
Abstract
Recent developments indicate that malware programs present a significant risk in the security and privacy of cloud systems. Existing research in malware detection encounters numerous significant challenges due to the constantly changing and advanced characteristics of malware. Malware detection systems frequently experience high rates of false positives and false negatives, where legitimate applications are incorrectly identified as malware or actual malware remains undetected, which results in operational inefficiencies. Traditional signature-based approaches struggle in recognizing new or modified malware. Additionally, sophisticated malware types, such as file less malware, ransom ware, and rootkits pose detection challenges as they integrate deeply into systems or alter their behaviour to evade detection. These challenges highlight the urgent need for ongoing advancements in this field. Existing methods of malware detection that rely on signatures have been found to be both inefficient and slow in the context of cloud environments. Also, Existing studies have focused on detecting malware by analysing input API calls. But, these models have encountered challenges such as limited accuracy and difficulties in effectively classifying malware types. In contrast, Deep Learning (DL) have shown success by analysing malware behaviour through API calls, which yields encouraging results. Additionally, the data produced by API calls necessitates more computational resources for training. To address these challenges, a new deep learning-based malware detection approach utilizes 2D grayscale images derived from API calls, along with an effective tuning strategy has been proposed. Initially, data are collected from cloud malware dataset. Then, API calls are converted into 2D gray scale images in order to construct gray scale image dataset. After getting the gray scale image, pre-processing is performed to reduce high level noise and to enhance the quality of image by weighted mean filter and anisotropic filter, which helps to improve the performance in classification. Next, these images are then passed into the feature extraction stage to extract sufficient features with an effective integrated densely connected squeeze MobileNet v2 (Ef-DeSMob2), which reduces the dimensionality issue and increase the computational complexity. Then, the collected features are passed into the classification phase to detect normal and malware classes from the samples using sparse attention with residual pyramidal depth wise separable convolutional neural networks (SA:ResPyDSC), which focus to enhance the security and reliability of the model. Finally, the hyper parameters in the classifier model like weights, bias are properly fine-tuned by utilizing hybrid white shark beluga optimization algorithm (Hy-WBeOp). The experimental findings illustrate that the proposed method attains accuracy of 98.06%, precision of 97.99%, recall of 97.05%, f1-score of 96.08% and error metrics like MSE AT 0.08, RMSE of 0.27 and MAE of 0.21, which shows that the proposed method helps to classify the malware classes accurately with less error rates. The proposed approach outperforms with the existing techniques because of its great efficiency. Overall, this approach establish a strong malware detection system classification and enhance the reliability and effectiveness of protection against malicious attacks.
Similar content being viewed by others
Introduction
Nowadays, the severity of cyber-related attack increases greatly, the main reason for different malware variants. Computer and network system is exploit due to malware, which is a kind of software and perform vulnerabilities and gain financial benefits. For different function, designed the malicious code variants and its family were designed to steel the sensitive data. Remote code execution allow and attack caused by distributed denial service (DDoS)1,2,3. Reliability and security of service depends on healthy functioning of ecosystem, transaction and operation depends on encryption of algorithm classical chromatography need to improve innovate solution. Quantum key distribution (QKD) and Quantum cryptography are developed to detect quantum communication attack breaches. Randomly generated qubits transmission line based on cryptography, which can exchange under all circumstances4,5,6.
In each year millions of malwares collected, their predecessor is evolved version of sample, malicious happen because of their extremely intelligent method. Consequently, malware code was made public, mostly released in a mutation engine7,8. Three cloud service models were identified by the national institute of standard technologies: infrastructure as a service (IaaS), platform as a service (PaaS), and software as a service (SaaS). Various deployment options, such as private, public, and hybrid clouds was encompassed from these models9,10. Anti-malware software is utilized for malware detection by verifying signatures against a repository11. A static and dynamic analysis modules equipped with complete anti-malware system (AMS). The file without execution detecting the static analysis, whereas file executed in first is known as dynamic analysis12,13.
Two essential components required for dynamic malware detection are the classification module and feature selection module14. The malware effectively identify by using feature selection other side classification algorithm can handle insecurity, the cloud server communicate with the system to analyses the trust node15. In feature selection current system of malware detection based on entropy value or information gain, to predict new types of malware behaviour it should enhance with constraint management module16,17. Malware detection especially used in cyber security field, which is performed by different DL algorithms. Various deep learning architecture are employed including deep neural network (DNN), recurrent neural network (RNN), deep belief networks (DBN), and convolution neural network (CNN) are used to expand the effectiveness of malware detection mechanism18,19.
2D CNN detects malwares in various applications by consuming deep learning algorithms to classify files of malware in dynamic analysis by use of machine learning, which is also used for malware detection in online 20. DL differs from other architecture like recurrent neural networks (RNNs), by utilizing CNN due to its simplicity and faster training speed21. The identification and categorization of malware allows for the development of scalable models through the utilization of deep learning techniques22. It can also identify more features and improve their accuracy by measure the data. After the training phase new pattern of malware identified by DL model23.
In order to accomplish a particular task, Virtual machines that are operating on the cloud are programmed to execute a predetermined set of processes. These processes are subject to change as they are dynamic in nature, with additional processes being created or deleted unexpectedly. Therefore, a significant number of running process are allocated to the fixed set, web service have web server process (Apache) and database process (MYSQL) to host a single VM configuration. Two methods, such as whitelisting and sophisticated are used to attach malware itself to legitimate the process. Whitelisting method is more effective24. In botnets Mirai malware is used to initiate (DDoS) attacks, information technology record the volume generated in data traffic. At peak of the attack, traffic generated 600bps in powerful devices. In DDoS there is new type, known as economic denial of service (EDoS) attack. It proposing services indeterminately and it potentially affect the cloud adaptor, which resultant in failure25.
In malicious mining code have multiple way of transmission it can spread through many channels such as software bundling, weak password blasting, vulnerability, social engineering. In the cloud server, worm modules with horizontal propagation are carried out in malicious mining code can spread through vulnerability and infect more targets 26. Over 350,000 new malicious programs have registered in AV-TEST a cloud security is a major concern for future internet of things and it is platform for cloud services running over virtualization. A performance requirement of AVs is important to detect malware, it protect financial and physical damage to loss of human lives27.
Motivation and problem statement
Deep learning is a branch of machine learning techniques mainly depends on acquiring representations. Different observations, such as images, can be described in various ways, but certain descriptions make it easier to analyse specific tasks using examples. Research in this field aims to determine what constitutes better descriptions and how to effectively study them. Before the advent of deep learning, techniques like extracting distinct levels of features from malicious samples were used for classification. However, these techniques failed to capture the overall attributes of malware. Moreover, classification based on diverse varieties raised concerns regarding dimensions, time, and computational resources. Deep learning proves to be a highly efficient method in the detection of malware due to its ability to provide a scalable solution for machine learning models. These models possess the capacity to handle vast amounts of data without continuously depleting excessive resources. By recognizing malware through general patterns, deep learning enables the identification of variations and attacks in malware. Moreover, comprehensive classification was conducted by deep learning and accuracy was enhanced by extracting a greater number of features in comparison to traditional machine learning techniques, achieved through multiple levels of feature extraction. This allows deep learning models to learn new patterns of malware detection after the initial training phase. However, there have been recent concerns regarding the security of deep learning. Machine learning algorithms, including deep learning, have been created with the premise that training and test data follow the same underlying probability distribution. This assumption makes them vulnerable to skilfully-crafted attacks that violate this hypothesis. Adversarial attacks can significantly impact deep learning methods by exploiting the learning algorithm’s experience to evade detection or by injecting harmful instances into the training data to manipulate classification and detection results. The research work significant contributions are outlined as follows.
