
Abstract
Speech perception is fundamental for human communication, but its neural basis is not well understood. Furthermore, while modern neural networks (NNs) can accurately recognize speech, whether they effectively model human speech processing remains unclear. Here, we introduce Wordsworth, a dataset designed to facilitate comparisons of speech representations between artificial and biological NNs. We synthesised 1,200 tokens for each of 84 monosyllabic words while controlling for acoustic parameters such as amplitude, duration, and background noise, thus encouraging the use of phonetic features known to be important for speech perception. Human listening experiments showed that Wordsworth tokens are intelligible. Additional experiments using convolutional NNs showed (i) that Wordsworth tokens were recognizable and (ii) that error patterns could be at least partially explained by acoustic phonetics. The control with which tokens were created permits end users to manipulate them in whatever ways might be useful for their purposes. Finally, a subset of tokens specifically for human neuroscience experiments was also created, with precise and known distributions of amplitude, onset, and offset times.
Similar content being viewed by others


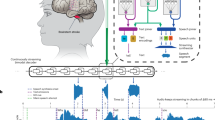
Background & Summary
Artificial neural networks (NNs) are being increasingly adopted as models of human perception. Given their performance and robustness on such tasks as object and word recognition1,2,3,4, many investigators have sought to understand how and whether representations in artificial NNs are similar to those in biological NNs (i.e., human brains5,6). However, while artificial NNs have been highly influential in modelling various aspects of human perception7,8,9,10,11, significant differences remain12,13. Humans still possess better generalisation abilities14,15, and discrepancies in the types of errors made between humans and artificial NNs persist15. Still, artificial NNs provide a simplified framework that can serve as a hypothesis generation tool for cognitive neuroscience research5,6,11,16,17,18,19,20, and addressing these shortcomings will bring us closer to models that better approximate human perception, thereby aiding in a better understanding of perception itself21.
One particularly successful example for artificial NNs - and convolutional NNs, in particular - as models of human perception is human vision22. Many studies using representational similarity analysis (RSA) between artificial NNs and human brain recordings during visual experiments have shown how artificial NNs can mimic the hierarchical structure of visual processing18. There have been comparatively fewer studies examining the utility of artificial NNs as a model of (human) auditory processing [but see10,23,24,25] and the extent to which artificial NNs effectively model human auditory processing is less well understood. In the context of speech processing/recognition, artificial NNs may operate at least superficially similarly to human auditory/speech processing26,27,28,29. Primary auditory cortex (A1), which is tonotopically organised, encodes time-varying spectral information. Beyond A1, the secondary auditory cortex processes increasingly abstract representations30,31,32,33,34. However, while certain classes of artificial NNs are able to recognize speech with very high accuracy, how accurately they model human speech perception remains a topic of debate16.
One unavoidable challenge in comparing speech representations between artificial NNs and human brains is what stimuli to use in both kinds of systems. Training artificial NNs on tasks regularly performed by humans requires large numbers of samples, which is impractical for human cognitive neuroscience experiments35,36,37,38. Moreover, the stimulus sets that have so far been used to study auditory and speech processing in artificial NNs inherently include confounding factors such as speaking rate, intensity, duration, and uncontrolled background noise39. These variations, while useful and potentially even necessary in training robust artificial NNs able to generalise to various input scenarios, make it difficult to directly compare their speech representations with those in human brains due to the potential for models to learn based on idiosyncratic features not typically thought to be important for human speech perception.
Here, we introduce Wordsworth, a novel monosyllabic word dataset comprising 1,200 utterances for each of 84 monosyllabic words (42 animate, 42 inanimate) that was generated using the Google text-to-speech API. Using generative AI with tunable parameters permitted strict control over potential confounding acoustic factors such as onset time, amplitude, and duration. Furthermore, because the tokens do not include background noise, end users are free to manipulate or degrade the tokens however desired for their own purposes. Differences across samples include timbre (different speakers), accents, and speaking scenario (casual or broadcast). The dataset can be used for training modern artificial NNs to perform word recognition, and also includes two 84-token subsets (one token of each word) that can be used in human neuroscience experiments. This subset was selected based on the criteria that the accent be American English, the speaker be male or female depending on which subset is desired, and to have a 25-ms maximum duration difference between any two tokens. End users are also free to create their own subsets using established OSF and Github repositories (cf. Data Records and Code Availability). To validate the dataset, we examined the extent to which both human listeners and artificial NNs could recognize Wordsworth tokens, and also evaluated whether the pattern of errors made by the models matched those that would be expected from acoustic phonetics. We focused on convolutional NN architectures, which are (i) manageable in size, (ii) easily interrogated and comparable with human neuroscience data, and (iii) have been shown previously to perform well on word-recognition tasks40,41,42.
