
Abstract
The question of what processes can take place without conscious awareness has generated extensive research. Yet there is still no consensus regarding the extent and scope of unconscious processing, and past research abounds with conflicting results. A possible reason for this lack of consensus is the diversity of methods in the field, as the methodological choices might influence the results. Thus far, such possible influence of methods, measures, and analyses has not been systematically investigated and mapped. Here, we present the UnconTrust database for studies of unconscious processing focusing on two major domains – semantic and attentional processing. The database allows researchers to explore potential influences and obtain a bird’s eye view on the field with respect to these domains. Currently, the database includes information about the methods and findings of 426 experiments (though notably, the data collected in these experiments is not included). The database is also presented as an interactive website.
Similar content being viewed by others


Background & Summary
The question of what processes can take place without conscious awareness has generated extensive research (for reviews, see1,2,3,4,5). Yet despite this ongoing effort, the field has yet to converge on an agreed-upon account regarding the extent and scope of unconscious processing6. While some researchers argue for high-level, extensive unconscious processing7,8 others claim that it is rather limited9,10.
These highly divergent conclusions reflect the difficulty of integrating the accumulated data into a cohesive account. The results abound with discrepancies, which might stem from the great variability in the methods used in the field. These different methodologies have been suggested to yield differential results11,12,13,14,15. Indeed, when examining a related field within consciousness science – namely, support for neuroscientific theories of consciousness16 – our group has recently showed that the methodological choices researchers make can predict the conclusions of their study, even when the results of the experiments are unknown to the predicting algorithm17. We accordingly hold that the field of unconscious processing will greatly benefit from being able to examine the methodological choices taken by researchers and explore their potential effect on the results of studies.
Here, we present the UnconTrust database (https://osf.io/2jgsx; see also http://uncontrustdb.tau.ac.il)18 for studies exploring semantic processing of, and attentional capture by, stimuli that are not consciously perceived. The database allows researchers to obtain a bird’s eye view on the field with respect to these domains, and better understand the way processing of such stimuli has been empirically studied. With 426 experiments currently included, the database is a valuable asset for researchers who are interested in unconscious processes. It provides a useful overview of the research questions and methods of the field of unconscious processing. As such, it constitutes a new meta-scientific tool that can be used in many ways to get a sense of the methods in the field.
The dataset includes information about the methods and research questions of experiments probing unconscious processing, pertaining to the features like the way conscious perception has been manipulated and measured, the type of unconscious processes probed, the sample size, and analysis choices (e.g., trial and participant exclusion). At the time of writing, the included experiments are based on classifications collected as part of two unpublished meta-analyses, focusing on semantic processing and attention allocation without awareness. As a result, it currently only includes data from healthy human adult participants and focuses on behavioral evidence for processing of stimuli that are not consciously perceived. It also misses other types of unconscious processing (e.g., emotional, perceptual). However, we plan to gradually add those types, as well as incorporate additional sample types (e.g., children, animals) and data (e.g., neuroscientific); This expansion will be conducted both by systematically search for studies of unconscious affective processing and of learning without awareness, and also by extracting the data from new papers exploring unconscious processing, which will be routinely uploaded to the interactive website where the data is stored (see Usage Notes for more information on the website). Note also that because the database focuses on studies investigating processing of stimuli that are not consciously perceived, it does not include experiments on implicit learning, where participants are aware of the stimuli, but not of the influence that these stimuli have on their behavior (for reviews, see19,20,21,22,23). Yet already at this point, UnconTrust is the largest, most comprehensive dataset with meta-data and classifications of studies of unconscious processes, which are Findable, Accessible, Interoperable and Reusable (FAIR24). Below we describe the current dataset and the methods for creating it.
Methods
The data for the database has originally been gathered for the purpose of conducting two meta-analyses: the first focused on attentional capture by visual stimuli which are not consciously perceived and the second on semantic processing of such stimuli. Below we detail the process of collecting the data for both and then the process of preparing the dataset for the purpose of the UnconTrust database.