-
To remove the noise and to improve the image quality, pre-processing techniques like weighted mean filter and anisotropic filter is employed.
-
To extract rich and informative features, a new method for feature extraction is utilized by an effective integrated densely connected squeeze MobileNet v2 (Ef-DeSMob2).
-
To improve the model ability and to classify the malware classes efficiently, a novel technique using sparse attention with residual pyramidal depth wise separable convolutional neural networks (SA: ResPyDSC).
-
The hyper parameters in the classifiers model have been fine-tuned using a hybrid white shark beluga optimization algorithm, which improves the efficacy of the classifier model.
The organization of the research paper is as follows. Section "Related works:" provides an explanation of the related work. Section "Proposed method" delves into the proposed methodology. Section "Results and discussion" presents the results and discussion and finally the conclusion and future work is ended with section "Conclusion".
Related works
Few of the recent research works related to malware detection by using several models, are termed in the following section
To classify malware variants Omar et al.28 introduced new framework using a hybrid model established on deep learning method. The primary objective of this work was to introduce a novel fusion design that integrates two extensive pre-trained models in a streamlined way. Data acquisition, deep neural network architecture design, training of deep neural network architecture and calculation were four main stages in the architecture. The method was verified on Malimg, Microsoft BIG 2015 and above Malevis datasets. The method can accurately classify malware. Specifically, while testing on the Malimg dataset, achieves 97.78% accuracy. However, it was noticed that detecting and classifying the malware was complex in this work.
For detecting the unknown malware Tom et al.29 examined Deep-Hook, a trusted framework in Linux- based cloud environments. The technology securely hooks into volatile memory of the VM and captures the memory dump to identify traces of malware. CNN based classifier analyses and converts these dumps into visual representations. Deep-Hook was tested in popular Linux virtual servers, utilizing four advanced CNN architectures, image resolutions of eight different types and volatile memory dumps of 22,400 from a wide range of benign and malicious Linux applications. Based on the results, Deep-Hook was effective in detecting and categorizing unknown malware with an impressive AUC and accuracy of up to 99.9%. However, it was noticed that this method was complex in this work.
Based on deep learning technique Jeffrey et al.30 utilized recurrent neural networks for identifying the malware in cloud virtual machines. Long Short Term Memory (LSTM) and Bidirectional RNN (BIDI) were the two primary architectures was designed to understand the patterns and characteristics of malware within time to analyze fine-grained system features namely memory, CPU, and disk usage during runtime. The approach was evaluated on a dataset of 40,680 benign as well as malicious samples. Process level features was obtained by execution of real malware from an unrestricted online cloud environment to replicate cloud supplier settings practically and capture the behavior accurately of sophisticated and stealthy malware. Hence, both models achieve 99% with high detection rate. However, it was noticed that malware samples was low in this model.
Donghai et al.31 uses hardware trace for detecting the malware in virtualization environments. Initially, the Intel Processor Trace (IPT) mechanism was engaged in gathering run time information to designated program. Subsequently, deep learning method based on CNNs was employed to transform the information into colour images to detect malware from these images. Then, Lamport’s ring buffer algorithm was employed to enhance the efficiency of the detection mechanism. Consequently, security checker and information collector were operate simultaneously and attains higher performance in detection. However, it was noticed that stealthy malware was not detected.
For capturing and combining the meaningful features Ce Li et al.32 introduce API sequence based on deep learning model. Initially, convolutional and embedding layers were utilized for creating unified demonstration of various API’s for capturing software behaviour. Subsequently, the semantic information of each API call was represented using the action and operation object of the API. Lastly, Bi-LSTM module was employed for extracting the relationship information between API’s. In this work, the model attains 0.973 accuracy then on a substantial real dataset F1-score achieves 0.9724. However, it was noticed that sequence squeezing was not used in this method.
Seungyeon et al.33 introduced two-stage hybrid malware detection (2- MaD) system based on deep learning strategy to safeguard IoT devices in a smart city environment by detecting obfuscated malware. The 2- MaD system consists of two stages. Static analysis was conducted to extract the opcode in the first stage. Next, bidirectional long short-term memory model was utilized in identifying benign files based on learned information. Moving on to the second stage, dynamic analysis within a nested virtual environment classifies as benign was performed on files. EfficientNet-B3 trained model detects the malware from the behaviour log, by extracting the information on behaviour and process memory. However, it was noticed that it takes more time for extracting the features.
Chen et al.34 introduced malware classification model with recurrent neural networks (RNN), specifically focuses Gated Recurrent Unit (GRU) models and Long Short-Term Memory. By analysing long sequences of API calls, this approach demonstrates high accuracy in classifying different variants of malware. The effectiveness of RNN model performs well in classifying the malware. However, it was noticed that accuracy was low in this method. For enhancing the classifier accuracy, attention mechanism can be used.
A time-controllable, fine-grained keyword search system that utilizes attribute-based comparable access control, enabling authorized users to search through indexes encrypted for specific time periods was developed by Miao et al. 35 on a large dataset, which encompasses code obfuscation, packed malware, as well as metamorphic and polymorphic variants. Additionally, secret sharing is implemented to create an enhanced framework that facilitates efficient user revocation. The formal proofs confirm that both frameworks are resilient against chosen-keyword and key collusion attacks while ensuring key confidentiality. Incorporating various visualizations into the malware analysis through image-based techniques can assist analysts in identifying key features. Overall, the visualizations will enhance the effectiveness of malware detection and classification. This approach could represent a promising avenue for the performance of the model. Furthermore, empirical experiments is conducted to validate the practicality and efficiency of our proposed frameworks with a real-world dataset. However, it was noticed that there was an issue in balancing the trade-off between search efficiency and security.
The rapid advancement of geographic location technology, coupled with the significant increase in data volume, has led to a substantial amount of spatial data being transferred to cloud servers. This shift aims to alleviate the local storage and computational demands, but it simultaneously raises security concerns. Thus, asymmetric Scalar-Product-Preserving Encryption (ASPE) was utilized for data encryption. However, ASPE has been shown to be vulnerable to known plaintext attacks. Additionally, many existing schemes necessitate that users provide extensive information regarding the query range, resulting in the generation of a large volume of cipher texts, which in turn imposes considerable storage and computational challenges. To address these problems, a foundational Privacy-preserving Spatial Data Query (PSDQ) scheme was introduced by Miao et al.36, which build on an enhanced ASPE. This new scheme employs a unified index structure that requires users to supply minimal information about the query range. Furthermore, t an improved PSDQ scheme (PSDQ +) is presented that utilizes a Geohash-based R-tree structure (referred to as GR-tree) along with an efficient pruning strategy, significantly reducing query time. Formal security analysis confirms that the schemes achieve In distinguishability under Chosen Plaintext Attack (IND-CPA) validate their efficiency in practical applications. However, it was noticed that, security can be improved by protecting the access pattern. The Table 1 contains the performance analysis of existing models.
Proposed method
Malware detection has been performed by employing sparse attention with residual pyramidal depth wise separable convolutional based malware detection with optimization mechanism. Utilizing the API calls, it converts into 2D gray scale image to detect the malware and predict the malware classes effectively. Malware detection has been gauged into numerous stages such as pre-processing, feature extraction and malware detection. Figure 1 labels the flow diagram of malware detection.

