
Abstract
Accurate and timely information on planting intensity and crop rotation is essential for guiding agricultural policies and ensuring food security. However, reliable and up-to-date maps for major crops—wheat, maize, rapeseed, soybean, and potatoes—are lacking in the Loess Plateau, a key grain-producing region in western China. To address this gap, this study aims to generate a high-resolution (10 m) crop planting pattern dataset for the Loess Plateau from 2018 to 2022. The research methodology involved four key steps: (1) Enhancing the sample dataset using phenological indices and the Dynamic Time Warping (DTW) algorithm; (2) Identifying crop planting intensity based on phenological growth curves; (3) Developing independent random forest classifiers tailored to agricultural climate zones; and (4) Constructing an optimal feature subset for crop classification. The resulting maps demonstrated high overall accuracies (OA) is greater than 0.81, with satellite-based estimates showing strong agreement with municipal statistical data (R2 ≥ 0.60). These results provide crucial insights for the management of agricultural ecosystems in the Loess Plateau and can support more informed decision-making in regional agriculture.
Similar content being viewed by others

Background & Summary
Food security is significantly influenced by the escalating population growth, ongoing social and economic development, and climate change1,2. The Loess Plateau in western China stands out for its abundant arable land resources and rich light and heat resources3, showcasing vast potential for agricultural production. It holds a prominent position as one of China’s key grain production hubs. Being a typical dryland agricultural region, the Loess Plateau primarily relies on precipitation for agricultural water supply, but limited rainfall and high evaporation rates pose challenges to agricultural progress. Optimizing the cropping structure, enhancing water resource efficiency and boosting grain production capacity in dryland regions are essential for safeguarding national food security4. Therefore, accurately mapping the planting pattern of the Loess Plateau is vital in promoting agricultural sustainability and ensuring food security5.
In recent years, the accessible and freely available remote sensing data with global coverage and satisfactory spatial resolution have significantly bolstered the data support for identifying crop types on national and global scales6,7,8. The main data types currently used include moderate resolution imaging spectroradiometer (MODIS) with a resolution of 250 m/8 days, Landsat data with a resolution of 30 m/15 days, Sentinel-2 image with a resolution of 10 m/5 days. China’s adoption of a household contract responsibility system has resulted in highly dispersed arable land, enabling farmers to selectively cultivate crops, leading to a marked diversity in crop types. The spatial resolution of MODIS data is too coarse to identify crop types in highly fragmented areas9. Furthermore, due to the brief crop growing season and the 16-day revisit interval frequency of Landsat data, there is an incapacity to provide consistent and stable crop phenology characteristics10. Sentinel-2 provides higher spatial and temporal resolution as well as more spectral bands, making it the optimal free satellite data source for large-scale crop mapping. For example, You et al.8 utilized Sentinel-2 data to produce 10-m crop type maps in Northeast China over 2017–2019, while Li et al.11 used Sentinel-2 data to map annual 10-m maize cropland changes in China during 2017–2021.
Remote sensing-based crop mapping methods can be categorized as phenology-based and machine learning (ML)-based approaches. Phenology-based methods focus on capturing the distinct phenology of various crop species through time-series growth curve characteristics12. This approach necessitates representative crop sample data and adequate satellite observation data to characterize crop phenology. However, satellite data with high temporal spatial resolution is susceptible to weather conditions, intraclass variability, and interclass similarity of spectral and temporal features across large spatial regions and multiple years, impacting crop classification accuracy. Machine learning methods rely on machine learning models to classify crops using remote sensing data. Popular machine learning classifiers such as Support Vector Machine (SVM)13, Random Forest (RF)8, and Neural Network (NN)14 are commonly employed. The advantage of machine learning lies in its ability to consider various recognition features like spectral reflectance, vegetation indices, temporal, and textural features comprehensively, enabling quick and autonomous exploration of crop-specific characteristics. However, machine learning methods are also subject to certain limitations in crop mapping in large areas. Firstly, there is a lack of reliable sample data in large areas, and the quantity and quality of sample data determine the identification accuracy of crop mapping. Secondly, the high dimensionality of feature variables employed in classification increases computational complexity and reduces classifier efficiency. Currently, several studies have integrated phenology with machine learning to address these challenges. Belgiu et al.15 utilized phenological information-based time-series similarity Dynamic Time Warping to create crop sample data for machine learning algorithms. Zhao et al.16 and Yin et al.17 selected optimal features based on phenological information to establish an optimal feature subset, maintaining classification accuracy while reducing computational costs. Therefore, it is promising to map large areas crop type using a combination of phenology and machine learning methods.