Information sources and search strategy
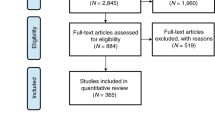
Included papers were detected in two ways (see Fig. 1). First, database searches were conducted in PsycInfo (for both meta-analyses) and also in Medline (for the semantic processing meta-analysis), Embase, Scopus and PubMed (for the attentional meta-analysis). Search strategies and key terms were developed by research librarians with expertise in systematic searching. With their help, the team composed a sensitive search utilizing keywords and subject headings for the databases. The search terms included strings that (1) limited the search to consciousness studies, specifying relevant stimuli and methods; (2) limited the search only to English language published papers, including ones in press; (3) filtered out any papers unrelated to psychology or neuroscience; (4) removed studies in which the participants were non-human or non-adult (for the full list of terms, see Appendix 1). Publication dates were defined to include papers from inception to December 2020 (for the semantic processing meta-analysis) or June 2020 (for the attentional meta-analysis).

PRISMA flow diagram of the process of selecting papers for (a) the meta-analysis of unconscious attentional processing; and (b) and the semantic meta-analysis of unconscious semantic processing, based on Page, et al.42. (license: https://creativecommons.org/licenses/by/4.0/).
Second, we went over previously published meta-analyses25,26,27 and review papers1,28,29,30,31,32,33,34,35,36,37, and included all relevant papers. We further scrutinized all studies citing those meta-analyses and reviews to detect potentially missing papers; if such papers were detected, they were added to the list of papers that underwent the screening process.
Data management and screening process
The screening of the papers was conducted in two stages. Title and abstract screening to identify potentially eligible records was performed using the systematic reviews web apps Covidence and Rayyan QCRI. At this stage, papers in doubt were included (see Fig. 1). This stage was conducted by FS for the attentional meta-analysis (with only the first 100 records screened also by another coder), and by MS for the semantic meta-analysis.
For the semantic meta-analysis (Fig. 1b), there was an additional step; In the first stage, where the initial pool of identified papers was screened for relevance by title and abstract, we casted a wider net, and identified studies potentially involving unconscious processing in general. Out of these papers, we then focused on papers including the following keywords which are related to semantic processing: semantic, semantic processing, meaning, semantical, semantically, semantic priming, translation, synonym, lexical and reading. The papers that were chosen underwent a subsequent title and abstract screening aimed to remove all papers not involving semantic processing.
For both meta-analyses, after the initial screening of irrelevant papers, a second screening took place, where the remaining papers were subjected to full-text screening. This screening was conducted independently by two coders. At this stage, it was decided whether each paper would be included in the meta-analysis. Any disagreements were discussed, and if needed, resolved in a discussion with LM.
This second screening was based on the following eligibility criteria: (a) Design: Original studies (not re-analyses of already published data) that were controlled and randomized; (b) Participants: Healthy human adults (18 years or older). Studies that featured other samples as well (such as children, animals, etc.) were only included if the data for the two groups had been provided separately; (c) Interventions: All experiments that measured either variations in allocation of attentional resources to visual stimuli in the absence of awareness, or the influence of the meaning of unconsciously presented stimuli on behavioral response. Absence of awareness had to be established by some measure of awareness. (d) Comparators: In cases where participants were reportedly unaware of the stimuli, we compared behavioral measures between the critical experimental conditions; (e) Outcomes: Experiments where the measure chosen for the processing is behavioral (e.g., reaction times, accuracy, eye movements); (f) Language and publication date: All relevant studies published in English since inception to December 2020 (for the semantic processing meta-analysis) or June 2020 (for the attentional meta-analysis); (g) Publication status: Any study, published in a peer-reviewed journal, that was found eligible according to the above-mentioned criteria.
Data collection process
Data extraction forms were completed in parallel by two coders. Discrepancies between the forms were resolved together with LM. From each paper, the following information was retrieved: The paradigm; the suppression method used to render stimuli unconscious; the measure for awareness; the power of objective measure for awareness; the type, size and duration of the stimuli; the processing domain; the measures outcome; and the task participants are asked to perform. In order to compute effect sizes and variance and to interpret the results, the following variables were also extracted: experimental design, key statistical results, and the reported statistics. When studies included more than one experiment, we coded these variables independently for each experiment. Appendix 2 describes further information about the variables in the extraction forms, their definitions and their theoretical justifications.
Dataset preparation
For the data to be accessible, interoperable and reusable, we combined the two datasets (collected separately for each meta-analysis) into one and unified the coding and structure conventions. As a first step, we defined a list of variables and possible levels that should be included for each experiment in the database (see Data records below). As not all variables were coded in both original datasets, we completed missing values.