Framework for proposed methodology.
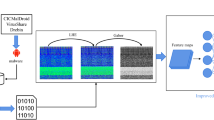
In the preliminary stage, for the generation of image datasets, the API calls were extracted and particular files were chosen from their sources for the grayscale image conversion. The files extracted from the API calls were interpreted in a binary bit stream and saved into byte matrix. Representation of grayscale image was utilized in this work, with pixel values ranging from 0 to 255. The byte matrix’s byte values can be directly converted into pixels in the final image. Consequently, in the byte matrix each byte was transformed into a value between 0 and 255, serving as a pixel in the resulting image. Figure 2 represents conversion of API calls to grayscale images.

Approach for converting API calls to gray scale images.
After that, input data are collected from the open source datasets, which are distributed into pre-processing stage to remove the noise in the images by using weighted mean filter and anisotropic filter. Now, relevant features are extracted from the removed images by means of Ef-DeSMob2. Next, the classification was performed to detect malware and normal classes by engaging SA: ResPyDSC. Finally, the hyper parameters are fine-tuned by using Hy-WBeOp, which helps to improve the speed of optimal search and enhance the efficacy as well as accuracy of the model.
Pre-processing
Pre-processing was done through different stages to remove the noise in the image namely weighted mean filter and anisotropic filter.
Weighted mean filter
Adaptive weighted man filter37 employs a variable window size that greatly degrades the standard of images to diminish excessive noise levels .Window dimensions is progressively enlarged in adaptive weighted mean filter until the lowest and highest pixel values of two consecutive window. In case the center pixel value of the window size is the lowest or highest, it will be reset to the average weighted value. Nevertheless, if the center pixel value is not the highest or lowest, the intensity value will stay the same. Coordinate \(x_{k,l}\) in the original image of the size \(M \times N\,\left( {x,y} \right)\) represents the center of the coordinate’s pixel intensity value. Dynamic range \(DR\) was defined as \(DR_{\min } \leqslant x_{j,k} \leqslant DR_{\max }\). Corrupted image, denoted as dr. To replace a faulty pixel, the maximum and minimum dynamic ranges \(DR_{\max }\) and \(DR_{\min }\) was employed in the image using an Eq. (1):
The likelihood of pixel distortion is influenced by the probabilities \(\,P\) of maximum (speckle) and lowest (Gaussian) noise’s effects, denoted as \(\,c\) and \(\,d\) in the equation.\(noise = c + d\). The primary concept behind WMF is to use the weighted mean value of the selected window to prevent false error detection and restore corrupted pixels. The mean value of the designated window \(\,W\) is calculated in Eq. (2).
Weight \(W_{j,k}\) is defined in Eq. (3)
Anisotropic filter
The primary objective of image filtering is to eliminate noise from digital photographs. This process generates a scale space from which a multitude of blurred images are obtained. Most image processing algorithms face difficulties when operating in noisy environments. To overcome this, an image filter is employed as a pre-processing technique. In this project, the anisotropic filter38, a specific type of filter, is utilized for denoising purposes. The image diffusion process is described using the anisotropic diffusion equation as stated below.
\(\nabla x\) defines the image gradient and diffusion coefficient. Below is a demonstration of an estimated discretization utilizing forward and backward differences.
\(N_4\) defines the Centre pixel. Based on the Eq. (6), noise pixels have significant diffusion action whereas signal pixels have mild diffusion action. While maintaining the signal the noise may be reduced. Various diffusion models utilize constant step size. The Eq. (7) is recommended with a better iteration step as.
\(\frac{1}{4}\) is used to guarantee the convergence of Eq. (5). The iterative process formula is
After, the pre-processing phase, feature extraction is performed to extract the important features.
Feature extraction using effective integrated densely connected squeeze MobileNetv2
The noise removed images are then passed into feature extraction stage to extract the features. Dense network is integrated with MobileNetv2 39 and squeeze excitation block to extract the relevant features. Figure 3 describes the architecture of Ef-DeSMob2.