Methods
Wordsworth token generation
To choose our word list, we started with 60 initial monosyllabic words whose images are included in a prior Mooney Image dataset43,44. 26 of these words represent animals, and 34 represent inanimate objects. We supplemented these word classes with an additional 16 words in the animals category and 8 words in the objects category, for a total of 42 monosyllabic animal words and 42 monosyllabic inanimate object words. For each word, we used DeepMind’s Google Text-to-Speech API to synthesise 1,200 unique utterances with different generating models (several of which have similar architectures, e.g., Wavenet and sub-architectures, Neural2, News, etc.), speaker sexes (male versus female), accents (e.g., American English, British English, Chinese-accented English, etc.), speaking rate, and speaking type (e.g., conversational versus for broadcast)45. As one example architecture, Wavenet consists of multiple causal convolutional layers and dilated causal convolutional layers and forms a set of skip-connected residual networks. The resulting signals were normalized to [−1, 1] and exported in 32-bit floating-point format using a sampling rate of 24 kHz. Importantly, speech generated using the Google Text-to-Speech API has been shown to be intelligible for human listeners across a wide age-range, despite the fact that at least most listeners recognize it as artificial45,46. Under the same text to speech generative model, the tokens converted from monosyllabic words are almost the same length (with same hyperparameter input), have the same timbre, and are without background noise. Therefore, through generative models, we can effectively control both semantic (i.e. animal versus object) and non-semantic features such as onset, offset, timbre, intonation (Fig. 1A), speaking scenario (casual or broadcast, controlled by different generative models), and accent (Fig. 1B), which encourages NN models to use phonetics as primary features.

(A) Distributions of onset, offset, maximum amplitude, and average spectral power of all tokens in Speech Command, Wordsworth, and Wordsworth subset. (B) Accent (x-axis) and generative model (y-axis) distribution of Wordsworth dataset, with corresponding marginal distributions.
Wordsworth subset for M/EEG experiments
Even after controlling the hyperparameters of generative models to generate minimally differentiated token sets, there was still substantial variance in the onset- and offset-time distributions (and accents) of the overall Wordsworth dataset (Fig. 1A). Reducing the variance of these distributions may have advantages when using Wordsworth tokens in human magnetoencephalography/electroencephalography (M/EEG) experiments, where temporal resolution of brain recordings is high and exact timing of onsets and offsets of acoustic stimuli matters. Therefore, a subset was created with even narrower onset- and offset-time distributions. These tokens were all generated by WaveNet (which was determined to sound the most natural in previous studies45) in both “male” and “female” voices with U.S. English accents, and an initial screening set of tokens was produced using several different speaking rates. The final two tokens from each class (one “male”, one “female”) were selected manually from this screening set such that the overall duration differences across all tokens was smaller than 25 ms. All tokens in the subset were upsampled to 48 kHz and exported in 16-bit PCM format, and can be heard directly from the OSF repository (note, also, that the same subset tokens can still be found as 24-kHz, 32-bit floating-point files, if desired).
Cochleagram generation
The human cochlea converts sound vibrations into electrical signals by the movement of the basilar membrane, resulting in the deflection of hair cell stereocilia and the generation of electrical signals. The electrical signals from the hair cells are sent via the ascending auditory pathway to the auditory cortex, where they are further processed and interpreted as sound. To simulate human auditory processing more realistically, for each token generated by the Google Text-to-Speech API, we generated a corresponding cochleagram using an artificial model of the cochlea47,48,49. All sounds were input into a filter bank comprising 211 filters (four high-pass, four low-pass, and 203 bandpass). Bandpass central frequencies ranged from 30 Hz to 7860 Hz. The four low- and high-pass filters (as well as the other 203 band-pass filters) stems from a 4x overcomplete sampling of the logarithmic frequency space and associated equivalent rectangular bandwidths23,50. For power envelopes in adjacent frequency bands, there was 87.5% overlap. Within each band, the envelope was raised to the power of 0.3 to simulate basilar membrane compression. Envelopes were downsampled to 200 Hz, which readily captures the temporal dynamics of the cochleagram (note that the sampling rate of the original wave files was 24 kHz), resulting in a cochleagram of size 211 x n_samples (in the time-frequency domain, reflecting the 200-Hz downsampled envelopes in each band)47,48,49 (Fig. 2). These cochleagrams were used as inputs to the NN models to evaluate their word recognition performance. Cochleagrams were chosen based on the fact that they are inspired by the representation of sound in the human auditory periphery. It would be interesting in future work to compare model performance with different types of input tokens (i.e. different types of auditory peripheral representations, e.g., mel spectrograms versus cochleagrams).

