
Abstract
Data and knowledge of spatial-temporal dynamics of multiple types of water body are significant for water resources management but remain very limited. Using the Landsat satellite data and weakly supervised deep learning techniques for long term mapping, we report annual maps of multiple types of inland water bodies on urban agglomeration scale in the middle reaches of the Yangtze River (MRYR) during 1990-2021 at 30m spatial resolution. Accuracy assessment from 14000 validation points in seven years indicates an overall accuracy of 94.50%. Quantitative and qualitative comparison with other water related mapping products further demonstrates the superiority on long time span, refined classification system, and the high precision. The Water-MRYR could support the government and the public in the challenging water resources management and wetland conservation.
Similar content being viewed by others
Background & Summary
Inland surface water bodies are critical components of ecosystems on earth. They play a vital role in supporting agriculture, industry, and human societies from regional to global1. The inland water are also closely associated with several of the Sustainable Development Goals (such as, SDG 6, 14 and 15). Different types of water bodies, such as rivers, lakes, and artificial water body, have different impacts on the ecological environment of cities2,3,4. The artificial ponds used for agriculture and aquaculture typically have higher carbon emissions5,6. Large-scale collection of artificial water bodies can impact the land surface dramatically, leading to changes of land cover types in lakes, rivers, and wetlands.
Numerous inland surface water body mapping data at various spatial resolutions have been created and applied in surface water body monitoring7,8,9,10,11. These binary maps (water and not water) reported the monthly or yearly dynamics of permanent and seasonal surface water bodies around the world. Besides, some land cover12,13,14 and wetland15,16 related researches have started to consider the classification of water and wetland (seasonal water) and their long-term trend17,18,19,20. However, the various types of surface waters have similar spectral features, which causes challenges when differentiating them. Threshold classification method based on the various calculated shape parameters, such as compactness, area and boundary index, has been applied to map the various water cover types21,22,23,24. Because of the challenging stable features extraction and extensive manually post-processing work, existing studies are constrained to a limited number of cities and years, preventing large-scale and longer-term mapping and analysis19,21.
The urban agglomeration in the middle reaches of the Yangtze River25,26 encompasses the major cities of Hubei, Hunan, and Jiangxi, covering an area of approximately 250,000 square kilometers, as shown in Fig. 1. This region is endowed with abundant water and wetland resources27, with key rivers such as the Yangtze River, Xiangjiang River, and Ganjiang River traverse the area, and significant inland lakes like Dongting Lake, Poyang Lake, and Hong Lake. In this case, high precision mapping of the surface water bodies and derived spatial-temporal dynamics information over the past few decades in this area are essential for the understanding of the roles of various water cover types in water security, but such information has not been well documented to the government and public, yet.

The research area is the urban agglomeration in the middle reaches of the Yangtze River.
In recent years, the deep learning methods, with their automatic feature learning and extraction capabilities, have shown advantages and widely applied in remote sensing image interpretation28,29,30, such as image classification, semantic segmentation, and object detection. Among these models, the deep learning based semantic segmentation models have the ability of capturing contextual information for pixel-level classification31, thus have been widely used to reveal the spatiotemporal distribution of the research object from remote sensing image in large scale32,33,34,35. In this study, we used deep learning techniques to map the multiple water body types of the urban agglomeration in the middle reaches of the Yangtze River from 1990 to 2021 at 30 resolution. Four types of water body are considered in this study, including lakes, rivers, wetlands, and artificial water bodies. A Semantic-to-Pixel framework is proposed combing the semantic segmentation deep model and binary water body maps for the mapping of water cover types. In addition, a weakly supervised long term mapping framework is proposed aiming at the automatic long term sample generation. The overall accuracy indicated by over 14000 validation points for seven years ranges from 0.9245 to 0.9598, which reflects the high precision of our method. The dataset can serve as a foundation for further studies on drivers of artificial water bodies expansion and their implications for socio-economic conditions and sustainable land use development, particularly regarding environmental impacts.
Methods
Study area
The urban agglomeration in the middle reaches of the Yangtze River25,26 encompasses 31 major cities of Hubei, Hunan, and Jiangxi, covering an area of approximately 250,000 km2 with a population of 130 million. It is an important component of the Yangtze River Economic Belt and holds a significant position in China’s economic and social development pattern. This urban agglomeration is one of the regions with the richest water resources in China, with three International Wetland cities, Wuhan, Changde, and Nanchang.
