
Abstract
Maps are fundamental medium to visualize and represent the real word in a simple and philosophical way. The emergence of the big data tide has made a proportion of maps generated from multiple sources, significantly enriching the dimensions and perspectives for understanding the characteristics of the real world. However, a majority of these map datasets remain undiscovered, unacquired and ineffectively used, which arises from the lack of numerous well-labelled benchmark datasets, which are of significance to implement the deep learning techniques into identifying complicated map content. To address this issue, we develop a large-scale benchmark dataset involving well-labelled datasets to employ the state-of-the-art machine intelligence technologies for map text annotation recognition, map scene classification, map super-resolution reconstruction, and map style transferring. Furthermore, these well-labelled datasets would facilitate map feature detection, map pattern recognition and map content retrieval. We hope our efforts would provide well-labelled data resources for advancing the ability to recognize and discover valuable map content.
Similar content being viewed by others

Background & Summary
According to the definition of International Cartographic Association (ICA)1, a map is defined as “a symbolized representation of geographic reality, representing selected features or characteristics, resulting from the creative effort of its author’s execution of choices, and is designed for use when spatial relationships are of primary relevance.” In other words, maps serve as a medium to visualize the real word in a simple and philosophical way, and connect people to the reality through an inspired imagination2. As shown in Fig. 1, in comparison to the true representation of satellite image, maps are not necessarily a true representation of the real landscape, but rather an interpreted result. The information in a map reflects the map producer’s opinions and perspectives on a place, providing a unique viewpoint on the characteristics of this place. By comparing and contrasting the content from different maps on the same place, we can gain a deeper understanding of the varied perspectives and themes associated with that place, such as transportation, tourism, and civilization.

The visual representation of map on real landscape, in case of Yosemite National Park.
A variety of maps have been emerged as a powerful tool for communication and representation throughout human history, serving as one of the three common human being’ languages, alongside music and drawing2. Researches regarding cartography and its relationship to socio-economic development have reported that maps could represent various aspects of the natural and social worlds including scientific principles (e.g. portraying scientific principles), cultural and artistic expressions (recording the art and cultures), social opinions (depicting public opinions), historical events (visualizing historical maps status.), legal systems (displaying administrative boundaries), and military conflicts (illustrating the historical wars)3,4,5. Thus, recognizing and discovering the map information is of value to understand the natural and social characteristics of the place visualized by these maps, and enhance the capability of geospatial analysis on natural landscape and socio-economic development.
The emergence of big data tide has revolutionized the paradigm of cartography and map analysis approaches, as massive maps are now available to be created, edited, published and shared to represent the producers’ personal viewpoints and subjective understandings. This has led to an explosion in the volume and variety of geospatial information available from massive maps generated by different countries, institutes and people are presented through various platforms including earth observation system, information cyberinfrastructures, and big data techniques2,6. Thus, classical non-content-based approaches such as metadata-based map analysis7 and file name-based map analysis8 might not be effective in recognizing the content in the maps accessed from massive sources. This is because the metadata and title of these maps often subjective and may vary making it difficult to accurately identify and retrieve specific maps9. Expert-based intelligent systems have been developed for map content analysis10. However, these labor-driven machine-person interactions are time-consuming and might be insufficient for addressing the diverse map content available from massive sources11. Other approaches including image morphology12, object-based feature detection13, and object-based image analysis14,15,16 always requires a manually-defined threshold, which are labor-intensive and inaccurate.
Deep learning techniques have garnered a significant attention in the communities of cartography and geospatial information science because of its powerful capability of feature learning. In previous decade, the-state-of-the-art machine learning and deep learning approaches have been employed to effectively extract map features and discover the geospatial information from standard maps being generated by professional mapping principles17,18,19. The deep learning approaches includes convolutional neural networks (CNNs) and vision transformer (ViT) regarding map scene classification20, multi-task classification21, map feature detection22, and map feature segmentation19,22. However, these approaches have been reported inefficient for addressing the content from volunteered maps, which are generated from diverse ways that fail to follow cartographical principles. The styles, symbols, scenes, and other map features in these maps can vary significantly, posing a challenge for developing a benchmark dataset that includes all types of map samples in sufficient numbers2,6,23. This makes it difficult for deep learning approaches to learn salient features from the map content. Figure 2 illustrates the varied representation of maps: the same sport field is visualized similar under different satellite images, but differently by different maps. This highlights the challenge of map recognition, which has to consider the difference of different maps. As a result, the researches of cartography and location-based services have found that a majority of map dataset have been unused and underutilized24,25, leading to the waste of plentiful information contained within these maps. Moreover, the map data used in many applications may not be entirely suitable for the authentic demands of these applications, resulting in the squandering of cartographical data processing and analysis6,26

Comparison of maps from different sources: in case of San Francisco and sport field.
