
Abstract
There have been growing trends using deep learning-based approaches for photo retouching which aims to enhance unattractive images and make them visually appealing. However, the existing methods only considered the RGB color space, which limited the available color information for editing. To address this issue, we propose a dual-color space network that extracts color representations from multiple color spaces to provide more robust color information. Our approach is based on the observation that converting an image to a different color space generates a new image that can be further processed by a neural network. Hence, we utilize two separate networks: a transitional network and a base network, each operating in a different color space. Specifically, the input RGB image is converted to another color space (e.g., YCbCr) using color space converter (CSC). The resulting image is then passed through the transitional network to extract color representations from the corresponding color space using color prediction module (CPM). The output of the transitional network is converted back to the RGB space and fed into the base network, which operates in RGB space. By utilizing global priors from each representation in different color spaces, we guide the retouching process to produce natural and realistic results. Experimental results demonstrate that our proposed method outperforms state-of-the-art methods on the MIT-Adobe FiveK dataset, and an in-depth analysis and ablation study highlight the advantages of our approach.
Similar content being viewed by others


Introduction
Digital images have become ubiquitous in our daily lives, taken with various devices such as smartphones, digital cameras, and drones, which provide significant visual information in diverse fields1,2,3. The quality of images, however, is not always optimal due to various factors, such as lighting conditions, color distortions, and camera settings. Photo retouching is a common practice to enhance the appearance of low-quality images by removing unwanted elements and improving the overall aesthetics. However, manually retouching images demands specialized expertise and training, making it difficult for everyday users to accomplish. Even for professional photo editors, retouching large batches of images can be time-consuming and monotonous. Therefore, there have been drastic demands for automated photo retouching solutions.
Recently, deep learning-based photo retouching methods have been proposed as an appropriate solution to improve image quality and visual fidelity, leveraging the power of Convolutional Neural Networks (CNNs)4,5,6. Furthermore, the pioneering study which involved gathering a vast collection of input images and their corresponding retouched images edited by experts resulted in the establishment of the MIT-Adobe FiveK dataset7. This has facilitated the advancement of supervised learning approaches8,9.
One of the challenges in deep learning-based photo retouching is how to efficiently and accurately represent the color information in an image. Generally, the most straightforward way to capture more color representation in the image required for retouching involves increasing either the number of layers in the network or the number of filters in each layer. However, previous photo retouching methods4,5,6,10 have focused such methods solely on images presented to the network in the RGB color space. Although the information obtained from the RGB space is valuable for editing the images, incorporating more diverse cues from different color spaces can facilitate the process of deep learning tasks11,12.
To address this issue, we aim to improve photo retouching performance by considering various color spaces. As a first step, we examined the images converted from RGB space into various alternative color spaces, such as YCbCr, HSV, LAB, and XYZ. As shown in Fig. 1, the input image show completely different histograms for each color space. In other words, transforming an image into an alternate color space results in the generation of a new image that can be effectively employed by a neural network. From this perspective, we leverage the images in multiple color spaces and their global priors to enhance the visual quality of images.
In this paper, we propose a dual-color space network that operates on two color spaces, which provides more robust color information compared to a single color space network. The network takes RGB image as input and the color representations are extracted from each color space. We obtain global priors from the each representation and utilize them to guide the retouching process towards natural and realistic results. Also, our network is designed to adopt a sequential processing framework that resembles the step-by-step workflow of humans5,6,13.

Histograms of an input image for different color spaces.
Our contribution can be summarized as follows:
-
We introduce a dual-color space network that leverages global priors in different color spaces to enhance the overall quality of the image. Moreover, the network employs a straightforward sequential process to simplify the architecture.
-
Color prediction module (CPM) and color space converter (CSC), which serve as integral components of our network, are introduced to extract features from diverse color spaces and transition between these color spaces.
-
We present an extensive analysis and ablation study that highlights the benefit of the proposed method and shows intriguing properties that can guide future research directions.