Materials
Satellite imagery
The Landsat on the Google Earth Engine (GEE), covering Landsat 5 Thematic Mapper (TM), Landsat 7 Enhanced Thematic Mapper Plus (ETM+), Landsat 8 Operational Land Imager (OLI), are used in this study. All of the images are from the Tire 1 of Landsat Collection 2, which is a dataset containing atmospherically corrected surface reflectance data. The spatial resolution of Landsat data is 30 meters, with six bands being used in our work, including the red, green, blue, near-infrared, and two shortwave infrared bands. The Quality Assessment (QA) band, which is driven from CFmask36,37 to mask observations affected by cloud or cloud shadow, is used to remove observations in low quality from each tiles.
For the semantic segmentation task, the median composite images are used for a clear observation. As the images from Landsat 5 are usually in low quality, the images from 1990 to 2010 are the composite using the adjacent years(three years composite for the middle year). After the launch of Landsat 8, the quality of the images has been greatly improved, therefore we use the median synthesis within the year.
Semantic segmentation Dataset
Precision annotated labels for model training are crucial for semantic segmentation tasks. However, there is currently a lack of publicly available benchmark datasets for mapping multiple types of water bodies. In this case, we start out by manually assign the labels for semantic segmentation. The median composite imagery in 2020 from Landsat 8 is selected for label generation. The image of the whole area is first crop into non-overlapping patches with size 512 × 512 pixels (2940 in total). We conduct stratified sampling based on the number of water bodies in the GSW_JRC7, which is a global surface water dataset developed by the European Commission’s Joint Research Centre as shown in Table 1. Then 466 (around 15%) patches are selected and manually labeled with four water body categories as shown in Table 2. Specifically, considering the resolution of remote sensing images and the complexity of annotation, for the category of artificial water bodies, we do not remove the tunnel gaps among them, but instead used a Semantic-to-Pixel framework (next section) for contour extraction. Finally, the semantic segmentation dataset is randomly divided into training and validation set of 4:1.
Binary water map
Binary water map is used to remove the tunnel gaps among the artificial water bodies and serve as weak guidance for long term training. The GSW Yearly Water Classification History7 provides YearlyHistory dataset with spatial information on permanent and seasonal water in GEE platform. However, the seasonal water category is a composition of the monthly bianry product, resulting in a relatively lower accuracy.
In order to decrease the omission for seasonal water, the widely used mNDWI-VIs algorithm8,9,38 is selected to generate the water frequency map Waterf. Waterf is developed using the time series Landsat data and three indices, NDVI39 (Normalized Difference Vegetation Index, equation (1)), EVI40 (Enhanced Vegetation Index, equation (2)), and mNDWI41 (Modified Normalized Difference Water Index, equation (3)). The water body detection algorithm is ((mNDWI > EVI or mNDWI > NDVI) and (EVI < 0.1)). The pixels satisfying the above condition are classified as water. In addition, the Shuttle Radar Topography Mission (SRTM)42 digital elevation model (DEM), as well as the slope, are used to remove terrain shadows in mountainous areas. The water frequency maps are then merged with a threshold 0 to get the binary water map with clear boundary. Finally, the binary water maps from GSW_YRC and mNDWI-VIs algorithm are intersected together to get the synthetic water map.
Multiple Water body types mapping using deep semantic segmentation models
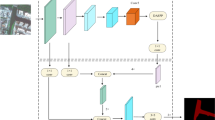
This study proposed a framework for mapping multiple water body types in urban agglomerations scale using satellite imagery and deep learning techniques. We first create a semantic segmentation dataset for the multiple water body types using the Landsat 8 median composite images and manually assigned labels. The Semantic-to-Pixel framework for the mapping of multiple types of water bodies is then applied to get the map in 2020 as shown in Fig. 2 step1. Then the weakly-supervised training framework, shown in Fig. 2 step2, is applied to train models for the mapping application in other years and the models are used for the long-term mapping.

The overall architecture of the method proposed in this study. Step 1 is the Semantic-to-Pixel framework for mapping of multiple water body types. Step 2 is the proposed weakly supervision method. It contains a student network and a teacher network, where the teacher is momentum-updated with the student. The labeled data from the baseline-year is directly fed into the student network for supervised training. Given an cross-year unlabeled image, we first use the teacher model to make a prediction, and then separate the pixels into reliable ones and unreliable ones based on their entropy. The reliable predictions are directly used as the pseudo-labels to advise the student. Besides, the subordinate relationships between the water bodies and their various categories are also used to constrain the network’s training.
