
Abstract
We introduce the Vector-QM24 (VQM24) dataset comprehensively covering all possible neutral closed-shell small organic and inorganic molecules with up to five heavy (p-block) atoms: C, N, O, F, Si, P, S, Cl, Br. All valid stoichiometries, Lewis-rule-consistent graphs, and stable conformers (identified via GFN2-xTB) were enumerated combinatorially, yielding 577k conformational isomers spanning 258k constitutional isomers and 5,599 unique stoichiometries. DFT (ωB97X-D3/cc-pVDZ) optimizations were performed for all, and diffusion quantum Monte Carlo (DMC@PBE0(ccECP/cc-pVQZ)) energies are provided for 10,793 lowest-energy conformers with up to 4 heavy atoms. VQM24 includes structures, vibrational modes, rotational constants, thermodynamic properties (Gibbs free energies, enthalpies, ZPVEs, entropies, heat capacities), and electronic properties such as atomization, electron interaction, exchange-correlation, dispersion energies, multipole moments (dipole to hexadecapole), alchemical potentials, Mulliken charges, and wavefunctions. Machine learning models of atomization energies on this dataset reveal significantly higher complexity than QM9, with none achieving chemical accuracy. VQM24 offers a rigorous, high-fidelity benchmark for evaluating quantum machine learning models.
Similar content being viewed by others
Background & Summary
High quality quantum mechanical datasets of molecular properties are a primary requirement for developing approximate physics and statistics based models to enhance the navigation of chemical compound space (CCS). Numerous datasets focusing on distinct, chemically relevant subspaces have paved the way for systematic and quantitative exploration of CCS such as in Refs. 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23. Most of the quantum mechanical (QM) datasets such as QM71, QM93, ANI10, QMrxn24, QMugs6, PubChemQC14 are derived from string based lists of compounds from the GDB25,26, ChEMBL27, PubChem28 databases while datasets like revQM929, GEOM7, MultiXC-QM98, G4MP2-QM929, QMspin30, QM-sym31,32, ANI-1x11, QM7-X12 correspond to extensions. The effectiveness of ML models relies on complete representativeness and accuracy of the relevant reference data. Unfortunately, and due to the combinatorial scaling of number of possible stable compounds with size and composition33, they are typically incomplete and consequently introduce considerable bias in machine learning (ML) models trained and assessed on them. Furthermore, while Density Functional Theory (DFT) has been key to the development of highly accurate and efficient ML models over the past decade34,35,36,37, there is still a lack of data exhaustively covering specific regions of chemical space at higher QM levels. Note that even for the simplest stoichiometries and smallest subsets of graphs, exhaustive lists of quantum properties are lacking. The primary reason behind this is the combinatorially intractable nature of the problem as the number of atoms and unique chemical elements grows. Nevertheless, it is important to systematically fill these gaps since limited chemical diversity limits the generalizability of ML models, as was pointed out recently38. Furthermore, exhaustive coverage of chemical spaces spanned by the smallest systems is key for ML models since locality can be exploited to achieve scalable statistical models of physical properties39,40,41,42.
Here, we tackle this task by reporting VECTOR-QM24 (VQM24), a diverse and comprehensive dataset of - small organic and inorganic molecules calculated at the ωB97X-D3/cc-pVDZ level of theory43,44,45,46. VQM24 comprises 5,599 unique stoichiometries, corresponding to 258,242 distinct molecular graphs and constitutional isomers. Ground state structures of these constitutional isomers were used to obtain 577,705 additional conformers, leading to a grand total of 835,947 molecular structures within the dataset. More specifically, this dataset has been generated by first evaluating all possible Lewis structures (according to SURGE47) for molecules consisting of up to five heavy atoms drawn from C, N, O, F, Si, P, S, Cl, Br with their most frequent valencies followed by saturation with hydrogens to obtain neutral closed-shell combinations. Thereafter, conformational isomers were generated for all graphs, using GFN2-xTB48,49, and subsequently relaxed using density functional theory (ωB97X-D3/cc-pVDZ). For all 835,947 converged molecules (post DFT optimization), we provide the corresponding optimized structures, an extensive list of thermal properties (internal, atomization, Gibbs free and zero point vibrational energies; enthalpy, entropy, heat capacities and rotational constants) along with vibrational modes and frequencies, electronic properties (electron repulsion, exchange-correlation, dispersion and moleculuar orbital energies; HOMO-LUMO gaps, electrostatic potentials at nuclei, dipole, quadrupole, octupole, hexadecapole moments) and wavefunctions. Goind beyond DFT, we also report diffusion quantum Monte Carlo (DMC) energies, converged to sub milli-Hartree statistical uncertainty, for the smaller sub-set of 10,793 energetically lowest lying conformers of molecules composed of only up to 4 heavy atoms. To the best of our knowledge, this constitutes the largest quantum Monte Carlo (QMC) dataset in chemical space reported yet. The molecules included in this dataset also constitute an overlapping as well as complementary set of the atoms-in-molecules (amons)39 dictionary that represents the local chemistries encoded by the GDB and ZINC50 lists.
Methods
Structure generation
In order to generate the structures for VQM24, all combinatorially possible sum formulas were calculated from molecules with up to five heavy atoms, drawn from the list of the following chemical elements: C, N, NX, O, F, Si, P, PX, S, SX, SY, Cl, Br (lower index syntax is in line with SURGE47 and correspond to less common valencies, as also listed in Table 1). This was done by generating all possible combinations for up to 5 selected elements (not counting hydrogen) using the native Python package itertools. Since there are 13 possible heavy elements, the number of combinations containing n-heavy atoms is equal to \(\frac{(12+n)!}{12!n!}=\) 13, 91, 455, 1820, and 6188 for n = 1, 2, 3, 4, and 5, respectively Fig. 1. The possible number of hydrogen atoms, nH, for any chosen combination of heavy atoms is then given by the following integer partitioning problem:
where n1, n2, n3 are integers respectively denoting the number of single, double and triple bonds in the system, while v denotes the total valency of the system (sum over atomic valencies of each element as displayed in Table 1). Note that this procedure also accounts for stoichiometries consistent with ring closures. As concrete illustrations, consider methylamine (CH3NH2): carbon (valency 4) plus nitrogen (valency 3) gives v = 7. With one C-N single bond (n1 = 1, n2 = n3 = 0), Eq. (1) yields nH = 7 − 2 × 1 = 5, producing CH3NH2. Likewise, for ethene (C2H4), two carbons (v = 4 + 4 = 8) with one C=C double bond (n2 = 1, n1 = n3 = 0) give nH = 8 − 4 × 1 = 4, yielding C2H4 . For Benzene (C6H6): six C atoms (v = 6 × 4 = 24) with three C-C single bonds and three C=C double bonds (n1 = 3, n2 = 3, n3 = 0) nH = 24 − 2 × 3 − 4 × 3 = 6, yielding C6H6 and capturing the ring closure topology automatically.