Schematic feature extraction model using Ef-DeSMob2.
Dense network
DenseNet is a deep learning structure where each layer is directly connected, allowing for efficient information flow. From all preceding layers every layer receives inputs then, feature maps are passed to complete subsequent layers. The current layer’s output feature maps are combined with those of the previous layer through concatenation to create the merged feature maps. All layers are connected to every following layer in the network, forming Dense Nets. The convolutional network processes an input image \(x_0\) through \(N\) layers, each performing a nonlinear transformation \(F_n (.)\). Layer n includes feature maps from all previous convolutional layers. From layers 0 to \(n - 1\), the input feature maps are concatenated and denoted as \(x_0 ,....,x_{n - 1}\). Therefore, the model has \(N(N + 1)/2\) connections in an \(N\)-layer network. The output of \(n^{th}\) layer represented as
The transition layer in the neural network consists of several consecutive operations. These operations consist of Rectified Linear units, Batch Normalization, and \(3 \times 3\) convolution. However, altering the size of the feature maps, concatenation operation becomes impractical. In such cases, the layers with different map sizes are down sampled. To ensure smooth transitions between Dense Conv blocks \(1 \times 1\) Conv and \(2 \times 2\) average pooling operations was inserted in the form of transition layers. These transition layers are placed between two adjacent dense blocks. In the neural network whole feature maps are utilized to make accurate predictions. The output layer comprises \(k\) neurons, delivers accurate contest for \(K\) malware families. ReLU function is utilized on the output feature maps, thereby introducing nonlinearity within CNNs. The ReLU function is defined by
MobileNetv2
MobileNetv2 is a CNN based model widely utilized for image classification. One key benefit of mobile net architecture is its ability to operate with lower computational resources compared to traditional CNN models, making it ideal for mobile and low capability computer devices. This simplified model includes a convolution layer that effectively balances parameter accuracy and latency by focusing on manageable features. Additionally, MobileNet excels in minimizing network size. MobileNet architecture demonstrates high efficiency by utilizing a minimal number of features. The architecture follows a depth-wise approach, incorporating various abstraction layers and convolutions that are quantized to evaluate problem complexity thoroughly. The \(1 \times 1\) complexity is referred to as a point wise complexity. MobileNetv2’s abstraction layers are structured in depth and point through a standard rectified linear unit. Additionally, to reduce the dimensionality of input images the resolution multiplier variable \(\omega\) is introduced and internal representations of each layer uniformly.
The input variable, denoted as \(\rho\), is processed through a size of feature vector map \(F_j \times F_j\) and size of filter denoted as \(F_k \times F_k\). The resulting output variable is documented as \(q\). Variable \(c_e\) represents computation efforts for the core abstract layers of the architecture and can be evaluated using Eq. (11).
\(\alpha\) sets at 1 denotes variable resolution multiplier. Through the variable \(\cos t_e\) computational evaluated by using Eq. (12)
Variable \(d\) is estimated over the Eq. (13)
Based on the context, the width multiplier and resolution multiplier are two hyper-features that assist in adjusting the optimal window size for accurate prediction. The image has an input size of \(224 \times 224 \times 3\). \(224 \times 224\) represents the width and height of first two values in the image, which would always be greater than 32. The third values indicates that the image has three input channels. The MobileNetv2 architecture consists of 32 filters with each filter having a size of \(3\times 3 \times 3 \times 32\). The underlying principle of architectures is to exchange difficult convolutional layers with simpler ones. Each layer of the architecture consists of a \(3 \times 3\) convolutional layer that processes input data, followed by a \(1 \times 1\) point wise convolutional layer which merges the filtered parameters to form an innovative component. This concept aims to simplify the model and improves its speed compared to traditional convolutional models.
Squeeze excitation block
The SE block serves as a versatile architectural component that can seamlessly integrate into any CNN. FCN was incorporated to maximize the benefits of SE block and confirm its effectiveness across different datasets. By utilizing global average pooling the SE block captures spatial dependencies and learns channel-specific descriptors. These descriptors are then used to recalibrate the feature maps, emphasizing the crucial channels.
A computational unit known as a SE block is constructed based on the transformation \(F_{tr}\), which maps an input feature \(X \in R^{{W^{\prime}} \times H^{\prime} \times C^{\prime} }\) to produce an output feature map \(U \in R^{W \times H \times C}\). The resulting output can be expressed as \(U = \left[ {u_{1,} u_{2,,............,} u_C } \right]\).
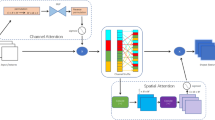
Convolution operator is denoted as \(\ast\),\(V_c = \left[ {v_c^1 ,v_c^2 ,......,v_c^{C^{\prime} } } \right]\), \(X = \left[ {X^1 ,X^2 ,_{............,} X^{C^{\prime} } } \right]\) and \(U \in R^{W \times H}\). A spatial kernel in 2D, represented by \(V_c^j\), denotes a single channel \(v_c\) which functions as channel \(X\). The fundamental process of the SE block can be elucidated in two stages as compression and activation. Figure 4 represents the block diagram of squeeze excitation block.

Illustration of network architecture with Squeeze and excitation block.
The squeeze operation aims to condense global spatial information into a descriptor specific to each channel. This is achieved by utilizing global average pooling in channel-wise statistics. In the case of time series data, the output transformation \(U\) can be reduced in the spatial dimension \(T\) to calculate channel-wise statistics \(Z \in R^C\). This involves in calculating \(Cth\) element of \(Z\), defined as follows
The excitation process maximizes the utilization of combined data obtained from the compression process by comprehensively grasping channel-specific dependencies. In order to accomplish this, the model needs to possess adaptability to understand a complex and non-disjoint connection among various channels. A singular gating mechanism incorporates to achieve a sigmoid activation function.
ReLU activation function is denoted as \(\delta\), \(W_1 \in R^{\frac{c}{r} \times c}\) and \(W_2 \in R^{\frac{c}{r} \times c}\). \(W^1\) And \(W_2\) are used to optimize complexity. The neural network denoted as \(F_{ex}\), the sigmoid function as \(\sigma\), reduction ratio represented as \(r\).
Ultimately, the SE blocks result is achieved by scaling \(U\) using the activation \(j\).Here, \([\tilde{x} = \tilde{x}_1 ,\tilde{x}_2 ,........,\tilde{x}]\) defines the channel-wise multiplication.
Malware detection using sparse attention with residual pyramidal depth wise separable convolutional neural networks
The significance of malware detection through the use of sparse attention combined with residual pyramidal and depth wise separable convolutional neural networks (CNNs) to effectively and accurately categorize malicious software within an increasingly intricate cybersecurity environment. Traditional malware detection techniques face challenges when dealing with high-dimensional data and the diverse behavioural patterns exhibited by malware, which complicates the task of achieving high detection rates while reducing false positives. By integrating sparse attention mechanisms, the model can concentrate on the most pertinent features in the input data, thereby filtering out unimportant noise and irrelevant information, which is essential for accurately differentiating between benign and harmful software. Moreover, the implementation of residual connections promotes improved gradient flow during the training process, allowing deeper architectures to learn more complex features without falling victim to the vanishing gradient issue. This leads to capturing detailed patterns in detecting malware. The pyramidal design further bolsters the model’s ability to learn multi-scale representations, which enhances its sensitivity to various types of malware. The incorporation of depthwise separable convolutions ensures that the architecture remains lightweight and computationally efficient, which makes it well-suited for real-time applications. In summary, the incorporation of these sophisticated techniques not only improves the accuracy and efficiency of malware detection but also enables rapid version to new threats. Figure 5 defines the architecture of SA: ResPyDSC.

