
Abstract
Hydropower is a critical electricity resource in the United States which, in addition to low-cost electricity generation, provides valuable ancillary grid services, and supports the integration of nondispatchable weather-dependent resources (e.g., wind and solar). Despite its value to the grid, there are very few comprehensive datasets available from which to study both historical and future impacts of climate, weather driven energy droughts, and integration of other weather driven generation. In this paper, we present a hydropower generation dataset covering 1,452 hydroelectric plants in the contiguous U.S. The dataset contains monthly and weekly hydropower generation estimates for both historical (1982–2019) and future (2020–2099) periods which includes 4 future climate scenarios. In addition, this dataset provides weekly and monthly constraints such as minimum and maximum power which are particularly useful in power system models which are used to study grid reliability, transmission planning and capacity expansion.
Similar content being viewed by others
Background & Summary
Hydropower is a critical electricity resource in the United States (U.S.) accounting for an average 6.63% of annual utility scale generation from 2013 to 2023.1 Hydropower can also provide a range of ancillary services such as load factoring, operating reserves, voltage support, and blackstart that are especially valuable as low-cost non-dispatchable resources are added to the grid.2 Despite the importance of hydropower to the grid, there are limited comprehensive datasets available from which to study both historical and future impacts of climate, weather driven energy droughts, and integration of other weather driven generation. In this paper, we present a hydropower generation dataset covering 1,452 hydroelectric plants in the contiguous U.S comprised of both federal and privately owned facilities. The dataset contains monthly and weekly hydropower generation estimates for both historical (1982–2019) and future (2020–2099) periods, the latter containing 4 different climate scenarios.
Power system models such as production cost models (PCMs) represent the power system as an optimization problem where energy demands are met with both dispatchable resources such as natural gas and non-dispatchable resources such as wind and solar. These models often treat hydropower as a dispatchable resource which requires operational constraints such as power targets, minimum generation, maximum generation, and ramping rates which serve as approximations of true hydropower operations. The data presented here includes these operational constraints and so can be readily used to represent nearly all existing conventional U.S. hydropower generation in power system models.
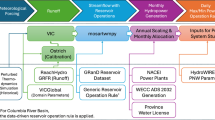
The development of hydropower generation and power constraints requires a series of models and data including meteorology, hydrology, routing, water management, and hydropower (Fig. 1). A distributed hydrology model takes meteorology data as input and computes gridded runoff, based on the calibrated hydrologic parameters. The runoff data is passed to a routing model which develops natural streamflow estimates within a river channel network developed on a uniform 1/8th degree grid. At certain grid cells where dams are present, the routing model must take into account human management, including reservoir operations and water demands. The final model in the chain converts regulated streamflow to hydropower. The following sections describe the models in greater detail.

Modeling chain used to develop hydropower estimates. The grey boxes indicate models or datasets, and the white boxes indicate the major output from each step of process.
Methods
Meteorology Data
In this study we used perturbed thermodynamics experiments3,4 (https://tgw-data.msdlive.org/) as meteorological forcing. The forcing data is a 1/8th degree dynamically downscaled product which contains both historical data and future projections over the contiguous United States (i.e. lower 48 states), southern Canada, and northern Mexico. The dynamically downscaled data is produced by initializing a WRF5 model using ERA56 boundary conditions. The future projections are developed by replicating the historical period (1980–2019) twice in the future (2020–2059, 2060–2099) while applying a warming signal that is derived from groups of Coupled Model Intercomparison Project (CMIP) 6 models.4 The warming scenarios are labeled as rcp45cooler, rcp45hotter, rcp85cooler, and rcp85hotter which represent a range of warming signals derived from climate models using the representative concentration pathway (RCP) 4.5 and 8.5 emissions scenarios.
