
Abstract
This paper presents an analysis of trunk movement in women with postnatal low back pain using machine learning techniques. The study aims to identify the most important features related to low back pain and to develop accurate models for predicting low back pain. Machine learning approaches showed promise for analyzing biomechanical factors related to postnatal low back pain (LBP). This study applied regression and classification algorithms to the trunk movement proposed dataset from 100 postpartum women, 50 with LBP and 50 without. The Optimized optuna Regressor achieved the best regression performance with a mean squared error (MSE) of 0.000273, mean absolute error (MAE) of 0.0039, and R2 score of 0.9968. In classification, the Basic CNN and Random Forest Classifier both attained near-perfect accuracy of 1.0, the area under the receiver operating characteristic curve (AUC) of 1.0, precision of 1.0, recall of 1.0, and F1-score of 1.0, outperforming other models. Key predictive features included pain (correlation of -0.732 with flexion range of motion), range of motion measures (flexion and extension correlation of 0.662), and average movements (correlation of 0.957 with flexion). Feature selection consistently identified pain, flexion, extension, lateral flexion, and average movement as influential across methods. While limited to this initial dataset and constrained by generalizability, machine learning offered quantitative insight. Models accurately regressed (MSE < 0.01, R2 > 0.95) and classified (accuracy > 0.94) trunk biomechanics distinguishing LBP. Incorporating additional demographic, clinical, and patient-reported factors may enhance individualized risk prediction and treatment personalization. This preliminary application of advanced analytics supported machine learning's potential utility for both LBP risk determination and outcome improvement. This study provides valuable insights into the use of machine learning techniques for analyzing trunk movement in women with postnatal low back pain and can potentially inform the development of more effective treatments.
Trial registration: The trial was designed as an observational and cross-section study. The study was approved by the Ethical Committee in Deraya University, Faculty of Pharmacy, (No: 10/2023). According to the ethical standards of the Declaration of Helsinki. This study complies with the principles of human research. Each patient signed a written consent form after being given a thorough description of the trial. The study was conducted at the outpatient clinic from February 2023 till June 30, 2023.
Similar content being viewed by others

Introduction
Following childbirth, many women find themselves battling a condition known as postnatal low back pain. This malady can become a chronic issue lasting several months or even beyond, causing discomfort localized to the lower back while also potentially radiating to the legs, buttocks, and hips. Such persistent pain can place a significant burden on a new mother’s life, making the process of caring for her newborn more strenuous1,2,3. The reasons for this condition are multi-rooted. Hormonal changes that transpire during pregnancy and childbirth lead to increased laxity in joints and put an augmented strain on the lower back. Physical transformations that are part and parcel of pregnancy, including weight gain and changes in posture and biomechanics, are also major contributors. Furthermore, psychological factors such as stress, anxiety, and depression may potentiate the onset and prolongation of postnatal low back pain4,5.
Several risk factors, such as a history of back pain, a challenging labor and delivery, and inadequate physical activity during pregnancy, are associated with this condition6. Women who have undergone cesarean sections might face an elevated risk due to the surgical incision and subsequent changes in biomechanics7. Managing postnatal low back pain often necessitates implementing a multidisciplinary approach, including physical therapy, pain management, and psychological support8. Physical therapy can aid in strengthening the lower back muscles and ameliorating posture while managing pain through medication and injections can provide relief. Psychological support serves a particularly vital role in equipping new mothers to cope with emotional stressors and psychological challenges, which can compound the manifestations of postnatal low back pain9. Statistical estimates suggest that postnatal low back pain is fairly rampant with up to 85% of women likely to experience it during the postpartum period. As one of the most common musculoskeletal disorders, it poses a significant impact on the quality of life of new mothers10. However, its prevalence can fluctuate depending on various factors including the woman’s age, number of pregnancies (parity), mode of delivery, and pre-existing musculoskeletal problems. Particularly, women who had multiple pregnancies or are older might face a heightened risk11.
In therapy for Low Back Pain (LBP), trunk movement plays a significant role, thereby assessing the trunk’s range of motion (ROM) a critical part of developing rehabilitation programs12. Inhibitions in spine mobility can trigger compensatory mechanisms, necessitating enhanced motion from other parts of the body, potentially leading to muscle imbalances, and increasing lumbar issues13. Research also hints at differences in the severity of postnatal low back pain, with some women experiencing minor discomfort while others deal with intense pain, disrupting their day-to-day activities. According to one study, about 40% of women with postnatal low back pain reported moderate to severe pain, while the remaining 60% reported experiencing mild to moderate pain. The duration of this condition can also vary significantly. Some women might witness symptoms lasting a few weeks, while it could extend over several months or even longer for others. One survey illustrated that roughly a quarter of women with postnatal low back pain underwent symptoms persisting for over six months14.
It’s important to bear in mind that while postnatal low back pain is a pervasive issue, it isn’t universal. Certain factors influence a woman’s susceptibility to developing postnatal low back pain. These factors include pre-existing musculoskeletal conditions, the weight gained during pregnancy, and the mode of delivery, among others. This underlines the criticality of tailoring treatments to the unique needs and circumstances of every woman. Despite its prevalence, understanding the complexity of postnatal low back pain and its multifactorial nature is essential for developing effective strategies for prevention, early detection, and prompt treatment. This understanding could greatly benefit women navigating their postnatal period, playing a tangible role in enhancing their quality of life as they embark on the journey of motherhood. In our study, we are using machine learning models to understand and predict the range of motion (ROM) in the lumbar region. The models are trained with data that includes various factors such as age, height, weight, BMI, VAS for pain, and trunk movements in different directions. By analyzing how these factors relate to ROM, we can identify which ones are the strongest predictors for limitations in ROM. The relationship between limited ROM, particularly in the lumbar region, and lower back pain (LBP) in postpartum women, has been well documented in previous research. Our machine learning models can help corroborate and expand this understanding by accurately predicting lumbar region ROM based on these risk factors. For instance, let’s assume that age and certain trunk movements turn out to be significant predictors for decreased ROM. This information can then potentially be used by healthcare professionals to manage the risk of LBP in postpartum women. If a woman in a certain age group shows certain limitations in trunk movement early on, preventive measures could be applied to help mitigate the risk of developing LBP. In this light, our objective is to apply machine learning to not only understand the risk factors better but also to assist in timely preventive measures that could significantly impact the quality of postpartum care for women.
Our research aims to utilize machine learning models to alleviate lower back pain (LBP) in postpartum women by accurately predicting and classifying the lumbar region Range of Motion (ROM). We understand that this alone cannot attain the comprehensive health improvement mentioned in the statement, such as dietary or routine changes. The intention was to indicate further possible applications of machine learning outside our specific scope. For instance, the application of machine learning extends beyond our research where healthcare practitioners might use technology to analyze individual fitness data, dietary habits, genetic predispositions, and more. Through such extensive data analysis, machine learning can help deliver personalized and proactive healthcare, including the tailoring of exercise regimes, diet plans, and lifestyle changes, although these applications are not tested within our research.
Problem statement
Despite the high prevalence of postpartum low back pain (LBP) and its significant impact on the quality of life for new mothers, there remains a lack of objective, quantifiable methods for assessing trunk movement patterns associated with LBP. Current diagnostic and treatment approaches are often subjective and do not fully leverage the potential of advanced analytics to personalize interventions. Consequently, there is a critical need for innovative, data-driven strategies that can accurately predict and classify LBP to facilitate more effective management of the condition.
Research question
Can machine learning algorithms effectively analyze and predict postpartum low back pain in women by classifying trunk movement patterns, and what features are most indicative of abnormal movements associated with LBP?