Related work
Color space conversion
Color spaces play a crucial role in several deep learning tasks, including image classification, salient object detection, and image segmentation. Various color spaces have been used for these tasks, and several approaches have been proposed to learn the features of different color spaces. By exploiting the strengths of each color space, these approaches can improve the performance and accuracy. ColorNet14 proposed an architecture that can learn to classify image using different color spaces, and show that certain spaces, such as LAB and HED, can improve classification performance compared to RGB space. MCSNet11 transformed the images into HSV and grayscale color spaces to capture additional information on saturation and luminance. The VGG-1615 backbone network is then used to extract features in parallel from both the RGB channels with color information and the channels with information on saturation and luminance of the scene. Abdelsadek et al.12 investigated the effect of using different color spaces on image segmentation. Four different color spaces, including RGB, YCbCr, XYZ, and HSV, were compared using various image segmentation methods. These studies demonstrate that the selection of color space has a notable influence on the results.
Color transform-based methods
The typical approach for these methods involves extracting features from a low-resolution image and then using them to predict parameters for predefined local or global color transformations. The predicted color transformation is then applied to the initial high-resolution image. Common color transformation techniques comprises of several functions such as curved-based transforms16,17,18, affine transforms4,19,20 and lookup tables21,22. The transformation functions learned by these methods can adjust to various image contents and are computationally efficient. However, their effectiveness is limited by the predetermined color transformation and may not be sufficient to accurately represent complex and non-linear color mappings between the input and retouched images.
Sequential processing methods
These methods belong to a category that imitates the retouching workflow of humans by representing the process as a sequence of color operations. Implementing this approach is challenging as it demands additional supervision to identify the most suitable editing sequence. CSRNet23 explored commonly used retouching operations and showed that these operations can be expressed as multi-layer perceptrons. The layers were affected by a 32-dimensional conditional vector obtained from the input image through global feature modulation. Shi et al.13 proposed an operation planning algorithm to produce synthetic ground-truth sequences that can facilitate the training of the network. NeurOps24 replicated the conventional color operators and acquired knowledge of color transformation at the pixel level, with its intensity being determined by a scalar. These approaches do not involve converting the image into different color spaces, instead, they utilize the original RGB image for performing photo retouching.

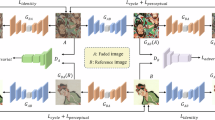
The overview of proposed dual-color space network. Our method consists of two separate networks, which operates in different color spaces.
Method
Dual-color space network
As shown in Fig. 2, the proposed framework includes a transitional network and a base network. The transitional network takes a low-quality image as input and produces a transitional image. Then the transitional image is fed into the base network. This structure allows the proposed method to utilize global priors from multiple spaces of a single image for enhancement.
Transitional network
Our study is driven by two key concepts:
-
1.
Neural networks perceive images as numerical values. Therefore, any conversion of the color space on these images should be interpreted by the network as a completely new image.
-
2.
Color spaces do not have a complete correlation with one another, and some images are better represented by different color spaces other than RGB space14.
Expanding on these concepts, two things can be concluded. Firstly, a single image can be transformed into multiple representations through color space conversion, thus achieving a similar effect to using multiple inputs. This means that we can obtain multiple global priors from a single image. Secondly, the combinations of these global priors can lead to better results. We implement the idea in the field of photo retouching by incorporating the transitional network.
Since we consider both quantitative measures and perceptual quality, we have chosen to use the YCbCr color space for the transitional network. The Y channel denotes the brightness or luminance of the image, while the Cb and Cr channels represent the chrominance. As the standard photo retouching dataset7 tends to feature images with an under-exposed condition, we utilize the Y channel to enhance visual results. The chrominance channels are employed together to modify color information.
As illustrated in Fig. 2(bottom left), the network consists of three CPMs and two CSCs, which will be explained carefully in Sects. 3.2 and 3.3. The network first converts the input image I from RGB to YCbCr. Next, the YCbCr input is processed through a series of CPMs that sequentially improve the input. Before the last CSC, the transitional YCbCr image \({I}^{Y}\) is saved to compute the reconstruction loss \({{\mathscr {L}}^{Y}}_{r}\). This approach allows the network to carry out retouching operations by using the global prior from the color space other than RGB. Finally, the network generates a transitional image \({I}^{T}\).
Base network
The base network takes \({I}^{T}\) as input, which is in the RGB color space. As shown in Fig. 2(bottom right), the base network is composed of three CPMs. The network utilizes the global prior from RGB space, contrary to the transitional network. The network produces the final retouched image \(I'\) and computes the reconstruction loss \({\mathscr {L}'}_{r}\).