Above of all, deep learning approaches always heavily rely on numerous well-labelled datasets. The absence of a benchmark dataset for map content hinders the implementation of deep learning techniques in identifying complex map content. Given the potentials of maps to enhance a variety of applications in terms of cultural narratives, navigations, location-based services, etc., the gap between sufficient map data and unproductive map utilization pose an urgent demand: developing a large-scale benchmark dataset that facilitate the state-of-the-art machine intelligence technologies to accurately detect map features, recognize map patterns and conduct map content retrieval. To address this need, we present the details of a large-scale benchmark dataset called CartoMark. Our goal is to provide a comprehensive dataset that enables researchers and practitioners to utilize cutting-edge machine intelligence techniques and evaluate their proposed approaches for map pattern recognition and map retrieval. By developing this dataset, we aim to facilitate the development of more accurate and efficient machine intelligence algorithms for map analysis, ultimately enhancing the utility of maps in various applications.
Methods
Data sources
Maps in CartoMark are accessed from three main types of source: Internet, data cyberinfrastructure/repositories, and social media. The maps on the Internet are accessed by commonly-used search engines including Google image search, Bing image search, and Baidu image search. The data cyberinfrastructure/repositories for collecting maps include USGS Earth Explorer, USGS Historical Topographic Map Explorer, and Tianditu Map. A small proportion of maps are accessed from the third data source—social media including Facebook, Twitter, Instagram and TikTok.
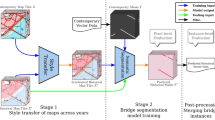
Architecture of CartoMark
Figure 3 illustrates the architecture of CartoMark, which supports four tasks of cartographical pattern recognition: map text annotation recognition, map super-resolution reconstruction, map scene classification, and map style transferring. Moreover, all datasets compatible with the-state-of-the-art machine intelligence techniques.
-
Map text annotation recognition aims to detecting and recognizing the text characters in maps. Its repository includes two data groups, with identical map files i in two formats: JPG and PNG. Each group provides map files and corresponding label files.
-
Map super-resolution reconstruction focuses on generating the higher resolution maps from the low-resolution original maps. Its repository includes two groups of map files, identical in content but different in format: JPG and PNG. Each group provides map files alone.
-
Map scene classification concentrates on classifying maps into various categories based on their content. Its repository includes two data groups, with identical map files in different formats: JPG and PNG. Each group provides map files and corresponding label file.
-
Map style transferring focuses on transferring the original maps into specific styles while maintaining the initial content. Its repository includes two groups of map files, identical in content but different in format: JPG and PNG. Each group provides map files alone.
To accommodate the input data requirement of various the state-of-the-art machine intelligence techniques, we provide two commonly-used map formats (JPG and PNG). Additionally, we offer a format conversion tool for users to convert the current formats into bmp. and tif. without any additional operations.
Besides datasets, we also provide three python-encoded programs (or tools) for users to process the map samples, which includes Image format conversion, Text line drawing, and Text annotation formation conversion.
-
Image format conversion: a tool to convert the available map format into other main formats.
-
Text line drawing: a tool for visualizing the bounding box that covers a map text.
-
Text annotation format conversion: a tool to transform the data structure of.txt files into other data structures required by various deep larnin techniques regarding optical character recognition (OCR).

Architecture of CartoMark.