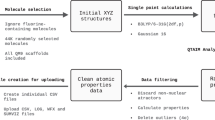
Workflow used to generate the VQM24 dataset. All possible stoichiometries were first calculated by choosing all combinations of up to 5 heavy atoms (non-Hydrogen) and saturating them with hydrogens to satisfy the valencies via integer partitioning. Heavy atoms included along with their valencies are reported in Table 1. For each stoichiometry, all possible graphs as identified by the SURGE47 package were evaluated. RDkit51 was then used to generate initial geometries which were first optimized at the GFN2-xTB48 level of theory, followed by a conformer search using CREST52. All conformers identified at the xTB level of theory were then optimized with DFT (ωB97X-D3/cc-pVDZ44– 46) using PSI455, followed by frequency calculations to identify the saddle point orders. For a smaller subset of the most stable conformers with up to 4 heavy atoms, subsequent diffusion quantum Monte Carlo (DMC) calculations were performed using QMCPACK71,72 along with nodal surfaces obtained at the PBE0/ccECP/cc-pVQZ74,75,77,78 level of theory using PySCF76.
For the calculated sum formulas, molecular graphs were generated using SURGE47. The graphs were then converted to geometries with MMFF94 as implemented in RDKit51, which were then optimized initially using the GFN2-xTB48 semi-empirical method. Following this, a conformer search was conducted with Crest52, and all conformers were added to the dataset. This workflow resulted in ~ 1.1M geometries.
DFT optimization and calculations
Subsequently, we optimized all geometries with DFT using the ωB97X-D3/cc-pVDZ level of theory44,45,46. This functional and dispersion correction combination was selected due to its excellent performance in main-group thermochemistry, kinetics, and noncovalent interaction benchmarks such as GMTKN5553, where it ranks among the most accurate methods—excluding more computationally demanding double hybrid functionals. Importantly, our choice aligns with other widely used datasets such as ANI-110, ANI-1x11, OrbNet Denali54, QMugs6, SPICE15, and MultiXC-QM98, all of which report values obtained from the ωB97X functional (or its variants) with a double-zeta basis set. This consistency ensures that ML models trained on VQM24 can be readily integrated with models developed on related datasets, facilitating broader interoperability and transfer learning across datasets.
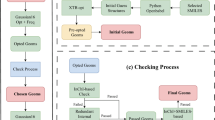
The Gaussian Tight convergence criteria (as implemented in PSI455) and density fitting (for computational efficiency) were employed in all calculations using the cc-pVDZ-JKFIT56 auxiliary basis set. All DFT calculations were conducted using the PSI4 software package (version 1.7)55. The optimization was performed in three passes. In the first pass the default settings in PSI4 for geometry optimizations were used (DIIS method57 for SCF and RFO for geometry optimization in redundant internal coordinates58) with a maximum of 100 optimization steps Fig. 2. The molecules that did not converge entered the second pass in which 2nd order SCF (using the keyword SOSCF) convergence method employing the full Newton step was used along with ultrafine Lebedev-Treutler59,60 exchange-correlation integration grid (590 spherical, 99 radial points) and a maximum of 100 geometry optimization steps. In the third pass, full Hessian evaluations were performed for the initial geometry and every 20th geometry optimization step afterwards with a maximum of 50 steps. The optimization was performed in Cartesian coordinates only, in conjunction with the settings employed in the 2nd pass. Those molecules that did not converge after all three passes were left unconverged, and have not been reported. Following this procedure, we obtained a grand-total of 835,947 converged molecules, and 262,542 that did not converge. Figure 3 shows an analysis of the most common stoichiometries that failed the DFT geometry optimizations. Panel (A) ranks the fifteen stoichiometries with the highest failure counts—fourteen of which contain silicon—highlighting a clear silicon bias in the convergence failures. This is consistent with previous reports that xTB-based conformer generation can struggle with silicon-containing compounds, often producing unreliable starting geometries or poor convergence behavior61,62. This is also evident from panel (B) which shows the mean number of CREST52-generated (GFN2-xTB48) conformers per constitutional isomer for these stoichiometries, which far exceeds the dataset average of 3 conformers.

Growth in the number of molecules (y) in the VQM24 dataset as a function of heavy atom count (N). Each black marker corresponds to the total number of molecular geometries (including conformers) reported in the last column of Table 2. A quadratic fit of the form \(\log (y)=a{N}^{2}+bN+c\) captures the observed combinatorial scaling, with an excellent correlation coefficient of R2 = 0.99. The red cross indicates the extrapolated estimate for N = 6, predicting approximately 33 million distinct molecular geometries.

Analysis of DFT geometry-optimization failures. (A) (Top) Bar chart of the fifteen stoichiometries with the highest number of unconverged ωB97X-D3/cc-pVDZ optimizations. Stoichiometries are ordered by descending failure count. (B) (Bottom) Conformer diversity for these stoichiometries, quantified as the mean number of unique CREST52-generated (GFN2-xTB48) conformers per constitutional isomer.
The relaxation of converged systems was subsequently followed by vibrational frequency calculations at the same level of theory to identify the saddle point orders of the geometries. In total we found 784,875 molecules to have converged to a local minimum and 51,072 to saddle points. All molecules have been included in the dataset with the minimum geometries and saddle points stored as separate datasets (see Data Records section below). Table 2 summarizes the number of unique stoichiometries, constitutional isomers, and geometries geometries (including conformers), grouped by the number of heavy atoms (excluding hydrogens) per molecule, based on the 784,875 minimum-energy geometries reported. Figure 2 illustrates the growth of the total number of molecules (corresponding to the last column of Table 2) obtained through our procedure. The dataset exhibits clear combinatorial scaling, with the projected number of molecules exceeding 30 million upon inclusion of species containing six heavy atoms.
