
Abstract
The anthropogenic material in-use stocks accumulated in products, buildings, and infrastructure are essential for satisfying basic human demands and ensuring well-being. They drive global resource demand and environmental impacts while representing valuable resource reservoirs for potential recycling through urban mining. A high-resolution understanding of global material in-use stocks was achieved by integrating reconciled night-time light imageries with national stock data on primary construction materials, including steel, aluminum, and cement. The integration enabled the estimates of global stocks from 2000 to 2019 at a 500 × 500 m grid resolution. The updated dataset mitigated saturation and blooming effects in prior satellite data compared to previous datasets, offering refined temporal and geographical representations despite some regional variations. The refined results systematically elucidate the spatiotemporal dynamics of material accumulation worldwide, highlighting distribution discrepancies between and within cities. The comprehensive database serves as a helpful resource for supporting waste management, circular economy, spatial planning, urban sustainability, and climate change mitigation efforts across various geographical scales.
Similar content being viewed by others
Introduction
Anthropogenic material stocks in products, buildings, and infrastructure form the foundation of human civilization1. Over the past century, these stocks have experienced a 23-fold increase globally, underpinning essential societal services such as shelter, mobility, and communication2,3. Resource and energy flows determine the dynamics of anthropogenic material in-use stocks, which in turn reflect historical resource flows4,5. Constructing and maintaining in-use stocks necessitate substantial resources and energy while generating considerable recyclable and non-recyclable waste materials6,7,8. Moreover, maintaining existing anthropogenic stocks while minimizing resource consumption and greenhouse gas emissions during operation requires substantial financial and environmental investments9,10,11.
Previous anthropogenic in-use stock characterization studies have employed either a top-down or bottom-up modeling approach12,13. The top-down approach focuses on material flows at global or national levels but lacks sufficient spatial resolution to capture variations at finer regional or city scales14. Conversely, the bottom-up approach provides high-resolution insights at the product and regional levels but necessitates significant human and financial resources for finer-scale mapping15. These traditional approaches inherently involve trade-offs between research scope and spatial resolution, hindering the simultaneous achievement of both objectives16,17. Most importantly, while existing stock knowledge provides insights at national or city levels, it often lacks the spatially explicit distribution needed for more localized applications18,19. Gridded data on a sub-city level are crucial for developing practical urban planning and waste management policies20, as they improve material stock assessments and carbon accounting for decarbonization strategies21,22. Additionally, it enables the analysis of relationships between stock accumulation and socioeconomic factors such as economic progression and population growth23,24, thereby facilitating the identification of future urban mining opportunities25,26. Such spatially explicit material stock information offers essential insights for developing and implementing future urban management and strategic planning initiatives10,27, which requires collaboration between governments and corporations28.
Combining nighttime light (NTL) data as proxies with macro-level material stock data from top-down or bottom-up models provides an alternative method for high-resolution estimation of anthropogenic stocks29,30. With rapid advancements in sensor accuracy and image processing technologies, hybrid NTL-driven methods have gained widespread use31. Hybrid approaches leveraging NTL data are increasingly employed to downscale global or national socio-economic indicators, such as urban development patterns32,33,34, physical risk assessment35, Gross Domestic Product (GDP)36,37, energy consumption38, population distribution39, and air pollutant emissions40. Researchers are actively utilizing NTL imagery to investigate spatial characteristics of anthropogenic stocks. For example, Rauch pioneered NTL and spatialized GDP data to map the global distribution of primary industrial metals (aluminum, copper, steel, and zinc) at a 1 km resolution in 200041. Peled and Fishman estimated European building stocks by leveraging NTL dispersion patterns to generate block-level data42. High-resolution mapping of material stocks has been conducted in various countries using different methodologies, including Sentinel satellite imagery with OpenStreetMap data in Germany and Austria43, NTL-based approaches in Japan44,45, and some Belt and Road countries like China and Singapore46. The static data typically produced by NTL-based material studies at global or national levels hinders tracking temporal changes in material stock growth47. The growth patterns of building stocks in China’s Yangtze River Delta (2000–2020) and Laos (1990–2015) were identified by comparing NTL imagery over multi-decade periods48,49. Yu mapped global anthropogenic stocks of bulk materials (steel, aluminum, and cement) on a 1 × 1 km grid from 1992 to 200950. However, the limitations in lighting conditions and sensor capabilities led to saturation and blooming effects in prior satellite data, compromising the accuracy of stock maps and restricting their resolution to 1 km51.
This article presents a global dataset for spatialized steel, aluminum, and cement in-use stocks at a 500 × 500 m resolution, covering the period from 2000 to 2019. The dataset is based on updated country-level material stocks and reconciled NTL data, aiming for spatial and temporal consistency. Based on average stocks and light intensity per unit area, country-specific regression models have been established for most regions, though with varying levels of certainty.