Taxonomy and folksonomy integrated map harvesting
-
(1)
Map-dataset harvesting
As mentioned above, maps from ubiquitous sources, which refers to the sources that maps are generated are distributed everywhere on the Internet, are always generated by different ways, thereby requiring a diverse approach to harvest original map dataset. Maps generated by professional cartographical rules can be assessed using standardized cartographical taxonomies. However, for the maps generated by volunteered ways that holds the similar content, it might include different names (tags), which belongs to folksonomy in the information retrieval. Thus, we combined standardized cartographical taxonomies for professionally-generated maps with folksonomies from volunteered maps to create keywords for harvesting or retrieving the original map dataset. The taxonomy and folksonomy integrated keywords are listed in Table 1.
Table 1 List of the taxonomy and folksonomy integrated keywords. Based on these keywords, we employed a search strategy that combined “keyword individual + map” to retrieve and collect map files from various sources, including commonly-used search engines, data cyberinfrastructure/repositories, and social media crawlers. For example, we used “San Francisco map”, “indoor map”, “airport map”, etc. to retrieve and collect all relevant map datasets. As mentioned above, the commonly-used search engines used include Google Image Search, Amazon Image Search, Yahoo Image Search, Bing Image Search, and Baidu Image Search. Specifically, all map datasets accessed from these commonly-used search engines are checked with consent. If a map dataset could be accessed but downloaded, we would remove this map datasets.
Data cyberinfrastructure/repositories including USGS Earth Explorer, USGS Historical Topographic Map Explorer, and Tianditu Map were also used, although the number of maps retrieved from these sources was limited due to their similar map styles and configurations. Social media crawlers were used to retrieve maps from platforms such as Facebook, Twitter, Instagram, and TikTok, but the amount of maps obtained from these sources was also limited due to the majority of social media platforms not being publicly accessible.
In total, around 20,000 maps were collected from the three sources using the map-dataset harvesting approach, and were stored in the original maps. The majority of the maps were obtained from web search engines.
-
(2)
Map-dataset cleaning and map filtering
Since a majority of retrieved original map datasets were generated by unprofessional ways, they may lack the necessary accuracy and clarity required for effective map pattern recognition. To address this issue, we propose an integrated strategy to filter and clean the original map datasets being unqualified to meet the required standards for use in benchmark datasets.. The workflow of this strategy includes five steps: image size filtering, image format unifying, image color and texture filtering, image noise removing and image content checking.
-
1.
Map resizing.
-
We set the minimal image size as 256*256, and removed all maps that smaller than this minimal size in horizontal or vertical dimension. The minimal size was determine based on the requirement of input data dimension of the state-of-the-art deep learning approaches.
-
For maps between 256*256 to 512*512 pixel, we cropped the central part of this map as the map sample in CartoMark.
-
For maps between 512*512 to 1024*1024 pixels, we would randomly partition this original map into two sub-parts as the map samples.
-
For maps larger than 1024*1024 pixels, we would randomly partition this original map into four sub-parts as the map samples. The cropping and partitioning were conducted according to the following rules.
Assuming the dimension of an original map dataset as (x, y), for the dimension proposal \((d,d=\,\max (x,y))\),
If \(d=\in (256,512)\), we cropped the central part of this map as the map sample, and the area of the cropped map is \((\frac{1}{4}x:\frac{3}{4}x,\frac{1}{4}y:\frac{3}{4}y)\).
If \(d=\in (512,1024)\), we randomly partitioned the map into two parts, and then selected the central part of each part as the original map samples.
If \(d=\in (1024,+\infty )\), we randomly partitioned the map into four parts, and then selected the central part of each part as the original map samples.
Because a proportion of volunteered maps were limited in size image resizing can filter a great amount of original map dataset. In practice, we generally removed around 8000 map datasets in this step.
-
2.
Map reformatting. Besides size issue, a proportion of the maps were not created in a machine-readable format, and we removed these unreadable maps by commonly-used data processing tools including OPENCV, Adobe Photoshop, and ArcGIS. The selected format included JPG, JPEG, PNG, BMP, TIFF, GIF, AI, CDR, EPS, SVG, and PSD. Moreover, for the dynamic maps generated by TIFF, we splitted them into multiple frames, and randomly selected one frame as the map sample. Finally, we converted all selected map samples into two format groups: JPG and PNG.
-
3.
