
Abstract
During a pandemic, knowledge, risk perceptions, trust in institutions and attitudes towards public health measures influence protective behaviours and mental health. The COVID-19 Snapshot Monitoring (COSMO) project collected psychosocial data on pandemic-related attitudes, feelings and behaviours from representative samples in Germany. In sixty-nine cross-sectional online surveys conducted between 03.03.2020 and 29.11.2022, N = 69,013 individuals were assessed. Our 332 variables show how COVID-19 was perceived (e.g., symptoms, risk perceptions), which behaviours were exhibited (e.g., mask wearing, keeping distance, being vaccinated, meeting other people), what attitudes and beliefs people held (e.g., towards vaccination, conspiracy beliefs, pandemic fatigue), which information sources they used and trusted, how their mental health was affected (e.g., worries, wellbeing, resilience) and what consequences the pandemic had for people (e.g., financial losses, alcohol consumption). Variables are available for at least five waves (i.e., roughly 5,000 participants), some variables are available for all waves. The data allow tracing population-level changes in pandemic perceptions and actions, assess the relationships between determinants and behaviours, and help prepare for future crises.
Similar content being viewed by others
Background & Summary
The COVID19-Snapshot Monitoring (COSMO) is a research project that aimed to gain insights into how the German population perceived the COVID-19 pandemic, the political measures taken to contain the pandemic and its psychosocial impact on everyday life in Germany between March 2020 and November 2022. The collected data were intended to provide political stakeholders, the media and the population with helpful knowledge about the psychological aspects of the pandemic and to prevent misinformation (e.g., regarding the acceptance of political measures) and knee-jerk reactions based on unfounded assumptions about how members of the public feel or behave1,2. In addition, the pandemic yielded a unique opportunity for social and behavioural scientists to study human behaviour in a crisis. The evidence gathered can support future pandemic preparedness3. In addition, the presented data can help evaluate some of the predictions made by behavioural science and thus also add to the discussion of behavioural science’s usefulness in guiding crisis responses4. For example, in the COSMO study, efforts were made to contextualise behaviours and public health measures that were heavily debated in the media, such as mask wearing5, rapid testing6 and nationwide lockdowns7. Future users can make use of the data by assessing perceptions in relations to such policy changes (e.g. as collected by the Oxford Covid-19 Government Response Tracker (OxCGRT8)).
Methods
A methodological preprint published at the survey’s outset9,10 was utilised to establish a standard protocol, which was recommended by WHO Europe11 for use as a WHO-tool12 and adopted by about 40 countries (e.g., Denmark13, Spain14, Finland15, Iran16).
Ethical review
Ethical clearance was obtained from the University of Erfurt’s institutional review board (#20200302/2020831/20200501). It was approved that the study follows the ethical guidelines of the University of Erfurt, that the safety and well-being of the subjects was ensured at any time, that there were no ethical concerns for the recruitment of the participants, the implementation of the study design or the subsequent data analysis and processing, and that the undertaken measures safeguard the ethical standards as proposed by the DGPs (German Psychological Society). Participants gave informed consent to take part in the study voluntarily, with the understanding that their data would be used solely for scientific purposes and for supporting public health communication efforts. They were informed that the anonymized data would be stored permanently and may be shared with other researchers for future scientific use. Informed consent was obtained through an online consent form, presented prior to the start of the actual study: Participants had to actively agree to the terms and confirm their understanding before proceeding to the questionnaire. To ensure privacy and data protection, all data was collected in an anonymized way. No personally identifying information (such as names or contact details) was collected or stored.
