
Abstract
Value, technology, and policy are three interactive societal factors affecting the willingness, capacity, and formal rules of human interactions with water. Existing human-water models generally neglect the dynamic and accumulated processes of these factors, failing to explain the societal causes of changes in water practices. Here we developed nine process-based quantitative datasets of Value-Technology-Policy regarding water. They contain 17,003 newspaper articles and 801 public submissions to reflect different water values, 1337 ancient technologies and 40,303 patents for water technologies, and 720 water policy documents at various spatial (national, regional, state, and river basin) and temporal (decades to hundreds of years) scales. A consistent, 4-step content analysis approach was adopted to identify, collect and manually code five key elements (processes) of value, technology and policy: the time (“when”), location (“where”), actor (“who”), theme (“what”), and perspective/tone (“what effects”). Inter-coder reliability tests were conducted to ensure the consistency and validity of the data. These datasets will contribute to more process-oriented understanding of societal factors for improved human-water system modelling in the Anthropocene.
Similar content being viewed by others
Background & Summary
Water is a fundamental natural element that links and supports the cycling of nutrients, energy, and carbon in the Earth System, and a critical resource at the core of the continued prosperity of the human society for food security, industrial development, and urbanization1. The emergence of the Anthropocene has marked the end of hydrological stationarity as a result of human activities2,3, making humans an integral part of the hydrological system rather than exogeneous drivers4,5.
Humans interact with water through their societal practices on water supply, water use and water management. Value, technology, and policy are three interactive and essential societal factors affecting human interactions with water. Values are a set of opinions, beliefs, norms, and attitudes shared by the majority of a regional population, which determine the human willingness of change in their water practices6,7. Technologies permeate all aspects of human lives, powering or constraining the interactions via changing the capacities of water utilizations8,9. Policies are the formal rules set by governments to regulate water supply and use10,11. Values affect the public’s choices of technologies and policy development by changing the expectation regarding water resources, and the implementations of policies and technologies in turn open new possibilities for changes in water values12,13. Over time, value, technology, policy and their interactions explain human development in the broadest sense and act as drivers for intended and unintended changes in the natural processes, forming highly complex, non-linear human-water systems.
There have been vibrant development of conceptual frameworks and models including coupled human-natural systems (CHNS)14, socio-ecological systems (SES)15, and socio-hydrology16 for simulating and predicting the complex human-water relationships. The “big data revolution” has enabled accesses to large online textual archives, providing “thick” descriptions of societal phenomena including value, technology and policy development for social science studies. Compared with quantitative data, texts (qualitative data) pose huge challenges for integrating them into quantitative analysis (e.g. hydrological modelling). The common approach adopted in the existing human-water system models is to use proxy indicators, for example using the level of insurance coverage to represent level of flood risk awareness17, using income and water price to represent water use behaviours18, and using levee height to represent technological flood protection capacity19. However, the singular representation of proxy indicators neglected the complex and dynamic processes of societal factors: what happened, who were involved, under what contexts, what were different perspectives on what happened, and what were the outcomes? All these processes, although highly descriptive, are necessary elements representing societal factors. Failing to link these processes in the human-water system models will result in failure to explain the societal causes of changes in water practices. Therefore, developing process-based datasets for quantifying the societal factors (value, technology and policy) from text archives regarding water will provide a more systemic representation of these factors, enabling formalization and incorporation of them into human-water system models.
To develop process-based datasets, we first adopted Harold Lasswell’s communication theory to systemically and consistently extract qualitative narratives of the three societal factors (value, technology and policy) regarding water from different textual sources. American sociologist Harold Lasswell in his book The Structure and Function of Communication in Society developed a “5 W” model containing five fundamental elements: Who, What, In Which Channel, To Whom, and With What Effect20. These questions represent the most salient elements of communication. As one of the earliest and most influential communication models, the “5 W” model has been widely used as a starting point by many theorists for the development of their own theories applying to specific fields21,22,23. Lasswell himself also expanded this model to “7 W” to reflect medias’ influences on policy decisions: (1) Participants: the people and organizations with a stake; (2) Perspectives: the varied viewpoints of these stakeholders; (3) Situations: where the stakeholders interact; (4) Base Values: assets used by stakeholders to pursue their goals (power, wealth, skills etc.); (5) Strategies: approaches used by stakeholders to achieve their goals, (6) the short term “outcomes” and (7) long-term “effects”24. Taking into consideration of the requirement of developing human-water models, the nature of the societal factors and of different data sources, our datasets adjusted the contents and numbers of Ws collected for each of the value, technology, and policy factors. For value, the perspective/sentiment expressed by people was coded as an important element reflecting people’s value regarding a water issue to replace “What Effect”. For technology and policy, “What Effect” was not included as the information was not documented in the data sources. More details can be found in the Methods and the Supplementary Information sections.