Map color and texture filtering. Some map datasets might have a visually-incorrect colors and textures due to a variety of reasons, such as format conversion, data editing, data quality, etc. Since the incorrect color and texture of these maps were not suitable for visual cognition and machine intelligence techniques, we manually removed these map datasets.
-
4.
Image noise filtering. Removing various types of noises in these maps generated by unprofessional ways would always be challenging with automatic methods. However, the capability of addressing noises is critical to the performance of the-state-of-the-art approaches for map pattern recognition. Thus, we manually checked all maps by visual interpretation, and removed the original map datasets that had significant noises affecting the representation of map content.
-
5.
Image content filtering. It is widely acknowledged that information from the Internet and cyberspace might contain illegal or immoral clues. As the benchmark dataset would be published and shared by the global users, we also manually checked all maps by visual interpretation and removed any maps that might include inappropriate or immoral clues.
By implementing this integrated strategy, we can ensure that the original map datasets are of high quality and meet the necessary standards for use in benchmark datasets. After cleaning and filtering, the total number of the map samples in CattoMark are listed in Table 2.
Map labelling
The map labelling process is depicted in Fig. 4. For each collected map sample, we first assigned a scene category label, and then generated the labelled map dataset regarding map scene. Next, we assigned a character proposal for each text unit, and then generated the labelled map dataset regarding text character. Finally, we respectively created two groups of low-resolution maps by bicubic interpolation and Gaussian filtering, and then generated the labelled map dataset regarding super-resolution reconstruction.

Workflow of map labelling.
(1) Map scene labelling
Based on the taxonomies defined by the cartographical classification systems and standards involving Chinese topographical mapping standard (GB/T 16820-2009: https://openstd.samr.gov.cn/bzgk/gb/newGbInfo?hcno=AADA46D2F301C30AF9103A6789C40089), USGS national maps (https://store.usgs.gov/) and land classification legend (https://www.usgs.gov/media/images/land-cover-class-legend), United Nations Maps&Geoservices (https://www.un.org/geospatial/mapsgeo/thematic), and European landscape classification (https://ec.europa.eu/eurostat/cache/metadata/en/lan_esms.htm), we designed a multi-dimensional hierarchical labelling system as shown in Fig. 5a.

Hierarchical labelling system of CartoMark. (a) Hierarchical labelling system, and (b) the example.
The labelling system includes five dimensions of hierarchies: map dimension, map theme, map scheme, map view and map hue. Moreover, each dimension includes various sub-categories. The details of these five dimensions of hierarchies are listed in Table 3.
So, each map sample would be labelled as five categories. Moreover, any individuals in each hierarchy are independent and exclusive. For example, a map could be labelled as: {two-dimension, traffic theme, digital scheme, orthographical angle of view, color}, but not {two-dimension, traffic theme, topographical theme, digital scheme, orthographical angle of view, color}, as traffic theme and topographical theme belong to the same hierarchy, and are mutually exclusive. The examples are shown in Fig. 5b.
(2) Map labelling for text annotation
The workflow of map labelling for text annotation includes two sequential steps: selecting map text annotation proposal and labelling text position. We created the map text annotation proposals based on the collected map samples, adhering to the following criteria::
-
a.
each proposal has distinct styles (e.g. variations in character form, glyph, color, and other features);
-
b.
each proposal has different character arrangements (e.g. curved or rotated characters, etc.);
-
c.
each proposal has varied backgrounds (e.g. noises, other map features that overlay characters).
Then, we use a state-of-the-art labelling tool called PaddleOCR to label the position of each text in a map. PaddleOCR can be accessed by this link: https://github.com/PaddlePaddle/PaddleOCR (accessed date: 04-25-2024). We draw a four-side polygon (rectangle or square) minimal bounding box for every map text in each map, and recorded the coordinates of four corners of the bounding box. The coordinate refers to the position of pixel that located at the corner of this minimal bounding box. Figure 6 displays the selected result of map labelling for text annotation, the product of which includes the map file and the red bounding box that represents the positions of each text.

The example of map labelling for text annotation.
(3) Map labelling for super-resolution reconstruction
The workflow of map labelling for super-resolution reconstruction includes map proposal selection and map interpolation. We selected the collected map samples as map proposals. Then, for each map proposal, we created three blurred maps (or low-resolution maps) by cubic spline interpolation and Gaussian filtering, respectively, with 2X, 3X and 4X scales. The details of cubic spline interpolation can be read in Reference27, and the function of Gaussian filtering is expressed as follows,
where (x,y) refers to the position of a pixel, σ refers to the variance.