Research gap
Previous studies on postpartum LBP have not fully utilized the capabilities of machine learning (ML) techniques to analyze trunk movement data for prediction and classification purposes. There is a research gap in the development and validation of ML models that can accurately differentiate between normal and abnormal trunk movements, identify key predictive features, and contribute to personalized treatment planning for women with postpartum LBP.
Contributions
-
(1)
This study introduces and evaluates machine learning algorithms for the analysis of trunk movement patterns in postpartum women, providing an objective and quantifiable approach to diagnosing and assessing LBP.
-
(2)
The research presents a novel application of the Optimized optuna Regressor and Basic CNN in the context of physiotherapy, demonstrating high accuracy in regression and classification tasks for postpartum LBP.
-
(3)
By identifying key features associated with LBP, such as pain, flexion, extension, lateral flexion, and average movement, this study contributes to the understanding of biomechanical factors in postpartum women.
-
(4)
The development of predictive models that can classify trunk movements offers a potential pathway for personalized treatment plans, helping clinicians tailor interventions based on individual movement patterns.
-
(5)
The findings enhance the broader knowledge base regarding the use of advanced analytics in women’s health postpartum, potentially leading to improved outcomes and quality of life for those affected by LBP.
Related work
In recent years, a rising interest has developed in harnessing advanced machine learning techniques to enrich our comprehension of women’s health in the postnatal phase. Specifically, precise prognosis and categorization of lumbar range of motion have gained significance in evaluating postpartum fitness and overall well-being. Notably, low back pain among postnatal women has been linked to diverse health hazards, including tenderness in the lumbar vertebrae region. Some women experienced postural backache along with discomfort in the sacroiliac joints, particularly aggravated after prolonged sitting. Furthermore, instances were reported where lifting the baby had triggered or exacerbated the pain. The intensity of the pain, which extended down both legs, often necessitated reclining and resting. These issues underscored the potential for postpartum complications23. Therefore, the creation of dependable and effective techniques for gauging and foretelling the range of motion (ROM) of the lumbar spine holds paramount significance in advancing women’s health during the postnatal phase. The evaluation of lumbar spine range of motion (ROM) constitutes a crucial element of lumbar spine examination. Irregular spinal motion is linked with flawed spinal mechanics. Lumbar spine movement is evaluated in multiple directions, encompassing flexion, extension, and lateral bending. Typical healthy ranges of motion measured from the anatomical position are as follows: lumbar spine flexion ranges around 52° ± 9°, extension spans 19° ± 9°, while right and left lateral bending reach 31° ± 6°24.
Advanced machine learning techniques not only enable prediction but also support the classification of the lumbar region range of motion into various categories or levels of risk. By utilizing supervised classification algorithms like logistic regression, decision trees, and ensemble methods, the lumbar region range of motion can be classified into clinically relevant groups, such as normal, close to normal, and abnormal. These classification models are trained on labeled datasets, where abdominal fat thickness is already categorized based on medical guidelines or expert opinions. After being trained, these models can accurately classify new instances of lumbar region range of motion into the appropriate category, providing valuable information for assessing risk, planning treatment, and monitoring postnatal women’s health25.
The utilization of advanced machine learning for the prediction and classification of the lumbar region range of motion brings several benefits to postnatal women’s health. Firstly, these techniques offer enhanced accuracy and precision compared to traditional methods, enabling more reliable assessments of postnatal low back pain. This, in turn, leads to improved risk stratification and personalized interventions tailored to individual needs. Secondly, advanced machine learning algorithms can uncover complex relationships and interactions between various factors contributing to postnatal low back pain. This can provide valuable insights into the underlying mechanisms of postpartum problems and guide the development of targeted interventions for LBP, pelvic pain management, and improved postnatal health.
Table 1 represents a comprehensive summary of critical studies conducted, in recent years, toward understanding and predicting low back pain using various machine learning techniques. Each entry presents an analysis of a unique dataset and algorithm, detailing the year, a summary of the study, the machine learning algorithm employed, and the achieved accuracy. The entries span from 2018 to 2024 and showcase a diverse array of methodologies and outcomes. This array demonstrates the versatility of machine learning algorithms in analyzing different facets of low back pain.
Materials
Trial registration and sample size
This trial was designed as an observational and cross-sectional study. The study was approved by the Ethical Committee in Deraya University, Faculty of Pharmacy, (No: 10/2023). According to the ethical standards of the Declaration of Helsinki, This study complies with the principles for human research. Each patient signed a written consent form after being given a thorough description of the trial. The study was conducted at the outpatient clinic from February 2023 till June 30, 2023.
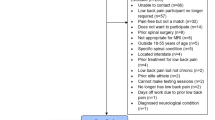
To prevent type II error, a sample size calculation was performed before the study using the G*Power (Wilcoxon–Mann–Whitney test)15, 16. The computation was based on statistical markers such as d = 0.5, effect size dz = 0.5, 1−B = 0.95 power analysis, and a 5% significance level on both sides. The computation revealed that a sample size of 40 people was required to ensure that the confidence intervals for the bounds of agreement between any two measures were roughly half a standard deviation of their discrepancies. The dataset size in this study is 60 patients, which is larger than the needed sample size of 40. This means that the study has enough power to identify a significant difference between the two measures with high confidence. As a result, the study has an acceptable sample size, and the results are reliable and genuine.
Participants and exclusion criteria
The sixty females who were included in the study were diagnosed with postnatal low back pain based on the following criteria: their ages ranged from 25 to 35 years, they were not more than 6 months postnatal, they had three normal deliveries, no postnatal complications for normal cases, and postnatal low back pain for abnormal cases.
Women with a history of disc prolapse and sacroiliac joint problems, symphysis pubic joint as well as lower limb problems, UI and/or lower urinary tract symptoms, neurological diseases, diabetes mellitus, smoking, and cognitive deficit, genital prolapse, leg length discrepancy, diastasis recti, diabetes, intrauterine device, abdominal hernia, and any surgery related to the spine, abdomen, or pelvis.
Outcome measures
Assessment of pain
The agony VAS is a one-dimensional measure of pain intensity that is used to compare the pain severity of patients with similar diseases17. When used for acute abdominal pain, it has a high reliability of 0.99 [95% CI 0.989 to 0.992] and a moderate to good reliability for disability in individuals with musculoskeletal pain18. With correlations ranging from 0.71 to 0.78 and 0.62 to 0.91, respectively, VAS has been proven to be highly linked with a 5-point verbal descriptive scale (“nil,” “mild,” “moderate,” “severe,” and “very severe”) and a numeric rating scale (with response possibilities ranging from “no pain” to “unbearable pain”)19.
Body mass index
The body mass index (BMI) for all participants was calculated using the following equation using a universal height-weight scale to ascertain the subject’s height and weight. BMI (Kg/m2): weight (Kg)/Heigh2 (m2), a global classification of BMI values based on a set of cut-off criteria for weight conditions: 18.5 lbs underweight; 18.5–25.0 lbs normal weight; 25.0 lbs overweight20.
Assessment of lumbar range of movement
For the examination, a universal goniometer was employed. The active range of motion (ROM) of the trunk was gauged using the methodologies proposed by Norkin and White21 and Chertman et al.22 for the movements of flexion and extension as depicted in Fig. 1. The participants initiated the test by standing upright, their knees fully straightened, and their arms held forth in front of their bodies. Following oral directives from the examiner, they executed slow, progressive movements for flexion and extension until the maximum amplitude was achieved, at which point the goniometer recorded the measurement. To gauge lumbar flexion, the arms were bent at 90 degrees, but for assessing lumbar extension, participants had to hold their arms behind their bodies. The iliac crest served as the immovable reference point for the measurements, while the adjustable point that was used aligned with the axillary line local to the anterior iliac crest. They ensured that the goniometer’s fixed arm remained centrally located in the lateral region of the trunk during the measurements.