Accurate and updated data on planting intensity and crop rotation are essential for advancing sustainable agricultural intensification, mitigating negative agricultural impacts, and ensuring food security. However, there is a lack of reliable updated maps with detailed descriptions on cropping intensity and crops rotations in Loess Plateau. Therefore, the objective of this study is to produce a 10 m resolution crop planting pattern dataset from 2018–2022 on the Loess Plateau. Our contributions encompass four main aspects: (1) Enhancement of the sample dataset based on phenological indices and DTW algorithm; (2) Discrimination of crop planting intensity based on crop phenological curves; (3) Development of independent random forest classifier by considering agricultural climate zones; (4) Construction of optimal feature subset for crop classification. The results of this study can provide important information for the management of agricultural ecosystem in the Loess Plateau.
Methods
Study area
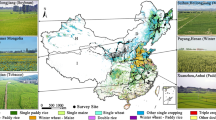
The Loess Plateau is situated in the middle and upper reaches of the Yellow River Basin (https://www.geodata.cn/), covering an area of 6.22 × 105 km2 and spanning latitude 33°69′ to 41°28′N, and longitude 100°86′ to 114°56′E (as shown in Fig. 1). It is characterized by a transitional climate from semi-humid to semi-arid, representing a typical continental monsoon climate with uneven spatial and temporal distribution of precipitation. Rainfall in the southeastern region exceeds 600 mm/day, while the northwestern arid region receives only 150–250 mm/year18. The region experiences high interannual variability in rainfall, with dry in winter and spring, and wet in autumn. Water scarcity and soil erosion act as significant constraints to the agricultural development and ecological restoration of the area. The Loess Plateau has historically been among China’s vital agricultural zones19, with cultivated land covering more than 20% of the total area, predominantly reliant on rain-fed agriculture20. The major crops are wheat, maize, rapeseed, potatoes, and soybean.

The location of the Loess Plateau (a), municipal boundary (b), county boundary (c).
The Loess Plateau encompasses 7 provinces, 44 cities and 332 counties (https://www.ngcc.cn/). Due to the influence of rainfall, terrain, and temperature, there are spatial differences in planting phenology, so the agricultural region is used for mapping crop planting patterns21,22. According to the “2019 National Cultivated Land Quality Grading Report” (https://www.gov.cn/), the study area spans six agricultural regions (as shown in Fig. 1). It includes the Jindong-Yuxi Hilly Mountain Agriculture, Forestry and Pastoral Zone (JAFP), Fenwei Valley Agricultural Zone (FVA), Jin-Shaan-Gan Loess Hills Gullies Pastoral and Forest Zone (LPF), Longzhong-Qingdong Hilly Agriculture and Pastoral Zone (LAP), Agriculture and Pastoral Zone along the Great Wall (GAP), and Meng-Ning-Gan Agriculture and Pastoral Zone (MAP). Generally speaking, the crop planting patterns within each agricultural region exhibit similarities. The phenological characteristics of 8 main crops of the Loess Plateau was obtained from fieldwork and referred to Phenology calendar data3, as shown in Fig. 2.

Crop calendar of the 8 major crops in the Loess Plateau.
Overview of the crop classification method
Figure 3 illustrates the workflow of this paper. Firstly, we completed the pre-processing of Sentinel-2 data from 2018 to 2022, and extracted cropland data based on FROM_GLC10 product. Secondly, we collected sample points in field surveys and visual interpretation, and the DTW algorithm is used to expand and enhance the data of crop sample points. Thirdly, we derived the cropping intensity based on crop phenological curve method. Fourthly, we used optimal crop features as inputs to train the crop classifier based on the RF algorithm, and then mapped crop pattern map with 10 m resolution from 2018 to 2022 on the Loess Plateau.

Integrated workflow for crop classification on the Loess Plateau (2018–2022), encompassing: (a) Image pre-processing; (b) Sample collecting; (c) Cropping intensity; (d) Feature construction; (e) Random Forest classification on GEE.