The remainder of the paper outlines the system definition, data sources, and methodology employed to generate and validate the dataset. The dataset provides an updated, spatially explicit overview of anthropogenic material stocks with global and temporal coverage. It offers spatially detailed estimates of stock distributions, which could be informative for countries with limited statistical data. The distribution dataset may support assessments of urban mining potential, socioeconomic development, and urban expansion, providing policymakers with high-resolution insights for resource management and urban sustainability. Additionally, the identified stock accumulation process, closely linked with societal factors, facilitates exploring the interplay between stock growth and economic development while helping to understand development pathways in less developed regions. The dataset will be maintained and periodically updated every 3–5 years to ensure its relevance and accuracy.
Methods
System definition and data sources
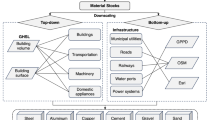
The upper portion of Fig. 1 illustrates the system definition for the anthropogenic cycles of the analyzed materials (steel, aluminum, and cement). Each cycle originates in the lithosphere and progresses through the production, manufacturing, use, and waste management phases. The model also incorporates international trade of raw materials, semi-products, and final products, represented by markets between processes. The modeling framework connects national stock estimates from the traditional top-down approach with time-series NTL data, with regressions tailored to individual countries, years, and materials. The spatiotemporal changes and material flow characteristics from 2000 to 2019 were evaluated using advanced geospatial analysis techniques in over 100 countries and regions. The resulting 500 × 500 m gridded stock data provide global coverage for the two-decade period.

System definition and modeling framework for global anthropogenic in-use steel, aluminum, and cement stocks at a 500 m grid level (2000–2019).
The anthropogenic stocks of steel52, cement53, and aluminum54 utilized in this study were derived from our previous research, which estimated the stocks up to around 2010. This work adopted similar research frameworks and extended the analysis to 2019, providing updated insights into material stock dynamics. Detailed data processing and parameters can be found in Supplementary File 1. The specific time series stock data for different countries are available in the Supplementary xlsx file Table S1. The time series data for the mining period were primarily sourced from the US Geological Surveys (https://www.usgs.gov), the statistical yearbooks of various countries and regions (including China Statistical Yearbook (http://www.stats.gov.cn), Japan Statistical Yearbook (https://www.stat.go.jp), U.S. Statistical Abstract (https://www.census.gov), and Eurostat databases (https://ec.europa.eu/eurostat)), and the World Bureau of Metal Statistics database (http://www.world-bureau.com). The UN Comtrade database (https://comtrade.un.org) was utilized to obtain trade quantities between nations, with data reconciled to account for inconsistencies. Material flows into various end-uses were assumed to follow normal lifetime distributions specific to each category and country, simulating the in-use phase from entry into service to retirement. National boundaries are delineated using data from the Global Administrative District Database (https://gadm.org) as a computation mask, which may differ slightly from actual administrative divisions.
The calculation for national anthropogenic stocks of steel, cement, and aluminum
Material Flow Analysis has been employed to estimate anthropogenic in-use stocks at national scales20,55,56,57. The in-use material stocks are calculated based on the difference between the inflows and outflows due to end-of-life disposal following the mass balance principle. Equation 1 is utilized to estimate the in-use stock of materials S(t) for a given year t. Here, t0 represents the initial year, t is the target year for computation, γ denotes the final use category, such as construction or transportation. Xinto use,γ (t) is the quantity of material entering the use phase for the category γ in year t. The function L(t-t′, τγ, σγ) represents the proportion of material exhausted due to lifecycle completion, following a normal distribution characterized by the mean lifetime τ and standard deviation σ specified to each category γ. t′ denotes the year in which the material initially entered into use. The in-use material stock is determined by aggregating the net inflows into end-uses from the initial year to the target year. Further details can be found in the Supplementary Information and previous works52,53,54.
Nighttime light data usage
This research utilizes pre-processed global NPP-VIIRS-like NTL data from 2000 to 2019, calibrated and harmonized across multiple sensors as detailed in our previous study58,59. The dataset combined Defense Meteorological Satellite Program-Operational Linescan System (DMSP-OLS) (https://www.ngdc.noaa.gov/eog/dmsp.html) and National Polar-orbiting Partnership-Visible Infrared Imaging Radiometer Suite (NPP-VIIRS) data (https://ncc.nesdis.noaa.gov/VIIRS/), aiming for consistency in spatial resolution and sensor performance through cross-sensor calibration techniques. Vegetation indices and auto-encoder models addressed oversaturation, blooming effects, and discrepancies across different NTL datasets. Consequently, the NPP-VIIRS-like dataset provides enhanced continuity and stability, with a spatial resolution of 15 arcsecs (500 m) and near-global coverage (longitude −180° to 180°, latitude −65° to 75°).