The batch size is set to 8 for the model training. The Segformer model43, which is developed from vision transformer, has demonstrated strong feature extraction capabilities and been widely used in remote sensing tasks, is selected as the backbone for wetland mapping. The Mean Intersection over Union (MIoU)) is selected as the metric index on the test dataset.
Due to the relatively lower resolution and the upsample structure in the semantic segmentation model. We ignore the tunnel gaps among the artificial water bodies and just get the semantic boundary while labeling and training the model. In order to get a more detailed mapping result, the outputs of the segmentation model are refined with the water frequency maps to correct the tunnel gaps and road among the clusters of artificial water bodies. The tunnel gaps among the artificial water body are masked as they are assigned not water in the binary water maps.
Long term multiple Water body types mapping via weakly supervision
Due to the domain shift from the different satellite sensors and imaging quality, the model trained with the remote sensing images and labels from one year could not be directly applied in mapping the images from other years even in the same place44. The long term stable training samples are generated using various ways17,19,22,45. However, manually annotated labels year by year is extremely time-consuming for decades observation. In this case, we proposed the weakly supervised long term mapping framework for the multiple water body types. For the long-term mapping, samples from the baseline year with labels \({D}_{l}={({x}_{i}^{l},{y}_{i}^{l})}_{i=1}^{{N}_{l}}\) and other years without labels \({D}_{u}={({x}_{i}^{u})}_{i=1}^{{N}_{u}}\) are used to train the semantic segmentation model. In order to achieve that, the proposed framework utilizes a standard teacher-student model, which consists two models of the same architecture. As for the weight updating, we adopt the commonly used exponential moving average(EMA)46 strategy, which means the teacher model’s weights are updated based on the weights of student model with a momentum.
The loss design is also important for the training process, we design three loss in this weakly supervised long term mapping framework. For the labeled images, the objective is to minimize the fully-supervised cross-entropy loss Ls shown in equation (4). As for the unlabeled images, the pixel-wise pseudo-labels are generated from the prediction of the teacher model. In order to select the high-confidence pseudo-labels, we calculate the entropy for each pixel and compare it with a dynamic percentile threshold θt. The entropy at pixel (i, j) is defined as in equation (5). The pij ∈ RC is the probability of each category after the softmax function in teacher model and C is the number of classes. The pixels with entropy lower than the θt are selected as reliable pseudo labels and the unsupervised loss Lu is calculated. During the training procedure, the pseudo-labels tend to be reliable gradually. Base on this intuition, the θt is updated with linear strategy every epoch, which is shown in equation (6) with t and T denoting the current epoch and total epoch (θ0 set to 80% in this study).
Besides, as the different water body types belong to water, the binary water maps are also used as supervision to get the water loss Lwater, which helps the model to differentiate between water and non water. The probability maps of the classes in water are merged and softmax to the binary output. The cross entropy loss is also used for the unsupervised loss and water loss. The final loss is shown in equation (7).
Accuracy assessment
To cross-validate our product, we design the accuracy assessments by a stratified random sampling approach. We evaluate the accuracy based on mapping from Landsat 30 m prediction. Accuracy assessment and area estimation of the mapping results are performed followed47,48. The overall accuracy (OA) is used to describe the overall performance of all categories in the mapping products. To evaluate each category, the F1 Score is chosen as it represents the harmonic mean of Precision (producer accuracy) and Recall (user accuracy), effectively balancing these two metrics.
The stratified random sampling is conducted on seven years (1990, 1995, 2000, 2005, 2010, 2015, and 2020) with about 2000 validation points for each year to assess the mapping accuracy. For each point, we determine the category the point belonged to using the Landsat mosaic imagery and the corresponding binary water map. Specifically, for the points from 2015 and 2020, we also use Sentinel-2 imagery with higher spatial resolution as a reference for annotation.
