
Abstract
Images captured in low light conditions suffer from low visibility, blurred details and strong noise, resulting in unpleasant visual appearance and poor performance of high level visual tasks. To address these problems, existing approaches have attempted to enhance the visibility of low-light images using convolutional neural networks (CNN). However, due to the insufficient consideration of the characteristics of the information of different frequency layers in the image, most of them yield blurry details and amplified noise. In this work, to fully extract and utilize these information, we proposed a novel Adaptive Frequency Decomposition Network (AFDNet) for low-light image enhancement. An Adaptive Frequency Decomposition (AFD) module is designed to adaptively extract low and high frequency information of different granularities. Specifically, the low-frequency information is employed for contrast enhancement and noise suppression in low-scale space and high-frequency information is for detail restoration in high-scale space. Meanwhile, a new frequency loss function are proposed to guarantee AFDNet’s recovery capability for different frequency information. Extensive experiments on various publicly available datasets show that AFDNet outperforms the existing state-of-the-art methods both quantitatively and visually. In addition, our results showed that the performance of the face detection can be effectively improved by using AFDNet as pre-processing.
Similar content being viewed by others
Introduction
In order to convert a given low-light image into a high-quality image with appropriate brightness, some low-light image enhancement methods have been proposed and achieved remarkable result. In general, low-light image enhancement methods can be divided into two branches: traditional methods1,2,3,4,5,6,7,8,9,10,11 and CNN-based methods12,13,14,15,16,17,18,19,20,21,22,23,24. Traditional methods mainly refer to histogram equalization (HE)-based and Retinex-based methods. HE-based methods1,2,3,4,5,6 stretch the dynamic range of the image by manipulating the corresponding histogram, and increase the local adaptability by adding constraints and side information. However, due to the lack of recognition and utilization of semantic information in the enhancement process, most HE-based methods are still not flexible enough to adjust the visual properties of local regions. When processing low-light images with complex information, problems such as color shift and amplification noise are prone to occur.
The Retinex-based methods are on the foundation of Retinex theory25 that the color of an object is not determined by the composition of light but from the object itself, and decomposed the image into reflection and illumination components. By further processing and combining, it can achieve the enhanced results. In the past decades, various priors and constraints7,8,9,10,11 is proposed to remove noise and recover high frequency detail information. These methods have achieved impressive results in stretching image contrast and denoising. However, these assumptions or models are established under specific conditions and cannot well deal with natural images formed under various complex imaging conditions. Therefore, Retinex-based methods have certain limitations in applicability.

Visual comparisons on a typical low-light image. Given a low-light RGB image (a), the result obtained by using the existing algorithm is (b,e,f). In comparison, the enhanced images obtained with AFDNet are closer to the ground truth (g) and have good perceptual quality. We apply a Gaussian filter to decompose (b) to obtain the low-frequency information (c) and the high-frequency information (d).
In recent years, convolutional neural networks (CNN) have been widely used in various fields of image processing15,26,27, including low-light image enhancement12,13,14,15,16,17,18,19,20,21,22,23,24. Due to its excellent performance and flexibility, CNN-based methods have received much attention from researchers. Specifically, Lore et al.14 used a deep autoencoder called Low-Light Net (LLNet) for simultaneous contrast enhancement and denoising. Inspired by this approach, more complex CNN architectures22,23,24 were used for low-light image enhancement. In16,18,19, Retinex structures are fused into effective deep network design to absorb the advantages of Retinex-based methods (i.e. good priori structure) and learning-based methods (i.e. the useful prior information extracted from large-scale datasets). Very recently, Liu et al.28 built a Retinex inspired unrolling framework(RUAS) with architecture search. Ma et al.29 develop a Self-Calibrated Illumination (SCI) learning framework for fast, flexible and frobust low-light image enhancement. There methods can better solve the degradation problem in the image, but there are still color distortion, noise amplification and detail lost.
In the field of image processing, recent works30,31,32 have introduced frequency decomposition networks, achieving impressive results. Specifically, Xu et al.33 proposed a two-stage enhancement method for frequency-based decomposition and enhancement. Xu et al.21 explored the frequency distributions of the feature maps extracted from different layers of a CNN model and try to seek the best representation for the illumination and edge information.
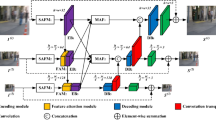
As shown in Fig. 1, given a low-light RGB image (Fig. 1a), the results obtained using the existing algorithm are (Fig. 1b,e,f), and it is obvious that the obtained results have the problems of color distortion (Fig. 1e), noise amplification (Fig. 1b), and detail blurring (Fig. 1f). In comparison, the enhanced images obtained with our method (Fig. 1h) are closer to the ground truth (Fig. 1g) and have good perceptual quality. To investigate the characteristics of the low-frequency and high-frequency components, We use Gaussian filtering to decompose the enhanced result (Fig. 1b) into two sub-images with low and high frequency layer (Fig. 1c,d). It is obvious that the low-frequency layer contains mainly luminance and color information, while the high-frequency layer contains rich noise and detail information. Then, we further analyze the frequency distributions of the feature maps extracted from different U-Net34 layers (hierarchical features). We found that in the low-scale space of U-Net mainly includes low-frequency information, and in the high-scale space mainly includes high-frequency information. To fully extract and utilize the frequency information of different layers, we propose a novel Adaptive Frequency Decomposition Network (AFDNet). Specifically, a adaptive frequency decomposition (AFD) module is introduced to mine frequency information in appropriate network layers, extracting low-frequency information from low-scale space (i.e. T3 and T4 layers in Fig. 2) and exploiting high-frequency information from high-scale space (i.e. T1 and T2 layers in Fig. 2). Verified by extensive experiments, AFDNet achieves more robust result for all degraded images. In general, the contributions are as follows:
-
Design a novel Adaptive Frequency Decomposition Network (AFDNet) to extract frequency information from coarse to fine. Adaptive Frequency Decomposition (AFD) module is the core of AFDNet, which connects shallow features and deep features to extract low-frequency and high-frequency information for detail recovery and noise suppression. Through end-to-end training, both low-frequency and high-frequency information of the image are effectively recovered.