Hydrology Model
For hydrologic modeling we use the variable infiltration capacity (VIC) model7,8 (https://vic.readthedocs.io/en/master/). VIC is a commonly used model for large scale distributed hydrologic modeling studies. Parameters are obtained from the VICGlobal9 dataset which contains vegetation and soil parameters on a 1/16th degree grid. We calibrate the parameters against the Global Reach-level River Flood Reanalysis data10 which is a global dataset of 1/20th degree runoff. Calibration is conducted for 1981–2000 at 1/16th degree resolution on a grid cell by grid cell basis. For automatic calibration we use the dynamically dimensioned search (DDS) algorithm11 through the Optimization Software Toolkit for Research Involving Computational Heuristics (OSTRICH) framework12 (https://doi-bor.github.io/ostrich/). The DDS algorithm is designed to provide a reasonably optimal solution within a limited computational budget, here we used 100 iterations of the DDS algorithm as testing indicated that more iterations provided marginal improvement to the objective function value. For the objective function we used the Kling-Gupta Efficiency (KGE) metric of monthly observed runoff as it provides a good balance between low and high runoff conditions. The KGE metric is described further in the validation section. Table 1 shows the calibration parameters and the ranges which are selected based on previous hydrologic studies using the VIC model9,10,13,14.
Routing and Water Management Model
Routing is conducted at a 1/8th degree scale by the mosartwmpy model15 (https://mosartwmpy.readthedocs.io/en/latest/), a Python implementation of the MOSART-WM model,16,17 which is part of the Energy Exascale Earth System Model (E3SM) (https://e3sm.org/). Routing alone produces gridded natural streamflow estimates but water management is required to develop estimates of regulated streamflow, storage, inflow, and outflow for hydropower projects, which mosartwmpy produces through the use of data driven reservoir operation rules18. Hydropower projects were mapped to the 1/8th degree grid as part of the 9505 federal assessment of hydropower19.
Hydropower Model
The final model in the chain takes the regulated streamflow values produced by mosartwmpy and generates weekly and monthly hydropower estimates, which we call B1hydro. At every hydropower plant, B1hydro models the power generation as a linear regression model with the form:
where Pt is the power at time t, O denotes the outflow, I denotes the inflow, S denotes the storage, which are outputs from the mosartwmpy model, βi,j are the regression parameters, and εt is the normally distributed error term. The lag parameter n is set to 12 and 52 for the monthly and weekly model respectively to account for annual hydrologic variability.
The data used to calibrate the regression parameters is the HydroWIRES B1 data20,21 (https://github.com/HydroWIRES-PNNL/B1-data), which contains weekly and monthly hydropower estimates that are disaggregated from U.S. Energy Information Administration (EIA) annual data22. The data is available for 2001–2019 which is used as the calibration period to develop both the historical and future hydropower data at every available hydropower plant location. Of the 1492 plants in the HydroWIRES B1 data, 1452 are included in the GODEEEP-hydro dataset, with the 40 plants excluded due to records that were too short (less than 2 years) or containing all zero values (i.e. decommissioned). The entire historical period (1982–2019) is included in the final dataset to provide (1) validation with observations and other derived datasets, (2) an extension the historical record beyond what is available in the HydroWIRES B1 data, and (3) a consistent record of hydropower that is coincident with other datasets derived from the perturbed thermodynamics experiment data (e.g.23).
In addition to total generation over the weekly or monthly period, the B1hydro model provides minimum and maximum power generation of the period and the average daily operational range (ador), which are directly useful in power system models. These values are defined as:
where Pmax,t and Pmin,t are the max and min allowed power generation at time t, Pador,t is average daily operational range at time t, Pt is the average power generation at time t, Pnp is the nameplate capacity of the plant, and amax, amin, and aador are parameters with values between 0 and 1 which can be derived from hourly power generation data.