Sentinel-2 images and pre-processing
Sentinel-2 data were obtained from the European Space Agency’s Copernicus Open Access Hub (https://scihub.copernicus.eu/). The Sentinel-2 Earth observation mission currently comprises two satellites, Sentinel-2A and Sentinel-2B, which were launched in 2015 and 2017, respectively. Together, the two satellites provide global coverage of the Earth’s surface every five days. Each satellite is equipped with a multispectral instrument capable of acquiring imagery across 13 spectral bands, spanning the visible, near-infrared, and shortwave infrared regions of the electromagnetic spectrum, with spatial resolutions of up to 10 meters.
Due to the unavailability of Level-2A surface reflectance (SR) products on the Google Earth Engine (GEE) platform for the Loess Plateau region prior to 20198, Level-1C top-of-atmosphere (TOA) reflectance data were used for the year 2018. From 2019 to 2022, we used the more reliable Level-2A SR data as they became accessible on the platform.
In this study, five key spectral bands were selected, including Red-edge 1 (RE1), Red-edge 2 (RE2), Red-edge 3 (RE3), Short-Wave Infrared 1 (SWIR1), and Short-Wave Infrared 2 (SWIR2). The red-edge bands are important indicators of plant pigment concentration and vegetation health status, while SWIR bands are sensitive to water content and other biochemical components in crop leaves. Among these, RE2, SWIR1, and SWIR2 demonstrated significant discriminatory power for distinguishing between maize and soybean (You et al., 2021).
In addition, four complementary vegetation indices were derived from different combinations of these spectral bands: the Normalized Difference Vegetation Index (NDVI)23,24, Enhanced Vegetation Index (EVI)25, Normalized Difference Senescent Vegetation Index (NDSVI)26, and Green Chlorophyll Vegetation Index (GCVI)27. These indices were selected to better capture the phenological characteristics of diverse crops under complex cropping structures. NDVI and EVI have been widely used to extract crop phenological indicators, with numerous studies identifying NDVI as a dominant vegetation index for vegetation monitoring28. EVI is more effective in minimizing background soil noise, making it particularly suitable for arid and semi-arid regions where vegetation cover is sparse and bare soil is prevalent. It also helps mitigate NDVI’s saturation issues in areas with high biomass. NDSVI is useful for monitoring crop growth and identifying senescence stages such as leaf yellowing and wilting, which supports improved analysis of crop phenological cycles29. GCVI, on the other hand, reflects crop photosynthetic capacity and nutrient status, and is particularly effective in the identification of soybean cultivation30. The functions of NDVI, EVI, NDSVI and GCVI are provided in Eqs. (1)–(4) as follows:
where, \({p}_{{nir}}\), \({p}_{{red}}\), \({p}_{{blue}}\), \({p}_{{swir}1}\), and \({p}_{{green}}\) are the near-infrared, red, blue, shortwave infrared bands, and green in the Sentinel-2A images, respectively.
Cropland mask
Wang et al.31 conducted a comparative analysis of six global high-resolution land use/land cover products (WorldCover10, FROM_GLC10, ESRI GLC10, FROM_GLC30, GLC_FCS30, and GlobeLand30), and found that FROM_GLC10 exhibited relatively high accuracy over China, with an overall accuracy of 65.57%, particularly in the classification of croplands. Similarly, Bie et al.32 evaluated three major global land cover products (FROM_GLC10, ESA World Cover, and ESRI Land Cover) over northwestern China and reported that FROM_GLC10 achieved the highest overall accuracy of 77.83%.
Considering that the Loess Plateau is one of China’s primary agricultural production regions, and that cropland areas did not undergo significant large-scale expansion or reduction between 2018 and 2022, this study focused on the classification of specific crop types—including maize, wheat, soybean, rapeseed, and potatoes—rather than distinguishing between cropland and non-cropland. To exclude non-cropland areas, we employed the FROM_GLC10 dataset, which has been shown to perform well in northwestern China.
The FROM_GLC10 product is a global scale land use dataset with 10 m resolution in 2017, which was obtained from the Department of Earth System Science, Tsinghua University, China (https://data-starcloud.pcl.ac.cn/zh).
Sample data collection and augmentation
The sample data used in this study were derived from both field surveys and augmentation based on the Dynamic Time Warping (DTW) algorithm.