-
The idea of self-regularization is introduced to both the Laplacian pyramid and the Generative Adversarial Network(GAN) to enhance detail recovery ability.
-
A multi-term loss function composed of frequency, content, adversarial, mutual consistency and total variation terms, allowing an efficient image quality estimation.
-
We conduct extensive experiments on six public datasets to demonstrate the superiority of our model in both qualitative and quantitative metrics.
The rest of this paper is organized as follows. “Related work” section briefly reviews related work. “Methodology” section introduces the proposed AFDNet for low-light image enhancement. Experimental results and concluding remarks are given in “Experiments” and “Conclusions” sections, respectively.
Related work
HE-based methods
HE1 was proposed to increase the contrast of an image by expanding the dynamic range of the entire image. In the beginning, the initial HE cannot solve complex problems such as severe noise and insufficient lighting in low-light images. Many researchers have made various improvements to the original HE to improve its performance. Lee et al.2 proposed to optimize contrast enhancement according to a 2D histogram hierarchical difference approach, and Wu et al.5 adaptively controlled contrast gain according to the intensity and potential visual importance of pixels.Subsequently, diversified constraints3,4 are proposed to improve the overall visual quality. In order to improve the local adaptive ability, some methods5,6 adopt a finer-grained way to better adjust the histogram. However, the HE-based method is not flexible enough for local area adjustment, resulting in poor local appearance such as underexposure/over-exposure and noise amplification.
Retinex-based methods
The Retinex theory25 decomposes an image into two parts: the reflectance and the illumination component, where the reflectance component is consistent under any lighting condition. Usually we can estimate the illumination component from the original image, and then try to remove or reduce it to achieve the purpose of low-light image enhancement. Based on Retinex theory, a series of methods are proposed. Single-scale Retinex (SSR)7 enhanced image edge information by filtering out low-frequency information and retaining high-frequency information. In order to solve the blurring of local details and the halo at strong edges after SSR processing, Multi-scale Retinex (MSR)8 fused SSRs of different scales. Multi-scale Retinex Band Color Restoration(MSRCR)9 added a color restoration factor to MSR to compensate for color distortion defects caused by contrast enhancement in local areas of the image. In recent years, Fu et al.35 proposed a weighted variational model in which more reflexive details are preserved by adding a better a priori representation for the regularization term. Li et al.36 extended the traditional Retinex model to a robust model with an explicit noise term and made the first attempt to estimate the noise map of this model by minimizing the alternating directions. Fu et al.10 proposed a straightforward and effective fusion-based low-light image enhancement method. Xu et al.11 designed a local derivative filter to extract structure and texture maps for regularizing the enhancement of illumination and reflectance layers. However, the hand-made constraints make it difficult to accurately decompose low-light images into reflectance and the illumination component, resulting in unnatural visual effects.
CNN-based methods
With the continuous development of deep learning technology, researchers have found that low-light image enhancement using deep learning has good flexibility and performance which gradually become the mainstream direction of low-light image enhancement. Zhu et al.24 proposed a two-stage edge-enhanced multiple-exposure fusion network for image enhancement. Lv et al.17 proposed a multi-branch low-light image enhancement network (MBLLEN) to extract a large number of features from multiple branches and fuse them into the final enhanced image. Shen et al.15 used CNN to simulate the traditional multi-scale Retinex low-light image enhancement process, and established an end-to-end model to learn the mapping from low-light images to normal-light images. Based on the Retinex theory, Zhang et al.16 built a fully convolutional network to complete the decomposition and enhancement operations, and introduced the BM3D37 denoising module to remove the noise in the reflection image. Zhang et al.18 designed a Kind network and constructed a fully convolutional network based on Retinex theory. Its network framework consists of three sub-networks, including: decomposition network, illumination map adjustment network and reflection map restoration network. It can better solve the problem of image degradation and noise in reflection map. Subsequently, the Kind++19 network was developed to illuminate the dark areas while also removing hidden artifacts and suppressing noise. In addition, the researchers have proposed some unsupervised deep network models for low-light image enhancement. Jiang et al.13 proposed an unsupervised generative adversarial network EnlightenGAN, which gains remarkable performance by imposing (i) gobal-local discriminator to balance global and local image enhancement; (ii) self-feature preservation loss and self-regularization attention mechanism Realize the idea of self-regularization. Guo et al.12 proposed a zero-reference learning framework Zero-DCE, which learns the mapping relationship between low-light images and curve parameters through a set of effective non-reference loss functions, and enhances image brightness and contrast in an iterative manner. Furthermore, Li et al.20 provided an accelerated version of Zero-DCE++, which significantly improves the efficiency of the computation and keeps the performance almost the same.
