
Abstract
The scarcity of long-term, high-resolution typhoon disaster data, particularly for agricultural metrics, poses significant challenges for stable typhoon agricultural disaster risk modeling, limiting predictive accuracy. To address this critical issue, we reconstructed a county-level dataset of typhoon-affected crop areas across China’s coastal regions (Shandong, Jiangsu, Shanghai, Zhejiang, Fujian, Guangdong, Guangxi and Hainan) from 1980 to 2022. Data used in this study included meteorological data from 530 county-level weather stations and 1,845 original disaster records (2004–2013; 75 typhoons were included) that could be matched to local weather stations (398 stations are covered). After error revisions, we obtained a dataset covering 530 stations and 514 typhoons from 1980 to 2022. To increase the applicability of the dataset, we categorized the disasters into four classes, light, moderate, severe, and extremely severe, regarding to single station and typhoon cases, respectively. Validation through comparative analyses confirmed the strong reliability of the reconstructed dataset. The reconstructed dataset can be used to advance typhoon disaster risk research, improve forecasting and early warning systems, and support related decision-making efforts.
Similar content being viewed by others
Background & Summary
Considering climate change1,2 and unprecedented economic growth3, tropical cyclone (TC, locally referred to as typhoon in the Northwest Pacific) risks are increasing for coastal regions worldwide, with both the frequency and intensity of TCs showing concerning upward trends4,5,6, especially in coastal China7,8,9. As a cornerstone of sustainable development10, agriculture is particularly vulnerable to extreme meteorological events such as typhoons. Among various meteorological hazards, typhoons pose particularly severe threats to coastal agricultural systems through torrential rainfall, destructive winds, storm surges11,12,13, and saltwater intrusion14, all of which can devastate crops within hours and cause long-term impacts on agricultural productivity and rural livelihoods. While numerous studies have investigated the impacts of typhoons on agricultural systems15,16,17, the spatial resolution of previous works is often insufficient to reach county level18,19. The existing county-level analyses of typhoon disasters are limited either by short temporal coverage20 or by restricted geographical scope21. Systematic research on typhoon-induced agricultural damage in China remains limited, which is primarily due to data scarcity in existing databases, with most studies focusing on isolated events rather than long-term patterns22. This highlights the urgent need for a comprehensive, high-resolution, and long-term dataset on crops affected by typhoons. Such a dataset is essential for improving impact assessment capabilities and developing robust risk management strategies.
Given that typhoons are relatively infrequent meteorological events, existing typhoon disaster datasets often have some limitations, such as inadequate temporal coverage, discontinuous spatial distributions, and insufficient resolution. Some international disaster datasets are widely used, such as the Emergency Events Database (EM-DAT) from the Centre for Research on the Epidemiology of Disasters (CRED), NatCat from Munich Re, Sigma of Swiss Re and the GLobal IDEntifier (GLIDE) database (https://glidenumber.net/glide/public/search/search.jsp) developed by the Asian Disaster Reduction Center23,24. However, these datasets predominantly focus on national-scale data and provide limited documentation of the impact on agriculture. Datasets with county-level resolution have been established in several regions, such as the United States (The Spatial Hazard Events and Losses Database for the United States, SHELDUS25), Canada (The Canadian Disaster Database, https://www.publicsafety.gc.ca/cnt/rsrcs/cndn-dsstr-dtbs/), Japan (KITAMOTO Asanobu @National Institute of Informatics (NII): http://agora.ex.nii.ac.jp/digital-typhoon/disaster/damage/), and Taiwan Province of China26, supporting local disaster management and risk assessment frameworks.
Although there are some national or provincial disaster databases in China, they are difficult to share or make publicly available, facing challenges in terms of data reliability, coverage extensiveness, and standard consistency27. Since 1984, the Shanghai Typhoon Institute (STI) and the National Climate Center (NCC) under the China Meteorological Administration (CMA) have systematically collected typhoon disaster data28, but these data are limited to the provincial-level spatial resolution. From 2004 to 2013, the NCC provided county-level typhoon disaster records covering 15 provinces in mainland China. Thus, most related studies using these data were constrained to this decade-long period29,30. Furthermore, records spanning longer than five years are available for only eight coastal provinces (Shandong, Jiangsu, Shanghai, Zhejiang, Fujian, Guangdong, Guangxi and Hainan). Based on records from these eight provinces, Wu et al.31 reconstructed a county-level dataset of typhoon-induced direct economic losses (DELs) from 1980 to 2018, which was subsequently applied to create a DEL preassessment model32. However, this dataset only focuses on DEL metrics and excludes other critical indicators, such as the crop area affected by typhoons.