We then adopted content analysis25, an approach commonly used in many social science studies, to transform the extracted qualitative narratives of three societal factors (value, technology and policy regarding water) from different textual sources into quantitative data. With a root in the Grounded Theory26, content analysis assumes that interpretations are “grounded in” observed empirical data. It follows specific coding techniques to classify and categorize text segments into a set of concepts, categories (constructs), and relationships, forming a context–mechanism–outcome configuration27. A codebook was created to guide the content coding process, which contained detailed description of each “W” in the communication model. An inductive coding approach that iteratively included additional contents for each element was used. Human coders manually coded all textual data collected, as it was believed that important meanings in texts were often implied, and that human coders were more alert to the implied and contextual meaning beneath the manifest content compared with computer coding, which typically extracted contents based on word appearance frequencies at the document level28. Using this time-intensive manual coding ensured that the datasets developed can be used to develop, calibrate and validate human-water system models29.
Finally, we adopted a long-time perspective to develop these datasets. As societal factors tend to have slow-changing characteristics30, and it is the interaction of the “fast” natural factors and the “slow” societal factors that determine the human-water system threshold which, if crossed, causes the system to move into a new state4,31. All data were thus collected from the longest possible timeframe, except where targeted research foci applied.
We developed nine datasets on three fundamental societal factors (value, technology and policy) regarding water. These datasets contain 17,003 newspaper articles, 801 public submissions, 1337 ancient technologies, 40,303 patents, and 720 policy documents in various spatial (national, regional, state, and river basin) and temporal (decades to hundreds of years) scales. They were extracted from either authoritative or widely used text archives (Tables 1–3).
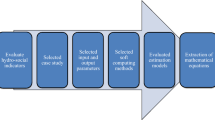
Four steps were followed to generate the datasets (Fig. 1). First, data sources on value, technology, and policy regarding water were identified. These data sources are authoritative and representative online archives with long-time data available, including the global news archives, governmental document repository, historical encyclopaedias, the World Intellectual Property Organization database, and national policy databases. Second, textual documents archived in these data sources were searched by designed keywords. If an excessive number of textual documents were returned from the search (e.g., newspaper articles with daily publications for over 100 years exceeding 40,000 articles), these documents were sampled to create a representative subset manageable for manual content analysis. Search keywords were designed to ensure documents collected had targeted focus on the research topic, and filtering was then conducted to remove duplicates, irrelevant, and out-of-scope documents. In the third step, a coding framework was consistently applied to all documents with five key elements of value, technology, and policy where possible. The five elements (referred to as “5Ws” thereafter) are the time (“when”), location (“where”), actor (“who”), theme (“what”), and perspective/tone (“what effects”), which together define the developmental processes of these societal factors. Finally, inter-coder reliability tests were conducted to ensure the consistency and validity of the coding results.

Workflow of data processing.
These datasets have potentially wide applications. First, these datasets can be used independently for clarifying goals, analysing local contexts, examining relationships between the “5Ws”, and identifying trends and patterns of value, technology, and policy related to water resource governance. This will allow determining and evaluating alternatives for future governance in their respective spatial contexts (China, Australia, and Chile). Second, they provide a starting point to integrate various datasets for comparisons and generating general insights on the three factors and their interactions across different case studies. This will allow developing systemic understanding of the societal drivers for intended and unintended changes in the complex human-water systems. Finally, these process-based quantitative datasets provide the first-hand data for development, calibration and validation of the human-water system models32. This improved modelling capacity will allow better prediction of the human-water relationships in the Anthropocene. Finally, we recognise that the data collected in these datasets only represent dominant forms of value, technology, and policy regarding water.
Methods
We applied a consistent, systematic content analysis approach to collect and transform textual information into quantifiable data that represented value, technology, and policy development regarding water. The detailed steps are as follows:
Data sources identification
Value
Societal values regarding water are a set of opinions, beliefs, norms, and attitudes shared by the majority of a regional population, which determine the human willingness of change in their water practices6. In these datasets, newspapers and public submissions were used to represent the development of societal values. Both data types provide long-term, traceable documentation of public interests and have been a crucial media to reflect societal opinions regarding water.
