
Abstract
This research work focuses on addressing the challenges of electric load forecasting through the combination of Support Vector Regression and Long Short-Term Memory (SVR/LSTM) methodology. The model has been modified by a flexible version of the Gorilla Troops optimization algorithm. The objective of this study is to enhance the precision and effectiveness of load forecasting models by integrating the adaptive functionalities of the Gorilla Troops algorithm within the SVR/LSTM framework. To assess the efficacy of the proposed methodology, a comprehensive series of experiments and evaluations have been undertaken, utilizing authentic data obtained from 200 residential properties located in Texas, United States of America. The dataset comprises historical records of electricity consumption, meteorological data, and other pertinent variables that exert an impact on energy demand. The presence of this general dataset enhances the dependability and inclusiveness of the empirical findings. The proposed methodology was evaluated against various contemporary load forecasting techniques that are widely employed in the industry. The results of a comprehensive evaluation and performance analysis indicate that the modified SVR/LSTM model exhibits superior performance compared to the existing methods in terms of accuracy and robustness. The comparison results unequivocally demonstrate the superiority of the proposed method in accurately forecasting electric load demand.
Similar content being viewed by others

Introduction
Background
Electricity load forecasting is a critical component in the management of energy systems1. It involves predicting the amount of electrical power that will be consumed in a particular region at a specific time2. This is crucial for maintaining grid stability, as it allows for the efficient allocation of resources and prevents overloading or underutilization of the power grid3.
Accurate load forecasting is also essential for resource planning. Energy providers need to know how much power they will need to generate to meet demand4. If the forecast is too high, they may waste resources by generating more power than is needed5. If the forecast is too low, they may not generate enough power, leading to blackouts or the need to purchase expensive emergency power6. Over the years, a variety of techniques have been used to improve the accuracy of load forecasting7. These include statistical methods, such as time series analysis and regression models, as well as more complex methods like artificial neural networks and support vector machines8.
For instance, Li et al.9 aimed to address the challenge of generalizing well in forecasting massive electrical load, given its various patterns. The researchers found that most learning algorithms performed better for dominant patterns on weekdays and less dominant patterns on weekends and holidays.
To improve accuracy, they clustered the load patterns, allowing independent clusters to be modeled using CNN-GRU. This approach effectively improved electric load forecasting accuracy by approximately 50% (WAPE = 0.67%). Additionally, it accelerated training by about 35% due to clustering. The proposed method has been implemented by the Korea Water Resources Corporation for load forecasting and system marginal price estimation.
Related works
However, in recent years, machine learning algorithms have gained popularity in this field. These algorithms are capable of capturing nonlinear relationships and temporal dependencies in data, which traditional statistical methods may struggle with. This makes them particularly well-suited to load forecasting, which often involves complex patterns and trends that can be difficult to model with traditional methods. Machine learning algorithms can be trained on historical load data, weather data, and other relevant factors to predict future load demand.
They can also adapt to new data, allowing them to improve their predictions over time. This adaptability is particularly useful for load forecasting, where patterns can change due to factors such as changes in consumer behavior or the introduction of new technologies.
For example, Li et al.10 focused on ultra-short-term power load forecasting using recent load and weather data. They developed a CEEMDAN-1SE-LSTM model that combined time series decomposition-reconstruction modeling with neural network forecasting. The goal was to accurately forecast the electricity load in Changsha, China, considering meteorological and holiday factors. By decomposing three years of power load data into components and reconstructing them based on sample entropy analysis, they captured fluctuation and trend characteristics. The LSTM neural network model was then used to predict and aggregate these components for final forecasts. Comparing their CEEMDAN-SE-LSTM model with other approaches such as ARMA, LSTM single-prediction, EEMD-LSTM, and CEEMDAN-LSTM models, the researchers found significant improvements in accuracy (RMSE: 62.102, MAE: 47.490, MAPE: 1.649%). The research enhanced ultra-short-term power load forecasting, aiding power dispatch in Changsha, and providing guidance for similar models in other cities.
Huang et al.11 proposed a wide-area multiple bus loads forecasting model. The RapidMIC values between bus loads were utilized as edge features to construct a similar-weighted spatial-temporal graph. This graph reflected the degree of correlation between bus loads without geographic or topological constraints. Neighboring node features were extracted through the spatial convolution layer (SCL) to enhance the full-domain node features. The extracted features were then transformed into temporal series and fed into the gated recurrent unit layer (GRUL) for short-term load forecasting of multiple buses in the wide area.
Experimental results using measured load data from 15 busbars showed improvement in evaluation metrics, with symmetric mean absolute percentage error (SMAPE) ranging from 3.19 to 5.89% and mean absolute error (MAE) ranging from 1.83 MW to 9.8 MW. The proposed model outperformed other methods, achieving a 1.82–5.94% improvement in SMAPE and demonstrating robustness in scenarios with abnormal load data.
Yotto et al.12 presented data from Benin from 2001 to 2020 to forecast the peak yearly demand for the electrical system. In particular, the Multilayer Perceptron (MLP) with backpropagation, a form of artificial neural network (ANN), is evaluated in the research along with three other methods for predicting power usage.
To guarantee precise and consistent predictions, the assessment is conducted using the mean square error (MSE) and correlation coefficient (R). The results show that the Bayesian regulatory variation of the MLP produces predictions during training and learning that closely match the actual data. With few prediction deviations, the verified model has good generalization ability.
Zambrano-Asanza et al.13 proposed a spatial-temporal load forecasting method to recognize and predict development patterns using historical dynamics and determine the development of consumers and electric load in small areas. An artificial neural network was integrated with a cellular automaton method to establish transition rules based on land-use preferences, neighborhood states, spatial constraints, and a stochastic disturbance. The main feature was the incorporation of temporality and the utilization of geospatial-temporal data analytics to calibrate and validate a holistic and integral framework.
Validation involved measuring the spatial error pattern during the training and testing phase. The method’s performance was assessed in the service area of an Ecuadorian power utility. Knowledge extraction from large-scale data, evaluation of parameter sensitivity and spatial resolution was done in reasonable times. It was concluded that adequate normalization and the use of temporality in spatial factors improved the error in spatial-temporal load forecasting.
Literature gap
There has been good progress in electric load forecasting, but there is still a lack of effective methods that use machine learning to predict electric load demand. Current methods like Support Vector Regression (SVR) and Long Short-Term Memory (LSTM) have shown some success, but they often face issues like high computational demands, low accuracy, and difficulty adapting to new data trends.
Most studies from the literature have concentrated on single machine learning techniques, such as SVR or LSTM, without considering the advantages of combining them. Also, the way these algorithms are optimized usually relies on traditional methods, which may not effectively capture the complex patterns in the data.
Motivation and contribution
The primary contribution of this work is the assessment and use of Support Vector Regression (SVR) and Long Short-Term Memory (LSTM), optimized using the Flexible version of the Gorilla Troops Optimization algorithm, for the prediction of home electrical usage. While LSTM is excellent at capturing temporal dependencies and patterns in time series data, SVR is great at capturing nonlinear correlations between input characteristics and load demand.
By improving accuracy and efficiency, this integration enables more accurate predictions from load forecasting models. The main objective is to create a model that makes use of past load data to precisely forecast future load demand. The suggested model makes use of both of the advantages of SVR and LSTM by integrating them.
The research concentrates on a set of homes with comparable characteristics, such as geographic location and construction type, to assure the validity and generalizability of the results. By doing this, it hopes to lessen the effect of seasonality and weather variations, guaranteeing that no outside variables affect the model’s performance. Real-world data from these homes were included in the suggested model’s evaluation, allowing for realistic deployment and evaluation.