Data Records
Water-MRYR dataset can be accessed at https://doi.org/10.57760/sciencedb.1299049. The dataset is a long term water body types mapping result of the urban agglomeration in the middle reaches of the Yangtze River from 1990 to 2021 at 30m spatial resolution, which has been produced using the developed pixel-semantic framework and weakly supervised deep learning technology. The accuracy of the mapping results is validated using over 14,000 verification points, achieving an overall accuracy (OA) of 94.50%. The mapping product reveals the spatiotemporal distribution of various water body types in the urban agglomeration, which is of great significance for ecological conservation and water resource management. The dataset contains 14 products, with one every five years from 1990 to 2010 and one every year from 2013 to 2021. All the files are stored in .tif format and named UA_MRYR_Year.tif for each year. The index numbers for 0 to 4 represent background, lake, river, wetland, and artificial water, as shown in Fig. 3.

The spatial characteristics of the multiple types of water bodies of the urban agglomeration in the MRYR. a. The overview of the distribution in the whole study area. b. The detailed mapping examples with the corresponding Landsat 8 image (Band 5-4-3 composite), 1, Honghu in Jingzhou, 2, Huangshi-Huanggang junction, 3, Dongting Lake in Changde.
Technical Validation
Accuracy assessment on the mapping product
Validation on sample points
Validated with our sample points, the OA of water cover mapping for the seven reference years are 92.45%, 93.41%, 93.61%, 95.49%, 95.33%, 95.98%, and 95.26%. The average OA for the seven years is 94.50%. The F1 score on different categories is shown in Table 3. The accuracy of lakes and artificial water bodies all exceeds 90%, while the accuracy of most rivers and wetlands exceeds 80%. The above results demonstrate the high accuracy of our products.
Validation on open-access validation sets
To get a more comprehensive accuracy verification, we evaluate our products based on two open-access validation sets. The first50 is a sample set for global land cover mapping, which is produced using all-season Landsat-8 imagery around 2015. We filter the samples in the study area and get 1008 points. After manually check the assign the water related category, the OA for our products (UA_MRYR_2015) is 98.91%. The GLobal Lakes and Wetlands Database(GLWD)51 is a summary of several global and reginal water-related dataset developed in 2004. We use the level-2 data, which contains 691 polygons with rough shape boundary for lakes and rivers, to validate our product (UA_MRYR_2005). After manual rectification some errors in GLWD according to the Landsat imagery in 2005, our mapping products are semantically consistent with 96.96% (670) of polygons, revealing the high accuracy of our mapping product.
Statistical-level validation
In addition to assessment on validation points, the consistency between mapping products and statistical data is also considered as an important aspect of evaluating mapping results. The city level area statistics are conducted using the mapping product in 2020 as shown in Fig. 4. Nearly 20% of the water resources are artificial water body, which significantly affect the economy and environment in the urban agglomerations. Our map reveals extensive artificial water body distributed around large rivers and lakes in most cities. The top ten cities account for 80.74% of the the urban agglomerations share of artificial water body coverage, including Jingzhou (28.67%), Wuhan (8.98%), Xiaogan (8.00%), Changde (6.40%), Yueyang (5.93%), Yiyang (5.65%), Huanggang (5.35%), Xiantao (5.12%), Qianjiang (3.33%) and Tianmen (3.33%). Among the top 20 cities, 13 cities are located in Hubei Province, which also has the largest amount of water resources.

The validation on artificial water body. (a) The extent of artificial water body aggregated to the city level in 2020. (b) The cumulative share of artificial water body as a function of gross domestic product (GDP) per capita in the urban agglomerations. (c) The correlation analysis between area of artificial water body and the gross output of fishery.
Our research also reveals the relationship between artificial water body area and fishery industry production in city level (https://www.stats.gov.cn). The data on the total value of fishery production comes from the official statistical data released by the Provincial Bureau of Statistics. The result shows a significant correlation between artificial water bodies and the total value of the fishery industry, with Pearson Correlation: 0.88*** and Spearman Correlation: 0.83***, suggesting a central role of artificial water body in supporting regional fishery economy.
Comparison with other water-related datasets
For a more comprehensive comparison, we assess the performance of our products with four water related mapping products in the MRYR, as shown in Fig. 5. The GSW_JRC7 contains permanent water and seasonal water. EA_Wetland23 is a wetland mapping product in east Asia in 10m resolution. The multiple water cover types are considered in this product, and the inland swamp and marsh are merged as the wetland category for comparison. The CWaM21 is a water cover map product in China developed with Sentinel-1 and 2 imagery. The rice filed and agriculture ponds are merged as artificial water. GLC_FCS30D18 is a dynamic global land cover product, which also considers wetland categories the same as GWL_FCS3016. The inland wetland, namely swamp, marsh and flooded flat are merged for comparison. ESA_Worldcover52 is a renowned global land cover map from the European Space Agency. The water, wetland, cropland, and grassland types are selected for comparison.

