
Abstract
Autonomous Vehicles (AV) is one of the most evolving industries in the last decade. However, one of the bottlenecks of this evolution is providing data that contains different scenarios and scenes to improve the models without exposing the privacy and security of the edge vehicles. The authors of this research propose a secure and efficient novel solution for lane segmentation in AVs through the use of Federated Learning (FL). FedLane involves initial training of U-Net, ResUNet, and ResUNet++ models, followed by real-time inference in edge devices and the application of FL to update the server model using clients’ data. The study found that FL has enhanced the performance of lane segmentation significantly over baseline, enabling decentralized privacy-preserving collaborative optimization with increased dice coef from 0.9429 to 0.9794 for U-Net, from 0.9291 to 0.9854 for ResUNet and from 0.9079 to 0.9675 for ResUNet++. Additionally, the models show increased stability over the training iterations, highlighting the potential of FL to play a significant role in the future of automation in the AV industry.
Similar content being viewed by others

Introduction
Lane detection is a crucial task in autonomous driving, which could serve as visual cues for Advanced Driver Assistance Systems (ADAS) to keep vehicles stably following lane markings. As a result, autonomous vehicles must pinpoint the precise location of each lane. Neural networks have been widely used in lane detection due to their compelling performance since the development of deep learning. Early deep learning-based methods detect lanes using a framework based on pixel-wise segmentation in which each pixel is assigned a binary label indicating whether it belongs to a lane or not. Recently, various anchor-based methods have been proposed, with different types of anchors used among these methods, aiming to let the networks focus the optimization on the line shape by regressing the relative coordinates. Furthermore, row-wise classification methods rely on lane shape priors to predict the location of each row. Parametric prediction methods directly output curve equation parameters for lines. Multi-task learning is combined even further to improve lane detection accuracy in a complex environment. Vanishing Point Guided Network (VPGNet)1, for example, combines road marking detection and vanishing point prediction to obtain auxiliary information for lane detection. Manual labelling, on the other hand, is time-consuming and labor-intensive.
Lane-keeping is a crucial functionality in self-driving cars. Despite the integration of multiple sensors such as Radio Detection and Ranging (RADAR), Light Detection and Ranging (LiDAR), ultrasonic sensors, and infrared cameras, ordinary color cameras remain indispensable due to their cost-effectiveness and ability to capture extensive information. Analyzing images captured by cameras is fundamental in this regard. Ensuring that the vehicle stays on track is one of the most vital tasks for a self-driving car. Traditionally, this involves breaking the task down into separate procedures, including lane detection, path planning, and control logic, which are often approached independently. Traditionally employed techniques for lane detection encompass color enhancement, Hough transform, edge detection, and other image processing methods. Path planning and control logic are executed accordingly once the lane markings are recognized in the initial stage.
The initial stage for automated vehicles is the standard cruise control, which maintains the vehicle’s speed at the value required to assist the driver. Automated vehicles have progressed from standard cruise control to Adaptive Cruise Control (ACC) and, more recently, ACC Collaborative (CACC) systems. ACC maintains a set distance from the car ahead, while CACC allows vehicles to communicate wirelessly, reducing gaps between them and improving road capacity. This advancement in vehicle communication has shown potential benefits such as increased driver safety, decreased traffic congestion, fewer accidents, and improved highway traffic flow2.
Lane changing is a well-developed automated driving activity for self-driving vehicles, often used as a precursor to more complex maneuvers such as highway lane changes, road exits, and overtaking3. This contributes to reducing car accidents, as human error is responsible for 90\(\%\) of highway accidents, with wrong calculations of distances and speeds leading to catastrophic outcomes4.
Also, as vehicles evolve with advanced safety features and self-driving capabilities, massive amounts of data are generated by a variety of on-board sensors, such as camera, RADAR, and LiDAR as well as proximity and temperature sensors5. One GB of data is predicted to be produced per second by an autonomous car. However, generated data is currently not routinely processed, archived, or examined for better inference. Due to their low computational complexity when solving optimization-based or combinatorial search problems and their capacity to extrapolate new features from a constrained set of features in a training dataset, Machine Learning (ML) algorithms have recently been developed to learn from sensor measurements.
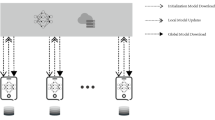
As shown in Fig. 1, the current trend in the application of ML in vehicular networks focuses on centralized algorithms, or Centralized Learning (CL), in which a powerful and effective learning algorithm, frequently a Neural Network (NN), is trained on a huge dataset gathered from the edge devices on the vehicles. The NN model offers a non-linear mapping between the input, which consists of vehicle sensor data, and the output, which might include sensor data labels. This mapping is learned using a supervised learning method that involves feeding the NN local sensor data from edge devices.