The calibrated NTL data products were projected using the Mollweide projection to support consistent spatial analysis across large-scale regions or the entire globe. This equal-area projection preserves area accuracy globally, which is crucial for comparing light intensity and mapping material distribution across different regions. Using the Zonal Statistics tool in ArcGIS Pro, the sum of NTL raster values within the boundaries of each country or region was calculated, focusing specifically on built-up areas to create the NTL indicators for spatial analysis. The approach facilitates the assessment of NTL intensity across various locations over multiple years. The dataset’s high resolution and improved quality surpasses the 1 km resolution of earlier datasets, enabling dynamic representations of human activity within cities over time. These enhancements make the dataset suitable for long-term dynamic urban development studies globally.
Regression models for estimating average anthropogenic stocks using NTL intensity at 500 m resolution
Anthropogenic stocks, mainly embodied in buildings, infrastructure, and products, are widely distributed throughout urban areas. Previous studies have demonstrated strong positive correlations between intra-city stocks and NTL intensity, revealing overall building stocks, steel usage, and cement inventories42,44,50. However, applying NTL data for estimating stocks at the national level often overlooks variations across countries, leading to significant discrepancies between estimated and reference stock values for certain countries. Double logarithmic regression models were employed to estimate anthropogenic stocks, establishing the relationship between average stocks (stock_per_area) and light intensity (light_per_area) per unit area (500 × 500 m grids). Each country’s average stock and light intensity were calculated by dividing the total stock and total light intensity by the number of unit areas within that country. The model, represented by Eq. 2 below, was applied to conduct NTL regression modeling for each year and each anthropogenic stock for individual nations. α, β, and γ are the basic, elastic, and modified regression coefficients in the regression equation.
A country adjustment coefficient gamma is incorporated into the double logarithmic regression model for 119 nations with known stock data (detailed in the Supplementary xlsx file Table S1) to account for the distinct developmental patterns across countries. The global average development coefficients are adopted for 137 countries and regions without statistical data (out of 256 total), with the γ value set to 0. The density-based spatial clustering of applications with noise (DBSCAN) method is applied to detect and remove outlier countries with abnormal relationships between total stock estimates and aggregated NTL intensity, prior to regression modeling. Detailed modeling methods and code can be found in Supplementary File 1. Figure 2 demonstrates correlations between average light intensity and material stock per unit area in 2019 for steel, aluminum, and cement, based on countries with known stocks and fitted with double logarithmic linear regressions. Additional information on the parameter values for each regression model is provided in the Supplementary xlsx file Table S2. Applying the equation to global NTL data yields distinct regression parameters for different nations, allowing for material-specific stock estimates for particular years.

Scatter plot and linear regressions of NTL values versus anthropogenic material stocks per unit area in 2019.
Data Records
The dataset comprises 60 TIFF files documenting the global distribution of three anthropogenic material stocks (aluminum, steel, and cement) over 20 years. Each material’s stock data is packaged in a ZIP file and uploaded to the Figshare website60, with file names structured as “Stock_[Material Type]_[Year]”. Each material includes 20 TIFF files, corresponding to each year from 2000 to 2019, as the calculation is based on annual NTL imagery. The raster data are stored as 500 × 500-meter grids in the WGS84 coordinate system using the Mollweide projection. Grid values represent the amount of anthropogenic stock measured in kilotons distributed across each grid cell. Figure 3 presents the global distribution of the three anthropogenic material stocks in 2019, mapped at a 500-meter grid resolution. Figure 3b–d provide a detailed view of three regions with the highest stock accumulation, namely North America, Europe, and East Asia, illustrating the spatial heterogeneity in the gridded stock estimates.

Global and regional mapping of anthropogenic stocks (sum of steel, aluminum, and cement) in 2019 at 500 m × 500 m grid scale: (a) Global. (b)North America. (c) Europe. (d) East Asia.
Technical Validation
Data validations were conducted at city, provincial, national, and global scales to assess the dataset’s validity and reliability. The validations indicate that the dataset is capable of representing spatial variations and temporal dynamics over two decades, supporting multi-scale sustainability assessment.
Assessment of accuracy for anthropogenic stocks across various urban areas
The gridded stock results, provided as TIFF files, were utilized and aggregated in ArcGIS Pro to calculate stocks at the city level. The city-level estimates were then compared with available assessments in the literature for the same coverages and years. Figure 4 provides a general overview of the comparison results, while the Supplementary xlsx file Table S3 offers detailed information about the specific comparison.

Half-violin plots of the differences between this dataset and literature-reported stock values at the city level. A positive value indicates that our estimate is higher than the corresponding literature value.
Figure 4 presents results from 44 bottom-up city-level cases for comparison worldwide, including 16 samples for steel, 13 for aluminum, and 15 for cement. Previous research61,62,63 has primarily focused on individual cities and stock values of one or several materials from 2000 to 2018. Relative differences were calculated using this study’s estimates as the baseline, with positive values indicating that estimates exceed those reported in the literature. Over 80% of the differences fall within −20% to 40%, indicating reasonable consistency. However, the comparison is limited by the geographic bias of available literature, which mostly covers certain countries and regions.