Numerous tests and comparisons with other approaches showed that the combined SVR-LSTM technique was more effective at forecasting electrical load demand. The performance of the model was improved by using the Flexible version of the Gorilla Troops Optimization method. With the help of this algorithm’s potent optimization algorithm, the SVR-LSTM model’s parameters may be adjusted to better suit forecasting needs.
SVR/LSTM model
These 2 models (“Support Vector Regression” and “Long Short-Term Memory”) have utilized the procedures of machine learning for the forecasting of time series. The SVR has been considered a technique of regression analysis that utilizes the machines of support vector (SVM) for predicting continuous parameters. LSTM, however, has been a kind of RNN (recurrent neural network), identified because of its potential in the simulation of consecutive data.
The integration of LSTM and SVR procedures is capable of enhancing the exactness of estimating on the grounds that SVR has the potential to catch the linear correlations in the data, whereas LSTM has the ability to catch the non-linear correlations as well as weathering dependences. The model optimization could be attained based on an amended procedure named the “Balanced Orca Predation” optimizer.
The motivation for the mentioned procedure comes from the orcas’ manner of hunting. Orcas are famous for their proficiency in harmonized hunting procedures. The BOP optimizer performs based on striking equilibrium amid the phases of exploitation and exploration over the search area. This applied procedure has been associated with a population-centric approach, where a set of possible results (or candidates) is assessed and renewed over the generations.
The optimizer does determine the cost value of all individuals in a considered generation employing a cost function that leads to determining the SVR-LSTM precision. Consequently, the optimizer continues to select the optimum individuals for the generation of new individuals, requiring the combination of genes from 2 distinctive candidates to generate a novel member.
A mutation factor has been included in the optimizer that causes an alteration in the genetics of candidates. Thus, it does introduce novel variants associated with the swarm set.
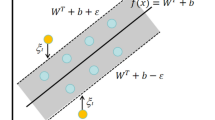
The BOP optimizer algorithm, applied for making the model of SVR-LSTM optimum, has the capability of enhancing the resilience and precision of the model that causes the efficacy increase in predicting process. An illustration of the SVR model has been represented in Fig. (1).

Illustration of the SVR model.
The applied materials in the presented work have been described in the following.
SVR (support vector regression)
The method of SVR, as a type of regression evaluation, does utilize the SVMs for forecasting variables that are continuous. The technique displays distinguished effectiveness when it comes to handling datasets whose properties make nonlinear relations amid the output and input parameters.
What is essential in underlying the SVR conception is to find a hyperplane that makes the difference aid the actual and estimated results optimum. The boundary could be considered the distance between the closest support vectors and the hyperplane without considering directions, interrelated to the points located in the hyperplane juxtaposition. An SVR stage involves the following phases:
The data preprocessing has ensured the appropriate formatting of input data employed via the SVR technique. Some practices may be required by this process including, the managing of missing amounts, the outliers’ elimination, and the alteration of data scaling.
The training of the model consists of repetitively amending a machine learning method variable to optimize its performance. The SVR technique training has been implemented on pre-refined data with the aim of a hyperplane recognizing which makes the border maximum. The math theory identified as the hyperplane has been determined over the description of a bias term(b) and weights (\(\:w\)) set.
Over the model assessment, the trained SVR has been evaluated on the basis of a testing dataset that is independent. The evaluation process has been done to measure the effectiveness of the SVR. Such a process might require some metrics’ computing like MAE and MSE (the mean squared / the mean absolute errors). The SVR technique owns numerous variables that could be amended to enhance the performance of the method. These factors are given in the following.
The kernel function has been employed for locating the input data on a region with higher dimensions which facilitates a hyperplane recognition that could detach the data. These functions include polynomial, linear, as well as RBF (radial basis function).
The regularization (\(\:C\)) factor has the responsibility of striking the balance between the margin maximizing and the error minimizing over the training statistics. Any growth in the \(\:C\) amount will cause a lessening in the width of the margin as well as an escalation in the complication of the model. Any decrease in the C amount, however, will cause an enhancement in the width of as well as a decrease in the complication of the model.
The zone magnitude has been established by \(\:\sigma\:\) that has been influenced by alterations of projected amounts from the real ones. The falling of data points over the mentioned zone has been assumed precisely forecasted and never caused any impact on the overall error.
The SVR method could be written based on the mathematics as the determination of a controlled optimizing issue. This formula has been expressed as:
subject to:
In this formula, \(\:{y}_{i}\) and \(\:{z}_{i}\) depict the input vector and its related output amount, the highest and lowest boundaries of the sigma zone are demonstrated by \(\:{\sigma\:}_{i}\) and \(\:{\sigma\:}_{i}^{\text{*}}\), finally, \(\:C\) illustrates the regulating factor.
The use of SVR for functions that are non-linear can be expanded by the kernel trick technique. Using this technique does enable the definite mapping of original (input) statistics into a property’s region of the upper dimension, thus it causes the linear connections’ identification to be facilitated. The SVR use does permit the evaluation and identification of non-linear arrangements to be represented over the dataset.
The kernel procedure results in replacing the dot product among \(\:{y}_{i}\) and \(\:{y}_{j}\)(input vectors) with a function named kernel. This function has had the responsibility of calculating the resemblance/difference amid the vectors in a properties region with higher dimensions. The revised SVR based on the kernel technique could be expressed as below:
subject to:
Here, \(\:K\left({y}_{i},{y}_{j}\right)\) represents the kernel function that computes the resemblance/difference amid the \(\:{y}_{i}\) and \(\:{y}_{j}\) over the feature region of higher dimensions. Choosing the kernel function has been correlated to the specific considered problem and the dataset’s intrinsic features. Here, the Polynomial Kernel has been utilized which is shown below.
Here \(\:\rho\:\), \(\:d,\) and \(\:r\) have been coefficients.
The polynomial kernel does facilitate the making of polynomial relations amid the input vectors.
SVR is able to capture non-linear relations amid the output and input data in an efficient way using appropriate functions of the kernel. By this function, the SVR becomes capable of inevitably functioning in a feature region of higher dimension, with no demand for definite computing of the altered vectors of feature, therefore growing its efficacy of computing.
Long short-term memory (LSTM)
The LSTM has been considered a special architectural type for RNNs that are established to tackle the disappearing gradient issue as well as to simulate long-term dependencies in consecutive data efficiently. Such actions are achieved by employing a memory cell as well as several mechanisms of gating that standardize the data transmission. The configuration of LSTM does include several vital mechanisms, being described in the next.
A memory cell is considered an overarching factor of an LSTM. The network has been allowed to retain and reclaim statics through comprehensive orders. Over every time chunk, renewing hidden and cell states (\(\:{h}_{t}\) and \(\:{c}_{t}\)) has been its responsibility.
Based on Gates, models of LSTM have included 3 distinctive gates: the input, forget, and output gates (\(\:{i}_{t}\), \(\:{f}_{t},\:\)and \(\:{o}_{t}\)). The main responsibility of these gates are regulation of the information flow. These gates’ function affects the statics alteration and recovery from the memory cell.
The responsibility of \(\:{i}_{t}\) is to regulate the novel information value that will be kept in the cell of memory. 2 inputs have been received by the function i.e., \(\:{y}_{t}\) and \(\:{h}_{t-1}\) that illustrate the present input as well as the former hidden, respectively. This causes an output generation to vary from zero to one.
The \(\:{f}_{t}\) responsibility is to regulate the degree, whereby the former state of the cell (\(\:{c}_{t-1}\)) will be neglected. The former hidden state and existing input have been accepted as inputs for the function that causes an output generation varied from zero to one.
