
Abstract
Minimally invasive image-guided surgery heavily relies on vision. Deep learning models for surgical video analysis can support surgeons in visual tasks such as assessing the critical view of safety (CVS) in laparoscopic cholecystectomy, potentially contributing to surgical safety and efficiency. However, the performance, reliability, and reproducibility of such models are deeply dependent on the availability of data with high-quality annotations. To this end, we release Endoscapes2023, a dataset comprising 201 laparoscopic cholecystectomy videos with regularly spaced frames annotated with segmentation masks of surgical instruments and hepatocystic anatomy, as well as assessments of the criteria defining the CVS by three trained surgeons following a public protocol. Endoscapes2023 enables the development of models for object detection, semantic and instance segmentation, and CVS prediction, contributing to safe laparoscopic cholecystectomy.
Similar content being viewed by others
Background & Summary
Image-guided procedures such as laparoscopic, endoscopic, and radiological interventions heavily rely on imaging1. Such minimally-invasive approaches have shown significant value for patients and healthcare systems. However, the heuristic nature of human visual perception can lead to erroneous interpretations of endoscopic and radiological images, contributing to serious adverse events that were rarer during traditional, open surgery procedures2.
In laparoscopic cholecystectomy (LC), an abdominal surgical procedure performed by most surgeons, human heuristic tricks operators into believing that the funnel-shaped structure in continuity with the gallbladder is the cystic duct while, at times, it is in fact the common bile duct2. On these occasions, surgeons can unintentionally transect the common bile duct and thereby cause a major bile duct injury, an adverse event resulting in a threefold increase in mortality in 1 year as well as major costs for surgeons and healthcare systems3,4. To prevent this visual perceptual illusion causing 97% of major BDI2, in 1995, Strasberg et al. proposed the so-called critical view of safety (CVS) to conclusively identify the cystic duct5. Currently, all guidelines on safe LC recommend obtaining the CVS6,7,8; yet, the rate of BDI remains stable9. A potential reason for this discrepancy is that CVS assessment is qualitative and subject to observer interpretation10,11.
Over the past decade, surgical data science12,13 teams from academia as well as from industry have been actively developing deep learning models for safe laparoscopic cholecystectomy, spanning from workflow analysis to intraoperative guidance and postoperative documentation14,15,16. Automated CVS assessment was first tackled by our prior work that introduced DeepCVS, a method for joint anatomical segmentation and CVS prediction17. For this initial work, 2854 images showing anterior views of hepatocystic anatomy were hand-picked from 201 LC videos and annotated by surgeons with a single, binary assessment for each of the three criteria defining the CVS. A subset of 402 images balancing optimal and suboptimal CVS achievements were further annotated with semantic segmentation masks. This initial dataset, while instrumental in enabling a proof-of-concept study, was characterized by two critical limitations: (1) the frame selection process introduced bias during both training and evaluation and (2) the small dataset limited testing to only 571 images for CVS assessment and 80 images for semantic segmentation.
Endoscapes2023 is a vastly expanded dataset from the same 201 videos used for DeepCVS development. Following a published annotation protocol18, the segment of the video that is relevant for CVS assessment was first isolated, then frames were extracted from this segment at 1 frame per second; this process eliminates the selection bias of the DeepCVS dataset.
For these frames, assessments of the CVS criteria as well as semantic segmentation masks (4 anatomical structures, 1 descriptor of surgical dissection, and 1 tool class) were annotated at regular intervals: 1 frame every 5 seconds for CVS and 1 frame every 30 seconds for segmentation. The assessments of CVS criteria were done independently by three surgeons trained on a robust annotation protocol to reduce bias. After several rounds of review to ensure optimal annotation consistency, a total of 11090 images with CVS assessments and 1933 images with semantic segmentation masks from the 201 LC videos were obtained. Additionally, bounding boxes and instance segmentation masks from the 1933 semantic segmentation masks were automatically extracted to augment the dataset with these labels.
