
Abstract
The name PM10 refers to small particles with a diameter of less than 10 microns. The present research analyses different models capable of predicting PM10 concentration using the previous values of PM10, SO2, NO, NO2, CO and O3 as input variables. The information for model training uses data from January 2010 to December 2017. The models trained were autoregressive integrated moving average (ARIMA), vector autoregressive moving average (VARMA), multilayer perceptron neural networks (MLP), support vector machines as regressor (SVMR) and multivariate adaptive regression splines. Predictions were performed from 1 to 6 months in advance. The performance of the different models was measured in terms of root mean squared errors (RMSE). For forecasting 1 month ahead, the best results were obtained with the help of a SVMR model of six variables that gave a RMSE of 4.2649, but MLP results were very close, with a RMSE value of 4.3402. In the case of forecasts 6 months in advance, the best results correspond to an MLP model of six variables with a RMSE of 6.0873 followed by a SVMR also with six variables that gave an RMSE result of 6.1010. For forecasts both 1 and 6 months ahead, ARIMA outperformed VARMA models.
Similar content being viewed by others

Introduction
The town of Gijón and its Port
Gijón is a town located on the north coast of Spain, in the Principality of Asturias. It is the most populated municipality of this region, with a total of 273,422 inhabitants according to 2016 census. This town, together with Oviedo (220,648 inhabitants) and Avilés (79,514 inhabitants) and other small towns, forms a metropolitan area with more than 850,000 inhabitants. It was founded in the fifth century B.C. During the twentieth century it underwent significant development due to industry, something which is still of great importance to the local economy.
The weather in Gijón is defined by its proximity to the sea and the low mean altitude. The annual level of precipitation is quite high, with a total of 920 L per square meter and year. Regarding temperature, the coldest month is January, with an average temperature of 8.9 °C, while the hottest is August with 19.7 °C. The average annual temperature is 13.8 °C. Winds are sporadic and seasonal. The wind regime is dominated by two main components1. During winter it blows from W-WSW, while in summer it comes from E-ENE on the coast.
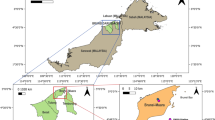
The Port of Gijón, named El Musel, is one of the main ports of the Atlantic Arc and the leading port in the movement of solid bulk in Spain. It is located in the Cantabrian Sea (43°34′N, 5°41′W). Figure 1a shows its position on the North Atlantic Spanish coast and Fig. 1b is an aerial picture of the town, where the location of the port can be observed.

Source: Google Maps, Map data©2019 Google; https://www.google.es/maps/@43.5547854,-5.6995551,9849m/data=!3m1!1e3. The map was edited with PowerPoint version: 16.0.12527.20260.
(a) position of the Port of Gijon on the North Atlantic coast of Spain, (b) aerial picture of Gijón and its Port (inside the red line) including the position of the weather station.
The commercial exploitation of this port started in 1907. In the 1990s there was a development plan that doubled its area and which led to a significant increase in its activity. Its infrastructure is adapted to modern market requirements in terms of drafts, springs and storage areas and a range of services with the best standards of quality. It has 415 hectares of land surface and 7,000 linear meters of dock, structured in areas with the appropriate characteristics to serve each kind of traffic, i.e. specialized terminals for solid bulks, liquids and containers, and multi-purpose facilities for various types of traffic.
In the beginning, the exports were mainly iron ore and coal. Subsequently, the port would expand on its breakwaters and piers, and in the 1940s became the main Spanish port in traffic movement. The industrial activity of the Principality of Asturias has its main ally in the Port of Gijón. Currently, it is the main bulk port in Spain and one of the most important ports of the Atlantic Arc. According to the traffic statistics of the Annual Report of 2018, a total of 18,226 ships entered the port during that year, which meant a total of 79,294 containers and 12.7 millions of tonnes in the dry bulk terminal, of which 6.4 corresponded to iron ore, 3.4 to iron steel and 2.8 to steam coal. The net revenue in 2018 was 42.2 million euros.
Pollution and particulate matter studies
The World Health Organisation has reported that air pollution has an adverse effect on people’s health and development2. It is well-known that long-term exposure to high levels of air pollution is linked to decrements in lung function in children3. A Swiss study found increased levels of allergic sensitisation in adults living in proximity to busy roads for periods longer than 10 years4. Also, the PM10 pollutant is amongst those regulated under the Air Quality Framework Directive on ambient air quality assessment and management5.
A continuous exposure to pollutants such as Carbon Monoxide (CO), Carbon Dioxide (CO2), oxides of nitrogen (NOx), and particulate matter is reported to cause health problems in the population living in the affected areas6,7. Particulate matter is formed by different chemical products, mostly produced by anthropogenic processes6 and with significantly variable diameters. Their anthropogenic origin is the reason why they are more present in urban areas8 than in unpopulated areas.