This study introduces a reconstructed county-level dataset of crop areas affected by typhoons from 1980 to 2022, which is derived from historical disaster records (2004–2013) from eight coastal provinces. We have developed and adopted a rigorous and robust reconstruction methodology, ensuring the accuracy and reliability of the reconstructed data. The reconstructed dataset can provide strong support for multiscale agricultural risk assessment and decision-making, from national policies to county-level strategies. Furthermore, this dataset can be applied to advance typhoon-related agricultural disaster research, increase forecasting accuracy, and improve early warning systems.
Methods
The 1980–2022 affected crop area dataset described in this paper is reconstructed by establishing the relationships between typhoon meteorological data and disaster data from 2004 to 2013 of each single station. The specific process is described in detail below.
Original data acquisition
The original typhoon disaster data, including 2,091 raw records across the eight coastal provinces from 2004 to 2013, is obtained from the National Climate Center during the cooperation of one National Key Research and Development Program of China, numbered 2019YFC1510205. One of the projects supporting this study was a further scientific exploration based on the previous project, so these original disaster data can be used for reconstruction. The data from this period is valuable and detailed. Each entry includes the typhoon name, the affected county and four impact metrics: DEL, affected crop area, affected population and death toll. In this study, we focused on the affected crop area.
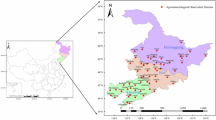
The meteorological data include daily precipitation observations (24-hour accumulation from 12:00 UTC on the previous day) and maximum daily wind speeds derived from 2-minute averages observed at 1-hour intervals, spanning the period 1980–2022. These data were provided by the National Meteorological Information Center (NMIC) of the CMA (http://idata.cma/cmadaas/), covering 530 meteorological stations matched with corresponding county-level administrative districts across the eight provinces (Fig. 1). Quality control procedures have been applied to these data33,34.

Distribution of the eight coastal provinces and 530 county-level stations in China.
The historical typhoon best track dataset was provided by the STI of the CMA (http://tcdata.typhoon.org.cn)35,36. This dataset includes positional coordinates and intensity information at 6-hour intervals35.
Province-level annual planting areas for major crops were acquired from the National Bureau of Statistics of China (https://data.stats.gov.cn/easyquery.htm?cn=E0103).
Data preprocessing
Due to the annual variability in crop planting areas, those areas of crop potentially impacted by typhoons vary over time. For the comparability of affected crop areas among different years, we standardized all historical records to 2022 using provincial data on annual planting areas of major crops. The adjustment was performed through the following formulas:
where Ai is the correction factor for a province for year i (i ∈ [2004, 2013]), accounting for relative variations in crop planting areas between the year i and 2022. S2022 and Si denote the total planting areas of major crops within the province for the baseline year (2022) and target year i, respectively. \({{Ls}}_{0}\) and \({{Ls}}_{1}\) represent the affected crop areas before and after standardization, respectively.
The daily precipitation and wind speed data of the 530 meteorological stations from 1980 to 2022 contain missing values, accounting for 1.06% and 1.61% of the total data, respectively. The lack of meteorological data may reduce the utilization of valuable disaster records in subsequent analyses. Thus, the inverse distance weighting (IDW) method was employed to interpolate and complete the missing meteorological values. The formula was as follows:
where w represents a weight parameter, which was set to 2; sn represents the number of neighboring stations, with a constant value of 10; di represents the distance between the target station and its ith neighboring station; q represents the original meteorological value of each neighboring station before interpolation; and q′ represents the interpolated meteorological value at the target station. When all neighboring stations reported missing values, the value for the target station was assigned as −999. Using this methodology, complete wind speed and precipitation data from 1980 to 2022 were successfully obtained.
The objective synoptic analysis technique (OSAT)37,38 was utilized in this study to differentiate typhoon-associated precipitation and wind data from precipitation and wind data associated with other meteorological events. Given that typhoon interactions may lead to the overidentification of the precipitation caused by typhoons without direct impacts, which may inflate the reconstructed values, the results obtained via the OSAT were further corrected. First, a polyline comprising the grid points that were closest to the actual coastline in a 0.5° × 0.5° latitude and longitude grid was selected to approximate the continental coastline. The minimum distance between the track coordinates of each typhoon and the coastline was computed. Typhoons that stayed more than 450 km away from the mainland coastlines were excluded. Through this objective identification and filtration process, we acquired metrics during the typhoon impact period, such as the total precipitation, maximum daily precipitation, and maximum wind speed, covering 570 typhoons affecting the eight coastal provinces from 1980 to 2022, stored in the file named ‘Typhoon meteorological data(1980–2022).xlsx’.
In this study, we defined that a station was affected by a typhoon if it experienced typhoon-related winds or precipitation, or both. To facilitate the establishment of empirical relationships between typhoons and their associated disasters, disaster records (2004–2013) were matched with typhoon meteorological data. Records were excluded if they were duplicates, if they lacked a corresponding station, or if they had null values for both the wind and precipitation metrics. Finally, 1,845 validated disaster records were retained, covering 398 county-level meteorological stations and 75 typhoons from 2004 to 2013.
