
Abstract
Dental diseases are one of the most common diseases that affect humans. Clinicians employ several techniques for diagnosing and monitoring dental diseases, with intra-oral periapical (IOPA) radiographs being among the most commonly utilized methods. The development of artificial intelligence (AI) technologies for analyzing oral radiographs is being explored across various imaging modalities. However, the limited availability of publicly accessible datasets has been a significant challenge. Although datasets of dental radiographs are available, most of these datasets contain panoramic radiographs with teeth segmentation only. This new data set includes IOPA radiographs with annotations of important landmarks along with tooth segmentation. The dataset includes 1000 images with marked landmarks, along with metadata. Researchers can leverage this resource to create AI solutions for analyzing IOPA radiographs.
Similar content being viewed by others

Background & Summary
Dental diseases are a significant public health concern worldwide. According to the Global Oral Health Status Report1, oral diseases impacted 3.5 billion people in 2019. This is 1 billion more than the total number of cases of the five major non-communicable diseases (NCDs), which include cardiovascular disease, diabetes mellitus, chronic respiratory diseases, mental disorders and cancers2. Untreated dental diseases could lead to several health complications such as tooth loss, pain and discomfort, which could also ultimately affect the quality of life3.
Early detection of dental diseases is crucial for effective management4. Thus, the clinical examination of the patient will be followed by appropriate investigations in order to arrive at a diagnosis of dental diseases 5.
Dental imaging is one such type of investigation that would facilitate the diagnosis, enhancing the accuracy of the findings achieved during clinical examination. These diagnostic imaging includes intraoral or extraoral plain x-rays and three-dimensional imaging modalities such as cone beam computed tomography (CBCT)5. Among intraoral radiographs, bitewing radiographs, particularly vertical bitewings, are often used to assess crest bone levels, as they provide an accurate depiction of the distance between the Cemento-Enamel junction (CEJ) and the alveolar crest, especially in cases with shallow periodontal pockets ( < 5 mm). However, in clinical situations involving deeper or irregular pocketing ( > 5 mm), bitewing radiographs do not adequately capture the full extent of bone loss. In such cases, periapical radiographs are considered more suitable, as they offer a greater vertical field of view. Intra-oral periapical (IOPA) radiographs, are essential for diagnosing a range of dental conditions, including assessing tooth structure and periodontal health, detecting periapical infections and bone abnormalities, monitoring endodontic status and identifying unerupted or impacted teeth6. IOPA radiographs are relatively simple and less expensive compared to other diagnostic imaging methods such as dental panoramic tomogram (DPT), making them a cost-effective option for dental check-ups7. Moreover, IOPA radiographs provide high-resolution images of the teeth and surrounding structures.
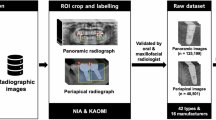
Artificial intelligence (AI) and computer vision-based systems capable of analysing the radiographs could be of significant assistance to dentists by reducing errors while enhancing the efficiency and accuracy of diagnoses8,9,10. In some cases, AI shows promising potential in diagnosing dental-related issues with reliability, transparency, and precision that could aid dentists in specific scenarios11. The use of computer vision and convolutional neural networks in dental research has been continuously growing since the first published application in 201512. To obtain these benefits, having a large and diverse dataset of radiographs is crucial. Although datasets of dental radiographs are available, most of these datasets contain panoramic radiographs with teeth segmentation only. Table 1 provides an overview of these datasets. This new data set includes IOPA radiographs with annotations of important landmarks along with tooth segmentation. With a sufficiently robust dataset, both machine learning and deep learning models could be developed and trained to automatically detect dental diseases, allowing early diagnosis and improved treatment outcomes.
Our dataset, DenPAR, consists of 1000 IOPA radiographs with detailed annotations, including tooth segmentation masks, Cemento-Enamel Junction (CEJ) points, apex points, and alveolar crestal bone levels, all annotated using the LabelBox annotation tool13. Sample images and annotations are shown in Figs. 1 and 2. Each image is also accompanied by metadata on age and sex.