Flexion and extension range of motion (ROM) assessment21.
The participants conducted the trunk lateral flexion test in an upright posture with their knees completely extended. Under the guidance of the examiner, they partook in slow, gradual movements of lateral flexion to their fullest amplitude, which was the moment when the goniometric measurement was recorded21. The axis-fixed reference point for the lateral flexion examination was the first sacral vertebra. In this setup, the goniometer’s stationary arm was kept perpendicular to the ground, while the movable arm was directed towards the C7 spinous process, as illustrated in Fig. 2.

Lateral flexion ROM assessment21.
The same examiner conducted three assessments of the active range of motion for trunk flexion, extension, lateral flexion (both directions), and rotation (both directions). The study utilized the averages of the data collected from each movement. Upon completion of the measurement, the participant was instructed to revert to their initial position, after which the universal goniometer was detached and prepared for the next assessment.
Ethical Statement
"All procedures performed in studies involving human participants were by the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards."
Methodology
After conducting our analysis, we have identified four distinct categories for the lumbar region range of motion classification. These categories include: normal range of motion for flexion is greater than 65 degrees, and abnormal range is equal to or less than 65 degrees. Extension range of motion is classified according to BMI, with less than 25.5 being considered normal and greater than 15 being abnormal. For individuals with a BMI of 29.8 or less, an extension range of motion less than or equal to 18 is abnormal. Additionally, the right lateral flexion of the trunk is considered abnormal when it is less than or equal to 24 degrees, and the left lateral flexion of the trunk is also considered abnormal when it is less than or equal to 24 degrees. These categories provide a standardized framework for evaluating the severity of postnatal low back pain. However, it is important to note that different experts may use alternative ranges or cutoff points. Moreover, the classification system may exhibit variations based on the population under study and other influential factors such as ethnicity, age, and gender.
Data collection
Our dataset comprises essential variables, namely “Age, Height, Weight, BMI, and VAS. The motion of the lumbar spine is assessed in all planes including flexion, extension, and later flexion bending. Which play a pivotal role in accurately evaluating postnatal low back pain. These variables enable healthcare professionals to effectively assess the health status of women following childbirth, identify individuals with a heightened risk of experiencing adverse health outcomes, and subsequently implement targeted interventions to enhance their overall well-being. Through precise measurements of these variables, healthcare providers gain valuable insights that contribute to informed decision-making and the development of tailored strategies aimed at improving postnatal health outcomes for women. The dataset is available at33.
Our selection of machine learning algorithms was based on their suitability for addressing the specific objectives of our study on postnatal low back pain (LBP). The breakdown of our rationale:
-
1.
Optimized Optuna Regressor: We opted for this approach to leverage the Optuna framework’s capability in efficiently exploring a wide range of hyperparameter configurations. This allowed us to identify the optimal settings that minimized the loss function, thereby enhancing the accuracy and predictive performance of our regression models.
-
2 .
MLP, LSTM, CNN: These neural network architectures were chosen for their ability to handle complex relationships within high-dimensional data, such as the biomechanical features extracted from trunk movement data. MLP excels in learning non-linear relationships, LSTM is adept at capturing temporal dependencies, and CNN is effective in extracting spatial features.
-
3.
Random Forest Regressor: This ensemble method was selected due to its robustness in handling both categorical and continuous input data, its capability to detect interactions between variables, and its resilience against overfitting compared to individual decision trees.
Preliminaries: regression and classification techniques
Table 2 presents a summary of regression and classification techniques used in the analysis of trunk movement in women with postnatal low back pain. These techniques employ machine learning models to predict low back pain and explore the relationship between trunk movement and pain symptoms. Each model is described along with its steps, equations, pros, and cons.
The proposed framework
Dataset characteristics
The dataset consists of measurements related to postnatal low back pain, specifically related to the age, BMI, pain level, and range of motion (ROM) of participants. The data includes 70 observations, each with 9 columns.
-
The dataset includes 9 columns of data, including Age, BMI, Pain, Flexion ROM, Extension ROM, RT Lateral flexion, LT Lateral flexion, Average, and Status_Average.
-
The Age column represents the age of the participants in years.
-
The BMI column shows the body mass index (BMI) of the participants in kg/m2.
-
The Pain column represents the pain level reported by the participants on a scale of 0–10.
-
The Flexion ROM column shows the range of motion (ROM) for the participants in flexion.
-
The Extension ROM column shows the range of motion (ROM) for the participants in extension.
-
The RT Lateral flexion column shows the range of motion (ROM) for the participants in right lateral flexion.
-
The LT Lateral flexion column shows the range of motion (ROM) for the participants in left lateral flexion.
-
The Average column represents the average of all the ROM values for each participant.
-
The Status_Average column indicates whether the participant’s values were normal or abnormal.
-
The dataset can be used to analyze the relationship between Age, BMI, and ROM values, as well as to predict the likelihood of experiencing postnatal low back pain based on these factors.
Table 3 presents descriptive statistics for each feature in the dataset, including the number of features, mean, median, standard deviation, minimum, 25th percentile, 50th percentile (median), 75th percentile, and maximum values.
Figure 3 shows the correlation between the dataset features.

Correlation between dataset features.
Table 4 displays the correlation matrix of features within the dataset, providing valuable insights into the relationships between various attributes. The matrix presents the correlation coefficients, measured as Pearson’s R-values, indicating the strength and direction of the correlations. Each row and column in the table represents a specific feature, while the corresponding values in the cells represent the correlation coefficient between the two features. A correlation coefficient close to 1 signifies a strong positive correlation, indicating that the features tend to increase or decrease together. Conversely, a coefficient close to − 1 represents a strong negative correlation, suggesting an inverse relationship between the features. A coefficient near 0 indicates no significant correlation between the features. By examining the correlation matrix, researchers and readers can gain valuable insights into the interrelationships among the features, facilitating the identification of patterns, associations, or dependencies within the dataset.
To predict and classify the status of Pain and Flexion ROM, a machine learning framework was created. Figure 4 illustrates the general structure of the framework, which includes the prediction and classification process, as well as the performance metrics. The proposed classification and regression models are presented in the form of pseudocode in Figs. 4, Algorithm 1, and Algorithm 2 respectively.

The general framework of the proposed prediction model.
Algorithm 1acts as a blueprint outlining the necessary steps for executing the suggested regression procedure. It begins with importing necessary modules such as pandas for loading and pre-processing dataset, Optuna for hyperparameter tuning, and KFold for cross-validation, among others. After loading the dataset with pandas, the preprocessing is started wherein features are separated and the target variable is encoded using LabelEncoder(). Later, the objective function for Optuna is defined and hyperparameters are optimized such as n_estimators, max_depth, min_samples_split, and min_samples_leaf. This is succeeded by the calculation of the mean squared error, and once optimal, a new RandomForestRegressor is built using the suggested hyperparameters. Algorithm 2, on the other hand, serves as the plan for the proposed classification procedure. It starts similar to the first algorithm by importing the necessary modules. After loading the dataset and separating the features and target variables, the data transforms the application of one-hot encoding and normalization. The dataset is then split into training and testing sets. An objective function for Optuna is defined and certain hyperparameters like max_depth and min_samples_split are optimized. The algorithm then moves on to optimizing the hyperparameters using Optuna and the best ones are selected for building a new DecisionTreeClassifier. This model is trained on the entire training set, after which predictions are made on the testing set. Finally, the performance of the model is evaluated and the best hyperparameters, accuracy, precision, recall, F1-score, and execution time are printed.