Cochleagrams of 84 individual tokens in Wordsworth that together comprise the human neuroscience subset. (A) Words representing animals (B) Words representing inanimate objects.
Comparison to previous datasets
Although the tokens contained in Wordsworth are synthetic, free of noise or degradation, and thus clearly intelligible, we sought to compare how performance of various models on the Wordsworth tokens compares with other datasets consisting of single words spoken by humans. For this purpose, we used Speech Commands, a widely used dataset in the fields of automatic speech recognition (ASR) and audio classification. It consists of a collection of short audio clips of spoken commands, typically lasting one to two seconds. The dataset includes a large variety of verbal words or phrases such as “yes”, “no”, “up”, “down”, “left”, “right”, and others, covering a diverse set of commands that can be used for various speech control applications (chance = 1/35 = 2.86%)51. As we described in the introduction, the Speech Command dataset does not control the number of syllables, audio length, amplitude, and background noise etc.51. This dataset also does not provide an acoustic stimulus subset that can be used as readily for human physiological or neuroimaging studies.
Model specification
To evaluate modern convolutional neural networks on their ability to recognize words from Wordsworth, we trained and tested each of four different model architectures, one 1D-waveform-based CNN used previously42, one 2D-cochleagram-based CNN used previously48, and two additional, modified variants of the previously used cochleagram-based CNN.
1D Waveform model
For the 1D audio model (Fig. 3), we employed the network architecture of the M5 model proposed by Dai42. This architecture consists of four convolutional layers and one fully connected layer. Each convolutional layer performs batch normalisation and max pooling. The first and second convolutional layers have 32 filters, while the third and fourth convolutional layers have 64 filters. The input layer has a filter size of 1 × 80, and the hidden layers have a filter size of 1 × 3. The number of output neurons of the fully connected layer correspond to the number of classes in the input dataset. Specifically, the architecture trained on the Speech Commands dataset has 35 output neurons, and the architecture trained on the Wordsworth dataset has 84 output neurons.

Waveform convolutional neural network architecture (Dai et al. 2016).
2D Cochleagram model
For the 2D cochleagram model (Fig. 4A), we first utilised the model architecture from Kell and colleagues48 that performed best on their 587-way word recognition task (i.e., a forced-choice word-recognition task with 587 alternatives, trained and tested on word tokens extracted from the TIMIT database52). This architecture includes five convolutional layers and two fully connected layers. The first and second convolutional layers perform local response normalisation, and max pooling is applied after the first, second, and fifth convolutional layers. The first layer has 96 channels with a filter size of 9 × 9. The second layer has 256 channels with a filter size of 5 × 5. The fourth layer has 1024 channels, while the remaining convolutional layers have 512 channels, all with a filter size of 3 × 3. The first fully connected layer has 1024 hidden neurons, and the second layer has the number of output neurons corresponding to the number of classes in the input dataset. For Wordsworth, the performance of this NN decreased to 70% (compared to 88% for Speech Commands) (Table 1), perhaps because the features available to the model (e.g., speech length, number of syllables) were more strictly controlled in Wordsworth compared to Speech Commands or the TIMIT dataset.

(A) Cochleagram convolutional neural network architecture (Kell et al. 2018). (B) Modified cochleagram convolutional neural network architecture. (C) Modified recurrent cochleagram convolutional neural network architecture.
Modified 2D cochleagram model
In order to achieve better performance on the Wordsworth dataset, we modified the architecture from Kell and colleagues to encourage less feature extraction and more abstraction by omitting the last two convolutional layers (less feature extraction) and increasing the number of neuronal connections of the fully connected layers (more abstraction) (Fig. 4B). This massively increased the number of parameters of the resulting, modified model (2D cochleagram model from Kell: 672,916; modified 2D cochleagram model: 16,867,540; recurrent modified 2D cochleagram model: 17,283,700; 1D waveform model from Dai: 30,100).
Recurrent modified 2D cochleagram model
We also tested a 4th model (Fig. 4C) that was identical to our modified 2D convolutional network except that it also included recurrent connections: for each convolution layer, we added a short-term memory architecture that captured the last batch feature and fed the next batch training.