Proposed architecture of classifier model using SA: ResPyDSC.
Depthwise separable convolutional network
Dilated separable convolution improves the malware detection process by increasing the network capability to capture long range dependencies and helps to improve computational efficiency and reduces the overfitting. Also, helps to classify the results fastly. Depthwise separable convolution can be broken down into two separate operations as depth wise convolution and \(1 \times 1\) convolution or point-by-point convolution. The depth wise convolution operates on every channel of input image individually, extracting spatial features along each dimension. On the other hand, the point-by-point convolution used to the feature map, merging the feature map across the channels. In case of depthwise convolution the input image has the size of \(D_e \times D_e \times M\) where \(D_e\) represents the height and width of the input image and \(N\) is the number of channels in the map. During the depthwise convolution process, a convolution kernel of size \(k \times k\) is assumed. The resulting output feature map obtained through convolution has a size of \(D_h \times D_h \times M\) where \(D_h\) represents the height and width of output image and it serves as an input for the subsequent convolution operation. For the point-by-point convolution, the convolution kernels have a size of \(1 \times 1\). The convolution kernel must have the same number of channels as the input feature map. Assuming there are \(N\) convolution kernels, the resulting output feature map after convolution would have a size of \(D_h \times D_h \times N\).
The convolution kernel of size \(k\) operates on input feature maps \(k \times k\) with dimensions \(D_e \times D_e \times N\) where the number of input channels is \(M\) and output channels is \(N\). The resulting output feature map \(G\) have dimension \(D_h \times D_h\).This defines a standard convolution operation as
Here, \(H_i\) represents the \(ith\) map within the set \(H\), \(G_j\) denotes the \(j^{th}\) map in the set \(G\), and \(K_i^j\) refers to the \(i^{th}\) slice of the \(j^{th}\) kernel. The term \(b_j\) indicates the bias associated with the output map \(G_j\). Additionally, the symbol \(.\) signifies the convolution operator. The total count of trainable parameters in the convolution process is denoted as \(P_1\), while the number of floating-point operations is represented as \(F_1\) for a standard convolution. These values can be determined using the formulas provided in Eqs. (19) and (20) below.
Here, the number of parameters as indicated in Eq. (2), is influenced by the kernel size, the number of input channels \(M\), and the number of output channels \(N\). Additionally, Eq. (3) illustrates that the count of floating-point operations relies on parameter \(P_1\) and the dimensions of the output feature map, which are \(D_h \times D_h\). Based on depth wise convolution, every kernel has one piece, which convolutes every input channel maps and the process is described as
Here, \(K_j\) represents the \(j^{th}\) depth-wise convolutional kernel. It is important to note that depth-wise convolution exclusively filters the input channels without merging them to form new features. Consequently, an additional layer utilizing a \(1 \times 1\) standard convolution is required to produce these new features. In the process of depth-wise separable convolution, the parameters \(P_2\) and the floating-point calculations \(F_2\) are derived from the combination of the depth-wise and \(1 \times 1\) pointwise convolutions. Therefore, \(P_2\) and \(F_2\) can be computed as illustrated in Eqs. (22) and (23) as,
The ratios of Eq. 22 and 19 and ratio of Eq. 23 and 20 is shown in Eq. (24) and Eq. (25) as,
Here, the analysis indicates that the parameters and computations involved in depth-wise separable convolution is only \(\frac{1}{N} + \frac{1}{K^2 }\) times that of standard convolution. This significantly lowers both the parameter count and computational expense within the model.
Pyramidal depthwise separable convolution
The pyramid structure enables the model to identify features across multiple scales, which is essential for recognizing malware variants that appear in various forms. Pyramid depth wise separable convolution employs a range of kernel sizes \(k = \left\{ {k_1 ,k_2 ,.....,k_N } \right\}\) for the depth wise convolutional layer, rather than relying on a single kernel size. Subsequently, it merges the output of these convolutions through concatenation prior to proceeding with the point wise \(1 \times 1\) convolution. The two ways of combining features are addition and concatenation.
Addition
The computational cost associated with \(M\) depthwise convolutions, represented as \(k = \left\{ {k_1 ,k_2 ,.....,k_M } \right\}\), when incorporating an additional combination is calculated \(h.w.d_i .\sum_{m = 0}^M k_m^2\). The cost incurred by the additional operator is \((M - 1).h.w.d_i\) Furthermore, the pointwise 1 × 1 convolution incurs a cost of \(h.w.d_i .\) In conclusion, the overall computational cost for pyramidal depth wise separable convolution for addition is \(h.w.d_i .{(M - 1 + \sum }_{m = 0}^N k_m^2 + d_j )\). Consequently, the ratio of the computational costs between standard convolution and Pyramidal depthwise convolution –Addition can be determined as,
Concatenation
The computational expense of \(M\) depth wise convolutions represented as \(k = \left\{ {k_1 ,k_2 ,.....,k_M } \right\}\) in a concatenation configuration is calculated as \(h.w.d_i .\sum_{m = 0}^N k_m^2\). The concatenation operation itself incurs no cost. Additionally, the point wise 1 × 1 convolution has a cost of \(h.w.d_i .d_j h.w.d_i .{(\sum }_{m = 0}^M k_m^2 + M.d_j )\). Therefore, the ratio of the computational costs between standard convolution and pyramidal depth wise separable convolution-Concatenation is,
Here, the concatenation will improve the classification model.
Residual unit
Residual connections effectively tackle the difficulties associated with deep neural networks, and solves the vanishing gradient issue that can delay the learning process. In the malware detection deep architectures are essential for identifying complex patterns. The connections enhance training efficiency by allowing gradients to propagate more freely throughout the network. As a result, this promotes quicker convergence and improves the detection of advanced malware patterns, which enables the network to learn deeper and more complex features to improve the performance of the model. The residual connections was utilized to improve the classification results by reducing deep network gradient dispersion. The residual unit comprises a single convolutional layer, a batch normalization (BN) layer, and a rectified linear unit (ReLU) layer, in addition to the identity mapping. The fundamental structure of the residual unit is defined as,
The residual function is represented as \(F\).\(X_j\) and \(X_{j + 1}\) are the input and output of the residual unit . To enhance the efficiency of model training, batch normalization is applied following each convolutional layer. Additionally, the rectified linear unit layer is employed to capture nonlinear features. This approach, utilizing skip connections, allows residual networks to construct very deep architectures while mitigating concerns related to the vanishing gradient issue. This is particularly beneficial for detecting malware.
Sparse attention network
Sparse attention enables the model to concentrate on the most significant areas of the input, such as harmful patterns or code fragments, while disregarding unimportant information. This targeted focus enhances the model’s capability to identify malware by highlighting essential characteristics by the large volume of harmless code present in the input. Additionally, sparse attention minimizes computational demands relative to conventional attention methods, thereby improving the efficiency of malware detection while preserving high levels of accuracy. A sparse attention mechanism is specifically designed for the target entity \(\hat{H}{\,}_g\) into the hidden tensor of the input sequence to detect malware. This approach computes the hidden matrix using the following equations as,
Here, the parameter matrix is defined as \(W^{ \ast \ast }\) of point convolution layer, parameter vector is defined as \(S\), and hidden matrix is denoted as \(\hat{H}{\,}_g\). Element wise product is defined as \(\Theta\).The dropout applied to the softmax layer can be viewed as a unique activation function that eliminates certain irrelevant components. This process aids in obtaining a weighted sparse hidden tensor and speeds up the subsequent computations. Thus, the proposed model improves the malware detection process by integrating sparse attention for targeted focus, residual connections to facilitate effective learning, a pyramidal design for extracting features at multiple scales, dilated convolutions to capture long-range dependencies, and separable convolutions to enhance computational efficiency. These advancements collectively deliver a strong, precise, and scalable approach to identifying malware classes, while maintaining rapid and efficient processing suitable for real-world applications.
Hybrid white shark beluga optimization algorithm
After the extraction of features, the hyper parameters were fine-tuned by using Hy-WBeOp. Beluga whale and white shark optimization are integrated together to extract the relevant information. BWO is an algorithm based on swarms that aims to solve optimization problems by taking inspiration from various activities of beluga whales, including swimming, hunting for prey, and whale fall. In order to enhance BWO’s convergence capability, the exploitative phase incorporates the Levy flight function. Initially, BWO was developed with the intention of emulating the behaviors of beluga whales includes swimming, hunting and whale fall. The subsequent section outlines the mathematical model of BWO. Beluga whales was regarded as search agents within BWO due to its population-based approach, where each beluga whale represents a candidate solution that undergoes updates during the optimization process. Search agents positions are symbolized in equation.
Based on the balancing factor \(B_k\), BWO algorithm switches from exploration to exploitation as determined by Eq. 35, here \(N\) represents beluga whale population size and \(D\) represents the dimension.
1. Exploration phase: The swimming performance of beluga whale is taken into account during the exploration phase. Beluga whales have been observed engaging in social-sexual behaviors in different poses, as seen in beluga whales held in human care, where a couple of closely spaced beluga whales swim in a corresponding manner. Consequently, the positions of beluga whales are simplified in Eq. 36.
T is defined as the current position, \(X_{kl}^{T + 1}\) represents the next iteration, the random variable is denoted as \(r_1\) and \(r_2\) .
2. Exploitation phase: In this stage, BWO utilizes the Levy flight strategy to enhance convergence. By considering the levy flight method the mathematical equation is represented as
Levy flight function is calculated as
The default constant established at 1.5, while \(u\) and \(v\) represent random values following a normal distribution as shown by Eq. 41 and 42.
3. Whale fall phase: During this phase, whale fall occurring among the individuals in the population as a basis for introducing minor variations in crowds to mimic the activities of whale falls in each cycle. It was assumed that these beluga whales either migrated or were intentionally placed into the depths of ocean. The position of beluga whales and whale fall scale were taken into account to establish the new position in order to sustain a consistent population size, as outlined in Eq. 43.
\(X_{step}^{\phantom{a}}\) is defined as
\(C_2^{\phantom{a}}\) is represented as
\(W_f\) is estimated as
The Pseudocode of hybrid white shark beluga optimization algorithm is represented in Table 2.
Results and discussion
Performance metrics
The proposed model performance results were calculated in terms of Accuracy, Precision, Recall, F1- score, Mean squared error (MSE), Root mean squared error (RMSE), Mean absolute percentage error (MAPE), Mean Absolute error (MAE), Training accuracy, Training loss, Testing accuracy and Testing loss. These metrics were compared with existing models of CNN, ResNet, BI-GRU and DSC.
Accuracy
Accuracy is calculated by dividing the total amount of accurate predictions by the whole quantity of predictions made.
Precision
Precision is considered by dividing the sum of correct positive outcomes by the overall number of positive outcomes expected by the classifier.
Recall
The recall metric represent the proportion of true positive instances correctly identified out of entire positive instances.
F1 score
F1 score is calculated as the harmonic mean of precision and recall, providing a measure of both the classifier’s accuracy in classifying instances correctly and its ability to avoid missing a significant number of instances. The formula of F1 score is given by
Mean squared error (MSE)
MSE serves as a widely utilized evaluation metric for assessing the average squared error between the expected value by the model and the true value within a dataset.
The number of predictions was denoted as n, the \(y_i\) vector represents the observed values of the variable that was being predicted, while \(\tilde{y}_i\) represents the predicted values.
Root mean squared error (RMSE)
RMSE is determined by finding the square root of the mean of the squared discrepancies among the predicted value and the actual value.
Mean absolute error (MAE)
The MAE assesses the total deviation between the dataset’s observations and the regression predictions by calculating the average of the absolute distances across all observations.
Mean absolute percentage error (MAPE)
The MAPE is a statistical size that evaluates the accuracy of a forecasting method in terms of prediction. It typically quantifies the accuracy by calculating a ratio using the following formula.
Dataset description
The cloud malware dataset comprises of 104 folders, with everyone corresponding a distinct malware on cloud experiment. These 104 executable malwares were acquired from Virus Total. Malware mostly falls into the types of DDos/Dos, Backdoor, Trojan, Virus, and Worm. The csv files are named based on the malware hash utilized in a specific experiment. Every experiment has duration of 60 min, with the initial 30 min being a benign phase. Within the subsequent 10 min, a single malware is randomly injected, followed by a malicious phase lasting 20 min. Throughout the experiment, performance metrics such as CPU, memory, and disk usage are recorded to whole methods running on the virtual machine within each 10 s. In each experiment, approximately 360 samples are collected, resulting in a total of approximately 37,440 samples across altogether experiments. Every single sample represents a vector of complete processes.
Performance analysis for dataset
The performance analysis of cloud malware dataset is described in the following section. The performance metrics calculated in this dataset are Accuracy, Recall, Precision, F1 score, MAE, MAPE, MSE, RMSE, Train accuracy, Training loss, Testing accuracy and loss. Figure 6 denoted the performance analysis of accuracy.