Diffusion Monte Carlo
Quantum Monte Carlo (QMC) techniques are methods that stochastically solve the many-body Schrödinger equation. By explicitly including many-body electronic interactions, these methods achieve mathematical rigor and, in principle, can resolve the Schrödinger equation exactly. However, practical applications require some approximations to maintain computational feasibility, although most of these are controlled and can be rigorously extrapolated at a computational cost. With the proliferation of high-performance computers reaching hundreds of petaflops and the recent deployment of exascale machines, (Summit at Oak Ridge National Laboratory and Aurora at Argonne National Laboratory), QMC methods are poised to significantly take advantage of this computational power; by utilizing stochastic numerical sampling, where samples are evaluated independently, QMC methods achieve embarrassingly parallel processing, enhancing their efficiency for high-performance computing.
While many variations exist, recent years have seen significant theoretical, algorithmic, and computational advances, particularly in Diffusion Monte Carlo (DMC). Using a projector or Green’s function based approach, DMC solves the Schrödinger equation in an imaginary time τ = it. This ensures that any initial state \(|\psi \rangle \), not orthogonal to the ground state \(|{\phi }_{0}\rangle \), will converge to the ground state in a long time limit. During this process, components corresponding to excited states diminish exponentially, ultimately yielding the true ground state.
The introduction of a constant energy offset, ET = ϵ0, stabilizes the long-time behavior of the system and keeps it finite. The imaginary time Schrödinger equation then resembles a diffusion equation given by:
The first term captures the diffusion of particles, while the second term is a branching term dependent on the potential capturing the change in the density of these particles. The potential V(R) in Coulombic systems is unbounded, which may cause the rate term \(\left(V({\bf{R}})-{E}_{T}\right)\) to diverge. This could lead to considerable fluctuations in particle density and cause substantial statistical errors. Additionally, the equation doesn’t account for the fermionic nature of electrons, which requires antisymmetry when particles are exchanged. This requirement introduces nodes in the fermionic wavefunction; if not constrained, would lead to a bosonic solution. This issue is addressed by the fixed-node (FN) approximation63. This approximation constrains the wavefunction to maintain the nodal structure of a trial wavefunction, thereby introducing the fixed-node error as the sole source of error in DMC when the reference wavefunction is not exact. The accuracy of DMC thus heavily relies on the quality of the nodes in the trial wavefunction. By introducing a guiding or trial function, \({\Psi }_{G}\left({\bf{R}}\right)\), that closely approximates the ground state, the following transformation is applied:
which modifies equation (3) to:
ET is referred to as a “trial energy” and is used to keep the solution normalized over long-time scales, with EL(R) representing the local energy at position R. The final term in Eq. (5) is a critical branching term that eliminates any ‘walker’ crossing a node (where the wavefunction changes sign) and duplicates any walker that reduces the system’s energy, bringing it closer to the ground state. This mechanism is often described as the birth and death process in stochastic simulations.
The accuracy of DMC hinges largely on the quality of the nodal surface defined by the underneath trial wavefunction. However, it is important to keep in mind that DMC is variational, meaning that the solutions we obtain are always an upper bound to the exact solution64. This allows for the opportunity of testing with various guiding functions to identify the one that minimizes energy. For instance, Bing et al.41 demonstrated that using DFT with 3 different exchange-correlation (XC) functionals as guiding functions yielded consistent results within statistical errors for more than 1000 molecules from the QM5 dataset. Additionally, hybrid functionals can be employed to fine-tune the percentage of exact exchange, optimizing the energy further65. More complex trial wavefunctions, such as multi-Slater determinants generated from selected Configuration Interaction (sCI)66,67,68,69 or an orbital optimization paired with a variational Monte Carlo in the presence of a Jastrow factor70, can also be utilized to improve accuracy. These approaches improve the nodal surface and therefore lower the FN-error associated to DMC, but often at a larger computational cost.
Computational details
All 10,793 constitutional isomers (most stable conformer for each) containing up to 4 heavy atoms in VQM24 were selected for DMC calculations. The total energy calculations were performed using the QMCPACK code71,72. For efficient sampling and to reduce statistical fluctuations, we utilized a Slater-Jastrow type trial wavefunction for all DMC energy evaluations73:
where \({D}_{k}^{\downarrow }(\varphi )\) denotes a Slater determinant composed of single-particle orbitals \({\varphi }_{i}={\sum }_{l}^{{N}_{b}}{C}_{l}^{i}{\Phi }_{l}\), in this study, constructed using PBE074,75 Kohn-Sham (KS) orbitals as implemented in the PySCF code76. Similarly to the study by Bing et al.41, using different functionals does not lead to very different nodal surfaces and results in energy differences of less than 1 kcal/mol in DMC, for the small subset of molecules tested. To enhance efficiency and minimize fluctuations in regions close to ionic cores, ccECP pseudopotentials were applied to substitute core electrons77,78. These pseudopotentials, optimized for precise many-body methods like DMC, address non-local effects using the determinant-localization approximation and the t-moves strategy (DLTM)79,80. DMC evolving in real space shows in general minimal basis set size dependency, as documented in prior studies69,81. However, when the the basis set is chosen to be too small, the quality of the trial wavefunction can be severly affected degrading the quality of the nodal surface. Given that the cost of evaluating larger basis function is marginal in QMC, we ran all our simulations with the cc-pVQZ basis set, tailored for ccECP.