Data Records
The data is stored in an independent repository (https://osf.io/2jgsx)18 and also in an interactive website (see Usage Notes).
For each paper, meta-data has been collected (i.e., the authors of the paper, the country in which the study took place, the journal in which the paper was published). In addition, the database contains detailed information we extracted regarding various aspects of experiments in the field: which paradigm was used in the experiment (for the entire list of values, see Table 1); information about the samples (Table 2); which tasks participants were asked to perform (Table 3); information about the stimuli used in the experiment (e.g., Tables 4, 5); which suppression method was used in order to present stimuli without them being perceived consciously (Table 6); what was the processing domain of the suppressed stimuli (Table 7); information regarding the awareness measures used to demonstrate unawareness of the suppressed stimuli (Table 8), and information regarding the experiment’s findings (i.e., which behavioral outcome was measured to assess the unconscious processing; Table 9). Note that the levels could be expanded to encompass new values based on added papers.
Technical Validation
The data acquired so far was validated by peer-reviewing and a double classification procedure, in line with the recommended practices for meta-analyses38. For each experiment, the classifications were extracted by two independent coders and were then compared (see methods section above). Any disagreements were resolved in consultation with LM. In addition, the structure of the database, the inclusion criteria and the scope were approved by a steering committee that includes, in addition to the authors of this paper, leading researchers in the field (see acknowledgements). The committee thus served as an additional monitoring and validation mechanism.
To further validate the data, we performed some sanity check analyses, whose results are reported below. These were aimed at (1) making sure that most experiments used the masking procedure39, followed by Continuous Flash Suppression40. This expectation was based on the literature2,13,41; (2) validating that the probed processes relate to either semantic processing (of different types) or to attention allocation, in line with the proclaimed goals of the meta-analyses on which this database is based; (3) demonstrating that we find compatible values when the data is analyzed in two different ways; and (4) that we have a good coverage of the journals in which papers in this topic are typically published. Figure 2 describes the results of all these sanity check analyses, which confirmed that the data indeed complies with our expectations, providing further validation for its integrity.

Sanity check analyses conducted to validate the database. (a) Masking is the most used procedure for rendering stimuli invisible, followed by Continuous Flash Suppression. (b) As expected, the experiments probe different types of semantic processing (lingual, visual and numerical), followed by attention allocation experiments. (c) A comparison of the types of experiments confirms the integrity of the data: both analyses reveal 319 experiments reporting positive effects, 113 reporting negative, and 37 experiments reporting mixed. (d) A distribution of the experiments to journals. This nicely shows that the database covers all the expected journals in the field (and some non-professional ones).
Importantly, we also established a validation procedure for new data that will be added to the database by future users. Each new entry will be vetted by at least one member of the steering committee. In addition, if the entry has not been added by the authors of the publication, we will send the classification to the authors for validation and approval.
Usage Notes
The database18 is hosted on an interactive website (http://uncontrustdb.tau.ac.il) that allows researchers to generate their own queries, to explore methodological trends in unconscious processing research, to examine co-occurrence of certain methodological decisions, to inspect how the results might be modulated by the methodological choices of the researchers and to upload their own papers to the database. If successful, it could serve as a blueprint for the development of similar initiatives in other fields where researchers would benefit from tools that enable an easy exploration of methodological choices. Thus, with time, the files downloaded there will include more papers beyond those reported here.
Code availability
All code used for the construction of the website is available on GitHub (https://github.com/Mudrik-Lab/Contrast2).
References
Kouider, S. & Dehaene, S. Levels of processing during non-conscious perception: A critical review of visual masking. in Philosophical Transactions of the Royal Society B: Biological Sciences. https://doi.org/10.1098/rstb.2007.2093 (2007).
Mudrik, L., & Deouell, L. Y. Neuroscientific evidence for processing without awareness. Annual review of neuroscience, 45(1), 403–423, https://doi.org/10.1146/annurev-neuro-110920-033151 (2022).
Van Gaal, S. & Lamme, V. A. F. Unconscious high-level information processing: Implication for neurobiological theories of consciousness. Neuroscientist 18. https://doi.org/10.1177/1073858411404079 (2012).