Differences in steel stock estimations range from −6% to 49%. This study’s original national stock data were generated using top-down approaches, whereas many literature values on the city level were based on bottom-up approaches. Due to the diverse range of iron-containing commodities found in buildings, cross-regional infrastructure, and large appliances, bottom-up data may not fully capture all intra-regional materials. Consequently, bottom-up statistics may tend to be slightly lower than top-down estimates due to methodological differences15.
For aluminum stock estimation, the differences consistently lie within the range of −24% to 37%. In contrast, the distribution of differences for cement stock is more scattered than the other two materials. The discrepancies in cement stock estimations are primarily attributed to the variation in cement-to-concrete conversion ratios and the diverse compositions of buildings and infrastructure across different regions. The ratios are typically calculated using national averages, with limited adjustments to account for local economic development or urban functions.
Verification of anthropogenic stock estimates at broader scales
The applicability of the dataset at larger scales is assessed by aggregating the gridded data within specified regions to calculate anthropogenic stock values. This section utilizes data from Chinese provinces and Japanese prefectures to validate the broader applicability of the generated dataset. Figure 5(a) shows the provincial-level steel stock in China for 2018, computed using the presented methodology and compared against bottom-up approaches reported in the literature51. The varying shades on the provincial maps illustrate the relative differences between these two methods, primarily driven by the inherent characteristics of the top-down and bottom-up approaches. Most provinces exhibit discrepancies ranging from 30% to 50%. Light and dark bars represent the results of this study (NTL-based estimation) and literature-reported values, respectively. Notably, when calculating the total steel stock across China, the top-down approach52 yields results approximately 40% higher than those obtained through the bottom-up method64. Moreover, the NTL-based estimation used in this study captures large-scale infrastructure stocks frequently overlooked by bottom-up approaches, particularly in sparsely populated areas with considerable infrastructure development. Likewise, Fig. 5(b) depicts Japan’s prefectural-level steel stock statistics in 2010, which were utilized to evaluate the dataset’s accuracy further. The comparison reveals a systematic spatial pattern with overestimation in northern/eastern prefectures and underestimation in western/southern regions, indicating limitations in capturing regional variations that may be linked to economic structures or urbanization patterns. Smaller disparities were observed when comparing the dataset with literature-reported values44 in Japan, suggesting the prefectural scale’s reliability. This cross-regional comparison helps identify potential inaccuracies, especially in regions with varying accumulation patterns and levels of economic development.

Comparison of steel stock estimates at the provincial/ prefecture level: (a) China in 2018, (b) Japan in 2010. Unit: thousand tons.
Comparative data for various countries across specific years are available in the Supplementary file Section 4. The compiled dataset generally aligns with previously reported values in the literature, with discrepancies typically ranging from −30% to 30%. This newly developed dataset offers improvements in spatial resolution compared to the previous global dataset32, and it can be suitable for researchers and practitioners requiring finer-scale material stock information. Figure 6 demonstrates the variances in data distribution between the enhanced dataset and the previous one. While the overall distribution patterns remain consistent, the improved approach notably enhances the representation of stocks in urban core areas. The enhancement reveals higher stock densities previously obscured due to saturation effects.

Global and regional comparison of anthropogenic material in-use stocks between the new dataset and previous estimates for 2008 at 1 km × 1 km grid scale. (a) Global differences. (b) North America. (c) Europe. (d) Japan.
Usage Notes
The complete dataset, including global raster files of steel, aluminum, and cement stocks from 2000–2019, is available in TIFF format through the repository. It can serve as a useful resource for waste management by identifying urban mining potential65, circular economy by quantifying recyclable material reservoirs66, spatial planning67, urban sustainability68, and climate change mitigation through embodied carbon assessment18. While NTL data serves as a proxy for estimating material stocks, it has limitations in rural and underdeveloped regions where minimal nighttime lighting leads to substantial underestimation of material stocks. In these areas, the approach may underestimate actual material distributions as traditional buildings and rural infrastructure often generate no detectable light signals. Users should exercise considerable caution when applying the dataset to rural areas or developing countries. Similarly, inaccuracies may occur in regions with excessive light pollution, such as metropolitan centers with intense artificial lighting or industrial flares. Additionally, NTL data does not capture the impact of natural disasters or wars that can significantly impact local material stocks. Furthermore, NTL data inherently cannot detect non-luminous human-made structures, which can lead to underestimation in certain areas. However, emerging methods leveraging satellite imagery and crowd-sourced databases like OpenStreetMap offer potential solutions to address the limitations.