The Jastrow function includes terms for one-body (electron-ion), two-body (electron-electron), and three-body (electron-electron-ion) interactions. The one- and two-body interactions were defined using spline functions82, and the three-body interactions were modeled using polynomials83. Specifically, the study utilized 16 parameters for each atom type in one-body terms with a cutoff of 8 Bohr, and 20 parameters per spin-channel for two-body terms with a cutoff of 10 Bohr. The three-body terms incorporated 26 parameters each, with a 5 Bohr cutoff. These parameters in the Jastrow factor were individually optimized for each molecular geometry using a linear optimization method developed by Umrigar et al.84. For all DMC simulations, we utilized a timestep of 0.001 a.u., eliminating the necessity for timestep extrapolation. The simulations involved 1500 blocks of 40 imaginary time steps each, with only the 40th step considered for calculating the standard deviation. We used 16,000 walkers to reduce autocorrelation and prevent population bias, achieving average error bars of 0.4 mHa across approximately 2.3 billion samples.
Given the large number of molecules, we used the NEXUS Workflow package85 to generate input files, manage, and monitor jobs across different stages of the calculations. This allowed for a “black box” and fully automated computational campaign. The trial wavefunction generation was conducted on the Argonne LCRC system, Improv, using a single node composed of 2x AMD EPYC 7713 with 64 cores at 2GHz. Each molecule, on average, required 45 seconds of computing, amounting to a total of 134 node hours for the whole set. The subsequent DMC calculations required 20 nodes per molecule on the Argonne Polaris HPC, using the AMD EPYC 7543P CPU with 64 cores at 2.8GHz. Each molecule took approximately 15 minutes to achieve a sub kcal/mol error bar, totaling around ~ 54,000 node hours.
Data Records
The dataset is available at Zenodo86. The DFT dataset is reported as separate .npz files for, conformational minima, constitutional minima and saddle point structures. Each property is reported in separate arrays with the ordering of the molecules across every array being the same. The keys for accessing each property from the DFT .npz files are tabulated in Table 2. DMC data is similarly reported in a separate .npz file with the corresponding keys recorded in Table 3. All of the data, including the wavefunction files as a single tarball, is publicly available at the Zenodo repository86. The wavefunction .molden files also contain molecular orbital energies.
Technical Validation
To analyze the structural diversity within the VQM24 dataset, we compared the distribution of normalized ratios of principal moments of inertia (NPMI) values with 4 other QM (DFT) datasets containing molecules with similar sizes. The corresponding scatter plots are shown in Fig. 4A. Although VQM24 contains molecules of smaller size than the other 4 datasets (Fig. 4B), it shows more comprehensive coverage of molecular shapes than the QM7b2, QM93 datasets and a similar distribution to the larger QM7-X12 dataset (with lower density). Due to the combinatorial sampling employed, the VQM24 dataset covers the 1-5 heavy atom chemical space more exhaustively than the other datasets as can be seen from Fig. 4B,C. Furthermore, due to the larger number of chemical elements included (10 for VQM24 compared to 5 for the others), greater chemical diversity can be expected within VQM24. This leads to the much larger number of unique stoichiometries present in VQM24 when compared to QM7b/QM7-X and QM9 (Fig. 4C).

Comparison of structural diversities between VQM24 and 4 other commonly used QM datasets, QM7b2, QM93, QM7-X12, ANI-1x11. (A) (Top) Scatter plots of normalized ratios of principal moments of inertia (NPMI) for all molecules from the 5 datasets. Title includes number of molecules within each dataset in brackets with k and M indicating thousand and million respectively. Rod, disc and sphere indicate NPMI values corresponding to linear, flat and spherical systems respectively. (B) (Middle) Histograms binning molecules by the number of heavy atoms (non-Hydrogen). (C) (Bottom) Bar plots indicating number of unique stoichiometries.
Energy ranges covered in VQM24 are shown in Fig. 5 which displays distibution plots of 12 properties derived from the total and electronic energies. The atomization energies reported in VQM24 cover a range of 1545 kcal/mol.

Distribution plots of 12 DFT (ωB97X-D3/cc-pVDZ) calculated energetics out of the various properties reported in the VQM24 dataset. (H) in the titles indicate thermodynamic quantities calculated via the harmonic approximation. The electrostatic potential (ESP) at nuclei plot shows the sum of the ESP values at each nucleus within a molecule. Units are mentioned in the x-axis labels.
To further assess the chemical diversity we trained and tested ML models for the task of predicting atomization energies within VQM24 and compare it to ML results obtained for the commonly used QM9 benchmark. Figure 6 presents the learning curves—i.e. the prediction error on atomization energies as a function of training-set size—for both datasets. We compare several kernel ridge regression (KRR)87,88 models using different atomic representations, alongside invariant (SchNet89) and equivariant (PaiNN90) message-passing graph neural networks (GNNs). The KRR and GNN models were trained and deployed using the QMLcode91 and Schnetpack92 libraries respectively. Atomic gaussian kernel was used alongside all KRR models and the hyper-parameters (length-scale l, regularizer λ) were optimized via grid-search. Logarithmic grids of \(\left[0.1({2}^{n})\,\forall \,n\,\in \{0,14\}\right]\) and \(\left[1{0}^{-3n}\,\forall \,n\,\in \{1,4\}\right]\) were employed for l and λ respectively. Optimizations were performed via 5-fold cross-validation. For both GNN models we employed the same hyper-parameters as in the PaiNN90 paper. We note here that we used 128 atomic basis functions with both PaiNN and SchNet leading to a total parameter count of 589k for both models. All models were trained for 1000 epochs using the Adam optimizer93 with a learning rate of 10−4. Scripts for training and using these KRR and GNN models are available in the GitHub repository specified in the Code Availability section below.

Atomization energy learning curves on the subset of 258k unique constitutional isomers from VQM24 and the QM9 dataset. Solid lines indicate ML models employing Kernel Ridge Regression (KRR) while dashed lines indicate Graph Neural Networks (GNN). Representations used alongside KRR models are : Coulomb matrix1 (CM), atom-centered symmetry functions97 (ACSF), many-body tensor representation98 (LMBTR), Faber-Christensen-Huang-Lilienfeld 1999,100 (FCHL19), convolutional many-body distribution functionals94,95 (cMBDF/MBDF). GNNs employ the equivariant PaiNN90 and invariant SchNet89 architectures. Test set size in both cases was 10,000 randomly-selected molecules. Plots show average of 5 such runs.