Sampling method
The project comprised 69 cross-sectional surveys conducted in Germany between March 2020 and November 2022. While the surveys were performed weekly to biweekly in the first year of the project, the frequency of survey administration decreased later. Each survey took between 20 and 30 minutes and was completed by approximately 1,000 individuals (N = 69,013). The data provider Bilendi GmbH recruited and compensated the respondents. Data collection typically took place between Tuesday afternoon and Wednesday at midnight during the data collection weeks. Such a short data collection period was chosen as at some timepoints during the pandemic COVID-19 cases, decisions and media debates about political measures were advancing quickly. As the survey aimed to provide a rather exact snapshot, the data were collected within roughly 36 hours. The sampling was quota-representative in terms of age (18–74 years of age) and gender (crossed), as well as the German federal states, according to census data17. Because the quota sample was based on the German census data, which did not include more than two genders at the time, only men and women were sampled by quota. For a better impression of the sample, Table 1 provides the quotas in the sample in comparison to the available census data. As can be seen, the sample was higher educated than the German population, but please note that this was not a stratification criterion. When quotas were completed, participants were screened out after providing their quota-relevant demographics.
Measurements
Table 2 provides an overview of constructs available in the dataset. Note that for most constructs there is a set of items or a validated scale available. The questionnaire covered socio-demographic information; the monitoring of risk perceptions18; emotional responses to the pandemic19,20,21; self-efficacy22,23, trust in institutions24; adherence to protective measures; a range of concerns; general burden and wellbeing; vaccination-related attitudes, intentions and behaviours; attitudes towards upcoming and implemented policies and conspiratorial tendencies25,26. All original questionnaires are available online (https://osf.io/w38cn/). Note that the single questionnaires may contain variables not included in the dataset, because there were not assessed at least five times, and this was the criterion for including the variables in this data set.
Due to extreme time pressure, high workload and limited resource there was no formalized advisory process regarding which variables to assess or to drop from the study; topics were gathered from press briefings and the news, interactions with study partners, meetings with government and administration representatives and discussions with other scientists (see acknowledgements). Thus, the process can be described as rather bottom up, problem-oriented and use-inspired, partially due to the speed of changes happening during the pandemic as well as the short intervals between the data collections. Most variables and items were therefore newly constructed as they responded to events or behaviours that became important over the course of the pandemic. Yet, there are several validated scales that were used repeatedly, namely the 5 C vaccination readiness27, conspiracy beliefs25,26, pandemic fatigue28, wellbeing (WHO520,21), resilience29 and satisfaction with life30. Detailed information about the items included in the data set, their measurement and English translations are presented in the codebook, which is also available in the repository31.
Data Records
The dataset is available at PsychArchives31 and provides as a csv and Excel file. For use in R we suggest using the csv file. All survey measures that were assessed in at least five surveys were considered for publication. This selection was made to create larger samples per potential question and identify themes and variables that were relevant for a substantial period of time. Some variables were assessed only once or belonged to single experiments and are not presented here. The data set contains a column for each measure and a row for each participant. Two columns identify the time point of the sampling in the form of the chronological number of the survey (TIME, numerical order from 1 to 70; the survey TIME = 36 was used for a related longitudinal follow-up survey, and is not included in the cross-sectional dataset described here), as well as the specific survey date (TIME_NOMINAL, ranging from 03.03.20 to 29.11.22; indicating the day on which the 36-hour data collection period began). Note that there is an additional time-point indicated by TIME = 71 from September 2023 that only includes socio-demographics, vaccination readiness and intention to get vaccinated. We do not consider this a full wave but report this follow up for completeness.
Technical Validation
The data provider guaranteed the data quality. The company regularly checked the quality of participants’ answers in its own surveys and removes bots and unreliable participants. We further ensured the cross-sectional nature of the data collection by not inviting participants who had participated in one of the previous 20 weeks to reduce conditioning effects. An additional check was also run in R, which identified and removed duplicates within a wave and in relation to previous waves for which a participant would still be blocked. Other than that, no validation or clean-up processes were implemented. Subsequent users of the dataset can further clean the data (e.g., by removing participants with fast or slow survey durations or whose answer patterns indicate inattentive responding).
Usage Notes
The presented dataset is unique, as it covers behavioural data from the pandemic from its beginning across almost three important and eventful years. The data collections were highly adaptive, which led to the rapid generation of items. While this confers the advantage that the themes and topics that were brought up by the media, society or politics could be integrated swiftly, creating a thorough theoretical foundation for each item or research question was not always possible. In addition, the large quantity of data allows us to explore a nearly endless number of relationships. While we believe that exploring the data may be valuable, confirmative research will require preregistration. We therefore suggest preregistering the research question and hypotheses at hand.