Users should also be aware of uncertainties in the dynamic material flow analysis modeling process, particularly regarding the normal distribution assumptions for material lifetimes, which may not fully capture regional variations. Additionally, uncertainties exist in regions with uneven or limited light distribution, such as polar areas. Earlier datasets may be less reliable than more recent ones due to advancements in sensor technology. Since the same regression equation is applied across entire countries, prediction biases may occur due to variations in economic structure and other factors. Future research will focus on region-specific analyses to address these issues. Users are encouraged to proceed with care, particularly in regions where the correlation between light intensity and material stock may be weaker, such as sparsely populated rural areas, regions with low electrification rates and countries with informal settlements. Regional factors, like economic structure, development levels, and special events, can affect local material stock distribution. It is recommended that users apply appropriate local projection transformations when conducting regional analysis, to improve the geometric accuracy of spatial operations such as area, distance, or overlay calculations. Users can align raster data with selected areas in GIS software for greater precision and better integration with spatial boundaries, by clipping or resampling the data to match the extent, resolution, and coordinate system of administrative or study-area boundaries.
Users can choose the stock map corresponding to the year of interest and import it into geospatial analysis software such as ArcGIS or QGIS. The data is provided in the WGS84 coordinate system under the Mollweide projection. Users can use the Zonal analysis tool under spatial analyst functions to select the stock map as the input value raster and polygon files for area parameters. The output statistics will provide the total material stock for the selected region, which is reported in thousands of tons. We aim to promote responsible and informed usage for various research applications by thoroughly grasping the dataset’s capabilities and limitations.
Code availability
The anthropogenic stock maps were spatially calculated by ArcGIS Pro 2.8. Supplementary xlsx file Table S2 displays parameter options for the double-log regression models for those stocks across different years. Supplementary File 1-Section 6 provides detailed step-by-step instructions and Python scripts, and the code is available via the dataset repository60.
References
Haberl, H. et al. Contributions of sociometabolic research to sustainability science. Nat Sustain 2, 173–184, https://doi.org/10.1038/s41893-019-0225-2 (2019).
Krausmann, F. et al. Global socioeconomic material stocks rise 23-fold over the 20th century and require half of annual resource use. Proceedings of the National Academy of Sciences 114, 1880–1885, https://doi.org/10.1073/pnas.1613773114 (2017).
Elhacham, E., Ben-Uri, L., Grozovski, J., Bar-On, Y. M. & Milo, R. Global human-made mass exceeds all living biomass. Nature 588, 442–444, https://doi.org/10.1038/s41586-020-3010-5 (2020).
Haberl, H. et al. A systematic review of the evidence on decoupling of GDP, resource use and GHG emissions, part II: synthesizing the insights. Environmental Research Letters 15, 065003, https://doi.org/10.1088/1748-9326/ab842a (2020).
Gontia, P., Thuvander, L. & Wallbaum, H. Spatiotemporal characteristics of residential material stocks and flows in urban, commuter, and rural settlements. J Clean Prod 251, 119435, https://doi.org/10.1016/J.JCLEPRO.2019.119435 (2020).
Torres, A. et al. Sustainability of the global sand system in the Anthropocene. One Earth 4, 639–650, https://doi.org/10.1016/j.oneear.2021.04.011 (2021).
Krausmann, F., Lauk, C., Haas, W. & Wiedenhofer, D. From resource extraction to outflows of wastes and emissions: The socioeconomic metabolism of the global economy, 1900–2015. Global Environmental Change 52, 131–140, https://doi.org/10.1016/j.gloenvcha.2018.07.003 (2018).
Fu, C., Deng, T. & Zhang, Y. Urban metabolic flow in China’s megacities doubled by material stock accumulation since the 21st century. npj Urban Sustainability 3, 1–14, https://doi.org/10.1038/s42949-023-00132-x (2023).
Müller, D. B. et al. Carbon Emissions of Infrastructure Development. Environ Sci Technol 47, 11739–11746, https://doi.org/10.1021/es402618m (2013).
Ding, Y., Geng, X., Wang, P. & Chen, W.-Q. How material stocks sustain economic growth: Evidence from provincial steel use in China. Resour Conserv Recycl 171, 105635, https://doi.org/10.1016/j.resconrec.2021.105635 (2021).
Pauliuk, S. & Müller, D. B. The role of in-use stocks in the social metabolism and in climate change mitigation. Global Environmental Change 24, 132–142, https://doi.org/10.1016/j.gloenvcha.2013.11.006 (2014).
Lanau, M. et al. Taking Stock of Built Environment Stock Studies: Progress and Prospects. Environ Sci Technol 53, 8499–8515, https://doi.org/10.1021/acs.est.8b06652 (2019).
Wiedenhofer, D. et al. Mapping and modelling global mobility infrastructure stocks, material flows and their embodied greenhouse gas emissions. J Clean Prod 434, 139742, https://doi.org/10.1016/J.JCLEPRO.2023.139742 (2024).