Model training
We trained and tested these four different NN architectures - 1D waveform model from Dai and colleagues, 2D cochleagram model from Kell and colleagues, modified 2D cochleagram model, and recurrent modified 2D cochleagram model (Table 1) - on both an 84-way word recognition task (for Wordsworth) and a 35-way word recognition task (for Speech Commands). Both datasets were divided with a ratio of 75% for training and 25% for testing. Cross-validation was not performed due to computational constraints. For the 1D audio model, the initial learning rate was set to 0.01 with a weight decay of 1 × 10−5. The learning rate decayed by a factor of 0.01 every two epochs42. For the 2D cochleagram model, the initial learning rate was set to 0.0001 with the same weight decay of 1 × 10−5. The learning rate was also decreased by a factor of 0.01 every two epochs42. Epoch iteration stopped when loss no longer decreased significantly (average absolute loss fluctuation < 0.01 within epoch).
Confusion matrices and clustering analyses
To examine the kinds of classification errors made by the models, we computed confusion matrices for the Wordsworth dataset for each of the four models we used. The confusion matrix represents how certain words are confused for each other, and applying graphical clustering methods could reveal if the NN models confuse words in a way that would be expected in humans based on acoustic phonetics. We applied two graphical clustering algorithms based on the confusion matrix (treated as an adjacency matrix) of the best performing model: Leiden cluster and Louvain hierarchical cluster from scikit-network to visualise clusters of words that the model was confused about53. For Leiden, we picked the cluster number with highest modularity level (Q-value). For the Louvain hierarchical cluster, we also picked the cluster number with highest Q-value for the root cluster and optimised each leaf cluster separately with highest Q-value modularity.
Ethics declarations
All human-subjects procedures were approved by the Institutional Review Board within the Office of Research at the University of Central Florida (study number 00007414). Written informed consent was obtained from each participant prior to their participation, and participants were compensated at a rate of 20 USD/hour for their time.
Data Records
The wave files and code associated with Wordsworth are available in open-access repositories under a CC-BY-4.0 licence and can be accessed at https://osf.io/pu7f2/54 for the wave files and models and at https://github.com/yunkz5115/Wordsworth for the data loaders and code used to transform wave files to cochleagrams23. The OSF repository also includes an excel xlsx file with 84 sheets (one for each word class) that lists all the relevant parameters for each of the 1,200 tokens within each word class.
In the OSF repository, we uploaded the stimulus waveforms and NN models:
Structure of the wordsworth_v1.0.zip
Wordsworth_v1.0.zip includes all waveform tokens as the structure of: root path/word/tokens. Each token was named by: word, speaking rate, accent, and AI talker (For example: ant_speed_0.75_en-US-Wavenet-J_.wav).
Structure of the DeepLearning_Superset.zip
DeepLearning_Superset.zip includes all waveform tokens from Wordsworth but split the whole set into the training set (ratio: 75%) and the testing set (ratio: 25%) for deep learning purposes. The structure is: root path/train or test/word/tokens. Each token has the same name coding as Wordsworth_v1.0.zip: word, speaking rate, accent, and AI talker.
Structure of the human_stimulus_subset folder
The Human_Stimulus_Subset folder includes two subsets of tokens for use with human-subjects experiments. All tokens under this folder were generated by Wavenet-J (male) or Wavenet-H (female), with a U.S.-English accent. Two zip files (Human_Stimulus_Subset_Male_voice.zip and Human_Stimulus_Subset_Female_voice.zip) include the tokens originally selected from the Wordsworth superset (32 bit floating-point, 24 kHz sampling rate). Two sub-folders (“Human Stimulus Subset Male voice 48kHz16bit” and “Human Stimulus Subset Female voice 48kHz16bit”) include the tokens that were upsampled to 48 kHz and exported in 16-bit PCM format. These upsampled tokens can be heard directly from the OSF repository. The maximum duration difference across tokens is 25 ms. Each token has the same name coding as Wordsworth_v1.0.zip.
Structure of the neuralnetwork_models.zip
NeuralNetwork_Models.zip includes all NNs for tokens’ identification. Four.pth file stored weight of all four NN models, named by WW_model name_input type_accuracy (for example: WW_Recurrent_Modified_Kell_cochleagram_acc86.pth). WW_models.py include four classes (corresponding to all four NN structures) and a model loader (use model = load_model(model_class(), weight_path) to load Pytorch NN models in Python).
Technical Validation
The words contained within Wordsworth are intelligible to human listeners
To evaluate whether Wordsworth tokens are intelligible to humans, we set up a word recognition experiment following a design used previously48. We recruited eight participants who were all native speakers of English and had clinically normal pure-tone thresholds (up to 8 kHz) and asked them to recognize random male tokens (all with American-English accents) from the larger Wordsworth dataset. No other parameters were controlled for when selecting words to be heard by the listeners. Within a block, each participant heard one example of each of the 84 words and gave a freely typed but increasingly constrained response. As participants typed, all words containing the already-typed characters were displayed on the screen (i.e., ‘ant’ and ‘ape’, if ‘a’ was typed, and subsequently only ‘ant’ if ‘an’ was typed). The block was repeated 5 times, thus each participant heard randomly selected words in a 5*84 = 420 trial experiment. The results showed that each participant achieved near-ceiling-level accuracy (all participants >95%) in recognizing these words.