-
(i)
Samples collected from field surveys. From April to October 2021, extensive field surveys were conducted across the main agricultural areas of the Loess Plateau, as shown in Fig. 1. A UniStrong G138BD handheld GNSS receiver with a horizontal accuracy of 2–5 meters was used to record the geographic coordinates of various crop types. After the field investigation was completed, all samples were visually inspected using high-resolution images from Google Earth to ensure quality and accuracy. The obtained sample points include: winter wheat, spring wheat, summer maize, spring maize, soybean, potatoes, winter rapeseed, spring rapeseed, and other cropland.
-
(ii)
Sample preparation based on phenology method. Based on the field-validated sample points, standard NDVI phenological curves were extracted for eight major crops: winter wheat, spring wheat, summer maize, spring maize, winter rapeseed, spring rapeseed, soybean, and potatoes. On the Google Earth Engine (GEE) platform, pixel-wise NDVI time series were compared with these reference phenological curves using the Dynamic Time Warping (DTW) algorithm to calculate temporal similarity. The resulting DTW distance rasters were then used to generate spatially distributed sample points through stratified random sampling within agricultural zones, thereby augmenting the training dataset with high-quality, geographically representative samples.
Sample point processing and Dynamic time warping
Before conducting sample point amplification using the DTW algorithm, it is necessary to distinguish the collected sample points as wheat in the study area is divided into winter wheat and spring wheat, maize includes summer maize and spring maize, and rapeseed includes winter rape and spring rape, and the planting and harvest times of these crops are different. Using the GEE platform and based on sentinel-2 remote sensing images, the NDVI of the collected sample points of wheat, maize and rapeseed during their growth periods was calculated, and a 10-day NDVI time series was synthesized. The NDVI range values of different types of crops in the study area could be obtained, and the standard NDVI curves of different types of crops could be drawn. As shown in Fig. 4, based on the NDVI curve, the NDVI characteristics of the samples at different times are utilized to distinguish crops such as winter wheat and spring wheat, forming sample points of winter wheat, spring wheat, summer maize, spring maize, winter rape, and spring rape.

Standard phenological curves of major crops on the Loess Plateau.
Dynamic Time Warping (DTW) algorithm measures the similarity between two non-linear time series curves by calculating the distance value. Assuming that the time series X = {x1, x2, …, xn} is the curve of an unknown pixel, and the time series Y = {y1, y2, …, ym} is the standard curve of a known maize pixel, and the lengths of the two curves are n and m respectively. The DTW algorithm measures the similarity between the two given time series using the Euclidean distance and can flexibly warp and stretch the time series X to align with the time series Y. Use dbase(i, j) to represent the distance matrix obtained by calculating the Euclidean distance between any two points in sequence X and sequence Y. The calculation is as follows:
Where Di is the i-th element in the regular path, and n is the total number of elements in the regular path. The expanded crop sample distribution map based on the DTW algorithm is shown in Fig. 5.

Crop sample distribution map based on DTW algorithm.
Cropping intensity mapping method
This study employed the framework proposed by Liu et al.33 to generate a 10 m resolution crop planting intensity dataset for the Loess Plateau, consisting of two main steps: (1) phenological phase identification and (2) cropping cycle detection.
In the first step, the Savitzky–Golay (SG) filter was applied to smooth NDVI time series, from which the annual NDVI minima and maxima were derived. Transition points were then identified when NDVI values exceeded 50% of the seasonal amplitude34, marking mid-greenup (increasing NDVI) and mid-greendown (decreasing NDVI) stages. The period between mid-greenup and mid-greendown was defined as a growing phase, while the reverse marked a non-growing phase.
For cropping cycle detection, the number of potential cropping cycles (\({N}_{{pc}}\)) was defined as the minimum between the number of mid-greenup (\({N}_{{up}}\)) and mid-greendown (\({N}_{{down}}\)) points:
To reduce false detections caused by NDVI anomalies, we followed Sakti and Takeuchi35 in setting a minimum crop growth duration of 48 days. Growth periods shorter than this threshold were classified as false cycles (\({N}_{{fc}}\)), and the actual cropping intensity (\({CI}\)) was calculated as:
In this study, cropping intensity data for each year (2018–2022) were produced based on this method.
