
Abstract
This study presents TOM500, a comprehensive multi-organ annotated orbital magnetic resonance imaging (MRI) dataset. It includes clinical data, T2-weighted MRI scans, and corresponding segmentations from 500 patients with thyroid eye disease (TED) during their initial visit. TED is a common autoimmune disorder with distinct orbital MRI features. Segmentations of nine orbital structures, including the optic nerve, orbital fat, lacrimal gland, eyeball, and five extraocular muscles (superior rectus and levator palpebrae superioris complex, inferior rectus, medial rectus, lateral rectus, and superior oblique), were generated by three junior annotators and reviewed by an expert radiologist. The consistency of the segmentations was evaluated using the intraclass correlation coefficient. Clinical data, including sex, age, disease duration, and smoking status, are also provided for disease diagnosis and classification. TOM500, the largest publicly available orbital MRI dataset with expert annotations, is designed to facilitate the development of advanced computational tools for TED diagnosis, classification, and observation.
Similar content being viewed by others
Background & Summary
Orbital magnetic resonance imaging (MRI) is an indispensable tool in the diagnosis and management of orbital diseases, particularly in the context of inflammatory conditions. Inflammatory orbital diseases, such as thyroid eye disease (TED), idiopathic orbital inflammation (IOI), and orbital cellulitis, present with distinct MRI characteristics1,2. In TED, MRI commonly shows enlarged extraocular muscles (EOMs) with increased T2-weighted signal intensity, indicative of edema3,4. IOI can manifest as diffuse or localized mass-like enhancement5, while orbital cellulitis often exhibits fat stranding and abscess formation4,6. Beyond inflammatory conditions, MRI is invaluable in detecting and characterizing other orbital pathologies, including neoplasms, vascular anomalies, and trauma, making it a cornerstone of comprehensive orbital assessment7.
Despite the central role of MRI in diagnosing orbital conditions, interpreting these images presents challenges, particularly due to the absence of a publicly available annotated orbital MRI database, which hampers clinical advancements and the development of fully automated algorithms. In orbital MRI, precise annotation of regions of interest (ROIs) is essential for accurate analysis. For example, in TED, the most common autoimmune orbital disorder, MRI characteristics differ as the disease progresses8,9. During the active inflammatory phase, MRI reveals enlarged extraocular muscles with high T2-weighted signal intensity due to edema3,10. In contrast, the chronic fibrotic phase shows persistent muscle enlargement with reduced signal intensity due to fibrosis, and sometimes orbital lipid hyperplasia10,11.
Accurate ROI annotation captures these pathological and physiological changes, such as increases in muscle volume, which are vital for radiomics quantification. This is particularly valuable in treatment planning, especially when using therapies like Teprotumumab, a monoclonal antibody targeting specific inflammatory pathways12,13. By quantifying muscle volume and monitoring changes over time, clinicians can assess therapy efficacy and tailor treatment plans more effectively. T2-weighted imaging (T2WI) is often preferred in TED assessment due to its superior ability to highlight edema, a key indicator of active inflammation, facilitating early diagnosis and timely intervention.
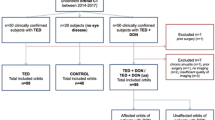
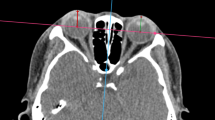
Furthermore, an annotated MRI dataset holds value beyond TED, as it provides a comprehensive reference for various orbital structures, especially soft tissues3. This dataset could also be adapted for use in non-TED patients through reinforcement learning techniques, expanding its utility in the field of research on orbital diseases. However, creating such large, annotated datasets for training and validating algorithms is labor-intensive, requiring extensive annotation efforts. Currently, only a few datasets are readily available for open usage, particularly for TED. This is primarily because such datasets can only be gathered and constructed in major clinical centers with large patient populations. Addressing this gap is fundamental for advancing research and enabling performance comparisons of segmentation, classification, and diagnostic algorithms. The panorama of our workflow proposed for dataset construction is illustrated in Fig. 1a below, while Fig. 1b highlights the specific orbital structures included in this process.