Neural networks can recognize wordsworth tokens
We next compared the word-recognition performance of four different NN architectures (two of which are already known to recognize words with high accuracy42,48) each trained and tested separately on Wordsworth and Speech Commands51 (a 35-word dataset spoken by humans) (Table 1). The slightly worse performance (in absolute terms) for Wordsworth versus Speech Commands could be due to (i) fewer idiosyncratic confounding token features (e.g. duration, specific instances of noise) in Wordsworth, (ii) the fact that for Wordsworth, the models were charged with recognizing words spoken with multiple accents, or (iii) the fact that Speech Commands included more tokens than Wordsworth (1,200 tokens per word class for Wordsworth versus 1,557–4,052 tokens per word class for Speech Commands). The slightly better (relative to chance) performance for Wordsworth versus Speech Commands is likely due to the curated and controlled (i.e. free of noise) nature of the tokens. Wordsworth therefore has the potential to enforce the use of token content we know to be important for word recognition (i.e., phonemes), and further has the potential to support future experiments designed to compare speech representations in humans and artificial NNs.
The patterns of errors made by NN models on wordsworth are phonetically predictable
To further validate Wordsworth as a dataset that could effectively be used to compare speech representations between humans and artificial NNs, we first examined whether the patterns of errors made by each of the four NN models either (i) co-varied with phonetic similarity between tokens (Fig. 5; Table 2) or (ii) clustered according to words containing similar phonemes (Fig. 6).

(A) Probability and (B) confusion matrices of classification for each of four different NN models on Wordsworth, with individual words sorted alphabetically. (C) Phonetic embedding similarity matrix of all words within Wordsworth dataset. High values in panel A indicate a high probability of the output of the model (columns) deciding for a particular input (rows). High off-diagonal values in panel B indicate for which pairs of model inputs (rows) and model outputs (columns) the models made relatively more errors. High values in panel C indicate high phonetic similarity between tokens. Note that the phonetic similarity matrix is symmetric (ST = S), while neither the probability nor decision-rate matrices are.

Confusion matrices and Leiden clustering results for the Wordsworth dataset, with words sorted according to which cluster they belonged to after Leiden clustering on the recurrent modified 2D cochleagram network. (A) Recurrent modified 2D cochleagram model. (B) Louvain hierarchical clustering (with same color code as Leiden clusters) (C) Modified 2D cochleagram model. (D) 2D cochleagram model. (E) 1D waveform model.
First, we examined the relationship between NN model outputs and phonetic similarity between tokens (Fig. 5; Table 2). Probability matrices (Fig. 5A) were constructed using the average logarithmic softmax probability vector (length 84) from the last fully connected layer across all examples within a given word class. Decision-rate matrices (Fig. 5B) were measured as the frequency of each predicted word for a given true word. Phonetic similarity between Wordsworth tokens (Fig. 5C), which quantifies the extent to which two words have similar sequences of phonemes, was calculated using phonetic embedding vectors55 and edited Levenshtein distance. We then computed both Frobenius distance and R2 values between each log-probability matrix (Fig. 5A) and the phonetic similarity matrix (Fig. 5C), akin to representational similarity analysis18 (Table 2). Monte Carlo simulations were used to evaluate statistical significance. Matrix elements were permuted 10,000 times to generate null distributions of both measures. The real Frobenius distance and R2 measures were both far outside their corresponding null distributions (all p < 0.0001), consistent with the idea that model errors were related to phonetic similarity.
Second, we examined whether the errors made by the NN models on Wordsworth cluster in a way that is predictable based on acoustic phonetics using Leiden clustering53,56 (Fig. 6). For the confusion matrices, pixels near the diagonal showed the highest levels of confusion, and this pattern appears as clusters for words containing similar phonemes. For example, the cluster shown in yellow contains words that almost exclusively begin with /s/ (e.g., sink) or /ʃ/ (e.g., shark), with the two phonemes mostly broken down into their own, non-overlapping sub-clusters. Another cluster contained words that exclusively ended with /n/. Even confusions made between words in different clusters contained similar phonemes (e.g., “fan” versus “phone”). These kinds of errors are consistent with acoustic phonetics, and similar patterns of errors would also be expected from human listeners. Similar confusion matrices for human participants and neural networks have also been observed previously in the context of musical genre classification10,48. Note that the layout and colour codes for all plots stem from the clustering results from our best-performing model. While slightly different clustering results were obtained for each of the other three models, it is visibly apparent that the clustering results from the best-performing model decently explain the patterns of errors in the other models, particularly our modified 2D cochleagram model (Fig. 6C) (R2 = 0.994) and the 1D waveform model (Fig. 6E) (R2 = 0.985), and less so for the unmodified 2D cochleagram model (Fig. 6D) (R2 = 0.774).
