
Abstract
Using visual place recognition (VPR) technology to ascertain the geographical location of publicly available images is a pressing issue. Although most current VPR methods achieve favorable results under ideal conditions, their performance in complex environments, characterized by lighting variations, seasonal changes, and occlusions, is generally unsatisfactory. Therefore, obtaining efficient and robust image feature descriptors in complex environments is a pressing issue. In this study, we utilized the DINOv2 model as the backbone for trimming and fine-tuning to extract robust image features and employed a feature mix module to aggregate image features, resulting in globally robust and generalizable descriptors that enable high-precision VPR. We experimentally demonstrated that the proposed DINO-Mix outperforms the current state-of-the-art (SOTA) methods. Using test sets having lighting variations, seasonal changes, and occlusions such as Tokyo24/7, Nordland, and SF-XL-Testv1, our proposed architecture achieved Top-1 accuracy rates of 91.75%, 80.18%, and 82%, respectively, and exhibited an average accuracy improvement of 5.14%. In addition, we compared it with other SOTA methods using representative image retrieval case studies, and our architecture outperformed its competitors in terms of VPR performance. Furthermore, we visualized the attention maps of DINO-Mix and other methods to provide a more intuitive understanding of their respective strengths. These visualizations serve as compelling evidence of the superiority of the DINO-Mix framework in this domain.
Similar content being viewed by others


Introduction
Visual place recognition (VPR), also known as image geo-localization (IG) or visual geo-localization, has been extensively applied in several fields, such as augmented reality1, robotics2, autonomous driving2,3, object tracking4, 3d reconstruction5, and intelligence gathering6. Currently, most VPR studies focus on image retrieval in urban scenarios. However, urban environment images may include many conditions, such as multiple shooting angles, illumination changes, seasonal variations, and occlusions, that can affect the successful retrieval of high-precision image features. Therefore, extracting robust and generalizable image feature descriptors for accurate image retrieval is critical.
In previous approaches to VPR, handcrafted scale-invariant feature transform (SIFT)7, histogram of oriented gradient (HOG)8, speeded-up robust features (SURF)9, oriented FAST and BRIEF (ORB)10, and other techniques have been used to extract features from images. These features were then aggregated using methods such as bag-of-words11, fisher vector12, and vector of locally aggregated descriptors (VLAD)13 to obtain image descriptors for image retrieval, enabling IG. More recently, deep-learning techniques have emerged as mainstream approaches for extracting image features14,15,16. These methods significantly improve VPR accuracy compared with handcrafted features. Examples include NetVLAD17, combining convolutional neural networks (CNNs) with VLAD, and other variants incorporating attention, semantics, context, and multiscale features. Other methods based on the generalized mean (GeM)18, such as CosPlace19, and those using fully-connected multilayer perceptron (MLP)-based feature aggregation, such as MixVPR20, have been proposed. However, these methods either use only handcrafted features or use models that have not been trained with large amounts of data as the backbone and are less robust. In practical testing, the accuracy of these methods for IG has been suboptimal under challenging conditions, such as different shooting angles, illumination changes, seasonal variations, and occlusions.
The rapid development of foundational visual models has enabled the generation of universal visual features from images21. By training on billions of data points, foundational visual models can extract image features that are more generalizable and robust than those extracted by conventional models. They can effectively handle the challenging conditions encountered in practice. Therefore, incorporating foundational visual models into VPR is a promising approach.
Considering the abovementioned challenges, this study proposes a novel VPR framework based on the DINOv221 model, called DINO-Mix, which combines foundational visual models with feature aggregation. This framework possesses exceptional discriminative power. Efficient and robust image features suitable for IG are extracted by fine-tuning and trimming. Furthermore, it uses a feature mixer22 module to aggregate image features, resulting in a global feature descriptor vector. DINO-Mix is experimentally demonstrated to achieve superior test accuracy on multiple benchmarks, surpassing state-of-the-art (SOTA) methods. The contributions of our work are as follows:
-
1.
We propose a novel VPR framework, DINO-Mix. The framework combines the excellent feature extraction capability of the foundational vision model and the feature aggregation capability of the feature mix module, which allows the framework to easily cope with challenges such as viewpoint changes, illumination changes, seasonal changes, and occlusion.
-
2.
We conduct a series of ablation experiments to pinpoint the optimal parameters for our framework, including the optimal number of mix layers, descriptor dimension, and backbone architecture. The experimental results demonstrate that the test accuracies of our framework with optimal parameters exceed those of existing SOTA methods.
-
3.
We present illustrative examples of VPR for our framework and other approaches and perform heat map visualizations to highlight the advantages of our framework.
The remainder of this paper is organized as follows. In Sect. 2, we summarize previous relevant research on visual place recognition. In Sect. 3, the DINO-Mix framework is introduced, and we provide details of the training set, testing set, and the training and evaluation parameters used in our experiments. Section 4 presents the results by comparing the proposed framework with existing methods in terms of accuracy and ablation experiments are conducted. We qualitatively demonstrate the DINO-Mix architecture by comparing it with other state-of-the-art methods through a typical VPR example and visualizing the corresponding attention map. Finally, our conclusions are presented in Sect. 5.