The aforementioned methods have a good performance in improving low-light image quality. However, due to the importance of frequency information to image reconstruction is not fully considered, most methods still cannot simultaneously solve all problems such as: noise amplification, color distortion, and fuzzy details. In this work, we explore the characteristics of low and high frequency information and analyze the frequency distribution of the feature maps extracted from different U-Net layers. Based on this, we designed an AFDNet to extract the illumination and edge features in different network layers, enabling the enhancement model to achieve satisfactory results. We design a novel frequency loss function to constrain the network to better recover the information of different frequency layers. Figure 2 shows the network framework of the proposed AFDNet.
Methodology
Laplacian pyramid
Inspired by38, we introduce a Laplacian pyramid in the image space to provide multi-scale residual information for the network. Specifically, the coarsest level of the Laplacian pyramid guides the network to adjust the global illumination, and the finer pyramid levels of the Laplacian pyramid force the correlation network to recover image local details. The input image \({I_1}\) is first decomposed into a five-level Laplacian pyramid, which can be formulated as follows:
where \(k\in (1,2,3,4)\) represents the level of the Laplacian pyramid. \(f_{\downarrow }\)and \(f_{\uparrow }\) are both down-sampling and up-sampling by bilinear interpolation. Noted that \({L_5}={I_5}\), which is acquired by downsampling the original image to the 1/16 scale. The Laplacian Pyramid has the following advantages: (1) Provide multi-scale Laplacian residual image features to guide the encoder-decoder architecture to recover image details. (2) Provide richer and more realistic texture features at multiple scales. (3) Add higher-level and more abstract features to improve the robustness of the network.

The overall architecture of AFDNet. The input is decomposed into five-scale Laplacian pyramids by decomposition, and feature fusion is performed by channel splicing in the encoding branch. In the decoding branch, the AFD model is used instead of the traditional skip connection method to gradually fuse the frequency features extracted by the encoding branch with the features extracted by other branches. The residual map output by the network is added to the result of multiplying the input image by \(\alpha \) to obtain the image enhancement result, where \(\alpha \) is a learnable parameter.
AFD module
In order to obtain more frequency-aware information for image enhancement, we propose AFD module to connect encoding and decoding, and its block diagram is shown in Fig. 3. The adaptive frequency decomposition process can be written as:
where \(i\in (1,2)\), \(C_a^i\) represents the contrast-aware attention map of different branches. \(f_{d_1^i}^i(\cdot )\) and \(f_{d_2^2}^i(\cdot )\) represent convolution operations with a kernel size of 3\(\times \)3, the dilation rates are \(d_1^i\) and \(d_2^i\), respectively. \(\delta (\cdot )\) is the linear activation function Leakyrelu. Inspired by33, \(C_a^i\) represents pixel-level contrast information, where pixels of high contrast are considered to be the high frequency layer of the image. The high-frequency information can be extracted by multiplying \(C_a^i\) by the input feature \(x_{en}\), and the low-frequency information can also be extracted by multiplying \((\alpha ^i-C_a^i)\) and \(x_{en}\). \(\alpha ^i\) represents a learnable parameter that controls the intensity of low-frequency information. The frequency-aware information of the two branches are concatenated to obtain the final low-frequency information \(low_f\) and high-frequency information \(high_f\). As shown in Fig. 3, the AFD module uses two branches to extract contrast-aware features with different granularity. Here are the reasons for this design. If we consider the frequency decomposition as a Gaussian filter, the sizes of the dilated convolution kernels of the different branches can be regarded as the sizes of the different Gaussian kernels in the Gaussian filter. In Gaussian filtering, the larger the Gaussian kernel is, the more blurring of the image after filtering. However, it is not the case that a larger Gaussian kernel is better. A too large Gaussian kernel will not only filter out the noise, but also smooth out the useful information in the image. Therefore, we need to simultaneously consider both the noise suppression effect and the preservation of useful content information when designing the dilated rate of the dilated convolution in different branches. Specific parameter settings are given in “Experiments” section. The frequency features of of different granularity and the features \(x_{dn}\) extracted by the decoder are concatenated to increase the receptive field39 to obtain more global information40, thereby improving the ability of network detail recovery. Subsequently, we use the channel attention mechanism to capture the relationship between different channels. Specifically, the concatenated features are then passed through a SE41 module to obtain a scaling vector v and multiplied with it to re-weight the importance of different channels. By adjusting the weight templates of different branches, the strategy of dynamic selection of main components mechanism42,43 is realized.

Overview of the proposed AFD module.
Analysis of CNN features
In this subsection, we considers the interrelationships between the frequency features and hierarchical features of a network, helping mine the low frequency and high frequency information of the optimal network layer. In the U-Net network, the feature scale of the encoding branch gradually decreases with the increase of depth. Inspired by Refs.21,44, the layers of different depths of the U-Net get different feature characteristics. The receptive field of high-scale layer is small, mainly including geometric details such as local details and noise; the receptive field of low-scale layer is large, mainly including semantic information such as background and illumination.

Extracting visual feature maps of different layers based on pre-trained U-Net. The first row is the result of normal U-Net output, and the second row is the result of embedding AFD module on top of it. The high-frequency information extracted at larger scales (i.e. T1 and T2) mainly contains local detail information; the low-frequency information at smaller scales (i.e. T3 and T4) mainly contains global information.