“It is the media that creates the reality and sets the public agenda33.” Newspapers provide an accessible, in-depth representation of topics reported to the public over a long timeframe. They shape and are shaped by public opinions according to the agenda setting theory, reflecting and deliberately framing the people and organizations involved, the situations in which they interact, and their perspectives28. While digital social media (e.g., Twitter, TikTok) have been increasingly used as platforms to reflect societal values, newspapers remain a dominant form of communication as people still consider them more authoritative and trust-worthy, thus reflecting the majority's values34. Likewise, leading newspapers with high circulation and broad readerships should be targeted to ensure sufficient representation of the development processes of values in a long time, and not geographically confined in terms of readerships35. Multiple online news archives, mainly Factiva and Trove were used as the data sources to collect historical newspapers.
Public submission documents are written comments submitted online or via mail regarding certain government initiatives. They have been one of the most common practices in social licensing procedures and used by government agencies to seek public participation globally36. Among other forms of public participation such as public hearings, open meetings, oral testimony, survey and interviews, these written comments submitted online or mailed in are directly sourced from people and organizations to reflect their background and sentiment on specific governance issues. These documents provide clear and authentic reflections of stakeholder inputs. They avoid potential bias or influences imparted from consultation reports prepared for the governing authorities. All submissions were retrieved from online repositories hosted by the receiving government agencies, including the Parliament of Australia, the Murray-Darling Basin Authority, and the News South Wales Department of Planning, Industry and Environment in Australia (Table 1).
Technology
Technological development co-exists with human history and is the major mean through which water is utilised. Technologies are broadly defined as the artefacts, methods, and practices “to fulfil certain human purposes in a specifiable and reproducible way”37. While data related to technological innovation have been readily available in the modern era (e.g., patents, scientific publications, research expenditures), historical technological development over a long timeframe is more difficult to retrieve yet has important value for modelling historical socio-hydrological phenomenon. In these datasets, historical encyclopaedias were selected as data sources to represent historical technological development, whereas patent documents were selected to represent modern technological development.
Historical encyclopedias integrate first-hand knowledge from ancient literature and excavations from archaeological discoveries. Compared with ancient literature and archaeological excavations, these documents are more accessible, less event-specific, and organized in a systematic, chronical manner covering the full duration of historical technological development. Encyclopaedias used for this dataset included: The History of Chinese Agricultural Technologies edited by Liang38, The History of Science and Technology in China - The Agriculture Chapter edited by Dong and Fan39, and The Development History of Chinese Agriculture edited by Yan and Yin40. In particular, the encyclopaedia edited by Liang38 and Dong and Fan39 highlighted in details the diverse spectrum of different technologies, while Yan and Yin40 focused on the co-development of technology and society. The History of Science and Technology in China edited by Dong and Fan is currently the most up-to-date and comprehensive encyclopedia in China about technologies, building from the renowned Science and Civilization of China by Joseph Needham39,41. All three encyclopedias were compiled by nation-wide research teams of archaeologists, historians, and sociologists, published by top Chinese publishing houses, and have been widely cited by the Chinese Agricultural Yearbooks42,43 and academic researchers44. Using all three encyclopaedias allows cross-validation of technologies documented, and a thorough coverage of the societal contexts, actors, and processes involved in their development.
For modern technologies, patents as one of the most common representatives of technology were used45. There are three major patent data sources globally: the Pantentscope (www.wipo.int/patentscope) administered by the World Intellectual Property Organization (WIPO), the Espacenet (www.espacenet.com) administered by the European Patent Office (EPO), and the U.S.PTO (https://www.uspto.gov/patents/search) administered by the United States Patent and Trademark Office (USPTO). Compared with the other two, Patentsocpe was selected in this dataset because it has comparatively higher filing standards, and focuses on global patent applications rather than those with local or country-specific focuses46,47. It stores more than 107 million patent documents from 193 countries, regions, and organizations dated back to 1782, providing full patent document texts on the specific technologies, the dates and locations of application and follows a consistent International Patent Classification (IPC) system to allow in-depth analysis of technologies over a long timeframe (Table 2).
Policy
Policies are formal institutions including laws, acts and regulations that determine who are at stake to make decisions and under what processes should the resources be used48. The policy documents can be seen as intentional abstract representations of formal governance that should be followed by managing authorities and resource users49. Different countries have different policy development frameworks. For example in Australia, acts form the highest level of legislation and other subordinate legislations are built based on acts. In Chile, formal regulations are sets of documents contained in legal frameworks called Laws, Decree-Law, Decree with Force of Law, Decrees and Resolutions. In these datasets, these policy documents were collected from official governmental repositories. The Australian Legal Information Institute (AUSTLII) (www.austlii.edu.au) contains all legislations and case laws ever enacted in Australia across all States, Territory, and the Commonwealth of Australia as early as the 1800s. Similarly, the Ley Chile (www.LeyChile.cl) data source is the most comprehensive archives storing over 245,000 policies in Chile since 1900 (Table 3).