Since QM9 does not contain conformational isomers, Fig. 6B shows learning curves of atomization energies considering only the subset of the 258k lowest energy conformers (unique constitutional isomers) from VQM24 to be directly comparable. While the range of atomization energies covered by VQM24 (1545 kcal/mol) is smaller than QM9 (2427 kcal/mol), evidently they are more challenging to learn as all ML models show upto ~ 8 times larger mean errors than on QM9 for the same training set size. This is likely due to the much larger chemical diversity of VQM24 which should make it a more challenging benchmark for the training and testing of ML models of the various chemically relevant physical properties reported.
Using the best KRR model from Fig. 6 (cMBDF94,95), we performed a prediction error analysis to detect outliers within the dataset. We trained KRR/cMBDF based ML models on 200k molecules (4 disjointed training sets) to make predictions on the remaining dataset. This was done on all the 784,875 equilibrium geometries (including conformers) reported in the dataset. The resulting distribution of errors on the entire dataset is shown in Fig. 7. For each molecule we used the prediction with the smallest error out of the 3 ML models that were not trained on it. The mean absolute error for the 784,875 predictions was obtained to be 0.75 kcal/mol with a standard deviation of 1.55 kcal/mol. The largest obtained error was 167.3 kcal/mol and the 25 largest outliers show a mean absolute error of 85.9 kcal/mol. These molecules are shown as insets in Fig. 7.

Atomization energy prediction errors on the 784,875 converged molecules from the VQM24 dataset. All predictions were made by KRR models employing the cMBDF94,95 representation after training on 200k molecules. Errors for all molecules were obtained by training four such models with disjointed training sets and using the smallest prediction error for all out-of-sample molecules. Mean absolute error (MAE) for the predictions is shown in the top right inset along with the standard deviation. Insets show molecules with the largest prediction errors. Atomic colours correspond to: grey-Carbon, white-Hydrogen, blue-Nitrogen, red-Oxygen, dark green-Fluorine, cream-Silicon, orange-Phosphorous, yellow-Sulfur, green-Chlorine, dark red-Bromine.
Usage Notes
The reported .npz files are available at Ref. 86 can be readily accessed using the Numpy96 library in Python. DFT properties for all 784,875 conformers in local minima; 258,242 constitutional isomers (most stable conformer) and 51,072 saddle point structures are available in the DFT_all.npz, DFT_uniques.npz and DFT_saddles.npz files respectively. DMC data for 10,793 constitutional isomers is available in the DMC.npz file. All molecules are ordered in the same way across every array. Keys for accessing each property are tabulated in the Key column of Tables 3 and 4. Usage example:
import numpy as np
data = np.load('DFT_all.npz', allow_pickle=True)
print(data.files) #see a list of all properties
key = 'freqs'
property = data[key] #DFT vibrational frequencies of all molecules
Code availability
Sample code for accessing the dataset is mentioned above. Code used for generating the data and more tools can be found at https://github.com/dkhan42/VQM24.
References
Rupp, M., Tkatchenko, A., Müller, K. & Lilienfeld, O. Fast and Accurate Modeling of Molecular Atomization Energies with Machine Learning. Phys. Rev. Lett. 108, 058301, https://doi.org/10.1103/PhysRevLett.108.058301 (2012).
Montavon, G. et al. Machine learning of molecular electronic properties in chemical compound space. New Journal Of Physics 15, 095003 (2013).
Ramakrishnan, R., Dral, P., Rupp, M. & Lilienfeld, O. Quantum chemistry structures and properties of 134 kilo molecules. Scientific Data. 1 (2014).
Chmiela, S. et al. Machine learning of accurate energy-conserving molecular force fields. Science Advances. 3, https://doi.org/10.1126/sciadv.1603015 (2017).
Christensen, A. & Lilienfeld, O. On the role of gradients for machine learning of molecular energies and forces. Machine Learning: Science And Technology 1, 045018, https://doi.org/10.1088/2632-2153/abba6f (2020).
Isert, C., Atz, K., Jiménez-Luna, J. & Schneider, G. QMugs, quantum mechanical properties of drug-like molecules. Scientific Data 9, 273, https://doi.org/10.1038/s41597-022-01390-7 (2022).
Axelrod, S. & Gómez-Bombarelli, R. GEOM, energy-annotated molecular conformations for property prediction and molecular generation. Scientific Data. 9, https://doi.org/10.1038/s41597-022-01288-4 (2022).
Nandi, S., Vegge, T. & Bhowmik, A. MultiXC-QM9: Large dataset of molecular and reaction energies from multi-level quantum chemical methods. Scientific Data. 10, https://doi.org/10.1038/s41597-023-02690-2 (2023).
Smith, J., Isayev, O. & Roitberg, A. ANI-1, A data set of 20 million calculated off-equilibrium conformations for organic molecules. Scientific Data. 4, https://doi.org/10.1038/sdata.2017.193 (2017).
Smith, J., Isayev, O. & Roitberg, A. ANI-1: an extensible neural network potential with DFT accuracy at force field computational cost. Chem. Sci. 8, 3192–3203, https://doi.org/10.1039/C6SC05720A (2017).
Smith, J. et al. The ANI-1ccx and ANI-1x data sets, coupled-cluster and density functional theory properties for molecules. Scientific Data. 7, https://doi.org/10.1038/s41597-020-0473-z (2020).
Hoja, J. et al. QM7-X, a comprehensive dataset of quantum-mechanical properties spanning the chemical space of small organic molecules. Scientific Data. 8, https://doi.org/10.1038/s41597-021-00812-2 (2021).
Qu, X. et al. The Electrolyte Genome project: A big data approach in battery materials discovery. Comput. Mater. Sci. 103, 56–67, https://doi.org/10.1016/j.commatsci.2015.02.050 (2015).
Nakata, M. & Shimazaki, T. PubChemQC Project: A Large-Scale First-Principles Electronic Structure Database for Data-Driven Chemistry. Journal Of Chemical Information And Modeling 57, 1300–1308 (2017).
Eastman, P. et al. SPICE, A Dataset of Drug-like Molecules and Peptides for Training Machine Learning Potentials. Scientific Data. 10, https://doi.org/10.1038/s41597-022-01882-6 (2023).