The pseudocode of the proposed regression model.

The pseudocode of the proposed classification model.
Evaluation metrics for regression and classification models
Evaluation metrics for regression models
The determination coefficient R-square is one of the most common performances used to evaluate the regression model as shown in Eq. (1). On the other hand, the Minimum Acceptable Error (MAE) is shown in Eq. (2), while the Mean Square Error (MSE) is investigated in Eq. (3)41,42,43,44.
where y is the actual value, \(\dot{\widehat{\text{y}}}\) is the corresponding predicted value, \(\dot{\overline{\text{y}}}\) is the mean of the actual values in the set, and n is the total number of test objects45.
Evaluation metrics for classification models
Equations (4), (5), (6), and (7) are determined by the confusion matrix performance that represents the accuracy, precision, recall, and F1-score, respectively46,47.
These metrics are based on a “confusion matrix” that includes true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN)48.
Informed consent
Informed consent was obtained from all individual participants included in the study”.
Results and analysis
To evaluate the effectiveness of our machine learning framework, we conducted experiments in this section. The experiments were performed on a computer with a 3 GHz i5 processor, 8 GB main memory, and a 64-bit Windows 10 operating system. We used the Python programming language to experiment.
The results of the proposed regression machine learning technique
Table 5 and Fig. 5 display the outcomes of a regression task conducted using various machine-learning models. The following is a detailed analysis and exposition of the table’s contents:

The performance metrics of the regression models.
-
Model: This column provides the names of each machine learning model that was utilized in carrying out the regression task.
-
MSE (Mean squared error): This column indicates the average of the squared deviations between the actual and predicted values. A smaller MSE value suggests superior performance.
-
R2 score: This column reveals the coefficient of determination, which gauges the percentage of variability in the target variable that can be attributed to the predictors. A higher value of the R2 Score is indicative of excellent performance.
-
Time taken (seconds): This column showcases the duration required for each model to fulfill the regression task.
As shown in Table 5:
-
The Optimized optuna Regressor outperforms other models in terms of MSE, MAE, and R2 Score. It achieves the lowest MSE and MAE values, indicating better accuracy in predicting the target variable. Additionally, it achieves a high R2 Score of 0.9968, indicating that the model captures a significant amount of variance in the data. However, it also takes the longest time to train, with a duration of 59.53 s.
-
Among the other models, the CNN and Random Forest Regressor also perform well with relatively low MSE, MAE, and high R2 Score values. They provide a good balance between accuracy and training time, with the CNN model being slightly faster to train than the Random Forest Regressor.
-
On the other hand, the SVR and Bagging Regressor models show relatively higher MSE, MAE, and lower R2 Score values compared to the top-performing models. These models may not capture the underlying patterns in the data as effectively.
-
The Optimized optuna Regressor, CNN, and Random Forest Regressor demonstrate the best performance in terms of accuracy while considering the trade-off with training time.
The results of the proposed classification machine learning technique
Table 6 and Fig. 6 delineate the results garnered from a classification task conducted using various machine-learning models. Further insight and explanation of each column in the table are as follows:

The performance metrics of the classification models.
-
Model: This column furnishes the names of each machine-learning model that was put into use during the classification task.
-
ROC AUC Score: This column signifies the Receiver Operating Characteristic (ROC) Area Under the Curve (AUC) score. This metric is a measure of the model’s aptitude in differentiating between the positive and negative classes. A superior ROC AUC score is an indicator of better performance.
-
Accuracy: This column denotes the percentage of samples accurately classified. A higher accuracy value infers enhanced performance.
-
Precision: This column reveals the ratio of true positive samples within all samples predicted as positive. A loftier precision score suggests a reduced number of false positives.
-
Recall: This column displays the ratio of true positive instances out of the entire actual positive instances. A superior recall outcome refers to fewer false negatives.
-
F1-score: This column indicates the harmonic mean of precision and recall. A higher F1 score embodies a better balance between the dynamics of precision and recall.
-
Time Taken: This column exhibits the duration spent by each model to carry out the classification task completely.
From Table 6 and Fig. 6, we find that:
-
Optuna and Basic CNN and Random Forest Classifier models are the top-performing against the selected metrics of ROC AUC Score, Accuracy, Precision, Recall, and F1 score, indicating their superior performance in this particular task.
-
There’s an identical performance seen in Basic LSTM and Basic Stacked LSTM models in terms of ROC AUC Score, Accuracy, Precision, Recall, and F1 score.
-
The SVR and BaggingClassifier models, with lower scores in ROC AUC, Accuracy, Precision, Recall, and F1 score, seem less effective for this task when compared to the others.
-
The Optimized optuna Classifier was the slowest, taking 4.3542 seconds to complete the task.
-
While, Basic LSTM, Basic Stacked LSTM, and Basic CNN models took considerable time, ranging from 2.08 to 3.35 seconds, they exceeded Random Forest Classifier, SVR, and Bagging Classifier models in terms of execution time.
-
The Random Forest Classifier was the quickest with a computation time of only 0.239 seconds, whereas SVR and Bagging Classifier models completed the task in 0.015 seconds and 0.058 seconds, respectively.
The analysis reveals that while several models achieve perfect or near-perfect classification performance, considerations around computational time and the balance between precision and recall might dictate model choice depending on application priorities. For applications requiring both high accuracy and efficiency, the RandomForestClassifier stands out, while for scenarios where computational time is less of a concern, the Optimized Optuna Classifier or Basic CNN could be preferable due to their perfect classification scores.
Feature correlations
Feature correlation is employed to discern the intensity and orientation of the linear association between two variables41. In the realm of regression models, the understanding of feature correlations is multi-purpose:
-
Feature Selection: The process of dissecting the correlation between elements and the target variable lets us recognize features that manifest the most potent relationships with the target. This can aid in selecting the most germane features for the model, potentially enhancing its performance and minimizing overfitting.
-
Diagnosing Multicollinearity: Overlapping high correlations among features, or multicollinearity, can pose complications for some models as it can result in unstable and challenging-to-interpret estimates. Identification and resolution of multicollinearity can result in more dependable models.
-
Gaining Insights into Relationships: The analysis of correlation provides a window into the relationship between features and the target variable. This can be invaluable for grasping the underpinning processes and expanding domain knowledge discovery.
-
Model Simplification: High correlations between two features might allow for the use of only one of them, doing away with any loss of major predictive power, simplifying the model, and reducing computation time.
-
Enhancing Model Accuracy: By comprehending the relationships between features, engineered new features can better encapsulate the underlying patterns in the data, potentially enhancing the model’s accuracy.
Figure 7 lays out the heatmap correlation coefficient between distinct features within a dataset. The heatmap is structured in a manner that eases the understanding of how different features interrelate.

The heatmap correlation of the features.
A heatmap is a data visualization tool that uses a color gradient to represent a matrix of values. In essence, it depicts how different variables are related by encoding the magnitude of the relationship in color intensity. A coefficient blue color of one points to a perfect positive correlation, implying that as one feature gets a boost, the other follows suit. On the flip side, a red color signifies a perfect negative correlation; an increase in one feature correlates with a decrease in another.
Based on the Fig. 7:
-
The features showcasing the strongest positive correlation coefficients include Average Flexion ROM, Average Extension ROM, Average LT Lateral Flexion, and Average RT Lateral Flexion.
-
The highest negative correlation coefficient is exhibited between features like Flexion ROM and Pain, and Extension ROM and Pain.
