
Abstract
The United Nations sustainable development agenda emphasizes the importance of forests. China’s forests cover 5% of the world’s forest area, significantly influencing global climate and ecology. In recent decades, China’s forests have undergone notable changes. Accurate forest cover maps are crucial for understanding forest distribution, conducting ecological research and sustainable management. However, there is a lack of forest cover maps satisfying the criteria. To this issue, this study focuses on developing a precise 16-m resolution forest cover map of China. For this purpose, we propose a forest classification framework based on weakly supervised deep learning and prior knowledge from open datasets. Utilizing this framework and GF-1 WFV satellite images, we generated China’s forest cover map in 2020 named FCM16. The FCM16 is evaluated using 136,385 sample points, achieving an overall accuracy of 94.64 ± 0.12%, producer’s accuracy of 91.12 ± 0.27% and user’s accuracy of 87.31 ± 0.34%. Additionally, FCM16 was compared with existing forest-related datasets, demonstrating its reliability. In general, FCM16 effectively represents China’s forest cover in 2020, providing a valuable resource for social and ecological analysis.
Similar content being viewed by others
Background & Summary
Forests permeate many of the sustainable development goals (SDGs) of the United Nations sustainable development agenda. They are the nexus of energy exchange between the biosphere and the atmosphere and are an important link in the carbon cycle. The protection and restoration of forests play an important role in the response to global issues such as climate change1, water conservation, biodiversity protection, and economic development. In recent decades, China has made great efforts to protect and restore the forests, and the area of forests has increased rapidly. While these changes have improved soil and water conservation, promoted carbon sequestration2, and protected the ecosystem, they have also brought new challenges, such as the decline of natural forests and the spread of forest pests and diseases3. Therefore, there is urgent needs to update and refine forest cover maps for China to better understand and manage these evolving dynamics and to strengthen sustainable forest management.
Remote sensing technology4,5,6,7 has been an effective and efficient tool for large-scale forest mapping with advancing of technologies. With the spectral properties of vegetation and multi-spectral satellite data, some vegetation indices8,9,10,11 have been designed to characterize vegetation cover and growth, such as the Normalized Difference Vegetation Index (NDVI), which is widely applied in forest cover classification tasks12,13,14 due to simplicity and reliability. Besides, the spectral, texture, and terrain features are also commonly used as inputs to classifiers. Classical machine learning algorithms15,16 such as random forests17 and support vector machines are popular for large-scale forest cover classification. More recently, deep learning models have demonstrated excellent performance in these tasks18,19,20,21, offering advanced capabilities for accurate forest monitoring.
Drawing on these techniques, scholars have produced some forest thematic maps22,23,24 and forest layers in land use land cover datasets25,26,27,28. Although several datasets can provide forest cover data, they differ greatly in classification schemes and definitions of forests driven by varying motivations and initiatives. In 2015, the United Nations (UN) launched “The 2030 Agenda for Sustainable Development” and proposed 17 Sustainable Development Goals (SDGs). The definition of forests provided by the Food and Agriculture Organization (FAO) has been adopted to SDGs assessments, like indicator SDG15.1.1(Forest area as a proportion of total land area). This definition has also been widely recognized in the academic community. Therefore, adhering to the FAO’s forest definition and producing forest maps that align with this definition will facilitate global forest resource management and promote the SDGs evaluation.
Large-scale forest monitoring heavily relies on satellite data. Earlier forest monitoring mostly utilized coarse-resolution satellite data. In recent years, owing to the advances in sensor technology, medium-resolution satellite images, such as Landsat and Sentinel, have become increasingly important. In recent years, China has launched a large number of Earth observation satellites, enriching the source of Earth observation data. The gaofen-1 (GF-1) is the first satellite of China’s high-resolution Earth observation system. It shows a powerful data acquisition capability allowing frequent acquisition of Earth observation data within a short period of time, which has enriched the data source of the global forest resources survey.
Therefore, in response to the lack of forest cover maps in China that satisfy the FAO’s forest definition, the primary objective of this study is to produce a precise forest cover map of China for the year 2020 using GF-1 WFV images. In this work, we propose an automated medium-resolution forest classification method based on weakly supervised deep learning and noisy learning. By incorporating the experience and priori knowledge extracting from existing datasets in sample creation and result fusion, we have improved the forest mapping area and statistical accuracy. Both quantitative and qualitative evaluations of FCM16 demonstrated that our data achieved satisfactory accuracy on both overall and local scales. Out dataset provide a new reliable map for forest research and management.
Methods
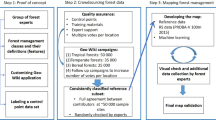
In this study, we employed a deep learning approach combined with prior knowledge to generate a forest cover map for China. The workflow is illustrated in Fig. 1. This section provides a detailed description of this process. The accuracy of FCM16 is quantitatively evaluated regionally and globally. The qualitative and quantitative comparisons are made with related datasets to verify the reliability of the forest cover map derived in this study.

Schematic representation of the process used for mapping forest cover in this study.