Difference between Centralized Learning and Federated Learning5.
Once the model has been trained, the model parameters are transmitted back to the edge devices for prediction. However, while aiming for larger and deeper NN architectures for effective training, the amount of data produced is huge. As a result, training a model with data transfer from edge devices to the cloud centre in a reliable way that may be excessively expensive in terms of bandwidth, incurring unacceptable delays and intruding on user privacy. This always makes a bottleneck in improving the performance of AVs as there is a trade-off between the improvement of the system and the privacy which can’t be sacrificed on either side.
Federated Learning (FL) has been recently introduced with the goal of bringing CL down to the edge, as illustrated in Fig. 1. In FL, the edge devices only send the gradients of the learnable parameters obtained from these local datasets to the cloud server rather than the local datasets themselves. The cloud server aggregates these gradients, and the model parameters are updated before being sent back to the edge devices. This procedure continues iteratively until convergence. The training technique is identical to that of CL, with the exception that FL does not require transmission of the entire dataset. This enables reducing both the complexity of ever-growing datasets at the edge devices in the vehicles and the transmission overhead of these datasets to the cloud servers6. As a result, FL is a promising approach for efficiently training learning models while maintaining raw data privacy and reducing transmission overhead in wireless communications. This will give advantages to the system as follows:
-
1.
All the AVs in the system will be improved from the data shown to each of them by aggregating the model through all of them, which will make lane annotation and decision-making inside the Vehicle more efficient.
-
2.
Providing a secure training process for edge devices (AVs) without exposing the senses inside each of them to the central node.
-
3.
Utilizes all the processing units in the system, including the AVs in the training process.
While FL has already received great interest within wireless networks, imparting FL to vehicular networks is more challenging due to the dynamic nature of the channel characteristics of vehicular environments.
The contributions of this work can be listed as follows:
-
Introducing an FL model for highly and accurate efficient lane segmentation in dynamic and complicated road scenarios.
-
Developing an algorithm to build up the labels for the Tusimple dataset7, which is used frequently in the lane segmentation task.
-
Benchmarking the performance of three traditional model U-Net8 , ResuNet9 and Resunet++10 model.
-
Transferring the traditional models to federated models and benchmark their performance, which outperforms the traditional ones.
-
Proposing FL framework trains a global model on the server using weighted model averaging to aggregate local updates from clients, enabling collaborative learning without raw data transmission.
-
Letting each client vehicle transmit local model weight updates to the central server, which are aggregated using weighted averaging to generate an improved global model that is then disseminated back to the clients.
The remainder of the paper is divided into the following sections: Section "Literature review" conducts the literature review utilizing deep learning techniques and conventional computer vision techniques for lane segmentation and detection. The methodology is described in Section "Methodology", along with the dataset selection and preprocessing, benchmark traditional lane segmentation models, FL, and real-world FL implementation. Results, analysis, comparisons, and restrictions in Section "Results". Section "Conclusion" provides the conclusion at the end.
Literature review
In this section, an informative review of previous related work will be presented.
The work conducted in Ref.11 represents a system model for blockchain-based FL (BFL) in vehicular networks. The main elements of the system are identified, including the blockchain, the miners, and the cars. Additionally, the delays that might exist in the system are deeply discussed, including communication latency and consensus delay. A fluid dynamical model is then created and utilized to examine the effects of various parameters, including the pace of block arrival and the volume of cars. Additionally, an online approach for reducing system latency is provided. After that, the authors use simulation and numerical results to support the conclusions of their performance analysis by demonstrating how maximizing the number of cars and the block arrival rate can greatly minimize system time. The authors also demonstrate how the online algorithm minimizes system delay. The related work in the literature on BFL in vehicular networks includes creating a fluid dynamical model of the system, suggesting an online algorithm for cutting down on system delay, and validating their findings with simulation and numerical results. Eventually, the authors conclude by outlining the major issues that must be resolved in order to enhance BFL’s performance in vehicular networks. These difficulties include creating more effective consensus methods, creating FL algorithms that protect user privacy, and creating BFL systems that are strong enough to survive malicious attacks.
In Ref.12, the authors evaluates the performance of centralized and federated machine learning (ML) approaches for predicting steering angles in autonomous driving using vision-based datasets, under various V2X communication channel conditions. The study finds that traditional ML performs adequately up to a certain bit error rate (BER) but suffers from noise-overfitting at higher BERs. Conversely, the federated learning (FL) approach not only maintains performance with less training time but also significantly reduces network load, being 250 times lighter in ideal conditions and 62 times lighter with channel errors. The paper concludes that FL is a viable alternative to centralized ML for this application, though future work should consider additional vehicle control inputs like brake and throttle values to improve prediction accuracy.
In Ref.13, the paper presents a novel peer-to-peer Deep Federated Learning (DFL) approach for training deep neural networks in a decentralized manner, eliminating the need for central orchestration. A new architecture, Federated Autonomous Driving Network (FADNet), is introduced to enhance model stability, ensure convergence, and address imbalanced data distribution issues. Experimental results on three datasets demonstrate that FADNet combined with DFL achieves superior accuracy compared to recent methods. Notably, this approach preserves user privacy by avoiding the collection of data on a central server. While the current deployment is limited to a mobile robot in an indoor environment, the proposed method shows significant promise for privacy-preserving autonomous driving applications.
Authors in Ref.14 introduces FedLANE, a federated learning-based lane detection technique exploring U-Net, U-Net LSTM, and AU-Net architectures. Evaluated on the TuSimple and CuLane datasets with 5, 10, and 15 clients over 50 epochs, FedLANE demonstrates comparable performance to traditional deep learning models in terms of accuracy, precision, recall, and F1-score for both IID and Non-IID data. It often matches and sometimes surpasses centralized learning, highlighting its suitability for privacy-sensitive and real-time applications. Future research could explore vertical, horizontal, and federated transfer learning in lane detection, along with improved user selection and aggregation methods.
The work in Ref.15 introduces a Clustering-based Personalized Federated Learning (CPFL) framework designed to enhance lane-change maneuver predictions using driver monitoring data. By integrating clustering parameters-head position threshold and average pre-lane-change preparation time-CPFL groups drivers with similar behaviors and deploys Long-Short Term Memory (LSTM) networks tailored to these clusters. Using data from human drivers in diverse scenarios within a Unity simulation, CPFL demonstrated significant improvements over the traditional FedAvg method. Specifically, it showed a 7.6-fold increase in training efficiency, a 4% rise in accuracy, a 0.2% reduction in false positives, and a 27.8% decrease in false negatives. The study underscores the importance of personalization in federated learning to balance user privacy with model adaptability, presenting a compelling case for CPFL’s superior performance in adapting to varied driving behaviors.
In Ref.16, the authors introduce FedBEVT, a federated transformer learning approach designed to improve Bird’s Eye View (BEV) perception in autonomous driving by addressing data heterogeneity issues such as diverse sensor poses and varying sensor numbers. To tackle these challenges, the authors propose Federated Learning with Camera-Attentive Personalization (FedCaP) and Adaptive Multi-Camera Masking (AMCM). Evaluated on a newly created dataset simulating four real-world federated use cases, FedBEVT consistently outperformed baseline methods. The study demonstrates that these novel techniques enhance federated learning performance by personalizing positional embeddings and increasing training data resources, underscoring the potential of federated learning for BEV perception in road traffic scenarios.
