled, and the process followed to obtain the information is shown in general terms in Fig. 3. Sampling and handling in the laboratory were independent.

Spatial distribution of soil sample collection sites.

Detailed diagram of the collection procedure, data integration and potential uses of the dataset.
Data Records
The dataset23 can be downloaded from the Figshare Platform (https://doi.org/10.6084/m9.figshare.22190185.v2). The downloaded file NaneSoil.xlsx includes 901 rows and 13 columns. The first row corresponds to the titles or attributes contained in the columns, as well as the units in which they are displayed. The thirteen columns are ordered as follows: sample identifier (A), UTM coordinates corresponding to zone 14 North (B and C), representative sample area (D), percentages of sand (E), silt (F) and clay (G), textural classification (H), bulk density (I), saturated moisture content (J), field capacity (K), permanent wilting point (L) and the saturated hydraulic conductivity (M). The USDA texture triangle was used for texture classification.
Technical Validation
Quality controls were performed on each of the experiments carried out in the laboratory, as well as on the samples taken in the field to verify the fidelity of the data obtained. Each of the samples taken in the field was labeled and carefully transferred to the laboratory for analysis. The label on each sample provided the UTM coordinates (Zone 14 North) from which the samples were collected. Special care was taken to place the samples in the corresponding containers before starting the measurements with the equipment to be used. Before starting the laboratory analysis, the samples were checked to ensure that they had not been previously processed by means of their ID to avoid duplication. At the end of the tests, the results were carefully analyzed and if there were any uncertainties about them, such as BD > 2.65 g/cm3 or the sum of the proportion of Sa, Si, Cl > 100%, the results were discarded and the collection of the sample from the field was started again, assigning it another ID for reprocessing (see Fig. 3).
All laboratory equipment used was previously calibrated according to the standards before starting the measurements, and it was checked that it was working in optimal conditions before taking the measurements of the next sample. After entering the data into the dataset, another person checked the records once again to make sure that the data were written correctly. After recording, the format of each column (numerical or string) was checked to correct any typing errors in the columns (e.g., soil texture and UTM coordinates where the samples were collected).
The textural classification was inspected in the texture triangle to ensure that its classification corresponded to the percentages of sand, silt and clay reported. In addition, a visual inspection of the distribution of the data in the columns containing numerical values (e.g., saturated moisture content, permanent wilting point, field capacity, saturated hydraulic conductivity) was performed, and outliers were manually verified by validating them with the original values written in the data logs during the development of the experiments.
Usage Notes
The soil sample analyses reported in the NaneSoil dataset were extracted from agricultural plots that have 2 crop cycles per year: spring-summer and autumn-winter, in which conventional preparations are made before, during and after each harvest. Saturated moisture contents, field capacity and permanent wilting point are reported as volumetric moisture contents. The user may contact the corresponding author for more information about the dataset and its use.
Code availability
All the data processing and data visualization were conducted using R (version 4.2.2)38. The source code is available on GitHub (https://github.com/Chagcarlos/NaneSoil_Figs). The Code contains detailed comments for the development of Fig. 1 related to the texture triangle. The map presented in Fig. 2 contains the soil sampling locations and was made using QGIS software version 3.16 (https://qgis.org/en/site/forusers/download.html) under GNU General Public License (CC BY-SA 3.0).
References
Allen, R. G., Pereira, L. S., Raes, D. & Smith, M. Crop Evapotranspiration-Guidelines for Computing Crop Water Requirements-FAO Irrigation and Drainage Paper 56. Fao, Rome 300, D05109 (1998).
Rai, R. K., Singh, V. P. & Upadhyay, A. Estimating Irrigation Design Parameters. in Planning and Evaluation of Irrigation Projects 243–282, https://doi.org/10.1016/B978-0-12-811748-4.00006-6 (Elsevier, 2017).