Remote sensing images processing
GF-1 satellite is equipped with two 2 m resolution panchromatic/8-meter resolution multi-spectral cameras and four 16-meter resolution multi-spectral cameras. The four 16-meter resolution multi-spectral cameras, also known as Wide Field of View (WFV) cameras, are available in red, green, blue, and near-infrared bands with a revisit period of 4 days. This study adopts GF-1 WFV images as the data source with all bands as inputs. Since the GF-1 WFV satellite data products lack a fixed grid, we manually selected high-quality images for each grid with reference to a grid of 100 km x 100 km29, ensuring that each pixel had at least one cloud-free pixel. Figure 2(a) illustrates the valid observations for each localized gird area. A total of 1967 images were acquired. Majority of the images were acquired in 2020, while some areas were acquired in 2018–2022 due to high cloudiness. These images are available freely through the China Centre for Resources Satellite Data and Application (https://data.cresda.cn).

(a) the valid observation for local area of each reference grid and (b) the distributions of validation samples.
The downloaded GF-1 WFV images are Level-1 products that have undergone system geometric correction. We performed pre-processing procedures on these images, including ortho-rectification and cloud detection. Specifically, we first conduct ortho-rectification30 on all images using ground control points and digital elevation model (DEM) data to improve the geometric position accuracy. Then a cloud mask is created according to Eq. 1, where value 1 means cloud and value 0 means non-cloud. Due to the risk of misclassifying some highlighted objects, we referenced the WorldCover and Esri Land Cover to remove such objects including built-up, bare land, and snow and ice. Although such an operation might lead to omission and misclassification of cloud pixels, its impact on the final results can be considered negligible as forests are dark objects.
Validation samples
A total of 136,385 sample points, including 64,463 forest points and 71,922 non-forest points, were obtained by random sampling to evaluate the accuracy of the forest cover maps. The distributiond of these sample points is presented in Fig. 2(b). These samples are visually interpreted concerning high-resolution satellite imagery embedded in QGIS, GF-2 satellite images, and Google Earth images.
Auxiliary datasets
LULC maps. In the experiment, we referenced and compared relevant open medium-resolution datasets (as shown in Table 1), including ESA WorldCover28, Esri Land Cover18, FROM-GLC1031, CRLC20, GLC-FCS3025, GlobeLand3027, CLCD26, TreeCover22, and GFC3024. These datasets were produced using different data sources. Specifically, WorldCover, Esri Land Cover, FROM-GLC10, and CRLC were derived from Sentinel-2 images with a spatial resolution of 10 m. It is worth noting that WorldCover also utilized Sentinel-1 images. In contrast, GLC-FCS30, GlobeLand30, CLCD, TreeCover, and GFC30 were primarily generated from Landsat data with a spatial resolution of 30 m. With respect to classification methods, Esri Land Cover and CLCD employ deep learning algorithms, while the other datasets use random forest algorithms. Apart from the data sources and methods, these datasets also differ in coverage. Except for CRLC and CLCD, which only cover the region of China, the other datasets have global coverage.
Generation of pseudo label, pseudo map and forest consistency map
We integrate the use of freely available datasets to draw insights from previous research and guide subsequent studies. Peng et al.32 demonstrated that in the case of the six datasets, including TreeCover, WorldCover, FROM-GLC10, Esri Land Cover, GlobeLand30, and GLC-FCS30, areas with voting results exceeding 4 achieved an accuracy as high as 97.35%. For areas with a voting result of 3, the accuracy of forest classification was approximately 60%. Based on such experience, we reference these six datasets to obtain a LULC map with uncertain areas, pseudo labels for forest/non-forest classification, and a forest spatial consistency (FSC) map.
The LULC products with different classification schemes and resolutions are firstly reclassified by class aggregation and resampled to 16 m resolution, to ensure comparability between the datasets. It should be mentioned that the class aggregation refers to the classification system of GlobeLand30, including crop, forest, grass, shrub, wetland, water, tundra, artificial surfaces, bare land, and snow and ice. Then the voting strategy is adopted to create the voting maps for each LULC class. Finally, the fused LULC map, pseudo forest/non-forest label, and forest distribution spatial consistency map are created by threshold segmentation. Specifically, based on the voting results of the forest, we divided the areas with votes greater than 0 into three levels using Eq. 2 to obtain the FSC map.
where, \({v}_{f}\) is the forest vote map. Some morphological operations including dilation and erosion are applied to optimize the FSC map.
Then, the areas with high consistency (AHC) for each class is created according to Eq. 3.
where, \({v}_{c}\) indicates the vote map of each class \(c\). \(t\) donates the threshold for vote map which is 4 for forest class and 3 for non-forest classes.
The AHC maps of different classes are fused to generate the LULC map. It is noted that when the maximum votes for the forest class are 6 and for non-forest is 5, there are no overlapping areas between the AHC map of different classes. Additionally, the fused LULC map includes some areas where the land cover class is uncertain. Lastly, the forest/non-forest pseudo labels with uncertain areas are created by aggregating the non-forest classes of the fused LULC map.
In this study, the main purposes of the prior knowledge are as follows. The fused LULC map is used to select representative and informative sample patches. The pseudo label is employed to train the deep model. The FSC serves to calculate the threshold for segmenting the predicted forest probability maps.
Mapping forest cover using deep learning
This study adopts a weakly supervised forest classification framework (WSFCF) proposed by Peng et al.33 as the primary method for forest mapping in China. This method is capable of overcoming issues like inaccurate and incomplete labeling, enabling accurate forest classification even with inaccurate samples. Moreover, it exhibits robustness to phenological changes, reducing the impact of phenological variations on the results. The WSFCF consists of three main components: sample location selection and optimization, dynamic correction of the pseudo label, and a deep learning model. The following is a description of the method, and for more detailed information, please refer to33.