Hourly hydropower generation is usually proprietary and business sensitive and therefore not publicly available. The Army Corps of Engineers Northwestern Division, which includes the Columbia River Basin, is one exception where historical hourly generation data from most federally-operated hydropower facilities is published on the Dataquery platform (https://www.nwd-wc.usace.army.mil/dd/common/dataquery/www/). The B1hydro model uses this hourly generation data to estimate the min and max power and ador at every hydropower plant in this study by assuming that amax, amin, and aador are equal to the average parameter values from all the hydropower facilities on the Dataquery platform. This approximation allows for reasonable constraints to be developed for power system models given the scarcity of publicly available hourly hydropower data.
Future Simulations
The four future climate scenarios in the TGW data (rcp45cooler, rcp45hotter, rcp85cooler, and rcp85hotter) are used to develop future hydropower simulations from 2020–2099. The calibrated VIC model is used to produce future runoff simulations for each scenario, which are then run through mosartwmpy, and finally the calibrated B1hydro model is used to produce monthly and weekly hydropower generation estimates.
Data Records
The data is available from Zenodo24 (https://doi.org/10.5281/zenodo.13776944).
The data is split into 10 data files, weekly and monthly data for each future scenario and the historical period. Each file has the naming convention <scenario>_ <monthly/weekly>.csv where <scenario> can be either “historical”, “rcp45cooler”, “rcp45hotter”, “rcp85cooler”, or “rcp85hotter” and <monthly/weekly> refers to the timestep of the data. Each of the data files has the following columns:
datetime The datetime stamp of the current timestep
eia_id An integer value with the EIA plant code that represents the facility
plant The name of the facility according to the EIA
power_predicted_mwh The total energy generated over the period in MWh, aka the energy target
n_hours The number of hours in the period, useful for converting between power and energy
p_avg Average power generation for the period
p_max Maximum allowable power generation for the period
p_min Minimum allowable power generation for the period
ador Average daily operational range for any given day in the period
scenario The name of the scenario, either “historical”, “rcp45cooler’, “rcp45hotter”, “rcp85cooler”, or “rcp85hotter”
Also included is the metadata file godeeep_hydro_plants.csv which contains metadata for each hydropower plant that is included in the dataset. Each row in this file refers to one hydropower facility. This file has the following columns:
eia_id An integer value with the EIA plant code that represents the facility
plant The name of the facility according to the EIA
mode Either “Storage” or “RoR” indicating if the plant is primarily operated as a storage or run-of-river facility
state Two letter U.S. state name
lat Latitude of the facility
lon Longitude of the facility
nameplate_capacity The total nameplate capacity of the facility according to the EIA
nerc_region Four letter code for the NERC region of the facility
ba Balacing authority of the facility
max_param Value of the amax parameter from Equation (2) used to derive p_max
min_param Value of the amin parameter from Equation (2) used to derive p_min
ador_param Value of the aador parameter from Equation (2) used to derive ador
huc2 Two digit hydrologic unit code (HUC) which contains the facility
Technical Validation
Hydrology model validation
The VIC hydrology model is calibrated at a monthly timestep for the period 1981–2000, and validated for 2001–2019, with the period 1979–1980 used as spin-up. We use the KGE metric to assess model performance25 on simulating runoff. KGE is a commonly used metric in hydrology where any value greater than −0.41 indicates performance better than the mean26. Figure 2 shows the calibration results for the study region. The calibration results are consistently above −0.41 and frequently much higher. The calibration results align well with previous CONUS-wide calibration efforts,27 with the best performance on the east and west coast and lower performance in the Midwest region east of the Rocky Mountains. The validation period has lower performance than the calibration period, which is to be expected, but overall the periods are similar which is encouraging.

KGE values for the calibrated VIC model in the calibration period (top) and the validation period (bottom).
Hydropower model validation
The first validation of the B1hydro model is designed to test the regression model using drop-one-year cross validation. In this procedure one year of data is dropped and the other years are used to predict the missing generation data. Using this approach on every year of data provides a complete record from which to assess the out-of-sample performance. Figure 3 shows a histogram of the KGE of all plant level hydropower models that are part of the B1hydro model. The performance is generally good, with only 2 out of 1,452 plants having performance less than −0.41.