Lorite, I. J. et al. Water Management and Climate Change in Semiarid Environments. in Water Scarcity and Sustainable Agriculture in Semiarid Environment 3–40, https://doi.org/10.1016/B978-0-12-813164-0.00001-6 (Elsevier, 2018).
Soil Science Division Staff. Soil Survey Manual. (United States Department of Agriculture, 2017).
Malek, K. & Peters, R. T. Wetting Pattern Models for Drip Irrigation: New Empirical Model. J. Irrig. Drain. Eng. 137, 530–536 (2011).
Aydinsakir, K. et al. Water productivity of soybeans under regulated surface and subsurface drip irrigation conditions. Irrig. Sci. 39, 773–787 (2021).
Rolbiecki, R. et al. Requirements and Effects of Surface Drip Irrigation of Mid-Early Potato Cultivar Courage on a Very Light Soil in Central Poland. Agronomy 11, 33 (2020).
Zapata-Sierra, A., Roldán-Cañas, J., Reyes-Requena, R. & Moreno-Pérez, M. Study of the Wet Bulb in Stratified Soils (Sand-Covered Soil) in Intensive Greenhouse Agriculture under Drip Irrigation by Calibrating the Hydrus-3D Model. Water 13, 600 (2021).
Saucedo, H., Zavala, M., Fuentes, C. & Castanedo, V. Optimal flow model for plot irrigation. Water Technol. Sci. 4, 135–148 (2013).
Fuentes, C. & Chávez, C. Analytic Representation of the Optimal Flow for Gravity Irrigation. Water 12, 2710 (2020).
Fuentes, S., Fuentes, C., Saucedo, H. & Chávez, C. Border Irrigation Modeling with the Barré de Saint-Venant and Green and Ampt Equations. Mathematics 10, 1039 (2022).
Chávez, C. & Fuentes, C. Design and evaluation of surface irrigation systems applying an analytical formula in the irrigation district 085, La Begoña, Mexico. Agric. Water Manag. 221, 279–285 (2019).
Fuentes, S. & Chávez, C. Modeling of Border Irrigation in Soils with the Presence of a Shallow Water Table. I: The Advance Phase. Agriculture 12, 426 (2022).
Chávez, C., Fuentes, S., Fuentes, C., Brambila-Paz, F. & Trejo-Alonso, J. How Surface Irrigation Contributes to Climate Change Resilience—A Case Study of Practices in Mexico. Sustainability 14, 7689 (2022).
Morris, P. J. et al. Saturated Hydraulic Conductivity in Northern Peats Inferred from other Measurements. Water Resour. Res. 58 (2022).
Tomasella, J., Pachepsky, Y. A., Crestana, S. & Rawls, W. J. Comparison of Two Techniques to Develop Pedotransfer Functions for Water Retention. Soil Sci. Soc. Am. J. 67, 1085–1092 (2003).
Khalili-Maleki, M., Poursorkhabi, R. V., Nadiri, A. A. & Dabiri, R. Prediction of hydraulic conductivity based on the soil grain size using supervised committee machine artificial intelligence. Earth Sci. Inform. 15, 2571–2583 (2022).
Erzin, Y., Gumaste, S. D., Gupta, A. K. & Singh, D. N. Artificial neural network (ANN) models for determining hydraulic conductivity of compacted fine-grained soils. Can. Geotech. J. 46, 955–968 (2009).
Trejo-Alonso, J., Fuentes, S., Morales-Durán, N. & Chávez, C. Evaluation and Development of Pedotransfer Functions and Artificial Neural Networks to Saturation Moisture Content Estimation. Water 15, 220 (2023).
Hodnett, M. G. & Tomasella, J. Marked differences between van Genuchten soil water-retention parameters for temperate and tropical soils: a new water-retention pedo-transfer functions developed for tropical soils. Geoderma 108, 155–180 (2002).
Vereecken, H., Maes, J., Feyen, J. & Darius, P. Estimating the Soil Moisture Retention Characteristic from Texture, Bulk Density, and Carbon Content. Soil Sci. 148, 389–403 (1989).