To verify the above view, We perform frequency analysis by using pre-trained U-Net (i.e. with and without AFD module) networks with frequency information extracted from different scales. For the design comparison experiments, we add AFD modules to the T1 and T2 layers of the U-Net benchmark model to extract high-frequency information and to extract low-frequency information in the T3 and T4 layers. Both models are trained on the public LOL-V116 training set and analyzed on the LOL-V1 test set. Then, we use the total variance (TV) loss45 to compute the local gradient values which can be considered as the local details. The larger its value, the more high-frequency information; the smaller its value, the more low-frequency information. To facilitate comparison, we normalize the TV loss distribution. As shown in Fig. 4 and Table 1, the low-frequency information distribution is closer to the low-scale space (i.e. T3 and T4), while the high-frequency information distribution is closer to the high-scale space (i.e. T1 and T2). As can be seen from Table 1, AFD module can improves frequency distribution in different scale spaces. Figure 4 depicts a visual comparison, which corrobarates the numerical result. Without the AFD module, the feature map has information overlap and interference, and the low and high-frequency features are not better represented. The noise and gradient information is amplified in the low-scale space, and the expected detail information is over-smoothed in the high-scale space. In addition, if we recover the low-frequency information better in the low-scale space and suppress the noise, it will also help the network to recover the high-frequency details in the high-scale space. Therefore, we extract the low-frequency information \(low_f\) in the low-scale space (i.e. T3 and T4) and extract the high-frequency information \(high_f\) in the high-scale layer (i.e. T1 and T2), so that the most abundant and important semantics contained in different scale spaces can be effectively utilized. In the following experiments, we use this setup for all analyses.
Loss function
To produce results with good reconstructed detail and guarantee satisfactory contrast and color distribution visually, we proposed a comprehensive loss function to train the network. Figure 5 shows the flowchart of the model with loss functions.

The flowchart of the adversarial generative learning.
We have a good balance of perceptual quality and fidelity in training the model via adversarial learning. The proposed AFDNet is worked as the generator, and the adversarial generative network model is formed with the designed discriminator. The discriminator CNN consists of seven convolutional layers each followed by a LeakyReLU. The seven convolutional layers, using kernel size 4 \(\times \) 4, stride 1, with kernel numbers of 64, 128, 256, 512, 512, 512, and 1 respectively. A sigmoidal activation function is applied to the outputs of the last fullyconnected layer and produces a probability of the input image with high-quality. Note that this is only a part of total loss function, and the overall loss consists of the following five components.
Frequency loss
Considering that AFDNet subdivides the image into low-frequency and high-frequency components, we design a novel frequency loss function to help the network recover more details with different frequency layers. The enhanced image is transformed into the frequency domain through the FFT, and after low-frequency filtering and high-frequency filtering respectively. The inverse FFT returns the low and high frequency domain to the image space. Wasserstein distance46 is used to minimize the difference between the low-frequency and high-frequency information of the enhanced and target images.
where \({\tilde{I}}_{low}\), \(I_{normal}\) and N are the enhanced image, ground truth and training batch size, respectively. \(\prod ({\tilde{I}}_{low}^i,I_{high}^i)\) represents the set of all possible joint distributions of the combined distributions \({\tilde{I}}_{low}^i\) and \(I_ {High}^i\). The formula after inf is to sample the sample pair \(({\tilde{I}}_{low}^i, I_{high}^i)\sim \gamma \) from the fixed joint distribution \(\gamma \), and calculate the expected value of the distance \(E_{(x,y)\sim [{\mid \mid {\tilde{I}}_{low}^i-I_{normal}^i\mid \mid }]}\) of this sample pair. inf denotes taking the maximum lower bound of the expected value.
Content loss
Our content loss (\(L_{content}\)) contains two parts: reconstruction loss (\(L_{rec}\)), and a perceptual loss (\(L_{vgg}\)). We use the L1 loss as the reconstruction loss, producing an enhanced image that is closer to the target image. Inspired by Refs.47,48,49, we use perceptual loss to calculate the VGG feature Euclidean distance between the enhanced image and the target image, encouraging them to have similar feature representations.
where C, H and W are the dimensions of the enhanced image\({{\tilde{I}}}_{low}\). \(C_{i,j}\), \(W_{i,j}\) and \(H_{i,j}\) denotes the number, height and width of the feature maps. \(\phi _{i,j}\) is the process of extracting deep features from the VGG-1650 network pretrained on ImageNet. i represents its i-th Max pooling, and j represents its j-th convolutional layer after its i-th Max pooling layer, i and j are set to 5 and 1 here.
Adversarial loss
Considering that frequency loss and content loss can easily make the network limited by high fidelity, which is not alway well aligned to human visual perception. To solve this problem, we introduce an adversarial loss obtained by an adversarial generative network. Here, the adversarial generative network consists of AFDNet and a discriminator, in which the discriminator is used to predict whether the input image is of high quality or not. As shown in the Fig. 5, we use high-quality images selected from the aesthetic visual analysis (AVA)51 dataset based on MOS values as a perceptual guide. Formally, We define the adversarial loss \(L_{adv}\) with the conception of cross-entropy:
where \({\tilde{I}}_{low}\) is the output enhanced image of AFDNet and Y denotes the unpaired random high quality image.
Mutual consistency loss
As the mutual consistency loss18 can solve the degradation problem in the luminance map, thus the edge information is strengthened and the smooth surface is uniform. Therefore, we introduce it for network training to guarantee mutual consistency between the enhanced image and the input image. The mutual consistency loss \(L_{mc}\) is defined as:
where \(\nabla \) stands for the first order derivative operator containing \(\nabla _x\)(horizontal) and \(\nabla _y\)(vertical) directions. c is a parameter that controls the shape of the function, called the penalty factor. The smaller the penalty factor c, the weaker the nonlinearity between M and \(L_{mc}\) ; the larger the value of the penalty factor c, the stronger the nonlinearity.