Sample location selection and optimization
The purpose is to select representative and informative sample patches for model training. The position of selected samples is primarily determined based on the fused LULC map at the beginning. Once the model shows some discrimination ability, the spacial areas such as forest areas with omission and commission and areas with missing labels are involved in constraining the position of the samples. This is designed to ensure challenging samples represented in the sample set.
Dynamic correction of pseudo label
The pseudo label contains a significant amount of noise, such as inaccurate and incomplete annotations. The model is trained with noisy labels because the model tends to learn from correct samples at the early stage of training. In the later stages, the pseudo labels are dynamically corrected according to the prediction probabilities. These updated labels continue to participate in the optimization of the model.
Spectral-Spatial network (SSNet)
The medium-resolution satellite images provide limited textural information on land cover but rich spectral information. The forests are densely populated with relatively fuzzy texture features. Additionally, forests share poor boundaries with other objects such as shrubs and grasslands. Given these characteristics, the Spectral-Spatial network (SSNet) is proposed for forest classification at medium-resolution, which can simultaneously factor in spectral and texture features. The spectral module of SSNet utilizes a multi-layer perceptron to model the spectral features of medium resolution images, and the spatial module employs a U-shaped network to capture spatial contextual relationships. The spectral and texture features are fused and input into the classifier to create the final classification result.
Create forest cover map grid-by-grid
The GF-1 WFV data product does not have a fixed orbit. To facilitate the fusion of results of multi-temporal images, we adopt a grid of 100 km x 100 km29 and divide China into 1171 regions. Based on this reference grid, a pixel-to-pixel composition method is employed to composite the final forest cover map. As illustrated in Fig. 3, this procedure consists of two parts, namely, segmenting single-image results and fusing multi-image results.

The post process of mapping forest cover map grid-by-grid.
We first segment the forest cover of single images and then fuse the results from multi-dates. A similar composition method is designed in such a process. Before describing the methods, two concepts, including valid image marks (VIM) and forest result marks (FRM), are first introduced. The VIM serves to mark the number of valid predictions for each pixel. This is closely related to the availability of pixels in the participating images for voting, meaning that the pixel is within a valid region and is not a cloud pixel. The FRM marks the number of times a pixel is predicted as forest. The VIM and the FRM are used to calculate the labeling probability (lp) of a pixel predicted as forest, as shown in Eq. 4.
As indicated in Eq. 5, if \(lp\ge 0.5\), the pixel is considered a forest pixel; otherwise, it is considered a non-forest pixel.
where, \(f\) represents the forest cover result.
Segment the forest/non-forest of single date with an adaptive threshold
The AHC contributes to the pseudo labels for the pursuit of more accurate labels, as they tend to be more easily classified correctly. In other words, we sacrifice the sample diversity for accuracy to some extent, resulting in a lack of samples from challenging areas. These areas typically include regions where planted forests are distributed, often found in northern China. The model might fail to learn the forest features of these areas. It is observed that the forest-predicted probabilities in these regions sometimes are lower than those in the AHC but are still significantly higher than the surrounding non-forest areas and medium-to-low consistency areas in the FSC map. The higher the spatial consistency of forest distribution within an area, the more accurate and stable the forest classification results, and the higher the forest prediction probability. Conversely, in areas with lower consistency (such as forest boundaries or transition zones), the forest classification results are less stable, and the forest prediction probability decreases accordingly.
Therefore, based on prior knowledge, a threshold segmentation method named Global Constraints and Local Adaptation (GCLA) was devised to segment the probability maps of single-date images, combining global constraints with local adaptation. This approach maximizes the utilization of prior knowledge to achieve more accurate forest cover results. Based on the FSC map, we design the implementation for GCLA threshold segmentation. Considering the average forest probability distribution across regions in the FSC map, we adopt a method to compute both global and local thresholds, as presented in Algorithm 1. Besides, \(o{t}_{mid}\) and \(o{t}_{high}\) are set to prevent calculation and classification anomalies in regions with lower FSC.
In the experiment, when calculating the global threshold constraints \({t}_{global}\), \(o{t}_{mid}\) and \(o{t}_{high}\) are set to 0.8 and 0.7 respectively. A sliding window with a 50% overlap is employed to calculate the local threshold constraint \({t}_{local}\). The window size is set to 500 pixels with \(o{t}_{mid}\) and \(o{t}_{high}\) both assigned the value of \({t}_{global}\).
Algorithm 1
Calculate the threshold t for forest probability segmentation.
The \(VI{M}_{s}\in [0,4]\) and \(FR{M}_{s}\in \,[0,4]\) for the single image predicted probability are finally acquired. The \(l{p}_{s}\in [0,4]\) and \({f}_{s}\in \{0,1\}\) are calculated based on the Eqs. (3–4). It is important to note that when pixel \(Pi{x}_{i,j}\) (i and j donating the row and column respectively) satisfy \(l{p}_{i,j} > 1\) or partially satisfy \({p}_{i,j}=1\), it indicates an exceptional case. In this scenario, all/partial images are identified as cloud pixels (i.e., \(VI{M}_{s}^{i,j}=0\)) and some cloud detection results are erroneous.