Sample images from the dataset, following anonymization, without annotations. (a) lower posterior, (b) upper posterior, (c) lower anterior, and (d) upper anterior.

Sample annotations. Cemento-Enamel junctions (CEJ) points (red) are highlighted with red circles, apex points (yellow) are highlighted with yellow circles, alveolar bone-level lines with green lines in gray-highlighted areas, and teeth are shown as blue masks.
This comprehensive annotated dataset of IOPA radiographs together with the relevant metadata can be used for advancements in automated technology in analysis of dental radiographs, which could improve the efficiency of dental diagnosis. The dataset and annotations can be utilized for training various models, including teeth segmentation models, multi-class or single-class tooth segmentation models, keypoint detection (CEJ and apex) models, and alveolar crestal bone level identification models. These can be further developed for advanced clinical decision support systems, such as alveolar bone loss detection using IOPA radiographs. Overall, this dataset holds significant potential for reuse and has the capability to make a meaningful impact on clinical practice, research, and technological advancements in dentistry.
Methods
The data set comprises 1000 IOPA radiographs acquired for routine dental treatments and diagnosis in the Radiology Unit of the Dental Hospital Peradeniya, Sri Lanka during the period from January 2020 to January 2023.
The sample includes radiographs of 440 male and 560 female patients, with an age range of 9 to 81 years. The age range for male patients is between 9 and 81 years, while in female patients it ranges from 12 to 79 years. The age and sex distribution of the patients is shown in Fig. 3, and the majority of the male and female patients were in the age range of 31-50 years.

Patient distribution by age and sex.
Out of the 1000 radiographs, 590 are from the lower arch and 410 are from the upper arch. In terms of anatomical orientation, 398 radiographs are from the right side, 380 from the left side, and 222 from the anterior region.

Overview of dataset structure. Contents are shown for the training folder; validation and testing folders follow the same structure.
Data Privacy
Ethical approval for this study was granted by the Ethics Review Committee of the Faculty of Dental Sciences, University of Peradeniya, Sri Lanka, under the Ethics clearance certificate containing the number ERC/FDS/UOP/2023/45. As part of the hospital’s standard registration process, patients provide general informed consent (blanket) that allows the use of their clinical records, including images, for research and educational purposes, provided that personal identifiers are removed. In this study, all data were fully de-identified prior to the analysis, in order to protect patient privacy. The use of this de-identified data for this research was also approved by the institution’s ethics committee. The original images had several details labeled, such as the patient’s name, age, and sex. Two steps were taken to anonymize the images. First, all images were renamed using random integer numbers to remove identifiable information. Second, an algorithm was employed to eliminate all personal details embedded within the images. Figure 1 displays examples of images following the anonymization process.
Data annotation
The annotation software used to create the dataset is Labelbox13. The annotations included CEJ points, apex points, alveolar crestal bone levels, and individual teeth. The CEJ was identified as the end point of the enamel, and it was marked on the proximal surfaces (mesial and distal) of each tooth. The tip of the root, as seen on the radiograph, was marked as the root apex. In multi-rooted teeth, the apex was marked for each root. The alveolar crestal bone levels were annotated based on the highest point of the crestal bone. All clearly identifiable CEJ points, apex points, and alveolar crestal bone levels in any given radiograph were annotated.
The annotations were performed collaboratively by two experienced specialists (MD in Restorative Dentistry), each with significant expertise in radiographic interpretation related to periodontal bone loss. Both experts followed standardized diagnostic criteria and reached consensus on each case to minimize subjectivity and bias in the annotation process. Figure 2 illustrates a sample of an image following Labelbox annotations.
Following annotation, all data were blindly reviewed and approved by two experienced specialists (MD in Oral Surgery, and MD in Restorative Dentistry) from the Department of Oral Medicine and Periodontology, Faculty of Dental Sciences, University of Peradeniya, Sri Lanka, both of whom have substantial expertise in dental radiographic interpretation.
Data Records
The compressed dataset is available on Zenodo (https://doi.org/10.5281/zenodo.16645076)14 under Creative Commons Attribution 4.0 license. The uncompressed folder consists of three directories: Training, Validation, and Testing, which can be used as official splits for training, validation, and testing machine learning models. Additionally, the folder includes one metadata spreadsheet file named “characteristics of radiographs included”.
Each directory contains five sub-directories, namely, Images, Masks (Radiograph-wise), Masks (Tooth-wise), Bone Level Annotations, and Key Points Annotations. The metadata spreadsheet file provides detailed information about the arch type, anatomical orientation, and FDI notation of each tooth in every radiograph.
Images and Masks (Radiograph-wise) subdirectories contain corresponding IOPA radiographs in .JPG format and teeth mask images for radiographs in .PNG format, respectively.
Key Points Annotations subdirectory contains key point annotation JSON files. Figure 5, illustrates the visualization of information from a key point annotation JSON file. In this visualization, the CEJ key points are highlighted with red circles, and the apex points are highlighted with blue circles. Each tooth is enclosed within an individual rectangular bounding box derived from its corresponding tooth mask. The bounding box coordinates are represented as [x-minimum, y-minimum, x-maximum, y-maximum], where x-minimum and y-minimum correspond to the top-left corner of the box, and x-maximum and y-maximum correspond to the bottom-right corner of the bounding box. These bounding boxes are included to meet the input requirements of certain keypoint detection models, which utilize bounding box constraints to enhance the localization and precision of keypoint detection.