Related work
By retrieving the most similar image from the image database, the geographical location of the retrieved image can be used as the location of the target image23. In recent years, numerous researchers have made significant contributions to the field of image retrieval for VPR. The features used in image retrieval can be broadly categorized into handcrafted and deep features. Zhang and Kosecka24 first extracted SIFT features from images to establish an image feature database. They performed a brute-force global database search and validated and ranked the top five candidate images using the random sample consensus algorithm25. Finally, the geographical location of the target image was obtained by triangulating the top three images. Zamir and Shah26 extracted SIFT feature vectors from images to build a database and used a nearest-neighbor tree search to improve retrieval efficiency. Zamir et al.27 further improved the nearest-neighbor matching technique by pruning outliers and applying the generalized minimum clique problem in conjunction with approximate feature matching. This resulted in a 5% improvement in localization accuracy compared to their previous study26. The advantages of using handcrafted features for VPR are their simplicity and strong interpretability. However, these methods tend to have high redundancy, require dimensionality reduction, are susceptible to environmental changes, and generally have low accuracy.
Deep features are extracted by neural networks with modules such as convolutional layers and attention mechanisms. These features often outperform handcrafted features owing to their strong expressive power, ability to freely define feature dimensions, and flexibility in designing neural network frameworks. Noh et al.28 proposed a deep local feature descriptor and an attention mechanism to identify semantic local features for key-point selection. Ng et al.29 introduced a global descriptor called second-order loss and attention for image retrieval that used spatial attention and descriptor similarity to perform large-scale image retrieval using second-order information. Chu et al.30 constructed a CNN to extract dense features, embedded an attention module within the network to score features, and proposed a grid feature point selection method to reduce the number of image features. Chu et al.31 combined deep with handcrafted features, extracted average pooling features from the intermediate layers of a CNN for retrieval on street-view datasets, and used SIFT to re-rank them. Yan et al.32 extracted hierarchical feature maps from CNNs and organically fused them for image feature representation. However, most of these methods are only based on the optimization improvement of CNN or attention modules and do not use feature aggregation modules, making it difficult to obtain robust global features.
To address environmental factors, Chu et al.33 used a CNN with a HOW module34 to extract local image features, aggregated them into a feature vector using VLAD, used the aggregated selective match kernel, and estimated the geographical location of the query image using kernel density prediction. Mishkin et al.35 used a bag-of-words method with multiple detectors, descriptors, and adaptive thresholds. Arandjelovic et al.17 designed a trainable NetVLAD layer inspired by VLAD, which provided a pooling mechanism that was integrated into other CNN structures. In addition, variants of NetVLAD have been proposed, such as CRN36, SPE-VLAD37, MultiRes-NetVLAD38, SARE39, and SFRS40. Ali-bey et al. proposed ConvAP41, which combines 1 × 1 convolutions with adaptive mean pooling to encode local features. The above methods improve the robustness of VPR in complex environments, but such methods tend to have higher computational complexity and feature vector dimensions and are more sensitive to noise, which limits the performance and accuracy of VPR.
Methodology
Proposed framework
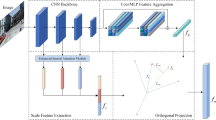
We aim to build robust VPR models to solve the problem of poor VPR accuracy of existing methods in scenarios such as multiple shooting angles, illumination changes, seasonal variations, and occlusions to improve the VPR accuracy. We propose a VPR framework integrating the foundational vision model with feature aggregation. The proposed framework uses the truncated DINOv221 model as the backbone. DINOv2 is well-suited for several downstream tasks due to its exceptional image understanding capability. Therefore, we pre-trained the DINOv2 model as the primary network for image feature extraction and used an efficient and lightweight mixer module to aggregate the obtained image features. The DINO-Mix visual geolocation architecture is illustrated in Fig. 1.

Visual place recognition (VPR) framework of DINO-Mix. The framework consists of two parts: firstly, the layer norms and head of the foundational vision model DINOv2 are pruned away and used as a backbone to extract the image feature vectors, and then the obtained feature vectors with dimensions N × D are transformed into h × w × s feature maps, and then robust global feature vectors are obtained by feature aggregation in the Mix module. During training, the front block in the backbone is frozen, and the parameters of the following few blocks and the Mix module are updated.
We modified the DINOv2 model by removing its layer norms and head, which were subsequently used as the backbone. Furthermore, to maximize the benefits of the DINOv2 pretraining, we used the output from the last layer of the vision transformer (ViT) blocks42 as the input to the mixer module. Given that the output of the modified ViT block module is a feature matrix of size N × D (number of channels × feature vector length), we transformed it into s feature maps of size h × w, as expressed by Eq. (1). These transformed feature maps served as inputs for the mix module (see Figs. 1 and 2).
where D is the length of the feature vector output by the backbone, N is the number of channels in the output of the backbone, h and w are the height and width of the feature map, respectively, and s is the number of feature maps.
From Fig. 1, it is evident that our DINO-Mix possesses a generalized image retrieval mode. This implies that DINO-Mix can be utilized for more than simple VPR tasks. It can identify the geographic location of a single image, enabling temporal modeling and tracking of sequential images. Moreover, it can extract ground image features to match with satellite images, facilitating cross-view image geo-localization. DINO-Mix can be employed in other domains for medical image retrieval to aid disease diagnosis and case studies. Furthermore, it can enhance the user shopping experience by applying to merchandise image retrieval and product recommendation.
Foundational vision model: DINOv2
Foundational vision models are typically built using structures such as CNNs or transformers. These models often have tens to hundreds of millions of parameters, giving them a greater representational capacity than smaller models. In addition, because of the use of larger and more diverse datasets during training, foundational vision models can learn more features and have better generalization capabilities.