The occurrence of the situation where the area \(VI{M}_{s}^{i,j}=0\) with \(l{p}_{s}^{i,j}\ge 1\) is due to the optimization of the VIM calculation with a value of 0 were re-labeling as 1. The primary purpose is to mitigate the interference of erroneous cloud detection results on the classification. It addresses scenarios where cloud pixel ranges might exceed actual conditions or where cloud detection results are inaccurate, but the classification algorithm accurately classify the pixels. Furthermore, such operation maximizes the utilization of each image, particularly in regions where cloud interference is significant, such as low latitudes and coastal areas.
Fusing multi-date forest/non-forest data using voting scheme
The forest cover results for each image are obtained. Subsequently, these individual results are fused to derive forest cover data for the target area. Based on the result of single images, the \(FR{M}_{grid}\in [0,C]\) (with C donating the number of images) of target area is determined using voting method. Simultaneously, the voting based on cloud mask results is conducted to obtain the \(VI{M}_{grid}\in [0,C]\). Areas labeled as 0 in the \(FR{M}_{grid}\) are reassigned to 1 to prevent anomalies. Ultimately, the composite forest cover result \({f}_{grid}\in \{0,1\}\) was obtained based on Eqs. (4) to (5).
Accuracy assessment
The validation for FCM16 followed by recommended practices by Olofsson et al.34. The accuracy of forest cover was evaluated from both global and local perspectives using quantitative evaluation metrics such as producer’s accuracy (PA), user’s accuracy (UA), OA, and F1 score. The forest cover map produced in this work is also compared with existing datasets circa 2020 in China from statistical accuracy and area estimation.
Data Records
The FCM16 dataset can be freely downloaded from (https://zenodo.org/records/1404318635). The dataset is defined in Albers projection with a spatial resolution of 16 m. It is in a GeoTIFF format and the pixel value indicate whether it is forest cover or not. Value 0 means non-forest cover and value 1 means forest cover. Each GeoTIFF file is named according to its reference gird name, i.e. the filename matches the grid name. The spatial extent of this dataset includes mainland China and neighboring regions covered by the reference grid file (17.38°–54.88°N, 72.41°–136.40°E). Beside, the reference grid file and sample list are available in Zenodo (https://zenodo.org/records/1404318635).
In this study, several freely available datasets are referenced in data processing procedures, including ESA WorldCover (https://zenodo.org/records/5571936), Esri Land cover (https://livingatlas.arcgis.com/landcoverexplorer), FROM-GLC10 (https://data-starcloud.pcl.ac.cn/zh/resource/1), CRLC (https://zenodo.org/records/7745603), GLC-FCS30 (https://zenodo.org/records/4280923), GlobeLand30 (https://www.webmap.cn/mapDataAction.do?method=globalLandCover or https://www.geodata.cn/datapplication/OrderStepList.html?dataguid=140236667788805), CLCD (https://doi.org/10.5281/zenodo.4417810), TreeCover (https://storage.googleapis.com/earthenginepartners-hansen/GFC-2021-v1.9/download.html), and GFC30 (https://data.casearth.cn/dataset/625e1760819aec2a46dcd2d8).
Technical Validation
Accuracy assessment
We have estimated the accuracy and forest area with a 95% confidence level following the recommended practice34. The estimated forest area of China in 2020 is 240.71 ± 1.12 million hectares. According to FCM16, the mapped forest area is 230.63 million hectares which is underestimated by 10.08 million hectares. We reported the accuracy of the FCM16 in Table 2. The result indicates that the produced map achieved satisfying accuracy with OA of 94.64 ± 0.12%. The UA and PA for forest are 91.12 ± 0.27% and 87.31 ± 0.34% respectively. As shown in Fig. 4, the map effectively reflects China’s forest distribution in 2020. Forests are mainly concentrated in China’s northeastern, southwestern and southern regions. There is less forest distribution in the Northwest and Qinghai-Tibetan Plateau regions.

The detail of FCM16. (a,b) are the map and the local statistical accuracy of the FCM16 respectively. (c–g) represent the high-resolution satellite maps and the FCM16 for the five sites (c–f) in sub-image (a) respectively. Site (c) is located in the densely forested distribution area in south China; site (d) is located in the Sichuan basin, where forests are small and interspersed with farmland; site (e) is located in the transition area of the Loess Plateau, where vast ecological protection forests have been planted; the site (f) locates in the Northeast, where a large number of planted forests are distributed; and the site (g) locates in the Altai Mountains, where the forests are relatively homogeneous and dominated by coniferous forests.
We also estimate the reliability of our FCM16 in regional scale. The local accuracy of the FCM16 were further calculated based on the reference grids, using metrics such as PA, UA, and F1 score. As illustrated in Fig. 4(b), the local UA map generally achieved a high level, indicating that FCM16 can provide high-quality and accurate forest cover data with high reliability and precision. However, the local PA map indicated that the forest cover map exhibits high accuracy in most regions but shows lower accuracy in some northern areas, suggesting that there is some underestimation of the forest cover in northern China.