Importantly, Endoscapes2023 complements existing open-source laparoscopic cholecystectomy datasets. The recently introduced Cholec80-CVS19, extends the foundational Cholec80 dataset20 with CVS assessments by a surgeon on video segments in which at least one CVS criterion can be evaluated. Endoscapes2023 expands on this important contribution by providing binary assessments of CVS criteria from 3 independent surgeons on regularly-sampled video frames from 201 unselected LC cases. Thanks to this increased scale as well as the availability of multiple independent assessments on unselected cases, we believe Endoscapes2023 has more consistent annotations, can help build better calibrated models, and will lead to improved method generalizability. Moreover, Endoscapes2023 uniquely provides spatial annotations of the fine-grained hepatocystic anatomy that is relevant for CVS assessment. This is a sizable improvement over existing anatomical segmentation datasets (e.g. CholecSeg8k21), which are generally more coarse-grained, focus on large organs and tools, and are limited in scale.
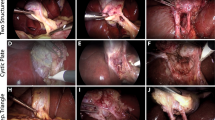
Recognizing the need for robust public datasets to foster research and development for surgical safety, our surgical data science team of computer scientists and surgeons has unified all of the aforementioned data and annotations into a centralized dataset called Endoscapes2023, the first sizable dataset with frame-wise annotations of CVS criteria assessments by three independent surgeons and surgical scene segmentations (illustrated in Fig. 1).

Endoscapes2023. A series of example images from Endoscapes2023, illustrating the various types of annotations and representing a range of CVS achievement states.
Methods
Data collection
Surgical videos were prospectively recorded at the Institute of Image-Guided Surgery (IHU-Strasbourg, France) between February 10, 2015, and June 7, 2019. As detailed in prior works17, 201 full-length endoscopic videos of standard LC performed by 22 surgeons (10 attending surgeons and 12 surgical residents) in patients older than 18 years operated for benign conditions were retrospectively collected following patients’ written consent. Videos were not further selected. Video preprocessing steps included: merging files of the same case, converting to 30 frames per seconds (FPS), and re-encoded at a resolution of 480 × 854 with H.264 codec.
The Ethics Committee of the University of Strasbourg approved the data collection within the “SafeChole - Surgical data science for safe laparoscopic cholecystectomy” study (ID F20200730144229). According to the French MR004 reference methodology, all data was collected with patient consent and de-identified by removing patient-specific information.
Video Editing and Frame Extraction
A surgeon annotated the time of the first incision on the hepatocystic triangle (“Start” timestamp) and when the first clip was applied on either the cystic duct or the cystic artery (“End” timestamp) to define the region of video of interest for CVS assessment. Since in most cases, some dissection is necessary before starting to visualize CVS criteria, a surgeon also annotated the moment when any of the 3 CVS criteria became evaluable (i.e., when the anatomical structures defining a CVS criteria become visible, herein referred to as “Criterion x evaluable” timestamp). While of potential interest for CVS assessment, the segment of video before the “Criterion x evaluable” timestamp most likely does not show any CVS criteria having been achieved and hence can be excluded from explicit annotation to decrease the annotation cost. Finally, the 201 LC videos were edited down to shorter video clips showing only from the “Criterion x evaluable” to the “End” timestamp (see Fig. 2). The average duration of these video clips is 283.1 ± 275.9 seconds. From this video clips, extracting 1 frame per second resulted in a dataset of 58813 frames. A detailed description of CVS criteria and their assessment, especially in edge cases, is provided in the checklist and CVS flashcards in Fig. 3.

Schematic representation of the video editing and frame extraction process. The top of the figure shows the visual cues marking the first incision on the hepatocystic triangle, a criterion becoming evaluable (in this case, the cystic duct and artery start to be visible in their tubular appearance) and the first clip applied on the cystic duct. The bottom of the figure represents the extraction of regularly spaced frames for manual segmentation and CVS criteria assessment.

Material to increase annotation quality. A checklist to revise frame level assessments of CVS criteria (right side of the image) as well as commented CVS flashcards (top left side of the image) and segmentation primers (bottom left side of the image) were shared with annotators and were made publicly available18.