Total variational loss
In order to reduce the noise, the total variational (TV) loss45 is adopted to ensure the spatial smoothness of the enhanced image. The total variation loss \(L_{TV}\) is defined as:
Total loss
The comprehensive loss function for AFDNet is weighted sum up above losses as follows:
where \(\lambda _1\), \(\lambda _2\), \(\lambda _3\), \(\lambda _4\) and \(\lambda _5\) are weighting parameters.
Experiments
Experimental setting
We have implemented the proposed model in the in PyTorch with CUDA acceleration. The LOL-V1 dataset16 is used as training set, which including 485 pairs of real low/normal-light images which captured by changing the camera’s exposure time and ISO, each PNG image size is 400 \(\times \) 600. During training we randomly crop and flip the input data horizontally. Using the Adam52 optimizer, the learning rate is set to 1e−4 for the first 200 epochs, and decays linearly to 0 for the subsequent 200 eporchs. The batch size N is 32, and the learnable amplification parameter \(\alpha ^i\) is set to 1 at the beginning of training. The dilated rates \(d_1^1\), \(d_1^2\), \(d_2^1\) and \(d_2^2\) of different branches are set to 1, 6, 1, and 12 respectively. The penalty factor c is set to 10. \(\lambda _1\), \(\lambda _2\), \(\lambda _3\), \(\lambda _4\) and \(\lambda _5\) are set to 5, 1, 0.5, 5, and 1. The whole training takes 5 h on 4 Nvidia 1080Ti GPUs.
Evaluation datasets and metrics
We evaluate AFDNet on widely public datasets, including LOL (V1 & V2)16, DICM2, LIME53, MEF54, and NPE55. These test sets are all downloaded from the evaluation set provided by Ref.13. We evaluate the performance of different methods from different perspectives. The evaluation metrics include reference metrics and no-reference metrics, including: PSNR, SSIM56, MSE, AB57, LPIPS58, NIQE59. Among them, PSNR, MSE, and SSIM are widely used IQA metrics in low-level vision tasks to evaluate the similarity between enhanced result and reference images. Learning Perceptual Image Patch Similarity (LPIPS) is also known as “perceptual loss”. Compared with traditional indicators, the LPIPS is estimated by calculating the distance metric between features, which is more suitable for human visual perception of texture. A lower LPIPS value indicates a higher perceptual similarity of the enhanced image to the corresponding groundtruth. The Average Brightness(AB) calculates the brightness of the enhanced image. Natural Image Quality Evaluator (NIQE) evaluates the quality of the enhanced image based on human perceptual similarity. The lower the value, the closer the enhanced image is to the natural. The higher the PSNR, SSIM, AB value, the better the quality, and the opposite for MSE, LPIPS, NIQE. The superiority of our method is demonstrated by quantitative and qualitative comparison with the state-of-the-art methods currently available with public code.
LOL (V1 & V2) dataset variational
The LOL (V1 & V2) test set is collected by controlling for exposure and ISO, and each low-light image has a corresponding normal-light image to calculate quantitative metrics. There are 15 pairs of images in LOL-v1 and 100 pairs of images in LOL-v2. For overall comparison, we select 12 most representative state-of-the-art methods, including LLNet14, MBLLEN17, Retinex-Net16, Zero-DCE12, Zero-DCE++20, EnlightenGAN13, Kind18, Kind++19, R2RNet60, SCI29, RUAS28 and HFMNet21. The evaluation results of our method and other state-of-the-art methods on the LOL (V1 & V2) dataset are presented in Table 2. Through quantitative comparison, AFDNet achieves better performance in all with and without reference metrics, especially higher PSNR and SSIM and lower LPIPS. Representative results are visually shown in Figs. 6 and 7. It clear that all the previous methods can effectively improve the brightness and contrast, but none of the previous methods can well restore global illumination and structures. Among them, the resulting images of LLNet, Zero-DCE and Zero-DCE++ have problems of brightness, low contrast and blurred images. MBLLEN, Retinex-Net and EnlightenGAN can produce better visual effects, but all cause false information and amplify noise in dark areas. In comparison, the enhanced images obtained by Kind and Kind++ are more natural, but the enhancement of contrast and brightness is slightly insufficient. R2RNet, SCI, RUAS and HFENet can improve the local and global contrast better, but still have the problem of missing details. Comparatively, AFDNet achieves good perceptual visual quality with sharp details, uniform color distribution, and better noise suppression.

Visual comparison with state-of-the-art low-light image enhancement methods on the LOL-v1 dataset.

Visual comparison with state-of-the-art low-light image enhancement methods on the LOL-v2 dataset.
Ablation study
To explore the effectiveness of laplace pyramid, adaptive frequency decomposition (AFD) module and loss function settings, we conduct experiments by removing the laplace pyramid, removing the AFD module and removing different loss functions, respectively. The LOL-V1 dataset is also used to calculate different enhancement result metrics. As shown in Table 3, removing the Laplace pyramid leads to performance degradation, because the Laplace pyramid provides richer and more realistic texture features at multiple scales to guide the encoder–decoder architecture recovery image details. Similarly, removing the AFD module also leads to performance degradation, because the AFD module can guide the enhancement network to extract low-frequency information for image noise suppression and high-frequency information for detail recovery, resulting in better performance. This verifies the effectiveness of AFD module in extracting useful features and suppressing harmful features in optimal scale features spaces. An additional visual comparison is shown in Fig. 8, the model without the laplace pyramid results in blur detail and the model without AFD module results in color deviation and obstinate noise. In contrast, the model with both Laplace pyramid and AFD module contributes to a better visual quality.