(a) The original radiograph image, (b) representation of information in keypoint annotation JSON file. CEJ points (red) are highlighted with red circles, apex points (blue) with blue circles, and bounding boxes (yellow) enclose each tooth containing keypoint information.
Bone Level Annotations subdirectory contains alveolar crestal bone-level annotation JSON files along with a Common Objects in Context (COCO) format annotation file. In the alveolar crestal bone-level annotation file, the alveolar crestal bone levels are represented as separate X and Y coordinates for each alveolar crestal bone level because, in 2D images, a bone level is a line, which is made up of multiple points. Radiograph-wise images and .JSON files are renamed with the corresponding name of the IOPA radiographs.
Masks (Tooth-wise) subdirectory contains sub-folders with the name of the corresponding IOPA radiographs and a COCO format annotation file. Each subfolder includes mask images of individual teeth in .PNG format.
The overview of the dataset structure is presented in Fig. 4. The figure illustrates the content structure of the “Training” folder, while the “Validation” and “Testing” folders follow the same structure.
Radiograph-wise masks help in tasks such as identifying all teeth in the radiograph, while tooth-wise masks help in tasks such as identifying each individual tooth within the radiograph. The COCO format annotation files can be used directly or with the pre-processing, depending on the requirements of machine learning models. This format is highly versatile and widely used because it allows for the creation of customized annotation files, making it adaptable to different computer vision tasks.
Figure 6 presents the distribution of image resolutions across the training, validation, and test sets. The average resolutions of the training, validation, and test sets are 1059 × 960 pixels, 1084 × 944 pixels, and 1066 × 953 pixels, respectively. For the training dataset, the resolutions range from a minimum of 549 × 717 pixels to a maximum of 1542 × 1537 pixels. For the validation dataset, the resolutions range from 627 × 698 pixels to 1366 × 1533 pixels. For the test dataset, the resolutions range from 567 × 685 pixels to 1542 × 1370 pixels.