The data is made available for public use (Sharing level 0), allowing open and immediate access (https://psycharchives.org/en/about#sharing_levels).
COVID-19 Behavioural data dashboard
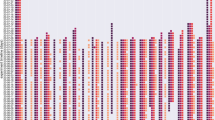
In order to explore the data in an interactive way, we also provide code for the COSMO Explorer (https://explore.healthpsychology.uni-bamberg.de/shiny/cosmo-explorer-en/), a web-based app that allows users to directly investigate variables (Fig. 1). The variables in the final version include risk perceptions, several protective behaviours, worries and fears, trust, attitudes towards several implemented and discussed measures and regulations, willingness to be vaccinated and several reasons for or against vaccination and belief in conspiracies. Details about the measurement of each variable (e.g., the measurement range) are directly described in a table below the visualisation. The recent version visualises:
-
(1)
The development of variable means over time (as shown in Fig. 1): The app allows users to examine how one or multiple variables unfold over time. Variables can be stratified according to various dimensions (as exemplified in Fig. 1), including demographics, such as age, gender, or education, as well as the acceptance of implemented response measures, allowing us to compare specific subgroups in the population. Confidence intervals allow users to estimate significant differences between timepoints and groups.
-
(2)
Development of variable distributions over time: The app visualizes the change of distributions for single variables. This information can help to better understand changes in mean values.
-
(3)
Correlations between variables: The app visualises relationships between variables by displaying the development of correlation coefficients over time (e.g., risk perception and acceptance of policies). While causation cannot be implied, information about the relationships between perceptions, attitudes and behaviours allows theory testing or development and can indicate important targets for future research questions, interventions and measures.

User interface for the COSMO Explorer. The interactive app allows users to investigate the development of variable means and distributions, as well as their correlations over time. *Major events: (1) first lockdown, 22.03.2020; (2) loosening of restrictions, 06.05.2020; (3) launch of Corona-Warning App, 16.06.2020; (4) first large protests in Berlin, 01.08.2020; (5) partial lockdown, 02.11.2020; (6) first vaccines undergoing approval, 15.11.2020; (7) lockdown, 16.12.2020; (8) first loosening of restrictions after lockdown, 01.03.2021; (9) 3 G regulations (access to public spaces when vaccinated, tested or recovered), 24.11.2021; (10) new government taking over, 08.12.2021; (11) expiration of 3 G regulations, 19.03.2021.
The development of variables and their correlations can be interpreted against the background of incidence rates and important pandemic events, which can also be displayed in the app (see Figure note; for more events consult respective repositories, e.g.8). The COSMO Explorer can be adapted to visualize COSMO data from other countries as well. The app is implemented in R using the Shiny framework. Researchers from other countries are invited to use the code and add other variables included in the dataset to the explorer.
Limitations
The urgency of the situation incurs some limitations to the study, including limited opportunities for scientific review and validation, as described above. This was also pointed out in the WHO standard protocol that was developed based on this work11.
Code availability
The code used to produce the shiny app (COSMO Explorer) is openly available on GitLab (https://gitlab.com/pidilab/cosmo-explorer) and can be used under a CC-BY-NC license.
References
Betsch, C. How behavioural science data helps mitigate the COVID-19 crisis. Nat Hum Behav 4, 438 (2020).
A vision for actionable science in a pandemic. Nat Commun 11, 4960 (2020).
Bavel, J. J. V. et al. Using social and behavioural science to support COVID-19 pandemic response. Nat Hum Behav 4, 460–471 (2020).
Ruggeri, K. et al. Evaluating Expectations from Social and Behavioral Science about COVID-19 and Lessons for the next Pandemic. https://doi.org/10.31234/osf.io/58udn (2022).
Betsch, C. et al. Social and behavioral consequences of mask policies during the COVID-19 pandemic. Proc Natl Acad Sci USA 117, 21851–21853 (2020).
Betsch, C. et al. Empirical evidence to understand the human factor for effective rapid testing against SARS-CoV-2. Proceedings of the National Academy of Sciences 118, e2107179118 (2021).