CVS Annotation
According to Strasberg et al.5, CVS is defined as the view of 2 and only 2 tubular structures, the cystic duct and the cystic artery, connected to the gallbladder (2-structure criterion, C1), a hepatocystic triangle cleared from fat and connective tissues (hepatocystic triangle criterion, C2) and the lower part of the gallbladder separated from the liver bed (cystic plate criterion, C3). For consistency, each of these 3 CVS criteria was assessed as either achieved or not in a binary fashion; if 3 out of 3 criteria were achieved, then CVS was considered obtained10. A detailed description of CVS criteria and their assessment, especially in edge cases, is provided in the checklist and CVS flashcards in Fig. 3.
Video annotation with binary assessments of CVS criteria was performed on all 201 LC cases by a trained surgeon using Excel (Microsoft Corporation, USA) spreadsheets. CVS was achieved in 84 (41.8%) of the included procedures, with C1, C2, and C3 being achieved in 170 (84.6%), 122 (60.7%), and 111 (55.2%) of the cases respectively.
Additionally, one frame every 5 seconds was sampled for manual annotation of CVS criteria. Each frame was by annotated by three independent surgeons specifically trained to annotate CVS criteria, and the most common assessment of each of the CVS criteria in each image was defined as the consensus ground truth. In the resulting dataset of 11090 frames, named Endoscapes-CVS201, CVS was achieved in 678 (6.1%) of the annotated frames, with C1, C2, and C3 being achieved in 1899 (17.1%), 1380 (12.4%), and 2124 (19.2%) of the frames respectively. Cohen’s kappa for inter-rater agreements for CVS, C1, C2, and C3 were respectively 0.38, 0.33, 0.53, 0.44; here, Cohen’s kappa values were first computed between each pair of annotators, then averaged across the three possible pairs for each of the three criteria and overall CVS.
Spatial Annotation
The gallbladder, the cystic duct, the cystic artery, the cystic plate, the dissection in the hepatocystic triangle (i.e., the “windows” between the cystic duct and the cystic artery, and between the cystic artery and the cystic plate) and surgical tools are the elements in the surgical scene evaluated for CVS assessment.
These 6 classes were manually segmented by 5 trained annotators, 3 surgeons and 2 computer scientists with domain-specific expertise, on 1 frame every 30 seconds, resulting in a dataset of 1933 frames with semantic segmentation. A subset of these, 493 frames from 50 LC cases selected as described in the associated technical report22, are publicly released as Endoscapes-Seg50. Finally, a dataset including 1933 frames with bounding boxes automatically extracted from the segmentation masks is being released as Endoscapes-BBox201.
The number and percentage of the 1933 frames that contain each spatial class is as follows: Gallbladder (1821, 94.2%), Cystic Duct (1478, 76.5%), Cystic Artery (1020, 52.8%), Cystic Plate (701, 36.3%), Hepatocystic Triangle Dissection (683, 35.3%), Tool (1771, 91.6%). A frame is considered to contain a spatial class if there is at least one bounding box with said class label.
Similarly, the number and percentage of the 493 frames that contain each spatial class is as follows: Gallbladder (466, 94.5%), Cystic Duct (374, 75.9%), Cystic Artery (283, 57.4%), Cystic Plate (192, 38.9%), Hepatocystic Triangle Dissection (146, 29.6%), Tool (450, 91.3%). A frame is considered to contain a spatial class if there is at least one pixel in the semantic segmentation mask with said class label.
Data Records
Data can be accessed at PhysioNet23. The data are also available at https://github.com/CAMMA-public/Endoscapes.
We have published a technical report22 which, beside describing dataset splits used in prior works and reporting extensive baselines to benchmark a variety of models, provides a comprehensive description of the file structure and annotation format; we summarize the key points here.
All extracted frames at 1 frame per second can be found in a directory entitled ‘all’.
The frames are also divided into training, validation, and testing subsets in correspondingly named folders to facilitate model development.