Distribution of image resolutions across training, validation, and test sets.
Technical Validation
The dataset was divided into 65%, 15%, and 20% for training, validation, and testing, respectively, based on statistical analysis to ensure an even distribution of images, facilitating effective use with machine learning models. Since the primary goal of this dataset is alveolar bone loss detection, each of the following attributes was considered equally important for ensuring a fair division:
i) Number of teeth in each radiograph: This refers to the total number of teeth visible in each radiograph image. ii) Radiograph arch (mandibular or maxillary): Each radiograph represents either the mandibular or maxillary arch. Ensuring a fair division of images from both arches is important for balanced dataset representation. iii) Number of alveolar crestal bone levels marked in a radiograph: These levels, marked by dentists, play a central role in the dataset’s purpose. These levels help identify alveolar bone loss. iv) Type of roots: Radiographs may include images of only single-rooted teeth, only multi-rooted teeth, or a combination of both. The dataset division ensured a fair representation of all these categories. v) Number of apex points in each radiograph: This refers to the total number of apex points visible in each radiograph image. Similarly, vi) Number of CEJ points in each radiograph: This refers to the total number of CEJ points visible in each radiograph image.
The dataset division, as shown in Fig. 7, ensures a fair distribution across six attributes. This balance is important for developing effective machine learning models, enabling them to train, validate, and test properly across all attributes.

Distribution of Six Attributes in Training, Validation, and Test Sets: Number of Teeth, Root Structure Classification, Number of CEJ Points, Number of APEX Points, Arch Type (Mandibular/Maxillary), and Alveolar Crestal Bone Level Count.
The YOLOv8 pose15 model was used to experiment with keypoint detection. YOLOv8 pose is a variant of YOLOv816 designed for detecting key points, such as joints in human pose estimation and other object keypoint tasks. YOLOv816 simultaneously detects key points associated with objects while localizing the objects using rectangular bounding boxes.
In our study, the key points of interest are the CEJ and the apex, while the objects are the individual teeth associated with these key points. Table 2 shows experimental results of detecting CEJ and apex key points separately, as well as the bounding boxes for their corresponding tooth objects. The output results for CEJ and apex key points are presented in Figs. 8 and 9, respectively, along with their ground truths. Ground truth key points and tooth bounding boxes are shown as red points and yellow boxes, while predicted key points and tooth bounding boxes are represented as blue points and red boxes.

Two different sets of radiograph images, shown from left to right: original image, ground truth CEJ points and teeth bounding boxes overlaid on original image, YOLOv8 pose output overlaid on original image.

Two different sets of radiograph images, shown from left to right: original image, ground truth apex points and teeth bounding boxes overlaid on original image, YOLOv8 pose output overlaid on original image.
This dataset is suitable for both teeth semantic segmentation and tooth instance segmentation. For semantic segmentation, masks from the ‘Masks (Radiograph-wise)’ folder were used. U-Net17 and U-Net with a ResNet34 encoder, leveraging the residual learning framework introduced by18, were employed in the experiments. Table 3 presents the experimental results of teeth semantic segmentation with our dataset, along with ground truth and output examples shown in Fig. 10.

Two different sets of radiograph images, shown from left to right: original image, ground truth mask, U-Net model predicted mask, and U-Net with ResNet34 encoder predicted mask.
For instance segmentation, the masks in the ‘Masks (Tooth-wise)’ folder and the COCO format annotation file included in this folder were used. YOLOv519 and Mask R-CNN20 were used in the experiments. Table 4 presents the experimental results of tooth instance segmentation with our dataset, along with ground truth and output results shown in Fig. 11.

Two different sets of radiograph images, shown from left to right: original image, ground truth mask with original image, YOLOv5 output with original image, and Mask R-CNN output with original image.
For alveolar crestal bone level detection, bone levels were first converted into masks with a specified thickness of 3 pixels. UNet++21 and MultiResUNet22 were then used in the experiments. Table 5 presents the experimental results of alveolar bone level detection using our dataset, with ground truth shown as green lines and output results as red lines in Fig. 12.