Ceriotti, M. Beyond potentials: Integrated machine learning models for materials. MRS Bulletin 47, 1045–1053, https://doi.org/10.1557/s43577-022-00440-0 (2022).
Musaelian, A. et al. Learning local equivariant representations for large-scale atomistic dynamics. Nature Communications. 14, https://doi.org/10.1038/s41467-023-36329-y (2023).
Batatia, I., Kovacs, D., Simm, G., Ortner, C. & Csanyi, G. MACE: Higher Order Equivariant Message Passing Neural Networks for Fast and Accurate Force Fields. Advances In Neural Information Processing Systems 35, 11423–11436 (2022).
Thomas, N. et al. Tensor Field Networks: Rotation- and Translation-Equivariant Neural Networks for 3D Point Clouds. ArXiv. abs/1802.08219 https://api.semanticscholar.org/CorpusID:3457605 (2018).
Chmiela, S. et al. Accurate global machine learning force fields for molecules with hundreds of atoms. Science Advances 9, eadf0873, https://doi.org/10.1126/sciadv.adf0873 (2023).
Browning, N., Faber, F. & Lilienfeld, O. GPU-accelerated approximate kernel method for quantum machine learning. The Journal Of Chemical Physics 157, 214801, https://doi.org/10.1063/5.0108967 (2022).
Lilienfeld, O., Müller, K. & Tkatchenko, A. Exploring chemical compound space with quantum-based machine learning. Nature Reviews Chemistry 4, 347–358, https://doi.org/10.1038/s41570-020-0189-9 (2020).
Bao, Z. et al. Revolutionizing drug formulation development: The increasing impact of machine learning. Advanced Drug Delivery Reviews 202, 115108 (2023).
Rudorff, G., Heinen, S., Bragato, M. & Lilienfeld, O. Thousands of reactants and transition states for competing E2 and S2 reactions. Machine Learning: Science And Technology 1, 045026 (2020).
Blum, L. & Reymond, J. 970 million druglike small molecules for virtual screening in the chemical universe database GDB-13. Journal Of The American Chemical Society 131, 8732–8733 (2009).
Ruddigkeit, L., Van Deursen, R., Blum, L. & Reymond, J. Enumeration of 166 billion organic small molecules in the chemical universe database GDB-17. Journal Of Chemical Information And Modeling 52, 2864–2875 (2012).
Gaulton, A. et al. ChEMBL: a large-scale bioactivity database for drug discovery. Nucleic Acids Research 40, D1100–D1107, https://doi.org/10.1093/nar/gkr777 (2011).
Kim, S. et al. PubChem Substance and Compound databases. Nucleic Acids Research 44, D1202–D1213, https://doi.org/10.1093/nar/gkv951 (2015).
Khan, D. et al. Adapting hybrid density functionals with machine learning. Science Advances 11.5, eadt7769, https://www.science.org/doi/10.1126/sciadv.adt7769 (2025).
Schwilk, M., Tahchieva, D. & Lilienfeld, O. Large yet bounded: Spin gap ranges in carbenes. ArXiv Preprint ArXiv:2004.10600 (2020).
Liang, J., Xu, Y., Liu, R. & Zhu, X. QM-sym, a symmetrized quantum chemistry database of 135 kilo molecules. Scientific Data. 6, https://doi.org/10.1038/s41597-019-0237-9 (2019).
Liang, J. et al. QM-symex, update of the QM-sym database with excited state information for 173 kilo molecules. Scientific Data. 7, https://doi.org/10.1038/s41597-020-00746-1 (2020).
Von Lilienfeld, O. First principles view on chemical compound space: Gaining rigorous atomistic control of molecular properties. International Journal Of Quantum Chemistry 113, 1676–1689 (2013).
Huang, B., Rudorff, G. & Lilienfeld, O. The central role of density functional theory in the AI age. Science 381, 170–175, https://doi.org/10.1126/science.abn3445 (2023).
Heinen, S. et al. Reducing Training Data Needs with Minimal Multilevel Machine Learning (M3L) (2023).
Faber, F. et al. Prediction Errors of Molecular Machine Learning Models Lower than Hybrid DFT Error. Journal Of Chemical Theory And Computation 13, 5255–5264 (2017).
Cignoni, E. et al. Electronic excited states from physically-constrained machine learning (2023).
Glavatskikh, M., Leguy, J., Hunault, G., Cauchy, T. & Da Mota, B. Dataset’s chemical diversity limits the generalizability of machine learning predictions. Journal Of Cheminformatics. 11, https://doi.org/10.1186/s13321-019-0391-2 (2019).
Huang, B. & Lilienfeld, O. Quantum machine learning using atom-in-molecule-based fragments selected on the fly. Nature Chemistry 12, 945–951, https://doi.org/10.1038/s41557-020-0527-z (2020).
Unke, O. et al. Biomolecular dynamics with machine-learned quantum-mechanical force fields trained on diverse chemical fragments. Science Advances 10, eadn4397 (2024).
Huang, B., Lilienfeld, O., Krogel, J. & Benali, A. Toward DMC Accuracy Across Chemical Space with Scalable Δ-QML. Journal Of Chemical Theory And Computation 19, 1711–1721 (2023).
Khan, D., Ach, M. & Lilienfeld, O. Adaptive atomic basis sets (2024).
Chai, J. & Head-Gordon, M. Long-range corrected hybrid density functionals with damped atom-atom dispersion corrections. Phys. Chem. Chem. Phys. 10, 6615–6620, https://doi.org/10.1039/B810189B (2008).
Dunning, J. Gaussian basis sets for use in correlated molecular calculations. I. The atoms boron through neon and hydrogen. The Journal Of Chemical Physics 90, 1007–1023, https://doi.org/10.1063/1.456153 (1989).
Chai, J. & Head-Gordon, M. Long-range corrected hybrid density functionals with damped atom-atom dispersion corrections. Physical Chemistry Chemical Physics 10, 6615–6620 (2008).
Grimme, S., Antony, J., Ehrlich, S. & Krieg, H. A Consistent and Accurate ab initio Parametrization of Density Functional Dispersion Correction (DFT-D) for the 94 Elements H-Pu. J. Chem. Phys. 132, 154104 (2010).