KGE values from the B1hydro model for all modeled hydropower plants for both monthly and weekly data.
Additionally, we validate the B1hydro model against observed hydropower data in the Columbia River Basin. Figure 4 shows boxplots of the difference in the annual generation between observed annual hydropower and the B1hydro model output. The greatest error of about 200 aMW is seen at Grand Coulee which has the highest hydropower generation of any plant in the region. In general, the error is proportional to the nameplate capacity of the hydropower plant and tends to bracket 0, indicating reasonable annual performance with no annual bias in the B1hydro model.

Annual verification of B1hydro predictions against generation reported by the Army Corps of Engineers Northwestern Division for Columbia River Basin hydropower plants.
Validation against 9505 data
The 9505 assessment is the Department of Energy funded assessment of the relationship between climate and hydropower in the U.S. (https://www.energy.gov/eere/water/hydropower-climate-change-assessment). One outcome of the 9505 assessment is the development of a hydropower dataset that uses a selection of hydrologic models, hydropower models, forcing datasets.28 Here we compare with two hydrology models, Precipitation-Runoff Modeling System (PRMS)29 and VIC, two hydropower models, wmpy-power (WMP) and WRES28, and one forcing dataset, Livneh30. To facilitate an accurate comparison, we have only compared the hydropower plants that are simulated by both datasets.
Figure 5 shows the average total monthly generation for each HUC2 in the contiguous U.S. The hydropower estimates from GODEEEP-hydro are generally in line with the 9505 estimates lending confidence to the methodology presented here. Some notable differences occur in the Great Lakes and Ohio basins where GODEEEP-hydro is higher than the 9505 models. This may be due to differences in the representation of hydropower between the U.S. and Canada.

Monthly comparison of average total generation for each HUC2 basin in the contiguous U.S. Included in this comparison is the godeeeep_hydro data (B1hydro_VIC_godeeep), and four hydropower datasets that are part of the 9505 assessment, the wmpy-power model using the PRMS hydrology model (WMP_PRMS_9505), the wmpy-power model using the VIC hydrology model (WMP_VIC_9505), the WRES model using the PRMS hydrology model (WRES_PRMS_9505), and the WRES model using the VIC hydrology model (WRES_VIC_9505).
Usage Notes
The data is provided in csv files which should be readable in any modern software package. Each row of data in every file data file represents one timestep (either 1 month or 1 week). Some metadata is provided in each data row such as the EIA id, plant name and scenario name. If desired, the full set of metadata from godeeep_hydro_plants.csv can be joined to any data file using the eia_id column.
A companion dataset and paper31 providing hydropower data and PCM constraints for western Canada is available.
References
EIA. Electricity data browser https://www.eia.gov/electricity/data/browser/ (2024).
Somani, A. et al. Hydropower’s contributions to grid resilience. Tech. Rep., Pacific Northwest National Laboratory (2021).
Jones, A. D. et al. Im3/hyperfacets thermodynamic global warming (tgw) simulation datasets (v1.0.0) https://doi.org/10.57931/1885756 (2022).
Jones, A. D. et al. Continental united states climate projections based on thermodynamic modification of historical weather. Scientific Data 10, https://doi.org/10.1038/s41597-023-02485-5 (2023).
Skamarock, W. et al. A description of the advanced research wrf version 3. Tech. Rep., National Center for Atmospheric Research (2008).
Copernicus Climate Change Service. Era5 hourly data on single levels from 1940 to present https://doi.org/10.24381/cds.adbb2d47 (2018).
Liang, X., Lettenmaier, D. P., Wood, E. F. & Burges, S. J. A simple hydrologically based model of land surface water and energy fluxes for general circulation models. Journal of Geophysical Research: Atmospheres 99, 14415–14428, https://doi.org/10.1029/94jd00483 (1994).