Semantic segmentation masks for the 50-video subset, namely Endoscapes-Seg50, are included in a folder named ‘semseg’. Instance segmentation masks are stored in a folder named ‘insseg’; each instance segmentation mask consists of two files - one NPY file containing a stack of binary masks where each binary mask represents an instance, as well as one CSV file containing the label of each instance.
Bounding box annotations and CVS annotations are provided for each data split (training/validation/testing) in two different COCO-style JSON files: ‘annotation_coco.json’ for the bounding boxes, and ‘annotation_ds_coco.json’ for the CVS labels (see22 for more details).
Lastly, all CVS annotations are additionally summarized in a single CSV file called ‘all_metadata.csv’. This file contains the CVS criteria labels by each annotator for each frame as well as the consensus CVS criteria labels (average of 3 annotators) for each frame.
Figure 4 details the file structure and various annotation files that comprise Endoscapes2023.

File Structure Overview. A detailed description of the file structure of Endoscapes2023.
Technical Validation
Annotators
Assessing CVS criteria entails evaluating the quality of the surgical dissection, requiring annotators with domain knowledge. For this reason, three surgeons aware of the principles of a safe cholecystectomy and specifically trained to perform image annotations performed the CVS criteria assessments. To reduce the likelihood of bias in the annotation process, two measures were taken: (1) the three surgeons were blinded to each other’s assessments during annotation, and (2) disagreements in CVS assessments among the three surgeons were not mediated to avoid introducing biases arising from discussion dynamics; instead all three assessments were included. Given the alignment of annotators achieved with specific training and protocols, we argue that eventual disagreements could indicate inherently low-information or low-quality frames.
Meanwhile, hepatocystic anatomy can be more objectively defined, especially when assessed on videos, outside of the time constraints and stress of operating rooms. For this reason, semantic segmentation of surgical images was performed by surgeons and computer scientists trained in the fundamentals of hepato-biliary anatomy. Given the time required to extensively segment surgical images, each extracted frame was semantically segmented once and revised as described later. All semantic segmentations were revised by at least one surgeon.
Annotation Tools
To efficiently annotate thousands of images with CVS criteria and segmentations, a custom application enabling loading and quick navigation between images to label CVS criteria and extra information with forms or free text comments was developed. Of note, the CVS annotation software presents a button to launch related LC videos at the exact time point showing the image to annotate for quick review of the surgical context (Fig. 5). In addition, an alternative interface allows comparing CVS assessments across annotators without revealing their identity, facilitating annotation review and flagging. The described software is freely available from https://github.com/CAMMA-public/cvs_annotator.

CVS annotation software. In the annotator interface (right side of the image), (a) allows to navigate the dataset specifying video and frames ids, (b) open related videos at the right video frame, (c) sets frame visualization preferences, (d) allows to annotate CVS criteria (1= 2-structure criterion, 2= hepatocystic triangle criterion, 3= cystic plate criterion), (e) allows to annotate auxiliary information (“roi” stands for region of interest, the hepatocystic triangle), (f) allows free text comments to discuss in annotation meetings, and, on the reviewer interface (left side of the image), (g) allows to compare blinded annotations and flag inconsistencies.
Finally, LabelMe24, a freely available, open-source software was used for polygon-based semantic segmentation of frames. The source code of LabelMe was similarly modified to allow opening videos at the exact time point showing the image to annotate.
Annotation Process and Auditing
Before starting, annotators participated in an annotation school in which they were trained on the importance, methods, and tools for consistent CVS assessment and surgical scene segmentation. In addition, an annotation protocol with checklists and flashcards was shared with annotators for reference throughout the annotation process18 (Fig. 3).
Annotations were completed between October 2020 and April 2021. Regular meetings (at 25%, 50%, 75%, and 100% of completed annotations) were held with all the involved annotators to review major inconsistencies identified across randomly extracted frames; frames identified as having high inter-rater variability in these meetings were then revised using the aforementioned annotation tool. Finally, all segmentation masks were reviewed by a surgeon and a computer scientist and revised iteratively until convergence.