Left: The overview of color prediction module (CPM). Right: The process of obtaining the control value.
Color prediction module (CPM)
We followed the sequential image retouching pipeline13,23 to build our CPM which maps each input pixel to the output pixels via pixel-wise manner. Our goal is to produce a retouched image \({I'}\in {{{\mathbb {R}}}^{{H}\times {W}\times {C}}}\) from an input image \({I}\in {{{\mathbb {R}}}^{{H}\times {W}\times {C}}}\) by implementing N pixel-wise mapping in a sequential manner. We set \(N = 3\) for both the transitional and base network. As illustrated in Fig. 3, our CPM takes 3D image I as the input and generates intermediate images \({I_{n}}\):
where \({I}_{0} = {I}\) and \({I}_{N} = {I}^{T}\) for the transitional network and \({I}_{0} = {I}^{T}\) and \({I}_{N} = {I'}\) for the base network.
Specifically, we utilize an equivariant mapping to build a simple translation24. As Fig. 3(left) shows, \({I}_{n-1}\) is converted into a 64D feature vector z. Then, we perform a straightforward translation in the feature space \({z'} = {z} + {v}\) where v is a control value that determines the magnitude of the translation. Lastly, the modified feature vector \(z'\) is converted back to the 3D RGB space resulting in the output \(I'\):
where G and H denote the mappings from 3D to 64D feature vector and vice versa, respectively.
We obtain v as illustrated in Fig. 3(right). To incorporate global image statistics, we downsample the 3D RGB image, denoted as \({{I}^{\downarrow }}_{n-1}\), and use \({7}\times {7}\) kernel size. We represent the prediction of v as a mapping function denoted by F:
where d is a feature space dimension.
F consists of a downsampling layer, two convolution layers, a pooling layer, and a fully connected layer. Firstly, the 3D RGB image is downsampled and the two convolutional layers are used to extract 32D feature maps. Next, three different pooling functions are utilized to determine the maximum, average, and standard deviation for each channel. These three 32D vectors are concatenated into a 96D vector, which we refer to as the global prior. As described in Sect. 3.1, our method employs the global priors from two color spaces. Finally, the fully connected layer maps the 96D global prior to a 64D control value v.
Color space converter (CSC)
To obtain more comprehensive set of color information from two separate type of global priors, the proposed method utilizes both the RGB and the YCbCr space for the enhanced retouching process. RGB represents colors by combining different intensities of red, green, and blue, and is the most commonly used color space in digital images. YCbCr represents color information using Y (luminance), Cb (Chroma blue), and Cr (Chroma red).
The conversion from RGB to YCbCr color space can be represented using a conversion matrix as follows:
The RGB to YCbCr color transformation can also be achieved by using a conversion matrix. The matrix is as follows:
As shown in Fig. 2(bottom left), we utilize CSCs to convert the color space between RGB and YCbCr, and implement them at the beginning and end stages of the transitional network.
Training objective
Given an RGB image I, we refer to its ground truth (GT) image as \({I}^{GT}\) and the retouched image predicted by the model as \(I'\). Also, referring to a YCbCr converted image \({I}^{Y}\), the GT image is denoted as \({I}^{{GT}_{Y}}\). The total loss \({{\mathscr {L}}}_{total}\) is composed of a RGB reconstruction loss \({\mathscr {L}'}_{r}\), a YCbCr reconstruction loss \({{\mathscr {L}}^{Y}}_{r}\), a total variation loss \({{\mathscr {L}}}_{tv}\), and a color loss \({{\mathscr {L}}}_{c}\).
Reconstruction loss
To train the model using both RGB and YCbCr color spaces, two distinct reconstruction losses are employed. Both of these losses measure the L1 difference between the predicted image and GT:
Total variation loss
We also include total variation loss25 to encourage smoother and more continuous image outputs:
where \(\nabla (\cdot )\) refers the gradient operator.
Color loss
We implement a color loss20 that considers RGB colors as 3D vectors and computes the angular differences between them:
where \(\angle (\cdot )\) operator calculates the average cosine of the angular differences between values at each pixel.
Total loss function
Therefore, the complete training object of our network is:
where \({\lambda }_{1}\), \({\lambda }_{2}\), and \({\lambda }_{3}\) are balancing hyper-parameters.