In general, there are considerable accuracy discrepancies among different parts of China, as depicted in the local F1 score map in Fig. 4(b). The northeastern and vast southern areas demonstrate elevated levels of classification precision. It is noteworthy that in the Khingan Mountains and the Southeast Hills, the F1 score generally exceeds 91%, with some areas reaching F1 scores of over 95%. In contrast, the local accuracy of FCM16 in the northern and northwestern regions exhibits lower levels, accompanied by notable variations. However, most areas in these regions still attain an accuracy exceeding 60%.
And the results of some typical areas are illustrated in the of Fig. 4(c–g). The visualization demonstrates that it is possible to accurately map the forest cover regardless of whether it is a region with dense forests (Fig. 4(c)) or with smaller forests (Fig. 4(d,g)). In addition, it is also able to accurately map some of the smaller and more dispersed plantation forests Fig. 4(e,f)). By directly comparing FCM16 with high-resolution satellite maps, we found that the FCM16 demonstrates satisfactory visualization performance for forests of different scales and characteristics.
Comparison with other maps
The FCM16 is produced entirely from GF-1 WFV images. It is compared with seven freely available datasets including WorldCover, Esri Land cover, FROM-GLC10, CRLC, GLC-FCS30, GlobeLand30, and CLCD. Except for FROM-GLC10, which represents forest cover in 2017, the other datasets reflect land cover information for the year 2020. However, considering the proximity to the target year (2020), FROM-GLC10 is also involved in the comparison.
The quantitative comparison is shown in Table 3. For forest cover, the FCM16’s UA reaches 91.12 ± 0.27%, while that of the comparison datasets is below 90%; the PA of FCM16 reached 87.31 ± 0.34%, second only to WorldCover at 88.45 ± 0.33%. The accuracy of FCM16 is higher than that of the comparison datasets, with OA reaching 94.64 ± 0.12% and F1 score of 89.17% and 96.44% for forest cover and non-forest cover respectively. The results demonstrate that the FCM16 outperforms other datasets in multiple metrics.
The forest area of these datasets was counted and estimated to compare the reliability, and the results are displayed in Table 4. The error of FCM16 between mapped area and estimated area is about 4.19% followed by WorldCover and FROM-GLC10. By comparing the mapped area and the estimated are, it is found that these maps generally underestimate China’s forest area, except for WorldCover. GlobeLand30 underestimates forest area with a maximum error of about 44.37 million hectares which is 17.39% of its estimated forest area. Its mapped area is 210.72 million hectares, which is the smallest of all datasets. But its estimated area is 255.09 ± 1.60 million hectares, which is the largest estimated area.
In contrast, WorldCover’s error area about 5.89 million hectares, approximately 2.47% of its estimated area. In WorldCover, the forest-related classes include “Trees” and “Mangroves”. The fused result includes but is not limited to forests; it also compasses other tree cover that might not meet the forest criteria. Concerning the definitions and metrics, it is inferred that the area and coverage of the fused result for WorldCover might be overestimated. Yet that is not the case. Therefore, the forest area is not sufficient to demonstrate the accuracy of the map.
Although, scholars have made a lot of efforts in assessing the accuracy of LULC maps34,36, it seems difficult for users to measure the reliability of a map based on a single metric. It may be necessary for us to choose the appropriate map according to the specific applications or target areas.
We further compared the local accuracy of these datasets. The local accuracy distribution map (Fig. 5) demonstrates that FCM16 displays notably superior local accuracy in predominant forest-covered regions compared to other datasets. However, its superiority is less prominent in northern and northwestern China. Although there are differences in local accuracy, these datasets form similar spatial distribution patterns in terms of local accuracy in their respective regions. Specifically, in areas with dense/large scale/high coverage forests, such as the northeast and south China, all datasets demonstrate high accuracy. However, in areas with more complex land cover and smaller-scale forests, such as north and northwest China, these datasets all exhibit varying degrees of decline in performance32.

The regional accuracy (F1 score) comparison of different datasets. (a) WorldCover, (b) Esri land cover, (c) FROM-GLC10, (d) CRLC, (e) GLC-FCS30, (f) GlobeLand30, (g) CLCD, and (h) FCM16.
In addition to spatial distribution patterns of local accuracy, these datasets share some similarities in the details of the results. For instance, in areas with concentrated forest cover (as depicted in Fig. 6), the results of non-forest are often less accurate and underestimated in extent. Conversely, in areas with concentrated non-forest cover, the results of non-forest tend to be overestimated in extent (as displayed in Fig. 7).

Comparison of different datasets in Khingan Mountains (49.85°N, 123.91°E). (a) VHR images, (b) FCM16, (c) WorldCover, (d) Esri land cover, (e) FROM-GLC10, (f) CRLC, (g) GLC-FCS30, (h) GlobeLand30, and (i) CLCD.

Comparison of different datasets in Sichuan Basin (30.30°N, 105.22°E). (a) VHR images, (b) FCM16, (c) WorldCover, (d) Esri land cover, (e) FROM-GLC10, (f) CRLC, (g) GLC-FCS30, (h) GlobeLand30, and (i) CLCD.
At the same time, there are certain differences between different datasets. These differences might be attributed to the limitations of satellite data resolution and production algorithms, resulting in varying levels of detail. As displayed in Fig. 6, the higher the resolution is, the higher the accuracy and the finer spatial details tend to be37.