DINOv221 can extract powerful image features and perform well across different tasks. DINOv2 has a broader scope of application and use areas compared with Segment Anything43. The architecture of the DINOv2 model is illustrated in Fig. 2. First, an input image W × H × C is passed through a patch embedding module consisting of a 2D convolutional layer with a kernel size of 14 × 14 and a stride of 14, followed by a normalization layer. This process uniformly outputs patches of size (P × P), and (W // 14) × (H // 14) is the number of channels N. These patches are then fed into ViT blocks, which vary in number according to the model’s size. The ViT blocks output a feature matrix of size N (number of channels) × D (dimension of the feature vector), which is then normalized by a layer-norm module before being transformed into a feature vector of size 1 × n. Finally, the head module can be flexibly selected based on specific image task requirements.

Structural diagram of the DINOv2 model and feature transformation.
DINOv2 has several key features: (a) it presents a novel approach for training high-performance computer vision models; (b) it offers superior performance without the need for fine-tuning; (c) it can learn from any image dataset and capture certain features that existing methods struggle with; and (d) it leverages knowledge distillation to transfer knowledge from more complex teacher models to smaller student models. Through knowledge distillation, three smaller models were obtained from the ViTg14 model: ViTl14 (large), ViTb14 (base), and ViTs14 (small) (see Table 1).
The primary advantage of DINOv2 lies in its training on a large-scale dataset. This dataset, LVD-142 M, comprises 142 million images and includes ImageNet-22k, ImageNet-1k, Google Landmarks, several fine-grained datasets, and image datasets crawled from the Internet. An Nvidia A100 40-GB GPU was used for model training, with a total of 22k GPU hours dedicated to training the DINOv2-g model.
Feature mixer
Currently, the most advanced techniques propose shallow aggregation layers that are inserted into very deep pre-trained backbones cropped to the last feature-rich layer. By contrast, Wang et al. proposed TransVPR44, which achieved good results in local feature matching. However, its global representation performance did not surpass NetVLAD17 or CosPlace19. Recent advances in isotropic architectures have demonstrated that self-attention is not crucial for ViT. However, the mixer uses feature maps extracted from a pre-trained backbone and iteratively merges global relationships into each feature map. This is achieved through an isotropic block stack composed of MLPs, referred to as a feature mixer22. The effectiveness of the mixer has been demonstrated through several qualitative and quantitative results, demonstrating its high performance and lightweight nature20; the architecture is illustrated in Fig. 3.

Architecture of the mixer.
The mixer treats the input feature map \(\:F\in\:{R}^{s\times\:h\times\:w}\) as a set of s 2D features, each of size \(\:h\times\:w\), as expressed by Eq. (2):
where \(\:{\text{X}}^{\text{i}}\) is the i-th activation map in the feature map \(\:F\). Secondly, each 2D feature map \(\:{X}^{i}\) is expanded into a 1D vector representation, resulting in a flattened feature map \(\:F\in\:{R}^{s\times\:n}\), where \(\:n=h\times\:w\).
The flattened feature maps are then fed into the feature mixer, which is composed of L MLPs with the same structure, as shown in Fig. 3. The feature mixer takes the flattened feature map ensemble as input and successively incorporates spatial global relationships into each \(\:{X}^{i}\in\:F\) as per Eq. (3):
where \(\:{W}_{1}\) and \(\:{W}_{2}\) are the weights of the two fully connected layers that make up the MLP, and σ is the ReLU nonlinear activation function.
For \(\:F\in\:{R}^{s\times\:n}\), the feature mixer produces an output \(\:\text{Z}\in\:{R}^{s\times\:n}\) with the same shape owing to its isotropic architecture, and feeds it into the second feature mixer block and so on until L consecutive blocks have been traversed, as per Eq. (4):
where Z and the feature map F have the same dimensions, two fully connected layers are used to successfully transform the channel and row dimensions to control the dimensions of the final global descriptor. First, a depth projection is used to map Z from \(\:{R}^{s\times\:n}\) to \(\:{R}^{d\times\:n}\), as given by Eq. (5):
where \(\:{W}_{d}\) is the weight of the fully connected layer. A row-wise projection is then used to map the output \(\:{Z}^{{\prime\:}}\) from \(\:{R}^{d\times\:n}\) to \(\:{R}^{d\times\:r}\), as given by Eq. (6):
where \(\:{W}_{r}\) is the weight of the fully connected layer. The final output O has dimensions of \(\:d\times\:r\), which are flattened, and L2 is normalized to form a global feature vector.
Implementation details
Datasets
Our model was trained using the GSV-Cities dataset41. The datasets used for evaluation purposes were Pittsburgh250k45 (contains 8k queries and 83k reference images collected from Google Street View and Pittsburgh30k-test), Pittsburgh30k-test45 (a subset of Pittsburgh250k, with 8k queries and 8k reference images), SF-XL-Val19, Tokyo24/746, Nordland47, and SF-XL-Testv119. The datasets contained extreme variations in lighting, weather, and seasons. Specific information regarding these datasets is presented in Table 2.
Architecture
We completed our experiments using two RTX 4090 GPUs, with the system powered by an Intel Xeon Platinum 8357 C CPU featuring 64 cores and equipped with SSD storage for efficient large-scale data computation. We used Pytorch as the deep-learning framework. To enable a fair comparison with other methods in terms of accuracy, we conducted precision tests on the VPR frameworks NetVLAD, GeM, ConvAP, CosPlace, and MixVPR and obtained the testing accuracy for other methods from their corresponding papers.