Experiments
Dataset and metrics
We conduct experiments on the MIT-Adobe FiveK dataset7 which is a widely-used set of raw images and corresponding retouched versions manually edited by five experts (A/B/C/D/E). We follow the common practice4,6,26,28, utilizing the retouched image of expert C as the GT in our experiments, and splitting training and testing sets into 4500 images and 500 images, respectively. All images are resized by reducing the longer edge to 500px while maintaining the aspect ratio.
We use PSNR29, SSIM30, and delta E (\(\triangle {E}^{*}\))31 as metrics to evaluate the performance. \(\triangle {E}^{*}\) is a color difference metric defined in the CIELAB color space and has been demonstrated to be consistent with human perception. Unlike PSNR and SSIM, a smaller \(\triangle {E}^{*}\) indicates better performance.
Implementation details
We implement our model using PyTorch framework32. All our experiments are conducted on a single NVIDIA RTX 3090 GPU. During training, the mini-batch size is set to 1 and run 600, 000 iterations. We use the Adam optimizer33 with \({\beta }_{1}\) = 0.9, \({\beta }_{2}\) = 0.99 and an initial learning rate is \(5{e}^{-5}\). The weights for the balancing hyper-parameters in Eq. 10 are \({\lambda }_{1}\) = 0.01 and \({\lambda }_{2}\) = \({\lambda }_{3}\) = 0.1. The base network contains three CPMs, and the transitional network contains three CPMs and two CSCs.
Comparisons with state-of-the-arts
We compare our model with state-of-the-art methods, including White-Box5, Distort-and-Recover6, DUPE26, Pix2Pix27, HDRNet4, CSRNet23, and NeurOp24 to demonstrate its effectiveness. For White-Box, Distort-and-Recover, DUPE, Pix2Pix, and HDRNet, we refer to the results from the previous work23. For the top two state-of-the-art methods, CSRNet and NeurOp, we retrained their models under the same experimental conditions as ours to ensure a fair comparison.
Quantitative comparison
The results presented in Table 1 demonstrate that our proposed model outperforms the previous state-of-the-art methods on the MIT-Adobe FiveK dataset7. Specifically, White-Box and Distort-and-Recover show low performance with less than 20dB in PSNR and necessitate millions of parameters. This is because they are reinforcement-learning-based methods and are not directly supervised by the GT image. One reason for this is that these methods use reinforcement learning and do not receive direct supervision from the GT image. DUPE and HDRNet exhibit fairly decent performance but require several hundred thousand parameters. Similarly, Pix2Pix performs reasonably well, but it relies on over ten million parameters.
For the top two state-of-the-art methods, CSRNet and NeurOp, our proposed model outperforms in terms of all metrics. Our model requires relatively more parameters than CSRNet and NeurOp, but less than ten thousand which is still light-weighted. The results show that the proposed method outperforms the existing methods and exhibits a lightweight architecture.

Visual comparison with state-of-the-art methods on MIT Adobe FiveK dataset. Zoom in for better visibility.
Visual comparison
A visual comparison with state-of-the-art methods is shown in Fig. 4. We only compared CSRNet and NeurOp, which show stable performance, as other models display poor quantitative metrics5,6,26, contain unpleasing artifacts27, or produce images with unrealistic color in some areas4. Compared with these two models, the retouched images demonstrate the effectiveness of our method. Specifically, the first, second, and third row shows that our method can enhance the input image vividly and naturally. For the fourth, fifth, and sixth rows, the results obtained from our method show the most realistic images that resemble the GT images. The seventh row of the human photo has a lower resemblance between all three methods and the GT images, but our results demonstrate the most realistic natural skin color and fewer color shifts.

MOS test ranking results. Rank 1 most closely represents the GT image and indicates the results most preferred by the participants..
User study
We have conducted a Mean Opinion Score (MOS) test to present a user study. We selected a total of 20 participants and randomly chose 50 images from the test set for each of them. Participants were asked to rank the retouched results from three versions, CSRNet23, NeurOp24, and ours based on their similarity to the GT image and visual appeal, assigning them 1st, 2nd, and 3rd place rankings. As shown in Fig. 5, our results achieve better visual ranking against CSRNet and NeurOp with 399 images ranked first and 281 images ranked third. These results indicate that our retouched results are visually more favorable to the participants compared to other methods.