Most of these datasets are produced with traditional machine learning algorithms based on pixel features like random forests. These algorithms tend to capture richer detail features but generate more salt-and-pepper noise (Figs. 7–8(e,g,h)). The deep learning algorithms often exploit spatial contextual features, which result in varying resolution reduction through convolution and downsampling38. Therefore, while datasets generated by deep learning algorithms show fewer salt-and-pepper noises, they tend to feature smoother boundaries and coarser details (Figs. 7–8(d)). Compared to others, FCM16 performs higher completeness while maintaining the local detail. Additionally, FCM16 demonstrates more stable accuracy and visualization performance for forests with different characteristics.

Comparison of different datasets at South Hills (21.76°N, 111.24°E). (a) VHR images, (b) FCM16, (c) WorldCover, (d) Esri land cover, (e) FROM-GLC10, (f) CRLC, (g) GLC-FCS30, (h) GlobeLand30, and (i) CLCD.
The uncertainties of the FCM16 and the future improvements
The FCM16 is compared with other medium-resolution datasets, demonstrating their capability to describe forests with different geographical environments and characteristics. Although FCM16 performs well in describing forest distribution patterns, there are still some uncertainties that require further exploration and resolution. Specifically, the extraction of forests in northern China is not accurate enough and is significantly less accurate compared to other regions. These less accurate regions are mainly distributed in the areas where the 3-North Shelter Forest Program is implemented. Such phenomena are prevalent in the compared datasets. These uncertainties may be attributed to the following factors.
-
(1)
Forest structure and distribution pattern. In contrast to the south and northeast areas, the forests areas such as the Loess Plateau and Northeast China Plain are small-scaled and scattered, predominantly composed of young/middle-age planted forests with significant differences in spectral and textural features compared to natural forests and mature planted forests. The forest in this area is sparse. Due to the influence of the background or environment, there is a significant mixed pixel in the images, which increase the difficulty of forest extraction. Additionally, soil and moisture also have a direct impact on the spectral properties of forests.
-
(2)
Limitation of medium-resolution satellite images39. Medium-resolution images contain extensive mixed pixels especially in transition areas of different land cover types. This increases the difficulty of forest classification, particularly for small-scale forests. In addition, the insufficient resolution limits the ability to capture spatial details of small-scale forests, weakening the representation of their distribution in the images. It also hampers the utilization of texture features or spatial context to capture the distribution of these small-scale forests. In addition, multispectral images fail to measure the vegetation height. Low dense woody vegetation such as shrublands and low scrub may in some cases be classified as forest cover, while sparse forest may be classified as non-forest.
-
(3)
Rationality of the sample sets. The diversity and representativeness of the sample sets directly impact the accuracy of the classification results40. The annotations of the samples are voting from existing datasets; however, there is poor spatial consistency among different datasets in this area32. Therefore, there might be a lack of reliable and sufficient representative samples. In addition, it has been found41,42 that volume and proportion of the samples for different LULC classes dramatically influence the classification results. Although the rationality of sample distribution and quantity are considered during the sample selection, we seemly have not fully addressed this issue. More specifically, it is only considered whether the patches contained multiple classes and whether enough patches are included. While this approach partially achieved sample diversity, the actual volume (number of pixels) of each class sample was overlooked.
Based on the analysis above, the aspects followed should be further strengthened in the subsequent study.
-
(1)
Samples: It is indicated by Zhu et al.41 that optimizing the quantity and proportion of samples for different classes could greatly improve the classification accuracy. We intended to start by enhancing the diversity and representativeness of samples used for model training to capture the characteristics of different land cover classes. Besides, it would be urgent to increase the samples in key areas particularly the planted forest in north China.
-
(2)
Remote sensing images: The forests in those areas with lower accuracy are largely immature and dispersed plantations that might be insufficiently characterized in a single image. The study by Yang et al.39 indicates that forest cover mapping based on medium-resolution satellite imagery often suffers from round-off errors due to resolution limitations, leading to underestimation of forest area. And high-resolution satellite images could alleviate such problems to some extent43. Although the effectiveness of high-resolution satellite images in improving forest mapping is acknowledged, the timely acquisition of large-scale and temporally consistent high-resolution satellite images poses great challenges in terms of the data cost, smaller swath width, timeliness constraints and massive calculation44.
The time-series satellite images have been demonstrated to reduce the impact of clouds and cloud shadows while improving accuracy19 proving to be superior to single-date images in land cover mapping40. Some studies have shown that time-series images are capable of effectively assisting in extracting plantation forests16,45, and this has been validated in both northeastern37 and northwestern46 China.
Therefore, we consider introducing higher-resolution remote sensing images and time-series satellite images to leverage the advantages of multi-source remote sensing imagery in addressing the challenges of forest classification in key regions.
Code availability
The codes used in data generation and processing are in Python. The codes and validation samples are available in Zenodo at: https://zenodo.org/records/1404318635.
References
Peng, S. S. et al. Afforestation in China cools local land surface temperature. Proc Natl Acad Sci USA 111, 2915–2919, https://doi.org/10.1073/pnas.1315126111 (2014).
Tong, X. et al. Forest management in southern China generates short term extensive carbon sequestration. Nat Commun 11, 129, https://doi.org/10.1038/s41467-019-13798-8 (2020).
Wenhua, L. Degradation and restoration of forest ecosystems in China. Forest Ecology and Management 201, 33–41, https://doi.org/10.1016/j.foreco.2004.06.010 (2004).