Air quality issues are relevant in ports and areas nearby. In general, the duty cycle of marine vessels is longer than that of roadside vehicles. This means that ship engines generally use older technology than cars and due to their engine power they are also much more pollutant9. Previous studies have analysed PM10 concentrations in ports and coastal areas like the Bay of Algeciras in Southern Spain10. Another study analysed the impact of PM2.5 particles from ship emissions in southern California11. In Turkey, shipping emissions in the regions of Candelari Gulf12 and Ambarli Port13, both with heavy shipping traffic, were investigated. Research carried out in the port14 of Tarragona, Spain, made use of multi-linear regression models to study the contribution of different harbour activities to the levels of particulate matter in its area. In the same line there is another study,15performed in Barcelona’s harbour, also located in Spain and about 80 kms. as the crow flies from Tarragona, which has estimated that around 50–55% of PM10 and PM2.5 concentrations measured at the port could be attributed to harbour activities and that such activities provide about 9–12% of the total PM10 concentration in the air and about 11–15% of PM2.5 to the metropolitan area of this city Another interesting and innovative study16 that deals with the problem of particulate matter in ports was performed in the port of Zhejiang. In this research, with the help of an unmanned aerial vehicle that integrated different sensors, authors have been able to create a profile of the vertical distribution of PM2.5, PM10 and total suspended particles from ground level to a height of 120 m. A study made at the port of Volos17, in Greece, found that the highest PM10 concentration values were associated with days of calm winds, meaning a wind speed under \(0.5\;\frac{m.}{{s.}}\). The only research into ports that made use of a supervised learning methodology was the one concerning the port of Koper 18. Koper is the only port in Slovenia and is located at the northern tip of the Adriatic Sea. Researchers made use of hourly PM10 concentrations and employed k-means clustering with Euclidean and city-block distances to cluster days. The results obtained showed the influence of rain intensity and wind speed in the clusters performed but the influence of any other pollutant was not studied. Finally, another study of interest was performed at the Port of Cork, which, like Gijón, is located on the Atlantic coast19.
Use of machine learning techniques to forecast pollutant concentrations
In general, machine learning can be understood as a subset of methodologies of the artificial intelligence field that are able to learn in an automatic way. In other words, they can learn from data and predict future events. Nowadays, the use of machine learning methodologies has extended to almost all branches of science, including environmental studies. One of the main reasons for the use of machine learning approaches for air quality forecasting is the ability of these methodologies to capture non-linear relationships among variables.
Interest in the forecasting of air pollution in urban area dates back to more than a century ago, when large cities began to have problems with pollution 20. In the 1970s, several statistical models for pollution forecasting were proposed21,22. The first applications of machine learning methodologies in this field were in the 1990s. In those days most research performed made use of artificial neural networks23,24.
Since then, the different studies performed have made use of other techniques such as genetic algorithms25, Hierarchical Agglomerative Clustering26, k-means27 or support vector machines as regressors28.
Genetic algorithms have been employed as a supporting methodology for selecting the input variables and designing the high-level architecture of neural networks models. In certain research works25, they were applied to the selection of the architecture and input variables of a multilayer-perceptron model for forecasting of hourly concentrations of NO. One of the limitations found by this technique is that training each neural network model is a time-consuming task and therefore, the number of parameters to be tuned must be limited.
Hierarchical agglomerative clustering is employed to group objects that are similar in subsets called clusters. The agglomerative clustering methodology starts with many small clusters and merges them together to create large ones. It has been successfully applied in order to study ozone exposure and cardiovascular-related mortality in Canada26. The results obtained showed that this methodology is useful for studying the long-term effects of air pollution on cardiovascular diseases.
A recent study has shown how k-means clustering can be employed to categorize different locations in a big and populated city representing the variability of pollution according to the variables employed for the study27. Finally, the use of support vector machines as a regressor has also been reported in some studies28,29. In one of these28 the support vector machine is employed as a regressor model for the forecast of the daily Beijing air quality index from 1st January 2014 to mid-2016, while in the others29,30 they are employed for the forecast of the daily average \({PM}_{10}\).
The aim of the present research is to forecast the air quality in a port area, specifically in the port area of the city of Gijón. For this purpose, the article applied different machine learning models (multilayer perceptron neural networks, support vector machine as regressor and MARS) and compared the performance of the predictions obtained for different time intervals with those given by two time series methodologies, one of them univariate (ARIMA) and the other multivariate (VARMA). This means that an exhaustive comparison is made of the prediction from 1 to 6 months in advance of the performance of five methods. This provides an interesting framework for the comparison of methodologies. All these methods were employed in the past for pollution forecasting, but never all in the same research, as far as the authors know. Therefore, the relevance of the present research is that it deals with the topic of monitoring air quality in a city, comparing different machine learning methodologies applied to the same data set.
The database
The information employed for this research has been obtained from one of the meteorological stations belonging to the network of Air Quality Monitoring of the Government of the Principality of Asturias, and more specifically from the one closest to the Port of Gijón, which is located at Argentina Avenue. This station records environmental measurements hourly. As is normal in all this kind of databases, about 0.23% of the raw observations taken each 15 min for all variables were missing. They were imputed with the help of the Multivariate Imputation by Chained Equiations (MICE) algorithm31.