Limitations of the Dataset
Endoscapes2023 is intrinsically limited by the fact that it only includes data from a single institution. While the dataset is significantly larger than previously available public datasets, and the unbiased video selection process might allow training more robust models, the dataset does not enable model generalizability studies. Still, we believe that by sharing Endoscapes2023 and detailing its development, we can greatly accelerate next efforts such as the SAGES CVS Challenge25 that aim to collect large-scale multicentric datasets.
Other potential limitations are the inter-rater variability in annotations (see Cohen’s kappa above) and the unbalanced nature of the dataset (see dataset statistics above). Given that comprehensive annotation guidelines were provided, all annotators were trained, and regular auditing was performed, we believe that this variability is largely due to limited information content in some images rather than errors or noise, thereby representing a useful signal in and of itself. Finally, the CVS, when feasible and performed correctly, is the result of a surgical dissection that allows moving on to the next surgical step. Consequently, most frames will show no or partial CVS, with only the last few frames showing achievement of most criteria. Altogether, CVS assessment, especially at the frame-level, is an intrinsically unbalanced problem and developed methods should account for this imbalance.
Usage Notes
The plethora of unlabeled images extracted from the most critical part of LC procedures, the many images with CVS criteria assessments, the low-frequency frames with bounding box annotations, and the relatively small subset with expensive segmentation masks not only effectively simulate realistic annotation budgets but also enable a huge diversity of experiments concerning mixed-supervision, semi-supervision, and temporal modeling. Dataset splits used in prior work and extensive baselines to benchmark a variety of models can be found in a related technical report22.
Code availability
As mentioned previously, source code for our custom annotation tool is publicly available at https://github.com/CAMMA-public/cvs_annotator. Meanwhile, instructions to download and use the dataset can be found at https://github.com/CAMMA-public/Endoscapes.
References
Mascagni, P. et al. New intraoperative imaging technologies: Innovating the surgeon’s eye toward surgical precision. Journal of surgical oncology 118, 265–282 (2018).
Way, L. W. et al. Causes and prevention of laparoscopic bile duct injuries: analysis of 252 cases from a human factors and cognitive psychology perspective. Annals of surgery 237, 460 (2003).
Rogers Jr, S. O. et al. Analysis of surgical errors in closed malpractice claims at 4 liability insurers. Surgery 140, 25–33 (2006).
Berci, G. et al. Laparoscopic cholecystectomy: first, do no harm; second, take care of bile duct stones (2013).
Strasberg, S., Hertl, M. & Soper, N. An analysis of the problem of biliary injury during laparoscopic cholecystectomy. Journal of the American College of Surgeons 180, 101–125 (1995).
Michael Brunt, L. et al. Safe cholecystectomy multi-society practice guideline and state-of-the-art consensus conference on prevention of bile duct injury during cholecystectomy. Surgical Endoscopy 34, 2827–2855 (2020).
Conrad, C. et al. Ircad recommendation on safe laparoscopic cholecystectomy. Journal of Hepato-Biliary-Pancreatic Sciences 24, 603–615 (2017).
Wakabayashi, G. et al. Tokyo guidelines 2018: surgical management of acute cholecystitis: safe steps in laparoscopic cholecystectomy for acute cholecystitis (with videos). Journal of Hepato-biliary-pancreatic Sciences 25, 73–86 (2018).
Pucher, P. H. et al. Outcome trends and safety measures after 30 years of laparoscopic cholecystectomy: a systematic review and pooled data analysis. Surgical endoscopy 32, 2175–2183 (2018).
Mascagni, P. et al. Formalizing video documentation of the critical view of safety in laparoscopic cholecystectomy: a step towards artificial intelligence assistance to improve surgical safety. Surgical endoscopy 34, 2709–2714 (2020).
Nijssen, M. et al. Complications after laparoscopic cholecystectomy: a video evaluation study of whether the critical view of safety was reached. World journal of surgery 39, 1798–1803 (2015).