Reconstruction
For the 530 stations in this study, an average of only 4.6 original disaster records per station was insufficient to establish reliable statistical relationships. Furthermore, about a quarter of those stations have no records. Given the limitations in terms of both the temporal span (10 years at most) and spatial coverage, it is essential to reconstruct a disaster dataset that covers a longer period and broader range through a systematic reconstruction approach. The reconstruction process involves three main phases (Fig. 2).

Flow chart of the reconstruction process for the reconstructed dataset of crop areas affected by typhoons.
Phase 1 Acquire extended datasets for single stations
The statistical reliability of the functional relationships was compromised for stations with insufficient disaster records, necessitating the integration of disaster data from adjacent stations. An adjacent station was defined as a station located within a certain distance parameter of D from the target station. According to Wu et al.31, D should be consistent for all stations. In this case, the results showed that the correlation between the reconstructed data and the original disaster records decreased as the increase of the D and the number of adjacent stations. To optimize the results of fitting quadratic polynomials, we implemented a variable sample size parameter, G (25 ≤ G ≤ 85), with seven values (G1-G7) at intervals of 10. For example, extended datasets for single stations can be obtained for G1 according to the following steps:
Step 1: Assess the sample-size requirements. For a single station, if the number of disaster records is equal to or exceeds G1, all the disaster records of that station should be included in its dataset without modification. Otherwise, the dataset expansion process moves on to Step 2.
Step 2: Define the adjacent stations. The extended distance parameter D is set so that the adjacent stations can be defined. For the station with fewer records than G1, its adjacent stations are defined as those stations within a distance D of the station. D ranges from 0 to 450 km at 25-km intervals until the total number of records from this station and its adjacent stations reaches G1.
Step 3: Compile the extended dataset for each station. The disaster records in the extended dataset of the single station consists of records from this station and its adjacent stations. The extended single-station datasets are subsequently used to establish fitting relationships between the typhoon disasters and comprehensive typhoon impact factors.
We compiled extended datasets for 530 stations from 2004 to 2013, meeting the sample size requirement of G1, with varying distance parameters D. Next, we replaced G1 with G2 through G7 in succession, repeating Steps 1 through 3 iteratively, and obtaining seven groups of extended datasets. These single-station extended datasets were stored in a zip file named ‘Extended datasets for single stations (2004–2013).zip’ with seven subfolders according to G1-G7, respectively.
Phase 2 Establish relationships between disasters and comprehensive typhoon impact factors
The following steps were performed based on the seven groups of extended datasets for 530 stations from 2004 to 2013:
Step 1: Standardize the affected crop area and meteorological data. To eliminate the differences in units and magnitudes among different variables, each variable in the extended single-station dataset was standardized using the Z score method. The formula is as follows:
i = 1, 2, 3, 4; j = 1, 2, 3, …, ns
s = 1, 2, …, 530
where s is an ordinal value of the meteorological stations; i takes the values 1, 2, 3 and 4, corresponding to the affected crop area (hm2), total precipitation (mm), maximum daily precipitation (mm), and maximum wind speed (m/s) during the typhoon impact period, respectively; ns represents the total number of samples in the extended dataset of the sth station; j denotes the sample ordinal; xsij and Zsij represent the values before and after the standardization of the jth sample for the ith variable, respectively; and μsi and σsi are the mean and variance of variable i for the sth station.
Step 2: Identify comprehensive typhoon impact factors. The canonical correlation analysis (CCA) method proposed by Hotelling39 was used to analyze the station-specific relationships between the affected crop area and the three typhoon impact factors. Thus, the weight coefficients of three standardized typical variables (total precipitation, maximum daily precipitation, and maximum wind speed), as, bs and cs, were obtained. These coefficients were subsequently utilized to construct comprehensive typhoon impact factors that were optimally correlated with the affected crop area. The formula is represented as follow:
s = 1, 2, …, 530
where ys represents the comprehensive typhoon impact factor sequence for the sth station; \({Z}_{s2}\), \({Z}_{s3}\) and \({Z}_{s4}\) represent the standardized total precipitation, maximum daily precipitation, and maximum wind speed sequences during the impact of the typhoon for the sth station, respectively; and as, bs and cs denote the corresponding weight coefficients for these normalized typical variables, respectively.