Hamman, J. J., Nijssen, B., Bohn, T. J., Gergel, D. R. & Mao, Y. The variable infiltration capacity model version 5 (vic-5): infrastructure improvements for new applications and reproducibility. Geoscientific Model Development 11, 3481–3496, https://doi.org/10.5194/gmd-11-3481-2018 (2018).
Schaperow, J. & Li, D. Vicglobal: soil and vegetation parameters for the variable infiltration capacity hydrological model https://doi.org/10.5281/zenodo.5038653 (2021).
Yang, Y. et al. Global reach-level 3-hourly river flood reanalysis (1980–2019). Bulletin of the American Meteorological Society 102, E2086–E2105, https://doi.org/10.1175/BAMS-D-20-0057.1 (2021).
Tolson, B. A. & Shoemaker, C. A. Dynamically dimensioned search algorithm for computationally efficient watershed model calibration. Water Resources Research 43, https://doi.org/10.1029/2005WR004723 (2007).
Matott, L. Ostrich: an optimization software tool, documentation and user’s guide, version 17.12.19. University at Buffalo Center for Computational Research (2017).
Demaria, E. M., Nijssen, B. & Wagener, T. Monte carlo sensitivity analysis of land surface parameters using the variable infiltration capacity model. Journal of Geophysical Research-Atmospheres 112, https://doi.org/10.1029/2006jd007534 (2007).
Oubeidillah, A. A., Kao, S. C., Ashfaq, M., Naz, B. S. & Tootle, G. A large-scale, high-resolution hydrological model parameter data set for climate change impact assessment for the conterminous us. Hydrology and Earth System Sciences 18, 67–84, https://doi.org/10.5194/hess-18-67-2014 (2014).
Thurber, T. et al. mosartwmpy: A python implementation of the mosart-wm coupled hydrologic routing and water management model. Journal of Open Source Software 6, 3221, https://doi.org/10.21105/joss.03221 (2021).
Li, H. Y. et al. A physically based runoff routing model for land surface and earth system models. Journal of Hydrometeorology 14, 808–828 https://doi.org/10.1175/Jhm-D-12-015.1 (2013).
Voisin, N. et al. On an improved sub-regional water resources management representation for integration into earth system models. Hydrology and Earth System Sciences 17, 3605–3622, https://doi.org/10.5194/hess-17-3605-2013 (2013).
Turner, S. W., Steyaert, J. C., Condon, L. & Voisin, N. Water storage and release policies for all large reservoirs of conterminous united states. Journal of Hydrology 603, 126843, https://doi.org/10.1016/j.jhydrol.2021.126843 (2021).
Broman, D. & Voisin, N. Existing hydropower assets (eha) plant database 9505 point of diversion https://doi.org/10.5281/zenodo.10520486 (2024).
Turner, S. W. D., Voisin, N. & Nelson, K. Revised monthly energy generation estimates for 1,500 hydroelectric power plants in the united states. Scientific Data 9, https://doi.org/10.1038/s41597-022-01748-x (2022).
Turner, S. W., Bracken, C., Voisin, N. & Oikonomou, K. HydroWIRES B1: Monthly and Weekly Hydropower Constraints Based on Disaggregated EIA-923 Data https://doi.org/10.5281/zenodo.13351949 (2024).
EIA. Form EIA-860 detailed data with previous form data (EIA-860A/860B). https://www.eia.gov/electricity/data/eia860/ (2022).
Campbell, A., Bracken, C., Underwood, S. & Voisin, N. A multi-decadal hourly coincident wind and solar power production dataset for the contiguous us. Submitted (2024).
Bracken, C., Voisin, N., Broman, D. & Son, Y. GODEEEP-hydro - Historical and projected power system ready hydropower data for the United States https://doi.org/10.5281/zenodo.14269763 (2024).
Gupta, H. V., Kling, H., Yilmaz, K. K. & Martinez, G. F. Decomposition of the mean squared error and nse performance criteria: Implications for improving hydrological modelling. Journal of Hydrology 377, 80–91, https://doi.org/10.1016/j.jhydrol.2009.08.003 (2009).