Ability to capture luminance
Since we used the YCbCr color space in our transitional network to utilize the luminance feature, we have presented quantitative and qualitative results for the Y channel. Table 2 demonstrates that our proposed method outperforms existing methods in both PSNR and SSIM on the Y channel. Specifically, our model achieves a higher PSNR/SSIM than CSRNet by 0.53db/0.003 and NeurOp by 0.22db/0.002. Additionally, Fig. 6 illustrates that our results show the highest PSNR/SSIM values and their histograms closely resemble those of the GT images. These results indicate that our method effectively extracts the luminance feature from the GT image and utilizes it to generate the final retouched image.
Ablation study
To validate the choice of YCbCr color space in the transitional network, we conducted ablation studies by training the model using three additional color spaces, HSV, LAB, and XYZ, and comparing their performance. For a fair comparison in the RGB space, we employed the same process as in other color spaces. The result was obtained using the entire network, including both the base network and transitional network from which CSCs were removed, to maintain the same number of parameters. The quantitative results, shown in Table 3, demonstrate that using multiple color spaces is generally more effective then using just one RGB color space. The LAB color space, which is utilized by the \(\triangle {E}^{*}\) metric, showed the best performance in terms of \(\triangle {E}^{*}\). In addition, we present visual comparison results in Fig. 7. All models using the different color spaces generated pleasing results without any artifacts or unnaturalness. However, our retouched images produces the most vivid and closest-to-GT results. The results suggest that it is possible to conduct further research by exploring different color spaces and various combinations of them.

Visual comparison on the Y channel of YCbCr space using the MIT-Adobe FiveK dataset. For better understanding, PSNR values and histograms are provided.

Visual comparison for the different color spaces of the transitional network on the MIT-Adobe FiveK dataset. Zoom in for better visibility.
Conclusion
This paper introduces a novel dual-color space network that provides robust color information by operating on two distinct color spaces, surpassing the capabilities of a single-color space network. By employing a transitional network and a base network, color representation is extracted from both color spaces. This approach allows the proposed network to incorporate global priors from both color spaces, guiding the retouching process toward producing natural and realistic results. Our experiments demonstrated that the proposed method achieves higher accuracy and generates retouched images that are more natural and visually striking compared to existing state-of-the-art methods. Our future work aims to investigate alternative color spaces and explore different combinations of them to further enhance the modeling capabilities of the network.
While our approach yields promising results, there are still limitations that need addressing. Although our proposed method outperforms previous methods across all metrics and retains a lightweight model, the process involved in converting between color spaces could elevate computational costs for high-resolution images. In addition, CPMs and CSCs in the transitional network primarily operate in the YCbCr color space, emphasizing the Y channel for luminance capture. Our choice was influenced by the commonly used MIT-Adobe FiveK dataset which contains under-exposed images. For an exceptional test set case that is relatively less low-exposure and GT image contains overall dark pixels, the results deviate from the GT images although the result is realistic and aesthetically pleasing. We hope that future research will introduce its practical application in real-world situations with various image conditions.
References
Shariati, S. & Khayatian, G. A new method for selective determination of creatinine using smartphone-based digital image. Microfluid. Nanofluidics 26, 30 (2022).
Liu, Y. et al. Remote-sensing estimation of potato above-ground biomass based on spectral and spatial features extracted from high-definition digital camera images. Comput. Electron. Agric. 198, 107089 (2022).
Demirhan, M. & Premachandra, C. Development of an automated camera-based drone landing system. IEEE Access 8, 202111–202121 (2020).
Gharbi, M., Chen, J., Barron, J. T., Hasinoff, S. W. & Durand, F. Deep bilateral learning for real-time image enhancement. ACM Trans. Graph. (TOG) 36, 1–12 (2017).
Hu, Y., He, H., Xu, C., Wang, B. & Lin, S. Exposure: A white-box photo post-processing framework. ACM Trans. Graph. (TOG) 37, 1–17 (2018).
Park, J., Lee, J.-Y., Yoo, D. & Kweon, I. S. Distort-and-recover: Color enhancement using deep reinforcement learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 5928–5936 (2018).