The responsibility of \(\:{o}_{t}\) is to control the data number that will be transmitted from the cell of memory. 2 inputs have been received by the function. These inputs, including the former hidden state and the existing input, cause an output generation ranging from zero to one.
The cell state renewing has been correlated with the\(\:\:{i}_{t}\), \(\:{f}_{t}\), and the former cell state. The \(\:{i}_{t}\) and \(\:{f}_{t}\) have been 2 vital components of the LSTM model. The responsibility of \(\:{i}_{t}\) is to determine the degree to which the former cell state ought to be conserved, whereas the \(\:{f}_{t}\) responsibility is to evaluate the degree to which new statics ought to be merged with the cell state.
The output gate and the renewed cell state overshadow the hidden state (\(\:{h}_{t}\)) computation which takes relevant statics from the memory unit to the consequent phase.
Concerning its variables, an LSTM includes components as below:
Weight matrices; these matrices have been related to the hidden state, input, as well as bias terms.
Bias terms; they have been connected to the\(\:{i}_{t}\), \(\:{f}_{t}\), \(\:{o}_{t}\), and cell state renewing.
The activation functions; have been normally the sigmoid function for \(\:{i}_{t}\), \(\:{f}_{t}\), \(\:{o}_{t}\), and \(\:tanh\) (the function of hyperbolic tangent) for renewing the hidden and cell states.
Over the stage of the training, the BPTT method (“Backpropagation Through Time”) has been utilized for gaining the parameters of LSTM, whereby the determination of gradients has been done for modifying the biases and weights in the subsequent phase14.
The models of LSTM have captured imaginations in various areas like evaluation of time series, recognition of speech, and processing of natural language. Such use of LSTM has been related to its significant potential in capturing long-term dependencies as well as efficiently processing consecutive statics. A block diagram of an LSTM has been demonstrated in Fig. (2).

A LSTM block diagram.
The configuration of LSTM does include numerous strata, encircling the input layer, the output layer, and LSTM strata. In the following, the math formulas for the 3 mentioned layers have been explained15.
The initial/input layer has the responsibility of taking the input categorization throughout every individual time period. \(\:{y}_{t}\) demonstrates the input at the t time. Transferring the input layer to the LSTM one has been the primary responsibility of the input layer. It is worth noting that this transfer has been implemented without the execution of any computing actions.
The layer of LSTM as a kind of RNN has been planned to act as the essential factor of the LSTM model. Numerous constituents form the system that consists of the input, output, and forget gates, hidden state, and the memory cell as an overarching item of computer memory.
The responsibility of the memory cell is to save and retrieve the statics. For the memory cell, the renewed formulas have been illustrated below:
Here, \(\:\text{s}\text{i}\text{g}\text{m}\text{o}\text{i}\text{d}\)(.) and \(\:tanh\left(.\right)\) represent the activation function of sigmoid and hyperbolic tangent. \(\:\text{*}\) is the sign of the matrix multiplication.
The penultimate layer in the LSTM model is the hidden state (\(\:{h}_{t})\) over the t-th time period. The transferring of related statics from the cell of memory into the next time zone has been implemented based on the subsequent formulas:
The ultimate/output layer has the responsibility of generating the forecasting of the network. The \(\:{h}_{t}\) at the ultimate time zone has been taken via the output layer. This used layer might differ considering the particular task and might contain a completely linked layer or other appropriate option. The ultimate result has been produced utilizing a function of activation to a linear change implemented via the output layer.
The above concept can be defined as a mathematical formula associated with the \(\:z\) variable, being related to the \(\:{W}_{z}\), \(\:{h}_{t}\), and the \(\:{b}_{z}\) (weight matrix, hidden state, and bias term), as expressed below:
In this formula \(\:f(.)\) does represent the function of activation, employing an element-wise attitude to the \(\:{W}_{z}\text{*}{h}_{t}+{b}_{z}\) vector, for yielding the ultimate result.
SVR/LSTM model
SVR as a machine learning method of optimizing has been frequently utilized for the analysis of regression16. The procedure utilizes the initial theories of SVM, a broadly adopted sorting procedure, and adjusts them to tackle anticipating regression problems. SVR is considered a cherished instrument in data analysis which has numerous dimensions.
In marked contrast, LSTM, as a variant of RNNs, represents the capacity to acquire and retain statics throughout the comprehensive data orders, therefore rendering it an effective device for examining time series statics. The capability of capturing long-term dependencies in sequence statics has been mainly profitable for accomplishing exact guesses in time series prediction.
The component of SVR has illustrated usefulness in the efficient management of statics with high dimensions, while the component of LSTM has displayed the capability of capturing long-term dependencies that exist in the statics. These 2 models’ integration has the capability of furnishing more and more accurate forecasts for patterns of load need in an MG (microgrid) over shortened and extended frames of time. Figure (3) demonstrates the integrated configuration for the SVR/LSTM model.

Integrated configuration for the SVR/LSTM model.
In the diagram, the periodic properties used, as the SVR 1s inputs, have been demonstrated. This facilitates the calculation of primary load amounts in an order. The represented work does employ the up-to-date documented statics point as a time frame. Using unusual features as the SVR inputs, particularly SVR 2, and LSTM models contains the integration of balanced and time frames as instances.
The Oz1 and Oz2 factors signify the gained outcomes from the SVR and LSTM models. The eventual result of the SVR-LSTM could be anticipated using the Oz1 and Oz2 combination, as indicated in17.
Indeed, the SVR-LSTM model aims to enhance the prediction of electric load demand based on the following structure:
-
Input Layer: This layer takes in historical load data, weather information, and other important factors that influence electric load demand.
-
SVR Layer: Initially, the SVR layer processes the input data. It is trained to understand the complex relationships between the input features and load demand. The SVR layer uses a radial basis function (RBF) kernel to transform the input data into a higher-dimensional space, making it easier to separate the data linearly.
-
LSTM Layer: The output from the SVR layer goes into the LSTM layer, which focuses on identifying time-related patterns in the data. This layer has several LSTM cells that handle the input data in sequence, using the output from one cell as the input for the next.
-
Output Layer: Finally, the output from the LSTM layer is sent to the output layer, which generates the predicted load demand.
Here, the SVR layer is trained on historical data to predict load demand, and these predictions serve as input for the LSTM layer. The LSTM layer learns the time-related patterns in the data, and its output is used to enhance the load demand predictions. The final output from the LSTM layer represents the predicted load demand. By combining SVR and LSTM, this method takes advantage of both models to boost the accuracy and reliability of electric load forecasting. The SVR layer offers a solid starting point for the LSTM layer, while the LSTM layer captures time-related patterns to improve the load demand predictions.
Gorilla troops optimization algorithm (GTO)
Artificial Gorilla Troops which is a novel metaheuristic method stemmed from gorillas’ behavior witnessed in a group. The method, explains two mathematical methods thoroughly including exploration and exploitation. Five different operators are used in the optimization process, which also comprises exploration and exploitation, and is based on how gorillas behave. In the exploration phase, three different operators are used which are explained below:
Improving the GTO exploration by moving to an undetermined location; and going closer to other gorillas to increase the ratio of exploration to exploitation are really important; a significant improvement in GTO’s capacity to move to a familiar location and investigate other optimization areas is the three phases mentioned above. The efficiency of the search during the exploitation phase is also significantly improved by using two operators.
generally, using GTO to look for information is in harmony with the regulations listed here:
-
1)
The GTO method optimization has three responses; if one of them is better than the current one, it will be used. The \(\:O\) is specified as the gorillas’ position vector, and the \(\:XO\) is the gorilla agent location vector created at every stage. The silverback remains the best solution found after each iteration.