Table 1 shows the minimum, mean, maximum and standard deviation of the pollutants measured at Gijón Port for the period of study. The values considered for the present research were average monthly measurements from January 2010 to June 2018. Information from January 2010 to December 2017 was employed to forecast values from January to June 2018. Pollutants measured at the Port of Gijón were SO2, NO, NO2, CO, O3 and PM10.
Materials and methods
The present research calculates predictive models of PM10 concentration by means of autoregressive integrated moving average (ARIMA), vector autoregressive moving-average (VARMA), multilayer perceptron neural networks (MLP), support vector machines as regressor (SVMR) and multivariate adaptive regression splines (MARS) models. In all cases the PM10 values were calculated in two ways: firstly, using the concentration of the six pollutants available as input variables and afterwards employing only four: SO2, NO, NO2 and PM10. The main reason why new models using only four variables of the six available are also trained and validated is that many meteorological stations, including some pertaining to the net of Air Quality Monitoring of the Government of the Principality of Asturias are only able to measure these four variables. In other words, the use of only the aforementioned four variables will allow us to compare the model performance according to the input variables employed and will serve as a reference for future studies. Please note that what was said before relates to all the models of the present research except for ARIMA, where only concentration of PM10 are employed for the forecasting. In all cases, for continuous variables minimum, mean, maximum and standard deviation were calculated.
Forecasts are performed from 1 to 6 months in advance. The reason why it might be of interest to perform forecasts 6 months in advance is two-fold. On the one hand, high PM10 concentrations have adverse effects on human health and on the other, having such a forecast would be helpful in order to take measurements that would make it possible to comply with European air quality standards. According to the results obtained, the best forecast of PM10 concentration 1 month ahead is obtained by the SVMR model calculated with six variables. In the case of the forecast 6 months ahead the results of the MLP with six variables are slightly better. In other words, in the short-term the best forecasts are given by SVMR but in the long-term it is outperformed by MLP.
Autoregressive integrated moving average (ARIMA)
ARIMA models can be considered as being an extension of ARMA (autoregressive moving average) known for their ability to provide a parsimonious description of a stationary stochastic process32. ARMA models are composed of two polynomial terms, one for autoregression (AR) and another for moving average (MA). Given a time series of data \(X_{t}\), the ARMA model can be expressed as:
where \(c\) is a constant, \(\varepsilon_{t}\) are white noise error terms, \(\sum\nolimits_{i = 1}^{P} {\varphi_{i} X_{t - i} }\) is the autoregressive addend where \(\varphi_{i}\) are parameters and \(X_{t - i}\) is the value of variable \(X\) in time \(t - i\). \(\sum\nolimits_{i = 1}^{qq} {\sigma_{i} \varepsilon_{t - i} }\) is the moving-average addend where \(\sigma_{i}\) are the parameters of the model.
ARIMA models are appropriate for those observation sets that are not necessarily generated by a time series, as is the case of the present problem. They considerably improve the empirical description of non-stationary time series29. A stochastic process can be characterized as an ARIMA model if the d-th difference of \(X_{t}\), constitutes an ARMA stationary and invertible process of \(p\), \(q\) orders.
In this case, \(p\) represents the order of the autoregressive part of the model, \(q\) is the order of the weighted moving average and another parameter called \(d\) represents the number of differencing required to reach stationarity33. If the differencing operator is denoted by \(\nabla\), the general ARIMA equation can be written as follows30:
where \(\emptyset_{p} \left( B \right)\) and \(\theta_{q} \left( B \right)\) are the autoregressive polynomials of weighted moving averages and \({\upvarepsilon }_{{\text{i}}}\) is the model perturbation.
A more in-depth explanation of ARIMA models goes beyond the scope of this research and can be found elsewhere34. All the models employed in the present research were calculated with the help of the statistical software R35. ARIMA models were calculated with the help of the series library36.
Vector autoregressive moving-average (VARMA)
The Vector autoregression Moving-Average (VARMA) method models the next step in each time series using an ARMA model. In other words, it can be considered the generalization of ARMA to multivariate time series. This kind of model makes it possible to compute a set of time series at the same time, obtaining their within-correlations and cross-correlations32. For these models calculus was performed with the help of the MTS library37.
If a k-dimensional time series is represented by \(z_{t}\), the vector autoregressive moving-average VARMA \(\left( {p,q} \right)\) process can be expressed as:
where \(\phi_{0}\) is a constant vector
are two matrix polynomials and \(a_{t}\) is a sequence of independent and identically-distributed random vectors with mean zero and positive-definitive covariance matrix \(\sum_{a}\).