Step 3: Establish the fitting relationships between the affected crop areas and the comprehensive typhoon impact factors. The relationship between the station-specific disaster variable \({Z}_{s1}\) (the standardized affected crop area sequence for the \({s}_{{th}}\) station) and the comprehensive typhoon impact factor sequence \({y}_{s}\) was fitted as a quadratic polynomial:
s = 1, 2, …, 530
where Ls represents the standardized fitted affected crop area sequence of the sth station, and \({d}_{0s}\), \({d}_{1s}\) and \({d}_{2s}\) are the constant, linear, and quadratic coefficients, respectively. Seven groups of fitting relationships were established based on the seven groups of extended datasets with different sample numbers (G1-G7). In other words, seven extended datasets with different sample sizes (G1-G7) are available for each station, as well as the seven corresponding fitting relationships.
Step 4: Screen the fitting relationships. To ensure the validity of the fitting relationships, the seven candidate fitting relationships for each station need to be screened according to the two-sided Pearson correlation test (similarly hereinafter regarding the correlation coefficient or significance level). The evaluation began with the G1-based relationship, progressing to higher G values only when the current relationship failed to meet the significance threshold (0.05). This process continued until a statistically valid relationship was identified. The G7-based relationship was selected by default when none of the preceding relationships are valid. Finally, 530 fitting relationships corresponding to the 530 stations were obtained and denoted as Ls (ys), where s represents the serial number of the station.
These final relationships of 530 stations are stored in the file ‘Final fitting relationships for 530 stations.xlsx’, whose 7 sheets are arranged according to different G values, recording the coefficients \({d}_{0s}\), \({d}_{1s}\) and \({d}_{2s}\), R2, and significance levels. The final number of stations for each sample size threshold was distributed as follows: 266 (G1), 73 (G2), 61 (G3), 124 (G4), 2 (G5), 1 (G6), and 3 (G7) stations. Notably, the number of significant relationships at the 0.05 level were 527 (99.43%), providing robust support for the reconstruction process.
Phase 3 Reconstruct the disaster dataset
Step 1: Introduce comprehensive typhoon impact factors from 1980 to 2022. First, the sample size for the sth station was expanded from ns (2004–2013, the original recording period) to \({n}_{s}^{{\prime} }\) (1980–2022, the reconstructed period). The comprehensive typhoon impact factor \({y}_{s}^{{\prime} }\) for the reconstructed period of 1980–2022 was subsequently calculated through Eqs. (4, 5), incorporating the previously determined parameters \({\mu }_{si}\) and \({\sigma }_{si}\) from Eq. (4) and as, bs, and cs from Eq. (5).
Step 2: Reconstruct the affected crop area data for each station. The derived \({y}_{s}^{{\prime} }\) values were then substituted into the fitting relationship \({L}_{s}({y}_{s})\) to generate the standardized affected crop area value \({L}_{s}^{{\prime} }\). Finally, these standardized values were transformed into absolute affected crop areas through an inverse standardization process using Eq. (7), completing the reconstruction of the station-specific data from 1980 to 2022.
s = 1, 2, …, 530
where Rs represents the affected crop area sequence (1980–2022) for the sth station, with nonpositive values taken as 0 to indicate the absence of a disaster. \({L}_{s}^{{\prime} }\) is the standardized affected crop area sequence (1980–2022) of the sth station derived from \({L}_{s}({y}_{s})\). \({\mu }_{s1}\) and \({\sigma }_{s1}\) are the mean and variance of the affected crop area in the expanded record dataset (2004–2013) of the sth station, respectively.
In addition, few disasters in the original records had a total precipitation of less than 4 mm and a maximum wind speed of less than 5 m/s. Consequently, the affected crop area values were set to zero in the reconstructed data under the same circumstances, indicating that no disaster occurred.
Step 3: Obtain the disaster dataset. The reconstructed disaster data from 530 individual stations from 1980 to 2022 were compiled as the preliminary reconstructed dataset. Statistical validation revealed a strong correlation (r = 0.6545, p < 0.01) between the 1,845 original disaster records and their corresponding reconstructed values. This indicates that there is a high degree of agreement between the recorded and reconstructed data.
Error revisions
To enhance the reliability of the preliminary reconstructed dataset, error analyses and revisions were conducted from two perspectives: single stations and typhoon cases. Since all disaster records are nonzero values, stations at which no typhoon disaster was recorded were assigned crop damage values of zero to facilitate analysis.
In the station-specific error revision process, we first calculated the mean error Means using the following formula:
s = 1, 2, …, 530
where \({R}_{s}(i)\) and \({S}_{s}(i)\) are the reconstructed and recorded affected crop area values, respectively, for the ith typhoon at the sth station; T1 refers to the total number of disaster-causing typhoons recorded from 2004 to 2013, which is a constant of 75; and Means is the mean error of the sth station.