-
2)
There is only one silverback in the entire swarm when it comes to the number of search parameters selected for the optimization procedure.
-
3)
Three different elements namely,\(\:XO\), \(\:O\), and Silverback solutions simulate gorillas’ community in the wildlife.
-
4)
Gorillas can become stronger by joining a great group or by finding better food supplies. The GTO method describes the solutions created after each iteration as \(\:XO\). The current solution stays in the memory \(\:\left(XO\right)\) if the newly found solution is not novel; otherwise, the new solution \(\:\left(XO\right)\) replaces the existing answer. Since gorillas like to live in teams, we seldom encounter them as individuals. Because of this, gorillas live in groups and have a silver-back commander who is in charge of making choices for the group. They also go hunting. In the algorithm, the weakest gorilla in the group is represented as the poorest solution, and gorillas tend to avoid them. In contrast, over-approaching the silverback, the best option improves all gorillas’ positions.
-
5)
The GTO has unique characteristics in many optimization issues due to the fact that it takes into account the fundamental ideas of gorilla’s group life and their pursuit of food, making it feasible to employ the strategy extensively. The GTO algorithm makes use of many techniques listed below for optimization procedures.
Stage of exploration
We start by looking at the processes used in the GTO’s exploring phase. Gorillas live in groups and are subject to the authority of a silverback. However, under specific circumstances, gorillas may decide to quit their group. Gorillas travel to different places after separation. Although they may know some of the places, there are some other places they may not know.
Every gorilla is considered an agent solution in the gorilla troops optimization technique, and the best one at every optimization procedure phase is referred to as a silverback gorilla. For the exploration phase, we used three different methods: transferring to other gorillas, emigrating to a familiar location, and emigrating to a foreign location. Each of these three methods is selected based on a broad strategy.
The \(\:b\) option is used to determine the emigration procedure to a foreign location. When \(\:rand\:<\:b\), the first procedure is established. However, when \(\:rand\:\ge\:\:\frac{1}{2}\), the action of moving in the direction of the animals is selected. Any of the procedures contribute to the enormous capability of the GTO technique, depending on the procedure used.
The strategy in the first step may admirably view the entire space of search. The exploration efficiency of the second process is enhanced; consequently, the third method keeps GTO from being stuck in local optimal positions. The three procedures used during the exploration phase have the following mathematical expressions:
\(\:XO(t+1)\) represents where the gorilla agent will be in iteration t after that. The current location of the gorilla is represented by \(\:O\left(t\right)\). The symbols for random quantities with a [0,1] limit and updated each iteration are\(\:\:{r}_{1},\:{r}_{2},\:{r}_{3}\), and \(\:rand\). \(\:d\) provides a parameter whose value is supplied before the optimization process and ranges from 0 to 1. This parameter specifies the possibility of selecting to emigrate to an unknown place.
The parameters’ lowest and highest boundaries are denoted by \(\:\underline{O}\)and \(\:\overline{O}\), respectively. \(\:{O}_{r}\:\)and \(\:X{O}_{r}\) are two organs of the gorillas in the group that were randomly selected from the complete swarm. One of the vectors of gorilla agent locations is randomly selected and contains the updated positions at any step. Finally, \(\:S\), \(\:C\), and \(\:F\) are calculated using the equations shown in the following.
In the aforementioned formulas, the number of current iterations is illustrated by \(\:It\), the entire number of iterations to perform the process of optimization is illustrated by \(\:MaxIt\), the cosine function is defined by \(\:cos\), haphazard quantity limited between [0,1] is described by \(\:{r}_{4}\) which is updated after each iteration. In accordance with the aforementioned equation, values with dramatic changes are created over a large period of time in the initial phases of the optimization process, and this gap of change is decreased in the final steps. A random value, known as \(\:c\), ranging from − 1 to 1 is used to compute the parameter \(\:C\).
Moreover, this formula is used to define silverback leadership. It’s possible that during the initial stages of group leadership, the silverback gorilla might make the wrong choices regarding the management of the group or the exploring food due to a lack of experience; however, it gains enough experience to achieve fine stability in its leadership.
The calculation of parameter \(\:F\) is as follows. In the following equation, \(\:y\) represents a random quantity in the dimensions of the issue and the range between \(\:-S\) and\(\:\:S\).
When the exploration phase is finished, the group organization process is accomplished. Additionally, the cost of each \(\:XO\) solution is calculated at this stage, and The \(\:XO\left(t\right)\) solution is used in place of the \(\:O\left(t\right)\) solution if the cost of \(\:XO\left(t\right)<O\left(t\right)\).
Phase of exploitation
Two behaviors that are put into practice in the GTO method’s exploitation phase are seeking the silverback and competing for mature couples. The silverback gorilla’s responsibilities include managing the group, making all decisions, planning group movements, and leading the troop to food sources. It is responsible for the group’s safety and well-being, and all of the gorillas in the group observe all the rules.
The gorillas may take control of the group if there is a disagreement between him and other male gorillas. Additionally, it’s possible that the silverback gorilla will get older and pass away. In this case, the blackback may control the troops. In accordance with the two procedures that were used in the phase of exploitation, the use of \(\:S\) makes it possible to decide whether to compete for mature females or follow the silverback. If \(\:S\ge\:Q\), the silverback procedure is chosen; otherwise, the competition for adult females is chosen.
Following the silverback
the silverback is healthy and young while trying to make a novel group, and the other male gorillas are young too, so they obey what the silverback commands. In other words, they comply with all of the silverback’s instructions to follow him and go to various locations to search for food supplies. Each group member contributes effectively to the motion of the whole group. When the S ≥ Q value is selected, this strategy is used. The formula that follows is defined to simulate this strategy.
\(\:X{O}_{i}\:\left(t\right)\) represent each agent gorilla’s vector location in iteration \(\:t\), \(\:N\) denotes the total number of gorillas, and\(\:{O}_{silverback}\) specifies the position of the vector for the silverback gorilla (the best solution), while \(\:O\left(t\right)\) defines the gorilla location vector.
Competition for mature females
When \(\:S<Q\), the second process of the exploitation phase is chosen. When the young gorillas get older, they desire to extend their group and choose a female; consequently, they fight each other. This fight is usually really dangerous, and usually engages other members in groups because it lasts for several days. In order to calculate the behavior mathematically, the following equation is used.
In the equations mentioned above, the silverback location vector is defined as \(\:{O}_{silverback}\), while the current location of the gorilla vector is indicated by \(\:O\left(t\right)\). \(\:W\) is described as a model for the force of impact, while \(\:{r}_{5}\) specifies random values between 0 and 1. The coefficient vector of \(\:A\) is illustrated in order to determine the extent to which the violence is serious. \(\:E\) is used to create a simulation from the impact of viciousness on the dimensions of the solutions. Moreover, \(\:\rho\:\) specifies a variable to be estimated before the optimization method. In terms of the dimensions of the issue and normal distribution, the quantity of \(\:E\) will be equal to random amounts if \(\:rand\ge\:\frac{1}{2}\); otherwise, a random amount in the normal distribution would be the result of \(\:E\).
At the end of the exploitation phase, the process of group organization is completed. Moreover, the fitness of each \(\:XO\) solution has been calculated. If the fitness of \(\:XO\left(t\right)<O\left(t\right)\), the \(\:XO\left(t\right)\) solution is used as the \(\:O\left(t\right)\) solution. So, the best solution that has been determined in this phase is considered silverback.