Visual comparison between Water-MRYR and other five water related products. A is the Zhangdu Lake in Wuhan. B is diaocha lake and its surrounding artificail water body in Xiaogan city. C is the Yangtze River near Xianning and Jingzhou city. D is the Wu Lake in Wuhan.
For wetland classification dataset, EA_Wetland has presented mapping with high spatial resolution (10m), but its performance in distinguishing multiple types of water bodies needs improvement. For the water specific data, the CWaM also clearly presents the spatial distribution of some water body categories, but it also contains a substantial amount of noise for the artificial ponds. For the land cover product, the GLC_FCS30D and ESA WorldCover mainly classify the artificial water body as cropland and grassland. In summary, our products best demonstrate the spatial information of multiple types of water body.
Comparison with long-term mapping products
The four mapping products mentioned above only provide the spatial information only in year 2021 except the GLC_FCS30D. To assess the presentation ability of spatiotemporal information, the GLC_FCS30D and the GSW_YRC are considered for comparison. The two products provide long-term (the nominal period is 1985-2021, but the data for 1985-1990 is incomplete due to the poor imaging quality) spatial information for water and land cover respectively. Different types of water bodies have different trends of change, but this information has not been reflected in current mapping products. In this case, the mapping results for the three products in Hong Lake(The largest lake in Hubei Province) are shown in Fig. 6.

Long term comparison between GSW_JRC and GLC_FCS30D in Hong Lake.
In terms of water bodies, our products maintain a high degree of consistency with GSW, but GSW lacks the specific category information for water bodies. The GSW_JRC shows the increase tendency of seasonal water body, which is actually the artificial water body as shown in our products. The GLC_FCS30D also shows the tendency of area increase for the water but fails to classifies the types of water body. In addition, GLC_FCS30D also misclassifies a large number of artificial water bodies as farmland and grassland, without correctly capturing the spatial semantic information of artificial water bodies. Our product clearly demonstrates the water cover types and reveals the significant expansion of artificial water body around the Hong Lake.
Usage Notes
The Water-MRYR dataset provides long-term (1990–2021) mapping of water body types(lake, river, wetland, and artificial water) in the urban agglomeration of the middle reaches of the Yangtze River, with a spatial resolution of 30 meters. We recommend that users view this data product using software such as ArcGIS or QGIS. Our data provides long-term spatiotemporal information on the changes of different water body types, which can be used to detect the expansion of artificial water bodies and their encroachment on other types of water bodies, such as wetlands.
Code availability
The experiments are conducted under the Pytorch environment on an NVIDIA RTX 4080GPU, with Python==3.8.16, torch==1.13.1, and torchvision==0.14.1. The code for long term mapping of multiple types of water with Landsat imagery can be accessed on GitHub at the following link (https://github.com/haozhengma/Water-MRYR). Additionally, we also provide the GEE code of mNDWI-VIs algorithm for water mapping.
References
Pi, X. et al. Mapping global lake dynamics reveals the emerging roles of small lakes. Nature communications 13, 5777 (2022).
Huang, X., Xie, C., Fang, X. & Zhang, L. Combining pixel-and object-based machine learning for identification of water-body types from urban high-resolution remote-sensing imagery. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 8, 2097–2110 (2015).
Wu, Q. et al. Satellites reveal hotspots of global river extent change. Nature communications 14, 1587 (2023).
Yao, F. et al. Satellites reveal widespread decline in global lake water storage. Science 380, 743–749 (2023).
Holgerson, M. A. & Raymond, P. A. Large contribution to inland water co2 and ch4 emissions from very small ponds. Nature Geoscience 9, 222–226 (2016).
Dong, B., Xi, Y., Cui, Y. & Peng, S. Quantifying methane emissions from aquaculture ponds in china. Environmental Science & Technology 57, 1576–1583 (2022).
Pekel, J.-F., Cottam, A., Gorelick, N. & Belward, A. S. High-resolution mapping of global surface water and its long-term changes. Nature 540, 418–422 (2016).