Performance analysis of accuracy.
The assessment of existing and proposed methodologies is defined in terms of accuracy. The proposed method is compared with DSC, BI-GRU, ResNet and CNN. The proposed model attains high accuracy of 98.06% than compared to existing methods. The existing CNN attains low accuracy of 89.64% whereas other existing models scored values of DSC of 95.24%, BI-GRU of 93.45% and Res-Net of 90.96%. DSC scores second place in accuracy. However, these existing models are too expensive to train. Thus, the proposed model is highly effective for classifying and provides good performance. Figure 7 represents the performance investigation of precision.

Performance analysis of precision.
The performance analysis of precision is illustrated for both models. The proposed models are compared with DSC, BI-GRU, ResNet and CNN. The proposed model attains higher precision of 97.99%. The existing CNN had achieved low precision value of 88.67%, DSC of 95.46%, BI-GRU of 92.34%, ResNet of 90.04%. As a result, the existing models had less computational complexity. Hence, the proposed model attains high precision value and produce better performance compared to others. Figure 8 shows the performance analysis of recall.

Performance analysis of recall.
The performance consequences of Recall is demonstrated for the existing and proposed. The proposed models are compared with DSC, BI-GRU, ResNet and CNN. The proposed model attains high recall of 97.05%. The existing models CNN scored values of 88.04%, DSC of 94.23%, BI-GRU of 92.35%, ResNet of 89.08%. DSC ranks the second place in recall. The existing models have high error chances and interpretability issues. Hence, the existing models obtains less recall values than proposed. Figure 9 describes the performance analysis of F1-score.

Performance analysis of F1-score.
The F1-score performance analysis is defined for the existing and suggested models. The existing models were compared with DSC, BI-GRU, ResNet, and CNN. The existing model CNN scored values of 85.67%, DSC of 92.07%, BI-GRU of 90.28%, ResNet of 87.45%. The proposed model scored high F1-score as 96.08%. The existing models have some privacy issues. Hence, the proposed method provides high f1-score values. Figure 10 denotes the performance analysis of MSE.

Performance analysis of MSE.
The performance results of MSE for the existing and proposed models is shown. The propose models are compared with DSC, BI-GRU, ResNet, and CNN .The existing models obtained values of DSC of 0.10, BI-GRU of 0.14, ResNet of 0.18 and CNN of 0.20.The existing model CNN attains high error rate. The established model achieves the values of 0.08. Suggested model obtained less error rate than other existing models. Figure 11 defines the performance analysis of RMSE.

Performance analysis of RMSE.
In this analysis denotes the RMSE for the existing and proposed model. The propose models are compared with DSC, BI-GRU, ResNet, and CNN .The existing models like CNN scored 0.39, BIGRU of 0.325, ResNet of 0.34 and DSC of 0.3 and proposed model obtains less error rate of 0.27. Hence, this model attains low error rate and provides better results in analysing RMSE. Figure 12 indicates the performance analysis of MAE.

Performance analysis of MAE.
It shows the performance results of MAE for proposed and existing models. It defines the average model performance error. The propose models are compared with DSC, BI-GRU, ResNet, and CNN. The existing models obtained values of DSC of 0.54, BI-GRU of 0.76, ResNet of 0.98 and CNN of 1.05. The existing model CNN attains high error rate. The established model achieves the values of 0.21. Proposed model obtained less error rate than other existing models. Figure 13 defines the performance analysis of MAPE.