Flowchart of dataset construction and orbital structures a. the overall workflow of the dataset construction and statistical analysis; b. 2d and 3d illustration of orbital structures. Abbreviations: SR = superior rectus (and levator palpebrae superioris complex), SO = superior oblique, LG = lacrimal gland, ON = optic nerve, LR = lateral rectus, MR = medial rectus, EB = eyeball, OF = orbital fat, IR = inferior rectus.
In this study, we propose TOM500 (TED Orbital MRI with 500 cases). TOM500 provides a multi-organ annotated orbital T2WI dataset, including 500 cases of TED patients, along with basic clinical characteristics. The dataset provides resources to support future developments in the diagnosis of orbital diseases and the segmentation of orbital structures. Additionally, this dataset establishes a referable paradigm for future datasets of normal orbital data and other orbital diseases.
Methods
MRI Data
Overall
A total of 500 cases were included in this dataset, with a resolution of 512 × 512 × 20. All images were stored with a bit depth of 12 in NIFTI format.
Participants
At their initial visit, clinical and radiological data from 500 anonymous patients with clinically confirmed TED14 were collected at Shanghai Ninth People’s Hospital between June 2016 and January 2021. The inclusion criteria were as follows: (1) Patients without complex systemic diseases or other orbital conditions; (2) High-quality MRI images adequate for analysis; (3) No history of orbital surgery or trauma. This manuscript adheres to STROBE guidelines. The study was approved by our Institutional Review Board (SH9H-2021-T246-2), and the requirement for informed consent was waived.
MRI data acquisition
Patients were examined using a 3.0 T MRI system (Ingenia, Philips Medical Systems) with a 32-channel head coil. During the scan, patients were positioned in the supine position with their eyes closed. Coronal T2-weighted Turbo Spin-Echo with 90° Flip-Back Pulse (T2-DRIVE) imaging was acquired with the following parameters: repetition time/echo time, 3000 ms/90 ms; image frequency, 127.77 MHz; field of view, 133.33 mm; slice thickness, 3.5 mm; spacing between slices, 3.85 mm; pixel spacing, 0.3125 × 0.3125 mm; acquisition matrix, 320 × 242.
Anonymization
All patient-identifiable data have been removed to ensure privacy protection and, therefore, were not included in this dataset.
Data preprocessing
Minimal preprocessing with linear normalization was performed using the existing rescale intercept (0028∣1052) and rescale slope (0028∣1053). These parameters define the linear transformation from the stored pixel values to the output pixel values in radiological imaging. This transformation can be expressed by the following equation:
where:
U is the output value in the desired units,
m is the rescale slope,
SV is the stored value of the pixel, and
b is the rescale intercept.
Annotation
ROIs were manually segmented on coronal T2WI images using ITK-SNAP software (v. 3.6.0; http://www.itksnap.org). Nine orbital structures, including the optic nerve (ON), orbital fat (OF), lacrimal gland (LG), eyeball (EB), and the separate extraocular muscles (EOMs): superior rectus (SR) (and levator palpebrae superioris complex), inferior rectus (IR), medial rectus (MR), lateral rectus (LR), and superior oblique (SO), were individually contoured using different labels. The contours of each ROI were drawn slice-by-slice, from the emergence of the OF in the anterior orbit to the disappearance of the EOMs in the posterior orbit. For all manual segmentations, three junior orbital radiologists reviewed each MRI and conducted ROI segmentations without knowing the disease status of the participants. Their annotations were fused into one using the Simultaneous Truth and Performance Level Estimation (STAPLE) algorithm and further reviewed by an orbital radiology expert for accuracy. STAPLE performs a pixel-wise combination of multiple input images, each representing a segmentation of the same scene15,16,17. The labelings in these images are weighted relative to each other based on performance estimated by an expectation-maximization algorithm. Through this process, a ground truth segmentation is estimated, and the performance of individual segmentations is evaluated relative to this ground truth. The algorithm iterates until it converges on the quality parameters that maximize the log-likelihood function:
where:
p(k), q(k) are the estimates of the expert performance level parameters at iteration k,
D is the matrix describing the binary decisions made for each segmentation at each voxel of the image,
T is the hidden binary true segmentation, and
p(k−1), q(k−1) are the previous estimates of the expert quality parameters.