Graedel, T. E. Material Flow Analysis from Origin to Evolution. Environ Sci Technol 53, 12188–12196, https://doi.org/10.1021/ACS.EST.9B03413/SUPPL_FILE/ES9B03413_SI_001.PDF (2019).
Hirato, T., Daigo, I., Matsuno, Y. & Adachi, Y. In-use Stock of Steel Estimated by Top-down Approach and Bottom-up Approach. Tetsu-to-Hagane 95, 96–101, https://doi.org/10.2355/tetsutohagane.95.96 (2009).
Augiseau, V. & Barles, S. Studying construction materials flows and stock: A review. Resour Conserv Recycl 123, 153–164, https://doi.org/10.1016/j.resconrec.2016.09.002 (2017).
Haberl, H. et al. Weighing the global built environment: High-resolution mapping and quantification of material stocks in buildings. J Ind Ecol, https://doi.org/10.1111/JIEC.13585 (2024).
Liu, G., Bangs, C. E. & Müller, D. B. Stock dynamics and emission pathways of the global aluminium cycle. Nat Clim Chang 3, 338–342, https://doi.org/10.1038/nclimate1698 (2013).
Müller, D. B., Wang, T. & Duval, B. Patterns of Iron Use in Societal Evolution. Environ Sci Technol 45, 182–188, https://doi.org/10.1021/es102273t (2011).
Müller, E., Hilty, L. M., Widmer, R., Schluep, M. & Faulstich, M. Modeling Metal Stocks and Flows: A Review of Dynamic Material Flow Analysis Methods. Environ Sci Technol 48, 2102–2113, https://doi.org/10.1021/es403506a (2014).
Allen, M. R. et al. Geological Net Zero and the need for disaggregated accounting for carbon sinks. Nature 2024 1–3, https://doi.org/10.1038/s41586-024-08326-8 (2024).
Wuyts, W. et al. How Can Material Stock Studies Assist the Implementation of the Circular Economy in Cities? Environ Sci Technol 56, 17523–17530, https://doi.org/10.1021/acs.est.2c05275 (2022).
Creutzig, F. et al. Upscaling urban data science for global climate solutions. Global Sustainability 2, e2, https://doi.org/10.1017/sus.2018.16 (2019).
Wu, B. et al. Global spatial patterns between nighttime light intensity and urban building morphology. International Journal of Applied Earth Observation and Geoinformation 124, 103495, https://doi.org/10.1016/j.jag.2023.103495 (2023).
Yu, B., An, R. & Zhao, G. Spatial and temporal disparity of the in-use steel stock for China. Resour Conserv Recycl 155, 104667, https://doi.org/10.1016/j.resconrec.2019.104667 (2020).
Cheng, K.-L., Hsu, S.-C., Li, W.-M. & Ma, H.-W. Quantifying potential anthropogenic resources of buildings through hot spot analysis. Resour Conserv Recycl 133, 10–20, https://doi.org/10.1016/j.resconrec.2018.02.003 (2018).
Liu, Q. et al. Product and Metal Stocks Accumulation of China’s Megacities: Patterns, Drivers, and Implications. Environ Sci Technol 53, 4128–4139, https://doi.org/10.1021/acs.est.9b00387 (2019).
Kılkış, Ş. et al. City–company collaboration towards aligned science-based target setting. Nature Sustainability 2024 8:1 8, 54–65, https://doi.org/10.1038/s41893-024-01473-w (2024).
Zhao, M. et al. Applications of Satellite Remote Sensing of Nighttime Light Observations: Advances, Challenges, and Perspectives. Remote Sensing 2019, Vol. 11, Page 1971 11, 1971, https://doi.org/10.3390/RS11171971 (2019).
Zhao, F. et al. Material stock analysis of urban road from nighttime light data based on a bottom-up approach. Environ Res 228, 115902, https://doi.org/10.1016/j.envres.2023.115902 (2023).
Chen, Z. et al. The potential of nighttime light remote sensing data to evaluate the development of digital economy: A case study of China at the city level. Comput Environ Urban Syst 92, 101749, https://doi.org/10.1016/j.compenvurbsys.2021.101749 (2022).
Ma, Q. et al. Quantifying spatiotemporal patterns of urban impervious surfaces in China: An improved assessment using nighttime light data. Landsc Urban Plan 130, 36–49, https://doi.org/10.1016/j.landurbplan.2014.06.009 (2014).
Liu, Z. et al. Adaptive Nighttime-Light-Based Building Stock Assessment Framework for Future Environmentally Sustainable Management. Remote Sens (Basel) 16, 2495, https://doi.org/10.3390/rs16132495 (2024).
Song, L., Huang, Y., Liu, Y., Li, N. & Chen, W. Q. Mapping manufactured capital in mainland China with harmonized night-time light images between 1992 and 2018. J Ind Ecol 28, 1103–1116, https://doi.org/10.1111/JIEC.13525 (2024).