Training
Most training weights were frozen during the training process owing to the excellent pre-trained weights of the DINO-Mix backbone. However, to make it more suitable for the VPR task, we fine-tuned the end of the backbone and trained the feature aggregation module. We trained DINO-Mix following the standard framework proposed in GSV-Cities41, which introduced a high-precision dataset of 67k locations described by 560k images. The batch size B was flexibly adjusted based on the model parameter size, and each location was trained with four images, resulting in a mini-batch of B × 4 images. A stochastic gradient descent method48 with a momentum of 0.9 and a weight decay of 0.001 was used for optimization. The initial learning rate was set to 0.05 and was divided by three every five epochs. Finally, the model was trained using images resized to 224 × 224 pixels over 50 epochs. Most existing VPR studies use a triplet loss function based on weak supervision49 for network training; however, this approach usually has a high computational overhead. Therefore, we used multi-similarity loss50 as the training loss function. Multi-similarity loss mitigates large interclass and small intraclass distances in metric learning by considering multiple similarities. Instead of relying solely on absolute spatial distance as the sole metric, it uses the overall distance distribution of other sample pairs within a batch size to weigh the loss. This computational approach effectively promotes model convergence in the early stages, as expressed by Eq. (7)
where \(\:{P}_{i}\) is the set of positive sample pairs for each instance in a batch size, \(\:{N}_{i}\) is the set of negative sample pairs for each instance in the same batch size, \(\:{S}_{ij}\) and \(\:{S}_{ik}\) are the similarities between the two images, and \(\:\alpha\:\), \(\:\beta\:\), and \(\:\lambda\:\) are hyperparameters.
Evaluation
In this study, we used top-k accuracy51 as a metric to evaluate the precision of the VPR methods. Top-k accuracy is a commonly used evaluation method in the VPR domain, where it is considered successful if at least one of the top-k localization results for a query image has a geographical distance of less than a threshold from the true location. In our experiments, we set to 25 m to align with existing methods.
Results and discussion
Comparison to the SOTA
We adopted the ViTb14 pre-trained model, which exhibited the best performance among the four models of DINOv2, as the backbone for DINO-Mix in the VPR task and modified the DINOv2 model by removing its layer norm and head modules. We used the mixer as a feature aggregation module to construct the model. During training, we updated the parameters of the last three blocks of the backbone and the entire mix feature aggregation module. The number of feature mixer blocks in the mix feature aggregation module was set to two, and the dimensionality of the image features output by the model was 4096. Using these optimal parameter settings, we conducted tests on six test sets for DINO-Mix and compared them with the existing methods, as shown in Table 3. In addition, Fig. 4 illustrates the difference in accuracy between DINO-Mix and other primary VPR methods.
As listed in Table 3, the test accuracy of the DINO-Mix model proposed in this study has comprehensively surpassed that of the SOTA methods, with further improvement in the Pittsburgh250k, Pittsburgh30k, and SF-XL-Val test sets focusing on changes in viewpoints, and especially in the Tokyo24/7, Nordland, and SF-XL-Testv1 test sets with changes in complex appearance environments.

Top-1 accuracy of DINO-Mix and other VPR methods for different test sets.
Ablation studies
Number of mix layers
In DINO-Mix, the number of layers L in the feature mixer is also critical for image retrieval accuracy. To determine the optimal number of mixer layers, we conducted tests on the Pitts30k-test, Pitts250k-test, Sf-xl-val, Tokyo24/7, Nordland, and Sf-xl-testv1 datasets with different numbers of mix layers L (1–7) for DINO-Mix using ViTb14 as the backbone. The TOP-1 accuracy is depicted in Fig. 5. A careful examination of the figure reveals that DINO-Mix exhibited a lackluster test accuracy without any mix layers across all six datasets. However, upon incorporating one mix layer, test accuracy was substantially improved. This observation highlights the pivotal role played by the feature aggregation module in elevating the precision of DINO-Mix. As the number of mix layers increased to two, there was a marginal improvement in test accuracy, where it peaked. As the number of mix layers continued to increase, DINO-Mix’s test accuracy on the six datasets displayed a slow decline with fluctuations, accompanied by a linear parameter increase. Based on the above analysis, this study adopted a two-layer mix scheme as the optimal feature aggregator in DINO-Mix.

Ablation on the number of feature mix blocks for each dataset.
Descriptor dimensionality
We conducted an ablation study on the dimensionality of image feature vectors extracted using the DINO-Mix model. The experiment used ViTb14, which exhibited the best performance as the backbone, with two layers in the mixer module. The test datasets used were the Pitts30k-test, Pitts250k-test, Sf-XL-val, Tokyo24/7, Nordland, and Sf-XL-testv1, and the image feature vector dimensionality was varied by changing the number of channels in the output vector of the mixer module. The tested dimensions of the image feature vectors were 128, 256, 512, 1,024, 2,048, 4,096, and 8,192. As depicted in Fig. 6, an increase in the dimensionality of image feature vectors was observed to positively impact the overall Top-1 test accuracy of DINO-Mix across all the datasets. This trend was particularly pronounced in the SF-XL-val, Tokyo24/7, Nordland, and SF-XL-testv1 datasets, where accuracy rapidly increased. Ultimately, the highest accuracy was achieved at a dimensionality of 4,096. This phenomenon suggests that using image feature vectors with a dimensionality that is too low may result in reduced robustness to variations such as changes in illumination and seasonal shifts in VPR tasks. Consequently, we adopted a final image feature dimensionality of 4,096 in this study.

Ablation on the dimensionality levels for each dataset.