A general VARMA \(\left( {p,q} \right)\) model is represented as follows37:
In this equation \(p\) and \(q\) are nonnegative integers, \(\phi_{0}\) is a vector of constants, \(\phi_{i}\) and \(\theta_{j}\) are two constant matrix and \(\left\{ {a_{t} } \right\}\) is a sequence of independent and identically-distributed random vectors with mean zero and positive definite covariance matrix.
According to Tsay and Wood37, the VARMA model expressed in the previous equation can be rewritten in a more convenient way as follows:
where \(\theta_{j}^{*} = \theta_{j} L\) where \(L\) is a lower triangular matrix with 1 being the diagonal elements. The determination of \(p\) and \(q\) values was performed following a methodology suggested in previous research38. Akaike information criterion39 (AIC) and Schwarz information criterion40 (SIC) were employed to balance the improvement in the value of the log-likelihood function with the loss of degrees of the freedom which results from increasing the lag order of a time series model. With the help of both the maximum \(p\) and \(q\) values were calculated. All those models with \(p\) and \(q\) values less or equal to then were calculated and finally, those with the best RMSE were presented in this paper.
Multilayer perceptron neural networks (MLP)
One of the first bio-inspired machine learning models was the one-layer perceptron. This kind of network was proposed by Rosemblatt41 as a possible modelization of the neuron of the human brain. The rule of the perceptron adaption consists of a supervised iterative method that modifies the neuron weights. The multilayer perceptron is useful as a way in which to modelize a function. In a neural network the outcome is modelled by an intermediary data set of unobservable variables called hidden variables, which are linear combinations of the original predictors. However, this linear combination is typically transformed by a nonlinear function.
Kolmogorov42 demonstrated that a two-layer network (one hidden layer and one output layer), with a non-linear differentiable activation function is able to approach any “soft” mapping if the number of neurons in the hidden layer is high enough. If a two-layer network like the one employed in the present research is considered, the operations for a system with \(p\) input variables, one output variable and \(q\) neurons in the hidden layer can be expressed as:
where \(y\left( n \right)\) and \(x\left( n \right)\) are the output and input of the net; \(\sigma\) is the activation function of the output layer; \(\varphi\) is the activation function of the hidden layer; \(w^{y}\) and \(w^{h}\) are the weights matrix for the output and hidden layer respectively.
One main requirement in order to make possible the MLP training43 is that \(\sigma\) and \(\varphi\) be continuously-differentiable functions. Training is performed with the backpropagation method, which is a recursive application of the gradient descent method. For the purposes of this research, the neural network models were trained and validated with the help of the library neuralnet44. The activation function employed is the logistic function. A more in-depth explanation of the foundations of neural networks may be found elsewhere45.
Support vector machines as regressor (SVMR)
Support Vector Machines were introduced by the work of Vapnik46. Although they were created by binary classification, nowadays they are used for different kinds of problems. Those employed for regression problems are called SVMR29.
Let a training data set \(S = \left\{ {\left( {x_{1} ,x_{2} } \right), \ldots \left( {x_{n} ,y_{n} } \right)} \right\}\), where \(x_{i} \in \Re^{d}\) and \(y_{i} \in \Re\) the regression task involves finding those parameters \(w = \left( {w_{1} , \ldots ,w_{d} } \right)\) that make it possible to find the following lineal function27:
As in practice it is not possible to find these parameters with a prediction error equal to zero, a concept called soft margin is employed. For this, variable \(\xi_{i}\) is employed and the equation is written as follows:
Please note that \(\xi_{i}^{ + } > 0\) when the forecast of the model \(f\left( {x_{i} } \right)\) is larger than its real value \(y_{i}\) and \(\xi_{i}^{ + } < 0\) in other cases.
With the help of the lagrangian function and the Karush–Kuhn–Tucker conditions, the problem can be expressed as follows:
where
In those cases where data cannot be adjusted with the help of a linear function, kernels are employed47. Kernels transform data into a new space called characteristics space.
The regressor associated to the lineal function in the new space is as follows:
please note that \(b^{*}\) is not included in the function as it can be included as a constant inside the kernel. The kind of kernel function to be employed depends on the problem to be solved. For example, the radial basis function has been shown to be very effective, but in those cases where the data set comes from a linear regression, the linear kernel function obtains better results48. The SVM as regressor models have been implemented with the functionalities of the library e107149. A good explanation of the use of SVM as regressor can be found in the work of Drucker et al.50.
Multivariate adaptive regression splines (MARS)
MARS is a non-parametric modelling method driven by the following equation51:
where \(y_{t}\) is the output variable for each time \(t\) and \(\beta_{i}\) are the model parameters for the different \(x_{it}\). \(\beta_{0}\) is the intercept and \(B\) represents the model basis functions.