Figure 7 illustrates the selected results of the map labelling for super-resolution reconstruction process. The resulting product comprises the original map file, a set of maps containing the 2X, 3X,and 4X map files generated by Gaussian filtering and another set of files containing the 2X, 3X,and 4X map files generated by cubic spline interpolation.

The example of map labelling for super-resolution reconstruction.
(4) Map labelling for style transferring
The labeling for map style transferring is used for transforming the original style of a map into other styles by the state-of-the-art deep learning techniques. The workflow of map labelling for style transferring includes style proposal selection and map style collection building. We used the collected map samples for map scene classification as style proposals, and organized them into map style collection.
Data Records
The benchmark dataset can be accessed by the following repositories:
-
Harvard Dataverse28: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/ZBXJD5.
-
Github: https://github.com/xrzhou/CartoMark.
As shown in Fig. 2, the datasets in CartoMark supports three tasks: map text annotation recognition, map scene classification, map super-resolution reconstruction, and map style transferring. The data modal and data format for each task are listed in Table 4.
The datasets of map text annotation recognition involve two modalities: imagery and text. The imagery modal dataset includes map images in two commonly-used formats: .JPG, and .PNG. The text modal dataset records the coordinates of each text proposal and is available in .TXT format.
The datasets of map scene classification also involve two modalities: imagery and text. The imagery modal dataset consists of two aforementioned formats: .JPG and .PNG. The text modal dataset records the category of each map image and is available in .TXT format.
The datasets of map super-resolution reconstruction involve the imagery modal dataset alone, which includes the original high-resolution map images and their corresponding low-resolution map images. The dataset is available in the two aforementioned formats: .JPG, and .PNG.
The datasets of map style transferring also involves the imagery modal dataset. The dataset includes the original map images and the maps that shares the similar content but different styles. The dataset is available in the two aforementioned formats: .JPG, and .PNG.
Technical Validation
Validation of map sample collection
Readability and format
We used OPENCV, Adobe Photoshop, and ArcGIS to verify each collected map sample, ensuring that these files are machine-readable. For we invited these people with different education backgrounds so that diverse opinions could be considered in the labelling of each map. For map color and texture, noise, and inappropriate content, three individuals with different education backgrounds provided separate interpretation results. If at least one results were not same, we would make a further discussion on the results and determine the final results. Moreover, we would remove the map sample that no agreement could be given.
In addition, the benchmark dataset in the community of computer vision and pattern recognition typically provides the images in formats including.JPG and.PNG. Thus, we generate every map sample in these two formats so that machine intelligence techniques are capability of processing and addressing these map files.
Redundancy
Extending the diversity of one category is the critical criterion of benchmark dataset Thus, we employed the algorithms called structural similarity (SSIM) and normalized mutual Information (NMI) to measure the similarity among pre-processed maps shown in Fig. 3. The SSIM is expressed as follows,
where i and j are two maps, mi and mj refers to the mean of i and j, si and sj refers to the variance of i and j, and covx,y refers to the covariance of i and j.
Moreover, the mean, variance and covariance of two maps are calculated based on their color space and grayscale.
The NMI is expressed as follows,
where Hi and Hj are the information entropy of two maps i and i, pi and pj refers to the marginal distribution of i and j, pi,j refers to the joint distribution of i and j.
For the maps identified as similar by SSIM and NMI, we then manually checked these maps and removed the similar one.
Map labelling validation
Map labeling validation was conducted in four categories: map scene labelling, map labelling for text annotation, and map labelling for super-resolution reconstruction. We designed a framework to evaluate the technical quality of each dataset by different approaches. A volunteer group involving two university faculties, four graduate students and two undergraduate students have joined the labelling validation. Since the labelling results might be varied based on different individuals, we invited these people with different education backgrounds so that diverse opinions could be considered in the labelling of each map. The details of validation are mentioned as follows.