The fused annotation was reviewed and, if necessary, modified by a radiology expert.
Data Records
TOM50018 is available in the public repository at https://doi.org/10.6084/m9.figshare.27133389. The dataset was released in September 2024, and any future updates will be published with the corresponding release dates. The dataset follows the directory/file structure outlined below:
The ‘image’ folder within the ‘train’ directory contains images from 400 cases, while the ‘image’ folder within the ‘val’ directory contains images from 100 cases. The ‘label’ folders within both the ‘train’ and ‘val’ directories contain ground truth annotations, which were initially reviewed by three junior annotators and subsequently validated by an expert. All files follow a consistent naming convention: ‘[patient id].nii.gz’. The files are in the same format, ensuring better compatibility across devices, making them more suitable for machine learning algorithms and data processing.
Technical Validation
For analysis, the STAPLE and reviewed ground truth were derived from all annotations. The Dice (D), Jaccard (J), sensitivity (Se), specificity (Sp), precision (Pr), recall (Re), and accuracy (Ac) similarity indices are standard objective measures used to quantify image segmentation performance19. These indices are computed based on true positives (TP), false positives (FP), false negatives (FN), and true negatives (TN)20. Sensitivity (or true positive rate) is defined as the proportion of true positives correctly identified21,22. Specificity (or true negative rate) is defined as the proportion of true negatives correctly identified21. Accuracy measures the degree of closeness between the segmentation and the ground truth. The performance indices are computed as follows:
Sensitivity can be misleading, especially in cases of poor segmentation where the segmented area is much larger than the ground truth23,24. Therefore, specificity serves as a necessary counterpart to sensitivity. However, in cases of poor segmentation that fail to detect the region of interest (ROI), which may still yield a perfect specificity value, we further analyze the data using the Jaccard and Dice indices. The Jaccard similarity index is the ratio of the intersection to the union of the predicted and true regions. The Dice similarity index is closely related to the Jaccard index, with one being derivable from the other25. These indices are defined as follows:
where A and Gt represent the ROI segmented by the annotator and the ground truth, respectively. By definition, 0 ≤ J ≤ 1 and 0 ≤ D ≤ 1.
Reviewer-wise segmentation variability analysis, with respect to the STAPLE ground truth and the reviewed ground truth, is presented in Table 1, using the performance indices mentioned above. Linear least-squares regression was employed for visualization (Fig. 2a,b).

Linear least-squares regression figures of segmentation performance a. STAPLE ground truth versus reviewers’ annotation; b. Reviewed ground truth versus reviewers’ annotation.
We acquired the average signal intensities of all ten structures involved (including nine orbital structures and the background), along with their volumes. The data were then analyzed using the intraclass correlation coefficient (ICC), with the results presented in Table 2. The ICC is a measure of measurement reliability, with a 95% confidence interval26. The closer the ICC is to 1.0, the stronger the linear relationship between two methods for the same measurement27. The results show satisfactory outcomes, with all ICCs exceeding 0.95.
Clinical characteristics
Among the 500 enrolled cases, 167 (33.4%) were male and 333 (66.6%) were female, yielding a sex ratio (female to male) of 2:1. The median age was 48 years, consistent with previous epidemiological studies28,29,30. With a median disease duration of 10 months, 77.8% of the cases were non-smokers. Further details can be found in Table 3.
Usage Notes
The TOM500 dataset includes clinical data, T2WI scans, and corresponding segmentations. These resources are intended for use by healthcare professionals in ophthalmology and researchers developing computational tools, such as those for patient diagnosis from T2WI images, orbital structure segmentation, or data augmentation. The authors encourage readers to explore a wide range of methods for image enhancement and data analysis using the provided dataset. The dataset is optimized for machine processing, with all analyses conducted in Python using standard libraries such as NumPy, Pandas, and scikit-learn. Maintaining resolution and bit depth is recommended to ensure reliable results. A suggested dataset split is also provided to promote consistency. The code implementing each processing step is presented in Table 4.