Eberenz, S., Stocker, D., Röösli, T. & Bresch, D. N. Asset exposure data for global physical risk assessment. Earth Syst Sci Data 12, 817–833, https://doi.org/10.5194/essd-12-817-2020 (2020).
Wang, T. & Sun, F. Global gridded GDP data set consistent with the shared socioeconomic pathways. Sci Data 9, 221, https://doi.org/10.1038/s41597-022-01300-x (2022).
Zhao, N., Liu, Y., Cao, G., Samson, E. L. & Zhang, J. Forecasting China’s GDP at the pixel level using nighttime lights time series and population images. GIsci Remote Sens 54, 407–425, https://doi.org/10.1080/15481603.2016.1276705 (2017).
Chen, J. et al. Global 1 km × 1 km gridded revised real gross domestic product and electricity consumption during 1992–2019 based on calibrated nighttime light data. Sci Data 9, 202, https://doi.org/10.1038/s41597-022-01322-5 (2022).
Song, J., Tong, X., Wang, L., Zhao, C. & Prishchepov, A. V. Monitoring finer-scale population density in urban functional zones: A remote sensing data fusion approach. Landsc Urban Plan 190, 103580, https://doi.org/10.1016/j.landurbplan.2019.05.011 (2019).
Zhou, Y., Chen, M., Tang, Z. & Zhao, Y. City-level carbon emissions accounting and differentiation integrated nighttime light and city attributes. Resour Conserv Recycl 182, 106337, https://doi.org/10.1016/j.resconrec.2022.106337 (2022).
Rauch, J. N. Global mapping of Al, Cu, Fe, and Zn in-use stocks and in-ground resources. Proc Natl Acad Sci USA 106, 18920–18925, https://doi.org/10.1073/pnas.0900658106 (2009).
Peled, Y. & Fishman, T. Estimation and mapping of the material stocks of buildings of Europe: a novel nighttime lights-based approach. Resour Conserv Recycl 169, 105509, https://doi.org/10.1016/j.resconrec.2021.105509 (2021).
Haberl, H. et al. High-Resolution Maps of Material Stocks in Buildings and Infrastructures in Austria and Germany. Environ Sci Technol 55, 3368–3379, https://doi.org/10.1021/acs.est.0c05642 (2021).
Liang, H. et al. Feasibility of a new-generation nighttime light data for estimating in-use steel stock of buildings and civil engineering infrastructures. Resour Conserv Recycl 123, 11–23, https://doi.org/10.1016/j.resconrec.2016.04.001 (2017).
Liu, Z. et al. Does Deep Learning Enhance the Estimation for Spatially Explicit Built Environment Stocks through Nighttime Light Data Set? Evidence from Japanese Metropolitans. Environ Sci Technol 57, 3971–3979, https://doi.org/10.1021/acs.est.2c08468 (2023).
Zhong, L. et al. Quantifying the spatiotemporal evolution of the in-use steel stock in countries along the Belt and Road. Resour Conserv Recycl 181, 106226, https://doi.org/10.1016/j.resconrec.2022.106226 (2022).
Watari, T. & Yokoi, R. International inequality in in-use metal stocks: What it portends for the future. Resources Policy 70, 101968, https://doi.org/10.1016/j.resourpol.2020.101968 (2021).
Wang, Y. et al. Comprehensive maps of material stock dynamics reveal increasingly coordinated urban development in the Yangtze River Delta of China. Resour Conserv Recycl 212, 107925, https://doi.org/10.1016/j.resconrec.2024.107925 (2025).
Vilaysouk, X. et al. Estimating the total in-use stock of Laos using dynamic material flow analysis and nighttime light. Resour Conserv Recycl 170, 105608, https://doi.org/10.1016/J.RESCONREC.2021.105608 (2021).
Yu, B. et al. Nighttime Light Images Reveal Spatial-Temporal Dynamics of Global Anthropogenic Resources Accumulation above Ground. Environ Sci Technol 52, 11520–11527, https://doi.org/10.1021/acs.est.8b02838 (2018).
Zheng, Q., Seto, K. C., Zhou, Y., You, S. & Weng, Q. Nighttime light remote sensing for urban applications: Progress, challenges, and prospects. ISPRS Journal of Photogrammetry and Remote Sensing 202, 125–141, https://doi.org/10.1016/J.ISPRSJPRS.2023.05.028 (2023).
Pauliuk, S., Wang, T. & Müller, D. B. Steel all over the world: Estimating in-use stocks of iron for 200 countries. Resour Conserv Recycl 71, 22–30, https://doi.org/10.1016/j.resconrec.2012.11.008 (2013).
Cao, Z., Shen, L., Løvik, A. N., Müller, D. B. & Liu, G. Elaborating the History of Our Cementing Societies: An in-Use Stock Perspective. Environ Sci Technol 51, 11468–11475, https://doi.org/10.1021/acs.est.7b03077 (2017).