One of the main characteristics of the MARS models is that they do not make use of any a priori hypothesis concerning the relationships among the variables52. The basis functions are defined as follows:
\(q\) is the power of the basis function as is always a value either equal o larger than zero. In order to adjust a MARS model and decide which basis functions are to be included, MARS makes use of the generalized cross validation (GCV). This represents the root mean squared error divided by a penalty parameter that is defined by the model complexity53. Its equation is as follows:
where \(M\) represents the number of basis functions in the equation and \(d\) is a penalty parameter for each base function included in the model. For this research, a value of 2 has been assigned to such a parameter, while the maximum number of tracer interaction type base functions is restricted to 3. The MARS models employed in this research are based on those programmed in the library earth54. A complete explanation of MARS models can be found in the original work of Friedman51. Also, an easy-to-read introduction to this methodology can be found in the works of Put et al.55.
Results and discussion
Table 2 shows the Pearson’s correlation coefficients of all the variables in the study. The largest correlation coefficient in absolute value corresponds to variables NO and NO2 with 0.8626, followed by NO and O3 with − 0.7593 (inverse relationship) and SO2 and NO2 and SO2 and NO with 0.7160 and 0.7090 respectively. Correlation coefficients of variables SO2, NO, NO2 and O3 with PM10 can be considered in absolute value terms as moderate as they range from 0.4320 (CO and PM10) to 0.5251 (NO2 and PM10).
Table 3 shows the results of the ARIMA model using the previous values of PM10 as the input variable. Tables 4, 5, 6, 7 and 8 show the results obtained using the different models of four (SO2, NO, NO2 and PM10) and six variables (SO2, NO, NO2, CO, O3 and PM10) employed in the present research. In all cases, the results are presented in the same way. The first line represents the forecast performed using information from January 2010 to December 2017 as training values. This forecast is performed for the following 6 months. The second line shows the forecast performed using information from January 2010 to January 2018 and the forecasts from February 2018 (1 month ahead) to June 2018 (5 months ahead) as training values. For all the cases, and in order to make an easy comparison of real values with forecasting, root mean squared errors (RMSE) forecasting values from 1 to 6 months ahead and 1 month ahead for all models are presented in Table 9. In the case of the ARIMA model (Table 3), the one that only makes use of past PM10 concentrations in order to predict their future values, the RMSE obtained for forecasts performed 1 month ahead was 6.3163 while the RMSE for forecast performed from 1 to 6 months ahead, the RMSE value was 7.6312. Please note that when we speak about the RMSE obtained for a forecast performed 1 month ahead, we refer to the values that are in the diagonal of the table (in the case of Table 3: 22.2217, 32.0564, 19.7957, 22.9000, 34.6428 and 29.6487) as they are the ones calculated 1 month ahead. Regarding the forecast from 1 to 6 months ahead, we compare real values with the forecast of the first row of the table from January 2018 to June 2018 (in the case of Table 3: 22.2217, 31.5194, 19.8269, 20.1082, 37.0095 and 31.8833). Please note that the real monthly averaged values from January to June 2018 were 29, 27, 26, 31, 29 and 24 respectively. These values are included in Tables 3, 4, 5, 6, 7 and 8 make comparisons more direct.
The RMSE values achieved 1 and up to 6 months ahead for all the models trained in the present research are shown in Table 9. For forecasting 1 month ahead, the best results are obtained for the six variables of SVMR and MLP models, followed by the same models including only four variables. These results give us the idea that all the variables included in the study have a certain relevance in terms of performing an accurate PM10 prediction. After the MLP and SVMR models, according to RMSE values the next best in forecasting 1 month ahead is the ARIMA model, the only one that makes exclusive use of past PM10 values in order to forecast future concentrations. The ARIMA model is followed by MARS with six and four variables, while VARMA are the models that give the worst performance.
In the case of a forecast of up to 6 months ahead, the best performance according to RMSE value is also achieved by 6 variables MLP and SVMR models followed by the same models using only four variables. A remarkable change when compared with the forecast 1 month ahead is that the MARS model that includes 6 variables performs better than the ARIMA model. Finally, and as also happened with the forecasts 1 month ahead, the worst performance was shown by the VARMA models.
From our point of view, a remarkable fact is that the model performance in terms of RMSE in both 1- and 6-month ahead models is not only linked to the number of variables considered in it, but also to the kind of model selected. In other words, it is possible to find a model of only one variable (ARIMA) that performs better than others that include six variables in both 1- and 6-month ahead predictions (VARMA). Finally, the importance of a variable is very easy to assess with the help of a MARS model. The importance order found for the prediction of PM10 was as follows: PM10 value in the previous moments, followed by the previous measurements of CO, NO, O3, SO2 and NO2.
The main limitation of this study is that although original data is taken each 15 min, forecasts are performed for average monthly values. The reason why average monthly values were forecasted is that the results obtained by the authors when daily or hourly forecasts were performed were not as stable as the average monthly values. This is due to the influence of the port traffic in the pollution area, which does not follow a fixed cycle like urban traffic. Another limitation to be overcome in future studies is that in order to improve the results obtained it would be of interest to introduce some meteorological variables such as temperature, humidity, pressure, sun radiation, rainfall and wind speed and direction.
