
Abstract
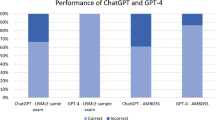
This study was designed to assess how different prompt engineering techniques, specifically direct prompts, Chain of Thought (CoT), and a modified CoT approach, influence the ability of GPT-3.5 to answer clinical and calculation-based medical questions, particularly those styled like the USMLE Step 1 exams. To achieve this, we analyzed the responses of GPT-3.5 to two distinct sets of questions: a batch of 1000 questions generated by GPT-4, and another set comprising 95 real USMLE Step 1 questions. These questions spanned a range of medical calculations and clinical scenarios across various fields and difficulty levels. Our analysis revealed that there were no significant differences in the accuracy of GPT-3.5's responses when using direct prompts, CoT, or modified CoT methods. For instance, in the USMLE sample, the success rates were 61.7% for direct prompts, 62.8% for CoT, and 57.4% for modified CoT, with a p-value of 0.734. Similar trends were observed in the responses to GPT-4 generated questions, both clinical and calculation-based, with p-values above 0.05 indicating no significant difference between the prompt types. The conclusion drawn from this study is that the use of CoT prompt engineering does not significantly alter GPT-3.5's effectiveness in handling medical calculations or clinical scenario questions styled like those in USMLE exams. This finding is crucial as it suggests that performance of ChatGPT remains consistent regardless of whether a CoT technique is used instead of direct prompts. This consistency could be instrumental in simplifying the integration of AI tools like ChatGPT into medical education, enabling healthcare professionals to utilize these tools with ease, without the necessity for complex prompt engineering.
Similar content being viewed by others

Introduction
ChatGPT and other large language models (LLMs) are venturing into clinical and research areas1,2,3,4,5. Prompt engineering is considered to be key in enhancing the performance of these models6,7. Research is looking into its use in medical contexts, such as evaluating soft skills through USMLE questions8,9,10.
Recent data shows ChatGPT (GPT-3.5) scores about 60% on the USMLE. GPT-4 scores an even more impressive 87%9,10. Studies of GPT-4's ability to craft multi-choice medical tests show AI's potential role in education11. The “chain of thoughts” (CoT) prompt method is designed to encourage the LLM to “reason step by step”, thereby, mimicking human problem-solving methods. However, CoT didn’t significantly boost GPT-4's USMLE scores. This is notable because the USMLE relies minimally on math12,13. CoT has proven useful in many non-medical tasks6,7. However, its impact on USMLE medical questions, particularly those with calculations, is still uncertain.
Our research focuses on GPT-3.5's performance with USMLE-like questions, separated into clinical and calculation-focused questions. We tested direct prompts, CoT, and a modified CoT. We reviewed various prompting strategies, and then selected direct prompts, Chain of Thought (CoT), and a modified CoT for our study. The choice of these strategies was influenced by their extensive discussion and acknowledgment in recent research. We chose direct prompting for its straightforward method of posing questions without prior context, serving as a key benchmark to assess the model's capacity to formulate responses based on its existing knowledge. Following this, CoT was applied to determine whether simulating human problem-solving techniques could enhance clinical reasoning. We then introduced mCoT, which adds further guidance and constraints to the CoT method to more closely tailor the model's thought process to the intricate demands of medical questions. Our study included questions generated by GPT-4 and actual USMLE Step 1 exams.
Methods
Study design
We evaluated ChatGPT (GPT-3.5-turbo) using three prompt strategies: direct, chain of thoughts (CoT), and a modified CoT14. Our analysis covered 95 USMLE Step 1 multiple-choice questions15. We also added two sets of questions we created with GPT-4, one set of medical calculations and another of clinical case questions, and the architecture and workflow of this experiment are detailed in Fig. 1. Analyses were performed during July 2023.

The figure illustrates a multi-step process in which GPT-4 generates 1000 USMLE-style medical questions with calculation and non-calculation, and GPT-3.5-turbo answers them using three prompting strategies direct, COT, and Modified COT. The generated questions span 19 clinical fields and various medical topics, and the model's answers aim to mimic human problem-solving behavior, enhancing reasoning ability and clarity in its responses.
Question generation
We used GPT-4 to create 1000 questions in USMLE style11,16. We split them evenly into two groups: 500 calculation-based and 500 non-calculation-based. The non-calculation set spanned diagnoses, treatment plans, lab test readings, disease courses, pathophysiology, public health, and preventive care. The calculation set included tasks like figuring out medication doses, clinical scores, diagnostic math, and statistical evaluations. GPT-4 also rated each question by difficulty—easy, medium, or hard, and by the medical field, covering 19 specialties such as Internal Medicine, Pediatrics, Psychiatry, Surgery, and others.
For generating questions, the prompt was:
Dear GPT-4, we are conducting research on prompt engineering and your help is needed to generate a high-quality medical question. This question should meet the following criteria:
-
- It should be like those found in the USMLE Step 1 examination.
-
- It should be in the field of {clinical field}.