Ablation study of the contribution of Laplace pyramid (lp), AFD module (AFD) and each loss (frequency loss \(L_{fre}\), adversarial loss \(L_{adv}\), mutual consistency loss \(L_{mc}\)). Note the edge details and overall illumination of the image.
Further, we remove the frequency loss, adversarial loss and the mutual consistency loss separately for experiments, and the experiments show that the removal of the frequency loss and the mutual consistency loss leads to the performance degradation. The result of the model without using frequency loss is decreased by 0.0228 dB and 0.1565 in terms of the PSNR and SSIM, and it is increased by 2.5726 in terms of the MSE. The result of the model without using adversarial loss is decreased by 0.0113 dB and 0.4120 in terms of the PSNR and SSIM, and it is increased by 0.1970 in terms of the MSE. The result of the model without using mutual consistency loss is decreased by 0.2106 dB and 0.0207 in terms of the PSNR and SSIM, and it is increased by 3.9717 in terms of the MSE. These results demonstrated the effectiveness of our loss function setting.
No-referenced image quality assessment
To fully evaluate AFDNet, we perform quantitative comparisons on four publicly available natural low-light datasets (DICM, NFE, LIME, MEF). Since the above datasets do not have paired reference images, we adopt four reference-free evaluation metrics(NIQE61, CEIQ62, LOE63, DE61). The results are shown in Tables 4 and 5.
The lower the values of NIQE and LOE, and the higher the values of CEIQ and DE, indicate that the image is more natural and closer to the normal light image distribution. The results further shows the superiority of AFDNet over other state-of-the-art methods in generating high-quality visual results. In order to verify the enhancement effect of our model under different lighting conditions, we conducted a comprehensive experiments covering a variety of lighting environments. As shown in Fig. 9, row 1–5 display non-uniform illumination, side lighting, backlight, nighttime and high noise scenes. It’s obvious to see that AFDNet achieved more satisfactory visualization results than others, in exposure control, noise suppression, color uniformity, etc.

Visual comparison with state-of-the-art low-light image enhancement methods whth various low-light conditions. Row 1–5 display non-uniform illumination, side lighting, backlight, nighttime and high noise scenes.

Example of face detection results. We used EnghtenGAN, MBLLEN and our AFDNet as preprocessing steps, and then used DSFD for detection.

Performance of face detection method DSFD in dark environments. PR curve and AP.
Pre-processing for improving detection
We investigate face detection performance in low-light conditions. Specifically, we use the DARK FACE dataset64, which contains 6100 real-world low-light images captured at night, including 6000 training/validation set images and 100 test set images. Because the annotations of the test set are not publicly available, we randomly select 100 images from the training set for evaluation. A well-performed face detector, Dual Shot Face Detector (DSFD)65, is adopted as the baseline model. We integrate different low-light image enhancement methods into DSFD for face detection, and Fig. 11 is the precision–recall (P–R) curve of different methods. In addition, we also compare average precision (AP) by using the evaluation tools provided in the DARK FACE dataset.
As shown in Fig. 11, after image enhancement, the accuracy of DSFD is greatly improved compared with the original unenhanced image. Among different methods, AFDNet and HFMNet perform eminently but AFDNet performs better in both precision and recall. Using our method as preprocessing, the average precision (AP) increases from 7.1 to 46.0%, which demonstrates that AFDNet can improve the performance of computer vision tasks. Two low-light real sceneries images are presented to illustrate the effectiveness of AFDNet. Compared with mainstrem enhancement networks MBLLEN and EnglightenGAN, the visulized images are shown in Fig. 10. AFDNet can significantly improve the image brightness and restore the details in dark areas, which greatly improving the performance of the detector.
Conclusion
In this research, we proposed a novel Adaptive Frequency Decomposition Network (AFDNet) to enhance low-light images. The proposed network increases the feature width through the Laplacian pyramid, which guides the encoder–decoder to recover image details. An Adaptive Frequency Decomposition (AFD) module is designed to connect encoding and decoding, which can adaptively extract frequency information from optimal scale feature space for detail recovery and image denoising. The end-to-end deep learning method proposed a novel comprehensive loss function to constrain model training, including frequency loss, content loss, adversarial loss, mutual consistency loss, and total variational loss. Among these, the adversarial loss improves the perceptual vidual quality of the image via adversarial learning, so that the enhanced image look more natural and have better visual effects. Additionally, a novel frequency loss function is used to help AFDNet recover more image details. Qualitative and quantitative evaluations on public datasets show that AFDNet has obvious advantages over state-of-the-art methods, and can achieve better visual quality, has unique advantages in detail recovery and noise suppression. It is also confirmed that AFDNet can effectively improve the performance of nighttime face detection. For future directions, we are interested in introducing image segmentation information to low-light image enhancement.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
Accession codes
The proposed AFDNet backbone network is available publicly for open accessat AFDNet source.
References
Pisano, E. D. et al. Contrast limited adaptive histogram equalization image processing to improve the detection of simulated spiculations in dense mammograms. J. Digit. Imaging 11, 193–200 (1998).
Lee, C., Lee, C. & Kim, C.-S. Contrast enhancement based on layered difference representation of 2d histograms. IEEE Trans. Image Process. 22, 5372–5384 (2013).
Ibrahim, H. & Kong, N. S. P. Brightness preserving dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 53, 1752–1758 (2007).
Lee, C., Kim, J.-H., Lee, C. & Kim, C.-S. Optimized brightness compensation and contrast enhancement for transmissive liquid crystal displays. IEEE Trans. Circuits Syst. Video Technol. 24, 576–590 (2013).