Performance analysis of MAPE.
The performance outcomes of MAPE for the existing and proposed models is mentioned. It defines the average model performance error .The propose models are compared with DSC, BI-GRU, ResNet, and CNN .The existing models obtained values of DSC of 1.32, BI-GRU of 1.54, ResNet of 1.89 and CNN of 2.08.The existing model of CNN attains more error rate. The proposed model achieves the values of 1.18. Proposed model obtained less error rate than other existing models. Figure 14 explains the performance analysis of Train accuracy.

Performance analysis of train accuracy.
In this, it depicts the analysis of training accuracy for the existing and proposed models. The propose model attains high accuracy from the range of above 95%. The existing CNN got last position in training accuracy 0f. below 86% and DSC obtained second rank position in this analysis. The proposed models were compared with existing models such as CNN, ResNet, BI-GRU and DSC. Figure 15 describes the performance analysis of training loss.

Performance analysis of train loss.
The valuation of training loss for the proposed and existing models is denoted. The propose models were compared with CNN, ResNet, BI-GRU and DSC. During training the loss of the classifiers are considered by changing the size of the epochs. The existing CNN model obtained first position in loss analysis. The existing models attained high loss due to some issues in feature extraction and optimization algorithms was not used to reduce the loss function. The proposed model attains less loss from the range of below 0.05. The existing models attains high loss of above 0.14. Figure 16 represents the performance analysis of Test accuracy.

Performance analysis of test accuracy.
The performance results in validating the accuracy are described. The propose models were compared with CNN, ResNet, BI-GRU and DSC. The existing CNN attains low accuracy in validation and the proposed scored high accuracy and the values goes high from 250 to 300 epochs. DSC scores second in testing accuracy. The proposed model outperforms the existing models. Figure 17 defines the performance analysis of train loss.

Performance analysis of test loss.
It symbolizes the loss while validation. The proposed models are compared with existing models such as CNN, ResNet, BI-GRU and DSC. The existing CNN model attains high loss value and the proposed model attains less loss below 0.5 and provides better performance. Thus, the proposed model provides good performance in compared with existing models. The Table 3 defines the performance analysis with the proposed and existing models.
Figure 18 defines the ablation study. Figure 18 (a) denotes the ablation study based on accuracy. Figure 18 (b) illustrates the ablation study based on precision. The ablation study based on recall is shown in Fig. 18 (c). Overall, the bar chart illustrates the findings of an ablation study that assessed five distinct modules. The vertical axis indicates the accuracy percentage, which ranges from 60 to 100%, while the horizontal axis identifies the five modules as Module-1 to Module-5. Module 1 has all stages and attains good performance with other modules. Module 2 is without pre-processing. Module 3 performs the results without feature extraction stage. Module 4 shows the results without sparse attention. Finally, module 5 provides the results without optimization. Module-1 stands out with the highest accuracy, and the proposed method shows superior performance in compared to the other modules. This ablation study underscores the varying contributions of each module and Module-1 shows highest accuracy with other modules. Table 4 denotes the values of ablation study based on accuracy.