Liu, G. & Müller, D. B. Centennial evolution of aluminum in-use stocks on our aluminized planet. Environ Sci Technol 47, 4882–4888, https://doi.org/10.1021/es305108p (2013).
Liu, G. & Müller, D. B. Mapping the global journey of anthropogenic aluminum: A trade-linked multilevel material flow analysis. Environ Sci Technol 47, 11873–11881, https://doi.org/10.1021/es4024404 (2013).
Rasmussen, K. D., Wenzel, H., Bangs, C., Petavratzi, E. & Liu, G. Platinum Demand and Potential Bottlenecks in the Global Green Transition: A Dynamic Material Flow Analysis. Environ Sci Technol 53, 11541–11551, https://doi.org/10.1021/acs.est.9b01912 (2019).
Rostek, L., Tercero Espinoza, L. A., Goldmann, D. & Loibl, A. A dynamic material flow analysis of the global anthropogenic zinc cycle: Providing a quantitative basis for circularity discussions. Resour Conserv Recycl 180, https://doi.org/10.1016/j.resconrec.2022.106154 (2022).
Chen, Z. et al. An extended time series (2000-2018) of global NPP-VIIRS-like nighttime light data from a cross-sensor calibration. Earth Syst Sci Data 13, 889–906, https://doi.org/10.5194/essd-13-889-2021 (2021).
Chen, Z. et al. An extended time-series (2000-2023) of global NPP-VIIRS-like nighttime light data - Harvard Dataverse, https://doi.org/10.7910/DVN/YGIVCD (2020).
Sun, K. et al. A global dataset for steel, aluminum, and cement in-use stocks at 500 m gridded level, 2000-2019, https://doi.org/10.6084/m9.figshare.19959362.v3 (2024).
Mao, R., Bao, Y., Huang, Z., Liu, Q. & Liu, G. High-Resolution Mapping of the Urban Built Environment Stocks in Beijing. Environ Sci Technol 54, 5345–5355, https://doi.org/10.1021/acs.est.9b07229 (2020).
Miatto, A. et al. A spatial analysis of material stock accumulation and demolition waste potential of buildings: A case study of Padua. Resour Conserv Recycl 142, 245–256, https://doi.org/10.1016/J.RESCONREC.2018.12.011 (2019).
Kleemann, F., Lederer, J., Rechberger, H. & Fellner, J. GIS‐based Analysis of Vienna’s Material Stock in Buildings. J Ind Ecol 21, 368–380, https://doi.org/10.1111/jiec.12446 (2017).
Song, L. et al. China material stocks and flows account for 1978–2018. Sci Data 8, 303, https://doi.org/10.1038/s41597-021-01075-7 (2021).
Han, J., Chen, W.-Q., Zhang, L. & Liu, G. Uncovering the Spatiotemporal Dynamics of Urban Infrastructure Development: A High Spatial Resolution Material Stock and Flow Analysis. Environ Sci Technol 52, 12122–12132, https://doi.org/10.1021/acs.est.8b03111 (2018).
Lin, C., Liu, G. & Müller, D. B. Characterizing the role of built environment stocks in human development and emission growth. Resour Conserv Recycl 123, 67–72, https://doi.org/10.1016/J.RESCONREC.2016.07.004 (2017).
Li, Q., Gummidi, S. R. B., Lanau, M., Yu, B. & Liu, G. Spatiotemporally Explicit Mapping of Built Environment Stocks Reveals Two Centuries of Urban Development in a Fairytale City, Odense, Denmark. Environ Sci Technol, https://doi.org/10.1021/acs.est.2c04781 (2022).
Lanau, M., Herbert, L. & Liu, G. Extending urban stocks and flows analysis to urban greenhouse gas emission accounting: A case of Odense, Denmark. J Ind Ecol 25, 961–978, https://doi.org/10.1111/jiec.13110 (2021).
Acknowledgements
This work is financially supported by the National Natural Science Foundation of China (92462301, 71991484), the Independent Research Fund Denmark (iBuildGreen), and the China Scholarship Council (202006730004 and 202107940001).
Author information
Authors and Affiliations
Contributions
G.L. conceived and designed the work. G.L. and B.Y. supervised the research. K.S. and Q.X.L. prepared the data and built the regression models. Z.C. and B.Y. provided and further processed the nighttime data. K.S., M.D., Q.C.L., S.R.B.G., W.C., and J.S. calibrated the data and experiments and analyzed the results. K.S. and G.L. drafted the manuscript, and all authors contributed to writing the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Sun, K., Li, Q., Dai, M. et al. A global dataset for steel aluminum and cement in-use stocks at 500 m gridded level 2000-2019. Sci Data 12, 1560 (2025). https://doi.org/10.1038/s41597-025-05618-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-05618-0