Conclusions
The results obtained in this research allow us to say that it is possible to predict PM10 concentration with the help of the value of this variable and the concentration of other pollutants by means of statistical and machine learning models. Also, another interesting issue is that as had already been found in previous studies,56 the use of the concentration of other pollutants helps to obtain a more accurate prediction. In fact, the most accurate results were obtained for two kind of machine learning models, SVMR and MLP, when they made use of the values of the six available variables. The results obtained show how regression-based models like SVMR, MARS and MLP outperform univariate and multivariate time series-based models (ARIMA and VARMA). According to the findings of this paper and other previous ones29, this is because the short-term relationships among pollutants are stronger than temporal relationships of PM10 concentration values with itself and with other variables. In other words, although it is possible to find certain seasonal patterns in monthly average pollutant values, the relationship of PM10 with the concentration of other pollutants is more important than the seasonal pattern.
Finally, this research affords the reader the opportunity to compare different machine learning and time series methodologies applied to the same data set to establish whether they are useful for PM10 concentration forecasting. If the average monthly values of PM10 from January to June 2018 are compared with those corresponding to the same months of the previous year, the RMSE result is 6.8557. This means that in forecasts 1 month ahead, MLP and SVM models of four and six variables and MARS of six variables outperform it. When forecasts are performed 6 months ahead MLP models of four and six variables and SVM of six variables outperform it. Although the proposed methodologies do not always outperform the mere use of the average values of PM10 concentrations of the same months of the previous year, they are a useful complementary tool for planning and taking decisions in advance.
References
González-Marco, D., Pau Sierra, J., Fernández de Ybarra, O. & Sánchez-Arcilla, A. Implications of long waves in harbour management: the Gijon port case study. Ocean Coast. Manag. 51, 180–201 (2018).
World Health Organization. Effects of air pollution on children’s health and development: A review of the evidence. (2005).
Gauderman, W. J. et al. The effect of air pollution on lung development from 10 to 18 years of age. New Engl. J. Med. 351(11), 1057–1067 (2004).
Wyler, C. et al. Exposure to motor vehicle traffic and allergic sensitization. Epidemiology 11(4), 450–456 (2000).
European Commission. Council Directive 1996/62/EC of 27 September 1996 on ambient air quality assessment and management. Official Journal of the European Communities, 55–63 (1996).
Ganguly, R., Sharma, D. & Kumar, P. Trend analysis of observational PM10 concentrations in Shimla city, India. Sustain. Cities Soc. 51, 101719 (2019).
Grange, S. K., Salmond, J. A., Trompetter, W. J., Davy, P. K. & Ancelet, T. Effect of atmospheric stability on the impact of domestic wood combustion to air quality of a small urban township in winter. Atmos. Environ. 70, 28–38 (2013).
Yadav, R., Sahu, L. K., Jaaffrey, S. N. A. & Beig, G. Temporal variation of particulate matter (PM) and potential sources at an urban station of Udaipur in Western India. Aerosol. Air Qual. Res. 14, 1613–1629 (2014).
Mueller, D., Uibel, S., Takemura, M., Klingelhoefer, D. & Groneberg, D. A. Ships, ports and particulate air pollution—an analysis of recent studies. J. Occup. Med. Toxicol. 5, 6–31. https://doi.org/10.1186/1745-6673-6-3 (2011).
Pandolfi, M., Gonzalez-Castanedo, Y., Alastuey, A., de la Rosa, J. D., Mantilla, E., de la Campa, A. S., Querol, X., Pey, J., Amato, F. & Moreno, T. Source apportionment of PM(10) and PM(2.5) at multiple sites in the strait of Gibraltar by PMF: impact of shipping emissions. Environ. Sci. Pollut. R. Int. 18(2), 260–269. doi: 10.1007/s11356–010–0373–4 (2011).
Agrawal, H. et al. Primary particulate matter from ocean-going engines in the Southern California Air Basin. Environ. Sci. Technol. 43, 5398–5402 (2009).
Deniz, C., Kilic, A. & Civkaroglu, G. Estimation of shipping emissions in Candarli Gulf, Turkey. Environ. Monit. Assess. 17(1–4), 219–228. https://doi.org/10.1007/s10661-009-1273-2 (2010).
Deniz, C. & Kilic, A. Estimation and assessment of shipping emissions in the region of Ambarli Port, Turkey. Environ. Prog. Sustain. 29(1), 107–115 (2009).
Alastuey, A. et al. Contribution of harbour activities to levels of particulate matter in a harbour area: Hada Project-Tarragona Spain. Atmos. Environ. 41(30), 6366–6378 (2007).
Pérez, N. et al. Impact of harbour emissions on ambient PM10 and PM2.5 in Barcelona (Spain): evidences of secondary aerosol formation within the urban area. Sci. Total Environ. 571, 237–250 (2016).
Shen, J. et al. Vertical distribution of particulates within the near-surface layer of dry bulk port and influence mechanism: a case study in China. Sustainability 11(24), 1–16 (2019).