Bychkovsky, V., Paris, S., Chan, E. & Durand, F. Learning photographic global tonal adjustment with a database of input/output image pairs. In CVPR 2011, 97–104 (IEEE, 2011).
Bianco, S., Cusano, C., Piccoli, F. & Schettini, R. Learning parametric functions for color image enhancement. In Computational Color Imaging: 7th International Workshop, CCIW 2019, Chiba, Japan, March 27-29, 2019, Proceedings 7, 209–220 (Springer, 2019).
Bianco, S., Cusano, C., Piccoli, F. & Schettini, R. Personalized image enhancement using neural spline color transforms. IEEE Trans. Image Process. 29, 6223–6236 (2020).
Zamir, S. W. et al. Learning enriched features for fast image restoration and enhancement. IEEE Trans. Pattern Anal. Mach. Intell. 45, 1934–1948 (2022).
Lee, K. & Jeong, J. Multi-color space network for salient object detection. Sensors 22, 3588 (2022).
Abdelsadek, D. A., Al-Berry, M. N., Ebied, H. M. & Hassaan, M. Impact of using different color spaces on the image segmentation. In The 8th International Conference on Advanced Machine Learning and Technologies and Applications (AMLTA2022), 456–471 (Springer, 2022).
Shi, J. et al. Learning by planning: Language-guided global image editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 13590–13599 (2021).
Gowda, S. N. & Yuan, C. Colornet: Investigating the importance of color spaces for image classification. In Computer Vision–ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, December 2–6, 2018, Revised Selected Papers, Part IV 14, 581–596 (Springer, 2019).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
Moran, S., McDonagh, S. & Slabaugh, G. Curl: Neural curve layers for global image enhancement. In 2020 25th International Conference on Pattern Recognition (ICPR), 9796–9803 (IEEE, 2021).
Kim, H., Choi, S.-M., Kim, C.-S. & Koh, Y. J. Representative color transform for image enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 4459–4468 (2021).
Song, Y., Qian, H. & Du, X. Starenhancer: Learning real-time and style-aware image enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 4126–4135 (2021).
Chai, Y., Giryes, R. & Wolf, L. Supervised and unsupervised learning of parameterized color enhancement. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 992–1000 (2020).
Liu, E., Li, S. & Liu, S. Color enhancement using global parameters and local features learning. In Proceedings of the Asian Conference on Computer Vision (2020).
Wang, T. et al. Real-time image enhancer via learnable spatial-aware 3d lookup tables. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2471–2480 (2021).
Yang, C. et al. Seplut: Separable image-adaptive lookup tables for real-time image enhancement. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XVIII, 201–217 (Springer, 2022).
He, J., Liu, Y., Qiao, Y. & Dong, C. Conditional sequential modulation for efficient global image retouching. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIII 16, 679–695 (Springer, 2020).
Wang, Y. et al. Neural color operators for sequential image retouching. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XIX, 38–55 (Springer, 2022).
Aly, H. A. & Dubois, E. Image up-sampling using total-variation regularization with a new observation model. IEEE Trans. Image Process. 14, 1647–1659 (2005).
Wang, R. et al. Underexposed photo enhancement using deep illumination estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6849–6857 (2019).
Isola, P., Zhu, J.-Y., Zhou, T. & Efros, A. A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1125–1134 (2017).
Chen, Y.-S., Wang, Y.-C., Kao, M.-H. & Chuang, Y.-Y. Deep photo enhancer: Unpaired learning for image enhancement from photographs with gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 6306–6314 (2018).
Huynh-Thu, Q. & Ghanbari, M. Scope of validity of psnr in image/video quality assessment. Electron. lett. 44, 800–801 (2008).
Wang, Z., Bovik, A. C., Sheikh, H. R. & Simoncelli, E. P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 13, 600–612 (2004).
Backhaus, W. G., Kliegl, R. & Werner, J. S. Color vision: Perspectives from different disciplines (Walter de Gruyter, 2011).
Paszke, A. et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems 32 (2019).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
Author information
Authors and Affiliations
Contributions
P.P. formulated the problem and designed the system. H.O. developed the system. H.K. guided the project and wrote the original draft. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Park, P., Oh, H. & Kim, H. Dual-color space network with global priors for photo retouching. Sci Rep 13, 19798 (2023). https://doi.org/10.1038/s41598-023-47186-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-47186-6