Flexible gorilla troops optimization (FGTO) algorithm
The decision to modify the algorithm, in this case, is driven by the need to enhance its performance and strike a better balance between exploration (diversification) and exploitation (intensification) during the search process. Metaheuristic algorithms like the gorilla troops optimization algorithm can benefit from modifications to improve their convergence rate, solution quality, and robustness. The modifications applied to the algorithm include a constriction factor and an elimination phase.
a) Constriction Factor: The use of a constriction factor in the algorithm helps control the velocity of the search process. It ensures that the particles or solutions in the search space converge more efficiently towards promising regions while exploring other areas as well. The constriction factor adjusts the acceleration coefficients based on the swarm’s best performance, limiting excessive movements and leading to faster convergence. In the following, the constraining factor has been applied to four random parameters, including \(\:{r}_{1},\:{r}_{2},\:{r}_{3}\), and \(\:rand\), as follows:
where \(\:\theta\:\) indicates a value less than or equal to 1 and \(\:\varphi\:\) represents a value higher than or equal to 4 (here, it is set to 5,6,7,8).
Based on the findings of the study, the most promising approach for achieving success is the implementation of a constraint factor across all dimensions. The study conducted in18 demonstrated that this specific strategy yields superior outcomes when compared to other comparable approaches documented in the extant body of published literature.
The present study introduces a novel adaptation of the constriction factor-based approach, a previously validated strategy in scientific inquiry. In lieu of maintaining the values of \(\:{r}_{1},\:{r}_{2},\:{r}_{3}\), and \(\:rand\). The proposed modification entails the gradual decrease of these variables over time in a linear manner. The method described above can be implemented by iteratively adjusting the value of \(\:\theta\:\) using the recursive formula provided in the following:
The variable \(\:L\) represents the maximum number of iterations that can be executed, while the variable \(\:j\) signifies the current iteration in progress. The identification of a constriction factor is crucial in ensuring the computational stability of the FGTO algorithm.
Improved convergence through the use of a constriction factor is a vital aspect of modifying metaheuristic algorithms like the gorilla troops optimization algorithm. By balancing exploration and exploitation, the algorithm can quickly converge towards optimal solutions. The constriction factor achieves this by adjusting the acceleration coefficients based on the swarm’s best performance, ensuring that the particles or solutions converge more efficiently towards promising regions while exploring other areas.
In addition to improved convergence, the modification also enhances the algorithm’s robustness. The adjustment of acceleration coefficients helps prevent premature convergence and escape local optima, which can be challenging in complex and dynamic problem landscapes. With these modifications, the gorilla troops optimization algorithm can better handle challenging optimization problems and provide more accurate and reliable solutions.
b) Elimination Phase: The elimination phase is a mechanism introduced to remove the worst-performing solutions or individuals from the population. This phase occurs after each iteration or generation, eliminating a portion of the population based on certain selection criteria (e.g., fitness value). Removing weaker solutions reduces their influence on the search, allowing better solutions to flourish and propagate in subsequent iterations.
In order to mathematically integrate the elimination phase into the algorithm, it is necessary to establish a set of criteria for identifying the solutions that exhibit the poorest performance. Additionally, a systematic procedure must be established to effectively eliminate these underperforming solutions from the population. The integration of the elimination phase into the algorithm can be represented as follows:
-
Initialize the population P with N individuals.
-
Evaluate the fitness of each individual in the population using the objective function.
-
Set the maximum number of iterations or termination condition (T).
-
Set the elimination rate (ER), which determines the proportion of solutions to be eliminated in each iteration.
-
Set the elimination criterion, such as selecting solutions based on their fitness values or other predefined criteria.
The pseudocode of the following algorithm is defined below:

Elimination Phase.
The elimination phase is executed subsequent to each iteration in this algorithm. The process entails the categorization of the population according to their fitness values, followed by the elimination of a specific quantity of solutions with the lowest performance (NE), as determined by the elimination rate (ER). Following the elimination phase, subsequent operations involving replacement or reproduction are executed in order to uphold the desired population size, thereby facilitating an ongoing progression of the population toward improved solutions.
The mathematical formulation illustrates the integration of the elimination phase into the algorithm as an iterative procedure, enabling the elimination of inferior solutions and the advancement of superior individuals in subsequent iterations. The precise implementation particulars, such as the criteria for selection and the methods for replacement, may differ based on the specific problem and the algorithm’s design decisions.
By incorporating these modifications, the algorithm becomes more efficient in terms of optimization performance, convergence speed, and adaptability to complex problem landscapes. The constriction factor enables a fine-tuned balance between exploration and exploitation, while the elimination phase helps to remove unfit solutions, promoting the evolution of better individuals.
Enhanced solution quality is achieved through the elimination phase, which is the removal of poor solutions, leading to a gradual improvement in the overall quality of the population. Additionally, diversity maintenance is ensured as weaker solutions are eliminated, preventing premature convergence and maintaining diversity within the population. This prevents stagnation in search space exploration and allows for a more thorough exploration of the solution space.
Algorithm validation of the FGTO algorithm
In this section, we present a validation process for the proposed algorithm using a random computer configuration. The method is evaluated on twelve distinct functions extracted from the “CEC-BC-2017 test suite”, and the results are compared with five different state-of-the-art methods. This suite is a comprehensive collection of benchmark problems designed to assess the performance of optimization algorithms. It includes 23 functions that present a variety of challenges, such as composition, shifted, and rotated functions, which are representative of real-world optimization problems.
The CEC-BC-2017 test suite is chosen for its rigorous and diverse set of functions, which allows for a thorough evaluation of the algorithm’s capabilities. The twelve functions selected for this study are extracted from this suite to represent a balanced mix of these challenges, ensuring that the algorithm’s performance is tested against both exploitative and explorative tasks. This selection is intended to demonstrate the algorithm’s adaptability and robustness across different types of optimization landscapes19.
The utilized algorithms in this study include the Squirrel search algorithm (SSA)20, Billiard-based Optimization Algorithm (BOA)21, Biogeography-Based Optimizer (BBO)22, Locust Swarm Optimization (LS)23, and the winner of the CEC 2017 competition, Jellyfish Search Optimizer (JSO)24. Table 1 indicates the set parameters of the utilized algorithms.
To ensure reliable results, all algorithms run 15 times on each test function. The computer configuration of this study can be defined as follows:
Processor: Intel Core i7-9700 K.
RAM: 16GB DDR4.
Storage: 512GB SSD.
Operating System: Windows 11.
Programming Language: MATLAB R2019b.
The assessment specifications utilized for conducting comparative analysis will consist of the Mean and standard deviation (StD) of the objective function values achieved by each algorithm. Table 2 displays a comparative evaluation of the results achieved using the FGTO algorithm and other algorithms examined in the study.
The data presented in Table 2 offers a thorough assessment of the FGTO algorithm’s performance in comparison to five other cutting-edge optimization algorithms across twelve different functions from the CEC-BC-2017 test suite. The evaluation criteria encompass the Mean and standard deviation (StD) of the objective function values attained by each algorithm.
It is evident from the results that the FGTO algorithm consistently surpasses the other algorithms in terms of Mean objective function values across various functions. For instance, in functions F1, F3, F4, F5, F6, F7, and F9, the FGTO algorithm achieves notably lower Mean values than its counterparts, highlighting its efficacy in optimizing these specific functions.
This indicates the FGTO algorithm’s proficiency in addressing a wide array of optimization challenges and effectively navigating complex landscapes to identify optimal solutions. Moreover, in terms of standard deviation (StD) values, which reflect the variability of solutions obtained by each algorithm, the FGTO algorithm demonstrates competitive performance.