Maier-Hein, L. et al. Surgical data science for next-generation interventions. Nature Biomedical Engineering 1, 691–696 (2017).
Maier-Hein, L. et al. Surgical data science–from concepts toward clinical translation. Medical image analysis 76, 102306 (2022).
Mascagni, P. et al. Computer vision in surgery: from potential to clinical value. npj Digital Medicine 5, 163 (2022).
Madani, A. et al. Artificial intelligence for intraoperative guidance: using semantic segmentation to identify surgical anatomy during laparoscopic cholecystectomy. Annals of surgery 276, 363–369 (2022).
Mascagni, P. et al. Multicentric validation of endodigest: a computer vision platform for video documentation of the critical view of safety in laparoscopic cholecystectomy. Surgical Endoscopy 36, 8379–8386 (2022).
Mascagni, P. et al. Artificial intelligence for surgical safety: automatic assessment of the critical view of safety in laparoscopic cholecystectomy using deep learning. Annals of surgery 275, 955–961 (2022).
Mascagni, P. et al. Surgical data science for safe cholecystectomy: a protocol for segmentation of hepatocystic anatomy and assessment of the critical view of safety. arXiv preprint arXiv:2106.10916 (2021).
Ríos, M. S. et al. Cholec80-cvs: An open dataset with an evaluation of strasberg’s critical view of safety for ai. Scientific Data 10, 194 (2023).
Twinanda, A. P. et al. Endonet: a deep architecture for recognition tasks on laparoscopic videos. IEEE transactions on medical imaging 36, 86–97 (2016).
Hong, W.-Y. et al. Cholecseg8k: a semantic segmentation dataset for laparoscopic cholecystectomy based on cholec80. arXiv preprint arXiv:2012.12453 (2020).
Murali, A. et al. The endoscapes dataset for surgical scene segmentation, object detection, and critical view of safety assessment: Official splits and benchmark. arXiv preprint arXiv:2312.12429 (2023).
Mascagni, P. et al. Endoscapes2023, a critical view of safety and surgical scene segmentation dataset for laparoscopic cholecystectomy (version 1.0.0). PhysioNet https://doi.org/10.13026/czwq-jh81 (2024).
Russell, B. C., Torralba, A., Murphy, K. P. & Freeman, W. T. Labelme: A database and web-based tool for image annotation. International Journal of Computer Vision 77, 157–173 (2008).
The critical view of safety challenge. https://www.cvschallenge.org/.
Acknowledgements
This study was partially supported by French State Funds managed by the Agence Nationale de la Recherche (ANR) under grants ANR-20-CHIA-0029-01 (National AI Chair AI4ORSafety) and ANR-10-IAHU-02 (IHU Strasbourg).
Author information
Authors and Affiliations
Contributions
P.M. and D.A. conceptualized the dataset, created annotation protocols, annotated, coordinated the annotation process, performed the technical validation, and drafted the manuscript. A. M. conceptualized the dataset, extracted bounding box and instance segmentation annotations, created the data repository, performed the technical validation, and drafted the manuscript. A.V. developed annotations tools, annotated, contributed to the technical validation, and revised the manuscript. A.G. and N.O. annotated, refined annotation protocols, contributed to the technical validation, and revised the manuscript. G.C., D.M., J.M. and B.D., contributed to data collection, provided clinical and scientific inputs to refine annotation protocols, and revised the manuscript. N.P. conceptualized and supervised the whole project, provided computer science and scientific inputs, and revised the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Mascagni, P., Alapatt, D., Murali, A. et al. Endoscapes, a critical view of safety and surgical scene segmentation dataset for laparoscopic cholecystectomy. Sci Data 12, 331 (2025). https://doi.org/10.1038/s41597-025-04642-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-025-04642-4
This article is cited by
-
Dynamic key vascular anatomy dataset for D2 lymph node dissection during laparoscopic gastric cancer surgery
Scientific Data (2025)
-
SwinCVS: a unified approach to classifying critical view of safety structures in laparoscopic cholecystectomy
International Journal of Computer Assisted Radiology and Surgery (2025)