Data collection
Sampling
This is an optional step applying only to some newspapers with daily publications over a long timeframe to ensure they were manageable for manual content analysis. Four weeks of newspaper articles from each year were sampled with two methods proposed by Lacy, et al.50 and have been consistently applied in former publications51,52,53,54. The four weeks contain two constructed weeks, which accounted for the cyclic reporting of news from Monday to Sunday and were randomly selected from the whole year; and two consecutive weeks accounted for the short-term events (e.g., the Australian Water Week). One constructed week and one consecutive week of news articles were collected in each half year. These sampling methods have been shown to reliably account for a full year’s news contents50,55.
Filtering
All text documents collected from the specified archives were stored either as word documents or searchable PDF files. They were screened individually by the authors. Duplicate documents were first removed. Documents containing only incidental mentions of the specified keywords with no direct relevance to the issue of focus were then removed. Finally, documents concerning issues outside the spatial scope of interest were also removed.
Content analysis
Coding table
We adopted a consistent coding framework based on the “5 W” model, which defined five key elements in the communication processes: “When”, “Where”, “What” happened, involving “Who” and leading to “What effect (perspective/tone)” (Table 4). A full list of contents under each element for each dataset can be found in the Supplementary Information.
The first and second elements provided information on the temporal and spatial scope of the values reflected in news articles, technologies and policies respectively. These two elements express “when” and “where” the developmental processes of the societal factors took place. The third element contained the actors involved in the news reporting, policy, or technology. They can be individuals, groups, and organizations responsible for the management and/or use of water resources and technologies, such as farmers, scientists, state and federal government, research institutes, private companies, and advocacy commissions. The fourth element stored the thematic content of the documents. This included the issues or topics about water, such as water quantity, quality and the ecosystem.
The fifth element was about the perspective/tone expressed in texts. For perspectives, two dimensions were coded to reflect people’s value inclination regarding certain water issues: “environmental sustainability oriented” or “economic development oriented”. Perspectives expressed as addressing economic development such as increasing water for irrigation were coded as “economic oriented”; whereas those expressing concerns for water over-allocation and degraded ecosystems were coded as “environmental sustainability oriented”. For sematic tone, three dimensions were coded to reflect people’s willingness regarding certain water issues: positive (supportive), negative (oppositive) and neutral.
Content coding
Manual content analysis was conducted to transform the unstructured textual information from each document into a structured format. Given the highly varied formats of different data sources, we believed that human coders were more alert to the implied and contextual arguments in text. All coders were professionally trained academics in the water resource governance field with English proficiency. Coders responsible for coding Chinese or Spanish documents were also proficient in the corresponding languages. They were trained before coding to be familiar with the coding framework, and disagreements in the coder’s interpretation of articles and classifications were resolved through discussions to further improve coding consistency.
We adopted an inductive coding approach. Coders conducted coding according to the “5 W” elements in Table 4 initially. As coding proceeded, the “5 W” elements that were not present in text were removed (e.g., the “What perspective/tone” element for technology and policy) and the contents were iteratively added and summarised as different thematic groups under each element to ensure all contents were included. All coders independently coded all documents. Inter-coder reliability tests were then conducted to calculate the rate of coding agreement using the Krippendorff’s alpha25 to quantify the consistency of coding. More details are outlined in the Validation section below.
Data Records
The datasets are stored in the Harvard Dataverse56. The “Data summary-final-v2.xslx” file stores the actors, themes, tones, temporal and spatial scales of each newspaper article, technology, and policy document. The Excel file contains 10 sheets in total, with the first being the “Content list” with links to the corresponding datasets, and the following sheets documented data for each of the following:
-
“1. AUS water news”: Evolution of societal values on water in Australia;
-
“2. CHN water news”: Evolution of societal values on water in China;
-
“3. International TGD news”: The international public’s opinions on the Three Gorges Dam (TGD) in China
-
“4. QLD flood news”: The public’s opinions changes between the two large floodings in the Brisbane River, Australia
-
“5. MDB submission”: Stakeholders’ opinions on the water reforms in the Murray-Darling Basin (MDB) in Australia
-
“6. Ancient tech”: Water and agricultural technologies in ancient China
-
“7. River patent”: Global river-related patents
-
“8. VIC water act”: Water regulations in Victoria, Australia
-
“9. Chile water act”: Water regulations in Chile
The variables included are explained below and can be referred to the Supplementary Information for more specific details:
-
1.
“When” / Time: the time of publication;
-
2.