In functions like F2, F8, F10, and F15, the FGTO algorithm showcases relatively low StD values, indicating consistency in solution discovery across multiple iterations. This consistency is crucial in practical optimization scenarios where stability and robustness are paramount. It is important to note that while the FGTO algorithm excels in most functions, there are instances, such as in functions F16, F17, and F20, where it exhibits slightly higher Mean values compared to specific competing algorithms. Nonetheless, the performance discrepancies are minimal, underscoring the FGTO algorithm’s strength across a diverse range of optimization tasks.
For more clarification, the Wilcoxon signed-rank test has been analyzed. In order to tackle this issue, we carried out a set of non-parametric statistical analyses, particularly focusing on the Wilcoxon signed-rank test. This test is ideal for comparing two correlated samples or multiple measurements on the same sample to determine if there are differences in their population mean ranks. Table 3 displays the outcomes of the Wilcoxon signed-rank test, which compares FGTO against various other algorithms.
The data presented in the table summarizes the performance analysis of the FGTO algorithm in comparison to four other cutting-edge methods. The p-values serve as an indication of the likelihood of observing the data under the assumption that there is no difference. A p-value lower than the commonly accepted threshold of 0.05 suggests that there is a statistically significant difference in performance. Based on the findings, it is evident that the FGTO algorithm demonstrates a significant improvement over SSA and LS, with p-values of 0.02 and 0.03, respectively.
However, in comparison to BOA, the results do not show a statistically significant difference, indicating that the performance of FGTO is similar to that of BOA. In summary, the non-parametric statistical analysis supports the notion that the FGTO algorithm outperforms certain algorithms, highlighting its reliability as an effective method for optimization tasks. This statistical method ensures that our conclusions are backed by thorough analysis, taking into account the stochastic nature of the FGTO algorithm.
FGTO algorithm for choosing the LSTM hyper-parameter
The performance and accuracy of LSTM have been significantly overshadowed by its various factors. The calculation of hyper-parameters holds significant importance in LSTM models. The variables that constitute the factors under consideration include the length of input (L), the size of the batch (batchsize), the number of hidden layers (H), and the maximum number of epochs for training.
By carefully selecting an appropriate input for variable L, it becomes feasible to eliminate unnecessary input data, resulting in an overall improvement in performance. The variable H has an impact on the outcome of the fitting process.
The performance and convergence of a Long Short-Term Memory model can be influenced by the number of epochs used. The issue of extensive computation arises when intelligent algorithms are required to select appropriate variables that strike a balance between prediction accuracy and computational efficiency.
The presented study highlights the introduction of FGTO as a promising and innovative approach for selecting optimal values for the LSTM. The flowchart illustrating the FGTO/LSTM model is presented in Fig. (4).

FGTO/LSTM Flowchart.
In the initial phase, two distinct sets of data have been generated, comprising the test group and the training group. Subsequently, the process of parameter configuration, establishment of the LSTM network, and the initialization technique have been completed. The FGTO has been subsequently utilized in the network to minimize network fitness, that is,
where,
The network’s necessary outcome has been illustrated by the variable \(\:{dO}_{ij}\left(t\right)\), while the resulting output of the network is represented by \(\:{z}_{ij}\left(t\right)\) according to the following formulation:
The primary focus of the presented study is to employ the Bounded Optimal Parameter Adjustment (BOPA) technique in order to minimize Eq. (36). The achievement of this objective has been accomplished through the optimization of the LSTM decision parameters and the implementation of a significantly more effective training technique to address the limitations of previous approaches.
Data set description
The research addressed in this study utilized data from the Pecan Street Inc. Dataport site, which is a valuable resource for electricity load data26. The Dataport site offers unique, circuit-level electricity use data at high-frequency intervals ranging from one minute to one second for approximately 800 homes in the US. In addition to electricity consumption data, it also includes information on Electrical Vehicles (EV) and Photovoltaics (PV) generation charging for a subset of these homes. For this research, a subset of 200 clients was selected from the Dataport dataset27.
These clients were specifically chosen because they have similar properties, namely detached-family homes, and are located in the same area, Texas. This selection ensures that the dataset represents a homogeneous group of houses, minimizing the influence of factors like building type and geographical location on load demand. The dataset used in this study covers a period from January 1st, 2019 to March 31st, 2019, with a one-hour resolution for the data.
By selecting a dataset with low weather fluctuations during this period, the study aims to focus solely on load forecasting without significant interference from seasonal variations. Ignoring the seasonal factor allows for a more precise evaluation of the proposed load forecasting model’s performance. To prepare the data for further analysis, each client’s electricity load data was processed and organized. This preparation likely involved cleaning the data to remove any outliers or inconsistencies, as well as transforming the data into a suitable format for analysis, such as aggregating the load readings into hourly intervals.
By ensuring the data is ready for analysis, researchers can confidently apply their forecasting models and draw meaningful insights from the results. The benchmark dataset consisting of records from 200 clients between January 1st, 2019 and March 31st, 2019, serves as a crucial resource for evaluating the performance of the proposed load forecasting model. By utilizing a real-world dataset with high-resolution data and a focus on a homogeneous group of houses, the study aims to provide robust and reliable results. The use of Pecan Street Inc.
Dataport data in this research provides several advantages. Firstly, the circuit-level electricity use data at such fine-grained intervals allows for a detailed analysis of load patterns and dependencies. Secondly, the inclusion of PV generation and EV charging data for some homes enables the exploration and potential integration of these factors into the load forecasting model. This comprehensive dataset enhances the realism and applicability of the proposed model to real-world scenarios. In summary, the benchmark dataset from the Pecan Street Inc.
The Dataport site offers unique and valuable electricity load data for conducting load forecasting research. The subset of 200 clients with similar properties located in Texas provides a homogeneous group of houses, facilitating accurate modeling and evaluation. By selecting a period with low weather fluctuations, the seasonal factor can be disregarded, ensuring a focused analysis of load forecasting models. The prepared dataset serves as a reliable foundation for assessing the performance of the proposed load forecasting model and drawing meaningful conclusions about its accuracy and efficiency.
In this benchmark, several data transformations and splits are applied to prepare the dataset for training and evaluating a load forecasting model. The first step is to transform the data to be within a scale in the range [0, 1]. This scaling process is commonly used in machine learning tasks to normalize the input data and ensure that all features have equal importance.
By scaling the data, variations in magnitude across different features or variables are eliminated, making it easier for the model to learn patterns and make accurate predictions.
The performance of the model in time series forecasting can be greatly influenced by the critical parameter of the sliding window’s size. The selection of the window size is typically determined by the unique attributes of the data and the desired patterns to be captured. A smaller window size is appropriate for capturing short-term trends and fluctuations, whereas a larger window size enables the model to learn longer-term dependencies and seasonal effects. The time series data is transformed into sliding windows with a look-back size of 15 and a look-ahead size of 1. This technique is known as windowing or lagged representation. It involves dividing the time series into overlapping segments, where each segment (window) includes the previous 15-time steps as input and predicts the next time step (look-ahead).
This approach allows the model to capture temporal dependencies and learn from historical patterns to forecast future values. After transforming the data into sliding windows, it is split into train and test subsets. The training subset is designated for training the load forecasting model, while the test subset is reserved for evaluating the model’s performance on unseen data. In this benchmark, a common split ratio of 70% for training and 30% for testing is used.
This split ensures that the majority of the data is available for training and allows for a sufficient amount of data to assess the model’s generalization ability. This benchmark design has several advantages. By scaling the data, the model is less likely to be biased toward variables with larger magnitudes, ensuring a fair representation of all features. The impact of the sliding window size on experimental outcomes is complex:
Learning Capacity: A larger window size offers a greater amount of historical data points for the model to learn from, potentially enhancing its ability to comprehend intricate patterns. Nevertheless, it also heightens the risk of overfitting if the model picks up on noise rather than the fundamental trend.