Advantages of using wordsworth over other speech corpora
The main advantages of using Wordsworth over other speech corpora (e.g., Speech Command51, the TIMIT databas52) are (i) how strictly Wordsworth controls for various speech features and (ii) the control and flexibility it affords investigators. Regarding control of speech features, Wordsworth mitigates the possibility for NNs to use idiosyncratic aspects of individual word tokens in recognition (e.g., onset, duration, etc.), thereby encouraging the use of phonetic features known to be important for speech perception in humans. Regarding flexibility, although Wordsworth is extensively curated, and while this potentially comes at the expense of naturalism of the tokens, other investigators are free to download and manipulate tokens within Wordsworth however they see fit for their own research questions. This includes manipulations such as adding various types of noise, compressing, expanding, padding, or otherwise manipulating the tokens, contextualising the tokens, etc.. Finally, Wordsworth, and in particular its subsets, can facilitate the comparison of speech representations in artificial and biological neural networks.
Usage Notes
In this dataset, we publish all neural network models and all waveforms (from which cochleagrams can be generated; cf. Code Availability). Please note that waveform does not work with 2D cochleagram models. Cochleagrams can be readily generated from the Wordsworth waveforms via a generator script based on previously implemented cochleagram models23,50. The neural networks are all built on the PyTorch platform. Torch version: 2.1.0, Cuda toolkit version: 11.8.
Code availability
The waveform data (and subsets) and corresponding neural networks (in PyTorch) were uploaded to an OSF repository (https://osf.io/pu7f2/). The code for loading the data and generating cochleagrams can be found in our associated GitHub repository. (https://github.com/yunkz5115/Wordsworth).
References
Nassif, A. B., Shahin, I., Attili, I., Azzeh, M. & Shaalan, K. Speech Recognition Using Deep Neural Networks: A Systematic Review. IEEE Access 7, 19143–19165 (2019).
Graves, A., Mohamed, A. & Hinton, G. Speech recognition with deep recurrent neural networks. in 2013 IEEE International Conference on Acoustics, Speech and Signal Processing 6645–6649 https://doi.org/10.1109/ICASSP.2013.6638947 (IEEE, Vancouver, BC, Canada, 2013).
Zhang, Y. et al. Towards End-to-End Speech Recognition with Deep Convolutional Neural Networks. Preprint at https://doi.org/10.48550/ARXIV.1701.02720 (2017).
Abdel-Hamid, O. et al. Convolutional Neural Networks for Speech Recognition. IEEEACM Trans. Audio Speech Lang. Process. 22, 1533–1545 (2014).
Groen, I. I. et al. Distinct contributions of functional and deep neural network features to representational similarity of scenes in human brain and behavior. eLife 7, e32962 (2018).
Martin Cichy, R., Khosla, A., Pantazis, D. & Oliva, A. Dynamics of scene representations in the human brain revealed by magnetoencephalography and deep neural networks. NeuroImage 153, 346–358 (2017).
Yamins, D. L. K. & DiCarlo, J. J. Using goal-driven deep learning models to understand sensory cortex. Nat. Neurosci. 19, 356–365 (2016).
Kriegeskorte, N. Deep Neural Networks: A New Framework for Modeling Biological Vision and Brain Information Processing. Annu. Rev. Vis. Sci. 1, 417–446 (2015).
Turner, M. H., Sanchez Giraldo, L. G., Schwartz, O. & Rieke, F. Stimulus- and goal-oriented frameworks for understanding natural vision. Nat. Neurosci. 22, 15–24 (2019).
Kell, A. J. & McDermott, J. H. Deep neural network models of sensory systems: windows onto the role of task constraints. Curr. Opin. Neurobiol. 55, 121–132 (2019).
Cichy, R. M. & Kaiser, D. Deep Neural Networks as Scientific Models. Trends Cogn. Sci. 23, 305–317 (2019).
Ullman, S., Assif, L., Fetaya, E. & Harari, D. Atoms of recognition in human and computer vision. Proc. Natl. Acad. Sci. 113, 2744–2749 (2016).