Sprengholz, P., Siegers, R., Goldhahn, L., Eitze, S. & Betsch, C. Good night: Experimental evidence that nighttime curfews may fuel disease dynamics by increasing contact density. Soc Sci Med 286, 114324 (2021).
Hale, T. et al. A global panel database of pandemic policies (Oxford COVID-19 Government Response Tracker). Nat Hum Behav 5, 529–538 (2021).
Betsch, C. et al. German COVID-19 Snapshot Monitoring (COSMO) - Welle 1 (03.03.2020). Preprint at https://doi.org/10.23668/PSYCHARCHIVES.2859 (2020).
Betsch, C., Wieler, L. H., Habersaat, K. & group, C. O. S. M. O. Monitoring behavioural insights related to COVID-19. Lancet 395, 1255–1256 (2020).
WHO Regional Office For Europe. COVID-19 Snapshot MOnitoring (COSMO Standard): Monitoring knowledge, risk perceptions, preventive behaviours, and public trust in the current coronavirus outbreak - WHO standard protocol (2020).
WHO tool for behavioural insights on COVID-19. https://www.who.int/europe/tools-and-toolkits/who-tool-for-behavioural-insights-on-covid-19.
Böhm, R. et al. The COVID-19 Snapshot Monitoring in Denmark. Samfundsøkonomen 2020, 62–69 (2020).
Rodríguez-Blázquez, C., Romay-Barja, M., Falcón, M., Ayala, A. & Forjaz, M. J. The COSMO-Spain Survey: Three First Rounds of the WHO Behavioral Insights Tool. Front. Public Health 9 (2021).
Hammer, C. C., Cristea, V., Dub, T. & Sivelä, J. High but slightly declining COVID-19 vaccine acceptance and reasons for vaccine acceptance, Finland April to December 2020. Epidemiology & Infection 149, e123 (2021).
Janani, L. et al. COVID-19 Population Survey of Iran (COPSIR) study protocol: Repeated survey on knowledge, risk perception, preventive behaviors, psychological problems, essential needs, and public trust during COVID-19 epidemic. Med J Islam Repub Iran 34, 52 (2020).
ZENSUS2011 - Bevölkerungs- und Wohnungszählung 2011. https://www.zensus2011.de/DE/Home/home_node.html.
Brewer, N. T. et al. Meta-analysis of the relationship between risk perception and health behavior: the example of vaccination. Health Psychology 26, 136 (2007).
Bradley, M. M. & Lang, P. J. Measuring emotion: The self-assessment manikin and the semantic differential. Journal of Behavior Therapy and Experimental Psychiatry 25, 49–59 (1994).
Bech, P. Health‐related quality of life measurements in the assessment of pain clinic results. Acta Anaesthesiol Scand 43, 893–896 (1999).
Organization, W. H. WHO (Fünf)-Fragebogen zum Wohlbefinden (Version 1998). Hillerød, Denmark: Psychiatric Research Unit, WHO Collaborating Center for Mental Health 4 (1998).
Bandura, A. Social Cognitive Theory: An Agentic Perspective. Annual Review of Psychology 52, 1–26 (2001).
Renner, B. & Schwarzer, R. Social-cognitive factors in health behavior change. Social psychological foundations of health and illness 169–196 (2003).
Grimmelikhuijsen, S. & Knies, E. Validating a scale for citizen trust in government organizations. International Review of Administrative Sciences 83, 583–601 (2017).
Bruder, M., Haffke, P., Neave, N., Nouripanah, N. & Imhoff, R. Measuring Individual Differences in Generic Beliefs in Conspiracy Theories Across Cultures: Conspiracy Mentality Questionnaire. Front. Psychol. 4 (2013).
Imhoff, R. & Lamberty, P. ‘A bioweapon or a hoax? The link between distinct conspiracy beliefs about the coronavirus disease (COVID-19) outbreak and pandemic behavior’: Corrigendum. Social Psychological and Personality Science 12, 143–144 (2021).