Two different sets of radiograph images, shown from left to right: original image, ground truth bone level mask with original image, UNet++ output with original image, and MultiResUNet output with original image.
Usage Notes
The researchers can download this dataset from zenodo14.
For those using machine learning, this dataset can help build and test models that detect and measure bone loss. For example, researchers could use TensorFlow or PyTorch to create models that identify areas of bone loss with respect to each individual tooth, measure how much bone is missing, or predict bone health status based on image patterns. They can also apply models trained on this data to other, similar datasets, helping make the models more reliable.
Finally, combining this dataset with other public data could help researchers understand how bone loss patterns vary in different groups. We encourage researchers to share any code, models, or tools they develop, as this could help others in the dental field improve the detection and treatment of alveolar bone loss.
Code availability
The custom code used for Technical Validation is available on GitHub. The repository includes scripts and documentation for reproducing the results described in this paper.
References
Organization, W. H.Global oral health status report: towards universal health coverage for oral health by 2030. Regional summary of the African Region (World Health Organization, 2023).
Elamin, A. & Ansah, J. P. Projecting the burden of dental caries and periodontal diseases among the adult population in the united kingdom using a multi-state population model. Frontiers in Public Health 11, 1190197 (2023).
Saintrain, M. Vd. L. & de Souza, E. H. A. Impact of tooth loss on the quality of life. Gerodontology 29, e632–e636 (2012).
AlGhamdi, A. M. et al. The benefits of early dental disease detection in improving the quality of life. Journal of Survey in Fisheries Sciences 10, 248–251 (2023).
Shah, N., Bansal, N. & Logani, A. Recent advances in imaging technologies in dentistry. World journal of radiology 6, 794 (2014).
Rasila Sainu, D. R. M., Majeed, T. A., Ravi, R. S., Sayeeganesh, N. & Jayachandran, D. Imaging techniques in periodontics: A review article. Journal of BioscienceAnd Technology 7, 739–747 (2016).
Mol, A. Imaging methods in periodontology. Periodontology 2000 34, 34–48 (2004).
Vashisht, R. et al. Artificial intelligence in dentistry-a scoping review. Journal of Oral and Maxillofacial Surgery, Medicine, and Pathology (2024).
Musleh, D. et al. Advancing dental diagnostics: A review of artificial intelligence applications and challenges in dentistry. Big Data and Cognitive Computing 8, 66 (2024).
Li, S. et al. Artificial intelligence for caries and periapical periodontitis detection. Journal of dentistry 122, 104107 (2022).
Patil, S. et al. Artificial intelligence in the diagnosis of oral diseases: applications and pitfalls. Diagnostics 12, 1029 (2022).
Schwendicke, F., Golla, T., Dreher, M. & Krois, J. Convolutional neural networks for dental image diagnostics: A scoping review. Journal of dentistry 91, 103226 (2019).
Rieger, B., Rasmuson, D. & Sharma, M. Labelbox: The leading training data platform for data labeling. http://labelbox.com Software (2021).
Rasnayaka, S. et al. Denpar: Annotated intra-oral periapical radiographs dataset, https://doi.org/10.5281/zenodo.16645076 (2024).
Maji, D., Nagori, S., Mathew, M. & Poddar, D. Yolo-pose: Enhancing yolo for multi person pose estimation using object keypoint similarity loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2637–2646 (2022).
Reis, D., Kupec, J., Hong, J. & Daoudi, A. Real-time flying object detection with yolov8 2305.09972 (2024).
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation 1505.04597 (2015).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition 1512.03385 (2015).
Ultralytics. YOLOv5: A state-of-the-art real-time object detection system. https://docs.ultralytics.com/yolov5 Accessed: July 24, 2024 (2021).