The spatial distribution of the mean errors across the 530 stations is presented in Fig. 3. For most stations, mean errors were positive, indicating that the reconstructed values were generally larger than the original records. Some stations in coastal regions, such as south-central and southeastern Jiangsu and southwestern Guangdong, have mean errors exceeding 5 thousand hm², with some reaching 10 thousand hm². Other notable errors (2.5–5 thousand hm2) were observed at stations in northeastern Zhejiang, northern Hainan, midwestern Guangdong, and the southern coast of Guangxi. Nevertheless, the reconstructed data is relatively accurate for approximately 83% of the stations, whose mean errors falling within the range of (0, 2.5] thousand hm2.

Distribution of the mean errors between the reconstructed and recorded affected crop areas across the 530 stations (unit: 103 hm2).
The reconstructed value of the affected crop area for the sth station was revised to \({R}_{s}^{{\prime} }\) by subtracting the mean error Means from Rs. A non-positive corrected value \({R}_{s}^{{\prime} }\) indicated that no disaster occurred, and was set to zero.
The typhoon-specific reconstruction error was further analyzed. The recorded and reconstructed affected crop areas of the 75 recorded typhoons (2004–2013) and their mean errors (MeanTC) are shown in Fig. 4. MeanTC was calculated using the following formula:
where Ri and Si represent the reconstructed and recorded values of affected crop area, respectively, for the ith typhoon among the 75 typhoons. T1 represents the total number of typhoons covered by the original records from 2004 to 2013, with a constant value of 75 events.

Recorded and reconstructed affected crop areas for the 75 recorded typhoons from 2004 to 2013 and their mean errors (the red line) (unit: 103 hm2).
MeanTC was calculated as 432.11 thousand hm2, necessitating further correction for typhoon cases. Notably, MeanTC exceeded the reconstructed values for some originally recorded disaster-causing typhoons. Subtracting MeanTC directly from the reconstructed value for each typhoon would yield unrealistic negative values. Thus, an alternative correction approach was applied:
where RTCmin represents the minimum reconstructed affected crop area among the 75 typhoon cases, STCmin denotes the corresponding recorded affected crop area, and DTC serves as a correction parameter, which was calculated as 86.90 thousand hm2.
The revised value of reconstructed affected crop area \({R}_{{t}_{0}}^{{\prime} }\) for typhoon t0 (570 in total, t0 = 1, 2, 3, …, 570) was obtained by subtracting the correction parameter DTC from the initial reconstruction result \({R}_{{t}_{0}}\). In this process, we excluded 56 typhoons with negative \({R}_{{t}_{0}}^{{\prime} }\) values, resulting in 514 validated typhoon events (t = 1, 2, 3, …, 514).
To account for the variations of the disaster severity among different typhoons at the same station, a secondary correction for station-specific disasters was implemented using the following coefficients:
t = 1, 2, 3, …, 514
where Ct is the correction coefficient for the tth typhoon; Rt represents the reconstructed affected crop area value of the tth typhoon before correction, which is the summation of the station-level values \({R}_{s}^{{\rm{{\prime} }}}\) across all stations affected by the tth typhoon; and \({R}_{t}^{{\prime} }\) represents the reconstructed affected crop area value of the tth typhoon after typhoon-specific correction. The final corrected station-level reconstructed affected crop area values \({R}_{s}^{{\prime} {\prime} }\) were obtained by applying the correction coefficients Ct to \({R}_{s}^{{\prime} }\):
After performing these two error corrections (station-specific and typhoon-specific), the correlation coefficients between the 1,845 original records and their reconstructed values increased from 0.6545 to 0.6625 and 0.6679, successively, at the 0.01 significance level. These results demonstrate the effectiveness of the corrections. The revised reconstructed dataset is stored in the file ‘Reconstructed dataset of crop area affected by typhoons.xlsx’.
Classification
The reconstructed disaster data were classified into four levels (light, moderate, severe, and extremely severe disasters) based on single stations and typhoon cases, respectively. Four methods were considered for this task: the percentile method (PM), natural break classification (NBC) method, K-means clustering algorithm, and optimal partition method (OPM). The PM relies on the subjective determination of grade percentages according to data distribution characteristics.
In terms of the station-level disaster data, after comprehensive analysis and comparative testing, a hybrid classification strategy was adopted. First, the 1,845 historical records was classified using the K-means algorithm. Then, the proportions of each class obtained in the first step were applied to the other sets of data. The K-means algorithm produced the following severity distributions: light (80.05%), moderate (16.05%), severe (3.47%), and extremely severe (0.43%). These proportions were applied to classify the reconstructed data with positive affected crop area values for both the 75 recorded typhoons (2004–2013) and 514 typhoons in reconstructed dataset (1980–2022). The detailed thresholds are presented in Table 1. This hybrid approach (K-means and PM) enhances the objectivity and rigor of the classification process.