Authors in Ref.1 proposed a new deep learning method called vanishing point guided network for lane and road marking detection in autonomous driving systems. Traditional approaches like edge detection and Hough transforms have a lot of limitations when challenging roads. Recent CNN methods are more robust but still struggle with complex road scenes. The proposed method introduced by the author addresses these limitations by using the vanishing point, where parallel lines converge, to guide the network detection and recognition of road markings, which provides a reliable way for identifying the structure of the road. The network is trained to predict lane markings based on the vanishing point and surrounding context. The research used a dataset of around 20,000 real-world driving images from Seoul, Korea, captured at 30 Frames Per Second (FPS) and sampled over 3 weeks. Finally, the results show that the vanishing point-guided network improves detection and recognition accuracy over existing methods, especially in difficult conditions like poor lighting and occlusions. This shows the benefit of using the vanishing point as a reference to guide road marking detection for autonomous driving.
Authors in Ref.17 begin by providing a thorough analysis of various FL protocols, examining their benefits and drawbacks in turn. It then introduces a ground-breaking strategy for real-time end-to-end FL that is built around an asynchronous version-based aggregating protocol. The work uses a crucial use case requiring steering wheel angle prediction in self-driving automobiles to demonstrate the effectiveness of this unique approach. As shown by the obtained findings, the model developed using the suggested strategy outperforms existing FL algorithms and widely used CL techniques in terms of prediction accuracy. Notably, the suggested method drastically lowers bandwidth costs by an astonishing 60\(\%\) and training time by a significant 70\(\%\). The work contributions are conducted through three distinct phases. Firstly, the debut of a new asynchronous aggregation protocol illustrates how effective it is in comparison to older synchronous protocols. The asynchronous protocol promotes greater model accuracy and considerably reduces the required bandwidth by allowing clients to update their models more frequently. The report also emphasizes how the suggested method can be used to achieve cutting-edge prediction accuracy in actual applications, emphasizing its relevance to the field of self-driving cars. The research then thoroughly analyzes the suggested approach, closely examining prediction accuracy, training time, and bandwidth cost. The thorough analysis supports the approach’s viability as a reliable and effective way for real-time FL by offering persuasive proof of its efficiency.
The authors in Ref.18 propose a new lane detection method using cubic Bezier curves, unlike prior segmentation, point detection, or polynomial curve approaches. Segmentation and point detection require heuristics to decode predictions or generate anchors. Polynomial methods have optimization difficulties. The proposed Bezier curve method avoids these limitations. It uses a feature flip fusion architecture to strengthen features from an encoder, which are pooled to 1D. Two 1D convolution layers predict Bezier curve control points. Flipped and original feature maps calculate deformable convolutions to align images. Visualizations show the model inferring ill-marked lanes from the scene context. Experiments on TuSimple7, CULane19, and LLAMAS20 datasets demonstrate state-of-the-art performance. TuSimple has 3626 training and 2782 test images under good lighting. CULane has 88880 training and 34680 test images. LLAMAS has 58269 training and 20929 test images. All are under good lighting and without complex recurrent or anchoring designs; optimizing Bezier curves naturally captures the continuous lane line properties. The simplicity yet high performance shows Bezier curves are a promising new technique for lane detection across varying conditions.
In Ref.21, SwiftLane is proposed which represents a new lane detection method that achieves real-time performance while maintaining accuracy even in complex scenarios. Many prior approaches like segmentation-based methods22 reliably detect lanes but perform too slowly for real-time applications, especially on limited hardware. SwiftLane uses a ResNet-14 backbone to extract features which are then flattened and passed through fully connected layers with dropout. Predictions go through false positive suppression and curve fitting to output lane markings. Compared to Ref.22, SwiftLane significantly improves inference speed while achieving better results. It also outperforms the previously fastest method, Ultra-fast structure-aware deep lane detection23, by 6.6\(\%\) in F1-measure. SwiftLane is comparable to Unifying lane-sensitive architectural search24 and row-wise classification25 but without reported speeds. Methods like26,27,28,29 achieve similar or better accuracy than SwiftLane, but their complex models are too slow for real-time use, especially on constrained platforms. By balancing accuracy and efficiency, SwiftLane enables reliable, real-time lane detection across environments without expensive hardware requirements. Its speed and performance show the promise of lightweight networks for time-critical autonomous driving tasks.
The 3D-LaneNet system, introduced by researchers, has been recognized as the pioneering approach to address the lane detection task using onboard sensors, thereby eliminating the reliance on pre-mapped environments or fixed lane width assumptions30. This method introduces two novel concepts: internetwork Inverse Perspective Mapping (IPM) and anchor-based lane representation. One of the notable strengths of the 3D-LaneNet system is its ability to detect multiple lanes in real-time, a significant improvement over conventional methods limited to detecting one lane at a time. This remarkable capability is achieved through the system’s end-to-end design, effectively leveraging both 2D and 3D information for lane detection, as depicted in the architecture. An important aspect of the 3D-LaneNet system is its computational efficiency, enabling real-time performance in resource-constrained environments, such as embedded systems in vehicles. The method has been trained and tested through two datasets, the 3D-Lanes dataset and the Synthetic 3D lane dataset, that have been generated using blender graphic engine. The results of the proposed system show improved performance compared to traditional lane detection methods in terms of accuracy, efficiency, and robustness. The use of a 3D representation of the road allows for improved performance in challenging scenarios, such as poor lighting conditions, shadows, and occlusions.
In Ref.31, a LaneNet, which is proposed in the paper, is proposed as a deep neural network-based method to explain lane detection into two stages: lane edge proposal and lane line localization. For the lane edge proposal, the model takes an image of the front view of a vehicle as input and outputs a lane edge probability map of the same size as the input image. For each training image, an annotation map is provided where ’1’ indicates a positive pixel laying on the edge of one lane segment and ’0’ elsewhere. The entire network is end-to-end optimized by stochastic gradient descent. For the lane line localization network, the model detects lane lines based on lane edge proposals by projecting an image to the consistent binary lane edge proposal map. While detecting the lane lines from a lane edge proposal map remains sophisticated. The network is designed to be computationally efficient, allowing real-time performance in resource-constrained environments, such as embedded systems in vehicles. The researchers have built their own dataset to make specific experimental scenarios to confirm the performance of the model. The results of the proposed system show that weak supervision loss constantly improves the detection of both easy and hard sub-datasets. Additional fine-tuning of the network using weakly labelled data improves the performance of samples with hard difficulties considerably. The fine-tuning using weakly labelled data allowed the author to enhance the network performance on severe instances at a low cost.
Methodology
In this section, the following steps to create and test our FL system for lane detection will be presented. Essential steps are included such as dataset selection and preprocessing, lane segmentation model creation, the definition of the optimization target and FL architecture, and real-world implementation.
Dataset preparation
Two datasets were mainly chosen for this work: TuSimple7 and CUlane19. In this part, dataset selection and preprocessing will be discussed more, with a detailed explanation for each part.
Dataset selection
In CUlane19, data were collected for lane detection in Beijing by mounting cameras on 6 vehicles and recorded over 55 hours of videos, resulting in 133,235 frames. The frames were divided into training (88,880), validation (9,675), and testing (34,680) sets. The test set was divided into normal and 8 challenging categories, with the challenging scenarios making up 72.3\(\%\) of the dataset. The lanes in each frame were manually annotated using cubic splines, including occluded or unseen lanes based on context. The focus was on detecting 4 lane markings out of all annotated lane markings, as shown in Fig. 2.