Betsch, C. et al. Beyond confidence: Development of a measure assessing the 5C psychological antecedents of vaccination. PLOS ONE 13, 0208601 (2018).
Lilleholt, L., Zettler, I., Betsch, C. & Böhm, R. Development and validation of the pandemic fatigue scale. Nature Communications 14, 6352 (2023).
Smith, B. W. et al. The brief resilience scale: Assessing the ability to bounce back. Int. J. Behav. Med. 15, 194–200 (2008).
Beierlein, C., Kovaleva, A., László, Z., Kemper, C. J. & Rammstedt, B. Eine single-item-skala zur erfassung der allgemeinen lebenszufriedenheit: Die kurzskala lebenszufriedenheit-1 (L-1) (2014).
Betsch, C. et al. COVID-19 Snapshot Monitoring (COSMO Germany) – Data of 69 surveys on pandemic attitudes, feelings and behaviours. PsychArchives https://doi.org/10.23668/PSYCHARCHIVES.15213 (2024).
Acknowledgements
The institutions contributing to the COVID-19 Snapshot Monitoring were the University of Erfurt (project lead: Cornelia Betsch; team: Sarah Eitze, Lisa Felgendreff, Lars Korn, Parichehr Shamsrizi, Regina Siegers, Philipp Sprengholz, Frederike Taubert), the Bernhard Nocht Institute for Tropical Medicine (Michael Ramharter, Marylynn Addo), the Federal Centre for Health Education (BZgA) (Heidrun Thaiss, Urusla von der Rüden), the Robert Koch Institute (RKI; Lothar Wieler, Patrick Schmich, Jenny Allen, Nora Schmid-Küpke, Mirjam Jenny), the Leibniz Institute for Psychology (ZPID; Michael Bosnjak, Lea Gerhards) and the German Science Media Centre (SMC; Volker Stollorz). For a rapid review of the summarised results of the monitoring, especially at the beginning of the pandemic, we are grateful to, in alphabetical order, Robert Böhm, Petra Dickmann, Wolfgang Gaissmaier, and Britta Renner. For a contribution to the questionnaires we would like to thank, in alphabetical order, Petra-Angela Ahrens, Robert Böhm, Dirk Brockmann, Martin Bruder, Molly Crockett, Cara Ebert, Petra Dickmann, Jens Eger, Jörg Faust, Wolfgang Gaissmaier, Donya Gilan, Luca Henkel, Roland Imhoff, Christian Krauth, Georg Lämmlin, Pia Lamberty, Klaus Lieb, Benjamin F. Maier, Saad B. Omer, Britta Renner, Frank Schlosser, Philipp Schmid, Sebastian Schneider, Janina Steinert and Johannes Thrul. The study was financially supported by the Klaus Tschira Foundation, the Federal Ministry of Health via the RKI and the BZgA, Thüringer Staatskanzlei, Thüringer Ministerium für Wirtschaft, Wissenschaft und Digitale Gesellschaft (total sum < 750.000€), and, indirectly and partially via the German Research Foundation (BE 3970/12-1 to CB) and the Leibniz Best Minds Program (P106/2020 to CB) (total sum ca. 1.5 Mio €).
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
Betsch, Cornelia, contributed to Conceptualisation, Methodology, Validation, Investigation, Resources, Supervision, Writing. Eitze, Sarah, contributed to Conceptualisation, Methodology, Validation, Investigation, Writing the Draft and Formal Analysis. Felgendreff, Lisa, contributed to Conceptualisation, Methodology, Validation, Investigation and Formal Analysis. Korn, Lars, contributed by Conceptualisation, Methodology, Validation, Investigation and Formal Analysis. Sprengholz, Philipp, contributed to Conceptualisation, Methodology, Validation, Investigation, Software, Writing the Draft and Formal Analysis. Tänzer, Anne contributed to Resources and Data Curation.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Betsch, C., Eitze, S., Korn, L. et al. Dataset of 69 German COVID-19 Snapshot Monitoring (COSMO) surveys on pandemic attitudes, feelings and behaviours. Sci Data 12, 1066 (2025). https://doi.org/10.1038/s41597-025-05275-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-05275-3