Sterzer, P., Stein, T., Ludwig, K., Rothkirch, M. & Hesselmann, G. Neural processing of visual information under interocular suppression: A critical review. Frontiers in Psychology 5. https://doi.org/10.3389/fpsyg.2014.00453 (2014).
Tsikandilakis, M., Bali, P., Derrfuss, J. & Chapman, P. The unconscious mind: From classical theoretical controversy to controversial contemporary research and a practical illustration of the “error of our ways”. Consciousness and Cognition 74, https://doi.org/10.1016/j.concog.2019.102771 (2019).
Berger, J. & Mylopoulos, M. On scepticism about unconscious perception. Journal of Consciousness Studies (2019).
Hassin, R. R. Yes It Can: On the Functional Abilities of the Human Unconscious. Perspectives on Psychological Science 8 (2013).
Velmans, M. Understanding consciousness. 2 edn (Routledge, 2009).
Loftus, E. F. & Klinger, M. R. Is the unconscious smart or dumb? American Psychologist 47 (1992).
Newell, B. R. & Shanks, D. R. Unconscious influences on decision making: A critical review. Behavioral and Brain Sciences 37, https://doi.org/10.1017/S0140525X12003214 (2014).
Rothkirch, M. & Hesselmann, G. What we talk about when we talk about unconscious processing - A plea for best practices. Front Psychol 8, 1–6 (2017).
Dubois, J. & Faivre, N. Invisible, but how? The depth of unconscious processing as inferred from different suppression techniques. Front Psychol 5 (2014).
Breitmeyer, B. G. Psychophysical ‘blinding’ methods reveal a functional hierarchy of unconscious visual processing. Conscious Cogn https://doi.org/10.1016/j.concog.2015.01.012 (2015).
Peremen, Z. & Lamy, D. Comparing unconscious processing during continuous flash suppression and meta-contrast masking just under the limen of consciousness. Front Psychol 5, 969 (2014).
Wernicke, M. & Mattler, U. Masking procedures can influence priming effects besides their effects on conscious perception. Consciousness and Cognition: An International Journal 71, 92–108 (2019).
Seth, A. K. & Bayne, T. Theories of consciousness. Nature Reviews Neuroscience 23, 439–452 (2022).
Yaron, I., Melloni, L., Pitts, M. & Mudrik, L. The ConTraSt database for analysing and comparing empirical studies of consciousness theories. Nat Hum Behav 6, 593–604 (2022).
Schreiber, M., Mudrik, L. & Stockart, F. The UnconTrust Database. OSF. https://doi.org/10.17605/OSF.IO/V4ND5 (2024).
Williams, J. N. The Neuroscience of Implicit Learning. Lang Learn 70 (2020).
Shanks, D. R. & St. John, M. F. Characteristics of dissociable human learning systems. Behavioral and Brain Sciences 17 (1994).
Moran, T., Nudler, Y. & Bar-Anan, Y. Evaluative Conditioning: Past, Present, and Future. Annual Review of Psychology 74, https://doi.org/10.1146/annurev-psych-032420-031815 (2023).
Giménez-Fernández, T., Luque, D., Shanks, D. R. & Vadillo, M. A. Rethinking Attentional Habits. Curr Dir Psychol Sci 32 (2023).
Dai, W. et al. Priming Behavior: A Meta-Analysis of the Effects of Behavioral and Nonbehavioral Primes on Overt Behavioral Outcomes. Psychol Bull 149 (2023).
Wilkinson, M. D. et al. Comment: The FAIR Guiding Principles for scientific data management and stewardship. Sci Data 3 (2016).
Hedger, N., Gray, K. L. H., Garner, M. & Adams, W. J. Are visual threats prioritized without awareness? A critical review and meta-analysis involving 3 behavioral paradigms and 2696 observers. Psychol Bull 142, 934–968 (2016).
Snodgrass, M., Bernat, E. & Shevrin, H. Unconscious perception at the objective detection threshold exists. Perception and Psychophysics https://doi.org/10.3758/BF03194982 (2004).
Van den Bussche, E., Van den Noortgate, W. & Reynvoet, B. Mechanisms of Masked Priming: A Meta-Analysis. Psychol Bull https://doi.org/10.1037/a0015329 (2009).
Chica, A. B. & Bartolomeo, P. Attentional routes to conscious perception. Front Psychol 3, 1–12 (2012).