Sample of CULane19.
TuSimple dataset7 is a dataset for lane detection in autonomous vehicles consisting of 6,408 road images from US highways with a resolution of 1280 x 720. The images are split into 3,626 for training, 358 for validation, and 2,782 for testing. The testing set includes images captured under various weather conditions, as shown in Fig. 3.

Sample of TUSimple7.
Among the CUlane and TuSimple datasets, the latter was chosen to be used as it is the most recent research in the scientific community. Also, it is well-captured and clean and can be used for training. On the other hand, the amount of noise in CULane wasn’t acceptable as most of the images don’t include lanes at all, which will be an obstacle to the model. After reviewing the dataset, it was found that the positioning of the camera that captures the data isn’t realistic enough to mimic the real-life application.
Dataset preprocessing
Data preprocessing stage of this work was conducted by designing a customized data loader that can handle the specification of the datasets. It is mainly responsible for loading the data to be used for model training and testing. The preprocessing was basic where it included data resizing, normalization, and shuffling. Firstly, dataset images were accessed one by one to be resized and normalized. Accordingly, the lane vectors (labels) corresponding to the original image were also accessed by creating a black image and drawing those vectors upon it. In the final preprocessing step, each image was resized to a consistent dimension, normalized to a common value range, and then batched together with other preprocessed images for model training also; for real-time inference, the image is then converted from Red Green Blue (RGB) to Hue Saturation Value (HSV), and noise is removed, and then in the final process Canny edge detection is used to identify the region of interest.
Lane segmentation
In this section, lane segmentation models, evaluation metrices, and hyperparameter selection will be discussed more with a detailed explanation for each part.
Proposed lane segmentation models for use case
In this part, three of the most common segmentation model architectures will be illustrated.
U-Net
U-Net has gained popularity in the field of image segmentation since its introduction in 2015 by Olaf Ronneberger, Philipp Fischer, and Thomas Brox8. This CNN architecture is known for its parameter usage and impressive performance in segmenting small objects. The U-Net framework consists of two paths: a contracting path that captures context and an expansive path for localization. In the contracting path, two 3x3 convolutions, ReLU activation, and 2x2 max-pooling, are applied repeatedly to downsample the input. At each downsampling step, the number of feature channels is doubled. The expansive path then upsamples the feature map. Combining it with a feature map from the contracting path to provide both context and localization information. With a total of 23 layers, this end-to-end trained network learns to map input images to segmented outputs. One key advantage of U-Net is its architecture, which allows it to be trained effectively with limited data availability. However, due to its design, U-Net’s capacity for learning representations is somehow limited. While it performs well in segmenting objects, it may face challenges when dealing with complex tasks. Moreover, training U-Net on images requires memory and computational resources. Techniques such as data augmentation and dropout can help address issues like overfitting that may arise from these limitations in model capacity.
Finally, U-Net offers an capable fully CNN framework, particularly for segmentation, for smaller objects. However it may face challenges when applied to intricate tasks.
ResUNet
ResUNet9 is a deep learning architecture for image segmentation applications like semantic segmentation, which combines the architectures of ResNet and U-Net. ResUNet’s encoder performs feature extraction similar to ResNet using residual connections, which makes the architecture easier to train extremely deep networks. To recover spatial dimensions and maintain localization accuracy, the decoder component uses upsampling similar to U-Net. The fundamental idea behind ResUNet is to combine the residual connections from ResNet with the encoder-decoder architecture of U-Net. The residual connections enable training very deep networks by addressing the vanishing gradients issue. This makes the upsampling decoder path enable precise localization and segmentation by extracting spatial dimensions. ResUNet’s advantages include rapidly handling small objects and fine details, providing high-resolution segmentation through upsampling, and maintaining information across the network using residual connections. Its primary flaws include difficulty training very deep networks despite residual connections, high computational costs caused by the complex architecture and numerous parameters, and high computational expenses. By utilizing the complementing strengths of ResNet and U-Net, ResUNet has demonstrated strong performance on numerous semantic segmentation benchmarks. Yet, it might not be the best solution for many applications. Depending on the dataset, simpler architectures can occasionally match ResUNet’s accuracy with fewer resources. For some segmentation tasks, other specialized architectures might be a better fit.
In conclusion, the ResUNet model gives an accurate and reliable network for picture segmentation by fusing leftover connections from ResNet with the encoder-decoder architecture of U-Net. Although it has drawbacks, including a high computational cost, it works well for many problems. ResUNet offers a solid baseline for semantic segmentation problems involving high resolution, small objects, or fine features. However, it is not a generally ideal architecture.
ResUNet++
ResUNet++10 is a deep neural network architecture designed for medical image segmentation tasks. It is an improvement over the original ResUNet architecture, which is based on the U-Net architecture. Also, in ResUNet++ architecture, the residual blocks help propagate information between layers, improving channel inter-dependencies and reducing computational costs. The architecture contains one stem block followed by three encoder blocks, an Atrous Spatial Pyramidal Pooling (ASPP) block, and three decoder blocks. The encoder blocks consist of two successive 3x3 convolutional blocks and an identity mapping with a strided convolution applied to reduce spatial dimension. The output of the encoder block goes through a squeeze-and-excitation block, followed by the ASPP block, which captures contextual information at various scales. In the decoding path, the attention blocks increase the effectiveness of feature maps, followed by up-sampling and concatenation with the encoding path. Finally, the output of the decoder block goes through ASPP and a 1x1 convolution with sigmoid activation to provide the segmentation map. The squeeze-and-excitation blocks enhance the representative power of the network, the ASPP block captures multi-scale information, and the attention blocks determine which parts of the network require more attention. ResUNet++ has several strengths, including its ability to effectively learn complex representations of the input image, its improved performance compared to other segmentation models, and its ability to perform well on a variety of medical image segmentation tasks. However, it also has some weaknesses, including the potential for overfitting. This can be mitigated through proper data augmentation and regularization techniques. Additionally, the architecture can be computationally intensive, requiring significant computational resources and training time. U-Net, ResUNet, and ResUNet++ will be included in the work to discuss the effect of model complexity and memory size in lane segmentation task, besides tackling the influence of FL in training of each model and how it improved along each iteration. In the next section, the performance metrices will be discussed to know more about the mathematical models that are included in the segmentation task and how it is performed.
Evaluation matrices and optimization equations
In this section, the performance evaluation matrices and specifications will be discussed and selected to be used in the experiment.
Dice coefficient
As the aim of the research is a segmentation task, the dice coefficient is selected as an evaluation criterion. The reason for this is that the dice coefficient provides a measure of the overlap between two sets of data, which is ideal for comparing the predicted segmentation mask to the ground truth mask. The dice coefficient is calculated as the ratio of the intersection between the predicted and ground truth masks to the union of the two masks. It ranges between 0 and 1, with a value of 1 indicating a perfect overlap and a value of 0 indicating no overlap. The use of the dice coefficient provides a robust evaluation metric for segmentation tasks, as it considers both the accuracy of the positive predictions and the completeness of the predicted masks. dice coefficient can be defined as:
where y is the ground truth, \(\hat{y}\) is the predicted segmentation. From this equation, the loss function was derived as dice coefficient loss that can be represented as:
Dice coefficient loss will be used to calculate the cost of the model and update it as the main loss function for the models.
Intersection over union
Intersection over Union (IoU) is used to measure the performance of the models and how it is dealing with the data. IoU is a widely used metric for evaluating the performance of object detection and image segmentation algorithms. It is calculated as the ratio of the area of the intersection of the predicted and ground truth bounding boxes (or segments) to the area of their union. IoU provides a simple and intuitive way to evaluate the performance of image segmentation algorithms, making them easy to understand and implement. It is a single number that summarizes the performance of the algorithm, making it easy to compare different algorithms and parameters. Additionally, IoU is robust to changes in scale and rotation, making it a useful metric for evaluating algorithms that may produce segments of different sizes or orientations. Being a commonly used and well-established metric in the computer vision community, it is easy to compare results with others. IoU is defined as:
where TP stands for True Positive, FP stands for False Positive, and FN stands for False Negative.
Adam optimizer