Validation of map scene labelling
Five volunteers labelled the category of every map. If there were at least four label results were consistent, this map would be categorized under that label. Otherwise, we would discuss the labelled categories and decide which category was the appropriate. Moreover, if a map had no agreement among the volunteers, we would remove it from the CartoMark to avoid any confusions regarding map scene. Specifically, the removed maps would be stored for future using.
Moreover, we have used the labeled map scene datasets to conduct map type classification20 and multi-ask map type classification21.
Validation of map labelling for text annotation
In the first stage of checking, one volunteer labelled the text proposals of each map, and another volunteer checked the quality of the text proposal, which might vary in style, arrangement, and color, were accurately annotated. In the second stage of checking, the third volunteer would verify that the bounding box of each text proposal fully encompassed all text characters.
Moreover, we have used the labeled map text datasets to conduct map text annotation detection with transfer learning25.
Validation of map labelling for super-resolution reconstruction
To ensure the quality of low-resolution maps, we employed two commonly-used interpolation approaches: Gaussian image filtering and cubic spline interpolation to generate the low-resolution maps. The results generated by these two approaches have been used to evaluate the state-of-the-art machine intelligence techniques29,30.
Moreover, we have used the labeled map super-resolution datasets to conduct map super-resolution reconstruction31.
Validation of map style transferring labelling
Five volunteers checked the consistency among maps with different styles. If there were at least four label results were consistent, these maps would be used as the style transferring. Otherwise, we would discuss the consistency and decide whether these maps were appropriate. Moreover, if a map had no agreement among the volunteers, we would remove it from the CartoMark, and specifically stored them for future using.
Program validation
All three programs were tested by different python encoding environments including Jupiter Anaconda, Pycharm, and Pysript. Moreover, these programs were tested on different operation systems including Windows (Windows 10 and Windows 11), Mac, and Ubuntu.
Code availability
All codes of programs mentioned in this manuscript could be found in the benchmark dataset, and are available to readers without undue qualifications.
References
Zhou, X. et al. Intelligent Map Image Recognition and Understanding: Representative Features, Methodology and Prospects. Geomatics and Information Science of Wuhan Univ. 47(5), 641–650 (2022).
Wang, J. Y., Fang, W. & Yan, H. Cartography: its past, present and future. Acta Geodaetica et Cartographica Sinica 51(6), 829 (2022).
Clarke, K. C., Johnson, J. M. & Trainor, T. Contemporary American cartographic research: A review and prospective. Cartogr Geogr Inf Sc 46(3), 196–209 (2019).
Gotlib, D., Olszewski, R. & Gartner, G. The Extended Concept of the Map in View of Modern Geoinformation Products. ISPRS Int J Geo-Inf 10(3), 142 (2021).
Li, H., Liu, J. & Zhou, X. Intelligent map reader: A framework for topographic map understanding with deep learning and gazetteer. IEEE Access 6, 25363–25376 (2018).
Usher, N. News cartography and epistemic authority in the era of big data: Journalists as map-makers, map-users, and map-subjects. New Media Soc 22(2), 247–263 (2020).
Victoria, R., Coetzee, S. & Iwaniak, A. Orchestrating OGC web services to produce thematic maps in a spatial information infrastructure[J]. Comput Environ Urban 37, 107–120 (2013).
Roth, R. E. Interactive maps: What we know and what we need to know. J Spatial Inf Sci 6, 59–115 (2013).
Ablameyko, S. et al. A complete system for interpretation of color maps. Int J Image Graph, 2(3), 453–480 (2002).
Pablo, A. & Harvey, F. Maps as geomedial action spaces: considering the shift from logocentric to egocentric engagements. GeoJournal 82(1), 171–183 (2017).
Chiang, Y. Y., Leyk, S. & A-Knoblock, C. A Survey of Digital Map Processing Techniques. ACM Computing Surveys 47(1), 1–44 (2014).
Liu, T., Xu, P. & Zhang, S. A Review of Recent Advances in Scanned Topographic Map Processing. Neurocomputing 328, 75–87 (2018).
Chiang, Y. Y. & Knoblock, C. Recognizing text in raster maps. GeoInformatica 19(1), 1–27 (2015).
Liu, T. et al. SCTMS: Superpixel based color topographic map segmentation method. J Vis Commun Image R 35, 78–90 (2016).