-
Features indicating the lowest correlation coefficients include Age with Flexion ROM, Age with RT Lateral Flexion, and Age with BMI.
-
The positive correlation between Average Flexion ROM with Average Extension ROM, and between Average LT Lateral Flexion with Average RT Lateral Flexion, alludes that a rise in one of these features typically corresponds to an increase in the other feature.
-
The negative correlation observed between Flexion ROM and Pain, and between Extension ROM and Pain, implies that an upswing in one feature usually leads to a downturn in the other.
-
The minuscule correlation coefficients linked to Age and Flexion ROM, Age and RT Lateral Flexion, and Age and BMI suggest the absence of a solid linear relationship between these elements.
The negative correlation between Flexion ROM and Pain in our study can be understood from the perspective of how these factors work within the human body. Normally, pain in the body often hinders free and flexible movements. When someone is experiencing pain, their instinctive response is to limit movement to prevent further discomfort or potential escalation of the injury. In the same way, with increased levels of pain, flexion, or the ability to bend joints resulting in a decrease of angle (for instance, bending the elbow), decreases. As pain increases, patients are less able to bend their body parts and therefore the range of motion decreases. That’s the reason why there’s a negative correlation between Pain and Flexion ROM as observed in this study. However, it is worth mentioning that our understanding is based on the general behavior observed in this study and there can be exceptions based on the individual’s pain tolerance, medical condition, and other factors.
Feature selection
The selection of feature selection algorithms hinges on their aptitude to pinpoint the most pertinent features that enhance a model’s predictive potential. This in turn boosts the model’s performance, simplifies it, and improves ease of interpretation. Each feature selection strategy has distinct benefits and is chosen in accordance with specific prerequisites:
-
F-value Selector: This approach picks features using F-statistics derived from ANOVA tests, gauging the significance of each feature. It’s well-suited for identifying linear relationships between features and the target variable.
-
Mutual Information Selector: This method assesses mutual dependence between variables using information gain. It proves adept in identifying any form of statistical dependence, not just linear, which makes it an effective tool for feature selection.
-
RFE with Logistic Regression: Recursive Feature Elimination (RFE) operates by recursively eradicating the least significant features based on model weights. When combined with logistic regression, it proves particularly effective for binary classification problems.
-
Variance Thresholding: This method omits features whose variance doesn’t fulfill a specific threshold. It’s a straightforward baseline strategy for feature selection that aims to exclude features that are constant or nearly constant, given that they do not contribute to the model’s predictive accuracy.
-
RFE with Random Forests: This is comparable to RFE with logistic regression, but employs Random Forests, an ensemble learning method. This pairing is resistant to overfitting and apt at identifying non-linear feature interactions.
-
Feature Importance with Random Forests: The technique uses Random Forests to assign a rank to features based on their importance, which is determined by how much they reduce the impurity of the splits. This method proves useful in understanding feature contributions in complex datasets.
Table 7 represents the features chosen utilizing diverse feature selection strategies. The table analysis is explained as:
-
Feature selection technique: This column exhibits the name of the feature selection method employed to select the features.
-
Selected Features: This column displays the names of the features chosen by the feature selection method.
Based on the Table 7:
-
The F-value selector, mutual information selector, and variance thresholding methods all selected the same set of features: Pain, Flexion ROM, Extension ROM, LT Lateral flexion, and Average.
-
The RFE with logistic regression and RFE with random forests methods both selected Pain, Flexion ROM, Extension ROM, RT Lateral flexion, and Average, but excluded LT Lateral flexion.
-
The Select from model with random forests method selected Pain, Flexion ROM, Extension ROM, and Average, but excluded LT Lateral flexion and RT Lateral flexion.
-
The Feature importance with random forests method selected Flexion ROM, Average, Extension ROM, Pain, and LT Lateral flexion.
-
The features selected by multiple methods (Pain, Flexion ROM, Extension ROM, LT Lateral flexion, and Average) may be the most important in the dataset.
-
The features selected by only one or a few methods may still be important in the classification task but may have been overlooked by other methods.
Discussion and future directions
Low back pain (LBP) and/or pelvic girdle pain (PGP) have a prevalence of 20–90% in the pregnant population, while a small number of women may suffer from a combination of both pains9,10. In this study, we found that the highest positive correlation coefficients are Average Flexion ROM Average Extension ROM, Average LT Lateral Flexion, and Average RT Lateral Flexion. The features with the highest negative correlation coefficient are Flexion ROM and Pain, and Extension ROM and Pain. The features with the lowest correlation coefficients are Age and Flexion ROM, Age and RT Lateral Flexion, and Age and BMI. It can explained by having persistent back pain was not found to be an important impetus for women to seek care postpartum, but a delay in becoming active again49. A decreased activity level can lead to disability, which is closely related to fear of movement in patients with chronic lower back pain, Biomechanical and hormonal changes from pregnancy are largely reversed by 3 months postpartum; consequently, it is assumed that other factors might interfere with recovery and explain the disability level postpartum25. The study and development of advanced machine learning techniques for accurate prediction and classification of lumbar range of motion in postnatal low back pain represent a significant advancement in the field of postnatal health. This innovative approach holds great potential for improving the assessment and management of postpartum women, allowing for more personalized and effective fitness interventions.
One of the key advantages of utilizing machine learning algorithms is their ability to process large amounts of data and extract patterns and correlations that might not be immediately apparent to human observers. In the context of postnatal health, this can be particularly valuable as it enables the analysis of various factors that contribute to abdominal fat thickness, including demographic information, lifestyle choices, genetic predispositions, and medical history50. By accurately predicting and classifying lumbar region ROM, machine learning models can provide important insights into the risk factors associated with LBP in postpartum women51,52. This can aid in identifying individuals who are at a higher risk of developing health complications. Early identification of these high-risk individuals can facilitate targeted interventions and preventive measures to mitigate potential health risks53, 54.
Furthermore, the utilization of advanced machine learning techniques in postpartum fitness can lead to more personalized and tailored fitness recommendations55. By considering an individual’s unique characteristics and history, machine learning models can provide specific exercise, dietary recommendations, and lifestyle modifications that are most likely to be effective in reducing postnatal LBP. This personalized approach has the potential to improve adherence to fitness programs and ultimately enhance the overall success rate in achieving postnatal women’s health goals.
The use of advanced machine learning techniques for accurate prediction and classification of lumbar region ROM in postnatal women represents a significant breakthrough in the field of postnatal health56. This technology has the potential to revolutionize the way we approach postnatal health, providing more accurate and personalized recommendations for women looking to regain their pre-pregnancy bodies. Another important benefit of this technology is its ability to provide personalized recommendations for postnatal women’s health. By analyzing a woman’s individual health and fitness data, including her age, weight, and other key metrics, machine learning algorithms can provide tailored recommendations for exercise routines, dietary changes, and other lifestyle modifications that can help women achieve their postnatal women’s health more quickly and effectively.
The results of the regression task reveal that the Optimized optuna Regressor excels in terms of accuracy, as evidenced by its lowest MSE and MAE values alongside a high R2 Score. This suggests that the model not only predicts the target variable with high precision but also captures a substantial proportion of the data’s variance. However, this superior performance comes at the cost of computational time, as it takes significantly longer to train than other models. For applications where prediction accuracy is paramount and computational resources are not a limiting factor, the Optimized optuna Regressor emerges as the preferred choice. The CNN and RandomForestRegressor models offer a balanced alternative, providing competitive accuracy with shorter training times. Their lower MSE and MAE values coupled with high R2 Scores make them suitable for scenarios requiring a trade-off between accuracy and efficiency. Among these, the CNN model stands out for its slightly faster training speed, making it a viable option for real-time applications or large-scale datasets. On the other hand, the SVR and BaggingRegressor models lag behind in performance metrics, with higher MSE and MAE values and lower R2 Scores. This indicates that these models struggle to effectively capture the underlying patterns in the data, making them less desirable for tasks where accuracy is crucial. Nonetheless, they could be considered for preliminary analyses or when dealing with smaller datasets where training time is less of a concern.