Manoli, E. et al. Polycyclic aromatic hydrocarbons and trace elements bounded to airborne PM10 in the harbor of Volos, Greece: Implications for the impact of harbor activities. Atmos. Environ. 167, 61–72 (2017).
Žibert, J. & Pražnikar, J. Cluster analysis of particulate matter (PM10) and black carbon (BC) concentrations. Atmos. Environ. 57, 1–12 (2012).
Healy, R. M. et al. Characterisation of single particles from in-port ship emissions. Atmos. Environ. 43, 6408–6414. https://doi.org/10.1016/j.atmosenv.2009.07.039 (2009).
Meisner Rosen, C. Businessmen against pollution in late nineteenth century Chicago. Bus. Hist. Rev. 69(3), 351–397 (1995).
Desalu, A., Gould, L. & Schweppe, F. Dynamic estimation of air pollution. IEEE Trans. Automat. Contr. 19(6), 904–910. https://doi.org/10.1109/TAC.1974.1100742 (1974).
Lamb, R. G. & Neiburger, M. An interim version of a generalized urban air pollution model. Atmos. Environ. 5, 239–264 (1971).
Roadknight, C. M., Balls, G. R., Mills, G. E. & Palmer-Brown, D. Modeling complex environmental data. IEEE Trans. Neural Netw. 8(4), 852–862. https://doi.org/10.1109/72.595883 (1997).
Spellman, G. An application of artificial neural networks to the prediction of surface ozone concentrations in the United Kingdom. Appl. Geogr. 19(2), 123–136 (1999).
Niska, H., Hiltunen, T., Karppinen, A., Ruuskanen, J. & Kolehmainen, M. Evolving the neural network model for forecasting air pollution time series. Eng. Appl. Artif. Intell. 17(2), 159–167. https://doi.org/10.1016/j.engappai.2004.02.002 (2004).
Cakmak, S., Hebbern, C., Vanos, J., Crouse, D. L. & Burnett, R. Ozone exposure and cardiovascular-related mortality in the Canadian Census Health and Environment Cohort (CANCHEC) by spatial synoptic classification zone. Environ. Pollut. 214, 589–599. https://doi.org/10.1016/j.envpol.2016.04.067 (2016).
Govender, P. & Sivakumar, V. Application of k-means and hierarchical clustering techniques for analysis of air pollution: a review (1980–2019). Atmos. Pollut. Res. 11(1), 40–56 (2020).
Liu, B. C., Binaykia, A., Chang, P. C., Tiwari, M. K. & Tsao, C. C. Urban air quality forecasting based on multi-dimensional collaborative support vector regression (SVR): a case study of Beijing–Tianjin–Shijiazhuang. PLoS ONE 12(7), 1–17 (2017).
García Nieto, P. J., Sánchez Lasheras, F., García-Gonzalo, E. & de Cos Juez, F. J. Estimation of PM10 concentration from air quality data in the vicinity of a major steelworks site in the metropolitan area of Avilés (Northern Spain) using machine learning techniques. Stoch. Env. Res. Risk A. 32(11), 3287–3298 (2018).
Riesgo García, M. V., Krzemień, A., del Campo, M., García-Miranda, C. E. & Sánchez Lasheras, F. Rare earth elements price forecasting by means of transgenic time series developed with ARIMA models. Resour. Policy. 59, 95–102 (2018).
Van Buuren, S. & Groothuis-Oudshoorn, K. Mice: multivariate imputation by chained equations in R. . J. Stat. Softw. 45, 1–67 (2011).
Ruey, S. T. Multivariate Time Series Analysis with R and Financial Applications (Wiley, New York, 2014).
Ordóñez, C., Sánchez Lasheras, F., Roca-Pardiñas, J. & de Cos Juez, F. J. A hybrid ARIMA–SVM model for the study of the remaining useful life of aircraft engines. J. Comput. Appl. Math. 346, 184–191 (2019).
Peter, J. B. & Davis, R. A. Introduction to Time Series and Forecasting (Springer, New York, 2002).
R Core Team. R: a language and environment for statistical computing. R Foundation for Statistical Computing (Vienna, Austria, 2019). https://www.R-project.org/.
Trapletti, A, & Hornik, K. tseries: Time Series Analysis and Computational Finance. R package version 0.10-47.
Ruey, S.T. & Wood, D. MTS: All-Purpose Toolkit for Analyzing Multivariate Time Series (MTS) and Estimating Multivariate Volatility Models. R package version 1.0. https://CRAN.R-project.org/package=MTS (2018).
Martin, V., Hurn, S. & Harris, D. Econometric Modelling with Time Series. Specification, Estimation and Testing (Cambridge University Press, Cambridge, 2013).
Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 19, 716–723 (1974).
Schwarz, G. Estimating the dimension of a model. Ann. Stat. 6, 461–464 (1978).
Rosenblatt, F. Principles of Neurodynamics (Spartan Books, Washington, 1962).
Kolmogorov, A. N. On the representation of continuous functions of many variables by superposition of continuous functions of one variable and addition. Dokl. Akad. Nauk SSSR 114(5), 953–956 (1957).