Wu, X., Liu, X., Hiramatsu, K. & Kashino, K. Contrast-accumulated histogram equalization for image enhancement. In 2017 IEEE International Conference on Image Processing (ICIP) 3190–3194 (IEEE, 2017).
Ying, Z., Li, G., Ren, Y., Wang, R. & Wang, W. A new image contrast enhancement algorithm using exposure fusion framework. In Computer Analysis of Images and Patterns: 17th International Conference, CAIP 2017, Ystad, Sweden, August 22–24, 2017, Proceedings, Part II 17 36–46 (Springer, 2017).
Jobson, D. J., Rahman, Z.-U. & Woodell, G. A. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 6, 451–462 (1997).
Rahman, Z.-U., Jobson, D. J. & Woodell, G. A. Multi-scale retinex for color image enhancement. In Proc. 3rd IEEE International Conference on Image Processing, Vol. 3, 1003–1006 (IEEE, 1996).
Jobson, D. J., Rahman, Z.-U. & Woodell, G. A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 6, 965–976 (1997).
Fu, X. et al. A fusion-based enhancing method for weakly illuminated images. Signal Process. 129, 82–96 (2016).
Xu, J. et al. Star: A structure and texture aware retinex model. IEEE Trans. Image Process. 29, 5022–5037 (2020).
Guo, C. et al. Zero-reference deep curve estimation for low-light image enhancement. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 1780–1789 (2020).
Jiang, Y. et al. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 30, 2340–2349 (2021).
Lore, K. G., Akintayo, A. & Sarkar, S. Llnet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recogn. 61, 650–662 (2017).
Shen, L. et al. Msr-net: Low-light image enhancement using deep convolutional network. Preprint at http://arxiv.org/abs/1711.02488 (2017).
Wei, C., Wang, W., Yang, W. & Liu, J. Deep retinex decomposition for low-light enhancement. Preprint at http://arxiv.org/abs/1808.04560 (2018).
Lv, F., Lu, F., Wu, J. & Lim, C. Mbllen: Low-light image/video enhancement using cnns. BMVC 4, 1 (2018).
Zhang, Y., Zhang, J. & Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proc. 27th ACM International Conference on Multimedia 1632–1640 (2019).
Zhang, Y., Guo, X., Ma, J., Liu, W. & Zhang, J. Beyond brightening low-light images. Int. J. Comput. Vis. 129, 1013–1037 (2021).
Li, C., Guo, C. & Loy, C. C. Learning to enhance low-light image via zero-reference deep curve estimation. IEEE Trans. Pattern Anal. Mach. Intell. 44, 4225–4238 (2021).
Xu, K. et al. Hfmnet: Hierarchical feature mining network for low-light image enhancement. IEEE Trans. Instrum. Meas. 71, 1–14 (2022).
Tao, L. et al. Llcnn: A convolutional neural network for low-light image enhancement. In 2017 IEEE Visual Communications and Image Processing (VCIP) 1–4 (IEEE, 2017).
Wang, R. et al. Underexposed photo enhancement using deep illumination estimation. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 6849–6857 (2019).
Zhu, M., Pan, P., Chen, W. & Yang, Y. Eemefn: Low-light image enhancement via edge-enhanced multi-exposure fusion network. In Proc. AAAI Conference on Artificial Intelligence 13106–13113 (2020).
Land, E. H. The retinex theory of color vision. Sci. Am. 237, 108–129 (1977).
Li, Z. et al. Feedback network for image super-resolution. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 3867–3876 (2019).
Deng, X., Zhang, Y., Xu, M., Gu, S. & Duan, Y. Deep coupled feedback network for joint exposure fusion and image super-resolution. IEEE Trans. Image Process. 30, 3098–3112 (2021).
Liu, R., Ma, L., Zhang, J., Fan, X. & Luo, Z. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 10561–10570 (2021).
Ma, L., Ma, T., Liu, R., Fan, X. & Luo, Z. Toward fast, flexible, and robust low-light image enhancement. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 5637–5646 (2022).
Rhee, H., Jang, Y. I., Kim, S. & Cho, N. I. Lc-fdnet: Learned lossless image compression with frequency decomposition network. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 6023–6032. https://doi.org/10.1109/CVPR52688.2022.00594 (2022).
Dinh, P.-H. Medical image fusion based on enhanced three-layer image decomposition and chameleon swarm algorithm. Biomed. Signal Process. Control 84, 104740 (2023).
Qin, X. et al. Improved image fusion method based on sparse decomposition. Electronics 11, 2321 (2022).
Xu, K., Yang, X., Yin, B. & Lau, R. W. Learning to restore low-light images via decomposition-and-enhancement. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 2281–2290 (2020).
Weng, W. & Zhu, X. Inet: Convolutional networks for biomedical image segmentation. IEEE Access 1 (2021).
Fu, X., Zeng, D., Huang, Y., Zhang, X.-P. & Ding, X. A weighted variational model for simultaneous reflectance and illumination estimation. In Proc. IEEE Conference on Computer Vision and Pattern Recognition 2782–2790 (2016).
Li, M., Liu, J., Yang, W., Sun, X. & Guo, Z. Structure-revealing low-light image enhancement via robust retinex model. IEEE Trans. Image Process. 27, 2828–2841 (2018).
Dabov, K., Foi, A., Katkovnik, V. & Egiazarian, K. Image denoising by sparse 3-d transform-domain collaborative filtering. IEEE Trans. Image Process. 16, 2080–2095 (2007).