Backbone architecture
DINOv2 encompasses four ViT models, with ViTg14 (giant) being the largest. Through model knowledge distillation, three smaller models were obtained from the distillation process, including ViTl14 (large), ViTb14 (base), and ViTs14 (small), as displayed in Table 1. To evaluate the performance of these four models in the DINO-Mix framework, we conducted training with GSV-Cities as the training set and tested the Pitts30k-test dataset using ViTg14-Mix, ViTl14-Mix, ViTb14-Mix, and ViTs14-Mix. The feature mixer was fixed at two layers, and the dimensionality of the image feature vectors was set to 4096. In addition, we trained and tested the DINO-Mix models with four different backbone networks under six scenarios: updating the weights of the last one, two, three, six, and nine blocks and not updating the weights of the backbone (none). The results are shown in Fig. 7.

DINO-Mix models with different weights for updating the number of layers.
From the perspective of the four differently sized backbones, ViTb14-Mix exhibited higher accuracy than the other three models, with a maximum Top-1 accuracy of 92.03%. In contrast, ViTg14-Mix exhibited the worst overall performance. This suggests that ViTg14’s large parameter count extracted deeper features from images, adversely affecting subsequent feature aggregation in the feature mixer.
Models without parameter updates for the backbone demonstrated poorer performance. As the number of updated blocks increased, ViTb14-Mix and ViTl14-Mix gradually improved test accuracy, reaching their highest values after updating the parameters of the last three blocks and stabilizing. In contrast, ViTs14-Mix achieved the highest test accuracy and stability after updating the parameters of the last two blocks. However, for ViTg14-Mix, the block parameter updates did not significantly enhance accuracy. Starting from the last three blocks, the ViTg14-Mix test accuracy showed a downward trend. This indicates that excessively deep block parameter updates may alter the original pre-trained parameters extensively.
Additionally, we evaluated the parameter counts (Params), floating-point operations (FLOPs), and average inference times (Avg. inference time) across six test sets for the four DINO-Mix models, as presented in Table 4. Vitg14-Mix and ViTl14-Mix exhibit high parameter counts, FLOPs, and extended average inference times. Conversely, ViTb14-Mix and ViTs14-Mix demonstrate significantly reduced parameter counts and FLOPs, with average inference times of only 10.3 ms and 10.2 ms, respectively. These results indicate that ViTb14-Mix and ViTs14-Mix can effectively meet the speed requirements for most VPR tasks.
In summary, updating the parameters of the last three blocks of the backbone yielded optimal results. We selected ViTb14-Mix, which has a moderate parameter count, low FLOPs, breakneck inference speed, and superior test accuracy, as the final model for DINO-Mix.
Image retrieval comparison
In this study, we compared the performance of DINO-Mix with those of SOTA methods, comprising MixVPR, NetVLAD, ConvAP, and CosPlace, in image retrieval tasks. To demonstrate the robustness of DINO-Mix for VPR in complex environments, we selected several representative image retrieval examples from the Tokyo24/7, SF-XL-Testv1, and Nordland datasets. We presented four challenging scenarios: viewpoint changes, illumination changes, object occlusions, and seasonal variations. In these examples, DINO-Mix succeeded, whereas the other methods failed to accurately locate the query image, as shown in Fig. 8.

Comparison of VPR results (Top-1) of DINO-Mix with other methods in complex cases. (a) Successful VPR cases of DINO-Mix. (b) Failed VPR cases of DINO-Mix. The green and red boxes in the table represent image retrieval success and failure, respectively. The yellow box represents correct image content, but the localization distance exceeds the threshold s.
Viewpoint change
Viewpoint changes encompass variations in the field angle and range, posing image retrieval challenges. Rows 1 and 2 in Fig. 8 (a) show viewpoint changes in field angle and field range. Only DINO-Mix resisted the interference caused by viewpoint changes and retrieved the correct image; the other methods retrieved similar but incorrect buildings or scenes.
Illumination change
Illumination change significantly affects image retrieval accuracy. Dim lighting conditions can blur image textures, adversely affecting feature extraction and image retrieval accuracy. Rows 3 in Fig. 8 (a) depict the image retrieval cases under dark conditions. Rows 4 and 5 present nighttime scenarios with artificial and natural light variations, respectively. DINO-Mix exhibited strong robustness against illumination changes, whereas the other methods suffered from the effects of lighting variations and failed to retrieve accurate results.
Occlusion
Image retrieval focuses primarily on objects, such as buildings, facilities, and natural landscapes. However, pedestrians, vehicles, and other objects can interfere with the semantic information in an image, posing challenges for image retrieval. As shown in rows 6 in Fig. 8 (a), where many pedestrians are present in the query images, and in row 7, where the influence of buildings is significant, these occlusions pose significant difficulties for image retrieval. MixVPR retrieved the correct content but exceeded the threshold (25 m) in the localization results. In contrast, despite these challenges, DINO-Mix successfully extracted the correct features from the images and retrieved accurate results.
Season change
The appearance characteristics of locations undergo significant changes in different seasons, such as heavy snowfall in winter (as illustrated in row 8 of Fig. 8 (a)) and leaves falling from trees (row 9). These seasonal variations also have a profound impact on image retrieval accuracy. Under such challenging circumstances, DINO-Mix overcame the drastic contrast caused by seasonal changes and achieved satisfactory results.
Failure cases
DINO-Mix cannot perform adequately in specific challenging scenarios. As illustrated in Fig. 8(b), the query image in the initial row was captured in the evening, with a narrow viewing angle and a blurry image—this significantly impaired DINO-Mix’s capacity to extract features, resulting in retrieval failure. The query image and the ground truth (GT) in the second row were taken at different periods, and the color of the same building has changed, which is evident that DINO-Mix cannot exclude the interference of such factors, leading to retrieval and localization failure. Other VPR techniques also falter in retrieving with precision. Therefore, image enhancement for VPR tasks and how to overcome the effects of scene changes over ample periods on VPR are directions worthy of further research.