Feature selection
According to the growth period of crops, different crops are distinguished by using spectral index, vegetation index and texture features. First, during the crop growth period, we combined remote sensing images into a 10-day time series. We selected five spectral reflection bands: RE1(B5), RE2(B6), RE3 (B7), SWIR1(B11) and SWIR2(B12). Secondly, the maximum, minimum and mean values of the vegetation indices (NDVI, EVI, NDSVI, GCVI) in each time series were calculated as another classification basis. Finally, we used the gray-level co-occurrence matrix function to add the texture features of the image, including the Angular second moment (ASM), Contrast, Correlation, and Entropy indicators (ENT). We take these three indices together as the characteristic values for crop classification (as shown in Table 1).
Random Forest algorithm
Random forest (RF) algorithm is an assembly method that builds multiple randomly uncorrelated decision trees (DT) to achieve an integrated classifier with better predictive performance36. A decision tree is a data structure that each path from the root (the attribute that contributes the most to the final classification result) to the leaf node (the final classification result) represents a rule for the decision37. RF is robust to noise and outlier data, and it solves the overfitting problem that plagues DT. The GEE platform has provided RF algorithm, which has been used to classify the crop types8, detect wetlands changes38, and detect forest fires39.
In this study, the RF algorithm was adopted to training crop classifiers, two parameters were set. (1) The parameter “numberOfTrees” (the number of trees determines the number of binary CART trees used to construct the RF model) was set to 100. (2) minLeafPopulation (the minimum sample size required for leaf nodes) is set to 10, and the remaining parameters are default in GEE.
Data Records
This dataset provides crop distribution maps at 10 meters on the Loess Plateau from 2018 to 2022 (Fig. 6), available in the figshare repository in Geotiff format40. The dataset is provided in the ESPG: 4326 (WGS_1984) spatial reference system. The range of the dataset is from 33°69 ‘to 41°28’ N latitude and 100°86 ‘to 114°56’ E longitude. The values of these crops types are: (1: winter wheat; 2: spring wheat; 3: winter rape; 4: spring rape; 5: spring maize; 6: summer maize; 7: soybean; 8: potatoes; 9: single others,; 10: winter wheat-summer maize; 11: winter rape-summer maize;12: winter wheat-others; 13: winter rape-others; 14: others-summer maize; 15: other double-cropping patterns). These data can be visualized and analyzed in ArcGIS, QGIS or other similar software.

Map of 10 m crops in the Loess Plateau from 2018 to 2022.
Technical Validation
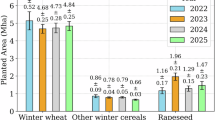
First of all, we compared the on-site data with the real data on the ground. Based on the evaluation of the sample points, we took 30% of the sample points as verification samples to generate a confusion matrix and evaluate the classification accuracy of eight crops. The results show that the overall accuracy from 81.08% to 84.54%, and the Kappa coefficient ranged from 78.35% to 82.26%. Secondly, we compared our crop data with the data from the municipal agricultural census. As can be seen from the Fig. 7, the coefficient of determination (R2) of the main crops of the Loess Plateau, maize and wheat, with the data in the statistical yearbook are relatively high, greater than 0.83. The R2 of soybeans, potatoes and are rapeseed greater than 0.61. These findings show that our crop products are consistent with the records in the statistical yearbook. However, the farmland mask data we used (Sources of error of FROM_GLC10 product) has an overall accuracy of 72.76%. Although the overall and Kappa coefficients are higher than other products, there are still errors, which will reduce the accuracy of crop map recognition. In the future, we plan to use all crop sample points to create a set of China’s latest detailed farmland maps based on current farmland data.

Verification of the results of the municipal statistical yearbook.
Usage Notes
The Loess Plateau is one of China’s important grain production areas. The crop planting area information of the Loess Plateau is of great significance to regional food security and agricultural development. In our study, we used field survey samples combined with DTW algorithm expansion, proposed a large-scale multi-category crop recognition model based on random forests, and provided a 10 m resolution crop distribution map of the Loess Plateau region from 2018 to 2022. This high-precision crop map can be used to predict agricultural productivity, evaluate the water suitability of dryland farmland, etc. Timely and high-resolution crop data is of great significance to the study of regional food balance and food security.
Code availability
The JavaScript code used to generate the crop type and crop type maps can be obtained from the figshare repository40.
References
Tariq, A., Yan, J., Gagnon, A. S., Riaz Khan, M. & Mumtaz, F. Mapping of cropland, cropping patterns and crop types by combining optical remote sensing images with decision tree classifier and random forest. Geo-Spat Inf Sci. 26(3), 302–320 (2023).