Knoben, W. J. M., Freer, J. E. & Woods, R. A. Technical note: Inherent benchmark or not? comparing nash-sutcliffe and kling-gupta efficiency scores. Hydrology and Earth System Sciences 23, 4323–4331, https://doi.org/10.5194/hess-23-4323-2019 (2019).
Newman, A. J. et al. Development of a large-sample watershed-scale hydrometeorological data set for the contiguous usa: data set characteristics and assessment of regional variability in hydrologic model performance. Hydrology and Earth System Sciences 19, 209–223, https://doi.org/10.5194/hess-19-209-2015 (2015).
Broman, D., Voisin, N., Kao, S.-C., Fernandez, A. & Ghimire, G. R. Multi-scale impacts of climate change on hydropower for long-term water-energy planning in the contiguous united states. Environmental Research Letters 19, 094057, https://doi.org/10.1088/1748-9326/ad6ceb (2024).
Regan, R. S. & LaFontaine, J. H. Documentation of the dynamic parameter, water-use, stream and lake flow routing, and two summary output modules and updates to surface-depression storage simulation and initial conditions specification options with the Precipitation-Runoff Modeling System (PRMS). US Geological Survey (2017).
Livneh, B. et al. A long-term hydrologically based dataset of land surface fluxes and states for the conterminous united states: Update and extensions. Journal of Climate 26, 9384–9392, https://doi.org/10.1175/JCLI-D-12-00508.1 (2013).
Son, Y., Bracken, C., Broman, D. & Voisin, N. A monthly hydropower generation dataset for western canada to support western-us interconnect grid system studies. Scientific Data https://doi.org/10.1038/s41597-025-05098-2 (2025).
Bracken, C. & Son, Y. Godeeep/tgw-hydro: Manuscript revision 1 https://doi.org/10.5281/ZENODO.15115742 (2025).
Son, Y., Bracken, C., Broman, D. & Voisin, N. Monthly Hydropower Generation Dataset for Western Canada, 1.1, https://doi.org/10.5281/zenodo.14984725 (2025).
Acknowledgements
This research was supported by the Laboratory Directed Research and Development (LDRD) Program at the Pacific Northwest National Laboratory (PNNL). This work leverages the capabilities of mosartwmpy, a Python version of the MOSART-WM model supported by the U.S. Department of Energy, Office of Science, as part of research in MultiSector Dynamics, Earth, and Environmental Systems Modeling Program and enhanced by the Energy Efficiency and Renewable Energies - Hydrological Sciences Program. This work also leverages early formulation developed under the HydroWIRES B1 project (grant 75563) sponsored by the Water Power Technologies Office under the HydroWIRES initiative. This research used resources of the Pacific Northwest Research Computing at the PNNL, which is a DOE Office of Science User Facility. The PNNL is a multi-program national laboratory operated by Battelle Memorial Institute for the U.S. Department of Energy (DOE) under Contract No. DE-AC05-76RL01830. Accordingly, the U.S. Government retains and the publisher, by accepting the article for publication, acknowledges that the U.S. Government retains a nonexclusive, paid-up, irrevocable, worldwide license to publish or reproduce the published form of this manuscript or allow others to do so, for U.S. Government purposes.
Author information
Authors and Affiliations
Contributions
All authors conceived the workflow. D.B., C.B. and Y.S. produced the forcings. C.B. and Y.S. conducted the calibrations. C.B. ran the historical simulations. Y.S. ran the future simulations. C.B. and N.V. developed the hydropower model. C.B. developed the initial manuscript. N.V. acquired funding and provided general supervision. All authors contributed to editing the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bracken, C., Son, Y., Broman, D. et al. GODEEEP-hydro: Historical and projected power system ready hydropower data for the United States. Sci Data 12, 875 (2025). https://doi.org/10.1038/s41597-025-05097-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-05097-3