Figure 8. Comparison of VPR results (Top-1) of DINO-Mix with other methods in complex cases. (a) Successful VPR cases of DINO-Mix. (b) Failed VPR cases of DINO-Mix. The green and red boxes in the table represent image retrieval success and failure, respectively. The yellow box represents correct image content, but the localization distance exceeds the threshold s.
Attention map visualization

Attention map visualization of the query image.
To provide a more intuitive demonstration of the superiority of DINO-Mix over other VPR methods, we visualized their attention maps as presented in Fig. 9. The attention scores are represented by varying colors from blue to green to red, indicating low to high attention levels. Our analysis reveals that DINO-Mix can focus more on buildings, object contours, and textures, which are crucial for image retrieval. In contrast, it effectively excludes negative elements such as pedestrians, cars, and occlusions. This suggests that DINO-Mix has a greater ability to capture essential features and extract more robust image representations. However, as shown in Fig. 9, row 10, the blurring and inadequate brightness of the image make it difficult for DINO-Mix to notice valuable features, which leads to retrieval failure. This deficiency is the direction in which the model needs to be improved.
Conclusions
In this study, we proposed a novel VPR framework called DINO-Mix. First, we modified and fine-tuned the structure of the DINOv2 model. We then converted the extracted features from the backbone into feature maps and used the mix feature aggregation module to aggregate these feature maps to obtain global feature vectors. The experimental results on different test sets demonstrate that the proposed DINO-Mix model outperforms SOTA methods regarding VPR accuracy, with an average improvement of 5.14% across test sets containing challenging conditions. Furthermore, through a series of image retrieval examples under difficult circumstances, we demonstrated that the performance of the DINO-Mix architecture significantly surpasses that of current SOTA architectures. However, our experiments revealed that DINO-Mix exhibits poor performance in scenarios involving dynamic blurring and inadequate brightness of images. Furthermore, scene changes occurring over extended periods diminished the accuracy of DINO-Mix. Consequently, our future work will involve delving into the image enhancement techniques for the VPR task and incorporating specialized training to address scene changes over ample periods, aiming to enhance VPR accuracy.
Data availability
The datasets generated and/or analysed during the current study are available in the DINO-Mix repository, https://github.com/GaoShuang98/DINO-Mix.
References
Middelberg, S., Sattler, T., Untzelmann, O. & Kobbelt, L. Scalable 6-DOF Localization on Mobile Devices. in (eds. Fleet, D., Pajdla, T., Schiele, B. & Tuytelaars, T.) vol. 8690 268–283 (2014).
Suenderhauf, N. et al. Place Recognition with ConvNet Landmarks: Viewpoint-Robust, Condition-Robust, Training-Free. in Robotics: Science and Systems XI (Robotics: Science and Systems Foundation, doi: (2015). https://doi.org/10.15607/RSS.2015.XI.022
Chaabane, M., Gueguen, L., Trabelsi, A., Beveridge, R. & O’Hara, S. End-to-end Learning Improves Static Object Geo-localization from Video. in Ieee Winter Conference on Applications of Computer Vision Wacv 2021 2062–2071 (Ieee, New York, 2021). doi: (2021). https://doi.org/10.1109/WACV48630.2021.00211
Wilson, D. et al. Object Tracking and Geo-localization from Street images. Remote Sens. 14, 2575 (2022).
Agarwal, S., Snavely, N., Simon, I., Seitz, S. M. & Szeliski, R. Building Rome in a Day. in IEEE 12th International Conference on Computer Vision (ICCV) 72–79 (2009). doi: (2009). https://doi.org/10.1109/ICCV.2009.5459148
Acampora, G., Anastasio, P., Risi, M., Tortora, G. & Vitiello, A. Automatic Event Geo-Location in Twitter. IEEE Access. 8, 128213–128223 (2020).
Lowe, D. Distinctive image features from Scale-Invariant keypoints. Int. J. Comput. Vision. 60, 91–110 (2004).
Dalal, N. & Triggs, B. Histograms of Oriented Gradients for Human Detection. in IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05) vol. 1 886–893 (IEEE, San Diego, CA, USA, 2005). (2005).
Bay, H., Tuytelaars, T. & Van Gool, L. S. U. R. F. Speeded up robust features. in Computer Vision – ECCV 2006 (eds Leonardis, A., Bischof, H. & Pinz, A.) vol 3951 404–417 (Springer Berlin Heidelberg, Berlin, Heidelberg, (2006).
Rublee, E., Rabaud, V., Konolige, K. & Bradski, G. O. R. B. An efficient alternative to SIFT or SURF. in International Conference on Computer Vision 2564–2571 (IEEE, Barcelona, Spain, 2011). doi: (2011). https://doi.org/10.1109/ICCV.2011.6126544
Tang, K., Li, F. F. & Koller, D. Learning latent temporal structure for complex event detection. in IEEE Conference on Computer Vision and Pattern Recognition 1250–1257 (IEEE, Providence, RI, 2012). doi: (2012). https://doi.org/10.1109/cvpr.2012.6247808
Jegou, H., Douze, M., Schmid, C. & Perez, P. Aggregating local descriptors into a compact image representation. in IEEE Computer Society Conference on Computer Vision and Pattern Recognition 3304–3311 (IEEE, San Francisco, CA, USA, 2010). doi: (2010). https://doi.org/10.1109/cvpr.2010.5540039
Jegou, H. et al. Aggregating local image descriptors into Compact codes. IEEE Trans. Pattern Anal. Mach. Intell. 34, 1704–1716 (2012).