Ward, E. J. Exploring Perceptual Illusions in Deep Neural Networks. 687905 https://www.biorxiv.org/content/10.1101/687905v1 (2019).
Geirhos, R. et al. Generalisation in humans and deep neural networks. ArXiv180808750 Cs Q-Bio Stat (2020).
Geirhos, R. et al. Partial success in closing the gap between human and machine vision. https://doi.org/10.48550/ARXIV.2106.07411 (2021).
Serre, T. Deep Learning: The Good, the Bad, and the Ugly. Annu. Rev. Vis. Sci. 5, 399–426 (2019).
Montavon, G., Samek, W. & Müller, K.-R. Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 73, 1–15 (2018).
Kriegeskorte, N. Representational similarity analysis – connecting the branches of systems neuroscience. Front. Syst. Neurosci. https://doi.org/10.3389/neuro.06.004.2008 (2008).
Saxe, A., Nelli, S. & Summerfield, C. If deep learning is the answer, what is the question? Nat. Rev. Neurosci. 22, 55–67 (2021).
Richards, B. A. et al. A deep learning framework for neuroscience. Nat. Neurosci. 22, 1761–1770 (2019).
Lake, B. M., Ullman, T. D., Tenenbaum, J. B. & Gershman, S. J. Building machines that learn and think like people. Behav. Brain Sci. 40 (2017).
Xu, Y. & Vaziri-Pashkam, M. Limits to visual representational correspondence between convolutional neural networks and the human brain. Nat. Commun. 12, 2065 (2021).
Feather, J., Leclerc, G., Mądry, A. & McDermott, J. H. Model Metamers Illuminate Divergences between Biological and Artificial Neural Networks. http://biorxiv.org/lookup/doi/10.1101/2022.05.19.492678 (2022).
Hamilton, L. S., Oganian, Y., Hall, J. & Chang, E. F. Parallel and distributed encoding of speech across human auditory cortex. Cell 184, 4626–4639.e13 (2021).
Drakopoulos, F., Baby, D. & Verhulst, S. A convolutional neural-network framework for modelling auditory sensory cells and synapses. Commun. Biol. 4, 827 (2021).
Davis, M. H. & Johnsrude, I. S. Hearing speech sounds: Top-down influences on the interface between audition and speech perception. Hear. Res. 229, 132–147 (2007).
Zhu, Y. et al. Isolating neural signatures of conscious speech perception with a no-report sine-wave speech paradigm. J. Neurosci. e0145232023 https://doi.org/10.1523/JNEUROSCI.0145-23.2023 (2024).
Scott, S. K. From speech and talkers to the social world: The neural processing of human spoken language. Science 366, 58–62 (2019).
Fedorenko, E., Piantadosi, S. T. & Gibson, E. A. F. Language is primarily a tool for communication rather than thought. Nature 630, 575–586 (2024).
Yin, P., Johnson, J. S., O’Connor, K. N. & Sutter, M. L. Coding of Amplitude Modulation in Primary Auditory Cortex. J. Neurophysiol. 105, 582–600 (2011).
Schreiner, C. E., Read, H. L. & Sutter, M. L. Modular Organization of Frequency Integration in Primary Auditory Cortex. Annu. Rev. Neurosci. 23, 501–529 (2000).
King, A. J. et al. Physiological and behavioral studies of spatial coding in the auditory cortex. Hear. Res. 229, 106–115 (2007).
Kuchibhotla, K. & Bathellier, B. Neural encoding of sensory and behavioral complexity in the auditory cortex. Curr. Opin. Neurobiol. 52, 65–71 (2018).
Chong, K. K., Anandakumar, D. B., Dunlap, A. G., Kacsoh, D. B. & Liu, R. C. Experience-Dependent Coding of Time-Dependent Frequency Trajectories by Off Responses in Secondary Auditory Cortex. J. Neurosci. 40, 4469–4482 (2020).
Giovannangeli, L., Giot, R., Auber, D., Benois-Pineau, J. & Bourqui, R. Analysis of Deep Neural Networks Correlations with Human Subjects on a Perception Task. in 2021 25th International Conference Information Visualisation (IV) 129–136, https://doi.org/10.1109/IV53921.2021.00029 (IEEE, Sydney, Australia, 2021).
Borra, D., Bossi, F., Rivolta, D. & Magosso, E. Deep learning applied to EEG source-data reveals both ventral and dorsal visual stream involvement in holistic processing of social stimuli. Sci. Rep. 13, 7365 (2023).
Xu, L. et al. Cross-Dataset Variability Problem in EEG Decoding With Deep Learning. Front. Hum. Neurosci. 14, 103 (2020).