Wösten, J. H. M., Pachepsky, Y. A. & Rawls, W. J. Pedotransfer functions: bridging the gap between available basic soil data and missing soil hydraulic characteristics. J. Hydrol. 251, 123–150 (2001).
Morales-Durán, N., Fuentes, S. & Chávez, C. NaneSoil. figshare https://doi.org/10.6084/m9.figshare.22190185.v2 (2023).
Trejo-Alonso, J., Quevedo, A., Fuentes, C. & Chávez, C. Evaluation and Development of Pedotransfer Functions for Predicting Saturated Hydraulic Conductivity for Mexican Soils. Agronomy 10, 1516 (2020).
Trejo-Alonso, J. et al. Saturated Hydraulic Conductivity Estimation Using Artificial Neural Networks. Water 13, 705 (2021).
Kourgialas, N. N. et al. A web-based GIS platform supporting innovative irrigation management techniques at farm-scale for the Mediterranean island of Crete. Sci. Total Environ. 842, 156918 (2022).
Shao, G. et al. Prediction of maize crop coefficient from UAV multisensor remote sensing using machine learning methods. Agric. Water Manag. 276, 108064 (2023).
Otto, R. et al. Nitrogen fertilizer management on cotton (Gossypium hirsutum L.) yield and quality in two tropical soils. Eur. J. Agron. 142, 126672 (2023).
Haj-Amor, Z., Ritzema, H., Hashemi, H. & Bouri, S. Surface irrigation performance of date palms under water scarcity in arid irrigated lands. Arab. J. Geosci. 11, 27 (2018).
Firouzabadi, A. G., Baghani, J., Jovzi, M. & Albaji, M. Effects of wheat row spacing layout and drip tape spacing on yield and water productivity in sandy clay loam soil in a semi-arid region. Agric. Water Manag. 251, 106868 (2021).
Harmonized World Soil Database version 2.0., https://doi.org/10.4060/cc3823en (FAO; International Institute for Applied Systems Analysis (IIASA); 2023).
Hengl, T. et al. SoilGrids1km — Global Soil Information Based on Automated Mapping. PLoS ONE 9, e105992 (2014).
Jabro, J. D., Stevens, W. B. & Iversen, W. M. Comparing Two Methods for Measuring Soil Bulk Density and Moisture Content. Open J. Soil Sci. 10, 233–243 (2020).
Al-Shammary, A. A. G. et al. Soil Bulk Density Estimation Methods: A Review. Pedosphere 28, 581–596 (2018).
NOM-021-SEMARNAT-2000, M. O. S. Establishing the specifications of fertility, salinity and soil classification. Studies, sampling and analysis. Official Gazette (2000).
Bouyoucos, G. J. Hydrometer Method Improved for Making Particle Size Analyses of Soils. Agron. J. 54, 464–465 (1962).
Nichols, V. A. et al. Maize root distributions strongly associated with water tables in Iowa, USA. Plant Soil 444, 225–238 (2019).
R. Core Team. R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria (2023).
Acknowledgements
This research was supported as part of a collaboration between the National Water Commission (CONAGUA, according to its Spanish acronym); The Irrigation District 023, San Juan del Rio, Queretaro and the Autonomous University of Queretaro, under the program RIGRAT 2015–2019.
Author information
Authors and Affiliations
Contributions
Carlos Chávez and Sebastián Fuentes conceived the design of the data framework. Nami Morales-Durán and Carlos Chávez extracted and integrated the data to the NaneSoil. Carlos Chávez and Sebastián Fuentes drafted the manuscript, and all authors revised and approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Morales-Durán, N., Fuentes, S. & Chávez, C. A soil database from Queretaro, Mexico for assessment of crop and irrigation water requirements. Sci Data 10, 429 (2023). https://doi.org/10.1038/s41597-023-02332-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-023-02332-7