García-Nieto, P. J., Martínez Torres, J., de Cos Juez, F. J. & Sánchez Lasheras, F. Using multivariate adaptive regression splines and multilayer perceptron networks to evaluate paper manufactured using Eucalyptus globulus. Appl. Math. Comput. 219(2), 755–763 (2012).
Fritsch, S., Guenther, F. & Wright, M.N. neuralnet: Training of Neural Networks. R package version 1.44.2. https://CRAN.R-project.org/package=neuralnet (2019).
Haykin, S. Neural Networks: A Comprehensive Foundation (Prentice Hall, Upper Saddle River, 1998).
Vapnik, V. The Nature of Statistical Learning Theory (Springer, Berlin, 2000).
Suárez Sánchez, A., Riesgo Fernández, P., Sánchez Lasheras, F., de Cos Juez, F. J. & García Nieto, P. J. Prediction of work-related accidents according to working conditions using support vector machines. Appl. Math. Comput. 218(7), 3539–3552 (2011).
Kuhn, M. & Johnson, K. Applied Predictive Modeling (Springer, New York, 2013).
Meyer, D., Dimitriadou, E., Hornik, K., Weingessel, A. & Leisch, F. e1071: Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), TU Wien. R package version 1.7-2. https://CRAN.R-project.org/package=e1071 (2019).
Drucker, H., Burges, C., Kaufman, L., Smola, A. & Vapnik, V. Support Vector Regression Machines. Adv. Neural Inf. 9, 155–161 (1997).
Friedman, J. H. Multivariate adaptive regression splines. Ann. Stat. 19(1), 1–67. https://doi.org/10.1214/aos/1176347963 (1991).
Sánchez Lasheras, F., García Nieto, P. J., de Cos Juez, F., Mayo Bayón, R. & González Suárez, V. A hybrid PCA-CART-MARS-based prognostic approach of the remaining useful life for aircraft engines. Sensors. 15(3), 7062–7083 (2015).
de Andrés Suárez, J., Lorca Fernández, P. & Sánchez Lasheras, F. Bankruptcy forecasting: a hybrid approach using Fuzzy c-means clustering and Multivariate Adaptive Regression Splines (MARS). Expert Syst. Appl. 38(3), 1866–1875 (2011).
Milborrow, S. Derived from mda:mars by Trevor Hastie and Rob Tibshirani. Uses Alan Miller's Fortran utilities with Thomas Lumley's leaps wrapper. earth: Multivariate Adaptive Regression Splines. R package version 5.1.1. https://CRAN.R-project.org/package=earth (2019).
Put, R., Xu, Q. S., Massart, D. L. & Vander Heyden, Y. Multivariate adaptive regression splines (MARS) in chromatographic quantitative structure–retention relationship studies. J. Chromatogr. A 1055(1–2), 11–19. https://doi.org/10.1016/j.chroma.2004.07.112 (2004).
García Nieto, P. J., Sánchez Lasheras, F., García-Gonzalo, E. & de Cos Juez, F. J. PM10 concentration forecasting in the metropolitan area of Oviedo (Northern Spain) using models based on SVM, MLP, VARMA and ARIMA: a case study. Sci. Total Environ. 621, 753–761 (2018).
Author information
Authors and Affiliations
Contributions
F.S.L. conceived the ideas, F.S.L. and P.J.G.N. designed the study and retrieved the information. F.S.L. and F.J.C.J. trained and validated the machine learning models. F.S.L., L.B. and E.G.G. wrote the draft of the manuscript. L.B. revised the manuscript.
Corresponding author
Ethics declarations
Competing interests
Laura Bonavera acknowledges the PGC 2018 project PGC2018-101948-B-I00 (MINECO/FEDER) and PAPI-19-EMERG-11 (UNIOVI). The rest of authors declare no other competing financial interest.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sánchez Lasheras, F., García Nieto, P.J., García Gonzalo, E. et al. Evolution and forecasting of PM10 concentration at the Port of Gijon (Spain). Sci Rep 10, 11716 (2020). https://doi.org/10.1038/s41598-020-68636-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-020-68636-5
This article is cited by
-
Integrating D–S evidence theory and multiple deep learning frameworks for time series prediction of air quality
Scientific Reports (2025)
-
Enhancing particulate matter prediction in Delhi: insights from statistical and machine learning models
Environmental Monitoring and Assessment (2025)
-
Fourier-Enhanced Deep Learning and Machine Learning Models for Predicting Multi-Scale PM2.5 Dynamics in Megacities: A Case Study of Delhi
Earth Systems and Environment (2025)
-
Meteorological variability and predictive forecasting of atmospheric particulate pollution
Scientific Reports (2024)
-
Forecasting of AQI (PM2.5) for the three most polluted cities in India during COVID-19 by hybrid Daubechies discrete wavelet decomposition and autoregressive (Db-DWD-ARIMA) model
Environmental Science and Pollution Research (2023)