Adam (Adaptive Moment Estimation) optimizer32 is a popular optimization algorithm used in deep learning to update network weights. The algorithm computes adaptive learning rates for each parameter by utilizing the first and second moments of the gradients. In particular, at each step “t”, the algorithm updates the parameters weights. Also, the algorithm combines the benefits of both gradient descent and root mean square propagation algorithms and uses a moving average of the gradient and squared gradient to scale the learning rate. This makes Adam’s adaptive learning rate method work well for training deep neural networks on large datasets with many parameters.
Hyperparameter selection
All the hyperparameters used are presented in this section for the training phase of the three selected models. The input images were resized to 256 x 256 along with label images resizing to the same size. The models are trained upon 100 epochs with: 20 steps per epoch; dice coefficient loss as the loss function; and Adam optimizer as the model optimizer with \(1e^{-3}\), 0.9, 0.999 for learning rate, beta 1, and beta 2, respectively. Also, callbacks were included, which are going to change the behavior of the training phase based on the performance matrices. Besides this, an algorithm is used to reduce the learning rate in case of no improvement. Based on monitoring validation loss for 3 sequential epochs, if there is no improvement, the learning rate will be reduced by 0.5 factors in the middle of the training phase.
Federated learning
In this partition, the method of applying FL is explained from two different perspectives.
Federated learning simulation
There were two suggested methods to apply FL on lane segmentation tasks, which were using the FL Framework or implementing an FL algorithm from scratch using the TensorFlow framework. The use of the FL Framework provided by Google for implementing FL algorithms offers several advantages over writing one’s own code. Firstly, the library provides pre-built components and functions that can significantly reduce the time and effort required to implement an FL algorithm. This can be especially beneficial for those who are new to the field or who want to quickly experiment with different approaches. Furthermore, the TensorFlow Federated library has been developed and maintained by a team of experts in the field, which provides FL with access to the latest techniques and best practices. This means that users of the library can be confident that they are using state-of-the-art methods and can rely on the expertise of others when developing their algorithms. Additionally, the TensorFlow Federated library has been thoroughly tested and optimized for performance, which can result in improved reliability and quality compared to code written from scratch. This can be especially important for critical applications where high levels of accuracy and robustness are required.
On the other hand, the writing of an FL algorithm from scratch offers several advantages that may make it a suitable choice for specific applications such as lane segmentation. One of these advantages is the capability for customization, as complete control over the implementation is provided, allowing for tailoring to the specific requirements of the use case. Another advantage is greater control over the inner workings of the algorithm, which can lead to optimized performance and improved accuracy. Additionally, flexibility is also a benefit, as the ability to implement only the relevant features and functions is offered, as opposed to being limited by the components provided in a library. Furthermore, the writing of an FL algorithm from scratch can also provide a valuable learning experience, as a deeper understanding of the underlying principles of FL and the different techniques and methods used in the field can be gained. While the writing of an FL algorithm from scratch offers several advantages, it also demands a higher level of expertise in both ML and distributed systems. As a result, the decision of whether to write one’s own code or to use a library will depend on the specific requirements and resources available.
As lane segmentation can be considered a sophisticated and customized task, it won’t an option to use Tensorflow Federated, so a novel implementation for FL applied to be customized and specified for the autonomous vehicles use case. And in next part, the implementation of FL simulation will be illustrated in details.
Data division and preprocessing
To ensure that the models are trained on a representative sample of the driving scenarios, TuSimple data is carefully divided and distributed among multiple clients. The distribution process is critical to ensure that each client has access to a diverse set of samples that includes a range of driving scenarios and road conditions. The distribution process used with TuSimple is known as the “Deck of Cards” method, which aims to divide the data into roughly equal portions for each client. This method is designed to ensure that each client receives a representative sample of the data with the goal of providing equal opportunities for each client to learn from different scenarios and conditions. In this method, the data is divided into equal portions, with each portion representing a “deck of cards”. Each client is then assigned a deck of cards, with each deck containing approximately 1208 samples, including both the data and the corresponding labels. The use of the Deck of Cards method for data distribution helps to ensure that all clients have equal opportunities to learn from a diverse set of data, thereby improving the overall performance of the models. This method can also help to reduce the risk of overfitting, where a model becomes too specialized to a specific set of data and is unable to generalize well to new scenarios. By providing each client with a representative sample of the data, the Deck of Cards method helps to ensure that the models can generalize well to a wide range of driving conditions and scenarios.
Training in federated learning
The training of clients will be nearly the same as training a traditional model, but with differences that will be discussed in the upcoming sentences. FL is a process in which multiple clients collaborate to train a deep-learning model. Several steps are followed to train clients in an FL system. The first step is initialization, where the server starts by initializing the global model with a set of starting weights. Next, each client trains its own local model using its own data. The client’s model is updated through deep learning techniques such as CNNs or Recurrent Neural Networks (RNNs). After completing the local training, the client calculates its scaling factor and scales its weights with this scale, then sends its updated model weights back to the global model. The server aggregates the weights received from all clients and computes the updated global model. This updated model is then sent back to the clients, who update their local models accordingly. This process is repeated until the model has converted to a satisfactory level of accuracy or a specified number of rounds, which is specified in the research with 100 rounds, has been completed, and the repetition of this stage is similar to iterations of training in traditional learning. Finally, the performance of the model is evaluated using a validation set. This allows for the determination of the accuracy of the model and the necessary adjustments to be made. By following these steps, the clients can collaborate to train a model that represents the overall data while preserving privacy and security threats. This approach is efficient and scalable and enables deep learning models to be trained on large and decentralized datasets.
Designing federated learning workflow
In this part, the FL mathematical will be discussed one by one, illustrating the aim and steps for each one. Firstly, in the federated learning model, the model has to calculate the scaling factor for the weights, which is a crucial component of FL systems, as it helps to ensure that the models are trained in a balanced and fair manner. So, to calculate the scaling factor for each client based on the number of samples that the client has provided for training. This is done by dividing the number of samples provided by each client by the total number of samples available for all clients. Having a weight scaling factor provides several benefits in FL. Firstly, it helps to ensure that each client’s contributions to the overall training process are weighted appropriately. This is important because some clients may have more or less data available for training, and the weight scaling factor helps to ensure that these differences are accounted for in the training process. By weighting each client’s contributions appropriately, the weight scaling factor helps to prevent certain clients from dominating the training process, which can lead to suboptimal models. Another benefit of the weight scaling factor is that it helps to prevent overfitting. Overfitting occurs when a model becomes too specialized to a specific set of data and is unable to generalize well to new scenarios. By weighting each client’s contributions based on the number of samples provided, the weight scaling factor helps to ensure that the models can generalize well to a wide range of data, reducing the risk of overfitting.
Secondly, the weights of the model should be scaled based on the contributions of each client. The federated model scales model weights by using the received weights of each client and its scaling factor and scales all the weights based on it. This helps to balance the influence of each client’s data on the overall model, ensuring that each client’s data is given appropriate weight and consideration. The function operates by taking in the model’s current weights and the scaling factor of the weights for the client, which represents the proportion of the overall data that the client has provided. The federated model then scales the weights of each layer in the model by multiplying them with the scaling factor of the weights. This scaling process is performed in an efficient and computationally effective manner, using linear algebra. The resulting scaled weights provide a balanced representation of the contributions of each client, helping to ensure that the overall model is representative of the data provided by all clients.
Previous two functions were implemented mainly to replace federated average method that is applying in FL process and the final step in this process it to sum all the scaled weights for each client to update the global model. This happens by iterating over each layer in all client models and using reduce sum method that is provided by TensorFlow to add them into one global model.
Federated learning implementation in real-life application
In this section, the use case of FL in AV will be discussed in detail, including each block and action as mentioned in Figs. 4 and 5. Moreover, the client process in federated learning will be presented.