Grootswagers, T. & Robinson, A. K. Overfitting the Literature to One Set of Stimuli and Data. Front. Hum. Neurosci. 15, 682661 (2021).
Giordano, B. L., Esposito, M., Valente, G. & Formisano, E. Intermediate acoustic-to-semantic representations link behavioral and neural responses to natural sounds. Nat. Neurosci. 26, 664–672 (2023).
Keil, A. et al. Committee report: Publication guidelines and recommendations for studies using electroencephalography and magnetoencephalography. Psychophysiology 51, 1–21 (2014).
Ahveninen, J. et al. Intracortical depth analyses of frequency-sensitive regions of human auditory cortex using 7TfMRI. NeuroImage 143, 116–127 (2016).
Dai, W., Dai, C., Qu, S., Li, J. & Das, S. Very Deep Convolutional Neural Networks for Raw Waveforms. Preprint at https://doi.org/10.48550/arXiv.1610.00087 (2016).
Flounders, M. W., González-García, C., Hardstone, R. & He, B. J. Neural dynamics of visual ambiguity resolution by perceptual prior. eLife 8, e41861 (2019).
Everingham, M. et al. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 111, 98–136 (2015).
Oord, A. et al. WaveNet: A Generative Model for Raw Audio. https://doi.org/10.48550/ARXIV.1609.03499 (2016).
Herrmann, B. The perception of artificial-intelligence (AI) based synthesized speech in younger and older adults. Int. J. Speech Technol. 26, 395–415 (2023).
McDermott, J. H., Schemitsch, M. & Simoncelli, E. P. Summary statistics in auditory perception. Nat. Neurosci. 16, 493–498 (2013).
Kell, A. J. E., Yamins, D. L. K., Shook, E. N., Norman-Haignere, S. V. & McDermott, J. H. A Task-Optimized Neural Network Replicates Human Auditory Behavior, Predicts Brain Responses, and Reveals a Cortical Processing Hierarchy. Neuron 98, 630–644.e16 (2018).
Glasberg, B. R. & Moore, B. C. J. Derivation of auditory filter shapes from notched-noise data. Hear. Res. 47, 103–138 (1990).
Feather, J. jenellefeather/chcochleagram. https://github.com/jenellefeather/chcochleagram (2025).
Warden, P. Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition. Preprint at https://doi.org/10.48550/arXiv.1804.03209 (2018).
Garofolo, J. S. et al. TIMIT Acoustic-Phonetic Continuous Speech Corpus. 715776 KB Linguistic Data Consortium https://doi.org/10.35111/17GK-BN40 (1993).
Bonald, T., de Lara, N., Lutz, Q. & Charpentier, B. Scikit-network: Graph Analysis in Python. https://doi.org/10.48550/ARXIV.2009.07660 (2020).
Zhu, Y. & Dykstra, A. Wordsworth: A generative word dataset for comparison of speech representations in humans and neural networks. https://doi.org/10.17605/OSF.IO/PU7F2 (2024).
Mortensen, D. R. et al. PanPhon: A Resource for Mapping IPA Segments to Articulatory Feature Vectors. in Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers 3475–3484 (2016).
Traag, V. A., Waltman, L. & Van Eck, N. J. From Louvain to Leiden: guaranteeing well-connected communities. Sci. Rep. 9, 5233 (2019).
Acknowledgements
This work was supported by a University of Miami Provost’s Research Award to AD and a Collaborative Data Science Award from the University of Miami Institute for Data Science and Computing to AD, YZ, and OS. We thank Carolina Fernandez, Miguel Silveira, Patrick Ganzer, Ozcan Ozdamar, and Jorge Bohorquez for helpful comments.
Author information
Authors and Affiliations
Contributions
Y. Zhu, O. Schwartz, and A. Dykstra designed the study. Y. Zhu, C. Gibson, C. Grier, D. Pearson, and A. Dyksztra conceived and created the stimulus tokens. Y. Zhu wrote the code and analysed the data. A. Dykstra, Y. Zhu, and O. Schwartz acquired funding for the project. Y. Zhu, C. Grier, and A. Garcia acquired human behavioural data. Y. Zhu drafted the manuscript. Y. Zhu, A. Dykstra, O. Schwartz, C. Grier and D. Pearson edited the manuscript. A. Dykstra and O. Schwartz supervised the project.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhu, Y., Grier, C., Garcia, A. et al. Wordsworth: A generative word dataset for comparison of speech representations in humans and neural networks. Sci Data 12, 1572 (2025). https://doi.org/10.1038/s41597-025-05769-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-025-05769-0