The result should be returned in a JSON format, with the following headers:

where
-
Clinical field one of 19 clinical fields (internal medicine, surgery, etc.).
-
Broad type either calculation or non-calculation.
-
Subtypes:
-
Calculation questions: Drug dosage calculations, Clinical score calculations, Diagnostic test calculations, Statistical data interpretation.
-
Non-calculation type questions: Diagnosis based on symptoms, Treatment selection, Interpretation of lab results, Disease progression and prognosis, Pathophysiology questions, and public health and preventive medicine questions.
-
Difficulty level easy, medium, or hard.
Question answering—prompt engineering
To query GPT-3.5, we used three prompting strategies:
-
The "direct prompt" strategy simply instructed the model to "answer the question."
-
The "CoT" strategy guided the model to "reason step by step and answer the question."
-
The "modified CoT" strategy directed the model to "read the problem carefully, break it down, devise a strategy for solving it, check each step for accuracy, and clearly and concisely convey your reasoning leading to your final answer." This approach sought to mimic human problem-solving behavior, with the aim to enhance the model's reasoning ability while promoting clarity and precision in its responses.
All prompts were submitted using openAI API with the following format, using default temperature (0.5) and max token length of 700:

where 'prompt' corresponded to:

The direct prompt was:

The CoT prompt was:

The modified CoT prompt was:

Human validation
Two emergency room attending physicians independently evaluated the first 50 questions generated by GPT-4 for appropriateness, type, subtype, difficulty level, clinical field, and correctness of the answer. Each aspect was reviewed blindly, and the assessments were quantified.
To clearly delineate the agreement calculations, each evaluator's judgments were compared against the features of GPT-4 generated questions, for example, appropriateness, type, and difficulty level. The percentage agreement for each evaluator was calculated by the ratio of matches (e.g. agreement with GPT-4 difficulty level assignment) to the total questions evaluated. We further analyzed the inter-rater reliability between the evaluators using Cohen’s Kappa to compare their levels of agreement.
Evaluation
The main metric of our evaluation was the accuracy of GPT-3.5 and GPT-4 answers and, we have mentioned their feature comparison in Table 1. In addition, we ran further analyses on the questions, looking at difficulty level, what type they were, and their medical specialty. This helped us get a full picture of ChatGPT's capabilities.
Statistical analysis
Statistical analyses were executed using Python version 3.9.16. Agreement between the human reviewers was statistically analyzed using Cohen’s Kappa to measure inter-rater reliability. We used the Chi-square test to examine the relation between prompt types and response accuracy. A p-value of less than 0.05 was considered statistically significant.
Results
Table 2 presents the aggregated results of the human readers’ validations. It shows the percentage of agreement between the two reviewers across various categories and the Cohen's Kappa values, indicating the degree of inter-rater reliability. The evaluations revealed high agreement in most categories, with variability in the assessment of question difficulty.
Our study's main findings are presented in Table 3. We checked GPT-3.5's performance with three prompt types: direct, chain of thoughts (CoT), and modified CoT. We tested this performance across three question sets: USMLE Step 1 samples, GPT-4 generated clinical questions, and GPT-4 generated calculation questions.
Across calculation, clinical, and USMLE Step 1 questions, the different prompting methods—direct, CoT, and modified CoT—showed no significant performance difference (see Table 3).
We split our sub-analysis of GPT-3.5's answers into two groups: calculation and clinical questions. We then sorted them by their difficulty level and specific subtypes.
For calculation-type questions, no one method of prompting was better than another, no matter the level of difficulty. For the easier questions, the three methods had similar accuracy: Direct Prompt had 64.2%, CoT had 63.1%, and Modified CoT had 61.9% (see Fig. 2). When we looked at the types of questions, no method stood out (refer to Fig. 3). The p-values were all above 0.05, showing no significant statistical differences.

Bar graph representing the success rates of different prompting strategies ('Direct Prompt', 'CoT', and 'Modified CoT') for 'calculation' type questions across different difficulty levels ('Easy', 'Medium', 'Hard'). Each bar corresponds to the average success rate for the respective prompting strategy and difficulty level.

Bar graph showing the success rates of various prompting strategies ('Direct Prompt', 'CoT', and 'Modified CoT') for different 'calculation' question subtypes. Each bar represents the average success rate of a particular prompting strategy for a specific subtype.
Similarly, in clinical questions, no method stood out. This was true for all levels of difficulty and subtypes of questions. For example, in diagnosing based on symptoms, success rates were close for all methods. Direct Prompt had 88.9%, CoT had 90.1%, and Modified CoT also had 90.1% (see Figs. 4 and 5). This pattern stayed the same in other areas, such as tracking disease progress, reading lab results, and picking treatments. The p-values showed no significant differences between the methods. Overall, our detailed analysis shows that while there might be small changes in how well different methods do in certain tasks, these are not large enough to be statistically important.