Zou, Z. et al. Divergent trends of open-surface water body area in the contiguous united states from 1984 to 2016. Proceedings of the National Academy of Sciences 115, 3810–3815 (2018).
Wang, X. et al. Gainers and losers of surface and terrestrial water resources in china during 1989–2016. Nature communications 11, 3471 (2020).
Li, Y., Dang, B., Zhang, Y. & Du, Z. Water body classification from high-resolution optical remote sensing imagery: Achievements and perspectives. ISPRS Journal of Photogrammetry and Remote Sensing 187, 306–327 (2022).
Han, W. et al. A survey of machine learning and deep learning in remote sensing of geological environment: Challenges, advances, and opportunities. ISPRS Journal of Photogrammetry and Remote Sensing 202, 87–113 (2023).
Chen, J. et al. Global land cover mapping at 30 m resolution: A pok-based operational approach. ISPRS Journal of Photogrammetry and Remote Sensing 103, 7–27 (2015).
Zhang, X. et al. Glc_fcs30: Global land-cover product with fine classification system at 30 m using time-series landsat imagery. Earth System Science Data Discussions 2020, 1–31 (2020).
Karra, K. et al. Global land use/land cover with sentinel 2 and deep learning. In 2021 IEEE international geoscience and remote sensing symposium IGARSS, 4704–4707 (IEEE, 2021).
Mao, D. et al. National wetland mapping in china: A new product resulting from object-based and hierarchical classification of landsat 8 oli images. ISPRS Journal of Photogrammetry and Remote Sensing 164, 11–25 (2020).
Zhang, X. et al. Gwl_fcs30: global 30 m wetland map with fine classification system using multi-sourced and time-series remote sensing imagery in 2020. Earth System Science Data Discussions 2022, 1–31 (2022).
Amani, M. et al. Wetland change analysis in alberta, canada using four decades of landsat imagery. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 14, 10314–10335 (2021).
Zhang, X. et al. Glc_fcs30d: the first global 30 m land-cover dynamics monitoring product with a fine classification system for the period from 1985 to 2022 generated using dense-time-series landsat imagery and the continuous change-detection method. Earth System Science Data 16, 1353–1381 (2024).
Wang, M. et al. Interannual changes of urban wetlands in china’s major cities from 1985 to 2022. ISPRS Journal of Photogrammetry and Remote Sensing 209, 383–397 (2024).
Lou, A., He, Z., Zhou, C. & Lai, G. Long-term series wetland classification of guangdong-hong kong-macao greater bay area based on apsmnet. International Journal of Applied Earth Observation and Geoinformation 128, 103765 (2024).
Li, Y. & Niu, Z. Systematic method for mapping fine-resolution water cover types in china based on time series sentinel-1 and 2 images. International Journal of Applied Earth Observation and Geoinformation 106, 102656 (2022).
Deng, Y. et al. Automated and refined wetland mapping of dongting lake using migrated training samples based on temporally dense sentinel 1/2 imagery. International Journal of Digital Earth 16, 3199–3221 (2023).
Wang, M. et al. Wetland mapping in east asia by two-stage object-based random forest and hierarchical decision tree algorithms on sentinel-1/2 images. Remote Sensing of Environment 297, 113793 (2023).
Peng, K. et al. Continental-scale wetland mapping: A novel algorithm for detailed wetland types classification based on time series sentinel-1/2 images. Ecological Indicators 148, 110113 (2023).
Zheng, Z. & Qingyun, H. Spatio-temporal evaluation of the urban agglomeration expansion in the middle reaches of the yangtze river and its impact on ecological lands. Science of The Total Environment 790, 148150 (2021).
Dai, X. et al. Spatio-temporal variations of ecosystem services in the urban agglomerations in the middle reaches of the yangtze river, china. Ecological Indicators 115, 106394 (2020).
Liu, Y., Lai, L. & Gao, Y. Mapping 10 m monthly surface water dynamics in the yangtze river basin from 2017 to 2020 using a robust atmc algorithm. Journal of Hydrology 626, 130327 (2023).
Zhu, X. X. et al. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE geoscience and remote sensing magazine 5, 8–36 (2017).
Ma, L. et al. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS journal of photogrammetry and remote sensing 152, 166–177 (2019).
Wang, L., Zuo, B., Le, Y., Chen, Y. & Li, J. Penetrating remote sensing: Next-generation remote sensing for transparent earth. The Innovation 4, 100519 (2023).