The affected crop area data of the typhoon events were classified in a similar way. The proportions of the four grades (light, moderate, severe, and extremely severe) accounted for 42.67%, 37.33%, 13.33%, and 6.67%, respectively. The detailed classification thresholds for all the datasets are presented in Table 1. Single-station disaster records and disaster-causing typhoons in the reconstructed dataset are graded according to the grading criteria in the last column of Table 1, respectively. This helps users to get a quick overview of the severity of the disaster.
Data Records
The reconstructed affected crop area dataset and its relevant files are uploaded and stored in a Figshare repository (https://doi.org/10.6084/m9.figshare.28388378.v1)40, with each entry representing an individual disaster record. Table 2 presents the descriptions of the dataset, introducing its every column. Table 3 shows the basic descriptions of other relevant files, including their file names, the summarizing descriptions of the files, and the contents.
Technical Validation
To better demonstrate the reliability of the reconstructed dataset, we compared the characteristics of the recorded and reconstructed data.
First, we analyzed the annual variations in the affected crop area from 2004 to 2013 through three metrics (Fig. 5). The annual cumulative affected crop area represents the total area of crops affected by typhoons across all stations within a year. The annual cumulative frequency is the total number of times that all affected stations recorded nonzero values for the affected crop area in one year.

Annual variations in (a) the annual cumulative affected crop area (unit: 103 hm2), (b) the annual cumulative frequency (unit: times), and (c) the annual cumulative number of disaster-causing typhoons on the basis of the 1,845 original records (red line with dots), reconstructed data corresponding to these 1,845 records (yellow line with diamond marks), reconstructed data of 75 recorded TCs (light blue line with square marks), and reconstructed data of all 117 TCs from 2004 to 2013 (dark blue line with triangular marks).
The changes in the annual cumulative affected area and frequency were consistent between the 1,845 records and their reconstructed counterparts (Fig. 5a,b), with correlation coefficients of 0.9807 and 0.9981, respectively, at the 0.01 significance level. In addition, the reconstructed data cover 117 disaster-causing typhoons from 2004 to 2013, which is more than the 75 recorded typhoons. This discrepancy indicates that 42 typhoons affected the mainland without any disaster data recorded. Furthermore, the reconstruction process have taken most affected stations into account, resulting in larger annual cumulative affected areas and more frequency in the reconstructed datasets for the 75 recorded typhoons and 117 reconstructed typhoons than in the original recorded data.
Figure 6 shows the spatial distributions of the average annual frequency and affected crop area for the recorded data from 2014 to 2013 and the reconstructed data over 10 years (2014–2013) and 43 years (1980–2022). A quantitative analysis of the spatial frequency distributions (Fig. 6a–c) revealed statistically significant correlations (p < 0.01) between the recorded and reconstructed data, with coefficients of 0.4414 and 0.4113 for the 10-year and 43-year reconstructions, respectively. These correlations indicate that the reconstructed data can generally capture the spatial patterns in the original records, although discrepancies exist in some regions. Overall, the average annual frequencies in the reconstructed data are greater than those in the recorded data. According to the recorded data (Fig. 6a), the most frequently impacted regions are the Zhejiang–Fujian and Guangxi–Guangdong provincial junctions and their adjacent areas. The maximum frequency clusters are observed in coastal regions among them. In terms of the two sets of reconstructed data, in addition to the aforementioned regions, some stations in central Guangdong and the Fujian-Guangdong junctions are also frequently affected. Besides, the differences between the coastal and inland areas are smaller.

Spatial distributions of the average annual frequency (a–c) (unit: times) and average annual affected crop area (d–f) (unit: 103 hm2) based on (a,d) 10-year (2004–2013) records; (b,e) 10-year (2004–2013) reconstructed data; (c,f) 43-year (1980–2022) reconstructed data.
The spatial distributions of the average annual affected crop area (Fig. 6d–f) exhibit consistent patterns across the three sets of data, with the disaster severity decreasing from coastal to inland areas. The southern coasts of Guangdong and Guangxi, northern Hainan, coastal Zhejiang and Fujian, and eastern coasts of Jiangsu experienced the worst typhoon disasters. The correlation coefficients between the records and the two reconstructed datasets were 0.5652 (2004–2013) and 0.5706 (1980–2022) at the 0.01 significance level, indicating that the reconstructed data effectively reflect the spatial patterns of the original disaster records. Nevertheless, there are discrepancies in some regions, such as central and southern Jiangsu. The reconstructed data show that several stations in this area were more severely affected compared to the historical records. These differences may have occurred owing to the inherent limitations of the correlation-based reconstruction approach or other objective factors, such as inconsistencies in local disaster documentation practices, and regional variations in disaster response and mitigation capabilities.