“Where” / Location: the spatial location in the document;
-
3.
“Who” / Participant or organization: the individuals and organizations involved in the document;
-
4.
“What”: the themes of the document coded according to the coding framework;
-
5.
“What perspective or tone”: whether there is “economic development-oriented” or “environmental sustainability-oriented” perspectives; and/or positive, negative or neutral sentiment expressed in text.
Technical Validation
The validations of data were conducted during the content coding processes, by ensuring that all qualified coders understood and followed the set rules throughout the coding processes. All coders were first trained before coding. Each document was first read and coded by two coders. They were asked to code all documents independently and a third coder with similar background was asked to code 50 randomly selected documents to check the consistency of coding. The disagreements in the coders’ interpretations of articles and classifications during the pilot coding were resolved through discussions. It is recognised that manual coding by human coders is laborious and time-consuming. On average, coding for each dataset required 12–24 months for the full coding process (including iterative coding and validation), varied depending on the data size.
The level of agreements among coders was measured by the Krippendorff’s alpha25, which was calculated below (Fig. 2):
-
All coders independently coded the contents for each document into each of the available elements defined in Table 4;
-
Constructed a disagreement matrix, with rows representing the documents and columns representing the pairs of coders (N = 3). Each cell represented the disagreement (d = 1) and agreement (d = 0). The total disagreement across all coders and elements was calculated as:
$${D}_{{disagree}}=\frac{\sum d}{N}$$ -
Calculated the Krippendorff’s alpha as:
where Drandom is a random matrix with the same size of the disagreement matrix, which serves as the expected agreement by chance.

Workflow of calculating the Krippendorff’s alpha.
The \(\alpha =1\) indicates perfect agreement among coders, lower \(\alpha \) represents lower coding consistency. For initial contents coded having Krippendorff’s alpha below 80%, any disagreement and ambiguity about the coded contents were thoroughly discussed and clarified among coders. These contents were then re-coded and the updated coding principles were then applied to the following contents. This process was applied iteratively to ensure all contents coded had Krippendorff’s alpha greater than 80% to pass the inter-coder reliability tests. After this iterative coding process, the final average Krippendorff’s alpha for coding the nine datasets was 86.2%. This is well above 80% as recommended by Poindexter and McCombs57 indicating a high level of inter-coder reliability.
Data availability
The datasets generated in this study are available in the Harvard Dataverse repository, https://doi.org/10.7910/DVN/PEENPN.
Code availability
No custom code was used to generate or process the data described in the manuscript.
References
Rodríguez, D. J., Paltán, H. A., García, L. E., Ray, P. & St. George Freeman, S. Water-related infrastructure investments in a changing environment: a perspective from the World Bank. Water Policy 23, 31–53, https://doi.org/10.2166/wp.2021.265 (2021).
Milly, P. C. D. et al. Stationarity is dead: whither water management. Science 319, 573–574, https://doi.org/10.1126/science.1151915 (2008).
Ajami, H. et al. On the non-stationarity of hydrological response in anthropogenically unaffected catchments: an Australian perspective. HESS 21, 281–294, https://doi.org/10.5194/hess-21-281-2017 (2017).
Sivapalan, M. Debates—Perspectives on socio-hydrology: Changing water systems and the “tyranny of small problems”—Socio-hydrology. Water Resources Research 51, 4795–4805, https://doi.org/10.1002/2015WR017080 (2015).
Wei, Y., Ison, R., Western, A. & Lu, Z. Understanding ourselves and the environment in which we live. Current Opinion in Environmental Sustainability 33, 161–166, https://doi.org/10.1016/j.cosust.2018.06.002 (2018).
Roobavannan, M. et al. Norms and values in sociohydrological models. HESS 22, 1337–1349, https://doi.org/10.5194/hess-22-1337-2018 (2018).
Wei, Y. et al. A socio-hydrological framework for understanding conflict and cooperation with respect to transboundary rivers. HESS 26, 2131–2146, https://doi.org/10.5194/hess-26-2131-2022 (2022).
Kandasamy, J. et al. Socio-hydrologic drivers of the pendulum swing between agricultural development and environmental health: a case study from Murrumbidgee River basin, Australia. HESS 18, 1027–1041, https://doi.org/10.5194/hess-18-1027-2014 (2014).
Wei, Y., Wu, S. & Tesemma, Z. Re-orienting technological development for a more sustainable human-environmental relationship. Current Opinion in Environmental Sustainability 33, 151–160, https://doi.org/10.1016/j.cosust.2018.05.022 (2018).
Ostrom, E. Governing the Commons: The Evolution of Institutions for Collective Action. (Cambridge University Press, 1990).