Xu, M. Queensland University of Technology,. Bridging the divide between visual place recognition and SLAM. doi: (2023). https://doi.org/10.5204/thesis.eprints.240786
Kanjilal, R. & Uysal, I. Rich learning representations for human activity recognition: how to empower deep feature learning for biological time series. J. Biomed. Inf. 134, 104180 (2022).
Costa, Y., Oliveira, L., Koerich, A. & Gouyon, F. Music genre recognition using gabor filters and LPQ texture descriptors. in Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications (ed Ruiz-Shulcloper, J.) (2013). & Sanniti Di Baja, G.) vol. 8259 67–74 (Springer Berlin Heidelberg, Berlin, Heidelberg.
Arandjelovic, R., Gronat, P., Torii, A., Pajdla, T. & Sivic, J. NetVLAD: CNN Architecture for weakly supervised Place Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 40, 1437–1451 (2018).
Radenovic, F., Tolias, G., Chum, O. & Fine-Tuning, C. N. N. Image Retrieval with no human annotation. IEEE Trans. Pattern Anal. Mach. Intell. 41, 1655–1668 (2019).
Berton, G., Masone, C. & Caputo, B. Rethinking Visual Geo-localization for Large-Scale Applications. in IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR 2022) 4868–4878 (IEEE Computer Soc, 10662 LOS VAQUEROS CIRCLE, PO BOX 3014, LOS ALAMITOS, CA 90720 – 1264 USA, 2022). doi: (2022). https://doi.org/10.1109/CVPR52688.2022.00483
Ali-Bey, A., Chaib-Draa, B. & Giguere, P. MixVPR: Feature Mixing for Visual Place Recognition. in IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2997–3006 (IEEE, Waikoloa, HI, USA, 2023). doi: (2023). https://doi.org/10.1109/wacv56688.2023.00301
Oquab, M. et al. DINOv2: Learning Robust Visual Features without Supervision. Preprint at (2023). https://doi.org/10.48550/arxiv.2304.07193
Tolstikhin, I. O. et al. MLP-Mixer: An all-MLP Architecture for Vision. in Advances in Neural Information Processing Systems (eds Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P. S. & Vaughan, J. W.) vol. 34 24261–24272 (Curran Associates, Inc., (2021).
Masone, C. & Caputo, B. A. Survey on Deep Visual Place Recognition. IEEE Access. 9, 19516–19547 (2021).
Zhang, W. & Kosecka, J. Image Based Localization in Urban Environments. in Third International Symposium on 3D Data Processing, Visualization, and Transmission, Proceedings (eds. Pollefeys, M. & Daniilidis, K.) 33–40Chapel Hill, NC, USA, doi: (2007). https://doi.org/10.1109/3dpvt.2006.80
Martin, A., Fischler, Robert, C. & Bolles Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM. 24, 381–395 (1981).
Zamir, A. R. & Shah, M. Accurate image localization based on Google maps Street View. in Computer Vision – ECCV 2010 (eds Daniilidis, K., Maragos, P. & Paragios, N.) vol. 6314 255–268 (Springer, (2010).
Zamir, A. R., Ardeshir, S. & Shah, M. GPS-Tag Refinement Using Random Walks with an Adaptive Damping Factor. in IEEE Conference on Computer Vision and Pattern Recognition 4280–4287 (IEEE, Columbus, OH, USA, 2014). doi: (2014). https://doi.org/10.1109/CVPR.2014.545
Noh, H., Araujo, A., Sim, J., Weyand, T. & Han, B. Large-Scale Image Retrieval with Attentive Deep Local Features. in IEEE International Conference on Computer Vision (ICCV) 3476–3485 (IEEE, Venice, 2017). doi: (2017). https://doi.org/10.1109/ICCV.2017.374
Ng, T., Balntas, V., Tian, Y. & Mikolajczyk, K. S. O. L. A. R. Second-Order Loss and Attention for Image Retrieval. in Computer Vision–ECCV 2020: 16th European Conference Part XXV 16 (eds. Vedaldi, A., Bischof, H., Brox, T. & Frahm, J.-M.) 253–270Springer International Publishing, Glasgow, UK, (2020).
Chu, T. Y., Chen, Y. M., Huang, L., Xu, Z. G. & Tan, H. Y. A Grid feature-point selection method for large-Scale Street View Image Retrieval based on deep local features. Remote Sens. 12, 3978 (2020).
Chu, T. Y. et al. IEEE, Waikoloa, HI, USA,. Street View Image Retrieval with Average Pooling Features. in IGARSS 2020–2020 IEEE International Geoscience and Remote Sensing Symposium 1205–1208 doi: (2020). https://doi.org/10.1109/IGARSS39084.2020.9323667
Yan, L. Q., Cui, Y. M., Chen, Y. J. & Liu, D. F. Hierarchical Attention Fusion for Geo-Localization. in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2021) 2220–2224 (IEEE, New York, 2021). doi: (2021). https://doi.org/10.1109/ICASSP39728.2021.9414517
Chu, T. Y. et al. A news picture geo-localization pipeline based on deep learning and street view images. Int. J. Digit. Earth. 15, 1485–1505 (2022).
Tolias, G., Jenicek, T. & Chum, O. Learning and Aggregating Deep Local descriptors for Instance-Level Recognition. in Computer Vision – ECCV 2020 (eds Vedaldi, A., Bischof, H., Brox, T. & Frahm, J. M.) 460–477 (Springer International Publishing, Cham, (2020).