He, K., Gkioxari, G., Dollár, P. & Girshick, R. Mask r-cnn 1703.06870 (2018).
Zhou, Z., Siddiquee, M. M. R., Tajbakhsh, N. & Liang, J. Unet++: A nested u-net architecture for medical image segmentation 1807.10165 (2018).
Ibtehaz, N. & Rahman, M. S. Multiresunet : Rethinking the u-net architecture for multimodal biomedical image segmentation. Neural Networks 121, 74–87, https://doi.org/10.1016/j.neunet.2019.08.025 (2020).
Thalji, N. et al. Segmented x-ray image data for diagnosing dental periapical diseases using deep learning. Data in Brief 54, 110539 (2024).
Zannah, R. et al. Semantic segmentation on panoramic dental x-ray images using u-net architectures. IEEE Access 12, 44598–44612, https://doi.org/10.1109/ACCESS.2024.3380027 (2024).
Chakrabarty, A. et al. Panoramic dental x-ray images. https://www.kaggle.com/dsv/8512626 (2024).
Brahmi, W. & Jdey, I. Automatic tooth instance segmentation and identification from panoramic x-ray images using deep cnn. Multimedia Tools and Applications 83, 55565–55585, https://doi.org/10.1007/s11042-023-17568-z (2024).
Budagam, D. et al. Instance segmentation and teeth classification in panoramic x-rays 2406.03747 (2024).
Do, H. V. et al. A dataset of apical periodontitis lesions in panoramic radiographs for deep-learning-based classification and detection. Data in Brief 54, 110486 (2024).
Zhang, Y. et al. Children’s dental panoramic radiographs dataset for caries segmentation and dental disease detection. Scientific Data 10, 380 (2023).
Iyer, S. Dental panoramic scan. https://figshare.com/articles/dataset/Dental_Panoramic_Scan/22580263 (2023).
Panetta, K., Rajendran, R., Ramesh, A., Rao, S. P. & Agaian, S. Tufts dental database: A multimodal panoramic x-ray dataset for benchmarking diagnostic systems. IEEE Journal of Biomedical and Health Informatics 26, 1650–1659, https://doi.org/10.1109/JBHI.2021.3117575 (2022).
Muramatsu, C. et al. Tooth detection and classification on panoramic radiographs for automatic dental chart filing: improved classification by multi-sized input data. Oral Radiology 37, 13–19, https://doi.org/10.1007/s11282-019-00418-w Epub 2020 Jan 1 (2021).
Sajad, M., Shafi, I. & Ahmad, J. Automatic lesion detection in periapical x-rays. In 2019 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), 1–6, https://doi.org/10.1109/ICECCE47252.2019.8940661 (2019).
Sajad, M. Periapical x-rays. https://www.kaggle.com/dsv/2664831 (2021).
Tuzoff, D. et al. Tooth detection and numbering in panoramic radiographs using convolutional neural networks. Dentomaxillofacial Radiology 48, 20180051, https://doi.org/10.1259/dmfr.20180051 (2019).
Jader, G. et al. Deep instance segmentation of teeth in panoramic x-ray images. In 2018 31st SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), 400–407, https://doi.org/10.1109/SIBGRAPI.2018.00058 (2018).
Betul Oktay, A. Tooth detection with convolutional neural networks. In 2017 Medical Technologies National Congress (TIPTEKNO), 1–4, https://doi.org/10.1109/TIPTEKNO.2017.8238075 (2017).
Acknowledgements
The author acknowledges the support received from the LK Domain Registry in publishing this paper.
Author information
Authors and Affiliations
Contributions
S.R., V.T., and I.N. conceptualized the study and methodology. S.R., A.J., D.L.B., and R.J. conducted the investigation. S.R., D.L.B., R.J., and V.T. provided the resources. C.W. and I.N. handled data curation. C.W., P.R., and S.W. contributed to the Software and Validation. S.R., D.L.B., V.T., R.R., and I.N. provided supervision. S.R., C.W., V.T., and I.N. wrote the original draft of the manuscript. All authors reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Rasnayaka, S., Leuke Bandara, D., Jayasundara, A. et al. DenPAR: Annotated Intra-Oral Periapical Radiographs Dataset for Machine Learning. Sci Data 12, 1615 (2025). https://doi.org/10.1038/s41597-025-05906-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-025-05906-9