Flowchart for edge device in Federated Learning system.

Flowchart for Server in Federated Learning system.
Real time inference
In driving mode, the real-time inference process is the main running component of the overall system. This process involves several stages, including capturing frames, preprocessing, segmentation, controlling the steering wheel and car speed, and saving the captured frames for later use in training. The first stage involves capturing the frames and saving them after resizing and finally extracting the region of interest. Then the model inputs the array and outputs its segmentation which is then processed to define the region of the lane between the two segmented lines using model of client’s car. Finally, the system decides the control of the steering wheel and motor speed based on the car’s localization within the lane. This process is crucial for ensuring the car’s safe and efficient navigation on the road.
Client training
When the client system enters parking mode (sleeping mode), the AV will start to segment the frames captured earlier using a high-performance model. The characteristics of this model are more complex and have high accuracy, but they are not compatible with real-time applications even after real-time algorithms are applied to it. The suggested model for this task is CLRNet33, as it proved its reliability based on many datasets and research papers such as CULane and TuSimple. After labeling the data using CLRNet, the data will be preprocessed next using the data preprocessing method. then the model training takes place. Finally, after training, calculate the scale factor for the weights and scale the weights to be applied to the weights of the client model before sending it to the Server.
Federated average calculation for global model
After the Client finish training, it generates the local weight file, then it seeks to establish a connection with the server using the transferring algorithm. which makes the client connects with the server using the server IP address and port number. The local weight file is then converted by the client into a binary representation (serializing) so that it can be easily communicated over the network.
The server reconstructs the local weight file through deserialization after receiving the data from the client and taking the appropriate actions to return the data to its original form. This guarantees that the server can handle the data processing and manipulation correctly. Following this, the client enters a wait mode, anticipating the reception of the updated global weights. During this period, the server collects the local weights from all the connected clients. Once all the local weights have been obtained, the server scales the weights and generates the updated global weights in the form of an updated global weight file. This file is then distributed to all the connected clients.
In summary, after the client completes training and generates local weights, it establishes a connection with the server and serializes the weights for transmission. The server receives the serialized data and deserializes it to retrieve the original weight file. The client then waits to receive the updated global weights, which are generated by the server after collecting and scaling the local weights from all the clients. Finally, the server sends the updated global weights to all the connected clients.
Results
The aim of the results of this work can be directed into two main parts. First, we compare our lane segmentation approach using different architectures (U-Net, ResUNet, and ResUNet++) to determine which one has the best performance depending on the evaluation metrices (loss, dice coefficient, and IoU. The second is to transfer these models to federated and compare between the regular model and the federated model to see improvement.
The experiments were run on a computer with the specification of Ryzen 5 5600X as CPU, 16 GB of RAM, and RTX 3060 as GPU.
Validating lane segmentation performance
The results in Table 1 demonstrate the superiority of the U-Net model over ResUNet and ResUNet++ in terms of dice coefficient and IoU with 0.9429 and 0.9233, respectively. The U-Net model’s ability to precisely detect small objects is a crucial factor in lane segmentation tasks and this advantage is reflected in its higher performance in the metrics mentioned above. The literature review supports the effectiveness of U-Net in this task as it has been widely used as a backbone for lane segmentation deep neural networks and has been improved upon by other models such as LaneNet30. ResUNet, on the other hand, is specifically designed for remotely sensed data, which makes it come after U-Net, as noted in the literature9,34. Despite this specialization, its performance is comparable to that of ResUNet++, which can be attributed to their similar architectures. Both ResUNet and ResUNet++ employ residual connections which have been shown to improve performance in deep neural networks. However, these models do not have the same level of precision as the U-Net model in detecting small objects, which is why the latter has better performance according to the metrics mentioned above. In Fig. 6, it is clear that U-Net model did not experience overfitting despite the limited size of TuSimple dataset. This is because U-Net model is designed to effectively be trained on small datasets which is a strength of the model. The results show that the model reached its optimal performance at epoch 30 and stopped improving after it indicating that the model has learned the pattern of lane segmentation and its marks in the input. Even though the model was trained for roughly three times as many epochs as necessary, the graphs in Fig. 6 demonstrates the stability of the findings in each epoch. This stability is a demonstration of the U-Net model’s strength and adaptability to new data. Overall, these results highlight the strengths of the U-Net model in handling small datasets and its ability to effectively learn the pattern of lane segmentation.