Computational Complexity: Larger windows escalate the computational burden, as more data points are analyzed for each prediction.
Relevance of Data: If the window is excessively large, it might encompass data points that are no longer pertinent to the current prediction, potentially diverting the model’s attention from recent trends that are more indicative of future outcomes. It is crucial to carry out experiments with various window sizes to identify the optimal setup for your specific dataset and forecasting objectives. This procedure entails striking a balance between capturing adequate historical information and upholding model simplicity and computational efficiency.
Simulation results
The pseudocode of the proposed SVR/LSTM/FGTO Algorithm is given in the following.

The pseudocode of the proposed SVR/LSTM/FGTO Algorithm.
System configuration
In our work, we conducted a comprehensive comparative evaluation of the FGTO (Gorilla Troops Optimization) algorithm against several other algorithms. The purpose was to assess the effectiveness and performance of the FGTO algorithm in solving optimization problems. Table 3 presents the results achieved using the FGTO algorithm and compares them with the outcomes obtained from other algorithms examined in the study. The comparative evaluation considered a range of benchmark functions, which are commonly used to assess the performance of optimization algorithms.
The computer configuration used in this study consisted of an Intel Core i7-9700 K processor, 16GB of DDR4 RAM, and a 512GB SSD for storage. The operating system utilized was Windows 11, providing a stable and efficient environment for conducting the research. The programming language of choice was MATLAB R2019b, known for its powerful analytical capabilities and extensive toolboxes. This configuration ensured that the research team had access to a high-performance computing setup, enabling them to carry out complex computations and data analysis efficiently.
Measurement indicators
The model’s performance in terms of prediction error is evaluated using Mean Absolute Percentage Error (MAPE) and Root Mean Square Error (RMSE). The MAPE quantifies the magnitude of the error relative to the actual value, expressed as a percentage, whereas RMSE enables the quantification of error in energy units. The equations for Root Mean Square Error (RMSE) and Mean Absolute Percentage Error (MAPE) are as follows:
where, \(\:M\) defines the number of predicted values, and \(\:{z}_{j}\) and \(\:{\widehat{z}}_{j}\) represent the actual and the predicted values.
The reason to select RMSE and MAPE is that RMSE has ability to quantify the average magnitude of errors in the predictions, its widespread application in load forecasting, and its reduced sensitivity to outliers, and also, MAPE was selected as it measures the average percentage error in our predictions, thereby providing an understanding of the model’s relative accuracy, and its percentage format enhances interpretability.
We limited our focus to these two metrics to emphasize the most pertinent and commonly utilized measures in load forecasting, ensuring a straightforward and succinct evaluation of our model’s performance without inundating the reader with excessive information. By concentrating on RMSE and MAPE, we achieve a well-rounded assessment of our model’s performance, striking a favorable balance between accuracy and clarity. Although other metrics may also offer valuable insights, we contend that RMSE and MAPE sufficiently evaluate our model’s performance, and the inclusion of additional metrics would not yield significant further insights.
Comparison results
The method has been compared with various related state-of-the-art methods. The methods include SVR28, LSTM network29, composite neural network and gravitational search optimization algorithm (NN/GSOA)30 and SVR/LSTM31, variational mode decomposition and extreme learning machine optimized by differential evolution (VMD/ELM/DE)32.
As elucidated in the preceding section, during the iterations, solely a subset of clients engages in training the model. The algorithms were evaluated and produced global models that were derived using the proposed SVR/LSTM/FGTO model. The models are assessed based on their Root Mean Square Error (RMSE) and Mean Absolute Percentage Error (MAPE). The comparative outcomes of all models are presented in Table 4. The comparative outcomes of all models are presented in Tables 4 and 5.
The findings for the clients who took part in the study are presented in Tables 4 and 5, which provide a summary of the results obtained using various methods. In this particular scenario, the load forecast is conducted at a detailed level, specifically for individual houses, and over a short-term period of one hour. As a result, the MAPE values obtained for different models, as presented in Tables 4 and 5, can be considered reasonable.
It is expected to achieve a similar level of accuracy, as previous studies have reported comparable values. These studies also indicate that the accuracy of forecasts is generally low when predicting for short-term time periods. The load profiles that were observed and the load profiles that were predicted are depicted in Fig. (5) and Fig. (6), respectively.

The load profile of the next hour consumption for client 4313 training for 15 periods.

The load profile of the next hour consumption for client 8467 training for 15 periods.
Both models accurately capture the overall patterns observed in the consumption profiles. It is determined that it is possible to train robust models for the consumption profiles of a population by utilizing only a subset of the users comprising said population. In order to meet the stringent accuracy demands of certain applications, it is possible to retrain the model. This process leads to the development of a personalized model that aligns more closely with the specific profile’s curves, thereby enhancing the precision of predictions. However, the forecasts derived from the global model can serve as a valuable initial reference for prospective clients who lack sufficient data for customization.
Conclusions
This study presents a novel methodology for electric load forecasting that integrates Support Vector Regression (SVR) and Long Short-Term Memory (LSTM) networks. The combination of SVR and LSTM models presents distinct benefits in the field of load forecasting. The SVR, a robust regression technique, has demonstrated its ability to effectively capture the complex and nonlinear relationships that exist between input features and load demand. This capability has resulted in a notable improvement in the accuracy of load demand prediction. The LSTM model, due to its inherent capacity to process time-dependent sequences, effectively captured the temporal dependencies and patterns present in the load data. Consequently, this enhanced the model’s ability to accurately capture both short-term fluctuations and long-term trends. The practicality and reliability of the proposed SVR-LSTM approach were demonstrated through its successful implementation and evaluation using real-world data. The objective was to improve the precision and effectiveness of load forecasting models by capitalizing on the advantages of both techniques. A flexible version of the gorilla troops optimization (FGTO) algorithm played a crucial role in the selection of hyperparameters for the LSTM network, in addition to the methodologies discussed. Renowned for its precision in optimizing time-dependent sequences, the FGTO algorithm was pivotal in meticulously adjusting the LSTM model to achieve exceptional predictive accuracy. By finely adjusting the discretization of time, the FGTO algorithm enabled a more nuanced refinement of the LSTM parameters, resulting in a better alignment with the electric load data. This optimization process was of utmost importance in ensuring that the LSTM model could effectively adapt to the intricate patterns within the dataset, ultimately enhancing the overall performance of the load forecasting model. In order to assess the efficacy of the proposed methodology, a comprehensive series of experiments and evaluations were undertaken, utilizing authentic data obtained from a sample of 200 residential properties located in Texas, United States of America. The dataset included historical records of electricity consumption, weather data, and other relevant factors that impact energy demand, thereby ensuring the dependability and inclusiveness of the findings. The study conducted a comprehensive evaluation of various contemporary load forecasting methods and found that the combined SVR-LSTM approach exhibited superior performance in terms of accuracy and robustness when compared to conventional techniques. The evaluation results unequivocally underscored the significance of the proposed methodology in effectively forecasting electric load demand, thereby demonstrating its viability for real-world application. The results provide valuable insights for professionals in the industry, researchers, and policymakers, allowing them to enhance the development of load forecasting models that are both precise and efficient. The SVR-LSTM model showed encouraging results in forecasting electric load demand; however, it is not without its limitations. It has been trained on a specific dataset and does not consider external influences such as economic and social trends. Future research could focus on overcoming these limitations by investigating multi-regional load forecasting, integrating external factors, conducting comparisons with alternative models, and establishing a real-time load forecasting system. In particular, efforts should be directed towards developing a model capable of predicting electric load demand across various regions, incorporating external factors to enhance accuracy and reliability, benchmarking against other advanced models to pinpoint areas for enhancement, and creating a real-time forecasting system that delivers precise predictions instantaneously, thereby facilitating more effective grid management and operations.