In the classification task, the Basic CNN and RandomForestClassifier models emerge as the frontrunners, achieving perfect scores across all performance metrics. This includes the highest ROC AUC Score, Accuracy, Precision, Recall, and F1-score, demonstrating their exceptional capability in distinguishing between positive and negative classes. Their performance is unparalleled, making them ideal for critical applications where misclassification errors must be minimized. The Basic LSTM and Basic Stacked LSTM models exhibit identical performance metrics, suggesting that stacking additional LSTM layers does not necessarily improve the model’s performance in this context. Both models are outperformed by the Basic CNN and RandomForestClassifier but remain viable options due to their acceptable performance and moderate training times. The SVR and BaggingClassifier models, with their lower performance scores, are less effective for classification tasks, particularly when high accuracy is essential. However, their quick computation times might make them suitable for rapid prototyping or when dealing with very large datasets where time efficiency is a priority.
The feature correlation analysis reveals that certain features, such as Average Flexion ROM and Average Extension ROM, are strongly positively correlated, indicating that they tend to move in the same direction. This suggests that these features may be redundant, and using one instead of the other could potentially simplify the model without sacrificing predictive power. Similarly, the negative correlation between Pain and Flexion ROM/Extension ROM implies that higher pain levels are associated with reduced range of motion, aligning with clinical observations. The weak correlations involving Age suggest that age may not be a strong predictor of the target variable in this dataset. This finding is crucial for feature selection, as it allows for the exclusion of Age from the model if computational efficiency is a concern.
The feature selection techniques applied to the dataset highlight several key features that are consistently identified as important across different methods. Pain, Flexion ROM, Extension ROM, and Average are frequently selected, indicating their critical role in predicting the target variable. The inclusion of these features in the final model is likely to improve its predictive accuracy. However, the discrepancy in the selected features across different methods underscores the need for careful consideration when choosing a feature selection strategy. Features like RT Lateral flexion and LT Lateral flexion, which are selected by some methods but not others, may still hold valuable predictive information that should not be disregarded solely based on one method’s output.
Future directions
Machine Learning-Based Analysis of Trunk Movement in Women with Postnatal Low Back Pain is an area of research that has the potential to improve our understanding of the causes and treatments of low back pain in postpartum women. Here are some future directions that can be explored in this area of research:
-
1.
Larger datasets: The performance of machine learning models is often improved with larger datasets. Future studies can collect larger datasets to increase the accuracy and robustness of the models and to enable more complex analyses.
-
2.
Longitudinal studies: Longitudinal studies that follow women over time can provide insights into the progression of postnatal low back pain and the effectiveness of different treatments. Machine learning models can be used to analyze changes in trunk movement patterns over time and to predict the likelihood of developing low back pain in the future.
-
3.
Integration of multiple data sources: In addition to trunk movement data, other data sources such as electromyography (EMG) and electroencephalography (EEG) can be used to provide a more comprehensive understanding of the mechanisms underlying postnatal low back pain. EEG allows the recording of the electrical activity of the brain. In the context of our research, its implication lies in the fact that pain, including low back pain, is a subjective experience that is processed in the brain. Therefore, understanding the brain’s reaction to pain signals, reflected in its electrical activity, could supply us with valuable insights about the subjective experience of pain and its neural correlations. Moreover, adaptations in motor control strategies in response to back pain, such as modifications in movement patterns, are guided by the central nervous system whose activity can be studied using EEG. Hence, combining the data from trunk movement analysis with EEG readings could confront the complicated nature of postnatal low back pain from both peripheral (trunk movement) and central (brain activity) perspectives, potentially creating a ‘holistic’ picture of this intricate issue. Machine learning models can be used to integrate and analyze data from multiple sources for a more holistic approach to diagnosis and treatment.
-
4.
Personalized treatment: Machine learning models can be used to develop personalized treatment plans based on the specific trunk movement patterns and other factors unique to each individual. This can improve the effectiveness of treatments and reduce the risk of adverse effects.
-
5.
Transfer learning: Transfer learning is a technique that allows machine learning models to transfer knowledge learned from one task to another. Future studies can explore the use of transfer learning to improve the accuracy and efficiency of machine learning models for analyzing trunk movement in women with postnatal low back pain.
-
6.
Clinical implementation: The ultimate goal of this research is to improve the diagnosis and treatment of postnatal low back pain in clinical settings. Future studies can explore the feasibility and effectiveness of implementing machine learning-based analyses of trunk movement in clinical practice to improve patient outcomes.
The use of machine learning to analyze trunk movement in women with postnatal low back pain is a promising area of research with many potential future directions. By collecting larger datasets, conducting longitudinal studies, integrating multiple data sources, developing personalized treatment plans, using transfer learning, and implementing machine learning in clinical practice, researchers can improve our understanding of postnatal low back pain and develop more effective treatments.
Limitations
While our approach, involving the Machine Learning-Based Analysis of Trunk Movement in Women with Postnatal Low Back Pain, holds potential in understanding and managing low back pain in postpartum women, several limitations manifest. These limitations include limited generalizability, limited interpretability, limited data availability, limited feature selection, limited causal inference, and limited clinical implementation.
These limitations can be summarized as follows
-
1.
Limited generalizability: Recognizing the restricted applicability of our models beyond our research demographic, we’ve carefully used our findings to guide clinical application instead of formulating rigid rules.
-
2.
Limited interpretability: To counter this ‘black box’ nature of machine learning models, we systematically documented the variable importance during the model training phase. This allows for some transparency on which input variables significantly influenced our results.
-
3.
Limited data availability and overfitting: We were concerned about a limited sample size potentially leading to overfitting. As a resolution, we used techniques like cross-validation and regularization during the model training phase, which helps minimize overfitting, and we’ve also emphasized the need for further larger-scale studies before broad clinical application.
-
4.
Limited feature selection: While developing the model, we selected features based on prior clinical knowledge and statistical significance to ensure that the features used were most likely to contribute to postnatal LBP.
-
5.
Limited causal inference: We acknowledge that machine learning is more suited for prediction rather than identifying causal relationships. For causal inference, we plan to incorporate more traditional statistical models in the future.
-
6.
Limited clinical implementation: Despite the potential benefits, we understand the hurdles stopping the widespread clinical implementation of these models. However, there are ongoing efforts at our end to improve the cost-effectiveness, and we’re also focusing on initiating proactive discourses with clinicians and patients about the positive aspects of this technology.