Jiang, S. et al. Sustainability of water resources for agriculture considering grain production, trade and consumption in China from 2004 to 2013. J Clean Prod. 149, 1210–1218 (2017).
Chen, X. et al. Tracking the spatio-temporal change of the main food crop planting structure in the Yellow River Basin over 2001–2020. Comput Electron Agric. 212, 108–102 (2023).
Liu, Q., Niu, J., Du, T. & Kang, S. A. Full-Scale Optimization of a Crop Spatial Planting Structure and its Associated Effects. Engineering-Prc. 28, 139–152 (2023).
Qiu, B. et al. Maps of cropping patterns in China during 2015–2021. Sci Data. 9(1), 479 (2022).
Chen, X. et al. Tracking the spatio-temporal change of the main food crop planting structure in the Yellow River Basin over 2001–2020. Comput Electron Agr 212, 108102 (2023).
Wang, S., Di Tommaso, S., Deines, J. M. & Lobell, D. B. Mapping twenty years of corn and soybean across the US Midwest using the Landsat archive. Sci Data. 7(1), 307 (2020).
You, N. et al. The 10-m crop type maps in Northeast China during 2017–2019. Sci data. 8(1), 41 (2021).
Liu, Y., Zhang, Z. & Wang, J. Regional differentiation and comprehensive regionalization scheme of modern agriculture in China. Acta Geogr Sin. 73(2), 203–218 (2018).
Yang, N. et al. Large-scale crop mapping based on machine learning and parallel computation with grids. Remote Sens-Basel. 11(12), 1500 (2019).
Li, Z. et al. Performance of GEDI data combined with Sentinel-2 images for automatic labelling of wall-to-wall corn mapping. Int J Appl Earth Obs. 127, 103643 (2024).
Zhang, C., Zhang, H. & Tian, S. Phenology-assisted supervised paddy rice mapping with the Landsat imagery on Google Earth Engine: Experiments in Heilongjiang Province of China from 1990 to 2020. Comput Electron Agr. 212, 108105 (2023).
Ni, R. et al. An enhanced pixel-based phenological feature for accurate paddy rice mapping with Sentinel-2 imagery in Google Earth Engine. ISPRS J Photogramm Remote Sens. 178, 282–296 (2021).
Wei, L. et al. Deep Convolutional Neural Network for Rice Density Prescription Map at Ripening Stage Using Unmanned Aerial Vehicle-Based Remotely Sensed Images. Remote Sens. 14(1), 46 (2021).
Belgiu, M., Bijker, W., Csillik, O. & Stein, A. Phenology-based sample generation for supervised crop type classification. Int. J. Appl. Earth Obs. Geoinf. 95, 102264 (2021).
Zhao, L. et al. In-season crop type identification using optimal feature knowledge graph. ISPRS J Photogramm Remote Sens. 194, 250–266 (2022).
Yin, L., You, N., Zhang, G., Huang, J. & Dong, J. Optimizing Feature Selection of Individual Crop Types for Improved Crop Mapping. Remote Sens. 12(1), 162 (2020).
Gao, X. et al. The spatial and temporal evolution of the actual evapotranspiration based on the remote sensing method in the Loess Plateau. Sci. Total Environ 708, 135111 (2020).
Fu, B. Soil erosion and its control in the Loess Plateau of China. Soil Use Manage. 5(2), 76–82 (1989).
Jin, N. et al. Effects of water stress on water use efficiency of irrigated and rainfed wheat in the Loess Plateau, China. Sci Total Environ. 642, 1–11 (2018).
Li, Z. et al. Performance of GEDI data combined with Sentinel-2 images for automatic labelling of wall-to-wall corn mapping. International journal of applied earth observation and geoinformation 127, 103643 (2024).
Liu, J. et al. Spatiotemporal characteristics, patterns, and causes of land-use changes in China since the late 1980s. Journal of geographical sciences 24, 195–210 (2014).
Tucker, C. J. Red and photographic infrared linear combinations for monitoring vegetation. Remote sensing of environment 8, 127–150 (1979).