Han, Z., Wei, Y. & Meng, J. Representing human agency in social-hydrological models, a water (re-) allocation perspective. JHyd 662, 133944, https://doi.org/10.1016/j.jhydrol.2025.133944 (2025).
Geels, F. W. Socio-technical transitions to sustainability: a review of criticisms and elaborations of the Multi-Level Perspective. Current Opinion in Environmental Sustainability 39, 187–201, https://doi.org/10.1016/j.cosust.2019.06.009 (2019).
Anderies, J. M., Janssen, M. A. & Schlager, E. Institutions and the performance of coupled infrastructure systems. Int J Commons 10, https://doi.org/10.18352/ijc.651 (2016).
Moallemi, E. A., Kwakkel, J., de Haan, F. J. & Bryan, B. A. Exploratory modeling for analyzing coupled human-natural systems under uncertainty. Global Environ. Change 65, 102186, https://doi.org/10.1016/j.gloenvcha.2020.102186 (2020).
Bialozyt, R. B., Roß-Nickoll, M., Ottermanns, R. & Jetzkowitz, J. The different ways to operationalise the social in applied models and simulations of sustainability science: A contribution for the enhancement of good modelling practices. Ecological Modelling 500, 110952, https://doi.org/10.1016/j.ecolmodel.2024.110952 (2025).
Vanelli, F. M., Kobiyama, M. & de Brito, M. M. To which extent are socio-hydrology studies truly integrative? The case of natural hazards and disaster research. HESS 26, 2301–2317, https://doi.org/10.5194/hess-26-2301-2022 (2022).
Viglione, A. et al. Insights from socio-hydrology modelling on dealing with flood risk – Roles of collective memory, risk-taking attitude and trust. JHyd 518, 71–82, https://doi.org/10.1016/j.jhydrol.2014.01.018 (2014).
Rachunok, B. & Fletcher, S. Socio-hydrological drought impacts on urban water affordability. Nature Water 1, 83–94, https://doi.org/10.1038/s44221-022-00009-w (2023).
Ciullo, A., Viglione, A., Castellarin, A., Crisci, M. & Di Baldassarre, G. Socio-hydrological modelling of flood-risk dynamics: comparing the resilience of green and technological systems. Hydrological Sciences Journal 62, 880–891, https://doi.org/10.1080/02626667.2016.1273527 (2017).
Lasswell, H. D. in The Communication of Ideas (ed L. Bryson) Ch. The structure and function of communication in society, 37-51 (The Institute for Religious and Social Studies, 1948).
Christensen, E. & Christensen, L. T. in Research Handbook on Strategic Communication (eds J. Falkheimer & M. Heide) Ch. 3 The saying and the doing: when communication is strategic, 33-45 (Edward Elgar Publishing, 2022).
Jeffres, L. W. Mass communication theories in a time of changing technologies. Mass Communication and Society 18, 523–530, https://doi.org/10.1080/15205436.2015.1065652 (2015).
Mian, I. S. & Rose, C. Communication theory and multicellular biology. Integr Biol 3, 350–367, https://doi.org/10.1039/c0ib00117a (2011).
Lasswell, H. D. in Communication Researchers and Policy–making (ed S. Braman) Ch. 4 The policy orientation, 85-104 (MIT Press, 2003).
Krippendorff, K. Content Analysis: An Introduction to Its Methodology. 4 edn, (SAGE Publications, Inc., 2019).
Strauss, A. & Corbin, J. in Handbook of Qualitative Research (eds Denzin N. K. & Lincoln Y. S.) Ch. Grounded theory methodology: An overview, 273-285 (Sage Publications, Inc, 1994).
Jackson, S. F. & Kolla, G. A new realistic evaluation analysis method: linked coding of context, mechanism, and outcome relationships. American Journal of evaluation 33, 339–349, https://doi.org/10.1177/1098214012440030 (2012).
Howland, D., Becker, M. L. & Prelli, L. J. Merging content analysis and the policy sciences: A system to discern policy-specific trends from news media reports. Pol. Sci. 39, 205–231 (2006).
Baden, C., Pipal, C., Schoonvelde, M. & van der Velden, M. A. C. G. Three gaps in computational text analysis methods for social sciences: a research agenda. Communication Methods and Measures 16, 1–18, https://doi.org/10.1080/19312458.2021.2015574 (2022).
Eldredge, N. & Gould, S. J. in Models in Paleobiology (ed J. M. S. Thomas) Ch. Punctuated equilibria: an alternative to phyletic gradualism, 82-115 (Freeman, Cooper and Company, 1972).