Zhang, D., Wang, H., Wang, X. & Lü, Z. Accuracy assessment of the global forest watch tree cover 2000 in China. International Journal of Applied Earth Observation and Geoinformation 87 https://doi.org/10.1016/j.jag.2019.102033 (2020).
Huang, X. et al. High-resolution urban land-cover mapping and landscape analysis of the 42 major cities in China using ZY-3 satellite images. Sci Bull (Beijing) 65, 1039–1048, https://doi.org/10.1016/j.scib.2020.03.003 (2020).
White, J. C., Wulder, M. A., Hermosilla, T. & Coops, N. C. Satellite time series can guide forest restoration. Nature 569, 630, https://doi.org/10.1038/d41586-019-01665-x (2019).
White, J. C. et al. Remote Sensing Technologies for Enhancing Forest Inventories: A Review. Canadian Journal of Remote Sensing 42, 619–641, https://doi.org/10.1080/07038992.2016.1207484 (2016).
Rouse, J. W. Monitoring vegetation system in the Great Plains with ERTS (1974).
Liu, H. Q. & Huete, A. A feedback based modification of the NDVI to minimize canopy background and atmospheric noise. IEEE transactions on geoscience and remote sensing 33, 457–465 (1995).
Huete, A. R. A soil-adjusted vegetation index (SAVI). Remote sensing of environment 25, 295–309 (1988).
Qi, J., Chehbouni, A., Huete, A. R., Kerr, Y. H. & Sorooshian, S. A modified soil adjusted vegetation index. Remote sensing of environment 48, 119–126 (1994).
Potapov, P. V. et al. Eastern Europe’s forest cover dynamics from 1985 to 2012 quantified from the full Landsat archive. Remote Sensing of Environment 159, 28–43, https://doi.org/10.1016/j.rse.2014.11.027 (2015).
Hansen, M. C. et al. Monitoring conterminous United States (CONUS) land cover change with Web-Enabled Landsat Data (WELD). Remote Sensing of Environment 140, 466–484, https://doi.org/10.1016/j.rse.2013.08.014 (2014).
Hansen, M. C. et al. Towards an operational MODIS continuous field of percent tree cover algorithm: examples using AVHRR and MODIS data. Remote Sensing of Environment 83, 303–319, https://doi.org/10.1016/S0034-4257(02)00079-2 (2002).
Gong, P. et al. Finer resolution observation and monitoring of global land cover: first mapping results with Landsat TM and ETM+ data. International Journal of Remote Sensing 34, 2607–2654, https://doi.org/10.1080/01431161.2012.748992 (2012).
Koskinen, J. et al. Participatory mapping of forest plantations with Open Foris and Google Earth Engine. ISPRS Journal of Photogrammetry and Remote Sensing 148, 63–74, https://doi.org/10.1016/j.isprsjprs.2018.12.011 (2019).
Belgiu, M. & Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS Journal of Photogrammetry and Remote Sensing 114, 24–31, https://doi.org/10.1016/j.isprsjprs.2016.01.011 (2016).
Karra, K. et al. in 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS 4704-4707 (2021).
Liu, S. et al. Land Use and Land Cover Mapping in China Using Multimodal Fine-Grained Dual Network. IEEE Transactions on Geoscience and Remote Sensing 61, 1–19, https://doi.org/10.1109/tgrs.2023.3285912 (2023).
Liu, Y., Zhong, Y., Ma, A., Zhao, J. & Zhang, L. Cross-resolution national-scale land-cover mapping based on noisy label learning: A case study of China. International Journal of Applied Earth Observation and Geoinformation 118 https://doi.org/10.1016/j.jag.2023.103265 (2023).
Li, Z. et al. Breaking the resolution barrier: A low-to-high network for large-scale high-resolution land-cover mapping using low-resolution labels. ISPRS Journal of Photogrammetry and Remote Sensing 192, 244–267, https://doi.org/10.1016/j.isprsjprs.2022.08.008 (2022).
Hansen, M. C. et al. High-resolution global maps of 21st-century forest cover change. Science 342, 850–853, https://doi.org/10.1126/science.1244693 (2013).
Shimada, M. et al. New global forest/non-forest maps from ALOS PALSAR data (2007–2010). Remote Sensing of Environment 155, 13–31, https://doi.org/10.1016/j.rse.2014.04.014 (2014).
Zhang, X. et al. Rapid generation of global forest cover map using Landsat based on the forest ecological zones. Journal of Applied Remote Sensing https://doi.org/10.1117/1.JRS.14.022211 (2020).
Zhang, X. et al. GLC_FCS30: global land-cover product with fine classification system at 30 m using time-series Landsat imagery. Earth System Science Data 13, 2753–2776, https://doi.org/10.5194/essd-13-2753-2021 (2021).
Yang, J. & Huang, X. The 30 m annual land cover dataset and its dynamics in China from 1990 to 2019. Earth System Science Data 13, 3907–3925, https://doi.org/10.5194/essd-13-3907-2021 (2021).
Chen, J. et al. Global land cover mapping at 30m resolution: A POK-based operational approach. ISPRS Journal of Photogrammetry and Remote Sensing 103, 7–27, https://doi.org/10.1016/j.isprsjprs.2014.09.002 (2015).
Zanaga, D. et al. (2021).