McKay, B., Yirik, M. & Steinbeck, C. Surge: a fast open-source chemical graph generator. Journal Of Cheminformatics 14, 24 (2022).
Bannwarth, C., Ehlert, S. & Grimme, S. GFN2-xTB—An Accurate and Broadly Parametrized Self-Consistent Tight-Binding Quantum Chemical Method with Multipole Electrostatics and Density-Dependent Dispersion Contributions. Journal Of Chemical Theory And Computation 15, 1652–1671, https://doi.org/10.1021/acs.jctc.8b01176 (2019).
Ramakrishnan, R., Dral, P., Rupp, M. & Lilienfeld, O. Big Data Meets Quantum Chemistry Approximations: The Δ-Machine Learning Approach. Journal Of Chemical Theory And Computation 11, 2087–2096 (2015).
Huang, B. & Lilienfeld, O. Dictionary of 140k GDB and ZINC derived AMONs (2020).
Landrum, G. Rdkit documentation. Release 1, 4 (2013).
Pracht, P., Bohle, F. & Grimme, S. Automated exploration of the low-energy chemical space with fast quantum chemical methods. Physical Chemistry Chemical Physics 22, 7169–7192 (2020).
Goerigk, L. et al. A look at the density functional theory zoo with the advanced GMTKN55 database for general main group thermochemistry, kinetics and noncovalent interactions. Physical Chemistry Chemical Physics 19, 32184–32215 (2017).
Christensen, A. et al. OrbNet Denali: A machine learning potential for biological and organic chemistry with semi-empirical cost and DFT accuracy. The Journal Of Chemical Physics155 (2021).
Smith, D. et al. PSI4 1.4: Open-source software for high-throughput quantum chemistry. The Journal Of Chemical Physics. 152 (2020).
Weigend, F. A fully direct RI-HF algorithm: Implementation, optimised auxiliary basis sets, demonstration of accuracy and efficiency. Phys. Chem. Chem. Phys. 4, 4285–4291, https://doi.org/10.1039/B204199P (2002).
Pulay, P. Convergence acceleration of iterative sequences. the case of scf iteration. Chemical Physics Letters 73, 393–398 (1980).
Bakken, V. & Helgaker, T. The efficient optimization of molecular geometries using redundant internal coordinates. The Journal Of Chemical Physics 117, 9160–9174, https://doi.org/10.1063/1.1515483 (2002).
Treutler, O. & Ahlrichs, R. Efficient molecular numerical integration schemes. The Journal Of Chemical Physics 102, 346–354, https://doi.org/10.1063/1.469408 (1995).
Lebedev, V. & Laikov, D. A QUADRATURE FORMULA FOR THE SPHERE OF THE 131ST ALGEBRAIC ORDER OF ACCURACY. Doklady Mathematics 59, 477–481 (1999).
Zhugayevych, A. et al. Benchmark Data Set of Crystalline Organic Semiconductors. Journal Of Chemical Theory And Computation 19, 8481–8490 (2023).
Komissarov, L. & Verstraelen, T. Improving the silicon interactions of gfn-xtb. Journal Of Chemical Information And Modeling 61, 5931–5937 (2021).
Anderson, J. Quantum chemistry by random walk. The Journal Of Chemical Physics 65, 4121–4127 (1976).
Ceperley, D. & Alder, B. Quantum Monte Carlo for molecules: Green’s function and nodal release. The Journal Of Chemical Physics 81, 5833–5844 (1984).
Busemeyer, B., Dagrada, M., Sorella, S., Casula, M. & Wagner, L. Competing collinear magnetic structures in superconducting FeSe by first-principles quantum Monte Carlo calculations. Phys. Rev. B 94, 035108, https://doi.org/10.1103/PhysRevB.94.035108 (2016).
Morales, M., McMinis, J., Clark, B., Kim, J. & Scuseria, G. Multideterminant Wave Functions in Quantum Monte Carlo. Journal Of Chemical Theory And Computation 8, 2181–2188, https://doi.org/10.1021/ct3003404 (2012).
Caffarel, M., Applencourt, T., Giner, E. & Scemama, A. Communication: Toward an improved control of the fixed-node error in quantum Monte Carlo: The case of the water molecule. The Journal Of Chemical Physics 144, 151103, https://doi.org/10.1063/1.4947093 (2016).
Scemama, A., Benali, A., Jacquemin, D., Caffarel, M. & Loos, P. Excitation energies from diffusion Monte Carlo using selected configuration interaction nodes. The Journal Of Chemical Physics 149, 034108 (2018).
Malone, F. et al. Systematic comparison and cross-validation of fixed-node diffusion Monte Carlo and phaseless auxiliary-field quantum Monte Carlo in solids. Physical Review B 102, 161104 (2020).
Slootman, E. et al. Accurate quantum Monte Carlo forces for machine-learned force fields: Ethanol as a benchmark. Journal of Chemical Theory and Computation 20.14, 6020–6027 (2024).
Kim, J. et al. QMCPACK: an open source ab initio quantum Monte Carlo package for the electronic structure of atoms, molecules and solids. Journal Of Physics: Condensed Matter 30, 195901 (2018).
Kent, P. et al. QMCPACK: Advances in the development, efficiency, and application of auxiliary field and real-space variational and diffusion quantum Monte Carlo. The Journal Of Chemical Physics 152, 174105 (2020).
Schmidt, K. & Moskowitz, J. Correlated Monte Carlo wave functions for the atoms He through Ne. The Journal Of Chemical Physics 93, 4172–4178 (1990).
Ernzerhof, M. & Scuseria, G. undefined (1999).
Adamo, C. & Barone, V. Toward reliable density functional methods without adjustable parameters: The PBE0 model. (AIP Publishing, 1999).
Sun, Q. et al. Recent developments in the PySCF program package. The Journal Of Chemical Physics 153, 024109, https://doi.org/10.1063/5.0006074 (2020).
Annaberdiyev, A. et al. A new generation of effective core potentials from correlated calculations: 3d transition metal series. J. Chem. Phys. 149, 134108 (2018).
Bennett, M. et al. A new generation of effective core potentials for correlated calculations. J. Chem. Phys. 147, 224106 (2017).