Cracraft, J. in Understanding Change: Models, Methodologies and Metaphors (eds A Wimmer & R. Kössler) Ch. 19 Reconstructing change in historical systems: are there commonalties between evolutionary biology and the humanities? 270-284 (Palgrave Macmillan UK, 2006).
Blöschl, G. et al. Twenty-three unsolved problems in hydrology (UPH) – a community perspective. Hydrological Sciences Journal 64, 1141–1158, https://doi.org/10.1080/02626667.2019.1620507 (2019).
Nelkin, D. Selling Science: How the Press Covers Science and Technology. 225 (W. H. Freeman & Co Ltd, 1995).
Levinsen, K. & Wien, C. Changing media representations of youth in the news–a content analysis of Danish newspapers 1953–2003. Journal of Youth Studies 14, 837–851, https://doi.org/10.1080/13676261.2011.607434 (2011).
Kandyla, A.-A. & De Vreese, C. News media representations of a common EU foreign and security policy. A cross-national content analysis of CFSP coverage in national quality newspapers. Comparative European Politics 9, 52–75, https://doi.org/10.1057/cep.2009.10 (2011).
Hood, N. E., Brewer, T., Jackson, R. & Wewers, M. E. Survey of community engagement in NIH‐funded research. Clinical and translational science 3, 19–22 (2010).
Anadon, L. D. et al. Making technological innovation work for sustainable development. Proceedings of the National Academy of Sciences 113, 9682–9690 (2016).
Liang, J. The History of Chinese Agricultural Technologies. (Agricultural Publisher, 1989).
Dong, K. Z. & Fan, C. Y. The History of Science and Technology in China - The Agriculture Chapter. (Science Publisher, 2000).
Yan, W. Y. & Yin, Y. H. The Development History of Chinese Agriculture. 458 (Tianjing Science and Technology Publisher, 1993).
Needham, J. & Bray, F. in Science and Civilisation in China Vol. 6 Biology and Biological Technology Ch. Agriculture, (Cambridge University Press, 1984).
Board, C. A. Y. E. China Agricultural Yearbook 1989. (China Agricultural Publisher, 1989).
Board, C. A. Y. E. China Agricultural Yearbook 2000. (China Agricultural Publisher, 2000).
Zeng, X. in A History of Chinese Science and Technology Vol. 1 (ed Y. Lu) Ch. Agriculture, 351-429 (Springer Berlin Heidelberg, 2015).
WIPO. Patents: what is patent?,<https://www.wipo.int/patents/en/> (2022).
Van Doren, D., Koenigstein, S. & Reiss, T. The development of synthetic biology: a patent analysis. Systems and synthetic biology 7, 209–220 (2013).
WIPO. PCT – The International Patent System, <https://www.wipo.int/pct/en/> (2021).
de Wee, G. Comparative policy analysis and the science of conceptual systems: a candidate pathway to a common variable. Foundations of Science 27, 287–304, https://doi.org/10.1007/s10699-021-09782-5 (2022).
Schwaninger, M. Model-based management: a cybernetic concept. Systems Research and Behavioral Science 32, 564–578, https://doi.org/10.1002/sres.2286 (2015).
Lacy, S., Riffe, D., Stoddard, S., Martin, H. & Chang, K.-K. Sample size for newspaper content analysis in multi-year studies. Journalism & Mass Communication Quarterly 78, 836–845, https://doi.org/10.1177/10776990010780041 (2001).
Wei, J., Wei, Y., Western, A., Skinner, D. & Lyle, C. Evolution of newspaper coverage of water issues in Australia during 1843-2011. Ambio 44, 319–331, https://doi.org/10.1007/s13280-014-0571-2 (2015).
Wei, J., Wei, Y., Tian, F., Xiong, Y. & Hu, H. Transition in the societal value and governance of water resources in Australia and China. Humanit Soc Sci Commun 10, 359, https://doi.org/10.1057/s41599-023-01857-x (2023).
Wei, J., Wei, Y. & Western, A. Evolution of the societal value of water resources for economic development versus environmental sustainability in Australia from 1843 to 2011. Global Environ. Change 42, 82–92, https://doi.org/10.1016/j.gloenvcha.2016.12.005 (2017).
Xiong, Y., Wei, Y., Zhang, Z. & Wei, J. Evolution of China’s water issues as framed in Chinese mainstream newspaper. Ambio 45, 241–253, https://doi.org/10.1007/s13280-015-0716-y (2016).
Riffe, D., Lacy, S., Fico, F. & Watson, B. R. Analyzing media messages: Using quantitative content analysis in research. 4 edn, 234 (Routledge, 2019).