Bar graph depicting the success rates of the three prompting strategies ('Direct Prompt', 'CoT', and 'Modified CoT') for 'non-calculation' type questions across different difficulty levels ('Easy', 'Medium', 'Hard'). Each bar corresponds to the average success rate for a specific prompting strategy and difficulty level.

Bar graph illustrating the success rates of different prompting strategies ('Direct Prompt', 'CoT', and 'Modified CoT') for various 'non-calculation' question subtypes. Each bar represents the average success rate for a certain prompting strategy for a given subtype.
We further looked at how GPT did in different medical fields (see Fig. 6). We again did not find a clear link to the kind of prompt used, but we did notice a clear overall pattern. Dermatology questions did the best with all methods, averaging around 79.5% success. In contrast, Anesthesiology questions did the worst, with an average success rate of about 49.4%.

Bar graph detailing the success rates of the three prompting strategies ('Direct Prompt', 'CoT', and 'Modified CoT') across diverse medical fields. Each bar denotes the average success rate for a specific prompting strategy within a particular field.
Discussion
Our study evaluated how well CoT prompt engineering works with ChatGPT for medical problems. We specifically separately evaluated calculation and clinical scenario question types. We tested three methods: direct prompt, the chain of thoughts (CoT), and a modified CoT. Surprisingly, we found no big differences in how they performed, even for medical calculation questions. All the methods did well in answering medical multiple-choice questions. We chose ChatGPT over GPT-4 for problem-solving. While GPT-4's power is clear, its high cost limits its use. The web interface of ChatGPT (GPT-3.5 model), on the other hand, is free. Also, GPT-3.5 API is much cheaper than GPT-4 API through OpenAI's API interface. GPT-3.5 API usage is around 30 times less costly than GPT-417, making it a good choice for many uses.
Our study shows that prompt engineering for medical questions is complex16. The methods we used had similar results, but they are just a few among many. We did not look at other methods like self-consistency CoT18, which uses the most common answer from several CoT attempts, or "few-shot learning"19. Each method has its own strengths and weaknesses, and more research is needed to fully understand them.
A peculiar finding in our study was a discrepancy in accuracy across medical specialties. While the exact composition of GPTs' training data remains proprietary, leading to some uncertainty, it is plausible that the model has been exposed to dermatology content more extensively, potentially due to its broader applicability and the availability of visual and descriptive data, as opposed to the specialized and complex domain of anesthesiology.
The way OpenAI trains ChatGPT is mostly unknown. We do not know much about the training or inference strategies, but it is reasonable that they might use known prompt engineering methods. Our finding that different prompts worked the same might show this. ChatGPT might already use these methods in its training or during inference, making extra prompt methods like CoT unnecessary.
The growing complexity of LLMs such as ChatGPT points to a future where these tools are key in medicine. So, it is important to study and include them in medical training. Our study showed that a straightforward prompt worked as well as more complex ones. This makes it easier for healthcare workers to use these models. They do not need to learn complicated prompt techniques, which could lead to more adaptation of these tools in healthcare education and clinical settings.
Our study has limitations. First, we only used USMLE-style questions, so our results might not apply to other types of questions or fields. Second, we only looked at GPT-3.5 (ChatGPT). Other LLMs might respond differently to these prompt methods. Third, we didn't consider all multiple existing prompt engineering techniques and focused on CoT. Other techniques might affect the results. Fourth, by dividing questions into 'calculation' and 'non-calculation' types, we might have missed the complex mix often found in medical problem-solving. Fifth, the assignment of difficulty levels to questions via generative AI may not consistently correlate with expert evaluations or actual student performance, reflecting inherent subjectivity in perceived question complexity. Lastly, LLMs and the data sources that they are trained on advance rapidly and the results from this work may not generalize to future iterations of them.