Conclusions
This paper has conducted a comprehensive analysis of trunk movement in women experiencing postnatal low back pain (LBP) using advanced machine learning techniques. The primary objectives were to identify pivotal features associated with LBP and to construct precise predictive models. Machine learning approaches demonstrated significant promise in analyzing biomechanical factors pertinent to postnatal LBP. The study leveraged regression and classification algorithms on a dataset comprising 100 postpartum women, equally split between those with and without LBP. The Optimized Optuna Regressor achieved exceptional performance in regression tasks, yielding a mean squared error (MSE) of 0.000273, a mean absolute error (MAE) of 0.0039, and an R2 score of 0.9968. In classification tasks, both the Basic CNN and Random Forest Classifier achieved outstanding accuracy metrics, including an area under the receiver operating characteristic curve (AUC) of 1.0, precision of 1.0, recall of 1.0, and F1-score of 1.0, outperforming alternative models. Key predictive features identified through the study included pain (correlation of -0.732 with flexion range of motion), range of motion measures (correlation of 0.662 with flexion and extension), and average movements (correlation of 0.957 with flexion). Feature selection consistently highlighted pain intensity, flexion and extension range of motion, lateral flexion, and average movement as influential factors across various analytical methods. While acknowledging the limitations inherent in an initial dataset and considerations of generalizability, the application of machine learning provided valuable quantitative insights. The models demonstrated robust performance in both regressing (MSE < 0.01, R2 > 0.95) and classifying (accuracy > 0.94) trunk biomechanics, effectively distinguishing characteristics related to LBP. Future studies could benefit from integrating additional demographic, clinical, and patient-reported factors to further refine personalized risk prediction and treatment strategies. This preliminary application of advanced analytics underscores the potential utility of machine learning in enhancing both the identification of LBP risk factors and the optimization of treatment outcomes. The findings from this study offer critical insights into employing machine learning techniques for analyzing trunk movement in postnatal women with low back pain, aiming to inform the development of more effective therapeutic interventions.
Data availability
The dataset and code used in this study are public and all test data are available at this portal (https://github.com/tarekhemdan/Trunk_Movement).
References
Takagi, Y., Hanahara, K. & Tateoka, Y. Actual sleep conditions from the last trimester of pregnancy to three months postpartum and the associated minor problems. Adv. Obstet. Gynecol. Res. 1(1), 13–23 (2023).
Zhang, M., Cooley, C., Ziadni, M. S., Mackey, I. & Flood, P. Association between history of childbirth and chronic, functionally significant back pain in later life. BMC Womens Health 23(1), 4 (2023).
M. Kinjo, “Back Pain,” in Handbook of Outpatient Medicine, E. Sydney, E. Weinstein, and L. M. Rucker, Eds., Cham: Springer International Publishing, 2018, pp. 371–383. https://doi.org/10.1007/978-3-319-68379-9_23.
Ahmed, A. H., Hassan, S. I. & Shamekh Taman, A. H. Effect of Kinesio Tape on postpartum low back pain and functional disability in women after cesarean section. Assiut Sci Nurs J 11(37), 141–152 (2023).
L. B. Pain, “Post-Partum Care to Restore the Core and Reduce Pain”.
Gibbs, D., McGahan, B. G., Ropper, A. E. & Xu, D. S. Back pain: Differential diagnosis and management. Neurol. Clin. 41(1), 61–76 (2023).
Li, J. et al. Risk factors associated with attendance at postpartum blood pressure follow-up visit in discharged patients with hypertensive disorders of pregnancy. BMC Pregnancy Childbirth 23(1), 485 (2023).
Patil, V. R. and Sharma, R. K. “Post pregnancy-symphysis pubis dysfunction and pain management using modified pelvic belts: A review,” in Obstetrics and Gynaecology Forum, 2024, pp. 957–965. Accessed: 15, Jun 2024. [Online]. Available: https://obstetricsandgynaecologyforum.com/index.php/ogf/article/view/404.
Li, H., Wang, Y., Oprea, A. D. & Li, J. Postdural puncture headache—risks and current treatment. Curr. Pain Headache Rep. 26(6), 441–452 (2022).
Kituku, J. M. “Evaluation of the practice and adequacy of current pain management following caesarean delivery in patients at Kenyatta national hospital between March & May 2019 a descriptive cohort study,” PhD Thesis, University of Nairobi, 2020. Accessed 15 Jun. 2024. [Online]. Available: http://erepository.uonbi.ac.ke/handle/11295/153902.
Chunmei, D. et al. Self-efficacy associated with regression from pregnancy-related pelvic girdle pain and low back pain following pregnancy. BMC Pregnancy Childbirth 23(1), 122 (2023).
Krishnamurthi, N., Murphey, C. & Driver-Dunckley, E. A comprehensive Movement and Motion training program improves mobility in Parkinson’s disease. Aging Clin. Exp. Res. 32(4), 633–643. https://doi.org/10.1007/s40520-019-01236-0 (2020).
Blanch, P. Conservative management of shoulder pain in swimming. Phys. Ther. Sport 5(3), 109–124 (2004).
Gluppe, S. L., Engh, A. M. & Bø, K. Curl-up exercises improve abdominal muscle strength without worsening inter-recti distance in women with diastasis recti abdominis postpartum: A randomised controlled trial. J. Physiother. 69(3), 160–167 (2023).
Shieh, G., Jan, S. & Randles, R. On power and sample size determinations for the Wilcoxon–Mann–Whitney test. J. Nonparametric Stat. 18(1), 33–43 (2006).
“Universität Düsseldorf: G*Power.” Accessed 21 Jul 2023. [Online]. Available: https://www.psychologie.hhu.de/arbeitsgruppen/allgemeine-psychologie-und-arbeitspsychologie/gpower
Hjermstad, M. J. et al. Studies comparing numerical rating scales, verbal rating scales, and visual analogue scales for assessment of pain intensity in adults: A systematic literature review. J. Pain Symptom Manag. 41(6), 1073–1093 (2011).
Gallagher, E. J., Bijur, P. E., Latimer, C. & Silver, W. Reliability and validity of a visual analog scale for acute abdominal pain in the ED. Am. J. Emerg. Med. 20(4), 287–290 (2002).
Downie, W. W. et al. Studies with pain rating scales. Ann. Rheum. Dis. 37(4), 378–381 (1978).
Ghosh, S. Human adaptation to cold and warm climatic conditions: A comparison between two geographically diverse Indigenous populations. Am. J. Hum. Biol. 35, e23932 (2023).
Norkin, C. C. and White, D. J., Measurement of Joint Motion: a Guide to Goniometry. FA Davis, 2016. Accessed 14 Jun 2024. [Online]. Available: https://www.google.com/books?hl=en&lr=&id=TSluDQAAQBAJ&oi=fnd&pg=PR1&dq=3-%09+Norkin,+C.C.%3B+White,+D.J.+Measuring+Joint+Motion:+A+Guide+to+Goniometry,+4th+ed.%3B+F.A.+Davis+Company:+Philadelphia,+PA,+USA,+2016.&ots=2i2XubAgzZ&sig=6dkFw11-NiyloVtjIt_DpyvyuL4.
Chertman, C. et al. A comparative study of lumbar range of movement in healthy athletes and non-athletes. Rev. Bras. Ortop. Engl. Ed. 45(4), 389–394 (2010).
Russell, R., Groves, P., Taub, N., O’Dowd, J. & Reynolds, F. Assessing long-term backache after childbirth. Br. Med. J. 306(6888), 1299–1303 (1993).
Troke, M., Moore, A. P., Maillardet, F. J. & Cheek, E. A normative database of lumbar spine ranges of motion. Man. Ther. 10(3), 198–206 (2005).
Gutke, A., Lundberg, M., Östgaard, H. C. & Öberg, B. Impact of postpartum lumbopelvic pain on disability, pain intensity, health-related quality of life, activity level, kinesiophobia, and depressive symptoms. Eur. Spine J. 20, 440–448 (2011).
Nait Aicha, A., Englebienne, G., Van Schooten, K. S., Pijnappels, M. & Kröse, B. Deep learning to predict falls in older adults based on daily-life trunk accelerometry. Sensors. 18(5), 1654 (2018).