Jiao, W. et al. Specifications for the Ready-to-Use (RTU) geogrid product of remote sensing data. China Science Data 5, 4, https://doi.org/10.11922/csdata.2020.0028.zh (2020).
Long, T., Jiao, W., He, G., Wang, G. & Zhang, Z. Digital orthophoto map products and automated generation algorithms of Chinese optical satellites. National Remote Sensing Bulletin 27, 635–650, https://doi.org/10.11834/jrs.20232041 (2023).
Gong, P. et al. Stable classification with limited sample: transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Science Bulletin 64, 370–373, https://doi.org/10.1016/j.scib.2019.03.002 (2019).
Peng, X. et al. User-Aware Evaluation for Medium-Resolution Forest-Related Datasets in China: Reliability and Spatial Consistency. Remote Sensing 15 https://doi.org/10.3390/rs15102557 (2023).
Peng, X., He, G., Wang, G., Yin, R. & Wang, J. A Weakly Supervised Semantic Segmentation Framework for Medium-resolution Forest Classification with Noisy Labels and GF-1 WFV Images. IEEE Transactions on Geoscience and Remote Sensing https://doi.org/10.1109/TGRS.2024.3404953 (2024).
Olofsson, P. et al. Good practices for estimating area and assessing accuracy of land change. Remote Sensing of Environment 148, 42–57, https://doi.org/10.1016/j.rse.2014.02.015 (2014).
Peng, X. et al. FCM16: a forest cover map of China in 2020 created entirely from GF-1 WFV images. Zenodo https://doi.org/10.5281/zenodo.14043186 (2024).
Tsendbazar, N. et al. Towards operational validation of annual global land cover maps. Remote Sensing of Environment 266 https://doi.org/10.1016/j.rse.2021.112686 (2021).
Wang, M. et al. Assessing Landsat-8 and Sentinel-2 spectral-temporal features for mapping tree species of northern plantation forests in Heilongjiang Province, China. Forest Ecosystems 9 https://doi.org/10.1016/j.fecs.2022.100032 (2022).
Cao, Y. & Huang, X. A coarse-to-fine weakly supervised learning method for green plastic cover segmentation using high-resolution remote sensing images. ISPRS Journal of Photogrammetry and Remote Sensing 188, 157–176, https://doi.org/10.1016/j.isprsjprs.2022.04.012 (2022).
Yang, F. et al. Improved fine-scale tropical forest cover mapping for Southeast Asia using Planet-NICFI and Sentinel-1 imagery. Journal of Remote Sensing 3, 0064, https://doi.org/10.34133/remotesensing.0064 (2023).
Gómez, C., White, J. C. & Wulder, M. A. Optical remotely sensed time series data for land cover classification: A review. ISPRS Journal of Photogrammetry and Remote Sensing 116, 55–72, https://doi.org/10.1016/j.isprsjprs.2016.03.008 (2016).
Zhu, Z. et al. Optimizing selection of training and auxiliary data for operational land cover classification for the LCMAP initiative. ISPRS Journal of Photogrammetry and Remote Sensing 122, 206–221, https://doi.org/10.1016/j.isprsjprs.2016.11.004 (2016).
Collins, L., McCarthy, G., Mellor, A., Newell, G. & Smith, L. Training data requirements for fire severity mapping using Landsat imagery and random forest. Remote Sensing of Environment 245 https://doi.org/10.1016/j.rse.2020.111839 (2020).
Yang, F. & Zeng, Z. Refined fine-scale mapping of tree cover using time series of Planet-NICFI and Sentinel-1 imagery for Southeast Asia (2016–2021). Earth System Science Data 15, 4011–4021, https://doi.org/10.5194/essd-15-4011-2023 (2023).
Yang, R. et al. Weakly-semi supervised extraction of rooftop photovoltaics from high-resolution images based on segment anything model and class activation map. Applied Energy 361 https://doi.org/10.1016/j.apenergy.2024.122964 (2024).
Cheng, K. et al. Mapping China’s planted forests using high resolution imagery and massive amounts of crowdsourced samples. ISPRS Journal of Photogrammetry and Remote Sensing 196, 356–371, https://doi.org/10.1016/j.isprsjprs.2023.01.005 (2023).
Li, P. et al. Mapping planted forest age using LandTrendr algorithm and Landsat 5–8 on the Loess Plateau, China. Agricultural and Forest Meteorology 344, 109795, https://doi.org/10.1016/j.agrformet.2023.109795 (2024).
Acknowledgements
This research was supported by the Second Tibetan Plateau Scientific Expedition and Research Program (grant no. 2019QZKK030701), the Strategic Priority Research Program of the Chinese Academy of Sciences (grant no. XDA19090300), and the program of the National Natural Science Foundation of China (grant no.62101531, no. 61731022).
Author information
Authors and Affiliations
Contributions
X.P. and G.H. proposed and conceived the topic of this study. X.P. and G.H. wrote and edit the article. X.P., G.W., R.Y., R.Y. and Y.P. provided help in the data processing. X.P., Y.C. and J.W. provided help in validation. All authors analyzed the results. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Peng, X., He, G., Wang, G. et al. GF-1 WFV satellite images based forest cover mapping in China supported by open land use/cover datasets. Sci Data 11, 1355 (2024). https://doi.org/10.1038/s41597-024-04202-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-024-04202-2