Zen, A., Brandenburg, J., Michaelides, A. & Alfè, D. A new scheme for fixed node diffusion quantum Monte Carlo with pseudopotentials: Improving reproducibility and reducing the trial-wave-function bias. J. Chem. Phys. 151, 134105 (2019).
Casula, M., Moroni, S., Sorella, S. & Filippi, C. Size-consistent variational approaches to nonlocal pseudopotentials: Standard and lattice regularized diffusion Monte Carlo methods revisited. J. Chem. Phys. 132, 154113 (2010).
Dubecký, M. Noncovalent Interactions by Fixed-Node Diffusion Monte Carlo: Convergence of Nodes and Energy Differences vs Gaussian Basis-Set Size. J. Chem. Theory Comput. 13, 3626–3635, https://doi.org/10.1021/acs.jctc.7b00537 (2017).
Esler, K., Kim, J., Ceperley, D. & Shulenburger, L. Accelerating Quantum Monte Carlo Simulations of Real Materials on GPU Clusters. Computing In Science Engineering 14, 40–51 (2012).
Drummond, N., Towler, M. & Needs, R. Jastrow correlation factor for atoms, molecules, and solids. Phys. Rev. B 70, 235119 (2004).
Umrigar, C., Toulouse, J., Filippi, C., Sorella, S. & Hennig, R. Alleviation of the Fermion-Sign Problem by Optimization of Many-Body Wave Functions. Phys. Rev. Lett. 98, 110201, https://doi.org/10.1103/PhysRevLett.98.110201 (2007).
Krogel, J. Nexus: A modular workflow management system for quantum simulation codes. Computer Physics Communications 198, 154–168 (2016).
Khan, D., Benali, A., Kim, S., Rudorff, G. & Lilienfeld, A. Vector-QM24 (VQM24) dataset. https://doi.org/10.5281/zenodo.15442257 (Zenodo,2025,5).
Cortes, C., Jackel, L., Solla, S., Vapnik, V. & Denker, J. Learning curves: Asymptotic values and rate of convergence. Advances In Neural Information Processing Systems. pp. 327–334 (1994).
Rasmussen, C. & Williams, C. Gaussian processes for machine learning (MIT Press, 2006).
Schütt, K. et al. SchNetPack: A Deep Learning Toolbox For Atomistic Systems. Journal Of Chemical Theory And Computation 15, 448–455, https://doi.org/10.1021/acs.jctc.8b00908 (2018).
Schütt, K., Unke, O. & Gastegger, M. Equivariant message passing for the prediction of tensorial properties and molecular spectra. CoRR. abs/2102.03150 https://arxiv.org/abs/2102.03150 (2021).
Christensen, A. et al. QML: A Python Toolkit for Quantum Machine Learning, https://github.com/qmlcode/qml, http://www.qmlcode.org (2017).
Schütt, K. et al. SchNet: A continuous-filter convolutional neural network for modeling quantum interactions. Advances In Neural Information Processing Systems. 30, https://proceedings.neurips.cc/paper/2017/file/303ed4c69846ab36c2904d3ba8573050-Paper.pdf (2017).
Kingma, D. & Ba, J. Adam: A method for stochastic optimization. Proceedings of the 3rd International Conference on Learning Representations (ICLR), Banff (2014).
Khan, D., Heinen, S. & Lilienfeld, O. Kernel based quantum machine learning at record rate: Many-body distribution functionals as compact representations. The Journal Of Chemical Physics 159, 034106, https://doi.org/10.1063/5.0152215 (2023).
Khan, D. & Lilienfeld, O. Generalized convolutional many body distribution functional representations. https://arxiv.org/abs/2409.20471 (2024).
Harris, C. et al. Array programming with NumPy. Nature 585, 357–362, https://doi.org/10.1038/s41586-020-2649-2 (2020).
Behler, J. Atom-centered symmetry functions for constructing high-dimensional neural network potentials. The Journal Of Chemical Physics 134, 074106 (2011).
Huo, H. & Rupp, M. Unified representation of molecules and crystals for machine learning. Machine Learning: Science And Technology 3, 045017 (2022).
Faber, F., Christensen, A., Huang, B. & Lilienfeld, O. Alchemical and structural distribution based representation for universal quantum machine learning. The Journal Of Chemical Physics 148, 241717 (2018).
Christensen, A., Bratholm, L., Faber, F. & Lilienfeld, O. FCHL revisited: Faster and more accurate quantum machine learning. The Journal Of Chemical Physics 152, 044107 (2020).
Acknowledgements
We acknowledge the support of the Natural Sciences and Engineering Research Council of Canada (NSERC), [funding reference number RGPIN-2023-04853]. Cette recherche a été financée par le Conseil de recherches en sciences naturelles et en génie du Canada (CRSNG), [numéro de référence RGPIN-2023-04853]. This research was undertaken thanks in part to funding provided to the University of Toronto’s Acceleration Consortium from the Canada First Research Excellence Fund, grant number: CFREF-2022-00042. O.A.v.L. has received support as the Ed Clark Chair of Advanced Materials and as a Canada CIFAR AI Chair. O.A.v.L. has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No. 772834). The authors are grateful to Compute Canada and the Acceleration Consortium for computational resources. A.B. was funded by the U.S. Department of Energy, Office of Science, Basic Energy Sciences, Materials Sciences and Engineering Division, as part of the Computational Materials Sciences Program and Center for Predictive Simulation of Functional Materials. DMC calculations used an award of computer time provided by the Innovative and Novel Computational Impact on Theory and Experiment (INCITE) program. This research used resources of the Argonne Leadership Computing Facility, which is a DOE Office of Science User Facility supported under contract DE-AC02-06CH11357. We also gratefully acknowledge the computing resources provided on IMPROV, a high-performance computing cluster operated by the Laboratory Computing Resource Center (LCRC) at Argonne National Laboratory.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Khan, D., Benali, A., Kim, S.Y.H. et al. Quantum mechanical dataset of 836k neutral closed-shell molecules with up to 5 heavy atoms from C, N, O, F, Si, P, S, Cl, Br. Sci Data 12, 1551 (2025). https://doi.org/10.1038/s41597-025-05428-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-05428-4