Data availability
All data generated or analysed during this study are included in this published article.
References
Wei, N. et al. Short-term load forecasting based on WM algorithm and transfer learning model. Appl. Energy. 353, 122087 (2024).
Wei, N. et al. Pseudo-correlation problem and its solution for the transfer forecasting of short-term natural gas loads. Gas Sci. Eng. 119, 205133 (2023).
Cao, Y. et al. Optimal operation of CCHP and renewable generation-based energy hub considering environmental perspective: an epsilon constraint and fuzzy methods. Sustainable Energy Grids Networks. 20, 100274 (2019).
Yang, Z. et al. Robust multi-objective optimal design of islanded hybrid system with renewable and diesel sources/stationary and mobile energy storage systems. Renew. Sustain. Energy Rev. 148, 111295 (2021).
Li, S. et al. Evaluating the efficiency of CCHP systems in Xinjiang Uygur Autonomous Region: an optimal strategy based on improved mother optimization algorithm. Case Stud. Therm. Eng. 54, 104005 (2024).
Yuan, Z., Wang, W., Wang, H. & Ghadimi, N. Probabilistic decomposition-based security constrained transmission expansion planning incorporating distributed series reactor. IET Generation Transmission Distribution. 14, 3478–3487 (2020).
Mahdinia, S., Rezaie, M., Elveny, M., Ghadimi, N. & Razmjooy, N. Optimization of PEMFC model parameters using meta-heuristics. Sustainability. 13, 12771 (2021).
Xu, Z., Sheykhahmad, F. R., Ghadimi, N. & Razmjooy, N. Computer-aided diagnosis of skin cancer based on soft computing techniques. Open Med. 15, 860–871 (2020).
Li, D., Tan, Y., Zhang, Y., Miao, S. & He, S. Probabilistic forecasting method for mid-term hourly load time series based on an improved temporal fusion transformer model. Int. J. Electr. Power Energy Syst. 146, 108743 (2023).
Li, K., Huang, W., Hu, G. & Li, J. Ultra-short term power load forecasting based on CEEMDAN-SE and LSTM neural network. Energy Build. 279, 112666 (2023).
Huang, N. et al. Gated spatial-temporal graph neural network based short-term load forecasting for wide-area multiple buses. Int. J. Electr. Power Energy Syst. 145, 108651 (2023).
Yotto, H. C. S. et al. in Adv. Eng. Forum 117–136 (Trans Tech Publ) (2019).
Zambrano-Asanza, S., Morales, R., Montalvan, J. A. & Franco, J. F. Integrating artificial neural networks and cellular automata model for spatial-temporal load forecasting. Int. J. Electr. Power Energy Syst. 148, 108906 (2023).
Fan, X. et al. Multi-objective optimization for the proper selection of the best heat pump technology in a fuel cell-heat pump micro-CHP system. Energy Rep. 6, 325–335 (2020).
Zhang, H. et al. Efficient design of energy microgrid management system: a promoted Remora optimization algorithm-based approach. Heliyon 10.1 (2024).
Zhang, M. et al. Improved chaos grasshopper optimizer and its application to HRES techno-economic evaluation. Heliyon 10.2 (2024).
Guo, J., Xie, Z., Qin, Y., Jia, L. & Wang, Y. Short-term abnormal passenger flow prediction based on the fusion of SVR and LSTM. IEEE Access. 7, 42946–42955 (2019).
Clerc, M. & Kennedy, J. The particle swarm-explosion, stability, and convergence in a multidimensional complex space. IEEE Trans. Evol. Comput. 6, 58–73 (2002).
Nemati, M., Zandi, Y. & Agdas, A. S. Application of a novel metaheuristic algorithm inspired by stadium spectators in global optimization problems. Sci. Rep. 14, 3078 (2024).
Jain, M., Singh, V. & Rani, A. A novel nature-inspired algorithm for optimization: Squirrel search algorithm. Swarm Evol. Comput. 44, 148–175 (2019).
Kaveh, A., Khanzadi, M. & Moghaddam, M. R. in Structures. 1722–1739 (Elsevier).
Simon, D. Biogeography-based optimization. IEEE Trans. Evol. Comput. 12, 702–713 (2008).
Cuevas, E., Fausto, F. & González, A. in New advancements in swarm algorithms: operators and applications 139–159 Springer, (2020).
Shen, Y., Liang, Z., Kang, H., Sun, X. & Chen, Q. A modified jso algorithm for solving constrained engineering problems. Symmetry. 13, 63 (2020).
Dhiman, G. & Kumar, V. Emperor penguin optimizer: a bio-inspired algorithm for engineering problems. Knowl. Based Syst. 159, 20–50 (2018).
Ghadimi, N. et al. SqueezeNet for the forecasting of the energy demand using a combined version of the sewing training-based optimization algorithm. Heliyon 9.6 (2023).
Ghadimi, N. et al. An innovative technique for optimization and sensitivity analysis of a PV/DG/BESS based on converged Henry gas solubility optimizer: a case study. IET Generation. Transmission Distribution. 17 (21), 4735–4749 (2023).
Chen, Y. et al. Short-term electrical load forecasting using the support Vector Regression (SVR) model to calculate the demand response baseline for office buildings. Appl. Energy. 195, 659–670 (2017).
Muzaffar, S. & Afshari, A. Short-term load forecasts using LSTM networks. Energy Procedia. 158, 2922–2927 (2019).
Heydari, A. et al. Short-term electricity price and load forecasting in isolated power grids based on composite neural network and gravitational search optimization algorithm. Appl. Energy. 277, 115503 (2020).
Chang, P., Zhao, X., Niu, Y. & Zhang, H. Short-term load forecasting Method based on LSTM-SVR considering generalized demand-side resources. J. Appl. Sci. Eng. Innov. 10, 21–30 (2023).
Lin, Y., Luo, H., Wang, D., Guo, H. & Zhu, K. An ensemble model based on machine learning methods and data preprocessing for short-term electric load forecasting. Energies. 10, 1186 (2017).
Author information
Authors and Affiliations
Contributions
Zhirong Zhang: Conceptualization, Data curation, Formal analysis, Methodology, Resources, Software, Writing – original draft, Writing – review & editing.Qiqi Zhang: Conceptualization, Data curation, Formal analysis, Methodology, Resources, Software, Writing – original draft, Writing – review & editing.Haitao Liang: Conceptualization, Data curation, Formal analysis, Methodology, Resources, Software, Writing – original draft, Writing – review & editing.Bizhan Gorbani: Conceptualization, Data curation, Formal analysis, Methodology, Resources, Software, Writing – original draft, Writing – review & editing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, Z., Zhang, Q., Liang, H. et al. Optimizing electric load forecasting with support vector regression/LSTM optimized by flexible Gorilla troops algorithm and neural networks a case study. Sci Rep 14, 22092 (2024). https://doi.org/10.1038/s41598-024-73893-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-73893-9
Keywords
This article is cited by
-
Knowledge graph-enhanced deep learning for pharmaceutical demand forecasting
Scientific Reports (2026)
-
Development of a Novel Hybrid Machine Learning Model for Predicting the Protection Factor of Disposable Facepieces in Tunnels
Arabian Journal for Science and Engineering (2026)
-
UniLF: A novel short-term load forecasting model uniformly considering various features from multivariate load data
Scientific Reports (2025)
-
Prediction of electrical energy consumption using principal component analysis and independent components analysis
The Journal of Supercomputing (2025)