In conclusion, CoT prompt engineering did not significantly change GPT-3.5's ability to handle USMLE-like medical calculations or clinical scenario questions. This suggests that ChatGPT's performance remains steady regardless of using the CoT technique. It could simplify AI's integration into medical education, allowing healthcare professionals to easily use tools like ChatGPT, without the need for intricate prompt engineering.
Data availability
All data generated or analyzed during this study are included in this published article: Supplementary data: MAIN-Supp-prompt-engineering-answers.xlsx—Supplementary Information’s 1 and 2. Example of calculation and non-calculation questions: Calculation-nonCalculation_QuestionType_SupplimentFile.xlsx—Supplementary Information 3. Examples of Various Prompts Questions and Answers according to specific Clinical Field: Prompt_Examples_ClinicalFields.xlsx—Supplementary Information 5. Supplementary Data in SVPSS format: Main_Prompteng_supplementary_question_and_answer.sav—Supplementary Information 4.
References
Nastasi, A. J. et al. A vignette-based evaluation of ChatGPT’s ability to provide appropriate and equitable medical advice across care contexts. Sci. Rep. 13(1), 17885 (2023).
Lahat, A. et al. Evaluating the use of large language model in identifying top research questions in gastroenterology. Sci. Rep. 13(1), 4164 (2023).
Sorin, V. et al. Large language model (ChatGPT) as a support tool for breast tumor board. NPJ Breast Cancer 9(1), 44 (2023).
Taloni, A. et al. Comparative performance of humans versus GPT-40 and GPT-35 in the self-assessment program of American Academy of Ophthalmology. Sci. Rep. 13(1), 18562 (2023).
Sabry Abdel-Messih, M. & Kamel Boulos, M. N. ChatGPT in clinical toxicology. JMIR Med. Educ. 9, e46876 (2023).
White, J., Fu, Q., Hays, S. et al. A prompt pattern catalog to enhance prompt engineering with ChatGPT. Preprint at https://doi.org/10.48550/arXiv.2302.11382 (2023).
Prompt Engineering Guide. www.PromptingGuide.ai (Accessed 7 May 2021).
Brin, D. et al. Comparing ChatGPT and GPT-4 performance in USMLE soft skill assessments. Sci. Rep. 13(1), 16492 (2023).
Liévin, V., Hother, C.E., Winther, O. Can large language models reason about medical questions? Preprint at https://doi.org/10.48550/arXiv.2207.08143 (2023).
Nori, H., King, N., McKinney, S.M. et al. Capabilities of GPT-4 on medical challenge problems. Preprint at https://doi.org/10.48550/arXiv.2303.13375 (2023).
Klang, E. et al. Advantages and pitfalls in utilizing artificial intelligence for crafting medical examinations: A medical education pilot study with GPT-4. BMC Med. Educ. 23(1), 772 (2023).
Kojima, T., Gu, S.S., Reid, M. et al. Large language models are zero-shot reasoners. Preprint at https://doi.org/10.48550/arXiv.2205.11916 (2023).
Wei, J., Wang, X., Schuurmans, D. et al. Chain-of-thought prompting elicits reasoning in large language models. Preprint at https://doi.org/10.48550/arXiv.2201.11903 (2023).
Introducing Chatgpt. openai.com. https://openai.com/blog/chatgpt (Accessed 7 May 2023).
United States Medical Licensing Examination. https://www.usmle.org/sites/default/files/2021-10/Step_1_Sample_Items.pdf (Accessed 7 May 2021).
Biswas, S. Passing is great: Can ChatGPT conduct USMLE exams?. Ann. Biomed. Eng. https://doi.org/10.1007/s10439-023-03224-y (2023).
Pricing Open AI. openai.com. https://openai.com/pricing (Accessed 7 May 2021).
Wang, X., Wei, J., Schuurmans, D. et al. Self-consistency improves chain of thought reasoning in language models. Preprint at https://doi.org/10.48550/arXiv.2203.11171 (2023).
Brown, T.B., Mann, B., Ryder, N. et al. Language models are few-shot learners. Preprint at https://doi.org/10.48550/arXiv.2005.14165 (2020).
Author information
Authors and Affiliations
Contributions
E.K. and D.P.: conceived the experiment(s), E.K. and D.P.: conducted the experiment(s), E.K., D.P., G.R., P.T., B.G., G.N., D.A., E.B., S.C.: analyzed the results. E.K., D.P., G.R., P.T., B.G., G.N., E.Z., R.F.: reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Patel, D., Raut, G., Zimlichman, E. et al. Evaluating prompt engineering on GPT-3.5’s performance in USMLE-style medical calculations and clinical scenarios generated by GPT-4. Sci Rep 14, 17341 (2024). https://doi.org/10.1038/s41598-024-66933-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-66933-x
Keywords
This article is cited by
-
The performance of ChatGPT on medical image-based assessments and implications for medical education
BMC Medical Education (2025)
-
Large language model agents can use tools to perform clinical calculations
npj Digital Medicine (2025)
-
Evaluating performance of large language models for atrial fibrillation management using different prompting strategies and languages
Scientific Reports (2025)
-
A chemical autonomous robotic platform for end-to-end synthesis of nanoparticles
Nature Communications (2025)
-
Evaluation of large language models in patient education for hyperthyroidism: A comparative study of chatgpt, gemini, and deepseek
Endocrine (2025)