Mishkin, D., Perdoch, M. & Matas, J. Place Recognition with WxBS Retrieval. in CVPR 2015 Workshop on Visual Place Recognition in Changing Environments vol. 30 9Boston, USA, (2015).
Kim, H. J., Dunn, E. & Frahm, J. M. Learned Contextual Feature Reweighting for Image Geo-Localization. in IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 3251–3260 (IEEE, Honolulu, HI, 2017). doi: (2017). https://doi.org/10.1109/CVPR.2017.346
Yu, J., Zhu, C. Y., Zhang, J., Huang, Q. M. & Tao, D. C. Spatial pyramid-enhanced NetVLAD with Weighted Triplet loss for Place Recognition. IEEE Trans. Neural Netw. Learn. Syst. 31, 661–674 (2020).
Khaliq, A., Milford, M. & Garg, S. MultiRes-NetVLAD: augmenting Place Recognition Training with Low-Resolution Imagery. IEEE Robot Autom. Lett.7, 3882–3889 (2022).
Liu, L., Li, H. D. & Dai, Y. C. Stochastic Attraction-Repulsion Embedding for Large Scale Image Localization. in IEEE/CVF International Conference on Computer Vision (ICCV) 2570–2579 (IEEE, Seoul, Korea (South), 2019). doi: (2019). https://doi.org/10.1109/iccv.2019.00266
Ge, Y., xiao, Wang, H., bo, Zhu, F., Zhao, R. & Li, H. Sheng. Self-supervising Fine-grained Region Similarities for Large-scale Image Localizationvol. 12349 369–386 (Springer International Publishing, 2020).
Ali-bey, A., Chaib-draa, B. & Giguère, P. GSV-Cities: toward Appropriate supervised Visual Place Recognition. Neurocomputing. 513, 194–203 (2022).
Dosovitskiy, A. et al. An image is worth 16x16 words: transformers for Image Recognition at Scale. in doi: (2021). https://doi.org/10.48550/arXiv.2010.11929
Kirillov, A. et al. Segment Anything. Preprint at (2023). http://arxiv.org/abs/2304.02643
Wang, R. T. et al. Transformer-Based Place Recognition with Multi-Level Attention Aggregation. in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 13638–13647 (IEEE, New Orleans, LA, USA, 2022). doi: (2022). https://doi.org/10.1109/cvpr52688.2022.01328
Torii, A., Sivic, J., Okutomi, M. & Pajdla, T. Visual Place Recognition with repetitive structures. IEEE Trans. Pattern Anal. Mach. Intell. 37, 2346–2359 (2015).
Torii, A., Arandjelovic, R., Sivic, J., Okutomi, M. & Pajdla, T. 24/7 Place Recognition by View Synthesis. IEEE Trans. Pattern Anal. Mach. Intell. 40, 257–271 (2018).
Sunderhauf, N., Neubert, P. & Protzel, P. Are we there yet? Challenging SeqSLAM on a 3000 km Journey Across All Four Seasons. in.
Ruder, S. An overview of gradient descent optimization algorithms. Preprint at.https://doi.org/10.48550/arXiv.1609.04747 (2017).
Hermans, A., Beyer, L. & Leibe, B. In Defense of the Triplet Loss for Person Re-Identification. in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)IEEE, (2018).
Wang, X., Han, X., Huang, W., Dong, D. & Scott, M. R. Multi-Similarity Loss With General Pair Weighting for Deep Metric Learning. in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 5017–5025 (IEEE, Long Beach, CA, USA, 2019). doi: (2019). https://doi.org/10.1109/CVPR.2019.00516
Huang, G. S., Zhou, Y., Hu, X. F., Zhao, L. Y. & Zhang, C. L. A survey of the Research Progress in Image Geo- localization. J. Geo-information Sci. 25, 1336–1362 (2023).
Yandex, A. B. & Lempitsky, V. Aggregating Deep Convolutional Features for Image Retrieval. in IEEE International Conference on Computer Vision (ICCV) 1269–1277 (IEEE, Santiago, Chile, 2015). doi: (2015). https://doi.org/10.1109/iccv.2015.150
Razavian, A. S., Sullivan, J., Carlsson, S. & Maki, A. Visual Instance Retrieval with Deep Convolutional Networks. ITE Trans. Media Technol. Appl. 4, 251–258 (2016).
Tolias, G., Sicre, R. & Jégou, H. Particular object retrieval with integral max-pooling of CNN activations. Preprint at (2016). http://arxiv.org/abs/1511.05879
Kordopatis-Zilos, G., Galopoulos, P., Papadopoulos, S. & Kompatsiaris, I. Leveraging EfficientNet and Contrastive Learning for Accurate Global-scale location estimation. in (2021).
Acknowledgements
This work is supported by the National Natural Science Foundation of China, grant number: 42001338.
Author information
Authors and Affiliations
Contributions
G. H. led the study design and experimental planning. Y. Z. as a senior advisor, guided the research direction, manuscript structure, and content review, while X. H. managed data acquisition. C. Z. contributed to algorithmic enhancements. L. Z. provided technical support in experiments. W.G. optimized algorithms. All authors collaborated on writing, reviewing, and approving the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Huang, G., Zhou, Y., Hu, X. et al. DINO-Mix enhancing visual place recognition with foundational vision model and feature mixing. Sci Rep 14, 22100 (2024). https://doi.org/10.1038/s41598-024-73853-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-73853-3
Keywords
This article is cited by
-
Enhancing cross view geo localization through global local quadrant interaction network
Scientific Reports (2025)
-
Fog computing-driven logistics: leveraging few-shot learning and foundational computer vision models
Cluster Computing (2025)