Performance graphs for U-Net model.
Figure 7 illustrates the issue of overfitting in the ResUNet model compared to U-Net and ResUNet++. The difference between the training graph and the testing graph is much greater in the ResUNet model, indicating that it is not generalizing and adapts well to new data. Despite outperforming ResUNet++, the ResUNet model lacks stability across the epochs, as it overfits significantly in the range of epochs 0 to 40. The cause of this overfitting can be attributed to the ResUNet model’s inability to effectively learn from the data and instead memorize the training data. This results in poor generalization to new data, as seen in the large gap between the training and testing graphs. These results highlight the importance of avoiding overfitting in deep neural networks, especially in the context of lane segmentation, where precise performance is crucial. By comparison, U-Net and ResUNet++ exhibit less overfitting and more stability across the epochs, indicating that they are better equipped to handle the challenges of lane segmentation.

Performance graphs for ResUNet model.
As shown in Fig. 8, the model struggled with overfitting early till epoch 25 but eventually stabilized. Despite having greater stability compared to U-Net, ResUNet still performed worse relative to both U-Net and ResUNet. Given that deep learning models often perform better with larger datasets, this might be the result of the model’s training being done on a smaller quantity of data. Recognizing that ResUNet++ is still a relatively young model that can benefit from additional adjustments and enhancements to increase performance. Nevertheless, its stability and potential for improvement make it a promising model for medical image segmentation tasks, particularly when trained on larger datasets.

Performance graphs for ResUNet++ model.
By knowing that Fig. 9 shows a sample input image and its corresponding lane lines accurate label, an output sample from each model is illustrated in Fig. 10 for more elaboration of the performance of the models with the data and their outputs in case of the same input image. The ResUNet model lacks stability across the epochs, as it overfits significantly in the range of epochs 0 to 40. The cause of this overfitting can be attributed.

Illustrating an original input scene (above image) and its corresponding ground truth label (below image).

Qualitative comparison among lane segmentation results of the models. (a) U-Net (b) ResUNet (c) ResUNet++.
Validating federated lane segmentation performance
It is found that the ResUNet model outperformed other models, such as U-Net and ResUNet++, with 0.9854 for the dice coefficient when using FL, as it appears in Table ??. This superior performance can be attributed to the distribution of data between all the clients, leading to better generalization of the models and reducing the risk of overfitting. Additionally, the study observed that all the models reached saturation faster in FL compared to normal training (Figs. 11, 12 and 13). This highlights the advantage of FL in terms of faster improvement of models with efficient utilization of available resources. These results demonstrate the potential for FL to provide improved model performance in real-world applications.

Performance graphs for federated U-Net model.

Performance graphs for federated ResUNet model.

Performance graphs for federated ResUNet++ model.
The results presented in Fig. 11 show that the stability in performance over epochs of U-Net improved through the usage of FL, making it the most stable among the trained models. It was the first to reach its saturation point, around epoch 45, and showed a slight improvement after that. This consistent performance can be attributed to the simplicity of the U-Net architecture compared to other suggested models, such as ResUNet, as shown in Fig. 12 and in Fig. 13 for ResUNet++. Additionally, the lack of disturbance during early epochs suggests that FL effectively improves the model’s stability and reduces the risk of overfitting.
Regarding the ResUNet model, as depicted in Fig. 12, it is observed that even though ResUNet was initially the most disturbed model among the others during traditional training, as in Fig. 7, it showed remarkable stability in performance over epochs improvement in federated training. The model reached its saturation point around epoch 55, at which point its performance in the lane segmentation task was exceptional. It is also worth noting that after reaching saturation, the behavior of ResUNet changed significantly and it became more stable compared to all other models in the saturation phase. In terms of FL, it is important to consider the nature and behavior of the ResUNet model, as it may affect its performance and ability to learn from decentralized data sources. By carefully monitoring its stability and performance during the training process, one can make necessary adjustments to enhance its efficiency in FL. The study found that ResUNet++ showed improved performance in the federated training phase compared to traditional training. As seen in Fig. 13, although there were initial difficulties in the early stages of training, ResUNet++ eventually stabilized at epoch 47. However, it should be noted that ResUNet++ is not the optimal architecture for lane segmentation despite its improved performance. This is a result of its demanding computing needs, which include a substantial memory requirement and can make it difficult to employ for some applications.
At the very least, it is notable how well the models function in the samples presented in Fig. 14 using the testing image illustrated in Fig. 15 because the segmentation of the models was as precise as the label.

Qualitative comparison among FL-Based lane segmentation results of the models.