Cohen, M. A., Cavanagh, P., Chun, M. M. & Nakayama, K. The attentional requirements of consciousness. Trends Cogn Sci 16, 411–417 (2012).
Faivre, N., Berthet, V. & Kouider, S. Sustained invisibility through crowding and continuous flash suppression: A comparative review. Frontiers in Psychology 5, https://doi.org/10.3389/fpsyg.2014.00475 (2014).
Hirschhorn, R., Kahane, O., Gur-Arie, I., Faivre, N. & Mudrik, L. Windows of Integration Hypothesis Revisited. Frontiers in Human Neuroscience 14, https://doi.org/10.3389/fnhum.2020.617187 (2021).
Koch, C. & Tsuchiya, N. Attention and consciousness: two distinct brain processes. Trends Cogn Sci 11, 16–22 (2007).
Ludwig, D. The functions of consciousness in visual processing. Neurosci Conscious 2023 (2023).
Marchetti, G. Against the view that consciousness and attention are fully dissociable. Front Psychol 3, 1–14 (2012).
Mudrik, L., Faivre, N. & Koch, C. Information integration without awareness. Trends in Cognitive Sciences 18, https://doi.org/10.1016/j.tics.2014.04.009 (2014).
Noah, S. & Mangun, G. R. Recent evidence that attention is necessary, but not sufficient, for conscious perception. Ann N Y Acad Sci 1464, 52–63 (2020).
Van Boxtel, J. J. A., Tsuchiya, N. & Koch, C. Consciousness and attention: On sufficiency and necessity. Frontiers in Psychology https://doi.org/10.3389/fpsyg.2010.00217 (2010).
Cooper, H., Hedges, L. V. & Valentine, J. C. The Handbook of Research Synthesis and Meta-Analysis 2nd Edition. The Hand. of Res. Synthesis and Meta-Analysis, 2nd Ed. (2009).
Breitmeyer, B. & Ogmen, H. Visual Masking: Time Slices Through Conscious and Unconscious Vision. Visual Masking: Time Slices Through Conscious and Unconscious Vision. https://doi.org/10.1093/acprof:oso/9780198530671.001.0001 (2010).
Tsuchiya, N. & Koch, C. Continuous flash suppression reduces negative afterimages. Nat Neurosci 8, 1096–1101 (2005).
Kim, C. Y. & Blake, R. Psychophysical magic: Rendering the visible ‘invisible’. Trends in Cognitive Sciences https://doi.org/10.1016/j.tics.2005.06.012 (2005).
Page, M. J. et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. The BMJ 372, https://doi.org/10.1136/bmj.n71 (2021).
Acknowledgements
This project is made possible through the support of a grant from the Canadian Institute for Advanced Research (CIFAR; CF-0431 - CP24-072) and a grant from Templeton World Charity Foundation, Inc (TWCF0608). The opinions expressed in this publication are those of the author(s) and do not necessarily reflect the views of Templeton World Charity Foundation. We thank Ned Block, Axel Cleeremans, Stephen Fleming, Dominique Lamy, Lucia Melloni, Megan Peters, and Anil Seth, who serve on the website’s steering committee. We are also in debt to Itay Yaron, who created the ConTraSt database, which inspired the current work. We also want to thank all the coders of the data: Eden Elbaz, Tomer Nadiv, Shaked Lublinsky, Adi Sarig, Shai Fischer and Oded Hirsch. Finally, we thank Drorsoft company for creating the website.
Author information
Authors and Affiliations
Contributions
Conceptualization: M.S., F.S., L.M. Data curation: M.S., F.S. Formal analysis: M.S., F.S. Funding acquisition: L.M. Investigation: M.S., F.S. Methodology: M.S., F.S., L.M. Project administration: L.M. Resources: L.M. Software: M.S., F.S. Supervision: L.M. Validation: M.S., F.S., L.M. Visualization: M.S., F.S., L.M. Writing – original draft: MS. Writing – review & editing: F.S., L.M.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Schreiber, M., Stockart, F. & Mudrik, L. The UnconTrust Database for Studies of Unconscious Semantic Processing and Attentional Allocation. Sci Data 12, 157 (2025). https://doi.org/10.1038/s41597-025-04465-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-04465-3