Lim, S. & Kim, W. Dslr: Deep stacked Laplacian restorer for low-light image enhancement. IEEE Trans. Multimedia 23, 4272–4284 (2020).
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5–9, 2015, Proceedings, Part III 18 234–241 (Springer, 2015).
Cui, H., Li, J., Hua, Z. & Fan, L. Progressive dual-branch network for low-light image enhancement. IEEE Trans. Instrum. Meas. 71, 1–18 (2022).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In Proc. IEEE Conference on Computer Vision and Pattern Recognition 7132–7141 (2018).
Li, X., Wang, W., Hu, X. & Yang, J. Selective kernel networks. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 510–519 (2019).
Singh, N. & Bhandari, A. K. Principal component analysis-based low-light image enhancement using reflection model. IEEE Trans. Instrum. Meas. 70, 1–10 (2021).
Liu, W. et al. Ssd: Single shot multibox detector. In Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14 21–37 (Springer, 2016).
Aly, H. A. & Dubois, E. Image up-sampling using total-variation regularization with a new observation model. IEEE Trans. Image Process. 14, 1647–1659 (2005).
Adler, J. & Lunz, S. Banach wasserstein gan. Adv. Neural Inf. Process. Syst. 31, 1 (2018).
Johnson, J., Alahi, A. & Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part II 14 694–711 (Springer, 2016).
Ledig, C. et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proc. IEEE Conference on Computer Vision and Pattern Recognition 4681–4690 (2017).
RichardWebster, B., Anthony, S. E. & Scheirer, W. J. Psyphy: A psychophysics driven evaluation framework for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 41, 2280–2286 (2018).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. Preprint at http://arxiv.org/abs/1409.1556 (2014).
Murray, N., Marchesotti, L. & Perronnin, F. Ava: A large-scale database for aesthetic visual analysis. In 2012 IEEE Conference on Computer Vision and Pattern Recognition 2408–2415 (IEEE, 2012).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. Preprint at http://arxiv.org/abs/1412.6980 (2014).
Guo, X., Li, Y. & Ling, H. Lime: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 26, 982–993 (2016).
Ma, K., Zeng, K. & Wang, Z. Perceptual quality assessment for multi-exposure image fusion. IEEE Trans. Image Process. 24, 3345–3356 (2015).
Wang, S., Zheng, J., Hu, H.-M. & Li, B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans. Image Process. 22, 3538–3548 (2013).
Wang, Z., Bovik, A. C., Sheikh, H. R. & Simoncelli, E. P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 13, 600–612 (2004).
Chen, Z., Abidi, B. R., Page, D. L. & Abidi, M. A. Gray-level grouping (glg): An automatic method for optimized image contrast enhancement-part I: The basic method. IEEE Trans. Image Process. 15, 2290–2302 (2006).
Zhang, R., Isola, P., Efros, A. A., Shechtman, E. & Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proc. IEEE Conference on Computer Vision and Pattern Recognition 586–595 (2018).
Mittal, A., Soundararajan, R. & Bovik, A. C. Making a “completely blind’’ image quality analyzer. IEEE Signal Process. Lett. 20, 209–212 (2012).
Hai, J. et al. R2rnet: Low-light image enhancement via real-low to real-normal network. J. Vis. Commun. Image Represent. 90, 103712 (2023).
Rahman, Z., Yi-Fei, P., Aamir, M., Wali, S. & Guan, Y. Efficient image enhancement model for correcting uneven illumination images. IEEE Access 8, 109038–109053 (2020).
Rahman, Z. et al. Efficient contrast adjustment and fusion method for underexposed images in industrial cyber-physical systems. IEEE Syst. J. 1, 1 (2023).
Rahman, Z. et al. Diverse image enhancer for complex underexposed image. J. Electron. Imaging 31, 041213 (2022).
Yang, W. et al. Advancing image understanding in poor visibility environments: A collective benchmark study. IEEE Trans. Image Process. 29, 5737–5752 (2020).
Li, J. et al. Dsfd: Dual shot face detector. In Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition 5060–5069 (2019).
Acknowledgements
This work was supported by The National Natural Science Foundation of China under the Grant Number 61903724 and by The Natural Science Foundation of Tianjin under Grant Number 18YFZCGX00360. This work was supported by the Tianjin Research Innovation Project for Postgraduate Students under Grant No. KYS202108.
Author information
Authors and Affiliations
Contributions
X.L. proposed the main idea of the manuscript , X.C. guided the whole research work and check the data results. K.R., X.M. and Z.C. did the data compilation and manuscript editing. Y.J. revised the manuscript, including conducting subsequent supplemental experiments and thoroughly proofreading and revising the writing. All authors reviewed the manuscript. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liang, X., Chen, X., Ren, K. et al. Low-light image enhancement via adaptive frequency decomposition network. Sci Rep 13, 14107 (2023). https://doi.org/10.1038/s41598-023-40899-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-40899-8
This article is cited by
-
Electrowetting display of multiscale Gamma based on dynamic histogram equilibrium
Scientific Reports (2025)
-
A hybrid framework for curve estimation based low light image enhancement
Scientific Reports (2025)
-
RetinexCT-Net: A Method for Suppressing Brightness Inconsistency Artifacts in Multi-Source Static CT
Sensing and Imaging (2025)
-
Low-light image enhancement method based on retinex theory and dual-tree complex wavelet transform
Journal of King Saud University Computer and Information Sciences (2025)
-
Arc bubble edge detection method based on deep transfer learning in underwater wet welding
Scientific Reports (2024)