Another testing input scene image and its corresponding ground truth label. (a) Original (b) Label.
Conclusion
In this work, the authors have presented a cutting-edge solution to address one of the major challenges facing the autonomous vehicle industry, providing a secure and efficient way to improve models while protecting the privacy of edge devices. The use of FL in lane segmentation tasks has shown promising results, with a significant improvement in the performance of the models and increased stability over the training iterations. FL has enhanced the loss of U-Net, ResUNet, and ResUNet++ models from 0.0571 to 0.0207, 0.0709 to 0.0147, and 0.0921 to 0.0318, respectively. Moreover, it enhanced the dice coef of U-Net, ResUNet, and ResUNet++ models from 0.9429 to 0.9794, 0.9291 to 0.9854, and 0.9079 to 0.9675, respectively, which outperforms many leading models in lane segmentation task.
Data availability
The dataset analyzed during the current study are available on the website: https://open-dataset.tusen.ai/.
References
Lee, S., Kim, J., Yoon, J.S., Shin, S., Bailo, O., Kim, N., Lee, T.-H., Hong, H.S., Han, S.-H., Kweon, I.S. Vpgnet: Vanishing point guided network for lane and road marking detection and recognition. In: 2017 IEEE International Conference on Computer Vision (ICCV) (2017).
Diakaki, C., Papageorgiou, M., Papamichail, I. & Nikolos, I. Overview and analysis of vehicle automation and communication systems from a motorway traffic management perspective. Transp. Res. A Policy Pract. 75, 147–165 (2015).
Naranjo, J. E., Gonzalez, C., Garcia, R. & de Pedro, T. Lane-change fuzzy control in autonomous vehicles for the overtaking maneuver. IEEE Trans. Intell. Transp. Syst. 9, 438–450 (2008).
Wan, L., Raksincharoensak, P., Maeda, K. & Nagai, M. Lane change behavior modeling for autonomous vehicles based on surroundings recognition. Int. J. Autom. Eng. 2, 7–12 (2011).
Elbir, A.M., Soner, B., Coleri, S., Gunduz, D., Bennis, M. Federated learning in vehicular networks. In: 2022 IEEE International Mediterranean Conference on Communications and Networking (MeditCom) (2022).
Hao, M. et al. Efficient and privacy-enhanced federated learning for industrial artificial intelligence. IEEE Trans. Industr. Inf. 16, 6532–6542 (2020).
Tusimple/Tusimple-benchmark.: Download datasets and ground truths. In: [Online] Available (https://github.com/tusimple/tusimple-benchmark/issues/3).
Ronneberger, O., Fischer, P., Brox, T. U-net: Convolutional networks for biomedical image segmentation. Lecture Notes in Computer Science, 234–241 (2015).
Zhang, Z., Liu, Q. & Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 15, 749–753 (2018).
Jha, D., Smedsrud, P.H., Riegler, M.A., Johansen, D., Lange, T.D., Halvorsen, P., D. Johansen, H. Resunet++: An advanced architecture for medical image segmentation. In: 2019 IEEE International Symposium on Multimedia (ISM) (2019).
Pokhrel, S. R. & Choi, J. Federated learning with blockchain for autonomous vehicles: Analysis and design challenges. Wireless Pers. Commun. 68(8), 4734–4746. https://doi.org/10.1109/TCOMM.2020.2990686 (2020).
M P, A., R, G., Panda, M. Steering angle prediction for autonomous driving using federated learning: The impact of vehicle-to-everything communication. In: 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), pp. 1–7. https://doi.org/10.1109/ICCCNT51525.2021.9580097 (2021).
Nguyen, A., Do, T., Tran, M., Nguyen, B.X., Duong, C., Phan, T., Tjiputra, E., Tran, Q.D.: Deep federated learning for autonomous driving. In: 2022 IEEE Intelligent Vehicles Symposium (IV), pp. 1824–1830. https://doi.org/10.1109/IV51971.2022.9827020 (2022).
Santhiya, S. et al. Fedlane: A federated u-net architecture for lane detection. Indones. J. Electr. Eng. Comput. Sci. 32, 1621. https://doi.org/10.11591/ijeecs.v32.i3.pp1621-1629 (2023).
Du, R., Han, K., Gupta, R., Chen, S., Labi, S., Wang, Z. Driver monitoring-based lane-change prediction: A personalized federated learning framework. In: 2023 IEEE Intelligent Vehicles Symposium (IV), pp. 1–7. https://doi.org/10.1109/IV55152.2023.10186757 (2023).
Song, R., Xu, R., Festag, A., Ma, J. & Knoll, A. Fedbevt: Federated learning bird’s eye view perception transformer in road traffic systems. IEEE Trans. Intell. Veh. 9(1), 958–969. https://doi.org/10.1109/TIV.2023.3310674 (2024).
Zhang, H., Bosch, J., Olsson, H. Real-time end-to-end federated learning: An automotive case study. In: Proc. 2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, pp. 459–468 (2021).
Feng, Z., Guo, S., Tan, X., Xu, K., Wang, M., Ma, L. Rethinking efficient lane detection via curve modeling. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022).
Pan, X., Shi, J., Luo, P., Wang, X., Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. In: Proc. AAAI Conference on Artificial Intelligence, vol. 32 (2018).
Behrendt, K., Soussan, R. Unsupervised labeled lane markers using maps. In: 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW) (2019).
Jayasinghe, O., Anhettigama, D., Hemachandra, S., Kariyawasam, S., Rodrigo, R., Jayasekara, P. Swiftlane: Towards fast and efficient lane detection. In: 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA) (2021).
Hou, Y., Ma, Z., Liu, C., Loy, C.C. Learning lightweight lane detection cnns by self-attention distillation. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (2019).
Qin, Z., Wang, H., Li, X. Ultra fast structure-aware deep lane detection. In: Computer Vision - ECCV 2020, pp. 276–291 (2020).
Xu, H., Wang, S., Cai, X., Zhang, W., Liang, X., Li, Z. Curvelane-nas: Unifying lane-sensitive architecture search and adaptive point blending. In: Computer Vision - ECCV 2020, pp. 689–704 (2020).
Yoo, S., Seok Lee, H., Myeong, H., Yun, S., Park, H., Cho, J., Hoon Kim, D. End-to-end lane marker detection via row-wise classification. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2020).
Ko, Y. et al. Key points estimation and point instance segmentation approach for lane detection. IEEE Trans. Intell. Transp. Syst. 23, 8949–8958 (2022).
Zheng, T., Fang, H., Zhang, Y., Tang, W., Yang, Z., Liu, H., Cai, D. Resa: Recurrent feature-shift aggregator for lane detection. In: Proc. AAAI Conference on Artificial Intelligence, vol. 35, pp. 3547–3554 (2021).
Tabelini, L., Berriel, R., Paixao, T.M., Badue, C., De Souza, A.F., Oliveira-Santos, T. Keep your eyes on the lane: Real-time attention-guided lane detection. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021).
Qu, Z., Jin, H., Zhou, Y., Yang, Z., Zhang, W. Focus on local: Detecting lane marker from bottom up via key point. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021).
Garnett, N., Cohen, R., Pe’er, T., Lahav, R., Levi, D. 3d-lanenet: End-to-end 3d multiple lane detection. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (2019).
Wang, Z., Ren, W., Qiu, Q. Lanenet: Real-time lane detection networks for autonomous driving (2018).
Kingma, D.P., Ba, J. Adam: A method for stochastic optimization. In: Proceedings of the International Conference on Learning Representations, pp. 1–15 (2015).
Zheng, T., Huang, Y., Liu, Y., Tang, W., Yang, Z., Cai, D., He, X. Clrnet: Cross layer refinement network for lane detection. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022).
Diakogiannis, F. I., Waldner, F., Caccetta, P. & Wu, C. Resunet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote. Sens. 162, 94–114 (2020).
Funding
Open access funding is provided by The Science, Technology and Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
In this work, we propose a secure and efficient novel solution for lane segmentation in AVs through the use of Federated Learning (FL). FedLane involves initial training of U-Net, ResUNet, and ResUNet++ models, followed by real-time inference in edge devices and the application of FL to update the server model using clients' data. The author's contribution is as follows: Eng. M.M.K.E. and Eng. M.T.A. did the solution implementation for segmentation. Eng. M.M.K.E. and Eng. M.T.A. did the figure generation and initial writing. Eng. R.Y. and Dr. M.S.D. revised the initial and final writing and the supervision during the AI algorithm development.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Eid Kishawy, M.M., Abd El-Hafez, M.T., Yousri, R. et al. Federated learning system on autonomous vehicles for lane segmentation. Sci Rep 14, 25029 (2024). https://doi.org/10.1038/s41598-024-71187-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-71187-8