Usage Notes
Combining county-level disaster records (2004–2013) with typhoon meteorological data (1980–2022), this study reconstructed a county-level dataset of crop area affected by typhoons across 8 coastal provinces in China for the period 1980–2022 using canonical correlation analysis (CCA), bias correction techniques and other statistical methods. This dataset is suitable for applications, such as studies on the development of typhoon risk forecasting and early warning models, and the formulation and implementation of disaster prevention policies. This study provided a detailed and transparent description of the dataset reconstruction methodology. Researchers who are interested can access the relevant data through the provided platforms to replicate the procedures, obtaining the same results. This transparency will facilitate systematic improvements on the dataset in the future. Furthermore, this transparency may inspire researchers undertaking reconstructions of analogous data, such as datasets for specific crops affected by typhoons, or other disaster metrics like the number of collapsed houses. All the data described in this study are publicly available and can be used with a citation.
Code availability
Most of the data used in this study were manually downloaded or provided by supporters. The dataset were reconstructed using Python. The Python codes are available at https://github.com/IjycbU/Reconstructed-dataset-of-crop-area-affected-by-typhoons. A full list of weather stations and TCs is also provided on our GitHub repository.
References
Knutson, T. R. et al. Tropical cyclones and climate change. Nat. Geosci. 3, 157–163 (2010).
Mendelsohn, R., Emanuel, K., Chonabayashi, S. & Bakkensen, L. The impact of climate change on global tropical cyclone damage. Nat. Clim. Change 2, 205–209 (2012).
Ye, M., Wu, J., Liu, W., He, X. & Wang, C. Dependence of tropical cyclone damage on maximum wind speed and socioeconomic factors. Environ. Res. Lett. 15, 094061 (2020).
Yamada, Y., Noda, A., Kajikawa, Y. & Yamada, K. Response of tropical cyclone activity and structure to global warming in a high-resolution global nonhydrostatic model. J. Clim. 30, 9703–9724 (2017).
Lee, C.-Y., Camargo, S. J., Sobel, A. H. & Tippett, M. K. Statistical–dynamical downscaling projections of tropical cyclone activity in a warming climate: two diverging genesis scenarios. J. Clim. 33, 4815–4834 (2020).
Pérez-Alarcón, A., Fernández-Alvarez, J. C. & Coll-Hidalgo, P. Global Increase of the intensity of tropical cyclones under global warming based on their maximum potential intensity and CMIP6 models. Environ. Process. 10, 36 (2023).
Wan, C. et al. Damage analysis of retired typhoons in mainland China from 2009 to 2019. Nat. Hazards 116, 3225–3242 (2023).
Li, X., Wang, X., Chen, Y., Lin, P. & Zhang, L. Recent increase in rapid intensification events of tropical cyclones along China coast. Clim. Dyn. 62, 331–344 (2023).
Wu, L., Lu, J. & Feng, X. Increased tropical cyclone intensification time in the western North Pacific over the past 56 years. Environ. Res. Lett. 18, 094031 (2023).
Hariembrundtland, G. World Commission on environment and development. Environ. Policy Law 14, 26–30 (1985).
Zhao, X. Research advances on spatial and temporal characteristics of tropical cyclones landfalling in China in the past 50 years and their impacts on agriculture. J. Mar. Meteor. 39, 1–11 (2019).
Hirano, A. Effects of climate change on spatiotemporal patterns of tropical cyclone tracks and their implications for coastal agriculture in Myanmar. Paddy Water Environ. 19, 261–269 (2021).
Gori, A., Lin, N., Xi, D. & Emanuel, K. Tropical cyclone climatology change greatly exacerbates US extreme rainfall–surge hazard. Nat. Clim. Change 12, 171–178 (2022).
Tillman, C. W., Sivillo, J. K. & Frolov, S. A. Managing typhoon related crop risk at WPC. Agric. Agric. Sci. Procedia 1, 204–211 (2010).
Chen, C.-C. & McCarl, B. Hurricanes and possible intensity increases: effects on and reactions from U.S. agriculture. J. Agric. Appl. Econ. 41, 125–144 (2015).
Boschetti, M. et al. Rapid assessment of crop status: an application of MODIS and SAR data to rice areas in Leyte, Philippines affected by Typhoon Haiyan. Remote Sens. 7, 6535–6557 (2015).
Chejarla, V. R., Mandla, V. R., Palanisamy, G. & Choudhary, M. Estimation of damage to agriculture biomass due to Hudhud cyclone and carbon stock assessment in cyclone affected areas using Landsat-8. Geocarto Int. 1–14, https://doi.org/10.1080/10106049.2016.1161079 (2016).
Chou, J., Dong, W., Tu, G. & Xu, Y. Spatiotemporal distribution of landing tropical cyclones and disaster impact analysis in coastal China during 1990–2016. Phys. Chem. Earth Parts A/B/C 115, 102830 (2020).
Wang, H. et al. Tropical cyclone damages in Mainland China over 2005–2016: losses analysis and implications. Environ. Dev. Sustain. 21, 3077–3092 (2019).