Code availability
The code is available under CC0 licensing on GitHub and is accompanied by anonymized patient information in CSV format. For data analysis and validation, Python version 3.9 was used. The dataset was released in September 2024. Any future updates to the database will be published with their respective release dates.
References
Zhou, M. et al. Role of Magnetic Resonance Imaging in the Assessment of Active Thyroid-Associated Ophthalmopathy Patients with Long Disease Duration. Endocrine Practice 25, 1268–1278 (2019).
Yokoyama, N., Nagataki, S., Uetani, M., Ashizawa, K. & Eguchi, K. Role of Magnetic Resonance Imaging in the Assessment of Disease Activity in Thyroid-Associated Ophthalmopathy. Thyroid 12, 223–227 (2002).
Kahaly, G. J. Imaging in thyroid-associated orbitopathy. European Journal of Endocrinology 145, 107–118 (2001).
Pakdaman, M. N., Sepahdari, A. R. & Elkhamary, S. M. Orbital inflammatory disease: Pictorial review and differential diagnosis. World J Radiol 6, 106–115 (2014).
Ding, Z. X., Lip, G. & Chong, V. Idiopathic orbital pseudotumour. Clinical Radiology 66, 886–892 (2011).
Diogo, M. C., Jager, M. J. & Ferreira, T. A. CT and MR Imaging in the Diagnosis of Scleritis. American Journal of Neuroradiology 37, 2334–2339 (2016).
Yuan, Y., Kuai, X.-P., Chen, X.-S. & Tao, X.-F. Assessment of dynamic contrast-enhanced magnetic resonance imaging in the differentiation of malignant from benign orbital masses. European Journal of Radiology 82, 1506–1511 (2013).
Lo, C., Ugradar, S. & Rootman, D. Management of graves myopathy: Orbital imaging in thyroid-related orbitopathy. Journal of American Association for Pediatric Ophthalmology and Strabismus 22, 256.e1–256.e9 (2018).
Zhang, H. et al. Application of Quantitative MRI in Thyroid Eye Disease: Imaging Techniques and Clinical Practices. Journal of Magnetic Resonance Imaging 60, 827–847 (2024).
Tortora, F. et al. Disease Activity in Graves’ Ophthalmopathy: Diagnosis with Orbital MR Imaging and Correlation with Clinical Score. The Neuroradiology Journal 26, 555–564 (2013).
Kirsch, E., Hammer, B. & von, A. Graves’orbitopathy: current imaging procedures. Swiss Medical Weekly 139, 618–618 (2009).
Douglas, R. S. et al. Teprotumumab for the Treatment of Active Thyroid Eye Disease. New England Journal of Medicine 382, 341–352 (2020).
Jain, A. P. et al. Teprotumumab reduces extraocular muscle and orbital fat volume in thyroid eye disease. British Journal of Ophthalmology 106, 165–171 (2022).
Bartalena, L. et al. The 2021 European Group on Graves’ orbitopathy (EUGOGO) clinical practice guidelines for the medical management of Graves’ orbitopathy. European Journal of Endocrinology 185, G43–G67 (2021).
Warfield, S., Zou, K. & Wells, W. Validation of image segmentation and expert quality with an expectation-maximization algorithm. in MEDICAL IMAGE COMPUTING AND COMPUTER-ASSISTED INTERVENTION-MICCAI 2002, PT 1 (eds. Dohi, T. & Kikinis, R.) 2488, 298–306 (2002).
Warfield, S. K., Zou, K. H. & Wells, W. M. Simultaneous truth and performance level estimation (STAPLE): an algorithm for the validation of image segmentation. IEEE Transactions on Medical Imaging 23, 903–921 (2004).