Wu, S. et al. Quantitative datasets of societal value, technology and policy for human-water system modelling v. 2, https://doi.org/10.7910/DVN/PEENPN (Harvard Dataverse, 2025).
Poindexter, P. M. & McCombs, M. E. Research in Mass Communication: A Practical Guide. 451 (Bedford/St. Martin’s Boston, MA, 2000).
Wei, J. Transition of societal value and governance on water resources in Australia over 1843-2017 v. 1, https://doi.org/10.7910/DVN/WX7CHH (Harvard Dataverse, 2023).
Xiong, Y. Replication Data for Transition of societal value and governance on water resources in China over 1946-2017 v. 1 https://doi.org/10.7910/DVN/KJM7B0 (Harvard Dataverse, 2023).
Wu, S. et al. A longitudinal analysis on the perspectives of major world newspapers on the Three Gorges Dam project during 1982–2015. Water Science and Technology: Water Supply 18, 94–107, https://doi.org/10.2166/ws.2017.088 (2018).
Hong, P., Wei, Y., Bouckaert, F., Johnston, K. & Head, B. Assessing stakeholder structure in water governance in the Murray-Darling Basin, a public submission perspective. Environmental Science & Policy 156, 103746, https://doi.org/10.1016/j.envsci.2024.103746 (2024).
Wu, S., Wei, Y., Head, B. & Hanna, S. Measuring the structure of a technology system for directing technological transition. Global Challenges 5, 2000073, https://doi.org/10.1002/gch2.202000073 (2020).
Wu, S., Wei, Y., Head, B., Zhao, Y. & Hanna, S. The development of ancient Chinese agricultural and water technology from 8000 BC to 1911 AD. Humanit Soc Sci Commun 5, 77, https://doi.org/10.1057/s41599-019-0282-1 (2019).
Wu, S., Wei, Y., Head, B., Zhao, Y. & Hanna, S. Using a process-based model to understand dynamics of Chinese agricultural and water technology development from 8000 BC to 1911 AD. Ambio 50(1101-1116), 7, https://doi.org/10.1007/s13280-020-01424-7 (2021).
Wu, S. List of ancient agricultural and water technologies developed in China v. 1 https://doi.org/10.7910/DVN/3VNACY (Harvard Dataverse, 2019).
Gan, L., Wei, Y. & Wu, S. Using the evolution of a river technology system to compare classification-based and citation-based technology networks. Water 16, 2856, https://doi.org/10.3390/w16192856 (2024).
Gan, L., Wei, Y. & Wu, S. Evolution of water technology from a structural perspective. Frontiers in Environmental Science 12, https://doi.org/10.3389/fenvs.2024.1447120 (2024).
Werdiningtyas, R., Wei, Y. & Western, A. W. The evolution of policy instruments used in water, land and environmental governances in Victoria, Australia from 1860–2016. Environmental Science & Policy 112, 348–360, https://doi.org/10.1016/j.envsci.2020.06.012 (2020).
Genova, P. & Wei, Y. A socio-hydrological model for assessing water resource allocation and water environmental regulations in the Maipo River basin. JHyd 617, 129159, https://doi.org/10.1016/j.jhydrol.2023.129159 (2023).
Genova, P., Wei, Y. & Olivares, M. A. Evolution of water environmental regulations in Chile since 1900. Water Policy 24, 1306–1324, https://doi.org/10.2166/wp.2022.053 (2022).
Acknowledgements
The research is funded by the Australian Research Council Special Research Initiative (SR200200186).
Author information
Authors and Affiliations
Contributions
Shuanglei Wu: Conceptualization, Data collection and processing, Writing of the first draft, Review of the manuscript. Yongping Wei: Conceptualization, Project supervision, Funding acquisition, Review of the manuscript. Jing Wei: Conceptualization, Data collection and processing, Review of the manuscript. Yonglan Xiong: Conceptualization, Data collection and processing, Review of the manuscript. Sarina Huang: Conceptualization, Data collection and processing, Review of the manuscript. Ratri Werdiningtyas: Conceptualization, Data collection and processing, Review of the manuscript. Paulina Genova: Conceptualization, Data collection and processing, Review of the manuscript. Paul Hong: Conceptualization, Data collection and processing, Review of the manuscript. Lin Gan: Conceptualization, Data collection and processing, Review of the manuscript. Chendi Song: Conceptualization, Data collection and processing, Review of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wu, S., Wei, Y., Wei, J. et al. Quantitative datasets of societal value, technology and policy for human-water system modelling. Sci Data 12, 1528 (2025). https://doi.org/10.1038/s41597-025-05885-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-025-05885-x