Abdollahi, M. et al. Using a motion sensor to categorize nonspecific low back pain patients: A machine learning approach. Sensors 20(12), 3600 (2020).
Rothstock, S., Weiss, H.-R., Krueger, D. & Paul, L. Clinical classification of scoliosis patients using machine learning and markerless 3D surface trunk data. Med. Biol. Eng. Comput. 58(12), 2953–2962. https://doi.org/10.1007/s11517-020-02258-x (2020).
Moniri, A., Terracina, D., Rodriguez-Manzano, J., Strutton, P. H. & Georgiou, P. Real-time forecasting of sEMG features for trunk muscle fatigue using machine learning. IEEE Trans. Biomed. Eng. 68(2), 718–727 (2020).
Phan, T. C. et al. Machine learning derived lifting techniques and pain self-efficacy in people with chronic low back pain. Sensors 22(17), 6694 (2022).
Thiry, P. et al. Machine learning identifies chronic low back pain patients from an instrumented trunk bending and return test. Sensors 22(13), 5027 (2022).
Rao, A. Z. et al. Sensor fusion and machine learning for seated movement detection with trunk orthosis. IEEE Access 12, 41676–41687 (2024).
tarekhemdan, “tarekhemdan/Trunk_Movement.” Jul. 05, 2023. Accessed 21 Jul, 2023. [Online]. Available: https://github.com/tarekhemdan/Trunk_Movement.
Yin, Y. & Liu, H. Air quality index prediction based on three-stage feature engineering, model matching, and optimized ensemble. Air Qual. Atmosphere Health. 16(9), 1871–1890 (2023).
Naskath, J., Sivakamasundari, G. & Begum, A. A. S. A study on different deep learning algorithms used in deep neural nets: MLP SOM and DBN. Wirel. Pers. Commun. 128(4), 2913–2936 (2023).
Zaheer, S. et al. A multi-parameter forecasting for stock time series data using LSTM and deep learning model. Mathematics 11(3), 590 (2023).
Dehghani, A. et al. Comparative evaluation of LSTM, CNN, and ConvLSTM for hourly short-term streamflow forecasting using deep learning approaches. Ecol. Inform. 75, 102119 (2023).
Borup, D., Christensen, B. J., Mühlbach, N. S. & Nielsen, M. S. Targeting predictors in random forest regression. Int. J. Forecast. 39(2), 841–868 (2023).
Ahmed, H. U., Mostafa, R. R., Mohammed, A., Sihag, P. & Qadir, A. Support vector regression (SVR) and grey wolf optimization (GWO) to predict the compressive strength of GGBFS-based geopolymer concrete. Neural Comput. Appl. 35(3), 2909–2926 (2023).
P. Sarang, “Ensemble: Bagging and Boosting,” in Thinking Data Science: A Data Science Practitioner’s Guide, P. Sarang, Ed., Cham: Springer International Publishing, 2023, pp. 97–129. https://doi.org/10.1007/978-3-031-02363-7_5.
Abdel Hady, D. A., Mabrouk, O. M. & Abd, E.-H. Employing machine learning for enhanced abdominal fat prediction in cavitation post-treatment. Sci. Rep. 14(1), 11004 (2024).
Abdel Hady, D. A. & Abd, E.-H. Revolutionizing core muscle analysis in female sexual dysfunction based on machine learning. Sci. Rep. 14(1), 4795. https://doi.org/10.1038/s41598-024-54967-0 (2024).
Abdel Hady, D. A. & Abd, E.-H. Predicting female pelvic tilt and lumbar angle using machine learning in case of urinary incontinence and sexual dysfunction. Sci. Rep. 13(1), 17940. https://doi.org/10.1038/s41598-023-44964-0 (2023).
Eliwa, E. H., El Koshiry, A. M., Abd El-Hafeez, T. & Omar, A. Optimal gasoline price predictions: Leveraging the ANFIS regression model. Int. J. Intell. Syst. 2024(1), 8462056. https://doi.org/10.1155/2024/8462056 (2024).
Bibi, S., Tsoumakas, G., Stamelos, I. & Vlahavas, I. Regression via Classification applied on software defect estimation. Expert Syst. Appl. 3(34), 2091–2101. https://doi.org/10.1016/j.eswa.2007.02.012 (2008).
Shams, M. Y., Abd El-Hafeez, T. & Hassan, E. Acoustic data detection in large-scale emergency vehicle sirens and road noise dataset. Expert Syst. Appl. 1(249), 123608. https://doi.org/10.1016/j.eswa.2024.123608 (2024).
Koshiry, A. M. E., Eliwa, E. H. I., El-Hafeez, T. A. & Khairy, M. Detecting cyberbullying using deep learning techniques: A pre-trained glove and focal loss technique. PeerJ Comput. Sci. 10, e1961. https://doi.org/10.7717/peerj-cs.1961 (2024).
S. Raschka, “An Overview of General Performance Metrics of Binary Classifier Systems,” ArXiv Prepr. ArXiv14105330, 2014.
Strube, P. Are pain specialists failing in treating patients with low back pain?. Top. Pain Manag. 39(8), 6–7 (2024).
Singh, S. et al. Deciphering the complex interplay of risk factors in type 2 diabetes mellitus: A comprehensive review. Metab. Open. 19, 100287 (2024).
Villalba-Meneses, F. et al. Classification of the pathological range of motion in low back pain using wearable sensors and machine learning. Sensors 24(3), 831 (2024).
Alimohammadi, E., Fatahi, E., Abdi, A. & Reza, B. S. Assessing the predictive capability of machine learning models in determining clinical outcomes for patients with cervical spondylotic myelopathy treated with laminectomy and posterior spinal fusion. Patient Saf. Surg. 18(1), 21 (2024).
Phan, T. C. et al. Regression-based machine learning for predicting lifting movement pattern change in people with low back pain. Sensors 24(4), 1337 (2024).
Ren, G. et al. Machine learning predicts recurrent lumbar disc herniation following percutaneous endoscopic lumbar discectomy. Glob. Spine J. 14(1), 146–152. https://doi.org/10.1177/21925682221097650 (2024).
Hurwitz, E. et al. Harnessing consumer wearable digital biomarkers for individualized recognition of postpartum depression using the all of us research program data set: Cross-sectional study. JMIR MHealth UHealth 12(1), e54622 (2024).
Vesting, S., Gutke, A., Fagevik Olsén, M., Rembeck, G. & Larsson, M. E. The impact of exercising on pelvic symptom severity, pelvic floor muscle strength, and diastasis recti abdominis after pregnancy: A longitudinal prospective cohort study. Phys. Ther. 104(4), pzad171 (2024).
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
This work was carried out in collaboration among all authors. Authors DAA and TAEH designed the study, performed the statistical analysis, and wrote the protocol. Authors DAA and TAEH managed the analyses of the study, managed the literature searches, and wrote the first draft of the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
A. Abdel Hady, D., Abd El-Hafeez, T. Utilizing machine learning to analyze trunk movement patterns in women with postpartum low back pain. Sci Rep 14, 18726 (2024). https://doi.org/10.1038/s41598-024-68798-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-68798-6
Keywords
This article is cited by
-
Bioelectronics for targeted pain management
Nature Reviews Electrical Engineering (2025)
-
Optimizing YOLOv11 for automated classification of breast cancer in medical images
Scientific Reports (2025)
-
Classification of musculoskeletal pain using machine learning
Scientific Reports (2025)
-
Using convolutional neural networks with late fusion to predict heart disease
Scientific Reports (2025)
-
Contraction ratio of multifidus and erector spinae muscles in unilateral sacroiliac joint pain: A cross-sectional trial
Scientific Reports (2025)