Li, W. et al. Multiclass crop interpretation via a lightweight attentive feature fusion network using vehicle-view images. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 18, 496–509 (2024).
Fan, R. et al. Urban informal settlements classification via a transformer-based spatial-temporal fusion network using multimodal remote sensing and time-series human activity data. International Journal of Applied Earth Observation and Geoinformation 111, 102831 (2022).
Fan, R. et al. Fine-scale urban informal settlements mapping by fusing remote sensing images and building data via a transformer-based multimodal fusion network. IEEE Transactions on Geoscience and Remote Sensing 60, 1–16 (2022).
Zhang, L. et al. A prolonged artificial nighttime-light dataset of china (1984-2020). Scientific Data 11, 414 (2024).
Tong, X. et al. Global area boom for greenhouse cultivation revealed by satellite mapping. Nature Food 1–11 (2024).
Zhu, Z. & Woodcock, C. E. Automated cloud, cloud shadow, and snow detection in multitemporal landsat data: An algorithm designed specifically for monitoring land cover change. Remote Sensing of Environment 152, 217–234 (2014).
Zhu, Z., Wang, S. & Woodcock, C. E. Improvement and expansion of the fmask algorithm: Cloud, cloud shadow, and snow detection for landsats 4–7, 8, and sentinel 2 images. Remote sensing of Environment 159, 269–277 (2015).
Zou, Z. et al. Continued decrease of open surface water body area in oklahoma during 1984–2015. Science of the Total Environment 595, 451–460 (2017).
Tucker, C. J. Red and photographic infrared linear combinations for monitoring vegetation. Remote sensing of Environment 8, 127–150 (1979).
Huete, A. et al. Overview of the radiometric and biophysical performance of the modis vegetation indices. Remote sensing of environment 83, 195–213 (2002).
Xu, H. Modification of normalised difference water index (ndwi) to enhance open water features in remotely sensed imagery. International journal of remote sensing 27, 3025–3033 (2006).
Farr, T. G. et al. The shuttle radar topography mission. Reviews of geophysics 45 (2007).
Xie, E. et al. Segformer: Simple and efficient design for semantic segmentation with transformers. Advances in Neural Information Processing Systems 34, 12077–12090 (2021).
Rolf, E., Klemmer, K., Robinson, C. & Kerner, H. Position: mission critical--satellite data is a distinct modality in machine learning. Proceedings of the 41 st International Conference on Machine Learning. (2024).
Wang, M. et al. Interannual changes of coastal aquaculture ponds in china at 10-m spatial resolution during 2016–2021. Remote Sensing of Environment 284, 113347 (2023).
Tarvainen, A. & Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Advances in neural information processing systems 30 (2017).
Olofsson, P. et al. Good practices for estimating area and assessing accuracy of land change. Remote sensing of Environment 148, 42–57 (2014).
Foody, G. M. Explaining the unsuitability of the kappa coefficient in the assessment and comparison of the accuracy of thematic maps obtained by image classification. Remote sensing of environment 239, 111630 (2020).
Ma, H., Wang, L., Yang, X., Fan, R. & He, K. Prolonged Water-Body Types Dataset of Urban Agglomeration in Central China(1990-2021), https://doi.org/10.57760/sciencedb.12990 (2024).
Li, C. et al. The first all-season sample set for mapping global land cover with landsat-8 data. Science Bulletin 62, 508–515 (2017).
Lehner, B. & Döll, P. Development and validation of a global database of lakes, reservoirs and wetlands. Journal of hydrology 296, 1–22 (2004).
Zanaga, D. et al. Esa worldcover 10 m 2021 v200, https://doi.org/10.5281/zenodo.7254221 (2022).
Acknowledgements
This paper is funded by National Natural Science Foundation of China (No.U21A2013) and the “CUG Scholar” Scientific Research Funds at China University of Geosciences (Wuhan) (Project No.2024013).
Author information
Authors and Affiliations
Contributions
W.L. conceived the experiment(s), M.H. and F.R. conducted the experiment(s), H.K. analysed the results, M.H. and Y.X. wrote the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ma, H., Yang, X., Fan, R. et al. Prolonged water body types dataset of urban agglomeration in central China from 1990 to 2021. Sci Data 12, 480 (2025). https://doi.org/10.1038/s41597-025-04794-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-04794-3