Stefan, L. & Boesch, R. Colors of the past: color image segmentation in historical topographic maps based on homogeneity. GeoInformatica 14(1), 1–21 (2010).
Miao, Q. et al. Guided Superpixel Method for Topographic Map Processing. IEEE T Geosci Remote 54(11), 1–15 (2016).
Usery, E. L. et al. GeoAI in the US Geological Survey for topographic mapping. T GIS 26(1), 25–40 (2022).
Robinson, A. C. et al. Geospatial big data and cartography: research challenges and opportunities for making maps that matter. Int J Cartogr 3(sup1), 32–60 (2017).
Kang Y., Gao S. & Roth R. E. Artificial intelligence studies in cartography: a review and synthesis of methods, applications, and ethics. Cartogr Geogr Inf Sc, 1-32. (2024).
Zhou X., et al. Deep convolutional neural networks for map-type classification. In AutoCarto 2018, ed. S. Freundschuh and D. Sinton, 147–55. Madison, WI.
Wen Y., et al. Multi-task deep learning strategy for map-type classification. Cartogr Geogr Inf Sc, 1–15. (2024).
Li, J. & Xiao, N. Computational cartographic recognition: Identifying maps, geographic regions, and projections from images using machine learning. Ann Am Assoc Geogr 113(5), 1243–1267 (2023).
Uhl, J. H. & Duan, W. Automating information extraction from large historical topographic map archives: New opportunities and challenges. Handbook of Big Geospatial Data, 509–522. (Springer, 2020)
Hu, Y. J. et al. Enriching the metadata of map images: a deep learning approach with GIS-based data augmentation. Int J Geogr Inf Sci 36(4), 1–23 (2021).
Zhai, Y., Zhou, X. & Li, H. Model and Data Integrated Transfer Learning for Unstructured Map Text Detection. ISPRS Int J Geo-Inf 12(3), 106 (2023).
Enescu, I. et al. Towards better WMS maps through the use of the styled layer descriptor and cartographic conflict resolution for linear features. Cartogr J 52(2), 125–136 (2015).
Gilman A., Bailey D. G. & Marsland S. R. Interpolation models for image super-resolution. 4th IEEE International Symposium on Electronic Design, Test and Applications, 23-25 January 2008, Hong Kong, China. IEEE, (2008).
Zhou, X. CartoMark v1. Harvard Dataverse https://doi.org/10.7910/DVN/ZBXJD5 (2024).
Wang, W. et al. Deep Learning for Single Image Super-Resolution: A Brief Review. IEEE T Multimedia 21(12), 3106–3121 (2019).
Wang, P. J., Bayram, B. & Sertel, E. A comprehensive review on deep learning based remote sensing image super-resolution methods. Earth Sci Review 232, 104110 (2022).
Li, H., Zhou, X. & Yan, Z. mapSR: A Deep Neural Network for Super-Resolution of Raster Map. ISPRS Int J Geo-Inf 12(7), 258 (2023).
Acknowledgements
We would like to thank the valuable comments from anonymous reviewers and editors, which significantly benefit the earlier version of this manuscript. This work was supported from the National Natural Science Foundation of China [42201473], Key Research and Development Program of Ningxia Hui Autonomous Region [2023BEG02068], State Key Laboratory of Geo-Information Engineering and Key Laboratory of Surveying and Mapping Science and Geospatial Information Technology of MNR, CASM [2024-04-13], Huzhou Key Research and Development Program [2023ZD2046] and Beijing Nova Program [20230484351].
Author information
Authors and Affiliations
Contributions
X. Zhou designed the architecture of benchmark dataset, examined the labelling dataset, organized the benchmark dataset, and wrote and revised the manuscript. Y. Wen collected the original dataset and labelled the map samples, H. Li, K. Li and X. Xie labelled the map samples. Z. Yan and Z. Shao checked the architecture of benchmark dataset, and examined the labelled dataset.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhou, X., Wen, Y., Shao, Z. et al. CartoMark: a benchmark dataset for map pattern recognition and map content retrieval with machine intelligence. Sci Data 11, 1205 (2024). https://doi.org/10.1038/s41597-024-04057-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-024-04057-7