Ablation study based on accuracy.
Table 5 defines the values of ablation study based on precision.
Table 6 shows the ablation study values of recall.
Conclusion
The progress in malware detection has become increasingly vital due to the evolving nature of cyber threats. The proposed detection methods greatly improve the precision and effectiveness of identifying harmful software. The proposed malware detection system based on deep learning, which utilizes 2D grayscale images derived from API calls along with a robust tuning strategy to enhance detection accuracy. The process initiates with the gathering of input data from an open-source dataset, followed by the transformation of API calls into 2D grayscale images for the purpose of malware analysis. These images undergo several stages and begins with pre-processing, where noise is eliminated through the application of a weighted mean and anisotropic filter, which results in cleaner inputs for subsequent analysis. Feature extraction is then conducted using the integrated Ef-DeSMob2 model, which adeptly identifies relevant features critical for precise malware detection. These features are classified into normal or malware categories utilizing a sparse attention-based residual pyramidal depth wise separable convolutional network, which improves detection accuracy. Finally, the model’s hyper parameters are optimized through Hy-WBeOp algorithm, which further enhances the classifier’s performance. This methodology significantly boosts the efficiency, accuracy in malware detection process. The experimental results shows that our proposed method attains high accuracy at 98.06%, Precision at 97.9%, Recall of 97.05%, %, precision of 97.99%, recall of 97.05%, f1-score of 96.08% and error metrics like MSE AT 0.08, RMSE of 0.27, MAE of 0.21, which illustrates the effectiveness of the proposed model. In future, more parameters tuning can be planned. Also, in the upcoming research, the design of SA:ResPyDSC model will be improved to enhance the effectiveness of malware detection. A comprehensive investigation and analysis of the proposed method must be conducted on a large dataset of malware images, which encompasses code obfuscation, packed malware, as well as metamorphic and polymorphic variants. Incorporating various visualizations into the malware analysis through image-based techniques can assist analysts in identifying key features. Overall, these visualizations will enhance the effectiveness of malware detection and classification. Furthermore, the increasing prevalence of the Internet of Things (IoT) and cloud computing suggests that future malware detection systems will likely integrate edge computing functionalities. This integration will enable real-time analysis and responses in various environments. Such developments point to a notable transition towards more holistic, adaptive, and intelligent malware detection frameworks that will be more adept at addressing the complexities associated with contemporary cyber threats. The abbreviations are denoted in Table 7.
References
Maniriho, Pascal, Abdun Naser Mahmood, and Mohammad Jabed Morshed Chowdhury. "A study on malicious software behaviour analysis and detection techniques: Taxonomy, current trends and challenges." Future Generation Computer Systems 130 (2022): 1–18.
Aslan, Ö., Ozkan-Okay, M. & Gupta, D. Intelligent behavior-based malware detection system on cloud computing environment. IEEE Access 9, 83252–83271 (2021).
Kleymenov, Alexey, and Amr Thabet. Mastering Malware Analysis: A malware analyst’s practical guide to combating malicious software, APT, cybercrime, and IoT attacks. Packt Publishing Ltd, 2022.
Djenna, Amir, Ahmed Bouridane, Saddaf Rubab, and Ibrahim Moussa Marou. "Artificial intelligence-based malware detection, analysis, and mitigation." Symmetry 15, no. 3 (2023): 677.
Szymanski, Ted H. "The “cyber security via determinism” paradigm for a quantum safe zero trust deterministic internet of things (IoT)." IEEE Access 10 (2022): 45893–45930.
Ahn, J. et al. Toward quantum secured distributed energy resources: Adoption of post-quantum cryptography (pqc) and quantum key distribution (qkd). Energies 15(3), 714 (2022).
Şırlancı, Melih. "Malicious code detection: run trace analysis by LSTM." Master’s thesis, Middle East Technical University, 2021.
Li, X. & Li, Qi. An IRL-based malware adversarial generation method to evade anti-malware engines. Comput. Secur. 104, 102118 (2021).
Zhang, S. et al. Practical adoption of cloud computing in power systems—Drivers, challenges, guidance, and real-world use cases. IEEE Transactions on Smart Grid 13(3), 2390–2411 (2022).
Boneder, Stefan. "Evaluation and comparison of the security offerings of the big three cloud service providers Amazon Web Services, Microsoft Azure and Google Cloud Platform." PhD diss., Technische Hochschule Ingolstadt, 2023.
Seraj, S., Khodambashi, S., Pavlidis, M. & Polatidis, N. HamDroid: permission-based harmful android anti-malware detection using neural networks. Neural Comput. Appl. 34(18), 15165–15174 (2022).
He, Shuai, Cai Fu, Hong Hu, Jiahe Chen, Jianqiang Lv, and Shuai Jiang. "MalwareTotal: Multi-Faceted and Sequence-Aware Bypass Tactics against Static Malware Detection." In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, pp. 1–12. 2024.
Rabitoy, Madeleine. "Development and integration of machine learning and AI pattern recognition in malware detection: a quantitative and summative analysis of models." (2023).
Zhang, J. et al. Malware detection based on multi-level and dynamic multi-feature using ensemble learning at hypervisor. Mobile Networks and Applications 26, 1668–1685 (2021).
Chen, L., Xia, C., Lei, S. & Wang, T. Detection, traceability, and propagation of mobile malware threats. IEEE Access 9, 14576–14598 (2021).
Lefoane, M., Ghafir, I., Kabir, S. & Awan, I.-U. Unsupervised learning for feature selection: A proposed solution for botnet detection in 5g networks. IEEE Trans. Industr. Inf. 19(1), 921–929 (2022).
Singh, Priyanka, Samir Kumar Borgohain, Achintya Kumar Sarkar, Jayendra Kumar, and Lakhan Dev Sharma. "Feed‐Forward Deep Neural Network (FFDNN)‐Based Deep Features for Static Malware Detection." International Journal of Intelligent Systems 2023, no. 1 (2023): 9544481.
Anand, Ankita, Shalli Rani, Divya Anand, Hani Moaiteq Aljahdali, and Dermot Kerr. "An efficient CNN-based deep learning model to detect malware attacks (CNN-DMA) in 5G-IoT healthcare applications." Sensors 21, no. 19 (2021): 6346.
Tsimenidis, S., Lagkas, T. & Rantos, K. Deep learning in IoT intrusion detection. J. Netw. Syst. Manage. 30(1), 8 (2022).
Akhtar, Muhammad Shoaib, and Tao Feng. "Detection of malware by deep learning as CNN-LSTM machine learning techniques in real time." Symmetry 14, no. 11 (2022): 2308.
Agga, Ali, Ahmed Abbou, Moussa Labbadi, Yassine El Houm, and Imane Hammou Ou Ali. "CNN-LSTM: An efficient hybrid deep learning architecture for predicting short-term photovoltaic power production." Electric Power Systems Research 208 (2022): 107908.
Dib, M., Torabi, S., Bou-Harb, E. & Assi, C. A multi-dimensional deep learning framework for iot malware classification and family attribution. IEEE Trans. Netw. Serv. Manage. 18(2), 1165–1177 (2021).
Darem, A. A. et al. An adaptive behavioral-based incremental batch learning malware variants detection model using concept drift detection and sequential deep learning. IEEE Access 9, 97180–97196 (2021).
Scientific, Little Lion. "ENHANCING MALWARE DETECTION EFFICACY: A COMPARATIVE ANALYSIS OF ENDPOINT SECURITY AND APPLICATION WHITELISTING." Journal of Theoretical and Applied Information Technology 102, no. 6 (2024).
Chawla, Nikhil. "MACHINE LEARNING METHODOLOGIES FOR LOW-LEVEL HARDWARE-BASED MALWARE DETECTION." PhD diss., Georgia Institute of Technology, 2021.
Li, S. et al. Malicious mining code detection based on ensemble learning in cloud computing environment. Simul. Model. Pract. Theory 113, 102391 (2021).
Farooq, Umar. "Cyber-physical security: AI methods for malware/cyber-attacks detection on embedded/IoT applications." PhD diss., Politecnico di Torino, 2023.
Aslan, Ömer, and Abdullah Asim Yilmaz. "A new malware classification framework based on deep learning algorithms." Ieee Access 9 (2021): 87936–87951.
Landman, T. & Nissim, N. Deep-Hook: A trusted deep learning-based framework for unknown malware detection and classification in Linux cloud environments. Neural Networks 144, 648–685 (2021).
Kimmel, J. C., Mcdole, A. D., Abdelsalam, M., Gupta, M. & Sandhu, R. Recurrent neural networks based online behavioural malware detection techniques for cloud infrastructure. IEEE Access 9, 68066–68080 (2021).
Tian, D. et al. MDCHD: A novel malware detection method in cloud using hardware trace and deep learning. Computer Networks 198, 108394 (2021).
Li, Ce. et al. A novel deep framework for dynamic malware detection based on API sequence intrinsic features. Computers & Security 116, 102686 (2022).
Baek, S., Jeon, J., Jeong, B. & Jeong, Y.-S. Two-stage hybrid malware detection using deep learning. Human-centric Computing and Information Sciences 11(27), 10–22967 (2021).
Li, C. & Zheng, J. API call-based malware classification using recurrent neural networks. Journal of Cyber Security and Mobility 10(3), 617–640 (2021).
Miao, Yinbin, Feng Li, Xinghua Li, Zhiquan Liu, Jianting Ning, Hongwei Li, Kim-Kwang Raymond Choo, and Robert H. Deng. "Time-controllable keyword search scheme with efficient revocation in mobile e-health cloud." IEEE Transactions on Mobile Computing 23, no. 5 (2023): 3650–3665.
Manivannan, R., Senthilkumar, S., Kalaivani, K. & Prathap, N. Performance Enhancement of Cloud Security with Migration Algorithm for choosing Virtual Machines in Cloud Computing. Engineering Research Express, 6(1), 015204 (2024).
Tan, W., Thitøn, W., Xiang, P. & Zhou, H. Multi-modal brain image fusion based on multi-level edge-preserving filtering. Biomedical Signal Processing and Control 64, 102280 (2021).
Yao, Y., Zhang, Y., Wan, Yi., Liu, X. & Guo, H. Heterologous images matching considering anisotropic weighted moment and absolute phase orientation. Geomatics and Information Science of Wuhan University 46(11), 1727–1736 (2021).
Almghraby, Mohamed, and Abdelrady Okasha Elnady. "Face mask detection in real-time using MobileNetv2." International Journal of Engineering and Advanced Technology 10, no. 6 (2021): 104–108.
Acknowledgements
Not Applicable
Funding
No funding received for this research work.
Author information
Authors and Affiliations
Contributions
All the authors contributed to this research work in terms of concept creation, conduct of the research work, and manuscript preparation.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not Applicable.
Consent for publication
Not Applicable.
Availability of data and materials
The datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ranjani, B., Chinnadurai, M. Sparse attention with residual pyramidal depthwise separable convolutional based malware detection with optimization mechanism. Sci Rep 14, 24414 (2024). https://doi.org/10.1038/s41598-024-76193-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-76193-4