Rohlfing, T., Russakoff, D. B. & Maurer, C. R. Performance-based classifier combination in atlas-based image segmentation using expectation-maximization parameter estimation. IEEE Transactions on Medical Imaging 23, 983–994 (2004).
Zhang, H. et al. TOM500: A Multi-Organ Annotated Orbital MRI Dataset for Thyroid Eye Disease. figshare https://doi.org/10.6084/m9.figshare.27133389 (2024).
Wang, Z., Wang, E. & Zhu, Y. Image segmentation evaluation: a survey of methods. Artificial Intelligence Review 53, 5637–5674 (2020).
Chang, H.-H., Zhuang, A. H., Valentino, D. J. & Chu, W.-C. Performance measure characterization for evaluating neuroimage segmentation algorithms. NeuroImage 47, 122–135 (2009).
Taha, A. A. & Hanbury, A. Metrics for evaluating 3D medical image segmentation: analysis, selection, and tool. BMC Medical Imaging 15, 29 (2015).
Lukac, P. et al. Simple comparison of image segmentation algorithms based on evaluation criterion. in Proceedings of 21st International Conference Radioelektronika 2011 1–4 (2011).
Dey, N., Rajinikanth, V., Ashour, A. S. & Tavares, J. M. R. S. Social Group Optimization Supported Segmentation and Evaluation of Skin Melanoma Images. Symmetry 10, (2018).
Chouhan, S. S., Kaul, A. & Singh, U. P. Soft computing approaches for image segmentation: a survey. Multimedia Tools and Applications 77, 28483–28537 (2018).
Garcia-Lamont, F., Cervantes, J., López, A. & Rodriguez, L. Segmentation of images by color features: A survey. Neurocomputing 292, 1–27 (2018).
Shrout, P. E. & Fleiss, J. L. Intraclass correlations: Uses in assessing rater reliability. Psychological Bulletin 86, 420–428 (1979).
Rousson, V. Assessing inter-rater reliability when the raters are fixed: Two concepts and two estimates. Biometrical Journal 53, 477–490 (2011).
Jaru-Ampornpan, P., Cheng, Y., Jiao, Q. & Douglas, R. S. Thyroid eye disease in Asians and recent advances in management. Chinese journal of endocrinology and metabolism 36, 541–562 (2020).
Tsai, C.-C., Kau, H.-C., Kao, S.-C. & Hsu, W.-M. Exophthalmos of patients with Graves’ disease in Chinese of Taiwan. Eye 20, 569–573 (2006).
Lim, S. L. et al. Prevalence, Risk Factors, and Clinical Features of Thyroid-Associated Ophthalmopathy in Multiethnic Malaysian Patients with Graves’ Disease. Thyroid 18, 1297–1301 (2008).
Acknowledgements
This work was supported by the National Natural Science Foundation of China (82388101 and 81930024); the Science and Technology Commission of Shanghai (20DZ2270800); and the Shanghai Key Clinical Specialty, Shanghai Eye Disease Research Center (2022ZZ01003).
Author information
Authors and Affiliations
Contributions
H.Y.Z., H.F.Z., X.Q.F., and X.F.S. contributed to the overall conception and design development. H.Y.Z., H.C.C., M.D.J., and X.F.T. were responsible for data collection and interpretation. H.C.C. and J.S.X. proofread the data. H.C.C. and J.S.X. performed data analysis. H.Y.Z., H.C.C. and J.S.X. completed the manuscript drafting. M.D.J., X.F.T., X.F.S., X.Q.F., and H.F.Z. edited and reviewed the manuscript. All authors read, discussed, and approved the final version of the manuscript. All authors had full access to the data in the study and take responsibility for the integrity of the data and the accuracy of the data analysis, as well as the decision to submit this manuscript for publication.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, H., Chan, H.C., Xu, J. et al. TOM500: A Multi-Organ Annotated Orbital MRI Dataset for Thyroid Eye Disease. Sci Data 12, 60 (2025). https://doi.org/10.1038/s41597-025-04427-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-04427-9