Lou, W., Chen, H., Shen, X., Sun, K. & Deng, S. Fine assessment of tropical cyclone disasters based on GIS and SVM in Zhejiang Province, China. Nat. Hazards 64, 511–529 (2012).
Guo, G., Yin, J., Liu, L. & Wu, S. Quantitative assessment of typhoon disaster risk at county level. J. Mar. Sci. Eng. 12, 1544 (2024).
Wen, S. et al. Economic sector loss from influential tropical cyclones and relationship to associated rainfall and wind speed in China. Glob. Planet. Change 169, 224–233 (2018).
Guha-Sapir, D. & Below, R. The Quality and Accuracy of Disaster Data: A Comparative Analysis of Three Global Datasets (2000).
Wang, Y., Yang, S. N., Zhang, L. S., Cao, Y. & Yin, Y. Z. Comparative analysis and outlook of three global databases for meteorological disasters. Clim. Change Res. 253–260, https://doi.org/10.12006/j.issn.1673-1719.2021.067 (2022).
Center for Emergency Management and Homeland Security. Spatial hazard events and losses database for the United States. Center for Emergency Management and Homeland Security (Arizona State University, 2022).
Su, Y. C., Shen, Y., Wu, C. Y. & Kuo, B. J. County-scale dataset indicating the effects of disasters on crops in Taiwan from 2003 to 2022. Sci Data 11, 205 (2024).
Liu, Y. et al. A study on the present status of disaster data and information sharing at home and abroad. J. Catastrophol. 23(3), 109–113+118 (2008).
Chen, P., Lei, X. & Ying, M. Introduction and application of a new comprehensive assessment index for damage caused by tropical cyclones. Trop. Cyclone Res. Rev. 2, 176–183 (2013).
Lu, Y., Zhu, W., Ren, F. & Wang, X. Changes of tropical cyclone high winds and extreme winds during 1980-2014 over China. Clim. Change Res. 413–421, https://doi.org/10.12006/j.issn.1673-1719.2016.030 (2016).
Zhu, J., Lu, Y., Ren, F., McBride, J. L. & Ye, L. Typhoon disaster risk zoning for China’s coastal area. Front. Earth Sci. 16, 291–303 (2021).
Wu, C., Ren, F., Zhu, J., Chen, P. & Lu, Y. Reconstruction of a county-level resolution typhoon disaster database from 1980 to 2018 for China’s coastal area. Front. Earth Sci. 10, https://doi.org/10.3389/feart.2022.1062824 (2023).
Wu, C. et al. Development of a dynamical statistical analog ensemble forecast model for landfalling typhoon disasters. Sci. Rep. 13, 16264 (2023).
Ren, Z., Wang, B. & Liu, X. Quality Control of Meteorological Observation Data—Surface. (China Meteorological Press, 2010).
Ren, Z. Development of three step quality control system of real time observation data from AWS in China. Meteor. Mon. 41, 1268–1277 (2015).
Ying, M. et al. An overview of the China meteorological administration tropical cyclone database. J. Atmos. Ocean. Technol. 31, 287–301 (2014).
Lu, X. et al. Western North Pacific tropical cyclone database created by the China Meteorological Administration. Adv. Atmos. Sci. 38(4), 690–699 (2021).
Wang, Y., Ren, F., Wang, X., Li, W. & Shao, D. The study on the objective technique for partitioning tropical cyclone precipitation in China. Meteorol. Monthly 32(3), 6–10 (2006).
Ren, F., Wang, Y., Wang, X. & Li, W. Estimating tropical cyclone precipitation from station observations. Adv. Atmos. Sci. 24, 700–711 (2007).
Hotelling, H. The most predictable criterion. J. Educ. Psychol. 26, 139–142 (1935).
Wang, W. Reconstructed county-level dataset of crop area affected by typhoons in coastal China from 1980 to 2022. https://doi.org/10.6084/m9.figshare.28388378.v1 (2025).
Acknowledgements
This study was supported by the Basic Research Fund of CAMS (2023Z016), the Key Laboratory of South China Sea Meteorological Disaster Prevention and Mitigation of Hainan Province (SCSF202307), the National Natural Scientific Foundation of China (42275037), and the Jiangsu Collaborative Innovation Center for Climate Change.
Author information
Authors and Affiliations
Contributions
Wenjing Wang performed data processing, data reconstruction, technique validation and drafting the manuscript. Caiming Wu helped to develop the reconstruction method, and to polish the manuscript. Fumin Ren initiated the projects which supported this work, and performed the review and editing of the draft.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, W., Wu, C. & Ren, F. Reconstructed county-level dataset of crop areas affected by typhoons in China’s coastal regions (1980–2022). Sci Data 12, 1581 (2025). https://doi.org/10.1038/s41597-025-05834-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-05834-8