Watanabe, D. S. Z., Barboza-Pinzon, E. G., Hesp, P. A., Schossler, V. & Salgado, E. T. Evolution of coastal transgressive aeolian sand sheets over 75 years (1948-2023) at Concheiros Barrier - Southern Brazilian coast. Geomorphology 470, 109520 (2025).
Huete, A. R., Liu, H. Q. & Batchily, K. van Leeuwen, W. A comparison of vegetation indices over a global set of TM images for EOS-MODIS. Remote sensing of environment 59, 440–451 (1997).
Zheng, G. et al. The Potential of Multispectral Vegetation Indices Feature Space for Quantitatively Estimating the Photosynthetic, Non-Photosynthetic Vegetation and Bare Soil Fractions in Northern China. Photogrammetric engineering and remote sensing 85, 65–76 (2019).
Zhi, F. et al. Rapid and Automated Mapping of Crop Type in Jilin Province Using Historical Crop Labels and the Google Earth Engine. Remote sensing 14, 4028 (2022).
Radočaj, D., Šiljeg, A., Marinović, R. & Jurišić, M. State of Major Vegetation Indices in Precision Agriculture Studies Indexed in Web of Science: A Review. Agriculture 13, 707 (2023).
Huang, L. et al. Rapid mapping of soybean planting areas under complex crop structures: A modified GWCCI approach. Computers and electronics In agriculture 235, 110326 (2025).
Huang, X., Vrieling, A., Dou, Y., Belgiu, M. & Nelson, A. A robust method for mapping soybean by phenological aligning of Sentinel-2 time series. Isprs journal of photogrammetry and remote sensing 218, 1–18 (2024).
Wang, Y. et al. Evaluation of six global high-resolution global land cover products over China. International Journal of Digital Earth 17(1), 2301673 (2024).
Bie, Q., Luo, J. & Lu, G. Accuracy performance of three 10-m Global Land Cover products around 2020 in an Arid Region of Northwestern China. IEEE Access 11, 133215–133228 (2023).
Liu, C. et al. A new framework to map fine resolution cropping intensity across the globe: Algorithm, validation, and implication. Remote Sens Environ. 251, 112095 (2020).
Bolton, D. K. et al. Continental-scale land surface phenology from harmonized Landsat 8 and Sentinel-2 imagery. Remote Sens Environ. 240, 111685 (2020).
Sakti, A. D., Takeuchi, W. Estimation of global crop calendar and intensity using the MODIS NDVI Time Series from 2001 to 2015. In: International Symposium on Remote Sensing (2018).
Razavi-Termeh, S. V., Sadeghi-Niaraki, A. & Choi, S. A new approach based on biology-inspired metaheuristic algorithms in combination with random forest to enhance the flood susceptibility mapping. J Environ Manage. 345, 118790 (2023).
Zhu, L., Qiu, D., Ergu, D., Ying, C. & Liu, K. A study on predicting loan default based on the random forest algorithm. Procedia Comput Sci. 162, 503–513 (2018).
Zhao, F., Feng, S., Xie, F., Zhu, S. & Zhang, S. Extraction of long time series wetland information based on Google Earth Engine and random forest algorithm for a plateau lake basin – A case study of Dianchi Lake, Yunnan Province, China. Ecol. Indic. 146, 109813 (2023).
Bar, S., Parida, B. R. & Pandey, A. C. Landsat-8 and Sentinel-2 based Forest fire burn area mapping using machine learning algorithms on GEE cloud platform over Uttarakhand, Western Himalaya. Remote Sens Appl. 18, 100324 (2020).
Zhao, X. et al. High-resolution (10 m) dataset of multi-crop planting structure on the Loess Plateau during 2018-2022. figshare. https://doi.org/10.6084/m9.figshare.27643137 (2025).
Acknowledgements
This research was supported by the National Natural Science Foundation of China (42125705, 42377346), and the National Key Research and Development Program of China (2021YFD1900700).
Author information
Authors and Affiliations
Contributions
X.Z. and J.W. designed the study and the methodology, Y.D. wrote the code and generated the data, X,G., C.L., H.H. and X.G. checked samples and evaluate the resulting maps. All authors analyzed the data, wrote, and edited the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhao, X., Wang, J., Ding, Y. et al. High-resolution (10 m) dataset of multi-crop planting structure on the Loess Plateau during 2018–2022. Sci Data 12, 1190 (2025). https://doi.org/10.1038/s41597-025-05529-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-05529-0
